llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署
文章目录
- 简介
- 支持的模型列表
- 2. 添加自定义数据集
- 3. lora 微调
- 4. 大模型 + lora 权重,部署
- 问题
- 参考资料
简介
文章列表:
- llama-factory SFT系列教程 (一),大模型 API 部署与使用
- llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署
- llama-factory SFT系列教程 (三),chatglm3-6B 命名实体识别实战
支持的模型列表
| 模型名 | 模型大小 | 默认模块 | Template |
|---|---|---|---|
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOM | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| DeepSeek (MoE) | 7B/16B/67B | q_proj,v_proj | deepseek |
| Falcon | 7B/40B/180B | query_key_value | falcon |
| Gemma | 2B/7B | q_proj,v_proj | gemma |
| InternLM2 | 7B/20B | wqkv | intern2 |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | - |
| LLaMA-2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| Mistral | 7B | q_proj,v_proj | mistral |
| Mixtral | 8x7B | q_proj,v_proj | mistral |
| OLMo | 1B/7B | att_proj | olmo |
| Phi-1.5/2 | 1.3B/2.7B | q_proj,v_proj | - |
| Qwen | 1.8B/7B/14B/72B | c_attn | qwen |
| Qwen1.5 | 0.5B/1.8B/4B/7B/14B/72B | q_proj,v_proj | qwen |
| StarCoder2 | 3B/7B/15B | q_proj,v_proj | - |
| XVERSE | 7B/13B/65B | q_proj,v_proj | xverse |
| Yi | 6B/9B/34B | q_proj,v_proj | yi |
| Yuan | 2B/51B/102B | q_proj,v_proj | yuan |
参考自:https://zhuanlan.zhihu.com/p/689333581
-
默认模块 作为 --lora_target 参数的默认值,也可使用 --lora_target all 参数指定全部模块;
-
–template 参数可以是 default, alpaca, vicuna 等任意值。但“对话”(Chat)模型请务必使用对应的模板。
项目所支持模型的完整列表请参阅 constants.py。
2. 添加自定义数据集
LLaMA-Factory 数据集说明,参考该文件给出的说明,在dataset_info.json 文件中添加配置信息;
参考如下数据集格式,定义自定义数据集;
[{"instruction": "用户指令(必填)","input": "用户输入(选填)","output": "模型回答(必填)","system": "系统提示词(选填)","history": [["第一轮指令(选填)", "第一轮回答(选填)"],["第二轮指令(选填)", "第二轮回答(选填)"]]}
]
新数据集内容如下:
diy.json
[{"instruction": "你是谁?","input": "","output": "我是Qwen,edit by JieShin.","history": []},{"instruction": "你能帮我干些什么?","input": "","output": "我能和你互动问答,我的其他功能正在开发中。","history": []}
]
添加自定义数据集的步骤如下:
- 将
diy.json文件保存到LLaMA-Factory/data文件夹下;

- 在 dataset_info.json 文件中,配置数据集
首先计算diy.json文件的sha1sum,sha1sum diy.json

vim dataset_info.json添加自定义数据集的配置信息, 把 diy.json 文件的sha1 值添加到文件中,"diy"为该数据集名;
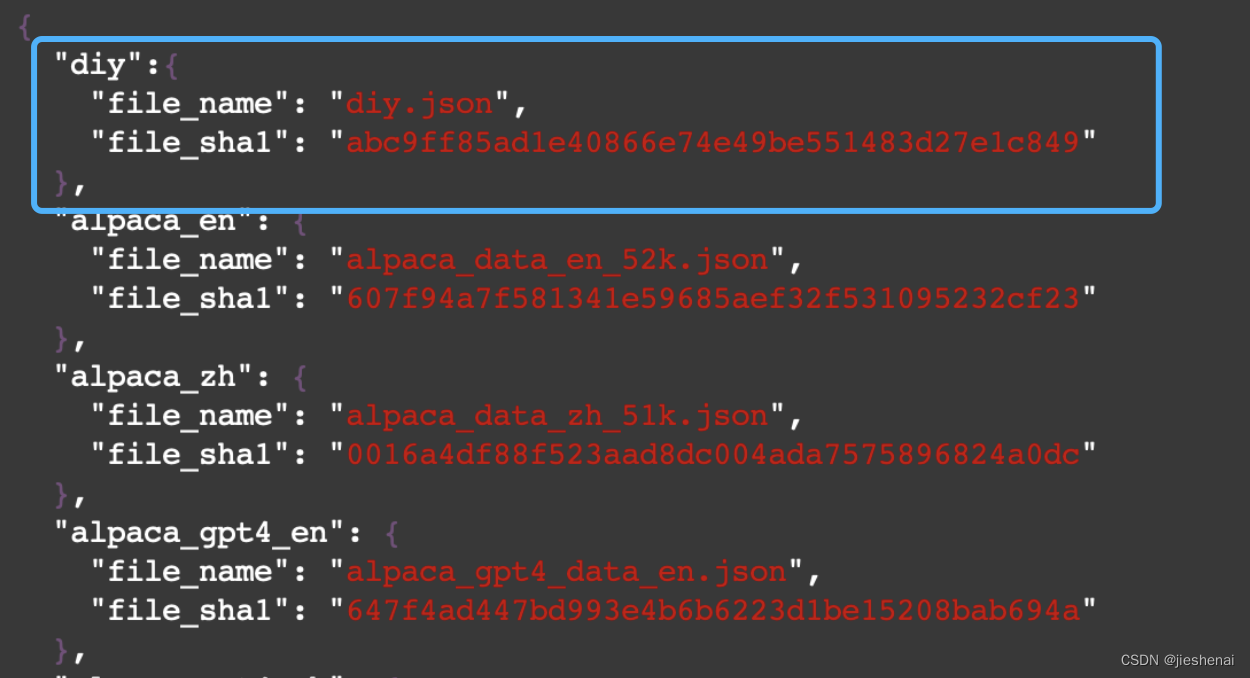
3. lora 微调
使用配置好的 diy 数据集进行模型训练;
--model_name_or_path qwen/Qwen-7B,只写模型名,不写绝对路径可运行成功,因为配置了export USE_MODELSCOPE_HUB=1
查看 配置是否生效,输出1 即为配置成功:
echo $USE_MODELSCOPE_HUB

CUDA_VISIBLE_DEVICES=0 python src/train_bash.py \
--stage sft \
--do_train \
--model_name_or_path qwen/Qwen-7B \
--dataset diy \
--template qwen \
--finetuning_type lora \
--lora_target c_attn \
--output_dir /mnt/workspace/llama_factory_demo/qwen/lora/sft \
--overwrite_cache \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 4 \
--lr_scheduler_type cosine \
--logging_steps 10 \
--save_strategy epoch \
--learning_rate 5e-5 \
--num_train_epochs 50.0 \
--plot_loss \
--fp16
训练完成的lora 权重,保存在下述文件夹中;
--output_dir /mnt/workspace/llama_factory_demo/qwen/lora/sft
模型的训练结果如下:
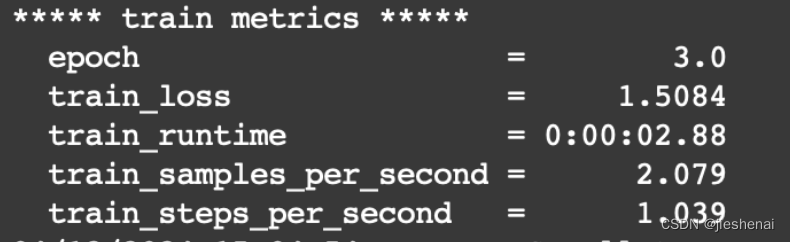
lora 训练后的权重如下图所示:

4. 大模型 + lora 权重,部署
由于llama-factory 不支持 qwen 结合 lora 进行推理,故需要把 lora 权重融合进大模型成一个全新的大模型权重;
可查看如下链接,了解如何合并模型权重:merge_lora GitHub issue
下述是合并 lora 权重的脚本,全新大模型的权重保存到 export_dir 文件夹;
CUDA_VISIBLE_DEVICES=0 python src/export_model.py \--model_name_or_path qwen/Qwen-7B \--adapter_name_or_path /mnt/workspace/llama_factory_demo/qwen/lora/sft/checkpoint-50 \--template qwen \--finetuning_type lora \--export_dir /mnt/workspace/merge_w/qwen \--export_size 2 \--export_legacy_format False
使用融合后到大模型进行推理,model_name_or_path 为融合后的新大模型路径
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 python src/api_demo.py \--model_name_or_path /mnt/workspace/merge_w/qwen \--template qwen \--infer_backend vllm \--vllm_enforce_eager \
~
模型请求脚本
curl -X 'POST' \'http://0.0.0.0:8000/v1/chat/completions' \-H 'accept: application/json' \-H 'Content-Type: application/json' \-d '{"model": "string","messages": [{"role": "user","content": "你能帮我做一些什么事情?","tool_calls": [{"id": "call_default","type": "function","function": {"name": "string","arguments": "string"}}]}],"tools": [{"type": "function","function": {"name": "string","description": "string","parameters": {}}}],"do_sample": true,"temperature": 0,"top_p": 0,"n": 1,"max_tokens": 128,"stream": false
}'
模型推理得到了和数据集中一样的结果,这说明 lora 微调生效了;

以为设置了
"stop": "<|endoftext|>",模型会在遇到结束符自动结束,但模型依然推理到了最长的长度后结束,设置的 stop 并没有生效;
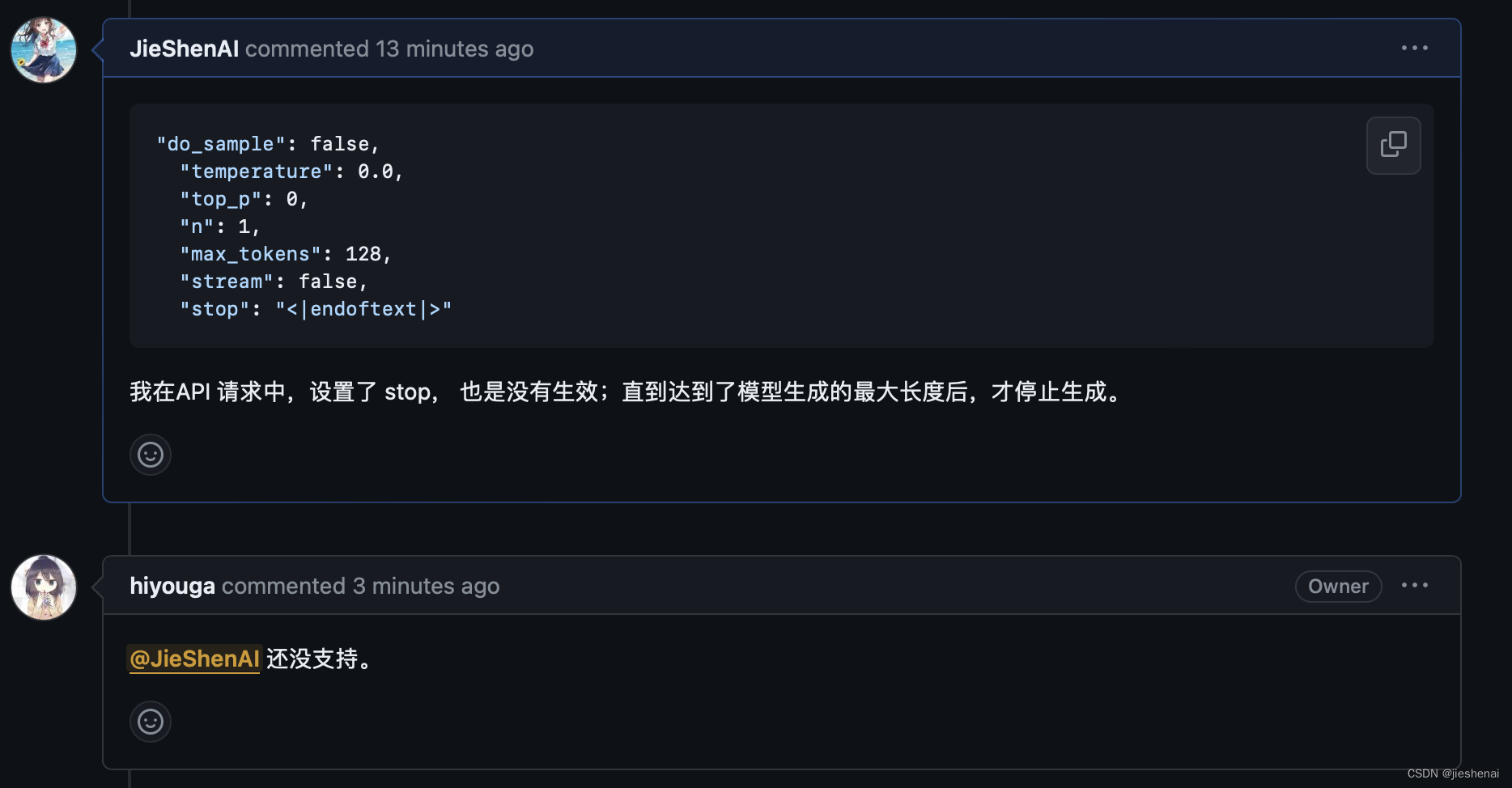
llama-factory的作者表示还没有支持stop,万一未来支持了stop功能,大家可以关注这个issue support “stop” in api chat/completions #3114
问题
虽然设置了 "temperature": 0 , 但是模型的输出结果依然变动很大,运行3-4次后,才出现训练数据集中的结果;
参考资料
- api 参数列表
- 使用LLaMa-Factory简单高效微调大模型
展示了支持的大模型列表;
相关文章:
llama-factory SFT系列教程 (二),大模型在自定义数据集 lora 训练与部署
文章目录 简介支持的模型列表2. 添加自定义数据集3. lora 微调4. 大模型 lora 权重,部署问题 参考资料 简介 文章列表: llama-factory SFT系列教程 (一),大模型 API 部署与使用llama-factory SFT系列教程 (二),大模型在自定义数…...
:贪吃蛇大作战(多人对战))
C语言游戏实战(11):贪吃蛇大作战(多人对战)
成果展示: 贪吃蛇(多人对战) 前言: 这款贪吃蛇大作战是一款多人游戏,玩家需要控制一条蛇在地图上移动,吞噬其他蛇或者食物来增大自己的蛇身长度和宽度。本游戏使用C语言和easyx图形库编写,旨在…...

腾讯测试岗位的面试经历与经验分享【一面、二面与三面】
腾讯两个月的实习一转眼就结束了,回想起当时面试的经过,感觉自己是跌跌撞撞就这么过了,多少有点侥幸.马上腾讯又要来校招了,对于有意愿想投腾讯测试岗位的同学们,写了一些那时候面试的经历和自己的想法,算不上经验,仅供参考吧! 一面 — —技术基础,全面…...

手机移动端网卡信息获取原理分析
有些场景我们需要获取当前手机上的网卡信息(如双卡双待、Wifi等)。本文准备研究一下这块的原理,以便更好的掌握相关技术原理。 1、底层系统接口 getifaddrs 使用 getifaddrs 接口可以达到我们的目的,该接口会返回本地所有网卡的信…...

无人新零售引领的创新浪潮
无人新零售引领的创新浪潮 在数字化时代加速演进的背景下,无人新零售作为商业领域的一股新兴力量,正以其独特的高效性和便捷性重塑着传统的购物模式,开辟了一条充满创新潜力的发展道路。 依托人脸识别、物联网等尖端技术,无人新…...

SD-WAN提升企业网络体验
在现代企业中,网络体验已成为提升工作效率与业务质量的关键因素。SD-WAN技术的出现,以其独特的优势,为企业提供了优化网络连接、加速数据传输、提升服务质量和应用访问体验,以及增强网络稳定性的解决方案。接下来,我们…...

Docker搭建Let‘s Encrypt
Let’s Encrypt是一个免费、开放和自动化的证书颁发机构(CA),它提供了一种简单、无需重复的机制来获取和更新SSL/TLS证书。Let’s Encrypt Docker镜像允许用户在容器化环境中轻松部署和使用Let’s Encrypt的服务。 主要功能包括:…...

单链表讲解
一.链表的概念以及结构 链表是一种物理结构上不连续,逻辑结构上连续的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。 链表的结构与火车是类似的,一节一节的,数据就像乘客一样在车厢中一样。 与顺序表不同的…...

DFS算法系列 回溯
DFS算法系列-回溯 文章目录 DFS算法系列-回溯1. 算法介绍2. 算法应用2.1 全排列2.2 组合2.3 子集 3. 总结 1. 算法介绍 回溯算法是一种经典的递归算法,通常被用来解决排列问题、组合问题和搜索问题 基本思想 从一个初始状态开始,按一定的规则向前搜索&…...
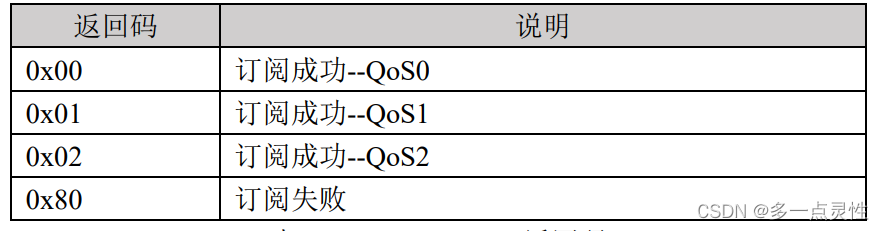
Linux C应用编程:MQTT物联网
1 MQTT通信协议 MQTT(Message Queuing Telemetry Transport,消息队列遥测传 输)是一种基于客户端-服务端架构的消息传输协议,如今,MQTT 成为了最受欢迎的物联网协议,已广泛应用于车联网、智能家居、即时聊…...
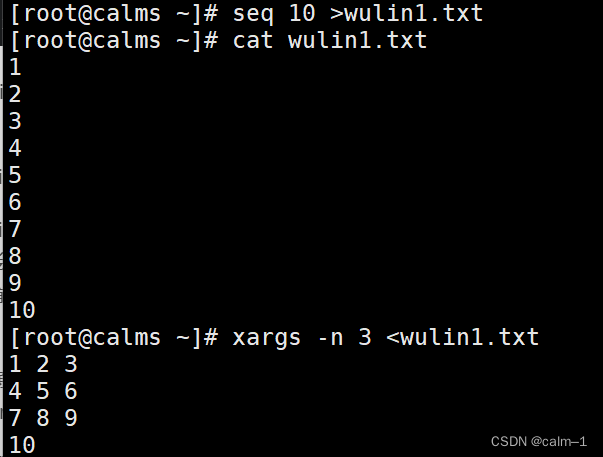
企业常用Linux文件命令相关知识+小案例
远程连接工具无法连接VMWARE: 如果发现连接工具有时连不上,ip存在,这时候我们查看网络编辑器,更多配置,看vnet8是不是10段,nat设置是否是正确的? 软件重启一下虚机还原一下网络编辑器 查看文件…...

Istio介绍
1.什么是Istio Istio是一个开源的服务网格(Service Mesh)框架,它提供了一种简单的方式来为部署在Kubernetes等容器编排平台上的微服务应用添加网络功能。Istio的核心功能包括: 服务治理:Istio能够帮助管理服务之间的…...

代码随想录算法训练营第四十七天|leetcode115、392题
一、leetcode第392题 本题要求判断s是否为t的子序列,因此设置dp数组,dp[i][j]的含义是下标为i-1的子串与下标为j-1的子串相同字符的个数,可得递推公式是通过s[i-1]和t[j-1]是否相等区分。 具体代码如下: class Solution { publ…...

将Ubuntu18.04默认的python3.6升级到python3.8
1、查看现有的 python3 版本 python3 --version 2、安装 python3.8 sudo apt install python3.8 3、将 python3.6 和 3.8 添加到 update-alternatives sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.6 1 sudo update-alternatives --insta…...
Python和Java哪个更适合后端开发?
Python和Java都是强大的后端开发语言,它们各自有鲜明的特点和适用场景。选择哪一个更适合后端开发,主要取决于具体的项目需求、团队技术栈、个人技能偏好以及长期发展考虑等因素。 下面是两者在后端开发中的优势和劣势: 「Python࿱…...

Python+pytest接口自动化之cookie绕过登录(保持登录状态)
前言 我们今天来聊聊pythonpytest接口自动化之cookie绕过登录(保持登录状态),在编写接口自动化测试用例或其他脚本的过程中,经常会遇到需要绕过用户名/密码或验证码登录,去请求接口的情况,一是因为有时验证…...

什么数据集成(Data Integration):如何将业务数据集成到云平台?
说到数据集成(Data Integration),简单地将所有数据倒入数据湖并不是解决办法。 在这篇文章中,我们将介绍如何轻松集成数据、链接不同来源的数据、将其置于合适的环境中,使其具有相关性并易于使用。 数据集成࿱…...

国外EDM邮件群发多少钱?哪个软件好?
在当今全球化市场环境下,电子邮件营销作为最有效的数字营销渠道之一,其影响力不容忽视。而高效精准的EDM(Electronic Direct Mail)邮件营销策略更是企业拓展海外市场、提升品牌知名度的关键手段。云衔科技以其创新的智能EDM邮件营…...

C语言入门算法——回文数
题目描述: 若一个数(首位不为零)从左向右读与从右向左读都一样,我们就将其称之为回文数。 例如:给定一个十进制数 56,将 56 加 65(即把 56 从右向左读),得到 121 是一个…...

OceanBase—操作实践
文档结构 1、概念简介2、核心设计3、操作实践3.3、数据同步 官方文档:https://www.oceanbase.com/docs/oceanbase-database-cn 1、概念简介 版本分为社区版和企业版,其中企业版兼容MySQL 和Oracle数据库语法; 2、核心设计 存储层 复制层 …...
)
Java 语言特性(面试系列1)
一、面向对象编程 1. 封装(Encapsulation) 定义:将数据(属性)和操作数据的方法绑定在一起,通过访问控制符(private、protected、public)隐藏内部实现细节。示例: public …...

盘古信息PCB行业解决方案:以全域场景重构,激活智造新未来
一、破局:PCB行业的时代之问 在数字经济蓬勃发展的浪潮中,PCB(印制电路板)作为 “电子产品之母”,其重要性愈发凸显。随着 5G、人工智能等新兴技术的加速渗透,PCB行业面临着前所未有的挑战与机遇。产品迭代…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

用docker来安装部署freeswitch记录
今天刚才测试一个callcenter的项目,所以尝试安装freeswitch 1、使用轩辕镜像 - 中国开发者首选的专业 Docker 镜像加速服务平台 编辑下面/etc/docker/daemon.json文件为 {"registry-mirrors": ["https://docker.xuanyuan.me"] }同时可以进入轩…...

Map相关知识
数据结构 二叉树 二叉树,顾名思义,每个节点最多有两个“叉”,也就是两个子节点,分别是左子 节点和右子节点。不过,二叉树并不要求每个节点都有两个子节点,有的节点只 有左子节点,有的节点只有…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

视觉slam十四讲实践部分记录——ch2、ch3
ch2 一、使用g++编译.cpp为可执行文件并运行(P30) g++ helloSLAM.cpp ./a.out运行 二、使用cmake编译 mkdir build cd build cmake .. makeCMakeCache.txt 文件仍然指向旧的目录。这表明在源代码目录中可能还存在旧的 CMakeCache.txt 文件,或者在构建过程中仍然引用了旧的路…...

NPOI Excel用OLE对象的形式插入文件附件以及插入图片
static void Main(string[] args) {XlsWithObjData();Console.WriteLine("输出完成"); }static void XlsWithObjData() {// 创建工作簿和单元格,只有HSSFWorkbook,XSSFWorkbook不可以HSSFWorkbook workbook new HSSFWorkbook();HSSFSheet sheet (HSSFSheet)workboo…...