分布式技术---------------消息队列中间件之 Kafka
目录
一、Kafka 概述
1.1为什么需要消息队列(MQ)
1.2使用消息队列的好处
1.2.1解耦
1.2.2可恢复性
1.2.3缓冲
1.2.4灵活性 & 峰值处理能力
1.2.5异步通信
1.3消息队列的两种模式
1.3.1点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
1.3.2发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
二、Kafka
2.1Kafka 定义
2.2Kafka 简介
2.3Kafka 的特性
2.3.1高吞吐量、低延迟
2.3.2可扩展性
2.3.3持久性、可靠性
2.3.4容错性
2.3.5高并发
三、Kafka 系统架构
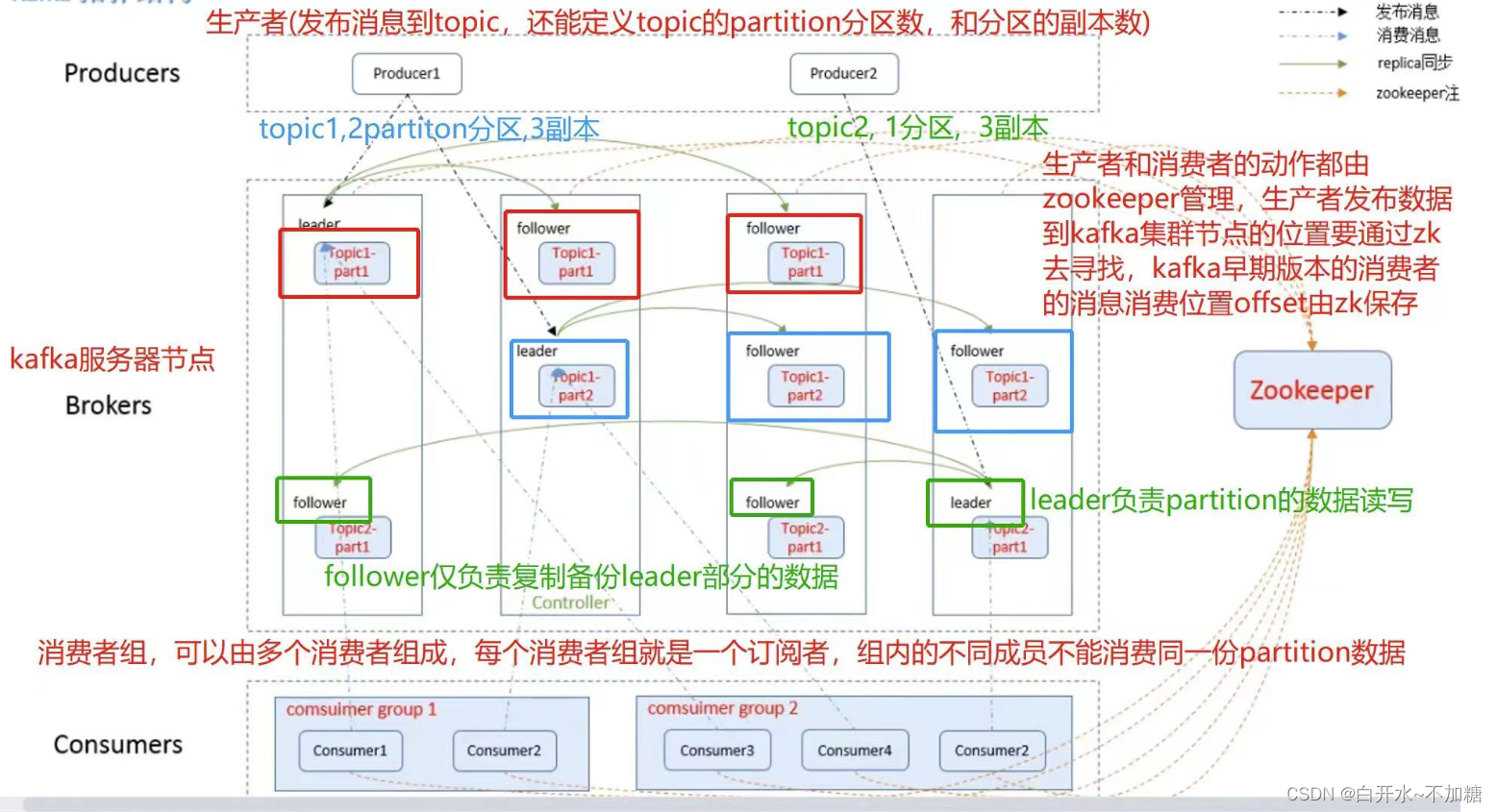
3.1Broker 服务器
3.2Topic 主题
3.3Partition 分区
3.3.1Partation 数据路由规则
3.3.2分区的原因
提高并发分区的原因
(1)Replica
(2)Leader
(3)Follower
(4) producer
(5)Consumer
(6)Consumer Group(CG)消费者组,由多个 consumer 组成。
(7)offset 偏移量
(8)Zookeeper
四、部署Zookeeper+ kafka 集群
4.1下载Kafka安装包
4.2安装 Kafka
4.3修改配置文件
4.4拷贝到其他主机进行配置
4.5修改环境变量
4.6配置 Zookeeper 启动脚本
4.7设置开机自启
4.8分别启动 Kafka
4.9Kafka 命令行操作
4.9.1创建topic
4.9.3查看当前服务器中的所有 topic
4.9.4查看某个 topic 的详情
4.9.5发布消息
4.9.6消费消息
4.9.7修改分区数
4.9.8删除 topic
五、数据可靠性保证
六、数据一致性问题
6.1follower 故障
6.2leader 故障
七、ack 应答机制
八、kafka报错分析
一、Kafka 概述
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
1.1为什么需要消息队列(MQ)
- 主要原因是由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞
- 比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
- 我们使用消息队列,通过异步处理请求,从而缓解系统的压力。
- 消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
雪崩:高并发情况下redis服务器无法同时处理大量请求,导致rdis崩溃直接查询数据库。
1.2使用消息队列的好处
1.2.1解耦
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
1.2.2可恢复性
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
1.2.3缓冲
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
1.2.4灵活性 & 峰值处理能力
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
1.2.5异步通信
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
1.3消息队列的两种模式
1.3.1点对点模式(一对一,消费者主动拉取数据,消息收到后消息清除)
消息生产者生产消息发送到消息队列中,然后消息消费者从消息队列中取出并且消费消息。消息被消费以后,消息队列中不再有存储,所以消息消费者不可能消费到已经被消费的消息。消息队列支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
点对点(一对一):消费者主动拉取数据,消费者将生产者生成的数据拉取完成则消费者将消息删除
1.3.2发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
消息生产者(发布)将消息发布到 topic 中,同时有多个消息消费者(订阅)消费该消息。
和点对点方式不同,发布到 topic 的消息会被所有订阅者消费。
发布/订阅模式是定义对象间一种一对多的依赖关系,使得每当一个对象(目对标象)的状态发生改变,则所有依赖于它的对象(观察者对象)都会得到通知并自动更新。
发布/订阅模式(一对多,又叫观察者模式,消费者消费数据之后不会清除消息)
二、Kafka
2.1Kafka 定义
Kafka 是一个分布式的基于发布/订阅模式的消息队列(MQ,Message Queue),主要应用于大数据实时处理领域
2.2Kafka 简介
Kafka 是最初由 Linkedin 公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于 Zookeeper 协调的分布式消息中间件系统
它的最大的特性就是可以实时的处理大量数据以满足各种需求场景,比如基于 hadoop 的批处理系统、低延迟的实时系统、Spark/Flink 流式处理引擎,nginx 访问日志,消息服务等等,
用 scala 语言编写,Linkedin 于 2010 年贡献给了 Apache 基金会并成为顶级开源项目。
2.3Kafka 的特性
2.3.1高吞吐量、低延迟
Kafka 每秒可以处理几十万条消息,它的延迟最低只有几毫秒。
每个 topic 可以分多个 Partition,Consumer Group 对 Partition 进行消费操作,提高负载均衡能力和消费能力
2.3.2可扩展性
kafka 集群支持热扩展
热扩展(数据在运行中可以不用停掉服务)
2.3.3持久性、可靠性
消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
2.3.4容错性
允许集群中节点失败(多副本情况下,若副本数量为 n,则允许 n-1 个节点失败)
2.3.5高并发
支持数千个客户端同时读写
三、Kafka 系统架构
3.1Broker 服务器
- 一台 kafka 服务器就是一个 broker
- 一个集群由多个 broker 组成
- 一个 broker 可以容纳多个 topic
3.2Topic 主题
- 可以理解为一个队列,生产者和消费者面向的都是一个 topic
- 类似于数据库的表名或者 ES 的 index
- 物理上不同 topic 的消息分开存储
topic:主题。每一个消息都属于某个主题,kafka通过主题来划分消息,是一个逻辑上的分类
3.3Partition 分区
为了实现扩展性,一个非常大的 topic 可以分布到多个 broker(即服务器)上,一个 topic 可以分割为一个或多个 partition,每个 partition 是一个有序的队列
Kafka 只保证 partition 内的记录是有序的,而不保证 topic 中不同 partition 的顺序。
每个 topic 至少有一个 partition,当生产者产生数据的时候,会根据分配策略选择分区,然后将消息追加到指定的分区的队列末尾
3.3.1Partation 数据路由规则
1.指定了 patition,则直接使用;
2.未指定 patition 但指定 key(相当于消息中某个属性),通过对 key 的 value 进行 hash 取模,选出一个 patition;
3.patition 和 key 都未指定,使用轮询选出一个 patition。
每条消息都会有一个自增的编号,用于标识消息的偏移量,标识顺序从 0 开始
每个 partition 中的数据使用多个 segment 文件存储
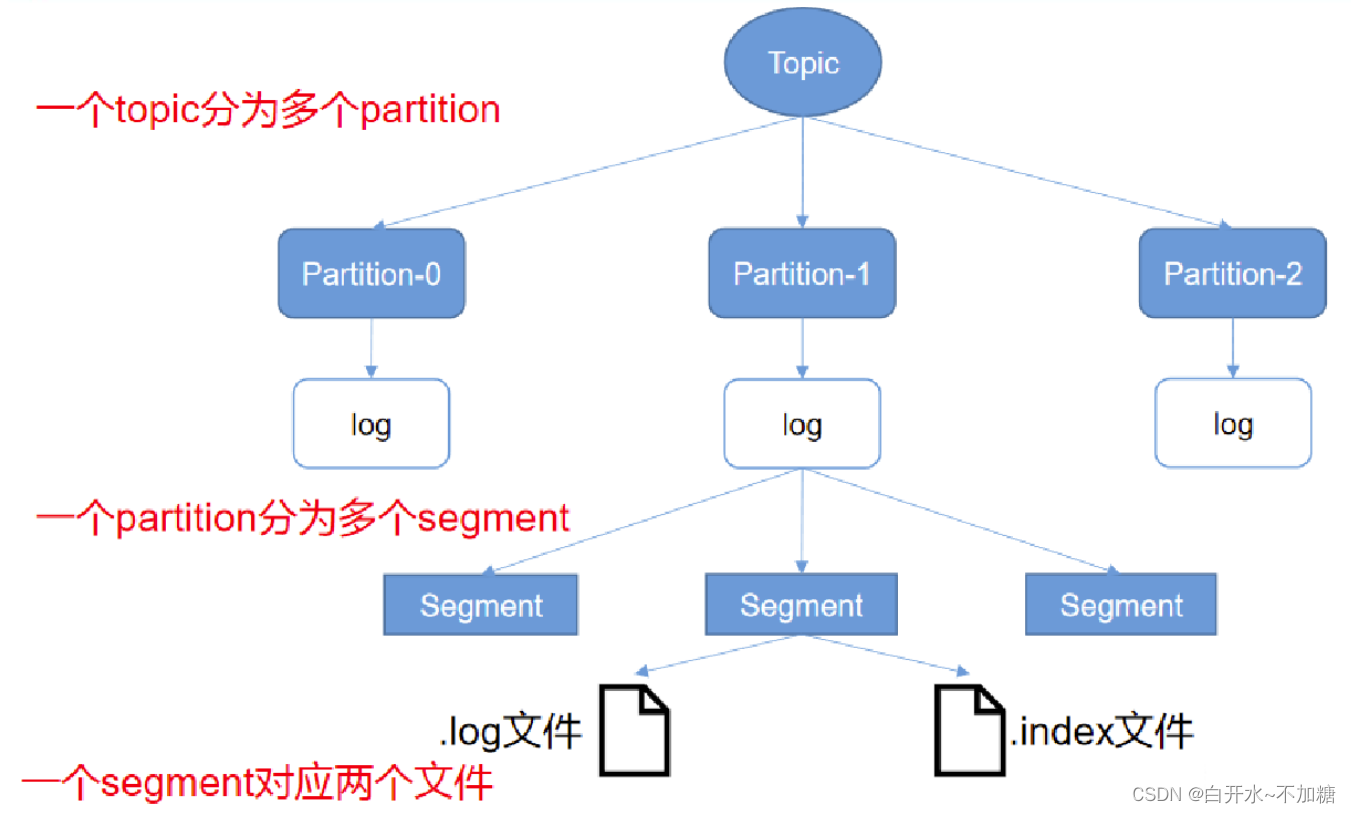
如果 topic 有多个 partition,消费数据时就不能保证数据的顺序。严格保证消息的消费顺序的场景下(例如商品秒杀、 抢红包),需要将 partition 数目设为 1。
●broker 存储 topic 的数据。如果某 topic 有 N 个 partition,集群有 N 个 broker,那么每个 broker 存储该 topic 的一个 partition。
●如果某 topic 有 N 个 partition,集群有 (N+M) 个 broker,那么其中有 N 个 broker 存储 topic 的一个 partition, 剩下的 M 个 broker 不存储该 topic 的 partition 数据。
●如果某 topic 有 N 个 partition,集群中 broker 数目少于 N 个,那么一个 broker 存储该 topic 的一个或多个 partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
3.3.2分区的原因
- 方便在集群中扩展,每个Partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
- 可以提高并发,因为可以以Partition为单位读写了
提高并发分区的原因
(1)Replica
副本,为保证集群中的某个节点发生故障时,该节点上的 partition 数据不丢失,且 kafka 仍然能够继续工作,kafka 提供了副本机制,一个 topic 的每个分区都有若干个副本,一个 leader 和若干个 follower
Replica:副本,一个分区可以有多个副本来提高容灾性,一般是设置一个分区2个副本
(2)Leader
每个 partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责数据的读写的 partition
(3)Follower
Follower 跟随 Leader,所有写请求都通过 Leader 路由,数据变更会广播给所有 Follower,Follower 与 Leader 保持数据同步。Follower 只负责备份,不负责数据的读写
如果 Leader 故障,则从 Follower 中选举出一个新的 Leader。
当 Follower 挂掉、卡住或者同步太慢,Leader 会把这个 Follower 从 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合) 列表中删除,重新创建一个 Follower。
leader负责读写,follow只负责复制和备份
(4) producer
生产者即数据的发布者,该角色将消息 push 发布到 Kafka 的 topic 中。
broker 接收到生产者发送的消息后,broker 将该消息追加到当前用于追加数据的 segment 文件中。
生产者发送的消息,存储到一个 partition 中,生产者也可以指定数据存储的 partition。
生产者,也就是写入消息的一方,将消息写入broker中
(5)Consumer
消费者可以从 broker 中 pull 拉取数据。消费者可以消费多个 topic 中的数据。
消费者,也就是读取消息的一方,从broker中读取消息
(6)Consumer Group(CG)消费者组,由多个 consumer 组成。
所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
可为每个消费者指定组名,若不指定组名则属于默认的组。
将多个消费者集中到一起去处理某一个 Topic 的数据,可以更快的提高数据的消费能力。
消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费,防止数据被重复读取。
消费者组之间互不影响
(7)offset 偏移量
可以唯一的标识一条消息
偏移量决定读取数据的位置,不会有线程安全的问题,消费者通过偏移量来决定下次读取的消息(即消费位置)
消息被消费之后,并不被马上删除,这样多个业务就可以重复使用 Kafka 的消息。
某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制。
消息最终还是会被删除的,默认生命周期为 1 周(7*24小时)
Offset:偏移量。消费者存在zookeeper上的记录自己访问到什么地方
(8)Zookeeper
Kafka 通过 Zookeeper 来存储集群的 meta 信息。
Zookeeper:kafka使用zookeeper来管理集群的元数据,以及控制器的选举等操作
meta:元信息
由于 consumer 在消费过程中可能会出现断电宕机等故障,consumer 恢复后,需要从故障前的位置的继续消费,所以 consumer 需要实时记录自己消费到了哪个 offset,以便故障恢复后继续消费。
Kafka 0.9 版本之前,consumer 默认将 offset 保存在 Zookeeper 中;从 0.9 版本开始,consumer 默认将 offset 保存在 Kafka 一个内置的 topic 中,该 topic 为 __consumer_offsets。
也就是说,zookeeper的作用就是,生产者push数据到kafka集群,就必须要找到kafka集群的节点在哪里,这些都是通过zookeeper去寻找的。消费者消费哪一条数据,也需要zookeeper的支持,从zookeeper获得offset,offset记录上一次消费的数据消费到哪里,这样就可以接着下一条数据进行消费
四、部署Zookeeper+ kafka 集群
(架构在Zookeeper集群之上搭建)
主机名 ip地址 安装软件 系统版本 zk_kfk1 192.168.246.7 apache-zookeeper-3.5.7-bin.tar.gz
kafka_2.13-2.7.1.tgz
centos7 zk_kfk2 192.168.246.9 apache-zookeeper-3.5.7-bin.tar.gz
kafka_2.13-2.7.1.tgz
centos7 zk_kfk3 192.168.246.12 apache-zookeeper-3.5.7-bin.tar.gz
kafka_2.13-2.7.1.tgz
centos7
1.下载安装包
官方下载地址:http://kafka.apache.org/downloads.htmlcd /opt
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz2.安装 Kafka
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka//修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}vim server.properties
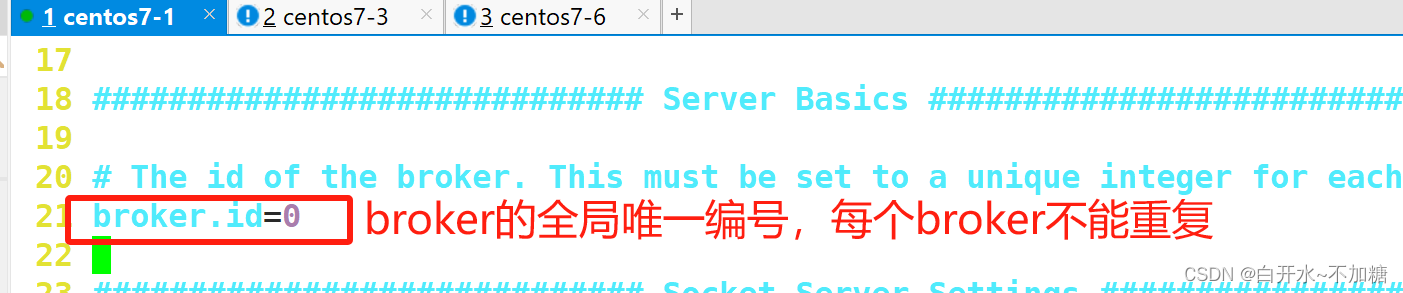
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.10.17:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168 #103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
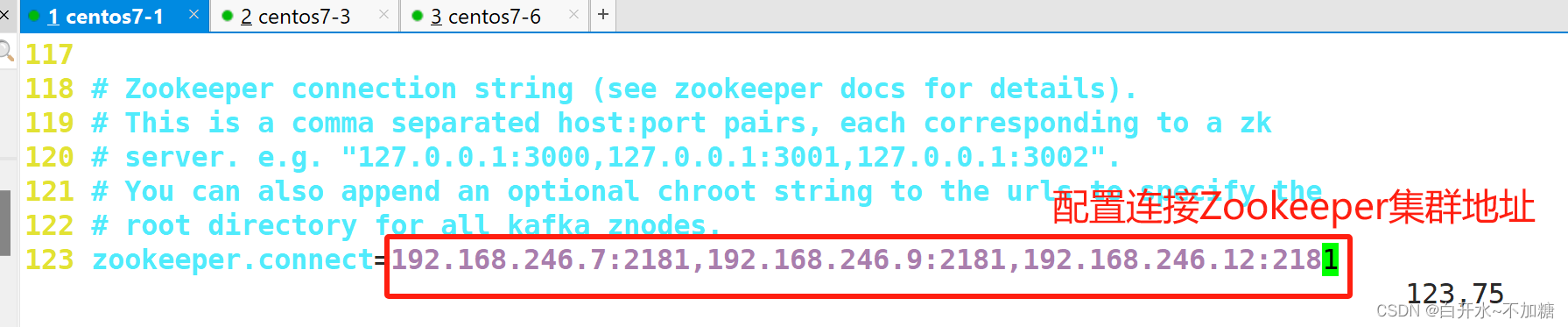
zookeeper.connect=192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 ●123行,配置连接Zookeeper集群地址//修改环境变量
vim /etc/profile
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile//配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac//设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka//分别启动 Kafka
service kafka start3.Kafka 命令行操作
//创建topic
kafka-topics.sh --create --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 --replication-factor 2 --partitions 3 --topic testkafka-topics.sh --create --zookeeper 192.168.10.17:2181,192.168.10.20:2181,192.168.10.21:2181 --replication-factor 2 --partitions 3 --topic test
-------------------------------------------------------------------------------------
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
-------------------------------------------------------------------------------------//查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181//查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181//发布消息
kafka-console-producer.sh --broker-list 192.168.10.17:9092,192.168.10.21:9092,192.168.10.22:9092 --topic test//消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.10.17:9092,192.168.10.21:9092,192.168.10.22:9092 --topic test --from-beginning-------------------------------------------------------------------------------------
--from-beginning:会把主题中以往所有的数据都读取出来
-------------------------------------------------------------------------------------//修改分区数
kafka-topics.sh --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 --alter --topic test --partitions 6//删除 topic
kafka-topics.sh --delete --zookeeper 192.168.10.17:2181,192.168.10.21:2181,192.168.10.22:2181 --topic test所有机器安装部署 kafka 集群
由于步骤相同,我这里只展示一台设备的搭建!!
4.1下载Kafka安装包
下载安装包
官方下载地址:http://kafka.apache.org/downloads.html
-------------------------------------
cd /opt
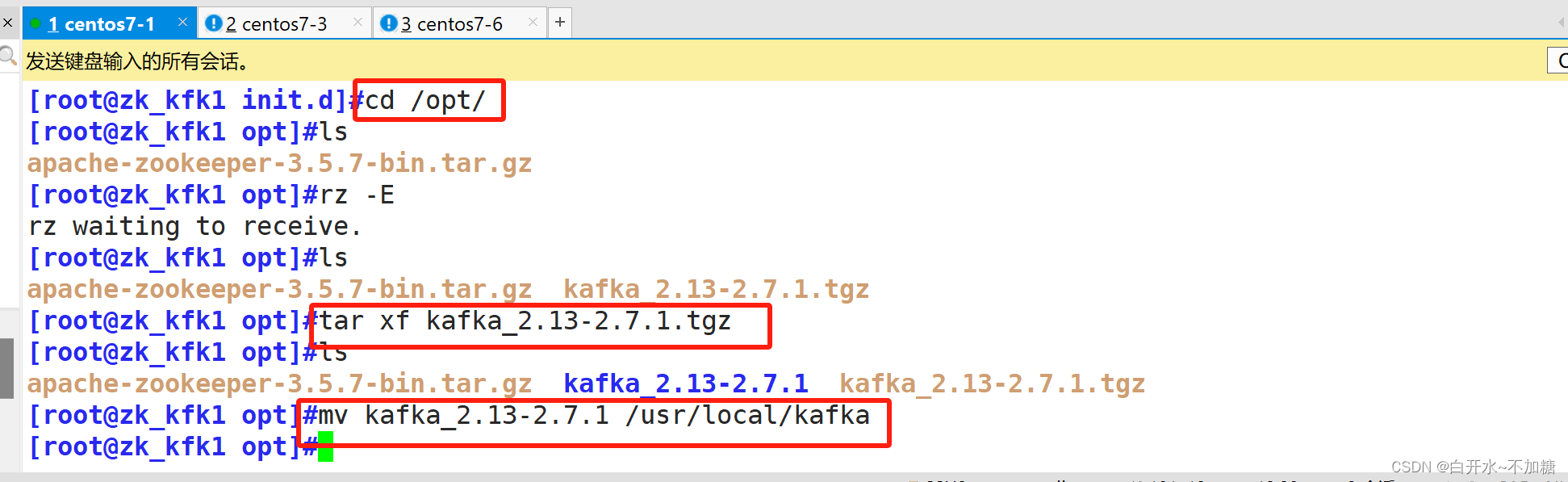
wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz4.2安装 Kafka
cd /opt
tar xf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
4.3修改配置文件
cd /usr/local/kafka/config/
cp server.properties{,.bak}vim server.properties
------------------------------------
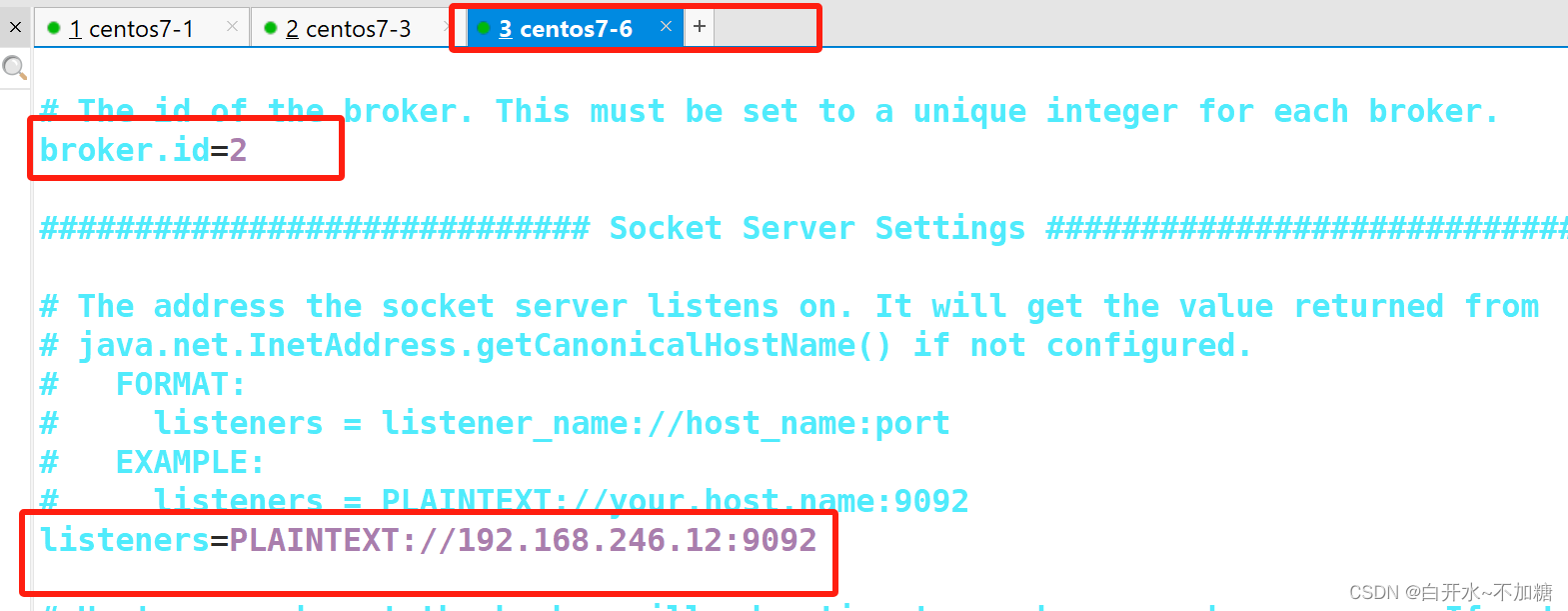
broker.id=0 ●21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.246.7:9092 ●31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3 #42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8 #45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400 #48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400 #51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600 #54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs #60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1 #65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1 #69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168
#103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824 #110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.246.7:2181,192.168.246.9:2181,192.168.246.12:2181 #123行,配置连接Zookeeper集群地址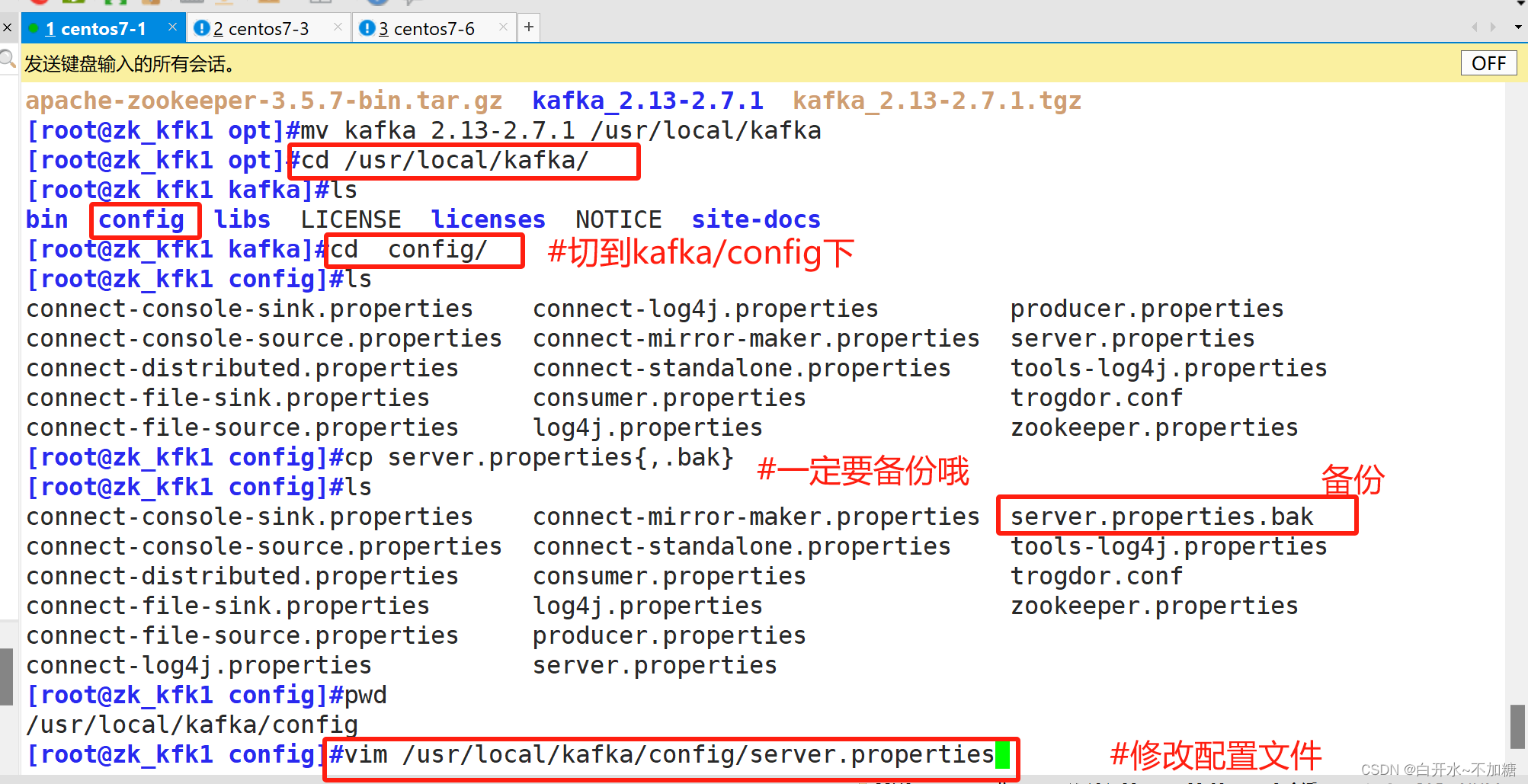




4.4拷贝到其他主机进行配置
scp /usr/local/kafka/config/server.properties 192.168.246.9:/usr/local/kafka/config/server.properties
scp /usr/local/kafka/config/server.properties 192.168.246.12:/usr/local/kafka/config/server.properties


4.5修改环境变量
vim /etc/profile
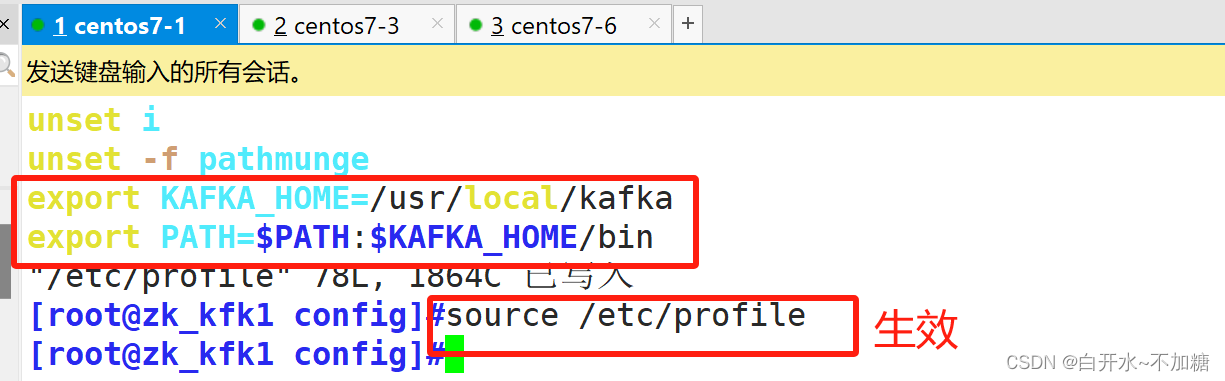
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/binsource /etc/profile
4.6配置 Zookeeper 启动脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)echo "---------- Kafka 启动 ------------"${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)echo "---------- Kafka 停止 ------------"${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)$0 stop$0 start
;;
status)echo "---------- Kafka 状态 ------------"count=$(ps -ef | grep kafka | egrep -cv "grep|$$")if [ "$count" -eq 0 ];thenecho "kafka is not running"elseecho "kafka is running"fi
;;
*)echo "Usage: $0 {start|stop|restart|status}"
esac4.7设置开机自启
chmod +x /etc/init.d/kafka
chkconfig --add kafka
4.8分别启动 Kafka
service kafka start
4.9Kafka 命令行操作
4.9.1创建topic
随便一台机器执行操作就可以
kafka-topics.sh --create --zookeeper 192.168.246.7:2181,192.168.246.9:2181,192.168.246.12:2181 --replication-factor 2 --partitions 3 --topic test-------------------------------------------------------------------------------------
--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
--replication-factor:定义分区副本数,1 代表单副本,建议为 2
--partitions:定义分区数
--topic:定义 topic 名称
kafka-topics.sh --create --zookeeper 192.168.246.7:2181,192.168.246.9:2181,192.168.246.12:2181 --replication-factor 2 --partitions 3 --topic test4.9.3查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.246.7:2181,192.168.246.9:2181,192.168.246.12:2181
4.9.4查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.246.7:2181,192.168.246.9:2181,192.168.246.12:2181
4.9.5发布消息
生产者推送数据
kafka-console-producer.sh --broker-list 192.168.246.7:9092,192.168.246.9:9092,192.168.246.12:9092 --topic test

4.9.6消费消息
#在另外一台主机输入消费信息的命令,查看是否可以收到发布的消息
--from-beginning:会把主题中以往所有的数据都读取出来
kafka-console-consumer.sh --bootstrap-server 192.168.246.7:9092,192.168.246.9:9092,192.168.246.12:9092 --topic test --from-beginning
4.9.7修改分区数
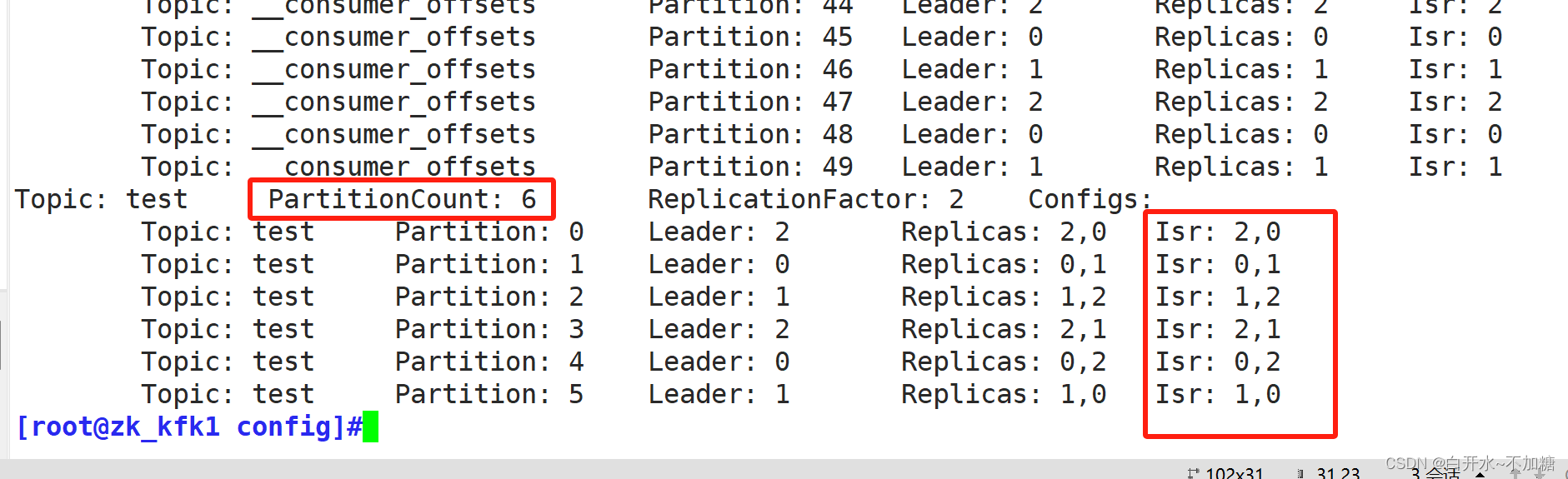
kafka-topics.sh --zookeeper 192.168.246.7:2181,192.168.246.9:2181,192.168.246.12:2181 --alter --topic test --partitions 6
4.9.8删除 topic
kafka-topics.sh --delete --zookeeper 192.168.246.7:2181,192.168.246.9:2181,192.168.246.12:2181 --topic test
五、数据可靠性保证
为保证 producer 发送的数据,能可靠的发送到指定的 topic,topic 的每个 partition 收到 producer 发送的数据后, 都需要向 producer 发送 ack(acknowledgement 确认收到),如果 producer 收到 ack,就会进行下一轮的发送,否则重新发送数据。
六、数据一致性问题

LEO:指的是每个副本最大的 offset;
HW:指的是消费者能见到的最大的 offset,所有副本中最小的 LEO。
6.1follower 故障
follower 发生故障后会被临时踢出 ISR(Leader 维护的一个和 Leader 保持同步的 Follower 集合),待该 follower 恢复后,follower 会读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 leader 进行同步。等该 follower 的 LEO 大于等于该 Partition 的 HW,即 follower 追上 leader 之后,就可以重新加入 ISR 了。
6.2leader 故障
leader 发生故障之后,会从 ISR 中选出一个新的 leader, 之后,为保证多个副本之间的数据一致性,其余的 follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 leader 同步数据。
注:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
七、ack 应答机制
对于某些不太重要的数据,对数据的可靠性要求不是很高,能够容忍数据的少量丢失,所以没必要等 ISR 中的 follower 全部接收成功。所以 Kafka 为用户提供了三种可靠性级别,用户根据对可靠性和延迟的要求进行权衡选择。
当 producer 向 leader 发送数据时,可以通过 request.required.acks 参数来设置数据可靠性的级别:
●0:这意味着producer无需等待来自broker的确认而继续发送下一批消息。这种情况下数据传输效率最高,但是数据可靠性确是最低的。当broker故障时有可能丢失数据。
●1(默认配置):这意味着producer在ISR中的leader已成功收到的数据并得到确认后发送下一条message。如果在follower同步成功之前leader故障,那么将会丢失数据。
●-1(或者是all):producer需要等待ISR中的所有follower都确认接收到数据后才算一次发送完成,可靠性最高。但是如果在 follower 同步完成后,broker 发送ack 之前,leader 发生故障,那么会造成数据重复。
三种机制性能依次递减,数据可靠性依次递增。
注:在 0.11 版本以前的Kafka,对此是无能为力的,只能保证数据不丢失,再在下游消费者对数据做全局去重。在 0.11 及以后版本的 Kafka,引入了一项重大特性:幂等性。所谓的幂等性就是指 Producer 不论向 Server 发送多少次重复数据, Server 端都只会持久化一条。
八、kafka报错分析
81 (id: -2 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[2024-04-12 23:09:56,300] WARN [Producer clientId=console-producer] Bootstrap broker 192.168.246.7:2181 (id: -1 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[2024-04-12 23:09:56,410] WARN [Producer clientId=console-producer] Bootstrap broker 192.168.246.12:2181 (id: -3 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[2024-04-12 23:09:56,517] WARN [Producer clientId=console-producer] Bootstrap broker 192.168.246.9:2181 (id: -2 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
生成者生产数据时,端口可能写错了,要写自己监听的端口,本文是9200
ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1(kafka.admin.TopicCommand$)##三台kafka只起来一台,查看是否配置文件中的broker.id相同了,或者其他俩台防火墙启动错误
安装zookeeper和kafka后启动报错,查看日志显示有no route host 没有路由等信息,则表示是三台中有防火墙未关闭
相关文章:
分布式技术---------------消息队列中间件之 Kafka
目录 一、Kafka 概述 1.1为什么需要消息队列(MQ) 1.2使用消息队列的好处 1.2.1解耦 1.2.2可恢复性 1.2.3缓冲 1.2.4灵活性 & 峰值处理能力 1.2.5异步通信 1.3消息队列的两种模式 1.3.1点对点模式(一对一,消费者主动…...

BGP扩展知识总结
一、BGP的宣告问题 在BGP协议中每台运行BGP的设备上,宣告本地直连路由在BGP协议中运行BGP协议的设备,来宣告通过IGP学习到的未运行BGP协议设备产生的路由;(常见) 在BGP协议中宣告本地路由表中路由条目时,将…...

华为OD-C卷-按身高和体重排队[100分]
题目描述 某学校举行运动会,学生们按编号(1、2、3…n)进行标识,现需要按照身高由低到高排列,对身高相同的人,按体重由轻到重排列;对于身高体重都相同的人,维持原有的编号顺序关系。请输出排列后的学生编号…...
云原生(八)、Kubernetes基础(一)
K8S 基础 # 获取登录令牌 kubectl create token admin --namespace kubernetes-dashboard1、 NameSpace Kubernetes 启动时会创建四个初始名字空间 default:Kubernetes 包含这个名字空间,以便于你无需创建新的名字空间即可开始使用新集群。 kube-node-lease: 该…...

Linux 系统解压缩文件
Linux系统,可以使用unzip命令来解压zip文件 方法如下 1. 打开终端,在命令行中输入以下命令来安装unzip: sudo apt-get install unzip 1 2. 假设你想要将zip文件解压缩到名为"target_dir"的目录中,在终端中切换到目标路…...

linux如何使 CPU使用率保持在指定百分比?
目录 方法1:(固定在100%) 方法2:(可以指定0~100%) 方法3:使用ChaosBlade工具(0~100%) 方法1:(固定在100%) for i in seq 1 $(cat /pro…...
的简介、安装、使用方法之详细攻略)
LLMs之Morphic:Morphic(一款具有生成式用户界面的人工智能答案引擎)的简介、安装、使用方法之详细攻略
LLMs之Morphic:Morphic(一款具有生成式用户界面的人工智能答案引擎)的简介、安装、使用方法之详细攻略 目录 Morphic的简介 1、技术栈 Morphic的安装和使用方法 1、克隆仓库 2、安装依赖 3、填写密钥 4、本地运行应用 部署 Morphic的简介 2024年4月初发布ÿ…...

[react] useState的一些小细节
1.无限循环 因为setState修改是异步的,加上会触发函数重新渲染, 如果代码长这样 一秒再修改,然后重新触发setTImeout, 然后再触发,重复触发循环 如果这样呢 还是会,因为你执行又会重新渲染 2.异步修改数据 为什么修改多次还是跟不上呢? 函数传参解决 因为是异步修改 ,所以…...
蓝桥杯【第15届省赛】Python B组
这题目难度对比历届是相当炸裂的简单了…… A:穿越时空之门 【问题描述】 随着 2024 年的钟声回荡,传说中的时空之门再次敞开。这扇门是一条神秘的通道,它连接着二进制和四进制两个不同的数码领域,等待着勇者们的探索。 在二进制…...
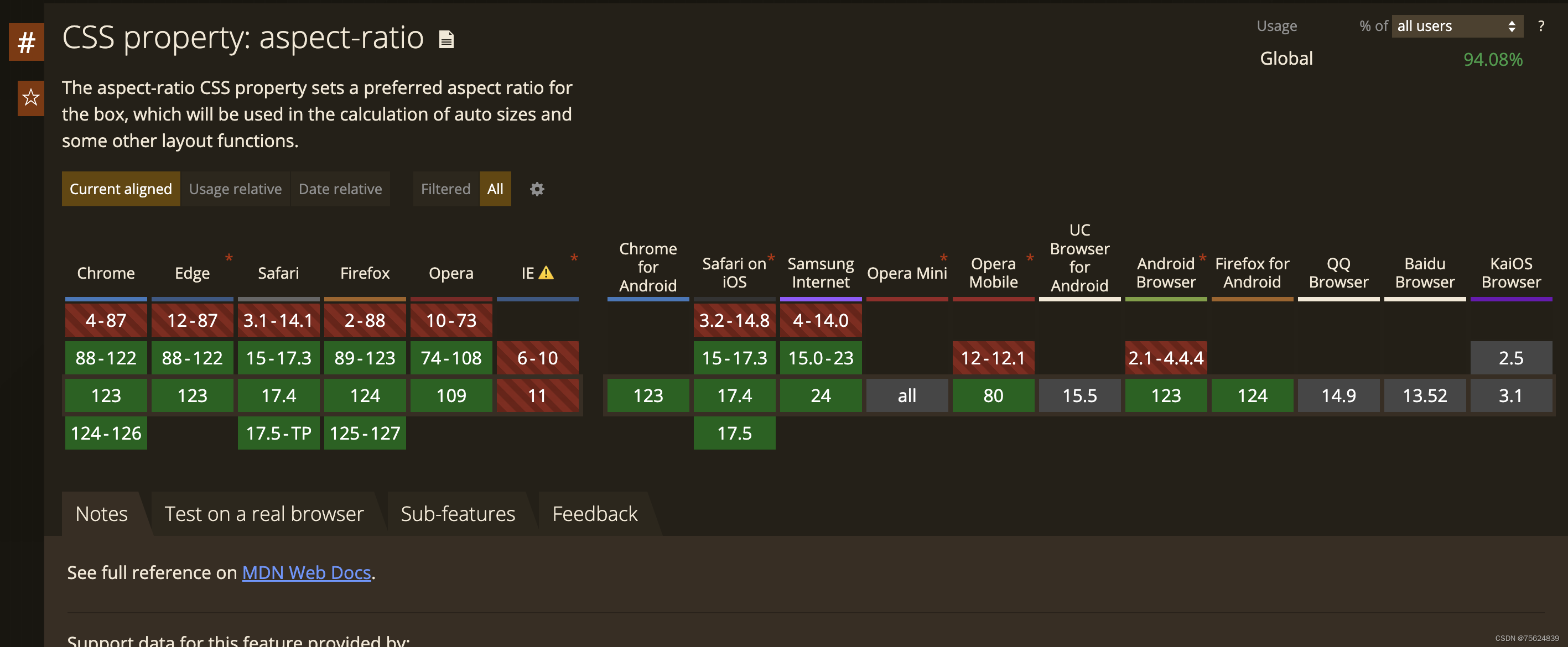
CSS aspect-ratio属性设置元素宽高比
aspect-ratio 是CSS的一个属性,用于设置元素的期望宽高比。它设置确保元素保持特定的比例,不受其内容或容器大小的影响。 语法: aspect-ratio: <ratio>;其中 <ratio> 是一个由斜杠(/)分隔的两个数字&…...

Jones矩阵符号运算
文章目录 Jones向量Jones矩阵 有关Jones矩阵、Jones向量的基本原理,可参考这个: 通过Python理解Jones矩阵,本文主要介绍sympy中提供的有关偏振光学的符号计算工具 Jones向量 Jones向量是描述光线偏振状态的重要工具,例如一个偏振…...

解决 App 自动化测试的常见痛点!
App 自动化测试中有些常见痛点问题,如果框架不能很好的处理,就可能出现元素定位超时找不到的情况,自动化也就被打断终止了。很容易打消做自动化的热情,导致从入门到放弃。比如下面的两个问题: 一是 App 启动加载时间较…...

2016NOIP普及组真题 1. 买铅笔
线上OJ: 一本通:http://ybt.ssoier.cn:8088/problem_show.php?pid1973 核心思想: 向上取整的代码 (m (n-1))/n 。(本题考点与2023年J组的第一和第二题一样) 比如需要买31支笔,每包30支,则需要…...
机器学习—数据集(二)
1可用数据集 公司内部 eg:百度 数据接口 花钱 数据集 学习阶段可用的数据集: sklearn:数据量小,方便学习kaggle:80万科学数据,真实数据,数据量大UCI:收录了360个数据集,覆盖科学、生活、经济等…...

华为S5735S核心交换配置实例
以下脚本实现创建vlan2,3,IP划分,DHCP启用,接口划分,ssh,telnet,http,远程登录启用 默认用户创建admin/admin123提示首次登录需要更改用户密码S5735产品手册更多功能配置,移步官网参考手册配置 system-viewsysname t…...

Mysql主从复制安装配置
mysql主从复制安装配置 1、基础设置准备 #操作系统: centos6.5 #mysql版本: 5.7 #两台虚拟机: node1:192.168.85.111(主) node2:192.168.85.112(从)2、安装mysql数据库 #详细安装和卸载的步骤…...

【刷题】图论——最小生成树:Prim、Kruskal【模板】
假设有n个点m条边。 Prim适用于邻接矩阵存的稠密图,时间复杂度是 O ( n 2 ) O(n^2) O(n2),可用堆优化成 O ( n l o g n ) O(nlogn) O(nlogn)。 Kruskal适用于稀疏图,n个点m条边,时间复杂度是 m l o g ( m ) mlog(m) mlog(m)。 Pr…...

使用uniapp实现小程序获取wifi并连接
Wi-Fi功能模块 App平台由 uni ext api 实现,需下载插件:uni-WiFi 链接:https://ext.dcloud.net.cn/plugin?id10337 uni ext api 需 HBuilderX 3.6.8 iOS平台获取Wi-Fi信息需要开启“Access WiFi information”能力登录苹果开发者网站&…...
回忆杀之手搓当年搓过的Transformer
整体代码 import mathimport paddle import paddle.nn as nn import paddle.nn.functional as Fclass MaskMultiHeadAttention(nn.Layer):def __init__(self, hidden_size, num_heads):super(MaskMultiHeadAttention, self).__init__()assert hidden_size % num_heads 0, &qu…...

【AR】使用深度API实现虚实遮挡
遮挡效果 本段描述摘自 https://developers.google.cn/ar/develop/depth 遮挡是深度API的应用之一。 遮挡(即准确渲染虚拟物体在现实物体后面)对于沉浸式 AR 体验至关重要。 参考下图,假设场景中有一个Andy,用户可能需要放置在包含…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

vscode里如何用git
打开vs终端执行如下: 1 初始化 Git 仓库(如果尚未初始化) git init 2 添加文件到 Git 仓库 git add . 3 使用 git commit 命令来提交你的更改。确保在提交时加上一个有用的消息。 git commit -m "备注信息" 4 …...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

dify打造数据可视化图表
一、概述 在日常工作和学习中,我们经常需要和数据打交道。无论是分析报告、项目展示,还是简单的数据洞察,一个清晰直观的图表,往往能胜过千言万语。 一款能让数据可视化变得超级简单的 MCP Server,由蚂蚁集团 AntV 团队…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...
中的KV缓存压缩与动态稀疏注意力机制设计)
大语言模型(LLM)中的KV缓存压缩与动态稀疏注意力机制设计
随着大语言模型(LLM)参数规模的增长,推理阶段的内存占用和计算复杂度成为核心挑战。传统注意力机制的计算复杂度随序列长度呈二次方增长,而KV缓存的内存消耗可能高达数十GB(例如Llama2-7B处理100K token时需50GB内存&a…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...