python爬取B站视频
参考:https://cloud.tencent.com/developer/article/1768680
参考的代码有点问题,请求头需要修改,上代码:
import requests
import re # 正则表达式
import pprint
import json
from moviepy.editor import AudioFileClip, VideoFileClip
from bs4 import BeautifulSoup as bsheaders = {# 防盗链 告诉服务器 我们请求的url网址是从哪里跳转过来的'referer': 'https://www.bilibili.com/a','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}def send_request(url):response = requests.get(url=url, headers=headers)return responsedef get_video_data(html_data):"""解析视频数据"""# 提取视频的标题soup = bs(html_data, 'lxml')title = soup.find_all(name='h1',attrs={"class":"video-title special-text-indent"})[0].get_text()# print(title)# 提取视频对应的json数据json_data = re.findall('<script>window\.__playinfo__=(.*?)</script>', html_data)[0]# print(json_data) # json_data 字符串json_data = json.loads(json_data)pprint.pprint(json_data)# 提取音频的url地址audio_url = json_data['data']['dash']['audio'][0]['backupUrl'][0]print('解析到的音频地址:', audio_url)# 提取视频画面的url地址video_url = json_data['data']['dash']['video'][0]['backupUrl'][0]print('解析到的视频地址:', video_url)video_data = [title, audio_url, video_url]return video_datadef save_data(file_name, audio_url, video_url):# 请求数据print('正在请求音频数据')audio_data = send_request(audio_url).contentprint('正在请求视频数据')video_data = send_request(video_url).contentwith open(file_name + '.mp3', mode='wb') as f:f.write(audio_data)print('正在保存音频数据')with open(file_name + '.mp4', mode='wb') as f:f.write(video_data)print('正在保存视频数据')def merge_data(video_name):print('视频合成开始:', video_name)audioclip = AudioFileClip(video_name+'.mp3')videoclip = VideoFileClip(video_name+'.mp4')# 3.获取视频和音频的时长video_time = videoclip.durationaudio_time = audioclip.duration# 4.对视频或者音频进行裁剪if video_time > audio_time:# 视频时长>音频时长,对视频进行截取videoclip_new = videoclip.subclip(0, audio_time)audioclip_new = audioclipelse:# 音频时长>视频时长,对音频进行截取videoclip_new = videoclipaudioclip_new = audioclip.subclip(0, video_time)# 5.视频中加入音频video_with_new_audio = videoclip_new.set_audio(audioclip_new)# 6.写入到新的视频文件中video_with_new_audio.write_videofile("output.mp4",codec='libx264',audio_codec='aac',temp_audiofile='temp-video.m4a',remove_temp=True)print('视频合成结束:', video_name)url = 'https://www.bilibili.com/video/BV1bK421a7qG/?spm_id_from=333.1007.tianma.6-4-22.click'
response = send_request(url)
response.encoding = requests.utils.get_encodings_from_content(response.text)[0]
html_data = response.text
video_data = get_video_data(html_data)
save_data(video_data[0], video_data[1], video_data[2])
merge_data(video_data[0])效果

小姐姐挺靓,就是左下角有水印,想办法去除水印,参考:python实战之去除视频水印&字幕_python 去除视频水印-CSDN博客
import os
import sys
import cv2
import numpy
from moviepy import editorTEMP_VIDEO = 'temp.mp4'class WatermarkRemover():def __init__(self, video_path, output, threshold: int, kernel_size: int):self.threshold = threshold # 阈值分割所用阈值self.kernel_size = kernel_size # 膨胀运算核尺寸self.video_path = video_pathself.output = output#根据用户手动选择的ROI(Region of Interest,感兴趣区域)框选水印或字幕位置。def select_roi(self, img: numpy.ndarray, hint: str) -> list:'''框选水印或字幕位置,SPACE或ENTER键退出:param img: 显示图片:return: 框选区域坐标'''COFF = 0.7w, h = int(COFF * img.shape[1]), int(COFF * img.shape[0])resize_img = cv2.resize(img, (w, h))roi = cv2.selectROI(hint, resize_img, False, False)cv2.destroyAllWindows()watermark_roi = [int(roi[0] / COFF), int(roi[1] / COFF), int(roi[2] / COFF), int(roi[3] / COFF)]return watermark_roi#对输入的蒙版进行膨胀运算,扩大蒙版的范围def dilate_mask(self, mask: numpy.ndarray) -> numpy.ndarray:'''对蒙版进行膨胀运算:param mask: 蒙版图片:return: 膨胀处理后蒙版'''kernel = numpy.ones((self.kernel_size, self.kernel_size), numpy.uint8)mask = cv2.dilate(mask, kernel)return mask#根据手动选择的ROI区域,在单帧图像中生成水印或字幕的蒙版。def generate_single_mask(self, img: numpy.ndarray, roi: list, threshold: int) -> numpy.ndarray:'''通过手动选择的ROI区域生成单帧图像的水印蒙版:param img: 单帧图像:param roi: 手动选择区域坐标:param threshold: 二值化阈值:return: 水印蒙版'''# 区域无效,程序退出if len(roi) != 4:print('NULL ROI!')sys.exit()# 复制单帧灰度图像ROI内像素点roi_img = numpy.zeros((img.shape[0], img.shape[1]), numpy.uint8)start_x, end_x = int(roi[1]), int(roi[1] + roi[3])start_y, end_y = int(roi[0]), int(roi[0] + roi[2])gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)roi_img[start_x:end_x, start_y:end_y] = gray[start_x:end_x, start_y:end_y]# 阈值分割_, mask = cv2.threshold(roi_img, threshold, 255, cv2.THRESH_BINARY)return mask#通过截取视频中多帧图像生成多张水印蒙版,并通过逻辑与计算生成最终的水印蒙版def generate_watermark_mask(self, video_path: str) -> numpy.ndarray:'''截取视频中多帧图像生成多张水印蒙版,通过逻辑与计算生成最终水印蒙版:param video_path: 视频文件路径:return: 水印蒙版'''video = cv2.VideoCapture(video_path)success, frame = video.read()roi = self.select_roi(frame, 'select watermark ROI')mask = numpy.ones((frame.shape[0], frame.shape[1]), numpy.uint8)mask.fill(255)step = video.get(cv2.CAP_PROP_FRAME_COUNT) // 5index = 0while success:if index % step == 0:mask = cv2.bitwise_and(mask, self.generate_single_mask(frame, roi, self.threshold))success, frame = video.read()index += 1video.release()return self.dilate_mask(mask)#根据手动选择的ROI区域,在单帧图像中生成字幕的蒙版。def generate_subtitle_mask(self, frame: numpy.ndarray, roi: list) -> numpy.ndarray:'''通过手动选择ROI区域生成单帧图像字幕蒙版:param frame: 单帧图像:param roi: 手动选择区域坐标:return: 字幕蒙版'''mask = self.generate_single_mask(frame, [0, roi[1], frame.shape[1], roi[3]], self.threshold) # 仅使用ROI横坐标区域return self.dilate_mask(mask)def inpaint_image(self, img: numpy.ndarray, mask: numpy.ndarray) -> numpy.ndarray:'''修复图像:param img: 单帧图像:parma mask: 蒙版:return: 修复后图像'''telea = cv2.inpaint(img, mask, 1, cv2.INPAINT_TELEA)return teleadef merge_audio(self, input_path: str, output_path: str, temp_path: str):'''合并音频与处理后视频:param input_path: 原视频文件路径:param output_path: 封装音视频后文件路径:param temp_path: 无声视频文件路径'''with editor.VideoFileClip(input_path) as video:audio = video.audiowith editor.VideoFileClip(temp_path) as opencv_video:clip = opencv_video.set_audio(audio)clip.to_videofile(output_path)def remove_video_watermark(self):'''去除视频水印'''if not os.path.exists(self.output):os.makedirs(self.output)filenames = [os.path.join(self.video_path, i) for i in os.listdir(self.video_path)]mask = Nonefor i, name in enumerate(filenames):if i == 0:# 生成水印蒙版mask = self.generate_watermark_mask(name)# 创建待写入文件对象video = cv2.VideoCapture(name)fps = video.get(cv2.CAP_PROP_FPS)size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)))video_writer = cv2.VideoWriter(TEMP_VIDEO, cv2.VideoWriter_fourcc(*'mp4v'), fps, size)# 逐帧处理图像success, frame = video.read()while success:frame = self.inpaint_image(frame, mask)video_writer.write(frame)success, frame = video.read()video.release()video_writer.release()# 封装视频(_, filename) = os.path.split(name)output_path = os.path.join(self.output, filename.split('.')[0] + '_no_watermark.mp4') # 输出文件路径self.merge_audio(name, output_path, TEMP_VIDEO)if os.path.exists(TEMP_VIDEO):os.remove(TEMP_VIDEO)def remove_video_subtitle(self):'''去除视频字幕'''if not os.path.exists(self.output):os.makedirs(self.output)filenames = [os.path.join(self.video_path, i) for i in os.listdir(self.video_path)]roi = []for i, name in enumerate(filenames):# 创建待写入文件对象video = cv2.VideoCapture(name)fps = video.get(cv2.CAP_PROP_FPS)size = (int(video.get(cv2.CAP_PROP_FRAME_WIDTH)), int(video.get(cv2.CAP_PROP_FRAME_HEIGHT)))video_writer = cv2.VideoWriter(TEMP_VIDEO, cv2.VideoWriter_fourcc(*'mp4v'), fps, size)# 逐帧处理图像success, frame = video.read()if i == 0:roi = self.select_roi(frame, 'select subtitle ROI')while success:mask = self.generate_subtitle_mask(frame, roi)frame = self.inpaint_image(frame, mask)video_writer.write(frame)success, frame = video.read()video.release()video_writer.release()# 封装视频(_, filename) = os.path.split(name)output_path = os.path.join(OUTPUT_PATH, filename.split('.')[0] + '_no_sub.mp4') # 输出文件路径self.merge_audio(name, output_path, TEMP_VIDEO)if os.path.exists(TEMP_VIDEO):os.remove(TEMP_VIDEO)# 去水印
video_path = 'video'
output_path = 'output'
remover = WatermarkRemover(video_path,output_path,threshold=80, kernel_size=5)
remover.remove_video_watermark()
#去字幕
# remover = WatermarkRemover(video_path,output_path,threshold=80, kernel_size=5)
# remover.remove_video_subtitle()
效果一般吧:
相关文章:
python爬取B站视频
参考:https://cloud.tencent.com/developer/article/1768680 参考的代码有点问题,请求头需要修改,上代码: import requests import re # 正则表达式 import pprint import json from moviepy.editor import AudioFileClip, Vid…...
深度学习500问——Chapter05: 卷积神经网络(CNN)(2)
文章目录 5.6 有哪些池化方法 5.7 1x1卷积作用 5.8 卷积层和池化层有什么区别 5.9 卷积核是否一定越大越好 5.10 每层卷积是否只能用一种尺寸的卷积核 5.11 怎样才能减少卷积层参数量 5.12 在进行卷积操作时,必须同时考虑通道和区域吗 5.13 采用宽卷积的好处有什么 …...

基于单片机的测时仪系统设计
**单片机设计介绍,基于单片机的测时仪系统设计 文章目录 一 概要二、功能设计设计思路 三、 软件设计原理图 五、 程序六、 文章目录 一 概要 基于单片机的测时仪系统设计是一个结合了单片机技术与测时技术的综合性项目。该设计的目标是创建一款精度高、稳定性强且…...
)
鸿蒙原生应用开发-网络管理Socket连接(三)
应用通过TLS Socket进行加密数据传输 开发步骤 客户端TLS Socket流程: 1.import需要的socket模块。 2.绑定服务器IP和端口号。 3.双向认证上传客户端CA证书及数字证书;单向认证只上传CA证书,无需上传客户端证书。 4.创建一个TLSSocket连接…...
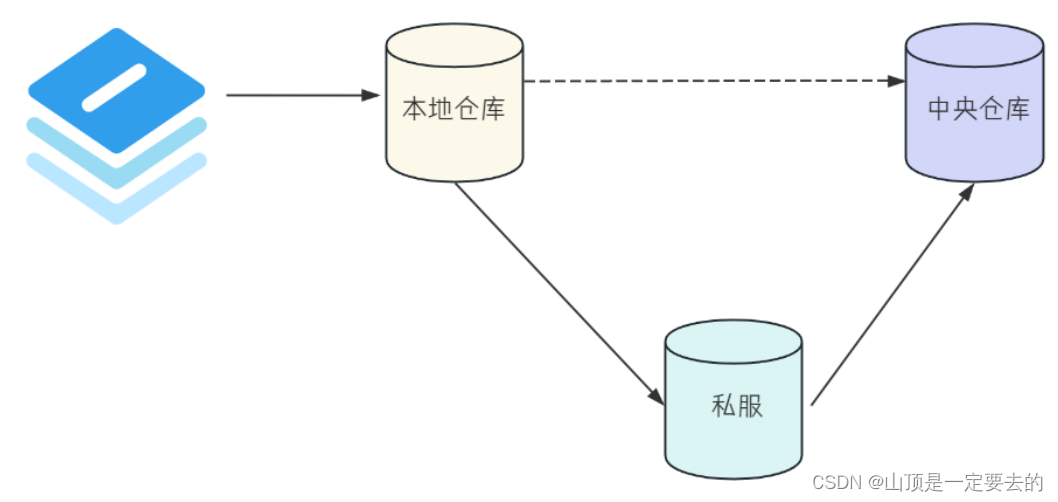
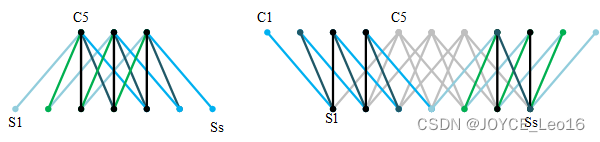
【Java EE】关于Maven
文章目录 🎍什么是Maven🌴为什么要学Maven🌲创建⼀个Maven项目🌳Maven核心功能🌸项目构建🌸依赖管理 🍀Maven Help插件🎄Maven 仓库🌸本地仓库🌸私服 ⭕总结 …...

每日一题:C语言经典例题之反转数
题目描述 给定一个整数,请将该数各个数位上的数字反转得到一个新数。新数也应满足整数的常见形式,即除非给定的原数为零,否则反转后得到的新数的最高位数字不应为零。 题目描述 给定一个整数,请将该数各个数位上的数字反转得到一个…...

RESTfull接口访问Elasticsearch
【数据库的健康值】 curl -X GET "ip:9200/_cat/health" 【查看所有索引】 curl -X GET "ip:9200/_cat/indices?v" 【查看索引index_name】 curl -X GET "ip:9200/索引?pretty" 【创建索引/文档】 PUT "ip:9200/索引/文档id" {请…...

NoSQL之Redis
目录 一、关系型数据库与非关系型数据库 1.关系数据库 2.非关系数据库 2.1非关系型数据库产生背景 3.关系型数据库与非关系型数据区别 (1)数据存储方式不同 (2)扩展方式不同 (3)对事物性的支持不同 …...
)
double二分(P3743 小鸟的设备)
题目:P3743 小鸟的设备 - 洛谷 | 计算机科学教育新生态 (luogu.com.cn) 代码: #include<bits/stdc.h> using namespace std; const int N2e510; double a[N],b[N]; int n; double p;bool check(double mid) {double sum0.0;for(int i1;i<n;i){if(a[i]*mi…...

【独立开发前线】Vol.36 为什么从2023年开始,独立开发者越来越多了?
不知道你有没有观察到,从2023年开始,国内的独立开发者越来越多了。 之前独立开发者是一个非常小众的群体,但现在很多互联网从业者都瞄准了这个方向,包括程序员、产品经理,运营等等。 我想可能是这样几个原因…...

GPT4不限制使用次数了!GPT5即将推出了!
今天登录到ChatGPT Plus账户,出现了如下提示: 已经没有了数量和时间限制的提示。 更改前:每 3 小时限制 40 次(团队计划为 100 次);更改后:可能会应用使用限制。 GPT-4放开限制 身边订阅了Ch…...

物联网实战--入门篇之(六)嵌入式-WIFI驱动(ESP8266)
目录 一、WIFI简介 二、基础网络知识 三、思路讲解 四、代码分析 4.1 状态机制 4.2 客户端连接 4.3 应用数据接收处理 4.4 数据发送 4.5 主函数调用 4.6 网络连接ID分配 五、总结 一、WIFI简介 WIFI在我们生活中太常见了,手机电脑都可以用WiFi连接路由器进行上…...

Java并发编程基础面试题详细总结
1. 什么是线程和进程? 1.1 何为进程? 进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。 在 Java 中,当我们启动 main 函数时其实就是启动了一个…...

EKO / 砍树
暴力是不行的,还得是二分吧 题目描述 伐木工人 Mirko 需要砍 M 米长的木材。对 Mirko 来说这是很简单的工作,因为他有一个漂亮的新伐木机,可以如野火一般砍伐森林。不过,Mirko 只被允许砍伐一排树。 Mirko 的伐木机工作流程如下&a…...

Kafka面试宝典
1 Kafka基础面试篇 Kafka的那些设计让它有如此高的性能? 1.partition,producer和consumer端的批处理:提高并行度;2.页缓存:大量使用页缓存,内存操作比磁盘操作快很多,数据写入直接写道页缓存,由操作系统负责刷盘,数据读取也是直接命中页缓存,从内存中直接拿到数据;…...

Redis性能管理
目录 1、内存碎片如何产生的? 2、跟踪内存碎片率对理解Redis实例的资源性能是非常重要的 3、解决碎片率大的问题 二、内存使用率 1、避免内存交换发生的方法 2、内回收key 三、缓存的穿透、击穿、雪崩 #查看Redis内存使用方法 info memory #进入数据库查看 re…...

计算机网络:局域网的数据链路层
✨✨ 欢迎大家来访Srlua的博文(づ ̄3 ̄)づ╭❤~✨✨ 🌟🌟 欢迎各位亲爱的读者,感谢你们抽出宝贵的时间来阅读我的文章。 我是Srlua小谢,在这里我会分享我的知识和经验。&am…...

Linux常见命令简介
Linux运行级别 六种运行级别: 0、关机 1、单用户(可用来找回密码) 2、多用户无网络 3、多用户有网络(多用于工作环境) 4、预留 5、图形界面(多用于学习环境) 6、重…...
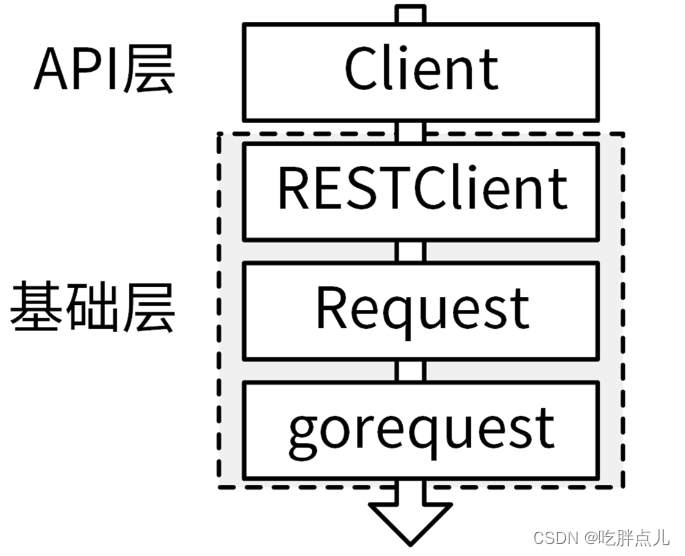
34-SDK设计(下):IAM项目GoSDK设计和实现
比如 Kubernetes的 client-go SDK设计方式。IAM项目参考client-go,也实现了client-go风格的SDK:marmotedu-sdk-go。 ,client-go风格的SDK具有以下优点: 大量使用了Go interface特性,将接口的定义和实现解耦࿰…...
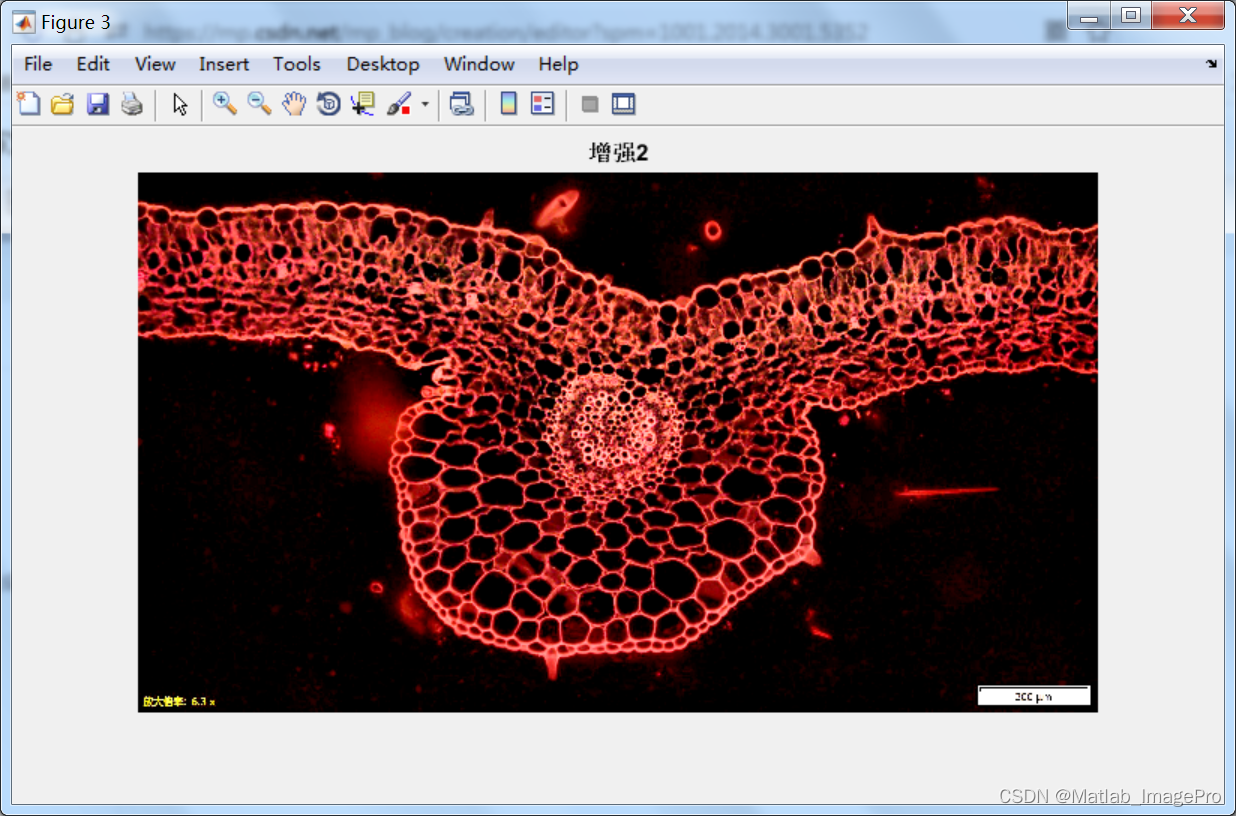
基于Matlab的血管图像增强算法,Matlab实现
博主简介: 专注、专一于Matlab图像处理学习、交流,matlab图像代码代做/项目合作可以联系(QQ:3249726188) 个人主页:Matlab_ImagePro-CSDN博客 原则:代码均由本人编写完成,非中介,提供…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

基于matlab策略迭代和值迭代法的动态规划
经典的基于策略迭代和值迭代法的动态规划matlab代码,实现机器人的最优运输 Dynamic-Programming-master/Environment.pdf , 104724 Dynamic-Programming-master/README.md , 506 Dynamic-Programming-master/generalizedPolicyIteration.m , 1970 Dynamic-Programm…...
多光源(Multiple Lights))
C++.OpenGL (14/64)多光源(Multiple Lights)
多光源(Multiple Lights) 多光源渲染技术概览 #mermaid-svg-3L5e5gGn76TNh7Lq {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-3L5e5gGn76TNh7Lq .error-icon{fill:#552222;}#mermaid-svg-3L5e5gGn76TNh7Lq .erro…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...

拟合问题处理
在机器学习中,核心任务通常围绕模型训练和性能提升展开,但你提到的 “优化训练数据解决过拟合” 和 “提升泛化性能解决欠拟合” 需要结合更准确的概念进行梳理。以下是对机器学习核心任务的系统复习和修正: 一、机器学习的核心任务框架 机…...
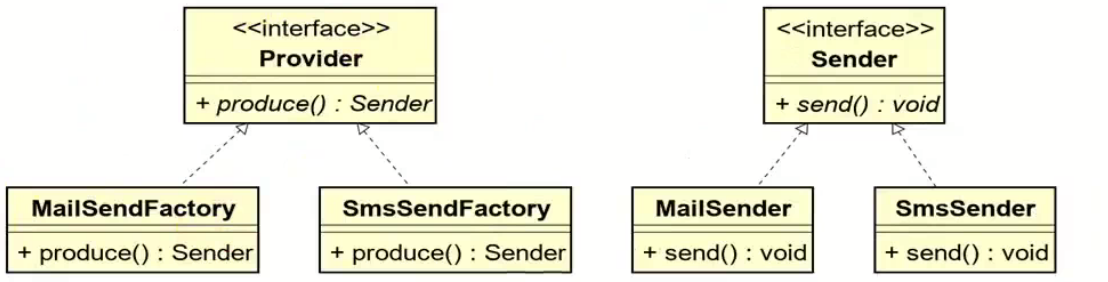
工厂方法模式和抽象工厂方法模式的battle
1.案例直接上手 在这个案例里面,我们会实现这个普通的工厂方法,并且对比这个普通工厂方法和我们直接创建对象的差别在哪里,为什么需要一个工厂: 下面的这个是我们的这个案例里面涉及到的接口和对应的实现类: 两个发…...

接口 RESTful 中的超媒体:REST 架构的灵魂驱动
在 RESTful 架构中,** 超媒体(Hypermedia)** 是一个核心概念,它体现了 REST 的 “表述性状态转移(Representational State Transfer)” 的本质,也是区分 “真 RESTful API” 与 “伪 RESTful AP…...
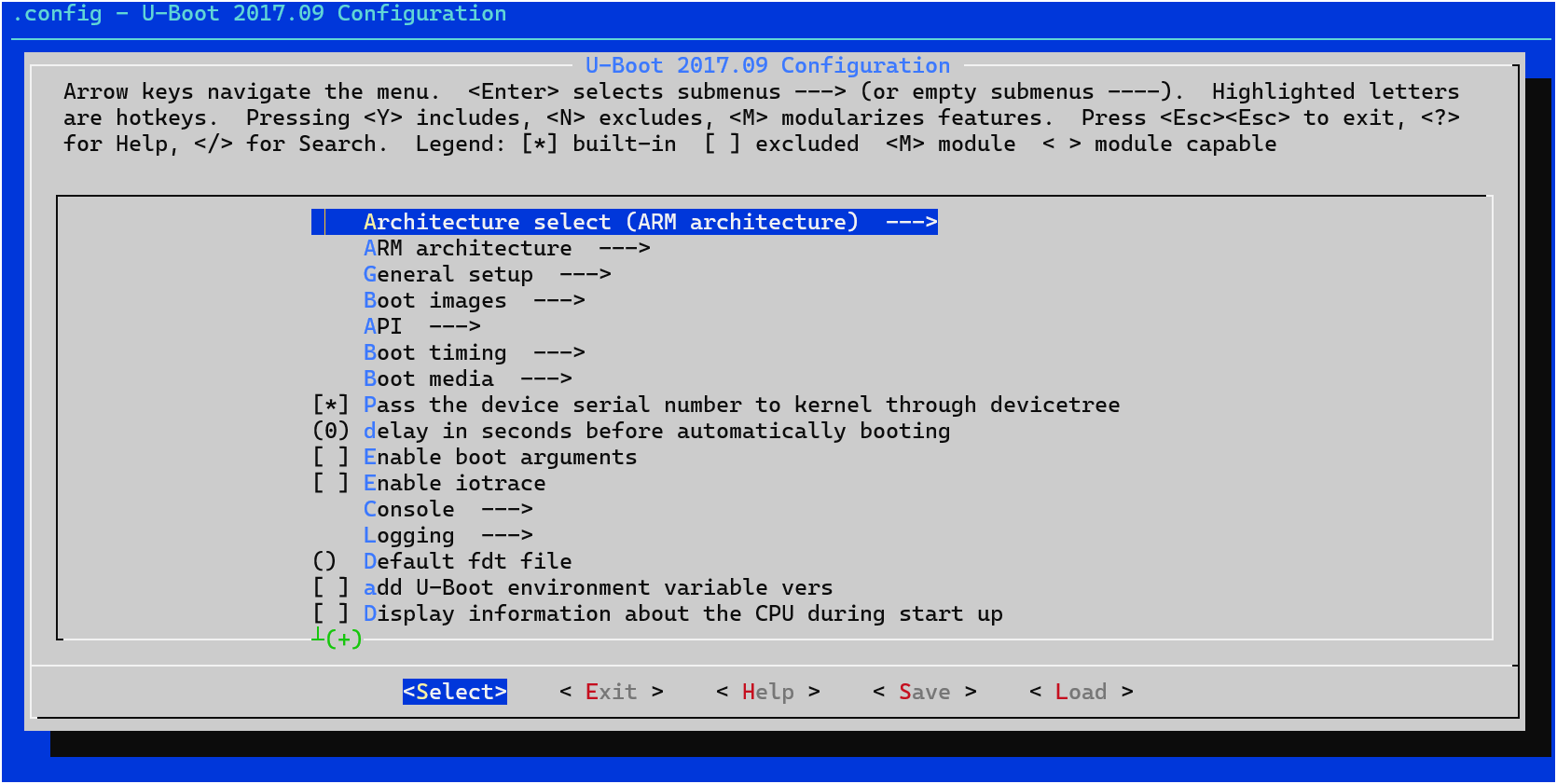
Linux【5】-----编译和烧写Linux系统镜像(RK3568)
参考:讯为 1、文件系统 不同的文件系统组成了:debian、ubuntu、buildroot、qt等系统 每个文件系统的uboot和kernel是一样的 2、源码目录介绍 目录 3、正式编译 编译脚本build.sh 帮助内容如下: Available options: uboot …...

河北对口计算机高考MySQL笔记(完结版)(2026高考)持续更新~~~~
MySQL 基础概念 数据(Data):文本,数字,图片,视频,音频等多种表现形式,能够被计算机存储和处理。 **数据库(Data Base—简称DB):**存储数据的仓库…...