基础知识点全覆盖(1)
Python基础知识点
1.基本语句
1.注释
- 方便阅读和调试代码
- 注释的方法有行注释和块注释
1.行注释
-
行注释以 **# **开头
# 这是单行注释
2.块注释
-
块注释以多个 #、三单引号或三双引号(注意: 基于英文输入状态下的标点符号)
# 类 # 似 # 于 # 多 # 行 # 效 # 果''' 这就是多行注释,也可以称为文档注释 '''""" 这也是多行注释,同上 """
2.输出
1.输出语句
# 输出 python基础知识
print("python基础知识")
2.输出语句使用
-
**python()**函数还有一些其他参数可以使用
-
end参数可以指定打印结束时使用的字符,默认是换行符**\n**
-
sep参数可以指定分隔符,默认时空格符 ” “
# 带参数的输出语句 print("a","b","c",sep=",",end="! \n") #输出格式 a,b,c!
-
-
f-string(格式化字符串)是一种方便的方式,可以在字符插入变量的值,使用f 前缀以及大括号**{ }**来引用变量或表达式
name = "Ailke" age = 15 print(f"My name is {name} and I am {age} years old.") # 输出格式 My name is Ailke and I am age years old.
3.多行输出语句
multi_line_string = """
This is a multi-line string.
It spans across multiple lines.
It can contain any characters, including 'quotes' and special characters like \n.
"""print(multi_line_string)
3.标识符
1.标识符命名规则
-
第一个字符必须是字母表中的字母或下划线
-
标识符的其他部分由字母、数字和下划线组成
-
标识符对大小写敏感
-
关键字不能作为变量名
# 不建议直接使用下划线命名(变量名前或后) # 通常情况下在变量名之前使用下划线,该变量表示私有的,虽然python不会阻止你访问这些变量
4.行与缩进
-
python最具特色的就是使用缩进来表示代码块
if True:print("True") else:print("False")''' 这就是一个错误示范 if True: print("True") else: print("False") '''
5.关键字
-
关键字指的是具有特殊功能的标识符
import keyword# 可以直接查询有哪些关键词 keywords_list = keyword.kwlist print(keywords_list) print(len(keywords_list)) # 35
| False | await | finally | is | return |
|---|---|---|---|---|
| None | continue | for | lambda | try |
| True | def | from | nonlocal | while |
| and | del | global | not | with |
| as | elif | if | or | yield |
| assert | else | import | pass | break |
| async | except | in | raise | class |
6.数据类型
1.整型类型
-
整数类型简称整型,用于表示整数,也是十进制整数的统称,默认整型是int型
# 整型的定义 number = 1024
1.独有函数特性
num = 450
# 获取整型的二进制
print(bin(num)) # 0b111000010
# 整型的独有功能
result = num.bit_length()
print(result) # 9
2.转换
-
常见的字符串和布尔值转换为整型
# 布尔值转整型 num1 = int(True) num2 = int(False)print(num1) # 1 print(num2) # 0# 字符串转整型 # 把字符串看成十进制的值,再转换为十进制 num3 = int("186", base=10) # 把字符串看成二进制的值,再转换为十进制 num4 = int("0b1101", base=2) # 把字符串看成十六进制的值,再转换为十进制 num5 = int("0x59a", base=16)# 浮点型(小数),向下取整 num6 = int(8.9)print(num3) # 186 print(num4) # 13 print(num5) # 1434 print(num6) # 8 -
补充知识点(进制)
-
二进制
- 由 0 和 1组成,由0x开头
- 计算机底层所有数据都是以0和1的形式存在
-
八进制
-
由0、1、2、3、4、5、6和7组成,由0o开头
# 把字符串看成八进制,再转为十进制 num1 = int("0o156", base=8)
-
-
十六进制
-
由0、1、2、3、4、5、6、7、8、9、a、b、c、d、e和f组成,由0x开头
# 十进制转换为十六进制 num = hex(28) print(num) # 0x1c
-
-
3.历史遗留问题
-
Python3版本之前
-
整型
-
长整型
-
整型(int),取值范围 -9223372036854775808~9223372036854775807;长整型(long),整数数值超出int范围之后自动转换为long类型
# 整除问题 print(9/2) # 4# 整除问题 from _future_ import division print(9/2) # 4.5
-
-
Python3版本之后
-
去除了long,只剩下整型(int),并且int长度不在限制
# 整除问题 print(9/2) # 4.5
-
4.补充知识点
1.数学函数
| 函数 | 返回值(描述) |
|---|---|
| abs(x) | 返回数字的绝对值 |
| ceil(x) | 返回数字的向上取整数 |
| cmp(x, y) | 如果x < y返回 -1,如果x == y 返回 0,如果 x > y 返回 1 |
| exp(x) | 返回e的x次幂 |
| fabs(x) | 返回数字的绝对值 |
| floor(x) | 返回数字向下取整 |
| log(x) | 如math.log(math.e)返回1.0 |
| log10(x) | 返回以10为基数的x的对数 |
| max(x1,x2,x3,…) | 返回给定参数的最大值,参数可以为序列 |
| min(x1,x2,x3,…) | 返回给定参数的最小值,参数可以为序列 |
| modf(x) | 返回x的整数部分与小数部分,两部分的数值符号与x相同,整数部分以浮点型表示 |
| pow(x, y) | x^y运算后的值 |
| round(x [, n]) | 返回浮点数的四舍五入值,如给出n值,则代表舍入到小数点后的位数 |
| sqrt(x) | 返回数字x的平方根 |
# 绝对值
print(abs(-10.1)) # 10.1
# 绝对值,转换为浮点数
print(math.fabs(-10)) # 10.0
# 向上取整
print(math.ceil(4.05)) # 5print(math.modf(123.32)) # (0.3199999999999932, 123.0)
print(type(math.modf(123.32))) # <class 'tuple'
# 幂运算
print(pow(3, 5)) # 243
2.随机数函数
| 函数 | 描述 |
|---|---|
| choice(seq) | 从序列的元素中随机挑选一个元素 |
| randrange([start,] stop [,step]) | 在指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为1 |
| random() | 随机生成一个实数,取值范围[0, 1) |
| seed([x]) | 改变随机数生成器的种子seed |
| shuffle(lst) | 将序列的所有元素随机排序 |
| uniform(x, y) | 随机生成一个实数,取值范围[x, y] |
# 随机获取range(10)中其中的一个元素
print(random.choice(range(10)))print(random.randrange(1, 10, 2))
3.三角函数
| 函数 | 描述 |
|---|---|
| acos(x) | 返回x的反余弦弧度值 |
| asin(x) | 返回x的反正弦弧度值 |
| atan(x) | 返回x的反正切弧度值 |
| atan2(y, x) | 返回给定的X以及y坐标值的反正切值 |
| cos(x) | 返回x的弧度的余弦值 |
| hypot(x, y) | 返回欧几里德范数sqrt(xx + yy) |
| sin(x) | 返回的x弧度的正弦值 |
| tan(x) | 返回x弧度的正切值 |
| degrees(x) | 将弧度切换为角度 |
| radians(x) | 将角度切换为弧度 |
# 反余弦弧度值
print(math.acos(0.59)) # 0.9397374860168752# 弧度的余弦值
print(math.cos(math.pi / 2)) # 6.123233995736766e-17
4.数学常量
| 常量 | 描述 |
|---|---|
| pi | 数学常量 pi (圆周率) |
| e | 数学常量 e (自然常数) |
2.浮点型类型
- 浮点型,一般在开发中用于表示小数
1.浮点型转换
- 在类型转换时,浮点型转换为整型时,会将小数部分去掉
num_float = 3.1415926
num = int(num_float)
print(num) # 3
-
想要保留小数位数
num_float = 3.1415927 num = round(num_float, 4) print(num) # 3.1415
2.浮点型补充知识点
-
浮点型数据底层存储原理
-
以39.29为例
-
整数部分二进制 100111
-
小数部分二进制(让小数部分乘以2,小于1则用结果继续乘,大于1则结果减1继续乘,等于1则结束)
小数相乘区 是否等于1 二进制取值区 0.29 *2 = 0.58 < 1 0 0.58 * 2 = 1.16 > 1 1 0.16 * 2 = 0.32 < 1 0 0.32 * 2 = 0.64 < 1 0 0.64 * 2 = 1.28 > 1 1 0.28 * 2 = 0.56 < 1 0 0.56 * 2 = 1.12 > 1 1 最终0.29的二进制,0100101…
-
浮点型39.29浮点型的二进制为: 100111.0100101…,科学计数法表示 1.001110100101… * 2^5
32位Float 1位(sign) 8位(exponent) 23位(fraction) - sign,用1位来表示浮点数正负,0表示正数,1表述负数
- exponent,用8位表示二进制小数的科学计数法中的指数部分的值,指数有可能位负数,范围在 -127 ~ 128,计算式[ 指数 + 127 ]得到的值换为二进制存储在此处
- fraction,用23位来表示二进制小数的科学计数法中的小数部分(不用管整数部分)
- 最终39.29的存储时的二进制为: 0 10000100 0011101…
-
-
-
实际应用,需要精确的小数
import decimalnum_float = decimal.Decimal("0.1") num_float1 = decimal.Decimal("0.2") print(num_float + num_float1) # 0.3
3.字符串类型
1.字符串的定义
str4 = "这是一个字符串"
str5 ='''
这也是一个字符串
我还可以保持该格式输出
'''
str6 = '这是一个"字符串"'print(str4) # 这是一个字符串
print(str5) # (同str5的字符串格式)
print(str6) # 这是一个"字符串"
2.字符串特性
-
判断字符串是否以**开头,得到一个布尔值
str7 = "This is a string" print(str7.startswith("This")) # True -
判断字符串是否以**结尾,得到一个布尔值
str7 = "This is a string"print(str7.endswith("string")) # True -
判断字符串是否为十进制数,得到一个布尔值
str8 = "124503651"# isdecimal()判断是否所有字符都是十进制 print(str8.isdecimal()) # True # isdigit()判断是否为数字并且存在 print(str8.isdigit()) # True -
去除字符串两边的空格、换行符、制表符,得到一个新的字符串
msg = " Hello,This is a test message "# 去掉字符串两边的空格、换行符、制表符 newMsg = msg.strip() print(newMsg) # Hello,This is a test message # 去掉左边的空格、换行符、制表符 newMsg_l = msg.lstrip() print(newMsg_l) # Hello,This is a test message (此处空格依旧存在) # 去掉右边的空格、换行符、制表符 newMsg_r = msg.rstrip() print(newMsg_r) # (此处空格依旧存在) Hello,This is a test message# 去掉两边(首或尾符合参数)的值 newMsg_t = newMsg.strip("H") print(newMsg_t) # ello,This is a test message # 去掉左边首部符合参数的值 newMsg_tl = newMsg.lstrip("H") print(newMsg_tl) # ello,This is a test message # 去掉右边尾部符合参数的值 newMsg_tr = newMsg.rstrip("e") print(newMsg_tr) # Hello,This is a test messag -
字符串变大写,得到一个新的字符串
# 字符串字母全部变为大写 print(newMsg.upper()) # HELLO,THIS IS A TEST MESSAGE -
字符串变小写,得到一个新的字符串
# 字符串字母全部变为小写 print(newMsg.lower()) # hello,this is a test message -
字符串内容替换,得到一个新的字符串
# 字符串内容替换 print(newMsg.replace("test", "real")) # Hello,This is a real message -
字符串切割,得到一个列表
# 字符串切割 str9 = "Ailke, 15, 11827****8@qq.com, 成都"# 通过,分割成一个列表 result = str9.split(",") print(result) # ['Ailke','15', '11827****8@qq.com', '成都'] print(result[1]) # 15# maxsplit 默认值 -1 print(str9.split(',', 2)) # ['Ailke', ' 15', ' 11827****8@qq.com, 成都']# rsplit()函数表示从右到左分割 # 不配置maxsplit参数,效果等同于split()函数 print(str9.rsplit(',')) # ['Ailke', ' 15', ' 11827****8@qq.com', ' 成都']print(str9.rsplit(',', 2)) # ['Ailke, 15', ' 11827****8@qq.com', ' 成都'] -
字符串拼接,得到一个新的字符串
# 字符串拼接 strs1 = "Hello " strs2 = "This is" strs3 = "a test message"print(strs1+','+strs2+" "+strs3) # Hello ,This is a test messagedata_list = ["This", "is", "a", "book"] print("_".join(data_list)) # This_is_a_book -
格式化字符串,得到一个新的字符串
# 格式化字符串 names = "{0}是全世界最好的语言之一,类似的还有{1}, {2}等等" data = names.format("Python", "Java", "C++") print(data) # Python是全世界最好的语言之一,类似的还有Java, C++等等names1 = "{}是全世界最好的语言之一,类似的语言还有{}、{}等等" data = names1.format("Python", "Java", "rust") print(data) # Python是全世界最好的语言之一,类似的语言还有Java、rust等等names2 = "{name}是全世界最好的语言之一,类似的语言还有{name1}、{name2}等等" data = names2.format(name="Python", name1="C", name2="Dart") print(data) # Python是全世界最好的语言之一,类似的语言还有C、Dart等等 -
字符串转换为字节类型
# 字符串转换为字节类型 data = "语言交流" print(data.encode("utf-8")) # b'\xe8\xaf\xad\xe8\xa8\x80\xe4\xba\xa4\xe6\xb5\x81' print(data.encode("gbk")) # b'\xd3\xef\xd1\xd4\xbd\xbb\xc1\xf7' # 字符串转换为字节类型需要符合编码格式 # print((data.encode("utf-8")).decode("gbk")) # error print((data.encode("utf-8")).decode("utf-8")) # 语言交流 -
将字符串内容局中、居右、居左展示
# 字符串内容局中、居右、居左展示 strs4 = "Python" # 居中 print(strs4.center(18, "-")) # ------Python------ # 居左 print(strs4.ljust(18, "-")) # Python------------ # 居右 print(strs4.rjust(18, "*")) # ************Python -
字符串内容填充
# 字符串填充 data = "10101" # 填充至8位 binNum = data.zfill(8) print(binNum) # 00010101 # 当填充的位数小于当前的位数,数据保持不变
3.字符串公共特性
-
相加: 字符串 + 字符串
# 相加效果类似于拼接 str = "这是" + "一本书" print(str) # 这是一本书 -
相乘:字符串 * 整数
str = "Python" * 3 print(str) # PythonPythonPython -
长度
str = "Python" print(len(str)) # 6 -
获取字符串的字符和索引
- 字符串中是能通过索引取值,无法修改值,想要修改只能重新创建
strs5 = "这是一本非常值得阅读的书籍"print(strs5[1]) # 是 print(strs5[2]) # 一 print(strs5[3]) # 本print(strs5[-1]) # 籍 print(strs5[-2]) # 书 print(strs5[-3]) # 的 -
获取字符串中的子序列、切片
# 字符串切片 message = "世界上优秀的开发语言包含Python等等" # 切片,下标以0开始,取前不取尾 如,[0:5],取字符串下标为0开始,到下标为5的切片,但是不包含下标为5的字符 print(message[0:3]) # 世界上 # 切片前面不输入参数,默认从0开始 print(message[:6]) # 世界上优秀的 # 切片后面不输入参数,默认读取前面参数开始到结束 print(message[8:]) # 语言包含Python等等 # 切片第二个参数如果是负数,表示从字符串末尾,从右到左排除参数绝对值的个数(字符串从右到左,下标计数从-1,-2,...) print(message[8:-2]) # 语言包含Pythonprint(id(message)) # 2041899283744# 字符串的切片只能读取数据,无法修改数据 message = message[:18] + "、Dart" + message[18:] print(message) # 世界上优秀的开发语言包含Python、Dart等等 # 注意点:字符串切片只能读取数据,不能修改字符串;通过id()函数查看message地址,两次地址不一样,这里下面的message是重新创建了不是修改初始的message print(id(message)) # 2041899283968 -
步长,跳着取字符串的内容
# 步长,通过步长来获取值 [参数1:参数2:参数3] # 参数1表示取值的起始点(下标0开始),参数2表示取值的结束点(不包含),参数3表示步长(简单理解跳过的数) title = "加强对AI方面的人才培养和资金投入" # [::2] 取这个字符串,以步长为2取值 print(title[::2]) # 加对I面人培和金入 # [1::3] 取字符串下标为1开始,以步长为3取值 print(title[1::3]) # 强I的培资入 print(title[:2:-1]) # 入投金资和养培才人的面方IA 【倒序】# 字符串完整翻转 # 字符串翻转效果一样,性能基本类似,根据喜好自行选择 print(title[::-1]) # 入投金资和养培才人的面方IA对强加 print(title[-1::-1]) # 入投金资和养培才人的面方IA对强加 -
循环
title = "将以更高标准建设科技强国迈出新步伐"# 通过while来遍历字符串 index = 0 while index < len(title):print(title[index])index += 1# 通过for循环来遍历字符串 for i in range(len(title)):print(title[i])# range() range(10) # [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] range(10, 0, -1) # [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
4.转换
# 转换
# 整型转为字符串
num = 12345
print(type(num)) # <class 'int'>
data = str(num)
print(type(data)) # <class 'str'>
print(data)
5.补充知识点
1.字符串不可被修改
message = "这是一条报错日志"
message[:2].replace('这', '那')
print(message) # 这是一条报错日志
print(message[:2].replace('这', '那')) # 那是
# 查看内存地址
print(id(message)) # 3224240467568
message = "那是一条报错日志"# 查看内存地址
print(id(message)) # 32242404676482.字符串格式化
-
Python支持格式化字符串的输出,最基本的用法是将一个值插入到一个字符串格式符 %s的字符串中
-
Python中,字符串格式化使用与C中 sprintf函数 一样的语法
符号 描述 %c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %u 格式化无符号整型 % 格式化无符号八进制数 %x 格式化无符号十六进制数 %X 格式化无符号十六进制数(大写) %f 格式化浮点数字,可指定小数点后的精度 %e 用科学计数法格式化浮点数 %E 作用同%e,用科学计数法格式化浮点数 %g %f和%e的简写 %G %f和%E的简写 %p 用十六进制数格式化变量的地址 print("学习了%s第%d天了" % ('Python', 3)) # 学习了Python第3天了 print("用十六进制数表示: %X" % 123456824) # 用十六进制数表示: 75BCD38 print("保存小数点后2位: %0.2f" % 123.489) # 保存小数点后2位: 123.49 print("用科学计数法表示: %e" % 123456789) # 用科学计数法表示: 1.234568e+08 print("用科学计数法表示并保留2位小数: %0.3g" % 1234556821) # 用科学计数法表示并保留2位小数: 1.2e+09
4.列表类型
- 列表,是一个有序且可变的容器,可以存放多个不同类型的元素
1.列表定义
# 定义
# 直接定义赋值
username_list = ['张三', '李四', '王五']# list()函数
userage_list = list([12, 18, 15, 46])# 先定义后赋值
user_list = []
user_list.append('赵六')
user_list.append(18)
user_list.append('四川省成都市')
print(user_list) # ['赵六', 18, '四川省成都市']2.列表类型特性
-
追加,append()函数
-
在原列表尾部追加值
# 字符串局中,不足用 * 填充 welcome = "欢迎使用NB游戏".center(30, '*') print(welcome)user_count = 0 while True:count = input("请输入游戏人数:")# isdecimal(),判断是否是所有字符都是十进制if count.isdecimal():# 将字符串转化为整型user_count = int(count)breakelse:print("输入格式错误,人数必须是数字。")message = "{}人参加游戏NB游戏。".format(user_count) print(message)user_name_list = []for i in range(1, user_count + 1):tips = "请输入玩家姓名({}/{}):".format(i, user_count)# 输入语句 input() 键盘输入name = input(tips)user_name_list.append(name)print(user_name_list)
-
-
批量追加,extend()函数
-
将一个列表中的元素逐一添加到另一个列表
addr_list = ["成都市", "绵阳市", "德阳市"] new_addr_list = ["达州市", "南充市"] addr_list.extend(new_addr_list) print(addr_list) # ['成都市', '绵阳市', '德阳市', '达州市', '南充市']
-
-
插入,insert()函数
-
在原列表的指定位置插入值
tools = ['python', 'java', 'c++'] tools.insert(0, 'C') tools.insert(2, 'Dart') print(tools) # ['C', 'python', 'Dart', 'java', 'c++']
-
-
删除,remove()函数
-
在原列表中根据传入的参数值删除相应的元素,注意元素不存在会报错
tools = ['C', 'python', 'Dart', 'java', 'c++'] tools.remove('C') print(random.choice(tools)) # 该值是列表中的任意其中一个
-
-
根据索引删除,pop()函数,返回值为当前元素
-
在原列表中根据索引删除某一个元素,
tools = ['python', 'Dart', 'java', 'c++'] tools.pop(1) print(tools) # ['python', 'java', 'c++']
-
-
清空,clear()函数
-
清空列表数据
tools.clear() print(tools) # []
-
-
值获取索引,index()函数
-
根据值获取索引,找不到报错,不建议使用
tools = ['C', 'python', 'Dart', 'java', 'c++'] index = tools.index('Dart') print(tools) # ['C', 'python', 'Dart', 'java', 'c++'] print(index) # 2
-
-
列表排序,sort()函数
-
排序时内部元素无法进行比较时,程序会报错,尽量数据类型统一
tools = ['C', 'python', 'Dart', 'java', 'c++'] tools.sort() print(tools) # ['C', 'Dart', 'c++', 'java', 'python']
-
-
反转原列表,reverse()函数
tools = ['C', 'python', 'Dart', 'java', 'c++'] tools.reverse() print(tools) # ['c++', 'java', 'Dart', 'python', 'C']
3.列表类型公共特性
-
相加
-
两个列表相加获取一个新的列表
addr_list = ["成都市", "眉山市"] new_addr_list = ["德阳市"] address = addr_list + new_addr_list print(address) # ["成都市", "眉山市", "德阳市"]
-
-
相乘
-
整个列表 * 整型,列表中的元素再创建 输入的整型,并生成一个新的列表
address = ["成都市", "遂宁市"] print(id(address)) # 2449742566784 address = address * 2 print(id(address)) # 2449742575936 print(address) # ['成都市', '遂宁市', '成都市', '遂宁市']# 注意,上面通过id()函数查看address变量的地址,发现是不同的列表
-
-
in
-
列表内部是多个元素组成,可以通过in来判断元素是否在列表中,采用逐一比较方式,效率比较低
address = ["成都市", "遂宁市", "绵阳市"] if "遂宁市" in address:address.remove("遂宁市") else:print("该列表不存在 遂宁市")
-
-
获取长度,len()函数
address = ["成都市", "遂宁市", "绵阳市"] print(len(address)) # 3 -
索引
-
索引实现读、改、删、增
address = ["成都市", "遂宁市", "绵阳市"]# 增 address.insert(1, "德阳市") print(address) # '成都市', '德阳市', '遂宁市', '绵阳市'] # 改 address[2] = "简阳市" print(address) # ['成都市', '德阳市', '简阳市', '绵阳市'] # 查 print(address[1]) # 德阳市 # 删 del address[2] address.pop(1) print(address) # ['成都市', '绵阳市']
-
-
切片
-
多个元素的操作(很少用)
userName_list = ["张三", "李四", "王五", "赵六"]# 读操作 print(userName_list[0:2]) # ['张三', '李四']# 改操作 userName_list[3:] = ["田七"] print(userName_list) # ['张三', '李四', '王五', '田七']# 删操作 del userName_list[3:] print(userName_list) # ['张三', '李四', '王五']
-
-
切片+步长
userName_list = ["张三", "李四", "王五", "赵六"]print(userName_list[0:3:2]) # ['张三', '王五'] print(userName_list[3:1:-1]) # ['赵六', '王五']# 翻转 userName_list.reverse() print(userName_list) # ['赵六', '王五', '李四', '张三']new_userName_list = userName_list[::-1] print(new_userName_list) # ['张三', '李四', '王五', '赵六'] -
for循环
userName_list = ["张三", "李四", "王五", "赵六"]# 循环 for item in userName_list:print(item)# 循环 for index in range(len(userName_list)):item = userName_list[index]print(item)# 删除首字带 "王" 的字段 for index in range(len(userName_list) - 1, -1, -1):item = userName_list[index]if item.startswith('王'):userName_list.remove(item) print(userName_list) # ['张三', '李四', '赵六']
4.转换
-
str
strs1 = "王者荣耀" data = list(strs1) print(data) # ['王', '者', '荣', '耀'] -
元组或集合
# 元组 v1 = (11, 23, 56, 68) # 元组转为列表 vv1 = list(v1) print(vv1)# 集合 v2 = {"alex", "Ailke", "Tom"} # 集合转为列表 vv2 = list(v2) print(vv2)
5.其他
-
嵌套
-
列表属于容器,内部可以存放各种数据,所以支持列表的嵌套
data = ["Tom", ["Python", "C", "C++"], False, [12, 56, 36]]print(data[1]) # ['Python', 'C', 'C++'] print(data[1][1]) # C
-
5.元组类型
- 元组,是一个有序且不可变的容器,在里面可以存放多个不同类型的元素
1.元组类型的定义
# 定义元组类型,建议在元素最后多加一个逗号,用于标识它是一个元组
tp_list = ("Python", "c++", "C", )# 注意点
v2 = (1)
v3 = 1
v4 = (1, )print(type(v2)) # <class 'int'
print(type(v3)) # <class 'int'
print(type(v4)) # <class 'tuple'
2.元组类型公共特性
-
相加
# 定义元组类型,建议在元素最后多加一个逗号,用于标识它是一个元组 tp_list = ("Python", "c++", "C", )tp_list_n = ("Java", "TS")# 两个列表相加获取生成一个新的列表 new_tp_list = tp_list + tp_list_n print(new_tp_list) # ('Python', 'c++', 'C', 'Java', 'TS') -
相乘
tp_list_n = ("Java", "TS",) # 列表 * 整型,将列表中的元素再创建 整型 倍份并生成一个新的列表 tp_list_d = tp_list_n * 2 print(tp_list_d) # ('Java', 'TS', 'Java', 'TS') -
获取长度
tp_list = ("Python", "c++", "C", ) # 获取长度 print(len(tp_list)) # 3 -
索引
tp_list = ("Python", "c++", "C", ) # 索引 print(tp_list[1]) # c++ -
切片
tp_list = ("Python", "c++", "C", ) # 切片 print(tp_list[1:]) # ('c++', 'C') -
步长+切片
tp_list = ("Python", "c++", "C", ) # 步长 print(tp_list[::2]) # ('Python', 'C') -
for循环
# 定义元组类型,建议在元素最后多加一个逗号,用于标识它是一个元组 tp_list = ("Python", "c++", "C", )tp_list_n = ("Java", "TS", )# 两个列表相加获取生成一个新的列表 new_tp_list = tp_list + tp_list_n print(new_tp_list) # ('Python', 'c++', 'C', 'Java', 'TS')for item in new_tp_list:print(item)for item in new_tp_list:if item == 'C':continueprint(item)
3.转换
-
其他类型转为元组,tuple(其他类型)函数实现,目前只有字符串和列表可以转换为元组
# 字符串转为元组 name = "Ailke" data = tuple(name) print(data) # ('A', 'i', 'l', 'k', 'e')# 列表转为元组 name_list = ["张三", 42, "Python"] data = tuple(name_list) print(data) # ('张三', 42, 'Python')
4.拓展
-
元组和列表都可以充当容器,内部可以放很多元素,并且也支持元素内的各种嵌套
tp_list = ("Ailke", 56, [12,35,36], ('Python', 'Java', 'C'))
6.字典类型
- 字典是无序(补充知识点(重点),Python3.7及以后,字典是有序的)、键不重复 且 元素只能是键值对的可变容器
1.字典的定义
# 字典的定义
# 空字典
v1 = {}
v2 = dict()'''
字典中对键值的要求- 键:必须可哈希,不可哈希列表、集合、字典- 值:任意类型'''
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"]
}2.字典类型特性
-
获取值
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 获取值 print(dict_student_info.get("name")) # 张三 -
获取所有键
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 获取所有键 print(dict_student_info.keys()) # dict_keys(['name', 'age', 'addr', 'hobby']) -
获取所有值
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 获取所有值 print(dict_student_info.values()) # dict_values(['张三', 18, '四川省成都市武侯区', ['Python', 'Java']]) -
获取所有键值
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 所有的键值 print(dict_student_info.items()) # dict_items([('name', '张三'), ('age', 18), ('addr', '四川省成都市武侯区'), ('hobby', ['Python', 'Java'])])# item是元组类型 for item in dict_student_info.items():print(item[0], item[1])# 效果等同上面 for key,value in dict_student_info.items():print(key, value) -
设置值
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 设置值 dict_student_info.setdefault("email", "jkfhs***hj@google.com") # 已有的键,更新值无效 dict_student_info.setdefault("name", "李四")print(dict_student_info) # {'name': '张三', 'age': 18, 'addr': '四川省成都市武侯区', 'hobby': ['Python', 'Java'], 'email': 'jkfhs***hj@gmail.com'} -
更新字典键值对
- 没有的键直接添加,有键的更改值
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 更新键值对 dict_student_info.update({"name": "李四", "age": 20, "email": "45602531@gmail.com"}) print(dict_student_info) # {'name': '李四', 'age': 20, 'addr': '四川省成都市武侯区', 'hobby': ['Python', 'Java'], 'email': '45602531@gmail.com'} -
移除指定键值对
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 移除键值对 dict_student_info.pop("age") print(dict_student_info) # {'name': '张三', 'addr': '四川省成都市武侯区', 'hobby': ['Python', 'Java']} -
按照顺序移除(后进先出)
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 按照顺序移除(后进先出) '''python3.6之后,popitem移除最后的值python3.6之前,popitem随机删除 ''' # 返回元组类型 print(dict_student_info.popitem()) # ('hobby', ['Python', 'Java'])
3.字典类型公共特性
-
并集(Python3.9加入)
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }dict_student_infos = {"age": 23,"email": "56981142@gmail.com" }# 并集 new_student_info = dict_student_info | dict_student_infos print(new_student_info) # {'name': '张三', 'age': 23, 'addr': '四川省成都市武侯区', 'hobby': ['Python', 'Java'], 'email': '56981142@gmail.com'} -
长度
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 长度 print(len(dict_student_info)) # 4 -
是否包含
# 是否包含(返回bool值)info1 = "name" in dict_student_info.keys() print(info1) # Trueinfo2 = 18 in dict_student_info.values() print(info2) # Trueinfo3 = "addr" in dict_student_info print(info3) # True -
索引(键)
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 索引 print(dict_student_info["addr"]) # 四川省成都市武侯区 -
根据键 修改、添加和删除值
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 修改值 dict_student_info["age"] = 23 print(dict_student_info) # {'name': '张三', 'age': 23, 'addr': '四川省成都市武侯区', 'hobby': ['Python', 'Java']} # 添加值 dict_student_info["gender"] = "male" print(dict_student_info) # {'name': '张三', 'age': 23, 'addr': '四川省成都市武侯区', 'hobby': ['Python', 'Java'], 'gender': 'male'} # 删除值 # 使用del删除键值对,键不存在就会报错 # del dict_student_info["gender"] # 效果同上,键不存在就会报错 dict_student_info.pop("gender") print(dict_student_info) # {'name': '张三', 'age': 23, 'addr': '四川省成都市武侯区', 'hobby': ['Python', 'Java']} -
for循环
dict_student_info = {"name": "张三","age": 18,"addr": "四川省成都市武侯区","hobby": ["Python", "Java"] }# 返回所有键 for item in dict_student_info:print(item)# 返回所有键 for item in dict_student_info.keys():print(item) # 返回所有值 for item in dict_student_info.values():print(item)# 返回键值对 for key, value in dict_student_info.items():print(key, value)
7.布尔型类型
- 布尔值,其实就是True 和 False
1.定义
data = True
alex_is_dog = Falseprint(True + True) # 2
2.转换
-
整数0、空字符串、空列表、空字典转为布尔值时均为False,其他均为True
flag1 = bool(0) flag2 = bool([]) flag3 = bool("") flag4 = bool(" ")print(flag1) # False print(flag2) # False print(flag3) # False print(flag4) # True -
在if、while条件后面写一个值当作条件时,默认转换为布尔值类型,再做条件判断
if 0:print("该布尔值为False") else:print(123) # 123if " ":print("该布尔值为True") # 该布尔值为True else:print(456)# 不要尝试此段代码,死循环(有可能导致电脑卡死) while 1 < 9:print("该条件将一直成立")
8.集合类型(set)
- 集合是一个无序、可变、不允许数据重复的容器
1.集合类型定义
# 定义集合
set_List = {'Python', 18, 'C', 12, 56}
# 无序,无法通过索引取值
# Class 'set' does not define '__getitem__', so the '[]' operator cannot be used on its instances
# print(set_List[1])# 可变,可以添加和删除元素
set_List.add('Ailke')
print(set_List) # {18, 'Python', 'Ailke', 56, 'C', 12}
# #删除指定参数
set_List.remove('Ailke')
print(set_List) # {18, 'C', 56, 'Python', 12}
# #删除集合任意元素并返回该元素
set_List.pop()
print(set_List) # {56, 'C', 12, 'Python'}# 不允许数据重复
set_List.add('C')
print(set_List) # {56, 'Python', 12, 'C'}
2.集合类型特性
-
添加元素
# 添加元素 set_list = {"Python", "C++", "C", "JAVA"} set_list.add("Dart") print(set_list) # {'Dart', 'C++', 'Python', 'C', 'JAVA'}set_lists = set() set_lists.add("Flutter") set_lists.add("Python") print(set_lists) # {'Flutter', 'Python'} -
删除元素
-
remove():删除指定元素,元素不存在则引发KeyError
-
pop():删除并返回集合中的任意元素,集合为空则引发KeyError
-
discard(): 删除指定元素,元素不存在则忽略,不会引发错误
# 删除元素 set_list.discard("C++") print(set_list) # {'C', 'JAVA', 'Python', 'Dart'}
-
-
交集
# 交集 set_intersection = set_list.intersection(set_lists) print(set_intersection) # {'Python'} -
并集
# 并集 set_union = set_list.union(set_lists) print(set_union) # {'C', 'Python', 'JAVA', 'Flutter', 'Dart'}# 效果同上 # set_union = set_list | set_lists # print(set_union) # {'C', 'Flutter', 'JAVA', 'Python', 'Dart'} -
差集
# 差集 # set_list集合有,set_lists集合没有的 set_difference = set_list.difference(set_lists) print(set_difference) # {'JAVA', 'Dart', 'C'}
3.集合类型公共特性
-
减,计算差集
# 差集 # set_list集合有,set_lists集合没有的 set_difference = set_list - set_lists print(set_difference) # {'JAVA', 'Dart', 'C'} -
&,计算交集
# 交集 set_intersection = set_list & set_lists print(set_intersection) # {'Python'} -
|,计算并集
set_union = set_list | set_lists print(set_union) # {'C', 'Flutter', 'JAVA', 'Python', 'Dart'} -
长度
# 长度 set_list = {"Python", "C++", "C", "JAVA"} set_list.add("Dart") print(set_list) # {'Dart', 'C++', 'Python', 'C', 'JAVA'} print(len(set_list)) # 5 -
for循环
# for循环 set_list = {"Python", "C++", "C", "JAVA"} set_list.add("Dart") print(set_list) # {'Dart', 'C++', 'Python', 'C', 'JAVA'}for item in set_list:print(item)
4.转换
-
其他类型转换为集合类型,可以通过set进行转换,并且如果数据有重复自动剔除
-
字符串、列表、元组、字典都可以转换为集合
# 字符串转为集合 str = "这是一句话,这也是一个人" set_str = set(str) print(set_str) # {'人', '这', '话', '也', '句', '是', '个', ',', '一'}# 列表转为集合 list = ["Python", 18, 23] set_list = set(list) print(set_list) # {'Python', 18, 23}# 元组转为集合 tuple = ("Python", 18, "C++",) set_tuple = set(tuple) print(set_tuple) # {'Python', 18, 'C++'}
5.拓展
- 元素必须可哈希
- 因存储原理,集合的元素必须是可哈希的值,即: 内部通过哈希函数把值换成一个数字
- 目前可哈希的数据类型: int、bool、str、tuple,而list、set是不可哈希的
- 集合的元素只能是int、bool、str、tuple
1.对比列表、集合和元组
| 类型 | 是否可变 | 是否有序 | 是否可哈希 | 转换 | 元素要求 | 定义空 |
|---|---|---|---|---|---|---|
| list | 是 | 是 | 否 | list(其他) | 无 | v = [ ]或v = list( ) |
| tuple | 否 | 是 | 是 | tuple(其他) | 无 | v = ()或v = tuple( ) |
| set | 是 | 否 | 否 | set(其他) | 可哈希 | v = set( ) |
2.import导包(库)和Python条件语句
1.导入包(库)
- 在python中,用import或者from…import来导入相应的模块
1.常见的导包方式
-
整个模块全部是导入
import somemodule -
从某个模块中导入某个函数
from somemodule import somefunction -
从某个模块中导入多个函数
from somemodule import firstfunc, secondfunc, thirdfunc -
将某个模块中的全部函数导入
from somemodule import * -
将某个模块改名(改为s)
import somemodule as s
2.条件语句
- Python不支持switch
1.if 判断语句
-
条件语句是通过一条或多条语句的执行结果(bool值)来决定执行的代码块
''' if 判断语句 - 格式 if 条件:语句''' str = "Python is best" if "Python" in str:print("Python is in str")
2.if else分支语句
-
Python中任何非0和非空(None)值为True,0和None为False
''' if else分支语句 - 格式 if 条件:语句 else:语句'''str = "JAVA is best" if "JAVA" in str:print("str包含JAVA这个词汇") else:print("str不包含JAVA词汇")
3.if elif else多分支语句
-
多个条件判断
''' if elif else 多分支语句 - 格式 if 条件:语句 elif 条件:语句 ... else:语句 ''' while True:print("请输入你的分数(0 ~ 100)".center(30, "*"))score = float(input())if score < 0.0 or score > 100.0:print("该分数不合法")else:break if score >= 90:print("可以获得 A") elif score >= 80:print("可以获得 B") elif score >= 60:print("可以获得 C") else:print("不及格")
3.循环语句
1.while循环语句
'''
while循环语句
- 格式
while 条件:语句[控制条件]如果while的没有控制条件,条件为True,while进入死循环
'''count = 0
while count < 10:# 打印10次print("当前是%d次输出" % count)count += 1
print("结束")
2.while循环语句 else
'''
while else循环语句
- 格式
while 条件:语句1[控制条件]
else:语句2while循环,条件执行完成之后;将执行语句2
'''
count = 0
while count < 10:# 打印10次print("当前输入%d次输出" % count)count += 1
else:print("count值大于9")
3.for循环语句
-
for循环可以遍历任何序列的项目
tup_list = (1, "Python", "addr", 'C', 23.23,) for item in tup_list:print(item) dict_str = {"name": "张三","age": 19,"addr": "四川省成都市" } for item in dict_str.items():print(item[0], item[1])
4.for 循环语句 else
- 在Python中,for…else表示这样的意思,for中的语句和普通没啥区别,else中语句会在循环正常执行完的情况下执行
# 判断质数
for num in range(10, 20):for i in range(2, num):if num % i == 0:j = num / iprint('%d 等于 %d * %d' % (num, i, j))breakelse:print('%d 是一个质数 ' % num)
5.循环控制语句
1.break语句
-
break语句用来终止循环语句,即循环条件没有False条件或序列没被完全递归完,也会停止执行循环语句
# break语句 for item in "Python":if item == 'h':breakprint("当前字母是%s" % item) # P y t print("执行结束")
2.continue语句
-
continue语句用来告诉Python跳过当前循环的剩余语句,然后进入下一轮循环
# continue str_list = ["Python", "JAVA", 18, "成都市"] for item in str_list:if item == 18:continueprint("当前的取值为:%s" % item) print("执行结束") # Python JAVA 成都市
3.pass 语句
-
pass是空语句,是为了保持程序结构的完整性
# pass str_list = ["Python", "JAVA", 18, "成都市"] for item in str_list:if item == 18:passcontinueprint("当前的取值为:%s" % item) print("执行结束") # Python JAVA 成都市
3.迭代器和Python日期
1.迭代器
-
迭代是Python最强大的功能之一,是访问集合元素的一种方式
-
迭代器是一个可以记住遍历的位置的对象
-
迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束,迭代器只能往前不会后退
-
迭代器有两个基本的方法: iter() 和 next()
str = "Python is best" it = iter(str) print(next(it))print("分隔符".center(30, "*")) for ch in it:print(ch) # y t h ....
2.Stoplteration
-
Stoplteration异常用于标识迭代的完成,防止出现无限循环的情况,在next()函数可以设置循环次数后触发Stoplteration异常来结束迭代
class RunNumbers:def __iter__(self):self.a = 1return selfdef __next__(self):if self.a <= 20:x = self.aself.a += 1return xelse:raise StopIterationRunNumber = RunNumbers() Runiter = iter(RunNumber) for x in Runiter:print(x) # 1 2 3 4 5 6 7...
3.生成器
-
在Python中,使用了yield的函数被称为生成器
-
跟普通函数不一样,生成器是一个返回迭代器的函数,只能用于迭代操作
-
在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行
''' 斐波那契数列 F(1) = 1, F(2) = 1, F(3) = 2,..., F(n) = F(n-1) + F(n-2) (n>=3, n属于整数)'''# 斐波那契 def fibonacci(n):a, b, counter = 1, 1, 1while True:if counter > n:returnyield aa, b = b, a + bcounter += 1f = fibonacci(10) while True:try:print(next(f), end=" ") # 1 1 2 3 5 8 13 34 55except StopIteration:sys.exit() -
补充知识点
-
yield from
def foo():yield 2yield 2yield 2def func():yield 1yield 1yield 1yield from foo()yield 1yield 1for item in func():print(item) # 1 1 1 2 2 2 1 1
-
4.Python日期
1.日期和时间
-
Python提供了一个time 和 calendar模块可以用于格式化 日期 和 时间
-
每个时间戳都是以自从1970年1月1日午夜经历了多长时间来表示
-
时间间隔是以秒为单位的浮点小数
import time# 获取时间戳 单位: 秒 ticks = time.time() print(ticks) # 1709796147.007354 (仅限测试的时间点)
2.时间元组
-
Python函数用一个元组装起来的9组数字处理时间
序列 字段 值 0 4位年数(tm_year) - 1 月(tm_mon) 1~12 2 日(tm_mday) 1~31 3 小时(tm_hour) 0~23 4 分钟(tm_min) 0~59 5 秒(tm_sec) 0~61(60或61是闰秒) 6 一周的第几天(tm_wday) 0~6 7 一年的第几日(tm_yday) 1~366 8 夏令时(tm_isdst) -1, 0, 1 -1是决定是否为夏令时的旗帜 # 获取时间元组 now = time.localtime() print(now) # time.struct_time(tm_year=2024, tm_mon=3, tm_mday=7, tm_hour=15, tm_min=35, tm_sec=53, tm_wday=3, tm_yday=67, tm_isdst=0)month = now.tm_mon print("当前年份是: %s" % month)
3.时间日期格式化
-
可以使用time模块的strftime()方法来格式化日期
符号 描述 范围 %y 表示两位数的年份 00~99 %Y 表示四位数的年份 000~9999 %m 表示月份 01~12 %d 表示月中的一天 0~31 %H 表示 24小时制小时数 0~23 %l 表示 12小时制小时数 01~12 %M 表示分钟数 00~59 %S 表示秒数 00~59 %a 表示本地简化星期名称 %A 表示本地完整星期名称 %b 表示本地简化的月份名称 %B 表示本地完整的月份名称 %c 表示本地相应的日期和时间 %j 表示年内的一天 001~366 %p 本地A.M或P.M的等价符 %U 表示一年中的星期数(00~53)星期天为星期的开始 %w 表示星期(0~6),星期天为星期的开始 %W 表示一年中的星期数(0~53) 星期一为星期的开始 %x 表示本地相应的日期表示 %X 表示本地相应的时间表示 %Z 表示当前时区的名称 %% 表示 % import time print(time.strftime("%Y-%m-%d %H:%M:%S %A %B %Z %X", time.localtime())) # 2024-03-07 16:21:17 Thursday March 中国标准时间 16:21:17timestamp = time.time() print(timestamp) # 1709799957.691324 timestamp = time.mktime(time.localtime()) print(timestamp) # 1709799957.0# 时间戳转换元组时间 local_time = time.localtime(3209788857.691324) print(time.strftime("%Y-%m-%d %H:%M:%S %A %B %Z %X", local_time)) # 2071-09-18 16:00:57 Friday September 中国标准时间 16:00:57# 指定时间换成时间戳 print(time.mktime(time.strptime("2025-08-08 17:05:30","%Y-%m-%d %H:%M:%S"))) # 1754643930.0#等待12s time.sleep(12)from datetime import datetime, timedelta # 获取当前的日期和时间 print(datetime.now()) # 2024-03-07 16:50:17.831371# 日期和时间算术运算 one_day_later = datetime.now() + timedelta(days=1) print(one_day_later) # 2024-03-08 16:52:09.437493# 创建特定的日期和时间对象 specific_date = datetime(2025, 8, 8, 10, 59) print(specific_date.strftime("%Y/%m/%d %H:%M:%S %A %B %Z")) # 2025/08/08 10:59:00 Friday August print(type(specific_date)) # <class 'datetime.datetime'>
相关文章:
)
基础知识点全覆盖(1)
Python基础知识点 1.基本语句 1.注释 方便阅读和调试代码注释的方法有行注释和块注释 1.行注释 行注释以 **# **开头 # 这是单行注释2.块注释 块注释以多个 #、三单引号或三双引号(注意: 基于英文输入状态下的标点符号) # 类 # 似 # 于 # 多 # 行 # 效 # 果 这就是多行注释…...

异常处理java
在Java中,异常处理可以使用"throws"关键字或者"try-catch"语句。这两种方法有不同的用途和适用场景。 "throws"关键字: 在方法声明中使用"throws"关键字,表示该方法可能会抛出异常,但是并不立即处理…...

个人博客项目_09
1. 归档文章列表 1.1 接口说明 接口url:/articles 请求方式:POST 请求参数: 参数名称参数类型说明yearstring年monthstring月 返回数据: {"success": true, "code": 200, "msg": "succ…...
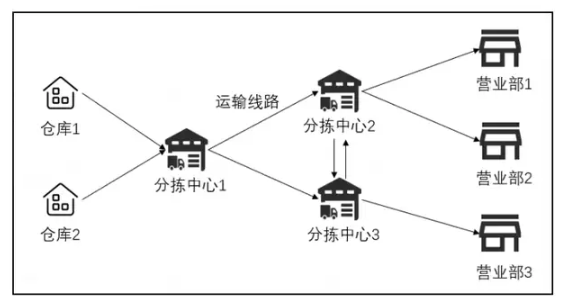
【2024年MathorCup数模竞赛】C题赛题与解题思路
2024年MathorCup数模竞赛C题 题目 物流网络分拣中心货量预测及人员排班背景求解问题 解题思路问题一问题二问题三问题四 本次竞赛的C题是对物流网络分拣中心的货量预测及人员排班问题进行规划。整个问题可以分为两个部分,一是对时间序列进行预测,二是对人…...

蓝桥杯省赛冲刺(3)广度优先搜索
广度优先搜索(Breadth-First Search, BFS)是一种在图或树等非线性数据结构中遍历节点的算法,它从起始节点开始,按层级逐步向外扩展,即先访问离起始节点最近的节点,再访问这些节点的邻居,然后是邻…...

网页内容生成图片,这18般武艺你会几种呢?
前言 关于【SSD系列】: 前端一些有意思的内容,旨在3-10分钟里, 500-1000字,有所获,又不为所累。 网页截图,windows内置了快捷命令和软件,chrome开发者工具也能一键截图,html2canva…...

pytest的时候输出一个F后面跟很多绿色的点解读
使用pytest来测试pyramid和kotti项目,在kotti项目测试的时候,输出一个F后面跟很多绿色的点,是什么意思呢? 原来在使用pytest进行测试时,输出中的“F”代表一个失败的测试(Failed),而…...

算法打卡day33
今日任务: 1)509. 斐波那契数 2)70. 爬楼梯 3)746.使用最小花费爬楼梯 509. 斐波那契数 题目链接:509. 斐波那契数 - 力扣(LeetCode) 斐波那契数,通常用 F(n) 表示,形成…...
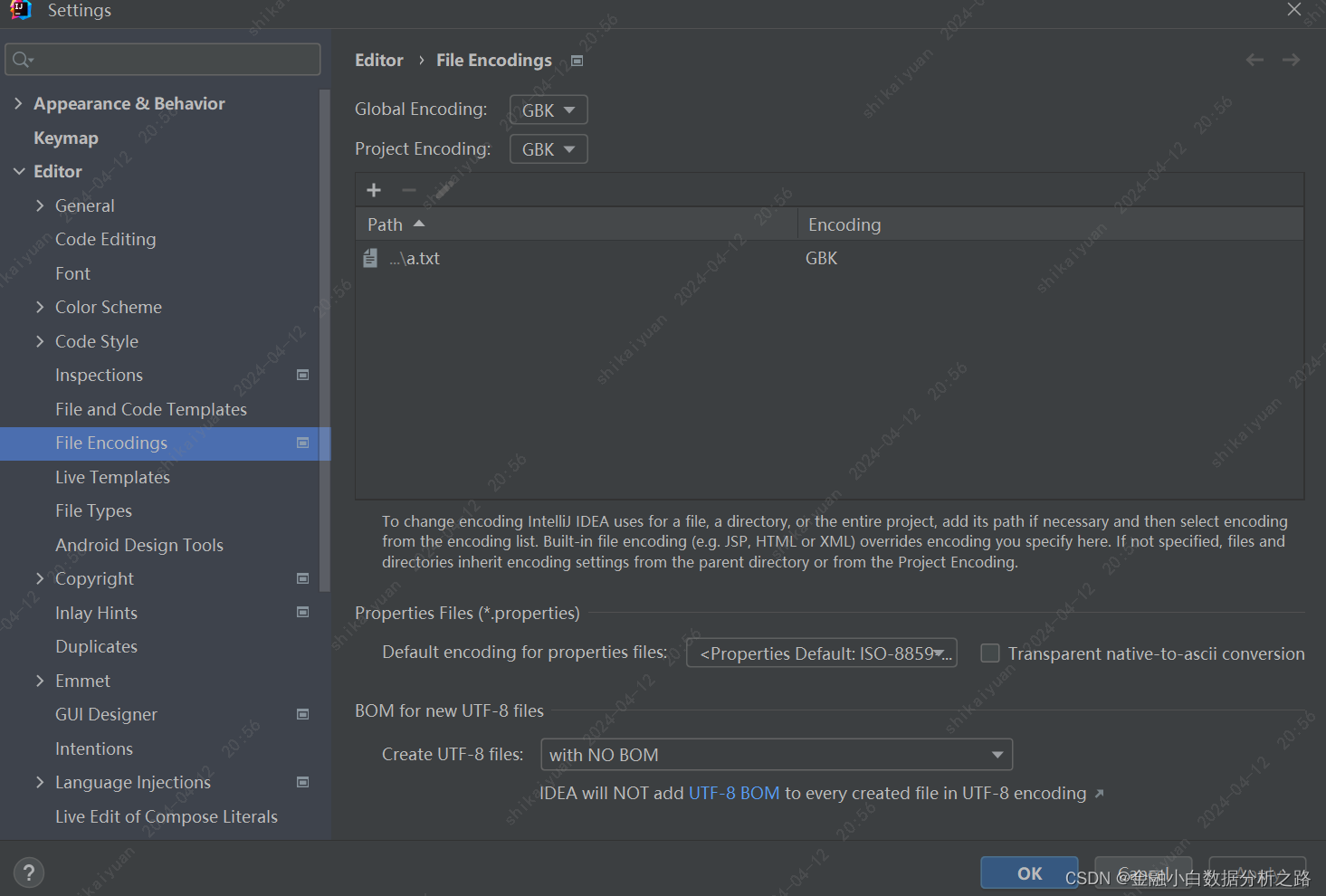
《疯狂java讲义》Java AWT图形化编程中文显示
《疯狂java讲义》第六版第十一章AWT中文没有办法显示问题解决 VM Options设置为-Dfile.encodinggbk 需要增加变量 或者这边直接设置gbk 此外如果用swing 就不会产生这个问题了。...

Python3 标准库,API文档链接
一、标准库 即当你安装python3 后就自己携带的一些已经提供好的工具模块,工具类,可以专门用来某一类相关问题,达到辅助日常工作或者个人想法的一些成品库 类似的 C ,Java 等等也都有自己的标准库和使用文档 常见的一些: os 模块…...
【Web】CTFSHOW-ThinkPHP5-6反序列化刷题记录(全)
目录 web611 web612 web613-622 web623 web624-626 纯记录exp,链子不作赘述 web611 具体分析: ThinkPHP-Vuln/ThinkPHP5/ThinkPHP5.1.X反序列化利用链.md at master Mochazz/ThinkPHP-Vuln GitHub 题目直接给了反序列化入口 exp: <?ph…...

AR智能眼镜方案_MTK平台安卓主板芯片|光学解决方案
AR眼镜作为一种引人注目的创新产品,其芯片、显示屏和光学方案是决定整机成本和性能的关键因素。在这篇文章中,我们将探讨AR眼镜的关键技术,并介绍一种高性能的AR眼镜方案,旨在为用户带来卓越的体验。 AR眼镜的芯片选型至关重要。一…...
Android网络抓包--Charles
一、Android抓包方式 对Https降级进行抓包,降级成Http使用抓包工具对Https进行抓包 二、常用的抓包工具 wireshark:侧重于TCP、UDP传输层,HTTP/HTTPS也能抓包,但不能解密HTTPS报文。比较复杂fiddler:支持HTTP/HTTPS…...
)
【LeetCode热题100】238. 除自身以外数组的乘积(数组)
一.题目要求 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 **不要使用除法,**且在…...
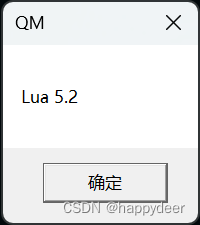
《哈迪斯》自带的Lua解释器是哪个版本?
玩过《哈迪斯》(英文名:Hades)吗?最近在研究怎么给这款游戏做MOD,想把它的振动体验升级到更高品质的RichTap。N站下载了一些别人做的MOD,发现很多都基于相同的格式,均是对游戏.sjon文件或.lua文…...

Java内存泄漏内存溢出
1.定义 OOM内存溢出是指应用程序尝试使用更多内存资源,而系统无足够的内存,导致程序崩溃。 内存泄漏是指应用程序中分配的内存未能被正确释放,导致系统中的可用内存逐渐减少。 2.内存泄漏的原因 可能包括对象引用未被释放、缓存未被清理等。 …...

【springboot】项目启动时打印全部接口方法
方法:在你springboot项目的基础上,创建下面的类: package com.llq.wahaha.listener;import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.ApplicationContext; import org.springframework…...

单例19c RMAN数据迁移方案
一、环境说明 源库 目标库 IP 192.168.37.200 192.168.37.202 系统版本 RedHat 7.9 RedHat 7.9 数据库版本 19.3.0.0.0 19.3.0.0.0 SID beg beg hostname beg rman 数据量 1353M 说明:源库已经创建数据库实例,并且存在用户kk和他创建的表空间…...
05—面向对象(上)
一、面向对象编程 1、类和对象 (1)什么是类 类是一类具有相同特性的事物的抽象描述,是一组相关属性和行为的集合。 属性:就是该事物的状态信息。行为:就是在你这个程序中,该状态信息要做什么操作&#x…...

【LeetCode热题100】【链表】两数相加
题目链接:2. 两数相加 - 力扣(LeetCode) 基本思路同:【leetcode】大数相加-CSDN博客 数值的位置已经倒过来了,用一个进位记录进位,用一个数记录和,链表到空了就当成0 class Solution { publi…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...
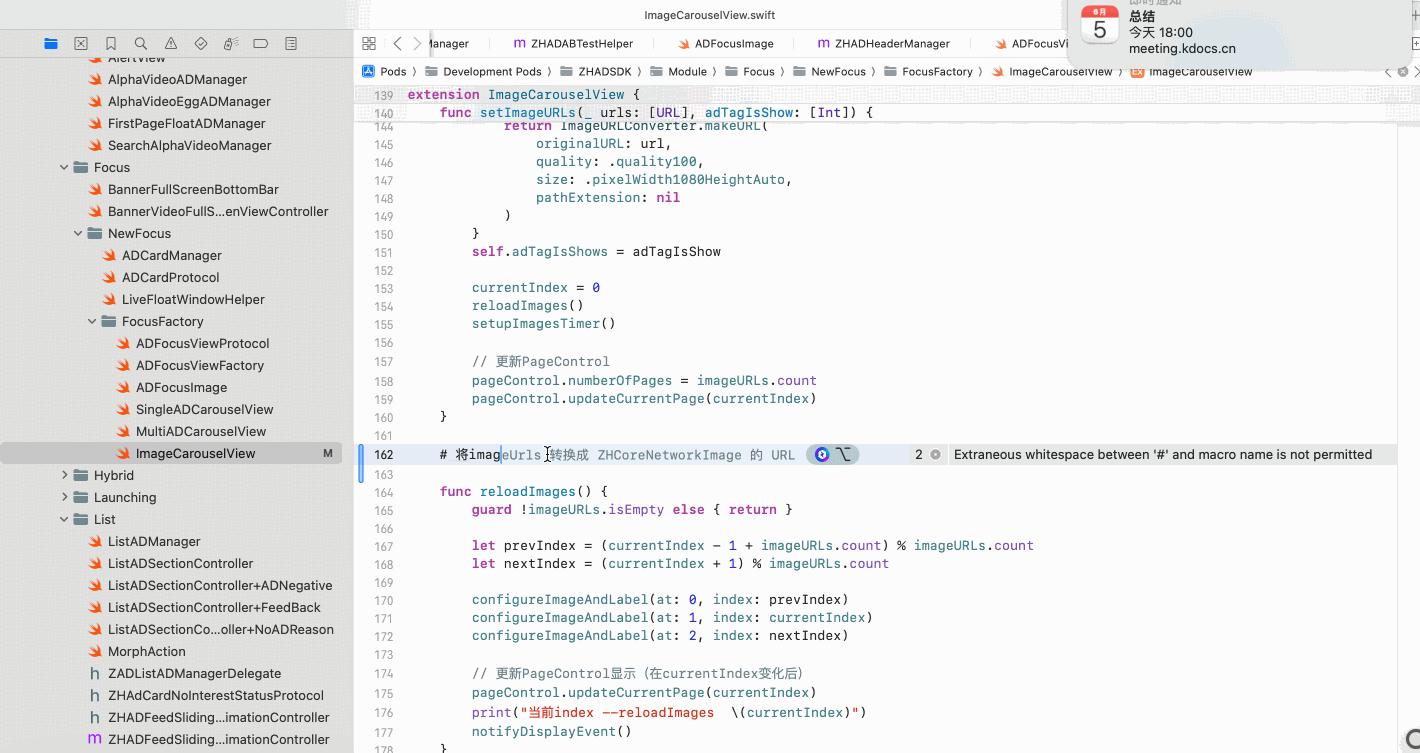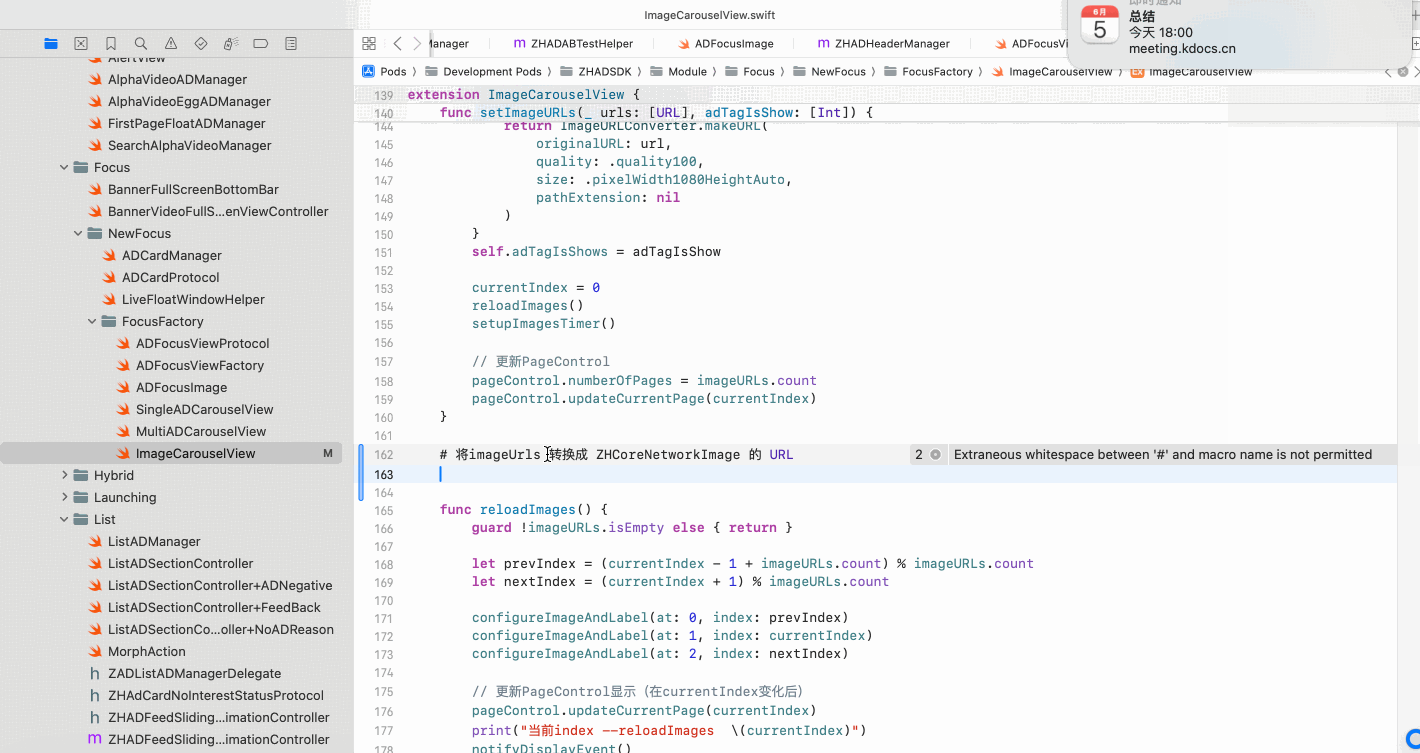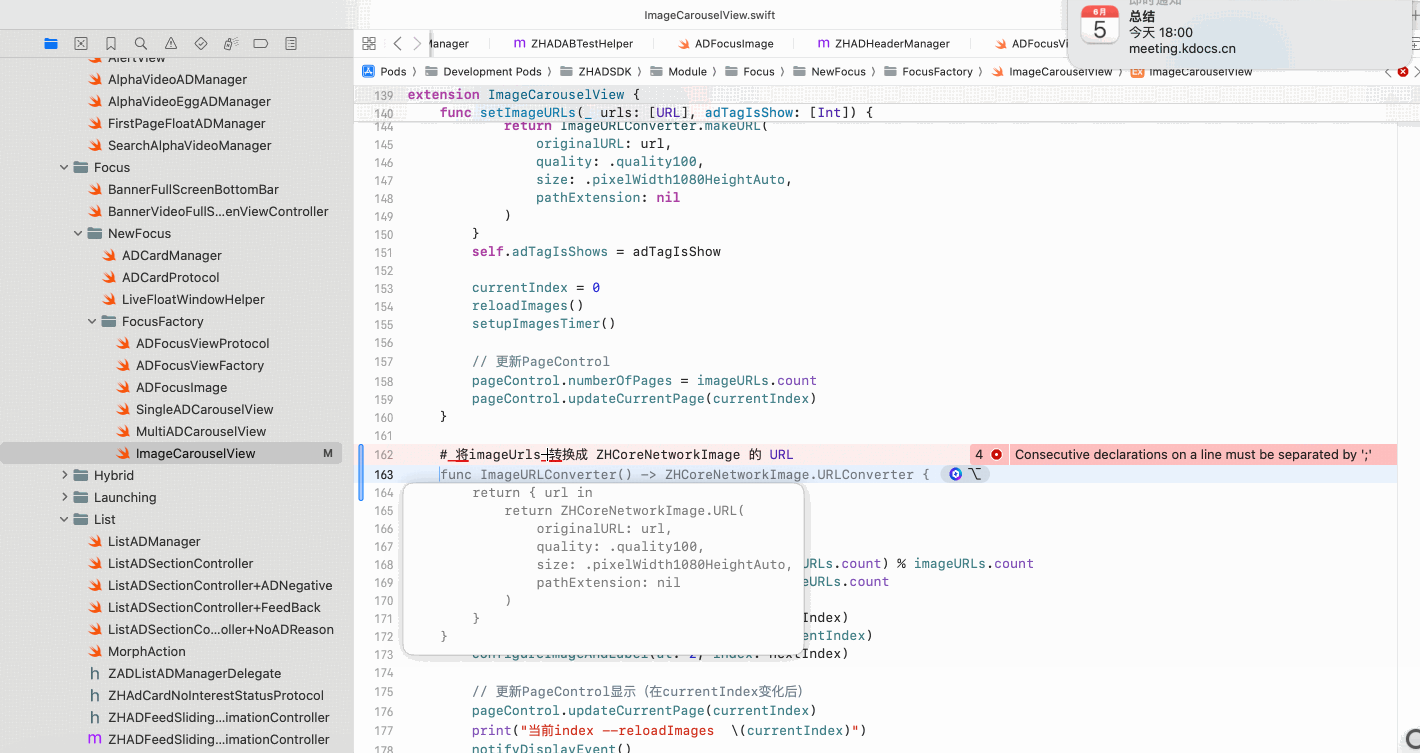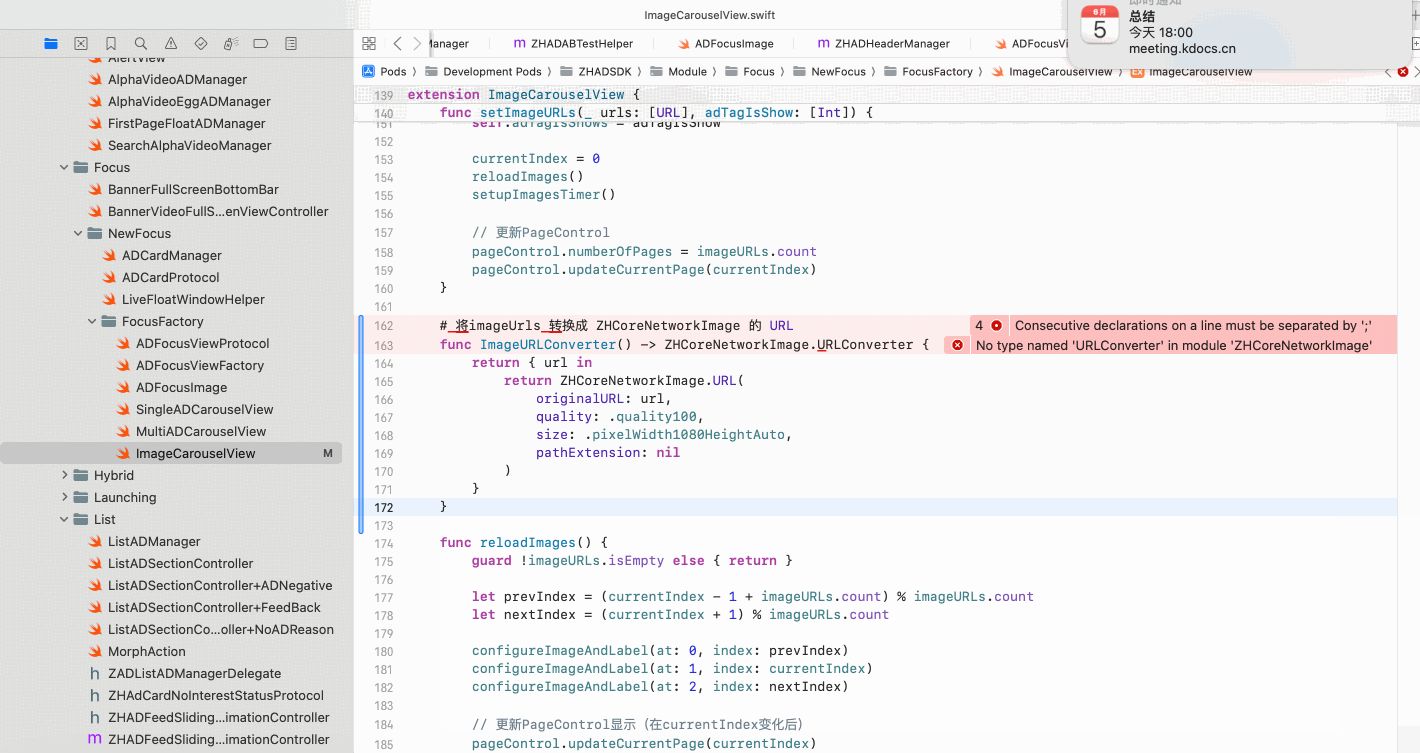
Copilot for Xcode (iOS的 AI辅助编程)
Copilot for Xcode 简介Copilot下载与安装 体验环境要求下载最新的安装包安装登录系统权限设置 AI辅助编程生成注释代码补全简单需求代码生成辅助编程行间代码生成注释联想 代码生成 总结 简介 尝试使用了Copilot,它能根据上下文补全代码,快速生成常用…...

前端打包工具简单介绍
前端打包工具简单介绍 一、Webpack 架构与插件机制 1. Webpack 架构核心组成 Entry(入口) 指定应用的起点文件,比如 src/index.js。 Module(模块) Webpack 把项目当作模块图,模块可以是 JS、CSS、图片等…...
)
Spring Boot 与 Kafka 的深度集成实践(二)
3. 生产者实现 3.1 生产者配置 在 Spring Boot 项目中,配置 Kafka 生产者主要是配置生产者工厂(ProducerFactory)和 KafkaTemplate 。生产者工厂负责创建 Kafka 生产者实例,而 KafkaTemplate 则是用于发送消息的核心组件&#x…...

NLP常用工具包
✨做一次按NLP项目常见工具的使用拆解 1. tokenizer from torchtext.data.utils import get_tokenizertokenizer get_tokenizer(basic_english) text_sample "Were going on an adventure! The weather is really nice today." tokens tokenizer(text_sample) p…...

Docker load 后镜像名称为空问题的解决方案
在使用 docker load命令从存档文件中加载Docker镜像时,有时会遇到镜像名称为空的情况。这种情况通常是由于在保存镜像时未正确标记镜像名称和标签,或者在加载镜像时出现了意外情况。本文将介绍如何诊断和解决这一问题。 一、问题描述 当使用 docker lo…...

Python训练营---DAY48
DAY 48 随机函数与广播机制 知识点回顾: 随机张量的生成:torch.randn函数卷积和池化的计算公式(可以不掌握,会自动计算的)pytorch的广播机制:加法和乘法的广播机制 ps:numpy运算也有类似的广播机…...
70年使用权的IntelliJ IDEA Ultimate安装教程
安装Java环境 下载Java Development Kit (JDK) 从Oracle官网或OpenJDK。推荐选择JDK 11或更高版本。 运行下载的安装程序,按照提示完成安装。注意记录JDK的安装路径(如C:\Program Files\Java\jdk-11.0.15)。 配置环境变量: 右键…...