Stable Diffusion文生图技术详解:从零基础到掌握CLIP模型、Unet训练和采样器迭代
文章目录
- 概要
- Stable Diffusion 底层结构与原理
- 文本编码器(Text Encoder)
- 图片生成器(Image Generator)
- 那扩散过程发生了什么?
- stable diffusion 总体架构
- 主要模块分析
- Unet 网络
- 采样器迭代
- CLIP 模型
- 小结
概要
Stable Diffusion 是一种先进的潜在扩散模型(Latent Diffusion Model),它在深度学习和概率建模领域具有开创性意义。它能够根据文本描述生成高质量、细节丰富的图像,并在图像修复、图像绘制、文本到图像转换和图像到图像转换等任务中表现出色。这种模型由 CompVis、Stability AI 和 LAION 的研究人员在 2022 年发布,其技术提出者 StabilityAI 公司在同年完成了 1.01 亿美元的融资,估值现已超过 10 亿美元。
Stable Diffusion 底层结构与原理
稳定扩散(Stable Diffusion)的底层结构与原理涉及到深度学习和概率建模的领域,尤其是生成模型的研究。以下是稳定扩散的一些基本原理:
稳定过程(Stable Process): 稳定扩散的核心概念之一是稳定过程。稳定过程是一类随机过程,其性质在一定条件下对于加法运算是稳定的。这意味着稳定过程的和仍然遵循相同的分布。在稳定扩散中,这个过程用于逐步生成数据,每一步都是通过添加具有稳定分布的随机变量来改变数据分布。
随机变量的迭代: 稳定扩散的生成过程涉及到对初始噪声进行迭代。初始噪声通常是从简单的分布中生成的,例如标准正态分布。然后,通过多个迭代步骤,每一步都会引入稳定分布的随机变量,逐渐改变数据分布。
生成模型架构: 稳定扩散通常是在生成模型的框架下实现的。生成模型是一类深度学习模型,用于学习数据的分布,并生成具有相似分布的新样本。在稳定扩散中,生成模型的架构可能采用了类似于生成对抗网络(GANs)的结构,其中包括生成器和判别器。
训练过程: 训练稳定扩散模型涉及到通过样本数据来学习模型参数,使得模型能够逐步生成与样本数据相似的数据。这可能包括通过最大似然估计等方法来优化模型参数。
数值方法: 由于稳定扩散涉及到对复杂分布的逐步生成,其中可能包括数值方法来有效地处理和优化生成过程。这可能包括数值稳定性的考虑和一些近似方法。
Stable Diffusion 技术是 Diffusion 模型的改进版本,它通过引入潜在向量空间(Latent Vector Space)来解决传统 Diffusion 模型在速度和效率上的瓶颈。这项技术不仅可以专门用于文本生成图像(Text-to-Image)任务,还可以广泛应用于图像生成图像(Image-to-Image)、特定角色生成、图像超分辨率(Super-Resolution)以及图像上色等多个计算机视觉领域。
下图是一个基本的文生图流程,把中间的 Stable Diffusion 结构看成一个黑盒,那黑盒输入是一个文本串“paradise(天堂)、cosmic(广阔的)、beach(海滩)”,利用这项技术,输出了最右边符合输入要求的生成图片,图中产生了蓝天白云和一望无际的广阔海滩。
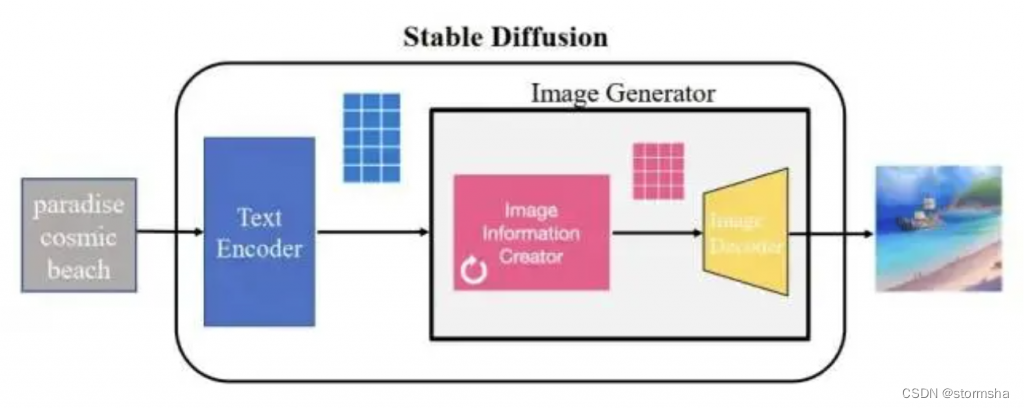
Stable Diffusion 核心思想是通过利用文本中包含的图像分布信息,将一张纯噪声的图片逐步去噪,最终生成一张与文本描述相匹配的高质量图像。这一过程的关键在于将人类可读的文本信息转换为机器可理解的数字表示,并使用这些数字表示来指导图像生成的过程。
文本编码器(Text Encoder)
在 Stable Diffusion 系统中,文本编码器(Text Encoder)是第一个关键模块。它的主要任务是将人类输入的文字字符串转换为计算机能够理解的数字表示,即语义向量(Semantic Vector)。文本编码器通常使用预训练的语言模型,如 CLIP(Contrastive Language-Image Pre-training),来理解文本的含义,并将其转换为一系列具有输入文字信息的语义向量。
图片生成器(Image Generator)
图片信息生成器是 stable diffusion 和 diffusion 模型的区别所在,也是性能提升的关键,有两点区别:
① 图片信息生成器的输入输出均为低维图片向量(不是原始图片),对应上图里的粉色 44 方格。同时文本编码器的语义向量作为图片信息生成器的控制条件,把图片信息生成器输出的低维图片向量进一步输入到后续的图片解码器(黄色)生成图片。(注:原始图片的分辨率为 512512,有RGB 三通道,可以理解有 RGB 三个元素组成,分别对应红绿蓝;低维图片向量会降低到 64*64 维度)
② Diffusion 模型一般都是直接生成图片,不会有中间生成低维向量的过程,需要更大计算量,在计算速度和资源利用上都比不过 stable diffusion;
那低维空间向量是如何生成的?是在图片信息生成器里由一个 Unet 网络和一个采样器算法共同完成,在 Unet 网络中一步步执行生成过程,采样器算法控制图片生成速度,下面会在第三部分详细介绍这两个模块。Stable Diffusion 采样推理时,生成迭代大约要重复 30~50 次,低维空间变量在迭代过程中从纯噪声不断变成包含丰富语义信息的向量,图片信息生成器里的循环标志也代表着多次迭代过程。
图像解码器(Image Decoder)
图像解码器(Image Decoder)是图片生成器的第二个子模块,它接收潜在空间生成器输出的潜在空间向量作为输入,并使用升维技术将潜在空间向量转换为实际的图像。图像解码器通常使用反卷积(Deconvolution)或转置卷积(Transposed Convolution)等操作来逐渐增加图像的分辨率,最终生成一张高质量的图像。
通过将文本编码器和图片生成器有机地组合在一起,Stable Diffusion 技术能够根据文本描述生成多样化、高质量的图像,为计算机视觉和自然语言处理等领域的研究和应用提供了新的思路和工具。
那扩散过程发生了什么?
扩散过程发生在图片信息生成器中,把初始纯噪声隐变量输入到 Unet 网络后结合语义控制向量,重复 30~50 次来不断去除纯噪声隐变量中的噪声,并持续向隐向量中注入语义信息,就可以得到一个具有丰富语义信息的隐空间向量(右下图深粉方格)。采样器负责统筹整个去噪过程,按照设计模式在去噪不同阶段中动态调整 Unet 去噪强度。
更直观看一下,如下图所示,通过把初始纯噪声向量和最终去噪后的隐向量都输到后面的图片解码器,观察输出图片区别。从下图可以看出,纯噪声向量由于本身没有任何有效信息,解码出来的图片也是纯噪声;而迭代 50 次去噪后的隐向量已经耦合了语义信息,解码出来也是一张包含语义信息的有效图片。
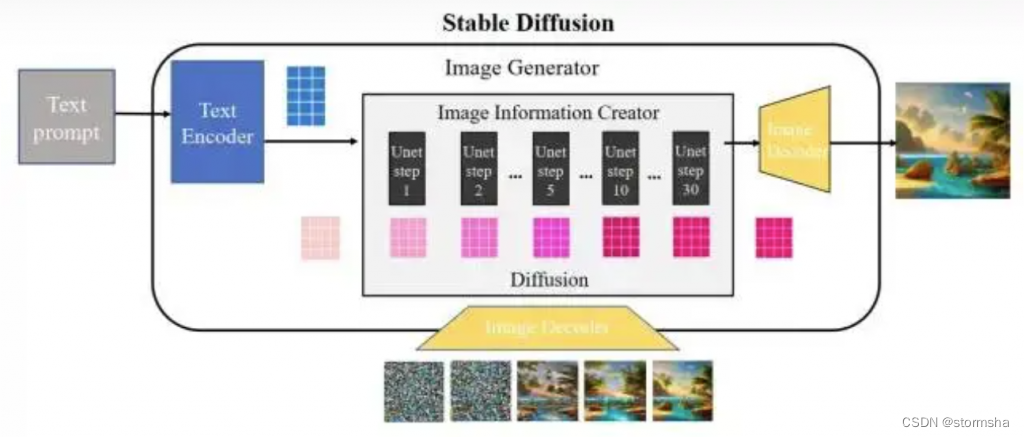
到这里,我们大致介绍了 Stable Diffusion 是什么以及各个模块思路,并且简单介绍了 stable diffusion 的扩散过程。第三部分我们继续分析各个重要组成模块的运行机制,更深入理解 Stable Diffusion 工作原理。
stable diffusion 总体架构
以下是从零基础角度介绍Stable Diffusion技术思路,主要聚焦于Stable Diffusion的文生图技术,并详细阐述其三个核心模块:CLIP模型、Unet训练和采样器迭代。
训练阶段和采样阶段的总体框架如下图所示:
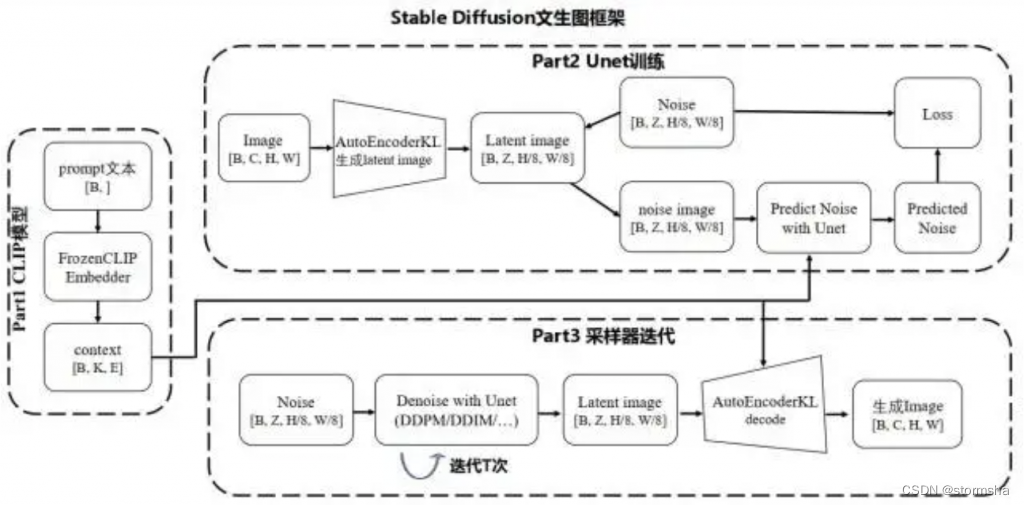
训练阶段
包含了图里 PART1 CLIP 模型和 PART2 Unet 训练,分成三步:
- 用 AutoEncoderKL 自编码器把输入图片从像素空间映射到隐向量空间,把 RGB 图片转换到隐式向量表达。其中,在训练 Unet 时自编码器参数已经训练好和固定的,自编码器把输入图片张量进行降维得到隐向量。
- 用 FrozenCLIPEmbedder 文本编码器来编码输入提示词 Prompt,生成向量表示 context,这里需要规定文本最大编码长度和向量嵌入大小。
- 对输入图像的隐式向量施加不同强度噪声,再把加噪后隐向量输入到 UNetModel 来输出预估噪声,和真实噪声信息标签作比较来计算 KL 散度 loss,并通过反向传播算法更新 UNetModel 模型参数;引入文本向量 context 后,UNetModel 在训练时把其作为 condition,利用注意力机制来更好地引导图像往文本向量方向生成;
采样阶段
包含了图里 PART1 CLIP 模型和 PART3 采样器迭代,分成三步:
- 用 FrozenCLIPEmbedder 文本编码器把输入提示词 Prompt 进行编码,生成维度为[B, K, E]的向量表示 context,与训练阶段的第 2 步一致。
- 利用随机种子随机产出固定维度的噪声隐空间向量,利用训练好的 UNetModel 模型,结合不同采样器(如 DDPM/DDIM/PLMS)迭代 T 次不断去除噪声,得到具有文本信息的隐向量表征。
- 用 AutoEncoderKL 自编码器把上面得到的图像隐向量进行解码,得到被映射到像素空间的生成图像。
上面对 stable diffusion 总体架构进行了介绍,那接下来进一步分析介绍下每个重要组成模块,分别是 Unet 网络、采样器和 CLIP 模型三个主要模块。
主要模块分析
Unet 网络
Stable Diffusion 里采用的 UNetModel 模型,采用 Encoder-Decoder 结构来预估噪声,网络结构如下图
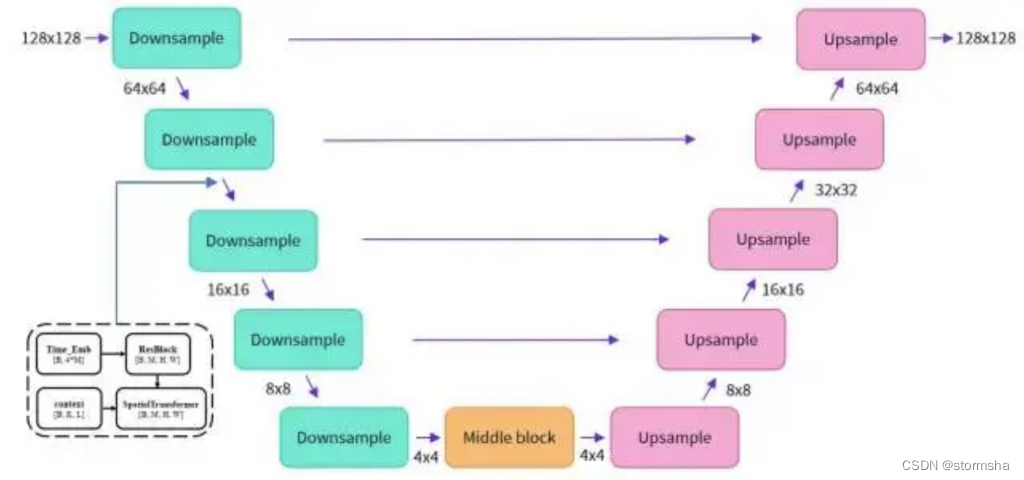
模型输入包括 3 个部分,
(1) 图像表示,用隐空间向量输入的维度为[B, Z, H/8, W/8]。
(2) timesteps 值,维度为[B, ]。
(3) 文本向量表示 context,维度为[B, K, E]。
其中[B, Z, H, W]分别表示[batch_size 图片数,C 隐空间通道数,height 长度,weight 宽度],K 和 E 分别表示文本最大编码长度 max length 和向量嵌入大小。
模型使用 DownSample 和 UpSample 进行样本的下上采样,在采样模块之间还有黑色虚线框的 ResBlock 和 SpatialTransformer,分别接收 timesteps 信息和提示词信息(这里只画出一次作为参考)。
ResBlock 模块的输入有:
① 来自上一个模块的输入和
②timesteps 对应的嵌入向量 timestep_emb(维度为[B, 4*M],M 为可配置参数)。
SpatialTransformer 模块的输入有:
① 来自上一个模块的输入
② 提示词 Prompt 文本的嵌入表示 context,以 context 为注意力机制里的 condition,学习提示词 Prompt 和图像的匹配程度。
最后,UNetModel 不改变输入和输出大小,隐空间向量的输入输出维度均为[B, Z, H/8, W/8]。
ResBlock 网络
ResBlock 网络,有两个输入分别是
① 来自上一个模块的输入
②timesteps 对应的嵌入向量 timestep_emb(维度为[B, 4*M],M 为可配置参数)
网络结构图如下所示。
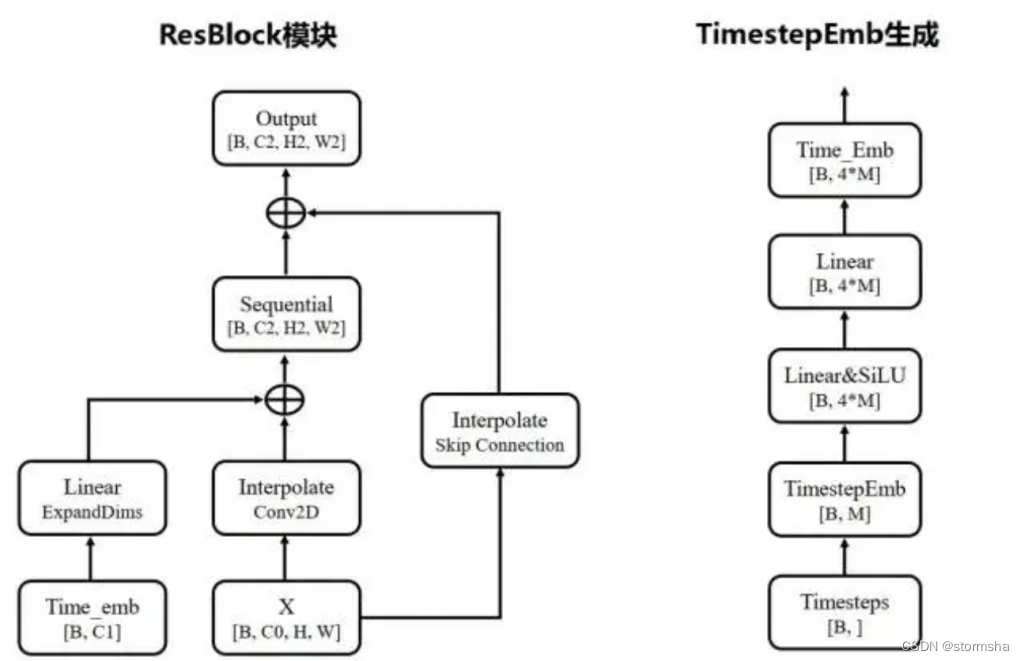
timestep_embedding 的生成方式,用的是“Attention is All you Need”论文的 Transformer 方法,通过 sin 和 cos 函数再经过两个 Linear 进行变换。
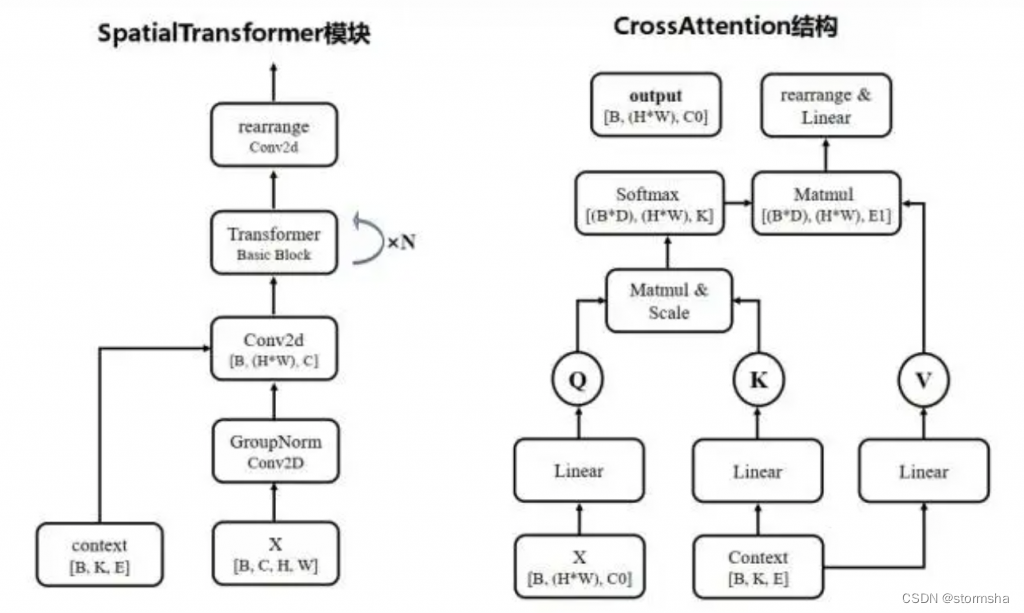
SpatialTransformer 结构
SpatialTransformer 这里,包含模块比较多,有两个输入分别是:
① 来自上一个模块的输入和
② 提示词 Prompt 文本的嵌入表示 context 作为 condition
两者使用 cross attention 进行建模。
其中,SpatialTransformer 里面的注意力模块 CrossAttention 结构,把图像向量作为 Query,文本表示 context 作为 Key&Value,利用 Cross Attention 模块来学习图像和文本对应内容的相关性。
注意力模块的作用是,当输入提示词来生成图片时,比如输入 “一匹马在吃草”,由于模型已经能捕捉图文相关性以及文本中的重点信息,当看到 “马”时,注意力机制会重点突出图像“马”的生成;当看到“草”时,注意力机制会重点突出图像 “草” 的生成,进而实现和文本匹配的图片生成。
Unet 如何训练?
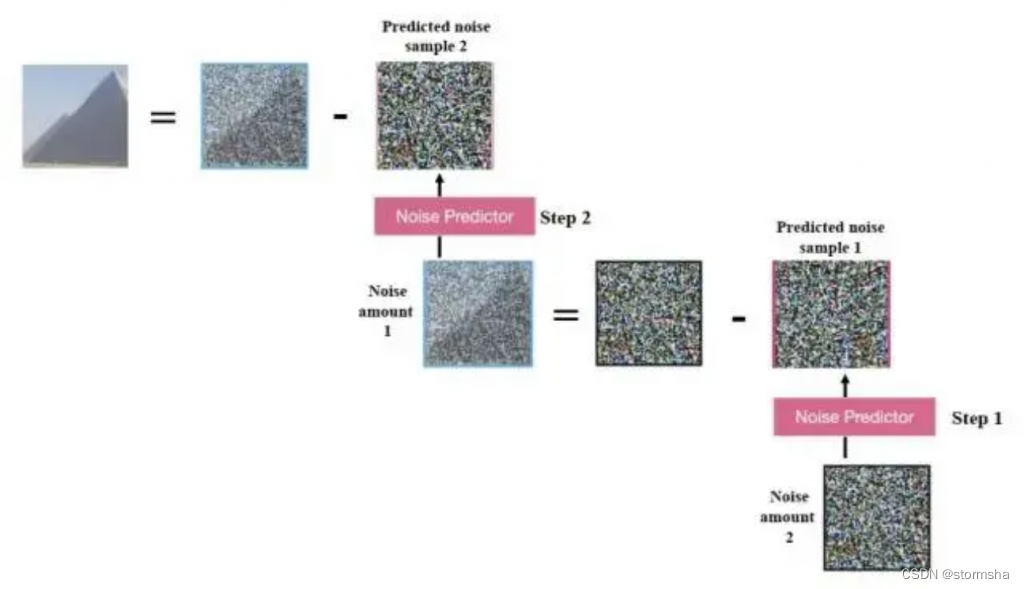
Stable Diffusion 里面 Unet 的学习目标是什么?简单来说就是去噪。那在为去噪任务设计训练集时,就可以通过向普通照片添加噪声来得到训练样本。具体来说,对于下面这张照片,用 random 函数生成从强到弱的多个强度噪声,比如下图 0~3 有 4 个强度的噪声。训练时把噪声强度和加噪后图片输入到 Unet,计算预测噪声图和真正噪声图之间的误差损失,通过反向传播更新 unet 参数。

训练好 Unet 后,如下图 所示,从加噪图片中推断出噪声后,就可以用加噪图减掉噪声来恢复原图;重复这个过程,第一步预测噪声图后再减去噪声图,用更新后的加噪图进行第二步去噪,最终就能得到一张很清晰的生成图片。由于使用了高斯分布的 KL 散度损失,Unet 生成图片实际上是接近训练集分布的,和训练集有着相同像素规律。也就是说,使用真实场景的写实训练集去训练模型,它的结果就会具有写实风格,尽量符合真实世界规律。
采样器迭代
这部分介绍下采样阶段中扩散模型如何多次迭代去除噪声,进而得到生成图片的潜在空间表示。提到采样器,要从最基础的采样器 DDPM(Denoising Diffusion Probabilistic Models)进行介绍[4]。DDPM 推导有点复杂,这里就用朴素一点的大白话结合几个关键公式来理清推导思路。
1、扩散模型的思路是,训练时先在图片上不断加噪来破坏图片,推理时对加噪后的图片去噪来恢复出原始图片。训练过程的 T 次迭代中,可推导出一个重要特性:任意时刻的 Xt 可以由 X0 和 β 表示,任意时刻的 X0 也可以由 Xt 和噪声 z 求得。
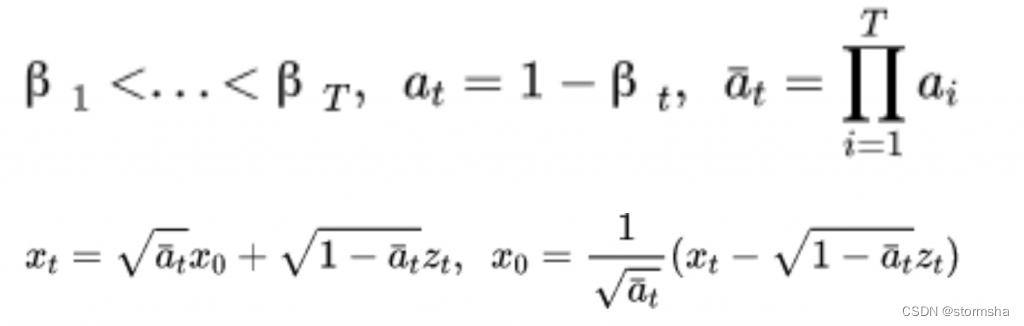
其中,第一行里 a 和 β 可以描述噪声强度;第二行,X0 为初始的干净图片,增加噪声 z 后生成加噪图片 Xt,后个公式由前个公式变换而来,表示加噪图片减去一定强度噪声,得到图片 X0。
2、问题变成,如何求逆向阶段的分布,即给定了一张加噪后图片,如何才能求得前一时刻没有被破坏得那么严重的略清晰图片。经过论文里的一顿推导,又得出两个重要结论:
① 逆向过程也服从高斯分布
② 在知道原始清晰图片时,能通过贝叶斯公式把逆向过程转换成前向过程,进而算出逆向过程分布。
在公式上体现如下:
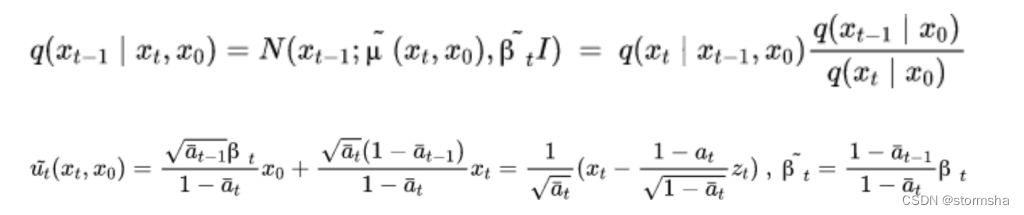
其中,第一行指的是给定 X0 情况下,逆向过程也服从高斯分布,并且利用贝叶斯公式把逆向过程转换成前向过程,前向过程是不断加噪的过程,可以被计算;第二行指的是,Xt 和 X0 由于可以相互转换,从公式上看,均值也可以从 Xt 减去不同噪声得到。
3、算出逆向过程分布后,就可以训练一个模型尽量拟合这个分布,而且模型预估结果也应该服从高斯分布:
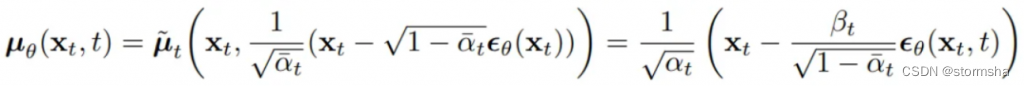
其中,求均值公式里只包含 Xt 和噪声,由于 Xt 在训练时已知,那只需要得到模型输出的预估噪声,该值可由模型用 Xt 和 t 预估得到。
4、把逆向过程分布(也就是 Label 值)和模型的预估分布做比较,由于 ①KL 散度可以用来描述两个分布之间的差异和 ② 多元高斯分布的 KL 散度有闭式解,经过一番推导发现损失函数变成计算两个高斯分布的 KL 散度。
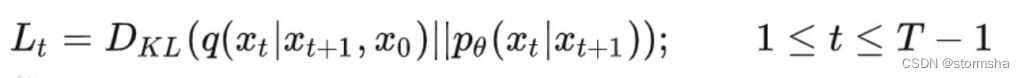
其中,q 分布是逆向过程分布,p 是模型预估分布,训练损失是求两个高斯分布的 KL 散度,即两个分布之间的差距。
5、DDPM 训练过程和采样过程的伪代码如下图所示。由于 DDPM 的高质量生成依赖于较大的 T(一般为 1000 以上),导致 Diffusion 前向过程特别缓慢,因此后续进一步有了 DDIM、PLMS 和 Euler A 等一些优化版采样器。

其中,训练阶段实际上是求真实噪声和模型预估噪声的 MSE 误差,再对 Loss 求导反向传播来训练模型;采样阶段,求得均值和方差后,采用重参数技巧来生成样本。
扩散模型采样阶段是对加噪后图片去噪来恢复出原始图片
① 任意时刻的图片均可以由原始图片和噪声表示
② 逆向过程的图片参数符合高斯分布,优化目标转化为计算逆向分布和预估分布的 KL 散度差异,并在采样阶段使用重参数技巧来生成图片。
CLIP 模型
在前面有提到,提示词 Prompt 文本利用文本模型转换成嵌入表示 context,作为 Unet 网络的 condition 条件。那问题来了,语义信息和图片信息属于两种模态,怎么用 attention 耦合到一起呢?这里介绍下用于提取语义信息的 CLIP 模型。
语义信息的好坏直接影响到了最终生成图片的多样性和可控性,那像 CLIP 这样的语言模型是如何训练出来的?是如何结合文本串和计算机视觉的呢?首先,要有一个具有文本串和计算机视觉配对的数据集。CLIP 模型所使用的训练集达到了 4 亿张,通过从网络上爬取图片及相应的标签或者注释。
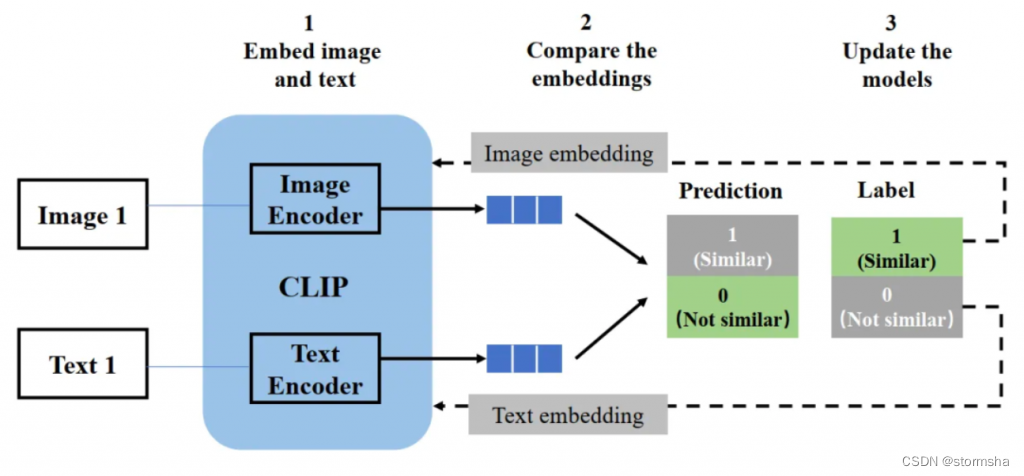
CLIP 模型结构包含一个图片 encoder 和一个文字 encoder,类似于推荐场景常用到的经典双塔模型。
-
训练时,从训练集随机取出一些样本(图片和标签配对的话就是正样本,不匹配的话就是负样本),CLIP 模型的训练目标是预测图文是否匹配;
-
取出文字和图片后,用图片 encoder 和文字 encoder 分别转换成两个 embedding 向量,称作图片 embedding 和文字 embedding;
-
用余弦相似度来比较两个 embedding 向量相似性,并根据标签和预测结果的匹配程度计算损失函数,用来反向更新两个 encoder 参数。
-
在 CLIP 模型完成训练后,输入配对的图片和文字,这两个 encoder 就可以输出相似的 embedding 向量,输入不匹配的图片和文字,两个 encoder 输出向量的余弦相似度就会接近于 0。
推理时,输入文字可以通过一个 text encoder 转换成 text embedding,也可以把图片用 image encoder 转换成 image embedding,两者就可以相互作用。在生成图片的采样阶段,把文字输入利用 text encoder 转换成嵌入表示 text embedding,作为 Unet 网络的 condition 条件。
小结
`
AI 绘画各种应用不断涌现,目前有关 Stable Diffusion 的文章主要偏向应用介绍,对于 Stable Diffusion 技术逻辑的介绍还是比较少。这篇文章主要介绍了 Stable Diffusion 技术结构和各个重要组成模块的基本原理,希望能够让大家了解 Stable Diffusion 是如何运行的,才能更好地控制 AI 绘画生成。AI 绘画虽然还面临一些技术挑战,但随着技术不断迭代和发展,相信 AI 能够在更多领域发挥出惊喜生产力。
参考文章
相关文章:
Stable Diffusion文生图技术详解:从零基础到掌握CLIP模型、Unet训练和采样器迭代
文章目录 概要Stable Diffusion 底层结构与原理文本编码器(Text Encoder)图片生成器(Image Generator) 那扩散过程发生了什么?stable diffusion 总体架构主要模块分析Unet 网络采样器迭代CLIP 模型 小结 概要 Stable …...

SDK-0.7.8-Release-实体管理 - ApiHug-Release
🤗 ApiHug {Postman|Swagger|Api...} 快↑ 准√ 省↓ GitHub - apihug/apihug.com: All abou the Apihug apihug.com: 有爱,有温度,有质量,有信任ApiHug - API design Copilot - IntelliJ IDEs Plugin | Marketplace 更多精彩…...
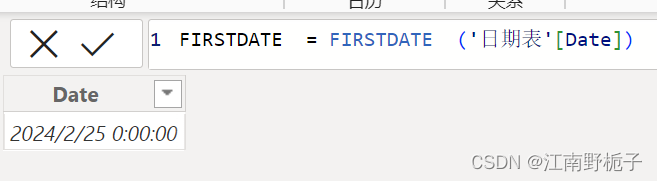
3. DAX 时间函数-- DATE 日期--一生二,二生三,三生万物
在数据分析过程中,经常需要从一个数据推到另外一个数据,日期数据也是如此,需要从一个日期推到另外一个相关的日期,或者从一群日期推到另外一个相关的日期/一群相关的日期。这一期说的就是日期之间彼此推衍的函数,会比之…...
c 解数独(通用方法,适用于9×9 数独)
折腾了一周时间,终于搞定99数独通用方法 思路:1.生成每行空位的值,也就是1-9中除去非0的数。 2.用行,列,宫判断每行中每个空位的最小取值范围后再重新生成每行。 3.随机提取生成的9行,判断每列之和是否等…...
)
一篇文章深入学习Java的AQS(AbstractQueuedSynchronizer)
深入理解AQS的设计和工作机制 Oracle官方文档中的AbstractQueuedSynchronizer部分讲解 AbstractQueuedSynchronizer(简称AQS)是Java并发包中的一个基础框架,它为实现依赖单个原子变量来表示状态的同步器提供了可靠的基础。这个框架被广泛用…...

Linux sed
文章目录 1. 基本功能2.sed替换ssed配合grep和管道操作符的例子 3.sed中的删除和添加3.1 d删除3.2 a i添加添加多行 4.sed行替换替换包含某字符的行 5.单字符替换 y6. p打印命令打印含有目标字符的行sed中包含多个指令,使用{} 7.sed w 写入文件8.sed r 读取文件9.se…...

【MySQL】MySQL在Centos 7环境安装
目录 准备工作 第一步:卸载不要的环境 第二步:下载官方的mysql 第三步 上传到Linux中 第四步 安装 正式安装 启动 编辑 登录 准备工作 第一步:卸载不要的环境 使用root进行安装 如果是普通用户,使用 su - 命令&#…...
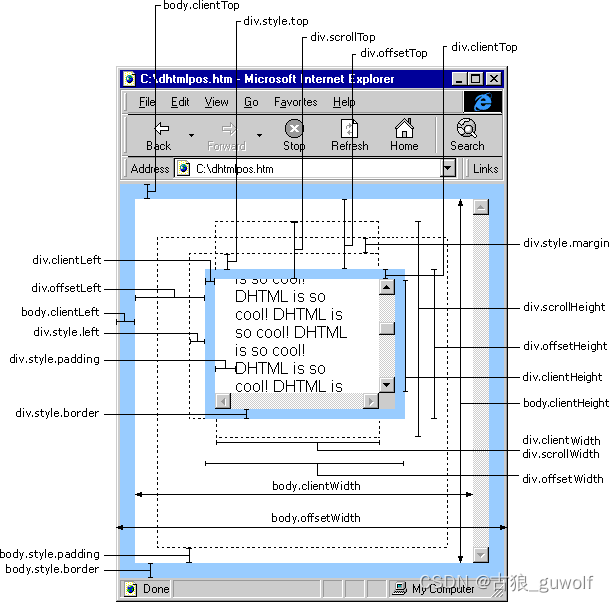
【CSS】一篇文章讲清楚screen、window和html元素的位置:top、left、width、height
一个Web网页从内到外的顺序是: 元素div,ul,table... → 页面body → 浏览器window → 屏幕screen 分类详情屏幕screen srceen.width - 屏幕的宽度 screen.height - 屏幕的高度(屏幕未缩放时,表示屏幕分辨率) screen.availLeft …...

铸造大型基础平板的结构应该怎样设计
设计大型基础平板的结构时,需要考虑以下几个方面: 地质条件:首先要了解工程所在地的地质条件,包括土质、地下水位、地震状况等。根据地质条件来选择合适的基础类型,如浅基、深基或地下连续墙等。 荷载分析:…...
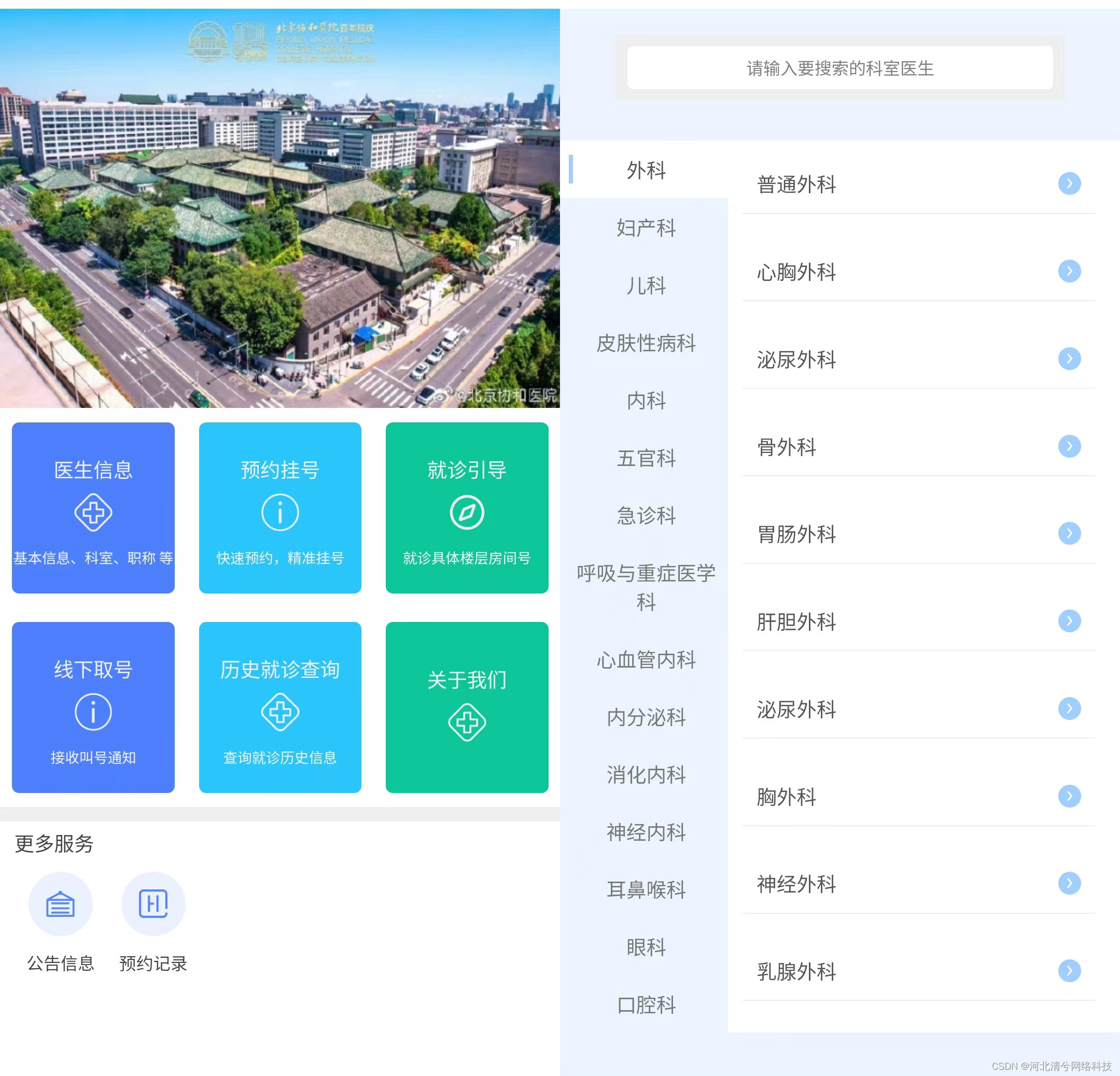
医院预约系统微信小程序APP前后端
医院预约系统具体功能介绍:展示信息、可以注册和登录, 预约(包含各个科室的预约,可以预约每个各个医生),就诊引导包含预约的具体信息,包含就诊时间、就诊科室、就诊医生以及就诊人信息、和支付状…...
springboot数字化智慧城市管理系统源码
目录 系统开发环境 系统功能模块 系统特点 1、智慧城管移动端 2、案件受理 3、AI视频智识别分析 系统应用价值 1、提升案件办理效率 2、提升监管效能 3、提升行政执法水平 4、推进行政执法创新 智慧城管综合执法办案系统功能 现场移动执法 一般程序案件的网上办…...
【鸿蒙开发】第二十一章 Media媒体服务(一)
1 简介 Media Kit(媒体服务)提供了AVPlayer和AVRecorder用于播放、录制音视频。 在Media Kit的开发指导中,将介绍各种涉及音频、视频播放或录制功能场景的开发方式,指导开发者如何使用系统提供的音视频API实现对应功能。比如使用…...

【QT教程】QT6 Web应用实战
QT6 Web应用实战 使用AI技术辅助生成 QT界面美化视频课程 QT性能优化视频课程 QT原理与源码分析视频课程 QT QML C扩展开发视频课程 免费QT视频课程 您可以看免费1000个QT技术视频 免费QT视频课程 QT统计图和QT数据可视化视频免费看 免费QT视频课程 QT性能优化视频免费看 免费…...

(我的创作纪念日)[MySQL]数据库原理7——喵喵期末不挂科
希望你开心,希望你健康,希望你幸福,希望你点赞! 最后的最后,关注喵,关注喵,关注喵,大大会看到更多有趣的博客哦!!! 喵喵喵,你对我真的…...

普乐蛙VR航天体验馆设备VR太空飞船VR元宇宙展厅
三天小长假就要来啦!五一假期也即将到来。老板们想捉住人流量这个财富密码吗?那快快行动起来!开启VR体验项目,假期赚翻天!小编亲测!!这款设备刺激好玩,想必会吸引各位家长小孩、学生…...

基于torch的图像识别训练策略与常用模块
数据预处理部分: 数据增强:torchvision中transforms模块自带功能,比较实用数据预处理:torchvision中transforms也帮我们实现好了,直接调用即可DataLoader模块直接读取batch数据 网络模块设置: 加载预训练…...
微信小程序制作圆形进度条
微信小程序制作圆形进度条 1. 建立文件夹 选择一个目录建立一个文件夹,比如 mycircle 吧,另外把对应 page 的相关文件都建立出来,包括 js,json,wxml 和 wxcc。 2. 开启元件属性 在 mycircle.json中开启 component 属…...

大模型(Large Models):探索人工智能领域的新边界
🌟文章目录 🌟大模型的定义与特点🌟模型架构🌟大模型的训练策略🌟大模型的优化方法🌟大模型的应用案例 随着人工智能技术的飞速发展,大模型(Large Models)成为了引领深度…...
缓存相关知识总结
一、缓存的作用和分类 缓存可以减少数据库的访问压力,提升整个网站的数据访问速度,改善数据库的写入性能。缓存可以分为两种: 缓存在应用服务器上的本地缓存:访问速度快,但受应用服务器内存限制 缓存在专门的分布式缓存…...

Mapmost Alpha:开启三维城市场景创作新纪元
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

元学习MAML的5大应用场景:从图像分类到强化学习的真实案例解析
元学习MAML的5大应用场景:从图像分类到强化学习的真实案例解析 在人工智能领域,快速适应新任务的能力一直是研究者们追求的目标。想象一下,一个模型只需少量样本就能学会识别从未见过的物体,或者一个机器人能在几分钟内掌握全新的…...
Transformer架构深度解析:丹青幻境绘制注意力机制动态图
Transformer架构深度解析:丹青幻境绘制注意力机制动态图 最近在和朋友聊起大模型时,发现一个挺有意思的现象:大家都能说出“Transformer”和“注意力机制”这些词,但真要问起它们内部到底是怎么工作的,很多人就卡壳了…...

大模型进阶必看:RAG技术详解与实战,让AI不再“胡说八道“,建议收藏
1、 为何RAG成为大模型的“刚需配置”? 用过ChatGPT、Claude等主流大模型的用户,大概率遇到过这样的困扰:它们给出的回答逻辑通顺、表述专业,可仔细核对后却发现**“看似正确,实则有误”**。这一问题的根源࿰…...
)
用 LiteLLM 打通 Codex CLI 与 Claude Code(有key即可实现编程自由)
前言 最近我一直在做一件事:既然 Codex CLI 已经可以通过 LiteLLM 接入 Azure GPT-5.4,那能不能进一步把 Claude Code 也打通,让两套 CLI 共用同一层代理、同一组模型别名、同一套启动方式? 更重要的是,这个过程不能…...

python-flask超市库存退货管理系统的设计与实现
目录需求分析技术选型数据库设计功能模块开发测试与部署迭代优化项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析 明确超市库存退货管理系统的核心功能需求,包括商品信息管理、退货…...

计算机视觉算法优化
计算机视觉算法优化:让机器更懂世界 计算机视觉作为人工智能的核心领域之一,正深刻改变着我们的生活。从人脸识别到自动驾驶,从医疗影像分析到工业质检,计算机视觉算法的性能直接决定了应用的准确性和效率。随着数据量的爆炸式增…...

5个实用技巧:如何通过 A/B 测试优化 Intro.js 引导流程
5个实用技巧:如何通过 A/B 测试优化 Intro.js 引导流程 【免费下载链接】intro.js Lightweight, user-friendly onboarding tour library 项目地址: https://gitcode.com/gh_mirrors/in/intro.js Intro.js 是一款轻量级、用户友好的引导流程库,能…...

CLIP ViT-H-14 API性能压测报告:QPS、延迟、错误率全维度分析
CLIP ViT-H-14 API性能压测报告:QPS、延迟、错误率全维度分析 1. 引言:为什么我们需要关注API性能? 想象一下,你正在开发一个智能相册应用,用户上传一张照片,系统需要在毫秒内从海量图库中找到最相似的图…...

AWPortrait-Z人像生成提效方案:快捷键Enter/F5+命令行运维速查
AWPortrait-Z人像生成提效方案:快捷键Enter/F5命令行运维速查 1. 快速上手:一键启动与高效操作 AWPortrait-Z是基于Z-Image精心构建的人像美化LoRA模型,通过二次开发的WebUI界面,让人像生成变得简单高效。无论你是设计师、内容创…...
附赠)
cv_resnet50_face-reconstruction新手必看:test_face.jpg预处理脚本(自动对齐/白平衡/直方图均衡)附赠
cv_resnet50_face-reconstruction新手必看:test_face.jpg预处理脚本(自动对齐/白平衡/直方图均衡)附赠 本文为初学者详细解析人脸重建项目中test_face.jpg的预处理技巧,包含自动对齐、白平衡和直方图均衡的完整实现代码࿰…...