从多模态生物图数据中学习Gene的编码-MuSeGNN
由于数据的异质性,在不同的生物医学背景下发现具有相似功能的基因对基因表示学习提出了重大挑战。在本研究中,作者通过引入一种称为多模态相似性学习图神经网络的新模型来解决这个问题,该模型结合了多模态机器学习和深度图神经网络,从单细胞测序和空间转录组数据中学习基因表示。利用来自10个组织、3种测序技术和3个物种的82个训练数据集,作者创建了用于模型训练和基因表示生成的信息图结构,同时结合正则化与加权相似学习和对比学习来学习跨数据集的基因-基因关系。这种新颖的设计确保了我们可以在联合空间中提供包含不同上下文功能相似性的基因表示。全面的基准分析表明,模型能够有效地捕获多种模态下的基因功能相似性,在基因表示学习方面比最先进的方法高出97.5%。此外,作者将生物信息学工具与基因表征相结合,以揭示pathway富集、调控网络以及疾病相关或剂量敏感基因的功能。因此,该模型有效地为基因功能、组织功能、疾病和物种进化的分析提供了统一的基因表示。
来自:MuSe-GNN: Learning Unified Gene Representation From Multimodal Biological Graph Data
工程地址:https://github.com/HelloWorldLTY/MuSe-GNN
目录
- 背景概述
- 相关工作
- 基因共表达网络分析
- 基于网络的生物表示学习
- 图Transformer
- 方法
- 前言
- 图构建
- Cross-Graph Transformer
- 图重建损失
- 相似性权重学习
- 自监督图对比学习
- Reference
背景概述
生物技术的进步扩大了生物数据的多样性。这种技术的一个主要例子是单细胞测序,它允许对单个细胞内的遗传信息进行全面表征。该技术提供了获取细胞转录组学、表观基因组学和蛋白质组学全部信息的途径,包括基因表达scRNA-seq、染色质可及性scATAC-seq、甲基化和抗体。通过对来自同一组织的不同时间点的细胞进行测序,我们还可以深入了解细胞活动随时间变化的模式。此外,细胞活动的空间信息代表了一个同样重要的额外维度。这样的数据被定义为空间数据。所有这些数据都被称为多组学数据,整合多组学数据是一个重大挑战。
然而,传统的以细胞为anchor的多组学数据整合思路不是完全适用的[56,87,39],因为存在以下挑战:
- 不同组学数据本身具有挑战。例如,空间转录组数据的观察单位与其他单细胞数据不同,因为单个空间位置包含来自不同细胞的混合信息(见图1a左侧部分),因此不适合基于基因表达相似性生成空间簇。目前的研究也表明染色体可及性特征并不是细胞水平上基因表达的有力预测因子[86]。
- atlas-level的研究中庞大的数据量对高性能计算提出了挑战,往往存在内存不足或超时错误的风险。由于人体有近37.2万亿个细胞,综合分析在计算上具有很大的难度。而且,严重的批次效应可能通过引入噪声对分析结果产生不利影响。
因此,迫切需要一种专注于多组学和多组织数据(称为多模态生物数据)分析的高效而强大的方法来应对这些挑战。
由于认识到细胞导向的观点所带来的困难,先前的工作开始将重点转移到基因视角。基于物种进化过程中的自然选择,使用基因集作为表达谱的总结,可能会提供更可靠的依据[8]。蛋白质编码相关的基因也被认为与药物具有相互作用[19],这与疾病和药物发现更相关。Gene2vec是受Word2vec启发的一种方法,它通过从共表达网络中生成skip-gram对来学习基因表示。最近,基于Node2vec和OhmNet的基于基因的数据整合与分析技术(gene -based data Integration and ANalysis Technique, GIANT)[16]被开发出来,用于学习单细胞和空间数据集中的基因表示。然而,如图1b所示,基于这两种模型的基因嵌入,没有观察到来自不同数据集但同一组织的基因的显著功能聚类,因为这些方法没有从不同的多模态数据推断相关基因的相似性。此外,他们没有提供定量评估基因嵌入性能的指标。
在这里,作者从基因的角度介绍了一种新的多模态相似学习图神经网络MuSe-GNN,用于多模态生物数据整合。MuSe-GNN的整体工作流程如图1a所示。图1b显示与GIANT和Gene2vec相比,MuSe-GNN通过合适的模型结构和新颖的损失函数,在跨数据集的基因之间学习功能相似性的能力更强。MuSe-GNN利用权值共享GNN将不同模态的基因编码到一个由相似学习策略和对比学习策略正则化的共享空间中。在单图层面,图神经网络的设计保证了MuSe-GNN能够学习到每个共表达网络中的邻居信息,从而保持基因功能的相似性。在跨数据层面,相似学习策略确保MuSe-GNN能够将功能相似的基因整合到一个共同的簇中,而对比学习策略则有助于区分功能不同的基因。

- 图1:介绍了MuSe-GNN的工作流程、基因嵌入的可视化以及GIANT和Gene2vec两种现有方法存在的问题。
- a:MuSe-GNN学习基因嵌入的过程。在这里,作者强调单细胞数据和空间数据的区别,以及基因嵌入的主要应用。单细胞数据中的每个点代表一个细胞,而空间数据中的每个点代表混合细胞。
- b:MuSe-GNN、Gene2vec和GIANT基因嵌入的UMAPs。它们是按数据集着色的。基于UMAPs,可以得出结论,Gene2vec和GIANT都未能基于来自同一组织的数据集学习基因相似性,而MuSe-GNN产生了与数据集无关的有意义的嵌入。
这是第一篇将多模态机器学习MM-ML概念与GNNs设计相结合的基因表示学习论文。这两种方法在SOTA机器学习研究中都很普遍,这激发了作者将它们应用于大规模多模态生物数据集的联合分析。作为应用实例,作者首先使用MuSe-GNN生成的基因嵌入来研究人体基因调控的关键生物过程和网络。然后,还将该模型应用于分析COVID和癌症数据集,旨在揭示基于特定差异共表达基因的潜在抗病机制或并发症。最后,利用MuSe-GNN的基因嵌入来提高基因功能的预测精度。在这里,基因共表达意味着两个基因与同一边相连。
鉴于缺乏评估基因嵌入的明确指标,作者提出了六个指标,灵感来自单细胞数据分析中的批次整合问题。作者使用来自一种技术的真实生物数据集来评估模型,基准测试结果表明MuSe-GNN在综合评估中从20.1%显着提高到97.5%。为了总结模型的优势,MuSe-GNN解决了关于跨数据基因相似性学习的问题,并提供了四个主要贡献:
- 为多结构生物数据提供了一种有效的表示学习方法。
- 将来自不同组学和组织数据的基因整合到一个联合空间中,同时保留生物异质性。
- 用相似性函数识别共表达基因。
- 推断基因的特殊网络以及基因与生物通路或基因与疾病之间的关系。
相关工作
基因共表达网络分析
虽然跨模态的基因功能联合分析的直接尝试是有限的,目前在识别基于单个数据集的相关网络方面存在研究。WGCNA[52]是一种采用分层聚类识别具有共享功能基因模块的代表性方法。然而,作为一种早期工具,WGCNA的功能有限。总之,对共表达网络的推断需要更严格的方法,并且应该应用于多模态数据。
基于网络的生物表示学习
除了直接生成基因共表达网络外,也可以在低维空间中学习定量的基因表示从而更好地描述基因关系并促进下游分析。Gene2vec基于给定数据库的共表达网络生成基因嵌入。然而,它忽略了表达谱信息,并基于2017年之前的旧基因表达Omnibus (GEO)。GIANT利用Node2vec和OhmNet,通过构造图进行训练,从单细胞和空间数据集中学习基因表示。然而,这种方法仍然通过去除表达谱来过度压缩多模态生物数据集。此外,由Pearson correlation建立的共表达网络具有较高的假阳性率。此外,GIANT使用的一些数据集质量很低。也有一些方法共享了从其他数据集学习嵌入的类似目标。GSS旨在使用主成分分析(PCA)和聚类分析从bulk-seq数据集中学习一组所有基因的通用表示。然而,它是用于bulk测序数据,不能直接应用于来自不同组织的单细胞数据集。Gemini[103]专注于整合不同的蛋白质功能网络,用图节点代表蛋白质而不是基因。
图Transformer
在深度学习领域,Transformer是最成功的模型之一,它利用了seq2seq结构设计、多头自注意力设计和位置编码设计。许多研究人员试图将Transformer的优点结合到图结构学习中。TransformConv[81]为监督分类任务的图版本引入了多头注意机制,并取得了显著的改进。MAGNA[98]考虑图数据中更高层次的跳关系来增强节点分类能力。Graphomer [110] 使用来自 Open Graph Benchmark Large-Scale Challenge 的数据展示了 Transformer 结构对各种任务的积极影响,GraphomerGD [111] 进一步扩展了该挑战。最近,GPS[75]通过考虑额外的编码类型,提出了一种通用的Graph Transformer。此外,Transformer架构也为一些生物学问题提供了解决方案[113]。scBERT使用预训练模型生成基因和细胞嵌入,以提高细胞类型注释的准确性。总之,这些努力的实质影响突出了Transformer结构对Graph数据学习的重要贡献。
方法
在介绍MuSe-GNN的以下部分中,作者详细说明利用多模态生物数据构建图的不同方法,然后解释所提出的权重共享网络架构和最终损失函数的元素。
前言
GNN,GNNs旨在学习具有图结构数据的节点(特征)的图表示。现代GNNs通过聚合其 k k k阶邻居( k ≥ 1 k≥1 k≥1)的表示并将其与当前表示结合来迭代更新节点的表示。考虑一个图 G = { V , E } G=\left\{V,E\right\} G={V,E},其节点为 V = { v 1 , . . . , v n } V=\left\{v_{1},...,v_{n}\right\} V={v1,...,vn},节点 v i v_{i} vi的聚合与更新为: a i ( l + 1 ) = A G G R E G A T E ( l + 1 ) ( { h j ( l ) : j ∈ N ( v i ) } ) h i ( l + 1 ) = C O M B I N E ( l + 1 ) ( h i ( l ) , a i ( l + 1 ) ) a_{i}^{(l+1)}=AGGREGATE^{(l+1)}(\left\{h_{j}^{(l)}:j\in N(v_{i})\right\})\\ h_{i}^{(l+1)}=COMBINE^{(l+1)}(h_{i}^{(l)},a_{i}^{(l+1)}) ai(l+1)=AGGREGATE(l+1)({hj(l):j∈N(vi)})hi(l+1)=COMBINE(l+1)(hi(l),ai(l+1))其中, h i ( l ) h_{i}^{(l)} hi(l)和 h i ( l + 1 ) h_{i}^{(l+1)} hi(l+1)分别是MPNN前后的节点特征。
问题定义,通过处理多模态生物数据集来解决基因嵌入生成任务,表示为 D = ( { V i , E i } i = 1 T ) D=(\left\{V_{i},E_{i}\right\}_{i=1}^{T}) D=({Vi,Ei}i=1T)。目标是构建模型 M ( ⋅ , θ ) M(\cdot,\theta) M(⋅,θ),设计产生基因embedding集 ε = { e 1 , . . . , e T } = M ( D , θ ) \varepsilon=\left\{e_{1},...,e_{T}\right\}=M(D,\theta) ε={e1,...,eT}=M(D,θ)。本质上,目标是在统一的投影空间内协调来自不同模态的基因信息,从而产生统一的基因表示。
图构建
在构建基因图之前,作者的第一个贡献涉及每个数据集的高可变基因hvg的选择。这些hvg构成了一组具有高度变异的基因,可以代表给定表达谱的生物学功能。此外,作者认为共表达网络对基因表征学习很重要,因为它使我们能够表征基因与基因之间的关系。由于测序深度(测序深度越高,我们对于每个单细胞的RNA表达数据就越准确和全面),或每个细胞的总计数,经常成为共表达网络推断的一个混淆因素[11],作者采用了两种独特的方法,scTransform和CS-CORE,来处理scRNA-seq和scATAC-seq数据,从而创建不受测序深度影响的基因表达谱和共表达网络(基于多模态单细胞数据构建共表达网络-MuSeGNN)。对于空间转录组学数据,重点是显示具有空间表达模式的基因。作者使用SPARK-X识别这些基因,然后应用scTransform和CS-CORE。在生成的所有图中,节点代表基因,边代表基因的共表达关系。
Cross-Graph Transformer
为了在训练过程中利用Transformer模型的优势,作者集成了一个具有多头自注意设计的图神经网络,称为TransformerConv,以合并共表达信息并生成基因嵌入。结合多模态信息可以估计出更准确的基因嵌入。cross-graph transformer可以在不同的图中高效地学习包含基因功能的基因嵌入。
TransformerConv
将 c c c作为注意力头的index,从节点 j j j到节点 i i i的GNN多头注意力表示为: q c , i ( l ) = W c , q ( l ) h i ( l ) + b c , q ( l ) k c , j ( l ) = W c , k ( l ) h j ( l ) + b c , k ( l ) e c , i j = W c , e e i j + b c , e α c , i j ( l ) = < q c , i ( l ) , k c , j ( l ) , e c , i j > ∑ u ∈ N ( i ) < q c , i ( l ) , k c , u ( l ) , e c , i u > q_{c,i}^{(l)}=W_{c,q}^{(l)}h_{i}^{(l)}+b_{c,q}^{(l)}\\ k_{c,j}^{(l)}=W_{c,k}^{(l)}h_{j}^{(l)}+b_{c,k}^{(l)}\\ e_{c,ij}=W_{c,e}e_{ij}+b_{c,e}\\ \alpha_{c,ij}^{(l)}=\frac{<q_{c,i}^{(l)},k_{c,j}^{(l)},e_{c,ij}>}{\sum_{u\in N(i)}<q_{c,i}^{(l)},k_{c,u}^{(l)},e_{c,iu}>} qc,i(l)=Wc,q(l)hi(l)+bc,q(l)kc,j(l)=Wc,k(l)hj(l)+bc,k(l)ec,ij=Wc,eeij+bc,eαc,ij(l)=∑u∈N(i)<qc,i(l),kc,u(l),ec,iu><qc,i(l),kc,j(l),ec,ij>其中, < q , k , e > = e q T k d <q,k,e>=e^{\frac{q^{T}k}{\sqrt{d}}} <q,k,e>=edqTk。 d \sqrt{d} d是用于减少梯度消失的标量。不同的 q q q, k k k代表不同的query vector和key vector, e e e代表边的特征。注意力 α c , i j ( l ) \alpha_{c,ij}^{(l)} αc,ij(l)代表第 c c c个注意力头(第 l l l层)输出的从节点 j j j到 i i i的注意力值。 h h h代表节点embedding。
定义节点embedding h i ( l + 1 ) h_{i}^{(l+1)} hi(l+1)的更新为: v c , j ( l ) = W c , v ( l ) h j ( l ) + b c , v ( l ) h i ( l + 1 ) = ∣ ∣ c = 1 C [ ∑ j ∈ N ( i ) α c , i j ( l ) ( v c , j ( l ) + e c , i j ) ] v_{c,j}^{(l)}=W_{c,v}^{(l)}h_{j}^{(l)}+b_{c,v}^{(l)}\\ h_{i}^{(l+1)}=||_{c=1}^{C}[\sum_{j\in N(i)}\alpha_{c,ij}^{(l)}(v_{c,j}^{(l)}+e_{c,ij})] vc,j(l)=Wc,v(l)hj(l)+bc,v(l)hi(l+1)=∣∣c=1C[j∈N(i)∑αc,ij(l)(vc,j(l)+ec,ij)]其中, ∣ ∣ c = 1 C ||_{c=1}^{C} ∣∣c=1C表示 C C C个注意力头的concat。
权重共享
考虑到多模态生物数据集之间的差异性,作者采用了权重共享机制来确保模型在不同的图中学习共享信息,这代表了一种学习交叉图关系的新方法。
数据集和多模态Graph Transformer
对于来自相同模态 m m m的每个graph ( G 1 , G 2 , … , G n ) (G_1, G_2,…, G_n) (G1,G2,…,Gn),作者不仅采用了数据集特定的GT layers L 1 , L 2 , … , L n L_1, L_2,…, L_n L1,L2,…,Ln,而且还将所有这些数据集特定的layers连接到一组共享的GT层,记为 D m D_m Dm。该设计展示了作者将权重共享纳入GT框架的新方法。给定网络参数为 θ ∗ θ∗ θ∗的数据集 i i i,MuSe-GNN的计算过程定义如下: X i ′ = D m ( L i ( G i ; θ L i ) ; θ D m ) X_{i}'=D_{m}(L_{i}(G_{i};\theta_{L_{i}});\theta_{D_{m}}) Xi′=Dm(Li(Gi;θLi);θDm)
Datasets Decoder
作者提出了一种基于MLP的数据集专用解码器结构。该解码器模型对于重建不同基因之间的共表达关系至关重要。给定图 G i G_i Gi及其对应的基因嵌入 e i e_i ei,则网络参数为 θ d e c , i θ_{dec,i} θdec,i的MuSe-GNN解码过程定义如下: E r e c = M L P ( e i e i T ; θ d e c , i ) E_{rec}=MLP(e_{i}e_{i}^{T};\theta_{dec,i}) Erec=MLP(eieiT;θdec,i)其中 E r e c E_{rec} Erec代表重建的共表达网络。
图重建损失
在单个Graph中,作者实现了一个受图自编码器(GAE)启发的损失函数。这个函数的目的是保持两个关键方面:1具有共同功能的基因之间的相似性,2具有不同功能的基因之间的区别。这种对GAE的损失函数使用构成了对方法设计的贡献。对于图 G i = { V i , E i } G_{i}=\left\{V_{i}, E_{i}\right\} Gi={Vi,Ei},定义edge重建的损失函数为: e i = D m ( L i ( G i ; θ L i ) ; θ D m ) E r e c = M L P ( e i e i T ; θ d e c , i ) e_{i}=D_{m}(L_{i}(G_{i};\theta_{L_{i}});\theta_{D_{m}})\\ E_{rec}=MLP(e_{i}e_{i}^{T};\theta_{dec,i}) ei=Dm(Li(Gi;θLi);θDm)Erec=MLP(eieiT;θdec,i)然后计算 E r e c E_{rec} Erec和 E i E_{i} Ei之间的BCE L B C E L_{BCE} LBCE(因为重建的是edge)。
相似性权重学习
为了整合来自不同数据集的共享生物信息,作者将输入图结构的重建损失与余弦相似学习损失融合在一起。在这个过程中,作者将每对数据集之间的共同HVG作为anchors。目标是最大化跨数据集的公共HVG的embedding相似度 c o s ( a , b ) cos(a,b) cos(a,b)(图2中的黄色blocks)。然而,在实践中,不同的公共HVG在两个数据集中可能具有不同程度的功能相似度,这很难直接量化。因此,作者采用共享社区得分作为间接度量,将其作为最终损失函数中不同公共HVG pairs余弦相似度的权重。
对于两个Graph G i G_{i} Gi和 G j G_{j} Gj,其中有一个共享基因 g g g,作者在两个图中得到了给定基因 g g g的共表达基因,记为 N i g N_{ig} Nig和 N j g N_{jg} Njg。因此,基因 g g g的权值 λ i j g λ_{ijg} λijg可表示为: λ i j g = ∣ N i g ∩ N j g ∣ ∣ N i g ∪ N j g ∣ λ_{ijg}=\frac{|N_{ig}\cap N_{jg}|}{|N_{ig}\cup N_{jg}|} λijg=∣Nig∪Njg∣∣Nig∩Njg∣我们可以在这两个图之间从1到 n n n遍历所有共享基因,最终得到一个向量 λ i j = [ λ i j 1 , . . . , λ i j n ] \lambda_{ij}=[\lambda_{ij1},...,\lambda_{ijn}] λij=[λij1,...,λijn]。该向量封装了所有公共HVG中两个图之间的相似性。然后,我们可以修改各种基因pair的余弦相似度,首先将这个向量与余弦相似度相乘,然后将所有基因的结果值相加。最终结果取负得到相似度损失 L s i m L_{sim} Lsim。
自监督图对比学习
具体而言,在整合多模态生物数据时,作者采用了对比学习策略,以确保功能相似的基因尽可能紧密地聚集在一起,而功能不同的基因则相互分离。作者利用信噪比估计(InfoNCE)作为损失函数的一部分来最大化anchor基因和具有相同功能的基因之间的相互信息。这种损失适用于训练过程中任意两个Graph中的不同基因。一般来说,如果我们表示 N N N个基因的embedding为 G e n e N = { e 1 , . . . , e N } Gene_{N}=\left\{e_{1},...,e_{N}\right\} GeneN={e1,...,eN},InfoNCE被设计为最小化: L i n f o N C E = − E [ l o g e x p ( e ⋅ k + / τ ) ∑ i = 0 K e x p ( e ⋅ k i / τ ) ] L_{infoNCE}=-\mathbb{E}[log\frac{exp(e\cdot k_{+}/\tau)}{\sum_{i=0}^{K}exp(e\cdot k_{i}/\tau)}] LinfoNCE=−E[log∑i=0Kexp(e⋅ki/τ)exp(e⋅k+/τ)]其中,样本 { k 0 , k 1 , k 2 … } \left\{k_0, k_1, k_2…\right\} {k0,k1,k2…}组成一组基因嵌入,称为一个字典, e e e是一个query基因嵌入。 k + k_{+} k+和 k i k_{i} ki分别是 e e e的正样本和负样本。

- MuSe-GNN的整体模型架构和损失函数设计。
Reference
[8]Computational principles and challenges in single-cell data integration
[11]Depth normalization for single-cell genomics count data
[16]A unified analysis of atlas single cell data
[19]Dgidb 3.0: a redesign and expansion of the drug–gene interaction database
[39]Integrated analysis of multimodal single-cell data
[52]Wgcna: an r package for weighted correlation network analysis
[56]Clustering of single-cell multi-omics data with a multimodal deep learning method
[75]Recipe for a general, powerful, scalable graph transformer
[81]Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification
[86]Dynamic genetic regulation of gene expression during cellular differentiation
[87]Comprehensive Integration of Single-Cell Data
[98]Multi-hop attention graph neural networks
[103]Gemini: memory-efficient integration of hundreds of gene networks with high-order pooling
[110]Do transformers really perform badly for graph representation?
[111]Rethinking the expressive power of GNNs via graph biconnectivity
[113]Applications of transformer-based language models in bioinformatics: A survey
相关文章:
从多模态生物图数据中学习Gene的编码-MuSeGNN
由于数据的异质性,在不同的生物医学背景下发现具有相似功能的基因对基因表示学习提出了重大挑战。在本研究中,作者通过引入一种称为多模态相似性学习图神经网络的新模型来解决这个问题,该模型结合了多模态机器学习和深度图神经网络࿰…...
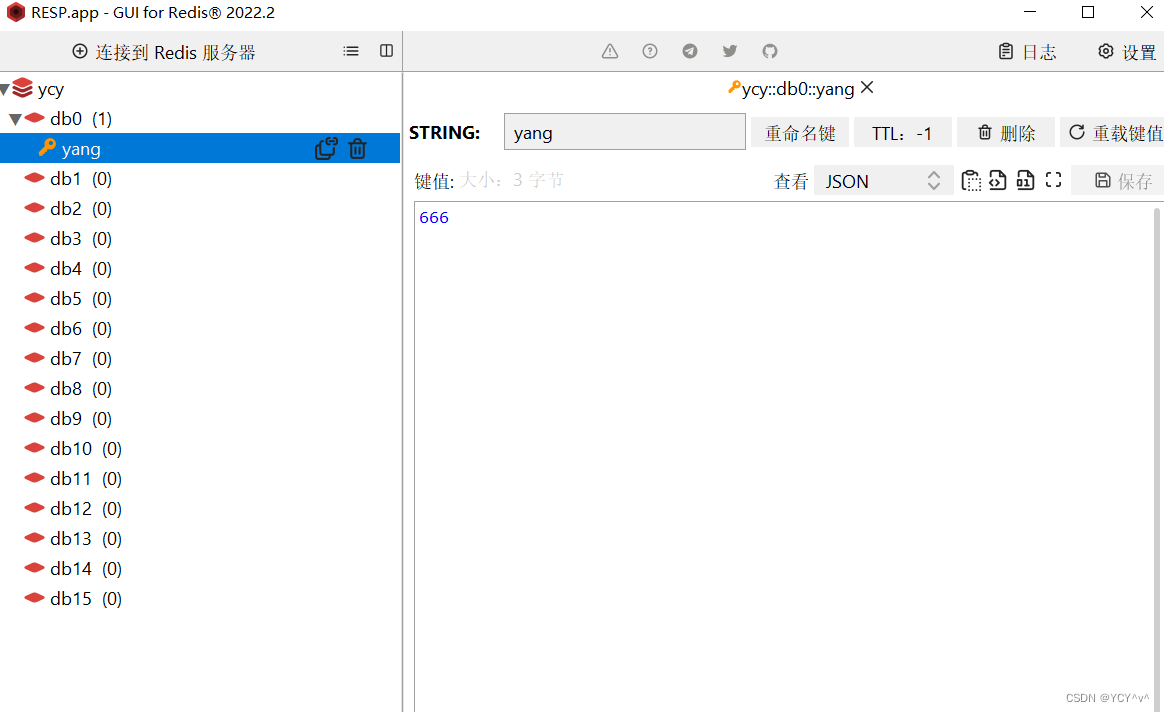
Redis Desktop Manager可视化工具
可视化工具 Redis https://www.alipan.com/s/uHSbg14XmsL 提取码: 38cl 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。 官网下载(不推荐):http…...

ARM汇编与逆向工程:揭秘程序背后的神秘世界
文章目录 一、ARM汇编语言:底层世界的密码二、逆向工程:软件世界的侦探工作三、ARM汇编与逆向工程的完美结合四、ARM汇编逆向工程的风险与挑战五、ARM汇编逆向工程的未来展望《ARM汇编与逆向工程 蓝狐卷 基础知识》内容简介作者简介译者简介ChaMd5安全团…...
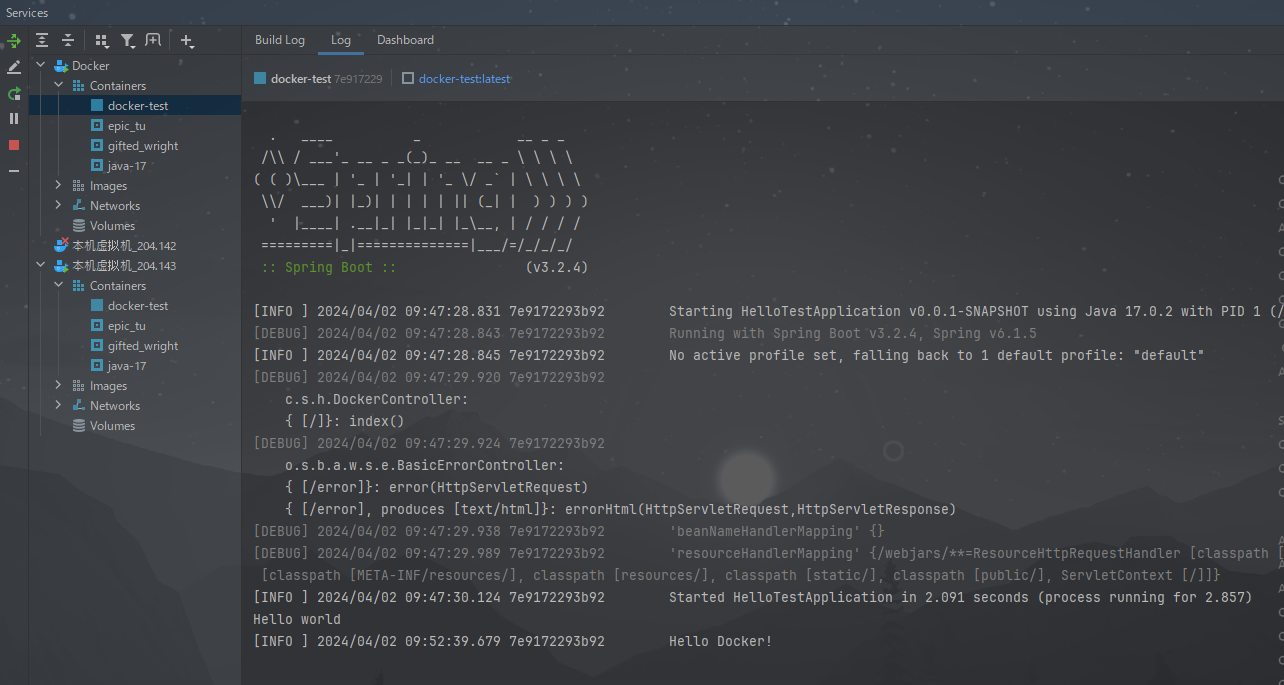
idea使用docker将Java项目生成镜像并使用
1:开启docker 远程访问 使用 vim 编辑docker服务配置文件 vim /lib/systemd/system/docker.service [Service] Typenotify # the default is not to use systemd for cgroups because the delegate issues still # exists and systemd currently does not suppor…...
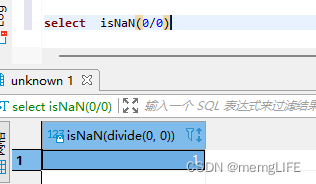
clickhouse sql使用2
1、多条件选择 multiIf(cond_1, then_1, cond_2, then_2, …, else) select multiIf(true,0,1) 当第一条件不成立看第二条件判断 第一个参数条件参数,第二参数条件成立时走 2、clickhouse 在计算时候长出现NaN和Infinity异常处理 isNaN()和isInfinite()处理...

jrebel
JRebel最新版(2024.1.2)在线激活_jrebel 激活 2024-CSDN博客 JRebelXRebel热部署插件激活支持IDEA2023.1_jrebel and xrebel 激活-CSDN博客...
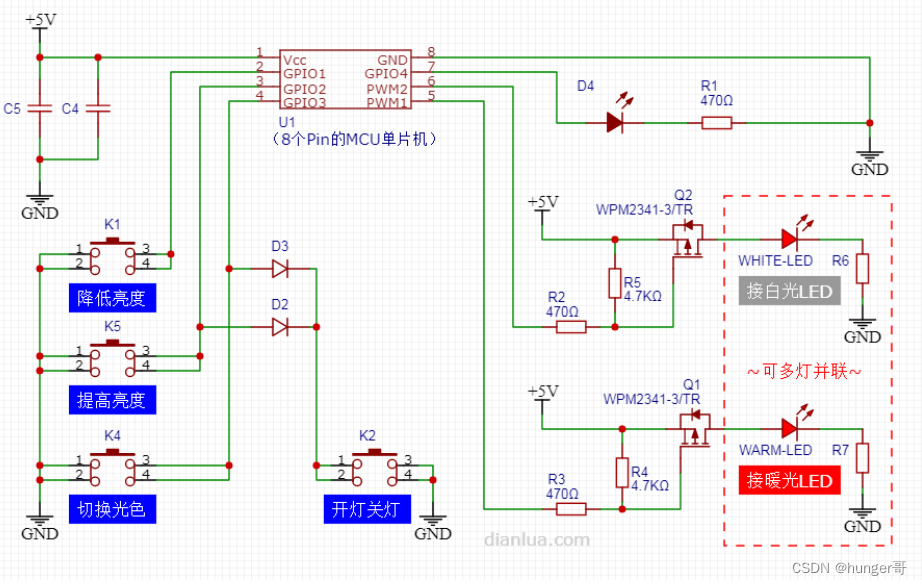
【单片机家电产品学习记录--红外线】
单片机家电产品学习记录–红外线 红外手势驱动电路,(手势控制的LED灯) 原理 通过红外线对管,IC搭建的电路,实现灯模式转换。 手势控制灯模式转换,详细说明 转载 1《三色调光LED台灯电路》,…...

Java入门教程||Java Applet基础
Java Applet基础 applet是一种Java程序。它一般运行在支持Java的Web浏览器内。因为它有完整的Java API支持,所以applet是一个全功能的Java应用程序。 如下所示是独立的Java应用程序和applet程序之间重要的不同: Java中applet类继承了 java.applet.Applet类Applet…...

Python可视化概率统计和聚类学习分析生物指纹
🎯要点 🎯使用Jupyter Notebook执行Dash 应用,确定Dash输入输出,设计回调函数,Dash应用中包含函数。🎯使用Plotly绘图工具:配置图对象选项,将图转换为HTML、图像。使用数据集绘图…...

yolo v8 教程(不出5行代码让你学会)
Solving environment: failedPackagesNotFoundError: The following packages are not available from current channels:- python3.8https://github.com/ultralytics 下滑来到 先来介绍为什么写这篇博客, 一. 是我之前的yolov5的博客挺多人访问的,但是…...

MongoDB集合结构分析工具Variety
工具下载地址:GitHub - variety/variety: Variety: a MongoDB Schema Analyzer 对于Mongo这种结构松散的数据库来说,如果想探查某个集合的结构,通过其本身提供的功能很不方便,通过调研发现一个很轻便的工具--variety,…...

详解Qt中访问数据库
在Qt中访问数据库涉及到几个关键步骤,主要包括加载数据库驱动、建立数据库连接、执行SQL语句、读取结果等。下面将详细介绍这些步骤,并给出一个简单的示例,这里假设使用的是SQLite数据库。 记得首先在pro文件中添加QT sql 1. 加载数据库驱动…...

《QT实用小工具·三》偏3D风格的异型窗体
1、概述 源码放在文章末尾 可以在窗体中点击鼠标左键进行图片切换,项目提供了一些图片素材,整体风格偏向于3D类型,也可以根据需求自己放置不同的图片。 下面是demo演示: 项目部分代码如下所示: 头文件部分ÿ…...

如何优化TCP?TCP的可靠传输机制是什么?
在网络世界中,传输层协议扮演着至关重要的角色,特别是TCP协议,以其可靠的数据传输特性而广受青睐。然而,随着网络的发展和数据量的激增,传统的TCP协议在效率方面遭遇了挑战。小编将深入分析TCP的可靠性传输机制&#x…...
DFS(基础,回溯,剪枝,记忆化)搜索
DFS基础 DFS(深度优先搜索) 基于递归求解问题,而针对搜索的过程 对于问题的介入状态叫初始状态,要求的状态叫目标状态 这里的搜索就是对实时产生的状态进行分析检测,直到得到一个目标状态或符合要求的最佳状态为止。对于实时产生新的状态…...
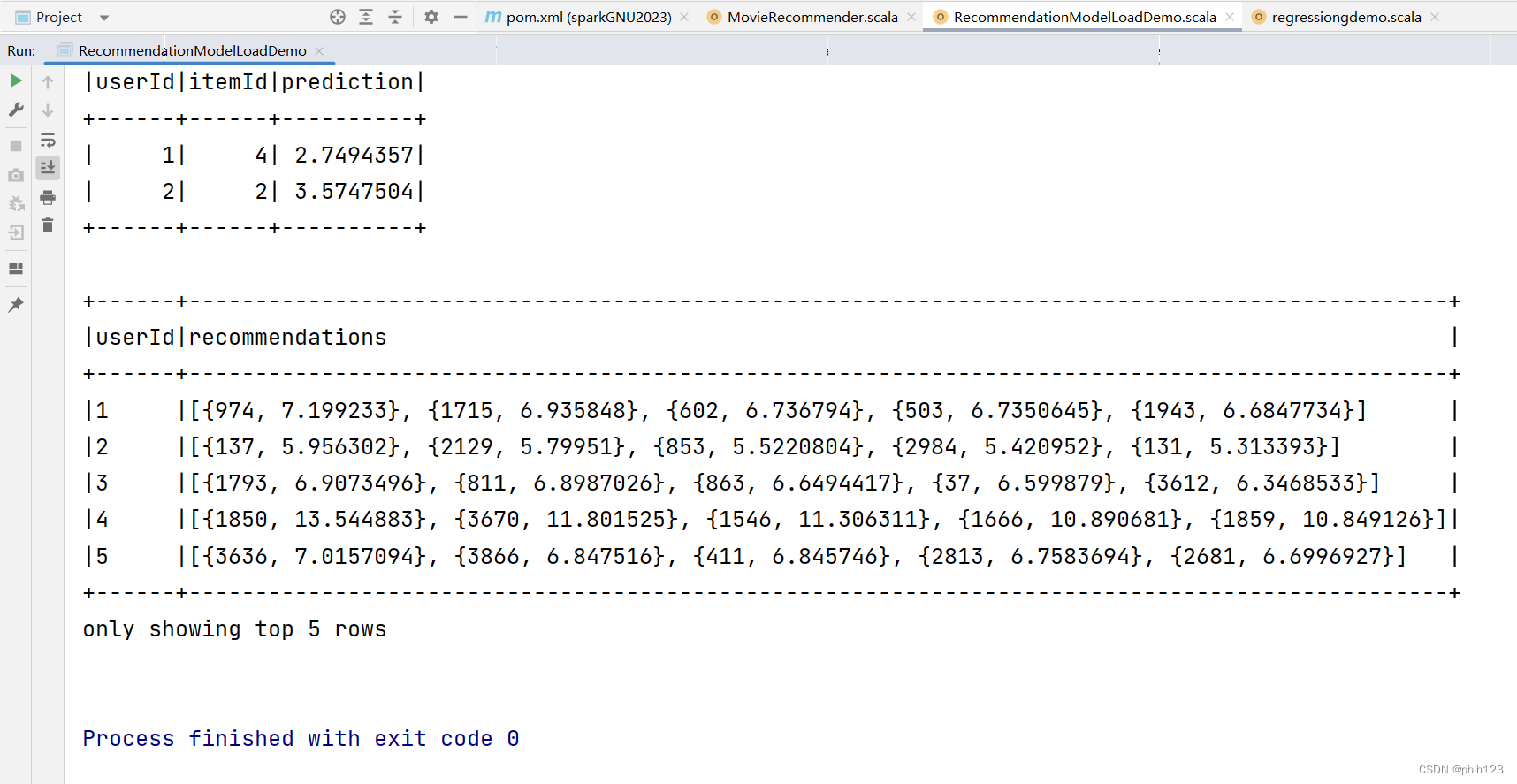
基于Scala开发Spark ML的ALS推荐模型实战
推荐系统,广泛应用到电商,营销行业。本文通过Scala,开发Spark ML的ALS算法训练推荐模型,用于电影评分预测推荐。 算法简介 ALS算法是Spark ML中实现协同过滤的矩阵分解方法。 ALS,即交替最小二乘法(Alte…...

Go语言和Java编程语言的主要区别
目录 1.设计理念: 2.语法: 3.性能: 4.并发性: 5.内存管理: 6.标准库: 7.社区和支持: 8.应用领域: Go(也称为Golang)和Java是两种不同的编程语言&…...

【TypeScript系列】与其它构建工具整合
与其它构建工具整合 构建工具 BabelBrowserifyDuoGruntGulpJspmWebpackMSBuildNuGet Babel 安装 npm install babel/cli babel/core babel/preset-typescript --save-dev.babelrc {"presets": ["babel/preset-typescript"] }使用命令行工具 ./node_…...

Java | Leetcode Java题解之第12题整数转罗马数字
题解: 题解: class Solution {String[] thousands {"", "M", "MM", "MMM"};String[] hundreds {"", "C", "CC", "CCC", "CD", "D", "DC…...
哈佛大学商业评论 --- 第五篇:智能眼镜之战
AR将全面融入公司发展战略! AR将成为人类和机器之间的新接口! AR将成为人类的关键技术之一! 请将此文转发给您的老板! --- 专题作者:Michael E.Porter和James E.Heppelmann 虽然物理世界是三维的,但大多…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

ssc377d修改flash分区大小
1、flash的分区默认分配16M、 / # df -h Filesystem Size Used Available Use% Mounted on /dev/root 1.9M 1.9M 0 100% / /dev/mtdblock4 3.0M...

vscode(仍待补充)
写于2025 6.9 主包将加入vscode这个更权威的圈子 vscode的基本使用 侧边栏 vscode还能连接ssh? debug时使用的launch文件 1.task.json {"tasks": [{"type": "cppbuild","label": "C/C: gcc.exe 生成活动文件"…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...