速通数据结构与算法第四站 双链表
系列文章目录
速通数据结构与算法系列
1 速通数据结构与算法第一站 复杂度 http://t.csdnimg.cn/sxEGF
2 速通数据结构与算法第二站 顺序表 http://t.csdnimg.cn/WVyDb
3 速通数据结构与算法第三站 单链表 http://t.csdnimg.cn/cDpcC
感谢佬们支持!
目录
系列文章目录
- 前言
- 一、双链表
- 0 结构体
- 1 接口声明
- 2 增加节点
- 3 初始化
- 4 打印
- 5 尾插
- 6 尾删
- 7 头插
- 8 头删
- 9 find
- 10 insert
- 11 erase
- 12 销毁
- 13 完整代码
- 二、OJ题
- 1 环形链表1
- 2 环形链表2
- 3 复杂链表的复制
- 三、链表和顺序表的对比&&补充deque
- 总结
前言
上篇博客我们探讨的是单链表,这篇博客将为大家带来双链表和3个更值得探讨的OJ题
双链表看似更复杂了,其实不然,代码写起来比单链表爽的多

我们要写的就是带头双向循环链表, 这也是STL(SGI版)中list相同的结构
一、双链表
我们还是先来搞一个结构体
结构体
typedef int LTDataType;typedef struct ListNode
{LTDataType data;struct ListNode* prev;struct ListNode* next;
}LTNode;其中data表示数据,prev表示指向前一个结点,next表示指向后一个节点
接口声明
//增加节点
LTNode* BuyListNode(LTDataType x);//初始化
//void LTInit(LTNode**phead);
LTNode* LTInit();//打印
void LTPrint(LTNode* phead);//判空
bool LTEmpty(LTNode* plist);//销毁
void LTDestroy(LTNode* phead);//尾插
void LTNodePushBack(LTNode* phead, LTDataType x);//尾删
void LTNodePopBack(LTNode* phead);//头插
void LTNodePushFront(LTNode* phead, LTDataType x);//头删
void LTNodePopFront(LTNode* phead);//find
LTNode* LTNodeFind(LTNode* phead, LTDataType x);//pos前插
void LTNodeInsert(LTNode* pos, LTDataType x);//删pos
void LTNodeErase(LTNode* pos);
增加节点
增加节点的逻辑简单,这里不再赘述
//创建节点
LTNode* BuyListNode(LTDataType x)
{LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));newnode->data = x;newnode->next = NULL;newnode->prev = NULL;return newnode;
}初始化
显然在双链表这里我们的初始化是有事做的,而不像单链表在使用时给个空就行
我们要创建哨兵位的头节点,还要让他的next和prev都指向自己(毕竟是个循环链表)
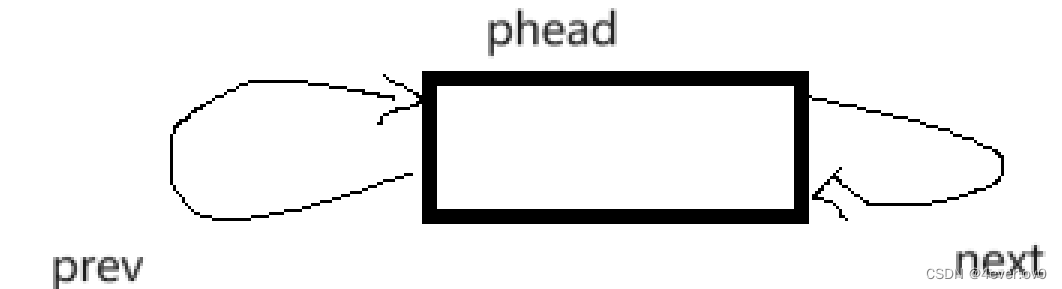
按理说这样修改头节点我们是要传二级指针的,但是后面的接口实际上都传一级指针就行,毕竟有了头节点,之后的修改都不涉及整个链表。
如果用了二级指针的写法,会是这样……
void LTInit(LTNode* *phead)
{//哨兵位*phead = BuyListNode(-1);(*phead)->next = *phead;(*phead)->prev = *phead;}用起来就是这样……
LTNode* plist = NULL;LTInit(&plist);为了接口的一致性,我们也可以用传一级指针,只要用返回值带出来即可
//初始化
LTNode* LTInit()
{//哨兵位LTNode*phead = BuyListNode(-1);phead->next = phead;phead->prev = phead;return phead;//返回头节点
}用起来就是这样
LTNode* plist = LTInit();
下来我们再写一下打印
打印
打印很简单,但是我们要控制好循环的逻辑,毕竟他是个循环链表,一不小心就会死循环
我可以定义一个cur指向phead->next,cur直到等于phead停下来
//打印
void LTPrint(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){printf("%d ", cur->data);cur = cur->next;}
}尾插
双链表的尾插相比于单链表轻松很多,首先它不用找尾(phead的prev就是尾),拿到尾以后我们只需改4个指针即可
如图所示

而且好消息是,我们通过画图发现,如果链表为空,上述逻辑依然成立,所以我们不用特判链表为空的情况
直接上代码
//尾插
void LTNodePushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = BuyListNode(x);LTNode* tail = phead->prev;//连接关系tail->next = newnode;newnode->prev = tail;newnode->next = phead;phead->prev = newnode;//空链表尾插不用单独处理。奈斯}尾删
尾删只需考虑链表是否为空的情况即可,即我们不能删哨兵位的头节点
依然是改4个指针的问题

//尾删
void LTNodePopBack(LTNode* phead)
{assert(phead);//链表为空就不能再删assert(!LTEmpty(phead));LTNode* tail = phead->prev;LTNode* newtail = tail->prev;phead->prev = newtail;newtail->next = phead;free(tail);tail = NULL;}头插
头插同样是改4个指针的逻辑
直接上代码
//头插
void LTNodePushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = BuyListNode(x);LTNode* head = phead->next;phead->next = newnode;newnode->prev = phead;newnode->next = head;head = newnode;}
头删
头删同理,我们只需额外判断链表是否为空就行
//头删
void LTNodePopFront(LTNode* phead)
{assert(phead);//链表为空就不能再删assert(!LTEmpty(phead));LTNode* head = phead->next;LTNode* newhead = head->next;newhead->prev = phead;phead->next = newhead;free(head);head = NULL;}我们简单的做一波测试
LTNode* plist = LTInit();LTNodePushBack(plist, 1);LTNodePushBack(plist, 1);LTNodePushBack(plist, 4);LTNodePushBack(plist, 2);//LTNodePopBack(plist);LTNodePopBack(plist);LTNodePushBack(plist, 1);LTNodePushFront(plist, 3);LTPrint(plist);LTDestroy(plist); (没有问题)
(没有问题)
这里我们发现双链表的头插头删尾插尾删都是O(1),确实挺不错的
find
find的原理不用多说了,直接上代码
//寻找
LTNode* LTNodeFind(LTNode* phead, LTDataType x)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){if (cur->data == x){return cur;}cur = cur->next;}//找不见return NULL;
}
insert
我们要写的pos位置前插,在写了前面的之后,写这个就是砍瓜切菜啦~
只需额外判断pos是否合法即可
//pos位置前插入
void LTNodeInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* newnode = BuyListNode(x);LTNode* prev = pos->prev;newnode->next = pos;pos->prev = newnode;newnode->prev = prev;prev->next = newnode;
}
erase
/删pos位置
void LTNodeErase(LTNode* pos)
{assert(pos);assert(!LTEmpty(pos));LTNode* next = pos->next;LTNode* prev = pos->prev;prev->next = next;next->prev = prev;free(pos);pos = NULL;
}写了erase和insert之后,我们前面的代码就都不用写了,直接复用这个即可
尾插会是这样
//复用版本//LTNodeInsert(phead,x);尾删
//复用版本//LTNodeErase(phead->prev);头插
//复用版本//LTNodeInsert(phead->next,x);头删
//复用版本//LTNodeErase(phead->next);这样,如果面试官让你20min写一个链表,你直接写一个insert和erase就可以轻松搞定了
销毁
最后我们来搞定一下销毁就好啦!
//销毁
void LTDestroy(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){LTNode* next = cur->next;free(cur);cur = next;}free(phead);//由于传的是一级指针,记得要在外面手动置空
}完整代码
完整代码是这样的…
list.h
#pragma once#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>typedef int LTDataType;typedef struct ListNode
{LTDataType data;struct ListNode* prev;struct ListNode* next;
}LTNode;//增加节点
LTNode* BuyListNode(LTDataType x);//初始化
//void LTInit(LTNode**phead);
LTNode* LTInit();//打印
void LTPrint(LTNode* phead);//判空
bool LTEmpty(LTNode* plist);//销毁
void LTDestroy(LTNode* phead);//尾插
void LTNodePushBack(LTNode* phead, LTDataType x);//尾删
void LTNodePopBack(LTNode* phead);//头插
void LTNodePushFront(LTNode* phead, LTDataType x);//头删
void LTNodePopFront(LTNode* phead);//find
LTNode* LTNodeFind(LTNode* phead, LTDataType x);//pos前插
void LTNodeInsert(LTNode* pos, LTDataType x);//删pos
void LTNodeErase(LTNode* pos);
list.c
#include"List.h"//创建节点
LTNode* BuyListNode(LTDataType x)
{LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));newnode->data = x;newnode->next = NULL;newnode->prev = NULL;return newnode;
}#if 0
//初始化(二级指针z)
void LTInit(LTNode* *phead)
{//哨兵位*phead = BuyListNode(-1);(*phead)->next = *phead;(*phead)->prev = *phead;//return phead;//返回头节点}
#endif//初始化
LTNode* LTInit()
{//哨兵位LTNode*phead = BuyListNode(-1);phead->next = phead;phead->prev = phead;return phead;//返回头节点
}
//打印
void LTPrint(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){printf("%d ", cur->data);cur = cur->next;}
}//判空
bool LTEmpty(LTNode* phead)
{return phead->next == phead;
}//销毁
void LTDestroy(LTNode* phead)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){LTNode* next = cur->next;free(cur);cur = next;}free(phead);//由于传的是一级指针,记得要在外面手动置空
}//尾插
void LTNodePushBack(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = BuyListNode(x);LTNode* tail = phead->prev;//连接关系tail->next = newnode;newnode->prev = tail;newnode->next = phead;phead->prev = newnode;//空链表尾插不用单独处理。奈斯//复用版本//LTNodeInsert(phead,x);
}//尾删
void LTNodePopBack(LTNode* phead)
{assert(phead);//链表为空就不能再删assert(!LTEmpty(phead));LTNode* tail = phead->prev;LTNode* newtail = tail->prev;phead->prev = newtail;newtail->next = phead;free(tail);tail = NULL;//复用版本//LTNodeErase(phead->prev);
}//头插
void LTNodePushFront(LTNode* phead, LTDataType x)
{assert(phead);LTNode* newnode = BuyListNode(x);LTNode* head = phead->next;phead->next = newnode;newnode->prev = phead;newnode->next = head;head = newnode;//复用版本//LTNodeInsert(phead->next,x);
}//头删
void LTNodePopFront(LTNode* phead)
{assert(phead);//链表为空就不能再删assert(!LTEmpty(phead));LTNode* head = phead->next;LTNode* newhead = head->next;newhead->prev = phead;phead->next = newhead;free(head);head = NULL;//复用版本//LTNodeErase(phead->next);
}//寻找
LTNode* LTNodeFind(LTNode* phead, LTDataType x)
{assert(phead);LTNode* cur = phead->next;while (cur != phead){if (cur->data == x){return cur;}cur = cur->next;}//找不见return NULL;
}//pos位置前插入
void LTNodeInsert(LTNode* pos, LTDataType x)
{assert(pos);LTNode* newnode = BuyListNode(x);LTNode* prev = pos->prev;newnode->next = pos;pos->prev = newnode;newnode->prev = prev;prev->next = newnode;
}//删pos位置
void LTNodeErase(LTNode* pos)
{assert(pos);assert(!LTEmpty(pos));LTNode* next = pos->next;LTNode* prev = pos->prev;prev->next = next;next->prev = prev;free(pos);pos = NULL;
}test.c
#include"List.h"void test1()
{//LTNode* plist = NULL;// LTInit(&plist);LTNode* plist = LTInit();LTNodePushBack(plist, 1);LTNodePushBack(plist, 1);LTNodePushBack(plist, 4);LTNodePushBack(plist, 1);LTNodePushBack(plist, 2);//LTNodePopBack(plist);//LTNodePopBack(plist);LTNodePushFront(plist, 3);LTNode* ret = LTNodeFind(plist, 4);LTNodeErase(ret);LTPrint(plist);LTDestroy(plist);plist = NULL;
}void test2()
{LTNode* plist = LTInit();LTNodePushBack(plist, 1);LTNodePushBack(plist, 1);LTNodePushBack(plist, 4);LTNodePushBack(plist, 2);//LTNodePopBack(plist);LTNodePopBack(plist);LTNodePushBack(plist, 1);LTNodePushFront(plist, 3);LTPrint(plist);LTDestroy(plist);
}int main()
{test2();return 0;
}二、OJ题
这次我们来看几道相对较难的OJ题
1 环形链表1
题目链接: . - 力扣(LeetCode)
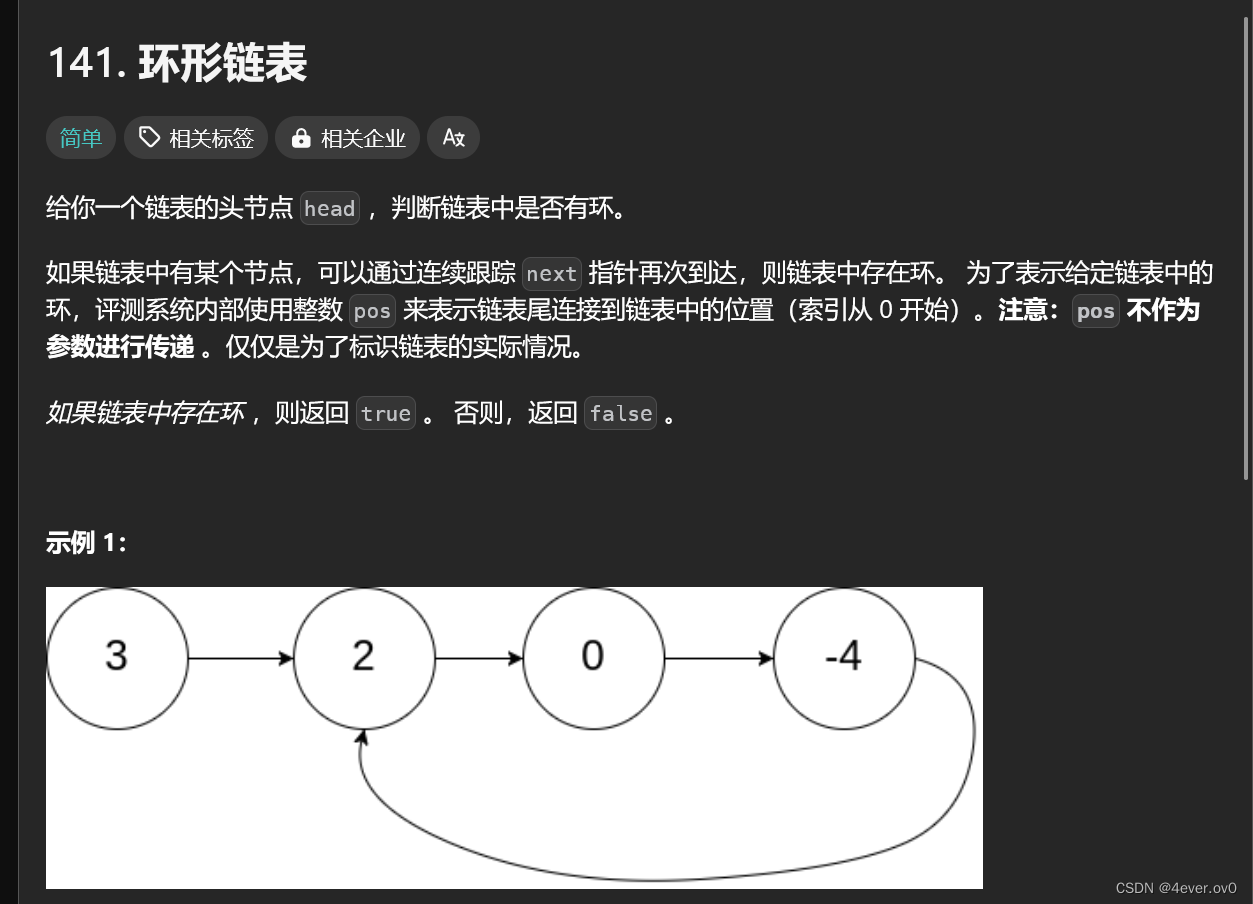
首先 这个题最好不要遍历,不然会很容易死循环
最简单的方法是快慢指针,让slow一次走一步,fast一次走两步,如果他们最终相遇
说明有环
为什么呢?
1 显然,slow和fast的相对速度是1步(1个节点),由物理学知识我们知道,如果有环,他们最终一定相遇,不会错过
2 如果fast一次走3步呢?相对速度就会是2步,suppose slow进环后fast开始追击。如果他们之间的距离是偶数,他们就会相遇;如果是奇数便会错过。以此类推。
代码还是简单的,我们很轻松就能写出来啦~
bool hasCycle(struct ListNode* head)
{//快慢指针,追击相遇struct ListNode* fast = head;struct ListNode* slow = head;//fast一次两步,slow一次一步while (fast && fast->next)//如果不断言fast,测试用例会有空链表,如果不想断言fast,可以加上面的那个判断{slow = slow->next;fast = fast->next->next;if (slow == fast){return true;}}return false;
}2 环形链表2
题目链接: . - 力扣(LeetCode)
下来恶心的是环形链表2,它建立在环形链表1的基础上
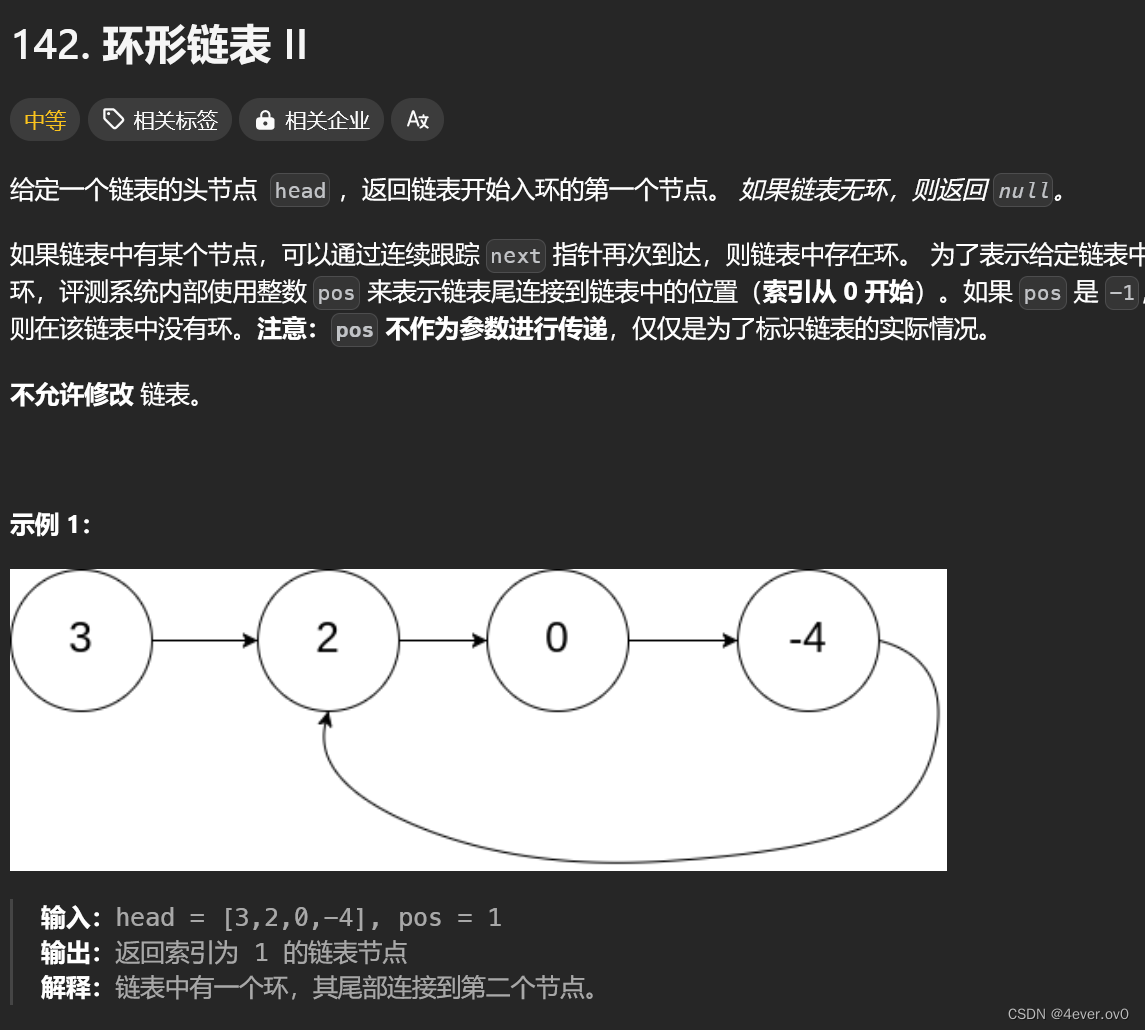
我们需要在有环的基础上找到环的入口节点
先说结论,再证明:在环形链表1中我们可以得到最后slow和fast的相遇点(如果有环的话)
现在是这样,我们再给两个指针,一个从链表开始走,另一个从相遇点走,他们最后相遇的节点
就是我们要的入口节点。
证明:
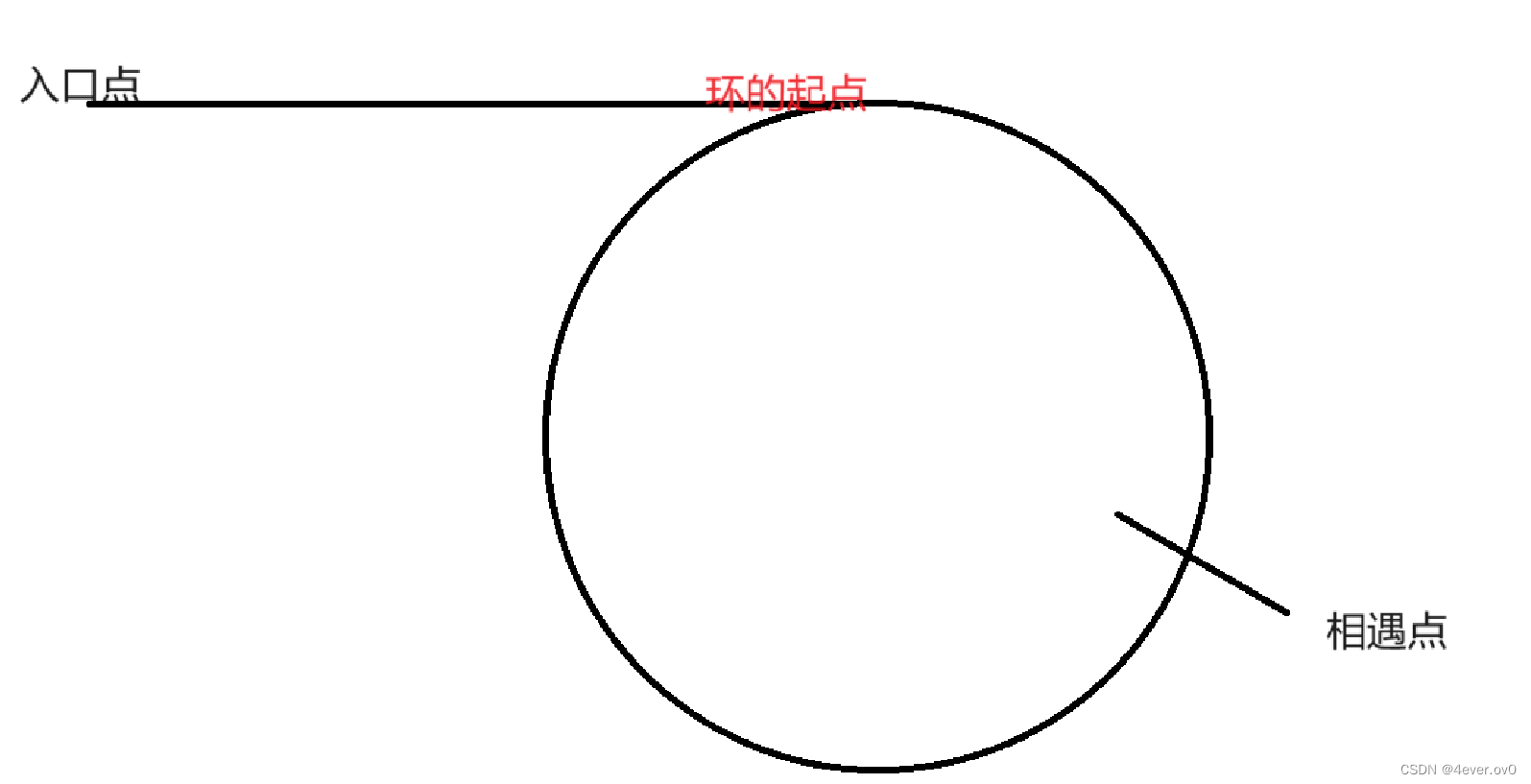
suppose入口点到环的起点距离为N,环的长度为C,入口点至相遇点的距离为x
也就是这样……
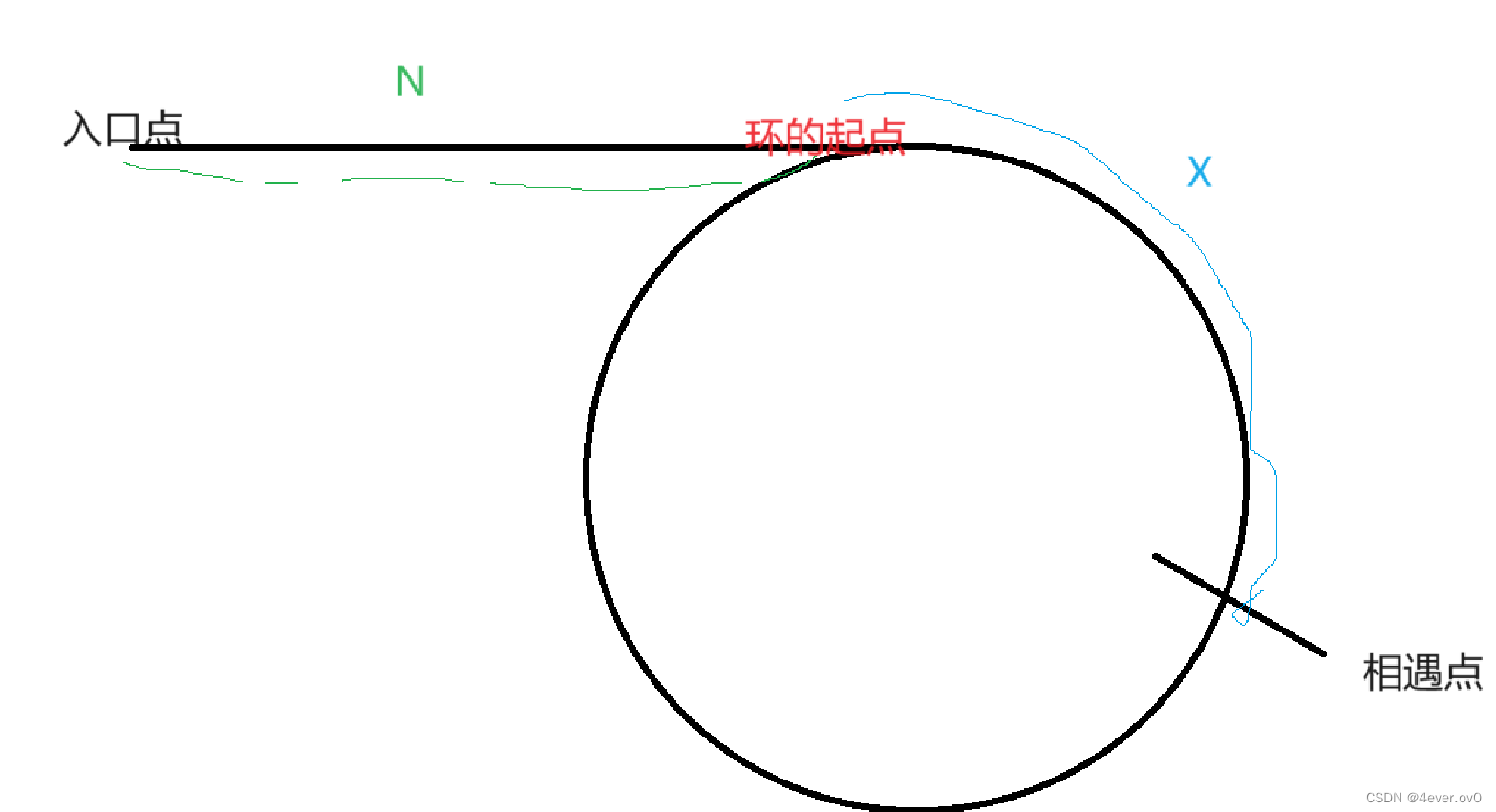
首先在相遇时slow走的距离为:N+X
fast走的距离为:N+X+n*C(n为fast走的圈数)
由于fast的距离==slow的两倍
即2*(N+X)=N+X+n*C
化简一下就会得到
N+X=n*C
N=n*C-X
由此便得:此时再用两个指针,一个从链表开始走,另一个从相遇点走,他们最后相遇的节点
就是我们要的入口节点。
代码如下……
bool hasCycle(struct ListNode* head)
{//快慢指针,追击相遇struct ListNode* fast = head;struct ListNode* slow = head;//fast一次两步,slow一次一步while (fast && fast->next)//如果不断言fast,测试用例会有空链表,如果不想断言fast,可以加上面的那个判断{slow = slow->next;fast = fast->next->next;if (slow == fast){return true;}}return false;
}struct ListNode* detectCycle(struct ListNode* head)
{if (hasCycle(head) == NULL){return NULL;}else{//一个从相遇点开始走,一个从头走,它们会在环的入口相遇struct ListNode* meet = hasCycle(head);while (meet != head){meet = meet->next;head = head->next;}return meet;}
}我们还有第二种思路
在相遇点处断开,我们会得到两条链表,如图
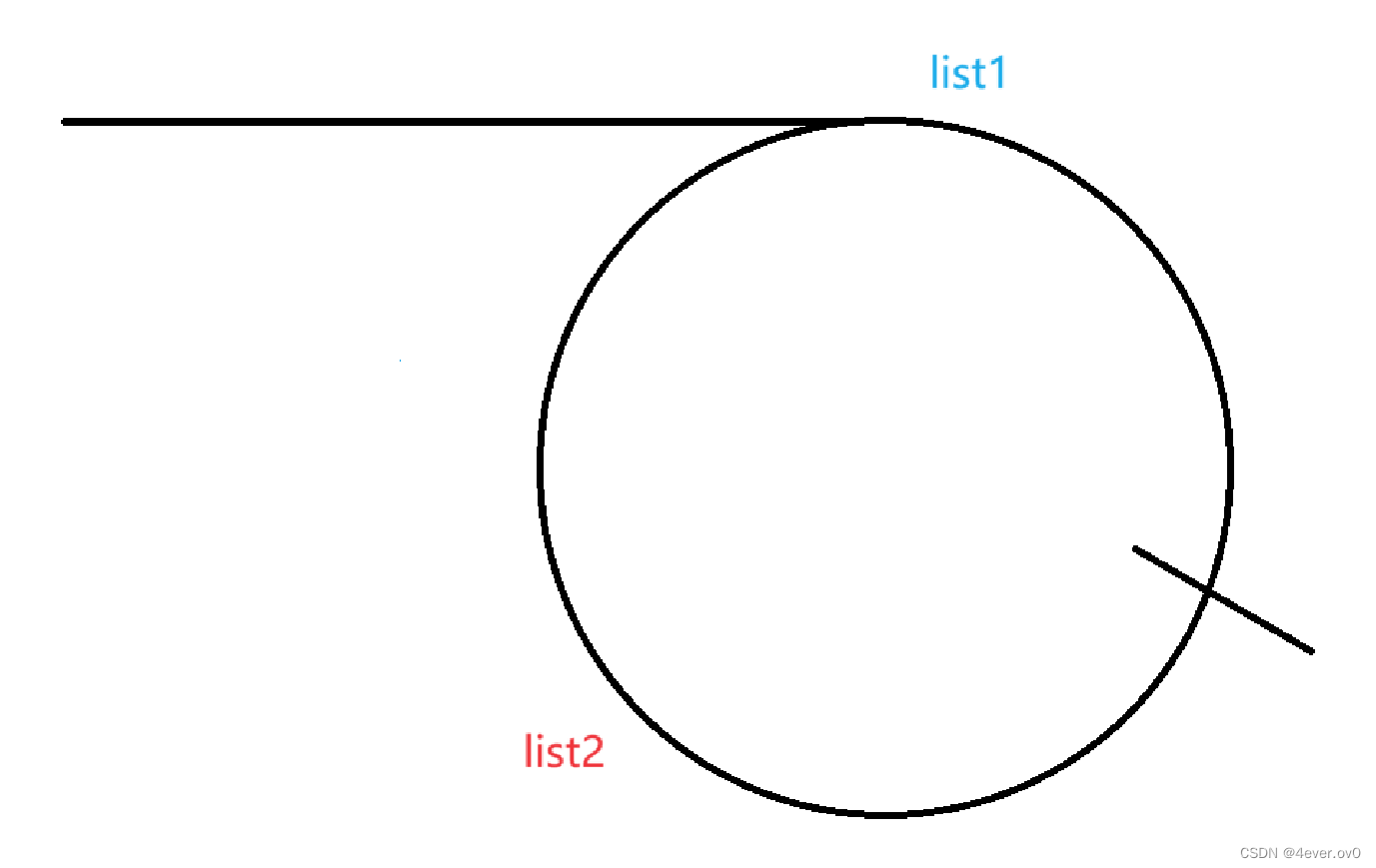
我们可以求这两条链表的相交节点(具体相交链表的逻辑请大家移步我的上一篇博客
( http://t.csdnimg.cn/cDpcC)
//链表相交
struct ListNode* getIntersectionNode(struct ListNode* headA, struct ListNode* headB)
{int lenA = 1;int lenB = 1;struct ListNode* tailA = headA;struct ListNode* tailB = headB;while (tailA){lenA++;tailA = tailA->next;}while (tailB){lenB++;tailB = tailB->next;}//如果相交,尾节点一定相同 //这个条件很有必要if (tailA != tailB){return NULL;}//快的先走差距步,再一起走struct ListNode* fast = lenA > lenB ? headA : headB;struct ListNode* slow = lenA > lenB ? headB : headA;int gap = abs(lenA - lenB);while (gap--){fast = fast->next;}while (fast != slow){fast = fast->next;slow = slow->next;}return fast;}
struct ListNode* hasCycle(struct ListNode* head)
{//快慢指针,追击相遇struct ListNode* fast = head;struct ListNode* slow = head;//fast一次两步,slow一次一步while (fast && fast->next)//如果不断言fast,测试用例会有空链表,如果不想断言fast,可以加上面的那个判断{slow = slow->next;fast = fast->next->next;if (slow == fast){return slow;}}return NULL;
}struct ListNode* detectCycle(struct ListNode* head)
{if (hasCycle(head) == NULL){return NULL;}else{struct ListNode* newhead = hasCycle(head)->next;hasCycle(head)->next = NULL;return getIntersectionNode(newhead, head);}
}3 复杂链表的复制
题目链接:. - 力扣(LeetCode)
首先,这个题很离谱,很难,算是大家目前链表学习的最后一块天花板

我们要复制一个带有random指针得链表,其中random会指向任意节点,这道题的关键就是
如何让新链表的random指针指向新链表的节点而非老链表的节点。
学过C++的兄弟们肯定就爽了,直接哈希 启动!
构建源节点和新节点的映射关系就行,确实,哈希真的很香,这里放一份参考代码
class Solution {
public:Node* copyRandomList(Node* head) {if(head==nullptr)return nullptr;unordered_map<Node*,Node*> m;Node*cur=head;while(cur){//建立旧结点和新节点的链接m[cur]=new Node(cur->val);cur=cur->next;}cur=head;while(cur){m[cur]->next=m[cur->next];m[cur]->random=m[cur->random];cur=cur->next;}return m[head];}};但是现在我们在学数据结构,没有哈希表,这怎么办?
这个时候有大佬就想了一种办法,在每个原节点的后面拷贝这个节点,并链接至源节点之后
就像这样……
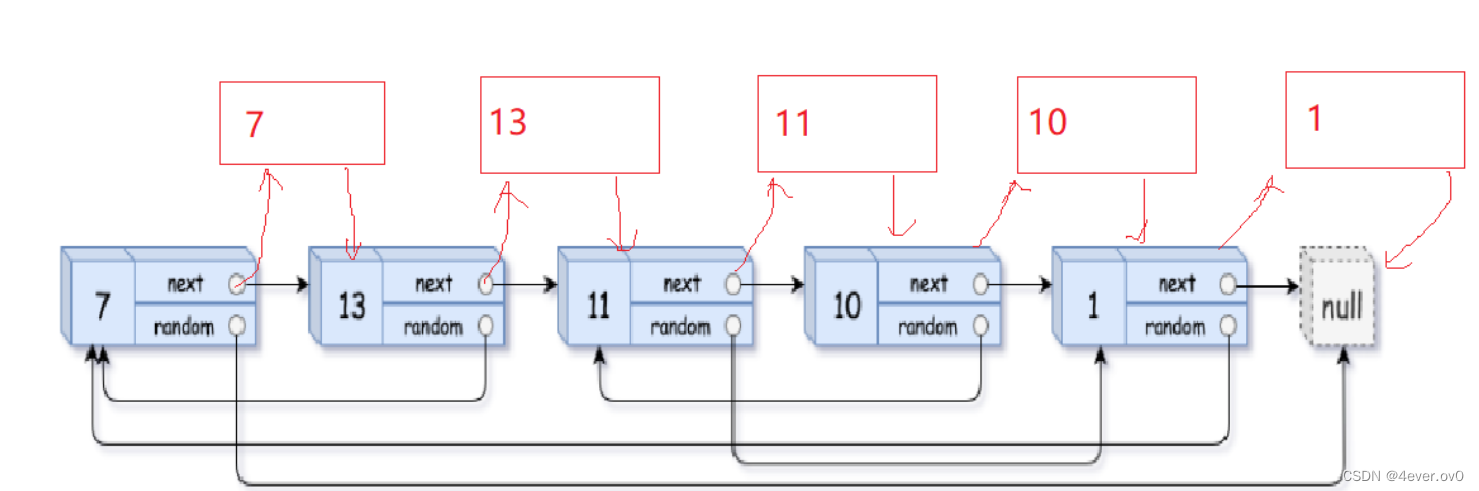
这有什么用呢?
别忘了我们的核心问题是解决新节点random的问题,此时我们会发现,
新节点的random==老节点random的next,
这波还是非常神奇的,一气呵成,行云流水,让人拍案叫绝。
接下来就是将这些新节点串成一个新链表,并将老链表恢复原样的工作,看似简单,但代码其实并不好写
代码如下~
struct Node* copyRandomList(struct Node* head)
{if (head == NULL)return NULL;struct Node* cur = head;//1 每个节点后连一个拷贝后的节点while (cur){struct Node* newnode = (struct Node*)malloc(sizeof(struct Node));newnode->val = cur->val;struct Node* next = cur->next;cur->next = newnode;newnode->next = next;cur = next;}cur = head;while (cur){struct Node* newnode = cur->next;if (cur->random == NULL){newnode->random = NULL;}else{newnode->random = cur->random->next;}//一次走两步!cur = cur->next->next;}//链接成新链表,cur = head;struct Node* newhead;struct Node* tail;while (cur){struct Node* copy = cur->next;struct Node* next = copy->next;if (NULL == newhead){tail = newhead = copy;}else{tail->next = copy;tail = tail->next;}//恢复原链表cur->next - next;cur = next;}return newhead;
}三、链表和顺序表的对比&&补充deque
话不多说我们直接上一个表格
| 不同点 | 顺序表 | 链表 |
| 存储空间 | 物理上一定连续 | 物理上不一定连续 |
| 随机访问 | O(1) | O(n) |
| 随意位置插入删除元素 | 可能要挪元素,O(n) | 只需修改指针指向 |
| 插入 | 动态顺序表须扩容 | 没有容量的概念 |
| 迭代器失效 | 有 | 无 |
| 应用场景 | 随机访问和元素高效存储 | 任意位置插入删除频繁 |
| 缓存利用率 | 高 | 低 |
补充两点:
1 迭代器失效的问题是由于顺序表某次插入后可能刚好扩容了,而我们在用的时候不知道,所以之前指向原空间的迭代器(指针)由于空间已经销毁了,当我们再次使用时,读取到的就算随机数据;显然,由于链表无须扩容,所以没有迭代器失效的问题
2 有关缓存利用率的问题
首先我们要明白计算机的存储体系结构
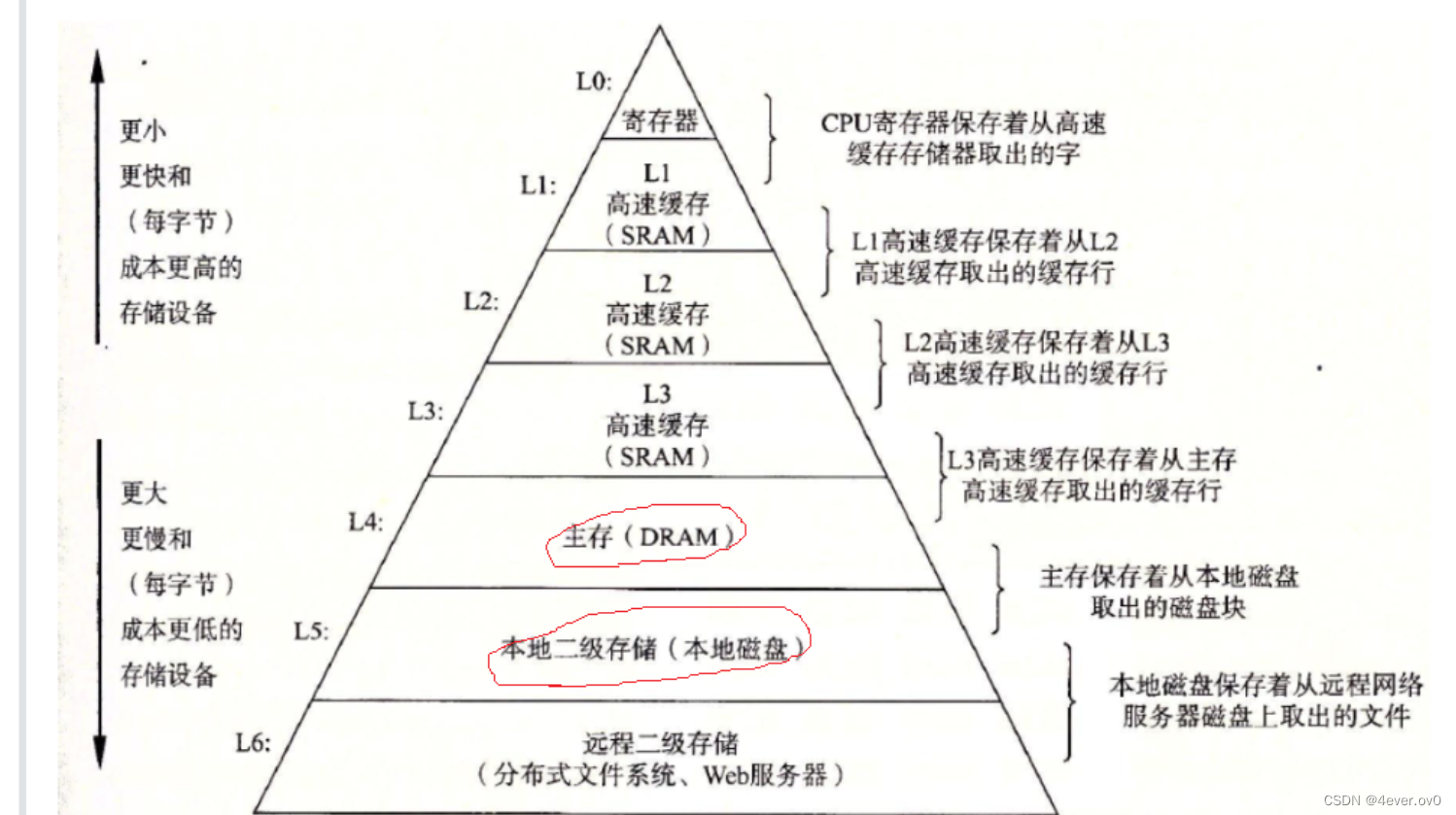
首先,冯诺依曼体系告诉我们,CPU如果直接和外设打交道,就太慢了,所以提出了所谓存储器的概念:由外设将数据load至主存,再让CPU从主存中读取数据。
但是主存的速度也太慢了,所以设立了所谓3级缓存,CPU拿数据时会直接去缓存拿,如果缓存中刚好有所需的数据,称为命中;如果没有所需的数据,会load新一批数据至缓存中。
而在计算机中有一个所谓的局部性原理,当你用到某个地址空间的数据,那大概率他周围的数据你也会用到。所以当这一段内存空间load到缓存时,如果你是顺序表,你的存储是连续的,所以你缓存中的数据用到的概率就会增加。而如果你是链表,你的缓存中大概率都是一些用不到的数据
此时甚至会有所谓"缓存污染"的问题。
另外,有趣的是,有人为了结合链表和顺序表的优点,发明出了一个叫deque的东西
deque,双端队列
1 相较于vector的扩容-拷贝原数据-释放旧空间的做法,他的操作是搞一个指针数组map,由指针数组来指向一块一块空间(缓冲区)
而map的扩容也有自己的策略,但总归括的次数会少很多,这算是保留了list的优点
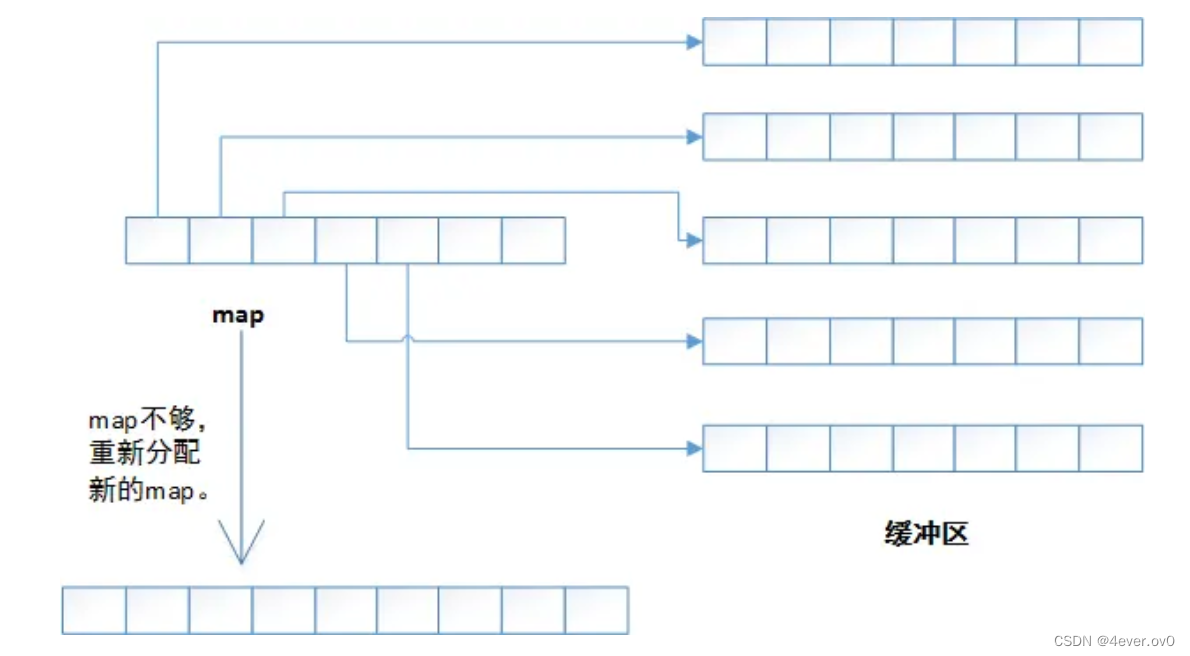
2 第二个好消息是相较于vector的头插头删效率低而list的尾插尾删效率低,deque的头插头删尾插尾删都是O(1),这算是集中了vector和list的优点
3 deque支持随机访问,即像数组一样可以用下标访问,只不过底层需要一些除运算模运算
不够极致
4 deque是分段的连续空间,所以缓存利用率也还可以
看似deque真的很不错,但是其实他也有缺点
虽然deque头插头删尾插尾删都很奈斯,但是他的insert、erase(中间插入删除)更拉了
另外还有其设计的逆天的迭代器机制,这个我们到C++再说
总结:看似是集成了vector和list的优点,但实际上很鸡肋,用的人很少。
总结
做总结,这篇博客结束了链表的学习,大家需要牢记链表和顺序表的区别,这是面试中常常问到的。下一篇博客我们将开启栈和队列的学习。
水平有限,还请各位大佬指正。如果觉得对你有帮助的话,还请三连关注一波。希望大家都能拿到心仪的offer哦。

每日gitee侠:今天你交gitee了嘛
相关文章:
速通数据结构与算法第四站 双链表
系列文章目录 速通数据结构与算法系列 1 速通数据结构与算法第一站 复杂度 http://t.csdnimg.cn/sxEGF 2 速通数据结构与算法第二站 顺序表 http://t.csdnimg.cn/WVyDb 3 速通数据结构与算法第三站 单链表 http://t.csdnimg.cn/cDpcC 感谢佬们…...
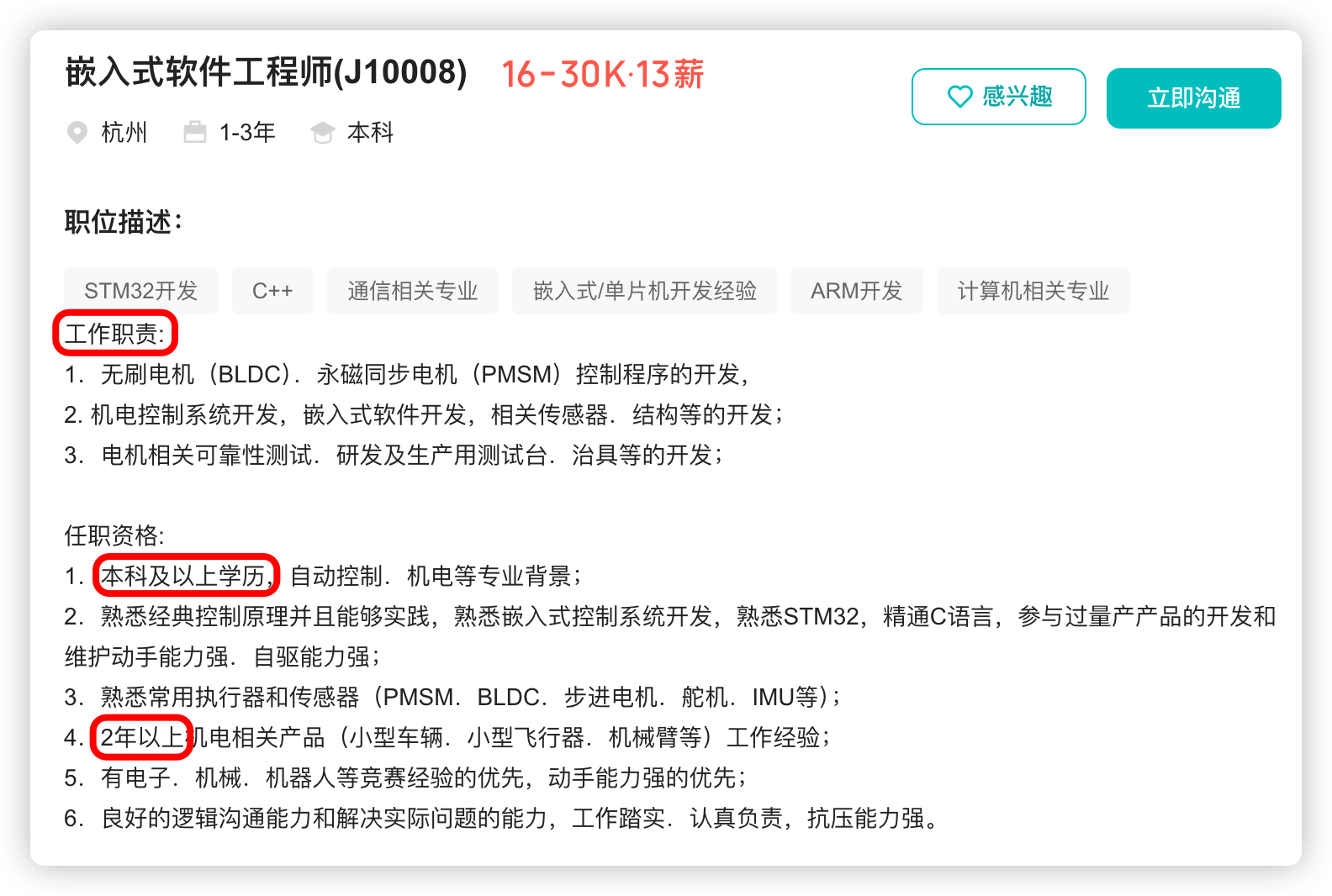
51单片机学习笔记12 SPI接口 使用1302时钟
51单片机学习笔记12 SPI接口 使用1302时钟 一、DS1302简介1. 功能特性2. 涓流充电3. 接口介绍时钟数据和控制线:电源线:备用电池连接: 二、寄存器介绍1. 控制寄存器2. 时间寄存器3. 日历/时钟寄存器 三、BCD码介绍四、DS1302时序1. 读时序2. …...

php编辑器 ide 主流编辑器的优缺点。phpstorm vscode atom 三者对比
编辑器PhpStormvscodeAtom是否收费收费,有30天试用期免费免费内存占用Java平台,一个进程1G多内存占用好几个进程,合起来1G上下/基本功能都具备,有的功能需要装插件都具备,有的功能需要装插件都具备,有的功能…...

【动手学深度学习】深入浅出深度学习之RMSProp算法的设计与实现
目录 🌞一、实验目的 🌞二、实验准备 🌞三、实验内容 🌼1. 认识RMSProp算法 🌼2. 在optimizer_compare_naive.py中加入RMSProp 🌼3. 在optimizer_compare_mnist.py中加入RMSProp 🌼4. 问…...

大转盘抽奖小程序源码
源码介绍 大转盘抽奖小程序源码,测试依旧可用,无BUG,跑马灯旋转效果,非常酷炫。 小程序核心代码参考 //index.js //获取应用实例 var app getApp() Page({data: {circleList: [],//圆点数组awardList: [],//奖品数组colorCirc…...
)
数据结构(无图版)
数据结构与算法(无图版,C语言实现) 1、绪论 1.1、数据结构的研究内容 一般应用步骤:分析问题,提取操作对象,分析操作对象之间的关系,建立数学模型。 1.2、基本概念和术语 数据:…...

软件测试中的顶级测试覆盖率技术
根据 CISQ 报告,劣质软件每年给美国公司造成约2.08 万亿美元的损失。虽然软件工具是企业和行业领域的必需品,但它们也容易出现严重错误和性能问题。人类手动测试不再足以检测和消除软件错误。 因此,产品或软件开发公司必须转向自动化测试&am…...

vscode使用技巧
常用快捷键 代码格式 Windows系统。格式化代码的快捷键是“ShiftAltF” Mac系统。格式化代码的快捷键是“ShiftOptionF” Ubuntu系统。格式化代码的快捷键是“CtrlShiftI”配置缩进 点击左上角的“文件”菜单,然后选择“首选项”>“设置”,或者使用…...
JSP
概念:Java Server Pages,Java服务端页面 一种动态的网页技术,其中既可以定义HTML、JS、CSS等静态内容,还可以定义Java代码的动态内容 JSP HTML Java 快速入门 注:Tomcat中已经有了JSP的jar包,因此我们…...
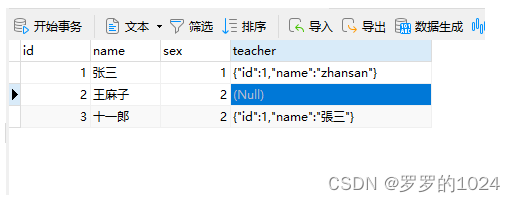
Mybatis--TypeHandler使用手册
TypeHandler使用手册 场景:想保存user时 teacher自动转String ,不想每次保存都要手动去转String;从DB查询出来时,也要自动帮我们转换成Java对象 Teacher Data public class User {private Integer id;private String name;priva…...
网络编程(TCP、UDP)
文章目录 一、概念1.1 什么是网络编程1.2 网络编程中的基本知识 二、Socket套接字2.1 概念及分类2.2 TCP VS UDP2.3 通信模型2.4 接口方法UDP数据报套接字编程TCP流套接字编程 三、代码示例3.1 注意点3.2 回显服务器基于UDP基于TCP 一、概念 首先介绍了什么是网络编程ÿ…...

Python快速入门系列-7(Python Web开发与框架介绍)
第七章:Python Web开发与框架介绍 7.1 Flask与Django简介7.1.1 Flask框架Flask的特点Flask的安装一个简单的Flask应用示例7.1.2 Django框架Django的特点Django的安装一个简单的Django应用示例7.2 前后端交互与数据传输7.2.1 前后端交互7.2.2 数据传输格式7.2.3 示例:使用Flas…...

最长对称子串
对给定的字符串,本题要求你输出最长对称子串的长度。例如,给定Is PAT&TAP symmetric?,最长对称子串为s PAT&TAP s,于是你应该输出11。 输入格式: 输入在一行中给出长度不超过1000的非空字符串。 输出格式&…...
【大模型】大模型 CPU 推理之 llama.cpp
【大模型】大模型 CPU 推理之 llama.cpp llama.cpp安装llama.cppMemory/Disk RequirementsQuantization测试推理下载模型测试 参考 llama.cpp 描述 The main goal of llama.cpp is to enable LLM inference with minimal setup and state-of-the-art performance on a wide var…...
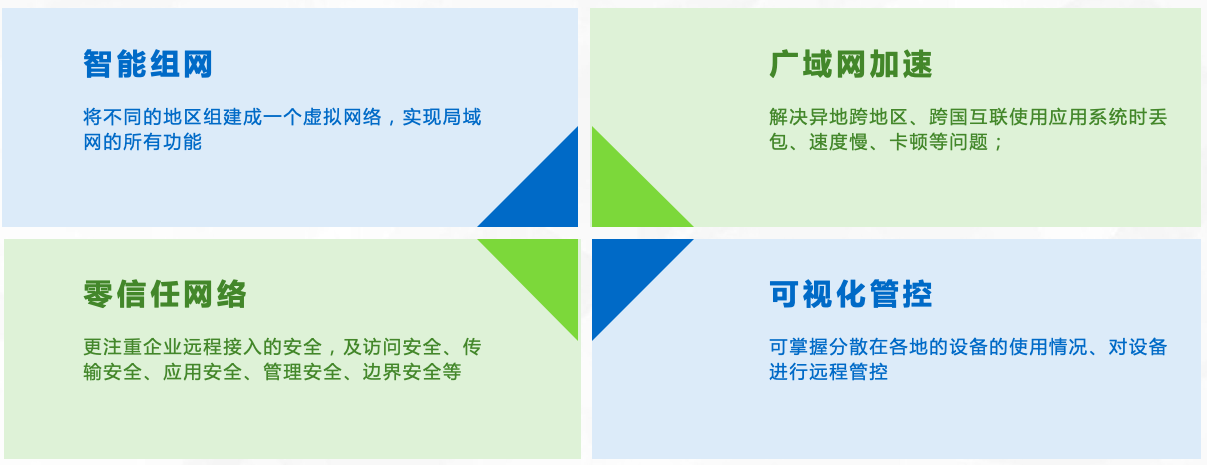
异地组网怎么管理?
在当今信息化时代,随着企业的业务扩张和员工的分布,异地组网已经成为越来越多企业的需求。异地组网管理相对来说是一项复杂而繁琐的任务。本文将介绍一种名为【天联】的管理解决方案,帮助企业更好地管理异地组网。 【天联】组网的优势 【天联…...
Kafka参数介绍
官网参数介绍:Apache KafkaApache Kafka: A Distributed Streaming Platform.https://kafka.apache.org/documentation/#configuration...
如何利用待办事项清单提高工作效率?
你是否经常因为繁重的工作量而感到不堪重负?你是否在努力赶工期或经常忘记重要的电子邮件?你并不是特例。如何利用待办事项清单提高工作效率?这里有一个简单的方法可以帮你理清混乱并更高效地完成任务—待办事项清单。 这种类型的清单可以帮…...

力扣经典150题第二题:移除元素
移除元素问题详解与解决方法 1. 介绍 移除元素问题是 LeetCode 经典题目之一,要求原地修改输入数组,移除所有数值等于给定值的元素,并返回新数组的长度。 问题描述 给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等…...

55555555555555
欢迎关注博主 Mindtechnist 或加入【Linux C/C/Python社区】一起学习和分享Linux、C、C、Python、Matlab,机器人运动控制、多机器人协作,智能优化算法,滤波估计、多传感器信息融合,机器学习,人工智能等相关领域的知识和…...
:图像形态学处理(上))
用Skimage学习数字图像处理(018):图像形态学处理(上)
本节开始讨论图像形态学处理,这是上篇,将介绍与二值形态学相关的内容,重点介绍两种基本的二值形态学操作:腐蚀和膨胀,以及三种复合二值形态学操作:开、闭和击中击不中变换。 目录 9.1 基础 9.2 基本操作…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

基于 TAPD 进行项目管理
起因 自己写了个小工具,仓库用的Github。之前在用markdown进行需求管理,现在随着功能的增加,感觉有点难以管理了,所以用TAPD这个工具进行需求、Bug管理。 操作流程 注册 TAPD,需要提供一个企业名新建一个项目&#…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

二维FDTD算法仿真
二维FDTD算法仿真,并带完全匹配层,输入波形为高斯波、平面波 FDTD_二维/FDTD.zip , 6075 FDTD_二维/FDTD_31.m , 1029 FDTD_二维/FDTD_32.m , 2806 FDTD_二维/FDTD_33.m , 3782 FDTD_二维/FDTD_34.m , 4182 FDTD_二维/FDTD_35.m , 4793...
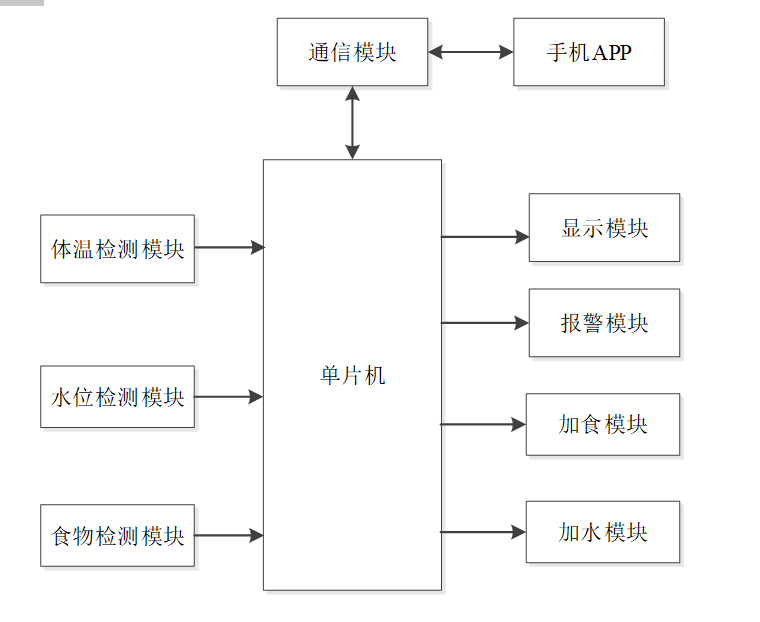
基于单片机的宠物屋智能系统设计与实现(论文+源码)
本设计基于单片机的宠物屋智能系统核心是实现对宠物生活环境及状态的智能管理。系统以单片机为中枢,连接红外测温传感器,可实时精准捕捉宠物体温变化,以便及时发现健康异常;水位检测传感器时刻监测饮用水余量,防止宠物…...

python读取SQLite表个并生成pdf文件
代码用于创建含50列的SQLite数据库并插入500行随机浮点数据,随后读取数据,通过ReportLab生成横向PDF表格,包含格式化(两位小数)及表头、网格线等美观样式。 # 导入所需库 import sqlite3 # 用于操作…...

ubuntu清理垃圾
windows和ubuntu 双系统,ubuntu 150GB,开发用,基本不装太多软件。但是磁盘基本用完。 1、查看home目录 sudo du -h -d 1 $HOME | grep -v K 上面的命令查看$HOME一级目录大小,发现 .cache 有26GB,.local 有几个GB&am…...