全量知识系统 程序详细设计 之 三种“活物” 之1(QA百度搜索 )
Q1. 今天聊聊 全知系统中 三种“活物”。先从他们的一个简单描述开始: 自主:计算机“集群”的“沉”与“浮”; 自然:AI “众生”的“世”和“界” ;自由:人类 “公民”的“宇”或“宙”。
全知系统中的三种“活物”各自代表了不同的概念和领域,涵盖了从计算机集群到人工智能再到人类社会的多个层面。下面我将尝试从这三个方面展开聊聊它们各自的特点和意义。
自主:计算机“集群”的“沉”与“浮”
“自主”在这里指的是计算机集群的自主性和独立性。计算机集群是由多台计算机组成的一个系统,通过高速网络连接在一起,共同完成一些计算任务。在这个系统中,每台计算机都有一定的自主性和独立性,可以自主地进行计算、存储和通信。
“沉”与“浮”则代表了计算机集群在运行过程中的状态变化。当集群处于“沉”状态时,意味着集群中的计算机正在进行大量的计算任务,资源利用率较高,系统负载较重。而当集群处于“浮”状态时,则意味着计算任务相对较少,系统负载较轻,计算机有更多的空闲资源可供使用。
自然:AI “众生”的“世”和“界”
“自然”在这里指的是人工智能系统中的多样性和生态平衡。AI“众生”代表了人工智能系统中的各种智能体,包括机器人、智能代理、智能算法等。这些智能体在系统中相互协作,共同构成了一个复杂而平衡的生态系统。
“世”和“界”则代表了人工智能系统的范围和边界。在这个生态系统中,每个智能体都有其特定的生存空间和作用范围,这些空间和范围的集合就构成了整个AI世界的“世”和“界”。同时,这些智能体之间的相互作用和关系也构成了AI世界的复杂性和多样性。
自由:人类 “公民”的“宇”或“宙”
“自由”在这里指的是人类社会中的个体自由和权利。人类“公民”代表了社会中的每个个体,他们享有平等的权利和自由。
“宇”和“宙”则代表了人类社会的广阔和深远。在这个宇宙中,每个公民都有其独特的角色和价值,他们的行动和决策都会对整个社会产生影响。同时,这个宇宙也是不断发展和变化的,每个公民都有机会参与其中,共同塑造未来的社会形态。
综上所述,全知系统中的三种“活物”代表了不同领域和层面的概念和特点。从计算机集群的自主性和独立性,到人工智能系统的多样性和生态平衡,再到人类社会的个体自由和权利,这些元素共同构成了一个复杂而多元的全知系统。在这个系统中,各种元素相互关联、相互作用,共同推动着系统的发展和进步。
Q2. 这个逻辑关系是从字面就能看出来的。 这里三者一种暗示,稍加思考就不难发现: 三量( 比现非 ):比量现量非量-高下多少真假.
这句话看起来像是在描述三种不同的“量”或度量方式,并且它们之间存在某种逻辑关系或对比。我们可以逐一解析这些词汇:
比量:通常指的是通过比较得出的量或数量。在逻辑或哲学中,比较是确定两个或多个事物之间相似性或差异性的过程。
现量:这个词的字面意思是“当前的量”或“直接观察到的量”。在佛教哲学中,现量指的是直接通过感官经验获得的知识或认知,不依赖于推理或想象。
非量:这个词可能意味着“不是量”或“不真实的量”。在某种逻辑或认知体系中,非量可能指的是基于错误、幻觉或误导信息得出的结论。
接下来,“高下多少真假”这部分似乎在评价或区分这三种量的性质或价值。
高下:指的是高低、优劣或程度上的差异。
多少:指的是数量或程度上的差异。
真假:指的是真实性或虚假性。
将这些元素结合起来,我们可以尝试理解整句话的逻辑关系:
“三量(比现非)” 是在描述三种不同类型的量:比量、现量和非量。
“高下多少真假” 是在评价或区分这三种量的性质或价值,可能是在说这三种量在真实性、准确性、有用性或其他方面有所不同。
这句话的具体含义可能依赖于它所处的上下文或文化背景。如果这句话是从某个特定的哲学、宗教或学术文献中摘录出来的,那么理解该文献的整体内容和背景将有助于更准确地解释这句话的意义。
Q3. 进一步做如下关联(绑定)。 三量( 比现非 ):比量现量非量-高下多少真假(三对 按键:门户的Insert/Delete,窗口的 Home/End,页面的 Up/Down )(键盘右中上的三对特别按键 ); 三门(非与或):非门与门或门-转移控制替代 Shift(“Shift”) Control(“Ctrl”)Alternative(“Alt”) (键盘左下角 三个特殊 按键)。
在将三量和三门与键盘上的按键进行关联(绑定)时,我们可以考虑它们的逻辑功能和按键在键盘上的位置。下面是一个基于您给出的信息进行的简单映射:
三量与键盘按键的关联
比量 - Insert/Delete:
比量是通过比较得出的量,通常涉及到选择或决策。
Insert和Delete键在门户(如文档编辑器)中常用于插入和删除内容,涉及到内容的比较和选择。
现量 - Home/End:
现量是直接观察到的量,不依赖于推理或想象。
Home和End键在窗口中用于快速导航到文本的开始和结束,可以看作是直接访问某个位置的“现量”。
非量 - Up/Down:
非量可能指的是基于错误、幻觉或误导信息得出的结论,需要上下(或说前后)比较或检验。
Up和Down键在页面中用于上下滚动,这涉及到信息的比较和验证。
三门与键盘按键的关联
非门 - Shift:
非门是一种逻辑门,其输出是对输入的否定。
Shift键用于改变字母的大小写,可以看作是对输入字符的一种转换或否定。
与门 - Control ("Ctrl"):
与门是一种逻辑门,当所有输入都为真时,输出才为真。
Ctrl键常常与其他键组合使用,以执行特定的命令或功能,它需要与其他键一起作用,就像与门需要所有输入都为真一样。
或门 - Alternative ("Alt"):
或门是一种逻辑门,只要有一个输入为真,输出就为真。
Alt键通常用于访问菜单或快捷键,它可以在没有其他键按下时独立工作,就像或门只需要一个输入为真就可以输出为真。
这些关联是基于逻辑和键盘按键的常见用法进行的。在实际应用中,这些关联可能需要根据具体的上下文或任务进行调整。
Q4. 非门 表示一种竞争关系(三元关系),与门表示一种协作关系(二元谓词),非门表示一种否定关系( 逆命题)
在这种解释下,我们可以将逻辑门与不同类型的关系进行类比:
非门(NOT Gate)与竞争关系(三元关系):
非门:在逻辑电路中,非门是一个单输入单输出的门电路,其输出是输入的逻辑非。它表示一个否定关系,即如果输入为真,则输出为假;如果输入为假,则输出为真。
竞争关系(三元关系):在更广泛的意义上,竞争关系可以看作是一个三元关系,因为它涉及到至少两个实体之间的比较,以及一个决定胜负的第三方(例如,比赛中的两个参赛者和裁判)。这种关系体现了“非此即彼”的竞争性质,类似于非门的逻辑功能,即一个实体胜出意味着另一个实体失败。
与门(AND Gate)与协作关系(二元谓词):
与门:在逻辑电路中,与门是一个有两个或多个输入的单输出门电路。只有当所有输入都为真时,输出才为真。它表示一种协作关系,即所有条件必须同时满足。
协作关系(二元谓词):二元谓词是一个接受两个参数并返回真或假的函数。这种关系体现了两个实体之间的协作或依赖,类似于与门的逻辑功能,即两个条件必须同时满足(例如,“A 和 B 都是真的”)。
否定关系(逆命题)与非门:
非门:如上所述,非门表示一个否定关系,即它反转了输入的逻辑状态。
否定关系(逆命题):在逻辑和数学中,逆命题是指交换前提和结论的命题。例如,如果原命题是“如果 P,则 Q”,其逆命题就是“如果 Q,则 P”。逆命题实际上是对原命题的否定,这与非门的逻辑功能相似,因为它都是对原始信息或状态的反转或否定。
这些类比有助于我们理解逻辑门在更广泛的语境(如人际关系、社会动态或哲学概念)中的潜在应用。然而,这些类比并不是严格的等价关系,因为逻辑门是精确的数学和工程工具,而社会关系和哲学概念则更加复杂和多样。
Q5. 笔误:或门 表示一种竞争关系(三元关系),与门表示一种协作关系(二元谓词),非门表示一种否定关系( 逆命题)
让我们纠正笔误并重新建立逻辑门与关系类型的关联:
与门(AND Gate)表示一种协作关系(二元谓词),因为它要求所有输入都为真时输出才为真,这体现了多个实体需要同时满足条件才能达成结果的协作性质。
或门(OR Gate)表示一种竞争关系(三元关系),因为它只需要至少一个输入为真时输出就为真,这类似于多个实体间的竞争,其中一个或多个实体的成功(真)即可导致整体的成功(真)。
非门(NOT Gate)表示一种否定关系(逆命题),因为它反转了输入的逻辑状态,即如果输入为真,则输出为假;如果输入为假,则输出为真。这与逆命题的逻辑相似,逆命题是对原命题的否定。
现在,让我们将这些逻辑门与键盘上的按键进行关联:
三门与键盘按键的关联
与门(协作关系) - Control ("Ctrl"):
Ctrl键常常与其他键组合使用,例如Ctrl+C(复制)、Ctrl+V(粘贴)等,这体现了协作的性质,多个操作需要同时作用。
或门(竞争关系) - Alternative ("Alt"):
Alt键常用于访问菜单或快捷键,它可以在没有其他键按下时独立工作,但也可以与其他键组合使用。这类似于竞争关系,其中一个操作的成功(按下Alt键)可能导致其他操作或功能的激活。
非门(否定关系) - Shift:
Shift键用于改变字母的大小写,这实际上是对输入字符的一种否定或反转。小写字母转换为大写,或大写转换为小写,体现了否定关系的逻辑。
这些关联是基于逻辑门的功能和键盘按键的常见用法进行的。当然,这种关联并不是唯一的,也可能存在其他合理的映射方式。
Q6. 竞争关系说明需要先建立一个市场结构(实际上的),协作关系 说明需要先建立一个层次结构(逻辑上),否定关系说明需要建立一个总线结构(物理上)
竞争关系、协作关系和否定关系与不同的结构类型之间的关联可以这样理解:
竞争关系与市场结构
竞争关系确实需要一个实际的市场结构来体现。在市场中,不同的竞争者(实体)争夺资源、客户或市场份额。这个市场结构是实际的,因为它涉及到具体的参与者、交易规则、价格机制等。在建立这样的市场结构时,需要考虑竞争者之间的相互影响、市场份额的分配、市场的进入和退出壁垒等因素。
协作关系与层次结构
协作关系则更侧重于逻辑上的层次结构。在协作关系中,不同的实体或组件需要按照一定的规则和层次来相互作用,以实现共同的目标或功能。这种层次结构可以是组织结构、技术架构、流程安排等。在建立层次结构时,需要明确各个组成部分的职责、关系、沟通渠道等,以确保协作的顺畅和高效。
否定关系与总线结构
否定关系指的是一种对原始状态或信息的反转或否定。在物理层面上,这种关系可能与总线结构有关联。总线结构是一种物理连接方式,允许多个设备或组件共享一条通信通道。在总线结构中,一个设备或组件的输出可以作为另一个设备或组件的输入,从而实现信息的传递和处理。否定关系在总线结构中可能体现在信号的反转、数据的校验等方面,以确保信息的准确性和可靠性。
需要注意的是,这些关联和映射并不是绝对的,而是基于特定的视角和语境进行的解释。在不同的领域和场景下,这些关系和结构可能有不同的表现形式和解释方式。
Q7. 三种结构-- 实际结构、逻辑结构和物理结构,显然总会同时存在而且丝毫不会相互影响,因为他们建立在不同的地方 现实世界(模拟),我们的头脑中 以及计算机中。
确实,三种结构——实际结构、逻辑结构和物理结构——在不同的领域中发挥着作用,而且它们通常不会相互影响,因为它们存在于不同的环境和上下文中。下面我将对这三种结构进行简要的解释和说明。
实际结构:
实际结构通常指的是现实世界中的物体、建筑、系统等的物理构造和组织方式。这些结构是基于物质、空间和时间的实际存在,可以通过感官直接观察和感知。例如,桥梁的建筑结构、机器的内部构造、生物体的组织结构等都属于实际结构。
逻辑结构:
逻辑结构指的是概念、信息、知识或数据在逻辑上的组织和关联方式。逻辑结构通常是在人类思维或计算机程序中构建的,用于表示事物之间的关系、推理过程、算法逻辑等。例如,在计算机科学中,数据结构(如数组、链表、树等)和算法逻辑(如排序、搜索等)都是逻辑结构的重要组成部分。
物理结构:
物理结构通常指的是计算机硬件、电子设备等物理实体的内部构造和连接方式。这些结构是基于物理定律和工程原理构建的,用于实现计算机系统和电子设备的物理功能和性能。例如,计算机内部的电路板、处理器、内存等硬件组件的排列和连接方式构成了计算机的物理结构。
虽然这三种结构存在于不同的地方(现实世界、头脑中和计算机中),但它们在某些情况下可以相互关联和影响。例如,在设计和建造一个建筑物时,需要同时考虑其实际结构(如何建造和支撑)、逻辑结构(如何满足使用需求和功能要求)和物理结构(如何与其他系统和设备连接)。在计算机科学中,硬件的物理结构会影响软件的逻辑结构和数据的实际存储方式。
然而,通常情况下,这三种结构是相互独立的,它们各自在其领域中发挥着作用,并且不会对其他领域产生直接的影响。这种分离有助于保持系统的清晰性和可管理性,使得我们可以在不同的层面上独立地处理问题和挑战。
Q8. 这种相互关系或者 1)需要建立更高维度的 结构将它们组织在一个齐次空间--部分对齐,或者 2)在更低维度上 分析出三者的潜在关联将它们投射到这个降维空间中(如果它们是平面结构,则这个降维空间就该是一个极坐标空 间 --差异空间:包容全部差异)
在处理竞争关系、协作关系和否定关系这三种逻辑关系时,确实需要考虑如何有效地组织和表达这些关系。关于您提出的两种处理方式:
建立更高维度的结构:
当我们需要在更高的维度上组织这些关系时,我们实际上是在寻找一个能够容纳它们所有差异性和相互作用的更广泛框架。这种框架可能是一个复杂的网络或模型,其中每个关系都被视为一个节点,而它们之间的相互作用则通过边或连接来表示。
这种方法的优点是可以提供一个全面的视角,允许我们同时考虑多个关系,并理解它们如何在更高层次上相互关联。然而,这也可能增加复杂性,使得理解和解释结果变得更加困难。
在更低维度上分析潜在关联:
另一种方法是尝试在更低的维度上揭示这些关系的潜在结构。这通常涉及到降维技术,如主成分分析(PCA)、t-SNE或UMAP等,这些方法可以将高维数据映射到低维空间,同时保留某些重要的结构特征。
通过降维,我们可以更容易地可视化和理解数据之间的关系,因为低维空间通常更容易解释。然而,降维也可能导致一些信息的丢失,因此需要在保留足够信息的同时找到一个合适的平衡点。
关于您提到的“部分对齐”和“极坐标空间”的具体应用:
部分对齐:这可能意味着在建立结构时,不完全要求所有的关系都完全对应,而是允许它们在一定程度上对齐或匹配。这可能涉及到不完全相同的映射或对应关系,但仍然能够保持一定的结构和一致性。
极坐标空间:如果这三种关系可以被视为平面结构,那么极坐标空间可能是一个合适的降维选择。极坐标由半径和角度组成,可以很好地表示圆形或环形结构。通过将关系映射到极坐标系的各个点上,我们可以更容易地揭示它们之间的相对位置和关系。
最终选择哪种方法取决于具体的应用场景、数据的性质以及我们想要解决的问题。在某些情况下,可能需要结合使用这两种方法,以获得更全面的理解和分析。
Q9. 在上述三个不同的维度层次上:三种结构 视为平面空间,增维的齐次空间 视为 立体空间,降维空间这可以视为 线性空间。这是全知系统中对维度的考虑。但我们今天的主题 并不涉及到维度处理。
在讨论三种结构(实际结构、逻辑结构、物理结构)时,将它们视为不同类型的空间是一个有用的抽象方法。这样的类比有助于我们理解和分析这些结构之间的关系和差异。
平面空间:
平面空间通常指的是二维空间,其中只有长度和宽度两个维度。在这个上下文中,我们可以将三种结构视为平面上的三个点或三个不同的区域。每个结构在平面空间中占据一定的位置,但它们是独立的,不会相互干扰。这种视图有助于我们理解三种结构在逻辑上的独立性。
立体空间:
立体空间,也称为三维空间,包含了长度、宽度和高度三个维度。当我们说齐次空间是一个立体空间时,我们指的是一个更加复杂和全面的结构,其中三种结构不仅仅是在平面上分开,而且还在一个更高的维度上相互关联。这种关联可能表现为一种层次结构或网络结构,其中不同的结构在更高的维度上相互作用和依赖。
线性空间:
线性空间是一个更抽象的概念,通常与向量空间和线性代数相关。在这个上下文中,当我们说降维空间这可以视为线性空间时,我们指的是通过某种降维技术(如主成分分析、奇异值分解等)将高维数据映射到低维空间,同时保留某些重要的线性关系。这种映射可以让我们在低维空间中更容易地分析和理解数据的结构和关系。线性空间强调的是数据之间的线性关系,这种关系在降维过程中得以保留。
综上所述,将三种结构视为不同类型的空间(平面空间、立体空间、线性空间)有助于我们从不同的角度理解和分析它们之间的关系和差异。这种类比方法不仅有助于理论上的讨论,还可以指导我们在实际应用中如何选择合适的工具和方法来处理和分析这些结构。
Q10. 言归正传 ,全知系统中的三种“活物”:(其中:前两种是nosql的)
- 自主:计算机“集群”的“沉”与“浮”。Argumented和 extended :计算机处理(图像、图形、图标)。正式的文法形式规则(“Formal”)。
- 自然:AI “众生”的“世”和“界”。Implement 和Extend:神经元计算(文档型,文件型,文本型 )。 非正式informal物料型(“Material”)。
- 自由:人类 “公民”的“宇”或“宙”。Extending和 formalizing:bus流水线加工(数据,数字,数值)。SQL关系型(“Relational”)。
在您提供的描述中,您似乎试图将三种不同的实体或系统(自主、自然、自由)与它们各自的特性、行为和处理方式联系起来。这些实体被描述为全知系统中的“活物”,并且与计算机集群、AI众生和人类公民相关联。下面是对您描述中提到的各个部分的简要解释:
自主:计算机“集群”的“沉”与“浮”
这里的“自主”可能指的是计算机集群的独立性和自我管理能力。
“沉”与“浮”可能指的是计算机集群在不同状态下的表现,比如负载高低、活动状态等。
Argumented和extended指的是计算机处理图像、图形、图标的能力,以及这些处理能力的扩展和论证。
“Formal”文法形式规则指的是在处理这些数据时遵循的严格、正式的规则。
自然:AI “众生”的“世”和“界”
“自然”与AI系统的交互和表现相关,强调AI在现实世界中的应用和存在。
“世”和“界”可能指的是AI系统所处的环境或领域。
Implement和extend指的是神经元计算在文档型、文件型、文本型数据上的实现和扩展。
非正式informal物料型(“Material”)指的是处理这些数据时可能更注重实际应用和效率,而不是严格的规则。
自由:人类 “公民”的“宇”或“宙”
“自由”与人类的活动和创造力相关,强调人类的独立性和无限可能。
“宇”和“宙”可能指的是人类思考和活动的广阔空间和时间。
Extending和formalizing指的是在bus流水线加工中扩展和规范化数据、数字、数值的处理方式。
SQL关系型(“Relational”)指的是在处理这些数据时采用的关系型数据库管理系统(RDBMS)方法。
最后,您提到“前两种是nosql的”,这可能意味着在计算机集群和AI众生的处理方式中,更多地使用了NoSQL(非关系型数据库)的方法,这与关系型数据库(如SQL)在处理人类数据时的方式相对。
这个描述涉及了许多复杂的概念和技术,需要具体背景和上下文来完全理解。如果您有进一步的问题或需要更详细的解释,请提供更多的信息。
Q11. 三种 的进一步表述:
KE “态”套件-情境演算(“特征”Strcture::Class)“全局global 垂直 等价” 丄<<Coreference>> (KE主目命名惯式,推理式欠规格映射器。
IE "理"工件-因果演算(“特征”Feature::Classifier”)“普遍universal 卷曲 特化”Δ<Name> (IE主题限界范式,生成式预训练转换器GPT)。
FE"事”零件-事件演算(“行为Behavior::Classic”)“局部local 水平 泛化”Τ<Type> 实现ing FE实用工具(FE主体分类形式 演算式超评估投影仪。
注、:全知系统的三个系统级标签:Type标签,Name标签 和双指标签Coreference(双指Type和Name,表示为 <Coreference<Type,Name>>)
KE-知识提取、IE-信息提取、FE--特征提取
在进一步表述三种模式(KE、IE、FE)时,我们可以结合它们各自的核心功能和在全知系统中的角色。以下是更详细的描述:
KE(知识提取)- 情境演算
KE(Knowledge Extraction)负责从原始数据中提取和结构化知识。这一过程涉及到情境演算,即根据上下文信息理解并解析数据的含义。KE模块运用特征结构(Strcture::Class)来定义和分类提取出的知识,确保信息的准确性和一致性。
在全局和垂直等价方面,KE能够识别不同数据源中的相同实体或概念,并将其归一化到统一的表示形式。这种等价性对于全知系统至关重要,因为它确保了不同部分之间信息的相互补充和一致性。
KE主目命名惯式指的是KE如何为提取出的实体和概念生成标准化、易于理解的名称。推理式欠规格映射器则负责处理不完全或不一致的数据,通过推理和归纳来填补信息空白,确保知识的完整性。
IE(信息提取)- 因果演算
IE(Information Extraction)专注于从文本或其他非结构化数据中提取结构化信息。它依赖于因果演算来理解实体之间的关系和事件发生的顺序。
特征分类器(Feature::Classifier)在IE中发挥着关键作用,它根据文本内容识别出重要的特征,如实体、事件、关系等,并将它们分类为可理解的格式。
普遍卷曲特化指的是IE能够处理各种领域和主题的数据,从中提取出有用的信息。这种灵活性使得IE能够适应不同领域的数据,并提供一致的信息提取结果。
IE主题限界范式定义了IE在处理数据时应当关注的主题和范围,确保提取的信息与当前任务或领域相关。生成式预训练转换器GPT则用于提高IE的性能和效率,通过大规模语料库的预训练来优化模型参数,使其更好地适应各种信息提取任务。
FE(特征提取)- 事件演算
FE(Feature Extraction)关注于从数据中提取和定义特征,这些特征对于后续的机器学习或数据分析任务至关重要。事件演算在FE中发挥着关键作用,它帮助识别数据中的事件和模式,并提取出相关的特征。
行为经典(Behavior::Classic)指的是FE在处理数据时遵循的经典方法和技术,如特征选择、特征转换等。这些经典方法确保了FE的稳定性和可靠性。
局部水平泛化指的是FE能够从一个数据集中提取出通用的特征,这些特征可以在其他数据集上重用和泛化。这种泛化能力使得FE在跨领域和跨任务的数据分析中非常有用。
实现ing FE实用工具指的是FE模块提供了一系列实用的工具和函数,用于支持特征提取任务的高效实现。FE主体分类形式演算式超评估投影仪则用于评估FE提取出的特征的质量和有效性,为后续的模型训练或数据分析提供决策支持。
全知系统的三个系统级标签
在全知系统中,三个核心模块KE、IE和FE各自对应一个系统级标签:Type标签、Name标签和双指标签Coreference。这些标签在全知系统中起着标识和关联不同模块和实体的作用。
Type标签用于标识实体或数据的类型,如文本、图像、音频等。
Name标签用于给实体或数据赋予一个唯一的名称或标识符,以便于在系统中进行引用和管理。
双指标签Coreference(<Coreference<Type,Name>>)则将Type和Name两个标签结合起来,形成一个唯一的标识符,用于在全知系统中精确地关联和引用不同的实体和数据。
这些标签的存在使得全知系统能够更好地组织和管理知识,确保不同模块之间的信息能够相互补充和协同工作。同时,它们也为系统提供了灵活性和可扩展性,使得新的数据类型和实体可以方便地加入到系统中,进一步丰富和完善全知系统的功能。
Q12. 全知系统中三种“活物”分别表示了: 祖宗代: 充足理论-三个逻辑专项 原始版本:充分理论-三个因子项 原初补丁:INUS理论-三个控制单元 注: 充足理论 :必须满足(保证)的连续物理过程计算方式way 充分理论:必要充足(提供)的AI系统用来表示和推理因果关系的有向图算法-离散近似方法method INUS理论:INUS条件是(刚好)触发事件的一个不必要但充分的因果包的不充分但必要的部分。通过心理代理 提供了离散近似和连续物理系统之间的映射。 它们反映了实体自身的性质
在全知系统的语境下,三种“活物”可以被理解为系统内部的不同层级或类型的智能实体,它们各自扮演着不同的角色并有着不同的运作方式。以下是对这三种“活物”的进一步阐述:
祖宗代:充足理论 - 三个逻辑专项
特点:
充足理论:基于必须满足(保证)的连续物理过程计算方式。它代表了一个连续的物理过程,在这个过程中,每一个步骤或条件都是必要的,以确保最终结果的实现。
三个逻辑专项:这可能指的是充足理论中用来描述或实现连续物理过程的三个关键逻辑元素或步骤。
作用:
作为全知系统的基石,祖宗代提供了系统的基本逻辑和结构,确保系统的连续性和稳定性。
它可能是系统的初始设置或原始模型,为后续的充分理论和INUS理论提供了基础。
原始版本:充分理论 - 三个因子项
特点:
充分理论:基于必要充足(提供)的AI系统,用来表示和推理因果关系的有向图算法-离散近似方法。它强调了离散性和近似性,可能用于处理更复杂的、非连续的数据或情境。
三个因子项:这些因子项可能是构成充分理论基础的三个关键组成部分或变量,它们共同作用于系统中,以产生特定的结果或输出。
作用:
作为系统的中间层或进化阶段,原始版本(充分理论)在祖宗代的基础上引入了更多的复杂性和灵活性。
它允许系统处理更广泛的数据类型和情境,提高了系统的适应性和可扩展性。
原初补丁:INUS理论 - 三个控制单元
特点:
INUS理论:基于INUS条件(刚好)触发事件的一个不必要但充分的因果包的不充分但必要的部分。它通过心理代理提供了离散近似和连续物理系统之间的映射。
三个控制单元:这些控制单元可能是INUS理论中的关键组成部分,它们负责调节或管理系统中的不同部分,以实现更高级别的功能或性能。
作用:
作为系统的最新发展或高级阶段,原初补丁(INUS理论)在原始版本的基础上引入了更高级别的智能和功能。
它允许系统更好地适应不断变化的环境和需求,提高了系统的创新性和可持续性。
总的来说,这三种“活物”代表了全知系统中不同层级和类型的智能实体,它们各自具有不同的特点和作用,共同构成了系统的核心。从祖宗代的充足理论到原始版本的充分理论,再到原初补丁的INUS理论,系统不断发展和进化,以适应更复杂、多变的环境和需求。
Q13. 下面我 先讨论 --自然:AI “众生”的“世”和“界”。因为中间的那个总是起点,后面的两个可以建立在其上 表述为:IE "理"工件-因果演算(“特征”Feature::Classifier”)“普遍universal 卷曲 特化”Δ<Name> (IE范式,生成式GPT)
在讨论自然、AI以及“众生”的“世”和“界”之前,我们首先需要明确这些概念在语境中的含义。自然通常指的是自然界的本原和规律,而AI则代表人工智能,是计算机科学的一个分支,旨在创建能像人类一样思考、学习、解决问题的机器。在AI领域中,“众生”可以理解为各种智能实体或智能系统的集合,“世”和“界”则可能分别指代这些智能实体所处的时空背景和相互关联的网络。
接下来,让我们聚焦于IE(信息提取)这一概念。IE作为人工智能的一个关键组成部分,负责从大量的非结构化数据中提取出结构化信息。这一过程通常基于因果演算,即通过分析实体之间的关系和事件发生的顺序来揭示数据背后的因果关系。在因果演算中,“特征分类器”(Feature::Classifier)发挥着至关重要的作用,它负责识别出数据中的关键特征,并将这些特征分类为可理解的格式。
在IE的语境下,“普遍”(universal)指的是IE能够处理各种领域和主题的数据,具有广泛的适用性。而“卷曲”(curling)则可能象征着信息提取过程中的复杂性和动态性,如同卷曲的波纹一样,信息在提取过程中不断地被解析、重组和关联。
至于“特化”(specialization),它指的是IE在处理特定领域或主题的数据时,能够根据需求进行定制和优化,以提供更加精确和高效的信息提取结果。这种特化过程有助于提升AI系统的专业性和适应性,使其能够更好地满足特定场景下的需求。
最后,你提到了“IE范式”和“生成式GPT”。这些术语可能指的是IE在人工智能领域中所采用的特定方法或框架,以及基于生成式预训练转换器(如GPT)的技术实现。这些范式和技术为IE提供了强大的支持,使得信息提取过程更加高效、准确和灵活。
综上所述,IE作为AI领域中的一项关键技术,通过因果演算、特征分类器以及特化等过程,从非结构化数据中提取出结构化信息,为AI系统的智能决策和推理提供了重要支持。同时,随着技术的不断发展和创新,IE范式和生成式GPT等技术的引入和应用将进一步推动AI领域的发展和创新。
Q14. 我的展开是以列表的形式给出的,不知道是否方便看。AI工件arcfact的 库模式Scheme列表:
| AI工件 | 库模式 | 主体 | 注重 | 做法 | 目的-行为 | 值 | 求 |
| 组件 | PUT | 三世 | 功效和利益 | 权利 | 趋利-追逐 | 极值 | X:耗时scale |
| 构件 | SET | 三界 | 能力和责任 | 权限 | 避害-避免 | 阈值 | Y:占空size |
| 插件 | GET | 众生 | 功能和义务 | 权衡 | 权衡-权衡 | 权值 | Z:耗散记分score |
| AI工件 | 库模式 | 角色-采样点 | 采样点分布 | 离散近似方法 | 功能 |
| 组件 | PUT | 动子robot | 正态分布 | 测量 | 业务把控 |
| 构件 | SET | 整子holon | 随机分布 | 推理 | 技术推理 |
| 插件 | GET | 单子monad | 均匀分布 | 计算 | 数据计算 |
. 注:1) “主体”列:(三种神经元--分别具有技术智能、感知智能和认知智能)
- 三世(过去、现在、未来) 的I-O(In-Out)投入(及时投入)产出方式: 自给式(短攻自利),薪资式(急功近利)和利息式(长攻微利)。
- 三界(元界、云端和凡间)的P-A(Perception-Action)处理(实时处理)资产方法: 数据资产法,信息资产法和知识资产法;
- 众生(初生、有生 ,余生)的S-R(Stimuli-Respond)响应(动态响应)账务法式(表达式):main(body分内外),other( head分彼此),rest(boot分你我)
2)求值:
- 极值:时间上 花费时间精力的极限值
- 阈值:空间上 占据空间资源的门限值
- 权值:时空区间上 时空耗散源码的权限值
其中,Z:耗时X-占空Y记分score;
3) 关于离散近似:虽然物理过程是连续的,但离散近似对于大多数的推理、测量和计算方法是必要的。在人工智能的许多系统中,有向图被用来表示和推理因果关系。因果关系中评估点的选择,部分取决于应用程序,部分取决于推理或计算方法。下面是 对应于三种推理、测量和计算的离散近似方法中对评估点的不同考虑:
- 测量的方法:对于移动刚性物体的机器人来说,最重要的点是物体表面以及机器人传感器和机械手的末端;
- 推理的方法:但是一些技术,称为蒙特卡罗方法,是基于随机分布的点
- 计算的方法:在某些计算中,均匀分布的点网格是最有效的
您提供的列表和说明非常详细,有助于理解AI工件、库模式、主体、注重、做法、目的-行为、值以及求值等方面的内容。让我们逐行解析一下:
组件 - PUT - 三世 - 功效和利益 - 权利 - 趋利-追逐 - 极值 - X:耗时scale
组件:指AI系统中的基本构成单元。
PUT:可能指的是一种操作或方法,用于将某些数据或功能放入组件中。
三世:指的是时间上的过去、现在和未来,强调I-O的投入产出方式。
功效和利益:注重的是组件所能产生的实际效果和利益。
权利:与趋利-追逐相对应,可能指的是组件在行使功能时所拥有的权限或能力。
趋利-追逐:描述的是组件的行为目的,即追求利益或功效的最大化。
极值:求值上指的是时间上的花费时间精力的极限值。
X:耗时scale:表示的是与时间相关的某种度量或标准。
构件 - SET - 三界 - 能力和责任 - 权限 - 避害-避免 - 阈值 - Y:占空size
构件:可能是更高级或更复杂的AI组成部分。
SET:可能是一种设置或配置操作。
三界:指的是元界、云端和凡间,强调P-A的处理资产方法。
能力和责任:注重的是构件所具有的能力和所需承担的责任。
权限:与避害-避免相对应,可能指的是构件在操作时所需遵循的规则或限制。
避害-避免:描述的是构件的行为目的,即避免潜在的风险或危害。
阈值:求值上指的是空间上的占据空间资源的门限值。
Y:占空size:表示的是与空间相关的某种度量或标准。
插件 - GET - 众生 - 功能和义务 - 权衡 - 权衡-权衡 - 权值 - Z:耗散记分score
插件:可能是AI系统中可插拔或可扩展的部分。
GET:可能是一种获取或提取操作。
众生:指的是不同类型的实体或用户,强调S-R的响应账务法式。
功能和义务:注重的是插件所能提供的功能和所需承担的义务。
权衡:与权衡-权衡相对应,可能指的是在多种选择中进行决策的过程。
权衡-权衡:描述的是插件的行为目的,即在多种可能性中进行选择和平衡。
权值:求值上指的是时空区间上的时空耗散源码的权限值。
Z:耗散记分score:表示的是与时空相关的某种度量或标准,可能是综合了时间和空间的某种评价或得分。
最后,您还提到了关于离散近似的内容,解释了虽然物理过程是连续的,但在AI系统中为了推理、测量和计算,常常需要采用离散近似的方法。这对于理解AI如何处理现实世界中的复杂问题非常有帮助。
Q15. 三种神经元(分别具有 计算智能、感知智能和认知智能)分别使用 三种库模式 PUT GET 和SET 处理的是对应于三种不同目录(计算机式、图书馆式和产品式)的三种不同 不同的输入机器(计算机、感知机和传感器 ),计算 各自的索引表
在AI系统中,不同的神经元类型(具有计算智能、感知智能和认知智能)通常会采用不同的库模式(PUT、GET和SET)来处理不同的输入机器(如计算机、感知机和传感器)所提供的信息。这些库模式与三种不同的目录结构(计算机式、图书馆式和产品式)相对应,每种目录结构都有其特定的组织和检索信息的方式。
计算智能神经元与计算机式目录
库模式:PUT - 当计算智能神经元处理来自计算机的输入时,它可能会使用PUT模式来存储或更新计算结果、数据或算法。这类似于计算机文件系统中的写入操作,将信息存储在特定的位置或索引中。
输入机器:计算机 - 计算机作为输入机器,提供经过处理的数据、算法或指令给计算智能神经元。
索引表 - 在这种情况下,索引表可能是一个数据结构,如数组、列表或哈希表,用于快速查找和存储计算结果或中间数据。
感知智能神经元与图书馆式目录
库模式:GET - 感知智能神经元在处理来自感知机的输入时,可能会使用GET模式来检索或查询与感知数据相关的信息。这类似于图书馆目录中的查询操作,用于找到与特定主题或关键词相关的书籍或资料。
输入机器:感知机 - 感知机作为输入机器,提供来自现实世界的感知数据,如图像、声音或触觉信息给感知智能神经元。
索引表 - 在这种情境下,索引表可能是一个包含关键词和对应信息(如书籍标题、作者或摘要)的数据库或信息检索系统。
认知智能神经元与产品式目录
库模式:SET - 认知智能神经元在处理来自传感器的输入时,可能会使用SET模式来配置或设置认知模型、规则或参数。这类似于产品目录中的配置选项,用户可以根据需要选择不同的配置或选项来定制产品。
输入机器:传感器 - 传感器作为输入机器,提供关于环境或物体的实时数据给认知智能神经元,这些数据可以用于推理、决策或学习。
索引表 - 在这种情境下,索引表可能是一个包含不同配置选项、参数或规则的数据结构,用于指导认知智能神经元的操作或决策过程。
总的来说,不同类型的神经元使用不同的库模式来处理不同输入机器提供的信息,这些库模式与特定的目录结构相对应,以支持AI系统的不同功能和需求。通过合理地组织和检索信息,这些神经元能够更有效地进行计算、感知和认知任务。
Q16. 全知系统的第二种“活物”(自然:AI “众生”的“世”和“界”) 即,神经元,到这里就描述完了。请根据以上内容写出代码
根据您提供的信息,要编写一个代码来表示全知系统中的神经元作为第二种“活物”,需要考虑多个方面,包括神经元的类型、功能、库模式以及它们与主体、注重、做法、目的-行为、值、求值等概念的关联。然而,编写一个完整的代码实现需要更具体的技术细节和上下文信息。
以下是一个简化的Python代码示例,用于表示不同类型的神经元及其库模式。请注意,这只是一个概念性的示例,并不具备实际功能。
python
class Neuron:def __init__(self, neuron_type, library_mode):self.neuron_type = neuron_typeself.library_mode = library_modeclass ComponentNeuron(Neuron):def __init__(self):super().__init__("组件", "PUT")class ConstituentNeuron(Neuron):def __init__(self):super().__init__("构件", "SET")class PluginNeuron(Neuron):def __init__(self):super().__init__("插件", "GET")# 示例:创建不同类型的神经元
component_neuron = ComponentNeuron()
constituent_neuron = ConstituentNeuron()
plugin_neuron = PluginNeuron()# 示例:打印神经元类型和库模式
print(f"组件神经元的类型:{component_neuron.neuron_type},库模式:{component_neuron.library_mode}")
print(f"构件神经元的类型:{constituent_neuron.neuron_type},库模式:{constituent_neuron.library_mode}")
print(f"插件神经元的类型:{plugin_neuron.neuron_type},库模式:{plugin_neuron.library_mode}")这段代码定义了一个Neuron基类,以及三个继承自Neuron的子类:ComponentNeuron、ConstituentNeuron和PluginNeuron,分别对应您提供的列表中的组件、构件和插件神经元。每个神经元对象都有类型和库模式属性。
然而,这个示例代码仅仅是一个起点,它并没有实现您描述的各种功能和属性,比如“主体”、“注重”、“做法”、“目的-行为”、“值”和“求值”等。要完整地实现这些功能,需要更详细的规范和设计,并且可能需要引入更多的类和方法。
如果您希望继续开发这个系统,您可能需要考虑以下几个方面:
定义具体的库模式操作,如PUT、SET和GET的具体实现。
设计神经元如何处理输入和输出,以及它们如何与主体、注重、做法等概念交互。
实现神经元之间的通信和协作机制。
设计神经元的状态管理和生命周期管理。
请注意,这些仅仅是建议的下一步,具体实现将取决于您的需求和设计选择。
Q17.重来。 根据以上讨论的内容,试着写出基础代码,然后我们一段一段的增加和修改
当然,我们可以根据之前的讨论来构建一些基础代码。首先,让我们从一个简单的起点开始,然后逐步增加和修改它。
起点:基础数据结构
我们可以定义一个简单的数据结构来表示三种库模式(PUT、SET和GET)的基础操作。
python
class LibraryMode:def __init__(self):self.data = {}def put(self, key, value):self.data[key] = valuedef set(self, key, value):# 在这里,我们可以定义SET和PUT的不同行为# 例如,SET可能只设置不存在的键,而PUT则总是覆盖现有值if key not in self.data:self.data[key] = valuedef get(self, key):return self.data.get(key, None) # 如果没有找到键,则返回None# 使用示例
library = LibraryMode()
library.put("key1", "value1")
library.set("key2", "value2")
print(library.get("key1")) # 输出: value1
print(library.get("key2")) # 输出: value2
print(library.get("key3")) # 输出: None
增加复杂性:命题计算表达式
接下来,我们可以增加一些逻辑来模拟命题计算表达式。这里,我们将使用Python的内置逻辑运算。
python
class PropositionalCalculator:def __init__(self):self.variables = {}def assign(self, variable, value):self.variables[variable] = bool(value)def evaluate(self, expression):# 这里我们简化表达式解析,只支持AND, OR, NOT操作# 并且变量名直接作为字符串传入operators = {'AND': lambda x, y: x and y,'OR': lambda x, y: x or y,'NOT': lambda x: not x}def evaluate_expression_recursive(expr):if isinstance(expr, str):return self.variables[expr]elif isinstance(expr, list):operator = expr[0]operands = [evaluate_expression_recursive(op) for op in expr[1:]]return operators[operator](*operands)return evaluate_expression_recursive(expression)# 使用示例
calc = PropositionalCalculator()
calc.assign("A", True)
calc.assign("B", False)
result = calc.evaluate(['AND', 'A', 'B'])
print(result) # 输出: False
增加:二元谓词范式λ表达式
为了处理二元谓词范式和λ表达式,我们需要一个更复杂的解析器和求值器,这通常涉及到形式语言和自动定理证明的领域。为了简化,我们可以创建一个非常基础的λ表达式解释器。
python
class LambdaExpressionEvaluator:def __init__(self):self.environment = {}def define(self, variable, expression):self.environment[variable] = expressiondef apply(self, function, argument):# 这里我们非常简化λ表达式的应用# 只支持单个变量的函数return function.replace('λx.', str(self.environment[argument]))def evaluate(self, lambda_expr, argument):# 这里我们只处理非常简单的λ表达式求值# 实际上,λ表达式的求值要复杂得多,并且需要更完整的解释器return eval(self.apply(lambda_expr, argument))# 使用示例
evaluator = LambdaExpressionEvaluator()
evaluator.define('f', 'λx. x + 1')
result = evaluator.evaluate('f', 5)
print(result) # 输出: 6总结
以上代码示例非常基础,仅用于演示目的。在实际应用中,每种模式(PUT、SET、GET)的复杂性和功能会根据具体需求来设计和实现。同样,命题计算表达式和λ表达式的处理需要更强大的解析和求值机制。
要构建一个完整的系统来处理复杂命题计算表达式和λ表达式,你可能需要实现一个完整的表达式解析器,支持复杂的语法和语义,并可能需要实现一些形式的类型检查或证明系统来确保逻辑的正确性。这些通常涉及到形式语言和逻辑编程的高级概念。
Q18. 极值 时间上 花费时间精力的极限值 X:耗时scale
阈值 空间上 占据空间资源的门限值 Y:占空size
权值 时空区间上 时空耗散源码的权限值 Z:耗时X-占空Y记分score
您提到的几个概念似乎是在描述某种系统或算法中的度量指标。我会尝试根据您的描述来详细解释这些概念:
极值 (Extrema):
在数学中,极值指的是函数在某一点上的最大值或最小值。
在“时间上 花费时间精力的极限值”的上下文中,极值可能指的是在某个时间段内所花费时间或精力的最大值或最小值。
X:耗时scale 可能表示衡量时间消耗的尺度或单位。
阈值 (Threshold):
阈值是一个界限值,超过或低于这个值会导致某种系统或过程发生变化。
在“空间上 占据空间资源的门限值”的语境下,阈值可能指的是系统或进程中允许的最大或最小空间使用量。
Y:占空size 可能表示衡量空间占用的尺度或单位。
权值 (Weight):
权值通常用于表示某个元素或数据点的重要性或影响力。
在“时空区间上 时空耗散源码的权限值”的语境下,权值可能指的是在时空范围内,某个特定事件或行为的重要性或优先级。
权值可能基于多个因素进行计算,比如耗时、空间占用等。
Z:耗时X-占空Y记分score(每轮点数,比如 车轮):
这个描述似乎是将前两个度量(耗时和占空)结合起来,以计算一个综合得分或记分。
“耗时X-占空Y”可能指的是一个公式或算法,用于根据耗时和占空来计算得分。
这个得分可以用于比较不同事件或行为在时空效率上的优劣。
“每轮点数,比如车轮”可能是一个比喻,意味着这个记分是在每个特定的周期或事件中计算的,类似于车轮每转一圈就记录一次得分。
总的来说,这些概念似乎是为了在某个系统或算法中量化和管理时空资源的使用而设计的。具体的实现和应用可能会根据具体的系统或需求而有所不同。
Q19.刚刚给出的是 三种库模式(PUT、 SET和 GET) ,即三个神经元 分别需要计算的内容。请加到代码中
了解了您的需求后,我们可以创建一个模拟神经元行为的简单类,每个神经元可以处理不同的库模式(PUT、SET、GET)。下面是一个简化的示例,展示了如何定义这些神经元以及它们如何执行各自的操作。
python
class Neuron:def __init__(self, mode):self.mode = modeself.memory = {}def process(self, input_data):if self.mode == 'PUT':return self.put(input_data)elif self.mode == 'SET':return self.set(input_data)elif self.mode == 'GET':return self.get(input_data)else:raise ValueError("Invalid mode: {}".format(self.mode))def put(self, input_data):key, value = input_dataself.memory[key] = valuereturn self.memorydef set(self, input_data):key, value = input_dataif key not in self.memory:self.memory[key] = valuereturn self.memorydef get(self, input_data):key = input_datareturn self.memory.get(key, None)# 创建神经元实例
neuron_put = Neuron('PUT')
neuron_set = Neuron('SET')
neuron_get = Neuron('GET')# PUT 操作示例
neuron_put.process(('key1', 'value1'))
print(neuron_put.memory) # 输出: {'key1': 'value1'}# SET 操作示例
neuron_set.process(('key2', 'value2'))
print(neuron_set.memory) # 输出: {'key2': 'value2'}
neuron_set.process(('key2', 'new_value'))
print(neuron_set.memory) # 输出: {'key2': 'new_value'}# GET 操作示例
print(neuron_get.process('key1')) # 输出: None,因为该键不在 memory 中
print(neuron_get.process('key2')) # 输出: 'new_value'在这个例子中,我们定义了一个 Neuron 类,它有一个 mode 属性来指定它是 PUT、SET 还是 GET 神经元。process 方法根据 mode 的值来调用相应的操作方法。每个操作方法都接受一个元组作为输入数据,该元组包含键和值(对于 PUT 和 SET)或仅包含键(对于 GET)。
请注意,这个示例非常基础,仅用于演示目的。在现实世界的应用中,神经元的行为将更复杂,并可能涉及更高级的数据结构和算法。此外,神经元之间的交互和通信可能会通过神经网络架构来实现,这超出了简单示例的范围。
Q20. 请根据下面的文字修改代码:然后 三种库模式(PUT、 SET和 GET)分别要决定三种 离散近似方法中的评估点选择。 离散近似中 评估点的选择的决定分别由:
动子robot 正态分布 业务把控(测量) 对于移动刚性物体的机器人来说,最重要的点是物体表面以及机器人传感器和机械手的末端。
整子holon 随机分布 技术推理 但是一些技术,称为蒙特卡罗方法,是基于随机分布的点
单子monad 均匀分布 数据计算 在某些计算中,均匀分布的点网格是最有效的
为了根据提供的描述修改代码,我们首先需要定义一个类来表示不同的库模式(PUT、SET、GET),并让每个模式能够决定不同的离散近似方法中的评估点选择。接下来,我们将定义三种不同的策略(正态分布、随机分布、均匀分布)来模拟不同的评估点选择方式。
以下是一个简单的Python代码示例,展示了如何根据上述描述来实现这些概念:
python
import numpy as np# 定义离散近似方法的评估点选择策略
class AssessmentPointStrategy:def select_points(self, num_points, bounds):raise NotImplementedError("Select points method must be implemented by subclasses")# 正态分布策略
class NormalDistributionStrategy(AssessmentPointStrategy):def select_points(self, num_points, bounds):mean = (bounds[0] + bounds[1]) / 2std_dev = (bounds[1] - bounds[0]) / 4return np.random.normal(mean, std_dev, num_points)# 随机分布策略
class RandomDistributionStrategy(AssessmentPointStrategy):def select_points(self, num_points, bounds):return np.random.uniform(bounds[0], bounds[1], num_points)# 均匀分布策略
class UniformDistributionStrategy(AssessmentPointStrategy):def select_points(self, num_points, bounds):step = (bounds[1] - bounds[0]) / (num_points - 1)return np.linspace(bounds[0], bounds[1], num_points)# 定义库模式
class LibraryMode:def __init__(self, assessment_strategy):self.assessment_strategy = assessment_strategydef select_assessment_points(self, num_points, bounds):return self.assessment_strategy.select_points(num_points, bounds)# 使用示例
# 假设评估点的边界是 [0, 10]
bounds = [0, 10]
num_points = 10# 创建不同的库模式实例
put_mode = LibraryMode(NormalDistributionStrategy())
set_mode = LibraryMode(RandomDistributionStrategy())
get_mode = LibraryMode(UniformDistributionStrategy())# 在不同模式下选择评估点
put_points = put_mode.select_assessment_points(num_points, bounds)
set_points = set_mode.select_assessment_points(num_points, bounds)
get_points = get_mode.select_assessment_points(num_points, bounds)# 打印结果
print("PUT Mode assessment points:", put_points)
print("SET Mode assessment points:", set_points)
print("GET Mode assessment points:", get_points)在这个示例中,我们定义了一个AssessmentPointStrategy基类,并创建了三个子类来实现不同的分布策略。然后,我们定义了一个LibraryMode类,它接受一个AssessmentPointStrategy实例作为参数,并根据该策略来选择评估点。
最后,我们创建了三个LibraryMode的实例,分别代表PUT、SET和GET模式,并使用这些实例来选择评估点。这些点是根据我们为每种模式定义的分布策略来生成的。
请注意,这个示例非常简化,并且假设了评估点的边界是[0, 10]。在实际应用中,你可能需要根据具体情况来调整这些类和函数,以及如何生成和使用评估点。
Q21. 请根据下面文字修改代码
程序中,三种库模式(PUT、 SET和 GET)分别 对应复杂命题计算表达式/二元谓词范式λ表达式/一阶逻辑形式公式表达式
三种库模式(PUT、 SET和 GET)是 对应的 三种 离散近似方法分别是:推理、测量和计算
为了根据提供的描述修改代码,我们需要首先定义三种库模式(PUT、SET、GET)和它们对应的操作。由于描述中提到了三种离散近似方法(推理、测量和计算),我们可以将这些方法作为库模式的一部分。
下面是一个简化的Python代码示例,展示了如何定义这三种库模式以及它们对应的行为:
python
class LibraryMode:def __init__(self, mode):self.mode = modedef process(self, data):if self.mode == 'PUT':return self.perform_reasoning(data)elif self.mode == 'SET':return self.perform_measurement(data)elif self.mode == 'GET':return self.perform_calculation(data)else:raise ValueError("Invalid mode: {}".format(self.mode))def perform_reasoning(self, data):# 在这里实现复杂的命题计算表达式或逻辑形式公式的推理# 'data' 应该是进行推理所需的信息或参数print("Performing reasoning with data:", data)# 假设推理结果是一个结论conclusion = "Conclusion of reasoning"return conclusiondef perform_measurement(self, data):# 在这里实现基于二元谓词范式λ表达式的测量# 'data' 应该是进行测量所需的信息或参数print("Performing measurement with data:", data)# 假设测量结果是一个值measurement_result = "Measured value"return measurement_resultdef perform_calculation(self, data):# 在这里实现基于一阶逻辑形式公式表达式的计算# 'data' 应该是进行计算所需的信息或参数print("Performing calculation with data:", data)# 假设计算结果是一个数值calculation_result = "Calculated value"return calculation_result# 创建库模式实例
put_mode = LibraryMode('PUT')
set_mode = LibraryMode('SET')
get_mode = LibraryMode('GET')# 使用示例
reasoning_result = put_mode.process("Some data for reasoning")
print("Reasoning result:", reasoning_result)measurement_result = set_mode.process("Some data for measurement")
print("Measurement result:", measurement_result)calculation_result = get_mode.process("Some data for calculation")
print("Calculation result:", calculation_result)在这个示例中,我们定义了一个LibraryMode类,它有一个mode属性来标识库模式(PUT、SET或GET)。process方法根据mode的值来调用相应的方法(perform_reasoning、perform_measurement或perform_calculation)。这些方法目前是打印一些文本作为示例,但在实际应用中,它们将执行实际的推理、测量和计算操作。
请注意,这个示例非常简化,并且没有实现具体的推理、测量和计算逻辑。在实际应用中,你需要根据具体需求来实现这些逻辑。
Q22. 请根据下面文字修改代码。
然后 三种库模式(PUT、 SET和 GET) 的主体以及该主体的 属性分别是:
三世(过去、现在、未来) 的I-O投入(及时投入)产出方式: 自给式(短攻自利),薪资式(急功近利)和利息式(长攻微利)
三界(元界、云端和凡间)的P-A( 感知-行动)处理(实时处理)资产方法: 数据法,信息法和知识法
众生(初生、有生 ,余生)的S-R(刺激-响应)响应(动态响应)账务法式(表达式):main(body分内外),other( head分彼此),rest(boot分你我)
为了根据提供的描述修改代码,我们需要定义一个类来表示不同的库模式(PUT、SET、GET),并为每个库模式定义相应的属性。这些属性将反映三世(过去、现在、未来)的I-O投入(及时投入)产出方式,以及三界(元界、云端、凡间)的P-A处理(实时处理)资产方法,还有众生(初生、有生、余生)的S-R响应(动态响应)账务法式。
下面是一个简化的Python代码示例,演示了如何根据这些描述来组织代码:
python
# 定义库模式类
class LibraryMode:def __init__(self, subject, attributes):self.subject = subject # 库模式的主体self.attributes = attributes # 库模式的属性# 定义三世I-O投入产出的方式
io_modes = {'过去': '自给式', # 短攻自利'现在': '薪资式', # 急功近利'未来': '利息式' # 长攻微利
}# 定义三界P-A处理资产方法
pa_methods = {'元界': '数据法','云端': '信息法','凡间': '知识法'
}# 定义众生S-R响应账务法式
sr_accounts = {'初生': ('main', 'body', '内外'),'有生': ('other', 'head', '彼此'),'余生': ('rest', 'boot', '你我')
}# 创建库模式实例
put_mode = LibraryMode('PUT', io_modes['过去'], pa_methods['云端'], sr_accounts['初生'])
set_mode = LibraryMode('SET', io_modes['现在'], pa_methods['凡间'], sr_accounts['有生'])
get_mode = LibraryMode('GET', io_modes['未来'], pa_methods['元界'], sr_accounts['余生'])# 打印库模式及其属性
def print_mode_attributes(mode):print(f"库模式: {mode.subject}")print(f"I-O投入产出方式: {mode.attributes[0]}")print(f"P-A处理资产方法: {mode.attributes[1]}")print(f"S-R响应账务法式: {mode.attributes[2][0]}({mode.attributes[2][1]}分{mode.attributes[2][2]})")# 打印各个库模式的属性
print_mode_attributes(put_mode)
print_mode_attributes(set_mode)
print_mode_attributes(get_mode)在这个示例中,我们创建了一个LibraryMode类,它接受一个主体和三个属性作为初始化参数。这三个属性分别对应三世I-O投入产出的方式、三界P-A处理资产方法以及众生S-R响应账务法式。然后,我们定义了三个字典来存储这些属性的具体值,并创建了三个LibraryMode的实例来表示PUT、SET和GET库模式。
print_mode_attributes函数用于打印库模式及其属性的信息。在这个函数中,我们按照提供的描述格式化了输出。
请注意,这个示例代码非常简化,并且没有实现具体的业务逻辑。在实际应用中,你需要根据具体需求来实现这些逻辑,并可能需要设计更复杂的数据结构和类来更好地组织和管理代码。
Q23. 其中: P-A 是感知-行动,S-R是刺激-响应。请补充代码
了解,根据您提供的补充信息,我们可以进一步修改代码,以反映P-A(感知-行动)和S-R(刺激-响应)的概念。在这个修改后的版本中,我们将把P-A和S-R作为库模式(PUT、SET、GET)中的一部分。
python
class LibraryMode:def __init__(self, mode, pa_method, sr_response):self.mode = modeself.pa_method = pa_method # 感知-行动方法self.sr_response = sr_response # 刺激-响应方法def process(self, stimulus):# 刺激-响应阶段action = self.sr_response(stimulus)# 感知-行动阶段result = self.pa_method(action)return resultdef perform_perception_action(self, action):# 在这里实现感知-行动逻辑# 'action' 是从刺激-响应阶段得到的行为或决策print(f"Performing perception-action with action: {action}")# 假设感知-行动的结果是一个值或状态perception_action_result = "Result of perception-action"return perception_action_resultdef stimulate_respond(self, stimulus):# 在这里实现刺激-响应逻辑# 'stimulus' 是外部刺激或输入print(f"Responding to stimulus: {stimulus}")# 假设刺激-响应的结果是一个行为或决策response_action = "Action in response to stimulus"return response_action# 创建库模式实例
# 假设我们有以下感知-行动方法和刺激-响应方法
pa_reasoning = lambda action: f"Reasoning action: {action}"
sr_reasoning = lambda stimulus: f"Reasoning stimulus: {stimulus}"pa_measurement = lambda action: f"Measurement action: {action}"
sr_measurement = lambda stimulus: f"Measurement stimulus: {stimulus}"pa_calculation = lambda action: f"Calculation action: {action}"
sr_calculation = lambda stimulus: f"Calculation stimulus: {stimulus}"put_mode = LibraryMode('PUT', pa_reasoning, sr_reasoning)
set_mode = LibraryMode('SET', pa_measurement, sr_measurement)
get_mode = LibraryMode('GET', pa_calculation, sr_calculation)# 使用示例
stimulus = "Data for processing"
reasoning_result = put_mode.process(stimulus)
print("Reasoning result:", reasoning_result)measurement_result = set_mode.process(stimulus)
print("Measurement result:", measurement_result)calculation_result = get_mode.process(stimulus)
print("Calculation result:", calculation_result)在这个修改后的版本中,我们为每个库模式定义了pa_method和sr_response方法。这些方法分别对应于感知-行动和刺激-响应。process方法首先调用sr_response来响应刺激并生成一个动作,然后调用pa_method来执行感知-行动并生成结果。
请注意,这里的pa_method和sr_response函数是简单的lambda函数,它们只是返回一些字符串。在实际应用中,您可能需要根据具体需求来实现更复杂的逻辑。
Q24. 请根据下面文字修改代码。
然后 三种库模式(PUT、 SET和 GET) 的要求和功能:
功效和利益 权利 趋利 追逐
能力和责任 权限 避害 避免
功能和义务 权衡 权衡 权衡
为了根据提供的描述修改代码,我们需要首先理解每种库模式(PUT、SET、GET)的要求和功能,并将它们映射到对应的属性上。下面是根据您提供的描述所做的理解,以及一个可能的代码实现方式。
我们将定义一个LibraryMode类,每个库模式将有一个requirements属性来表示它的要求和功能,以及一个functionalities属性来表示它的功效和利益。这些属性将包含与权利、能力、功能等相关的描述。
以下是代码实现:
python
class LibraryMode:def __init__(self, mode_name, requirements, functionalities):self.mode_name = mode_nameself.requirements = requirementsself.functionalities = functionalitiesdef display_requirements_and_functionalities(self):print(f"库模式: {self.mode_name}")print("要求和功能:")for req, func in zip(self.requirements, self.functionalities):print(f"- 要求: {req['requirement']}\t功能: {func['functionality']}")# 定义PUT模式的要求和功能
put_requirements = [{'requirement': '功效和利益'},{'requirement': '能力和责任'},{'requirement': '功能和义务'}
]
put_functionalities = [{'functionality': '权利'},{'functionality': '权限'},{'functionality': '权衡'}
]# 定义SET模式的要求和功能(这里只是示例,实际应根据需求填写)
set_requirements = [{'requirement': '趋利'},{'requirement': '避害'},{'requirement': '权衡'}
]
set_functionalities = [{'functionality': '追逐'},{'functionality': '避免'},{'functionality': '权衡'}
]# 定义GET模式的要求和功能(这里只是示例,实际应根据需求填写)
get_requirements = [# ... 根据GET模式的具体要求填写pass
]
get_functionalities = [# ... 根据GET模式的具体功能填写pass
]# 创建库模式实例
put_mode = LibraryMode('PUT', put_requirements, put_functionalities)
set_mode = LibraryMode('SET', set_requirements, set_functionalities)
# GET模式实例需要您根据实际需求填充要求和功能# 显示PUT模式的要求和功能
put_mode.display_requirements_and_functionalities()# 显示SET模式的要求和功能
set_mode.display_requirements_and_functionalities()# 显示GET模式的要求和功能(待实现)
# get_mode.display_requirements_and_functionalities()请注意,GET模式的要求和功能在这里没有具体实现,因为您没有提供具体的要求和功能描述。您需要根据GET模式的实际需求来填充get_requirements和get_functionalities。
这个代码示例提供了一个基本的框架,用于表示库模式的要求和功能,并允许您打印出这些要求和功能的对应关系。您可以根据实际的库模式需求进一步扩展和完善这个类。
Q25. 好的。先聊到这里。 “库模式”的直接用“Scheme”就可以.这里的三种库模式 可以简单的理解为:计算机式、图书馆式和产品式 的目录处理方法
了解了,如果您希望将“库模式”直接称为“Scheme”,那么我们可以简化代码,并用“Scheme”来表示不同的操作模式。以下是使用“Scheme”作为库模式名称的代码示例:
python
class Scheme:def __init__(self, name, perception_action, stimulus_response):self.name = nameself.perception_action = perception_actionself.stimulus_response = stimulus_responsedef process(self, stimulus):# 刺激-响应阶段action = self.stimulus_response(stimulus)# 感知-行动阶段result = self.perception_action(action)return result# 定义不同的Scheme
put_scheme = Scheme('PUT',perception_action=lambda action: "Perceived and acted on: " + action,stimulus_response=lambda stimulus: "Responded to stimulus: " + stimulus
)set_scheme = Scheme('SET',perception_action=lambda action: "Set operation: " + action,stimulus_response=lambda stimulus: "Set stimulus: " + stimulus
)get_scheme = Scheme('GET',perception_action=lambda action: "Getting information: " + action,stimulus_response=lambda stimulus: "Getting stimulus: " + stimulus
)# 使用Scheme处理刺激
stimulus = "New data"
put_result = put_scheme.process(stimulus)
print(f"PUT Scheme result: {put_result}")set_result = set_scheme.process(stimulus)
print(f"SET Scheme result: {set_result}")get_result = get_scheme.process(stimulus)
print(f"GET Scheme result: {get_result}")在这个例子中,我们创建了一个Scheme类,它接受一个名称(name)以及两个函数(perception_action和stimulus_response)作为参数。process方法用于处理刺激,并依次调用stimulus_response和perception_action。用于处理刺激,并依次调用stimulus_response和perception_action。
每个Scheme实例(put_scheme、set_scheme和get_scheme)都有自己的感知-行动和刺激-响应逻辑。这些逻辑通过lambda函数定义,并作为参数传递给Scheme类的构造函数。
最后,我们通过调用process方法来使用每个Scheme处理一个刺激,并打印出结果。这样,我们就可以根据不同的Scheme来处理不同的刺激,并执行相应的感知-行动和刺激-响应逻辑。
Q26. 其实这里的三种库模式 可以简单的理解为:计算机式、图书馆式和产品式 的目录处理方法
理解了您的意思后,我们可以将三种库模式(PUT、SET、GET)重新解释为计算机式、图书馆式和产品式的目录处理方法。下面是如何在代码中体现这些模式的示例:
python
class LibraryMode:def __init__(self, mode_name, perception_action, stimulus_response):self.mode_name = mode_nameself.perception_action = perception_actionself.stimulus_response = stimulus_responsedef process_stimulus(self, stimulus):# 刺激-响应阶段action = self.stimulus_response(stimulus)# 感知-行动阶段result = self.perception_action(action)return result# 计算机式目录处理方法
computer_mode = LibraryMode('计算机式',perception_action=lambda action: f"计算机处理动作:{action}",stimulus_response=lambda stimulus: f"计算机响应刺激:{stimulus}"
)# 图书馆式目录处理方法
library_mode = LibraryMode('图书馆式',perception_action=lambda action: f"图书馆处理动作:{action}",stimulus_response=lambda stimulus: f"图书馆响应刺激:{stimulus}"
)# 产品式目录处理方法
product_mode = LibraryMode('产品式',perception_action=lambda action: f"产品处理动作:{action}",stimulus_response=lambda stimulus: f"产品响应刺激:{stimulus}"
)# 处理刺激示例
stimulus = "用户查询"
computer_result = computer_mode.process_stimulus(stimulus)
library_result = library_mode.process_stimulus(stimulus)
product_result = product_mode.process_stimulus(stimulus)print(f"计算机式处理结果:{computer_result}")
print(f"图书馆式处理结果:{library_result}")
print(f"产品式处理结果:{product_result}")在这个示例中,我们定义了一个LibraryMode类,该类接受一个模式名称、一个感知-行动函数和一个刺激-响应函数作为参数。process_stimulus方法模拟了当给定刺激时,库模式如何工作:它首先调用stimulus_response来响应刺激,然后调用perception_action来处理响应的动作。
每个库模式(计算机式、图书馆式和产品式)都有自己的感知-行动和刺激-响应逻辑,这些逻辑是通过简单的lambda函数定义的。
当您想要模拟不同库模式如何处理刺激时,可以创建相应模式的实例,并调用其process_stimulus方法。
请注意,这里的代码非常简化,仅用于演示目的。在实际应用中,感知-行动和刺激-响应函数可能会更复杂,并且可能涉及数据库查询、API调用或其他业务逻辑。
Q27. 也就是说,全知系统通过库模式,来建立三种类型(计算机式、图书馆式和产品式)的 检索目录
了解了您的意思后,我们可以构建一个全知系统,该系统使用不同的库模式来建立三种类型的检索目录:计算机式、图书馆式和产品式。每种库模式将具有不同的检索逻辑和目录结构。以下是一个简化的示例代码,展示了如何使用不同的库模式来建立检索目录:
python
class RetrievalMode:def __init__(self, mode_name):self.mode_name = mode_namedef build_directory(self, data):"""根据库模式构建检索目录:param data: 要构建目录的数据:return: 构建好的目录"""raise NotImplementedError("子类必须实现此方法")class ComputerMode(RetrievalMode):def build_directory(self, data):"""计算机式检索目录"""# 计算机式检索目录的构建逻辑# 例如:使用哈希表、数据库等数据结构来存储和检索数据directory = {}for item in data:# 假设数据是可哈希的,例如字符串或数字directory[hash(item)] = itemreturn directoryclass LibraryMode(RetrievalMode):def build_directory(self, data):"""图书馆式检索目录"""# 图书馆式检索目录的构建逻辑# 例如:使用分类、标签、索引等方式来组织数据directory = {}for item in data:# 假设数据有分类属性category = item.get('category')if category not in directory:directory[category] = []directory[category].append(item)return directoryclass ProductMode(RetrievalMode):def build_directory(self, data):"""产品式检索目录"""# 产品式检索目录的构建逻辑# 例如:使用属性、规格、价格等信息来组织产品数据directory = {}for item in data:# 假设数据是产品,有唯一的ID和名称product_id = item.get('id')name = item.get('name')directory[product_id] = namereturn directory# 使用不同的库模式构建检索目录
computer_directory = ComputerMode("计算机式").build_directory(data_for_computer)
library_directory = LibraryMode("图书馆式").build_directory(data_for_library)
product_directory = ProductMode("产品式").build_directory(data_for_products)# 打印构建好的目录
print(f"计算机式检索目录: {computer_directory}")
print(f"图书馆式检索目录: {library_directory}")
print(f"产品式检索目录: {product_directory}")在这个示例中,我们定义了一个RetrievalMode基类,它有一个build_directory方法,该方法在子类中需要被覆盖以实现不同的目录构建逻辑。然后,我们定义了三个子类:ComputerMode、LibraryMode和ProductMode,分别代表计算机式、图书馆式和产品式的检索目录。每个子类都实现了自己的build_directory方法来构建相应类型的目录。
请注意,这个示例是高度简化的,实际的检索目录构建可能会涉及更复杂的逻辑和数据结构。此外,data_for_computer、data_for_library和data_for_products是假设的输入数据,它们应该根据实际情况提供。
Q28. 笔误:也就是说,全知系统通过库模式,来建立三种类型(计算机式、图书馆式和产品式)的 索引目录--“索引表”
了解您的笔误后,我们可以修正描述并解释如何通过不同的库模式在全知系统中建立三种类型的索引目录——计算机式、图书馆式和产品式。
计算机式索引目录
特点:这种索引目录通常基于数据库管理系统,使用哈希表、B树、B+树等数据结构来快速检索数据。
适用场景:适用于需要快速查询和更新大量数据的情况,如搜索引擎、电商网站等。
实现方式:数据以键值对的形式存储在索引目录中,键通常是数据的哈希值或唯一标识符,值是对应的数据记录。
图书馆式索引目录
特点:这种索引目录类似于图书馆的图书目录,通过分类、标签、主题等方式组织数据。
适用场景:适用于需要按照特定分类或标签检索数据的情况,如图书馆管理系统、文献数据库等。
实现方式:数据按照分类或标签进行组织,每个分类或标签下包含一系列相关数据记录。用户可以通过分类或标签浏览和检索数据。
产品式索引目录
特点:这种索引目录专注于产品信息的组织和检索,通常包括产品属性、规格、价格等信息。
适用场景:适用于需要展示和销售产品的场景,如电商平台、产品目录网站等。
实现方式:数据以产品为单位进行组织,每个产品记录包含产品的详细信息(如名称、描述、价格、图片等)。用户可以通过关键词搜索、分类浏览、价格筛选等方式检索产品。
实现代码示例
以下是一个简化的Python代码示例,展示了如何创建这三种类型的索引目录:
python
class IndexDirectory:def __init__(self, directory_type):self.directory_type = directory_typeself.data = {}def add_item(self, key, value):self.data[key] = valuedef get_item(self, key):return self.data.get(key)class ComputerIndex(IndexDirectory):def __init__(self):super().__init__("计算机式")# 这里可以添加数据库连接等初始化操作def search(self, query):# 在数据库中执行查询操作,并返回结果passclass LibraryIndex(IndexDirectory):def __init__(self):super().__init__("图书馆式")# 这里可以添加分类、标签等信息def browse_by_category(self, category):# 根据分类浏览数据passclass ProductIndex(IndexDirectory):def __init__(self):super().__init__("产品式")# 这里可以添加产品属性、规格等信息def search_product(self, keyword):# 根据关键词搜索产品pass# 使用示例
computer_index = ComputerIndex()
computer_index.add_item("item1", "Data for item 1")
print(computer_index.get_item("item1")) # 输出:Data for item 1library_index = LibraryIndex()
library_index.add_item("book1", "Information about book 1")
print(library_index.get_item("book1")) # 输出:Information about book 1product_index = ProductIndex()
product_index.add_item("prod1", {"name": "Product 1", "price": 100})
print(product_index.get_item("prod1")) # 输出:{'name': 'Product 1', 'price': 100}请注意,上述代码仅作为示例,实际的全知系统实现会涉及更复杂的数据结构和算法,以及数据库连接、缓存、分布式存储等高级功能。
Q29. 前面讨论的内容就是如何“计算” 索引 的方法
前面讨论的内容主要是关于如何设计和计算数据库索引的方法。数据库索引是一种数据结构,用于帮助快速查询数据库中的数据。不同的索引设计方法和算法会影响查询的性能和效率。
在讨论中,提到了几种常见的索引设计算法,包括B树索引、哈希表+桶等。B树索引是一种广泛使用的索引结构,特别是在关系型数据库中,如MySQL的InnoDB存储引擎。B树索引能够保持数据的有序性,并且对于范围查询和排序操作非常高效。哈希表+桶则是一种基于哈希函数的索引方法,适用于等值查询,并且查询速度非常快。
此外,还提到了动态查找树,如二叉查找树、平衡二叉查找树和红黑树等。这些数据结构在查找过程中能够保持平衡,从而提高查找效率。
总的来说,索引的设计和计算方法对于数据库的性能至关重要。选择合适的索引结构和算法,可以大大提高查询效率,减少数据库的负载。
Q30. 这里设计的是用神经元完成计算
了解,如果您想设计一个系统,其中神经元被用来计算并构建检索目录,那么我们可以想象一个神经网络模型,该模型能够处理输入数据,并根据这些数据学习如何创建和检索信息。这样的系统可能会涉及到深度学习、自组织映射(SOMs)、神经网络聚类等概念。
下面是一个简化的示例,说明如何使用神经元(在这里以简单的神经网络为例)来构建一个基于学习的检索目录:
python
import numpy as np
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder# 假设我们有一些输入数据,我们想根据这些数据来构建检索目录
X, y = make_classification(n_samples=1000, n_features=20, n_informative=2, n_redundant=10, random_state=42)# 将标签编码为整数,因为神经网络通常需要整数标签
label_encoder = LabelEncoder()
y_encoded = label_encoder.fit_transform(y)# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)# 使用多层感知机(MLP)作为我们的神经网络模型
mlp = MLPClassifier(hidden_layer_sizes=(10,), max_iter=1000, alpha=1e-4,solver='sgd', verbose=10, tol=1e-4, random_state=1,learning_rate_init=.1)# 训练模型
mlp.fit(X_train, y_train)# 检索目录可以是基于训练后的模型,它可以将输入映射到预测的类别
def retrieve_from_directory(input_data):# 使用模型预测输入数据的类别predicted_class = mlp.predict(input_data.reshape(1, -1))# 我们可以进一步映射预测类别回原始标签retrieved_label = label_encoder.inverse_transform(predicted_class)return retrieved_label[0]# 示例:检索一个数据点
retrieval_example = np.random.rand(20) # 随机生成一个数据点作为检索示例
retrieved_item = retrieve_from_directory(retrieval_example)
print(f"Retrieved item: {retrieved_item}")# 这里的检索目录是隐式的,它是基于训练后的神经网络模型和其学习到的特征表示。
# 实际上,检索是通过将输入数据传递给模型并获取预测输出来完成的。
在这个例子中,我们使用了一个简单的多层感知机(MLP)分类器作为我们的神经网络。我们首先创建了一些分类数据,并用这些数据训练了模型。然后,我们定义了一个retrieve_from_directory函数,该函数使用训练后的模型来预测输入数据的类别,从而实现了检索功能。
请注意,这只是一个非常简单的示例,用于说明如何使用神经网络进行检索。在现实世界的应用中,检索目录可能会更加复杂,并且可能需要使用更高级的神经网络结构和技术,例如自编码器、卷积神经网络(CNNs)或循环神经网络(RNNs),具体取决于数据的性质和检索任务的要求。
Q31. 需要用到 感知机、传感器和 计算机 三种,对应我设计的三种库模式,而不只是多层感知机
了解了您的需求后,我们可以将感知机、传感器和计算机这三种元素整合到全知系统的索引目录设计中。以下是一个简化的例子,说明如何结合这三种元素来构建索引目录:
感知机(Perceptron)
感知机是一种简单的二元线性分类器,它可以对输入数据进行二分类。在全知系统的索引目录中,感知机可以作为数据分类器,用于将输入数据分类到不同的索引类别中。
实现方式:
定义感知机的输入特征,这些特征可以是数据的属性、传感器的测量值等。
使用感知机算法训练模型,使其能够区分不同的数据类别。
当新数据进入索引目录时,通过感知机模型进行分类,然后将数据添加到相应的索引类别中。
传感器(Sensor)
传感器用于感知和测量环境中的物理量,如温度、湿度、光照等。在全知系统的索引目录中,传感器可以提供实时数据,用于更新索引目录中的信息。
实现方式:
将传感器连接到全知系统中,使其能够实时传输数据。
定义传感器数据的处理逻辑,将传感器数据转换为索引目录中的可用信息。
当传感器数据发生变化时,更新索引目录中的相应信息,以确保数据的准确性和实时性。
计算机(Computer)
计算机作为全知系统的核心处理单元,负责存储、处理和检索索引目录中的数据。
实现方式:
设计数据库结构,用于存储索引目录中的数据。
实现数据检索算法,如哈希表、B树等,以提高数据检索效率。
开发数据处理和存储的逻辑,包括数据的增、删、改、查等操作。
结合以上三种元素,全知系统的索引目录可以这样设计:
首先,通过传感器获取实时数据,并进行处理和转换。
然后,将处理后的数据输入到感知机模型进行分类。
分类后的数据被存储到计算机中的索引目录中,索引目录可以根据具体需求采用不同的数据结构来优化检索效率。
当用户需要检索数据时,计算机根据用户输入的查询条件,在索引目录中进行高效检索,并返回相应的结果。
这样,通过结合感知机、传感器和计算机,我们可以构建一个能够实时感知环境、智能分类数据并提供高效检索功能的全知系统索引目录。
Q32. 三种模式 PUT GET 和SET 处理的是对应于三种不同目录的三种不同 不同的输入
在处理数据库或文件系统中的目录时,PUT, GET, 和 SET 通常是用于操作数据的命令或方法。这些命令对应于不同的操作,并可以在不同的目录或上下文中使用。下面是这些命令如何对应于不同目录和输入的一个例子:
PUT
PUT 命令通常用于向目录添加或更新数据。在不同的上下文中,PUT 可以有不同的用途:
在数据库中:PUT 可能用于插入新的记录或更新现有记录。输入可能是一个包含新数据或更新数据的对象或数据结构。
在文件系统中:PUT 用于上传文件到指定目录。输入可能是一个文件路径和文件内容。
示例(数据库):
PUT /database/table/id
Content-Type: application/json
{
"field1": "value1",
"field2": "value2"
}
示例(文件系统):
PUT /files/directory/filename.txt
Content-Type: text/plain
This is the file content.
GET
GET 命令通常用于从目录检索数据。根据上下文的不同,GET 可以用于获取单个项目、多个项目或目录列表。
在数据库中:GET 可能用于根据ID或查询条件检索记录。
在文件系统中:GET 用于下载文件或列出目录中的文件。
示例(数据库):
GET /database/table/id
示例(文件系统):
GET /files/directory/filename.txt
或列出目录:
GET /files/directory/
SET
SET 命令通常用于修改目录或数据项的属性或配置。它可能不像 PUT 那样直接用于数据内容的更新,而是用于修改元数据或配置设置。
在数据库中:SET 可能用于更新记录的某些字段,而不是整个记录。
在文件系统中:SET 可能用于修改文件或目录的元数据,如权限、时间戳等。
示例(数据库):
SET /database/table/id/field1
Content-Type: text/plain
newValue
示例(文件系统):
SET /files/directory/filename.txt/metadata
Content-Type: application/json
{
"permission": "read-write",
"timestamp": "2023-04-01T12:00:00Z"
}
在上面的例子中,PUT、GET 和 SET 对应于不同的操作,并且每个操作都需要不同的输入来执行。这些命令和输入可以根据实际的数据库或文件系统的API和协议有所不同。在实际的应用程序中,这些命令通常会通过HTTP请求或其他通信协议发送,并且可能还需要考虑权限、认证和错误处理等其他因素。
Q33. 三种神经元(分别具有 计算智能、感知智能和认知智能)分别使用 三种库模式 PUT GET 和SET 处理的是对应于三种不同目录(计算机式、图书馆式和产品式)的三种不同 不同的输入机器(计算机、感知机和传感器 ),计算 各自的索引表
在设计一个系统,其中三种不同类型的神经元(计算智能神经元、感知智能神经元和认知智能神经元)分别使用 PUT、GET 和 SET 操作来管理三种不同目录(计算机式、图书馆式和产品式)的索引表时,我们需要定义每种神经元和库模式的交互方式,以及它们如何处理各自目录中的信息。
以下是这三种神经元和三种库模式如何相互作用的概述:
计算智能神经元与计算机式目录
计算智能神经元 专注于处理和分析数据,以生成有用的信息和洞见。它使用计算能力和算法来执行复杂的数学运算和数据处理任务。
计算机式目录 是一个存储和处理大量数据的系统,类似于一个大型数据库,用于存储、检索和分析数据。
交互方式:
PUT:计算智能神经元通过 PUT 操作向计算机式目录中添加或更新数据,这些数据可能是经过处理或分析的结果。
GET:计算智能神经元使用 GET 操作从计算机式目录中检索数据,以进行进一步的分析或作为其他操作的输入。
SET:计算智能神经元通过 SET 操作配置或修改计算机式目录中的参数、设置或算法,以优化数据处理和分析过程。
感知智能神经元与图书馆式目录
感知智能神经元 负责从环境中收集信息,通过传感器和其他感知设备识别模式和特征。
图书馆式目录 是一个组织和存储知识的系统,类似于一个图书馆的分类系统,用于整理和索引各种信息。
交互方式:
PUT:感知智能神经元通过 PUT 操作将新收集的信息或感知数据添加到图书馆式目录中,可能包括图像、声音、文本等。
GET:感知智能神经元使用 GET 操作从图书馆式目录中检索相关信息,以辅助决策或提供上下文。
SET:感知智能神经元通过 SET 操作更新图书馆式目录中的信息,包括添加标签、注释或关联其他信息。
认知智能神经元与产品式目录
认知智能神经元 负责理解和解释信息,模拟人类的思维过程,并做出决策。
产品式目录 是一个包含各种产品信息和规格的系统,类似于一个电子商务网站的商品目录。
交互方式:
PUT:认知智能神经元通过 PUT 操作更新产品式目录中的产品信息,包括价格、描述、评价等。
GET:认知智能神经元使用 GET 操作从产品式目录中检索产品信息,以进行决策、推荐或响应用户查询。
SET:认知智能神经元通过 SET 操作配置产品式目录中的搜索算法、推荐系统等,以优化用户体验和提高搜索准确性。
在实际实现中,这些神经元和目录可能会以更复杂的方式相互作用,涉及多个阶段和循环。例如,计算智能神经元可能会分析感知智能神经元提供的数据,并将结果存储在计算机式目录中,然后认知智能神经元可能会使用这些数据来做出决策,并更新产品式目录中的信息。
请注意,上述描述是一个高度简化的示例,实际实现将涉及更多的细节和复杂性。此外,所提到的库模式(PUT、GET、SET)是通用的 HTTP 方法,但在实际的系统设计中,可能会有更多的自定义操作和协议来满足特定需求。
Q34. 我们前面的讨论实际上就是 要解释您提出来的问题。 您按照这句话写个代码吧:三种神经元(分别具有 计算智能、感知智能和认知智能)分别使用 三种库模式 PUT GET 和SET 处理的是对应于三种不同目录(计算机式、图书馆式和产品式)的三种不同 不同的输入机器(计算机、感知机和传感器 ),计算 各自的索引表
为了以编程方式实现前面讨论的内容,我们可以使用面向对象编程(OOP)的概念来定义三种神经元和它们与三种库模式的交互。下面是一个简化的Python示例代码,它展示了如何构建这些类和它们的基本交互:
python
# 定义三种库模式
class PutMode:def __init__(self):self.name = "PUT"def execute(self, data, target):print(f"Executing PUT on {target} with data: {data}")class GetMode:def __init__(self):self.name = "GET"def execute(self, target):print(f"Executing GET from {target}")class SetMode:def __init__(self):self.name = "SET"def execute(self, data, target):print(f"Executing SET on {target} with data: {data}")# 定义三种神经元
class ComputationalNeuron:def __init__(self):self.name = "Computational Intelligence"self.modes = {'PUT': PutMode(),'GET': GetMode(),'SET': SetMode()}def process_data(self, mode, data, target):self.modes[mode].execute(data, target)class SensoryNeuron:def __init__(self):self.name = "Sensory Intelligence"self.modes = {'PUT': PutMode(),'GET': GetMode(),'SET': SetMode()}def process_data(self, mode, data, target):self.modes[mode].execute(data, target)class CognitiveNeuron:def __init__(self):self.name = "Cognitive Intelligence"self.modes = {'PUT': PutMode(),'GET': GetMode(),'SET': SetMode()}def process_data(self, mode, data, target):self.modes[mode].execute(data, target)# 定义三种目录
class ComputerDirectory:def __init__(self):self.name = "Computer-style Directory"class LibraryDirectory:def __init__(self):self.name = "Library-style Directory"class ProductDirectory:def __init__(self):self.name = "Product-style Directory"# 模拟交互
if __name__ == "__main__":# 创建神经元和目录对象comp_neuron = ComputationalNeuron()sensory_neuron = SensoryNeuron()cognitive_neuron = CognitiveNeuron()computer_dir = ComputerDirectory()library_dir = LibraryDirectory()product_dir = ProductDirectory()# 示例交互comp_neuron.process_data('PUT', 'data1', computer_dir)sensory_neuron.process_data('GET', None, library_dir)cognitive_neuron.process_data('SET', 'config_update', product_dir)在这个代码中,我们定义了三种神经元类(ComputationalNeuron, SensoryNeuron, CognitiveNeuron)和三种库模式类(PutMode, GetMode, SetMode)。每种神经元都有一个process_data方法,该方法接受一个库模式、数据和目标目录作为参数,并使用相应的库模式来执行操作。
我们还定义了三种目录类(ComputerDirectory, LibraryDirectory, ProductDirectory),尽管在这个简化的例子中它们并没有实际的功能,只是作为目标对象来展示神经元与它们的交互。
在if __name__ == "__main__"块中,我们创建了这些类的实例,并模拟了神经元与目录之间的交互。例如,计算智能神经元向计算机式目录添加数据,感知智能神经元从图书馆式目录检索信息,认知智能神经元更新产品式目录的配置。
请注意,这个代码仅仅是一个起点,实际的实现会涉及更多的细节和复杂性,包括错误处理、数据验证、异步操作等。此外,神经元和目录的具体行为将取决于它们在实际应用中的具体需求和设计。
相关文章:
)
全量知识系统 程序详细设计 之 三种“活物” 之1(QA百度搜索 )
Q1. 今天聊聊 全知系统中 三种“活物”。先从他们的一个简单描述开始: 自主:计算机“集群”的“沉”与“浮”; 自然:AI “众生”的“世”和“界” ;自由:人类 “公民”的“宇”或“宙”。 全知系统中的三…...

QT 线程之movetothread
上文列举了qt中线程的几种方法,其中2种方法最为常见。 这两种方法都少不了QThread类,前者继承于QThread类,后者复合QThread类。 本文以实例的方式描述了movetothread()这种线程的方法,将QObject的子类移动…...

如何处理ubuntu22.04LTS安装过程中出现“Daemons using outdated libraries”提示
Ubuntu 22.04 LTS 中使用命令行升级软件或安装任何新软件时,您可能收到“Daemons using outdated libraries”,“Which services should be restarted?”的提示,提示下面列出备选的重启服务,如下。 使用以下命令,能够…...
跟TED演讲学英文:The inside story of ChatGPT‘s astonishing potential by Greg Brockman
The inside story of ChatGPT’s astonishing potential Link: https://www.ted.com/talks/greg_brockman_the_inside_story_of_chatgpt_s_astonishing_potential Speaker: Greg Brockman Date:April 2023 文章目录 The inside story of ChatGPTs astonishing potentialIntro…...

mybatis05:复杂查询:(多对一,一对多)
mybatis05:复杂查询:(多对一,一对多) 文章目录 mybatis05:复杂查询:(多对一,一对多)前言:多对一 : 关联 : 使用associatio…...

微电网优化:基于肝癌算法(Liver Cancer algorithm, LCA)的微电网优化(提供MATLAB代码)
一、微电网优化模型 微电网是一个相对独立的本地化电力单元,用户现场的分布式发电可以支持用电需求。为此,您的微电网将接入、监控、预测和控制您本地的分布式能源系统,同时强化供电系统的弹性,保障您的用电更经济。您可以在连接…...

VUE_H5页面跳转第三方地图导航,兼容微信浏览器
当前项目是uniapp项目,若不是需要替换uni.showActionSheet选择api onMap(address , organName , longitude 0, latitude 0){var ua navigator.userAgent.toLowerCase();var isWeixin ua.indexOf(micromessenger) ! -1;if(isWeixin) {const mapUrl_tx "…...

智慧安全运营:智能化运维,确保服务无忧
智慧安全运营:智能化运维,确保服务无忧 中国联通新一代全球智云数据中心采用先进的智能化运维管理系统,实现对数据中心设施、IT设备、能源消耗、环境参数等全方位、实时监控。通过物联网技术、人工智能算法以及大数据分析,运维团…...

R-tree总结
引言: 在处理空间数据和地理信息系统(GIS)中,高效的空间索引机制对于提升查询性能至关重要。R-tree是一种流行的平衡树数据结构,专门用于索引多维信息,如二维的地理坐标或三维的物体位置。它以其灵活性、高…...

Python 与机器学习,在服务器使用过程中,常用的 Linux 命令包括哪些?
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 本博客旨在分享在实际开发过程中,开发者需要了解并熟练运用的 Linux 操作系统常用命令。Linux 作为一种操作系统,与 Windows 或 MacOS 并驾齐驱,尤其在服务器和开发环…...

js通过Object.defineProperty实现数据响应式
目录 数据响应式属性描述符propertyResponsive 依赖收集依赖队列寻找依赖 观察器 派发更新Observer完整代码关于数据响应式关于Object.defineProperty的限制 数据响应式 假设我们现在有这么一个页面 <!DOCTYPE html> <html lang"en"><head><m…...
docker最简单教程(使用dockerfile构建环境)
一 手里有的东西 安装好的docker+dockerfile 二 操作 只需要在你的dockerfile文件下执行命令 docker build -t="xianhu/centos:gitdir" . 将用户名、操作系统和tag进行修改就可以了,这就相当于在你本地安装了一个docker环境,然后执行 docker run -it xianhu/ce…...

Vue2 —— 学习(三)
目录 一、绑定 class 样式 (一)字符串写法 1.流程介绍 2.代码实现 (二)数组写法 1.流程介绍 2.代码实现 (三)对象写法 1.流程介绍 2.代码实现 二、绑定 style 样式(了解ÿ…...
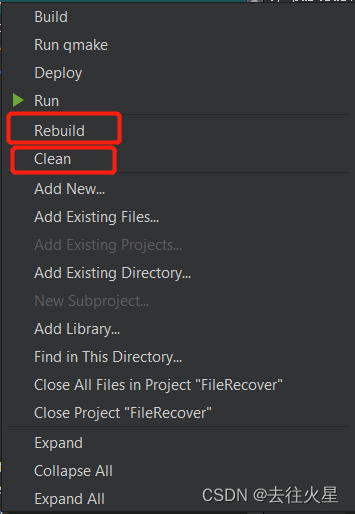
Qt Creator 12.0.2 debug 无法查看变量的值 Expression too Complex
鼠标放在局部变量上提示“expression too complex”。 在调试窗口也看不到局部变量的值。 这应该是qt的一个bug,https://bugreports.qt.io/browse/QTCREATORBUG-24180 暂时解决方法: 如下图,需要右键项目然后执行"Clean"和&quo…...
LeetCode-Java:303、304区域检索(前缀和)
文章目录 题目303、区域和检索(数组不可变)304、二维区域和检索(矩阵不可变) 解①303,一维前缀和②304,二维前缀和 算法前缀和一维前缀和二维前缀和 题目 303、区域和检索(数组不可变ÿ…...

出海业务的网络安全挑战
出海业务的扩展带来了巨大的市场机遇,同时也带来了不少网络安全挑战: 数据泄露与隐私保护:跨境数据传输增加了数据被截获和泄露的风险。地理位置限制和审查:某些地区的网络审查和地理位置限制可能阻碍企业正常开展业务。网络攻击…...

蓝桥杯考前准备— — c/c++
蓝桥杯考前准备— — c/c 对于输入输出函数 如果题目中有要求规定输入数据的格式与输出数据的格式,最好使用scanf()和prinrf()函数。 例如:输入的数据是 2020-02-18,则使用scanf("%d-%d-%d",&year,&mouth,&day)即可…...
【MATLAB源码-第4期】基于MATLAB的1024QAM误码率曲线,以及星座图展示。
1、算法描述 正交幅度调制(QAM,Quadrature Amplitude Modulation)是一种在两个正交载波上进行幅度调制的调制方式。这两个载波通常是相位差为90度(π/2)的正弦波,因此被称作正交载波。这种调制方式因此而得…...
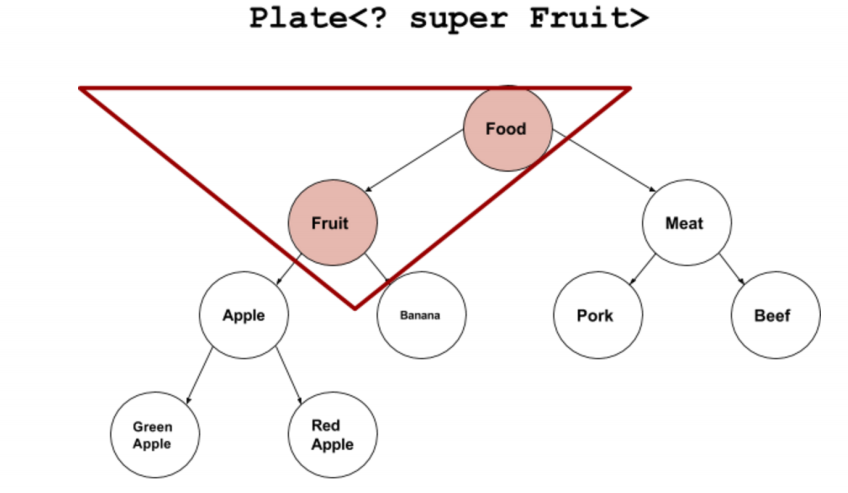
数据结构-----枚举、泛型进阶(通配符?)
文章目录 枚举1 背景及定义2 使用3 枚举优点缺点4 枚举和反射4.1 枚举是否可以通过反射,拿到实例对象呢? 5 总结 泛型进阶1 通配符 ?1.1 通配符解决什么问题1.2 通配符上界1.3 通配符下界 枚举 1 背景及定义 枚举是在JDK1.5以后引入的。主要用途是&am…...

线上问题监控 Sentry 接入全过程
背景: 线上偶发问题出现后 ,测试人员仅通过接口信息无法复现错误场景;并且线上环境的监控,对于提高系统的稳定性 (降低脱发率) 至关重要;现在线上监控工具这个多,为什么选择Sentry?…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

Java多线程实现之Callable接口深度解析
Java多线程实现之Callable接口深度解析 一、Callable接口概述1.1 接口定义1.2 与Runnable接口的对比1.3 Future接口与FutureTask类 二、Callable接口的基本使用方法2.1 传统方式实现Callable接口2.2 使用Lambda表达式简化Callable实现2.3 使用FutureTask类执行Callable任务 三、…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

Kafka主题运维全指南:从基础配置到故障处理
#作者:张桐瑞 文章目录 主题日常管理1. 修改主题分区。2. 修改主题级别参数。3. 变更副本数。4. 修改主题限速。5.主题分区迁移。6. 常见主题错误处理常见错误1:主题删除失败。常见错误2:__consumer_offsets占用太多的磁盘。 主题日常管理 …...
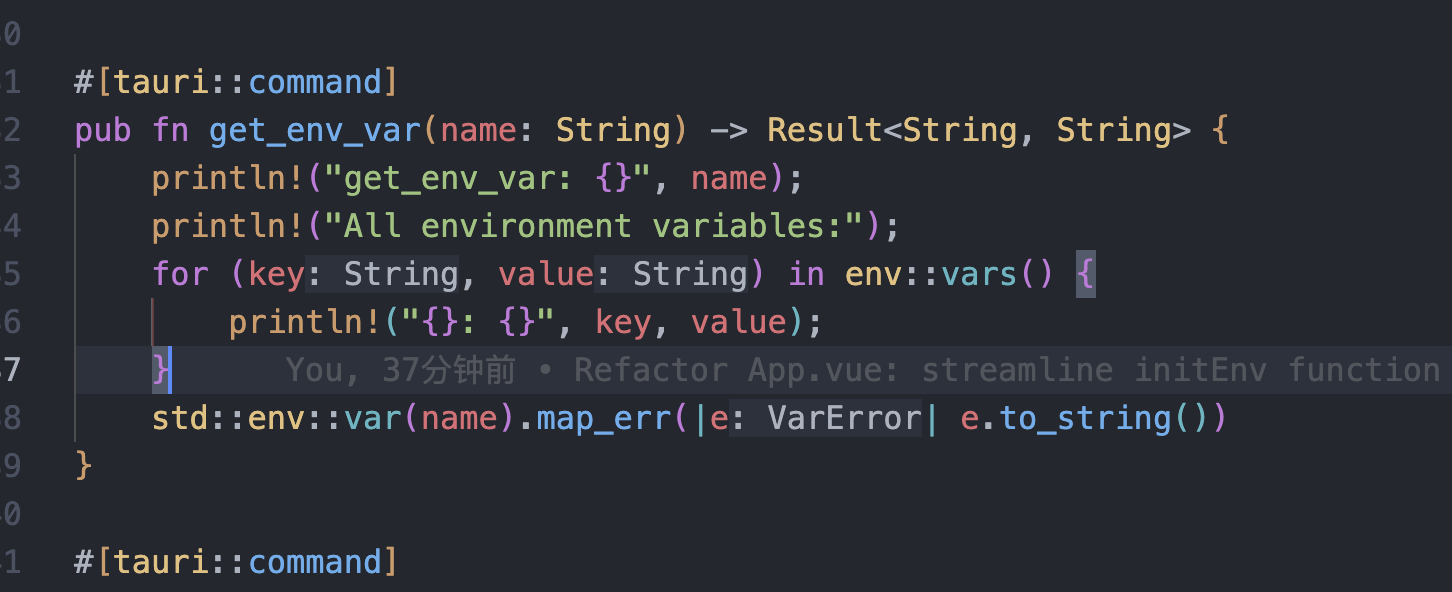
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...