java-Stream原理及相关操作详解(filter、map、flatMap、peek、reduce、anyMatch等等)
java-Stream原理及相关操作详解
- Stream流前言
- Stream流原理介绍
- Stream-Api常用方法介绍
- filter()
- map()
- flatMap
- peek
- reduce
- max、min
- findAny、 findFirst
- allMatch、anyMatch、noneMatch
- sorted
- count
Stream流前言
Java8特性主要是Stream流以及函数式接口的出现;本片文章主要对StreamApi中的常用方法进行讲解,再学习Stream流之前个人建议需要对函数式接口要有充分理解并能熟练掌握,对于函数式编程的学习大家可以参考:java 函数式编程(Function、Supplier、Predicate、Consumer)
本片文章主要讲解流相关的操作以及部分原理介绍;
Stream流原理介绍
Stream流本质上是一个执行计算的过程,将流当中的中间操作组成一个流管道的形式,流管道由源(可能是数组,集合,生成器函数,I / O通道等),零个或多个中间操作 (将流转换为另一个流,如filter(Predicate) )组成,以及终端操作 (产生结果或副作用,例如count()、forEach(Consumer) 、collect(?); 对于collect()方法来讲是Stream的重中之重,collect()方法的实现依赖于Collector,对于流的终端收集操作(Collector)会放在后续进行讲解;
流本身是由三个部分组成,分别是源、中间操作、终止操作;大家先看个例子:
int sum = widgets.stream().filter(w -> w.getColor() == RED).mapToInt(w -> w.getWeight()).sum();
widgets认为是一个集合本身的引用,通过widgets.stream()则创建了一个源,中间的filter()和mapToInt() 操作是流的中间操作过程,sum是流的一个终端终止操作;
大家再来观察一下stream()方法;
default Stream<E> stream() {return StreamSupport.stream(spliterator(), false);}public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {Objects.requireNonNull(spliterator);return new ReferencePipeline.Head<>(spliterator,StreamOpFlag.fromCharacteristics(spliterator),parallel);}
stream() 是 Collection 中的 default 方法,实际上调用的是StreamSupport.stream() 方法,返回的是 ReferencePipeline.Head的实例;ReferencePipeline表示的是流阶段的中间阶段,ReferencePipeline.Head表示流的源阶段;一个流的只会创建一次源,而流的中间操作可以没有或者多个;ReferencePipeline.Head 的构造函数传递是 ArrayList 中实现的 spliterator 。常用的集合都实现了 Spliterator 接口以支持 Stream。可以这样理解,Spliterator 定义了数据集合流入流水线的方式。
接下来将对Stream的构造方法也就是流的的创建过程以及中间操作阶段的具体实现进行分析,来进一步理解流的创建以及流是怎么将每一个中间阶段链接起来并且怎么将每一个阶段的输出通知给下游流; 我们先分析stream()方法的最终实现:其实是AbstractPipeline,而ReferencePipeline继承了AbstractPipeline:
AbstractPipeline(Spliterator<?> source,int sourceFlags, boolean parallel) {//表示上一个阶段,如果这是源阶段,也就是流创建的阶段并没有上游所以这里为null。this.previousStage = null;//流管道中的源拆分器;实际行为是和sourceSupplier配合将集合中的元素驶向流this.sourceSpliterator = source;//流管道的源阶段this.sourceStage = this;// 此管道对象表示的中间操作的操作标志this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;// The following is an optimization of:// StreamOpFlag.combineOpFlags(sourceOrOpFlags, StreamOpFlag.INITIAL_OPS_VALUE);//源和所有操作的组合源标志和操作标志,直到此流水线对象表示的操作为止(包括该流水线对象所代表的操作)。 在管道准备进行评估时有效。this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;//如果是顺序的,则此管道对象与流源之间的中间操作数;如果是并行的,则为先前有状态的中间操作数。 在管道准备进行评估时有效this.depth = 0;//表示并行还是串行流this.parallel = parallel;}
对于stream()的构造方法我认为previousStage 、sourceStage 、depth 三个属性即可,能更快捷的去了解流;
构造方法执行完成之后流的创建也完成了。创建了源;
- previousStage 并没有上一个阶段,赋予null,
- sourceStage 原阶段就是当前创建的流对象;
- depth 为0,我们目前并没有执行下游流的操作;
好了~到目前为止,流的创建阶段也就完成了;我们再看看下游流是怎么创建的呢?(拿filter()举例)
@Overridepublic final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {Objects.requireNonNull(predicate);// 返回一个匿名无状态操作的管道return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SIZED) {@Override// 下游生产线所需要的回调接口Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {@Overridepublic void begin(long size) {downstream.begin(-1);}// 真正执行操作的方法,依靠ChainedReference内置ReferencePipeline引用下游的回调@Overridepublic void accept(P_OUT u) {// 只有满足条件的元素才能被下游执行if (predicate.test(u))downstream.accept(u);}};}};}
StatelessOp是非常重要的,定义了流中无状态操作的属性;我这里直接点击到了StatelessOp中具体的构造方法大家再看看一下:
/**
* previousStage入参表示流对象,我们上步骤创建好的流对象
*/AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {if (previousStage.linkedOrConsumed)throw new IllegalStateException(MSG_STREAM_LINKED);// 表示如果该流管道被消费或者链接则为true,上面我们创建了stream()流,调用filter方法则表示我们将filter这个阶段已经连接到流previousStage.linkedOrConsumed = true;// 流管道的下一个阶段,上步骤创建好的流对象下一个对象就是当前对象previousStage.nextStage = this;// 此时该流管道中的上一个阶段便是源阶段this.previousStage = previousStage;this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);// 源阶段只有一个仍然是previousStage.sourceStage;this.sourceStage = previousStage.sourceStage;if (opIsStateful())sourceStage.sourceAnyStateful = true;// 新增了一个filter操作,深度便+1;this.depth = previousStage.depth + 1;}
在和源阶段的构造方法和下游流创建的构造方法拿出来对比会发现:
- previousStage.linkedOrConsumed = true表示上面我们创建了stream()流,调用filter方法则表示我们将filter这个阶段已经连接到流
- previousStage(上一个阶段) :对于源的创建来讲没有上一个阶段,该属性为null,对于下游流来讲上一个阶段就是原阶段;
- linkedOrConsumed (是否消费或链接):流创建阶段没有被链接或者消费默认为fasle,创建下游流之后被链接上之后为true
- previousStage.nextStage:上游流的下个阶段,可以理解为源的下一个阶段便是filter
- depth ,源阶段没有任何中间操作未创建下游流,depth = 0,创建链接之后便+1;
其实发现previousStage.nextStage = this previousStage.linkedOrConsumed = this; 通过连接上游流和指向下游流发现流的特性是很像一个双向链表
到目前为止,流的创建(源阶段以及中间阶段)就结束了,接下来我们再看一下ReferencePipeline.Head 代表流的源看看数据是怎么走向的呢?我们来观察一下ReferencePipeline.Head类:
/*** Source stage of a ReferencePipeline.** @param <E_IN> type of elements in the upstream source * @param <E_OUT> type of elements in produced by this stage* @since 1.8*/static class Head<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {//方法目前已经省略便于观看;}其中有两个泛型参数E_IN、E_OUT,显而易见一个表示进,一个表示出,E_IN表示的是上游源的元素的类型,E_OUT表示的是当前阶段所生成的元素类型
比如我们使用steam: stream().map().filter()… 对于map()阶段来说,E_IN则是stream生成的源(Spliterator),E_OUT表示map()处理完之后生成的元素,这个元素可能是对象、集合等等。 对于filter()来说 filter()的输入元素就是map()所输出的元素,filter()的输出元素则会作为下一个中间动作的输入元素。。。。
流的创建以及数据流向已经介绍完了,接下来我们简单介绍流的每一个阶段是怎么进行通知的:Sink
-
Sink 这个接口,它继承自 Consumer 接口,又定义了begin()、end()、cancellationRequested() 方法。Sink 直译过来是水槽,如果把数据流比作水,那水槽就是水会流过的地方。begin() 用于通知水槽的水要过来了,里面会做一些准备工作,同样 end() 是做一些收尾工作。cancellationRequested() 是原来判断是不是可以停下来了。Consumer 里的accept() 是消费数据的地方。
-
每一个 Sink 都有自己的职责,但具体表现各有不同。无状态操作的 Sink 接收到通知或者数据,处理完了会马上通知自己的 下游。有状态操作的 Sink 则像有一个缓冲区一样,它会等要处理的数据处理完了才开始通知下游,并将自己处理的结果传递给下游。例如 sorted() 就是一个有状态的操作,一般会有一个属于自己的容器,用来记录处自己理过的数据的状态。sorted() 是在执行 begin 的时候初始化这个容器,在执行 accept 的时候把数据放到容器中,最后在执行 end 方法时才正在开始排序。排序之后再将数据,采用同样的方式依次传递给下游节点。最后数据流到终止节点,终止节点将数据收集起来就结束了。
好了~ ~ 流我们有了一个基础理念、并掌握函数式接口之后我们再来回顾一下Stream中常用方法~~~
Stream-Api常用方法介绍
filter()
Stream<T> filter(Predicate<? super T> predicate);
在对Api讲解时,将不再对流的原理进行介绍,只关注方法本身的入参,出参以及使用;
可以看到filter入参是Predicate(接受一个参数不返回值) 出参仍返回一个Stream,方法本身返回由此流中满足给定的Predicate行为后元素组成的流;
举个例子:集合中有四个元素分别是字符类型"supplier", “function”, “predicate”, “consumer”,需要将符合条件的元素捞取出来(其中符合元素的条件根据业务可调整)当前例子是将元素长度=8的元素过滤出来。。
@Testvoid stream(){List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");list.stream().filter(item -> item.length() == 8).forEach(System.out::println);}打印结果为:supplier function consumer;结果中predicate元素长度等于9 不满足Predicate行为;
map()
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
返回一个流,包括将给定函数应用到该流元素的结果。 入参是一个Function(接受一个参数并返回值),出参是Stream
对于map()方法的使用我们需要将集合中的元素进行处理,处理完之后并返回新的结果时,便可使用map
举个例子:
@Testvoid stream(){List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");//将list中每一个元素末尾加“~~”list.stream().map(item -> item + "~~").forEach(System.out::println);}结果打印:supplier~~ function~~ predicate~~ consumer~~
flatMap
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
将集合中的每一个元素铺开汇聚成新结果以Stream的形式返回
举个例子:有两个集合list1、list2 铺开形成一个list
@Testvoid stream(){// 有两个集合list1、list2需要两个集合中的元素长度等于10的元素收集起来并返回新的集合List<String> list1 = Arrays.asList("supplier1", "function1", "predicate1", "consumer1");List<String> list2 = Arrays.asList("supplier2", "function2", "predicate2", "consumer2");List<List<String>> list = Arrays.asList(list1, list2);List<String> collect = list.stream().flatMap(Collection::stream).filter(item -> item.length() == 10).collect(Collectors.toList());collect.forEach(System.out::println);}输出结果:predicate1 predicate2这样使用起来大家觉得可能用处比较少不属于常用方法,但对于oracle来讲对于批量查询如果数据过多会报错,需要对数据进行分片,分片之后在进行查询;
写一个方法大家应该就理解了
/*** @param list string的列表,根据这个去数据库查* @param function 具体的查询方法* @param <T> 返回的list的对象* @return 返回数据库查出的具体方法*/public static <T> List<T> partitionThousandGet(List<String> list, Function<List<String>, List<T>> function) {return Lists.partition(list, 1000).stream().map(function).flatMap(Collection::stream).collect(Collectors.toList());}
其中使用flatMap便可执行分片查询功能,在function参数中传入指定的dao层方法即可;
peek
Stream<T> peek(Consumer<? super T> action);
peek的意思是偷看,入参是Consumer 返回一个Stream,返回由该流的元素组成的流,并在所提供的流中执行所提供的每个元素上的动作
举一个例子:
学生类有名字和分数两个属性;
@Data
public class Student {private String name;private int score;
}@Test
void stream(){Student student1 = new Student("zhangsan", 21);Student student2 = new Student("lisi", 82);Student student3 = new Student("wangwu", 32);// 分别有三个学生;需要将lisi的分数改为100分List<Student> list = Arrays.asList(student1, student3, student2);list.stream().peek(item -> {if (item.getName().equals("lisi")) {item.setScore(100);}}).forEach(System.out::println);
}
打印结果为:
Student(name=zhangsan, score=21)
Student(name=wangwu, score=32)
Student(name=lisi, score=100)
reduce
/**T identity,输入元素BinaryOperator<T> accumulator 累加器,接受两个相同结果的入参返回一个值;BinaryOperator<U> combiner 合成器,在使用并行流时使用;
*/
T reduce(T identity, BinaryOperator<T> accumulator);Optional<T> reduce(BinaryOperator<T> accumulator);<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);
reduce本身时汇聚的一个过程,可以将目标元素通过累加器合成最终目标结果元素;reduce 操作可以实现从Stream中生成一个值,其生成的值不是随意的,而是根据指定的计算模型。比如,之前提到count、min和max方法,因为常用而被纳入标准库中。事实上,这些方法都是reduce操作。
举个例子
学生类有名字和分数两个属性;@Datapublic class Student {private String name;private int score;}@Testvoid stream(){Student student1 = new Student("zhangsan", 21);Student student2 = new Student("lisi", 82);Student student3 = new Student("wangwu", 32);//需要计算学生分数总和List<Student> list = Arrays.asList(student1, student3, student2);int sum = list.stream().mapToInt(Student::getScore).reduce(Integer::sum).getAsInt();System.out.println(sum);}
max、min
Optional<T> max(Comparator<? super T> comparator);Optional<T> min(Comparator<? super T> comparator);
两个方法入参都是Comparator,出参是Optional对象;返回流中最大或者最小的元素
举个例子:
@Testvoid stream(){List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");//获取流中最大的元素String maxString = list.stream().max(String::compareToIgnoreCase).get();System.out.println(maxString);}打印:supplier
findAny、 findFirst
Optional<T> findAny();Optional<T> findFirst();
- findFirst(): findFirst()方法返回流中的第一个元素(根据流的顺序)。它在并行流操作中的行为更可预测,通常会返回流的第一个元素。如果流为空,则返回一个空的Optional对象。
- findAny(): findAny()方法返回流中的任意一个元素。它对于并行流操作提供了更好的性能,因为它可以在多个线程中并行地搜索元素。不同的运行时环境可能会对元素的选择有所不同。如果流为空,则返回一个空的Optional对象。
当流具有确定顺序的情况下(例如使用List创建的流),findFirst()和findAny()通常返回相同的结果。但是,在并行流操作中,由于并行执行的特性,findAny()可能更适合并行化操作,而且在某些情况下可能具有更好的性能。
举个例子:
@Testvoid stream(){//对于串行流来讲有序集合两个方法返回的都是同一个元素List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");String string1 = list.stream().findFirst().get();String string2 = list.stream().findAny().get();System.out.println(string1 + "--" + string2);}输出:supplier--supplier
但是对于并行流来讲findAny会随机返回一个元素:
@Testvoid stream(){List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");String string1 = list.parallelStream().findFirst().get();String string2 = list.parallelStream().findAny().get();System.out.println(string1 + "--" + string2);}打印:supplier--predicateallMatch、anyMatch、noneMatch
boolean allMatch(Predicate<? super T> predicate);
boolean anyMatch(Predicate<? super T> predicate);
boolean noneMatch(Predicate<? super T> predicate);
三个方法都是接受一个Predicate参数返回boolean值;三个操作都是Stream中的终止操作
- allMatch 用于检查流中所有元素是否满足判断条件 如果都满足返回true 其中有一个不满足返回false;
- anyMatch用于检查流中至少有一个元素满足判断条件,当流中至少有一个元素满足时,返回ture,否则false
- 验证流中元素没有一个满足条件时返回true
我们举个例子来说明:
@Testvoid stream(){List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");String str = "supplier";boolean anyMatchResult = list.stream().anyMatch(item -> item.equals(str));boolean allMatchResult = list.stream().allMatch(item -> item.equals(str));boolean noneMatchResult = list.stream().noneMatch(item -> item.equals(str));System.out.println("anyMatchResult结果:" +anyMatchResult+ " allMatchResult结果:" + allMatchResult + " noneMatchResult结果: "+noneMatchResult);}运行结果为:anyMatchResult结果:true allMatchResult结果:false noneMatchResult结果:false我们可以看到对于anyMatch方法 集合中有一个元素等于我们定义的字符串supplier,条件成立返回true,对于allMatch并不是所有元素都等于我们定义的字符串supplier,条件不成立返回false;对于noneMatch来讲并不是所有元素都不符合条件,返回false;
sorted
Stream<T> sorted();Stream<T> sorted(Comparator<? super T> comparator);
- sorted()将元素从小到大排序
@Testvoid stream(){List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");list.stream().sorted().forEach(System.out::println);}输出 consumerfunctionpredicatesupplier
- sorted(Comparator<? super T> comparator) 比较器自定义排序
@Testvoid stream(){//根据字符串长度进行排序List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");list.stream().sorted(Comparator.comparing(String::length)).forEach(System.out::println);}输出:supplierfunctionconsumerpredicate
count
返回流中元素的个数
举个例子:
@Testvoid stream(){List<String> list = Arrays.asList("supplier", "function", "predicate", "consumer");long count = list.stream().count();System.out.println(count);}打印:4
相关文章:
)
java-Stream原理及相关操作详解(filter、map、flatMap、peek、reduce、anyMatch等等)
java-Stream原理及相关操作详解 Stream流前言Stream流原理介绍Stream-Api常用方法介绍filter()map()flatMappeekreducemax、minfindAny、 findFirstallMatch、anyMatch、noneMatchsortedcount Stream流前言 Java8特性主要是Stream流以及函数式接口的出现;本片文章主…...
基于Springboot中小企业设备管理系统设计与实现(论文+源码)_kaic
摘 要 随着信息技术和网络技术的飞速发展,人类已进入全新信息化时代,传统管理技术已无法高效,便捷地管理信息。为了迎合时代需求,优化管理效率,各种各样的管理系统应运而生,各行各业相继进入信息管理时代&a…...

ORACLE 12 C估算 用户历史上的CPU消耗
在使用ASH不能满足,需要从AWR,即HIST系列表估算每个用户的cpu消耗,只能进行大概估算 先计算各用户使用的cpu time计算出各用户占比将用户cpu time 与osstat的cpu 使用率相乘 with cpu_usage as (select snap_id,BUSY_TIME/(IDLE_TIMEBUSY…...

Zookeeper 简明使用教程
Zookeeper 简明使用教程 ZooKeeper是一个开源的分布式协调服务,用于管理和维护分布式系统中的配置信息、命名服务、分布式锁、分布式队列等。 一、环境 JDK环境 二、下载 $ wget https://dlcdn.apache.org/zookeeper/zookeeper-3.9.2/apache-zookeeper-3.9.2-bin…...
JS 利用 webcam访问摄像头 上传到服务器
webcam JS 较为详细的指南 定义标题 <!doctype html> <html> <head><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>How to capture picture from webcam with Webcam.js</title></…...

【微信小程序】【小程序样式加载不出来】
微信小程序配置sass 第一步:找配置文件 在项目中找到 project.config.json文件,在setting属性中添加 useCompilerPlugins属性,值为sass即可,若是 less,将数组里面的值改为less即可 "useCompilerPlugins": ["sas…...

【THM】Exploit Vulnerabilities(利用漏洞)-
介绍 在这个房间里,我们将讨论一些识别漏洞的方法,并结合我们的研究技能来了解这些漏洞是如何被滥用的。 此外,您还会发现一些公开可用的资源,这些资源是您在执行漏洞研究和利用时的技能和工具的重要补充。然后,您将在房间的最后将所有这些应用到实际挑战中。 自动化与…...
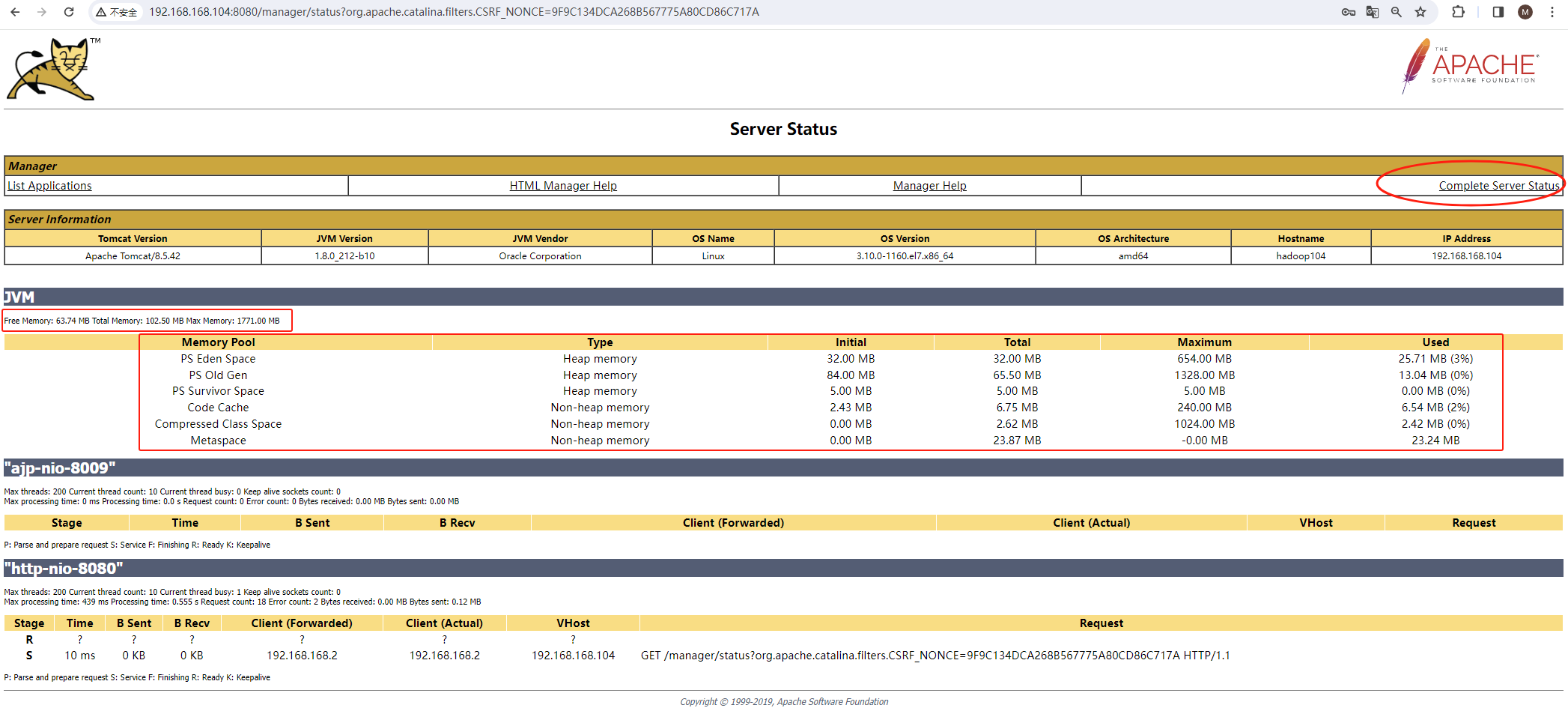
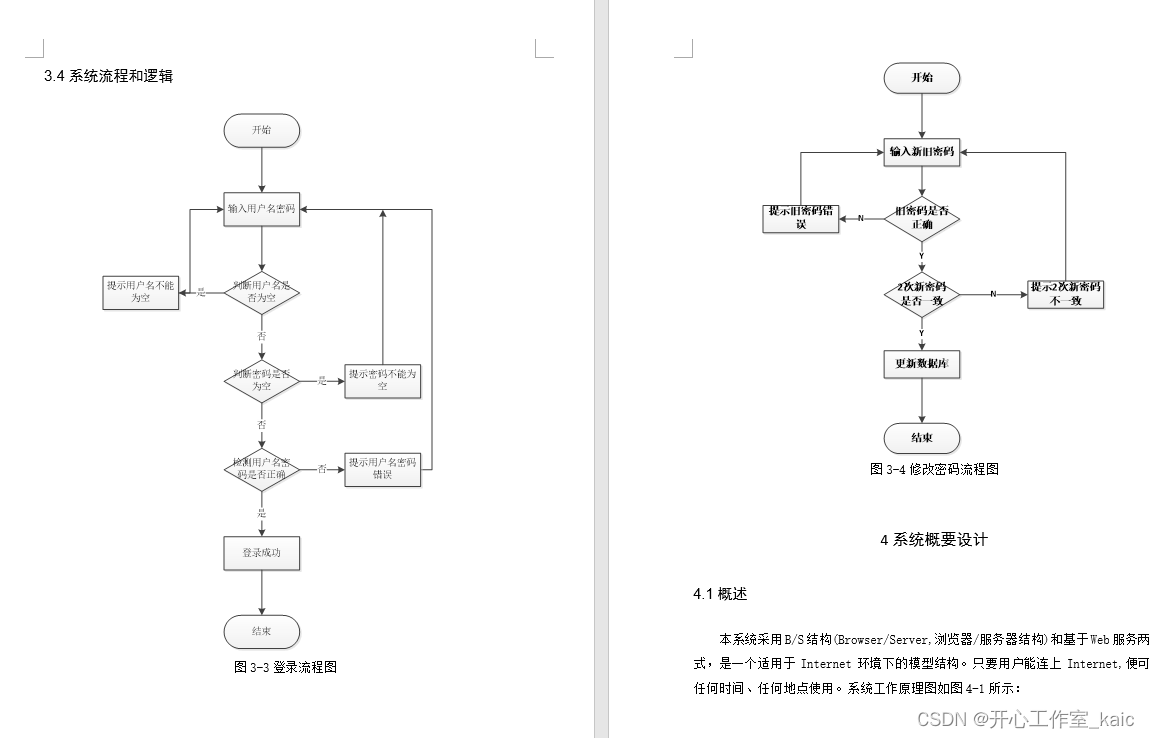
Tomcat管理配置
Tomcat管理配置 1 host-manager项目2 manager项目 Tomcat 提供了Web版的管理控制台,位于webapps目录下。Tomcat 提供了用于管理Host的host-manager和用于管理Web应用的manager。 1 host-manager项目 Tomcat启动之后,可以通过 http://localhost:8080/ho…...

C++模版简单认识与使用
目录 前言: 1.泛型编程 2.函数模版 3.类模版 为什么要有类模版?使用typedef不行吗? 类模版只能显示实例化: 注意类名与类型的区别: 注意类模版最好不要声明和定义分离: 总结: 前言&…...
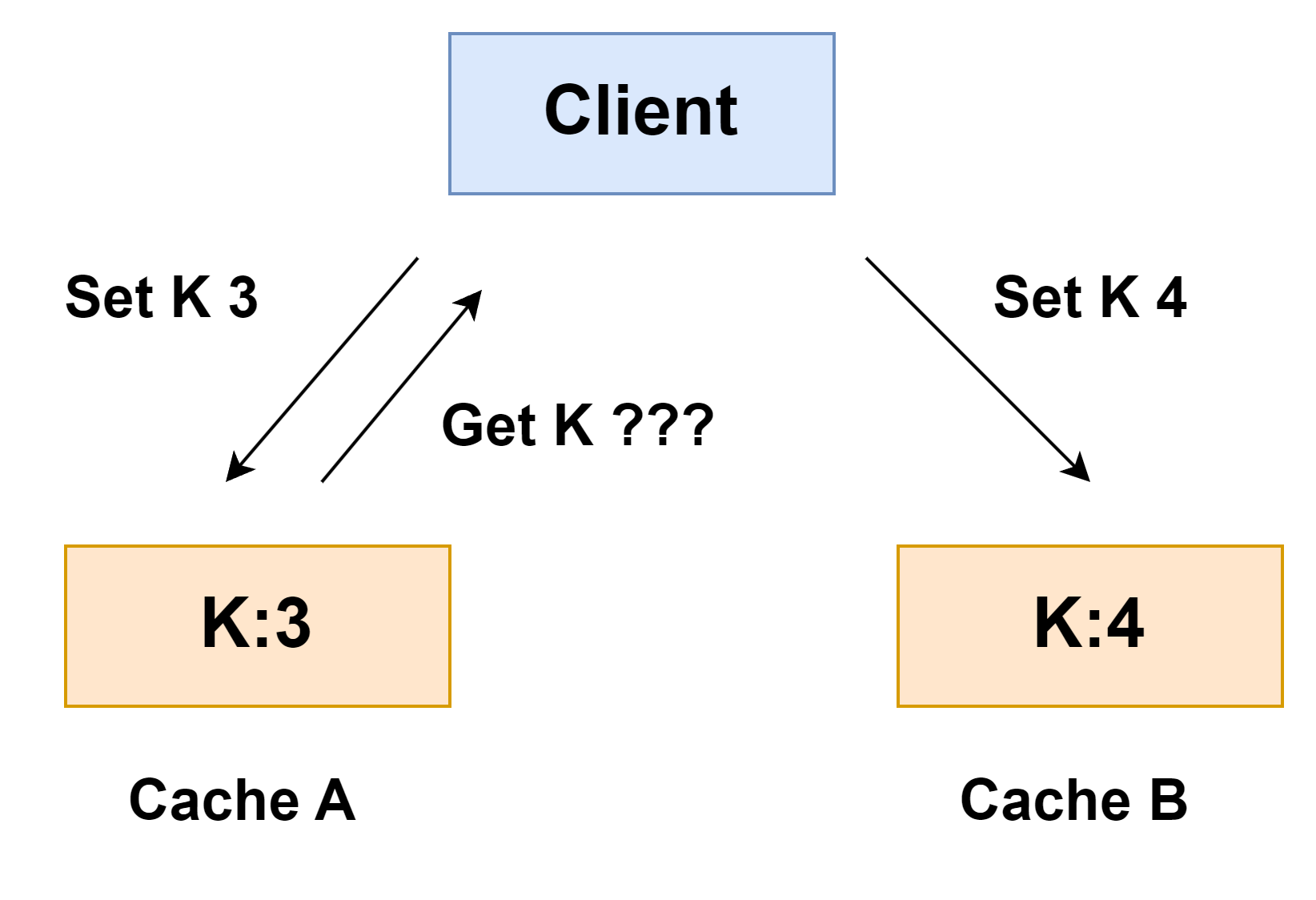
图解大型网站多级缓存的分层架构
前言 缓存技术存在于应用场景的方方面面。从浏览器请求,到反向代理服务器,从进程内缓存到分布式缓存,其中缓存策略算法也是层出不穷。 假设一个网站,需要提高性能,缓存可以放在浏览器,可以放在反向代理服…...
基于Vision Transformer的迁移学习在乳腺X光图像分类中的应用
乳房X线摄影(MG)在乳腺癌的早期发现中起着重要作用。MG可以在早期阶段发现乳腺癌,即使是感觉不到肿块的小肿瘤。基于卷积神经网络(CNN)的DL最近吸引了MG的大量关注,因为它有助于克服CAD系统的限制(假阳性、不必要的辐射暴露、无意义的活组织检查、高回调…...

WebGIS 地铁交通线网数据可视化监控平台
数字孪生技术在地铁线网的管理和运维中的应用是一个前沿且迅速发展的领域。随着物联网、大数据、云计算以及人工智能技术的发展,地铁线网数字孪生在智能交通和智慧城市建设中的作用日益凸显。 图扑软件基于 HTML5 的 2D、3D 图形渲染引擎,结合 GIS 地图&…...

批量导入svg文件作为图标使用(vue3)vite-plugin-svg-icons插件的具体应用
目录 需求svg使用简述插件使用简述实现安装插件1、配置vite.config.ts2、src/main.ts引入注册脚本3、写个icon组件4、使用组件 需求 在vue3项目中,需要批量导入某个文件夹内数量不确定的svg文件用来作为图标,开发完成后能够通过增减文件夹内的svg文件&a…...

X服务器远程连接问题解决:Bad displayname ““‘或Missing X server or $DISPLAY
X服务器远程连接问题 报错1 ImportError: this platform is not supported: (failed to acquire X connection: Bad displayname "", DisplayNameError()) Try one of the following resolutions: * Please make surethat you have an X server running, and that …...
matlab:五点中心差分求解Navier边界的Biharmonic方程(具有纳维尔边界的双调和方程)
我们考虑如下形式的双调和方程的数值解 其中,Ω是欧氏空间中的多边形或多面体域,在其中,d为维度,具有分段利普希茨边界,满足内部锥条件,f(x) ∈ L2(Ω)是给定的函数,∆是标准的拉普拉斯算子。算…...
详细介绍微信小程序app.js
这一节,我们详细介绍app.js 这个文件。这个文件的重要性我就不再赘述,前面已经介绍了。 一、app.js是项目的主控文件 任何一个程序都是需要一个入口的,就好比我们在学c的时候就会有一个main函数,其他语言基本都是一样。很明确的…...

【六 (2)机器学习-EDA探索性数据分析模板】
目录 文章导航一、EDA:二、导入类库三、导入数据四、查看数据类型和缺失情况五、确认目标变量和ID六、查看目标变量分布情况七、特征变量按照数据类型分成定量变量和定性变量八、查看定量变量分布情况九、查看定量变量的离散程度十、查看定量变量与目标变量关系十一…...
Java集合——Map、Set和List总结
文章目录 一、Collection二、Map、Set、List的不同三、List1、ArrayList2、LinkedList 四、Map1、HashMap2、LinkedHashMap3、TreeMap 五、Set 一、Collection Collection 的常用方法 public boolean add(E e):把给定的对象添加到当前集合中 。public void clear(…...

Python TensorFlow 2.6 获取 MNIST 数据
Python TensorFlow 2.6 获取 MNIST 数据 2 Python TensorFlow 2.6 获取 MNIST 数据1.1 获取 MNIST 数据1.2 检查 MNIST 数据 2 Python 将npz数据保存为txt3 Java 获取数据并使用SVM训练4 Python 测试SVM准确度 2 Python TensorFlow 2.6 获取 MNIST 数据 1.1 获取 MNIST 数据 …...

EChart简单入门
echart的安装就细不讲了,直接去官网下,实在不会的直接用cdn,省的一番口舌。 cdn.staticfile.net/echarts/4.3.0/echarts.min.js 正入话题哈 什么是EChart? EChart 是一个使用 JavaScript 实现的开源可视化库,Echart支持多种常…...
详解)
后进先出(LIFO)详解
LIFO 是 Last In, First Out 的缩写,中文译为后进先出。这是一种数据结构的工作原则,类似于一摞盘子或一叠书本: 最后放进去的元素最先出来 -想象往筒状容器里放盘子: (1)你放进的最后一个盘子(…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

MySQL JOIN 表过多的优化思路
当 MySQL 查询涉及大量表 JOIN 时,性能会显著下降。以下是优化思路和简易实现方法: 一、核心优化思路 减少 JOIN 数量 数据冗余:添加必要的冗余字段(如订单表直接存储用户名)合并表:将频繁关联的小表合并成…...

人工智能--安全大模型训练计划:基于Fine-tuning + LLM Agent
安全大模型训练计划:基于Fine-tuning LLM Agent 1. 构建高质量安全数据集 目标:为安全大模型创建高质量、去偏、符合伦理的训练数据集,涵盖安全相关任务(如有害内容检测、隐私保护、道德推理等)。 1.1 数据收集 描…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...

使用SSE解决获取状态不一致问题
使用SSE解决获取状态不一致问题 1. 问题描述2. SSE介绍2.1 SSE 的工作原理2.2 SSE 的事件格式规范2.3 SSE与其他技术对比2.4 SSE 的优缺点 3. 实战代码 1. 问题描述 目前做的一个功能是上传多个文件,这个上传文件是整体功能的一部分,文件在上传的过程中…...