八大排序算法(面试被问到)
1.八大排序算法都是什么?
八大排序算法有:插入排序、冒泡排序、归并排序、选择排序、快速排序、希尔排序、堆排序、基数排序(通常不提)。此外,还可以直接调用Arrays.sort()进行排序。
2.八大排序算法时间复杂度和稳定性?
这里有一个口诀记法:
插(插入)帽(冒泡)龟(归并),他很稳(稳定);
插冒归喜欢选(选择)插(插入)帽(冒泡),插完他就方了O(n^2);
快(快速)归(归并)队(堆),n老O(logn);
基(基数)你太稳(稳定);
3.算法讲解?
(1) 冒泡排序
过程:
①从数列的开头开始,在这趟遍历中对没有进行比较的一对两两比较,直到数列的结尾;
②如果第一个元素比第二个元素大,则交换它们的位置,这样较大的元素就逐渐“浮”到数列的末尾;
③然后,算法再次从数列的开始执行相同的操作,但是排好序的元素(即最大的元素)不再参与比较;这个过程一直持续到整个数列都排好序为止。
代码实现:
public class BubbleSort {
11 public static void main(String[] args) {
12 int[] arr={5,4,2,1};
13 bubblesort(arr);
14 System.out.println("Sorted array:"+ Arrays.toString(arr));
15 for(int i=0;i<arr.length;i++){
16 System.out.print(arr[i]+" ");
17 }
18 }
19
20 private static void bubblesort(int[] arr) {
21 int n=arr.length;
22 for(int i=0;i<n;i++){//控制整个冒泡排序的次数
23 for(int j=0;j<n-1-i;j++){//控制两两交换的次数
24 if(arr[j]>arr[j+1]){
25 int temp=arr[j];
26 arr[j]=arr[j+1];
27 arr[j+1]=temp;
28 }
29 }
30 }
31 }
34 }优点:
稳定性——在排序过程中,相同元素的相对顺序保持不变。
缺点:
不适合大规模数据——对于大规模乱序序列的排序效率较低,时间复杂度较高。
(2)插入排序
过程:
①将第一个元素视为已排序序列。
②从第二个元素开始,将其与已排序序列中的元素逐个比较,并插入到正确的位置上。这个过程不断重复,直到整个数组变得有序。
③在实现上,插入排序使用双层循环,外层循环遍历数组中的每个元素,内层循环则在已排序的部分中查找新元素应插入的位置。
代码实现:
public class InsertSort {
11 public static void main(String[] args) {
12 int[] arr={23,46,87,11,24,1};
13 System.out.println("Original array:"+ Arrays.toString(arr));
14 insertsort(arr);
15 System.out.println("Sorted array:"+Arrays.toString(arr));
16 for(int i=0;i<arr.length;i++){
17 System.out.print(arr[i]+" ");
18 }
19 }
20 public static void insertsort(int[] arr){
21 //遍历除第一个数之外的所有数字
22 for(int i=1;i<arr.length;i++){
23 //当前数字比前一个数字小
24 if(arr[i]<arr[i-1]){
25 //把当前数字保存起来,当前位置腾开
26 int temp=arr[i];
27 //当前数字和他之前所有数字进行比较
28 int j=0;
29 for(j=i-1;j>=0&&arr[j]>temp;j--){//如果前面的数字大于temp,右移
30 arr[j+1]=arr[j];
31 }
32 arr[j+1]=temp;//如果前面的数字小于等于temp,将temp放入
33 }
34 }
35 }
36
37 }优点:
稳定性——在排序过程中,相同元素的相对顺序保持不变。
缺点:
不适合大规模数据——对于大规模乱序序列的排序效率较低,时间复杂度较高。
(3)归并排序
过程:
①分解(Divide):将数组递归地分成两半,直到数组被分解为单个元素。
②解决(Conquer):对每一对分解后的子数组进行排序,这一过程通常通过归并排序递归地完成。
③合并(Merge):将已排序的子数组合并成一个完整的、有序的数组。
代码实现:
public class MergeSort {
11 public static void main(String[] args) {
12 int[] arr={12,11,13,43,5,9};
13 System.out.println("Original Array:"+ Arrays.toString(arr));
14 mergesort(arr,0,arr.length-1);
15 System.out.println("Sorted Array:"+Arrays.toString(arr));
16 }
17
18 private static void mergesort(int[] arr,int left,int right) {
19 if(left<right){
20 int mid=(left + right) / 2;
21 mergesort(arr,left,mid);
22 mergesort(arr,mid+1,right);
23 Merge(arr,left,mid,right);
24 }
25
26 }
27
28 private static void Merge(int[] arr, int left, int mid, int right) {
29 int i=left;int j=mid+1;int k=0;
30 int[] temp=new int[right-left+1];
31 while(i<=mid&&j<=right){
32 if(arr[i]<arr[j]){
33 temp[k++]=arr[i++];
34 }else{
35 temp[k++]=arr[j++];
36 }
37 }
38 while(i<=mid){
39 temp[k++]=arr[i++];
40 }
41 while(j<=right){
42 temp[k++]=arr[j++];
43 }
44 //按照排好的顺序给arr赋值
45 for(int t=0;t<temp.length;t++){
46 arr[t+left]=temp[t];
47 }
48 }
49 }优点:
稳定性——在排序过程中,相同元素的相对顺序保持不变。
缺点:
内存占用大——在划分和合并过程中,需要额外的内存来存储列表的两半和最终排序的列表,
(4)选择排序
过程:
①从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置;
②再从剩余的未排序元素中继续寻找最小(或最大)元素,然后放到已排序序列的末尾;
③重复操作,直到所有元素均排序完毕。
代码实现:
public class SelectSort {
11 public static void main(String[] args) {
12 int[] arr={12,45,72,32,10};
13 System.out.println("Original Array:"+ Arrays.toString(arr));
14 insertsort(arr);
15 System.out.println("Sorted Array:"+Arrays.toString(arr));
16 for(int i=0;i<arr.length;i++){
17 System.out.print(arr[i]+" ");
18 }
19 }
20 public static void insertsort(int[] arr){
21 int n=arr.length;
22 for(int k=0;k<n;k++){
23 int min=k;//设置第一个下标为最小值
24 for(int i=k+1;i<n;i++){//将其他元素与最小值作比较
25 if(arr[i]<arr[min]){
26 min=i;//更新最小值对应的下标
27 }
28 }
29 int temp=arr[k];//交换,将最小值标记到最前面,之后k++,寻找第二个最小值,循环
30 arr[k]=arr[min];
31 arr[min]=temp;
32 }
33 }
35 }优点:
可读性高——简单易懂、易于实现,以及它是原地排序算法,不占用额外的内存空间。
缺点:
时间复杂度较高——无论数据是否有序,都需要进行O(n²)次比较,处理大规模数据集时效率较低。
不稳定——这意味着在排序过程中相等元素的相对位置可能发生变化,导致相同元素的相对顺序不同。
(5)快速排序
过程:
①选择基准元素:从待排序序列中选取一个元素作为基准(pivot)。
②分区操作:通过比较其他元素与基准元素的大小,将序列分为两部分。所有比基准元素小的元素放在其左边,所有比基准元素大的元素放在其右边。
③递归排序:对基准元素左右两边的子序列递归执行上述步骤,直到子序列的长度为0或1,此时子序列已经有序。
代码实现:
public class QuickSort {
11 //快速排序:
12 //首先在序列中随机选择一个基准值(privot)
13 //除了基准值以外的数分为:“比基准值小的数”、“比基准值大的数”,再将其排列成以下形式 【比基准值小的数】 基准值 【比基准值大的数】
14 //对【】中的数据进行递归,同样使用快速排序
15 public static void main(String[] args) {
16 int[] arr={12,45,67,81,1,2};
17 System.out.println("Original array:"+ Arrays.toString(arr));
18 quicksort(arr,0,arr.length-1);
19 System.out.println("Sorted array:"+Arrays.toString(arr));
20 for(int i=0;i<arr.length;i++){
21 System.out.print(arr[i]+" ");
22 }
23 }
24 public static void quicksort(int[] arr,int left,int right){
25 if(left<right) {
26 int partitionIndex=partition(arr,left,right);
27 quicksort(arr,left,partitionIndex-1);
28 quicksort(arr,partitionIndex+1,right);
29 }
30 }
31 public static int partition(int[] arr,int left,int right) {
32 int privot=arr[left];
33 while(left<right){
34 while(left<right&&arr[right]>=privot){
35 right--;
36 }
37 arr[left]=arr[right];
38 while(left<right&&arr[left]<=privot){
39 left++;
40 }
41 arr[right]=arr[left];
42 }
43 //在left==right时候,将privot放进去,此时privot左边都是比privot小的,privot右边都是比privot大的
44 arr[left]=privot;
45 return left;
46 }
47 }优点:
高效率——快速排序的平均时间复杂度为O(NlogN),使其在处理大量数据时表现出色。
数据移动少——在排序过程中,快速排序需要移动的数据量相对较小。
缺点:
不稳定——当处理大量重复元素时,可能会导致递归深度过大,甚至栈溢出。
(6)堆排序
过程:
①最大堆调整(Max Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点;
②创建最大堆(Build Max Heap):将堆中的所有数据重新排序(按照最大堆调整);
③堆排序(HeapSort):移除位在第一个数据的根节点(最大堆顺序就会被打乱),并重复做最大堆调整的递归运算。
代码实现:
public class HeapSort {
11 //大顶堆:
12 // 孩子节点下标为i时,父节点下标:(i-1)/2
13 //父亲节点下标为k时,左孩子下标(k*2)+1;右孩子下标k*2+2
14 public static void main(String[] args) {
15 //测试用例
16 int[] arr={12,45,72,32,10};
17 System.out.println("Original Array:"+ Arrays.toString(arr));
18 heapsort(arr);
19 System.out.println("Sorted Array:"+Arrays.toString(arr));
20 for(int k:arr){
21 System.out.print(k+" ");
22 }
23 }
24
25 //堆排序函数
26 private static void heapsort(int[] arr) {
27 int n=arr.length;
28 //建堆
29 buildMaxHeap(arr,n);
30 for(int i=n-1;i>0;i--){
31 //交换
32 swap(arr,0,i);
33 //维护最大堆的性质
34 heapify(arr,0,i);
35 }
36 //
37 }
38
39 private static void heapify(int[] arr, int x, int n) {
40 int father=x;
41 int left=2*x+1;
42 int right=2*x+2;
43 if(left<n&&arr[left]>arr[father]){
44 father=left;
45 }
46 if(right<n&&arr[right]>arr[father]){
47 father=right;
48 }
49 if(father!=x){
50 swap(arr,x,father);
51 heapify(arr,father,n);//向下调整维护大堆性质
52 }
53
54 }
55
56 private static void swap(int[] arr, int a, int b) {
57 int temp=arr[a];
58 arr[a]=arr[b];
59 arr[b]=temp;
60 }
61
62 private static void buildMaxHeap(int[] arr, int n) {
63 //寻找最后一个非叶子节点
64 for(int i=n/2-1;i>=0;i--){
65 heapify(arr,i,n);
66 }
67 }
68 }优点:
速度快——时间复杂度为O(nlogn),这意味着无论数据规模多大,堆排序都能在多项式时间内完成。排序空间复杂度O(1),这意味着它不需要额外的存储空间来保存数据,这使得堆排序在空间效率方面表现优异;
稳定——堆排序是一种稳定的排序算法,堆排序适用于多种场景,包括在数据频繁变动的情况下,因为它可以在不重建整个堆的情况下更新堆顶元素。
缺点:
堆维护问题——需要频繁地重建和维护堆,这可能会在数据频繁变动的情况下导致效率降低,因为每次数据更新都可能需要调整堆的结构,这增加了额外的计算负担。
(7)希尔排序
希尔排序是一种改进后的插入排序算法,也被称为缩小增量排序。
过程:
①选择一个小于数组长度的增量(gap),最开始gap=n/2,然后将数组分为多个子序列,每个子序列的元素间隔为这个增量值,对每个子序列分别进行直接插入排序。
②逐渐减小增量值(减半),再次进行子序列的划分和排序。
③直到增量减至1,此时整个数组被当作一个序列进行插入排序。
代码实现:
public class ShellSort {
11 public static void main(String[] args) {
12 int[] arr=new int[]{12,23,11,5,65,88};
13 System.out.println("Original Array:"+ Arrays.toString(arr));
14 shellsort(arr);
15 System.out.println("Sorted Array:"+Arrays.toString(arr));
16 for(int i=0;i<arr.length;i++){
17 System.out.print(arr[i]+" ");
18 }
19 }
20
21 private static void shellsort(int[] arr) {//时间复杂度n^1.3
22 int n=arr.length;
23 //初始化间隔为数组长度的一半
24 int gap=n/2;
25 while(gap>0){
26 //对每个间隔进行直接插入排序
27 for(int i=gap;i<n;i++){
28 int temp=arr[i];
29 int j=0;
30 //对间隔为 gap 的元素进行插入排序
31 for(j=i;j>=gap&&temp<arr[j-gap];j=j-gap){
32 arr[j]=arr[j-gap];
33 }
34 arr[j]=temp;
35 }
36 // 缩小间隔
37 gap=gap/2;
38 }
39 }
40 }优点:
速度快——由于开始时增量的取值较大,每个子序列中的元素较少,所以排序速度快;随着增量逐渐减小,虽然子序列中的元素个数增多,但是由于前面工作的基础,大多数元素已经基本有序,因此排序速度仍然较快。希尔排序的时间复杂度为O(n^1.3)至O(n^2)。
缺点:
不稳定——取决于增量序列的选择,它是一种非稳定排序算法,这意味着在排序过程中,相同的元素可能会移动位置,导致最终顺序与原始顺序不同。
相关文章:
)
八大排序算法(面试被问到)
1.八大排序算法都是什么? 八大排序算法有:插入排序、冒泡排序、归并排序、选择排序、快速排序、希尔排序、堆排序、基数排序(通常不提)。此外,还可以直接调用Arrays.sort()进行排序。 2.八大排序算法时间复杂度和稳定…...

SCP指令详细使用介绍
SCP(Secure Copy Protocol)是一种用于在计算机之间安全地传输文件的协议。它通过加密的方式在网络上安全地复制文件。SCP基于SSH(Secure Shell)协议,因此它提供了加密的连接和身份验证,确保数据在传输过程中…...

《前端面试题》- JS基础 - 防抖和节流
在界面触发点击,滚动,输入校验等事件时,如果对事件的触发频率不加以限制,会给浏览器增加负担,且对用户不友好。防抖和节流就是针对类似情况的解决方案。 防抖 防抖(debounce):当连续触发事件时࿰…...
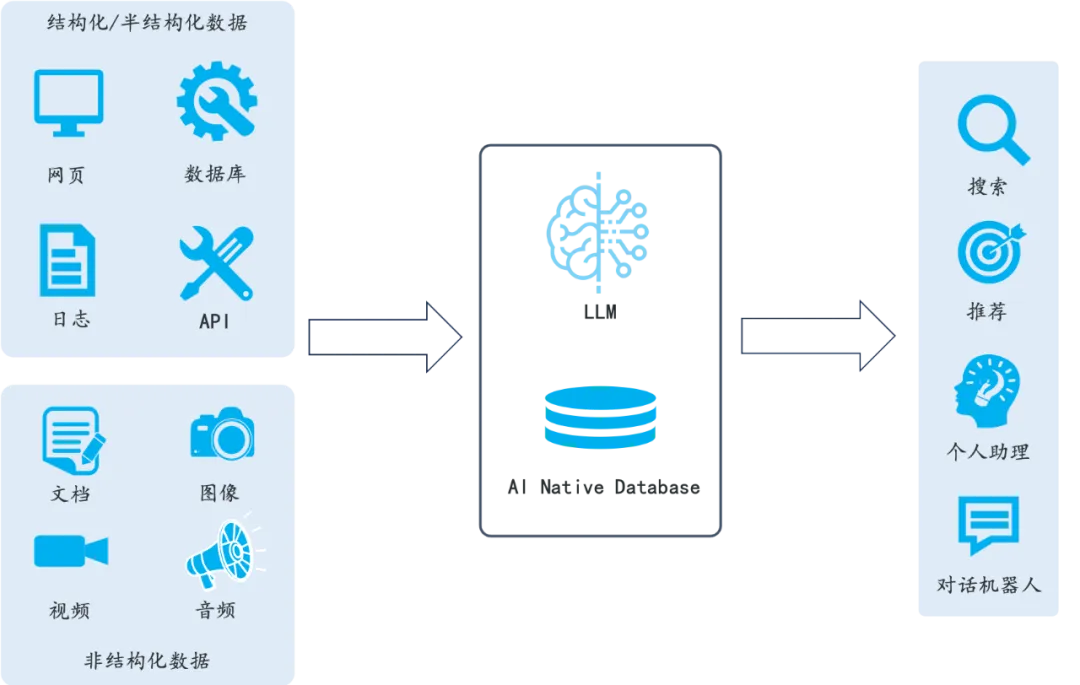
RAGFlow:基于OCR和文档解析的下一代 RAG 引擎
一、引言 在人工智能的浪潮中,检索增强生成(Retrieval-Augmented Generation,简称RAG)技术以其独特的优势成为了研究和应用的热点。RAG技术通过结合大型语言模型(LLMs)的强大生成能力和高效的信息检索系统…...

正则表达式|*+?
在理解编程语言和编译技术的上下文中,了解正则表达式(regular expressions)和正则集(regular sets)的概念是非常重要的。这些概念主要用于描述一组字符串的模式,广泛应用于词法分析中识别各类标记ÿ…...
前端开发攻略---根据音频节奏实时绘制不断变化的波形图。深入剖析如何通过代码实现音频数据的可视化。
1、演示 2、代码分析 逐行解析 JavaScript 代码块: const audioEle document.querySelector(audio) const cvs document.querySelector(canvas) const ctx cvs.getContext(2d)这几行代码首先获取了 <audio> 和 <canvas> 元素的引用,并使用…...

【计算机毕业设计】基于Java+SSM的实战开发项目150套(附源码+演示视频+LW)
大家好!我是程序猿老A,感谢您阅读本文,欢迎一键三连哦。 🧡今天给大家分享150的Java毕业设计,基于ssm框架,这些项目都经过精心挑选,涵盖了不同的实战主题和用例,可做毕业设计和课程…...

STM32H7的MPU学习和应用示例
STM32H7的MPU学习记录 什么是MPU?MPU的三种内存类型内存映射MPU保护区域以及优先级 MPU的寄存器XN位AP位TEX、C、B、S位SRD 位SIZE 位CTRL 寄存器的各个位 示例总结 什么是MPU? MPU(Memory Protection Unit,内存保护单元…...
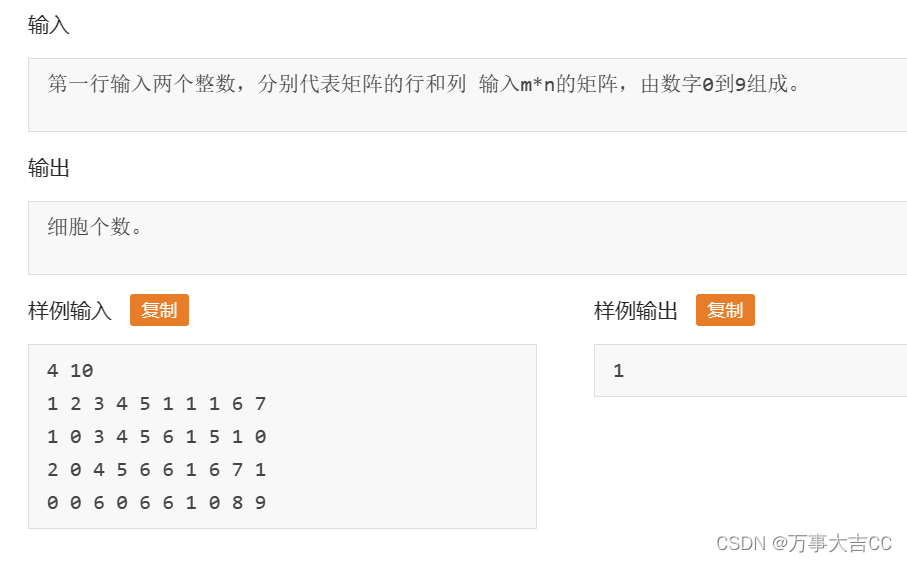
964: 数细胞
样例: 解法: 1.遍历矩阵 2.判断矩阵[i][j],若是未标记细胞则遍历相邻所有未标记细胞并标记,且计数 实现:遍历相邻所有未标记细胞 以DFS实现: function dfs(当前状态) {if (终止条件) {}vis[标记当前状…...

流程图步骤条
1.结构 <ul class"stepUl"> <li class"stepLi" v-for"(item, index) in stepList" :key"index"> <div class"top"> <p :class"{active: currentState > item.key}">{{ item.value }}…...

GPT知识库浅析
一、引言 上篇文章《GPT简介及应用》介绍了GPT的应用场景,里面提到GPT bot的基本使用:基于GPT训练好的数据,回答用户的问题。 但在使用过程中,如果用户的问题里面出现最新的术语,就会出现这种提示: 截至我…...

SpringMVC--SpringMVC的视图
目录 1. 总述 2. ThymeleafView视图 3. 转发视图 4. 重定向视图 5. 视图控制器view-controller 1. 总述 在SpringMVC框架中,视图(View)是一个非常重要的概念,它负责将模型数据(Model)展示给用户。简单…...
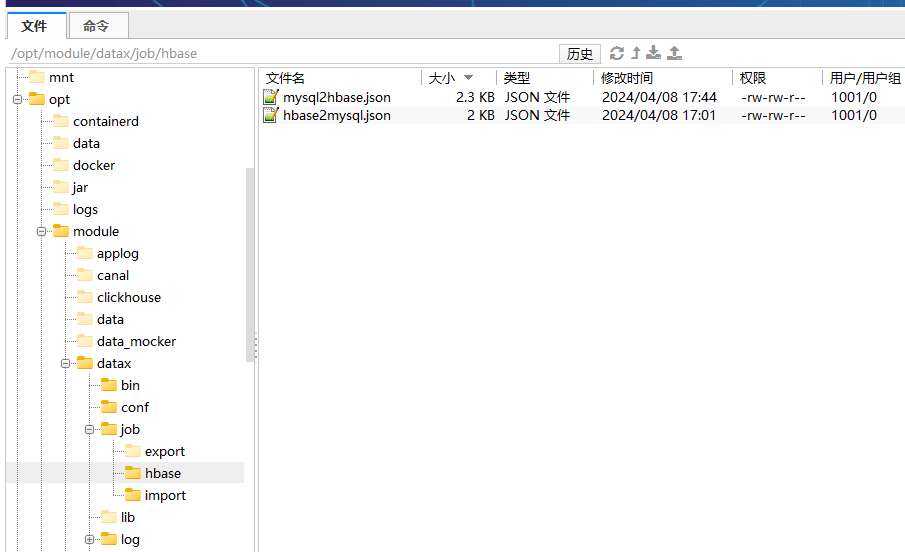
Datax,hbase与mysql数据相互同步
参考文章:datax mysql 和hbase的 相互导入 目录 0、软件版本说明 1、hbase数据同步至mysql 1.1、hbase数据 1.2、mysql数据 1.3、json脚本(hbase2mysql.json) 1.4、同步成功日志 2、mysql数据同步至hbase 1.1、hbase数据 1.2、mysql…...

ubuntu spdlog 封装成c++类使用
安装及编译方法:ubuntu spdlog 日志安装及使用_spdlog_logger_info-CSDN博客 h文件: #ifndef LOGGING_H #define LOGGING_H#include <iostream> #include <cstring> #include <sstream> #include <string> #include <memor…...

【C语言】——字符串函数的使用与模拟实现(上)
【C语言】——字符串函数 前言一、 s t r l e n strlen strlen 函数1.1、函数功能1.2、函数的使用1.3、函数的模拟实现(1)计数法(2)递归法(3)指针 - 指针 二、 s t r c p y strcpy strcpy 函数2.1、函数功能…...

数据库(1)
目录 1.什么是事务?事务的基本特性ACID? 2.数据库中并发一致性问题? 3.数据的隔离等级? 4.ACID靠什么保证的呢? 5.SQL优化的实践经验? 1.什么是事务?事务的基本特性ACID? 事务指…...

VirtualBox - 与 Win10 虚拟机 与 宿主机 共享文件
原文链接 https://www.cnblogs.com/xy14/p/10427353.html 1. 概述 需要在 宿主机 和 虚拟机 之间交换文件复制粘贴 貌似不太好使 2. 问题 设置了共享文件夹之后, 找不到目录 3. 环境 宿主机 OS Win10开启了 网络发现 略虚拟机 OS Win10开启了 网络发现 略Virtualbox 6 4…...

深入浅出 useEffect:React 函数组件中的副作用处理详解
useEffect 是 React 中的一个钩子函数,用于处理函数组件中的副作用操作,如发送网络请求、订阅消息、手动修改 DOM 等。下面是 useEffect 的用法总结: 基本用法 import React, { useState, useEffect } from react;function Example() {cons…...

《QT实用小工具·十九》回车跳转到不同的编辑框
1、概述 源码放在文章末尾 该项目实现通过回车键让光标从一个编辑框跳转到另一个编辑框,下面是demo演示: 项目部分代码如下: #ifndef WIDGET_H #define WIDGET_H#include <QWidget>namespace Ui { class Widget; }class Widget : p…...
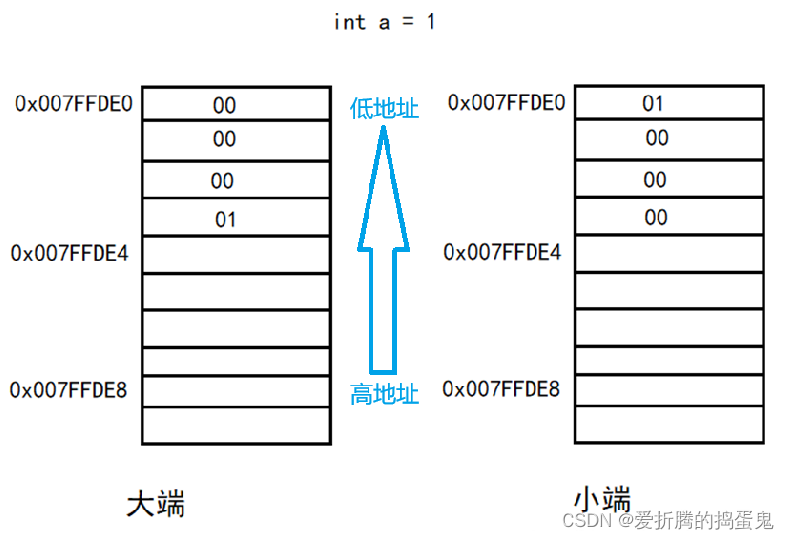
基本的数据类型在16位、32位和64位机上所占的字节大小
1、目前常用的机器都是32位和64位的,但是有时候会考虑16位机。总结一下在三种位数下常用的数据类型所占的字节大小。 数据类型16位(byte)32位(byte)64位(byte)取值范围char111-128 ~ 127unsigned char1110 ~ 255short int / short222-32768~32767unsigned short222…...
)
嵌入式开发实战:SPI模式驱动SD NAND的完整流程与避坑指南(基于STM32F10x)
嵌入式开发实战:STM32F10x SPI驱动SD NAND全流程与高频问题解析 在物联网终端设备和便携式仪器仪表开发中,嵌入式存储解决方案的选择往往直接影响产品可靠性和生产成本。SD NAND作为贴片式存储芯片的代表,兼具SD卡的大容量特性和SPI Flash的硬…...

告别PyQt!用NiceGUI在浏览器里5分钟搞定Python数据可视化大屏
用NiceGUI在5分钟内构建Python数据可视化大屏 最近在帮一个客户快速搭建数据监控面板时,我彻底抛弃了传统的PyQt方案。原本需要两天的工作,用NiceGUI只用了不到半小时就完成了部署。这个基于浏览器的Python GUI框架,让数据可视化变得前所未有…...

OFA图像描述模型惊艳案例:复杂场景与抽象艺术的理解与描述
OFA图像描述模型惊艳案例:复杂场景与抽象艺术的理解与描述 你有没有想过,让AI看一幅画,然后让它像一位艺术评论家那样,为你娓娓道来画中的故事与意境?这听起来像是科幻电影里的场景,但今天,OFA…...

ANIMATEDIFF PRO性能实测:RTX 3060也能跑?显存不足应急方案
ANIMATEDIFF PRO性能实测:RTX 3060也能跑?显存不足应急方案 1. 当电影级渲染遇到入门级显卡 最近在星图GPU平台上折腾ANIMATEDIFF PRO,说实话,一开始我是抱着“试试看”的心态。毕竟官方推荐配置写着“RTX 4090最佳”࿰…...

【限时开源】GitHub星标破2k的cancat-fd调试框架深度拆解:如何用200行C代码实现FD帧过滤、延迟注入与FPGA协同仿真
第一章:cancat-fd调试框架的架构设计与开源价值 cancat-fd 是一个面向嵌入式 Linux 系统的轻量级、高精度函数调用跟踪与数据流调试框架,其核心设计理念是“零侵入、低开销、可组合”。它通过 eBPF(extended Berkeley Packet Filterÿ…...
:异步节点与LangChain v0.3+协同调用的11个兼容性断点及修复补丁)
Dify架构师内部分享实录(非公开资料首次流出):异步节点与LangChain v0.3+协同调用的11个兼容性断点及修复补丁
第一章:Dify自定义节点异步处理架构设计图全景概览Dify 的自定义节点(Custom Node)机制支持开发者以插件化方式扩展工作流逻辑,其核心异步处理架构采用事件驱动 消息队列 任务分发的三层协同模型。整个流程从用户触发工作流开始…...
)
工业相机选型必看:Mono8、Mono10、Mono12这些像素格式到底该怎么选?(附应用场景对比)
工业相机像素格式深度解析:从Mono8到Mono12的实战选型指南 在工业视觉系统中,像素格式的选择往往被工程师们低估——直到项目遇到瓶颈。我曾亲眼见证一个价值数百万的检测产线因为像素格式选型不当,导致良品率统计出现5%的偏差。这不是理论问…...
的实战对比与避坑指南)
别再乱选融合方法了!ENVI 5.6.2里6种图像融合工具(GS、NNDiffuse等)的实战对比与避坑指南
ENVI 5.6.2图像融合工具深度评测:从原理到实战的完整决策指南 在遥感图像处理领域,图像融合技术就像一位技艺高超的调酒师,能够将多光谱影像丰富的光谱信息与全色影像锐利的空间细节完美调和,创造出兼具两者优势的"鸡尾酒&qu…...

WeKnora部署教程:小白友好,快速搭建零幻觉问答系统
WeKnora部署教程:小白友好,快速搭建零幻觉问答系统 1. 项目简介与核心价值 WeKnora是一个基于Ollama框架构建的知识库问答系统,它能将任意文本转化为即时知识库,并基于这些内容提供精准可靠的问答服务。与通用聊天机器人不同&am…...

别再被“AI幻觉”骗了!一文看懂RAG:给大模型挂上最强“外挂大脑”
你是否有过这样的经历:问大模型(LLM)一个最新的新闻,或者你们公司的内部制度,它要么一本正经地胡说八道(幻觉),要么委婉地告诉你它的知识库只更新到2023年。这就是大模型的“先天缺陷…...