[尚硅谷flink] 检查点笔记
在Flink中,有一套完整的容错机制来保证故障后的恢复,其中最重要的就是检查点。
文章目录
- 11.1 检查点
- 11.1.1 检查点的保存
- 1)周期性的触发保存
- 2)保存的时间点
- 3)保存的具体流程
- 11.1.2 从检查点恢复状态
- 11.1.3 检查点算法(状态保存的具体算法)
- 1 检查点分界线(Barrier)
- 2 Barrier对齐的精准一次
- 3 Barrier对齐的至少一次
- 4 非Barrier对齐的精准一次(flink 1.11 之后出现)
- 11.1.4 检查点配置
- 1 启用检查点
- 2 检查点存储
- 3 其它高级配置
- 4 demo代码
- 5 **通用增量checkpoint (changelog)**
- 6 最终检查点
- 11.1.5 检查点总结
11.1 检查点
在流处理中,我们可以用存档读档的思路,就是将之前某个时间点所有的状态保存下来,这份“存档”就是所谓的“检查点”(checkpoint)。
遇到故障重启的时候,我们可以从检查点中“读档”,恢复出之前的状态,这样就可以回到当时保存的一刻接着处理数据了。
:::info
这里所谓的“检查”,其实是针对故障恢复的结果而言的:故障恢复之后继续处理的结果,应该与发生故障前完全一致,我们需要“检查”结果的正确性。所以,有时又会把checkpoint叫做“一致性检查点”。
:::
11.1.1 检查点的保存
1)周期性的触发保存
“随时存档”确实恢复起来方便,可是需要我们不停地做存档操作。如果每处理一条数据就进行检查点的保存,当大量数据同时到来时,就会耗费很多资源来频繁做检查点,数据处理的速度就会受到影响。所以在Flink中,检查点的保存是周期性触发的,间隔时间可以进行设置。
2)保存的时间点
我们应该在所有任务(算子)都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。
这样做可以实现一个数据被所有任务(算子)完整地处理完,状态得到了保存。
:::info
如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了。
:::
当然这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;kafka就是满足这些要求的一个最好的例子。
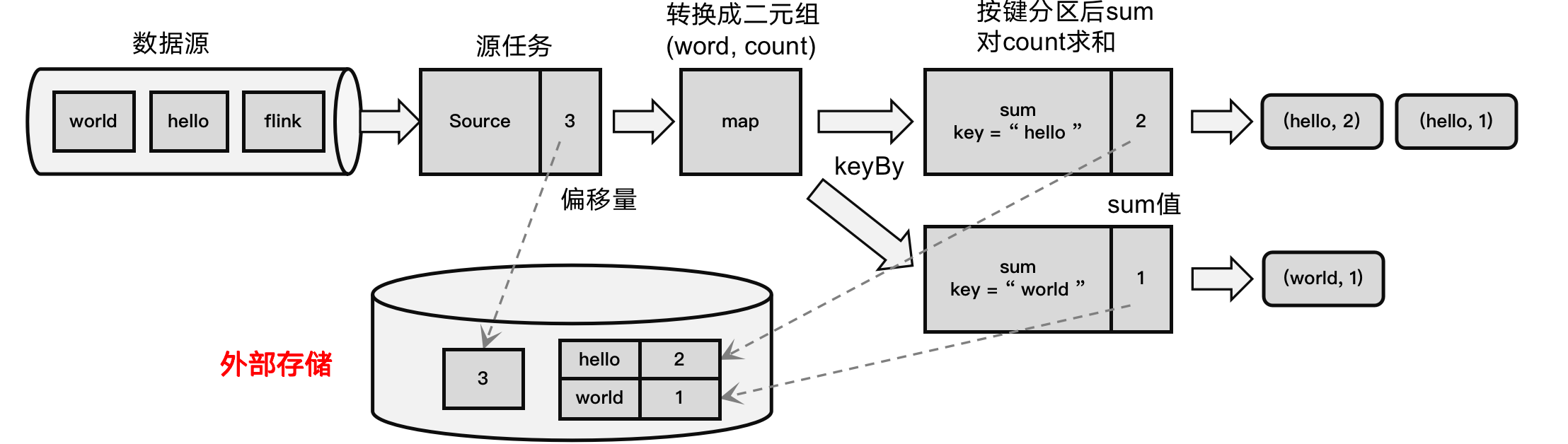
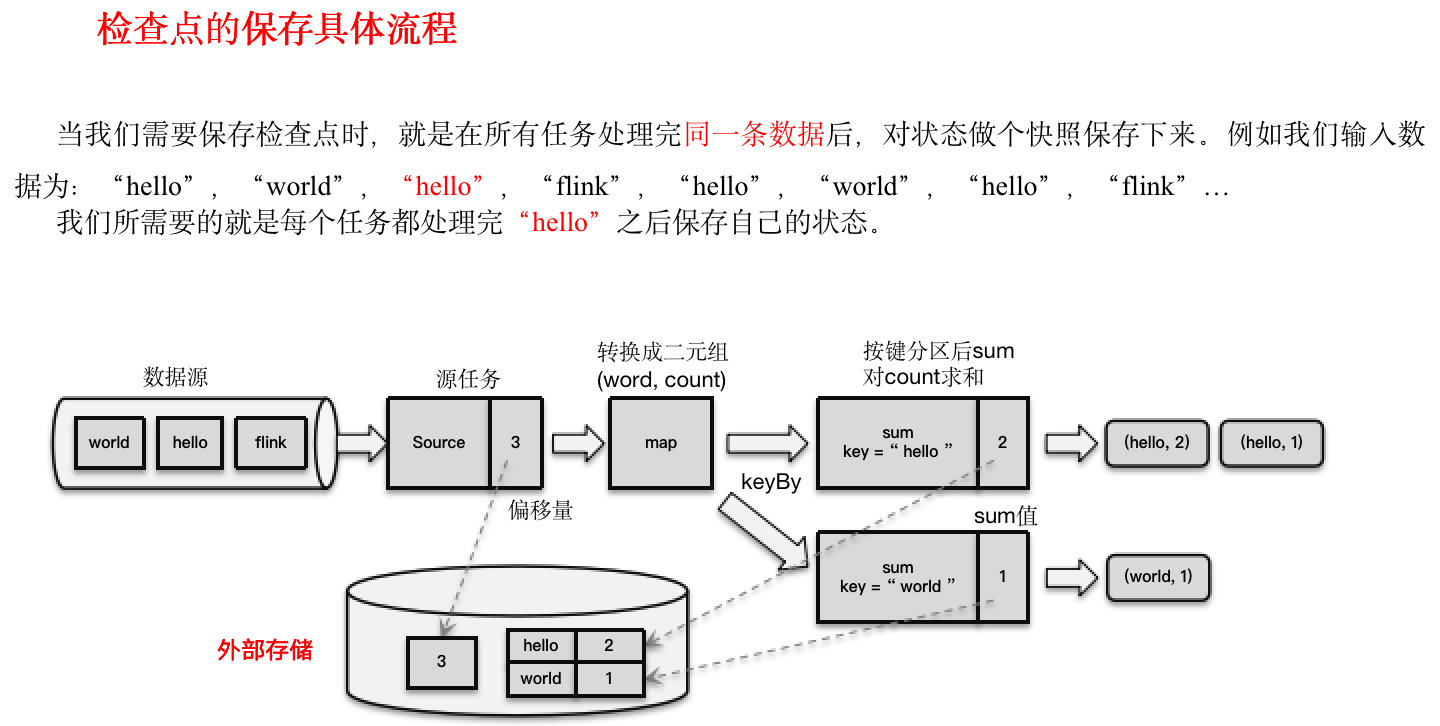
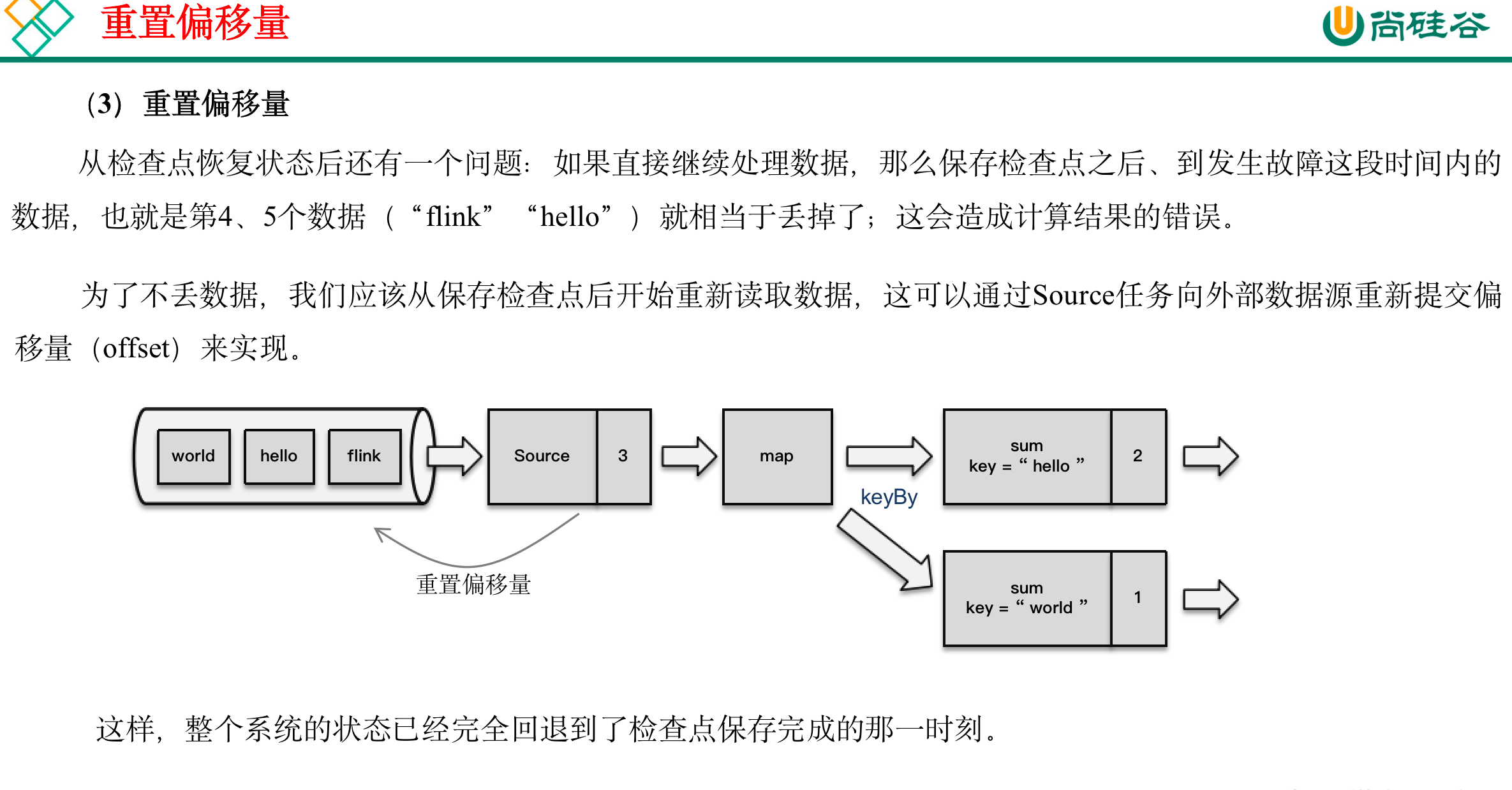
3)保存的具体流程
检查点的保存,最关键的就是要等所有任务将“同一个数据”处理完毕。下面我们通过一个具体的例子,来详细描述一下检查点具体的保存过程。
回忆一下我们最初实现的统计词频的程序——word count。这里为了方便,我们直接从数据源读入已经分开的一个个单词,例如这里输入的是:
“hello”,“world”,“hello”,“flink”,“hello”,“world”,“hello”,“flink”…
我们所需要的就是每个任务都处理完“hello”之后保存自己的状态。
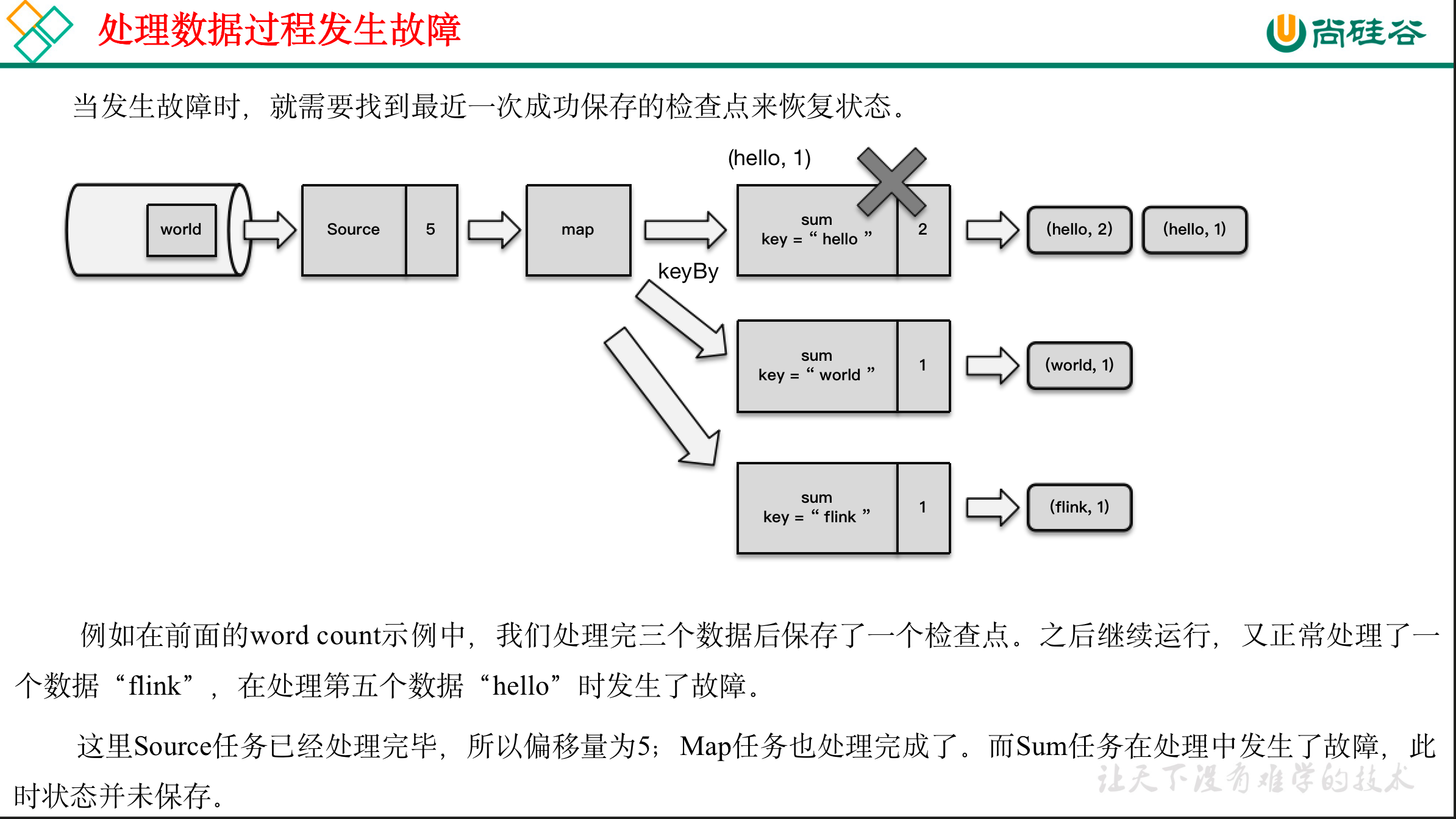
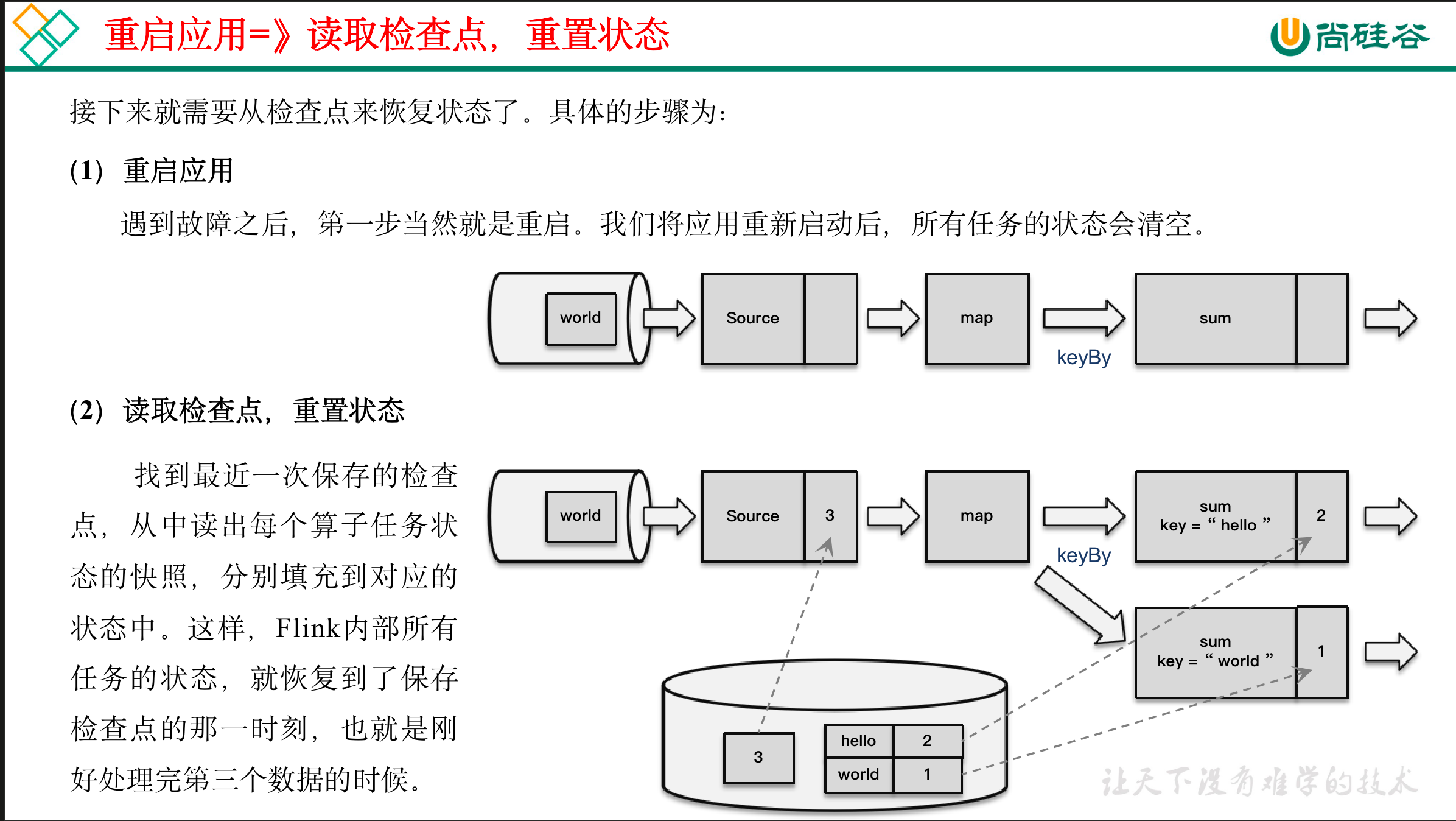
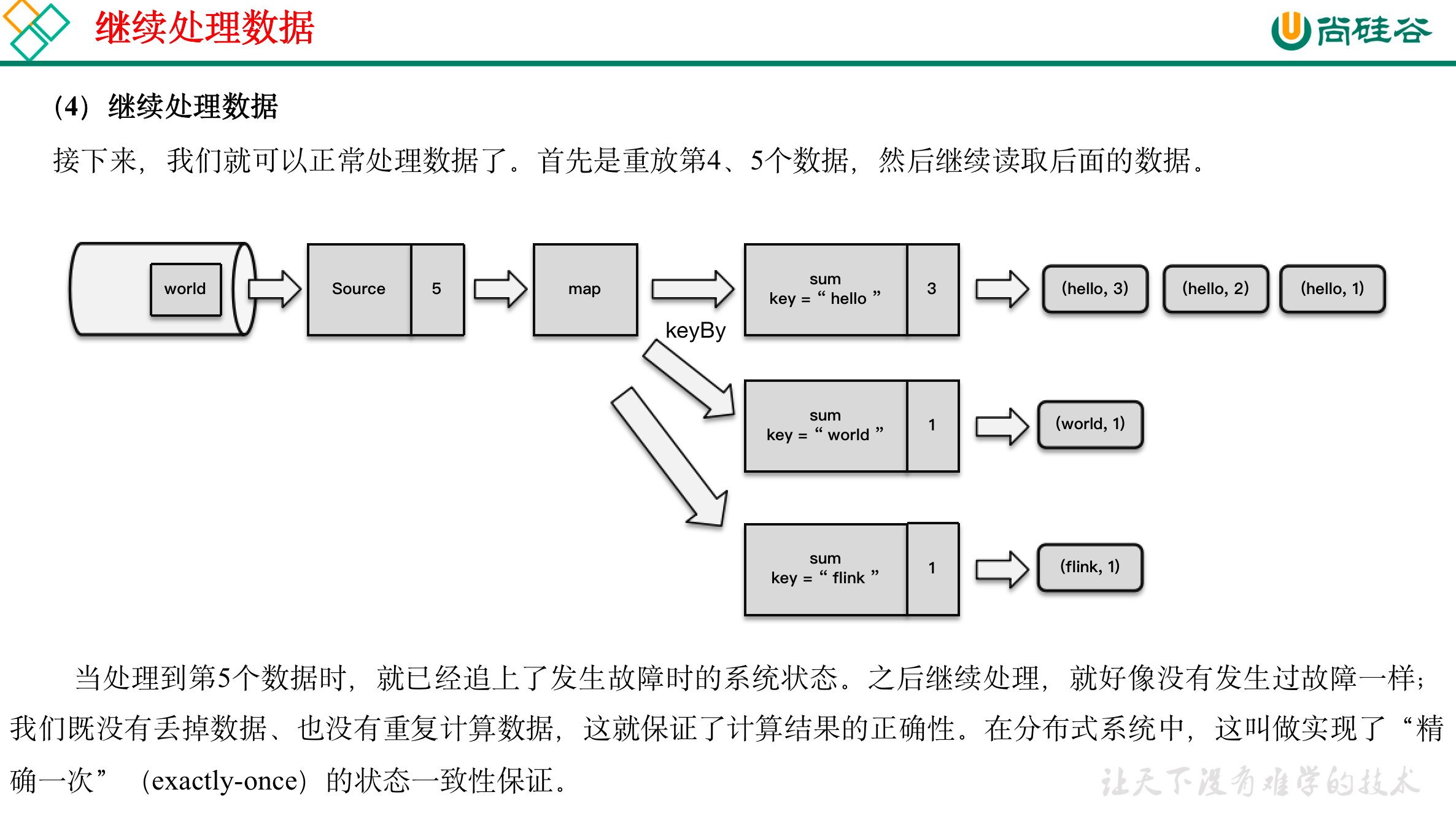
11.1.2 从检查点恢复状态
:::info
- 重启应用
- 读取检查点,重置状态
- 重置偏移量(向外部数据源重新提交偏移量,比如说Kafka)
- 继续处理数据
:::
11.1.3 检查点算法(状态保存的具体算法)
在Flink中,采用了基于Chandy-Lamport算法的分布式快照,可以在不暂停整体流处理的前提下,将状态备份保存到检查点。
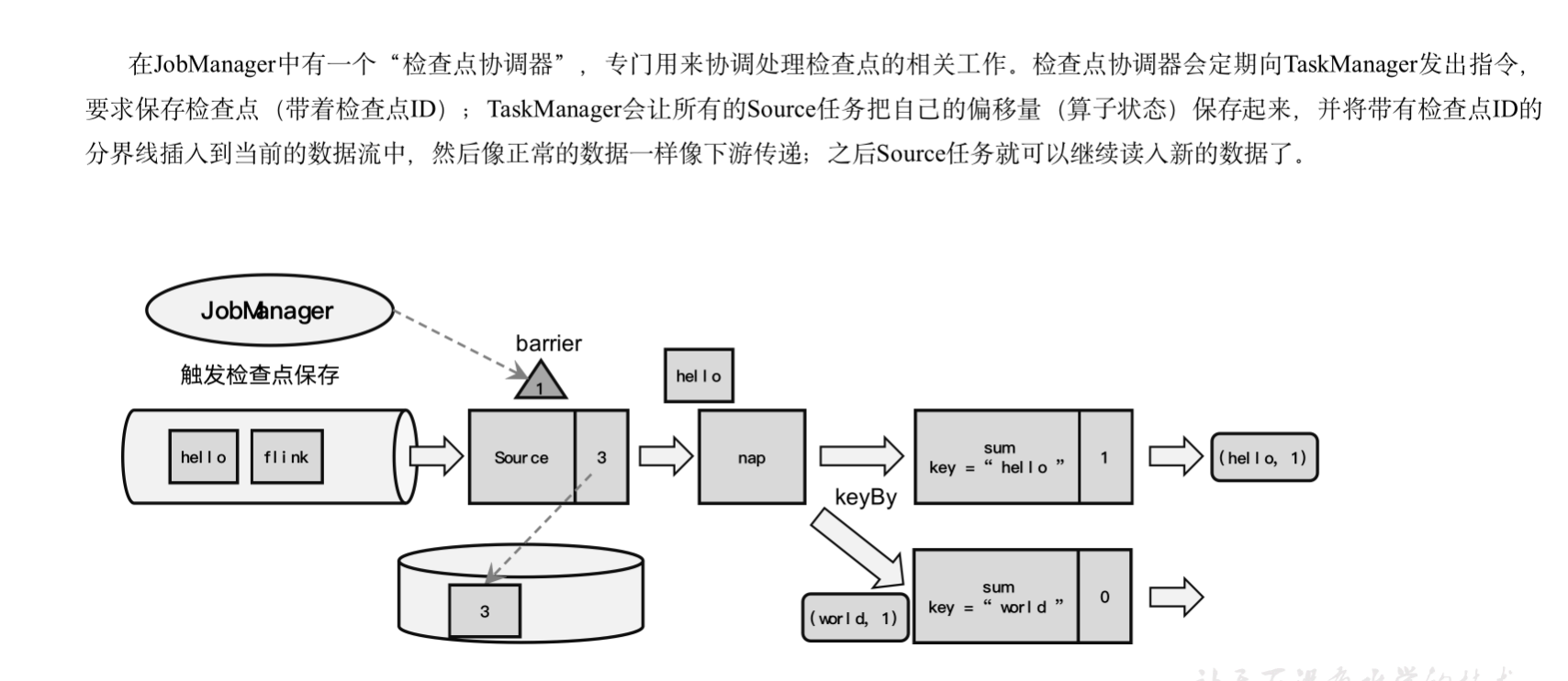
1 检查点分界线(Barrier)
:::info
借鉴水位线的设计,在数据流中插入一个特殊的数据结构,专门用来表示触发检查点保存的时间点。
barrier肯定是从source算子开始。
:::
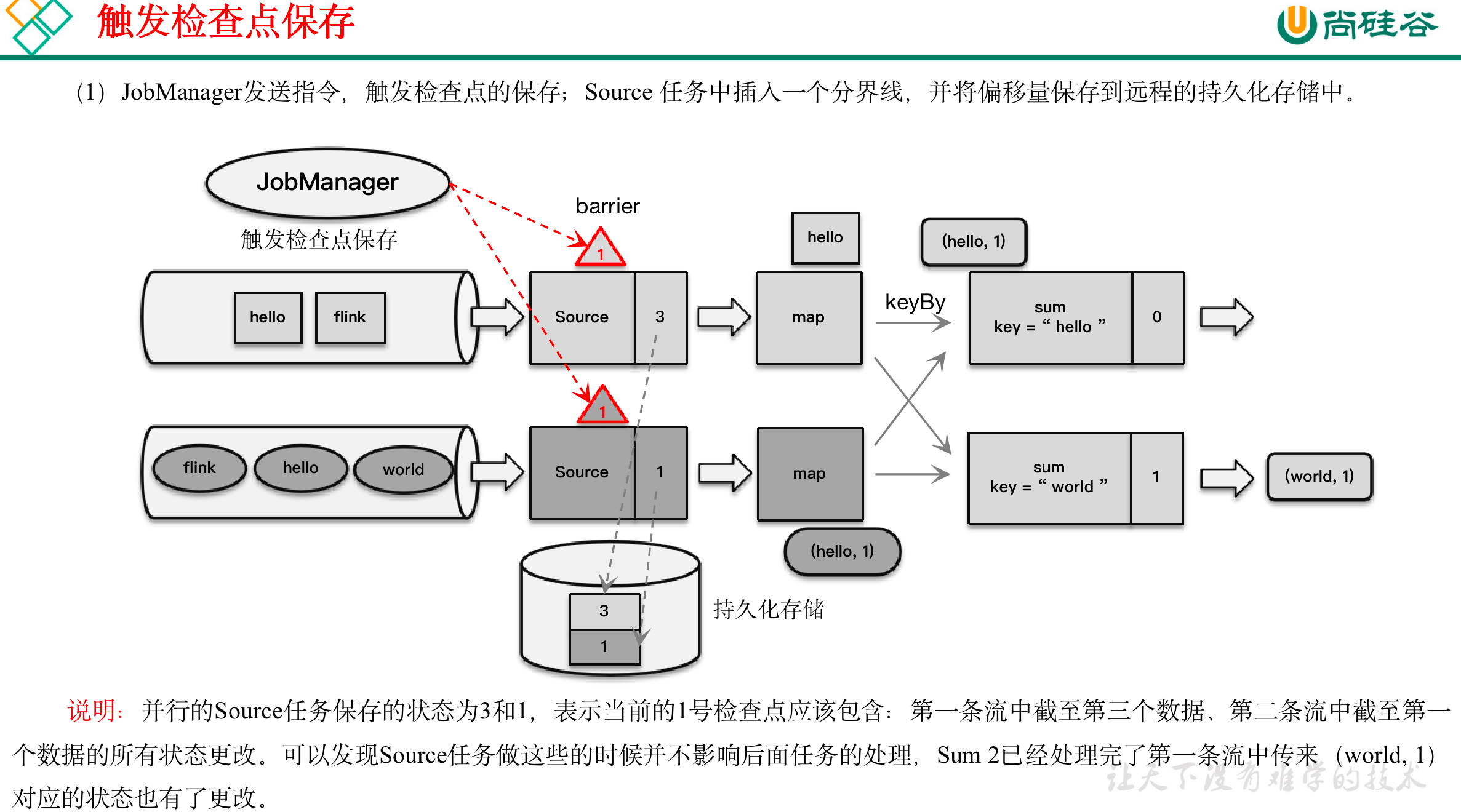
收到保存检查点的指令后,Source任务可以在当前数据流中插入这个结构;
之后的所有任务只要遇到它就开始对状态做持久化快照保存。
由于数据流是保持顺序依次处理的,因此遇到这个标识就代表之前的数据都处理完了,可以保存一个检查点;而在它之后的数据,引起的状态改变就不会体现在这个检查点中,而需要保存到下一个检查点。
这种特殊的数据形式,把一条流上的数据按照不同的检查点分隔开,所以就叫做检查点的“分界线”(Checkpoint Barrier)。
2 Barrier对齐的精准一次
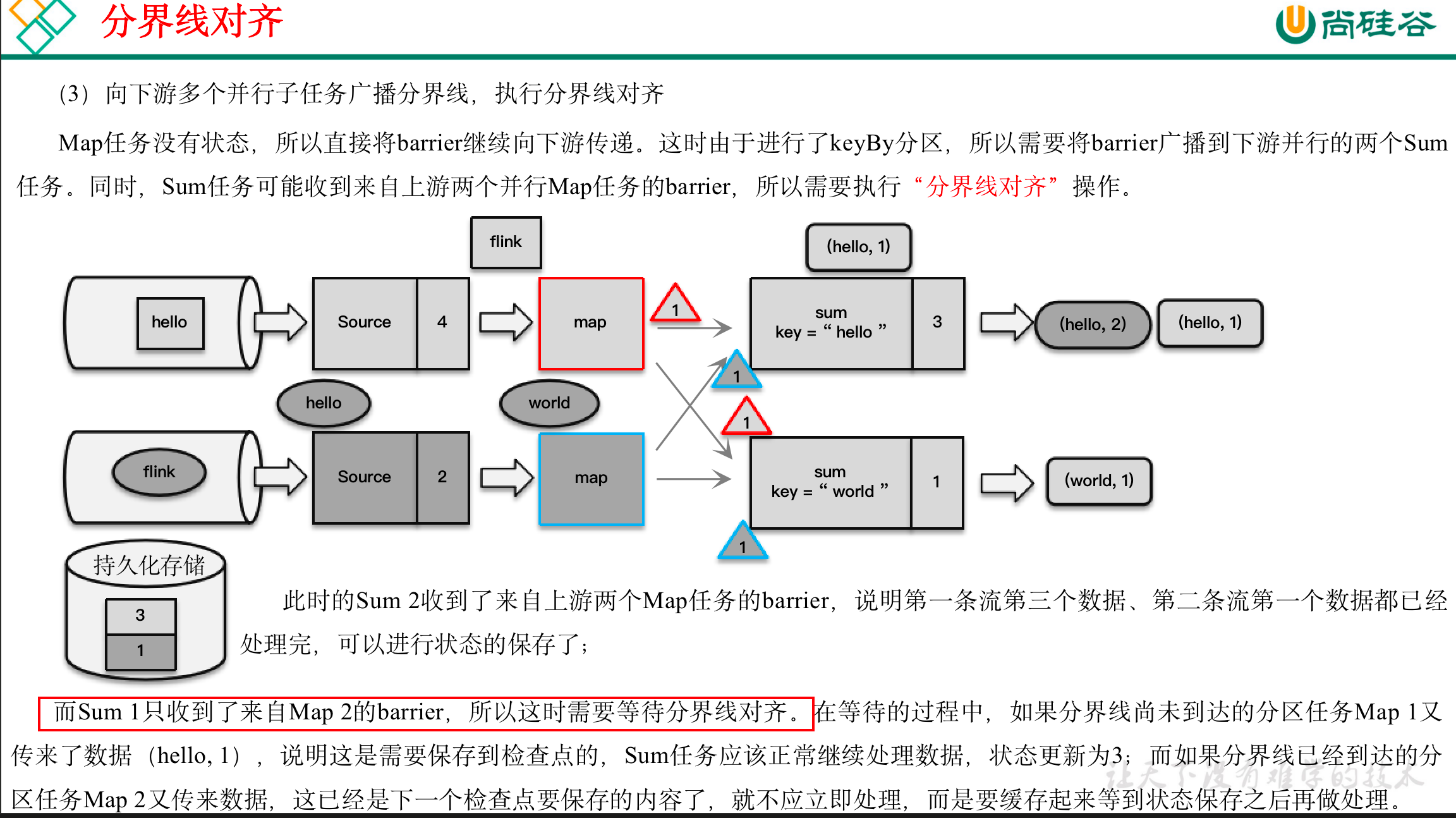
watermark指示的是“之前的数据全部到齐了”,而barrier指示的是“之前所有数据的状态更改保存入当前检查点”:它们都是一个“截止时间”的标志。所以在处理多个分区的传递时,也要以是否还会有数据到来作为一个判断标准。
:::info
具体实现上,Flink使用了Chandy-Lamport算法的一种变体,被称为“异步分界线快照”算法。算法的核心就是两个原则:
- 当上游任务向多个并行下游任务发送barrier时,需要广播出去;
- 而当多个上游任务向同一个下游任务传递分界线时,需要在下游任务执行“分界线对齐”操作,也就是需要等到所有并行分区的barrier都到齐,才可以开始状态的保存。
:::
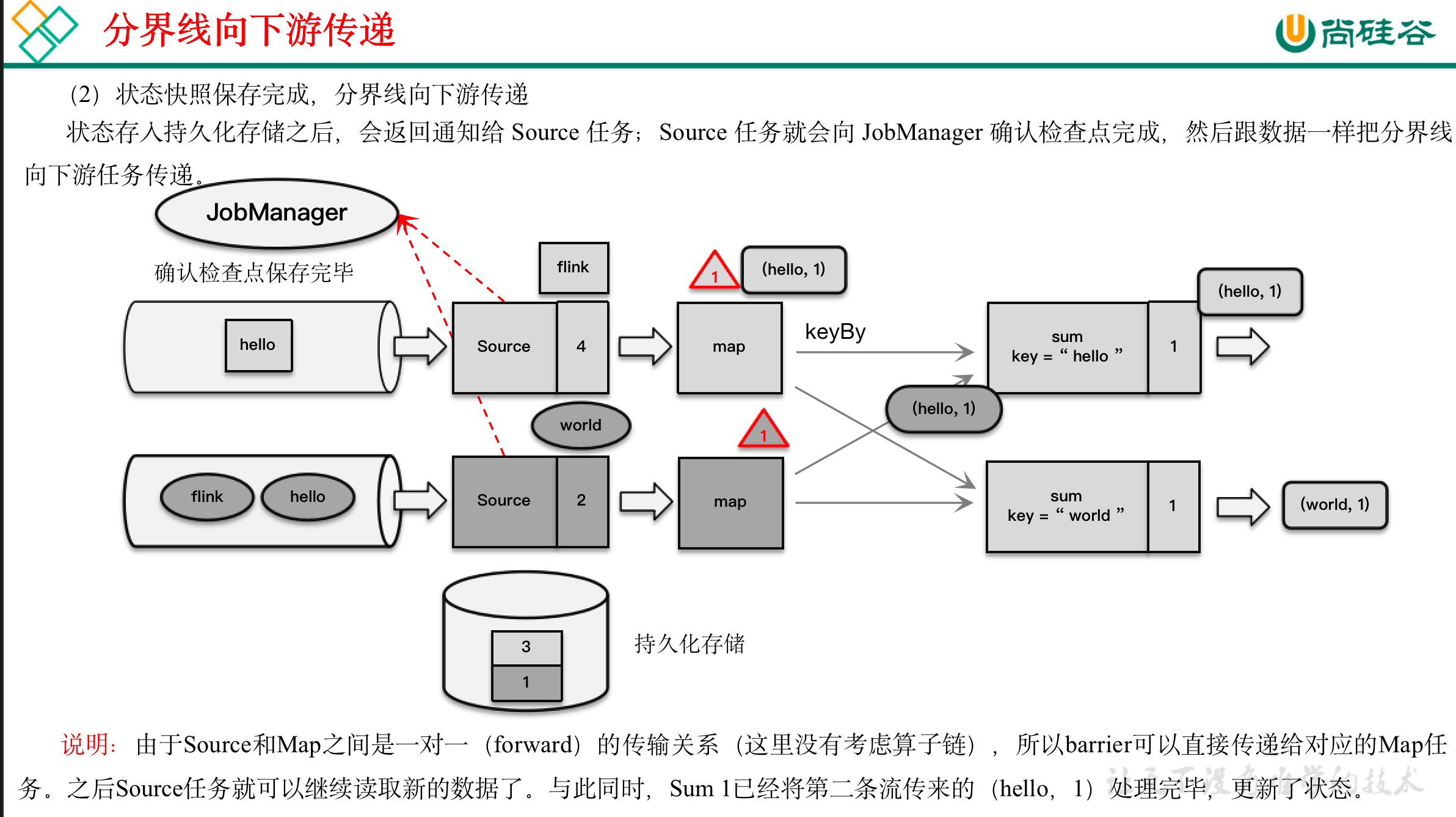
检查点保存算法具体过程为:
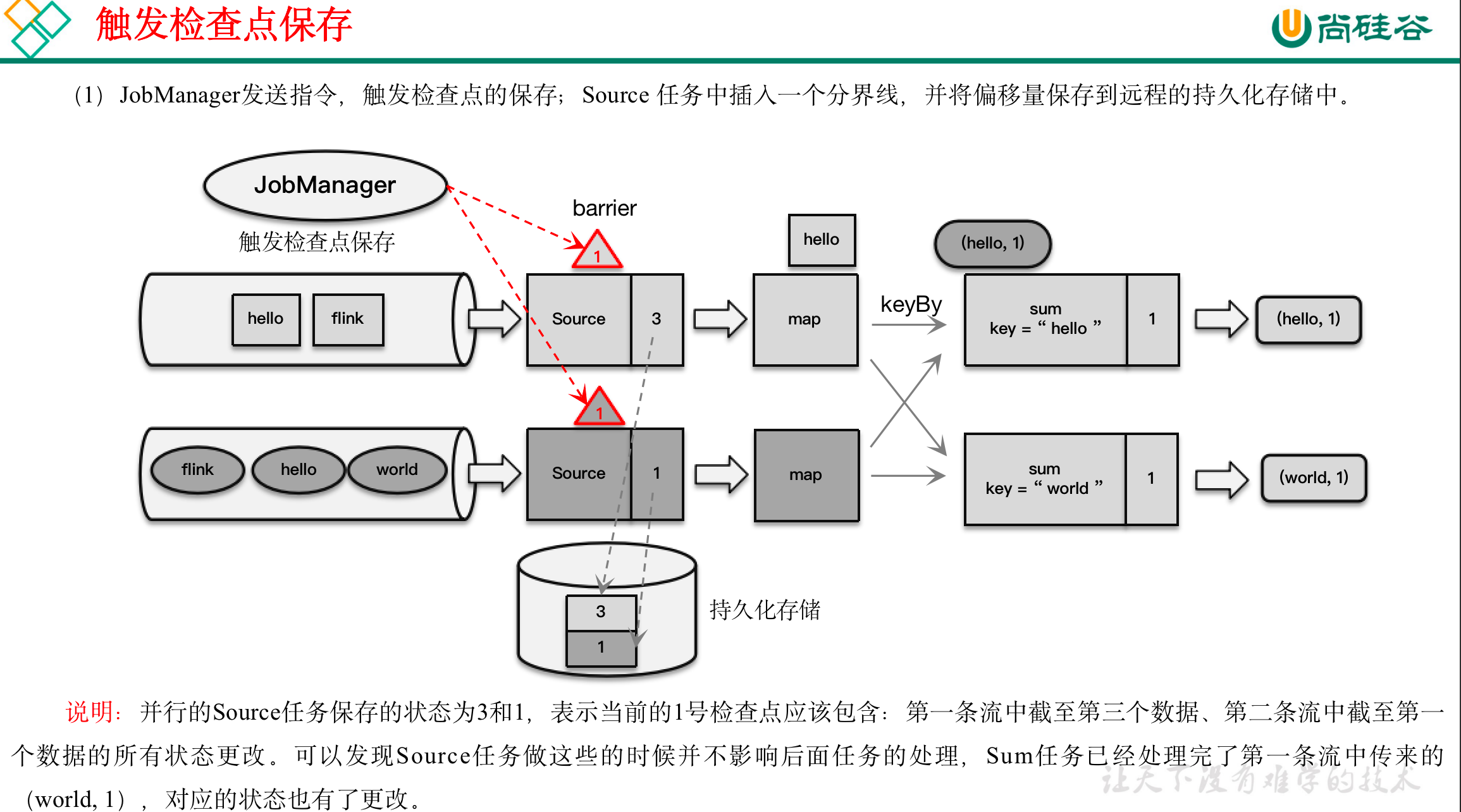
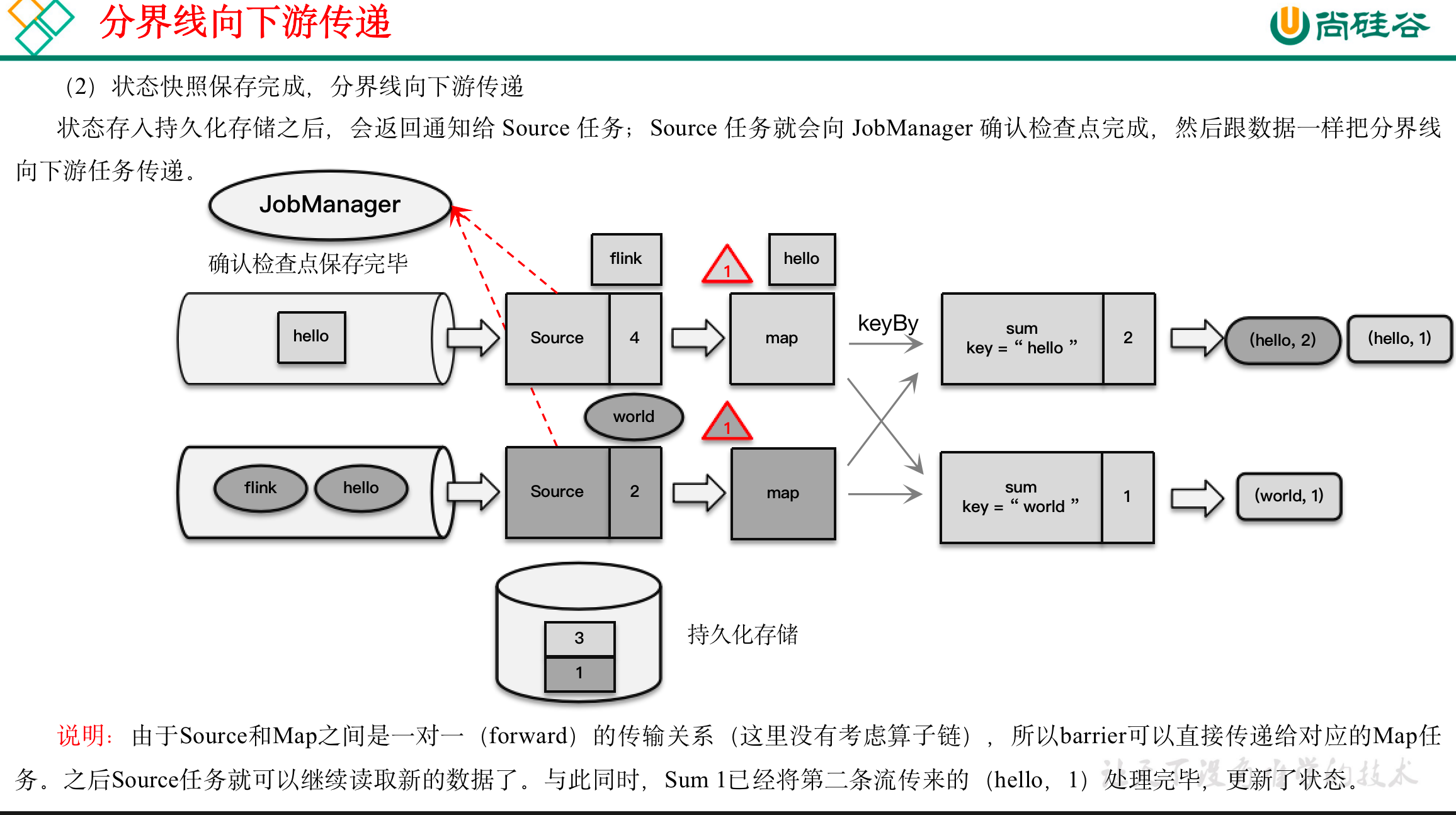
(1)触发检查点:JobManager向Source发送Barrier;
(2)Barrier发送:向下游广播发送;
(3)Barrier对齐:下游需要收到上游所有并行度传递过来的Barrier才做自身状态的保存;
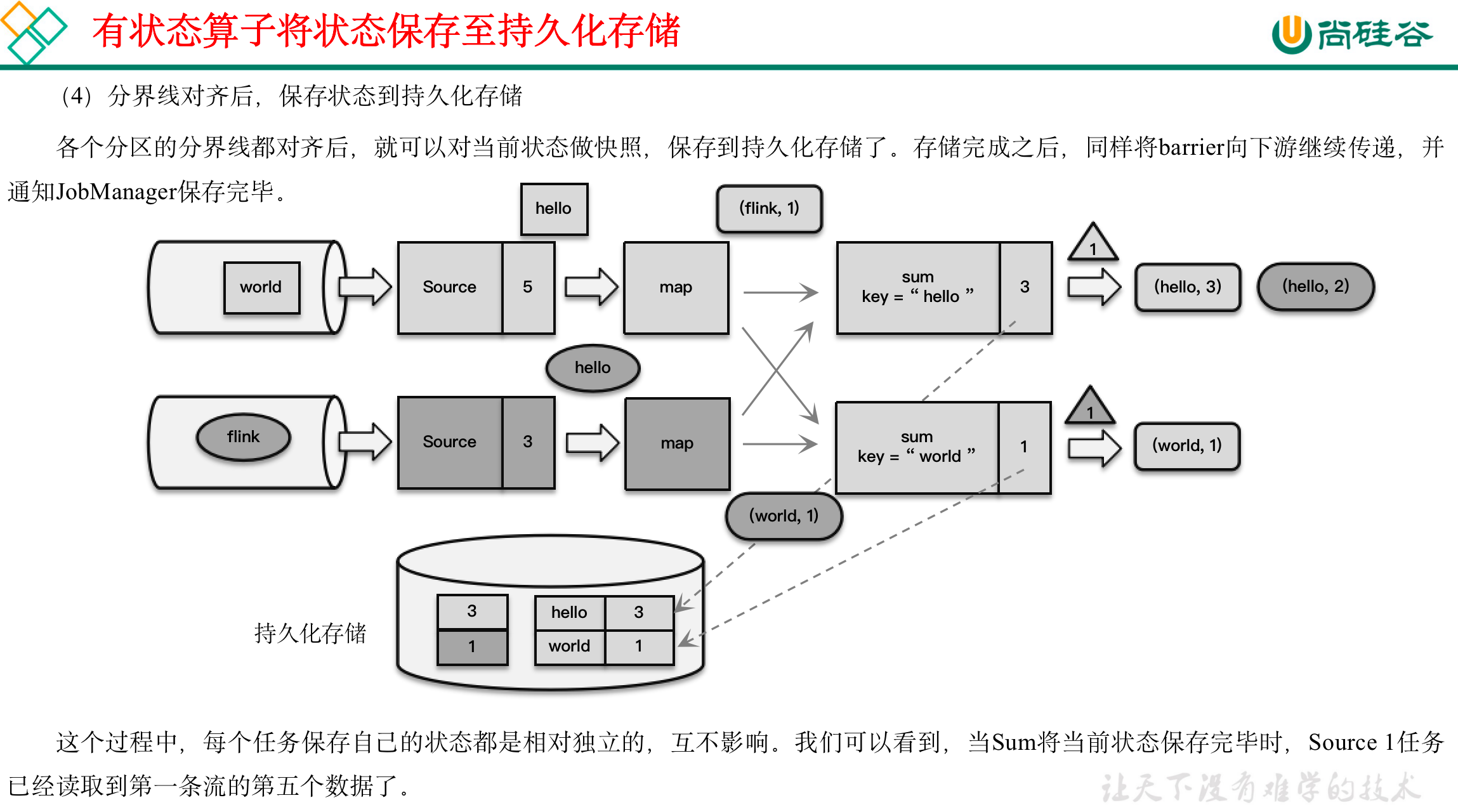
(4)状态保存:有状态的算子将状态保存至持久化。
(5)先处理缓存数据,然后正常继续处理
完成检查点保存之后,任务就可以继续正常处理数据了。这时如果有等待分界线对齐时缓存的数据,需要先做处理;然后再按照顺序依次处理新到的数据。当JobManager收到所有任务成功保存状态的信息,就可以确认当前检查点成功保存。之后遇到故障就可以从这里恢复了。
(补充)由于分界线对齐要求先到达的分区做缓存等待,一定程度上会影响处理的速度;当出现背压时,下游任务会堆积大量的缓冲数据,检查点可能需要很久才可以保存完毕。
为了应对这种场景,Barrier对齐中提供了至少一次语义以及Flink 1.11之后提供了不对齐的检查点保存方式,可以将未处理的缓冲数据也保存进检查点。这样,当我们遇到一个分区barrier时就不需等待对齐,而是可以直接启动状态的保存了。
3 Barrier对齐的至少一次
:::info
精准一次性,在分界线对齐时,barrier 后面的数据需要等待对齐。而至少一次,可以直接进入算子进行计算。
:::
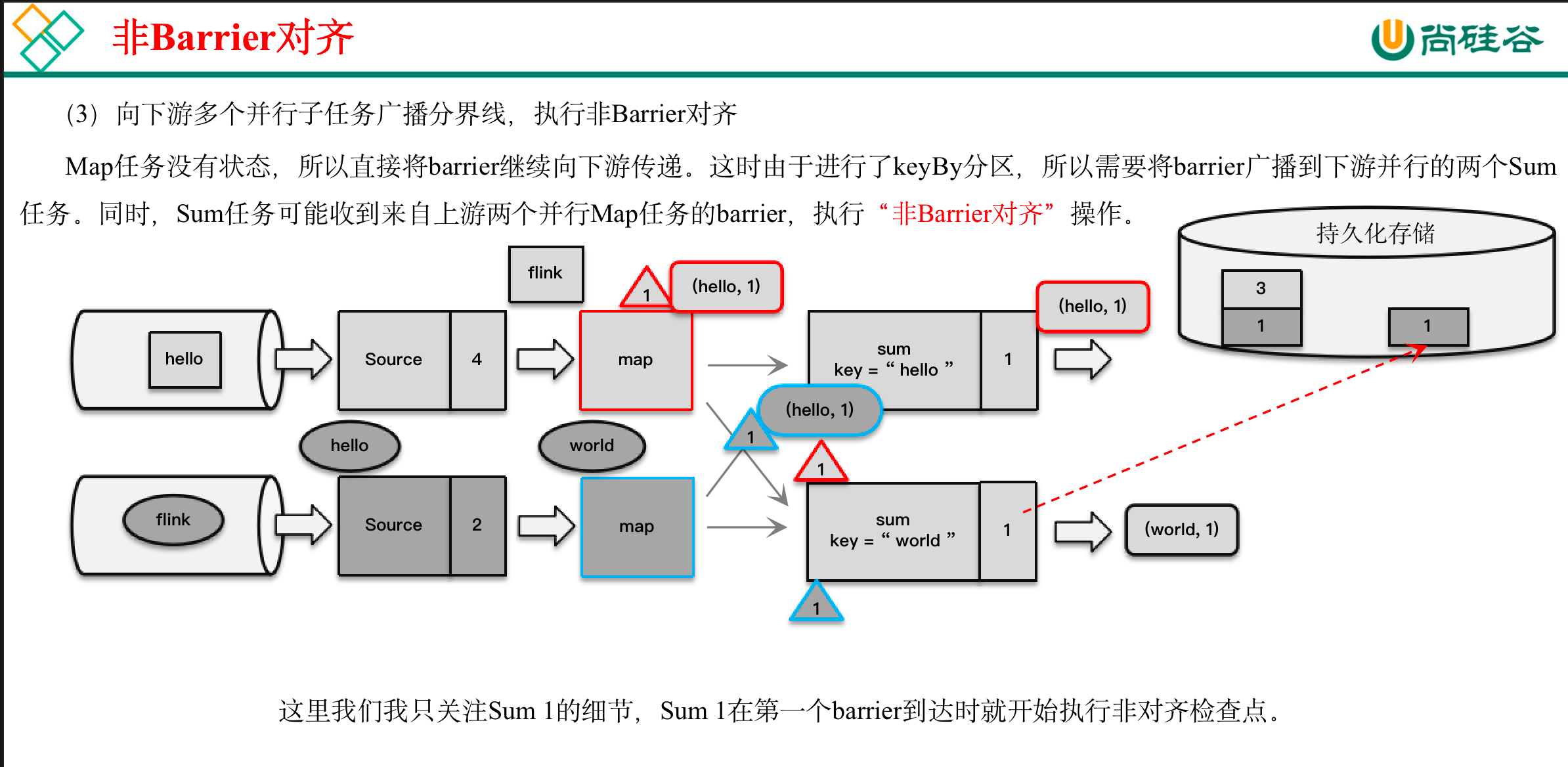
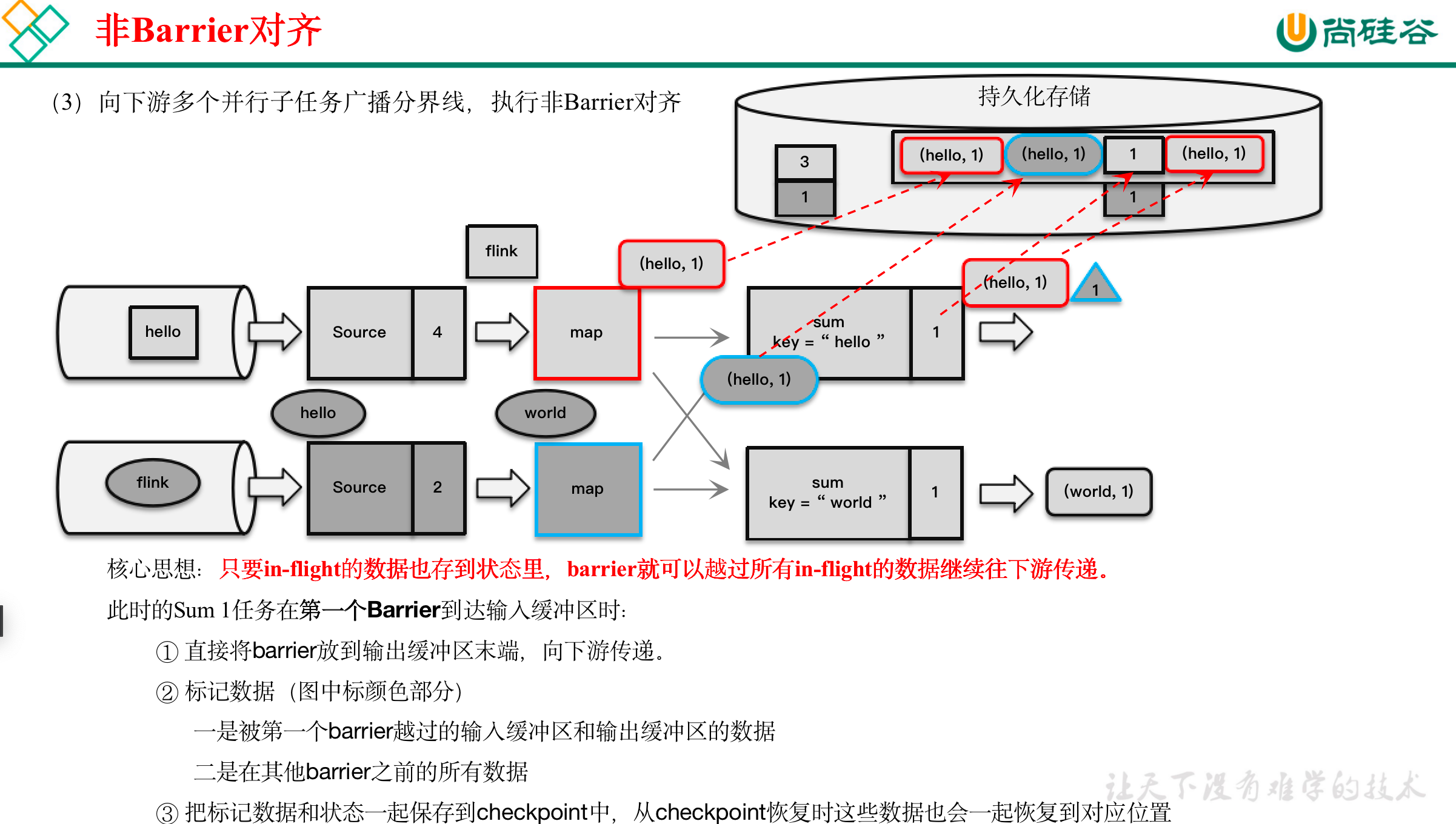
4 非Barrier对齐的精准一次(flink 1.11 之后出现)
:::info
与barrier,在分界线对齐,保存状态的时候,引入了输入缓冲区,以及输出缓冲区,当barrier到来时,不进行计算,直接传入道输出缓冲区的最后一个,然后继续接收数据进行处理,处理完毕后就是输出缓冲区排队。
所以与barrier最大的区别就是在保存状态时,连同缓冲区的数据队列状态一起保存。类似于空间换时间的思想。
:::
11.1.4 检查点配置
检查点的作用是为了故障恢复,我们不能因为保存检查点占据了大量时间、导致数据处理性能明显降低。为了兼顾容错性和处理性能,我们可以在代码中对检查点进行各种配置。
1 启用检查点
默认情况下,Flink程序是禁用检查点的。如果想要为Flink应用开启自动保存快照的功能,需要在代码中显式地调用执行环境的.enableCheckpointing()方法:
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// 每隔1秒启动一次检查点保存
env.enableCheckpointing(1000);
这里需要传入一个长整型的毫秒数,表示周期性保存检查点的间隔时间。如果不传参数直接启用检查点,默认的间隔周期为500毫秒,这种方式已经被弃用。
检查点的间隔时间是对处理性能和故障恢复速度的一个权衡。如果我们希望对性能的影响更小,可以调大间隔时间;而如果希望故障重启后迅速赶上实时的数据处理,就需要将间隔时间设小一些。
2 检查点存储
检查点具体的持久化存储位置,取决于“检查点存储”的设置。默认情况下,检查点存储在JobManager的堆内存中。而对于大状态的持久化保存,Flink也提供了在其他存储位置进行保存的接口。
具体可以通过调用检查点配置的.setCheckpointStorage()来配置,需要传入一个CheckpointStorage的实现类。Flink主要提供了两种CheckpointStorage:作业管理器的堆内存和文件系统。
// 配置存储检查点到JobManager堆内存
env.getCheckpointConfig().setCheckpointStorage(new JobManagerCheckpointStorage());// 配置存储检查点到文件系统
env.getCheckpointConfig().setCheckpointStorage(new FileSystemCheckpointStorage("hdfs://namenode:40010/flink/checkpoints"));
对于实际生产应用,我们一般会将CheckpointStorage配置为高可用的分布式文件系统(HDFS,S3等)。
3 其它高级配置
检查点还有很多可以配置的选项,可以通过获取检查点配置(CheckpointConfig)来进行设置。
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
1)常用高级配置
- 检查点模式(CheckpointingMode)
设置检查点一致性的保证级别,有“精确一次”(exactly-once)和“至少一次”(at-least-once)两个选项。默认级别为exactly-once,而对于大多数低延迟的流处理程序,at-least-once就够用了,而且处理效率会更高。
- 超时时间(checkpointTimeout)
用于指定检查点保存的超时时间,超时没完成就会被丢弃掉。传入一个长整型毫秒数作为参数,表示超时时间。
- 最小间隔时间(minPauseBetweenCheckpoints)
用于指定在上一个检查点完成之后,检查点协调器最快等多久可以出发保存下一个检查点的指令。这就意味着即使已经达到了周期触发的时间点,只要距离上一个检查点完成的间隔不够,就依然不能开启下一次检查点的保存。这就为正常处理数据留下了充足的间隙。当指定这个参数时,实际并发为1。
- 最大并发检查点数量(maxConcurrentCheckpoints)
用于指定运行中的检查点最多可以有多少个。由于每个任务的处理进度不同,完全可能出现后面的任务还没完成前一个检查点的保存、前面任务已经开始保存下一个检查点了。这个参数就是限制同时进行的最大数量。
- 开启外部持久化存储(enableExternalizedCheckpoints)
用于开启检查点的外部持久化,而且默认在作业失败的时候不会自动清理,如果想释放空间需要自己手工清理。里面传入的参数ExternalizedCheckpointCleanup指定了当作业取消的时候外部的检查点该如何清理。
DELETE_ON_CANCELLATION:在作业取消的时候会自动删除外部检查点,但是如果是作业失败退出,则会保留检查点。
RETAIN_ON_CANCELLATION:作业取消的时候也会保留外部检查点。
- 检查点连续失败次数(tolerableCheckpointFailureNumber)
用于指定检查点连续失败的次数,当达到这个次数,作业就失败退出。默认为0,这意味着不能容忍检查点失败,并且作业将在第一次报告检查点失败时失败。
2)开启非对齐检查点
- 非对齐检查点(enableUnalignedCheckpoints)
不再执行检查点的分界线对齐操作,启用之后可以大大减少产生背压时的检查点保存时间。这个设置要求检查点模式(CheckpointingMode)必须为exctly-once,并且最大并发的检查点个数为1。
- 对齐检查点超时时间(alignedCheckpointTimeout)
该参数只有在启用非对齐检查点的时候有效。参数默认是0,表示一开始就直接用非对齐检查点。如果设置大于0,一开始会使用对齐的检查点,当对齐时间超过该参数设定的时间,则会自动切换成非对齐检查点。
4 demo代码
public class CheckPointConfig {public static void main(String[] args) throws Exception {Configuration configuration = new Configuration();// 指定本地WEB-UI端口号configuration.setInteger(RestOptions.PORT, 8082);StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(configuration);env.setParallelism(1);// 代码中用到hdfs,需要导入hadoop依赖、指定访问hdfs的用户名System.setProperty("HADOOP_USER_NAME", "atguigu");// TODO 检查点配置// 1、启用检查点: 默认是barrier对齐的,周期为5s, 精准一次env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);CheckpointConfig checkpointConfig = env.getCheckpointConfig();// 2、指定检查点的存储位置
// checkpointConfig.setCheckpointStorage("hdfs://hadoop102:8020/chk");checkpointConfig.setCheckpointStorage("file:///Users/xx/project/big_data/flink/flink_study/chk");// 3、checkpoint的超时时间: 默认10分钟checkpointConfig.setCheckpointTimeout(60000);// 4、同时运行中的checkpoint的最大数量checkpointConfig.setMaxConcurrentCheckpoints(1);// 5、最小等待间隔: 上一轮checkpoint结束 到 下一轮checkpoint开始 之间的间隔,设置了>0,并发就会变成1checkpointConfig.setMinPauseBetweenCheckpoints(1000);// 6、取消作业时,checkpoint的数据 是否保留在外部系统// DELETE_ON_CANCELLATION:主动cancel时,删除存在外部系统的chk-xx目录 (如果是程序突然挂掉,不会删)// RETAIN_ON_CANCELLATION:主动cancel时,外部系统的chk-xx目录会保存下来checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION);// 7、允许 checkpoint 连续失败的次数,默认0--》表示checkpoint一失败,job就挂掉checkpointConfig.setTolerableCheckpointFailureNumber(10);// TODO 开启 非对齐检查点(barrier非对齐)// 开启的要求: Checkpoint模式必须是精准一次,最大并发必须设为1checkpointConfig.enableUnalignedCheckpoints();// 开启非对齐检查点才生效: 默认0,表示一开始就直接用 非对齐的检查点// 如果大于0, 一开始用 对齐的检查点(barrier对齐), 对齐的时间超过这个参数,自动切换成 非对齐检查点(barrier非对齐)checkpointConfig.setAlignedCheckpointTimeout(Duration.ofSeconds(1));env.socketTextStream("localhost", 7777).flatMap((String value, Collector<Tuple2<String, Integer>> out) -> {String[] words = value.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1));}}).returns(Types.TUPLE(Types.STRING, Types.INT)).keyBy(value -> value.f0).sum(1).print();env.execute();}
}
5 通用增量checkpoint (changelog)
了解
6 最终检查点
如果数据源是有界的,就可能出现部分Task已经处理完所有数据,变成finished状态,不继续工作。从Flink 1.14 开始,这些finished状态的Task,也可以继续执行检查点。自1.15 起默认启用此功能,并且可以通过功能标志禁用它:
Configuration config = new Configuration();
config.set(ExecutionCheckpointingOptions.ENABLE_CHECKPOINTS_AFTER_TASKS_FINISH, false);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(config);
11.1.5 检查点总结
- Barrier对齐: 一个Task 收到 所有上游 同一个编号的 barrier之后,才会对自己的本地状态做备份
- 精准一次:在barrier对齐过程中,barrier后面的数据 阻塞等待(不会越过barrier)
- 至少一次:在barrier对齐过程中,先到的barrier,其后面的数据 不阻塞 接着计算
- 非Barrier 对齐:一个Task 收到 第一个 barrier时,就开始 执行备份,能保证 精准一次(fhink 1.11出的新算法)
先到的barrier,将 本地状态 备份,其后面的数据接着计算输出未到的barrier,其 前面的数据 接着计算输出,同时 也保存到备份中最后一个barrier到达 该Task时,这个Task的备份结束
相关文章:
[尚硅谷flink] 检查点笔记
在Flink中,有一套完整的容错机制来保证故障后的恢复,其中最重要的就是检查点。 文章目录 11.1 检查点11.1.1 检查点的保存1)周期性的触发保存2)保存的时间点3)保存的具体流程 11.1.2 从检查点恢复状态11.1.3 检查点算法…...

JVM虚拟机(五)强引用、软引用、弱引用、虚引用
目录 一、强引用二、软引用三、弱引用四、虚引用五、总结 引文: 在 Java 中一共存在 4 种引用:强、软、弱、虚。它们主要指的是,在进行垃圾回收的时候,对于不同的引用垃圾回收的情况是不一样的。下面我们就一起来看一下这 4 种引用…...
itext7 freemarker动态模板转pdf)
(最新)itext7 freemarker动态模板转pdf
1.引入依赖 <!--PDF导出POM--> <dependency><groupId>com.itextpdf</groupId><artifactId>itext7-core</artifactId><version>8.0.3</version><type>pom</type> </dependency> <dependency><grou…...

solidworks electrical 2D和3D有什么区别
SolidWorks Electrical 是一款专为电气设计开发的软件工具,它提供了两种主要的工作环境:2D电气设计和3D电气集成设计。两者在功能和应用场景上存在显著的区别: SolidWorks Electrical 2D 设计 特点与用途: SolidWorks Electrica…...
进行语音识别)
4.2、ipex-llm(原bigdl-llm)进行语音识别
ipex-llm环境配置及模型下载 由于需要处理音频文件,还需要安装用于音频分析的 librosa 软件包。 pip install librosa下载音频文件 !wget -O audio_en.mp3 https://datasets-server.huggingface.co/assets/common_voice/--/en/train/5/audio/audio.mp3 !wget -O a…...

上海亚商投顾:创业板指低开低走 黄金、家电股逆势大涨
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 一.市场情绪 沪指4月12日震荡调整,创业板指尾盘跌超1%。黄金板块延续强势,莱绅通灵9连板࿰…...
AIGC革新浪潮:大语言模型如何优化企业运营
在当今快速发展的商业环境中,企业对于有效管理知识资产的需求日益增长。知识管理作为企业核心竞争力的关键组成部分,对于提高决策质量、增强创新能力和优化运营流程起着至关重要的作用。随着数字化转型的推进,企业对知识管理系统提出了新的要…...

Golang基础-12
Go语言基础 介绍 目录操作 创建 删除 重命名 遍历目录 修改权限 文件操作 创建 打开关闭 删除 重命名 修改权限 读文件 写文件 文件定位 拷贝 测试 单元测试 基准测试 示例 介绍 本文介绍Go语言中目录操作(创建目录、删除目录、重命名、遍历…...

python递归统计文件夹下pdf文件的数量
python递归统计文件夹下pdf文件的数量 import os from docx import Documentdef count_all_pages(root_dir):total_pages 0# 遍历文件夹for dirpath, dirnames, filenames in os.walk(root_dir):for filename in filenames:# if filename.endswith(.docx) or filename.endswit…...

Kafka 硬件和操作系统
目录 一. 前言 二. Kafka 硬件和操作系统(Hardware and OS) 2.1. 操作系统(OS) 2.2. 磁盘和文件系统(Disks and Filesystem) 一. 前言 Kafka 是 I/O 密集型而非计算密集型的框架,所以对 CP…...

Kolla-ansible部署OpenStack集群
0. OpenStack 部署 系统要求 单机部署最低配置: 2张网卡8G内存40G硬盘空间 主机系统: CentOS Stream 9Debian Bullseye (11)openEuler 22.03 LTSRocky Linux 9- Ubuntu Jammy (22.04) 官方不再支持CentOS 7作为主机系统,我这里使用的是R…...

SHARE 203S PRO:倾斜摄影相机在地灾救援中的应用
在地质灾害的紧急关头,救援队伍面临的首要任务是迅速而准确地掌握灾区的地理信息。这时,倾斜摄影相机成为了救援测绘的利器。SHARE 203S PRO,这款由深圳赛尔智控科技有限公司研发的五镜头倾斜摄影相机,以其卓越的性能和功能&#…...
(附R语言和python代码实现))
MATLAB算法实战应用案例精讲-【数模应用】中介效应分析(补充篇)(附R语言和python代码实现)
目录 前言 几个高频面试题目 中介效应分析与路径分析的区别 1.中介效应分析 2.路径分析 注意事项...
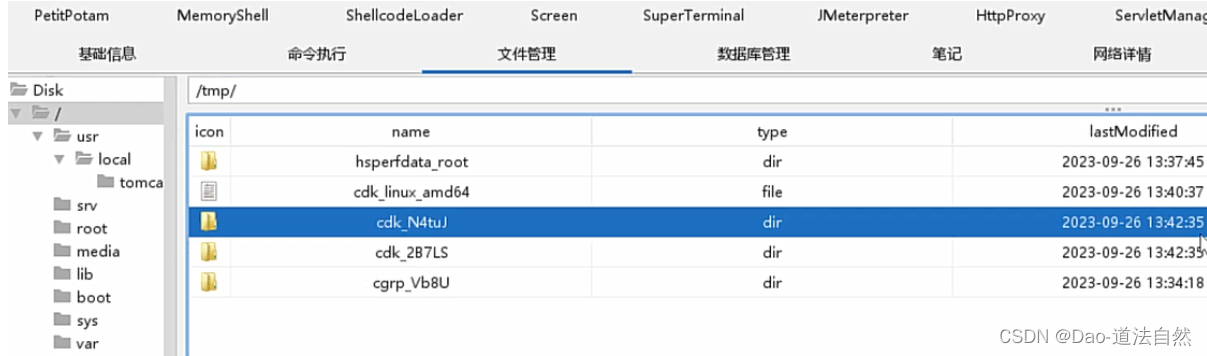
Day96:云上攻防-云原生篇Docker安全系统内核版本漏洞CDK自动利用容器逃逸
目录 云原生-Docker安全-容器逃逸&系统内核漏洞 云原生-Docker安全-容器逃逸&docker版本漏洞 CVE-2019-5736 runC容器逃逸(需要管理员配合触发) CVE-2020-15257 containerd逃逸(启动容器时有前提参数) 云原生-Docker安全-容器逃逸&CDK自动化 知识点࿱…...

python botos s3 aws
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/s3.html AWS是亚马逊的云服务,其提供了非常丰富的套件,以及支持多种语言的SDK/API。本文针对其S3云储存服务的Python SDK(boto3)的使用进行介绍。 …...
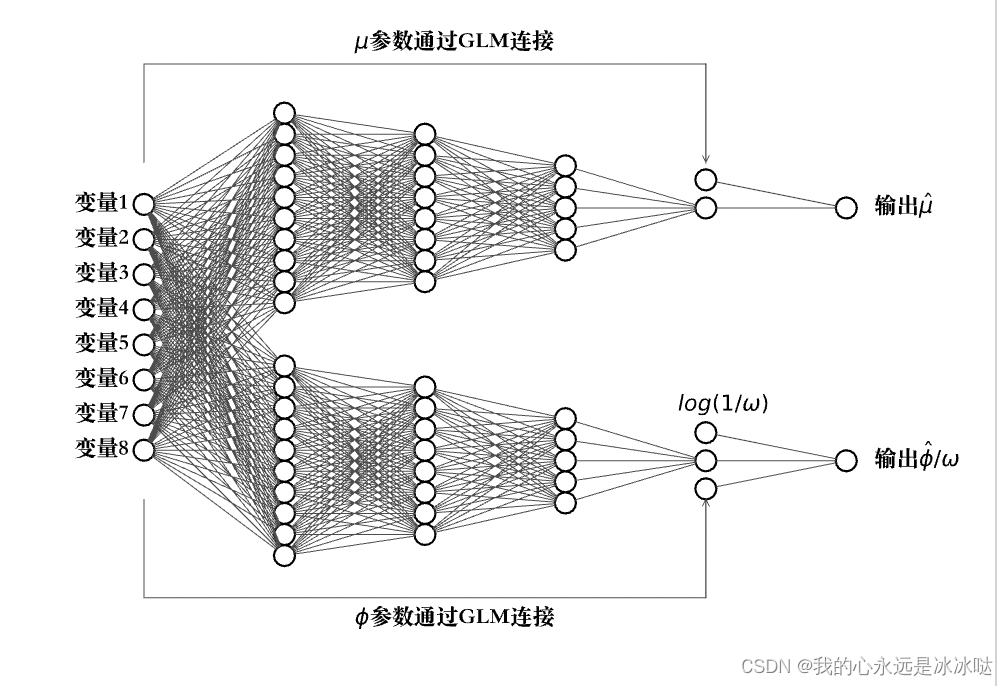
python画神经网络图
代码1(画神经网络连接图) from math import cos, sin, atan import matplotlib.pyplot as plt # 注意这里并没有用到这个networkx这个库,完全是根据matploblib这个库来画的。 class Neuron():def __init__(self, x, y,radius,nameNone):self.x xself.y …...

Bash 编程精粹:从新手到高手的全面指南之逻辑控制
在 Unix 和 Linux 系统中,Bash(Bourne-Again Shell)是一种广泛使用的 shell,提供了强大的脚本编程能力。本文将详细介绍 Bash 脚本中的逻辑控制结构,包括条件判断、分支选择、循环控制以及退出控制等内容。 条件判断&…...
Ansible 实战之自定义插件)
自动化运维(三十)Ansible 实战之自定义插件
Ansible 自定义插件允许你扩展其功能,以满足特定的自动化需求。Ansible 支持多种类型的插件开发,如动态库存、查找、回调、过滤器、变量等。这里我们将通过实例,介绍如何开发、部署和使用一个自定义插件。 开发自定义查找插件 查找插件用于在 Ansible 任务中动态获取数据。…...

实习僧网站的实习岗位信息分析
目录 背景描述数据说明数据集来源问题描述分析目标以及导入模块1. 数据导入2. 数据基本信息和基本处理3. 数据处理3.1 新建data_clean数据框3.2 数值型数据处理3.2.1 “auth_capital”(注册资本)3.2.2 “day_per_week”(每周工作天数…...
C语言中局部变量和全局变量是否可以重名?为什么?
可以重名 在C语言中, 局部变量指的是定义在函数内的变量, 全局变量指的是定义在函数外的变量 他们在程序中的使用方法是不同的, 当重名时, 局部变量在其所在的作用域内具有更高的优先级, 会覆盖或者说隐藏同名的全局变量 具体来说: 局部变量的生命周期只在函数内部,如果出了…...

HTML 语义化
目录 HTML 语义化HTML5 新特性HTML 语义化的好处语义化标签的使用场景最佳实践 HTML 语义化 HTML5 新特性 标准答案: 语义化标签: <header>:页头<nav>:导航<main>:主要内容<article>&#x…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

什么是EULA和DPA
文章目录 EULA(End User License Agreement)DPA(Data Protection Agreement)一、定义与背景二、核心内容三、法律效力与责任四、实际应用与意义 EULA(End User License Agreement) 定义: EULA即…...

JDK 17 新特性
#JDK 17 新特性 /**************** 文本块 *****************/ python/scala中早就支持,不稀奇 String json “”" { “name”: “Java”, “version”: 17 } “”"; /**************** Switch 语句 -> 表达式 *****************/ 挺好的ÿ…...

2023赣州旅游投资集团
单选题 1.“不登高山,不知天之高也;不临深溪,不知地之厚也。”这句话说明_____。 A、人的意识具有创造性 B、人的认识是独立于实践之外的 C、实践在认识过程中具有决定作用 D、人的一切知识都是从直接经验中获得的 参考答案: C 本题解…...