深入探索自然语言处理:用Python和BERT构建文本分类模型
在当今的信息时代,自然语言处理(NLP)技术正在改变我们理解和处理自然语言的方式。NLP使计算机能够解读、理解和生成人类语言,从而在多种应用中实现自动化,如聊天机器人、情感分析和文本分类。本文将详细介绍如何使用Python和BERT(Bidirectional Encoder Representations from Transformers)模型来构建一个高效的文本分类系统。
## 自然语言处理简介
自然语言处理是人工智能领域的一个重要分支,它涉及计算机和人类(自然)语言之间的交互。文本分类是NLP的一个常见任务,它的目的是将文本数据按照预定的分类标签进行分类。
## 开发环境设置
在开始之前,确保你的Python环境中已安装了以下库:
- TensorFlow:一个由Google开发的强大的机器学习库。
- Transformers:提供预训练模型如BERT进行NLP任务的库。
您可以使用pip命令安装这些库:
```bash
pip install tensorflow transformers
```
## 选择数据集
为了本教程,我们将使用“20 Newsgroups”数据集,这是一个用于文本分类的常见数据集,包含20个不同主题的新闻组文章。
## 加载和预处理数据
首先,我们需要加载数据集并进行必要的预处理,以适应BERT模型的输入要求。
```python
from transformers import BertTokenizer
from sklearn.datasets import fetch_20newsgroups
# 加载数据集
data = fetch_20newsgroups(subset='all')['data']
# 初始化BERT分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 分词处理
tokens = [tokenizer.encode(text, max_length=512, truncation=True, padding='max_length') for text in data]
```
## 构建模型
使用TensorFlow和Transformers库构建BERT模型。
```python
import tensorflow as tf
from transformers import TFBertModel
# 加载预训练的BERT模型
bert = TFBertModel.from_pretrained('bert-base-uncased')
# 构建用于文本分类的模型
input_ids = tf.keras.Input(shape=(512,), dtype='int32')
attention_masks = tf.keras.Input(shape=(512,), dtype='int32')
output = bert(input_ids, attention_mask=attention_masks)[1]
output = tf.keras.layers.Dense(20, activation='softmax')(output)
model = tf.keras.Model(inputs=[input_ids, attention_masks], outputs=output)
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
```
## 训练模型
准备输入数据并训练模型。
```python
import numpy as np
# 划分训练集和测试集
train_tokens, test_tokens, train_labels, test_labels = train_test_split(tokens, labels, test_size=0.1)
# 训练模型
model.fit([np.array(train_tokens), np.zeros_like(train_tokens)], np.array(train_labels), epochs=3, batch_size=8)
# 评估模型
model.evaluate([np.array(test_tokens), np.zeros_like(test_tokens)], np.array(test_labels))
```
## 结论
通过这个示例,我们展示了如何利用BERT和TensorFlow来构建一个强大的文本分类模型。这只是自然语言处理可以达到的浅层应用之一。随着模型和技术的不断进步,NLP的应用领域将持续扩展,为各行各业带来革命性的变革。不断学习和实验是掌握NLP技术的关键,期待每位读者都能在这一领域发光发热。
这篇教程不仅介绍了NLP的基础知识和BERT的应用,还通过实际代码示例指导了如何实现复
杂的NLP任务,帮助读者从理论走向实践,开启AI和机器学习的探索之旅。
相关文章:

深入探索自然语言处理:用Python和BERT构建文本分类模型
在当今的信息时代,自然语言处理(NLP)技术正在改变我们理解和处理自然语言的方式。NLP使计算机能够解读、理解和生成人类语言,从而在多种应用中实现自动化,如聊天机器人、情感分析和文本分类。本文将详细介绍如何使用Py…...

在Visual Studio Code中编辑React项目时,以下是一些推荐的扩展
ESLint:这个扩展可以集成ESLint到VS Code中,帮助你在编写代码时发现和修复JavaScript和TypeScript的语法错误和代码风格问题。 Prettier - Code formatter:Prettier是一个代码格式化工具,可以自动格式化你的代码以保持一致的代码…...
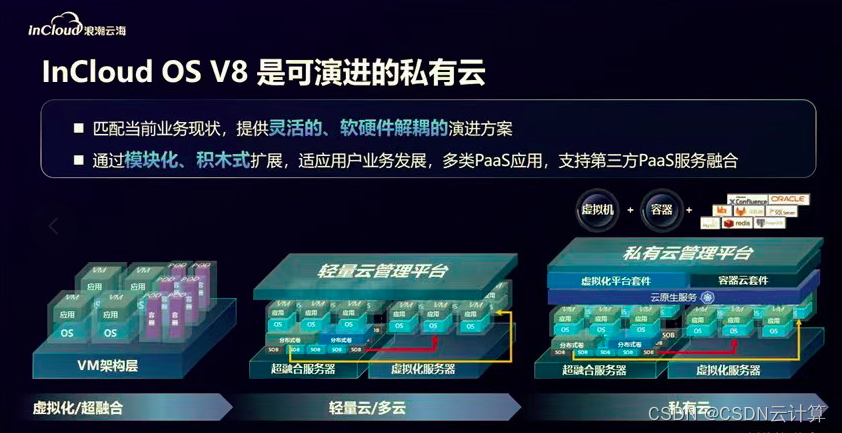
智算时代的基础设施如何实现可继承可演进?浪潮云海发布 InCloud OS V8 新一代架构平台
从 2023 年开始持续火爆的 AIGC 正在加速落地应用,为全行业带来生产生活效率的变革与升级。面对数字化转型与智能化转型,对于技术团队来说,既要根据业务与 AI 应用去部署以云为基础的 AI 算力,又要与已有数据和系统(甚…...

LDF、DBC、BIN、HEX、S19、BLF、ARXML、slx等
文章目录 如题 如题 LDF是LIN报文格式文件,把这个直接拖到软件里面,可以发报文和接收报文 DBC是CAN报文格式文件,把这个直接拖到软件里面,可以发报文和接收报文 BIN文件烧录在BOOT里面(stm32),…...
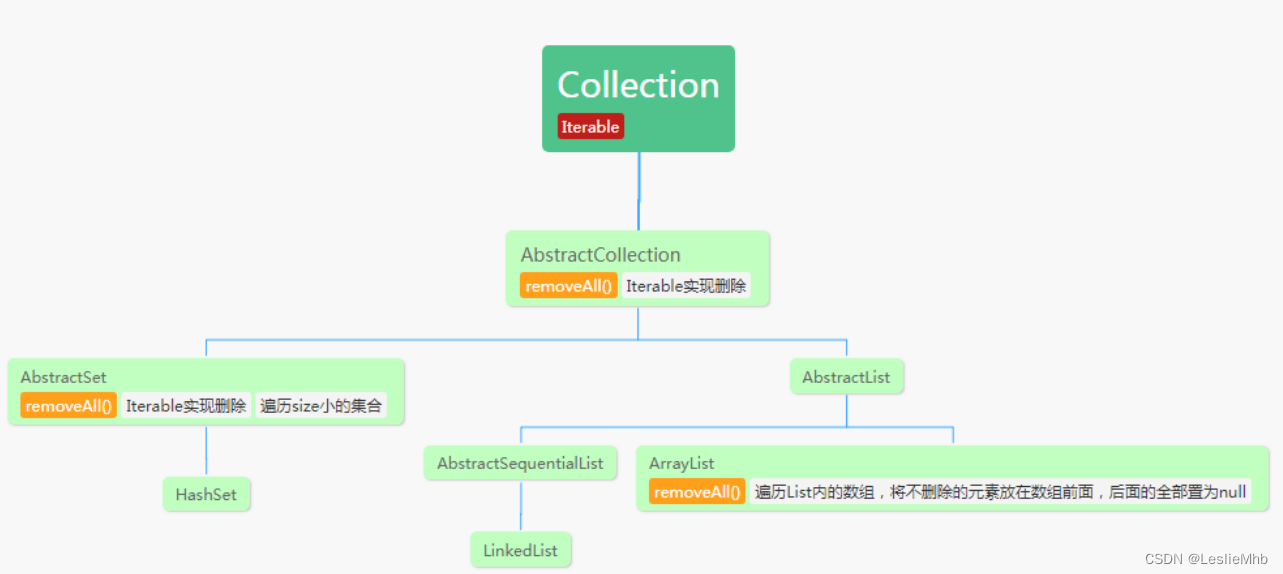
因为使用ArrayList.removeAll(List list)导致的机器重启
背景 先说一下背景,博主所在的业务组有一个核心系统,需要同步两个不同数据源给过来的数据到redis中,但是每次同步之前需要过滤掉一部分数据,只存储剩下的数据。每次同步的数据与需要过滤掉的数据量级大概在0-100w的数据不等。 由…...
Let‘s Encrypt
创建文件夹 mkdir /usr/local/develop/ 安装Certbot客户端 yum install certbot 首先确保example.com和www.example.com这两个域名通过DNS解析绑定了你的web 服务器的公网 IP 就是说先要完成域名解析到服务器 下面命令会验证 /var/www/example 他会将一些命令文件存在…...

C语言 | Leetcode C语言题解之第24题两两交换链表中的节点
题目: 题解: struct ListNode* swapPairs(struct ListNode* head) {struct ListNode dummyHead;dummyHead.next head;struct ListNode* temp &dummyHead;while (temp->next ! NULL && temp->next->next ! NULL) {struct ListNod…...

【LeetCode热题100】【回溯】电话号码的字母组合
题目链接:17. 电话号码的字母组合 - 力扣(LeetCode) 组合的过程是一个长树的过程,可以用深度遍历实现,每一个数字对应的字符串都是一层,一种字母组合就是一条路径,当递归的深度达到层数就找到了…...

解析mysql的DDL语句生成高斯内表及表字段主键配置
mysql的DDL语句如下: CREATE TABLE gg_zr (id bigint(20) NOT NULL COMMENT 责任信息表主键id,zrdm varchar(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL COMMENT 责任代码,zrmc varchar(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAU…...

ANSYS Electromagnetics Suite 2023 R2 三维电磁(EM)仿真软件下载
Ansys家最新的三维电磁(EM)仿真软件ANSYS Electromagnetics Suite 2023 R2日前发布了,老wu这次分享得有点晚  ̄ω ̄,现在已经将资源上传到了网盘供大家免费下载,同时,为了让大家都能与…...
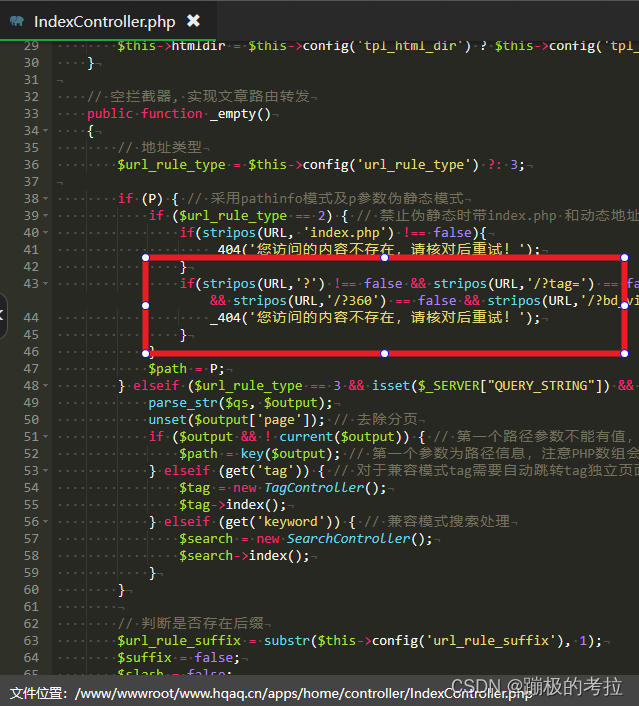
pbootcms百度推广链接打不开显示404错误页面
PbootCMS官方在2023年4月21日的版本更新中(对应V3.2.5版本),对URL参数添加了如下判断 if(stripos(URL,?) ! false && stripos(URL,/?tag) false && stripos(URL,/?page) false && stripos(URL,/?ext_) false…...
springboot 整合 swagger2
整合步骤 pom 添加依赖 <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version></dependency><dependency><groupId>io.springfox</groupId>&…...
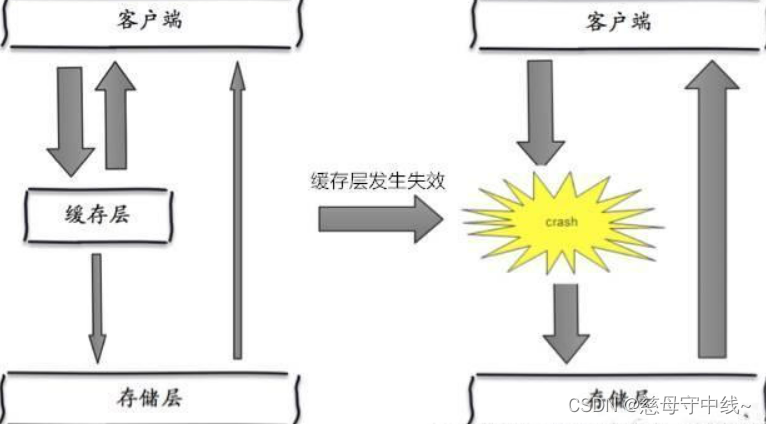
redis-缓存穿透与雪崩
一,缓存穿透(查不到) 在默认情况下,用户请求数据时,会先在缓存(Redis)中查找,若没找到即缓存未命中,再在数据库中进行查找,数量少可能问题不大,可是一旦大量的请求数据&a…...
)
K8S临时存储-本地存储-PV和PVC的使用-动态存储(StorageClass)
介绍 容器中的文件在磁盘上是临时存放的,当容器崩溃或停止时容器上面的数据未保存, 因此在容器生命周期内创建或修改的所有文件都将丢失。 在崩溃期间,kubelet 会以干净的状态重新启动容器。 当多个容器在一个 Pod 中运行并且需要共享文件时…...
jeecg-boot安装
我看大家都挺关注,所以集中上传了下代码和相关工具,方便大家快速完成 链接:https://pan.baidu.com/s/1-Y9yHVZ-4DQFDjPBWUk4-A 提取码:op1r 1. 下载代码 下载地址 : JEECG官方网站 - 基于BPM的低代码开发平台(低代码平台_零代…...

Unity面经(自整)——移动开发与Shader
Unity与Android混合开发 为什么使用Flutter构建 Flutter 是 Google 的开源工具包,用于从单个代码库为移动、Web、桌面和嵌入式设备构建应用程序(一套代码跨平台构建app是它最大的优点),并且可以构建高性能、稳定和丰富UI的应用程…...

Nginx实现反向代理、负载均衡、动静分离
1. 什么是Nginx的反向代理? Nginx的反向代理是指Nginx作为服务器的前端,接收客户端的请求,然后将请求转发给后端的真实服务器,并将真实服务器的响应返回给客户端。这种代理方式使得客户端并不知道真实服务器的存在,它…...
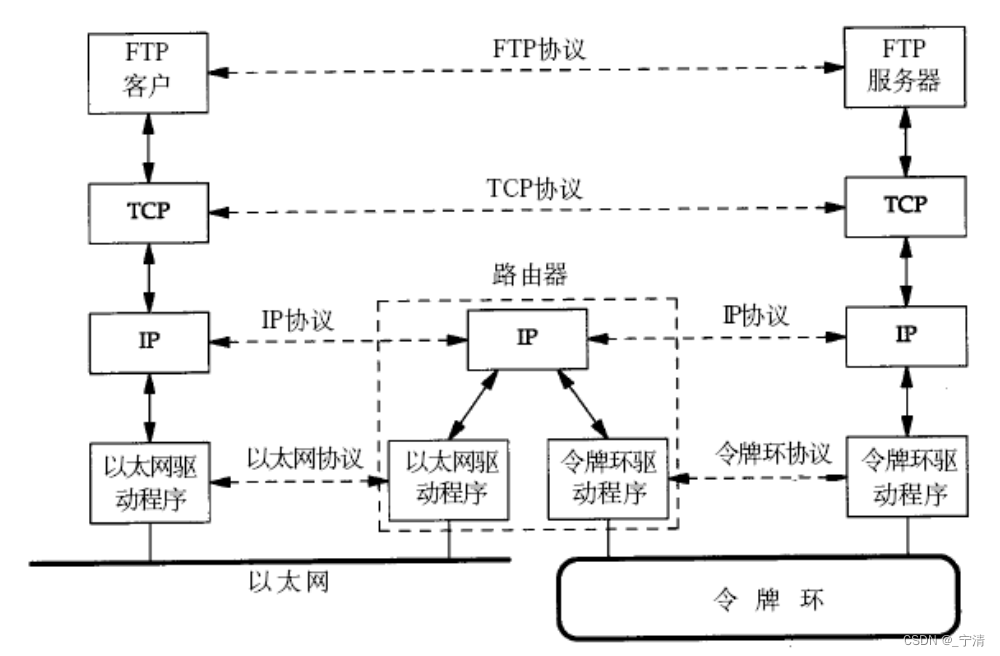
【Linux】网络基础(一)
文章目录 一、计算机网络背景1. 网络发展2. 认识“协议” 二、网络协议初识1. 协议分层2. OSI七层模型3. TCP/IP五层(或四层)模型 三、网络传输基本流程1. 同局域网的两台主机通信数据包封装和分用封装分用 2. 跨网络的两台主机通信 四、网络中的地址管理…...
)
前端小白学习Vue框架(二)
一.属性计算、属性监听、属性过滤 1.认识MVVM V (用户视图界面)通过VM (应用程序) 向Model(数据模型) 取值与赋值的过程! 数据双向绑定 视图改变更新数据,数据改变更新视图 2.属性计算 //在vue实例中通过computed去计算new …...

飞书api增加权限
1,进入飞书开发者后台:飞书开放平台 给应用增加权限 2,进入飞书管理后台 https://fw5slkpbyb3.feishu.cn/admin/appCenter/audit 审核最新发布的版本 如果还是不行,则需要修改数据权限,修改为全部成员可修改。 改完…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...

页面渲染流程与性能优化
页面渲染流程与性能优化详解(完整版) 一、现代浏览器渲染流程(详细说明) 1. 构建DOM树 浏览器接收到HTML文档后,会逐步解析并构建DOM(Document Object Model)树。具体过程如下: (…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

ip子接口配置及删除
配置永久生效的子接口,2个IP 都可以登录你这一台服务器。重启不失效。 永久的 [应用] vi /etc/sysconfig/network-scripts/ifcfg-eth0修改文件内内容 TYPE"Ethernet" BOOTPROTO"none" NAME"eth0" DEVICE"eth0" ONBOOT&q…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...

数学建模-滑翔伞伞翼面积的设计,运动状态计算和优化 !
我们考虑滑翔伞的伞翼面积设计问题以及运动状态描述。滑翔伞的性能主要取决于伞翼面积、气动特性以及飞行员的重量。我们的目标是建立数学模型来描述滑翔伞的运动状态,并优化伞翼面积的设计。 一、问题分析 滑翔伞在飞行过程中受到重力、升力和阻力的作用。升力和阻力与伞翼面…...