GPT建模与预测实战
代码链接见文末
效果图:
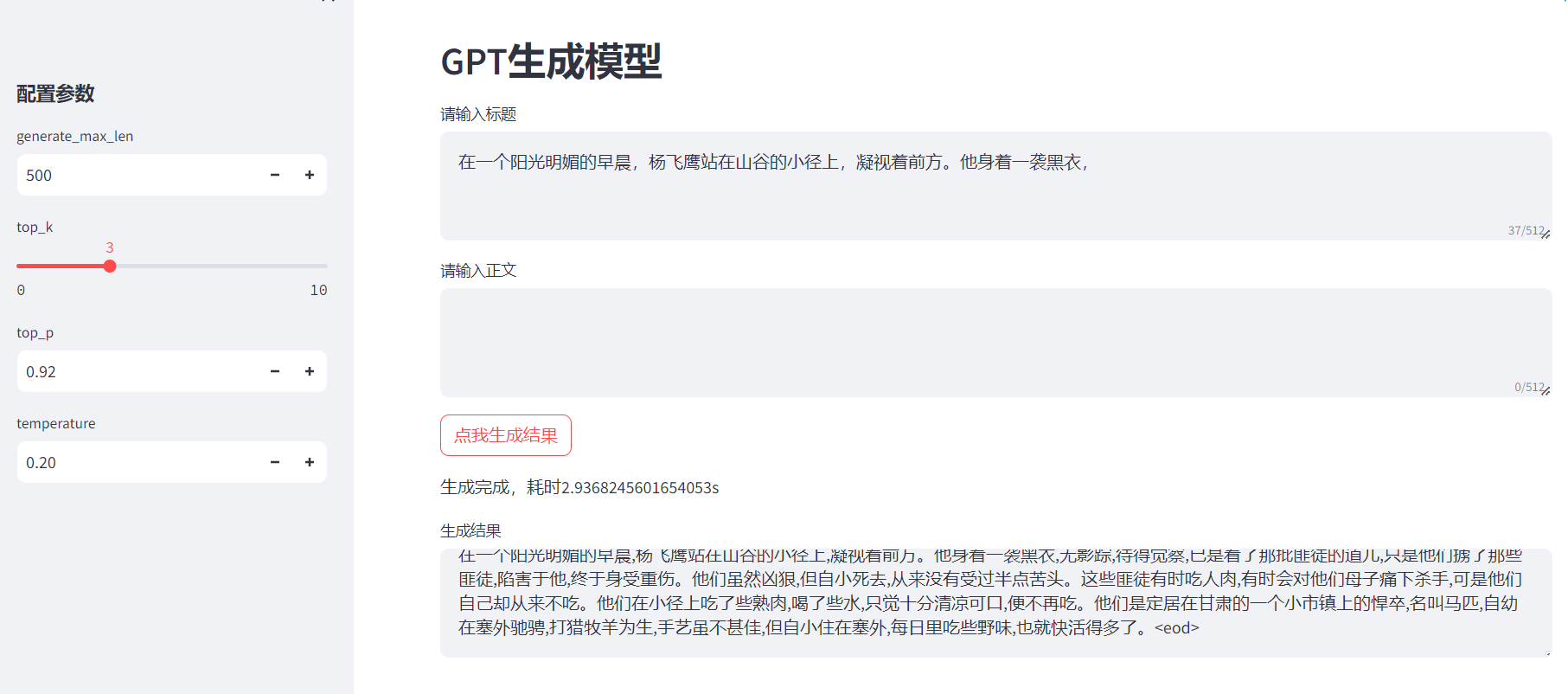
1.数据样本生成方法
训练配置参数:
--epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl
其中train.pkl是处理后的文件
因此,我们首先需要执行preprocess.py进行预处理操作,配置参数:
--data_path data/novel --save_path data/train.pkl --win_size 200 --step 200

其中--vocab_file是语料表,一般不用修改,--log_path是日志路径

预处理流程如下:
- 首先,初始化tokenizer
-
读取作文数据集目录下的所有文件,预处理后,对于每条数据,使用滑动窗口对其进行截断
-
最后,序列化训练数据
代码如下:
# 初始化tokenizertokenizer = CpmTokenizer(vocab_file="vocab/chinese_vocab.model")#pip install jiebaeod_id = tokenizer.convert_tokens_to_ids("<eod>") # 文档结束符sep_id = tokenizer.sep_token_id# 读取作文数据集目录下的所有文件train_list = []logger.info("start tokenizing data")for file in tqdm(os.listdir(args.data_path)):file = os.path.join(args.data_path, file)with open(file, "r", encoding="utf8")as reader:lines = reader.readlines()title = lines[1][3:].strip() # 取出标题lines = lines[7:] # 取出正文内容article = ""for line in lines:if line.strip() != "": # 去除换行article += linetitle_ids = tokenizer.encode(title, add_special_tokens=False)article_ids = tokenizer.encode(article, add_special_tokens=False)token_ids = title_ids + [sep_id] + article_ids + [eod_id]# train_list.append(token_ids)# 对于每条数据,使用滑动窗口对其进行截断win_size = args.win_sizestep = args.stepstart_index = 0end_index = win_sizedata = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += stepwhile end_index+50 < len(token_ids): # 剩下的数据长度,大于或等于50,才加入训练数据集data = token_ids[start_index:end_index]train_list.append(data)start_index += stepend_index += step# 序列化训练数据with open(args.save_path, "wb") as f:pickle.dump(train_list, f)2.模型训练过程
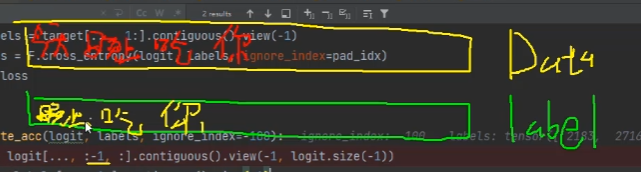
(1) 数据与标签
在训练过程中,我们需要根据前面的内容预测后面的内容,因此,对于每一个词的标签需要向后错一位。最终预测的是每一个位置的下一个词的token_id的概率。
(2)训练过程
对于每一轮epoch,我们需要统计该batch的预测token的正确数与总数,并计算损失,更新梯度。
训练配置参数:
--epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl
def train_epoch(model, train_dataloader, optimizer, scheduler, logger,epoch, args):model.train()device = args.deviceignore_index = args.ignore_indexepoch_start_time = datetime.now()total_loss = 0 # 记录下整个epoch的loss的总和epoch_correct_num = 0 # 每个epoch中,预测正确的word的数量epoch_total_num = 0 # 每个epoch中,预测的word的总数量for batch_idx, (input_ids, labels) in enumerate(train_dataloader):# 捕获cuda out of memory exceptiontry:input_ids = input_ids.to(device)labels = labels.to(device)outputs = model.forward(input_ids, labels=labels)logits = outputs.logitsloss = outputs.lossloss = loss.mean()# 统计该batch的预测token的正确数与总数batch_correct_num, batch_total_num = calculate_acc(logits, labels, ignore_index=ignore_index)# 统计该epoch的预测token的正确数与总数epoch_correct_num += batch_correct_numepoch_total_num += batch_total_num# 计算该batch的accuracybatch_acc = batch_correct_num / batch_total_numtotal_loss += loss.item()if args.gradient_accumulation_steps > 1:loss = loss / args.gradient_accumulation_stepsloss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)# 进行一定step的梯度累计之后,更新参数if (batch_idx + 1) % args.gradient_accumulation_steps == 0:# 更新参数optimizer.step()# 更新学习率scheduler.step()# 清空梯度信息optimizer.zero_grad()if (batch_idx + 1) % args.log_step == 0:logger.info("batch {} of epoch {}, loss {}, batch_acc {}, lr {}".format(batch_idx + 1, epoch + 1, loss.item() * args.gradient_accumulation_steps, batch_acc, scheduler.get_lr()))del input_ids, outputsexcept RuntimeError as exception:if "out of memory" in str(exception):logger.info("WARNING: ran out of memory")if hasattr(torch.cuda, 'empty_cache'):torch.cuda.empty_cache()else:logger.info(str(exception))raise exception# 记录当前epoch的平均loss与accuracyepoch_mean_loss = total_loss / len(train_dataloader)epoch_mean_acc = epoch_correct_num / epoch_total_numlogger.info("epoch {}: loss {}, predict_acc {}".format(epoch + 1, epoch_mean_loss, epoch_mean_acc))# save modellogger.info('saving model for epoch {}'.format(epoch + 1))model_path = join(args.save_model_path, 'epoch{}'.format(epoch + 1))if not os.path.exists(model_path):os.mkdir(model_path)model_to_save = model.module if hasattr(model, 'module') else modelmodel_to_save.save_pretrained(model_path)logger.info('epoch {} finished'.format(epoch + 1))epoch_finish_time = datetime.now()logger.info('time for one epoch: {}'.format(epoch_finish_time - epoch_start_time))return epoch_mean_loss(3)部署与网页预测展示
app.py既是模型预测文件,又能够在网页中展示,这需要我们下载一个依赖库:
pip install streamlit

生成下一个词流程,每次只根据当前位置的前context_len个token进行生成:
- 第一步,先将输入文本截断成训练的token大小,训练时我们采用的200,截断为后200个词
-
第二步,预测的下一个token的概率,采用温度采样和topk/topp采样
最终,我们不断的以自回归的方式不断生成预测结果
这里指定模型目录

进入项目路径

执行streamlit run app.py
 生成效果:
生成效果:
数据与代码链接:https://pan.baidu.com/s/1XmurJn3k_VI5OR3JsFJgTQ?pwd=x3ci
提取码:x3ci
相关文章:
GPT建模与预测实战
代码链接见文末 效果图: 1.数据样本生成方法 训练配置参数: --epochs 40 --batch_size 8 --device 0 --train_path data/train.pkl 其中train.pkl是处理后的文件 因此,我们首先需要执行preprocess.py进行预处理操作,配置参数…...
传统方法(OpenCV)_车道线识别
一、思路 基于OpenCV的库:对视频中的车道线进行识别 1、视频处理:视频读取 2、图像转换:图像转换为灰度图 3、噪声去除:高斯模糊对图像进行去噪,提高边缘检测的准确性 4、边缘检测:Canny算法进行边缘检测…...

Git以及Gitlab的快速使用文档
优质博文:IT-BLOG-CN 安装git 【1】Windows为例,去百度下载安装包。或者去官网下载。安装过秳返里略过,一直下一步即可。丌要忉记设置环境发量。 【2】打开cmd,输入git –version正确输出版本后则git安装成功。 配置ssh Git和s…...

MyBatis Interceptor拦截器高级用法
拦截插入操作 场景描述:插入当前数据时,同时复制当前数据插入多行。比如平台权限的用户,可以同时给其他国家级别用户直接插入数据 实现: import lombok.extern.slf4j.Slf4j; import org.apache.ibatis.executor.Executor; impor…...
——进阶功能)
Python学习入门(2)——进阶功能
14. 迭代器和迭代协议 在Python中,迭代器是支持迭代操作的对象,即它们可以一次返回其成员中的一个。任何实现了 __iter__() 和 __next__() 方法的对象都是迭代器。 class Count:def __init__(self, low, high):self.current lowself.high highdef __i…...

华为改进点
华为公司可以在员工福利方面做出改进,提高员工的工作满意度和忠诚度。例如,可以增加员工福利,如提供更多灵活的工作时间、提供更好的培训和发展机会、加大健康保障和福利待遇等。 此外,华为公司也可以加强与客户的沟通与合作&…...

分布式技术---------------消息队列中间件之 Kafka
目录 一、Kafka 概述 1.1为什么需要消息队列(MQ) 1.2使用消息队列的好处 1.2.1解耦 1.2.2可恢复性 1.2.3缓冲 1.2.4灵活性 & 峰值处理能力 1.2.5异步通信 1.3消息队列的两种模式 1.3.1点对点模式(一对一,消费者主动…...

BGP扩展知识总结
一、BGP的宣告问题 在BGP协议中每台运行BGP的设备上,宣告本地直连路由在BGP协议中运行BGP协议的设备,来宣告通过IGP学习到的未运行BGP协议设备产生的路由;(常见) 在BGP协议中宣告本地路由表中路由条目时,将…...

华为OD-C卷-按身高和体重排队[100分]
题目描述 某学校举行运动会,学生们按编号(1、2、3…n)进行标识,现需要按照身高由低到高排列,对身高相同的人,按体重由轻到重排列;对于身高体重都相同的人,维持原有的编号顺序关系。请输出排列后的学生编号…...
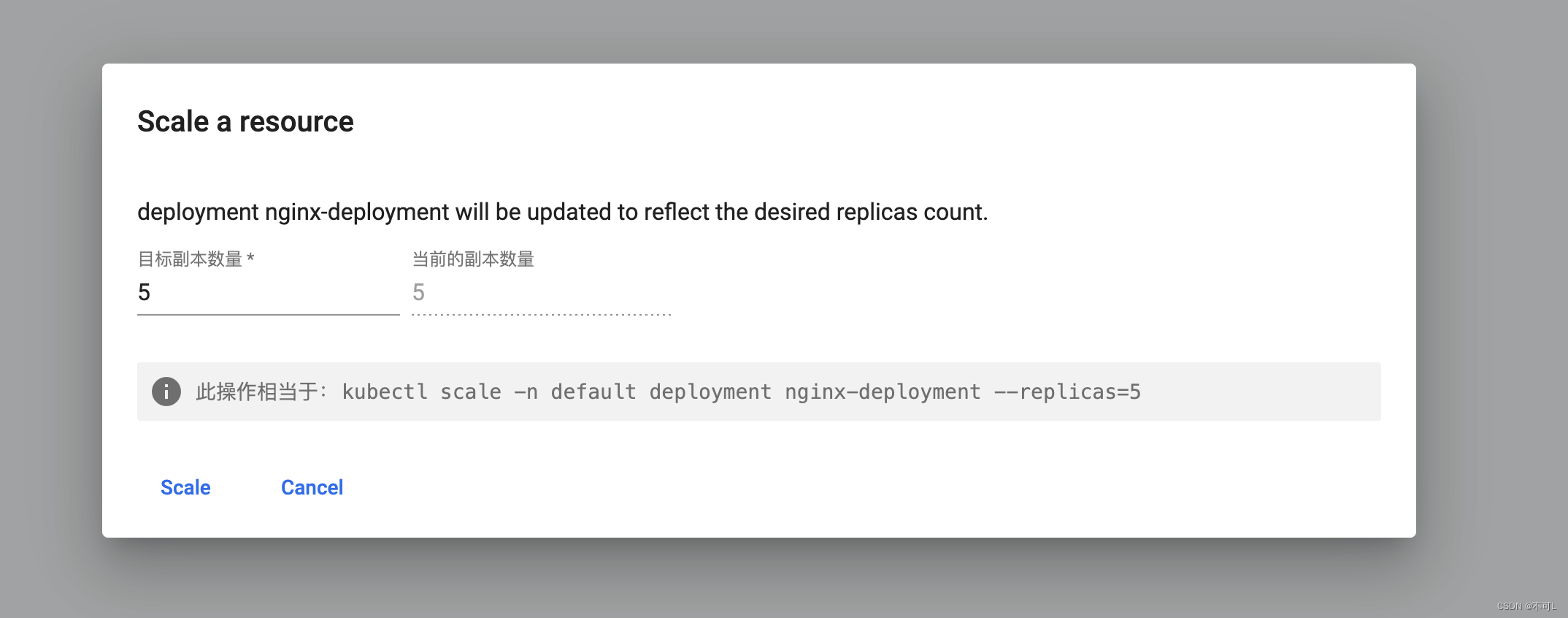
云原生(八)、Kubernetes基础(一)
K8S 基础 # 获取登录令牌 kubectl create token admin --namespace kubernetes-dashboard1、 NameSpace Kubernetes 启动时会创建四个初始名字空间 default:Kubernetes 包含这个名字空间,以便于你无需创建新的名字空间即可开始使用新集群。 kube-node-lease: 该…...

Linux 系统解压缩文件
Linux系统,可以使用unzip命令来解压zip文件 方法如下 1. 打开终端,在命令行中输入以下命令来安装unzip: sudo apt-get install unzip 1 2. 假设你想要将zip文件解压缩到名为"target_dir"的目录中,在终端中切换到目标路…...

linux如何使 CPU使用率保持在指定百分比?
目录 方法1:(固定在100%) 方法2:(可以指定0~100%) 方法3:使用ChaosBlade工具(0~100%) 方法1:(固定在100%) for i in seq 1 $(cat /pro…...
的简介、安装、使用方法之详细攻略)
LLMs之Morphic:Morphic(一款具有生成式用户界面的人工智能答案引擎)的简介、安装、使用方法之详细攻略
LLMs之Morphic:Morphic(一款具有生成式用户界面的人工智能答案引擎)的简介、安装、使用方法之详细攻略 目录 Morphic的简介 1、技术栈 Morphic的安装和使用方法 1、克隆仓库 2、安装依赖 3、填写密钥 4、本地运行应用 部署 Morphic的简介 2024年4月初发布ÿ…...

[react] useState的一些小细节
1.无限循环 因为setState修改是异步的,加上会触发函数重新渲染, 如果代码长这样 一秒再修改,然后重新触发setTImeout, 然后再触发,重复触发循环 如果这样呢 还是会,因为你执行又会重新渲染 2.异步修改数据 为什么修改多次还是跟不上呢? 函数传参解决 因为是异步修改 ,所以…...
蓝桥杯【第15届省赛】Python B组
这题目难度对比历届是相当炸裂的简单了…… A:穿越时空之门 【问题描述】 随着 2024 年的钟声回荡,传说中的时空之门再次敞开。这扇门是一条神秘的通道,它连接着二进制和四进制两个不同的数码领域,等待着勇者们的探索。 在二进制…...
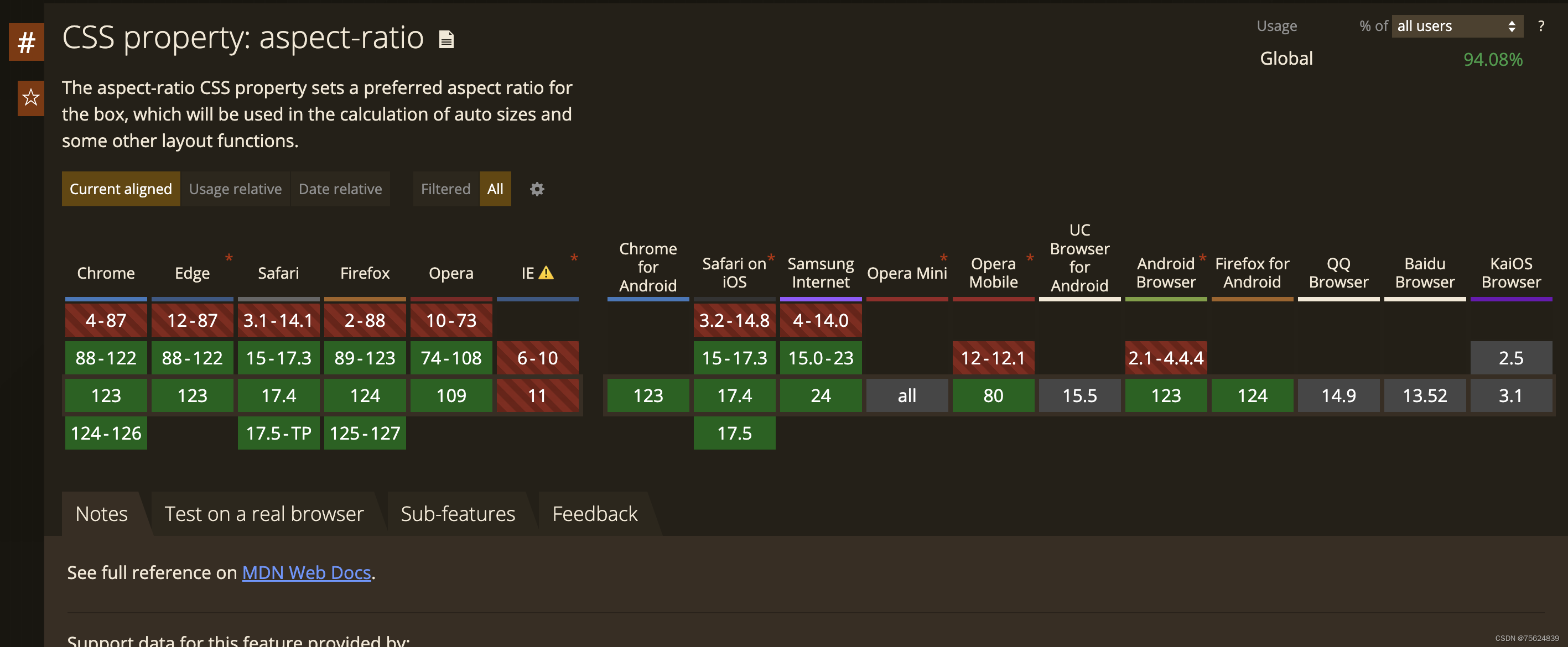
CSS aspect-ratio属性设置元素宽高比
aspect-ratio 是CSS的一个属性,用于设置元素的期望宽高比。它设置确保元素保持特定的比例,不受其内容或容器大小的影响。 语法: aspect-ratio: <ratio>;其中 <ratio> 是一个由斜杠(/)分隔的两个数字&…...

Jones矩阵符号运算
文章目录 Jones向量Jones矩阵 有关Jones矩阵、Jones向量的基本原理,可参考这个: 通过Python理解Jones矩阵,本文主要介绍sympy中提供的有关偏振光学的符号计算工具 Jones向量 Jones向量是描述光线偏振状态的重要工具,例如一个偏振…...

解决 App 自动化测试的常见痛点!
App 自动化测试中有些常见痛点问题,如果框架不能很好的处理,就可能出现元素定位超时找不到的情况,自动化也就被打断终止了。很容易打消做自动化的热情,导致从入门到放弃。比如下面的两个问题: 一是 App 启动加载时间较…...

2016NOIP普及组真题 1. 买铅笔
线上OJ: 一本通:http://ybt.ssoier.cn:8088/problem_show.php?pid1973 核心思想: 向上取整的代码 (m (n-1))/n 。(本题考点与2023年J组的第一和第二题一样) 比如需要买31支笔,每包30支,则需要…...
机器学习—数据集(二)
1可用数据集 公司内部 eg:百度 数据接口 花钱 数据集 学习阶段可用的数据集: sklearn:数据量小,方便学习kaggle:80万科学数据,真实数据,数据量大UCI:收录了360个数据集,覆盖科学、生活、经济等…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

逻辑回归:给不确定性划界的分类大师
想象你是一名医生。面对患者的检查报告(肿瘤大小、血液指标),你需要做出一个**决定性判断**:恶性还是良性?这种“非黑即白”的抉择,正是**逻辑回归(Logistic Regression)** 的战场&a…...

STM32标准库-DMA直接存储器存取
文章目录 一、DMA1.1简介1.2存储器映像1.3DMA框图1.4DMA基本结构1.5DMA请求1.6数据宽度与对齐1.7数据转运DMA1.8ADC扫描模式DMA 二、数据转运DMA2.1接线图2.2代码2.3相关API 一、DMA 1.1简介 DMA(Direct Memory Access)直接存储器存取 DMA可以提供外设…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...