Scrapy 爬取m3u8视频
Scrapy 爬取m3u8视频
【一】效果展示
- 爬取ts文件样式
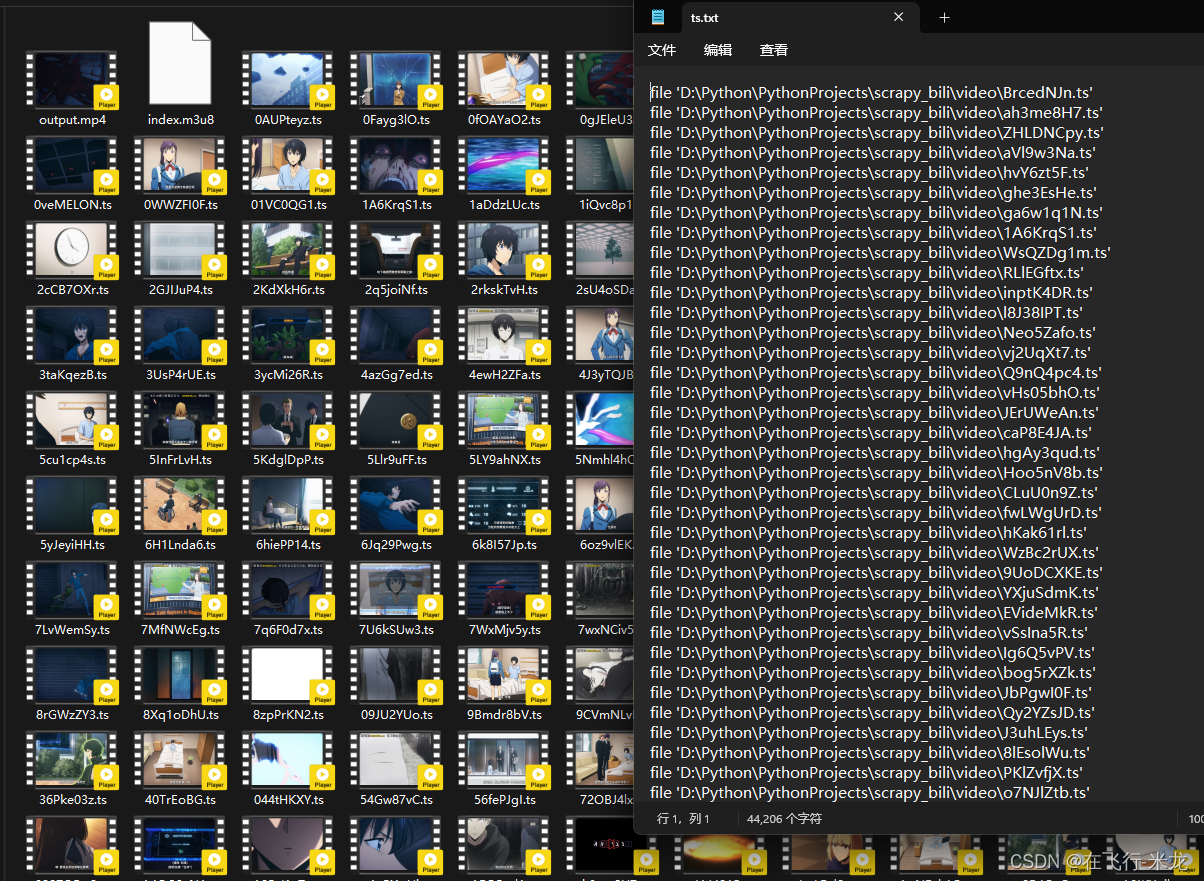
- 合成的MP4文件

【二】分析m3u8文件路径
- 视频地址:
[在线播放我独自升级 第03集 - 高清资源](https://www.physkan.com/ph/175552-8-3.html)
【1】找到m3u8文件
- 这里任务目标很明确
- 就是找m3u8文件
- 打开浏览器
- 进入开发者模式F12
- 搜索m3u8文件
- 查看响应内容含有ts文件的m3u8文件
- 再次查看标头地址即可
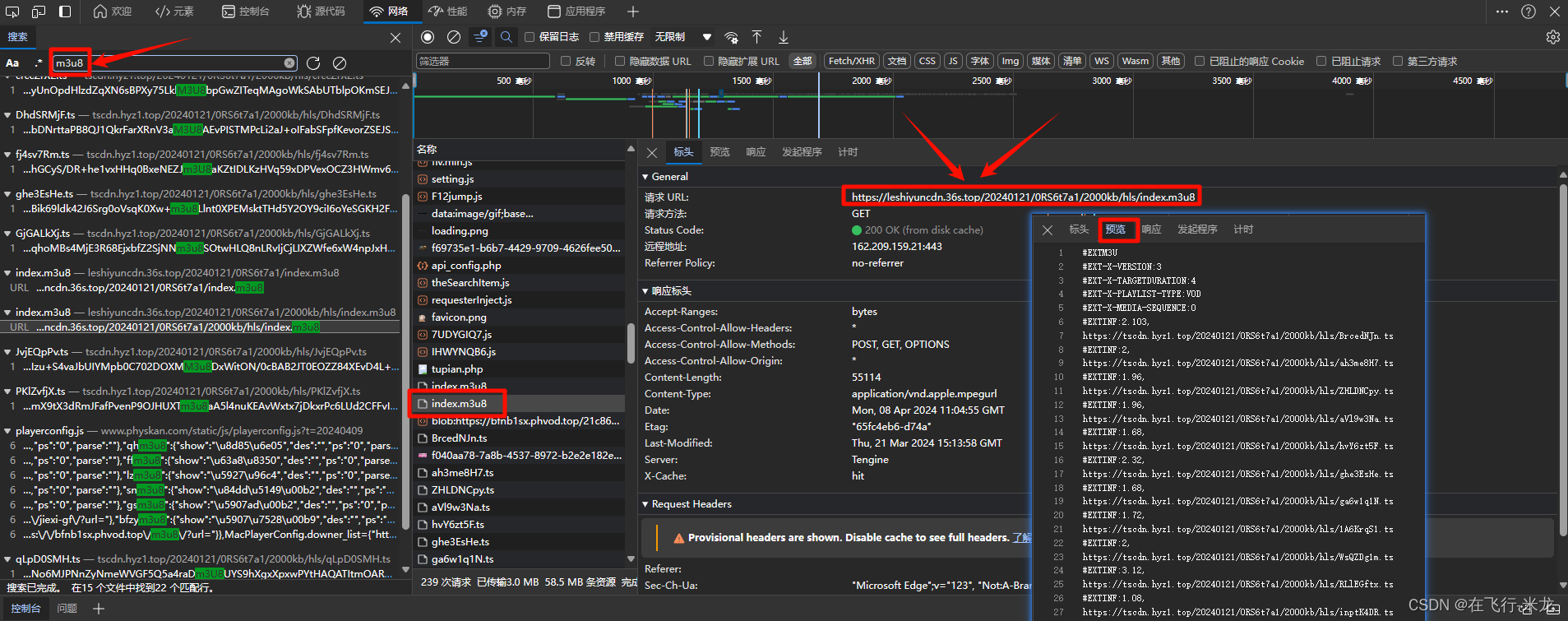
【2】分析m3u8路径
https://leshiyuncdn.36s.top/20240121/0RS6t7a1/2000kb/hls/index.m3u8- 按照/拆分:leshiyuncdn.36s.top----20240121----0RS6t7a1----2000kb----hls
- 笨办法:一个个的进行搜索
- 查看哪个找到m3u8的路径
- 其中搜索
leshiyuncdn.36s.top这个的时候- 查看响应中含有m3u8地址
- 那么就继续分析这个地址
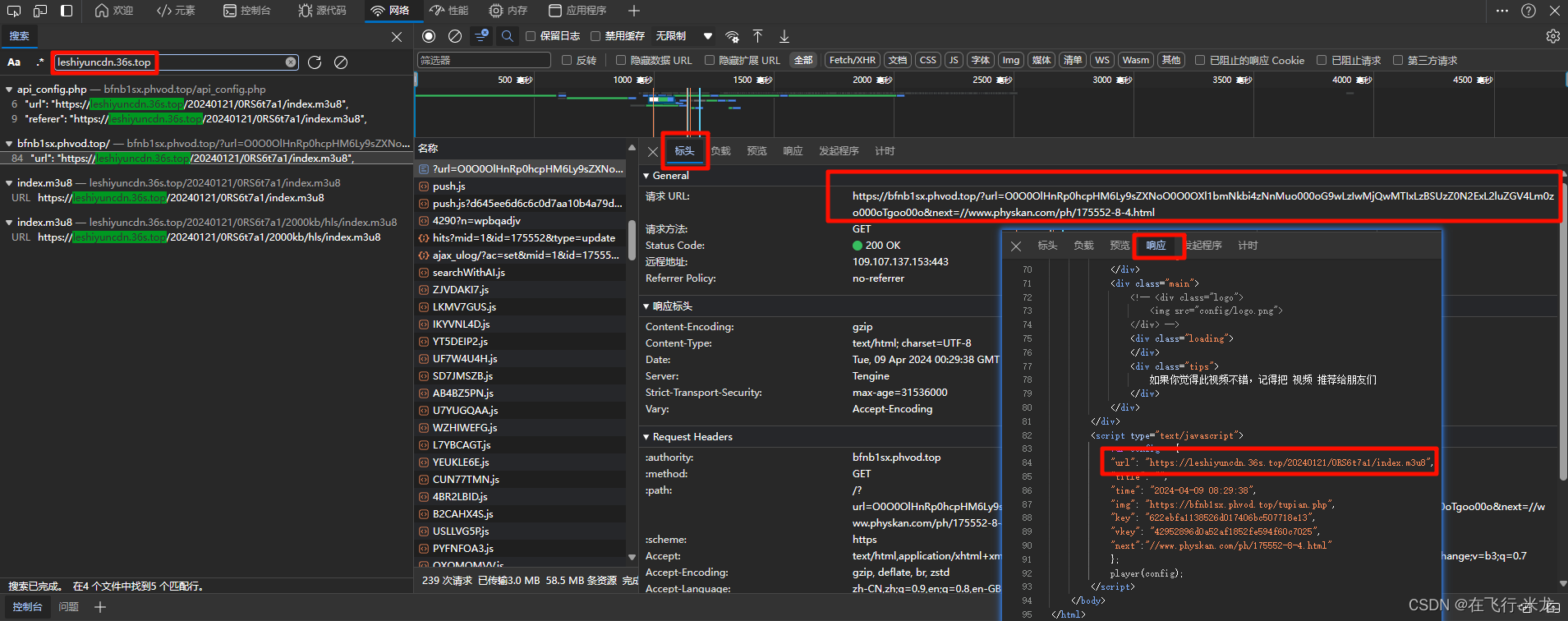
https://bfnb1sx.phvod.top/?url=O0O0OlHnRp0hcpHM6Ly9sZXNoO0O0OXl1bmNkbi4zNnMuo000oG9wLzIwMjQwMTIxLzBSUzZ0N2ExL2luZGV4Lm0zo000oTgoo00o&next=//www.physkan.com/ph/175552-8-4.html- 同样的采用笨方法:拆分一个一个的找
- 在搜索
O0O0OlHnRp0hcpHM6Ly9sZXNoO0O0OXl1bmNkbi4zNnMuo000oG9wLzIwMjQwMTIxLzBSUzZ0N2ExL2luZGV4Lm0zo000oTgoo00o的时候- 找到
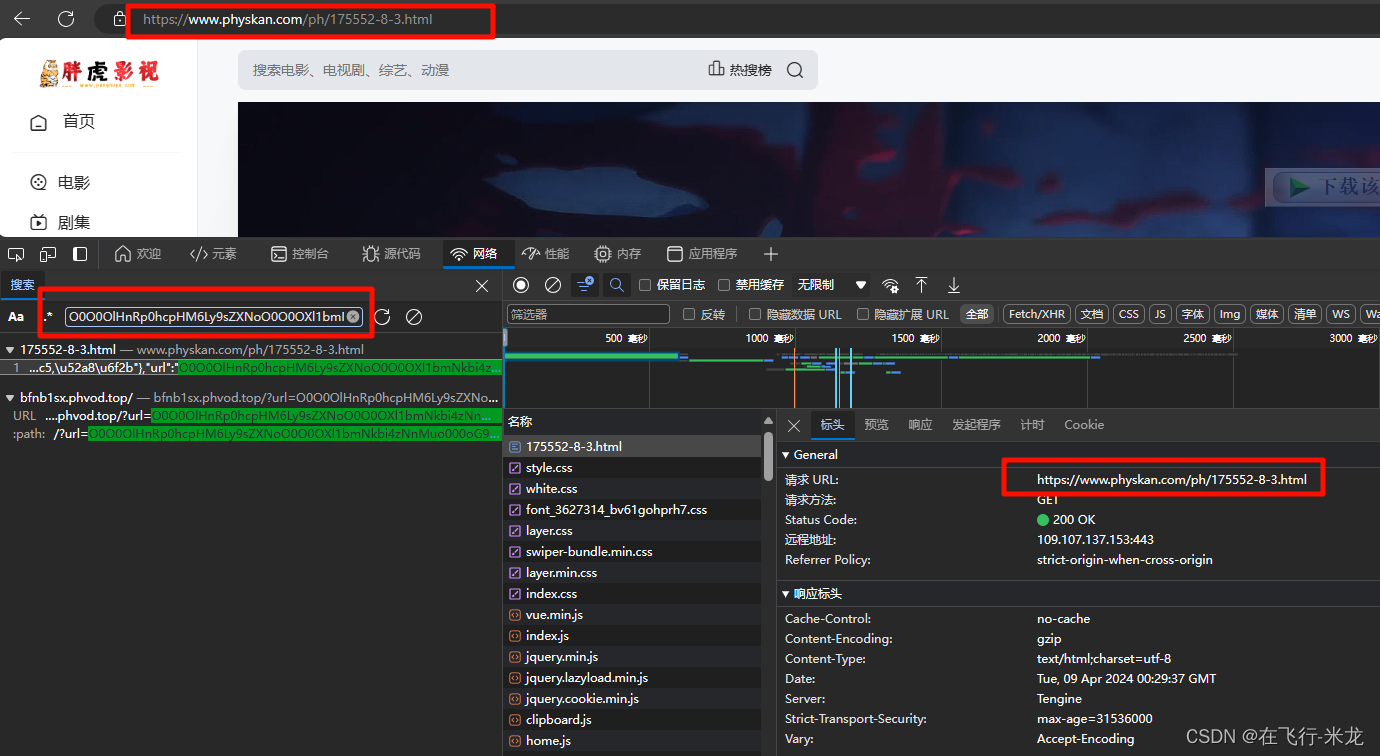
https://www.physkan.com/ph/175552-8-3.html里面含有我们搜索的内容 - 并且这个地址就是浏览器的访问视频的地址
- 好了,就是它了
- 找到
【三】scrapy代码
【1】基础内容
class M3U8Spider(scrapy.Spider):# 爬虫文件名name = "m3u8"# 可访问的域名列表allowed_domains = ["www.physkan.com", 'bfnb1sx.phvod.top', 'leshiyuncdn.36s.top', 'tscdn.hyz1.top']# 起始地址start_urls = ["https://www.physkan.com/ph/175552-8-3.html"]# 视频存储路径video_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(__file__))), 'video')# 确保文件创建好os.makedirs(video_path, exist_ok=True)# m3u8文件路径m3u8_path = os.path.join(video_path, 'index.m3u8')# ts文件路径ts_info_path = os.path.join(video_path, 'ts.txt')
【2】分析获取m3u8路径
- 我们需要的数据发现在script的player_aaaa中
- 正则匹配,json格式转换为字典格式,方便读取数据
- 其中url含有我们需要的路径参数,但是不全
- 所以补全路径发起请求
def parse(self, response):# 获取网页源码page_source = response.text# 分析源码可以发现需要的地址在script的player_aaaa中# 通过正则匹配获取pattern = r'var player_aaaa=({.*?})</script>'url_info_str = re.findall(pattern, page_source, re.DOTALL)[0]# json格式转换为字典,方便拿数据url_info_dict = json.loads(url_info_str)# 拼接m3u8路径m3u8_info_url = 'https://bfnb1sx.phvod.top/?url=' + url_info_dict['url']yield scrapy.Request(url=m3u8_info_url, callback=self.get_m3u8_url)
- 这个地址还并非是直接的m3u8路径
- 同样的获取m3u8路径参数
- 拼接完整路径参数,就可以得到m3u8的真正路径
def get_m3u8_url(self, response):page_source = response.textpattern = r'var config = ({.*?})'m3u8_info_str = re.findall(pattern, page_source, re.DOTALL)[0]m3u8_info_dict = json.loads(m3u8_info_str)m3u8_url = m3u8_info_dict['url']m3u8_url = m3u8_url.rsplit('/', 1)[0] + '/2000kb/hls/index.m3u8'yield scrapy.Request(url=m3u8_url, callback=self.get_ts_list)
【3】获取过滤ts
- 通过上面的地址获取到了index.m3u8文件
- 先保存在本地一份,方便查看
- 使用正则表达式过滤出ts视频
- 还要保存一份ts文件路径在本地
- 因为接下来使用ffmpeg工具进行视频合成
- 格式要求:
file '视频路径.ts'
- 最后异步发起ts视频文件请求
def get_ts_list(self, response):# 获取页面txt信息page_source = response.text# 保存在index.m3u8文件在本地with open(self.m3u8_path, mode='wt', encoding='utf8') as fp:fp.write(page_source)# 使用正则过滤拿出ts路径ts_urls = re.findall(r'https://tscdn.hyz1.top/[^\s]+.ts', page_source)# 保存的ts视频文件需要按照合成视频ffmpeg的格式拼接with open(self.ts_info_path, mode='wt', encoding='utf8') as fp:for ts in ts_urls:file_name = ts.rsplit('/', 1)[-1]file_path = os.path.join(self.video_path, file_name)# 保存ts文件,保存的为ts文件路径fp.write(f"file '{file_path}'" + '\n')# 异步发起ts视频文件的请求yield scrapy.Request(url=ts, callback=self.save_ts_file, meta={'file_path': file_path})
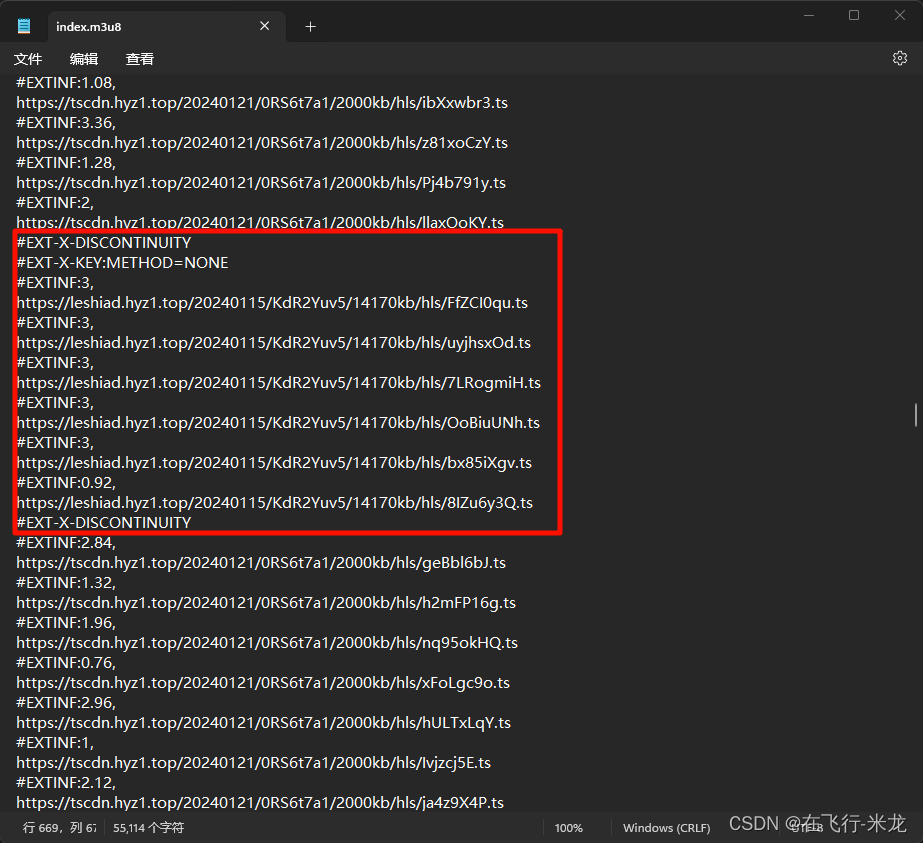
(3.1)小插曲
- 在m3u8文件中
- 你会发现这个不一样的地址
- 其实这部分是广告,可以过滤掉
【4】保存ts文件、合成MP4文件
- 首先进行ts文件保存
- 这个没有什么好说的
- 直接保存吧
def save_ts_file(self, response):# 保存ts文件本地file_path = response.meta.get('file_path')with open(file_path, mode='wb') as fp:fp.write(response.body)# 输出日志写不写都行self.log(f'保存成功:>>>{file_path.rsplit("/", 1)[-1]}')
-
拼接ts文件为MP4视频文件
-
需要用的工具是ffmpeg
-
官网:Download FFmpeg
-
去安装配置好环境变量即可
-
-
合成MP4视频
- 首先使用os模块切换到保存的ts文件路径下
- 然后执行ffmpeg命令
- ffmpeg -f concat -safe 0 -i ts.txt -c copy output.mp4
- ts.txt是之前的保存的ts文件路径文件
- 格式要求:
file '视频路径.ts'
- 格式要求:
- output.mp4是合成后的mp4文件
- 可自定义文件名等
def close(spider, reason):# 爬虫执行完毕以后,拼接视频 工具:ffmpegos.chdir(f'{spider.video_path}')os.system(f'ffmpeg -f concat -safe 0 -i ts.txt -c copy output.mp4')
免责声明
-
本爬虫仅用于收集特定网站的信息,目的是进行数据分析,不得用于非法目的或侵犯他人隐私。对于因使用本爬虫造成的任何损失或法律责任,本人概不负责。
-
本爬虫的数据可能存在不准确、不完整或不可用的情况,对于用户或第三方可能因此造成的任何损失,本人概不负责。
相关文章:
Scrapy 爬取m3u8视频
Scrapy 爬取m3u8视频 【一】效果展示 爬取ts文件样式 合成的MP4文件 【二】分析m3u8文件路径 视频地址:[在线播放我独自升级 第03集 - 高清资源](https://www.physkan.com/ph/175552-8-3.html) 【1】找到m3u8文件 这里任务目标很明确 就是找m3u8文件 打开浏览器…...

LVGL简单记录
1、 vs中代码旁边有个小锁删除git 2、Visual Studio 试图编译已删除的文件, 如果这个文件也是你不再需要编译的文件,且已经从文件系统中删除,你需要从 .vcxproj 文件中移除或者注释掉这一行,以停止Visual Studio尝试去编译一个不…...

计算机网络——ARP协议
前言 本博客是博主用于复习计算机网络的博客,如果疏忽出现错误,还望各位指正。 这篇博客是在B站掌芝士zzs这个UP主的视频的总结,讲的非常好。 可以先去看一篇视频,再来参考这篇笔记(或者说直接偷走)。 …...
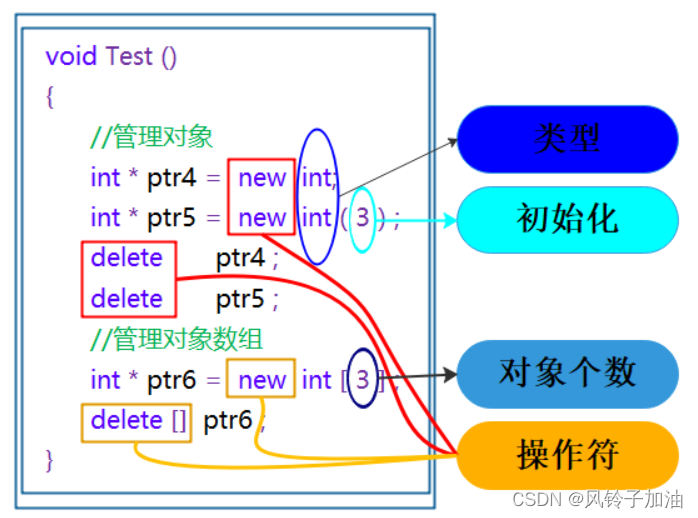
【C++]C/C++的内存管理
这篇博客将会带着大家解决以下几个问题 1. C/C内存分布 2. C语言中动态内存管理方式 3. C中动态内存管理 4. operator new与operator delete函数 5. new和delete的实现原理 6. 定位new表达式(placement-new) 1. C/C内存分布 我们先来看下面的一段代码和相关问题 int global…...

深入理解计算机网络分层结构
一、 为什么要分层? 计算机网络分层的主要目的是将复杂的网络通信过程分解为多个相互独立的层次,每个层次负责特定的功能。这样做有以下几个好处: 模块化设计:每个层次都有清晰定义的功能和接口,使得网络系统更易于设…...

亚马逊云科技CTO带你学习云计算降本增效秘诀
2023亚马逊云科技一年一度的重磅春晚--Re:invent上有诸多不同话题的主题Keynote,这次小李哥带大家复盘来自亚马逊CTO: Wener博士的主题演讲: 云架构节俭之道1️⃣节俭对于云计算为什么重要? ▶️企业基础设施投入大,利用好降本策略可以减少巨…...
快速上手Vue
目录 概念 创建实例 插值表达式 Vue响应式特性 概念 Vue是一个用于 构建用户界面 的 渐进式 框架 构建用户界面:基于数据渲染出用户看到的页面 渐进式:Vue相关生态:声明式渲染<组件系统<客户端路由<大规模状态管理<构建工具 V…...

java 目录整理
Java知识相关目录主要参考黑马程序员 风清扬老师的视屏,参考链接为 Java_黑马刘意(风清扬)2019最新版_Java入门视频_Java入门_Java编程_Java入门教程_黑马教程_黑马程序员_idea版_哔哩哔哩_bilibili 1、java 基础 java基本认识?java跨平台原理?jdk、jre、jvm的联系? 链接:…...

使用Python的Pillow库进行图像处理书法参赛作品
介绍: 在计算机视觉和图像处理领域,Python是一种强大而流行的编程语言。它提供了许多优秀的库和工具,使得图像处理任务变得轻松和高效。本文将介绍如何使用Python的wxPython和Pillow库来选择JPEG图像文件,并对选中的图像进行调整和…...

docker 容器指定utf-8编码
在运行 Docker 容器的时候,如果容器内应用需要使用 UTF-8 编码来正常处理中文,你可以通过设置环境变量来指定编码。 可以使用 -e 或者 --env 标志来设置环境变量。比如,设置 LANG 和 LC_ALL 环境变量为 C.UTF-8 或者 en_US.UTF-8:…...
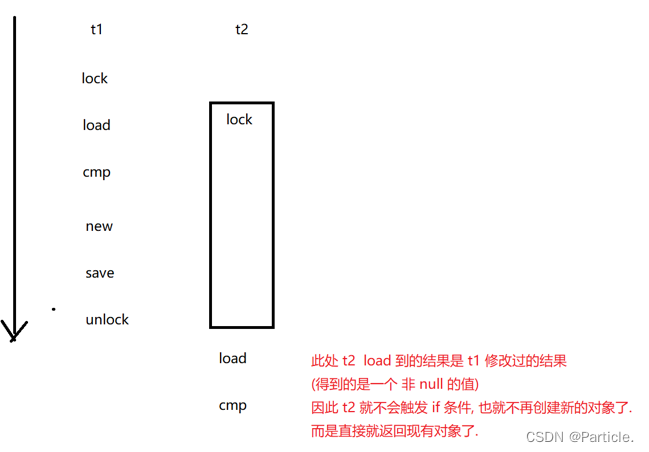
单例模式以及常见的两种实现模式
单例模式是校招中最常考的设计模式之一. 设计模式其实就是类似于“规章制度”,按照这个套路来进行操作。 单例模式能保证某个类在程序中只存在唯一 一份实例。而不会创建出多个实例,如果创建出了多个实例,就会编译报错。而不会创建出多个实…...
 和 equals()的若干问题解答)
Java hashCode() 和 equals()的若干问题解答
Java hashCode() 和 equals()的若干问题解答 本章的内容主要解决下面几个问题: 1 equals() 的作用是什么? 2 equals() 与 的区别是什么? 3 hashCode() 的作用是什么? 4 hashCode() 和 equals() 之间有什么联系? …...

高级IO——React服务器简单实现
3.4Reactor服务器实现 1.connect封装 每一个连接都要有一个文件描述符和输入输出缓冲区,还有读、写、异常处理的回调方法; 还包括指向服务器的回指指针; class connection; class tcpserver;using func_t std::function<void(s…...

Qt使用插件QPluginLoader 机制开发
简介: 插件(Plug-in,又称addin、add-in、addon或add-on,又译外挂)是一种遵循一定规范的应用程序接口编写出来的程序。 Qt 提供了2种APIs来创建插件: 一种高级API,用于为Qt本身编写插件:自定义数据库驱动程序,图像格…...

双子座 Gemini1.5和谷歌的本质
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
二百三十、MySQL——MySQL表的索引
1 目的 梳理一下目前MySQL维度表的索引情况,当然网上也有其他博客专门讲MySQL索引的,我这边只是梳理一下目前的索引状况而已 2单列索引 2.1 索引截图 2.2 建表语句 3 联合索引 3.1 索引截图 3.2 建表语句 4 参考的优秀博客 http://t.csdnimg.cn/ZF7…...
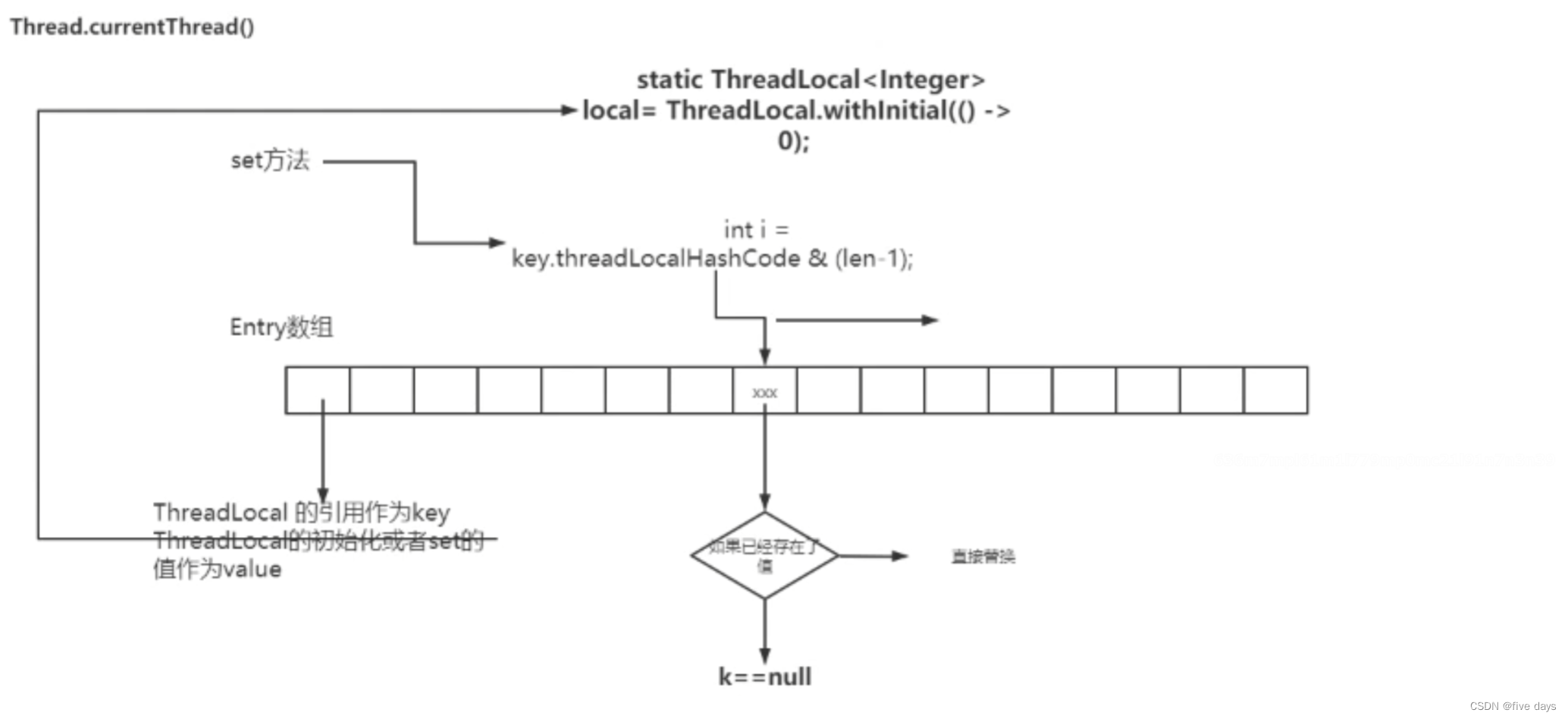
并发编程之ThreadLocal使用及原理
ThreadLocal主要是为了解决线程安全性问题的 非线程安全举例 public class ThreadLocalDemo {// 非线程安全的private static final SimpleDateFormat sdf new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");public static Date parse(String strDate) throws ParseExc…...

软件测试 测试开发丨Pytest结合数据驱动-yaml,熬夜整理蚂蚁金服软件测试高级笔试题
编程语言 languages: PHPJavaPython book: Python入门: # 书籍名称 price: 55.5 author: Lily available: True repertory: 20 date: 2018-02-17 Java入门: price: 60 author: Lily available: False repertory: Null date: 2018-05-11 yaml 文件使用 查看 yaml 文件 pych…...

软考数据库---2.SQL语言
主要记忆:表、索引、视图操作语句;数据操作;通配符、转义符;授权;存储过程;触发器 这部分等等整理一下: “”" 1、 数据定义语言。 SQL DDL提供定义关系模式和视图、 删除关系和视图、 修改关系模式的…...
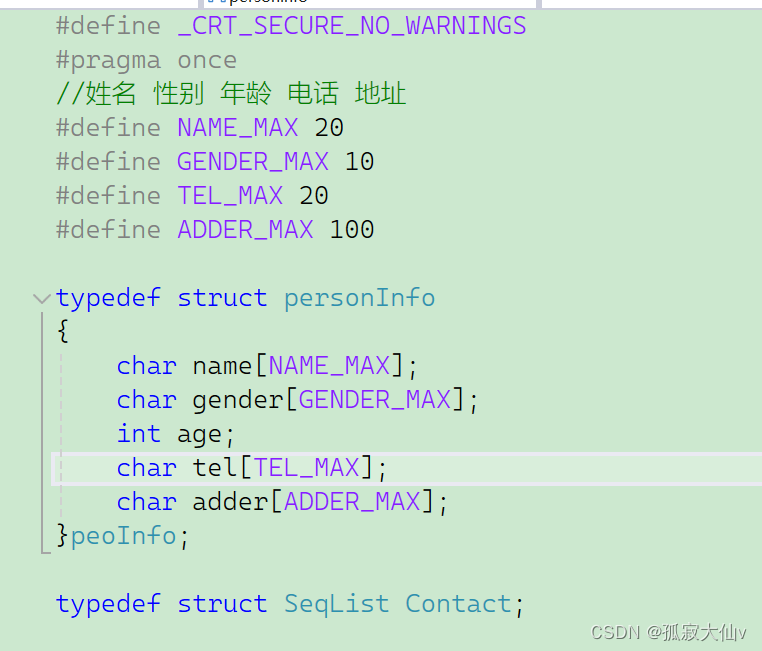
基于顺序表实现通讯录
上篇我们讲了顺序表是什么,和如何实现顺序表。这篇文章我们将基于顺序表来实现通讯录。 文章目录 前言一、基于顺序表是如何实现的二、通讯录的头文件和实现文件三、通讯录的实现3.1 定义通讯录结构3.2 初始化通讯录3.3 销毁通讯录3.4 通讯录添加数据3.5 查找联系人…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

java调用dll出现unsatisfiedLinkError以及JNA和JNI的区别
UnsatisfiedLinkError 在对接硬件设备中,我们会遇到使用 java 调用 dll文件 的情况,此时大概率出现UnsatisfiedLinkError链接错误,原因可能有如下几种 类名错误包名错误方法名参数错误使用 JNI 协议调用,结果 dll 未实现 JNI 协…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

算法笔记2
1.字符串拼接最好用StringBuilder,不用String 2.创建List<>类型的数组并创建内存 List arr[] new ArrayList[26]; Arrays.setAll(arr, i -> new ArrayList<>()); 3.去掉首尾空格...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

windows系统MySQL安装文档
概览:本文讨论了MySQL的安装、使用过程中涉及的解压、配置、初始化、注册服务、启动、修改密码、登录、退出以及卸载等相关内容,为学习者提供全面的操作指导。关键要点包括: 解压 :下载完成后解压压缩包,得到MySQL 8.…...
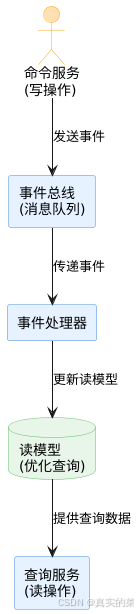
消息队列系统设计与实践全解析
文章目录 🚀 消息队列系统设计与实践全解析🔍 一、消息队列选型1.1 业务场景匹配矩阵1.2 吞吐量/延迟/可靠性权衡💡 权衡决策框架 1.3 运维复杂度评估🔧 运维成本降低策略 🏗️ 二、典型架构设计2.1 分布式事务最终一致…...

大模型真的像人一样“思考”和“理解”吗?
Yann LeCun 新研究的核心探讨:大语言模型(LLM)的“理解”和“思考”方式与人类认知的根本差异。 核心问题:大模型真的像人一样“思考”和“理解”吗? 人类的思考方式: 你的大脑是个超级整理师。面对海量信…...