大创项目推荐 深度学习+opencv+python实现昆虫识别 -图像识别 昆虫识别
文章目录
- 0 前言
- 1 课题背景
- 2 具体实现
- 3 数据收集和处理
- 3 卷积神经网络
- 2.1卷积层
- 2.2 池化层
- 2.3 激活函数:
- 2.4 全连接层
- 2.5 使用tensorflow中keras模块实现卷积神经网络
- 4 MobileNetV2网络
- 5 损失函数softmax 交叉熵
- 5.1 softmax函数
- 5.2 交叉熵损失函数
- 6 优化器SGD
- 7 学习率衰减策略
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 **基于深度学习的昆虫识别算法研究与实现 **
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:4分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 课题背景
中国是农业大国,在传统的农业生产中,经常会受到病虫害问题的困扰。在解决病虫害问题时,第一步是识别昆虫。在传统的昆虫识别方法中,昆虫专家根据专业知识观察昆虫的外部特征,并对照相关的昆虫图鉴进行识别,费时费力。如今,传统的昆虫识别方法逐渐被昆虫图像识别技术代替。目前常用的昆虫识别技术有图像识别法、微波雷达检测法、生物光子检测法、取样检测法、近红外及高光谱法、声测法等。近年来,随着人工智能的迅速发展,深度学习技术在处理自然语言、机器视觉等方面取得了很多成果,随着深度学习的发展,已经有研究人员开始将深度学习技术应用于昆虫的图像识别。文章旨在利用基于深度学习的图像识别技术解决昆虫识别问题,希望能给现实生活中的病虫害识别问题提供新的解决问题的思路。
2 具体实现




3 数据收集和处理
数据是深度学习的基石
数据的主要来源有: 百度图片, 必应图片, 新浪微博, 百度贴吧, 新浪博客和一些专业的昆虫网站等
爬虫爬取的图像的质量参差不齐, 标签可能有误, 且存在重复文件, 因此必须清洗。清洗方法包括自动化清洗, 半自动化清洗和手工清洗。
自动化清洗包括:
- 滤除小尺寸图像.
- 滤除宽高比很大或很小的图像.
- 滤除灰度图像.
- 图像去重: 根据图像感知哈希.
半自动化清洗包括:
- 图像级别的清洗: 利用预先训练的昆虫/非昆虫图像分类器对图像文件进行打分, 非昆虫图像应该有较低的得分; 利用前一阶段的昆虫分类器对图像文件 (每个文件都有一个预标类别) 进行预测, 取预标类别的概率值为得分, 不属于原预标类别的图像应该有较低的得分. 可以设置阈值, 滤除很低得分的文件; 另外利用得分对图像文件进行重命名, 并在资源管理器选择按文件名排序, 以便于后续手工清洗掉非昆虫图像和不是预标类别的图像.
- 类级别的清洗
手工清洗: 人工判断文件夹下图像是否属于文件夹名所标称的物种, 这需要相关的昆虫学专业知识, 是最耗时且枯燥的环节。
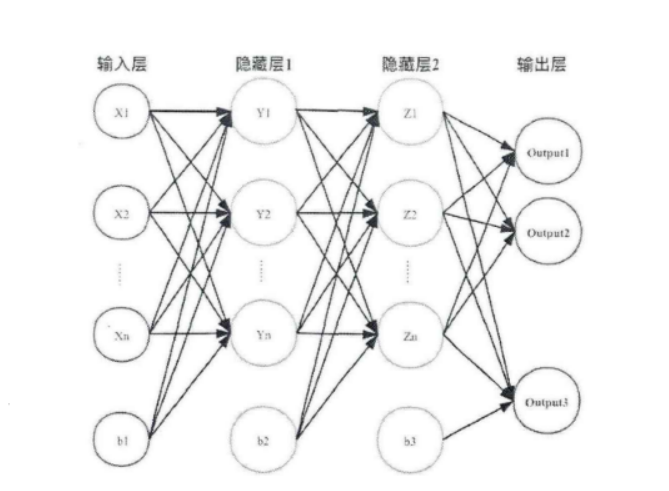
3 卷积神经网络
卷积神经网络(Convolutional Neural
Netwoek,CNN)是一种前馈神经网络,它的人工神经元可以局部响应周围的神经元,每个神经元都接收一些输入,并做一些点积计算。它通常包含卷积层、激活层、池化层、全连接层。
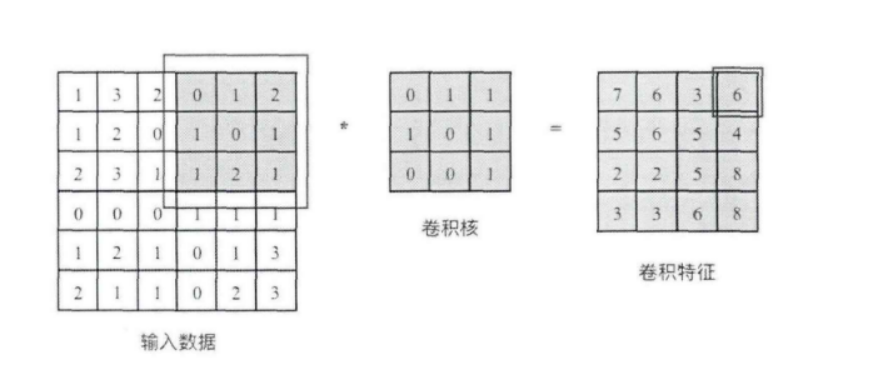
2.1卷积层
卷积核相当于一个滑动窗口,示意图中3x3大小的卷积核依次划过6x6大小的输入数据中的对应区域,并与卷积核滑过区域做矩阵点乘,将所得结果依次填入对应位置即可得到右侧4x4尺寸的卷积特征图,例如划到右上角3x3所圈区域时,将进行0x0+1x1+2x1+1x1+0x0+1x1+1x0+2x0x1x1=6的计算操作,并将得到的数值填充到卷积特征的右上角。
2.2 池化层
池化操作又称为降采样,提取网络主要特征可以在达到空间不变性的效果同时,有效地减少网络参数,因而简化网络计算复杂度,防止过拟合现象的出现。在实际操作中经常使用最大池化或平均池化两种方式,如下图所示。虽然池化操作可以有效的降低参数数量,但过度池化也会导致一些图片细节的丢失,因此在搭建网络时要根据实际情况来调整池化操作。[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-
UTsB7AhE-1658995487680)![(C:\Users\Administrator\AppData\Roaming\Typora\typora-
user-images\image-20220709114210181.png)]](https://img-blog.csdnimg.cn/7ef9889ba5c5434e8d3d87034ef7a154.png)
2.3 激活函数:
激活函数大致分为两种,在卷积神经网络的发展前期,使用较为传统的饱和激活函数,主要包括sigmoid函数、tanh函数等;随着神经网络的发展,研宄者们发现了饱和激活函数的弱点,并针对其存在的潜在问题,研宄了非饱和激活函数,其主要含有ReLU函数及其函数变体
2.4 全连接层
在整个网络结构中起到“分类器”的作用,经过前面卷积层、池化层、激活函数层之后,网络己经对输入图片的原始数据进行特征提取,并将其映射到隐藏特征空间,全连接层将负责将学习到的特征从隐藏特征空间映射到样本标记空间,一般包括提取到的特征在图片上的位置信息以及特征所属类别概率等。将隐藏特征空间的信息具象化,也是图像处理当中的重要一环。
2.5 使用tensorflow中keras模块实现卷积神经网络
class CNN(tf.keras.Model):def __init__(self):super().__init__()self.conv1 = tf.keras.layers.Conv2D(filters=32, # 卷积层神经元(卷积核)数目kernel_size=[5, 5], # 感受野大小padding='same', # padding策略(vaild 或 same)activation=tf.nn.relu # 激活函数)self.pool1 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)self.conv2 = tf.keras.layers.Conv2D(filters=64,kernel_size=[5, 5],padding='same',activation=tf.nn.relu)self.pool2 = tf.keras.layers.MaxPool2D(pool_size=[2, 2], strides=2)self.flatten = tf.keras.layers.Reshape(target_shape=(7 * 7 * 64,))self.dense1 = tf.keras.layers.Dense(units=1024, activation=tf.nn.relu)self.dense2 = tf.keras.layers.Dense(units=10)def call(self, inputs):x = self.conv1(inputs) # [batch_size, 28, 28, 32]x = self.pool1(x) # [batch_size, 14, 14, 32]x = self.conv2(x) # [batch_size, 14, 14, 64]x = self.pool2(x) # [batch_size, 7, 7, 64]x = self.flatten(x) # [batch_size, 7 * 7 * 64]x = self.dense1(x) # [batch_size, 1024]x = self.dense2(x) # [batch_size, 10]output = tf.nn.softmax(x)return output
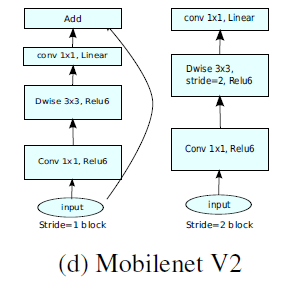
4 MobileNetV2网络
简介
MobileNet网络是Google最近提出的一种小巧而高效的CNN模型,其在accuracy和latency之间做了折中。
主要改进点
相对于MobileNetV1,MobileNetV2 主要改进点:
- 引入倒残差结构,先升维再降维,增强梯度的传播,显著减少推理期间所需的内存占用(Inverted Residuals)
- 去掉 Narrow layer(low dimension or depth) 后的 ReLU,保留特征多样性,增强网络的表达能力(Linear Bottlenecks)
- 网络为全卷积,使得模型可以适应不同尺寸的图像;使用 RELU6(最高输出为 6)激活函数,使得模型在低精度计算下具有更强的鲁棒性
- MobileNetV2 Inverted residual block 如下所示,若需要下采样,可在 DW 时采用步长为 2 的卷积
- 小网络使用小的扩张系数(expansion factor),大网络使用大一点的扩张系数(expansion factor),推荐是5~10,论文中 t = 6 t = 6t=6
倒残差结构(Inverted residual block )
ResNet的Bottleneck结构是降维->卷积->升维,是两边细中间粗
而MobileNetV2是先升维(6倍)-> 卷积 -> 降维,是沙漏形。
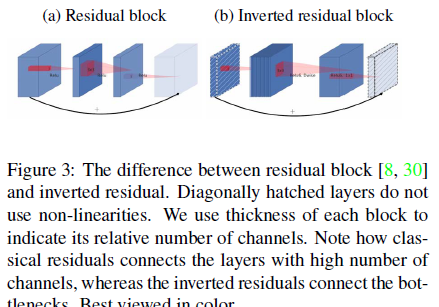 区别于MobileNetV1,
区别于MobileNetV1,
MobileNetV2的卷积结构如下:
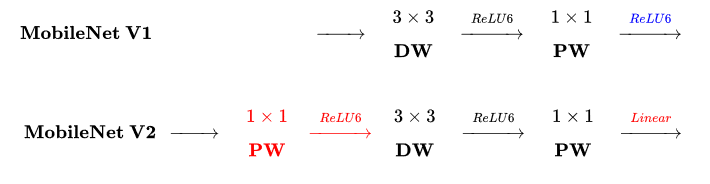
因为DW卷积不改变通道数,所以如果上一层的通道数很低时,DW只能在低维空间提取特征,效果不好。所以V2版本在DW前面加了一层PW用来升维。
同时V2去除了第二个PW的激活函数改用线性激活,因为激活函数在高维空间能够有效地增加非线性,但在低维空间时会破坏特征。由于第二个PW主要的功能是降维,所以不宜再加ReLU6。
tensorflow相关实现代码
import tensorflow as tfimport numpy as npfrom tensorflow.keras import layers, Sequential, Modelclass ConvBNReLU(layers.Layer):def __init__(self, out_channel, kernel_size=3, strides=1, **kwargs):super(ConvBNReLU, self).__init__(**kwargs)self.conv = layers.Conv2D(filters=out_channel, kernel_size=kernel_size, strides=strides, padding='SAME', use_bias=False,name='Conv2d')self.bn = layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='BatchNorm')self.activation = layers.ReLU(max_value=6.0) # ReLU6def call(self, inputs, training=False, **kargs):x = self.conv(inputs)x = self.bn(x, training=training)x = self.activation(x)return xclass InvertedResidualBlock(layers.Layer):def __init__(self, in_channel, out_channel, strides, expand_ratio, **kwargs):super(InvertedResidualBlock, self).__init__(**kwargs)self.hidden_channel = in_channel * expand_ratioself.use_shortcut = (strides == 1) and (in_channel == out_channel)layer_list = []# first bottleneck does not need 1*1 convif expand_ratio != 1:# 1x1 pointwise convlayer_list.append(ConvBNReLU(out_channel=self.hidden_channel, kernel_size=1, name='expand'))layer_list.extend([# 3x3 depthwise conv layers.DepthwiseConv2D(kernel_size=3, padding='SAME', strides=strides, use_bias=False, name='depthwise'),layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='depthwise/BatchNorm'),layers.ReLU(max_value=6.0),#1x1 pointwise conv(linear) # linear activation y = x -> no activation functionlayers.Conv2D(filters=out_channel, kernel_size=1, strides=1, padding='SAME', use_bias=False, name='project'),layers.BatchNormalization(momentum=0.9, epsilon=1e-5, name='project/BatchNorm')])self.main_branch = Sequential(layer_list, name='expanded_conv')def call(self, inputs, **kargs):if self.use_shortcut:return inputs + self.main_branch(inputs)else:return self.main_branch(inputs)
5 损失函数softmax 交叉熵
5.1 softmax函数
Softmax函数由下列公式定义
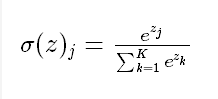
softmax 的作用是把 一个序列,变成概率。
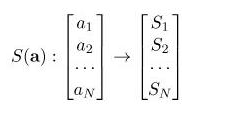
softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,所有概率的和将等于1。
python实现
def softmax(x):shift_x = x - np.max(x) # 防止输入增大时输出为nanexp_x = np.exp(shift_x)return exp_x / np.sum(exp_x)
PyTorch封装的Softmax()函数
dim参数:
-
dim为0时,对所有数据进行softmax计算
-
dim为1时,对某一个维度的列进行softmax计算
-
dim为-1 或者2 时,对某一个维度的行进行softmax计算
import torch x = torch.tensor([2.0,1.0,0.1]) x.cuda() outputs = torch.softmax(x,dim=0) print("输入:",x) print("输出:",outputs) print("输出之和:",outputs.sum())
5.2 交叉熵损失函数
定义如下:

python实现
def cross_entropy(a, y):return np.sum(np.nan_to_num(-y*np.log(a)-(1-y)*np.log(1-a)))# tensorflow version
loss = tf.reduce_mean(-tf.reduce_sum(y_*tf.log(y), reduction_indices=[1]))# numpy version
loss = np.mean(-np.sum(y_*np.log(y), axis=1))
PyTorch实现
交叉熵函数分为二分类(torch.nn.BCELoss())和多分类函数(torch.nn.CrossEntropyLoss()
# 二分类 损失函数loss = torch.nn.BCELoss()l = loss(pred,real)# 多分类损失函数loss = torch.nn.CrossEntropyLoss()
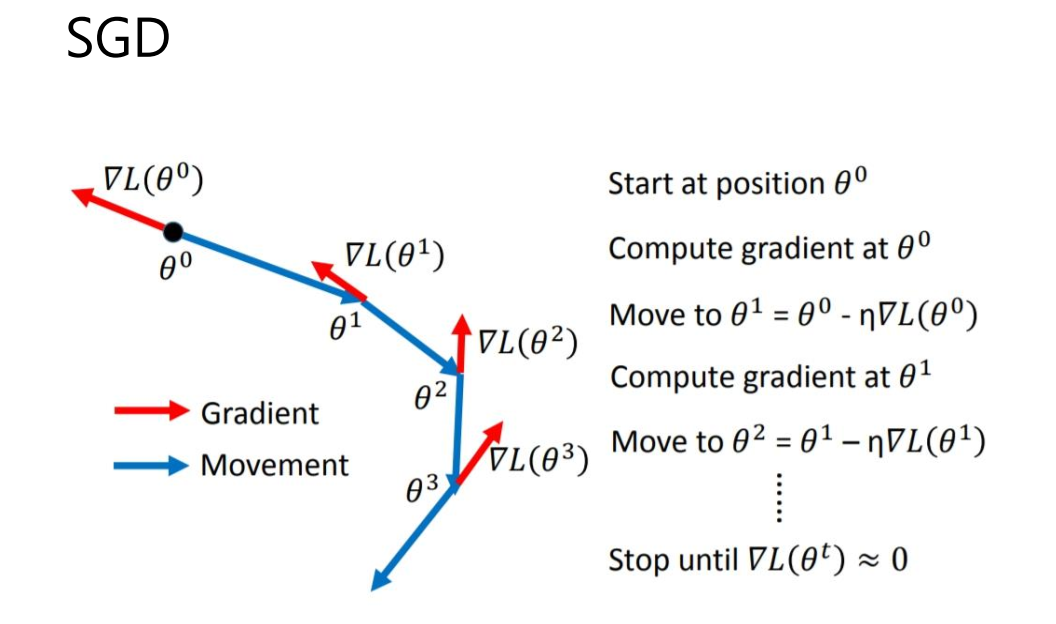
6 优化器SGD
简介
SGD全称Stochastic Gradient Descent,随机梯度下降,1847年提出。每次选择一个mini-
batch,而不是全部样本,使用梯度下降来更新模型参数。它解决了随机小批量样本的问题,但仍然有自适应学习率、容易卡在梯度较小点等问题。
pytorch调用方法:
torch.optim.SGD(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False)
相关代码:
def step(self, closure=None):"""Performs a single optimization step.Arguments:closure (callable, optional): A closure that reevaluates the modeland returns the loss."""loss = Noneif closure is not None:loss = closure()for group in self.param_groups:weight_decay = group['weight_decay'] # 权重衰减系数momentum = group['momentum'] # 动量因子,0.9或0.8dampening = group['dampening'] # 梯度抑制因子nesterov = group['nesterov'] # 是否使用nesterov动量for p in group['params']:if p.grad is None:continued_p = p.grad.dataif weight_decay != 0: # 进行正则化# add_表示原处改变,d_p = d_p + weight_decay*p.datad_p.add_(weight_decay, p.data)if momentum != 0:param_state = self.state[p] # 之前的累计的数据,v(t-1)# 进行动量累计计算if 'momentum_buffer' not in param_state:buf = param_state['momentum_buffer'] = torch.clone(d_p).detach()else:# 之前的动量buf = param_state['momentum_buffer']# buf= buf*momentum + (1-dampening)*d_pbuf.mul_(momentum).add_(1 - dampening, d_p)if nesterov: # 使用neterov动量# d_p= d_p + momentum*bufd_p = d_p.add(momentum, buf)else:d_p = buf# p = p - lr*d_pp.data.add_(-group['lr'], d_p)return loss
7 学习率衰减策略
余弦退火衰减
这可以理解为是一种带重启的随机梯度下降算法。在网络模型更新时,由于存在很多局部最优解,这就导致模型会陷入局部最优解,即优化函数存在多个峰值。这就要求,当模型陷入局部最优解时,能够跳出去,并且继续寻找下一个最优解,直到找到全局最优解。要使得模型跳出局部最优解,就需
多周期的余弦退火衰减示意图如下:
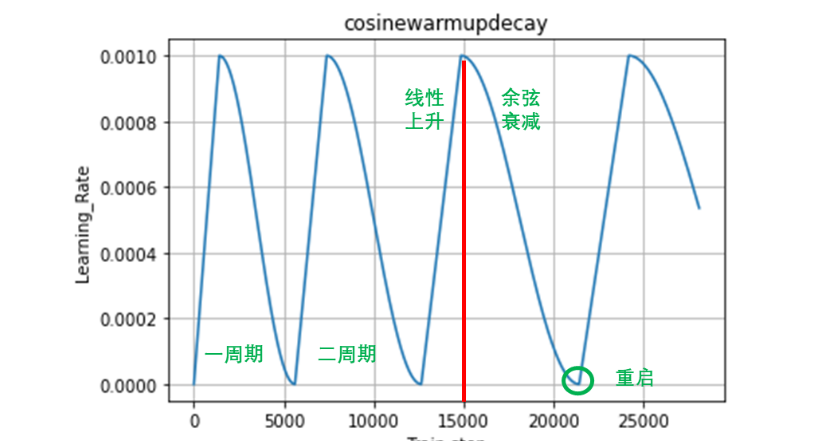
相关代码实现
# ----------------------------------------------------------------------- ## 多周期余弦退火衰减# ----------------------------------------------------------------------- ## eager模式防止graph报错tf.config.experimental_run_functions_eagerly(True)# ------------------------------------------------ #import math# 继承自定义学习率的类class CosineWarmupDecay(keras.optimizers.schedules.LearningRateSchedule):'''initial_lr: 初始的学习率min_lr: 学习率的最小值max_lr: 学习率的最大值warmup_step: 线性上升部分需要的steptotal_step: 第一个余弦退火周期需要对总stepmulti: 下个周期相比于上个周期调整的倍率print_step: 多少个step并打印一次学习率'''# 初始化def __init__(self, initial_lr, min_lr, warmup_step, total_step, multi, print_step):# 继承父类的初始化方法super(CosineWarmupDecay, self).__init__()# 属性分配self.initial_lr = tf.cast(initial_lr, dtype=tf.float32)self.min_lr = tf.cast(min_lr, dtype=tf.float32)self.warmup_step = warmup_step # 初始为第一个周期的线性段的stepself.total_step = total_step # 初始为第一个周期的总stepself.multi = multiself.print_step = print_step# 保存每一个step的学习率self.learning_rate_list = []# 当前步长self.step = 0# 前向传播, 训练时传入当前step,但是上面已经定义了一个,这个step用不上def __call__(self, step):# 如果当前step达到了当前周期末端就调整if self.step>=self.total_step:# 乘上倍率因子后会有小数,这里要注意# 调整一个周期中线性部分的step长度self.warmup_step = self.warmup_step * (1 + self.multi)# 调整一个周期的总step长度self.total_step = self.total_step * (1 + self.multi)# 重置step,从线性部分重新开始self.step = 0# 余弦部分的计算公式decayed_learning_rate = self.min_lr + 0.5 * (self.initial_lr - self.min_lr) * \(1 + tf.math.cos(math.pi * (self.step-self.warmup_step) / \(self.total_step-self.warmup_step)))# 计算线性上升部分的增长系数kk = (self.initial_lr - self.min_lr) / self.warmup_step # 线性增长线段 y=kx+bwarmup = k * self.step + self.min_lr# 以学习率峰值点横坐标为界,左侧是线性上升,右侧是余弦下降decayed_learning_rate = tf.where(self.step<self.warmup_step, warmup, decayed_learning_rate)# 每个epoch打印一次学习率if step % self.print_step == 0:# 打印当前step的学习率print('learning_rate has changed to: ', decayed_learning_rate.numpy().item())# 每个step保存一次学习率self.learning_rate_list.append(decayed_learning_rate.numpy().item())# 计算完当前学习率后step加一用于下一次self.step = self.step + 1# 返回调整后的学习率return decayed_learning_rate6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
大创项目推荐 深度学习+opencv+python实现昆虫识别 -图像识别 昆虫识别
文章目录 0 前言1 课题背景2 具体实现3 数据收集和处理3 卷积神经网络2.1卷积层2.2 池化层2.3 激活函数:2.4 全连接层2.5 使用tensorflow中keras模块实现卷积神经网络 4 MobileNetV2网络5 损失函数softmax 交叉熵5.1 softmax函数5.2 交叉熵损失函数 6 优化器SGD7 学…...

Python小工具提升工作效率【附完整版,可下载word】
1、多个ppt汇总成一个ppt的python代码实现: import win32com.client as win32 import os import re def find(s): pat = re.compile(r"\d+") result = pat.match(s) return int(result.group(0)) def join_ppt(path:str): """ :param path: ppt所…...
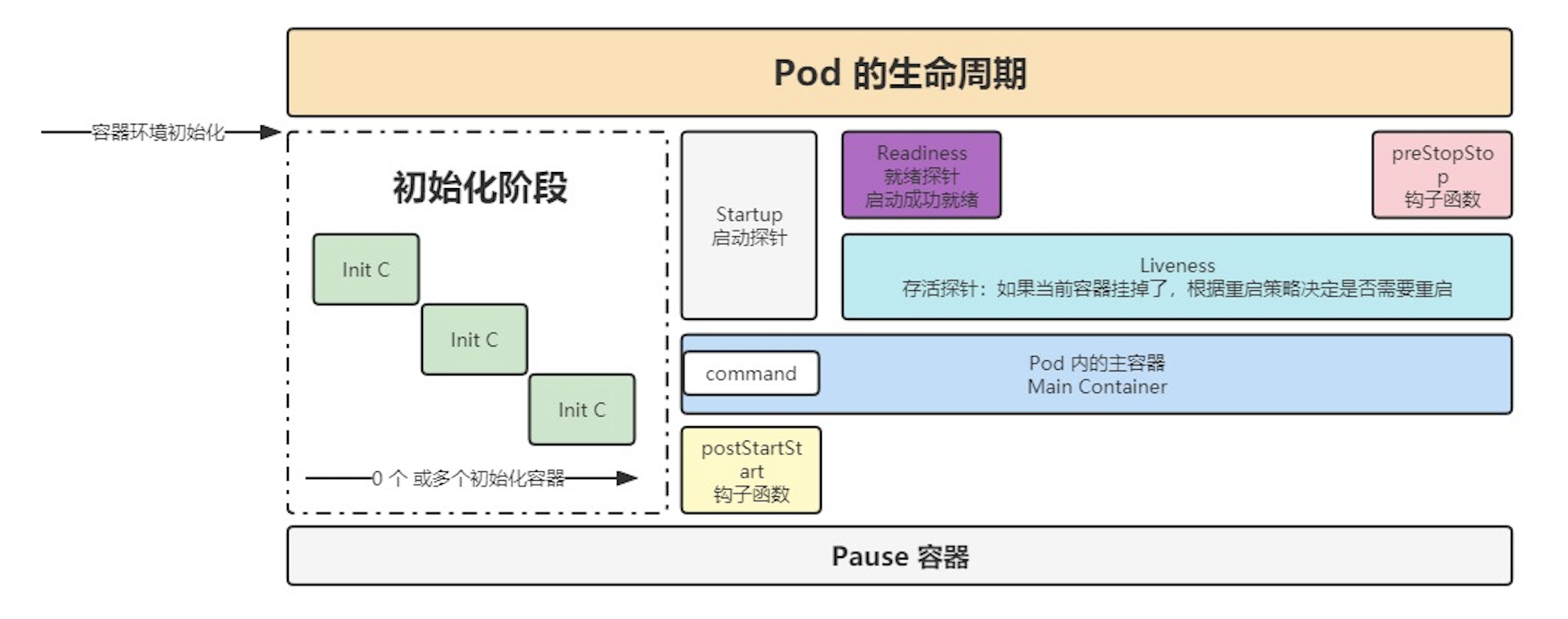
k8s-Pod
文章目录 k8s-Podpod 配置文件详解pod 生命周期pod 探针StartupProbeLivenessProbeReadinessProbe探针使用建议 初始化容器钩子函数 k8s-Pod pod 是k8s 中可以调度的最小单位 每个Pod中都可以包含一个或者多个容器,这些容器可以分为两类: 用户程序所在的…...

智能网络新纪元:机器学习赋能未来计算机网络高速发展
🧑 作者简介:阿里巴巴嵌入式技术专家,深耕嵌入式人工智能领域,具备多年的嵌入式硬件产品研发管理经验。 📒 博客介绍:分享嵌入式开发领域的相关知识、经验、思考和感悟,欢迎关注。提供嵌入式方向的学习指导…...

大数据之kafka应用
大数据之kafka应用 2024启kafkakafka常见命令生产上重放信息jmxjmx的配置和开启jmx的使用jmx例子一 jmx例子二jmx例子三jmx例子四(special) 2024启kafka kafka常见命令 指定jmx端口启动kafka lsof -i :9999 JMX_PORT9999 /opt/kafka_2.12-3.1.0/bin/kaf…...
嵌入式操作教程_数字信号处理_音频编解码:3-6 AAC音频解码实验
一、实验目的 了解AAC音频格式,掌握AAC音频解码的原理,并实现将AAC格式的音频解码为PCM 二、实验原理 音频编解码的主要对象是音乐和语音,音频的编解码格式可分为无压缩的格式、无损压缩格式、有损音乐压缩格式、有损语音压缩格式和合成算…...

【从浅学到熟知Linux】冯诺依曼体系结构及进程概念详谈!
🏠关于专栏:Linux的浅学到熟知专栏用于记录Linux系统编程、网络编程等内容。 🎯每天努力一点点,技术变化看得见 文章目录 冯诺依曼体系结构操作系统如何理解管理操作系统概念设计操作系统目的系统调用和库函数概念 进程基本概念描…...

word转pdf(前后端最全保姆级别)
word转pdf vue2java 文章目录 word转pdf vue2java一、前端 vue-pdf1、下载依赖2、封装的组件 二、java使用aspose(付费)1.引入库2.封装的工具类3、付费密钥文件 总结 提示:以下是本篇文章正文内容,下面案例可供参考 一、前端 vue…...

深度学习简介
深度学习简介 一、引言:深度学习的兴起 简短介绍深度学习的历史背景 深度学习,作为人工智能领域的一颗冉冉升起的新星,其根源可以追溯到上世纪的感知机学习算法。这种算法模拟人类的神经元行为,是最早期的尝试之一。然而&#x…...

深入探索:使用C++构建顶级性能的网络服务器
在数字化浪潮的推动下,网络服务器作为信息交互的核心枢纽,其性能与稳定性直接决定了互联网应用的服务质量和用户体验。C++,作为一种兼具高效性与灵活性的编程语言,已然成为构建高性能网络服务器的首选工具。本文旨在深入剖析C++在构建顶级性能网络服务器中的关键技术、最佳…...
SpringBoot学习笔记四
SpringBoot学习笔记四-监听机制 1. SpringBoot监听器1.1 无需配置1.1.1 CommandLineRunner使用1.1.2 ApplicationRunner的使用1.1.3 CommandLineRunner与ApplicationRunner的区别 1.2 需要创建META-INF文件,并在其中创建spring.factories,配置相关的信息…...

雄安建博会:中矿雄安新区的总部开工建设
中矿落位雄安:助力国家战略与新区发展 雄安新区,作为中国未来发展的重要战略支点,正迎来一系列央企总部的疏解与建设。最近,中国矿产资源集团有限公司(简称“中矿”)在雄安新区的总部项目正式开工建设&…...

蒙特卡洛方法【强化学习】
强化学习笔记 主要基于b站西湖大学赵世钰老师的【强化学习的数学原理】课程,个人觉得赵老师的课件深入浅出,很适合入门. 第一章 强化学习基本概念 第二章 贝尔曼方程 第三章 贝尔曼最优方程 第四章 值迭代和策略迭代 第五章 强化学习实践—GridWorld 第…...

构建第一个ArkTS之声明式UI描述
ArkTS以声明方式组合和扩展组件来描述应用程序的UI,同时还提供了基本的属性、事件和子组件配置方法,帮助开发者实现应用交互逻辑。 创建组件 根据组件构造方法的不同,创建组件包含有参数和无参数两种方式。 说明 创建组件时不需要new运算…...

pytest教程-25-生成覆盖率报告插件-pytest-cov
领取资料,咨询答疑,请➕wei: June__Go 上一小节我们学习了pytest多重断言插件pytest-assume,本小节我们讲解一下pytest生成覆盖率报告插件pytest-cov。 测量代码覆盖率的工具在测试套件运行时观察你的代码,并跟踪哪些行被运行,…...

特征工程总结
后期总结 Reference [1] 特征工程总结 - 知乎...

JUC并发编程2(高并发,AQS)
JUC AQS核心 当有线程想获取锁时,其中一个线程使用CAS的将state变为1,将加锁线程设为自己。当其他线程来竞争锁时会,判断state是不是0,不是自己就把自己放入阻塞队列种(这个阻塞队列是用双向链表实现)&am…...

Golang 为什么需要用反射
本质上是可以动态获取程序运行时的变量(类型) 比如现在我想实现一个通用的db插入函数,支持我传入所有类型的struct,每一种类型的struct是一个单独的表,以struct的名称作为表名,然后插入到不同的表中。 pa…...
【Linux的进程篇章 - 进程终止和进程等待的理解】
Linux学习笔记---008 Linux之fork函数、进程终止和等待的理解1、fork函数1.1、什么是fork?1.2、fork的功能介绍1.3、fork函数返回值的理解1.4、fork函数的总结 2、进程的终止2.1、终止是在做什么?2.2、进程终止的3种情况 3、进程的终止3.1、进程终止的三种情况3.2、…...
》)
《策略模式(极简c++)》
本文章属于专栏- 概述 - 《设计模式(极简c版)》-CSDN博客 本章简要说明适配器模式。本文分为模式说明、本质思想、实践建议、代码示例四个部分。 模式说明 方案:策略模式是一种行为设计模式,它定义了一系列算法,将每…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...