Transformer学习: Transformer小模块学习--位置编码,多头自注意力,掩码矩阵
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Transformer学习
- 1 位置编码模块
- 1.1 PE代码
- 1.2 测试PE
- 1.3 原文代码
- 2 多头自注意力模块
- 2.1 多头自注意力代码
- 2.2 测试多头注意力
- 3 未来序列掩码矩阵
- 3.1 代码
- 3.2 测试掩码
1 位置编码模块
P E ( p o s , 2 i ) = sin ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i)=\sin(pos/10000^{2i/d_{\mathrm{model}}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = cos ( p o s / 1000 0 2 i / d m o d e l ) PE(pos,2i+1)=\cos(pos/10000^{2i/d_\mathrm{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel)
pos 是序列中每个对象的索引, p o s ∈ [ 0 , m a x s e q l e n ] pos\in [0,max_seq_len] pos∈[0,maxseqlen], i i i 向量维度序号, i ∈ [ 0 , e m b e d d i m / 2 ] i\in [0,embed_dim/2] i∈[0,embeddim/2], d m o d e l d_{model} dmodel是模型的embedding维度
1.1 PE代码
import numpy as np
import matplotlib.pyplot as plt
import math
import torch
import seaborn as snsdef get_pos_ecoding(max_seq_len,embed_dim):# 初始化位置矩阵 [max_seq_len,embed_dim]pe = torch.zeros(max_seq_len,embed_dim])position = torch.arange(0,max_seq_len).unsqueeze(1) # [max_seq_len,1]print("位置:", position,position.shape)div_term = torch.exp(torch.arange(0,embed_dim,2)*-(math.log(10000.0)/embed_dim)) # 除项维度为embed_dim的一半,因为对矩阵分奇数和偶数位置进行填充。pe[:,0::2] = torch.sin(position/div_term)pe[:,1::2] = torch.cos(position/div_term)return pe
1.2 测试PE
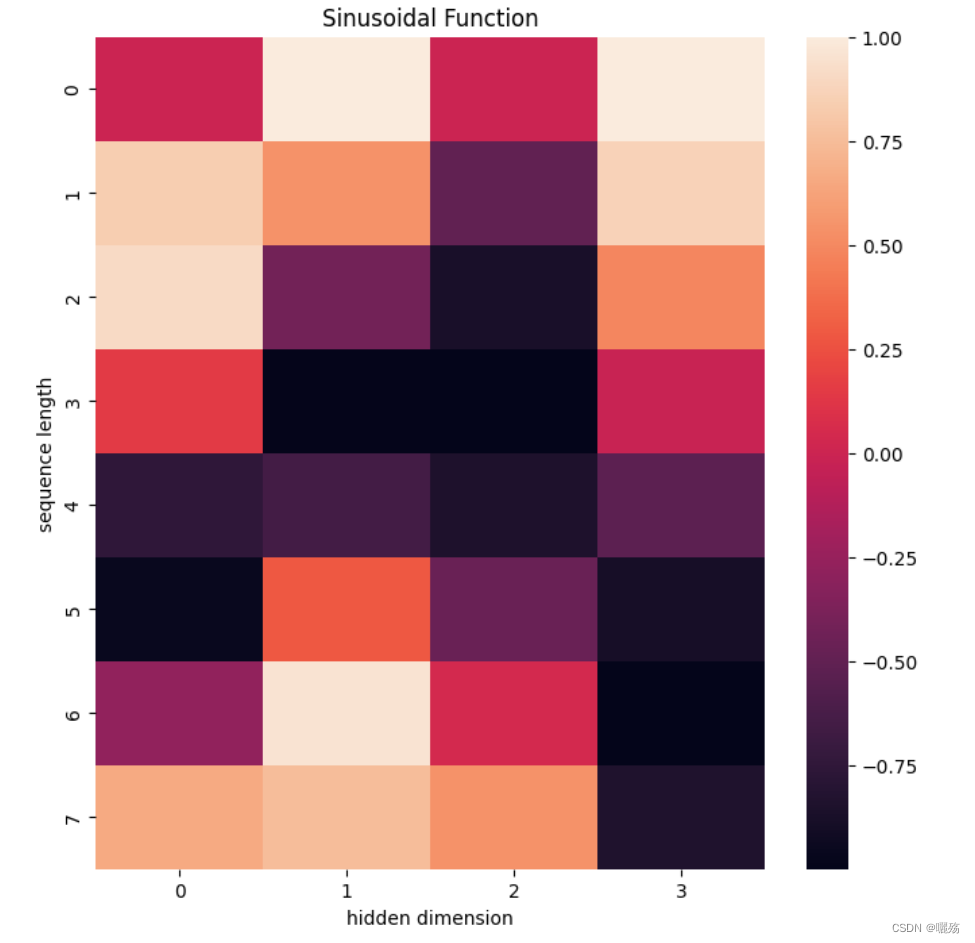
pe = get_pos_ecoding(8,4)
plt.figure(figsize=(8,8))
sns.heatmap(pe)
plt.title("Sinusoidal Function")
plt.xlabel("hidden dimension")
plt.ylabel("sequence length")
输出:
位置: tensor([[0],
[1],
[2],
[3],
[4],
[5],
[6],
[7]]) torch.Size([8, 1])
除项: tensor([1.0000, 0.0100]) torch.Size([2])
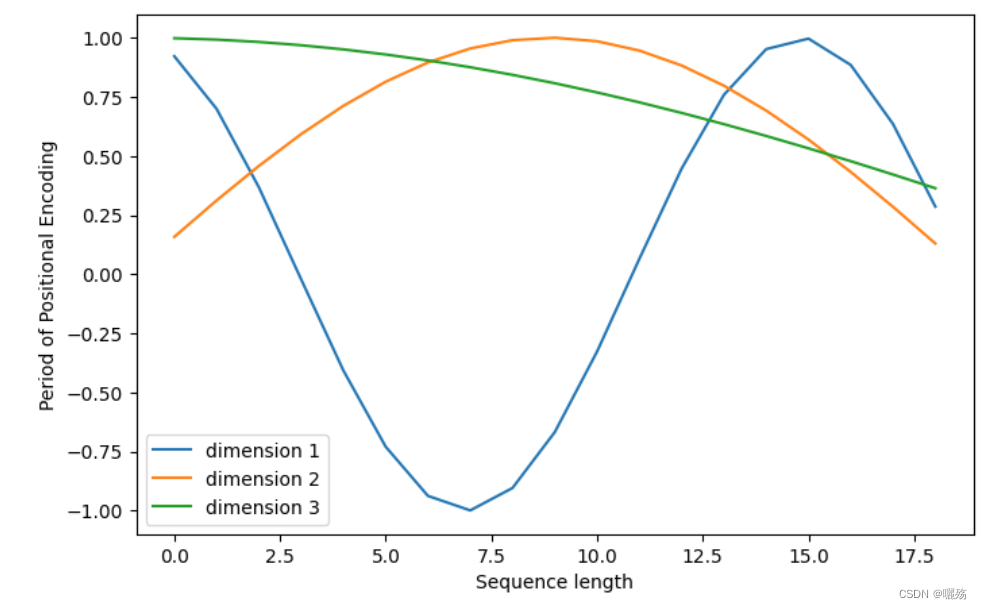
plt.figure(figsize=(8, 5))
plt.plot(positional_encoding[1:, 1], label="dimension 1")
plt.plot(positional_encoding[1:, 2], label="dimension 2")
plt.plot(positional_encoding[1:, 3], label="dimension 3")
plt.legend()
plt.xlabel("Sequence length")
plt.ylabel("Period of Positional Encoding")
1.3 原文代码
class PositionalEncoding(nn.Module):"Implement the PE function."def __init__(self, d_model, dropout, max_len=5000):# max_len 序列最大长度,自定义的,不是真正的最大长度# d_model 模型嵌入维度super(PositionalEncoding, self).__init__()# 实例化dropout层self.dropout = nn.Dropout(p=dropout)# Compute the positional encodings once in log space.# 初始化一个位置编码矩阵, shape: (max_len, d_model)pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)#二维张量扩充为三维张量 shape: (1,max_len, d_model)pe = pe.unsqueeze(0)# 将位置编码注册为模型的buffer,注册为buffer之后,不会进行更新# 注册为buffer后可以再模型保存后重新加载时候将这个位置编码器和模型参数加载进来self.register_buffer('pe', pe) # 注册的名字pe,变量也是pedef forward(self, x):# x 序列的嵌入表示# pe是按max_len进行注册的,太长了,将第二个维度(max_len对应的维度)缩小为真正的序列x的最大长度# Variable(self.pe[:, :x.size(1)], requires_grad=False) 即位置编码x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)return self.dropout(x)
2 多头自注意力模块
2.1 多头自注意力代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import copy# 复制网络,即使用几层网络就改变N的数量
# 如 4层线性层 clones(nn.Linear(model_dim,model_dim),4)
def clones(module, N):"Produce N identical layers."return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])# 计算注意力
def attention(q, k, v, mask=None, dropout=None):# q,k,v [bs,-1,head,embed_dim//head], q.size(-1) = embed_dim//headd_k = q.size(-1)# (head,embed_dim//head)*(embed_dim//head,head)scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:# 如果使用mask, 0的位置用-1e9填充scores = scores.masked_fill(mask == 0, -1e9)# 对scores的最后一个维度进行softmaxp_attn = F.softmax(scores, dim = -1)# 判断是否需要进行dorpout处理if dropout is not None:p_attn = dropout(p_attn)# 返回添加注意力后的结果,注意力系数return torch.matmul(p_attn, v), p_attn# 计算多头注意力
class Multi_Head_Self_Att(nn.Module):def __init__(self,head,model_dim,dropout=0.1):super(Multi_Head_Self_Att,self).__init__()+# 判断嵌入维度能否被head整除,不能整除抛出异常assert model_dim % head == 0self.d_k = model_dim//headself.head = headself.linears = clones(nn.Linear(model_dim,model_dim),4)self.att = Noneself.dropout = nn.Dropout(p=dropout)def forward(self,q,k,v,mask=None):if mask is not None:# 掩码非空,扩充维度,代表多头中的第n个头mask = mask.unsqueeze(1)nbatches = q.size(0)# zip函数 将线性层与q,k,v分别对应(self.linears,q),(self.linears,k),(self.linears,v)# q,k,v [bs,-1,head,embed_dim/head]# 使用线性层l处理x,把处理后的x形状view成(nbatches,-1,int(self.head),int(self.d_k)).transpose(1,2)) 第二个维度自适应维度大小# transpose(1,2) 让代表序列长度的维度与词向量的维度相邻q,k,v = [l(x).view(nbatches,-1,int(self.head),int(self.d_k)).transpose(1,2) for l,x in zip(self.linears,(q,k,v))] # 返回计算注意力之后的值作为x和注意力分数x, self.attn = attention(q, k, v, mask=mask, dropout=self.dropout)# 通过多头注意力计算后,得到了每个头计算结果组成的4维张量,需要将其转换成与输入一样的维度# 将第2个维度和第三个维度换回来,维度组成(nbatches,-1,model_dim)# contiguous()使得转置之后的张量能够运用view方法x = x.transpose(1, 2).contiguous().view(nbatches, -1, int(self.head * self.d_k))# 之前建立了四个线性层,前面q,k,v用了三个线性层,最后一个现成层对注意力结果进行一次线性变换return self.linears[-1](x),self.attn
2.2 测试多头注意力
# 模型参数
head = 4
model_dim = 128
seq_len = 10
dropout = 0.1# 生成示例输入
q = torch.randn(seq_len, model_dim)
k = torch.randn(seq_len, model_dim)
v = torch.randn(seq_len, model_dim)# 创建多头自注意力模块
att = Multi_Head_Self_Att(head, model_dim, dropout=dropout)# 运行模块
output,att = att(q, k, v)# 输出形状
print("Output shape:", output.shape)
print(att.shape())
sns.heatmap(att.squeeze().detach().cpu())
输出
Output shape: torch.Size([10, 1, 128])
torch.Size([10, 4, 1, 1])
3 未来序列掩码矩阵
作用:
- 解码器中的掩码是防止泄露未来要预测的部分,掩码矩阵是一个除对角线的上三角矩阵
- 序列填充部分的掩码是判断哪些部位是填充的部位,填充的部位在计算注意力时保证期注意力分数为0【以添加一个负无穷的小数,使得其softmax值为0】
3.1 代码
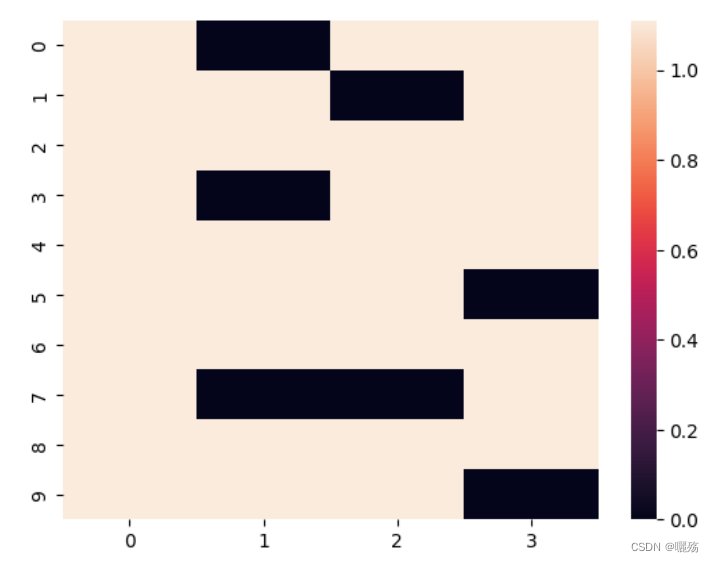
def subsequent_mask(size):"Mask out subsequent positions."attn_shape = (1, size, size)subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype('uint8')print("掩码矩阵:",subsequent_mask)return torch.from_numpy(subsequent_mask) == 0
测试掩码
plt.figure(figsize=(5,5))
print(subsequent_mask(8),subsequent_mask(8).shape)
plt.imshow(subsequent_mask(8)[0])
掩码矩阵:
[[[0 1 1 1 1 1 1 1]
[0 0 1 1 1 1 1 1]
[0 0 0 1 1 1 1 1]
[0 0 0 0 1 1 1 1]
[0 0 0 0 0 1 1 1]
[0 0 0 0 0 0 1 1]
[0 0 0 0 0 0 0 1]
[0 0 0 0 0 0 0 0]]]
tensor([[[ True, False, False, False, False, False, False, False],
[ True, True, False, False, False, False, False, False],
[ True, True, True, False, False, False, False, False],
[ True, True, True, True, False, False, False, False],
[ True, True, True, True, True, False, False, False],
[ True, True, True, True, True, True, False, False],
[ True, True, True, True, True, True, True, False],
[ True, True, True, True, True, True, True, True]]]) torch.Size([1, 8, 8])
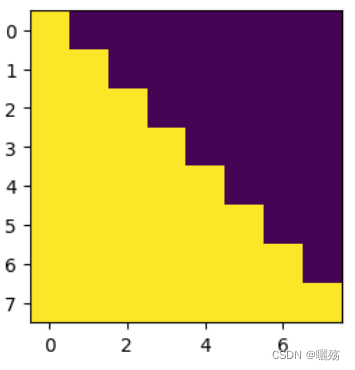
紫色部分为添加掩码的部分
3.2 测试掩码
import torch
from torch.autograd import Variable# 函数接受两个参数 tgt 和 pad,其中 tgt 是目标序列的张量,pad 是表示填充的值
def make_std_mask(tgt, pad):"Create a mask to hide padding and future words."# 首先,创建一个掩码 tgt_mask,其形状与 tgt 的形状相同,用于指示哪些位置不是填充位置。# 这是通过将 tgt 张量中不等于 pad 的位置设置为 True(1),其余位置设置为 False(0)来实现的。# unsqueeze(-2) 的作用是在倒数第二个维度上添加一个维度,以便后续的逻辑运算。tgt_mask = (tgt != pad).unsqueeze(-2)# 调用 subsequent_mask 函数,生成一个用于遮挡未来词的掩码。这个掩码是一个上三角矩阵,# 其对角线及其以下的元素为 True(1),其余元素为 False(0)。# tgt_mask = tgt_mask & Variable(subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data)):# 将 tgt_mask 和生成的未来词掩码进行逻辑与操作,将未来词位置的掩码设置为 False,即遮挡掉未来词。tgt_mask = tgt_mask & Variable(subsequent_mask(tgt.size(-1)).type_as(tgt_mask.data))return tgt_maskdef subsequent_mask(size):"Mask out subsequent positions."attn_shape = (1, size, size)subsequent_mask = torch.triu(torch.ones(*attn_shape), diagonal=1)return subsequent_mask == 0# 示例数据
tgt = torch.tensor([[1, 2, 3, 0, 0], [4, 5, 0, 0, 0], [6, 7, 8, 9, 10]]) # 目标序列,假设填充值为 0
pad = 0 # 填充值# 创建掩码
tgt_mask = make_std_mask(tgt, pad)# 打印结果
print("目标序列:")
print(tgt)
print("\n生成的掩码:")
print(tgt_mask)
输出:
目标序列:
tensor([[ 1, 2, 3, 0, 0],
[ 4, 5, 0, 0, 0],
[ 6, 7, 8, 9, 10]])
生成的掩码:
tensor([[[ True, False, False, False, False],
[ True, True, False, False, False],
[ True, True, True, False, False],
[ True, True, True, False, False],
[ True, True, True, False, False]],
[[ True, False, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False]],
[[ True, False, False, False, False],
[ True, True, False, False, False],
[ True, True, True, False, False],
[ True, True, True, True, False],
[ True, True, True, True, True]]])
相关文章:
Transformer学习: Transformer小模块学习--位置编码,多头自注意力,掩码矩阵
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 Transformer学习 1 位置编码模块1.1 PE代码1.2 测试PE1.3 原文代码 2 多头自注意力模块2.1 多头自注意力代码2.2 测试多头注意力 3 未来序列掩码矩阵3.1 代码3.2 测试掩码 1 …...

easyexcel 动态列导出
1. 引入easyexcel <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.2.1</version></dependency> 2.导出write public void export(HttpServletResponse response) {try {String f…...
flink源码编译-job提交
1、启动standalone集群的taskmanager standalone集群中的taskmanager启动类为 TaskManagerRunner 2 打开master启动类 通过 ctrln快捷键,找到、并打开类: org.apache.flink.runtime.taskexecutor.TaskManagerRunner 3 修改运⾏配置 基本完全按照mas…...
Mysql密码修改问题
docker安装mysql,直接拉取镜像,挂载关键目录即可启动,默认3306端口。此时无法直接连接,需要配置密码。docker进入mysql容器中 docker exec -it mysql bash #mysq是容器名称,也可以用容器id通过修改mysql的配置进行免密…...

建独立站,对FP商家有什么好处?
2024年都过去四分之一了,还有许多人对是否投身于跨境独立站领域仍犹豫不决。然而,观望不如实践,如果渴望在跨境电商领域开创一片新天地,那么现在就是行动的最佳时机。 特别是对于FP商家来说,由于电商平台对于黑五类产品…...
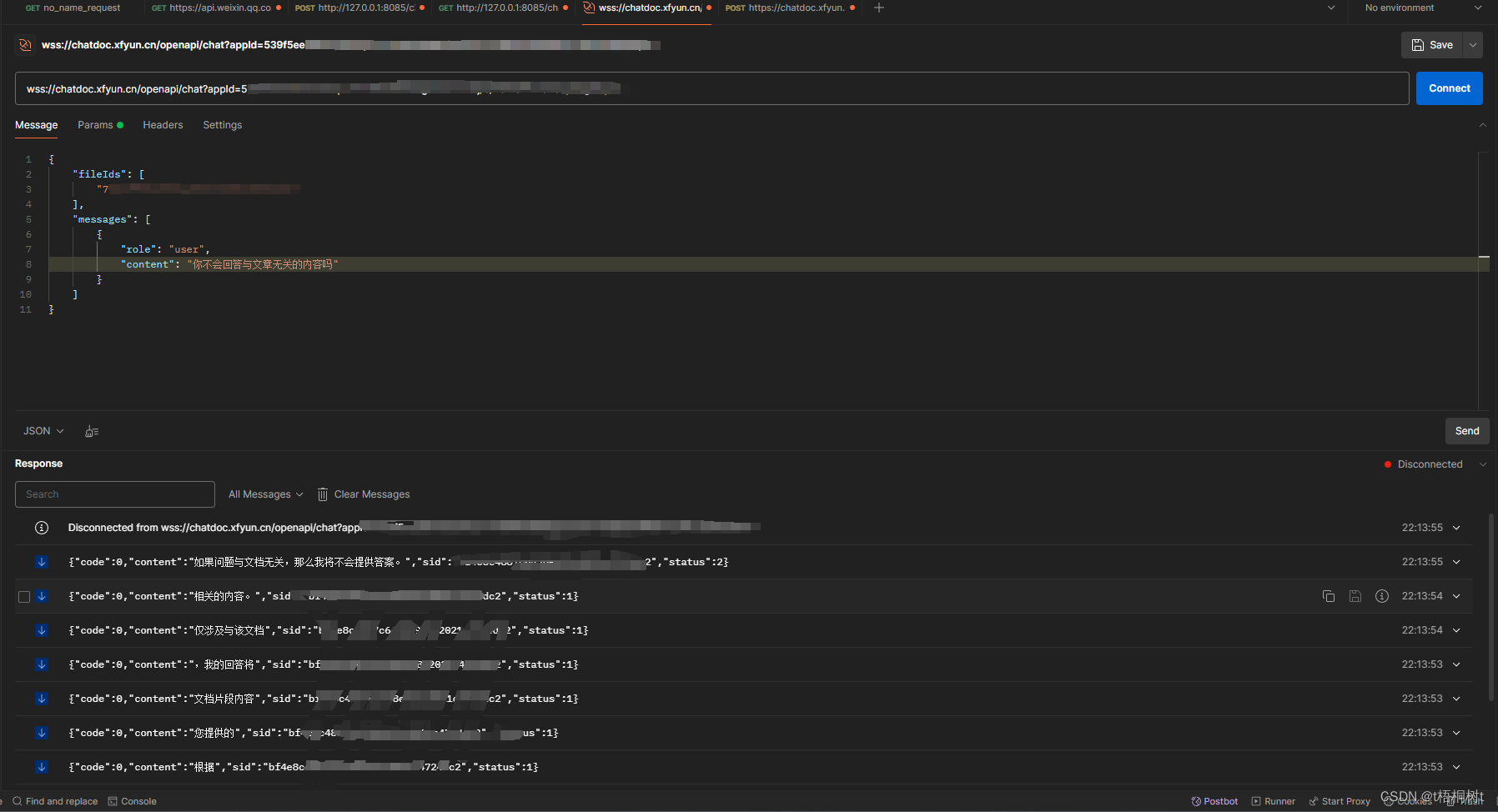
使用Postman进行websocket接口测试
因为最近要搞关于基于AI的文本接口测试.需要用到websocket协议,于是看了一下发现postman也可以测而且很方便 位置 File->New->WebSocket 可以看到不止WebSocket还支持其他的各种协议 使用 首先先点击connect进行连接 连接成功之后可以选择多种文本格式添加请求参数 每…...

Android音视频开发 - MediaMetadataRetriever 相关
Android音视频开发 - MediaMetadataRetriever 相关 MediaMetadataRetriever 是android中用于从媒体文件中提取元数据新的类. 可以获取音频,视频和图像文件的各种信息,如时长,标题,封面等. 1:初始化对象 private MediaMetadataRetriever mediaMetadataRetriever new MediaMe…...
注解(Annotation)
10.1 注解概述 10.1.1 什么是注解 注解(Annotation)是从JDK5.0开始引入,以“注解名”在代码中存在。例如: Override Deprecated SuppressWarnings(value”unchecked”) Annotation 可以像修饰符一样被使用,可用于修饰…...

蓝桥杯:七步诗 ← bfs
【题目来源】https://www.lanqiao.cn/problems/3447/learning/【题目描述】 煮豆燃豆苴,豆在釜中泣。本是同根生,相煎何太急?---曹植 所以,这道题目关乎豆子! 话说赤壁之战结束后,曹操的船舰被刘备烧了,引领军队从华容…...

Vue 如何快速上手
目录 1. Vue 是什么 (概念) 1.1. Vue 的两种使用方式 1.2. 优点 1.3. 缺点 2. 创建 Vue 实例,初始化渲染 2.1. 步骤(核心步骤 4步) 2.2. 练习——创建一个Vue实例 3. 插值表达式 {{ }} 3.1. 介绍 3.2. 作用…...

Vue3:组件间通信-provide和inject实现祖先组件与后代组件间直接通信
一、情景说明 我们学习了很多的组件间通信 这里在学习一种,祖先组件与后代组件间通信的技术 这里的后代,可以是多层继承关系,子组件,子子组件,子子子组件等等。 在祖先组件中通过provide配置向后代组件提供数据在后代…...

微信小程序——小程序和页面生命周期详解
小程序的生命周期 小程序的生命周期主要分为以下几个阶段: 创建(onLoad): 当小程序启动时,或者从其他页面跳转到当前页面时,会触发 onLoad 生命周期函数。 这个阶段通常用于初始化页面数据,从服…...

android studio中添加module依赖
android常用的三种依赖 库依赖(Library dependency):以访问网址的形式将依赖库相应版本下载到本地; 文件依赖(File dependency): 将下载下来的依赖库以.jar文件的形式添加依赖. module依赖(Modu…...

【.NET全栈】.NET全栈学习路线
一、微软官方C#学习 https://learn.microsoft.com/zh-cn/dotnet/csharp/tour-of-csharp/ C#中的数据类型 二、2021 ASP.NET Core 开发者路线图 GitHub地址:https://github.com/MoienTajik/AspNetCore-Developer-Roadmap/blob/master/ReadMe.zh-Hans.md 三、路线…...
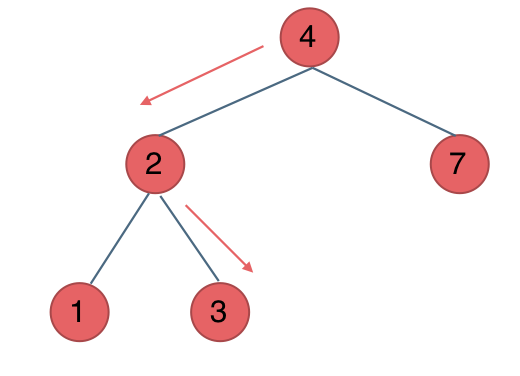
代码随想录阅读笔记-二叉树【二叉搜索树中的搜索】
题目 给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。 例如, 在上述示例中,如果要找的值是 5,但因为没有节点…...

1、初识drf
drf的学习需要学习者有django基本使用知识。 文章目录 什么是drf,有什么作用CBV是什么初步使用drf 下载以及django创建项目django最小启动内容修改setting修改 url 编写drf视图编辑url测试返回结果 什么是drf,有什么作用 drf(django rest-framework),让…...

速盾:cdn高防御服务器租用有哪些好处
随着互联网的发展,网络安全问题日益突出。攻击者利用各种手段不断对网站进行攻击,给网站的安全运行带来威胁。为了保障网站的正常运行和数据的安全,越来越多的网站开始租用CDN高防御服务器。那么,租用CDN高防御服务器有哪些好处呢…...

【跟小嘉学 Linux 系统架构与开发】四、文件和目录的权限
系列文章目录 【跟小嘉学 Linux 系统架构与开发】一、学习环境的准备与Linux系统介绍 【跟小嘉学 Linux 系统架构与开发】二、Linux发型版介绍与基础常用命令介绍 【跟小嘉学 Linux 系统架构与开发】三、如何查看帮助文档 【跟小嘉学 Linux 系统架构与开发】四、文件和目录的权…...
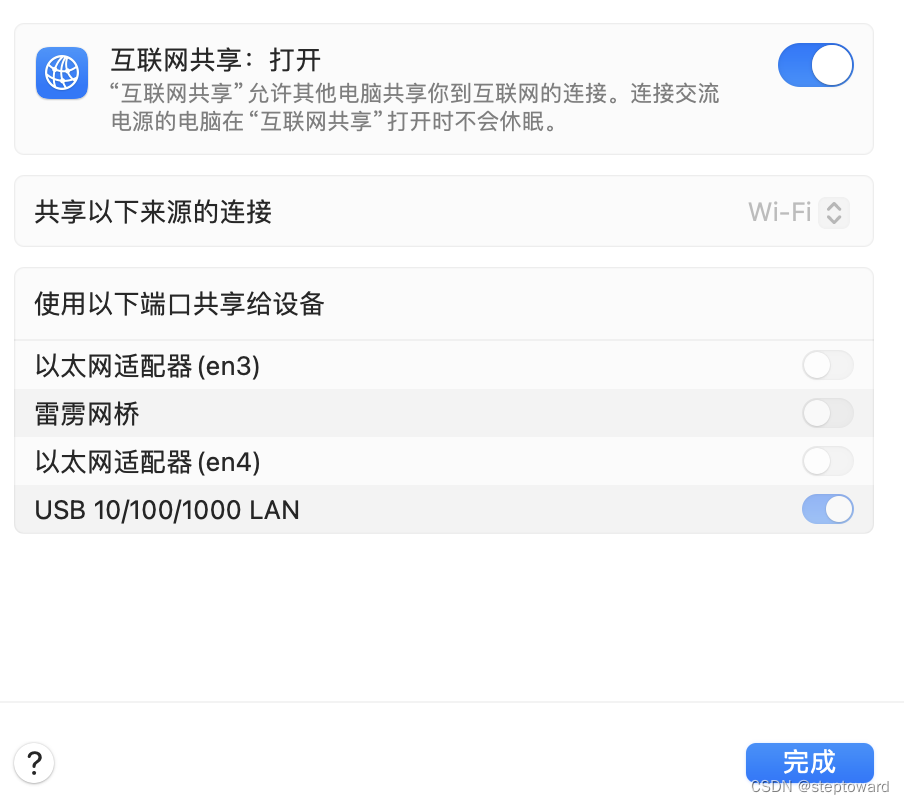
ubuntu18.04图形界面卡死,鼠标键盘失灵, 通过MAC共享网络给Ubuntu解决!
ubuntu18.04图形界面卡死,鼠标键盘失灵, 通过MAC共享网络给Ubuntu解决! 1. 尝试从卡死的图形界面切换到命令行界面2. 进入bios和grub页面3. 更改Grub中的设置,以进入命令行4. 在命令行页面解决图形界面卡死的问题5. Mac共享WI-FI网…...

ESG认证(ESG=环境、社会和治理 Environmental, Social, and Governance)
什么是ESG认证 ESG认证是指根据企业在环境、社会和治理(Environmental, Social, and Governance)方面的表现而设立的一种评价或评级体系。 环境(Environmental):这一维度关注企业如何管理其对环境的影响,包…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

Qt Widget类解析与代码注释
#include "widget.h" #include "ui_widget.h"Widget::Widget(QWidget *parent): QWidget(parent), ui(new Ui::Widget) {ui->setupUi(this); }Widget::~Widget() {delete ui; }//解释这串代码,写上注释 当然可以!这段代码是 Qt …...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...