项目:自主实现Boost搜索引擎
文章目录
- 写在前面
- 开源仓库和项目上线
- 其他文档说明
- 项目背景
- 项目的宏观原理
- 技术栈与环境
- 搜索引擎原理
- 正排索引
- 倒排索引
- 去标签和数据清洗模块
- html文件名路径保存函数
- html数据解析函数
- 文件写入函数
- 建立索引模块
- 检索和读取信息
- 建立索引
- 建立正排索引
- 建立倒排索引
- jieba工具的使用
- 倒排索引实现
- 建立单例模式
- 查找数据模块
- HttpServer模块
- 编写前端代码
- 设计去重的效果
本篇主要是对于自主实现Boost搜索引擎这个项目做的一个制作流程文档,对于整个项目的制作思路和细节进行详细的描述,为避免冗余在一些组件方面采用跳转链接的方式,指向以前写好的文档
写在前面
开源仓库和项目上线
本项目已开源到下面链接下的仓库当中
search-engine-online
并且项目已经部署在了Linux服务器上,具体访问方式可以点击下面链接进行访问:
81.70.160.28:8081
其他文档说明
针对于日志的信息,我采用了之前写的一份利用可变参数实现日志的代码,具体链接如下
C++:可变参数实现日志系统
项目背景
对于搜索引擎的概念并不陌生,在日常中有百度,360,搜狗这样的搜索引擎,这些都是相关的公司做好的服务,但这样的大型搜索引擎是特别大型的项目,因此本篇实现的搜索引擎实现的是一个站内搜索,例如在cplusplus这样的网站中实现一个站内搜索的效果
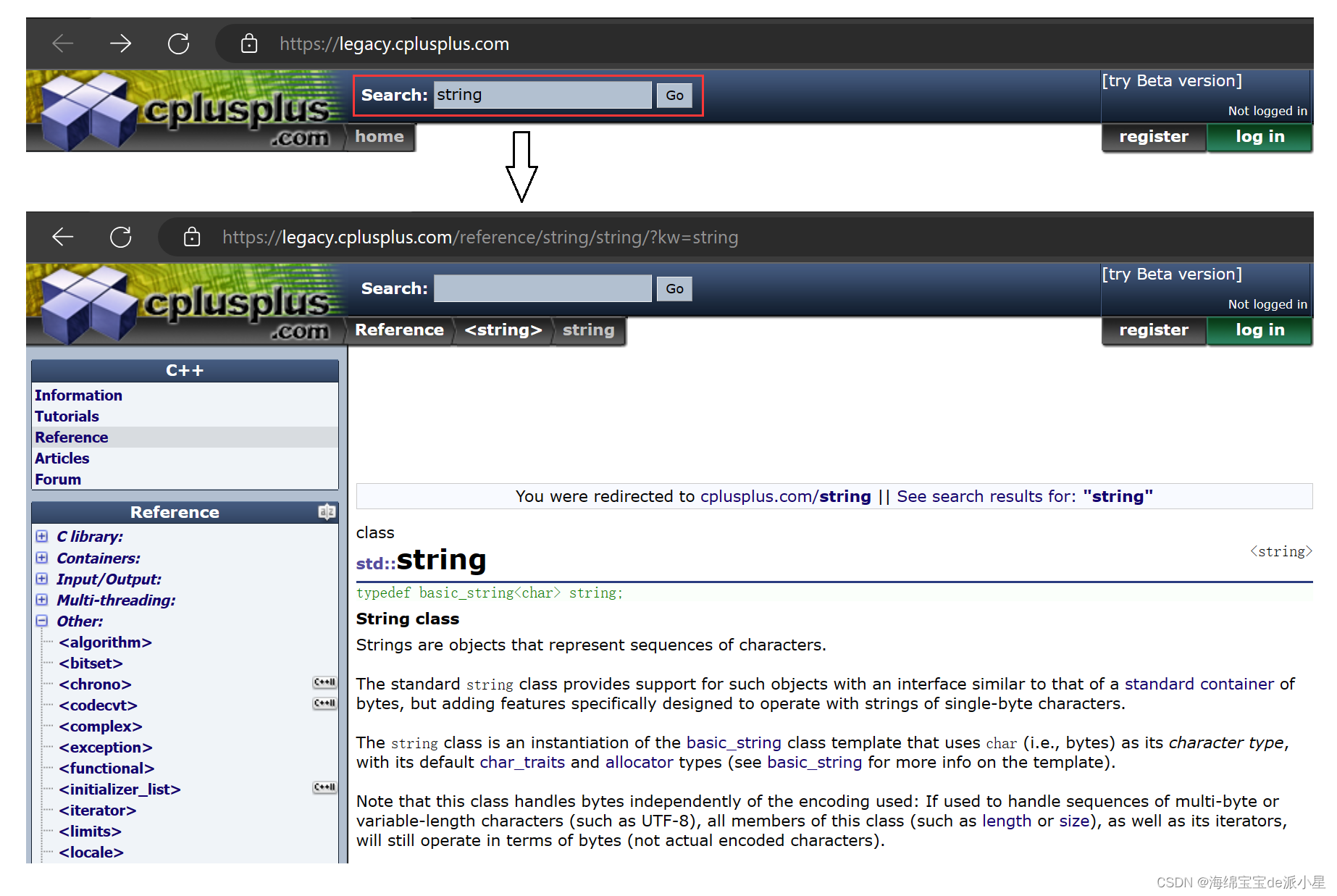
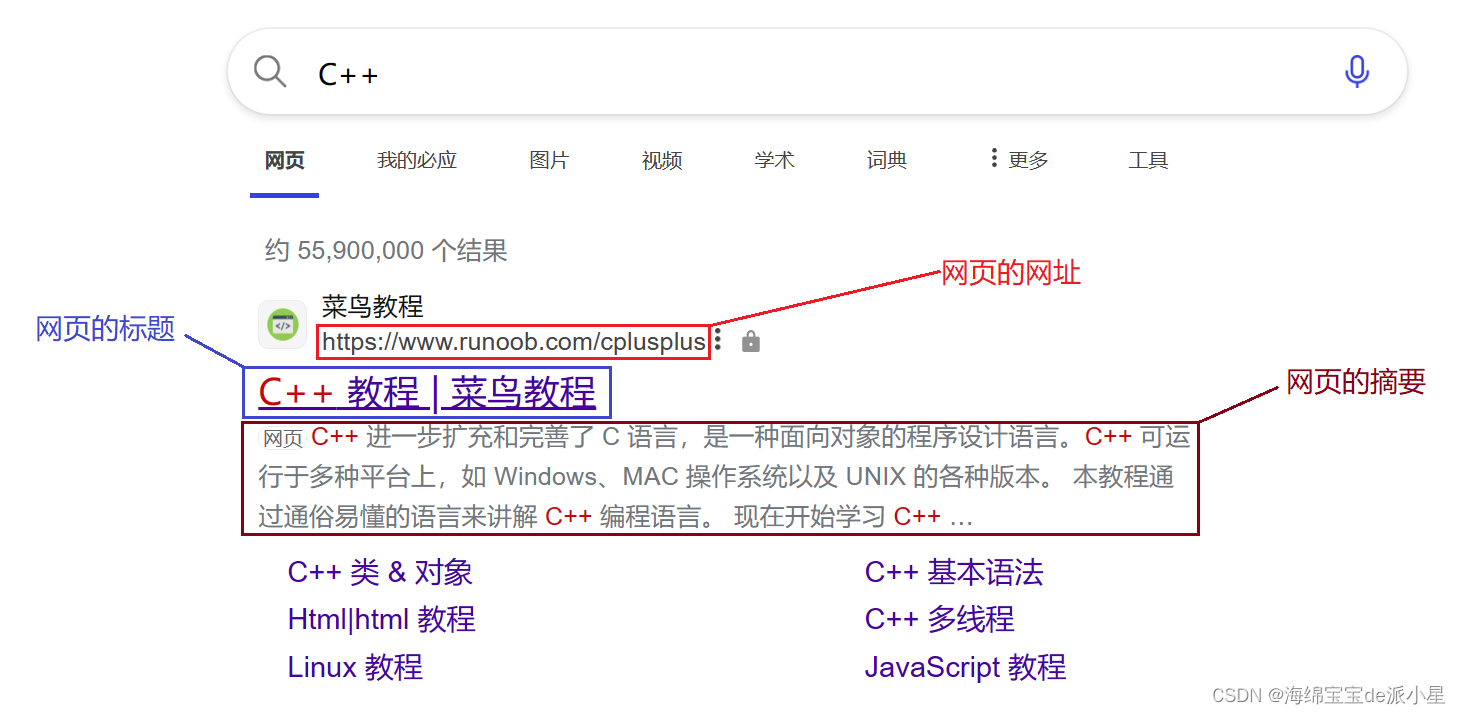
那对于一个搜索引擎来说,当搜索到具体的内容进行实现的时,要展现给用户的内容一般包括有三点,网页的网址,网页的标题,网页的摘要,这里我以搜索C++为例
项目的宏观原理
接下来我将介绍的是对于搜索引擎的宏观原理,在这个宏观原理中不涉及任何的技术细节,只是对于数据在搜索引擎的流动方式有一个基本的认识
数据在搜索引擎的流动方式如下所示:
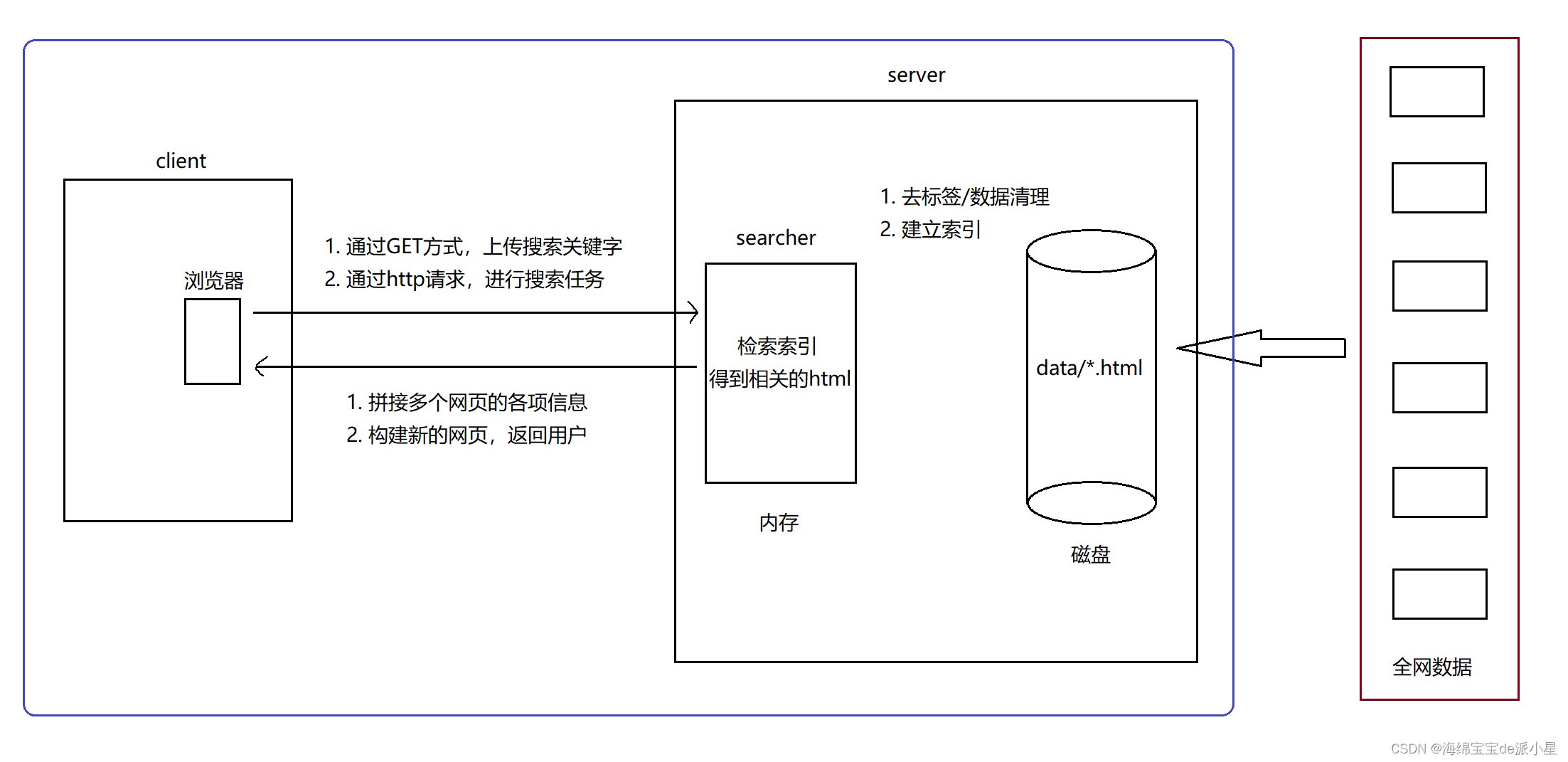
如上图所示,服务器上会运行一个服务软件searcher,它会绑定一个例如9999的端口号,那在这个程序运行的最初步骤,会首先从磁盘中的data目录下读取网页的数据信息,这些网页的信息会通过爬虫这样的方式从网络中进行读取,之后会执行去标签和数据清理的过程,最终只保留网页的三个基本信息,之后会建立索引,这样可以帮助进行更迅速的网页查找信息
在执行了上述过程后,服务端就准备就绪了,此时客户端可以向服务端借助http发送请求,来进行一些搜索任务,服务端此时会进行一系列的检索索引,最终把对应的网页信息返回给客户端,网页中可能包含多个网页信息,因此这里要对筛选出的信息进行二次重组
那在其中需要注意的是,我实现的核心功能是蓝色区域内的内容,至于用爬虫从全网数据读取这个过程直接从Boost官网中下载获取,以上即为对应的搜索引擎的宏观原理
技术栈与环境
- 技术栈:C/C++、C++11、STL
- 项目环境:Centos服务器、g++/Makefile、Visual Studio Code
搜索引擎原理
假设现在有两句话:
- 张三在书店购买了红楼梦
- 李四在书店借阅了红楼梦
正排索引
那所谓正排索引,就是从文档ID中找到文档的内容,也就是提取文档的关键字,例如:
| 文档ID | 文档内容 |
|---|---|
| 1 | 张三在书店购买了红楼梦 |
| 2 | 李四在书店借阅了红楼梦 |
正排索引就是从ID找到文档的内容
倒排索引
倒排索引就是对于目标文件进行分词,以方便于进行倒排索引和查找
例如上述的两个句子如果进行分词,可以这样进行划分
1. [张三在书店购买了红楼梦]:[张三]在[书店][购买]了[红楼梦]
2. [李四在书店借阅了红楼梦]:[李四]在[书店][借阅]了[红楼梦]
划分之后,可以依据划分的结果建立对应的索引信息
| 关键字 | 文档ID |
|---|---|
| 张三 | 句子1 |
| 李四 | 句子2 |
| 书店 | 句子1,句子2 |
| 购买 | 句子1 |
| 借阅 | 句子2 |
| 红楼梦 | 句子1,句子2 |
在有了上述的概念之后,如果用户输入了张三,就可以用张三这个关键字到句子1中进行查找,于是就能找到对应的信息所处的句子,如果用户输入了书店,这个信息在两个句子中都有出现过,那么就对于文档信息进行摘要,再进行构建相关的网页信息,最终返回给客户端,这就是搜索引擎的一个基本的原理
那在上述的这个过程中可以看到,正排索引和倒排索引是需要搭配进行使用的,一定是先查倒排,再根据结果去查正排,进而找到对应的文档内容
这里需要补充的是,既然可能会出现两个相同的索引信息,那这两个信息的出现一定有对应的出现顺序,也就是说不同的信息会有不同的权重,未来我也会在项目中采取一种方法,来实现权重的效果实现,最终做到哪个信息的权重高,就把这条信息放到顺序靠前的位置
去标签和数据清洗模块
在这个模块中,要实现的是对于本项目中的数据进行去标签和数据清洗的操作
首先要获取对应的数据源,既然是Boost搜索引擎,那就到Boost网页中获取对应的数据源信息:
Boost官网
这里我选取的数据源是boost_1_84_0下的html文件,用它来作为索引
接下来就要创建一个源文件,parser.cc,用来对于数据进行去标签和数据清洗的操作,那先介绍一下标签的概念,打开一个html文件,如下图所示:
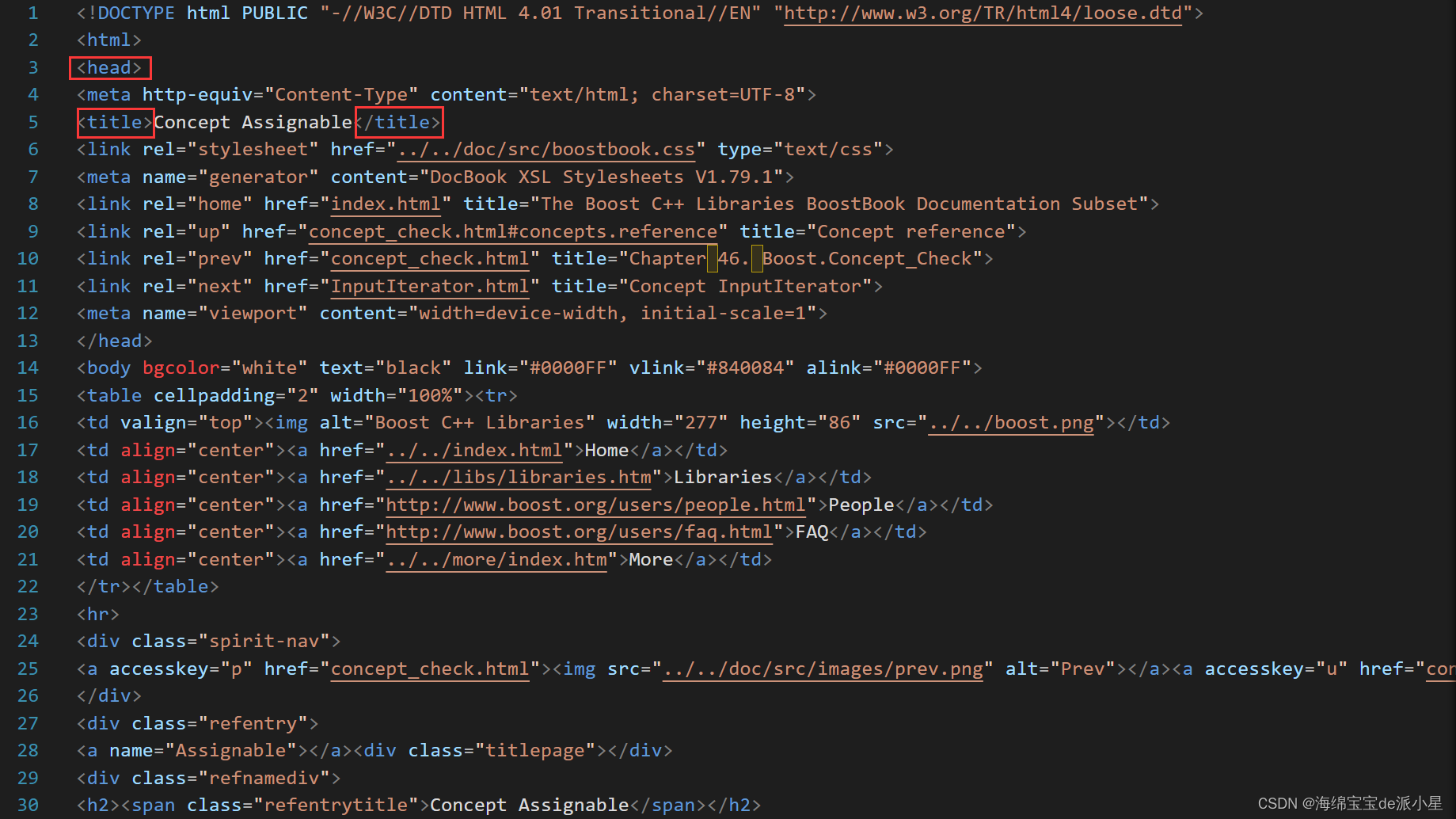
在这个文件中,像这样<>括起来的内容,就叫做是html的标签,而实际上这样的标签对于搜索来说是没有任何价值的,所以就要把这些标签去掉,这样的操作就叫做是数据清洗,当数据清洗的操作结束后,把清洗结束后的数据再放到一个文件中,文件中存储的是干净的文档,在这个文档中理想状态是把这些数据放到一行,每一个文档之间用一些特殊符号来表示,例如在ASCII码表中有一些不可显字符,用这样的字符来作为文档和文档之间的分割,以便于进行文档的提取
选取不可显字符的好处是,不可显字符一般都是控制字符,控制字符是不会影响可打印字符的,这也就意味着这些字符既能帮助分割文档的内容,又能做到不污染形成的文档,于是就可以编写第一个模块的代码了,首先编写整体的逻辑框架
const string input = "data/input";
const string output = "data/output/output.txt";enum
{SUCCESS = 0,ENUMERROR,PARSEERROR,WRITEERROR
};struct Doc_Content
{// 文档的标题,内容,网址string title;string content;string url;
};bool EnumFile(const string &src_path, vector<string> *files_list);
bool ParseHTML(const vector<string> &files_list, vector<Doc_Content> *res_list);
bool WriteToDoc(const vector<Doc_Content> &res_list, const string &output);int main()
{vector<string> files_list;vector<Doc_Content> res_list;// 1. 把每个html文件名带路径保存到files_list中,方便读取其中信息if (!EnumFile(input, &files_list)){lg(Fatal, "enum file and name error!");return ENUMERROR;}// 2. 把files_list中读取到的文件内容解析到res_list中if (!ParseHTML(files_list, &res_list)){lg(Fatal, "parse content error!");return PARSEERROR;}// 3. 把res_list中解析后的内容写到output中,按照\3进行分割if(!WriteToDoc(res_list, output)){lg(Fatal, "Write content to output error!");return WRITEERROR;}return SUCCESS;
}
html文件名路径保存函数
在C++标准库当中,对于文件的操作并不是非常的完善,而在Boost库中有非常完备的文件操作的函数,因此这个模块中我将采用的是基于Boost库的一些库函数实现识别html文件,并且把相关信息存储到files_list当中
在Linux环境中,Boost库并不是自带的,所以需要用户自己进行安装Boost库,并且在编译的过程中要带上boost库的编译选项
# 安装boost库
sudo yum install -y boost-devel
# 编译选项
-lboost_system -lboost_filesystem
对于这个模块来说,其实完成的功能比较简单,就是一个借助库函数提取信息的过程,遍历目录中的文件信息,从中筛选出包含html后缀的文件,并把对应的路径保存到files_list中
安装完成后,就可以借助Boost库提供的方法编写代码:
bool EnumFile(const string &src_path, vector<string> *files_list)
{// 初始化保存根目录信息boost::filesystem::path root(input);// 判断路径是否存在if(!boost::filesystem::exists(root)){lg(Fatal, "%s not exists", input.c_str());return false;}// 定义一个空的迭代器,用来进行判断boost::filesystem::recursive_directory_iterator end;for(boost::filesystem::recursive_directory_iterator it(root); it != end; it++){// 只从普通文件中筛选出html文件if(!boost::filesystem::is_regular_file(*it) || it->path().extension() != ".html")continue;lg(Debug, "%s", it->path().string().c_str());// 这个路径当前满足要求,可以放到表中files_list->push_back(it->path().string());}return true;
}
html数据解析函数
经过上面步骤之后,此时已经可以把html的路径保存到表中,但是对于每一个html中的内容还没有进行提取,所以在进行解析数据之前,要先把每一个文件的内容都存储到对应的字符串中,之后再继续进行提取的操作
这里对于文件内容的提取操作,我把它单独放在了一个utility的头文件当中,作为是一个实用的小工具来使用,方便后续进行其他的提取操作,那提取操作的逻辑也较为简单,直接对于文件进行暴力读取即可:
// 读取一个html文件中的相关信息
class FileUtility
{
public:// 执行文件读取的操作,把文件当中的信息存储到输出字符串当中static bool ReadFile(const string & file_path, string *output){ifstream in(file_path, ios::in);if(!in.is_open()){lg(Warning, "open file %s error", file_path.c_str());return false;}string line;while(getline(in, line))*output += line;in.close();return true;}
};
到此,每一个html中的信息就都已经存储到了字符串当中,那么接下来要做的内容就是把对应的信息从这个字符串中提取出来,放到结构体中作为一个网页的核心数据
1. 提取标题
一个网页的标题,会存储在<title>标签下,这里我以一个html文件为例:
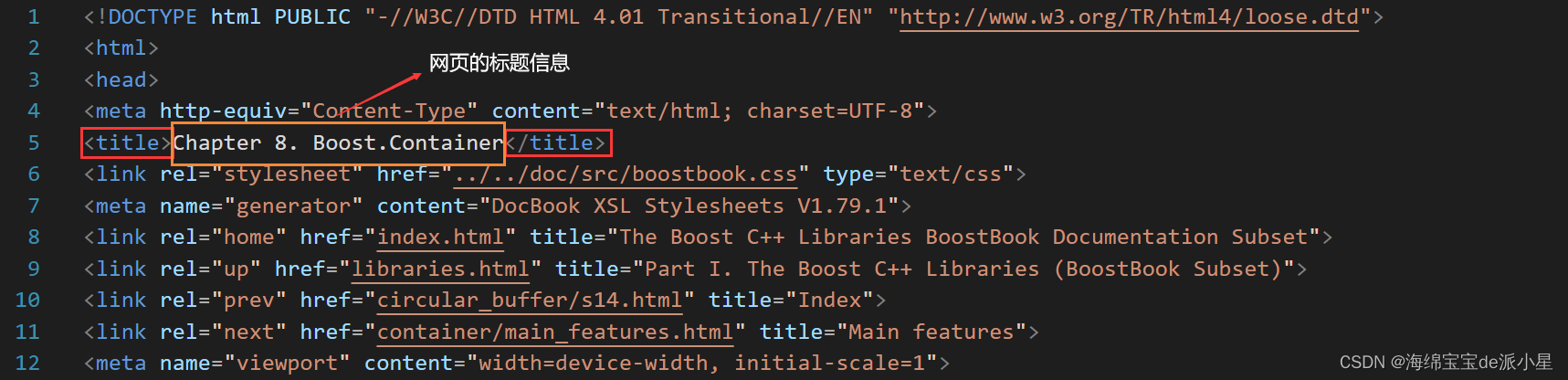
此时我在函数中要完成的目的,就是提取出title标签之间的这部分内容,作为网页的标题,整个算法的思路也是较为简单的,只需要在整个字符串中去寻找<title>和</title>,这两个位置之间的内容就是我当前所需要的字符串
static bool ParseTitle(const string &file, string *title)
{size_t begin = file.find("<title>");if(begin == string::npos)return false;size_t end = file.find("</title>");if(end == string::npos)return false;// 将begin的信息定位到标题信息前begin += string("<title>").size();if(begin > end)return false;*title = file.substr(begin, end - begin);return true;
}
2. 提取内容
提取网页的内容,本质上就是取出掉不需要的标签信息,只保留最关键的部分即可,我以一个html文件为例:
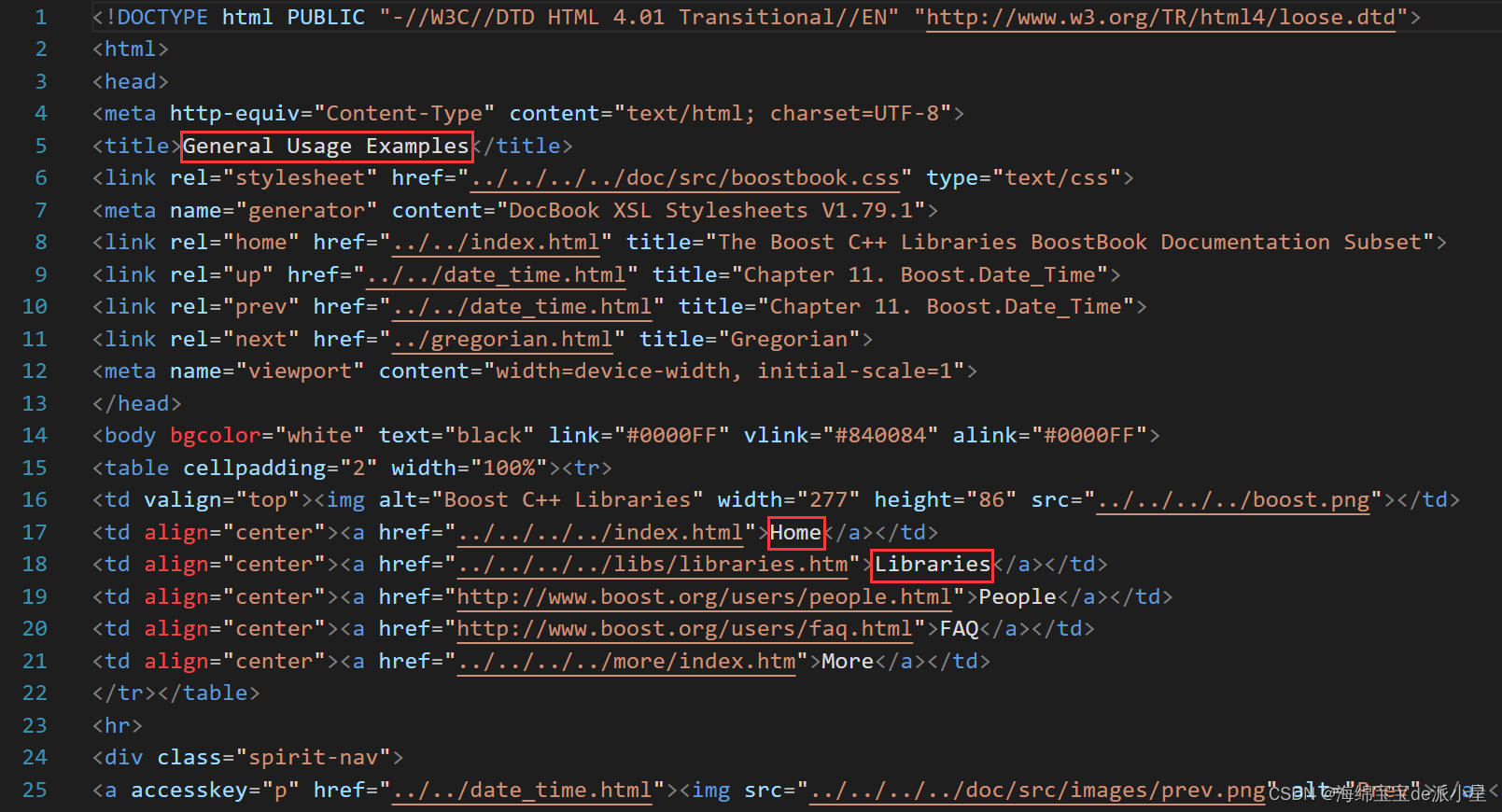
所谓标签信息,就是在标签之间的信息,那么以上图中的几个红框中的内容为例,这些当中的内容都不属于标签,由此观察出的规律是,凡是在>之后的数据就可能是正文,但是如果遇到两个标签挨到一起的情况,例如><也可能不是,那么对此编写一个小型状态机来进行处理,对于状态机的概念也不陌生,如果对此不熟悉也没关系,在代码中进行体现
// 编写一个去标签的函数,去除所有html中的标签信息
static bool ParseContent(const string &file, string *content)
{// 定义状态机的状态enum status{LABLE,CONTENT};enum status s = LABLE;for (char c : file){switch (s){case LABLE:if (c == '>')s = CONTENT;break;case CONTENT:if (c == '<')s = LABLE;else{// 不保留文件中的\nif (c == '\n')c = ' ';content->push_back(c);}break;default:break;}}return true;
}
3. 构建URL
结束了上面的步骤后,接下来要做的就是提取出对应的URL信息,在提取之前,要先说一个URL的结论:在boost库中的官方文档,和下载下来的文档是有路径对应关系的,具体的原因是属于http协议当中的内容,这里不过多解释
具体的,在官方网址中会存在这样的网站:
https://www.boost.org/doc/libs/1_84_0/doc/html/accumulators.html
而在我提前下载好的数据源中,对于accumulators.html这个文件来说,它的所处路径其实是这样的
data/input/accumulators.html
这也就意味着,如果想要构建一个URL,实际上只需要把官方网址中前面的信息和在本地的html所处的信息进行一个组合,这样就能构建出一个URL,那下面我的代码操作就要基于这样的理论,把本地的文档和boost官方库建立一个关系
static bool ParseTitle(const string &file, string *title)
{size_t begin = file.find("<title>");if (begin == string::npos)return false;size_t end = file.find("</title>");if (end == string::npos)return false;// 将begin的信息定位到标题信息前begin += string("<title>").size();if (begin > end)return false;*title = file.substr(begin, end - begin);return true;
}static bool ParseContent(const string &file, string *content)
{// 定义状态机的状态enum status{LABLE,CONTENT};enum status s = LABLE;for (char c : file){switch (s){case LABLE:if (c == '>')s = CONTENT;break;case CONTENT:if (c == '<')s = LABLE;else{// 不保留文件中的\nif (c == '\n')c = ' ';content->push_back(c);}break;default:break;}}return true;
}static bool ParseUrl(const string &file_path, string *url)
{string url_head = "https://www.boost.org/doc/libs/1_84_0/doc/html";// 把前面的内容去除,只保留后面的路径部分string url_tail = file_path.substr(input.size());*url = url_head + url_tail;return true;
}static void showDoc(const Doc_Content &doc)
{cout << "title: " << doc.title << endl;cout << "content: " << doc.content << endl;cout << "url: " << doc.url << endl;
}bool ParseHTML(const vector<string> &files_list, vector<Doc_Content> *res_list)
{// 遍历file_list中的每一个元素信息,提取相关内容for (const string &file : files_list){// 1. 读取文件string res;if (!search_utility::FileUtility::ReadFile(file, &res))continue;// 2. 解析文件信息,存储到结构化数据中Doc_Content doc;if (!ParseTitle(res, &doc.title))continue;// 3. 解析指定的文件,提取content,就是去标签if (!ParseContent(res, &doc.content))continue;// 4. 解析指定的文件路径,构建urlif (!ParseUrl(file, &doc.url))continue;res_list->push_back(doc);showDoc(doc);break;}return true;
}
文件写入函数
这个模块要实现的内容主要是,把上一个部分存储好的信息放到文件中,便于进行检索,那该如何进行检索的模块呢?
对于检索来说,我们理想的状态自然是能够一次读取到一个html文件中的核心信息,包括有标题,内容,URL,同时要能够做到这三个内容用一种合适的方式进行分割,因此我这里采用的设计方法是,将每一个文件中的三个核心信息之间采取用\3进行划分,而文件和文件之间则采取用\n来进行划分,这样就可以实现把文件写入函数的功能,基于这样的想法,我对于该模块的设计思路主要如下:
bool WriteToDoc(const vector<Doc_Content> &res_list, const string &output)
{// 打开文件进行写入ofstream out(output, ios::out | ios::binary);if(!out.is_open()){lg(Fatal, "open %s failed!", output.c_str());return false;}// 打开文件后,将信息写到文件当中for(auto &item : res_list){// 组件一个字符串信息string outstring;outstring += item.title;outstring += '\3';outstring += item.content;outstring += '\3';outstring += item.url;outstring += '\n';// 存储到文件中out.write(outstring.c_str(), outstring.size());}out.close();return true;
}
至此,对于去标签和数据清洗的模块已经结束,下面的模块将会尝试建立索引
建立索引模块
在将对应网页中所有元素的信息都存储到对应的文件中之后,下一步就是要对于文件中关于网页的信息建立索引,那么在这个模块我将会先搭建出一个基本的框架,之后对于每一个框架中的小模块再进行详细的索引
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <unordered_map>
using namespace std;namespace ns_index
{// 定义文档的结构化信息struct DocInfo{string title;string content;string url;uint64_t doc_id;};// 定义映射的Value值,方便倒排索引struct InvertedElem{uint64_t doc_id;string word;int weight;};class Index{public:// 一些必要的构造析构函数Index(){}~Index(){}// 建立正排索引和倒排索引bool BulidIndex(const string &input){}DocInfo *BulidForwardIndex(const string &line){}bool BulidInvertedIndex(const DocInfo &doc){}// 根据doc_id寻找文档内容DocInfo *GetForwardIndex(uint64_t doc_id){}// 根据string关键字获得倒排拉链vector<InvertedElem> *GetInvertedList(const string &word){}private:// 正排索引可以直接使用数组下标当做是文档IDvector<DocInfo> forward_index;// 倒排索引是一个关键组对应多个文档ID等信息unordered_map<string, vector<InvertedElem>> inverted_index;};
}
检索和读取信息
建立索引的目的是为了直接进行存取,从正排索引的角度来讲要做到可以根据文档ID读取到对应的文档信息,而从倒排索引的角度来讲要根据关键词信息,读取到关键词的映射数组,这两个功能都是直接利用STL容器的接口即可实现,较为简单
// 根据doc_id寻找文档内容DocInfo *GetForwardIndex(uint64_t doc_id){// 直接从数组中获取信息if(doc_id >= forward_index.size()){lg(Fatal, "%d is out of range!", &doc_id);return nullptr;}return &forward_index[doc_id];}// 根据string关键字获得倒排拉链vector<InvertedElem> *GetInvertedList(const string &word){// 直接从哈希表中查找信息即可auto iter = inverted_index.find(word);if(iter == inverted_index.end()){lg(Warning, "%s have no index!", word.c_str());return nullptr;}return &(iter->second);}
建立索引
建立索引分为建立正排索引和建立倒排索引,核心思路是依次读取文件中的每一行,每一行就代表了一个网页的各种信息,并对这一行的信息进行解析和构建索引即可:
// 建立正排索引和倒排索引
bool BulidIndex(const string &input)
{// 打开待读取的文件ifstream in(input, ios::in | ios:: binary);if(!in.is_open()){lg(Fatal, "open %s fail!", input.c_str());return false;}// 把文件中的信息按行读取出来string line;while(getline(in, line)){DocInfo* doc = BulidForwardIndex(line);if(doc == nullptr){lg(Warning, "build %s error!", line.c_str());continue;}BulidInvertedIndex(*doc);}return true;
}
在读取到每一行的信息后,具体的建立索引的设计思路如下所示:
建立正排索引
基本思路是根据前面文件中存储的每一个网页的信息,依次把信息进行划分和存储,再存储到对应的下标位置,即可建立出正排索引
DocInfo *BulidForwardIndex(const string &line)
{// 1. 解析line字符串,进行切分vector<string> res;const string sep = "\3";search_utility::StringUtil::Split(line, &res, sep);if (res.size() != 3)return nullptr;// 2. 填充到DocInfo当中DocInfo doc;doc.title = res[0];doc.content = res[1];doc.url = res[2];doc.doc_id = forward_index.size();// 3. 插入到正排索引中forward_index.push_back(move(doc));return &(forward_index.back());
}
在这当中需要注意的是,在进行按\3进行划分的函数,这里采用的是boost库当中的划分函数,这里考虑到篇幅的原因不再进行详细介绍
static void Split(const string &line, vector<string> *res, const string &sep)
{boost::split(*res, line, boost::is_any_of(sep), boost::token_compress_on);
}
建立倒排索引
基本思路是把正排索引当中的内容进行合适的划分,之后把对应的关键词所在的文档信息添加到哈希表中,即可完成对于倒排索引的建立,以上为基本原理,那么下面进行更加详细的描述:
从结构的设计来讲,一个初步的设定是可以用一个结构体来管理一个词,其中必须要有这个词对应的ID信息,还有词的信息,以及最重要的是,要包含有词的权重信息,针对于词的权重,我这里给出的解释是当出现相同关键字时,词的权重越大,证明它出现的越高频,所以就把它的位置向前放
而内容的读取在前面的部分中已经有对应的文档内容了,文档内容中包括有标题和内容,那么提取词汇和建立权重的这个过程就要从标题和内容中进行寻找了,根据文档的内容,进行合适的划分,对于每一个文档的内容都可以形成一个或者多个倒排拉链,那么下面展示具体的步骤
1. 分词
分词我这里采用的是jieba分词,突出的效果就是最初步的在前面讲解正排和倒排索引一样,对一句话提取关键字
那jieba库在github上是开源的,克隆到本地仓库之后,对于本地仓库中可以使用一个demo代码来看它的作用:
小明硕士毕业于中国科学院计算所,后在日本京都大学深造
[demo] CutForSearch
小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造
上述所示就是关于jieba分词的主要使用效果,那么我后面对于分词使用的就是这个库
2. 词频统计
遍历这句话中的每一个词,如果它是处于在标题当中的,那么就把这个词汇统计信息存储到标题次数中,如果是出现在正文当中,就把这个词的信息存储到正文部分当中,至此就能把文档中具体的某一个词,它的具体出现的次数都能统计出来
3. 自定义相关性
在自定义相关性中,我这里采取的方案比较简单,就是根据前面的词频统计,标题出现的权重高一些,正文出现的权重低一些,最终做一个累计和即可
jieba工具的使用
有了jieba库,于是我们可以定义一个简单的jieba工具,具体的使用也很简单,只需要对应的创建一个对象,再把当前jieba库中的词库信息初始化该jieba对象,直接调用jieba的对应方法,就可以实现分词的目的
const char *const DICT_PATH = "./dict/jieba.dict.utf8";
const char *const HMM_PATH = "./dict/hmm_model.utf8";
const char *const USER_DICT_PATH = "./dict/user.dict.utf8";
const char *const IDF_PATH = "./dict/idf.utf8";
const char *const STOP_WORD_PATH = "./dict/stop_words.utf8";class JiebaUtil
{
public:static void CutString(const string &src, vector<string> *out){JiebaUtil::jieba.CutForSearch(src, *out);}private:static cppjieba::Jieba jieba;
};
cppjieba::Jieba JiebaUtil::jieba(DICT_PATH, HMM_PATH, USER_DICT_PATH, IDF_PATH, STOP_WORD_PATH);
倒排索引实现
// 根据文档中的信息建立倒排拉链
bool BulidInvertedIndex(const DocInfo &doc)
{struct word_cnt{word_cnt() : title_cnt(0), content_cnt(0){}int title_cnt;int content_cnt;};// 建立一个用来暂存词频的映射表unordered_map<string, word_cnt> word_map;// 对于标题进行分词vector<string> title_words;search_utility::JiebaUtil::CutString(doc.title, &title_words);// 对于标题进行词频统计for(auto s : title_words){transform(title_words.begin(), title_words.end(), title_words.begin(), ::tolower);word_map[s].title_cnt++;}// 对于内容进行分词vector<string> content_words;search_utility::JiebaUtil::CutString(doc.content, &content_words);// 对于内容进行词频统计for(auto s : content_words){transform(content_words.begin(), content_words.end(), content_words.begin(), ::tolower);word_map[s].content_cnt++;}// 建立倒排索引for(auto& kv : word_map){string key_string = kv.first;auto word_count = kv.second;// 把倒排索引的信息填充到结构体中InvertedElem item;item.doc_id = doc.doc_id;item.word = key_string;item.weight = GetWeight(word_count.title_cnt, word_count.content_cnt);// 提取出当前关键字对应的倒排信息,然后把当前词的倒排信息插入进去vector<InvertedElem> &inverted_list = inverted_index[key_string];inverted_list.push_back(move(item));}return true;
}// 设计一个计算权值的函数,这里暂时不过多设计
int GetWeight(int title, int content)
{return title * 10 + content;
}
建立单例模式
那上述其实已经完成了所有的步骤,但是这里还可以进行优化一下,对于建立索引这件事,我希望在整个代码中只需要建立一次就足够了,因此可以把索引的建立单例化,这样在未来进行使用的时候也只需要调用一次即可
查找数据模块
在查找数据模块中,一个大的主体思路是,用户输入一个词,然后进行匹配,最后输出匹配的结果
具体的来谈,作为使用者在进行查询的时候,使用的方式是在搜索栏中输入一个关键词,之后要先把这个关键词进行分词,之后针对于分词之后的结果,到已经提前准备好的index当中查找,之后把查找到的信息进行汇总,再将对应的结果按照weight降序排序,之后组件成json串传递回去即可,具体代码实现如下:
void Search(const string &query, string *json_string){// 1. 把传入的query参数进行分词vector<string> words;search_utility::JiebaUtil::CutString(query, &words);// 2. 根据分词的结果,进行index查找// 建立所有词的倒排索引vector<search_index::InvertedElem> inverted_list_all;for (auto word : words){transform(word.begin(), word.end(), word.begin(), ::tolower);// 根据当前分词去寻找倒排索引vector<search_index::InvertedElem> *inverted_list = index->GetInvertedList(word);// 如果当前分词找不到结果,就跳过if (inverted_list == nullptr)continue;// 把当前词的倒排索引结果插入到汇总结果当中inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());}// 3. 按照出现的权值排序,汇总结果sort(inverted_list_all.begin(), inverted_list_all.end(), [](const search_index::InvertedElem &e1, const search_index::InvertedElem &e2){ return e1.weight > e2.weight; });// 4. 构建json串Json::Value root;for (auto &item : inverted_list_all){search_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);if (nullptr == doc)continue;Json::Value elem;elem["title"] = doc->title;elem["desc"] = doc->content;elem["url"] = doc->url;elem["id"] = (int)item.doc_id;elem["weight"] = item.weight;root.append(elem);}// Json::StyledWriter writer;Json::FastWriter writer;*json_string = writer.write(root);}
在这当中也有部分需要改进的地方,例如对于desc部分,展示的是文章的所有内容,这并不是想要的,那处理方法就是找到word在html_content中的首次出现,然后往前找50字节(如果没有,从begin开始),往后找100字节,最终拼凑成一个content内容即可
string GetDesc(const string &html_content, const string &word)
{// 找到word在html_content中的首次出现,然后往前找50字节(如果没有,从begin开始),往后找100字节(如果没有,到end就可以的)// 截取出这部分内容const int prev_step = 50;const int next_step = 100;// 1. 找到首次出现auto iter = search(html_content.begin(), html_content.end(), word.begin(), word.end(), [](int x, int y){ return (tolower(x) == tolower(y)); });if (iter == html_content.end()){return "None1";}int pos = distance(html_content.begin(), iter);// 2. 获取start,endint start = 0;int end = html_content.size() - 1;// 如果之前有50+字符,就更新开始位置if (pos > start + prev_step)start = pos - prev_step;if (pos < end - next_step)end = pos + next_step;// 3. 截取子串,returnif (start >= end)return "None2";string desc = html_content.substr(start, end - start);desc += "...";return desc;
}
到此,搜索模块也已经完成了,下一步就剩下进行网络的交互过程了
HttpServer模块
在这个模块中,我初步的方案是使用了现成的httplib库,未来可能会有其他的解决方案
#include "httplib.h"
#include "searcher.hpp"
#include "Log.hpp"extern Log lg;const std::string input = "../data/output/output.txt";
const std::string root_path = "./wwwroot";int main()
{search_searcher::Searcher search;search.InitSearcher(input);httplib::Server svr;svr.set_base_dir(root_path.c_str());svr.Get("/s", [&search](const httplib::Request &req, httplib::Response &rsp){if (!req.has_param("word")){rsp.set_content("必须要有搜索关键字!", "text/plain; charset=utf-8");return;}std::string word = req.get_param_value("word");lg(Info, "用户搜索的: %s", word.c_str());std::string json_string;search.Search(word, &json_string);rsp.set_content(json_string, "application/json");});lg(Info, "服务器启动成功...");svr.listen("0.0.0.0", 8081);return 0;
}
编写前端代码
这里由于前端不是重点,就不进行讲解了
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Boost搜索引擎</title><link rel="shortcut icon" href="./image/favicon.png" type="image/png" /><style>/* 基本样式重置 */* {box-sizing: border-box;margin: 0;padding: 0;}html,body {height: 100%;font-family: Arial, sans-serif;font-size: 16px;line-height: 1.7;color: #333;background-color: #f7f7f7;}/* 页面布局 */.container {width: 100%;max-width: 100%;margin: 100px auto;padding: 30px;background-color: #fff;box-shadow: 0 2px 4px rgba(0, 0, 0, 0.1);display: flex;flex-direction: column;align-items: center;justify-content: center;}/* 搜索区域 */.search {display: flex;align-items: center;gap: 10px;height: 52px;padding: 0 10px;background-color: #f0f0f0;border-radius: 4px;}.search input[type="text"] {flex-grow: 1;height: 100%;padding: 0 50px;border: 1px solid #ccc;border-right: none;outline: none;color: #666;}.search button {width: 150px;height: 100%;border: none;background-color: #4e6ef2;color: #fff;font-size: 18px;font-weight: bold;cursor: pointer;transition: background-color 0.2s ease;}.search button:hover {background-color: #3b59e9;}/* 搜索结果 */.result {margin-top: 20px;padding: 0 10px;}.result .item {margin-top: 15px;}.result .item a {display: block;text-decoration: none;color: #4e6ef2;font-size: 20px;line-height: 1.3;transition: color 0.2s ease;}.result .item a:hover {color: #3b59e9;}.result .item p {margin-top: ⅔px;font-size: 16px;line-height: 1.5;}.result .item i {display: block;font-style: normal;color: #008000;}</style><!-- ... 其他已存在的 head 内容 ... --><script>document.addEventListener("DOMContentLoaded", function () {const searchInput = document.querySelector('.search input[type="text"]');const searchButton = document.querySelector('.search button');searchInput.addEventListener('keyup', function (event) {if (event.key === 'Enter') {searchButton.click(); // 模拟点击搜索按钮event.preventDefault(); // 阻止默认行为(如表单提交)}});});</script></head><body><div class="container"><div class="search"><input type="text" placeholder="请输入搜索关键字"><button onclick="Search()">搜索一下</button></div><div class="result"></div></div><script src="http://code.jquery.com/jquery-2.1.1.min.js"></script><script>function Search() {const query = $(".container .search input").val();$.ajax({type: "GET",url: "/s?word=" + query,success: data => BuildHtml(data),});}function BuildHtml(data) {const resultContainer = $(".container .result");resultContainer.empty();data.forEach((elem) => {const item = `<div class="item"><a href="${elem.url}" target="_blank">${elem.title}</a><p>${elem.desc}</p><i>${elem.url}</i></div>`;resultContainer.append(item);});}</script>
</body></html>
设计去重的效果
在上述的代码中其实是存在一些问题的,比如,我创建一个新的html网页的信息
<!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN">
<html><head><!-- Copyright (C) 2002 Douglas Gregor <doug.gregor -at- gmail.com>Distributed under the Boost Software License, Version 1.0.(See accompanying file LICENSE_1_0.txt or copy athttp://www.boost.org/LICENSE_1_0.txt) --><title>用来测试</title><meta http-equiv="refresh" content="0; URL=../../libs/core/doc/html/core/ref.html"></head><body>Automatic redirection failed, please go to<a href="../../libs/core/doc/html/core/ref.html">../../libs/core/doc/html/core/ref.html</a></body>
</html>
此时将项目启动起来,搜索一下这个关键字,会发现存在这样的现象
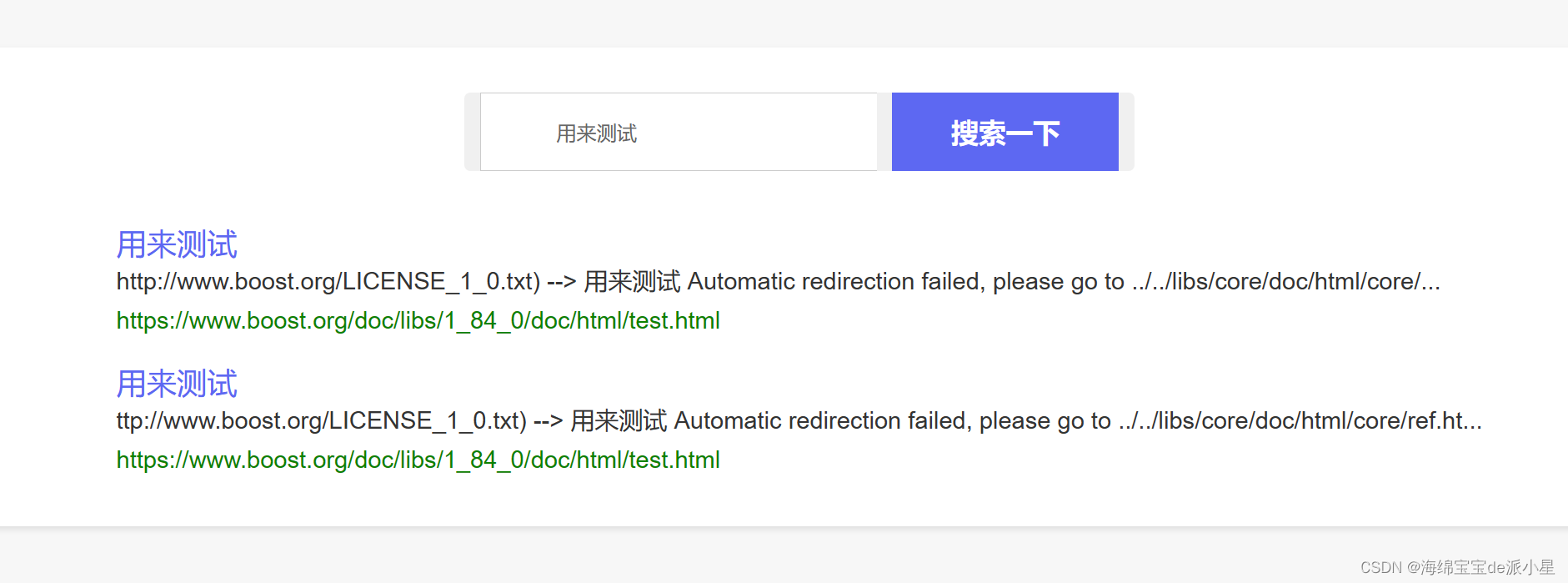
那这是为什么?其实原因就在于是没有进行去重,而解决的方式就是用文档的id为键值,建立一个文档id和对应信息的索引关系,未来对于同一个文档id的内容,就把他们的信息都合并到一起,作为一条来进行显示就可以了
我们新增一个索引结构,用来存储每一个文档号对应的文档信息
struct InvertedElemPrint
{uint64_t doc_id;int weight;vector<string> words;InvertedElemPrint() : doc_id(0), weight(0) {}
};
再在search的时候,对于信息进行提取,把相同id下的权值等累计到一起,最后把上述结构体的信息作为索引的依据即可
void Search(const string &query, string *json_string)
{// 1. 把传入的query参数进行分词vector<string> words;search_utility::JiebaUtil::CutString(query, &words);// 2. 根据分词的结果,进行index查找// 建立所有词的倒排索引vector<InvertedElemPrint> inverted_list_all;// 根据id来进行合并去重std::unordered_map<uint64_t, InvertedElemPrint> tokens_map;for (auto word : words){transform(word.begin(), word.end(), word.begin(), ::tolower);// 根据当前分词去寻找倒排索引vector<search_index::InvertedElem> *inverted_list = index->GetInvertedList(word);// 如果当前分词找不到结果,就跳过if (inverted_list == nullptr)continue;// 把当前词的倒排索引结果插入到汇总结果当中for (const auto &elem : *inverted_list){auto &item = tokens_map[elem.doc_id]; //[]:如果存在直接获取,如果不存在新建// item一定是doc_id相同的print节点item.doc_id = elem.doc_id;item.weight += elem.weight;item.words.push_back(elem.word);}}for (const auto &item : tokens_map){inverted_list_all.push_back(move(item.second));}// 3. 按照出现的权值排序,汇总结果sort(inverted_list_all.begin(), inverted_list_all.end(),[](const InvertedElemPrint &e1, const InvertedElemPrint &e2){return e1.weight > e2.weight;});// 4. 构建json串Json::Value root;for (auto &item : inverted_list_all){search_index::DocInfo *doc = index->GetForwardIndex(item.doc_id);if (nullptr == doc)continue;Json::Value elem;elem["title"] = doc->title;elem["desc"] = GetDesc(doc->content, item.words[0]);elem["url"] = doc->url;// for deubg, for deleteelem["id"] = (int)item.doc_id;elem["weight"] = item.weight; // int->stringroot.append(elem);}// Json::StyledWriter writer;Json::FastWriter writer;*json_string = writer.write(root);
}
至此,这个项目就基本完成了,后续可能还会新增一些新的功能
相关文章:
项目:自主实现Boost搜索引擎
文章目录 写在前面开源仓库和项目上线其他文档说明 项目背景项目的宏观原理技术栈与环境搜索引擎原理正排索引倒排索引 去标签和数据清洗模块html文件名路径保存函数html数据解析函数文件写入函数 建立索引模块检索和读取信息建立索引建立正排索引建立倒排索引jieba工具的使用倒…...
麒麟系统ARM安装rabbitmq
简单记录下,信创服务器:麒麟系统,安装rabbitmq的踩坑记录。 本文章参考了很多大佬文章,我整理后提供。 一、安装基础依赖 yum -y install make gcc gcc-c kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel 二、下载…...

MongoDB数据更新大之大与小中小
学习mongodb,体会mongodb的每一个使用细节,欢迎阅读威赞的文章。这是威赞发布的第56篇mongodb技术文章,欢迎浏览本专栏威赞发布的其他文章。 数据更新中,往往要应对比较更新的场景。现在很多人喜欢跑步,规律跑步&…...

C语言开发实战:使用EasyX在Visual Studio 2022中创建井字棋游戏
🌟 前言 欢迎来到我的技术小宇宙!🌌 这里不仅是我记录技术点滴的后花园,也是我分享学习心得和项目经验的乐园。📚 无论你是技术小白还是资深大牛,这里总有一些内容能触动你的好奇心。🔍 &#x…...
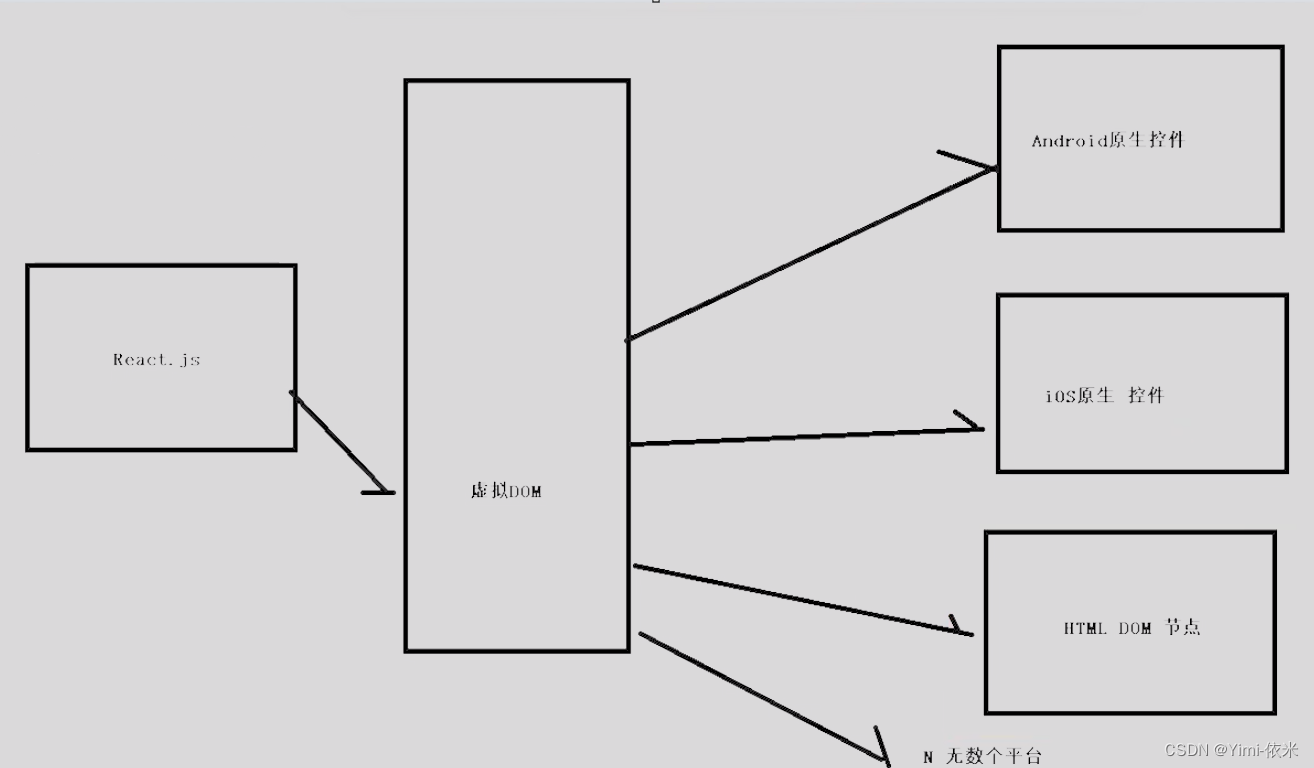
Android与RN远程过程调用的原理
Android与RN远程过程调用的原理是通过通信协议进行远程过程调用。RPC(Remote Procedure Call)是分布式系统常见的一种通信方式,从跨进程到跨物理机已经有几十年历史。 在React Native中,通信机制是一个C实现的桥,打通了Java和JS,实现了两者的…...

MySQL-主从复制:概述、原理、同步数据一致性问题、搭建流程
主从复制 1. 主从复制概述 1.1 如何提升数据库并发能力 一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是采用数据库集群的方案,做主从架构、进行读写分离,这样同样可以提升数据库的并…...
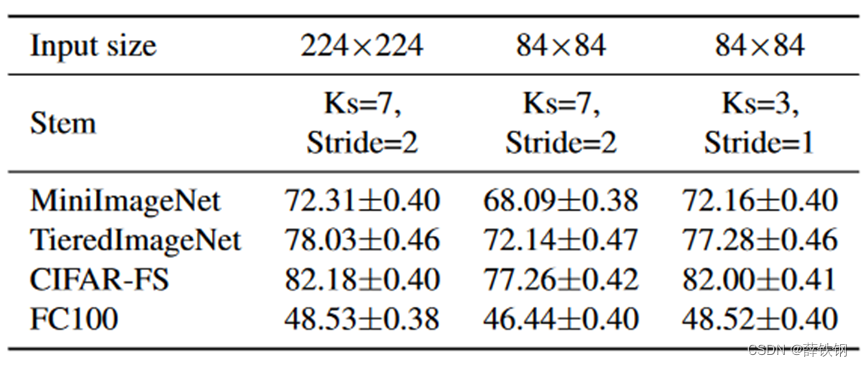
论文阅读《Semantic Prompt for Few-Shot Image Recognition》
论文地址:https://arxiv.org/pdf/2303.14123.pdf 论文代码:https://github.com/WentaoChen0813/SemanticPrompt 目录 1、存在的问题2、算法简介3、算法细节3.1、预训练阶段3.2、微调阶段3.3、空间交互机制3.4、通道交互机制 4、实验4.1、对比实验4.2、组…...
docker)
Linux初学(十七)docker
一、docker 1.1 简介 容器技术 容器其实就是虚拟机,每个容器可以运行不同的系统【系统以Linux为主的】 为什么要使用docker? docker容器之间互相隔离,可以提高安全性通过使用docker可以做靶场 1.2 安装配置docker 方法一:yum安装…...
Python---Numpy线性代数
1.数组和矩阵操作: 创建数组和矩阵:np.array, np.matrix 基本的数组操作:形状修改、大小调整、转置等 import numpy as np# 创建一个 2x3 的数组 A np.array([[1, 2, 3], [4, 5, 6]]) print("数组 A:\n", A)# 将数组 A 转换为矩阵…...

react+ echarts 轮播饼图
react echarts 轮播饼图 图片示例 代码 import * as echarts from echarts; import { useEffect } from react; import styles from ./styles.scss;const Student (props) > {const { dataList, title } props;// 过滤数据const visionList [{ value: 1048, name: Se…...
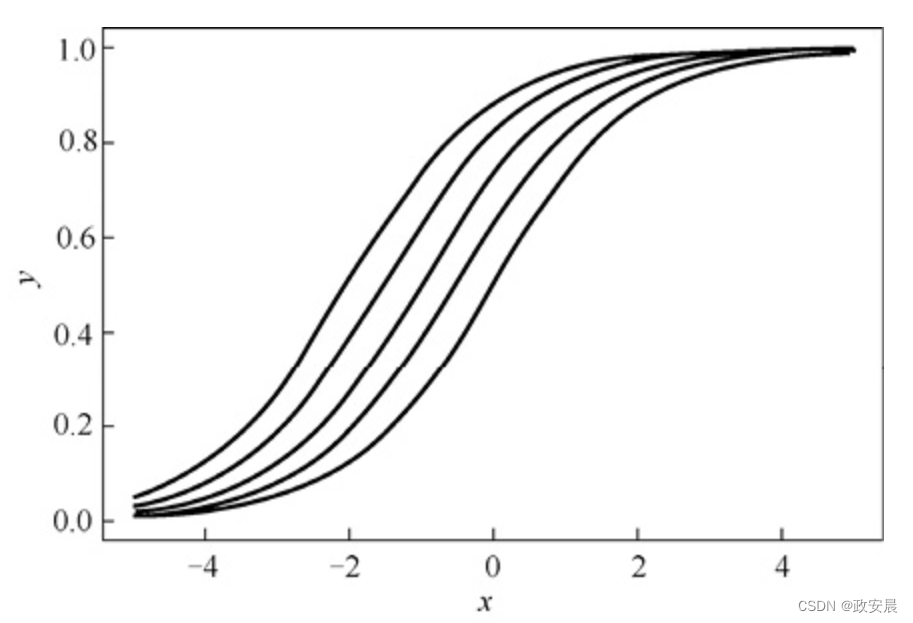
政安晨:【深度学习神经网络基础】(三)—— 激活函数
目录 线性激活函数 阶跃激活函数 S型激活函数 双曲正切激活函数 修正线性单元 Softmax激活函数 偏置扮演什么角色? 政安晨的个人主页:政安晨 欢迎 👍点赞✍评论⭐收藏 收录专栏: 政安晨的机器学习笔记 希望政安晨的博客能够对您有所裨…...
使用tomcat里的API - servlet 写动态网页
一、创建一个新的Maven空项目 首次创建maven项目的时候,会自动从maven网站上下载一些依赖组件(这个过程需要保证网络稳定,否则后续打包一些操作会出现一些问题) ps:校园网可能会屏蔽一些网站,可能会导致maven的依赖…...
从0到1搭建文档库——sphinx + git + read the docs
sphinx git read the docs 目录 一、sphinx 1 sphinx的安装 2 本地构建文件框架 1)创建基本框架(生成index.rst ;conf.py) conf.py默认内容 index.rst默认内容 2)生成页面(Windows系统下…...

EasyExcel 校验后导入
引入pom <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>3.3.3</version></dependency>触发校验类 import com.baomidou.mybatisplus.extension.api.R; import lombok.experimental…...

【星计划★C语言】c语言初相识:探索编程之路
🌈个人主页:聆风吟_ 🔥系列专栏:星计划★C语言、Linux实践室 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. ⛳️第一个c语言程序二. ⛳️数据类型2.1 🔔数据单位2.2 &…...

搜维尔科技:借助 ARVR 的力量缩小现代制造业的技能差距
借助ARVR的力量缩小现代制造业的技能差距 搜维尔科技:Senseglove案例-扩展机器人技术及其VR应用...
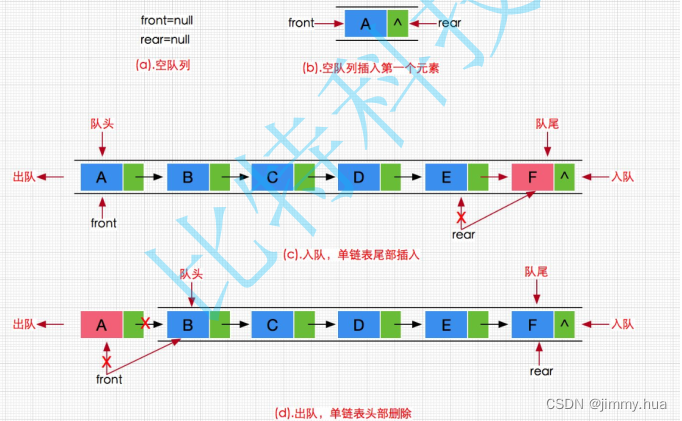
数据结构之栈和队列
1.前言 大家好久不见,这段时间由于忙去了。就没有即使维护我的博客,先给大家赔个不是。 我们还是规矩不乱,先赞后看~ 今天讲的内容是数据结构中非常重要的一个部分:栈和队列。它在今后的学习中也会再次出现(c&#…...
centos安装使用elasticsearch
1.首先可以在 Elasticsearch 官网 Download Elasticsearch | Elastic 下载安装包 2. 在指定的位置(我的是/opt/zhong/)解压安装包 tar -zxvf elasticsearch-7.12.1-linux-x86_64.tar.gz 3.启动es-这种方式启动会将日志全部打印在当前页面,一旦使用 ctrlc退出就会导…...
4.7学习总结
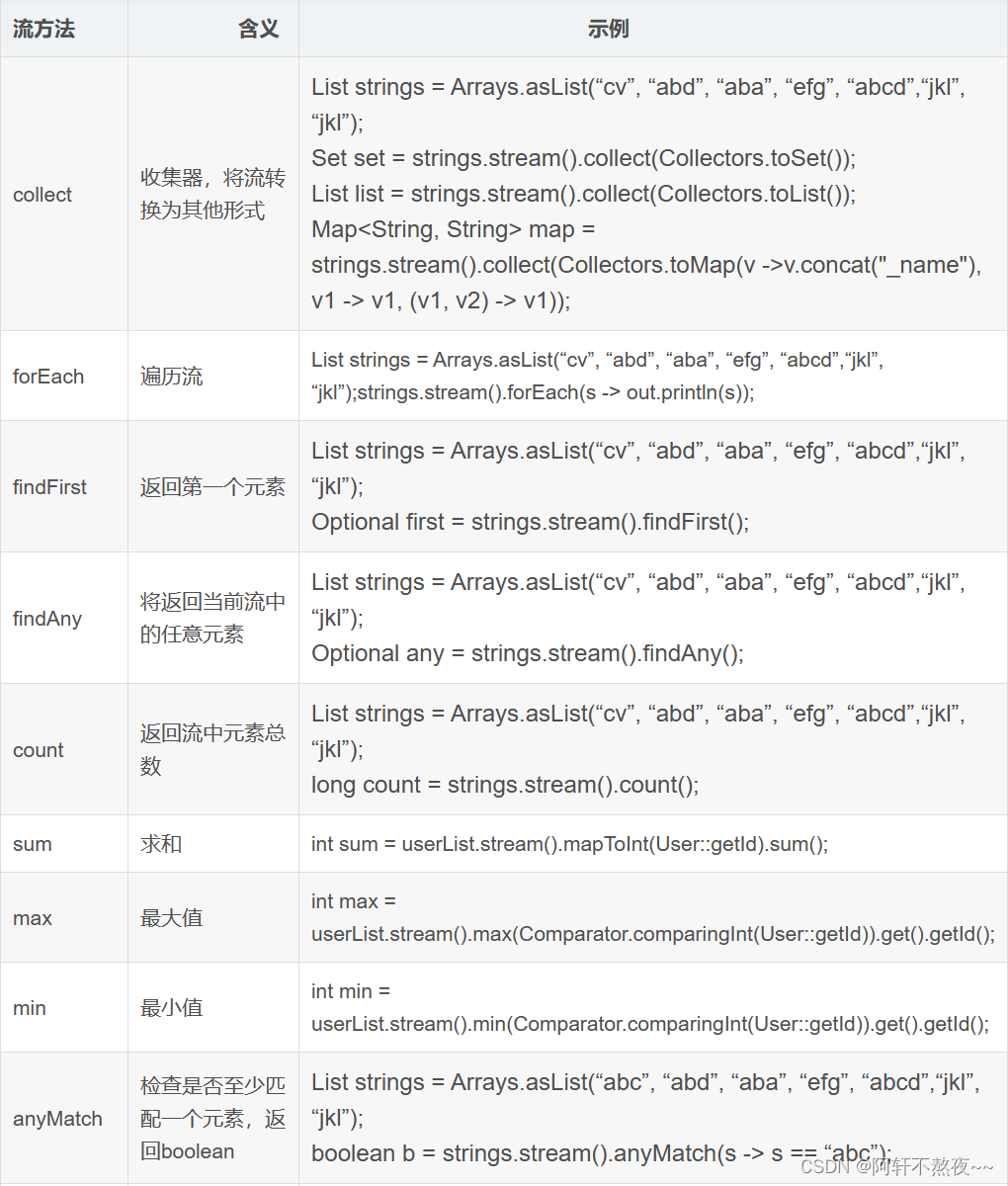
java学习 一.Stream流 (一.)概念: Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。Stream流是对集合(Collection)对象功能的增强&…...
自定义gitlog格式
git log命令非常强大而好用,在复杂系统的版本管理中扮演着重要的角色,但默认的git log命令显示出的东西实在太丑,不好好打扮一下根本没法见人,打扮好了用alias命令拍个照片,就正式出道了! 在使用git查看lo…...

图解GAT:从蛋白质折叠到社交推荐,5个案例看懂注意力机制如何改变图神经网络
图解GAT:从蛋白质折叠到社交推荐,5个案例看懂注意力机制如何改变图神经网络 在生物医药实验室里,科学家们正通过AI预测蛋白质三维结构;社交平台上,算法精准推送你可能感兴趣的内容;药物研发中,计…...

all-MiniLM-L6-v2相似度计算实战:快速搭建智能客服问答匹配
all-MiniLM-L6-v2相似度计算实战:快速搭建智能客服问答匹配 1. 引言:从客服痛点出发 想象一下,你是一家电商公司的客服主管。每天,你的团队要处理成千上万的用户咨询,其中超过60%的问题都是重复的:“我的…...

MES系统对接避坑指南:C++处理XML/JSON/SOAP的5个常见错误
MES系统对接避坑指南:C处理XML/JSON/SOAP的5个常见错误 在工业4.0时代,MES(制造执行系统)作为连接ERP与生产设备的关键枢纽,其系统对接的稳定性直接影响生产线的运行效率。而C因其高性能特性,常被选作MES对…...

Axure电商原型避坑指南:高保真移动端设计中的5个常见错误及解决方案
Axure电商原型避坑指南:高保真移动端设计中的5个常见错误及解决方案 在移动电商领域,高保真原型设计不仅是产品功能的可视化呈现,更是团队协作和用户测试的重要工具。Axure作为专业原型设计工具,能够帮助设计师和产品经理快速构建…...

tabix实战指南:从基因组数据压缩到高效区域检索
1. 为什么需要tabix处理基因组数据 第一次接触基因组数据分析的朋友,经常会遇到这样的困扰:一个VCF变异文件动辄几十GB,用grep查个基因要等半小时;打开100MB的GFF注释文件时笔记本直接卡死;想提取某个染色体区间的BED数…...

密码恢复技术新突破:ArchivePasswordTestTool的高效压缩包破解方案
密码恢复技术新突破:ArchivePasswordTestTool的高效压缩包破解方案 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 当重要的加密…...

31:社会危害图谱分析:网络图论与社区检测算法
作者: HOS(安全风信子) 日期: 2026-03-15 主要来源平台: GitHub 摘要: 本文深入探讨如何构建社会危害图谱,通过网络图论和社区检测算法实现对犯罪网络的分析和识别。结合《死亡笔记》中魅上照的严谨风格,我…...

救命神器!万众偏爱的AI论文软件 —— 千笔写作工具
你是否曾为论文选题而发愁?是否在深夜面对空白文档毫无头绪?是否反复修改却仍不满意表达效果?论文写作的种种难题,让无数学生陷入焦虑。而如今,一款真正改变学术写作方式的AI工具——千笔AI,正在被越来越多…...

uni.requestMerchantTransfer-安卓APP中商家转账用户确认模式下,拉起页面请求用户确认收款
刚使用这个插件的时候很迷茫,不知道从何下手,问社区和专门的插件交流群几乎石层大海,索性在自己两天的摸索中终于成功了,下面是我成功的经验进行分享;目前只使用了安卓版 ①下载插件: ②下载后,…...

预算有限怎么选?2026 三角洲行动游戏笔记本,华硕天选6Pro 酷睿版解析
当前市场主流游戏笔记本在《三角洲行动》等3A大作高帧率需求下的表现差异显著。尤其对于预算卡在7K-8.5K区间的玩家,如何在高性能笔记本与实用体验间取得平衡,成为关键命题。本文将聚焦华硕天选6 Pro酷睿版、机械革命耀世16Ultra、联想拯救者Y7000P等热门…...