K8s pod 动态弹性扩缩容 HPA
一、概述
Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标自动调整 Deployment 、ReplicaSet 或 StatefulSet 或其他类似资源,实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适用于无法缩放的对象,例如DaemonSet。
官方文档:https://kubernetes.io/zh-cn/docs/tasks/run-application/horizontal-pod-autoscale/
实际生产中,一般使用这四类指标:
Resource metrics——CPU核 和 内存利用率指标。
Pod metrics——例如网络利用率和流量。
Object metrics——特定对象的指标,比如Ingress, 可以按每秒使用请求数来扩展容器。
Custom metrics——自定义监控,比如通过定义服务响应时间,当响应时间达到一定指标时自动扩容。
二、安装 metrics-server
1)HPA 前提条件
默认情况下,Horizontal Pod Autoscaler 控制器会从一系列的 API 中检索度量值。集群管理员需要确保下述条件,以保证 HPA 控制器能够访问这些 API:
对于资源指标,将使用 metrics.k8s.io API,一般由 metrics-server 提供。它可以作为集群插件启动。
对于自定义指标,将使用 custom.metrics.k8s.io API。它由其他度量指标方案厂商的“适配器(Adapter)” API 服务器提供。检查你的指标管道以查看是否有可用的 Kubernetes 指标适配器。
对于外部指标,将使用 external.metrics.k8s.io API。可能由上面的自定义指标适配器提供。
Kubernetes Metrics Server:
Kubernetes Metrics Server 是 Cluster 的核心监控数据的聚合器,kubeadm 默认是不部署的。
Metrics Server 供 Dashboard 等其他组件使用,是一个扩展的 APIServer,依赖于 API Aggregator。所以,在安装 Metrics Server 之前需要先在 kube-apiserver 中开启 API Aggregator。
Metrics API 只可以查询当前的度量数据,并不保存历史数据。
Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 下维护。
必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 kubelet Summary API 获取数据。
2)开启 API Aggregator
# 添加这行# --enable-aggregator-routing=true### 修改每个 API Server 的 kube-apiserver.yaml 配置开启 Aggregator Routing:修改 manifests 配置后 API Server 会自动重启生效。cat /etc/kubernetes/manifests/kube-apiserver.yaml
3)开始安装 metrics-server
GitHub地址:https://github.com/kubernetes-sigs/metrics-server/releases
下载
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/metrics-server-helm-chart-3.8.2/components.yaml修改
... template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --secure-port=4443 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --kubelet-insecure-tls # 加上该启动参数,不加可能会报错 image: registry.aliyuncs.com/google_containers/metrics-server:v0.6.1 # 镜像地址根据情况修改 imagePullPolicy: IfNotPresent...metrics-server pod无法启动,出现日志unable to fully collect metrics: ... x509: cannot validate certificate for because ... it doesn't contain any IP SANs ...
解决方法:在metrics-server中添加--kubelet-insecure-tls参数跳过证书校验

开始安装
kubectl apply -f components.yamlkubectl get pod -n kube-system | grep metrics-server# 查看kubectl get pod -n kube-system | grep metrics-server# 查看node和pod资源使用情况kubectl top nodeskubectl top pods
三、Horizontal Pod Autoscaler 工作原理
1)原理架构图

自动检测周期由 kube-controller-manager 的 --horizontal-pod-autoscaler-sync-period 参数设置(默认间隔为 15 秒)。
metrics-server 提供 metrics.k8s.io API 为pod资源的使用提供支持。
15s/周期 -> 查询metrics.k8s.io API -> 算法计算 -> 调用scale 调度 -> 特定的扩缩容策略执行。
2)HPA扩缩容算法
从最基本的角度来看,Pod 水平自动扩缩控制器根据当前指标和期望指标来计算扩缩比例。
期望副本数 = ceil[当前副本数 * (当前指标 / 期望指标)]1、扩容
如果计算出的扩缩比例接近 1.0, 将会放弃本次扩缩, 度量指标 / 期望指标接近1.0。
2、缩容
冷却/延迟: 如果延迟(冷却)时间设置的太短,那么副本数量有可能跟以前一样出现抖动。默认值是 5 分钟(5m0s)--horizontal-pod-autoscaler-downscale-stabilization
3、特殊处理
丢失度量值:缩小时假设这些 Pod 消耗了目标值的 100%, 在需要放大时假设这些 Pod 消耗了 0% 目标值。这可以在一定程度上抑制扩缩的幅度。
存在未就绪的pod的时候:我们保守地假设尚未就绪的 Pod 消耗了期望指标的 0%,从而进一步降低了扩缩的幅度。
未就绪的 Pod 和缺少指标的 Pod 考虑进来再次计算使用率。如果新的比率与扩缩方向相反,或者在容忍范围内,则跳过扩缩。否则,我们使用新的扩缩比例。
指定了多个指标, 那么会按照每个指标分别计算扩缩副本数,取最大值进行扩缩。
3)HPA 对象定义
apiVersion:autoscaling/v2beta2kind:HorizontalPodAutoscalermetadata:name:nginxspec:behavior:scaleDown:policies:-type:Podsvalue:4periodSeconds:60-type:Percentvalue:10periodSeconds:60stabilizationWindowSeconds:300scaleTargetRef:apiVersion:apps/v1kind:Deploymentname:nginxminReplicas:1maxReplicas:10metrics:-type:Resourceresource:name:cputarget:type:UtilizationaverageUtilization:50HPA对象默认行为
behavior: scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 100 periodSeconds: 15 scaleUp: stabilizationWindowSeconds: 0 policies: - type: Percent value: 100 periodSeconds: 15 - type: Pods value: 4 periodSeconds: 15 selectPolicy: Max四、示例演示
1)编排yaml
apiVersion: autoscaling/v2kind: HorizontalPodAutoscalermetadata: name: hpa-nginxspec: maxReplicas: 10 # 最大扩容到10个节点(pod) minReplicas: 1 # 最小扩容1个节点(pod) metrics: - resource: name: cpu target: averageUtilization: 40 # CPU 平局资源使用率达到40%就开始扩容,低于40%就是缩容# 设置内存# AverageValue:40type: Utilizationtype: Resource scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: hpa-nginx---apiVersion: v1kind: Servicemetadata: name: hpa-nginxspec:type: NodePort ports: - name: "http" port: 80 targetPort: 80 nodePort: 30080 selector: service: hpa-nginx---apiVersion: apps/v1kind: Deploymentmetadata: name: hpa-nginxspec: replicas: 1 selector: matchLabels: service: hpa-nginx template: metadata: labels: service: hpa-nginx spec: containers: - name: hpa-nginx image: nginx:latest resources: requests: cpu: 100m memory: 100Mi limits: cpu: 200m memory: 200Mi主要参数解释如下:
scaleTargetRef:目标作用对象,可以是Deployment、ReplicationController或ReplicaSet。
minReplicas和maxReplicas:Pod副本数量的最小值和最大值,系统将在这个范围内进行自动扩缩容操作,并维持每个Pod的内存使用率为40%,这个值就是上面设置的阈值averageUtilization。
metrics:目标指标值。在metrics中通过参数type定义指标的类型;通过参数target定义相应的指标目标值,系统将在指标数据达到目标值时(考虑容忍度的区间,见前面算法部分的说明)触发扩缩容操作。
对于CPU使用率,在target参数中设置averageUtilization定义目标平均CPU使用率。
对于内存资源,在target参数中设置AverageValue定义目标平均内存使用值。
执行
kubectl apply -f test.yaml2)使用 ab 工具进行压测
进入apache官网 http://httpd.apache.org/ 下载apache即可,或者直接通过yum安装apache都行,这里选择最简单的方式yum安装
yum install httpd -y开始压测
ab -n 100000 -c 800 http://local-168-182-112:30080/#-c:并发数#-n:总请求数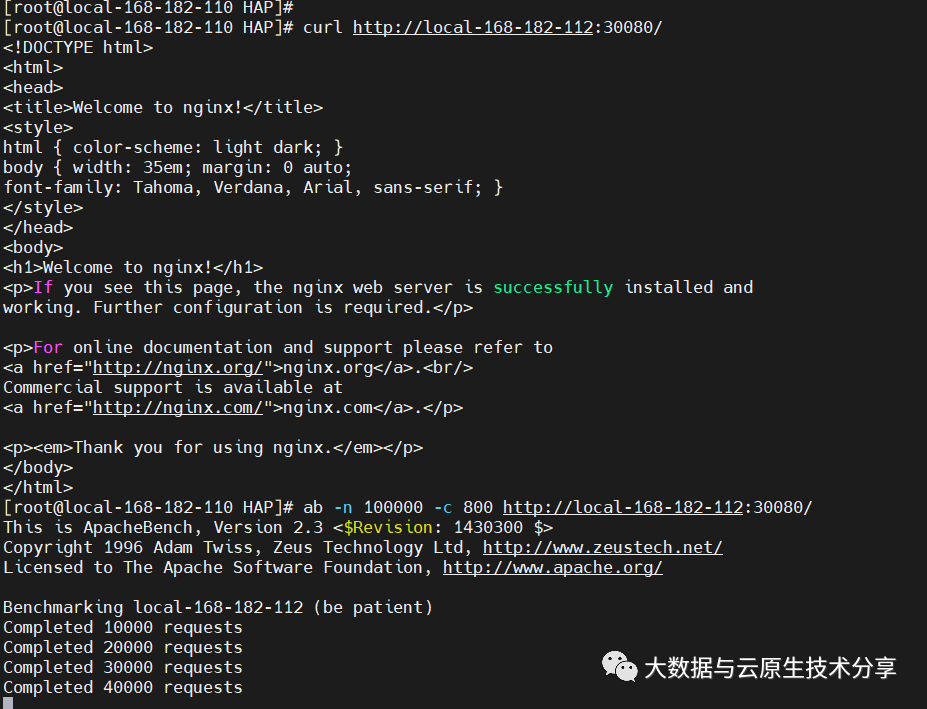
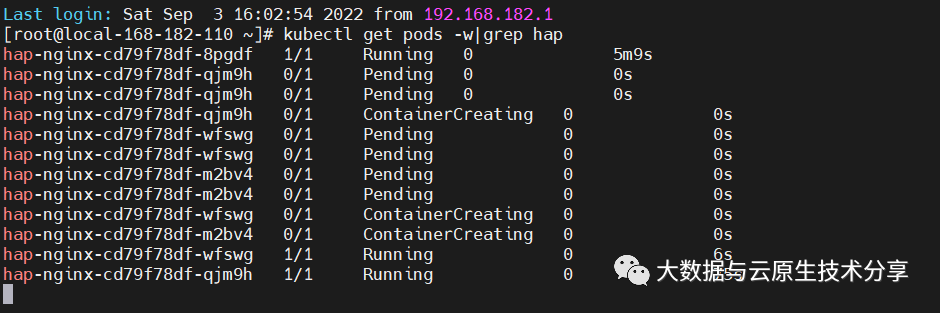
从上图发现已经实现了根据CPU 动态扩容了
相关文章:
K8s pod 动态弹性扩缩容 HPA
一、概述Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据平均 CPU 利用率、平均内存利用率或你指定的任何其他自定义指标自动调整 Deployment 、ReplicaSet 或 StatefulSet 或其他类似资源,实现部署的自动扩展和…...

C++中的类简要介绍
文章目录前言一、什么是类什么是对象1.类的概述2.对象的概述二、如何创建使用类三、class和struct创建类时的区别1.访问级别2.继承方式总结前言 本篇文章讲给大家介绍一个C中重要的概念,了解了这个概念大家就明白了为什么C会叫做面向对象编程了。 一、什么是类什么…...
项目管理工具DHTMLX Gantt灯箱元素配置教程:只读模式
DHTMLX Gantt是用于跨浏览器和跨平台应用程序的功能齐全的Gantt图表。可满足项目管理应用程序的大部分开发需求,具备完善的甘特图图表库,功能强大,价格便宜,提供丰富而灵活的JavaScript API接口,与各种服务器端技术&am…...

从LiveData迁移到Kotlin的 Flow,才发现是真的香!
LiveData 对于 Java 开发者、初学者或是一些简单场景而言仍是可行的解决方案。而对于一些其他的场景,更好的选择是使用 Kotlin 数据流 (Kotlin Flow)。虽说数据流 (相较 LiveData) 有更陡峭的学习曲线,但由于它是 JetBrains 力挺的 Kotlin 语言的一部分&…...
【BOOST C++】组件编程(2)-- 组件的设计原理
GitHub - ros2/demos at foxy 一、说明 为了研究ROS2的组件编程,首先要理解如何何为组件。组件本是微软的发明物体,但是在ubuntu上需要自己从底层实现,就说ROS2不用你写,但是就能看明白也是需要一点理论功底的。本篇按照COM内幕的…...

基于单细胞多组学数据无监督构建基因调控网络
在单细胞分辨率下识别基因调控网络(GRNs,gene regulatory networks)一直是一个巨大的挑战,而单细胞多组学数据的出现为构建GRNs提供了机会。 来自:Unsupervised construction of gene regulatory network based on si…...

蓝桥杯-最优清零方案(2022省赛)
蓝桥杯-最优清零方案1、问题描述2、解题思路3、代码实现1、问题描述 给定一个长度为 N 的数列 1,2,⋯,A1,A2,...,ANA_1,A_2,...,A_NA1,A2,...,AN 。现在小蓝想通过若干次操作将 这个数列中每个数字清零。 每次操作小蓝可以选择以下两种之一: 1. 选择一个大于 0 的整数, 将…...
)
Mac免费软件下载网站推荐(最全免费,替代MacWk)
一、Appstorrent 官方网站: https://appstorrent.ru/ 这是一个俄语网站,其他很多网站资源都来自这里。点击右上角切换到中文。不需要登录网站,直接从软件详情页下载即可。体验非常好。 二、Xclient 官方网站: https://xclie…...
GPU是什么
近期ChatGPT十分火爆,随之而来的是M国开始禁售高端GPU显卡。M国想通过禁售GPU显卡的方式阻挡中国在AI领域的发展。 GPU是什么?GPU(英语:Graphics Processing Unit,缩写:GPU)是显卡的“大脑”&am…...

20230305学习计划
目录 第二天学习开发框架 前言 一、巩固复习第一天20230304学习笔记 二、SpringMVC中的控制器是不是单例模式?如果是,如何保证线程安全? 1、控制器是单例模式,是线程不安全的。 2、Spring中保证线程安全的方法: …...

SocketCan 应用编程
SocketCan 应用编程 由于 Linux 系统将 CAN 设备作为网络设备进行管理,因此在 CAN 总线应用开发方面,Linux 提供了SocketCAN 应用编程接口,使得 CAN 总线通信近似于和以太网的通信,应用程序开发接口更加通用,也更加灵…...

从零学习python - 04函数方法与返回值
函数:Function-也称为方法,是组织好的、可重复使用的,用来实现指定功能的代码块。函数的定义与调用:创建函数目的是封装业务逻辑,实现代码复用# 创建函数关键字:def(definition)def fun1(x, y):print(x y)函数的参数:python函数中…...
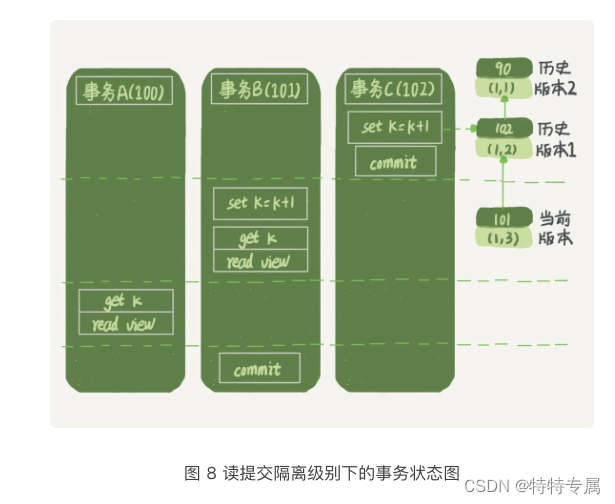
MySQL实战之事务到底是隔离的还是不隔离的
1.前言 我们在MySQL实战之事务隔离:为什么你改了我还看不见讲过事务隔离级别的时候提到过,如果是可重复读隔离级别,事务T启动的时候会创建一个视图read-view,之后事务T执行期间,即使有其他事务修改了数据,事务T看到的…...
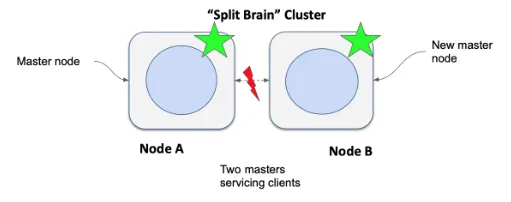
Elasticsearch:理解 Master,Elections,Quorum 及 脑裂
集群中的每个节点都可以分配多个角色:master、data、ingest、ml(机器学习)等。 我们在当前讨论中感兴趣的角色之一是 master 角色。 在 Elasticsearch 的配置中,我们可以配置一个节点为 master 节点。master 角色的分配表明该节点…...
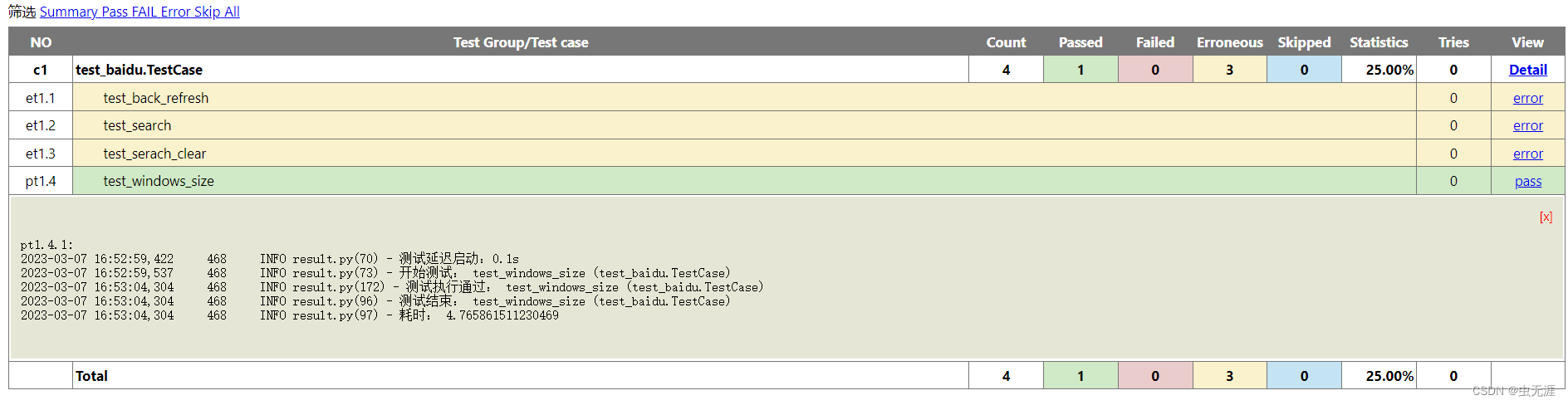
【致敬女神】HTMLReport应用之Unittest+Python+Selenium+HTMLReport项目自动化测试实战
HTMLReport应用之UnittestPythonSeleniumHTMLReport项目自动化测试实战1 测试框架结构2 技术栈3 实现思路3.1 使用HtmlTestRunner3.2 使用HTMLReport4 TestRunner参数说明4.1 源码4.2 参数说明5 框架代码5.1 common/reportOut.py5.2 common/sendMain.py5.3 report5.3.1 xxx.htm…...

JAVA的16 个实用代码优化小技巧
一、类成员与方法的可见性最小化 举例:如果是一个private的方法,想删除就删除。 如果一个public的service方法,或者一个public的成员变量,删除一下,不得思考很多。 二、使用位移操作替代乘除法 计算机是使用二进制…...

并发编程的三大挑战之原子性及其解决方案
目录 一、原子性问题 1、带来原子性问题的原因 2、如何解决线程切换带来的原子问题 2.1、使用synchronized关键字来保证 2.2、使用CAS来保证原子性 2.3、使用lock锁来保证 一、原子性问题 1、带来原子性问题的原因 线程切换是带来原子的根本原因,java的并发程…...
)
QML动画(其他的动画)
PauseAnimation (暂停动画) 为动画提供暂停 Rectangle{id:rect1width: 100;height: 100;x:100;y:100color: "lightBlue"SequentialAnimation{running: trueColorAnimation {target: rect1;property: "color";…...
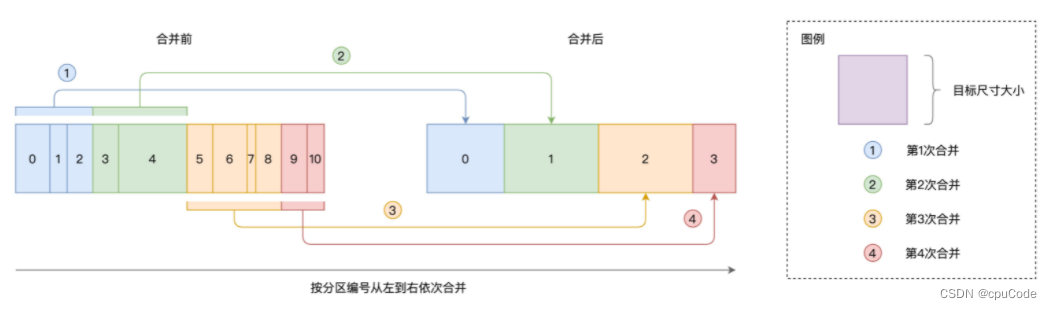
Spark 配置项
Spark 配置项硬件资源类CPU内存堆外内User Memory/Spark 可用内存Execution/Storage Memory磁盘ShuffleSpark SQLJoin 策略调整自动分区合并自动倾斜处理配置项分为 3 类: 硬件资源类 : 与 CPU、内存、磁盘有关的配置项Shuffle 类 : Shuffle 计算过程的配置项Spark SQL : Spar…...

掌握Vue3模板语法,助你轻松实现高效Web开发
Vue3作为前端开发中的一种主流框架,为我们提供了多种灵活的方式来处理模板语法。除了基础的模板语法,Vue3还提供了一些高级的语法,可以让我们更好地处理组件、响应式数据和UI逻辑等。在这篇博客中,我们将介绍Vue3中的一些高级模板…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...
)
GitHub 趋势日报 (2025年06月06日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 590 cognee 551 onlook 399 project-based-learning 348 build-your-own-x 320 ne…...

Web中间件--tomcat学习
Web中间件–tomcat Java虚拟机详解 什么是JAVA虚拟机 Java虚拟机是一个抽象的计算机,它可以执行Java字节码。Java虚拟机是Java平台的一部分,Java平台由Java语言、Java API和Java虚拟机组成。Java虚拟机的主要作用是将Java字节码转换为机器代码&#x…...