大模型笔记:Prompt tuning
1 NLP模型的几个阶段
1.1 第一阶段(在深度学习出现之前)
- 通常聚焦于特征工程(feature engineering)
- 利用领域知识从数据中提取好的特征
1.2 第二阶段(在深度学习出现之后)
- 特征可以从数据中习得——>研究转向了结构工程(architecture engineering)
- 通过设计一个合适的网络结构,学习好的特征
1.3 第三阶段(预训练 + 微调)
- 用一个固定的结构预训练一个语言模型(language model, LM)
- 预训练的方式就是让模型补全上下文(比如完形填空)
- 预训练不需要专家知识,因此可以在网络上搜集的大规模文本上直接进行训练
- 这一阶段的一个研究方向是目标工程(objective engineering)
- 为预训练任务和微调任务设计更好的目标函数
- 让下游任务的目标与预训练的目标对齐是有利的
- 几种经典预训练任务
-
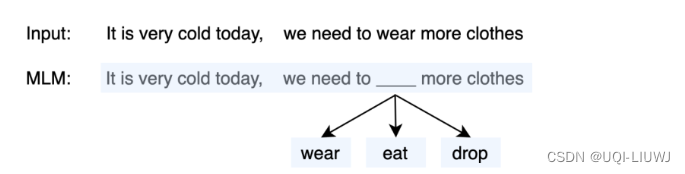
Masked Language Modeling(MLM)
- 随机选取一个固定长度的词袋区间,然后挖掉中心部分的词,让模型预测该位置的词
-
Next Sentence Prediction(NSP)
- 给定两个句子,来判断他们之间的关系
- 存在三种关系
- entailment(isNext)
- 紧相邻的两个句子
- contradiction(isNotNext)
- 这两个句子不存在前后关系,例如两个句子来自于不同的文章
- Neutral
- 中性关系,当前的两个句子可能来自于同一篇文章,但是不属于isNext关系的
- entailment(isNext)

-
1.4 第四阶段(预训练 + Prompt Tuning)
- 通过添加模板的方法来避免引入额外的参数,从而让语言模型可以在小样本(Few-shot)或零样本(Zero-shot)场景下达到理想的效果
2 prompt tuning
- Prompt的目的是将Fine-tuning的下游任务目标转换为Pre-training的任务
2.1 举例说明
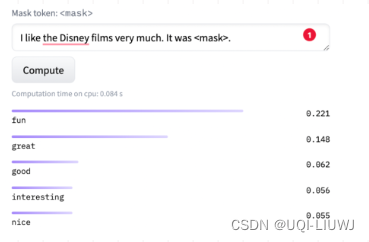
给定一个句子
[CLS] I like the Disney films very much. [SEP]
- 传统的Fine-tuning方法
- 通过BERT的Transformer获得
[CLS]表征 - 之后再喂入新增加的MLP分类器进行二分类,预测该句子是积极的(positive)还是消极的(negative)
- 需要一定量的训练数据来训练
- 通过BERT的Transformer获得
- Prompt-Tuning
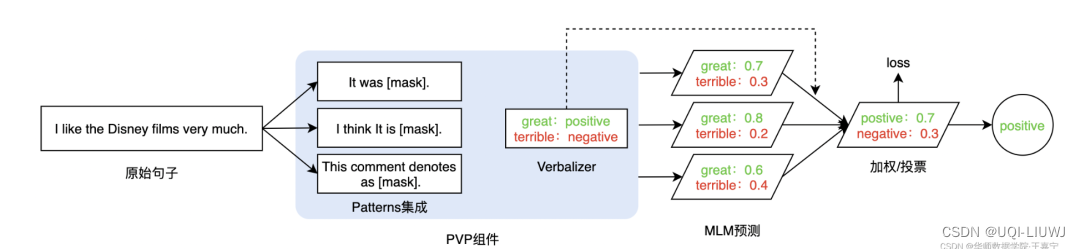
- 构建模板(Template Construction)
- 通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
[MASK]标记的模板 - 拼接到原始的文本中,获得Prompt-Tuning的输入
- [CLS] I like the Disney films very much. [SEP] It was [MASK]. [SEP]
- 将其喂入BERT模型中,并复用预训练好的MLM分类器,即可直接得到
[MASK]预测的各个token的概率分布
- 通过人工定义、自动搜索、文本生成等方法,生成与给定句子相关的一个含有
- 标签词映射(Label Word Verbalizer)
- 因为
[MASK]部分我们只对部分词感兴趣【比如 positive/negative】 - ——>需要建立一个映射关系
- 如果
[MASK]预测的词是“great”,则认为是positive类 - 如果是“terrible”,则认为是negative类
- 如果
- 因为
- 训练
- 只对预训练好的MLM head进行微调
- 构建模板(Template Construction)
3 PET(Pattern-Exploiting Training)
《Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference》(EACL2021)
3.1 pattern 和verbalizer
3.1.1 Pattern(Template)
- 记作T ,即上文提到的模板,为额外添加的带有
[mask]标记的短文本 - 通常一个样本只有一个Pattern(因为我们希望只有1个让模型预测的
[mask]标记) - 不同的任务、不同的样本可能会有其更加合适的pattern
- ——> 如何构建合适的pattern是Prompt-Tuning的研究点之一
3.1.2 Verbalizer
- 记作V ,即标签词的映射,对于具体的分类任务,需要选择指定的标签词(label word)。
- 例如情感分析中,期望Verbalizer可能是
- V(positive)=great; V(negative)=terrible
- (positive和negative是类标签)
- 如何构建Verbalizer是另一个研究挑战 。
上述两个组件被称为Pattern-Verbalizer-Pair(PVP),一般记作P=(T,V)
3.2 Patterns Ensembling
- 一般情况下,一个句子只能有一个PVP
- 这可能并不是最优的,是否可以为一个句子设计多个不同的PVP呢?
- ——>Prompt-Tuning的集成
- Patterns Ensembling :同一个句子设计多个不同的pattern
3.3 Verbalizers Ensembling
- 在给定的某个Pattern下,并非只有1个词可以作为label word。
- 例如positive类,则可以选择“great”、“nice”、“wonderful”。当模型预测出这三个词时,均可以判定为positive类。
- 在训练和推理时,可以对所有label word的预测概率进行加权或投票处理,并最后获得概率最大的类
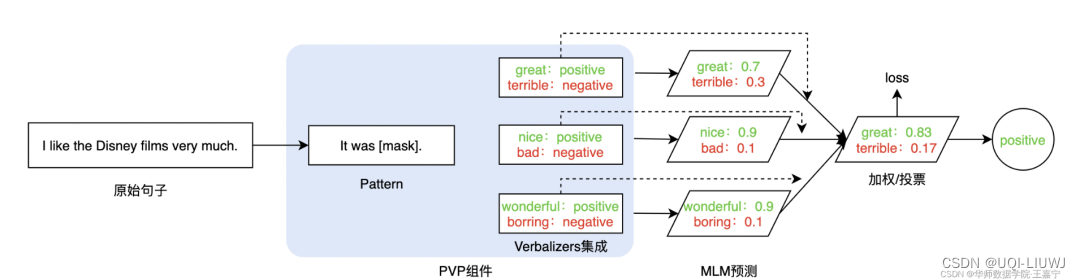
3.4 PVPs Ensembling(Prompt Ensembling)
- Pattern和Verbalizer均进行集成,此时同一个句子有多个Pattern,每个Pattern又对应多个label word
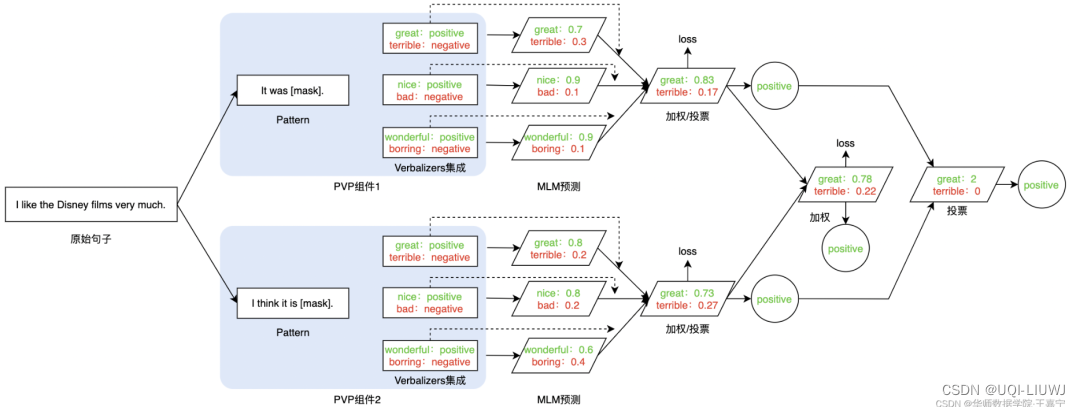
3.5 选择不同的Pattern和Verbalizer会产生差异很大的结果
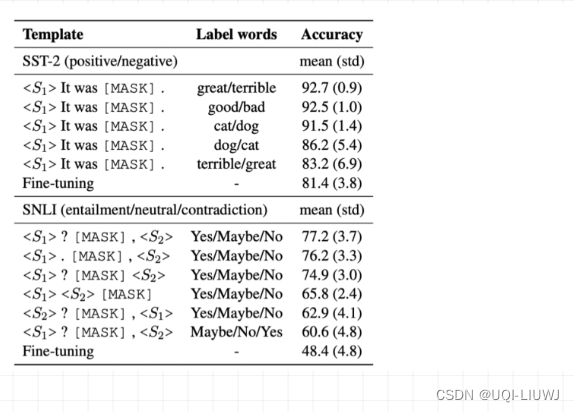
4 挑选合适的pattern
- 从3.5可以看出,不同的pattern对结果影响很大,所以如何挑选合适的pattern,是近几年学术界的一个热点
- 离散的模板构建(Hard Prompt)
- 直接与原始文本拼接显式离散的字符,且在训练中这些离散字符的词向量(Word Embedding) 始终保持不变
- ——>很难寻找到最佳的模板
- ——>效果不稳定
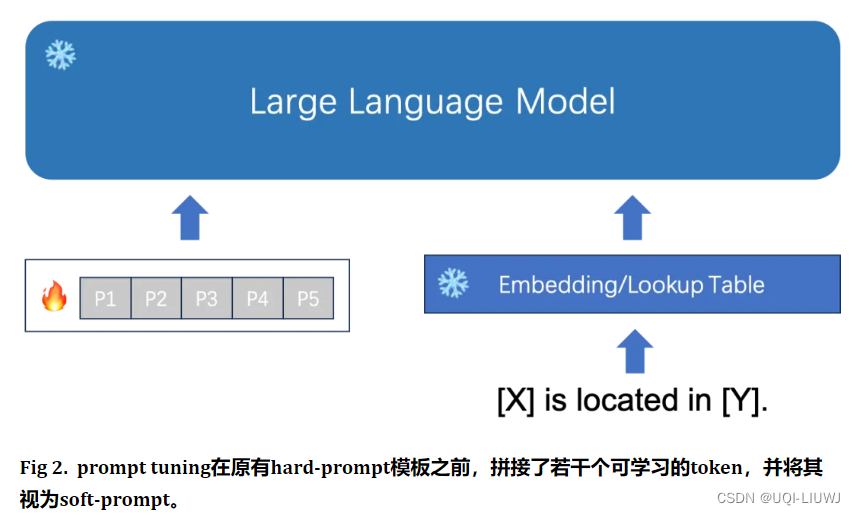
- 连续的模板构建(Soft Prompt)
- 让模型在训练过程中根据具体的上下文语义和任务目标对模板参数进行连续可调
- 离散的模板构建(Hard Prompt)
| 离散的模板构建 Hard Prompt | 启发式法(Heuristic-based Template) | 通过规则、启发式搜索等方法构建合适的模板 |
| 生成(Generation) | 根据给定的任务训练数据(通常是小样本场景),生成出合适的模板 | |
| 连续的模板构建 Soft Template | 词向量微调(Word Embedding) |
|
| 伪标记(Pseudo Token) | 不显式地定义离散的模板,而是将模板作为可训练的参数 |
4.1 soft prompt
The Power of Scale for Parameter-Efficient Prompt Tuning, EMNLP 2021
- 记Y是LLM的输出,X是输入token,θ是Transformer的权重参数
- NLP中的文本生成任务可以表示为
- NLP中的文本生成任务可以表示为
- 之前的hard Prompting在生成 Y 时向模型添加额外信息以作为条件:
- 这一过程可以表示为
- 也就是将prompt的语句和输入token 连接在一起,输入给pre-train 模型,在pre-train 模型中,用它的参数生成 embedding,经过一系列的流程得到对应的输出
- 这一过程可以表示为
- soft prompt/prompt tuning 使用一组特殊Token作为prompt
- 给定一系列 n 个Token,
- 第一步是将这些Token向量化,形成一个矩阵
- 【使用pre-train 模型的参数】
- (e是向量空间的维度)
- soft prompt以参数
的形式表示
- (p是prompt的长度)
- 将prompt与向量化后的输入连接起来,形成一个整体矩阵
- 该矩阵接着正常地通过编码器-解码器流动
- 模型旨在最大化
的概率,但仅更新prompt参数θP
- 第一步是将这些Token向量化,形成一个矩阵
- 给定一系列 n 个Token,
参考内容:一文详解Prompt学习和微调(Prompt Learning & Prompt Tuning)
相关文章:
大模型笔记:Prompt tuning
1 NLP模型的几个阶段 1.1 第一阶段(在深度学习出现之前) 通常聚焦于特征工程(feature engineering)利用领域知识从数据中提取好的特征 1.2 第二阶段(在深度学习出现之后) 特征可以从数据中习得——>…...
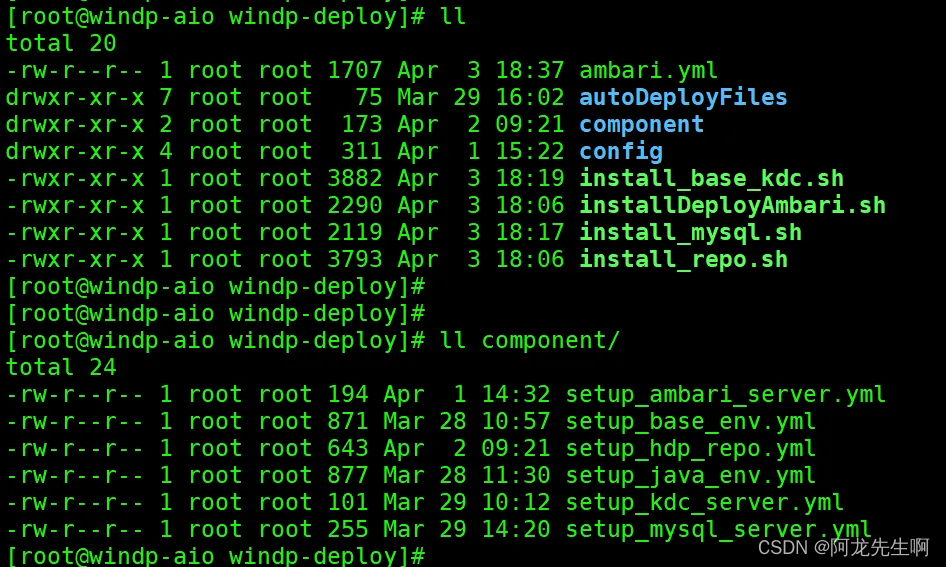
【Ambari】Ansible自动化部署大数据集群
目录 一.版本说明和介绍信息 1.1 大数据组件版本 1.2 Apache Components 1.3 Databases支持版本 二.安装包上传和说明 三.服务器基础环境配置 3.1global配置修改 3.2主机名映射配置 3.3免密用户名密码配置 3.4 ansible安装 四. 安…...
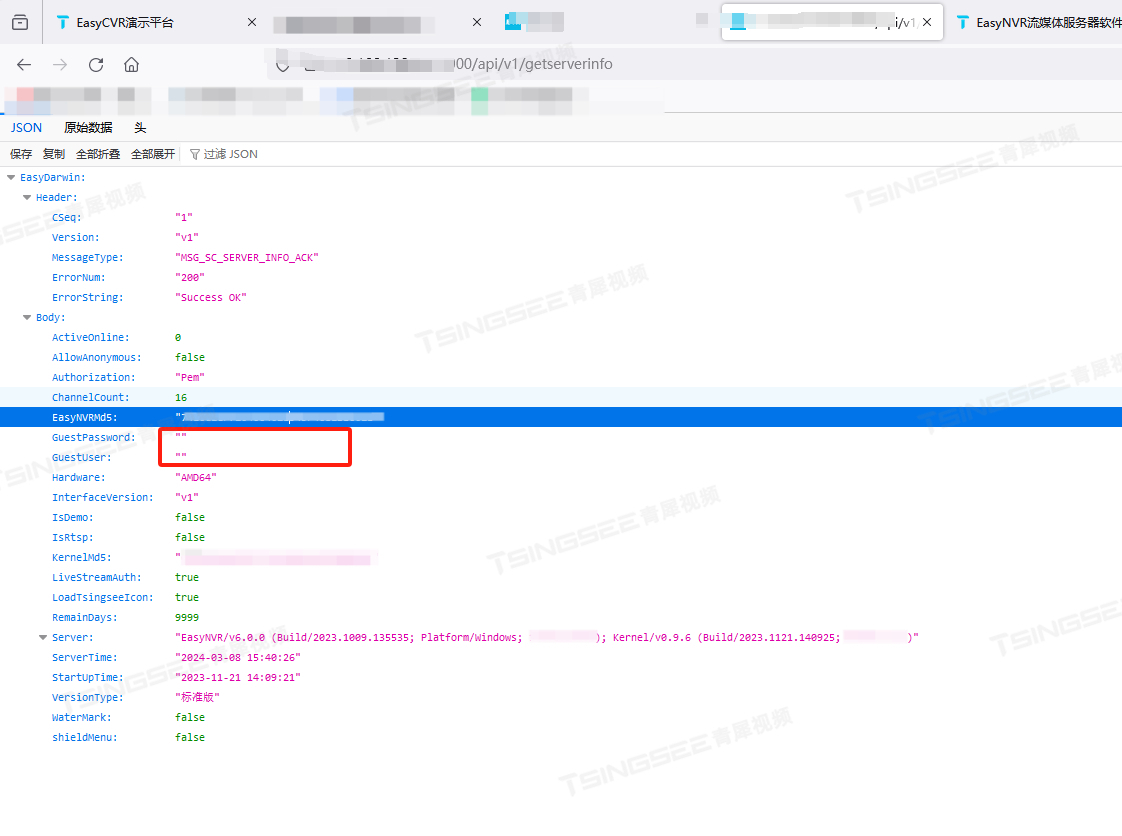
RTSP/Onvif视频安防监控平台EasyNVR调用接口返回匿名用户名和密码的原因排查
视频安防监控平台EasyNVR可支持设备通过RTSP/Onvif协议接入,并能对接入的视频流进行处理与多端分发,包括RTSP、RTMP、HTTP-FLV、WS-FLV、HLS、WebRTC等多种格式。平台拓展性强、支持二次开发与集成,可应用在景区、校园、水利、社区、工地等场…...

opencv基础图行展示
"""试用opencv创建画布并显示矩形框(适用于目标检测图像可视化) """ # 创建一个黑色的画布,图像格式(BGR) img np.zeros((512, 512, 3), np.uint8)# 画一个矩形:给定左上角和右下角坐标࿰…...
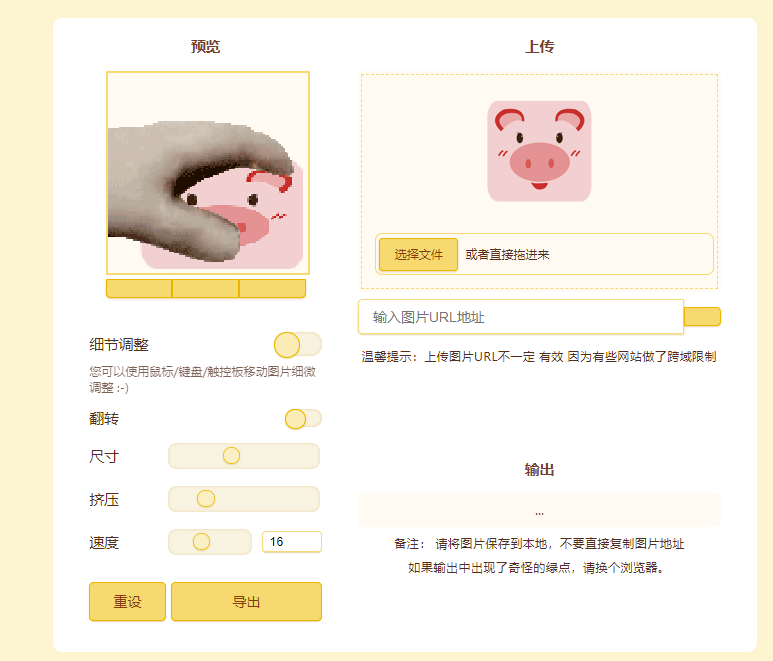
GIF在线生成器
上传图片就能生成GIF的前端WEB工具 源码也非常简单 <!DOCTYPE html> <html lang"zh" class"dark"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1, m…...

使用JavaScript制作一个简单的天气应用
随着Web开发技术的不断发展,JavaScript已经成为前端开发中不可或缺的一部分。它不仅可以用于创建动态和交互式的用户界面,还可以用于处理各种复杂的任务,如数据验证、动态内容更新、实时通信等。以下是一个使用JavaScript来创建一个简单天气应…...

说说对WebSocket的理解?应用场景?
文章目录 一、是什么二、特点全双工二进制帧协议名握手优点 三、应用场景参考文献 一、是什么 WebSocket,是一种网络传输协议,位于OSI模型的应用层。可在单个TCP连接上进行全双工通信,能更好的节省服务器资源和带宽并达到实时通迅 客户端和…...

网路维护基础知识
1、路由器 路由器:路由器就是将一个可以接入互联网的网路地址分成若干个网路地址可供终端设备连接的网路设备,设备既可以通过有线连接也可以通过无线连接进入互联网 2、交换机 交换机:个人感觉交换机只是为那些有线网路设计的,…...
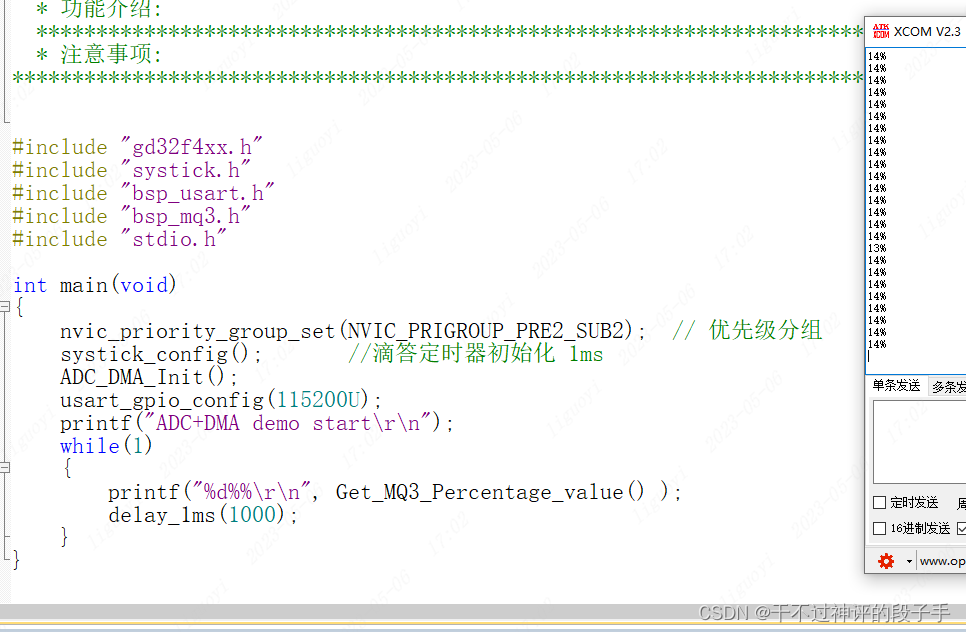
【GD32】MQ-3酒精检测传感器
2.31 MQ-3酒精检测传感器 MQ-3气体传感器所使用的气敏材料是在清洁空气中电导率较低的二氧化锡(Sn0)。当传感器所处环境中存在酒精蒸气时,传感器的电导率随空气中酒精蒸气浓度的增加而增大。使用简单的电路即可将电导率的变化转换为与该气体浓度相对应的输出信号。…...
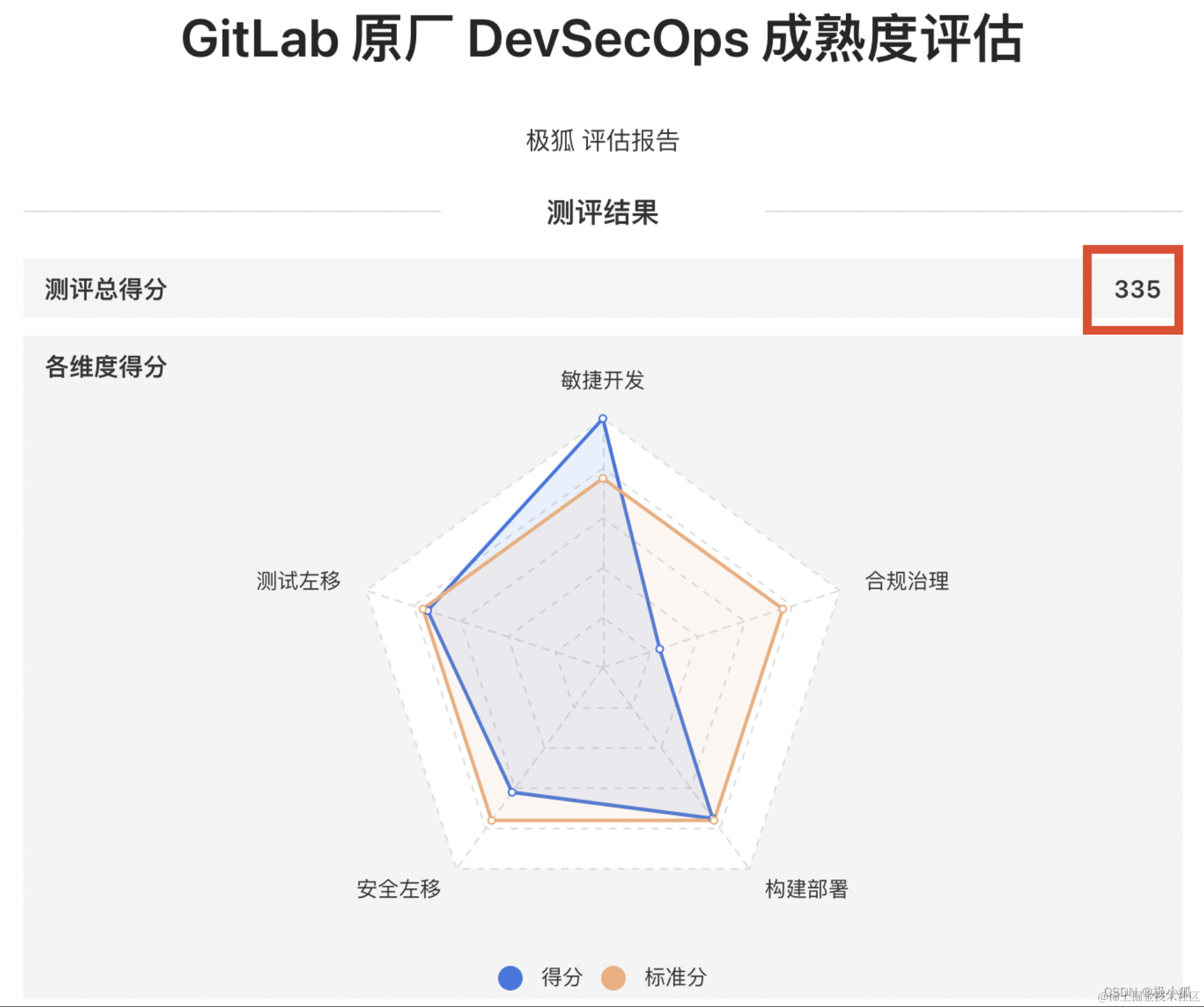
如何在极狐GitLab 启用依赖代理功能
本文作者:徐晓伟 GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 本文主要讲述了如何在[极狐GitLab…...

ES6中 Promise的详细讲解
文章目录 一、介绍状态特点流程 二、用法实例方法then()catchfinally() 构造函数方法all()race()allSettled()resolve()reject() 三、使用场景# 参考文献 一、介绍 Promise,译为承诺,是异步编程的一种解决方案,比传统的解决方案(…...

网站建设也会涉及商标侵权,需要注意些!
以前普推知产老杨碰到建站涉及知识产权侵权的,但是大多数是其它方面的,前几天看到某同行说由于给客户建设网站,由于网站名称涉及商标被起诉要索赔几十万。 当时同行给做网站时还看了下营业执照,上面的主体名称与网站名称也是一致…...

Leetcode算法训练日记 | day25
一、组合总和Ⅲ 1.题目 Leetcode:第 216 题 找出所有相加之和为 n 的 k 个数的组合,且满足下列条件: 只使用数字1到9每个数字 最多使用一次 返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺…...
第23次修改了可删除可持久保存的前端html备忘录:增加了百度引擎
第22次修改了可删除可持久保存的前端html备忘录视频背景分离,增加了本地连接,增加了纯CSS做的折叠隐藏修改说明 <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><meta name"viewport…...

vue3中使用antv-S2表格(基础功能版)
先看展示效果: 可以调整行宽、列宽、自定义字段图标、表头图标、添加排序、显示总计、小计等 首先确保搭建一个vue3项目环境,从0开始的小伙伴着重看第一点: 一、搭建vue3项目环境 首先创建一个vue3vitets项目,可以查看下面相关…...
算数逻辑单元
目录 一、王道考研ppt总结 二、个人理解 一、王道考研ppt总结 二、个人理解 74181是一款经典的ALU 可以进行加减乘除和与或非、异或等计算;还有移位和求补等 输入有一个CU信号,即控制单元信号,有一个M信号,当M为1时,进…...

clickhouse深入浅出
基础知识原理 极致压缩率 极速查询性能 列式数据库管理 ,读请求多 大批次更新或无更新 读很多但用很少 大量的列 列的值小数值/短字符串 一致性要求低 DBMS:动态创建/修改/删除库 表 视图,动态查/增/修/删,用户粒度设库…...

TPS2041A 至 TPS2044A 、TPS2051A 至 TPS2054A
这份文件是德州仪器(Texas Instruments)关于一系列电流限制型电源分配开关的数据手册,型号包括 TPS2041A 至 TPS2044A 和 TPS2051A 至 TPS2054A。这些开关适用于可能遇到重负载电容负载和短路的应用程序。以下是该数据手册的核心内容概要&…...

Excel从零基础到高手【办公】
第1课 - 快速制作目录【上篇】第1课 - 快速制作目录【下篇】第2课 - 快速定位到工作表的天涯海角第3课 - 如何最大化显示工作表的界面第4课 - 给你的表格做个瘦身第5课 - 快速定位目标区域所在位置第6课 - 快速批量填充序号第7课 - 按自定义的序列排序第8课 - 快速删除空白行第…...

AI图书推荐:如何在课堂上使用ChatGPT 进行教育
ChatGPT是一款强大的新型人工智能,已向公众免费开放。现在,各级别的教师、教授和指导员都能利用这款革命性新技术的力量来提升教育体验。 本书提供了一个易于理解的ChatGPT解释,并且更重要的是,详述了如何在课堂上以多种不同方式…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

PA100K数据集实战:从下载到结构化解析全流程
1. PA100K数据集初探:为什么选择它?如果你正在研究行人属性识别,PA100K绝对是个绕不开的宝藏数据集。这个数据集包含了10万张真实监控场景下的行人图像,每张图都标注了26种常见属性——从衣着风格(比如是否穿T恤、裙子…...

CANN-昇腾NPU-RAG推理-检索增强生成怎么部署
RAG(Retrieval-Augmented Generation)是 LLM 知识库的组合:先检索相关文档,再让 LLM 基于文档回答。昇腾NPU 上部署 RAG 需要两个组件:Embedding 模型(做向量检索)和 LLM(做生成&am…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

AI算力要上天?别笑,太空数据中心真能干翻地球电费!
前言你有没有算过,训练一个大模型,相当于烧掉多少吨煤?如今AI狂飙突进,算力需求指数级增长,可地球上的电——不够用了!更别说建个数据中心还得跟地方政府“斗智斗勇”,抢地皮、配储能、扛审批&a…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南
Adobe-GenP 3.0:轻松激活Adobe全家桶的完整指南 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP 3.0是一款专为Adobe Creative Cloud系列软件…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...

基于KS距离度量交通流分布偏移:提升DRL交通信号控制鲁棒性的工程实践
1. 项目概述与核心挑战在智能交通系统(ITS)领域,基于深度强化学习(DRL)的交通信号控制(Traffic Signal Control)正从研究走向实际部署。作为一名长期关注AI落地应用的从业者,我见过太…...