低延时+高并发+强事务丨DolphinDB 交易型内存存储引擎 IMOLTP 使用指南
1. 背景
在一些数据库应用场景中,例如金融行业的交易系统,其主要工作负载来源于对关系表的高频度、高并发的更新和查询操作。这样的应用场景要求数据的读写和计算能够具有低延迟、高并发的特征,同时保证极高的数据一致性,并提供 ACID 事务的支持,是典型的在线事务处理(OLTP)场景。
传统的存储引擎由于其架构的设计出发点是将数据存储在磁盘上,在面对上述场景要求时,软硬件层面面临巨大挑战,无法很好地满足上述苛刻的性能要求。而在这些场景中,往往需要维护的数据量实际上没有那么大,那么,能否把所有的数据都维护在内存里呢?这样就可以减少读写磁盘的带宽,能够大大降低数据库的延迟和提升数据库的并发度。
基于这个想法,DolphinDB 设计并实现了一款纯自研的内存 OLTP 数据库,它有以下特点:
- 将所有数据都存储在内存中,省去磁盘 I/O 的开销;
- 以行存的形式来组织数据,主要适用于 OLTP 的场景;
- 支持创建 B+ 树索引 (主键索引和二级索引) 来应对高频度、高并发的更新和查询操作;
- 支持事务,默认为 snapshot isolation;
- 实现 Write-Ahead-Logging 和 checkpoint 机制以保证数据的持久化和恢复;
- 为加速重启时的恢复过程,实现了并行恢复机制。
下文将介绍 OLTP 的使用方式。
需要在配置文件里加上 enableIMOLTPEngine=true 来开启 OLTP 引擎。
2. DDL
2.1 建库
使用 database 函数来创建 OLTP 数据库,语法与创建 OLAP/TSDB 数据库一样,但是有以下注意事项:
- directory 必须以
oltp://开头。 - engine 必须为
IMOLTP。 - OLTP 目前只支持单机版本,分区方式可以任意填写。
dbName = "oltp://test_imoltp"
db = database(dbName, VALUE, 1..100, , "IMOLTP")2.2 建表
使用 createIMOLTPTable 函数来创建 OLTP 表,语法如下:
createIMOLTPTable(dbHandle, table, tableName, primaryKey, [secondaryKey], [uniqueFlag])primaryKey 用来指定主键索引的键。主键索引有且只有一个,每个 OLTP 表都必须指定。主键索引是 unique 的,插入数据时会检查是否满足唯一性约束(即不能插入重复元素),若违反则报错。主键可以包含多个字段(字段即为列名)。
secondaryKey 用来指定二级索引的键。二级索引可选,并且每个 OLTP 表可以创建多个二级索引。二级索引有 unique 和 non-unique 两种,两者的区别在于 unique 索引需要满足唯一性约束,而 non-unique 索引没有这个限制。由 uniqueFlag 来指定二级索引是否是 unique 的。二级索引的键同样可以包含多个字段。
// pt1 以 id 为主键,没有二级索引
pt1 = db.createIMOLTPTable(table(1:0, ["id", "val1", "val2", "sym"], [LONG, INT, LONG, STRING]),"test_table_1",primaryKey=`id
)// pt2 以 id,sym 为主键,有一个 unique 二级索引:以 val2,sym 为键
pt2 = db.createIMOLTPTable(table(1:0, ["id", "val1", "val2", "sym"], [LONG, INT, LONG, STRING]),"test_table_2",primaryKey=`id`sym,secondaryKey=`val2`sym,uniqueFlag=true
)// pt3 以 id 为主键,有一个非 unique 二级索引:以 val1 为键;一个 unique 二级索引:以 sym 为键
pt3 = db.createIMOLTPTable(table(1:0, ["id", "val1", "val2", "sym"], [LONG, INT, LONG, STRING]),"test_table_3",primaryKey=`id,secondaryKey=[`val1, `sym],uniqueFlag=[false, true]
)通常来说,对于查询效率:主键索引优于二级索引优于非索引,如果查询时不能利用任何索引,则只能进行全表扫描。合理地创建二级索引可以提升查询的效率,但是相应地会降低写入的效率,因为写入时 (insert/delete/update) 需要修改相应的索引。
2.3 删库/删表
使用 dropTable 和 dropDatabase 来删表删库,使用方式与 OLAP/TSDB 没有区别。
db.dropTable("test_table_1")if (existsDatabase(dbName)) {dropDatabase(dbName)
}3. DML
后文的例子假设已经执行过下面的脚本来建库建表:
dbName = "oltp://test_imoltp"
tableName = "test_table"if (existsDatabase(dbName)) {dropDatabase(dbName)
}db = database(dbName, VALUE, 1..100, , "IMOLTP")// pt 以 id 为主键,没有二级索引
pt = db.createIMOLTPTable(table(1:0, ["id", "val1", "val2", "sym"], [LONG, INT, LONG, STRING]),tableName,primaryKey=`id
)3.1 写入数据
写入数据可以用 append! 和 insert into,使用方式与 OLAP/TSDB 一样。
pt = loadTable("oltp://test_imoltp", "test_table")id = 1..100
val1 = id * 10
val2 = rand(10000, size(id))
sym = take(`aaa`bbb`ccc`ddd`eee, size(id))
pt.append!(table(id, val1, val2, sym))insert into pt values(200, 2000, 1111, `xxx)
insert into pt values(201, 2010, 2222, `yyy)
insert into pt values(211..220, (211..220)*10, take(9527, 10), take(`xxx`yyy`zzz, 10))insert into pt(id, sym) values(1000, `aaa)
insert into pt(id, sym, val1) values(1001, `bbb, 10010)3.2 查询数据
使用 SQL 来查询数据。where 条件非常重要,如果一次查询无法利用索引,那么性能会大幅降低。
pt = loadTable("oltp://test_imoltp", "test_table")select * from pt where id = 10 // 点查,用主键索引
select * from pt where id > 100, id < 200 // 范围查询,用主键索引select * from pt where val1 = 1000 // 全表扫描,无法利用索引3.3 更新数据
使用 SQL 来更新数据。
pt = loadTable("oltp://test_imoltp", "test_table")update pt set val1 = 100 where id = 1
update pt set val1 = id + val1 where id < 103.4 删除数据
使用 SQL 来删除数据。
pt = loadTable("oltp://test_imoltp", "test_table")delete from pt where id = 1
delete from pt where id >= 100, id <= 1104. 事务
使用 transaction 语句块可以在一个事务内执行多条 DML 语句,在一个事务范围内,所有的 DML 操作都会一起成功或一起失败。若一个事务执行的时候有异常抛出,会自动撤销本次事务的所有更改。
pt = loadTable("oltp://test_imoltp", "test_table")delete from pttransaction {insert into pt values(0, 0, 0, `aaa)insert into pt values(1, 1, 1, `bbb)insert into pt values(2, 2, 2, `ccc)commit // 提交事务(可以省略)
}
assert (exec id from pt order by id) == [0,1,2]transaction {insert into pt values(3, 3, 3, `ddd)insert into pt values(4, 4, 4, `eee)delete from pt where id = 1update pt set id = 10 where id = 0assert (exec id from pt order by id) == [2,3,4,10]rollback // 强制回滚事务,撤销所有修改
}
assert (exec id from pt order by id) == [0,1,2]commit 表示提交本次事务的所有更改,rollback 表示撤销本次事务的所有更改。不需要显式地写 commit,出了 transaction 语句块的作用域时会自动 commit。
若不显式地使用 transaction 语句块,则每一句 SQL 都是一个事务。
注意:DDL 语句(即建表,删表等)不能放在transaction语句块里面,因为 DDL 目前不支持事务。
5. 配置参数
目前 OLTP 有以下配置参数可以设置:
- enableIMOLTPEngine,bool 类型。表示是否开启 OLTP 引擎。默认为 false。
- enableIMOLTPRedo,bool 类型。表示是否开启 WAL(Write-Ahead-Log),开启之后才能保证数据不会丢失。默认为 true。
- IMOLTPRedoFilePath,string 类型。表示 redo 文件(即 WAL 文件)的路径(注意不是目录),可以为绝对路径或者相对路径。当为相对路径时,相对于 home 目录下的
IMOLTP目录。默认为 home 目录下的IMOLTP/im_oltp.redo。 - IMOLTPSyncOnTxnCommit,bool 类型。只在 enableIMOLTPRedo 为 true 时(即开启了 WAL)有意义。默认为 false。详细解释见下文。
- enableIMOLTPCheckpoint,bool 类型。表示是否开启 checkpoint。默认为 true。
- IMOLTPCheckpointFilePath,string 类型。表示 checkpoint 文件的路径(注意不是目录),可以为绝对路径或者相对路径。当为相对路径时,相对于 home 目录下的
IMOLTP目录。默认为 home 目录下的IMOLTP/im_oltp.ckp。 - IMOLTPCheckpointThreshold,long 类型,单位为 MiB。 表示:如果 redo 文件里面的 log 大小达到该阈值后,会触发一次 checkpoint。默认为 100 MiB。
- IMOLTPCheckpointInterval,long 类型,单位为秒。表示每隔 # 秒之后强制做一次 checkpoint。默认为 60 秒。
关于 IMOLTPSyncOnTxnCommit 的含义:
在开启 WAL 后,事务对数据进行修改之前,会先写日志到持久化存储。系统重启时会回放 redo 文件里的日志,恢复到重启之前的状态。
如果 IMOLTPSyncOnTxnCommit 为 false,事务 commit 成功之后,保证日志写到了操作系统的缓存里,但是不保证日志已经写到了持久化存储上。因此,如果进程崩溃, 数据不会丢失, 但是当操作系统崩溃(机器掉电), 可能会有数据丢失。
如果 IMOLTPSyncOnTxnCommit 为 true,在事务 commit 成功之后,保证日志已经写到了持久化存储上,即使操作系统崩溃,数据也不会丢失。(但是如果存储设备故障, 还是可能有数据丢失)。
如果需要持久化数据,并且对数据的一致性要求较高,绝对无法忍受数据丢失,推荐把 enableIMOLTPRedo 和 IMOLTPSyncOnTxnCommit 都设置为 true。这种模式下,(写入)性能较差。
如果需要持久化数据,并且可以容忍操作系统崩溃(比如机器掉电等小概率事件)导致的数据丢失,推荐把 enableIMOLTPRedo 设置为 true, 把 IMOLTPSyncOnTxnCommit 设置为 false。这种模式下,(写入)性能较好。默认为这种配置。
6. 内置函数 triggerCheckpointForIMOLTP
当开启了 checkpoint 时(即 enableIMOLTPCheckpoint 配置为 true ),系统会在达到以下两个条件之一时自动触发 checkpoint:
- redo 文件里面的 log 大小达到阈值(IMOLTPCheckpointThreshold MiB);
- 或者,距离上一次 checkpoint 过去了 IMOLTPCheckpointInterval 秒。
用户也可以手动调用 triggerCheckpointForIMOLTP 函数来触发 checkpoint。函数语法如下:
triggerCheckpointForIMOLTP([force=false], [sync=false])参数:
- force,bool 类型,可选。表示是否强制做 checkpoint。如果为 false,并且当前并没有达到做 checkpoint 的条件(即 redo 文件里的 log 大小没有达到
IMOLTPCheckpointThreshold),则忽略这次请求。默认为 false。 - sync,bool 类型,可选。表示是否异步。如果为 false,则该函数请求一次异步的 checkpoint,并不会等到请求完成再返回;否则该函数会等到请求完成(注意不一定做了 checkpoint)再返回。默认为 false。
7. 总结
DolphinDB 推出的 OLTP 内存数据库适用于高并发、低延迟的在线事务处理场景。该数据库将数据存储在内存中,支持 B+ 树索引、事务、Write-Ahead-Logging 和 checkpoint 机制。事务通过 transaction 语句块实现,保证了操作的原子性。用户还可以通过配置参数的配置以及内置函数 triggerCheckpointForIMOLTP 的使用,手动触发 checkpoint。
总体而言,DolphinDB 的 OLTP 引擎适用于对数据一致性和性能要求较高的场景。
相关文章:

低延时+高并发+强事务丨DolphinDB 交易型内存存储引擎 IMOLTP 使用指南
1. 背景 在一些数据库应用场景中,例如金融行业的交易系统,其主要工作负载来源于对关系表的高频度、高并发的更新和查询操作。这样的应用场景要求数据的读写和计算能够具有低延迟、高并发的特征,同时保证极高的数据一致性,并提供 …...

写代码的修养
看山是山,看水是水 此境界 对业务的思考是浅层的,代码写的不通用,扩展性差,表现在无设计模式 看山不是山,看水不是水 此境界 对业务的思考是中层的,代码写的通用,扩展性好,表现为…...
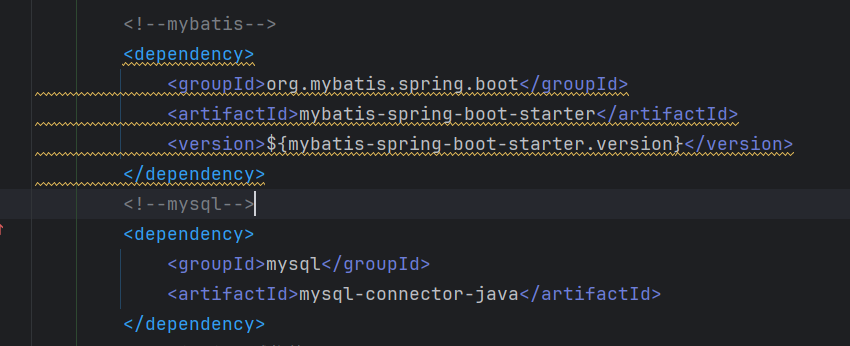
springboot 问题整合
springboot 启动后访问报错 问题:org.apache.ibatis.binding.BindingException: Invalid bound statement (not found): 原因:mybatis 的全局配置文件和 sql 映射文件没有写 解决:在 application.yml 中添加 mybatis 配置 mybatis:# 全局配…...

UNIAPP二维码展示页亮度调至最亮返回恢复进入前亮度
onLoad(params) {let num plus.screen.getBrightness().toString(); //转字符串是要存到stoage中number类型会存储失败plus.storage.setItem("pmld", num)plus.screen.setBrightness(1); //设置屏幕亮度,范围0-1 }onUnload() {let platformuni.getSystem…...

Golang ProtoBuf 初学者完整教程:安装
一、Protobuf 特点 更高效:使用二进制编码,相比XML/JSON更加高效 跨语言支持:Protobuf 在 .proto 定义需要处理的结构化数据,可以通过 protoc 工具,将 .proto 文件转换为 C、C、Golang、Java、Python 等多种语言的代…...
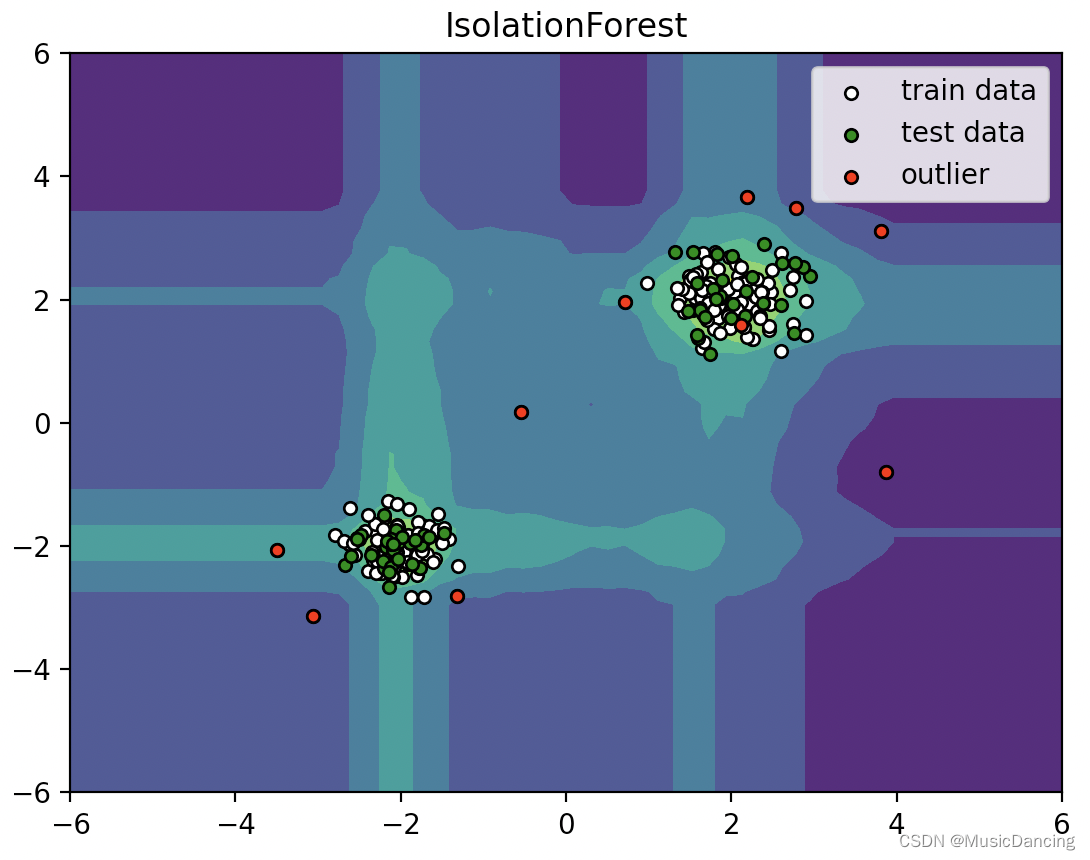
Isolation Forest 简介
1. 简介 孤立森林 iForest(Isolation Forest)是一种无监督学习算法,用于识别异常值。其基本原理是:异常数据由于数量较少且与正常数据差异较大,因此在被隔离时需要较少的步骤。 两个假设: 1. 异常的值是非常少的(如果异常值很多&…...

Java爬虫携带sign签名
站点:https://www.mytokencap.com/ 代码分析先不写了,大家自行解决,贴代码 1、业务请求设计 public static void md5Pro() {String url "https://api.mytokenapi.com/ticker/currencylistforall";Map<String, String> he…...
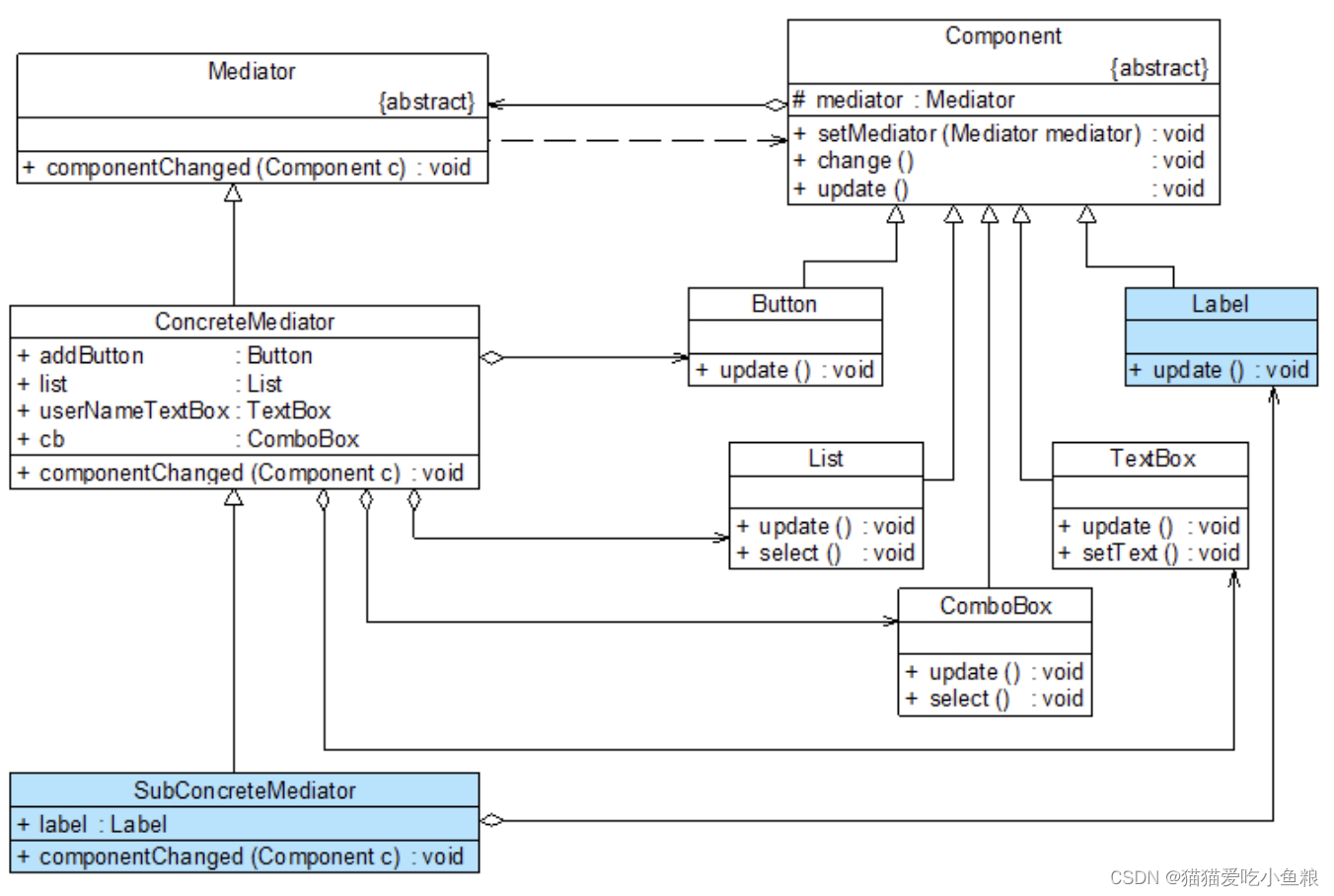
设计者模式之中介者模式(下)
3)中介者与同事类的扩展 1.结构图 新增了具体同事类Label和具体中介者类SubConcreteMediator。 2.代码实现 //文本标签类:具体同事类 public class Label extends Component {public void update() {System.out.println("文本标签内容改变&#…...
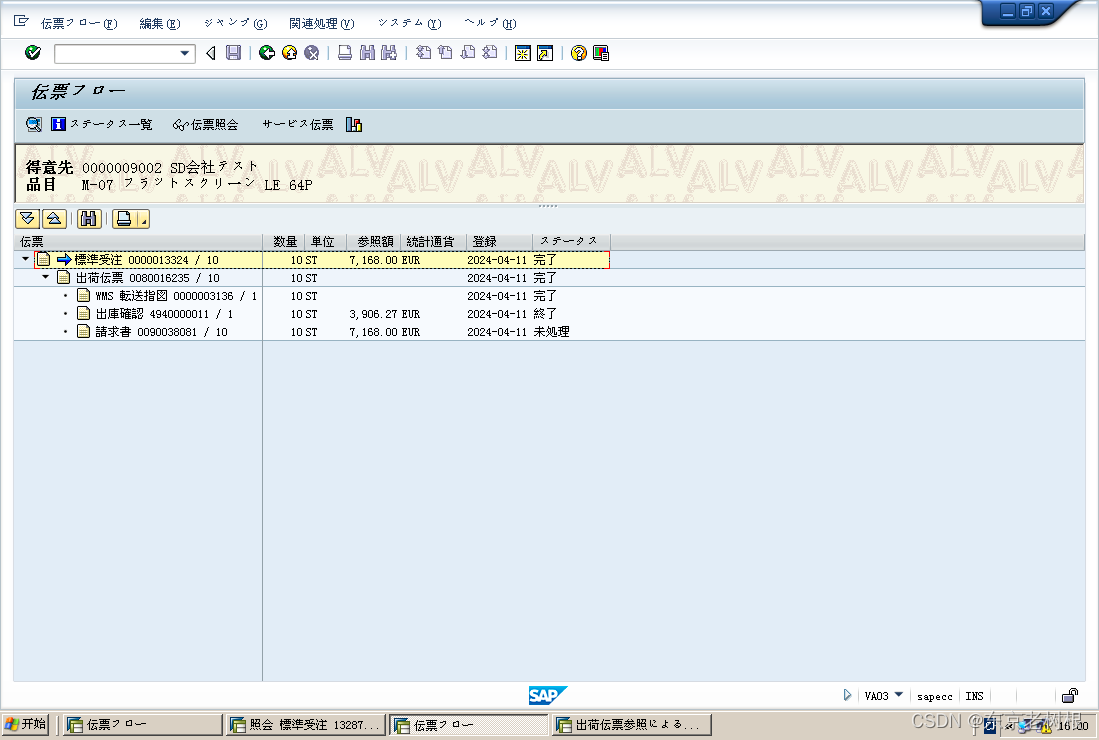
SAP SD学习笔记04 - 出荷Plant(交货工厂),出荷Point(装运点),输送计划,品目的可用性检查,一括纳入/分割纳入,仓库管理
上一章讲了SD的主数据。 SAP SD学习笔记03 - SD模块中的主数据-CSDN博客 本章讲出荷Plant(交货工厂),出荷Point(装运点)和出和路线。 还是偏理论多一些,后面的文章尽量多加些练习巩固一下。 1࿰…...
)
bind包装器——C++新特性(三)
文章目录 bindbind函数模板的原型bind 包装器的用途其他使用示例 🎖 博主的CSDN主页:Ryan.Alaskan Malamute 📜 博主的代码仓库主页 [ Gitee ]:ryanala [GitHub]: Ryan-Ala bind bind也是一种函数包装器…...

MXNet的下载安装及问题处理
1、MXNet介绍: MXNet是一个开源的深度学习框架,以其灵活性和效率著称,支持多种编程接口,包括Python、C、R、Julia、Scala等。MXNet支持大规模分布式训练,同时兼顾CPU和GPU的计算资源,尤其擅长于模型并行和数…...

Python 中的列表排序和排序规则
Python 中的列表排序和排序规则 在 Python 中,列表的排序是一个常见的操作,可以使用内置函数 sorted() 或列表对象的 sort() 方法来完成。下面将介绍这两种方法以及排序规则的使用方式。 1. 使用 sorted() 函数排序列表(临时性排序…...

面经整理1
感觉好几个都是backtracking Letter Combinations of a Phone Number - LeetCode 典型的backtracking,注意String的处理 class Solution {String[] keyboard new String[]{"", "", "abc","def","ghi","…...
)
ChatGPT个人专用版 SSRF漏洞复现(CVE-2024-27564)
0x01 产品简介 ChatGPT个人专用版是一种基于 OpenAI 的 GPT-3.5 、GPT-4.0语言模型的产品。它是设计用于 Web 环境中的聊天机器人,旨在为用户提供自然语言交互和智能对话的能力。PHP版调用OpenAI接口进行问答和画图,采用Stream流模式通信,一边生成一边输出。前端采用EventS…...

Python中的可哈希与不可哈希对象详解
文章目录 1. 前置知识:哈希是什么2. 可哈希和不可哈希对象的定义2.1可哈希2.2 不可哈希 3. 对象的哈希方法3.1 自定义对象的哈希方法3.2 可哈希性与等价性3.3 哈希值的用途 推荐 在复习可变对象和不可变对象时,学到了这个内容 1. 前置知识:哈…...

【嵌入式DIY实例】-DIY速度计
DIY速度计 文章目录 DIY速度计1、硬件准备1.1 NEO-6M GPS模块介绍1.2 硬件接线原理图2、代码实现本文将介绍如何使用模拟仪表和 GPS 模块制作 DIY Arduino 速度计。 仪表用于显示当前速度,而GPS模块用于实时跟踪速度。 该项目将 Arduino 板与 GPS 模块相结合,在经典模拟仪表上…...

1.0 Hadoop 教程
1.0 Hadoop 教程 分类 Hadoop 教程 Hadoop 是一个开源的分布式计算和存储框架,由 Apache 基金会开发和维护。 Hadoop 为庞大的计算机集群提供可靠的、可伸缩的应用层计算和存储支持,它允许使用简单的编程模型跨计算机群集分布式处理大型数据集…...

【无人机/平衡车/机器人】详解STM32+MPU6050姿态解算—卡尔曼滤波+四元数法+互补滤波(文末附3个算法源码)
效果: MPU6050姿态解算-卡尔曼滤波+四元数+互补滤波 目录 基础知识详解 欧拉角...

智能水务系统:构建高效节水的城市水网
随着城市化进程的加速和人民生活水平的提高,对水务管理的需求也越来越高。传统的水务管理方式已经无法满足现代社会的需求,而智能水务系统的出现为水务管理带来了新的变革。本文将从项目背景、需求分析、建设目标、建设内容、技术方案、安全设计等方面&a…...

【JavaEE初阶系列】——网络编程 UDP客户端/服务器 程序实现
目录 🚩UDP和TCP之间的区别 🎈TCP是有连接的 UDP是无连接的 🎈TCP是可靠传输 UDP是不可靠传输 🎈TCP是面向字节流 UDP是面向数据报 🎈TCP和UDP是全双工 👩🏻💻UDP的socket ap…...
)
Unity开发HoloLens应用:从打包到安装的完整避坑指南(2024最新版)
Unity开发HoloLens应用:从打包到安装的完整避坑指南(2024最新版) 如果你正在尝试将Unity项目部署到HoloLens设备上,可能会遇到各种意想不到的问题。作为一位经历过无数次打包、部署、调试循环的开发者,我想分享一些实战…...

告别手动:Python/Shell双环境实战,让Certbot自动续期通配符证书稳如泰山
Python/Shell双环境实战:Certbot自动续期通配符证书的终极方案 当你的服务器集群同时存在Python和Shell环境时,如何构建一个统一的证书自动化管理体系?这个问题困扰着许多技术负责人。通配符证书的自动续期看似简单,但在混合技术栈…...

Android崩溃分析进阶:结合addr2line与IDA Pro精准定位SO文件崩溃点
1. 从崩溃日志到问题定位:为什么SO文件这么难缠? 每次看到Android应用崩溃日志里出现"signal 11 (SIGSEGV)"这种字样,我就知道今晚又要加班了。特别是当崩溃发生在SO文件中时,那种无力感就像在漆黑的房间里找一根掉落的…...

3大颠覆:Umi-OCR如何重新定义离线文字识别体验?
3大颠覆:Umi-OCR如何重新定义离线文字识别体验? 【免费下载链接】Umi-OCR Umi-OCR: 这是一个免费、开源、可批量处理的离线OCR软件,适用于Windows系统,支持截图OCR、批量OCR、二维码识别等功能。 项目地址: https://gitcode.com…...

高效音频获取与资源管理:喜马拉雅下载工具全解析
高效音频获取与资源管理:喜马拉雅下载工具全解析 【免费下载链接】xmly-downloader-qt5 喜马拉雅FM专辑下载器. 支持VIP与付费专辑. 使用GoQt5编写(Not Qt Binding). 项目地址: https://gitcode.com/gh_mirrors/xm/xmly-downloader-qt5 在数字内容消费时代&a…...

如何用dashdot打造高颜值服务器监控面板?完整配置教程
如何用dashdot打造高颜值服务器监控面板?完整配置教程 【免费下载链接】dashdot A simple, modern server dashboard, primarily used by smaller private servers 项目地址: https://gitcode.com/gh_mirrors/da/dashdot dashdot是一款现代化的服务器监控面板…...

MusePublic显存利用率提升方案:CPU卸载+自动清理策略详解
MusePublic显存利用率提升方案:CPU卸载自动清理策略详解 1. 项目背景与显存挑战 MusePublic是一款专为艺术感时尚人像创作设计的轻量化文本生成图像系统。基于专属大模型和safetensors格式封装,系统针对艺术人像的优雅姿态、细腻光影和故事感画面进行了…...
)
用AI看牙新姿势:5张手机照片,TeethDreamer帮你生成3D牙齿模型(附保姆级复现思路)
从5张照片到3D牙齿模型:TeethDreamer技术全解析与实战指南 想象一下,你只需要用手机拍摄5张口腔照片,就能生成一个精确的3D牙齿模型——这不再是科幻电影中的场景。TeethDreamer作为2024年MICCAI会议上的突破性研究,将扩散模型与3…...
)
别再用鼠标点来点去了!用JavaScript原生DOM操作实现按钮高亮切换(附完整代码)
别再用鼠标点来点去了!用JavaScript原生DOM操作实现按钮高亮切换(附完整代码) 在Web开发中,交互式按钮状态管理是最基础却最常被忽视的技能之一。很多开发者习惯依赖jQuery或前端框架提供的便捷方法,却对原生JavaScrip…...

AsyncAPI消息模式匹配:基于内容路由消息的终极指南
AsyncAPI消息模式匹配:基于内容路由消息的终极指南 【免费下载链接】spec The AsyncAPI specification allows you to create machine-readable definitions of your asynchronous APIs. 项目地址: https://gitcode.com/gh_mirrors/spec/spec AsyncAPI规范允…...