传统文字检测方法+代码实现
文章目录
- 前言
- 传统文字检测方法
- 1、基于最大稳定极值区域(MSER)的文字检测
- 1.1 MSER(MSER-Maximally Stable Extremal Regions)
- 基本原理
- 代码实现——使用Opencv中的`cv2.MSER_create()`接口
- 2、基于笔画宽度变换(Stroke Width Transform,SWT)的场景文字检测
- SWTloc库
- 代码实现
- 总结
前言
尽管现在基于深度学习的文字检测方法精度高,速度快,加速了 O C R OCR OCR 技术的发展,但是传统的检测方法的思想和方法也是非常精妙,依旧有值得学习的地方。本文主要介绍两种传统的场景文件检测方法,分别是基于最大稳定极值区域( M S E R MSER MSER)的文字检测和基于笔画宽度变换( S W T SWT SWT)的场景文字检测方法,介绍了其基本思想和步骤,并在车牌数据集上简单的实现了他们,得到了较不错的效果。🧐
传统文字检测方法
1、基于最大稳定极值区域(MSER)的文字检测
1.1 MSER(MSER-Maximally Stable Extremal Regions)
基本原理
- 一种用于检测图像中稳定的区域的算法。它的主要思想是在图像中寻找极值区域,这些区域在不同尺度下保持稳定性。
- 主要步骤:
- 将一幅图像进行转换为灰度图像
- 取阈值对图像进行二值化处理,阈值从 0 − 255 0-255 0−255依次递增,图像逐渐变成纯黑的图像或纯白的图像(如下图所示),每一幅二值化图像中的黑色/白色的连通域就是一个极值区域 Q Q Q。任选两个极值区域,只有两种关系,一种是没有交集,一种是包含。
在相邻阈值的二值化图像中,极值区域 Q 1 , Q 2 , Q 3 , Q 4 . . . Q_{1},Q_{2},Q_{3},Q_{4}... Q1,Q2,Q3,Q4...构成嵌套关系,即 Q i ∈ Q i + 1 Q_{i}\in Q_{i+1} Qi∈Qi+1
极值区域::定义与灰度阈值有关。设定好灰度阈值后,在图像中的某个区域能够成为极值区域的条件是无法再找到一个不大于所设定的灰度阈值的像素点去扩大当前区域。

- 当且仅当下面公式中的 q ( i ) q(i) q(i)取最小值时,对应的 Q ( i ) 成为 M S E R Q(i)成为MSER Q(i)成为MSER,式中 Δ \Delta Δ表示灰度阈值的微小增加量

代码实现——使用Opencv中的cv2.MSER_create()接口
- cv2.MSER_create()函数参数

- 代码:
import cv2# 读取图像
image = cv2.imread('car.png')# 转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 创建 MSER 对象
mser = cv2.MSER_create()# 检测图像中的稳定区域
regions, _ = mser.detectRegions(gray)# 绘制检测到的区域
for region in regions:x, y, w, h = cv2.boundingRect(region)cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 1)cv2.imshow('MSER Regions', image)
cv2.waitKey(0)
结果:

很明显中间的车牌区域是我们的目标区域,但是现在得到的检测框太多冗余和非目标区域的了,所以接下来需要进行一些微调,直至得到想要的结果。
import cv2# 读取图像
image = cv2.imread('car.png')gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)# 先得到车牌的大致区域
mser = cv2.MSER_create(delta=15)
regions, _ = mser.detectRegions(gray)
max_area = 1
result = None
for region in regions:x, y, w, h = cv2.boundingRect(region)if w*h > max_area:max_area = w*h result = [x, y, w, h]# 裁剪出车牌
cropped_image = image[result[1]:result[1]+result[3], result[0]:result[0]+result[2],:]
cropped_image_gray = cv2.cvtColor(cropped_image, cv2.COLOR_BGR2GRAY)mser1 = cv2.MSER_create(delta = 5)
regions, _ = mser.detectRegions(cropped_image_gray)for region in regions:x, y, w, h = cv2.boundingRect(region)# 去除长宽比差异较大的区域 以及 面积过大的区域if w/h > 3 or w/h < 1/3 or h*w > (cropped_image.shape[0]*cropped_image.shape[1]*0.8):continuecv2.rectangle(cropped_image, (x, y), (x + w, y + h), (0 ,0 ,255), 1)cv2.namedWindow('MSER Regions', cv2.WINDOW_NORMAL)
cv2.imshow('MSER Regions', cropped_image)
cv2.waitKey(0)
结果
大部分的字符都得到了比较好的检测结果,但是依旧存在一些问题,如·漏检、误检等

- 为了应用于更加一般的车牌识别(假设已经抠出了车牌所在的区域),可以使用以下代码,当然如果结合更多的一些先验条件和判断方法,将会得到更好的检测效果。👀
import cv2
image = cv2.imread('car_plate_rec\car_3001.jpg')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
height,width = gray.shape[0],gray.shape[1]
area = height * width # 计算图像面积,用于后续的判断mser = cv2.MSER_create()
regions, _ = mser.detectRegions(gray)# 定义函数,用于筛选多余框
def judge_box(w,h):if w * h > (area / 7): # 车牌一共有7个字符,因此可以根据面积过滤掉一些大的区域return Falseif w > width/7 or h > 0.95*height or h < (height/4): # 太窄和太宽的区域可以过滤掉return Falseelse :return Trueli : list = [cv2.boundingRect(regions[0])]
max_H : int = 0 # 所有检测框中最高的框的高度,然后按照这个长度去裁剪单个字符所在的区域def is_effect(li:list,x,y,w,h): # 对于部分重叠的框,只保留靠最左上角的框n = 1for i in li:if abs(x - i[0]) >= 13:continueelif abs(x - i[0]) <= 7: n = 0if x > i[0]:li[li.index(i)] = (x,y,w,h)if n == 1 :li.append((x,y,w,h))for region in regions:x, y, w, h = cv2.boundingRect(region)if judge_box(w,h):is_effect(li,x,y,w,h)if h > max_H:max_H = h# 去掉重复框
li = list(set(li)) for region in li:x, y, w, h = regionif judge_box(w,h):print("x,y,w,h:",x,y,w,h)cv2.rectangle(image, (x, y), (x + w, y + max_H), (0, 255, 0), 1)# 显示结果
cv2.namedWindow('MSER Regions', cv2.WINDOW_NORMAL)
cv2.imshow('MSER Regions', image)
cv2.waitKey(0)




2、基于笔画宽度变换(Stroke Width Transform,SWT)的场景文字检测
- 基本原理:利用笔画宽度,也就是平行字符边缘的点对之间的距离,来区分文本和非文本的区域。在一般的文本图像中,由于字符的笔画宽度值比较稳定,而非字符笔画宽度值变化程度较大,据此就可以将文本区域和非文本区域进行区分。
- 主要步骤:参考文章:基于残差网络及笔画宽度变换的场景文本检测
- 首先使用
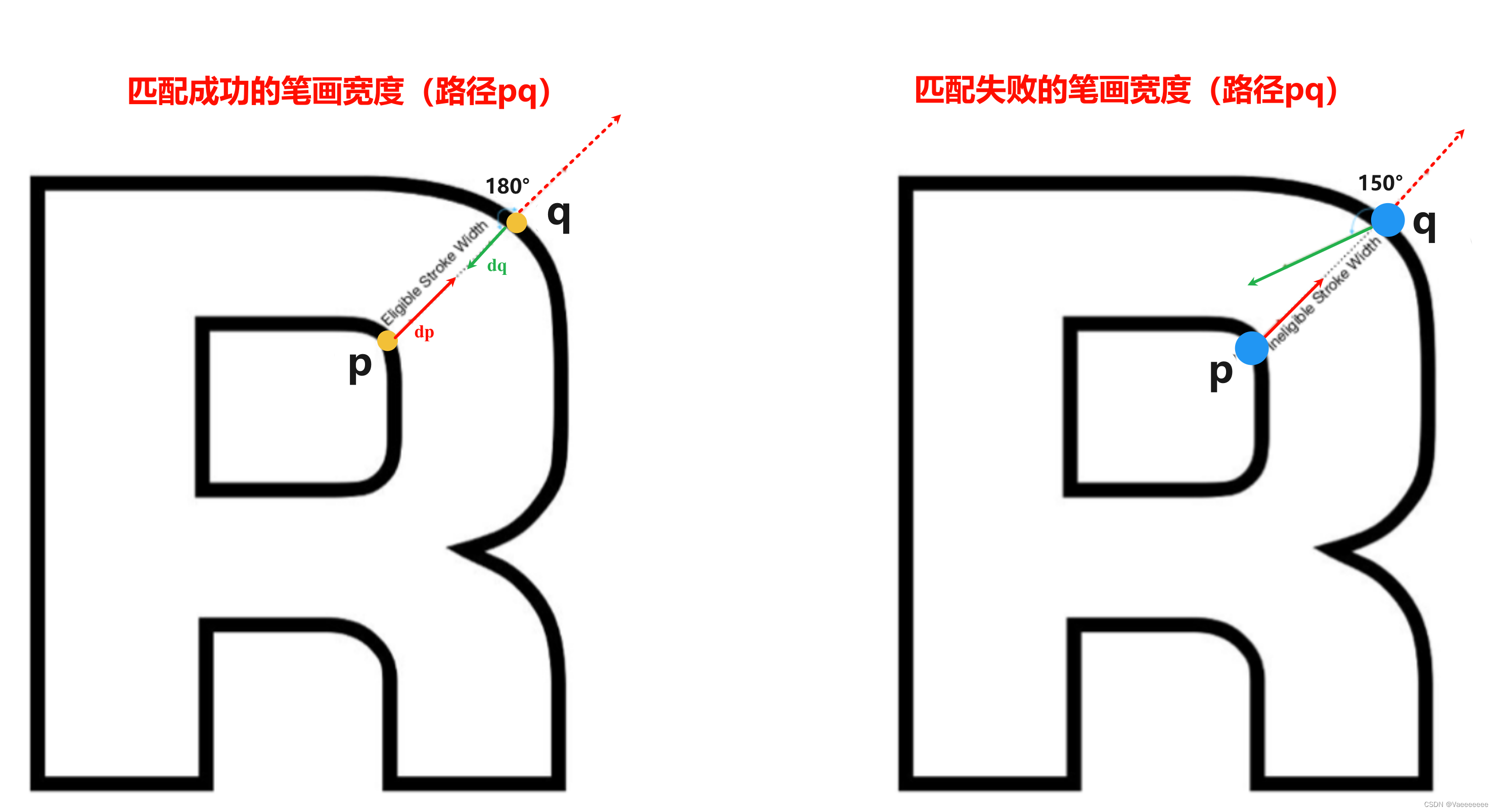
Canny算子对图像进行边缘检测,得到每个边缘像素点 p p p ;然后使用Sobel算子获取每个边缘像素点的梯度值 d p d_{p} dp。 - 对于像素点 p p p,根据梯度方向 d p d_{p} dp 沿着路径 r = p + n ∗ d p ( n ≥ 0 ) r=p+n*d_{p}(n\geq0) r=p+n∗dp(n≥0)寻找对应边缘上的一个像素点 q q q,其梯度方向为 d q d_{q} dq。
- 若 d p d_{p} dp 与 d q d_{q} dq 方向相反,即满足 d q = − d p ± π 6 ( π 6 是可接受的角度偏差,也自设定其他的角度 ) d_{q}=-d_{p}±\frac{\pi}{6}(\frac{\pi}{6}是可接受的角度偏差,也自设定其他的角度) dq=−dp±6π(6π是可接受的角度偏差,也自设定其他的角度),则匹配成功, [ p , q ] [p,q] [p,q]路径上的所有像素点标记其笔画宽度值为 p p p与 q q q间的距离 ∣ ∣ p − q → ∣ ∣ ||\overrightarrow{p-q}|| ∣∣p−q∣∣;若不满足条件,则废弃此路径。如下图所示,左边字符中的路径 p q pq pq 属于匹配成功,右边字符中的路径 p q pq pq 就属于匹配失败,废弃掉该路径。
- 重读步骤2,3,直至标记该图像上所有没被废弃掉的路径上像素的笔画宽度值。若有像素点被多次赋值,则保留最小值。
- 矫正拐点。计算每一条路径上的像素的笔画宽度的中值,若该路径上像素点的笔画宽度值大于中值,则对该像素点赋值为该路径上笔画宽度的中值。
- 由于存在亮底暗字背景和暗底亮字背景两种情况,从梯度相反方向重复 步骤2 至 步骤5 进行二次搜索。
- 若8邻域内像素与中心像素的笔画宽度之比在 [ 1 / 3 , 3 ] [1/3,3] [1/3,3]内,则聚合成连通域。计算每个有效连通域的笔画宽度的均值和方差,滤除方差大于阈值的连通域。
- 首先使用
- 因为源码是使用
C++写的,所以想自己动手使用 p y t h o n python python实现这个算法,可惜能力不够,费了很长时间也没有预期效果。😫不过发现已经有大佬在 22 22 22 年直接将该算法集成到 p y t h o n python python单独的一个库了:SWTloc,不过目前网上基本没有对这个库的详细介绍,所以干脆详细了解一下这个库,以此来快速实现一下 S W T SWT SWT算法。
SWTloc库
✔安装库:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple swtloc
-
SWTLocalizer类充当对图像执行转换的入口点,是一个初始化方法。它可以接受- 单图像路径
- 多个图像路径
- 单个预加载图像
- 多个预加载图像
-
SWTImage.transformImage:笔画宽度变换
| 输入参数 | 参数说明 |
|---|---|
| text_mode | 文本模式参数: { d b _ l f : 深色背景上的浅色文本 l b _ d f : 浅色背景上的深色文本 \begin{cases}db\_lf:深色背景上的浅色文本\\lb\_df:浅色背景上的深色文本 \end{cases} {db_lf:深色背景上的浅色文本lb_df:浅色背景上的深色文本 |
| engine | 引擎参数: { “ n u m b a ” : 默认参数 “ p y t h o n ” \begin{cases}“numba”:默认参数\\“python” \end{cases} {“numba”:默认参数“python” |
| gaussian_blurr | 是否应用高斯模糊器,default = True |
| gaussian_blurr_kernel | 高斯模糊的核大小 |
| edge_function | 边缘函数: { ′ a c ′ : 默认值。 A u t o − C a n n y 函数 , 一个内置函数 , 生成 C a n n y 图像 自定义函数 \begin{cases}'ac':默认值。Auto-Canny函数,一个内置函数,生成 Canny 图像\\自定义函数 \end{cases} {′ac′:默认值。Auto−Canny函数,一个内置函数,生成Canny图像自定义函数 |
| auto_canny_sigma | A u t o − C a n n y Auto -Canny Auto−Canny函数的 S i g m a Sigma Sigma值,default=0.33 |
| minimum_stroke_width | 最小允许行程长度参数 [默认 = 3];在寻找从图像中任何边坐标发出的合格描边时,此参数控制最小描边长度,低于该描边将被取消资格。 |
| maximum_stroke_width | 最大允许行程长度参数 [默认 = 200];在寻找从图像中任何边坐标发出的合格描边时,此参数控制了描边将被取消资格的最大描边长度。 |
| check_angle_deviation | 是否检查角度偏差 [default = True] |
| maximum_angle_deviation | 入射边缘点梯度矢量中可接受的角度偏差[default = np.pi/6] |
| display | 控制是否显示该特定阶段的进程 |
运行后得到4幅图像:原始图像、灰度图像、边缘图像和SWT变换图像
看一下具体效果:
import swtloc as swt
imgpath1 = 'car.png'
imgpath2 = 'car1.png'swtl = swt.SWTLocalizer(image_paths=[imgpath1, imgpath2]) # Initializing the SWTLocalizer class with the image path
swtImgObj = swtl.swtimages # Accessing the SWTImage Object which is housing this image
swtimg0 = swtImgObj[1]
swt_mat = swtimg0.transformImage(text_mode='db_lf', maximum_stroke_width=40)

SWTImage.localizeLetters:根据相关参数定位字符。
| 输入参数 | 参数说明 |
|---|---|
| minimum_pixels_per_cc | 区域中的最小像素数,低于该值的区域被视为非字符区域 |
| maximum_pixels_per_cc | 区域中的最大像素数,高于该值的区域被视为非字符区域 |
| acceptable_aspect_ratio | 纵横比(宽度/高度)小于的所有连接组件都将被修剪 |
| localize_by | 可以为此函数提供三个可能的参数 { m i n _ b b o x :最小边界框边界计算和标注 e x t _ b b o x :极端边界框边界计算和标注 o u t l i n e :轮廓(等高线)边界计算和标注 \begin{cases}min\_bbox : 最小边界框边界计算和标注\\ext\_bbox : 极端边界框边界计算和标注\\outline:轮廓(等高线)边界计算和标注 \end{cases} ⎩ ⎨ ⎧min_bbox:最小边界框边界计算和标注ext_bbox:极端边界框边界计算和标注outline:轮廓(等高线)边界计算和标注 |
| padding_pct | 在标注过程中,有时标注会紧密地贴合在组件本身上,这会导致计算出的边界被扩大。该参数仅适用于和定位。 |
比较关键的就是前三个参数,下面通过设置前三个参数看一下具体检测字符的效果:
import swtloc as swt
imgpath1 = 'car.png'
imgpath2 = 'car1.png'swtl = swt.SWTLocalizer(image_paths=[imgpath1, imgpath2]) # Initializing the SWTLocalizer class with the image path
swtImgObj = swtl.swtimages # Accessing the SWTImage Object which is housing this image
swtimg0 = swtImgObj[1]
swt_mat = swtimg0.transformImage(text_mode='db_lf', maximum_stroke_width=40)
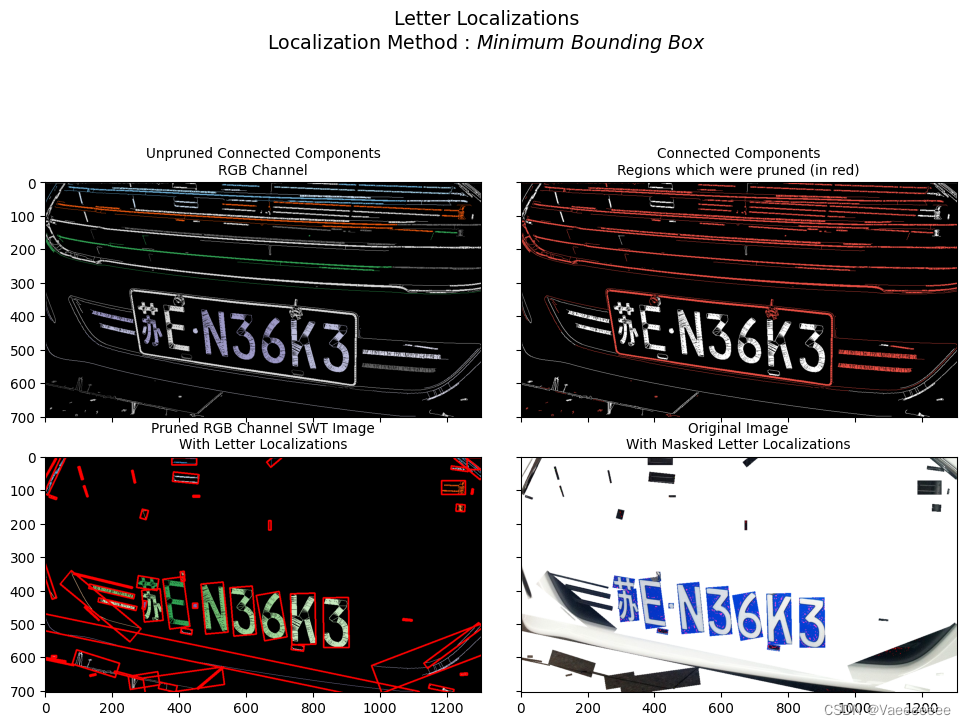
local = swtimg0.localizeLetters()
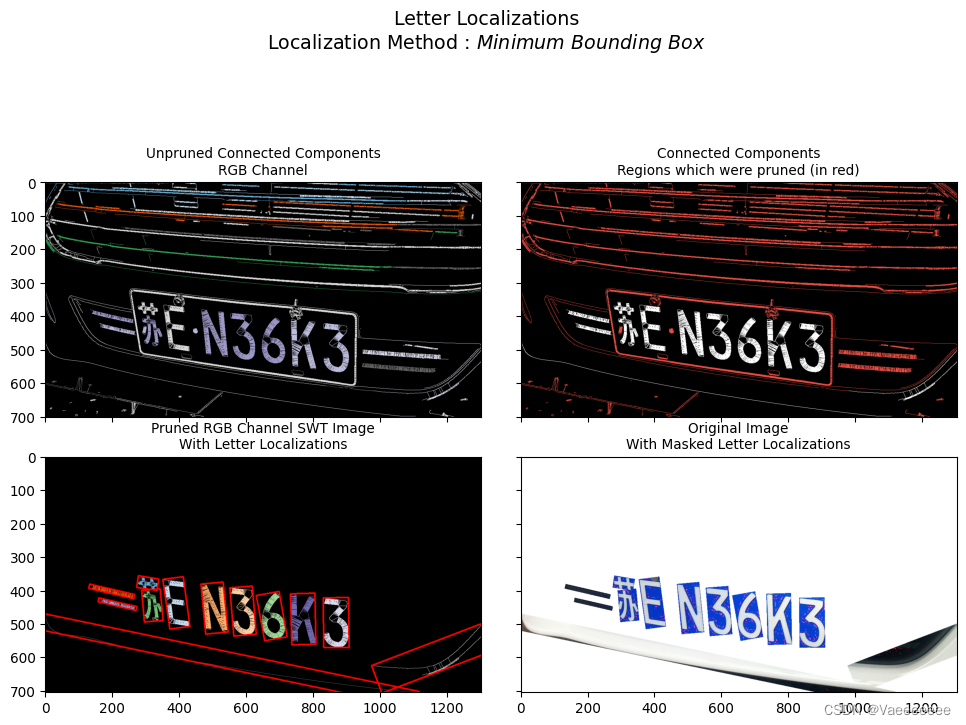
local = swtimg0.localizeLetters(minimum_pixels_per_cc=800)
local = swtimg0.localizeLetters(minimum_pixels_per_cc=800,maximum_pixels_per_cc=5000)
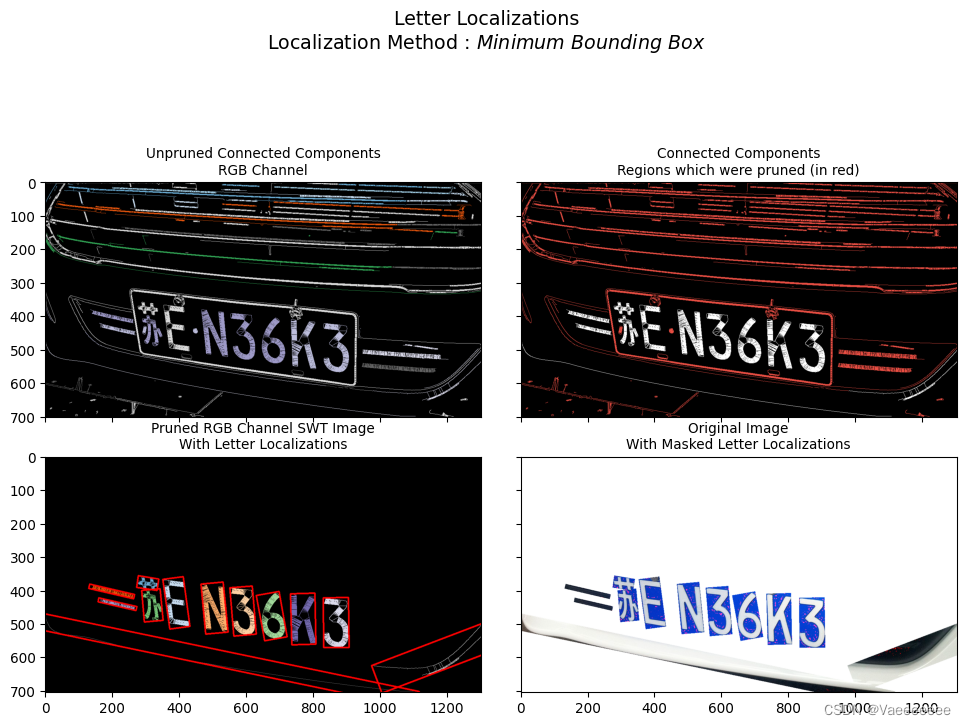
local = swtimg0.localizeLetters(minimum_pixels_per_cc=800,maximum_pixels_per_cc=5000,acceptable_aspect_ratio=0.5)
- 还有其他的一些高级用法, 这里不过多介绍,有需要的可以直接看官方文档 → \xrightarrow{} 📌swtloc
代码实现
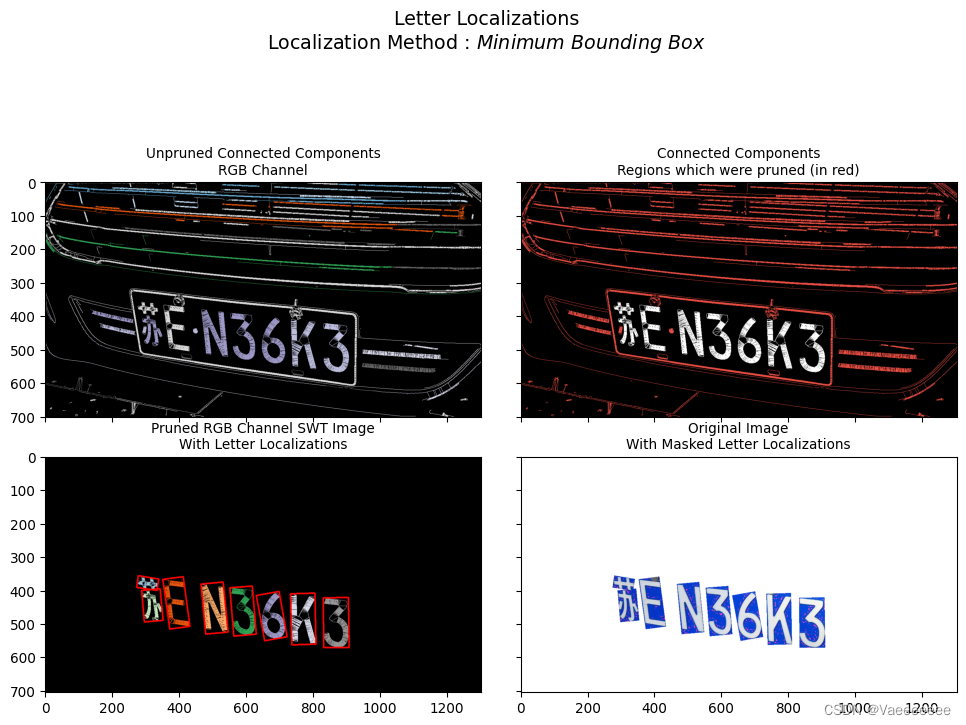
- 👀 看看在车牌数据集上的大致效果:也基本很快速的得到了较好的效果。不过两幅图中都绘制了一个异常的较大的矩形框,可以加上前面
MSER算法中对矩形框做些筛选处理的代码即可滤除掉。
# 针对car_plate_rec这个车牌数据集
import swtloc as swt
import cv2imgpath = 'car_plate_rec/car_1901.jpg'swtl = swt.SWTLocalizer(image_paths=imgpath) # Initializing the SWTLocalizer class with the image path
swtImgObj = swtl.swtimages # Accessing the SWTImage Object which is housing this image
swtimg0 = swtImgObj[0]swt_mat = swtimg0.transformImage(text_mode='db_lf', maximum_stroke_width=40) # SWT算法
local = swtimg0.localizeLetters(minimum_pixels_per_cc=100,maximum_pixels_per_cc=2000,acceptable_aspect_ratio = 0.1,localize_by='ext_bbox') #检测单个字段区域li = [] # 存储绘制的矩形框
for i in local.values():li.append(i.ext_bbox)def draw_rect(image, li):for region in li:cv2.polylines(image, [region], isClosed=True, color=(0, 255, 0), thickness=1)img = cv2.imread(imgpath)
draw_rect(img,li)
cv2.namedWindow('img', cv2.WINDOW_NORMAL)
cv2.imshow('img',img)
cv2.waitKey(0)

总结
使用python简单实现了基于最大稳定极值区域( M S E R MSER MSER)的 和基于笔画宽度变换( S W T SWT SWT)的文字检测方法,希望对不太了解该算法的伙伴们有所帮助。👍👍👍
相关文章:

传统文字检测方法+代码实现
文章目录 前言传统文字检测方法1、基于最大稳定极值区域(MSER)的文字检测1.1 MSER(MSER-Maximally Stable Extremal Regions)基本原理代码实现——使用Opencv中的cv2.MSER_create()接口 2、基于笔画宽度变换(Stroke Wi…...

Jmeter从数据为查找结果集数据方法随笔
一、Jmeter连接数据库 1.下载对应数据库的驱动包到jmeter安装目录的lib下ext文件中,并导入到jmeter的测试计划中,本实例中使用的是mysql如下所示: 点击测试计划–>点击浏览–>选中mysql驱动jar包–>打开 2.添加线程组,…...

Objective-C网络请求开发的高效实现方法与技巧
前言 在移动应用开发中,网络请求是一项至关重要的技术。Objective-C作为iOS平台的主要开发语言之一,拥有丰富的网络请求开发工具和技术。本文将介绍如何利用Objective-C语言实现高效的网络请求,以及一些实用的技巧和方法。 1.Objective-C技…...

Java:OOP之术语或概念
■■ 编程和程序设计 ■□ 程序员和编程■ 程序员:programmer■ 编程:program, programming■ 面向过程:Process oriented■ 面向对象:object-oriented● 面向对象分析:OOA,全称Object-oriented Analysis●…...
内存地产风云录:malloc、free、calloc、realloc演绎动态内存世界的楼盘开发与交易大戏
欢迎来到白刘的领域 Miracle_86.-CSDN博客 系列专栏 C语言知识 先赞后看,已成习惯 创作不易,多多支持! 在这个波澜壮阔的内存地产世界中,malloc、free、calloc和realloc四位主角,共同演绎着一场场精彩绝伦的楼盘开…...
个人博客项目笔记_05
1. ThreadLocal内存泄漏 ThreadLocal 内存泄漏是指由于没有及时清理 ThreadLocal 实例所存储的数据,导致这些数据在线程池或长时间运行的应用中累积过多,最终导致内存占用过高的情况。 内存泄漏通常发生在以下情况下: 线程池场景下的 ThreadL…...
)
基础知识点全覆盖(1)
Python基础知识点 1.基本语句 1.注释 方便阅读和调试代码注释的方法有行注释和块注释 1.行注释 行注释以 **# **开头 # 这是单行注释2.块注释 块注释以多个 #、三单引号或三双引号(注意: 基于英文输入状态下的标点符号) # 类 # 似 # 于 # 多 # 行 # 效 # 果 这就是多行注释…...

异常处理java
在Java中,异常处理可以使用"throws"关键字或者"try-catch"语句。这两种方法有不同的用途和适用场景。 "throws"关键字: 在方法声明中使用"throws"关键字,表示该方法可能会抛出异常,但是并不立即处理…...

个人博客项目_09
1. 归档文章列表 1.1 接口说明 接口url:/articles 请求方式:POST 请求参数: 参数名称参数类型说明yearstring年monthstring月 返回数据: {"success": true, "code": 200, "msg": "succ…...
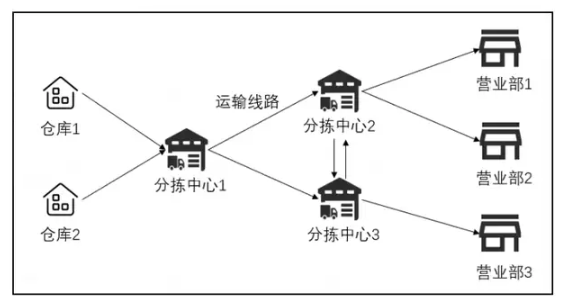
【2024年MathorCup数模竞赛】C题赛题与解题思路
2024年MathorCup数模竞赛C题 题目 物流网络分拣中心货量预测及人员排班背景求解问题 解题思路问题一问题二问题三问题四 本次竞赛的C题是对物流网络分拣中心的货量预测及人员排班问题进行规划。整个问题可以分为两个部分,一是对时间序列进行预测,二是对人…...

蓝桥杯省赛冲刺(3)广度优先搜索
广度优先搜索(Breadth-First Search, BFS)是一种在图或树等非线性数据结构中遍历节点的算法,它从起始节点开始,按层级逐步向外扩展,即先访问离起始节点最近的节点,再访问这些节点的邻居,然后是邻…...

网页内容生成图片,这18般武艺你会几种呢?
前言 关于【SSD系列】: 前端一些有意思的内容,旨在3-10分钟里, 500-1000字,有所获,又不为所累。 网页截图,windows内置了快捷命令和软件,chrome开发者工具也能一键截图,html2canva…...

pytest的时候输出一个F后面跟很多绿色的点解读
使用pytest来测试pyramid和kotti项目,在kotti项目测试的时候,输出一个F后面跟很多绿色的点,是什么意思呢? 原来在使用pytest进行测试时,输出中的“F”代表一个失败的测试(Failed),而…...

算法打卡day33
今日任务: 1)509. 斐波那契数 2)70. 爬楼梯 3)746.使用最小花费爬楼梯 509. 斐波那契数 题目链接:509. 斐波那契数 - 力扣(LeetCode) 斐波那契数,通常用 F(n) 表示,形成…...
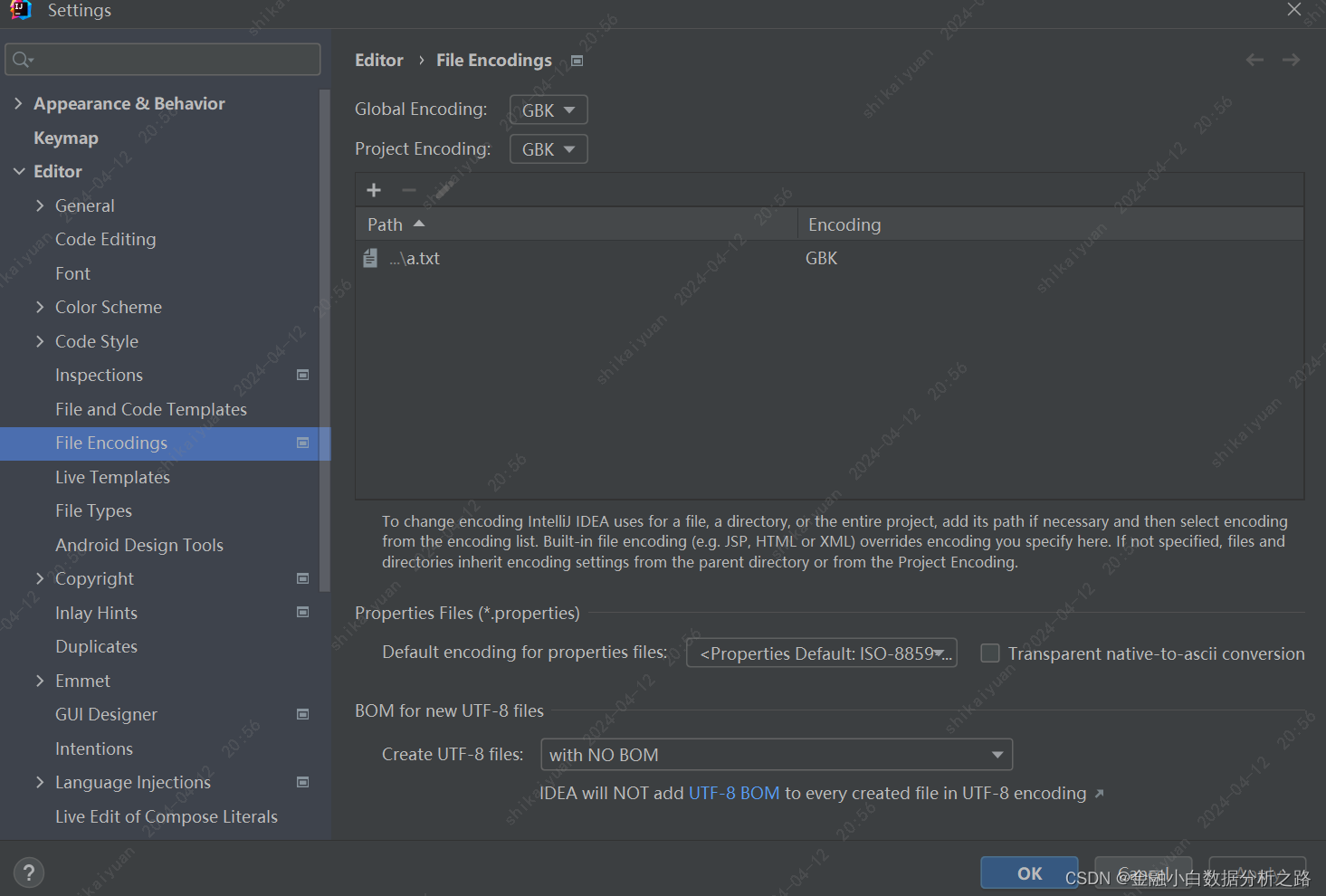
《疯狂java讲义》Java AWT图形化编程中文显示
《疯狂java讲义》第六版第十一章AWT中文没有办法显示问题解决 VM Options设置为-Dfile.encodinggbk 需要增加变量 或者这边直接设置gbk 此外如果用swing 就不会产生这个问题了。...

Python3 标准库,API文档链接
一、标准库 即当你安装python3 后就自己携带的一些已经提供好的工具模块,工具类,可以专门用来某一类相关问题,达到辅助日常工作或者个人想法的一些成品库 类似的 C ,Java 等等也都有自己的标准库和使用文档 常见的一些: os 模块…...
【Web】CTFSHOW-ThinkPHP5-6反序列化刷题记录(全)
目录 web611 web612 web613-622 web623 web624-626 纯记录exp,链子不作赘述 web611 具体分析: ThinkPHP-Vuln/ThinkPHP5/ThinkPHP5.1.X反序列化利用链.md at master Mochazz/ThinkPHP-Vuln GitHub 题目直接给了反序列化入口 exp: <?ph…...

AR智能眼镜方案_MTK平台安卓主板芯片|光学解决方案
AR眼镜作为一种引人注目的创新产品,其芯片、显示屏和光学方案是决定整机成本和性能的关键因素。在这篇文章中,我们将探讨AR眼镜的关键技术,并介绍一种高性能的AR眼镜方案,旨在为用户带来卓越的体验。 AR眼镜的芯片选型至关重要。一…...
Android网络抓包--Charles
一、Android抓包方式 对Https降级进行抓包,降级成Http使用抓包工具对Https进行抓包 二、常用的抓包工具 wireshark:侧重于TCP、UDP传输层,HTTP/HTTPS也能抓包,但不能解密HTTPS报文。比较复杂fiddler:支持HTTP/HTTPS…...
)
【LeetCode热题100】238. 除自身以外数组的乘积(数组)
一.题目要求 给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 **不要使用除法,**且在…...

conda相比python好处
Conda 作为 Python 的环境和包管理工具,相比原生 Python 生态(如 pip 虚拟环境)有许多独特优势,尤其在多项目管理、依赖处理和跨平台兼容性等方面表现更优。以下是 Conda 的核心好处: 一、一站式环境管理:…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

docker详细操作--未完待续
docker介绍 docker官网: Docker:加速容器应用程序开发 harbor官网:Harbor - Harbor 中文 使用docker加速器: Docker镜像极速下载服务 - 毫秒镜像 是什么 Docker 是一种开源的容器化平台,用于将应用程序及其依赖项(如库、运行时环…...
)
进程地址空间(比特课总结)
一、进程地址空间 1. 环境变量 1 )⽤户级环境变量与系统级环境变量 全局属性:环境变量具有全局属性,会被⼦进程继承。例如当bash启动⼦进程时,环 境变量会⾃动传递给⼦进程。 本地变量限制:本地变量只在当前进程(ba…...

【ROS】Nav2源码之nav2_behavior_tree-行为树节点列表
1、行为树节点分类 在 Nav2(Navigation2)的行为树框架中,行为树节点插件按照功能分为 Action(动作节点)、Condition(条件节点)、Control(控制节点) 和 Decorator(装饰节点) 四类。 1.1 动作节点 Action 执行具体的机器人操作或任务,直接与硬件、传感器或外部系统…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

Vue ③-生命周期 || 脚手架
生命周期 思考:什么时候可以发送初始化渲染请求?(越早越好) 什么时候可以开始操作dom?(至少dom得渲染出来) Vue生命周期: 一个Vue实例从 创建 到 销毁 的整个过程。 生命周期四个…...