机器学习KNN最邻近分类算法
文章目录
- 1、KNN算法简介
- 2、KNN算法实现
- 2.1、调用scikit-learn库中KNN算法
- 3、使用scikit-learn库生成数据集
- 3.1、自定义函数划分数据集
- 3.2、使用scikit-learn库划分数据集
- 4、使用scikit-learn库对鸢尾花数据集进行分类
- 5、什么是超参数
- 5.1、实现寻找超参数
- 5.2、使用scikit-learn库实现
- 6、特征归一化
- 6.1、实现最大最小值归一化
- 6.2、实现零均值归一化
- 6.3、scikit-learn归一化使用
- 7、KNN实现回归任务
- 7.1、实现KNN回归代码
- 7.2、使用scikit-learn库实现
- 8、根据Boston数据集建立回归模型
1、KNN算法简介
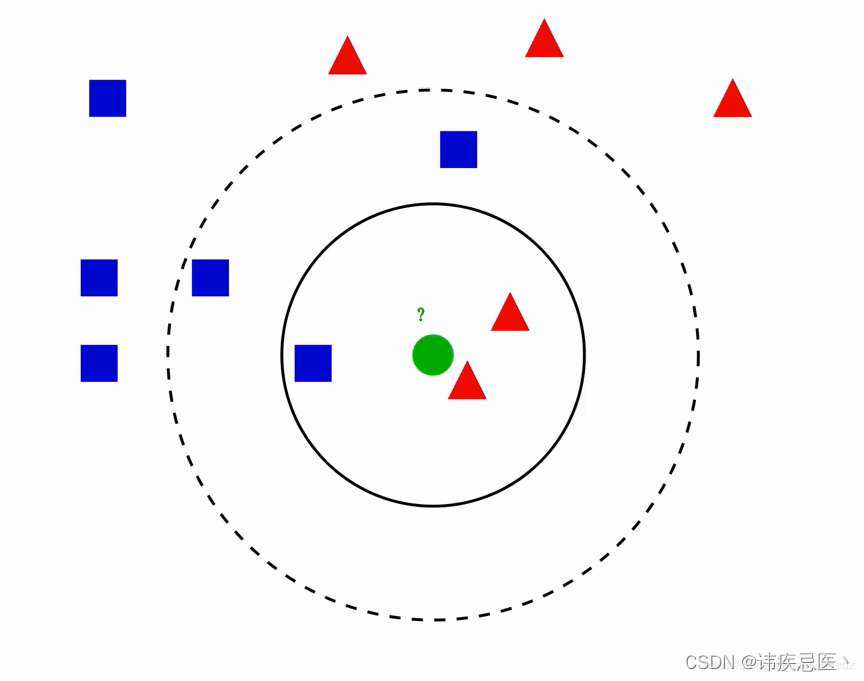
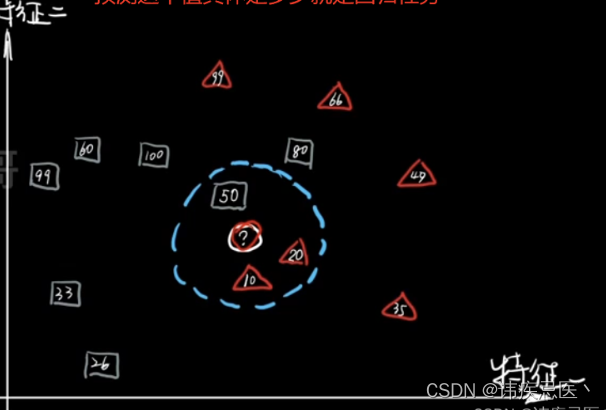
KNN (K-Nearest Neighbor) 最邻近分类算法,其核心思想“近朱者赤,近墨者黑”,由你的邻居来推断你的类别。
图中绿色圆归为哪一类?
1、如果k=3,绿色圆归为红色三角形
2、如果k=5,绿色圆归为蓝色正方形
参考文章
knn算法实现原理:为判断未知样本数据的类别,以所有已知样本数据作为参照物,计算未知样本数据与所有已知样本数据的距离,从中选取k个与已知样本距离最近的k个已知样本数据,根据少数服从多数投票法则,将未知样本与K个最邻近样本中所属类别占比较多的归为一类。(我们还可以给邻近样本加权,距离越近的权重越大,越远越小)
2、KNN算法实现
1、k值选择:太小容易产生过拟合问题,过度相信样本数据,太大容易产生欠拟合问题,与数据贴合不够解密,决策效率低。
2、样本数据归一化:最简单的方式就是所有特征的数值都采取归一化处置。
3、一个距离函数计算两个样本之间的距离:通常使用的距离函数有:欧氏距离、曼哈顿距离、汉明距离等,一般选欧氏距离作为距离度量,但是这是只适用于连续变量。在文本分类这种非连续变量情况下,汉明距离可以用来作为度量。通常情况下,如果运用一些特殊的算法来计算度量的话,K近邻分类精度可显著提高。

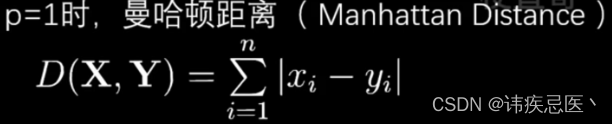

4、KNN优点:
1.简单,易于理解,易于实现,无需估计参数,无需训练
2. 适合对稀有事件进行分类
3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), KNN比SVM的表现要好
5、KNN缺点:
KNN算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数,如下图所示。该算法只计算最近的邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。
可理解性差,无法给出像决策树那样的规则。
实现KNN算法简单实例
1、样本数据散点图展示
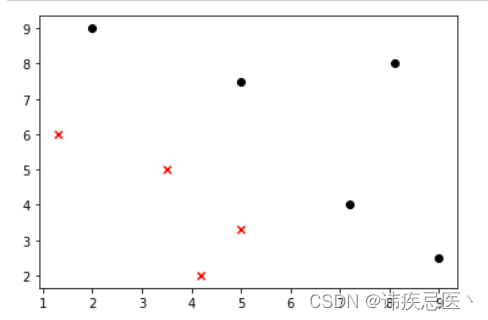
# KNN算法实现
import numpy as np
import matplotlib.pyplot as plt# 样本数据
data_X = [[1.3,6],[3.5,5],[4.2,2],[5,3.3],[2,9],[5,7.5],[7.2,4],[8.1,8],[9,2.5],]
# 样本标记数组
data_y = [0,0,0,0,1,1,1,1,1]# 将数组转换成np数组
X_train = np.array(data_X)
y_train = np.array(data_y)# 散点图绘制
# 取等于0的行中的第0列数据X_train[y_train==0,0]
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='red',marker='x')
# 取等于1的行中的第1列数据X_train[y_train==1,0]
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='black',marker='o')
plt.show()
2、新的样本数据,判断它属于哪一类
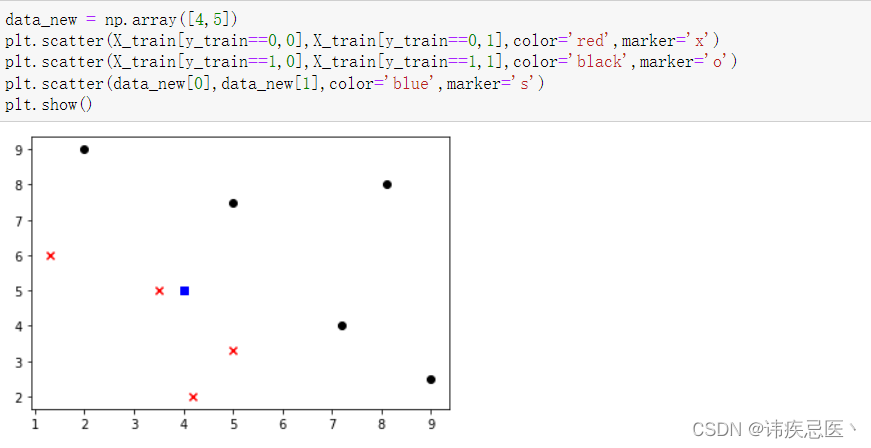
data_new = np.array([4,5])
plt.scatter(X_train[y_train==0,0],X_train[y_train==0,1],color='red',marker='x')
plt.scatter(X_train[y_train==1,0],X_train[y_train==1,1],color='black',marker='o')
plt.scatter(data_new[0],data_new[1],color='blue',marker='s')
plt.show()
3、计算新样本点与所有已知样本点的距离
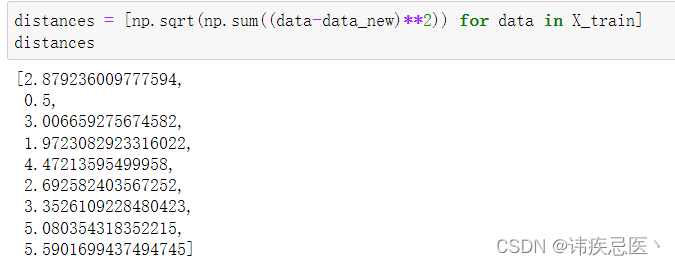
Numpy使用
# 样本数据-新样本数据 的平方,然后开平,存储距离值到distances中
distances = [np.sqrt(np.sum((data-data_new)**2)) for data in X_train]
# 按照距离进行排序,返回原数组中索引 升序
sort_index = np.argsort(distances)# 随机选一个k值
k = 5# 距离最近的5个点进行投票表决
first_k = [y_train[i] for i in sort_index[:k]]# 使用计数库统计
from collections import Counter
# 取出结果为类别0
predict_y = Counter(first_k).most_common(1)[0][0]
predict_y
2.1、调用scikit-learn库中KNN算法
2007年,Scikit-learn首次被Google Summer of Code项目开发使用,现在已经被认为是最受欢迎的机器学习Python库。
安装:pip install scikit-learn

# 使用scikit-learn中的KNN算法
from sklearn.neighbors import KNeighborsClassifier
# 初始化设置k大小
knn_classifier = KNeighborsClassifier(n_neighbors=5)
# 喂入数据集,以及数据类型
knn_classifier.fit(X_train,y_train)
# 放入新样本数据进行预测,需要先转换成二维数组
knn_classifier.predict(data_new.reshape(1,-1))
3、使用scikit-learn库生成数据集
生成的数据,画出的散点图
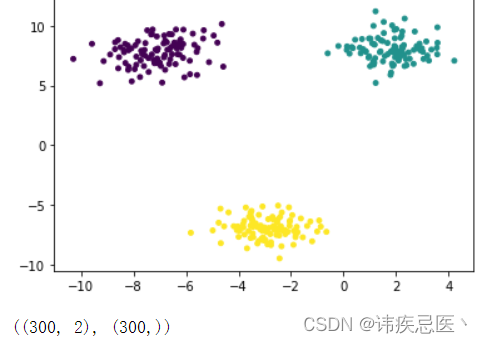
# 数据集生产
import numpy as np
from matplotlib import pyplot as plt
from sklearn.datasets import make_blobs
x,y = make_blobs(n_samples=300, # 样本总数n_features=2, # 生产二维数据centers=3, # 种类数据cluster_std=1, # 类内的标注差center_box=(-10,10), # 取值范围random_state=233, # 随机数种子return_centers=False, # 类别中心坐标反回值
)
# c指定每个点颜色,s指定点大小
plt.scatter(x[:,0],x[:,1],c=y,s=15)
plt.show()
x.shape,y.shape
3.1、自定义函数划分数据集
将生成好的数据集,划分成训练数据集和测试数据集
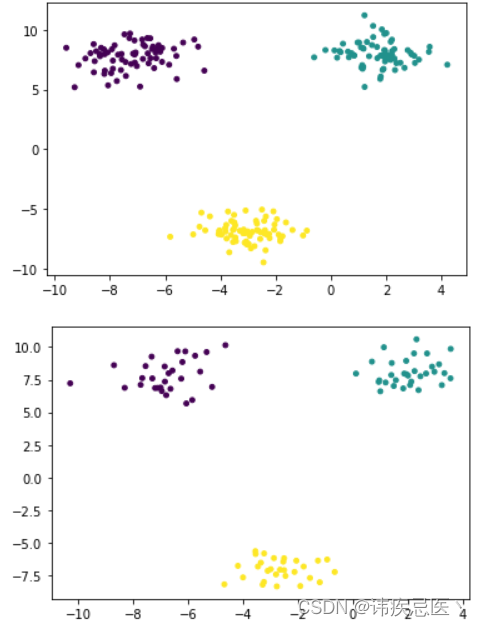
# 数据集划分
np.random.seed(233)
# 随机生成数组排列下标
shuffle = np.random.permutation(len(x))
train_size = 0.7train_index = shuffle[:int(len(x)*train_size)]
test_index = shuffle[int(len(x)*train_size):]
train_index.shape,test_index.shape# 通过下标数组到数据集中取出数据
x_train = x[train_index]
y_train = y[train_index]
x_test = x[test_index]
y_test = y[test_index]# 训练数据集
plt.scatter(x_train[:,0],x_train[:,1],c=y_train,s=15)
plt.show()# 测试数据集
plt.scatter(x_test[:,0],x_test[:,1],c=y_test,s=15)
plt.show()
3.2、使用scikit-learn库划分数据集
# sklearn划分数据集
from sklearn.model_selection import train_test_split
# 保证3个样本数保持原来分布,添加参数stratify=y
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.7,random_state=233,stratify=y)
from collections import Counter
Counter(y_test)
4、使用scikit-learn库对鸢尾花数据集进行分类
# 使用鸢尾花数据集
import numpy as np
from sklearn import datasets# 加载数据集
iris = datasets.load_iris()
# 获取样本数组,样本类型数组
X = iris.data
y = iris.target# 拆分数据集
# 不能直接拆分因为现在的y已经是排序好的,需要先乱序数组
# shuffle_index = np.random.permutation(len(X))
# train_ratio = 0.8
# train_size = int(len(y)*train_ratio)
# train_index = shuffle_index[:train_size]
# test_index = shuffle_index[train_size:]
# X_train = X[train_index]
# Y_train = y[train_index]
# X_test = X[test_index]
# Y_test = y[test_index]from sklearn.model_selection import train_test_split
# 保证3个样本数保持原来分布,添加参数stratify=y
x_train,x_test,y_train,y_test = train_test_split(X,y,train_size=0.8,random_state=666)# 预测
from sklearn.neighbors import KNeighborsClassifier
# 初始化设置k大小
knn_classifier = KNeighborsClassifier(n_neighbors=5)
# 喂入数据集,以及数据类型
knn_classifier.fit(x_train,y_train)# 如果关心预测结果可以跳过下面所有score返回得分
knn_classifier.score(x_test,y_test)y_predict = knn_classifier.predict(x_test)# 评价预测结果 将y_predict和真是的predict进行比较就可以了
accuracy = np.sum(y_predict == y_test)/len(y_test)
# accuracy# sklearn中计算准确度的方法
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_predict)
5、什么是超参数
在看机器学习时,经常碰到一个叫超参数的参数(hyper-parameter)的概念,通常情况下,需要对超参数进行优化,给学习选择一组最优超参数,以提高学习的性能和效果。
KNN算法中超参数表示什么,表示K的最近邻居有几个,是分类表决还是加权表决。
5.1、实现寻找超参数
1、加载鸢尾花数据集,并拆分数据集
# 超参数
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as npdata = load_iris()
X = data.data
y = data.target
X.shape,y.shape
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=233,stratify=y)
X_train.shape,X_test.shape,y_train.shape,y_test.shape
2、寻找最优的一组超参数
# 遍历所有超参数,选取准确率
# uniform权重一直,越近权重越高distance
# p等于1折线曼哈顿距离计算方式,p=2欧式距离best_score = -1
best_n = -1
best_p = -1
best_weight = ''for i in range(1,20):for weight in ['uniform','distance']:for p in range(1,7):neigh = KNeighborsClassifier(n_neighbors=i,weights=weight,p = p)neigh.fit(X_train,y_train)score = neigh.score(X_test,y_test)if score>best_score:best_score = scorebest_n = ibest_p = pbest_weight = weight
print(best_n,best_p,best_weight,best_score)
5.2、使用scikit-learn库实现
# 使用skleran超参数搜索
from sklearn.model_selection import GridSearchCV
params = {'n_neighbors':[n for n in range(1,20)],'weights':['uniform','distance'],'p':[p for p in range(1,7)]
}grid = GridSearchCV(estimator=KNeighborsClassifier(),# 分类模型器param_grid=params,# 参数n_jobs=-1 # 自动设置并行任务数量
)
# 传入数据集
grid.fit(X_train,y_train)
# 得到超参数和得分
grid.best_params_
print(grid.best_score_)# knn对象对测试数据集进行预测
y_predict = grid.best_estimator_.predict(X_test)# sklearn中计算准确度的方法
from sklearn.metrics import accuracy_score
accuracy_score(y_test,y_predict)
6、特征归一化
为什么做归一化?
比如说,现在有一组身高和体重的数据集(斤,米),求欧式距离的时候,可以发现身高在数据集中影响非常小,所以需要将数据归一化。
6.1、实现最大最小值归一化
最值归一化适用于,值分布在有限的范围里面,比如说考试分数0-100,它受特殊值影响比较大,比如正常体重在0-150斤,如果有一个1000斤,那么这个归一化的数据就会失真。
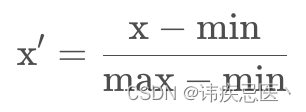
对上面数据做最大最小归一化操作
# 对数据做归一化
X[:5]
X[:,0] = (X[:,0] - np.min(X[:,0]))/(np.max(X[:,0])-np.min(X[:,0]))
X[:,1] = (X[:,1] - np.min(X[:,1]))/(np.max(X[:,1])-np.min(X[:,1]))
X[:,2] = (X[:,2] - np.min(X[:,2]))/(np.max(X[:,2])-np.min(X[:,2]))
X[:,3] = (X[:,3] - np.min(X[:,3]))/(np.max(X[:,3])-np.min(X[:,3]))
X[:5]
6.2、实现零均值归一化
除了数据有明显的边界值,这种方式是最好的,原始数据-均值 / 标准差。

假设有一组数据集:[3, 6, 9, 12, 15]计算平均值:
平均值 = (3 + 6 + 9 + 12 + 15) / 5 = 9计算方差:
方差 = ((3-9)^2 + (6-9)^2 + (9-9)^2 + (12-9)^2 + (15-9)^2) / 5 = 18计算标准差:
标准差 = √方差 = √18 ≈ 4.24
# 零均值归一化
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as npdata = load_iris()
X = data.data
y = data.targetX[:5]# 求均值
np.mean(X[:,0])
# 标准差
np.std(X[:,0])X[:,0] = (X[:,0]- np.mean(X[:,0]))/(np.std(X[:,0]))
X[:,1] = (X[:,1]- np.mean(X[:,1]))/(np.std(X[:,1]))
X[:,2] = (X[:,2]- np.mean(X[:,2]))/(np.std(X[:,2]))
X[:,3] = (X[:,3]- np.mean(X[:,3]))/(np.std(X[:,3]))
X[:5]
6.3、scikit-learn归一化使用

# scikit-learn中归一化
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as npdata = load_iris()
X = data.data
y = data.targetX[:5]from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standard_scaler.fit(X)# 输出4列特征的均值
standard_scaler.mean_
# 输出标4列特标准差
standard_scaler.scale_# X本身没有改变,我们需要将结果重新赋值给X
X = standard_scaler.transform(X)
X[:5]
7、KNN实现回归任务
预测这个值是多少,就是回归任务,思想和上面做分类一致,也是近朱者赤,近墨者黑,也是找距离最近k个点,也是民主投票,区别在于这里是求最近k个点的均值
7.1、实现KNN回归代码
# KNN 实现回归任务
# KNN算法实现
import numpy as np
import matplotlib.pyplot as plt# 样本数据
data_X = [[1.3,6],[3.5,5],[4.2,2],[5,3.3],[2,9],[5,7.5],[7.2,4],[8.1,8],[9,2.5],]
# 样本标记数组
data_y = [0.1,0.3,0.5,0.7,0.9,1.1,1.3,1.5,1.7]X_train = np.array(data_X)
y_train = np.array(data_y)
data_new = np.array([4,5])
plt.scatter(X_train[:,0],X_train[:,1],color='black')
plt.scatter(data_new[0],data_new[1],color='b',marker='s')
for i in range(len(y_train)):plt.annotate(y_train[i],xy=X_train[i],xytext=(-15,-15),textcoords='offset points')
plt.show()distance = [np.sqrt(np.sum((i-data_new)**2)) for i in X_train]
sort_index = np.argsort(distance)
k = 5
first_k = [y_train[i] for i in sort_index[:k]]
np.mean(first_k)
7.2、使用scikit-learn库实现
# 使用scikit-learn实现
from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor(n_neighbors=5)
knn_reg.fit(X_train,y_train)predict_y = knn_reg.predict(data_new.reshape(1,-1))
predict_y
8、根据Boston数据集建立回归模型
import numpy as np
import matplotlib.pyplot as plt
import sklearn
from sklearn.model_selection import train_test_split
import pandas as pd # 加载波士顿房屋数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]# 数据准备
X = data
y = target
X.shape,y.shape# 数据集划分
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=233)# 建立回归模型
from sklearn.neighbors import KNeighborsRegressor
knn_reg = KNeighborsRegressor(n_neighbors=5,weights='distance',p=2)
knn_reg.fit(X_train,y_train)
# 计算得分,发现得分很低,原因是因为没有做归一化处理导致
knn_reg.score(X_test,y_test)
做归一化处理之后输出得分
# 归一化操作
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler()
standard_scaler.fit(X_train)# 对x train进行归一化操作
x_train = standard_scaler.transform(X_train)
x_test = standard_scaler.transform(X_test)knn_reg.fit(x_train,y_train)
knn_reg.score(x_test,y_test)
相关文章:
机器学习KNN最邻近分类算法
文章目录 1、KNN算法简介2、KNN算法实现2.1、调用scikit-learn库中KNN算法 3、使用scikit-learn库生成数据集3.1、自定义函数划分数据集3.2、使用scikit-learn库划分数据集 4、使用scikit-learn库对鸢尾花数据集进行分类5、什么是超参数5.1、实现寻找超参数5.2、使用scikit-lea…...
)
分享一个Python爬虫入门实例(有源码,学习使用)
一、爬虫基础知识 Python爬虫是一种使用Python编程语言实现的自动化获取网页数据的技术。它广泛应用于数据采集、数据分析、网络监测等领域。以下是对Python爬虫的详细介绍: 架构和组成:下载器:负责根据指定的URL下载网页内容,常用的库有Requests和urllib。解析器:用于解…...
算法:树形dp(树状dp)
文章目录 一、树形DP的概念1.基本概念2.解题步骤3.树形DP数据结构 二、典型例题1.LeetCode:337. 打家劫舍 III1.1、定义状态转移方程1.2、参考代码 2.ACWing:285. 没有上司的舞会1.1、定义状态转移方程1.2、拓扑排序参考代码1.3、dfs后序遍历参考代码 一…...
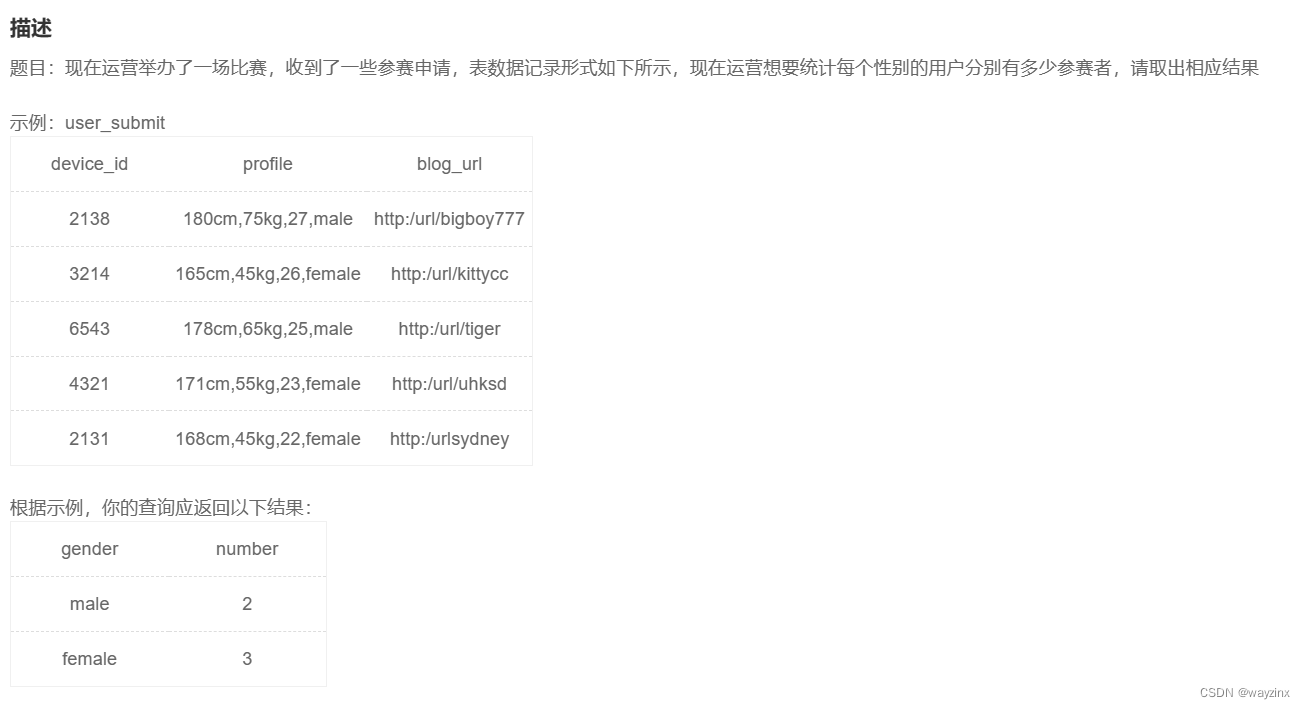
SQL语句学习+牛客基础39SQL
什么是SQL? SQL (Structured Query Language:结构化查询语言) 是用于管理关系数据库管理系统(RDBMS)。 SQL 的范围包括数据插入、查询、更新和删除,数据库模式创建和修改,以及数据访问控制。 SQL语法 数据库表 一个…...
动态规划)
竞赛常考的知识点大总结(五)动态规划
DP问题的性质 动态规划(Dynamic Programming,DP)是指在解决动态规划问题时所依赖的一些基本特征和规律。动态规划是一种将复杂问题分解为更小子问题来解决的方法,它适用于具有重叠子问题和最优子结构性质的问题。动态规划问题通常…...
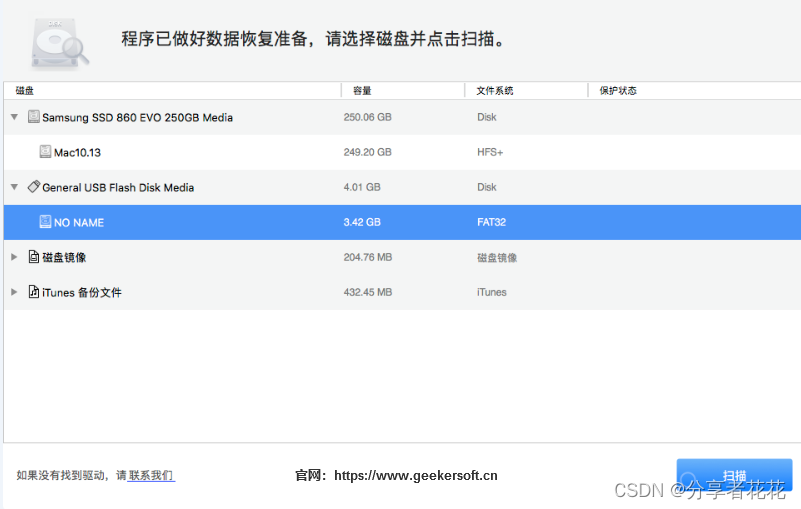
如何在 Mac 上恢复已删除的数据
如果您丢失了 Mac 上的数据,请不要绝望。恢复数据比您想象的要容易,并且有很多方法可以尝试。 在 Mac 上遭受数据丢失是每个人都认为永远不会发生在他们身上的事情之一......直到它发生。不过,请不要担心,因为您可以通过多种方法…...

Java笔试题总结
HashSet子类依靠()方法区分重复元素。 A toString(),equals() B clone(),equals() C hashCode(),equals() D getClass(),clone() 答案:C 解析: 先调用对象的hashcode方法将对象映射为数组下标,再通过equals来判断元素内容是否相同 以下程序执行的结果是: class X{…...
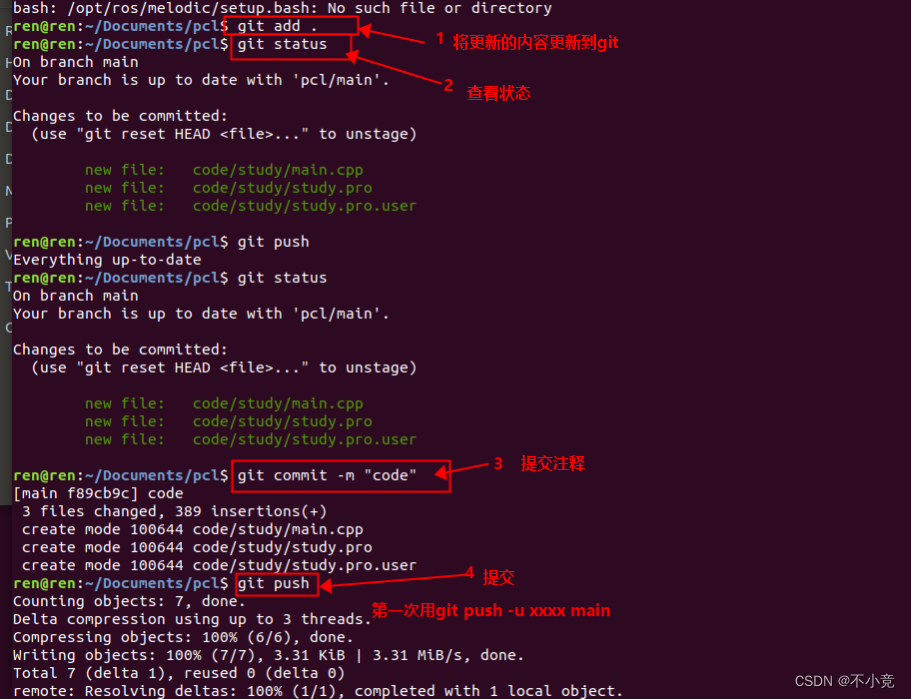
github本地仓库push到远程仓库
1.从远程仓库clone到本地 2.生成SSH秘钥,为push做准备 在Ubuntu命令行输入一下内容 [rootlocalhost ~]# ssh-keygen -t rsa < 建立密钥对,-t代表类型,有RSA和DSA两种 Generating public/private rsa key pair. Enter file in whi…...

Error: TF_DENORMALIZED_QUATERNION: Ignoring transform forchild_frame_id
问题 运行程序出现: Error: TF_DENORMALIZED_QUATERNION: Ignoring transform for child_frame_id “odom” from authority “unknown_publisher” because of an invalid quaternion in the transform (0.0 0.0 0.0 0.707) 主要是四元数没有归一化 Eigen::Quatern…...

Linux从入门到精通 --- 2.基本命令入门
文章目录 第二章:2.1 Linux的目录结构2.1.1 路径描述方式 2.2 Linux命令入门2.2.1 Linux命令基础格式2.2.2 ls命令2.2.3 ls命令的参数和选项2.2.4 ls命令选项的组合使用 2.3 目录切换相关命令2.3.1 cd切换工作目录2.3.2 pwd查看当前工作目录2.4 相对路径、绝对路径和…...
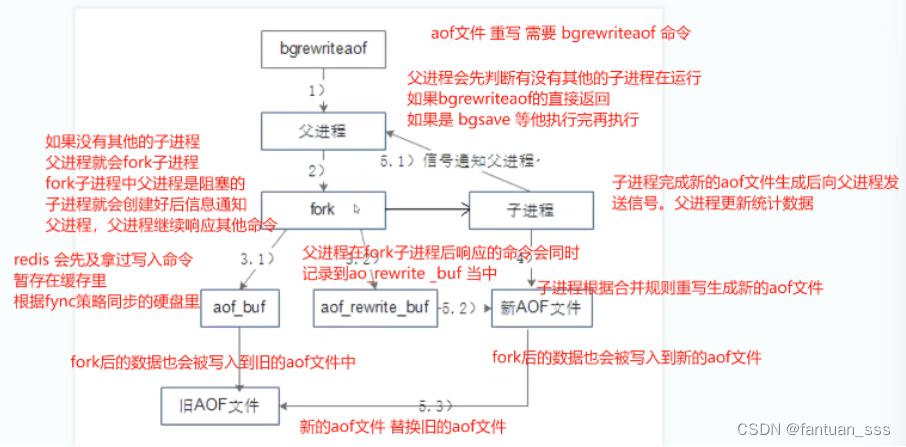
Redis常用命令补充和持久化
一、redis 多数据库常用命令 1.1 多数据库间切换 1.2 多数据库间移动数据 1.3 清除数据库内数据 1.4 设置密码 1.4.1 使用config set requirepass yourpassword命令设置密码 1.4.2 使用config get requirepass命令查看密码 二、redis高可用 2.1 redis 持久化 2.1.1 持…...
二次开发时的错误码)
【记录】海康相机(SDK)二次开发时的错误码
海康相机(SDK)二次开发时的错误码 在进行海康sdk二次开发的时候,经常碰到各种错误,遂结合官方文档和广大网友的一些经验,把这些错误码记录一下,方便查找。笔者使用的SDK版本是HCNetSDKV6.1.9.4。 错误类型…...

端盒日记Day02
JS 本本本本本地存储 localStorage 作用:可以将数据永久存储在本地(用户电脑),除非手动删除,否则关闭页面也会存在 特性:a.可多窗口(页面)共享(同一浏览器可以共享&a…...

考研高数(平面图形的面积,旋转体的体积)
1.平面图形的面积 纠正:参数方程求面积 2.旋转体的体积(做题时,若以x为自变量不好计算,可以求反函数,y为自变量进行计算)...

选择企业邮箱,扬帆迈向商务新纪元!
企业邮箱和个人邮箱不同,它的邮箱后缀是企业自己的域名。企业邮箱供应商一般都提供手机app、桌面端、web浏览器访问等邮箱使用途径。那么什么是企业邮箱?如何选择合适的企业邮箱?好用的企业邮箱应具备无缝迁移、协作、多邮箱管理等功能。 企…...

2024.3.25力扣每日一题——零钱兑换2
2024.3.25 题目来源我的题解方法一 动态规划 题目来源 力扣每日一题;题序:518 我的题解 方法一 动态规划 给定总金额 amount 和数组 coins,要求计算金额之和等于 amount 的硬币组合数。其中,coins的每个元素可以选取多次&#…...

包子凑数【蓝桥杯】/完全背包
包子凑数 完全背包 完全背包问题和01背包的区别就是,完全背包问题每一个物品能取无限次。 思路:当n个数的最大公约数不为1,即不互质时,有无限多个凑不出来的,即n个数都可以表示成kn,k为常数且不为1。当n个…...

口语 4.6
drop the gun :逃避 radically 极大程度地 vastly cognition:认知能力 flaw缺陷 flawless:没有缺陷 interface:接口,交流处 retain:保留 down the rabbit hole:进入未知领域了 wrap your head aro…...

使用Docker 部署jenkins 实现自动化部署
使用Docker部署jenkins实现自动化部署ruoyi-vue docker jenkinsJava jenkinsfilevue jenkinsfileDockerfile 部署脚本Java Dockerfilenginx Dockerfilenginx-dev.conf 使用docker部署Jenkins,项目: https://gitee.com/y_project/RuoYi-Vue 作为部署项目示范 docker…...
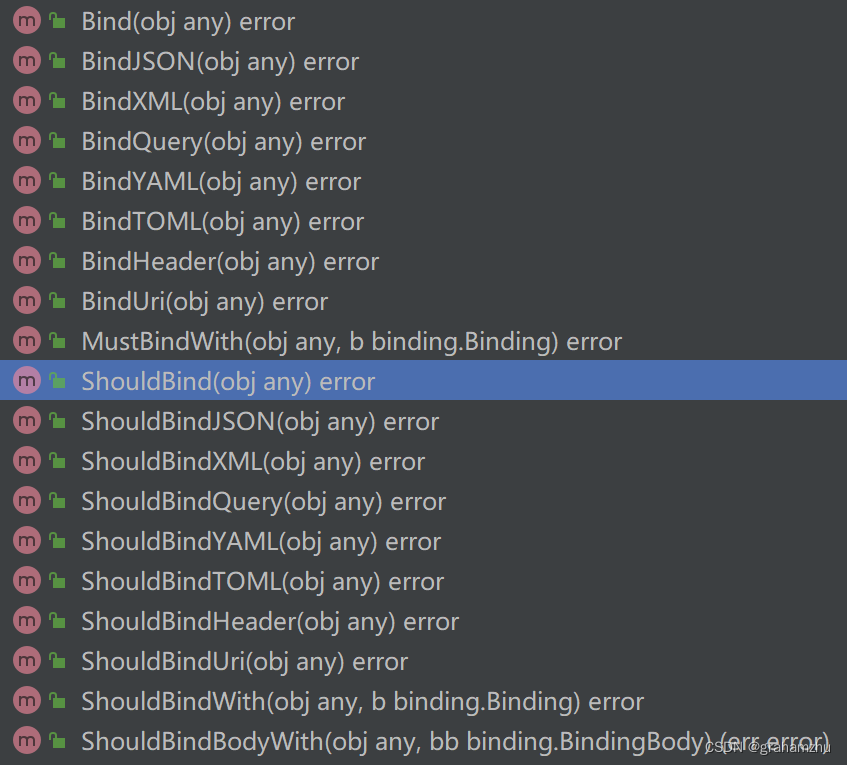
golang语言系列:Web框架+路由 之 Gin
云原生学习路线导航页(持续更新中) 本文是golang语言学习系列,本篇对Gin框架的基本使用方法进行学习 1.Gin框架是什么 Gin 是一个 Go (Golang) 编写的轻量级 http web 框架,运行速度非常快,如果你是性能和高效的追求者…...

高效利用CompactGUI社区协作:释放游戏压缩数据价值的全方位指南
高效利用CompactGUI社区协作:释放游戏压缩数据价值的全方位指南 【免费下载链接】CompactGUI Transparently compress active games and programs using Windows 10/11 APIs 项目地址: https://gitcode.com/gh_mirrors/co/CompactGUI 在数字游戏时代…...

RePKG完整指南:Wallpaper Engine资源提取与格式转换工具全解析
RePKG完整指南:Wallpaper Engine资源提取与格式转换工具全解析 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 一、功能解析:掌握RePKG核心能力 1.核心功能…...

Llama-3.2V-11B-cot部署教程:双卡4090一键启动视觉推理工具
Llama-3.2V-11B-cot部署教程:双卡4090一键启动视觉推理工具 1. 项目概述 Llama-3.2V-11B-cot是基于Meta多模态大模型开发的高性能视觉推理工具,专为双卡4090环境优化。它解决了传统大模型部署复杂、视觉权重加载失败等痛点,让普通用户也能轻…...

Python 入门第一课:为什么选择 Python?3 分钟搭建你的第一个程序
一、先聊点人话:为啥要学 Python? 说实话,当初我选编程语言的时候也纠结过。Java?太啰嗦。C?头都大了。JavaScript?浏览器里跑着玩还行… 直到我遇见了 Python。 这玩意儿有多友好? 这么说吧&…...

实时手机检测-通用模型教程:如何用Gradio搭建检测界面
实时手机检测-通用模型教程:如何用Gradio搭建检测界面 1. 引言与模型概述 1.1 手机检测的应用价值 在现代计算机视觉应用中,手机检测是一个具有广泛实用场景的技术。从智能监控系统中的打电话行为识别,到公共场所的手机使用管理࿰…...
)
告别虚拟机!在Windows 11上零配置搭建Masm汇编实验环境(保姆级图文教程)
在Windows 11上零配置搭建Masm汇编实验环境:从入门到实战 对于计算机专业的学生和开发者来说,汇编语言是理解计算机底层工作原理的重要工具。然而,传统的汇编环境搭建往往需要复杂的配置步骤或依赖虚拟机,这给初学者带来了不小的门…...

ai辅助开发:基于快马平台为trea国际版添加汇率数据智能分析功能
最近在开发Trea国际版应用时,遇到了一个需求:如何让用户更直观地理解汇率波动趋势,并通过自然语言交互获得分析结果。这个功能看似复杂,但借助InsCode(快马)平台的AI辅助开发能力,整个过程变得异常简单。下面分享我的实…...

不止于dhclient:深入理解Ubuntu网络初始化与127.0.0.1困局的系统级排查
不止于dhclient:深入理解Ubuntu网络初始化与127.0.0.1困局的系统级排查 当你在Ubuntu服务器上输入ifconfig,却发现除了lo接口外其他网卡全部"消失",IP地址被锁定在127.0.0.1时,那种感觉就像被困在数字世界的孤岛。本文将…...

人工智能应用- AI 增强显微镜:02.AI 增强显微图像
人工智能,尤其是深度学习技术的进步,为突破传统显微镜的瓶颈提供了新的思路。通过构建神经网络模型,AI 可以从低分辨率、噪声较多的显微图像中,推断出更高清、更细腻的图像;甚至可以在没有染色的情况下,生成…...

基于STM32的智能鱼缸毕设任务书:新手入门实战指南与系统架构详解
最近在指导几位学弟学妹做毕业设计,发现“基于STM32的智能鱼缸”这个题目虽然经典,但新手在实际动手时,往往从第一步硬件选型就开始迷茫,到代码调试阶段更是问题频出。为了让大家少走弯路,我结合自己的项目经验&#x…...