Elasticsearch分布式搜索
实用篇-ES-环境搭建
ES是elasticsearch的简称。我在SpringBoot学习 '数据层解决方案' 的时候,写过一次ES笔记,可以结合一起看一下。
之前在SpringBoot里面写的相关ES笔记是基于Windows的,现在我们是基于docker容器来使用,需要你们提前准备好自己的docker容器以及掌握docker操作
常见的分布式搜索的技术,如下
- 1、Elasticsearch: 开源的分布式搜索引擎
- 2、Splunk: 商业项目,收费
- 3、Solr: Apache的开源搜索引擎

随着业务发展,数据量越来越庞大,传统的MySQL数据库难以满足我们的需求,所以在微服务架构下,一般都会用到一种分布式搜索的技术,下面我们会学分布式搜索中最流行的一种,也就是elasticsearch的用法。包括学习elasticsearch的概念、安装、使用。其中学习elasticsearch的使用的时候,主要通过两个方面,一方面是elasticsearch对于索引库(类似于数据库,把数据导入进索引库,导入的数据就是所谓的文档,我们要实现文档的增删改查)的操作,另一方面我们还会学习elasticsearch官方提供的Restful的API(也就是Java客户端),来更方便的操作elasticsearch
1. 什么是elasticsearch
elasticsearch(读 yī læ sī tǐ kě sè chǐ)
kibana (读 kī bā nǎ)
elasticsearch是一款非常强大的开源搜索引擎技术,可以帮助我们从海量数据中快速找到需要的内容
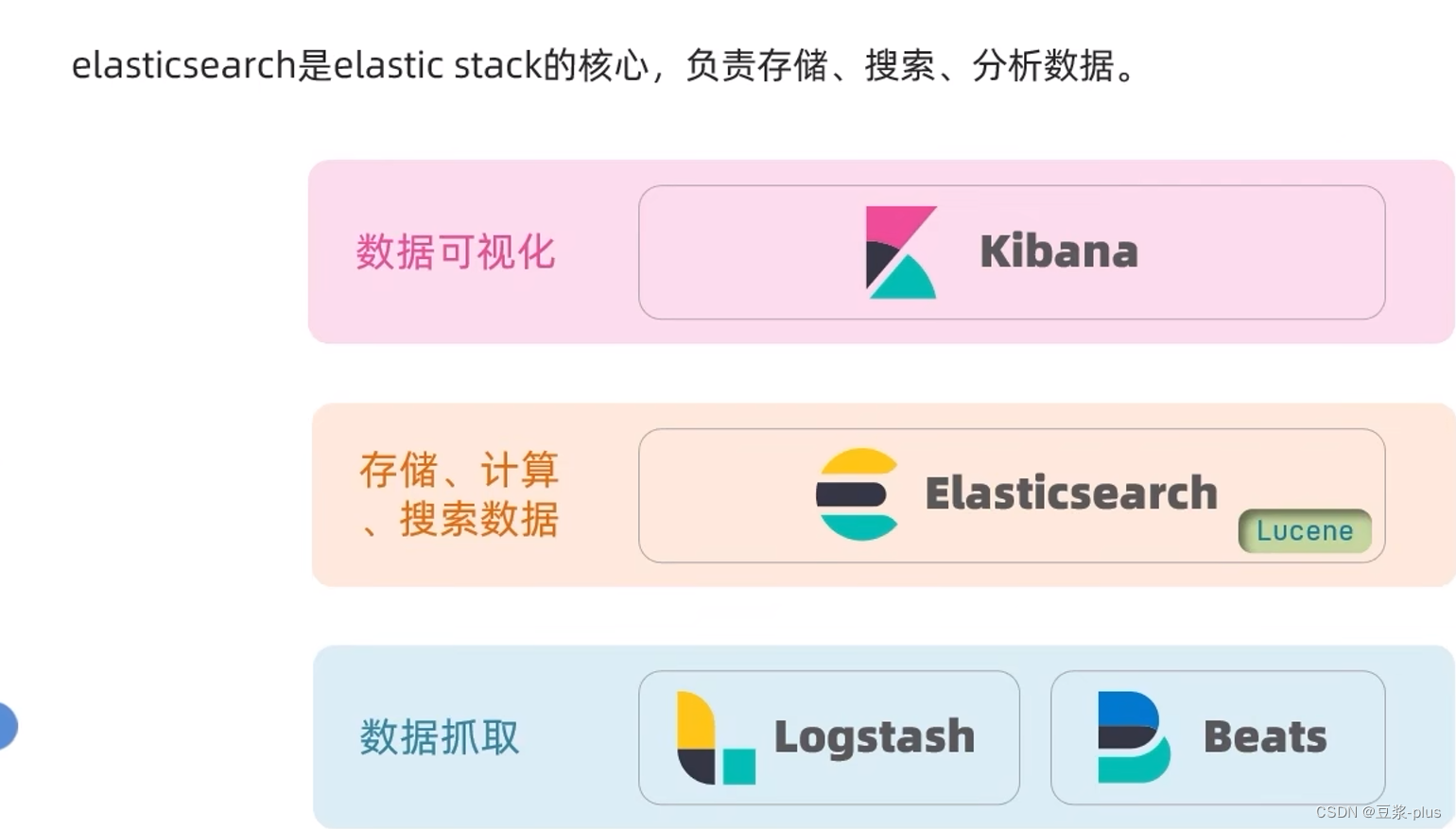
1、elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。我们主要学习这个,elasticsearch底层实现是基于Lucene技术
2、Kibana是数据可视化的组件,也就是展示搜索出来的数据。elasticsearch的相关技术,了解即可
3、Logstash、Beats是负责数据抓取的组件。elasticsearch的相关技术,了解即可
Lucene是一个Java语言的搜索引擎类库(其实就是一个jar包),是Apache公司的顶级项目,由DougCutting于1999年研发
Lucene官网: https://lucene.apache.org
Lucene的优势
1、易扩展
2、高性能 (基于倒排索引)
Lucene的缺点
1、只限于Java语言开发
2、学习曲线陡峭,也就是API复杂不利于学习
3、不支持水平扩展,只负责如何实现搜索,不支持高并发、集群扩展
由于Lucene的缺点,诞生出了elasticsearch,与Lucene相比,elasticsearch(基于Lucene,且Compass是elasticsearch的前身)具有以下优点
1、支持分布式,可水平扩展
2、提供Restful接口,可被任何语言调用
elasticsearch的核心技术是倒排索引,下面会学

2. 倒排索引
传统数据库(例如MySQL)采用正向索引,例如给下表(tb_goods)中的id创建索引
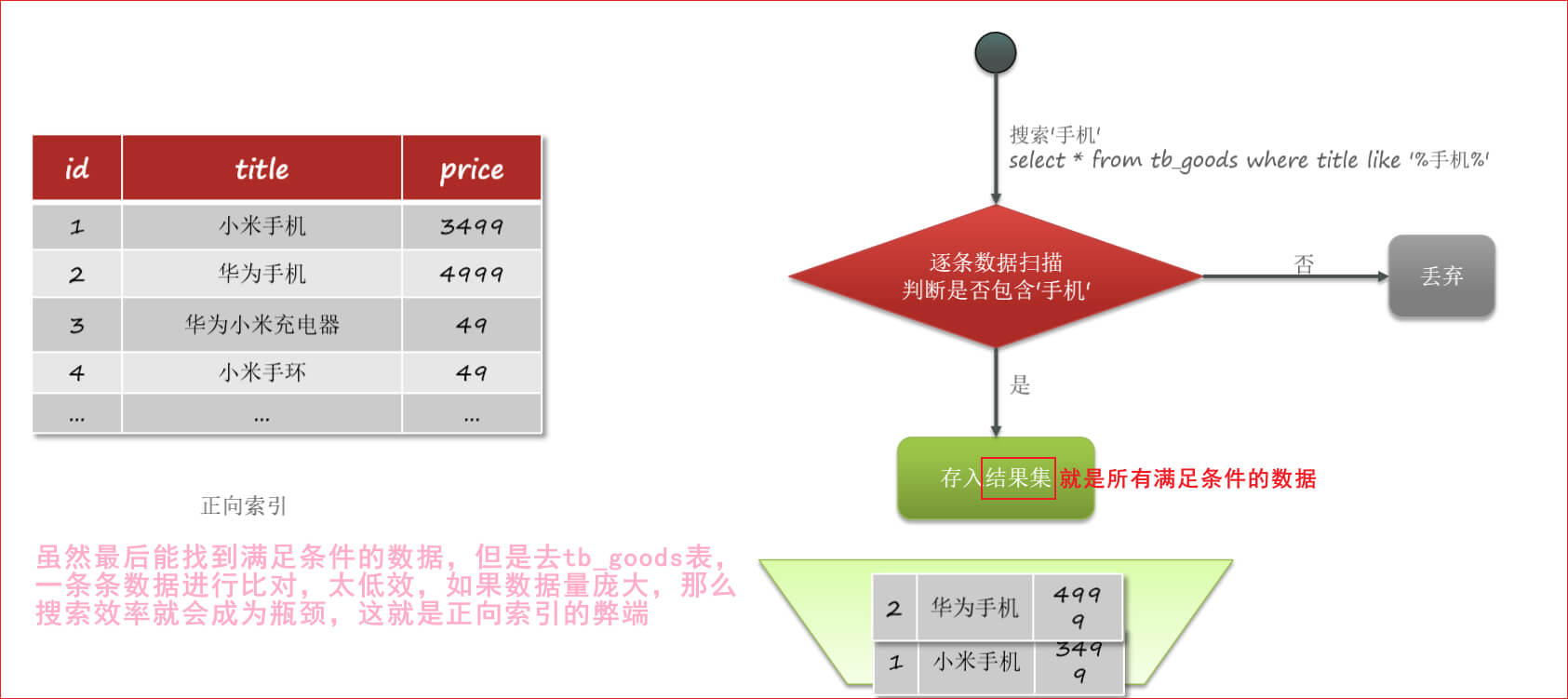
elasticsearch采用倒排索引,例如给下表(tb_goods)中的id创建索引

总结
1、正向索引: 基于文档id来创建索引。查询词条时必须先找到文档,而后判断是否包含词条
2、倒排索引: 对文档内容进行分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条去查询文档id,然后获取到文档
3. elasticsearch对比mysql
elasticsearch
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。注意elasticsearch的文档是以json形式存储的,也就是说,我们把数据(也叫文档)存储进elasticsearch时,这些文档数据就会自动被序列化为json格式,然后才存储进elasticsearch
elasticsearch的索引: 相同类型的文档的集合。索引和映射的概念,如下图

下面的表格是介绍elasticsearch中的各个概念以及含义,看的时候重点看第二、三列,第一列是为了让你更理解第二列的意思,所以在第一列拿MySQL的概念来做匹配。例如elasticsearch的Index表示索引也就是文档的集合,就相当于MySQL的Table(也就是表)
| MySQL | Elasticsearch | 说明 |
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row)。这里的文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
我们下面会学习映射的创建,以及文档的增删改查。这些操作在MySQL里面是通过SQL语句实现,但我们在elasticsearch中,会使用的是DSL语句来操作。
在elasticsearch中,当我们写好DSL语句,要通过http请求发给elasticsearch,elasticsearch才会响应,原因是在elasticsearch对外暴露的是Restful接口
上面基本都是在讲elasticsearch,那么是不是elasticsearch已经完全代码MySQL,答案并不是,两者擅长的事情不一样,如下
- 1、MySQL: 擅长事务类型的操作,可以确保数据的安全和一致性。一般用于增删改
- 2、Elasticsearch: 擅长海量数据的搜索、分析、计算。一般用于查询
- 两者是互补关系,不是替代关系,因此在业务系统架构中,两者都会存在,让用户在MySQL里面增删改数据,然后MySQL把数据同步给elasticsearch,用户要查询的时候,就在elasticsearch里面进行查询

4. 安装elasticsearch
elasticsearch(读 yī læ sī tǐ kě sè chǐ)。注意elasticsearch、kibana、IK分词器,这三者通常是一起使用的
注意: 我们学习elasticsearch是基于docker容器来使用,需要你们提前准备好自己的docker容器以及掌握docker操作。elasticsearch一般都是搭配kibana(下节会学如何安装)来使用,kibana的作用是让我们非常方便的去编写elasticsearch中的DSL语句,从而去操作elasticsearch
【安装elasticsearch,简称es】
第一步: 创建网络。因为我们还需要部署kibana容器,因此需要让es和kibana容器互联

systemctl start docker # 启动docker服务
docker network create es-net #创建一个网络,名字是es-net
第二步: 加载es镜像。采用elasticsearch的7.12.1版本的镜像,这个镜像体积有800多MB,所以需要在Windows上下载链接安装包,下载下来是一个es的镜像tar包,然后传到CentOS7的/root目录
es.tar下载: https://cowtransfer.com/s/c84ac851b9ba44kibana.tar下载: https://cowtransfer.com/s/a76d8339d7ba4d
第三步: 把在CentOS7的/root目录的es镜像,导入到docker
docker load -i es.tar
docker load -i kibana.tar
docker images
第四步: 创建并运行es容器,容器名称就叫es。在docker(也叫Docker大容器、Docker主机、宿主机),根据es镜像来创建es容器
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
●-e "cluster.name=es-docker-cluster":设置集群名称
●-e "http.host=0.0.0.0":监听的地址,可以外网访问
●-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小,不能低于512
●-e "discovery.type=single-node":运行模式,例如非集群模式
●-v es-data:/usr/share/elasticsearch/data:挂载数据卷,绑定es的数据目录
●-v es-logs:/usr/share/elasticsearch/logs:挂载数据卷,绑定es的日志目录
●-v es-plugins:/usr/share/elasticsearch/plugins:挂载数据卷,绑定es的插件目录
●--privileged:授予数据卷访问权
●--network es-net :加入一个名为es-net的网络中
●-p 9200:9200:端口映射配置,向外暴露的http请求端口,用于用户访问
●-p 9300:9300:端口映射配置,是es容器各个节点之间互相访问的端口,由于我们是单节点部署,所以用不到
●elasticsearch:7.12.1: 镜像名称,要把哪个镜像创建为容器,注意带版本号

然后,在浏览器中输入:http://你的ip地址:9200 即可看到elasticsearch的响应结果
http://192.168.200.231:9200/
5. 安装kibana
注意,是跟上一节的 '4. 安装elasticsearch' 一起操作,也就是说同一个实验。注意elasticsearch、kibana、IK分词器,这三者通常是一起使用的
kibana (读 kī bā nǎ)的作用: 让我们非常方便的去编写elasticsearch中的DSL语句,从而去操作elasticsearch(读 yī læ sī tǐ kě sè chǐ)
第一步: 确保docker是启动的
# 启动docker服务
systemctl start docker
第二步: 加载kibana镜像。这个镜像体积有1.04G,所以需要在Windows上下载链接安装包,下载下来是一个es的镜像tar包,然后传到CentOS7的/root目录
es镜像: https://cowtransfer.com/s/1c16f55edf2341
第三步: 把在CentOS7的/root目录的kibana镜像,导入到docker
docker load -i kibana.tar
第四步: 创建并运行kibana容器,容器名称就叫kibana。在docker(也叫Docker大容器、Docker主机、宿主机),根据kibana镜像来创建kibana容器
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1# --name: 指定容器的名字,例如kibana
# --network es-net: 加入一个名为es-net的网络中,与elasticsearch在同一个网络中
# -e ELASTICSEARCH_HOSTS: 由于kibana和es会被我们设置在同一个网络,所以这里的kibana可以通过容器名直接访问es,es的容器名我们在上一节设置的是es
# -e ELASTICSEARCH_HOSTS: 设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
# -p 5601:5601: 端口映射配置,向外暴露的http请求端口,用于用户访问

第五步: kibana启动一般比较慢,需要多等待一会,可以通过命令
docker logs -f kibana#查看运行日志,当查看到下面的日志,说明成功

第六步: 测试。在浏览器中输入:http://你的ip地址:5601 即可看到elasticsearch的响应结果





注意,我们在浏览器写DSL语句的时候,是带有提示功能的,非常好用
6. 安装IK分词器

IK分词器官网: https://github.com/medcl/elasticsearch-analysis-ik。注意elasticsearch、kibana、IK分词器,这三者通常是一起使用的
es在创建倒排索引时,需要对文档进行分词。在搜索时,需要对用户输入的内容进行分词。但默认的分词规则不支持中文处理,默认是只支持对英文进行分词,但是在正常业务中,我们需要处理的文档大多是中文,所以我们需要对中文进行分词,所以就需要安装IK分词器
为了直观的体现,es的分词规则不支持英文,我们可以做下面的小演示如下
#测试分词器
POST /_analyze
{"text": "我正在学习安装IK分词器","analyzer": "english"
}
上图,就算分词器名称改成chinese或standard,对于中文的分词也是一字一分。解决: IK分词器。下面开始具体的安装IK分词器的操作
第一步: 我们在 '4. 安装elasticsearch' 创建elasticsearch容器时,指定了数据卷目录,其中有个数据卷指定了自定义名称为es-plugins,表示存放插件的数据卷
我们使用inspect命令把es-plugins数据卷的路径信息查询出来
docker volume inspect es-plugins
第二步: 下载ik.zip压缩包到Windows,下载后解压出来是ik文件夹
根据上面查询出来的es-plugins数据卷的路径,把ik文件夹上传到CentOS7的 /var/lib/docker/volumes/es-plugins/_data 目录
cd /var/lib/docker/volumes/es-plugins/_data
第三步: 重启elasticsearch容器,我们在 '4. 安装elasticsearch' 创建elasticsearch容器时,指定了自定义容器名称为es
# 重启elasticsearch容器
docker restart es
第四步: 查看elasticsearch容器的启动日志
docker logs -f es
第五步: 确保elasticsearch、kibana已正常运行
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器
第五步: 测试。在浏览器中输入:http://你的ip地址:5601 即可看到elasticsearch的响应结果
IK分词器包含两种模式:
- ●ik_smart:最少切分,根据语义分词,正常分词
- ●ik_max_word:最细切分,也是根据语义分词,分的词语更多,更细



7. IK分词器的词典扩展和停用
Ik分词器的分词,底层是一个字典,在字典里面会有各种各样的词语,当ik分词器需要对分词文本进行分词时,ik分词器就会拿着这个文本(乱拆成多个词或词语),一个个去字典里面匹配,如果能匹配到,证明某个词(乱拆成多个词或词语)是词,就把这个证明后的词分出来,作为一个词
第一个问题: 字典的分词效果是有限的,只能对日常生活中常见的语义相关的词,进行分词,由于字典的词汇量少,所以我们需要对字典进行扩展。
第二个问题: 字典的分词效果往往存在违禁词,我们不希望IK分词器能匹配并成功把词典里的违禁词作为分词,解决: 禁用某些敏感词条
解决:
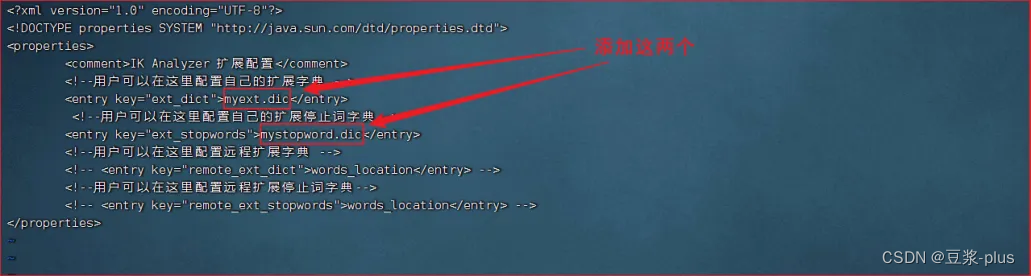
1、要拓展或禁用ik分词器的词库,只需要修改一个分词器目录中的config目录中的IKAnalyzer.cfg.xml文件,如下
cd /var/lib/docker/volumes/es-plugins/_data/ik/config
vi IKAnalyzer.cfg.xml<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典--><entry key="ext_dict">ext.dic</entry><!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典--><entry key="ext_stopwords">stopword.dic</entry>
</properties>
2、在config目录新建myext.dic文件,写入自己想要的特定词,也就是扩展词。新建mystopword.dic文件,写入自己想要禁用的特定词,也就是不参与分词的词
cd /var/lib/docker/volumes/es-plugins/_data/ik/configtouch myext.dic
vi myext.dictouch mystopword.dic
vi mystopword.dic
3、重新启动elasticsearch、kibana
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器4、测试。在浏览器中输入:http://你的ip地址:5601 即可看到elasticsearch的响应结果
http://192.168.200.231:5601IK分词器包含两种模式:
- ●ik_smart:最少切分,根据语义分词,正常分词
- ●ik_max_word:最细切分,也是根据语义分词,分的词语更多,更细

根据上图,确实可以根据我们指定的扩展词进行分析,违禁词也确实被禁用没有被分词
实用篇-ES-DSL操作文档
1. mapping属性
mapping属性的官方文档: https://elastic.co/guide/en/elasticsearch/reference/current/index.html
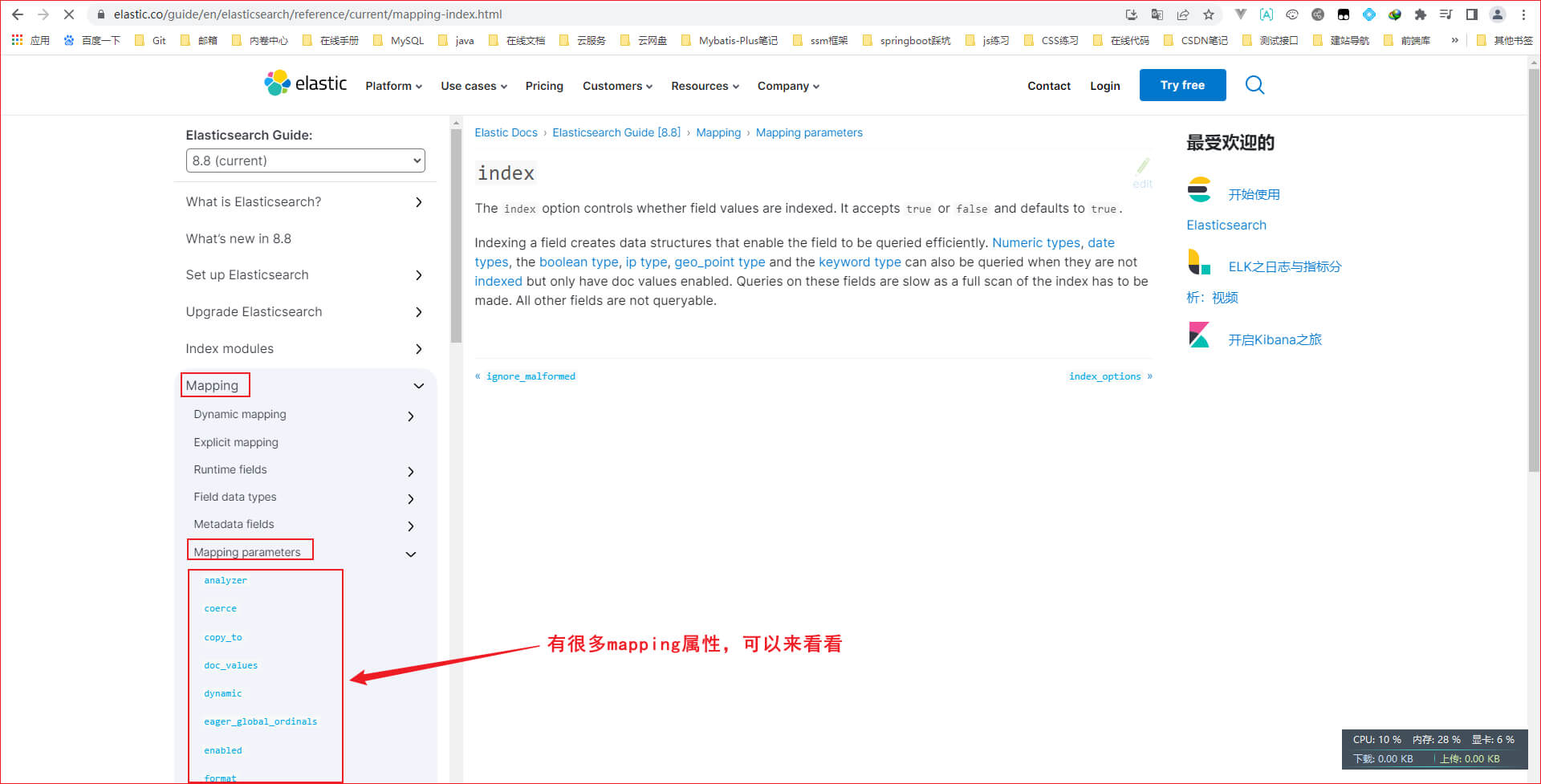
下面的表格是介绍elasticsearch中的各个概念以及含义,看的时候重点看第二、三列,第一列是为了让你更理解第二列的意思,所以在第一列拿MySQL的概念来做匹配。例如elasticsearch的Index表示索引也就是文档的集合,就相当于MySQL的Table(也就是表)
| MySQL | Elasticsearch | 说明 |
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row)。这里的文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |

mapping是对索引库中文档(es中的文档是json风格)的约束,常见的mapping属性包括如下
●type: 字段数据类型
○字符串(分两种): text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址等不可分词的词语)
○数值: long、integer、short、byte、double、float
○布尔: boolean
○日期: date
○对象:object
●index: 是否创建倒排索引,默认为true(也就是可参与分词搜索),改成false的话,别人就搜索不到你
●analyzer: 分词器,当字段类型是text时必须指定分词器。如果字段类型是keyword,那么不需要指定分词器
●properties: 子字段,也就是属性和子属性
2. 创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下

PUT /索引库名称
{"mappings": {//映射"properties": {//字段"字段名":{"type": "text","analyzer": "ik_smart"},"字段名2":{"type": "keyword","index": false //false表示这个字段不参与搜索,该字段不会创建为倒排索引,false不加双引号},"字段名3":{"properties": {//这个就是子字段"子字段": {"type": "keyword"}}},// ...略}}
}
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器
第一步: 浏览器访问 http://你的ip地址:5601 。输入如下,注意把注释删掉
http://192.168.200.231:5601# 创建索引库,名字自定义,例如huanfqc
PUT /huanfqc
{"mappings": {"properties": {"xxinfo": {"type": "text", //文本类型,可以被分词器分词"analyzer": "ik_smart" //必须指定分词器},"xxemail": {"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的"index": false //不参与搜索,用户不能通过搜索搜到xxemail字段},"name": {"type": "object", //对象类型"properties": { //父字段"firstName": { //子字段"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的"index": true //参与搜索,用户通过可搜索到firstName字段},"lastName": { //子字段"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的"index": true //参与搜索,用户通过可搜索到lastName字段}}}}}
}# 创建索引库,名字自定义,例如huanfqc
PUT /huanfqc
{"mappings": {"properties": {"xxinfo": {"type": "text","analyzer": "ik_smart"},"xxemail": {"type": "keyword","index": false},"name": {"type": "object","properties": {"firstName": {"type": "keyword","index": true},"lastName": {"type": "keyword","index": true}}}}}
}
3. 查询、修改、删除索引库
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器

1、查询索引库语法
GET /索引库名
2、往索引库添加新字段,注意: 索引库是无法被修改的,但是可以添加新字段(不能和已有的重复,否则报错)
PUT /索引库名/_mapping
{"properties": {"新字段名":{"type": "integer"}}
}//例如如下
PUT /huanfqc/_mapping
{"properties": {"age": {"type": "integer"}}
}
3、删除索引库语法
DELETE /索引库名
4. 新增、查询、删除文档
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作。并且已经创建了名为huanfqc的索引库
1、新增文档的DSL语法,其实就是告诉kibana,我们要把文档添加到es的哪个索引库,如果省略文档id的话,es会默认随机生成一个,建议自己指定文档id
POST /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2","字段3": {"子属性1": "值3","子属性2": "值4"},// ...
}#创建文档
POST /huanfqc/_doc/1
{"xxinfo":"焕发@青春-学Java","email": "123@huanfqc.cn","name":{"firstName":"张","lastName":"三"}
}
2、查询文档。语法: GET /索引库名/_doc/文档id 。例如如下
#查询文档
GET /huanfqc/_doc/1
3、删除文档。语法: DELETE/索引库名/_doc/文档id 。例如如下
#删除文档
DELETE /huanfqc/_doc/1
5. 修改文档
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作。并且已经创建了名为huanfqc的索引库、文档id为1的文档
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器
方式一: 全量修改,会删除旧文档,添加新文档。修改文档的DSL语法,如下
注意: 这种操作是直接用新值覆盖掉旧的,如果只put一个字段那么其它字段就没了,所以,你不想修改的字段也要原样写出来,不然就没了
注意: 如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
#修改文档
PUT /索引库名/_doc/文档id
{"字段1": "值1","字段2": "值2",// ... 略
}#修改文档
PUT /huanfqc/_doc/1
{"xxinfo":"修改你了-焕发@青春-学Java","email": "123@huanfqc.cn","name":{"firstName":"修改你了-张","lastName":"三","xxupdate":"我还加了一个"}
}

方式二: 增量修改。修改指定字段的值
注意: 如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
#修改文档
POST /索引库名/_update/文档id
{"doc": {"要修改的字段名": "新的值",}
}#修改文档
POST /huanfqc/_update/1
{"doc": {"firstName": "修改-法外狂徒张三"}
}


实用篇-ES-RestClient操作文档
下面的全部内容都是连续的,请不要跳过某一小节
1. RestClient案例准备
对es概念不熟悉的话,先去看上面的 '实用篇-ES-索引库和文档',不建议基础不牢就直接往下学
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求来发送给ES。
官方文档地址: https://www.elastic.co/guide/en/elasticsearch/client/index.html

下面就使用java程序进行操作es,不再像上面那样使用浏览器页面进行操作es
在下面会逐步完成一个案例: 下载提供的hotel-demo.zip压缩包,解压后是hotel-demo文件夹,是一个java项目工程文件,按照条件创建索引库,索引库名为hotel,mapping属性根据数据库结构定义。还要下载一个tb_hotel.sql文件,作为数据库数据
hotel-demo.zip下载:https://cowtransfer.com/s/36ac0a9f9d9043tb_hotel.sql下载: https://cowtransfer.com/s/716f049850a849
第一步: 打开database软件,把tb_hotel.sql文件导入进你的数据库
create database if not exists elasticsearch;
use elasticsearch;


第二步: 把下载好的hotel-demo.zip压缩包解压,得到hotel-demo文件夹,在idea打开hotel-demo


第三步: 修改application.yml文件,配置正确的数据库信息

2. hotel数据结构分析
在es中,mapping要考虑的问题: 字段名、数据类型、是否参与搜索、是否分词、如果分词那么分词器是什么。
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
我们刚刚在mysql导入了tb_hotel.sql,里面有很多数据,我们需要基于这些数据结构,去分析并尝试编写对应的es的mapping映射
先看mysql中的数据类型(已有),如下
CREATE TABLE `tb_hotel` (`id` bigint(20) NOT NULL COMMENT '酒店id',`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',`price` int(10) NOT NULL COMMENT '酒店价格;例:329',`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
根据mysql的数据类型等信息,编写es(没有,自己对着上面的sql写的)。注意经纬度在es里面是geo_point类型,且经纬度是写在一起的
# 酒店的mapping
PUT /hotel
{"mappings": {"properties": {"id":{"type": "keyword","index": true},"name":{"type": "text","analyzer": "ik_max_word"},"address":{"type": "keyword","index": false},"price":{"type": "float","index": true},"score":{"type": "float","index": true},"brand":{"type": "keyword","index": true},"city":{"type": "keyword","index": true},"business":{"type": "keyword","index": true},"xxlocation":{"type": "geo_point","index": true},"pic":{"type": "keyword","index": false}}}
}


3. 初始化RestClient
操作主要是在idea的hotel-demo项目进行,hotel-demo项目(不是springcloud项目,只是springboot项目)是前面 '1. RestClient案例准备',跳过的可回去补
第一步: 在hotel-demo项目的pom.xml添加如下
<elasticsearch.version>7.12.1</elasticsearch.version><!--引入es的RestHighLevelClient,版本要跟你Centos7里面部署的es版本一致-->
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version>
</dependency>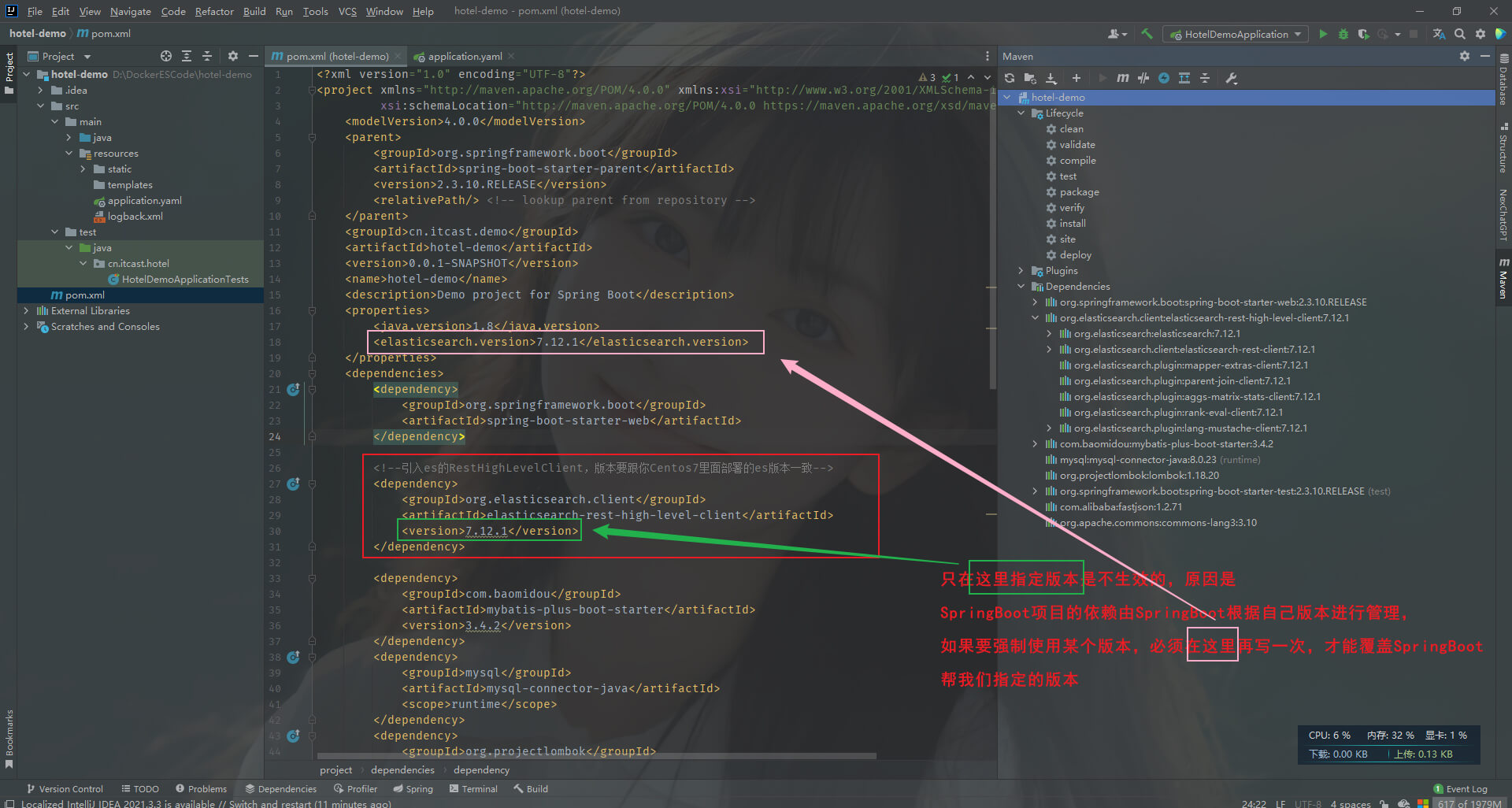
第二步: 在hotel-demo项目的src/test/java/cn.itcast.hotel目录新建HotelIndexTest类,写入如下
package cn.itcast.hotel;import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.io.IOException;public class HotelIndexTest {private RestHighLevelClient xxclient;@BeforeEach//该注解表示一开始就完成RestHighLevelClient对象的初始化void setUp() {this.xxclient = new RestHighLevelClient(RestClient.builder(//指定你Centos7部署的es的主机地址HttpHost.create("http://192.168.200.231:9200")));}@AfterEach//该注解表示销毁,当对象运行完之后,就销毁这个对象void tearDown() throws IOException {this.xxclient.close();}@Test//现在才是测试代码,对象已经在上面初始化并且有销毁的步骤了,下面直接打印void yytestInit() {System.out.println(xxclient);}
}
第三步: 确保下面的服务你都在Centos7里面启动了
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
第四步: 运行HotelIndexTest类yytestInit方法

4. 创建索引库

不是通过kibana的浏览器控制台,通过DSL语句来进行操作es,在es里面创建索引库
而是通过上一节初始化的RestClient对象,在Java里面去操作es,创建es的索引库。根本不需要kibana做中间者
第一步: 在src/main/java/cn.itcast.hotel目录新建constants.HotelConstants类,里面写DSL语句,如下
其中长长的字符串就是我们在前面 '2. hotel数据结构分析' 里面写的。忘了怎么写出来的,可以回去看看
package cn.itcast.hotel.constants;public class HotelConstants {public static final String xxMappingTemplate = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"float\",\n" +" \"index\": true\n" +" },\n" +" \"score\":{\n" +" \"type\": \"float\",\n" +" \"index\": true\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true,\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true,\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\",\n" +" \"index\": true\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
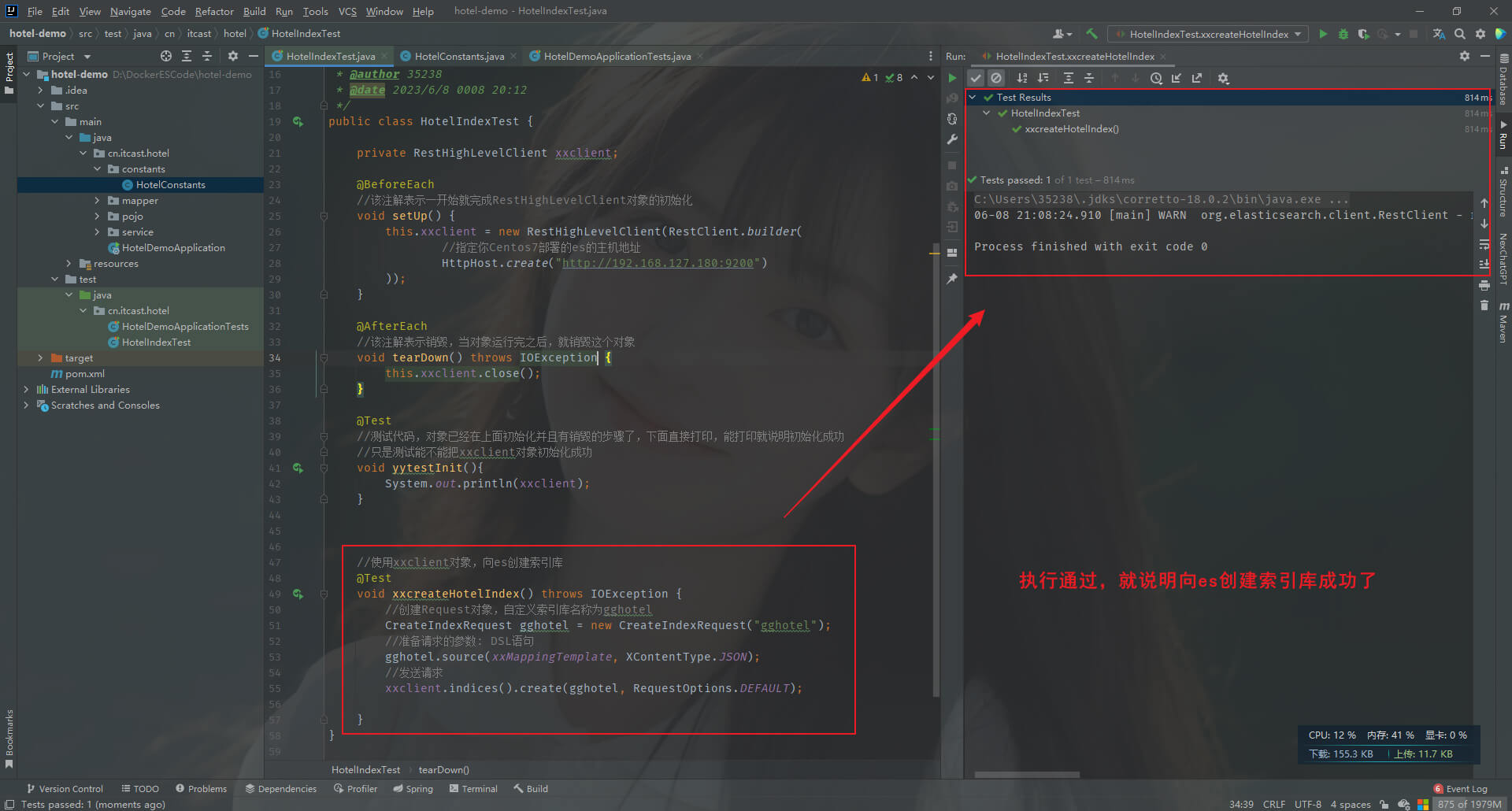
第二步: 在hotel-demo项目的HotelIndexTest类,添加如下
//使用xxclient对象,向es创建索引库
@Test
void xxcreateHotelIndex() throws IOException {//创建Request对象,自定义索引库名称为gghotelCreateIndexRequest request = new CreateIndexRequest("gghotel");//准备请求的参数: DSL语句request.source(xxMappingTemplate, XContentType.JSON);//注意xxMappingTemplate是第一步定义的的静态常量,导包别导错了//发送请求xxclient.indices().create(request, RequestOptions.DEFAULT);
}
第三步: 确保下面的服务你都在Centos7里面启动了
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
第四步: 验证。运行HotelIndexTest类的xxcreateHotelIndex测试方法
第五步: 如何更直观地验证,es里面确实有刚刚创建的索引库(刚刚创建的索引库是叫gghotel)
那就不得不运行kibana了,这样才能打开web浏览器页面,进行查询
docker restart kibana #启动kibana容器
浏览器访问 http://你的ip地址:5601
5. 删除和判断索引库
首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作。不需要浏览器操作es,所以不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
1、删除索引库。在hotel-demo项目的HotelIndexTest类,添加如下。然后运行xxtestDeleteHotelIndex方法
//删除索引库
@Testvoid xxtestDeleteHotelIndex() throws IOException {//创建Request对象,指定要删除哪个索引库DeleteIndexRequest request = new DeleteIndexRequest("gghotel");//发送请求xxclient.indices().delete(request, RequestOptions.DEFAULT);
}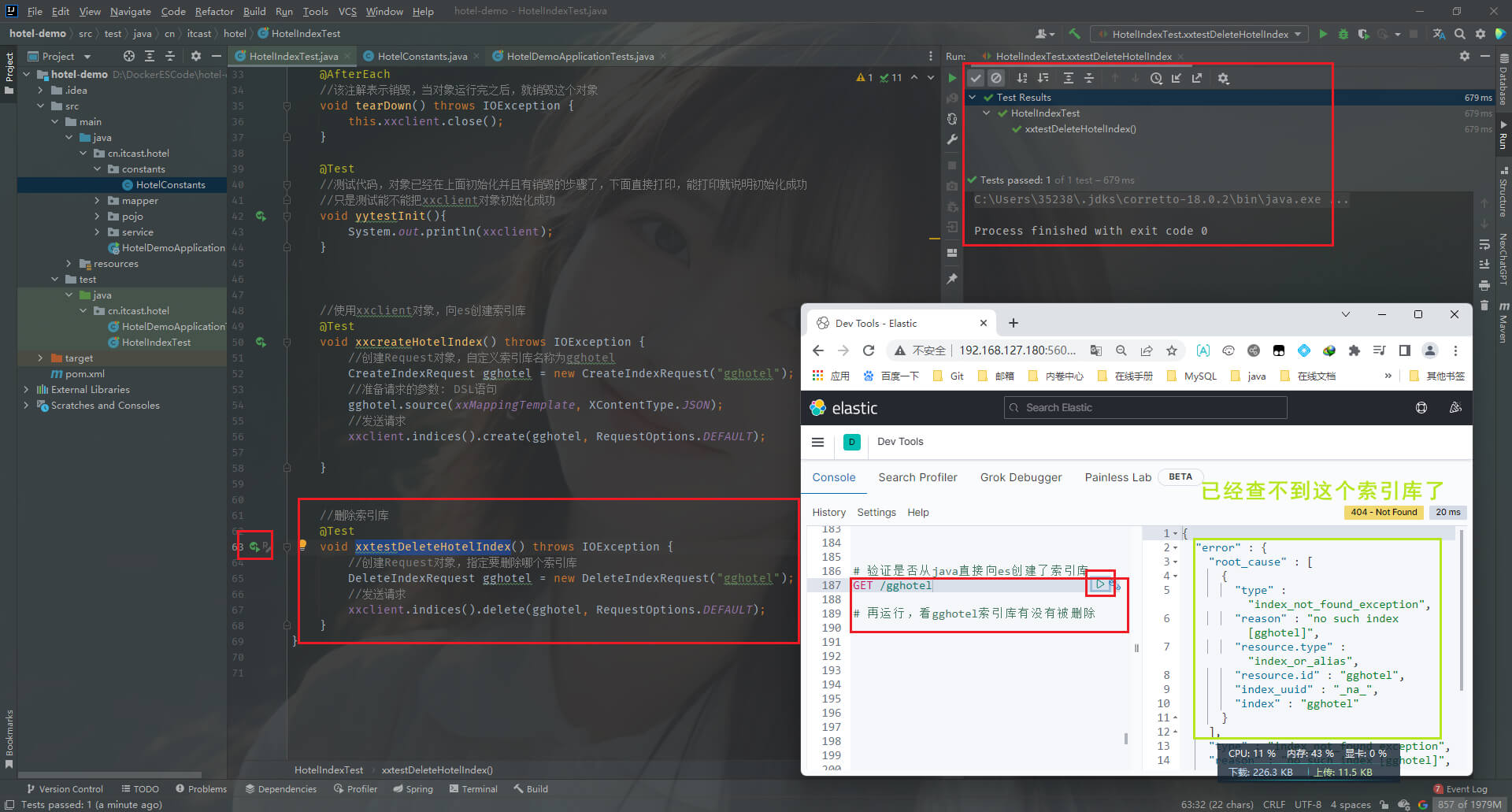
2、判断索引库是否存在。在hotel-demo项目的HotelIndexTest类,添加如下。然后运行xxtestDeleteHotelIndex方法
//判断索引库是否存在
@Testvoid xxtestExistsHotelIndex() throws IOException {//创建Request对象,判断哪个索引库是否存在在esGetIndexRequest request = new GetIndexRequest("gghotel");//发送请求boolean ffexists = xxclient.indices().exists(request, RequestOptions.DEFAULT);//输出一下,看是否存在System.out.println(ffexists ? "索引库已经存在" : "索引库不存在");
}

6. 新增文档
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
案例: 去数据库查询酒店数据,把查询到的结果导入到hotel索引库(上一节我们已经创建一个名为gghotel的索引库),实现酒店数据的增删改查
简单说就是先去数据查酒店数据,把结果转换成索引库所需要的格式(新增文档的DSL语法)然后写到索引库,然后在索引库对这些酒店数据进行增删改查
【必备操作】
你们拿到代码的时候,这些操作已经做好,不需要再去做,我只是写出来方便后续复习
(1)、在pojo目录里面有一个Hotel类,作用是指定根数据库交互的字段,写入了如下
package cn.itcast.hotel.pojo;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;@Data
@TableName("tb_hotel")
public class Hotel {@TableId(type = IdType.INPUT)private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String longitude;private String latitude;private String pic;
}
(2)、在pojo目录里面有一个HotelDoc类,作用是跟es的索引库交互的字段,也就是跟我们索引库里面的字段类型联调,写入了如下
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String xxlocation;private String pic;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.xxlocation = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}
(3)、在service新建了IHotelService接口,作用是写mybatis-plus向数据库发送请求用于查询数据库的数据
package cn.itcast.hotel.service;
import cn.itcast.hotel.pojo.Hotel;
import com.baomidou.mybatisplus.extension.service.IService;public interface IHotelService extends IService<Hotel> {}
(4)、在service新建了impl目录,在impl目录里面有一个HotelService类,是IHotelService接口的实现类
package cn.itcast.hotel.service.impl;import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.service.IHotelService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {}
【具体操作】
第一步: 在hotel-demo项目的src/test/java/cn.itcast.hotel目录新建HotelDocumentTest类,写入如下
package cn.itcast.hotel;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import static cn.itcast.hotel.constants.HotelConstants.xxMappingTemplate;/*** @author 35238* @date 2023/6/9 0009 8:51*/
@SpringBootTest
public class HotelDocumentTest {private RestHighLevelClient xxclient;@BeforeEach//该注解表示一开始就完成RestHighLevelClient对象的初始化void setUp() {this.xxclient = new RestHighLevelClient(RestClient.builder(//指定你Centos7部署的es的主机地址HttpHost.create("http://192.168.127.180:9200")));}@AfterEach//该注解表示销毁,当对象运行完之后,就销毁这个对象void tearDown() throws IOException {this.xxclient.close();}//-----------------------------上面是初始化,下面是操作文档的测试-------------------------------------------@Autowired//注入写好的IHotelService接口,用于去数据库查询数据private IHotelService xxhotelService;@Test//新增文档到gghotel索引库,请保证你的es里面已经存在gghotel索引库void testAddDocument() throws IOException {//去数据库查询数据,我们简单查询一下id为61083的数据。由于在实体类里面定义的id是Long类型,所以要加L表示该数字是Long类型Hotel xxdataExample = xxhotelService.getById(61083L);//把上一行数据库查询出来的字段类型转为es的索引库的文档类型,才能往索引库里面新增文档HotelDoc xxhotelDoc = new HotelDoc(xxdataExample);//准备Request对象,往哪个索引库添加文档,文档的id需要自定义,xxdataExample.getId().toString()表示文档id跟数据库的id一致IndexRequest xxrequest = new IndexRequest("gghotel").id(xxdataExample.getId().toString());//准备JSON文档.JSON.toJSONString()是com.alibaba.fastjson提供的API,用于把JSON转为Stringxxrequest.source(JSON.toJSONString(xxhotelDoc),XContentType.JSON);//发送请求xxclient.index(xxrequest,RequestOptions.DEFAULT);}
}
第二步: 验证。运行HotelDocumentTest类的testAddDocument方法

第三步: 如何更直观地验证,es里面的gghotel索引库里面有刚刚我们新增的文档,文档id就是数据里面的字段id
那就不得不运行kibana了,这样才能打开web浏览器页面,进行查询
docker restart kibana #启动kibana容器
浏览器访问 http://你的ip地址:5601

7. 查询文档
我们在刚刚,为了直观地验证是否成功新增文档,需要启动kibana,然后去浏览器页面进行查询,非常的麻烦,下面就来学习通过Java代码,进行查询文档
难点: 根据id查询到的文档数据类型是json,需要反序列化为java对象
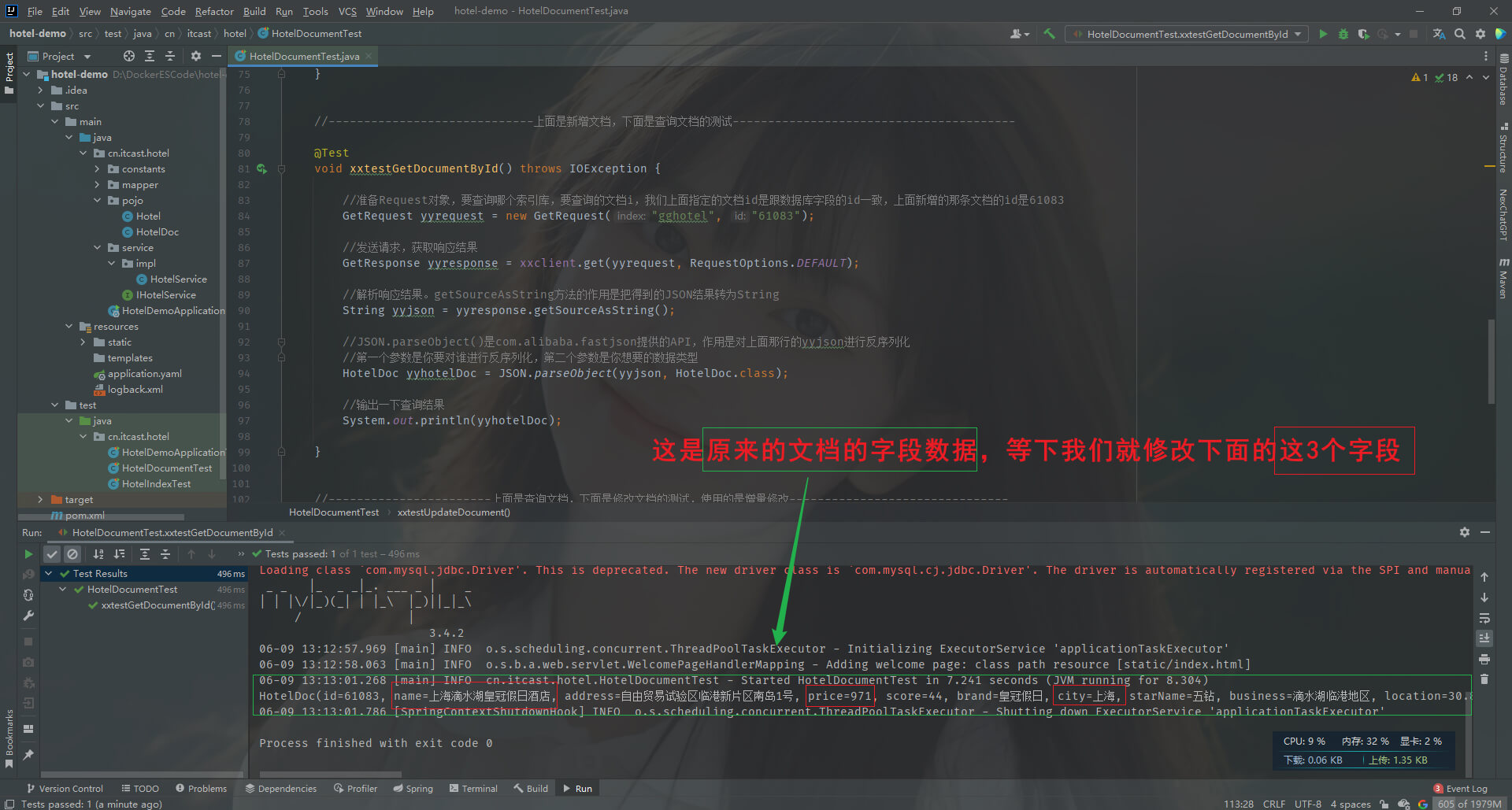
第一步: 在HotelDocumentTest类,添加如下
@Test
void xxtestGetDocumentById() throws IOException {//准备Request对象,要查询哪个索引库,要查询的文档i,我们上面指定的文档id是跟数据库字段的id一致,上面新增的那条文档的id是61083GetRequest yyrequest = new GetRequest("gghotel", "61083");//发送请求,获取响应结果GetResponse yyresponse = xxclient.get(yyrequest, RequestOptions.DEFAULT);//解析响应结果。getSourceAsString方法的作用是把得到的JSON结果转为StringString yyjson = yyresponse.getSourceAsString();//JSON.parseObject()是com.alibaba.fastjson提供的API,作用是对上面那行的yyjson进行反序列化//第一个参数是你要对谁进行反序列化,第二个参数是你想要的数据类型HotelDoc yyhotelDoc = JSON.parseObject(yyjson, HotelDoc.class);//输出一下查询结果System.out.println(yyhotelDoc);}
第二步: 运行HotelDocumentTest类的xxtestGetDocumentById方法

8. 修改文档
根据id修改酒店数据。修改es的索引库的文档的数据,有两种方式,前面在学kibana操作文档的时候学过,可前去 '实用篇-ES-索引库和文档' 进行复习
1、全量修改,会删除旧文档,添加新文档。注意: 这种操作是直接用新值覆盖掉旧的,如果只put一个字段那么其它字段就没了,所以,你不想修改的字段也要原样写出来,不然就没了。如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
2、增量修改(我们学习这种)。修改指定字段的值。如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
首先保证你已经做好了 '实用篇-ES-环境搭建' ,以及上面的五小节,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
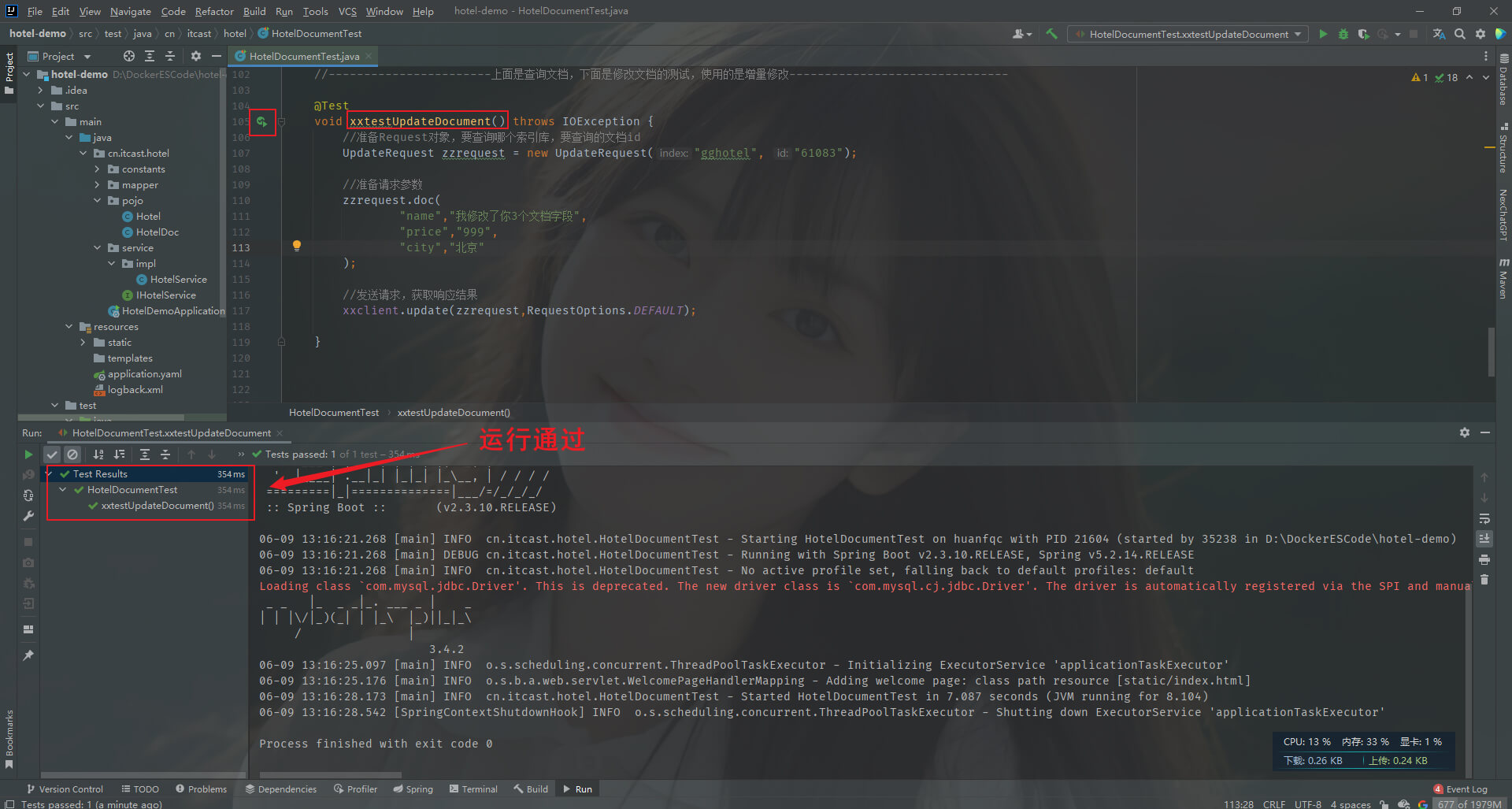
第一步: 在HotelDocumentTest类,添加如下
@Test
void xxtestUpdateDocument() throws IOException {//准备Request对象,要修改哪个索引库,要修改的文档idUpdateRequest zzrequest = new UpdateRequest("gghotel", "61083");//准备请求参数,要修改哪些字段,修改成什么zzrequest.doc("name","我修改了你3个文档字段","price","999","city","北京");//发送请求,获取响应结果xxclient.update(zzrequest,RequestOptions.DEFAULT);
}
第二步: 先查一下原来的id为61083的文档(es中的文档就相当于mysql的一行)的数据。运行HotelDocumentTest类的xxtestGetDocumentById方法
第三步: 运行HotelDocumentTest类的xxtestUpdateDocument方法,作用是修改数据,也就是我们第一步写的代码
第四步: 在去查一下文档的数据,验证第三步是否修改成功。运行HotelDocumentTest类的xxtestGetDocumentById方法

9. 删除文档
首先保证你已经做好了 '实用篇-ES-环境搭建' ,以及上面的五小节,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器第一步: 在HotelDocumentTest类,添加如下
@Test
void wwtestDeleteDocument() throws IOException {//准备Request对象,要删除哪个索引库,要删除的文档idDeleteRequest wwrequest = new DeleteRequest("gghotel", "61083");//发送请求xxclient.delete(wwrequest,RequestOptions.DEFAULT);
}
第二步: 先查一下原来的id为61083的文档(es中的文档就相当于mysql的一行)能不能查询到。运行HotelDocumentTest类的xxtestGetDocumentById方法
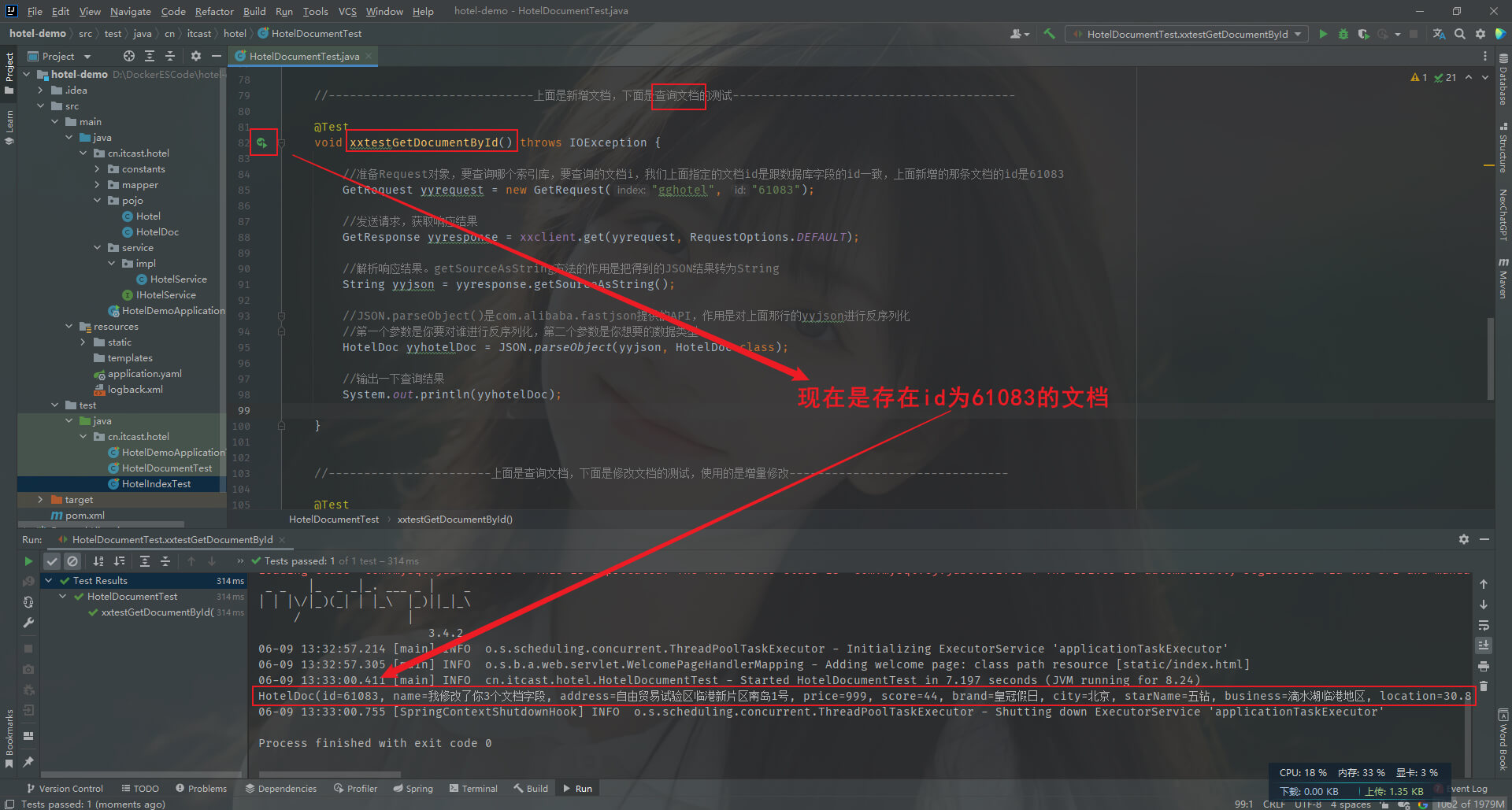
第三步: 删除id为61083的文档(相当于删除mysql中id为某个数的那一行)。运行HotelDocumentTest类的wwtestDeleteDocument方法

第四步: 验证。再次执行第二步,也就是运行HotelDocumentTest类的xxtestGetDocumentById方法

10. 批量导入文档
建议去前面的 '6. 新增文档' 复习一下,在索引库里面新增一条文档,是怎么实现的
在上面的6、7、8、9节中,我们一直都是操作一条id为61083的文档(相当于数据库表的某一行)。我们如何把mysql的更多数据导入进es的索引库(相当于mysql的表)呢,下面就来学习批量把文档导入进索引库
思路:
1、利用mybatis-plus把MySQL中的酒店数据查询出来
2、将查询到的酒店数据转换为文档类型的数据
3、利用RestClient中bulk批处理方法,实现批量新增文档
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
第一步: 在HotelDocumentTest类,添加如下
@Test
void testBulkRequest() throws IOException {//向数据库批量查询酒店数据,list方法表示查询数据库的所有数据List<Hotel> kkhotels = xxhotelService.list();//创建RequestBulkRequest vvrequest = new BulkRequest();//准备参数,实际上就是添加多个新增的Requestfor (Hotel kkhotel : kkhotels) {//把遍历拿到的每个kkhotels转换为文档类型的数据HotelDoc ffhotelDoc = new HotelDoc(kkhotel);//HotelDoc是我们写的一个实体类//往哪个索引库批量新增文档、新增后的文档id是什么,文档类型是JSONvvrequest.add(new IndexRequest("gghotel").id(ffhotelDoc.getId().toString())//JSON.parseObject()是com.alibaba.fastjson提供的API,作用是对ffhotelDoc进行反序列化准换为json类型.source(JSON.toJSONString(ffhotelDoc),XContentType.JSON));}//发送请求xxclient.bulk(vvrequest,RequestOptions.DEFAULT);
}
第二步: 运行HotelDocumentTest类的testBulkRequest方法

\
第三步: 如何更直观地验证,es里面的gghotel索引库里面有刚刚我们新增的文档。那就不得不运行kibana了,这样才能打开web浏览器页面,进行查询
docker restart kibana #启动kibana容器浏览器访问 http://你的ip地址:5601
输入如下DSL语句,表示查询某个索引库的所有文档
GET /gghotel/_search
上面我们导入了很多文档(相当于数据库的行,很多行),下面我们将着重学习使用DSL对这些文档数据,进行查询
实用篇-ES-DSL查询文档
官方文档: https://elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl。DSL是用来查询文档的
Elasticsearch提供了基于JSON的DSL来定义查询,简单说就是用json来描述查询条件,然后发送给es服务,最后es服务基于查询条件,把结果返回给我们
常见的查询类型包括如下:
1、查询所有: 查询出所有数据,一般在测试的时候使用
match_all
2、全文检索查询: 利用分词器对用户输入内容进行分词,然后去倒排索引库中匹配
match_querymulti_match_query
3、精确查询: 根据精确的词条值去查找数据,一般是查找keyword、数值、日期、boolean等类型的字段。这些字段是不需要分词的,但是依旧会建立倒排索引,把字段的整体内容作为一个词条,并存入倒排索引。在查找的时候,也就不需要分词,直接把搜索的内容去跟倒排索引匹配即可
ids,表示根据id,进行精确匹配range,表示根据数值范围,进行精确匹配term,表示根据数据的值,进行精确匹配
4、地理查询: 根据经纬度查询
geo_distancegeo_bounding_box
5、复合查询: 复合查询可将上述各种查询条件组合一起,合并查询条件
bool,利用逻辑运算把其它查询条件组合起来function_score,用于控制相关度算分,算分会影响性能下面会一个个学
1. DSL基本语法
查询的基本语法

#查询所有
GET /hotel/_search
{"query":{"match_all": {}}
}
【具体操作】
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
浏览器访问 http://你的ip地址:5601
输入如下

存在一个问题,我们明明查询的是所有文档,查询结果也显示查询出所有的文档了,为什么上图右侧,鼠标往下拉,最多才只有10条文档数据呢
原因: 受默认的分页条件限制,后面学习的时候,会进行解决
2. 全文检索查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
全文检索查询,分为下面两种,会对用户输入内容进行分词之后,再进行匹配。也就是利用分词器对用户输入内容进行分词,然后去倒排索引库中匹配。
【第一种全文检索查询】
GET /索引库名/_search
{"query": {"match": {"字段名": "TEXT"}}
}
match查询(也就是match_query查询): 全文检索查询的一种,会对用户输入的内容进行分词,然后去倒排索引库检索
具体操作如下,为了让大家知道gghotel索引库有哪些字段,我把当初建立gghotel索引库的类先放出来
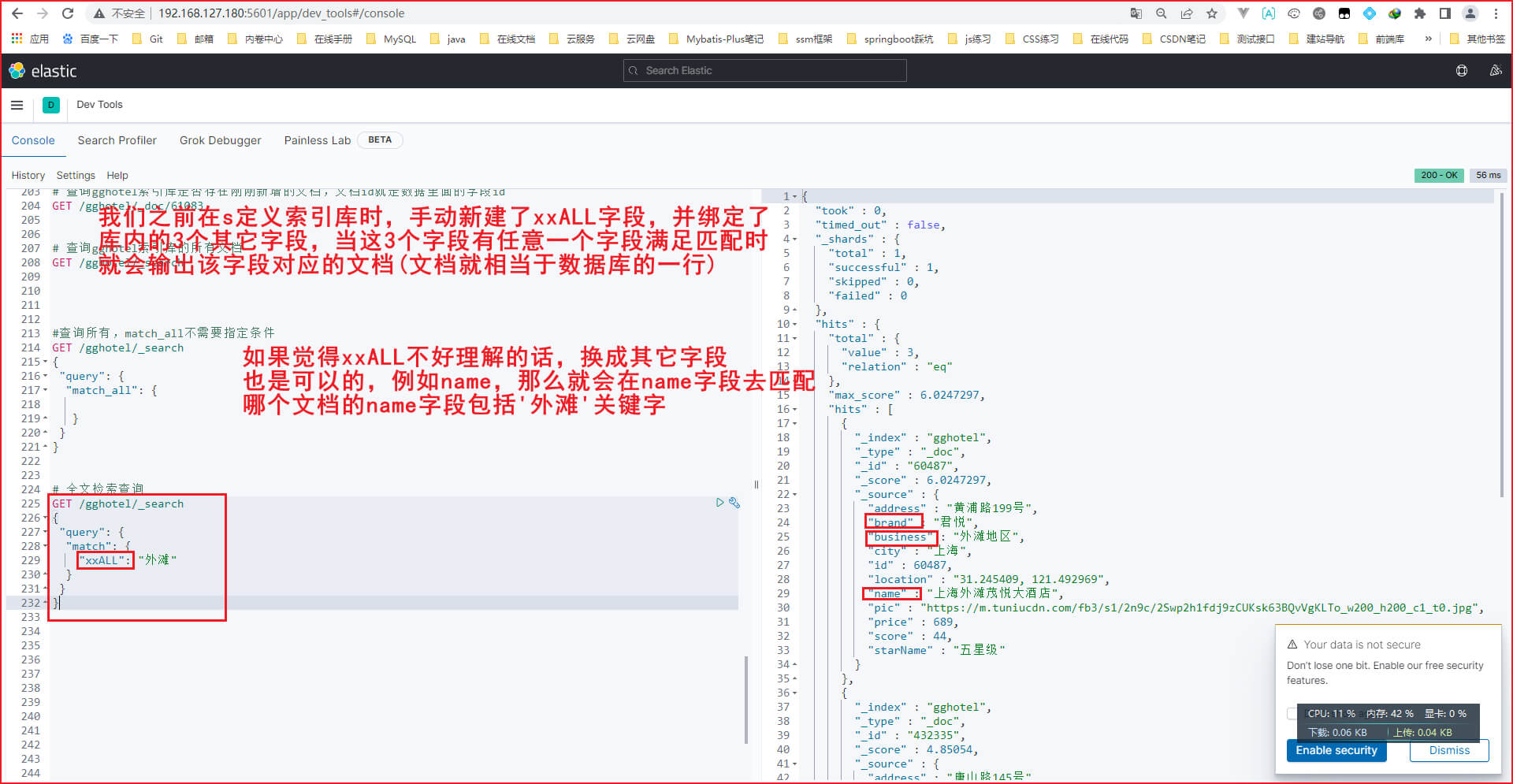
注意: 我要解释一下,上面有个字段叫xxALL,那个字段是当时自定义的,不清楚的话可回去看 '实用篇-ES-RestClient操作' 的 '2. hotel数据结构分析'。
xxALL的作用如下图,相当于一个大的字段,里面存放了几个小字段,优点是我们可以在这个大的字段里面搜索到多个小字段的信息

然后,我们就正式开始全文检索查询,输入如下。注意xxALL换成其它字段也没事,例如换成name字段。正常来说,我们检索name字段,就只在那么字段检索匹配的分词文档,但是在XXALL字段里面检索时,也会检索到name、brand、business字段,原因如上面那个图的copy_to属性
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示查询某个索引库的所有文档
【第二种全文检索查询】
GET /索引库名/_search
{"query": {"multi_match": {"query": "TEXT","字段名": ["FIELD1", " FIELD12"]}}
}
multi_match(也就是multi_match_query查询): 与match查询类似,只不过允许同时查询多个字段
例如,输入如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示查询查询business、brand、name字段中包含'如家'的文档,满足一个字段即可

3. 精确查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。精确查询常见的有两种:
term: 根据词条的精确值查询,强调精确匹配range: 根据值的范围查询,例如金额、时间
【第一种精确查询 term】
具体操作如下
GET /索引库名/_search
{"query": {"term": {"字段名": {"value": "VALUE"}}}
}
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示查询city字段为 '上海' 的文档,必须是 '上海' 才能被匹配,不对'上海'进行分词,也就是不会拆成'上'和'海'

【第一种精确查询 range】
具体操作如下
GET /索引库名/_search
{"query": {"range": {"字段名": {"gte": 10,"lte": 20}}}
}
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示查找price字段满足200~300数值的文档,注意字段类型不能是binary,也就是price字段的类型不能是binary
gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
# 第一种精确查询 term。
GET /gghotel/_search
{"query":{"term": {"city": {"value": "上海"}}}
}
4. 地理查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
根据经纬度查询。常见的使用场景包括: 查询附近酒店、附近出租车、搜索附近的人。使用方式有很多种,介绍如下
geo_bounding_box: 查询geo_point值落在某个矩形范围的所有文档,用两个点来围成的矩形范围geo_distance: 查询到指定中心点,且小于某个距离值的所有文档,圆心到圆边的范围
【第一种地理查询 geo_bounding_box 不演示这种,不常用】
GET /索引库名/_search
{"query": {"geo_bounding_box": {"字段名": {"top_left": {"lat": 31.1,"lon": 121.5},"bottom_right": {"lat": 30.9,"lon": 121.7}}}}
}
【第一种地理查询 geo_distance 下面演示这种】
GET /索引库名/_search
{"query": {"geo_distance": {"distance": "15km","字段名": "31.21,121.5"}}
}
具体操作如下,但是,为了让大家知道gghotel索引库有哪些字段,我把当初建立gghotel索引库的类先放出来
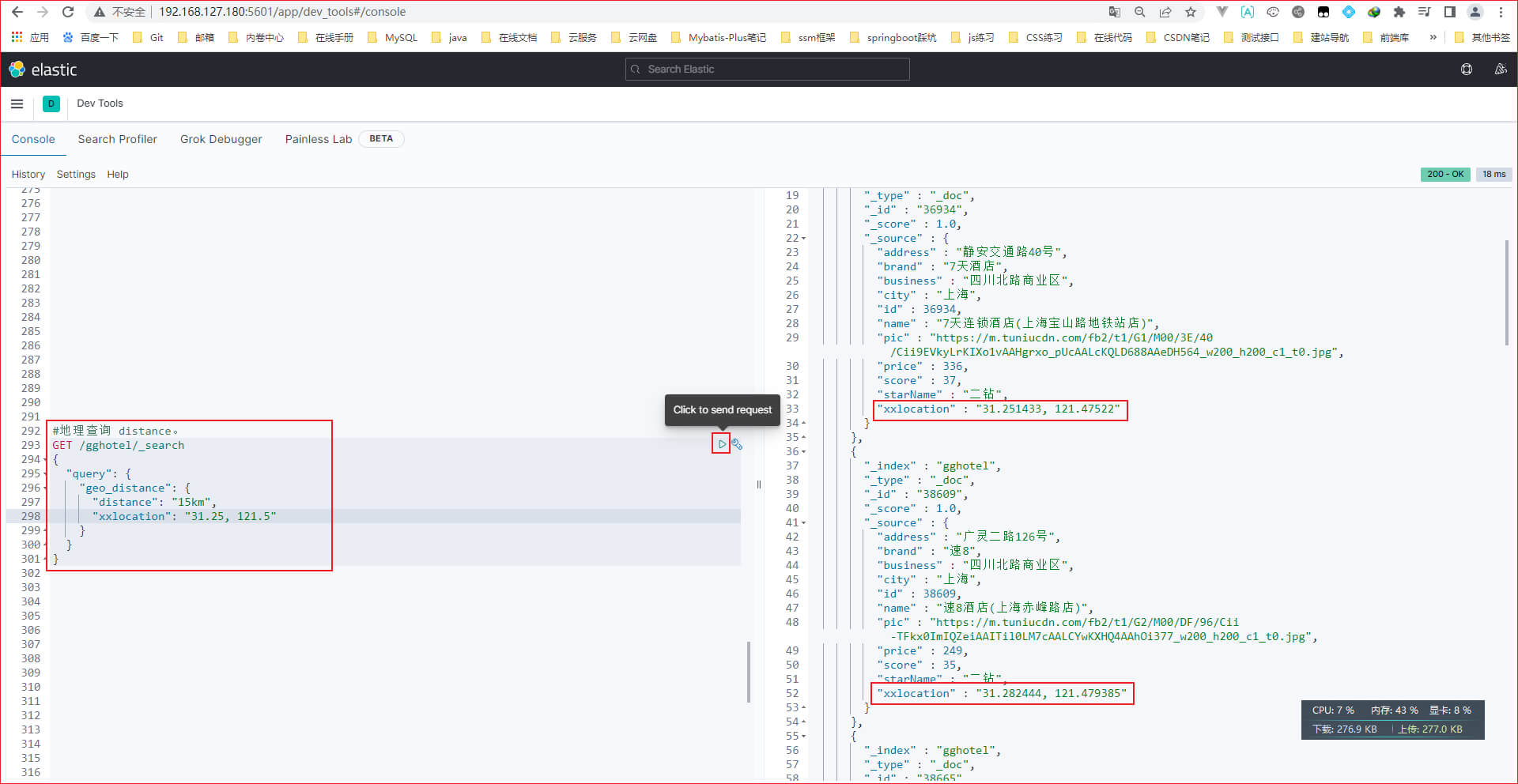
上面的xxlocation字段类型必须是geo_point,否则该字段不能用于地理查询
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句。表示查找xxlocation字段在(31.25±15km,121.5±15km)范围内的文档
5. 相关性算分
上面学的全文检索查询、精确查询、地理查询,这三种查询在es当中都称为简单查询,下面我们将学习复合查询。复合查询可以其它简单查询组合起来,实现更复杂的搜索逻辑,其中就有 '算分函数查询' 如下
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
算分函数查询(function score): 可以控制文档相关性算分、控制文档排名。例如搜索'外滩' 和 '如家' 词条时,某个文档要是都能匹配这两个词条,那么在所有被搜索出来的文档当中,这个文档的位置就最靠前,简单说就是越匹配就排名越靠前


GET /索引库名/_search
{"query": {"match": {"字段名": {"query": "词条"}}}
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
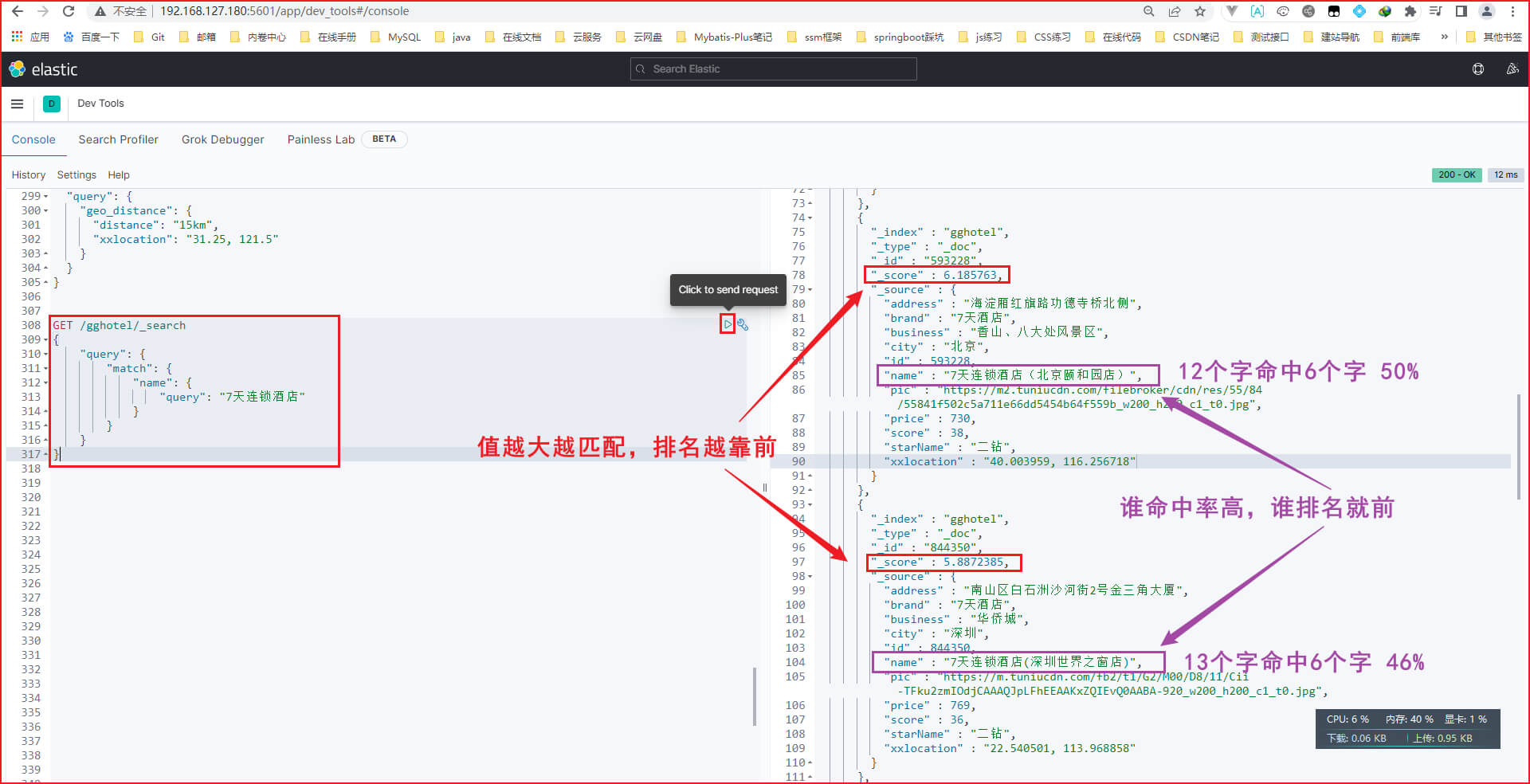
第二步: 输入如下DSL语句,表示在name字段,哪个文档的匹配度高,排名就靠前
GET /gghotel/_search
{"query": {"match": {"name": {"query": "7天连锁酒店"}}}
}
6. 函数算分查询
这是第一种复合查询
上面只是简单演了相关性打分中的函数算分查询,文档与搜索关键字的相关度越高,打分就越高,排名就越靠前。不过,有的时候,我们希望人为地去控制控制文档的排名,例如某些文档我们就希望排名靠前一点,算分高一点,此时就需要使用函数算分查询,下面就来学习 '函数算分查询'
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
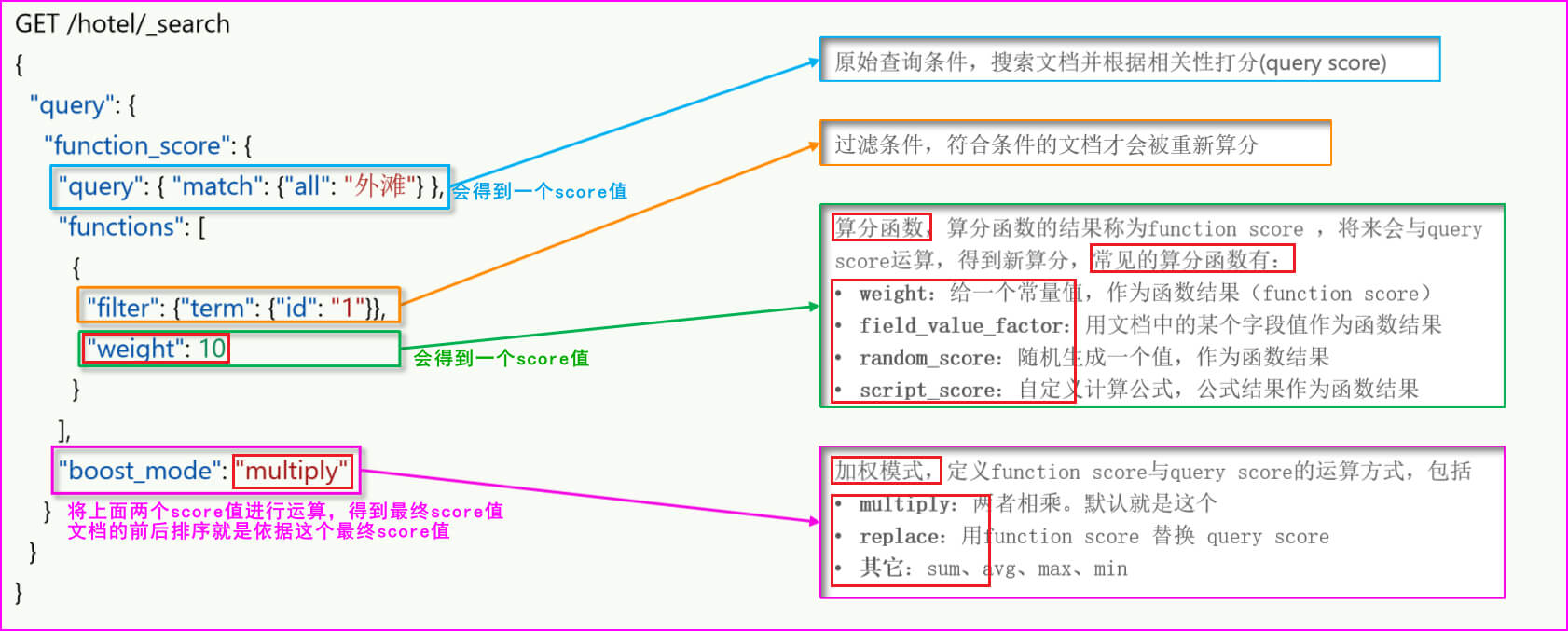
使用 ’函数算分查询(function score query)’,可以在原始的相关性算分的基础上加以修改,得到一个想要的算分,从而去影响文档的排名,语法如下
GET /索引库名/_search
{"query": {"function_score": {"query": { "match": {"字段": "词条"} },"functions": [{"filter": {"term": {"指定字段": "值"}},"算分函数": 函数结果}],"boost_mode": "加权模式"}}
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
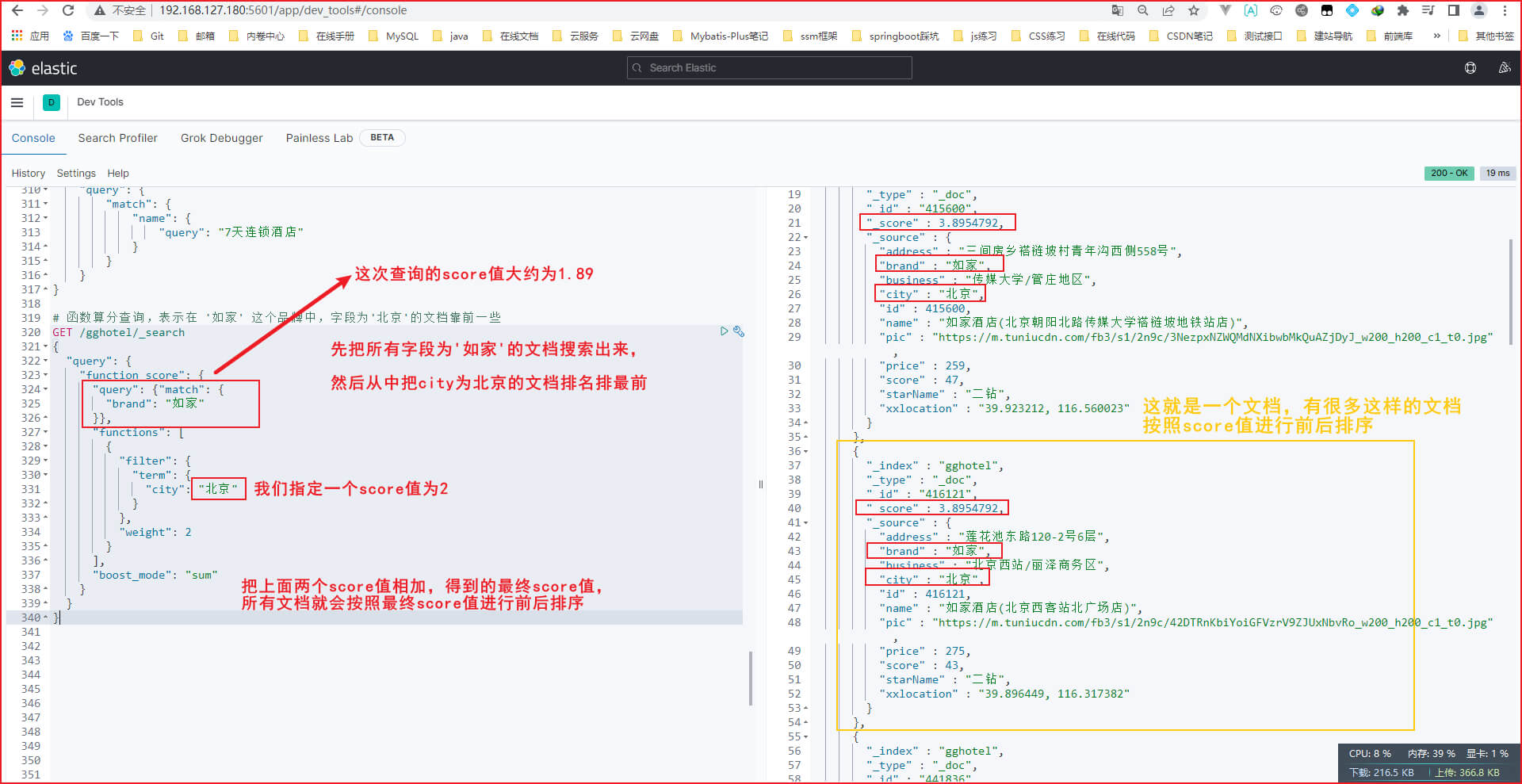
第二步: 输入如下DSL语句,表示在 '如家' 这个品牌中,字段为'北京'的酒店排名靠前一些
GET /gghotel/_search
{"query": {"function_score": {"query": {"match": {"brand": "如家"}},"functions": [{"filter": {"term": {"city": "北京"}},"weight": 2}],"boost_mode": "sum"}}
}
7. 布尔查询
这是第二种复合查询
布尔查询不会去修改算分,而是把多个查询语句组合成一起,形成新查询,这些被组合的查询语句,被称为子查询。子查询的组合方式有如下四种
1、must:必须匹配每个子查询,类似"与"
2、should:选择性匹配子查询,类似"或"
3、must_not:必须不匹配,不参与算分,类似"非"
4、filter:必须匹配,不参与算分

systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
GET /索引库名/_search
{"query": {"bool": {"must": [{"term": {"字段名": "字段值" }}],"should": [{"term": {"字段名": "字段值" }},{"term": {"字段名": "字段值" }}],"must_not": [{ "range": { "字段名": { "lte": 最小字段值 } }}],"filter": [{ "range": {"字段名": { "gte": 最大字段值 } }}]}}
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
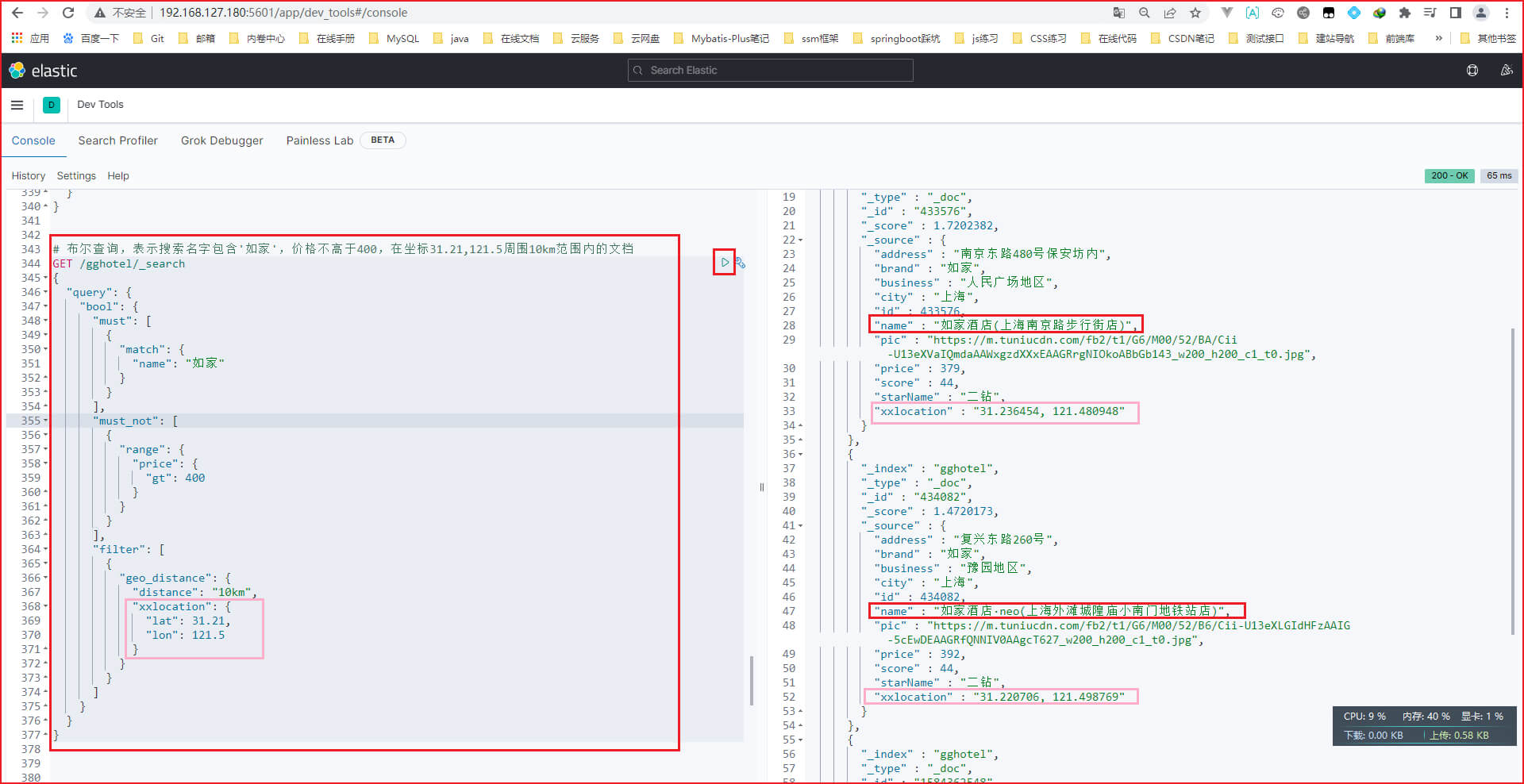
第二步: 输入如下DSL语句,表示搜索名字包含'如家',价格不高于400,在坐标31.21,121.5周围10km范围内的文档
must表示匹配条件(注意写在must里面就会参与算分,也就是查询出来的score值会更高),must_not表示取反,filter表示过滤
GET /gghotel/_search
{"query": {"bool": {"must": [{"match": {"name": "如家"}}],"must_not": [{"range": {"price": {"gt": 400}}}],"filter": [{"geo_distance": {"distance": "10km","xxlocation": {"lat": 31.21,"lon": 121.5}}}]}}
}
8. 搜索结果处理-排序
elasticsearch(称为es)支持对搜索的结果,进行排序,默认是根据 '相关度' 算分,也就是score值,根据score值进行排序。
可以排序的字段类型有: keyword类型、数值类型、地理坐标类型、日期类型
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
sort里面可以指定多个排序字段,用花括号隔开。排序方式: ASC(升序)、DESC(降序)
GET /索引库名/_search
{"query": {"match_all": {}},"sort": [{"需要排序的字段名": "排序方式"}]
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
【案例一】
第二步: 输入如下DSL语句,表示对所有的文档,根据评分(score)进行降序排序,如果评分相同就根据价格(price)升序排序
GET /gghotel/_search
{"query": {"match_all": {}},"sort": [{"score": "desc"},{"price": "asc"}]
}
上图的_score算分为null,是因为我们如果做了排序,那么打分就没有意义了,所以es就会放弃打分不再做相关性算分,提高效率
【案例二】
获取国内任意位置的经纬度的网站: 获取鼠标点击经纬度-地图属性-示例中心-JS API 2.0 示例 | 高德地图API
longitude 经度 latitude 纬度 (经度,纬度): 这是我们描述经纬度的写法,先经度再纬度,但是在下面写的时候
第三步: 输入如下DSL语句,表示找到(121.66053,28.28811)周围的文档,并按照距离进行升序排序
下面两种写法都是一样的,注意第二种写法前面写的是纬度,后面写的是经度
第一种写法
GET /gghotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"xxlocation": {"lat": 28.28811,"lon": 121.66053},"order": "asc"}}]
}第二种写法
GET /gghotel/_search
{"query": {"match_all": {}},"sort": [{"_geo_distance": {"xxlocation": "28.28811,121.66053","order": "asc"}}]
}
上图右侧的sort表示距离 '28.28811,121.66053' 有多少公里,例如281547.94km。
上图的_score算分为null,是因为我们如果做了排序,那么打分就没有意义了,所以es就会放弃打分不再做相关性算分,提高效率
9. 搜索结果处理-分页
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
elasticsearch(称为es)默认情况下只返回前10 条数据。而如果要查询更多数据就需要修改分页参数,分页参数包括from和size,语法如下
GET /索引库名/_search
{"query": {"要查询的字段": {}},"from": 要查第几页, // 分页开始的位置,默认为0"size": 每页显示多少条文档, // 期望获取的文档总数"sort": [ //表示排序{"price": "排序方式"}]
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示对所有的文档,根据价格(price)进行升序排序,每次分页显示20条数据,看的是第六页
size默认是10,表示一页显示多少条文档。from默认是0,表示你要看的是第一页
GET /gghotel/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}],"from": 0,"size": 20
}
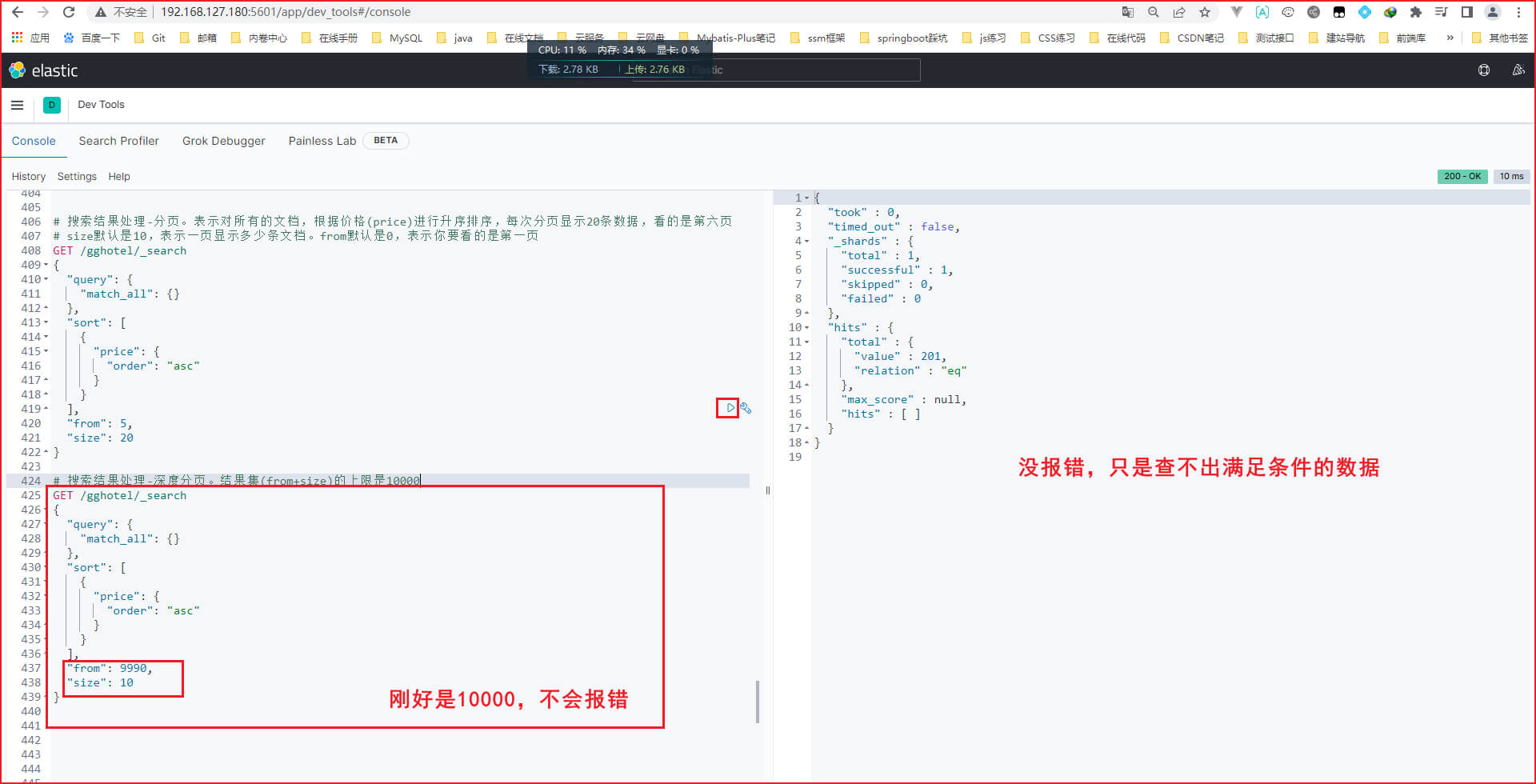
上面是基础的分页用法,下面来详细了解es的分页。es的底层使用的是倒排索引,是不利于做分页的,es采用的是逻辑上的分页,就会导致当是分布式的时候,就会产生下面的问题,因此es限制结果集最多为10000
ES是分布式的,所以会面临深度分页的问题。例如按price排序后,获取from=990,size=10的数据,如下图

深度分页查询的演示,输入如下DSL语句,表示
GET /gghotel/_search
{"query": {"match_all": {}},"sort": [{"price": {"order": "asc"}}],"from": 9991,"size": 10
}

百度在这方面,最多能查76页,每页显示十条。京东在这方面,最多能查第100页,所以深度分页我们不需要担心,10000的限制足够了。但是,如果说一定要去解决深度分页问题的话,ES提供了两种解决方案(两种分页方式),如下
官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html
1、search after: 分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。缺点: 只能向后翻页,不能向前翻页
场景: 没有随机翻页需求的搜索,例如手机向下滚动翻页。虽然没有查询上限,但是size不能超过10000
2、scroll: 原理将排序数据形成快照,保存在内存。官方已经不推荐使用。缺点: 由于是快照,所以不能查到实时数据,由于是保存在内存,所以消耗内存
场景: 海量数据的获取和迁移。从es7.1开始不推荐
我们上面用的分页方式是 'from+size' 。优点: 支持随机翻页。缺点: 存在深度分页问题。场景: 百度、京东、谷歌、淘宝
10. 搜索结果处理-高亮
高亮: 就是在搜索结果中把搜索关键字突出显示。高亮显示的原理如下
1、将搜索结果中的关键字用标签标记出来
2、在页面中给标签添加css样式

首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
语法
GET /索引库名/_search
{"query": {"match": { //match表示带关键字的查询"字段": "TEXT"}},"highlight": {"fields": {"字段名": {"require_field_match": "false",//默认是true,表示 '字段' 要和 '字段名' 要一致。如果我们写的是不一致的话,就需要修改为false"pre_tags": "<em>", // 用来标记高亮字段的前置标签,es会帮我们把标签加在关键字上。默认是<em>"post_tags": "</em>" // 用来标记高亮字段的后置标签,es会帮我们把标签加在关键字上。默认是</em>}}}
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示
GET /gghotel/_search
{"query": {"match": {"xxALL": "北京"}},"highlight": {"fields": {"name": {"require_field_match": "false","pre_tags": "<em>","post_tags": "</em>"}}}
}


11. 搜索结果处理-总结
搜索结果处理的整体语法
GET /索引库名/_search
{"query": {"match": {"字段名": "如家"}},"from": 0, // 分页开始的位置"size": 20, // 期望获取的文档总数"sort": [ { "price": "asc" }, // 普通排序{"_geo_distance" : { // 距离排序"location" : "31.040699,121.618075", "order" : "asc","unit" : "km"}}],"highlight": {"fields": { // 高亮字段"字段名": {"pre_tags": "<em>", // 用来标记高亮字段的前置标签"post_tags": "</em>" // 用来标记高亮字段的后置标签}}}
}实用篇-ES-RestClient查询文档
1. 快速入门
上面的查询文档都是依赖kibana,在浏览器页面使用DSL语句去查询es,如何用java去查询es里面的文档(数据)呢

我们通过match_all查询来演示基本的API,注意下面演示的是 'match_all查询,也叫基础查询'
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
在进行下面的操作之前,确保你已经看了前面 '实用篇-ES-RestClient操作文档' 学的 '1. RestClient案例准备',然后在进行下面的操作
第一步: 在src/test/java/cn.itcast.hotel目录新建HotelSearchTest类,写入如下
package cn.itcast.hotel;import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
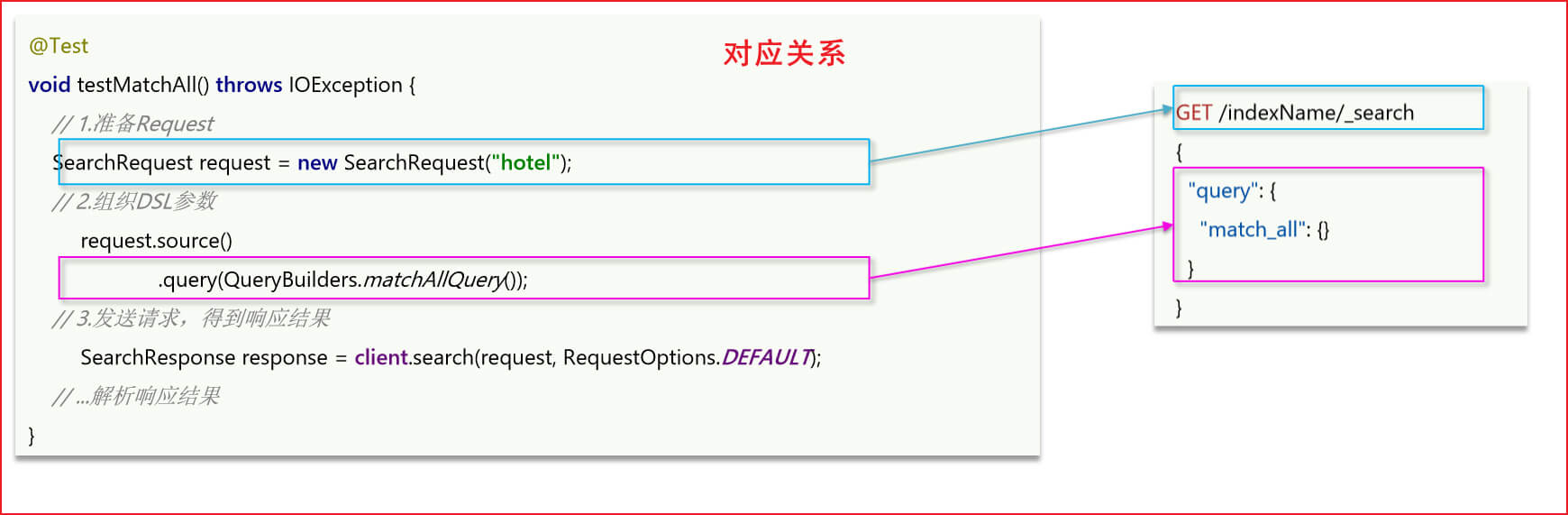
import org.junit.jupiter.api.Test;import java.io.IOException;public class HotelSearchTest {private RestHighLevelClient xxclient;@BeforeEach//该注解表示一开始就完成RestHighLevelClient对象的初始化void setUp() {this.xxclient = new RestHighLevelClient(RestClient.builder(//指定你Centos7部署的es的主机地址HttpHost.create("http://192.168.127.180:9200")));}@AfterEach//该注解表示销毁,当对象运行完之后,就销毁这个对象void tearDown() throws IOException {this.xxclient.close();}//-----------------------------上面是初始化,下面是查询文档-快速入门的测试-------------------------------------------@Testvoid xxtestMatchAll() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型xxrequest.source().query(QueryBuilders.matchAllQuery());//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//在控制台输出结果System.out.println(xxresponse);}
}
上面java代码以及对应的DSL语句如下图
第二步: 把控制台里面我们需要的数据解析出来。返回的数据很多,我们主要是解析hits里面的数据就行了
把HotelSearchTest类修改为如下,主要的修改是sout之前做了一次解析,拿到我们想要的数据
package cn.itcast.hotel;import cn.itcast.hotel.pojo.HotelDoc;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;import java.io.IOException;public class HotelSearchTest {private RestHighLevelClient xxclient;@BeforeEach//该注解表示一开始就完成RestHighLevelClient对象的初始化void setUp() {this.xxclient = new RestHighLevelClient(RestClient.builder(//指定你Centos7部署的es的主机地址HttpHost.create("http://192.168.127.180:9200")));}@AfterEach//该注解表示销毁,当对象运行完之后,就销毁这个对象void tearDown() throws IOException {this.xxclient.close();}//-----------------------------上面是初始化,下面是查询文档-快速入门的测试-------------------------------------------@Testvoid xxtestMatchAll() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型xxrequest.source().query(QueryBuilders.matchAllQuery());//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}}
}
上面java代码以及对应的DSL语句如下图

2. match的三种查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器

全文检索的 match 和 multi_match 查询与 match_all 的API基本一致。差别是查询条件,也就是query的部分,如下图

我们刚刚在第一节演示的是 match_all(也叫基本查询) 查询,下面将演示 match(也叫单字段查询) 和 multi_match(也叫多字段查询) 查询
【matc_all查询,也叫基本查询,我们在 '快速入门' 已经演示过】
在HotelSearchTest类添加如下(已做可跳过)
@Test
void xxtestMatchAll() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型xxrequest.source().query(QueryBuilders.matchAllQuery());//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
【match 查询,也叫单字段查询】
在HotelSearchTest类添加如下
@Test
void xxtestMatch() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型xxrequest.source().query(QueryBuilders.matchQuery("name","如家"));//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
【multi_match 查询,也叫多字段查询】
在HotelSearchTest类添加如下
@Testvoid xxtestMutilMatch() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型xxrequest.source().query(QueryBuilders.multiMatchQuery("如家","name","business"));//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}}
总结: 要构建查询条件,只要记住一个QueryBuilders类即可
3. 解析代码的抽取
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
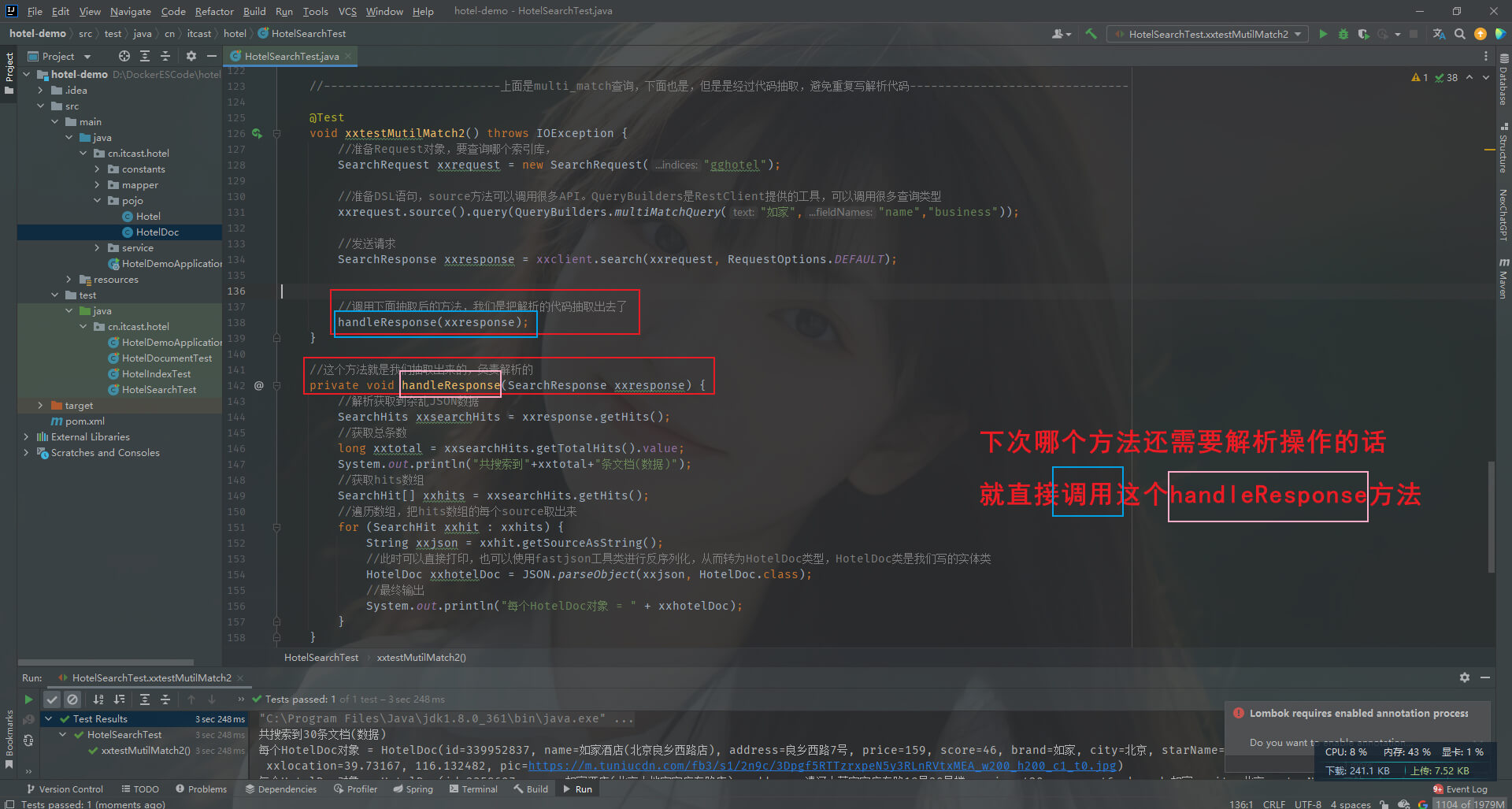
我们发现对于 match、multi_match、match_all 查询,的解析部分的代码都是相同的,所以我们可以对解析部分的代码进行抽取(ctrl+alt+m),如下
//这个方法就是我们抽取出来的,负责解析的
private void handleResponse(SearchResponse xxresponse) {//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
4. term、range精确查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。精确查询常见的有两种:
term: 根据词条的精确值查询,强调精确匹配range: 根据值的范围查询,例如金额、时间
java代码和DSL语句的对应关系如下图。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于

【term查询】在HotelSearchTest类添加如下
@Test
void xxtestTerm() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型xxrequest.source().query(QueryBuilders.termQuery("city","上海"));//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
【range查询】在HotelSearchTest类添加如下
@Test
void xxtestTerm() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型xxrequest.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(150));//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
总结: 要构建查询条件,只要记住一个QueryBuilders类即可
5. bool复合查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
java代码和DSL语句的对应关系如下图

【bool查询】在HotelSearchTest类添加如下
@Test
void xxtestBool() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//创建布尔查询BoolQueryBuilder xxboolQuery = QueryBuilders.boolQuery();//添加must条件xxboolQuery.must(QueryBuilders.termQuery("city","上海"));//添加filter条件xxboolQuery.filter(QueryBuilders.rangeQuery("price").lte(200));//把上面的布尔对象传进来,就可以生效了xxrequest.source().query(xxboolQuery);//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
总结: 要构建查询条件,只要记住一个QueryBuilders类即可
6. geo_distance地理查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
【geo_distance查询】在HotelSearchTest类添加如下
@Test
void xxtestGeoDistance() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//创建一个地理位置查询构造器,指定了要查询字段的是xxlocationGeoDistanceQueryBuilder xxgeoQuery = QueryBuilders.geoDistanceQuery("xxlocation");xxgeoQuery.point(31.25, 121.5);//设置查询的中心点坐标,这里的经度和纬度分别为 31.25 和 121.5xxgeoQuery.distance(5, DistanceUnit.KILOMETERS);//设置查询的半径距离和单位,这里的 5 即表示 5 公里// 创建一个查询构造器SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 将查询条件添加到查询构造器对象searchSourceBuilder.query(xxgeoQuery);// 将查询构造器的对象,添加到查询请求对象xxrequest中,就可以生效了xxrequest.source(searchSourceBuilder);//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
总结: 要构建查询条件,只要记住一个QueryBuilders类即可
7. 排序和分页
上面是各种查询的学习,当我们把文档查询出来的时候,接下来就是对文档的处理,也就是你要把查询结果怎么展示出来。API以及对应的DSL语句如下图
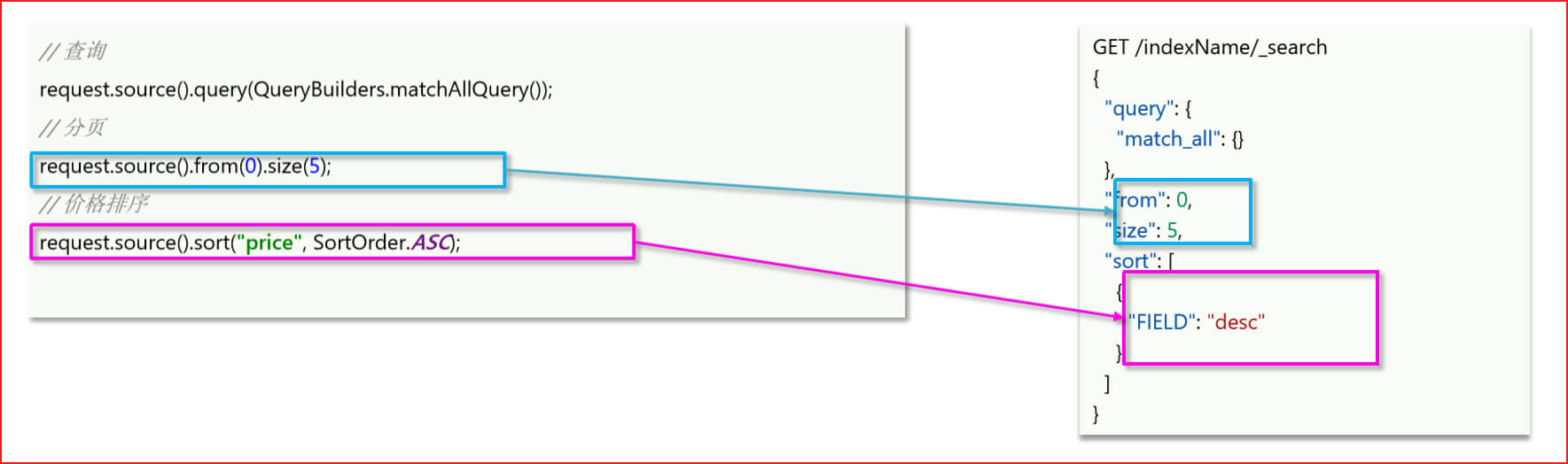
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
【排序、分页】在HotelSearchTest类添加如下
@Test
void xxtestPageAndSort() throws IOException {//页面、每页大小。如果你要翻第二页,就把下面的xxpage改成2int xxpage = 1, xxsize = 5;//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//查询全部xxrequest.source().query(QueryBuilders.matchAllQuery());//sort排序,asc升序,desc降序xxrequest.source().sort("price", SortOrder.ASC);//from、size分页。例如查第一页,每页显示5条文档(数据)。from表示当前页,我们使用公式动态设定xxrequest.source().from((xxpage-1)*xxsize).size(5);//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
8. 高亮显示
高亮API包括请求DSL构建和结果解析两部分,API和对应的DSL语句如下图,下图只是构建,再下面还有解析,高亮必须由构建+解析才能实现

解析,如下图

首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
【高亮显示-】在HotelSearchTest类添加如下
@Test
void xxtestHightlight() throws IOException {//准备Request对象,要查询哪个索引库,SearchRequest xxrequest = new SearchRequest("gghotel");//【构建】//查询name字段的文档xxrequest.source().query(QueryBuilders.matchQuery("name","上海"));//对查询出来的文档,的特定字段进行高亮显示xxrequest.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(true).preTags("<em>").postTags("</em>"));//发送请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析获取到杂乱JSON数据SearchHits xxsearchHits = xxresponse.getHits();//获取总条数long xxtotal = xxsearchHits.getTotalHits().value;System.out.println("共搜索到"+xxtotal+"条文档(数据)");//获取hits数组SearchHit[] xxhits = xxsearchHits.getHits();//遍历数组,把hits数组的每个source取出来for (SearchHit xxhit : xxhits) {String xxjson = xxhit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);//【解析】获取高亮结果Map<String, HighlightField> xxhighlightFields = xxhit.getHighlightFields();//使用CollectionUtils工具类,进行判空,避免空指针if (!CollectionUtils.isEmpty(xxhighlightFields)){//根据字段名获取高亮结果HighlightField xxhighlightField = xxhighlightFields.get("name");//判断name不为空if (xxhighlightField != null) {//获取高亮值String xxname = xxhighlightField.getFragments()[0].string();//覆盖非高亮结果xxhotelDoc.setName(xxname);}}//最终输出System.out.println("每个HotelDoc对象 = " + xxhotelDoc);}
}
实用篇-ES-黑马旅游案例
这个案例我做了两遍才做出来了,第一遍排了一上午的错,所以很有必要进行环境准备,下面我将带领你对一下我的环境,全网最详细的自创笔记
1. 环境准备-docker
企业部署一般都是采用Linux操作系统,而其中又数CentOS发行版占比最多,因此我们接下来会在CentOS下安装Docker
CentOS7镜像快速下载,我正在用的
https://cowtransfer.com/s/56423adc78374f远程软件FinalShell快速下载,我正在用的
https://cowtransfer.com/s/b4c8fcb5c15244
idea+jdk下载
https://cowtransfer.com/s/7dcb0c66154d45
mysql下载
https://cowtransfer.com/s/567413055c9a4f
第一步: 在VMware虚拟机安装CentOS7系统,安装完成之后,使用finalshell远程软件进行远程连接,然后安装yum工具,执行如下
yum install -y yum-utils \device-mapper-persistent-data \lvm2 --skip-broken
第二步: 更新本地镜像源,执行如下
# 设置docker镜像源
yum-config-manager \--add-repo \https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.reposed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repoyum makecache fast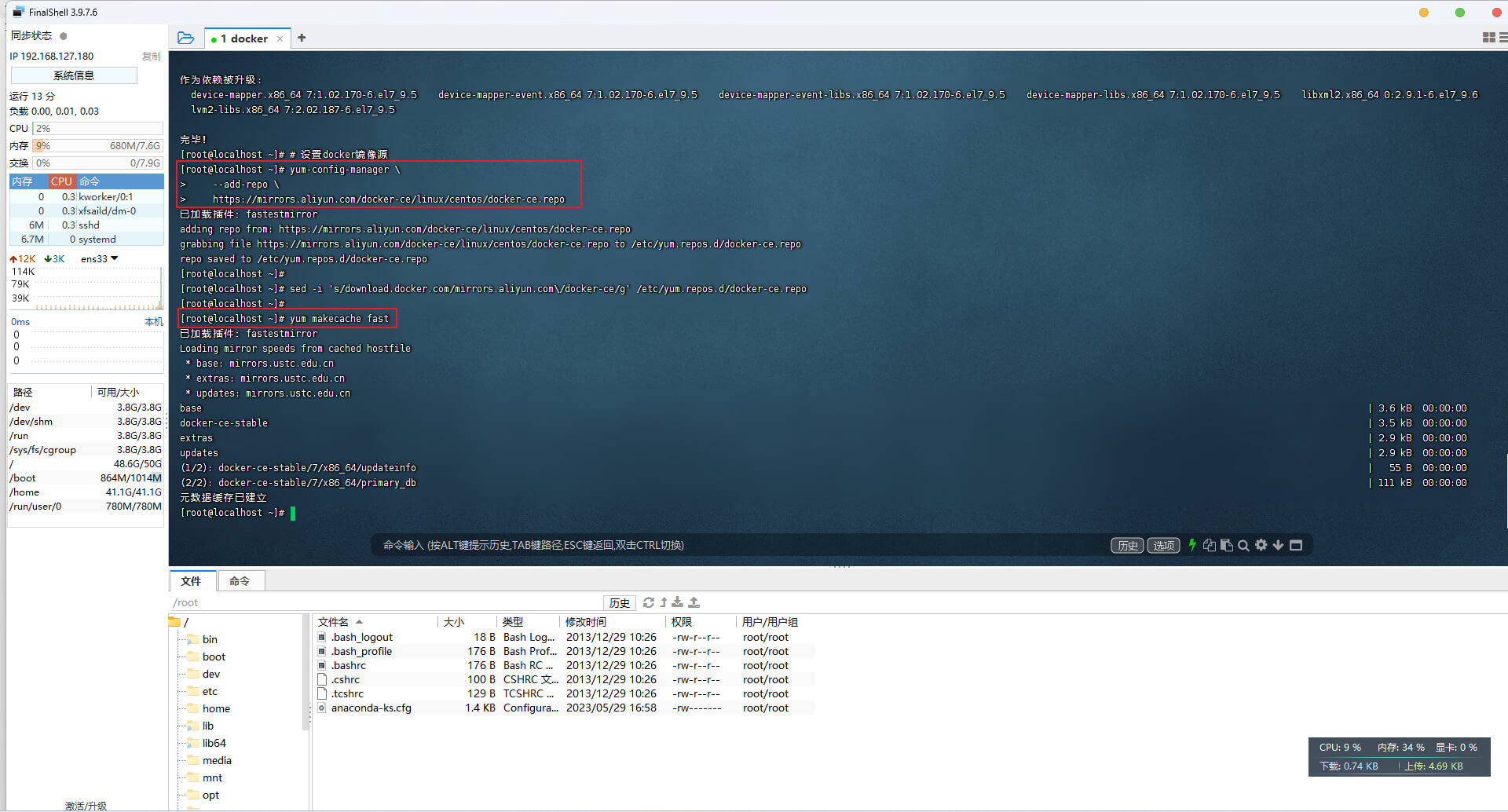
第三步: 执行如下安装docker,稍等片刻,docker即可安装成功。docker-ce为社区免费版本
yum install -y docker-ce
第四步: 由于Docker应用需要用到各种端口,逐一去修改防火墙设置,会非常麻烦,所以学习期间直接关闭防火墙即可
# 关闭
systemctl stop firewalld
# 禁止开机启动防火墙
systemctl disable firewalld
第五步: 通过命令启动docker
systemctl start docker # 启动docker服务systemctl stop docker # 停止docker服务systemctl restart docker # 重启docker服务systemctl status docker # 查看docker的启动状态docker -v # 查看docker版本
第六步: 配置docker镜像仓库,设置为国内的镜像仓库,以后在docker里面下载东西的时候速度会更快。分别执行如下命令
sudo mkdir -p /etc/docker # 创建文件夹sudo tee /etc/docker/daemon.json <<-'EOF'
{"registry-mirrors": ["https://93we6x1g.mirror.aliyuncs.com"]
}
EOF # 在刚刚创建的文件夹里面新建daemon.json文件,并写入花括号里面的数据sudo systemctl daemon-reload # 重新加载daemon.json文件sudo systemctl restart docker # 重启docker
2. 环境准备-elasticsearch
第一步: 创建网络
systemctl start docker # 启动docker服务
docker network create es-net #创建一个网络,名字是es-net
第二步: 加载es镜像。采用elasticsearch的7.12.1版本的镜像,这个镜像体积有800多MB,所以需要在Windows上下载链接安装包,下载下来是一个es的镜像tar包,然后传到CentOS7的/root目录
es.tar下载: https://cowtransfer.com/s/c84ac851b9ba44kibana.tar下载: https://cowtransfer.com/s/a76d8339d7ba4d
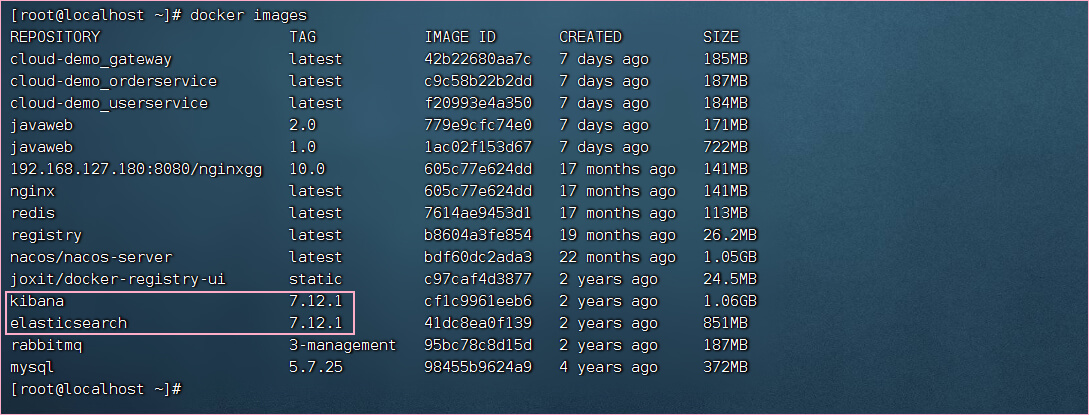
第三步: 把在CentOS7的/root目录的es镜像,导入到docker
docker load -i es.tar
第四步: 创建并运行es容器,容器名称就叫es。在docker(也叫Docker大容器、Docker主机、宿主机),根据es镜像来创建es容器
docker run -d \--name es \-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \-e "discovery.type=single-node" \-v es-data:/usr/share/elasticsearch/data \-v es-plugins:/usr/share/elasticsearch/plugins \--privileged \--network es-net \-p 9200:9200 \-p 9300:9300 \
elasticsearch:7.12.1
然后,在浏览器中输入:http://你的ip地址:9200 即可看到elasticsearch的响应结果

3. 环境准备-mysql
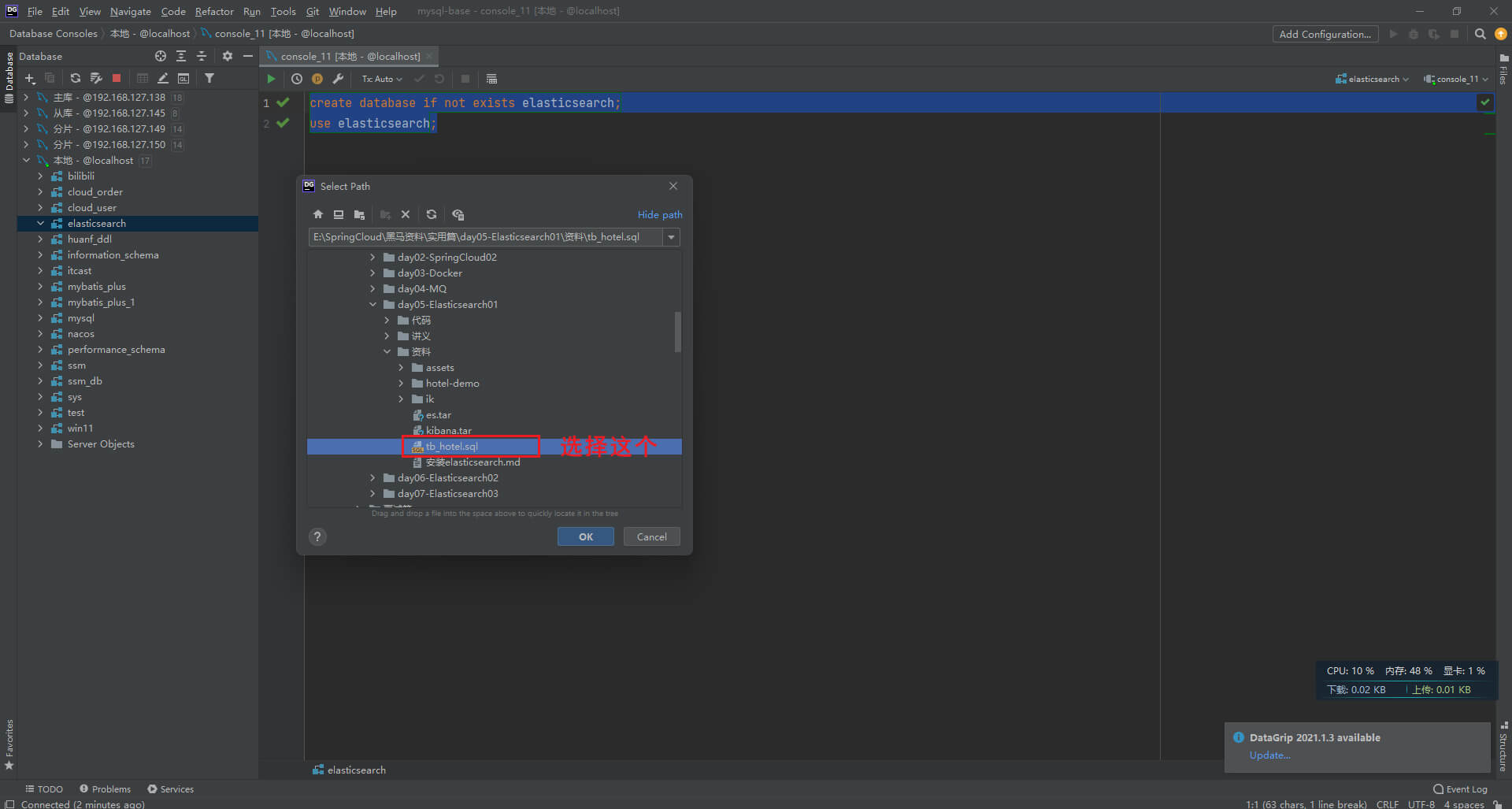
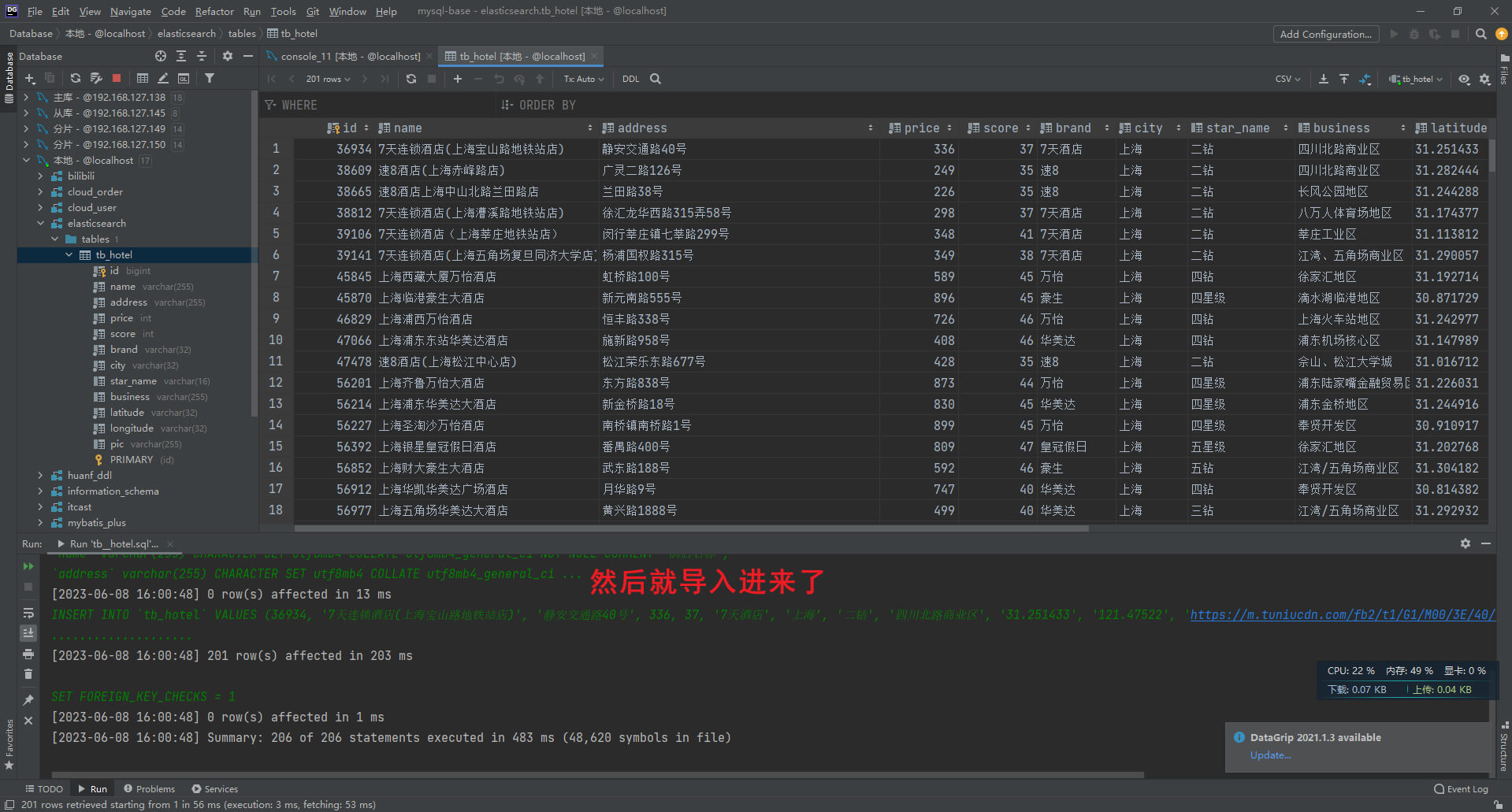
第一步: 打开database软件,把tb_hotel.sql文件导入进你的数据库
tb_hotel.sql下载: https://cowtransfer.com/s/68c94a66d17248create database if not exists elasticsearch;
use elasticsearch;
4. 环境准备-项目导入
第一步: 把下载好的hotel-demo.zip压缩包解压,得到hotel-demo文件夹,在idea打开hotel-demo
hotel-demo.zip下载:https://cowtransfer.com/s/36ac0a9f9d9043
第二步: 修改application.yml文件,配置正确的数据库信息

第三步: 把pom.xml修改为如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.10.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>cn.itcast.demo</groupId><artifactId>hotel-demo</artifactId><version>0.0.1-SNAPSHOT</version><name>hotel-demo</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version><elasticsearch.version>7.12.1</elasticsearch.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--引入es的RestHighLevelClient,版本要跟你Centos7里面部署的es版本一致--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.12.1</version></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-boot-starter</artifactId><version>3.4.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><scope>runtime</scope></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintage-engine</artifactId></exclusion></exclusions></dependency><!--FastJson--><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.71</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build></project>
5. 环境准备-同步数据
把mysql的数据导入进es,我们需要使用前面学的es提供的RestClient,就可以通过java代码创建索引库,并往这个索引库导入文档(文档就是数据的意思)
第一步: 在hotel-demo项目的 src/test/java/cn.itcast.hotel 目录新建 HotelIndexTest 类,用于在es中创建名为hotel的索引库,写入如下
写完就运行xxcreateHotelIndex方法,把索引库创建出来
package cn.itcast.hotel;import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
import static cn.itcast.hotel.constants.HotelConstants.xxMappingTemplate;public class HotelIndexTest {private RestHighLevelClient xxclient;@BeforeEach//该注解表示一开始就完成RestHighLevelClient对象的初始化void setUp() {this.xxclient = new RestHighLevelClient(RestClient.builder(//指定你Centos7部署的es的主机地址HttpHost.create("http://192.168.127.180:9200")));}@AfterEach//该注解表示销毁,当对象运行完之后,就销毁这个对象void tearDown() throws IOException {this.xxclient.close();}//删除索引库(如果下面创建hotel索引库的时候,出现已存在,那么就执行这里的删除操作,把hotel索引库删掉,再创建)@Testvoid xxtestDeleteHotelIndex() throws IOException {//创建Request对象,指定要删除哪个索引库DeleteIndexRequest gghotel = new DeleteIndexRequest("hotel");//发送请求xxclient.indices().delete(gghotel, RequestOptions.DEFAULT);}//使用xxclient对象,向es创建索引库@Testvoid xxcreateHotelIndex() throws IOException {//创建Request对象,自定义索引库名称为hotelCreateIndexRequest gghotel = new CreateIndexRequest("hotel");//准备请求的参数: DSL语句gghotel.source(xxMappingTemplate, XContentType.JSON);//发送请求xxclient.indices().create(gghotel, RequestOptions.DEFAULT);}
}
第二步: 在hotel-demo项目的 src/main/java/cn.itcast.hotel 目录新建 constants.HotelConstants类,为es准备数据,写入如下
package cn.itcast.hotel.constants;public class HotelConstants {public static final String xxMappingTemplate = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\",\n" +" \"index\": true\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\",\n" +" \"index\": true\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true,\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true,\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\",\n" +" \"index\": true\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": true\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
}
第三步(这一步好像项目本身做好了,已做可跳过): 在hotel-demo项目的 src/main/java/cn.itcast.hotel/pojo 目录新建Hotel、HotelDoc类,写入如下
package cn.itcast.hotel.pojo;import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;@Data
@TableName("tb_hotel")
public class Hotel {@TableId(type = IdType.INPUT)private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String longitude;private String latitude;private String pic;
}package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}
第四步: 在hotel-demo项目的 src/test/java/cn.itcast.hotel 目录新建 HotelDocumentTest类,用于把mysql的数据批量导入进es,写入如下
写完就运行testBulkRequest方法,把数据往索引库里面批量导入
package cn.itcast.hotel;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;import java.io.IOException;
import java.util.List;@SpringBootTest
public class HotelDocumentTest {private RestHighLevelClient xxclient;@BeforeEach//该注解表示一开始就完成RestHighLevelClient对象的初始化void setUp() {this.xxclient = new RestHighLevelClient(RestClient.builder(//指定你Centos7部署的es的主机地址HttpHost.create("http://192.168.127.180:9200")));}@AfterEach//该注解表示销毁,当对象运行完之后,就销毁这个对象void tearDown() throws IOException {this.xxclient.close();}@Autowired//注入写好的IHotelService接口,用于去数据库查询数据private IHotelService xxhotelService;@Testvoid testBulkRequest() throws IOException {//向数据库批量查询酒店数据,list方法表示查询数据库的所有数据List<Hotel> kkhotels = xxhotelService.list();//创建RequestBulkRequest vvrequest = new BulkRequest();//准备参数,实际上就是添加多个新增的Requestfor (Hotel kkhotel : kkhotels) {//把遍历拿到的每个kkhotels转换为文档类型的数据HotelDoc ffhotelDoc = new HotelDoc(kkhotel);//HotelDoc是我们写的一个实体类//往哪个索引库批量新增文档、新增后的文档id是什么,文档类型是JSONvvrequest.add(new IndexRequest("hotel").id(ffhotelDoc.getId().toString())//JSON.parseObject()是com.alibaba.fastjson提供的API,作用是对ffhotelDoc进行反序列化准换为json类型.source(JSON.toJSONString(ffhotelDoc),XContentType.JSON));}//发送请求xxclient.bulk(vvrequest,RequestOptions.DEFAULT);}}
6. 搜索、分页
【请保证网络正常,否则页面的静态资源部分加载不了】
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
实现步骤如下
一、根据前端的请求,定义实体类来接收前端的请求

(1)在pojo目录新建RequestParams类,写入如下
package cn.itcast.hotel.pojo;import lombok.Data;@Data
public class RequestParams {//搜索关键字private String key;//当前页码private Integer page;//每页大小private Integer size;//将来的排序字段private String sortBy;
}二、定义controller接口,接收页面请求,调用IHotelService的search方法

(1)在pojo目录新建PageResult类,写入如下
package cn.itcast.hotel.pojo;import lombok.Data;
import java.util.List;@Data
public class PageResult {//总条数private Long total;//类型private List<HotelDoc> hotels;//不带参构造函数public PageResult() {}//带参构造函数public PageResult(Long total, List<HotelDoc> hotels) {this.total = total;this.hotels = hotels;}
}(2)、把IHotelService接口,修改为如下
package cn.itcast.hotel.service;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import com.baomidou.mybatisplus.extension.service.IService;public interface IHotelService extends IService<Hotel> {PageResult search(RequestParams params);
}
(3)、把HotelDemoApplication启动类,修改为如下
package cn.itcast.hotel;import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;@MapperScan("cn.itcast.hotel.mapper")
@SpringBootApplication
public class HotelDemoApplication {public static void main(String[] args) {SpringApplication.run(HotelDemoApplication.class, args);}@Bean//注入es提供的RestHighLevelClient类public RestHighLevelClient client(){return new RestHighLevelClient(RestClient.builder(//指定你Centos7部署的es的主机地址HttpHost.create("http://192.168.127.180:9200")));}}
(4)、在src/main/java/cn.itcast.hotel目录新建web.HotelController类,写入如下
package cn.itcast.hotel.web;import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/hotel")
public class HotelController {//注入项目准备好的IHotelService接口@Autowiredprivate IHotelService hotelService;@PostMapping("/list")//使用@RequestBody注解,接收前端的请求。PageResult、RequestParams是我们刚刚定义的实体类public PageResult search(@RequestBody RequestParams params){return hotelService.search(params);}
}
三、定义IHotelService中的search方法,利用match查询实现根据关键字搜索酒店信息
(4)、把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowired//注入在引导类声明好的@Beanprivate RestHighLevelClient client;@Overridepublic PageResult search(RequestParams params) {try {//准备Request对象,要查询哪个索引库,SearchRequest request = new SearchRequest("hotel");//【关键字搜索功能】String key = params.getKey();//前端传过来的搜索关键字//判断前端传的key是否为空,避免空指针if (key == null || "".equals(key)) {//matchAllQuery方法表示查es的全部文档,不需要条件request.source().query(QueryBuilders.matchAllQuery());} else {//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空request.source().query(QueryBuilders.matchQuery("all", key));}//【分页功能】int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型request.source().from((page - 1) * size).size(size);//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下SearchResponse response = client.search(request, RequestOptions.DEFAULT);//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回return handleResponse(response);} catch (IOException e) {throw new RuntimeException(e);}}//这个方法就是我们抽取出来的,负责解析的private PageResult handleResponse(SearchResponse response) {//解析获取到杂乱JSON数据SearchHits searchHits = response.getHits();//获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+total+"条文档(数据)");//获取hits数组SearchHit[] hits = searchHits.getHits();//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合List<HotelDoc> hotels = new ArrayList<>();for (SearchHit hit : hits) {String json = hit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);hotels.add(hotelDoc);}//封装返回return new PageResult(total,hotels);}
}
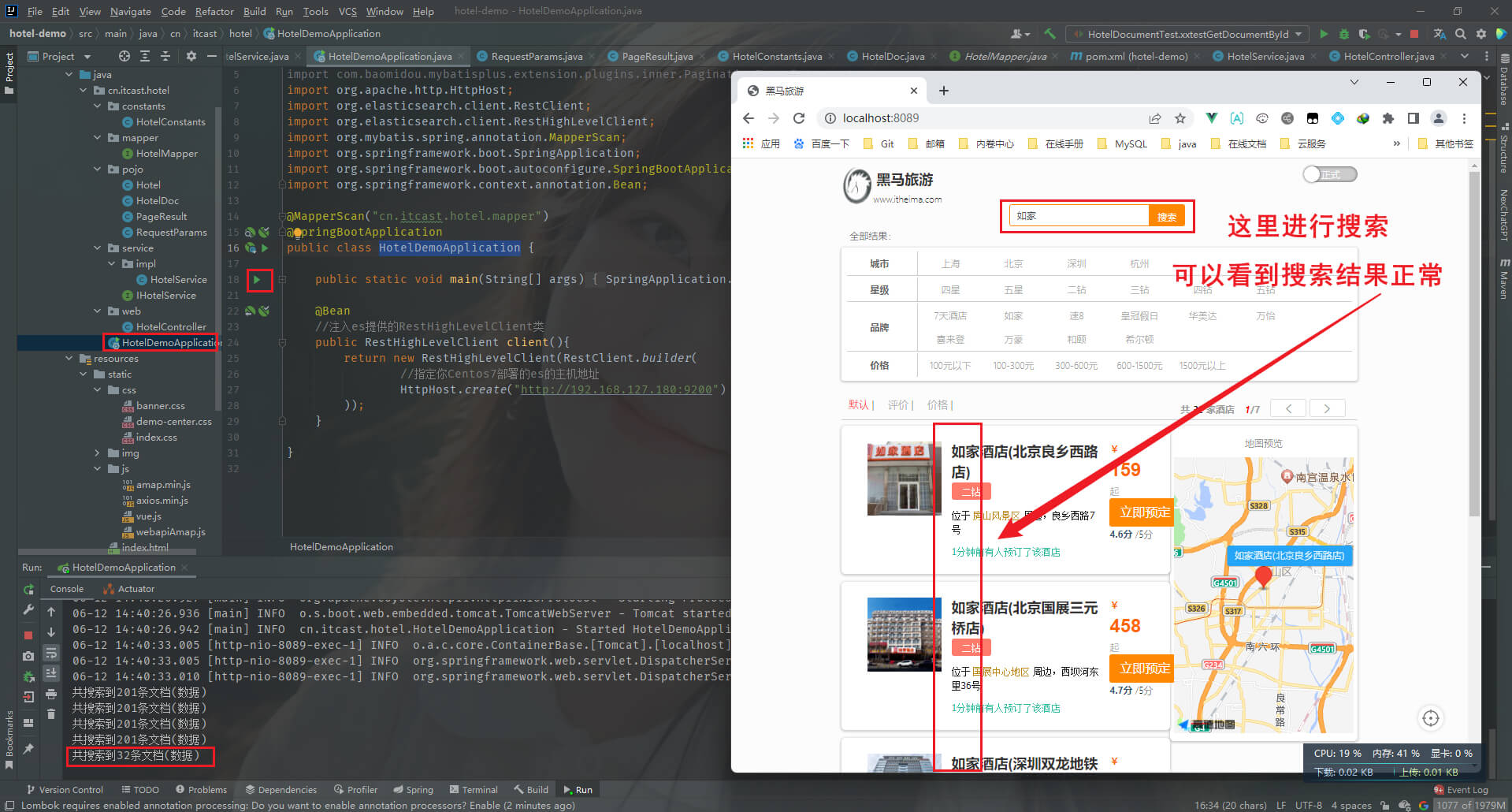
四、运行HotelDemoApplication引导类,浏览器访问 http://localhost:8089/
7. 条件过滤
先看需求。添加品牌、城市、星级、价格等条件过滤功能

分析:
1、修改RequestParams类,添加brand、city、startName、minPrice、maxPrice等参数
2、修改HotelService类的search方法的实现,在关键字搜索时,如果brand等参数存在,就需要对其做过滤
3、注意多个条件之间是AND关系,组合多条件用BooleanQuery
4、参数存在才需要过滤,做好非空判断
5、city精确匹配,brand精确匹配,startName精确匹配,price范围过滤
第一步: 把RequestParams类,修改为如下
package cn.itcast.hotel.pojo;import lombok.Data;@Data
public class RequestParams {//搜索关键字private String key;//当前页码private Integer page;//每页大小private Integer size;//将来的排序字段private String sortBy;//城市private String city;//品牌private String brand;//星级private String starName;//价格最小值private Integer minPrice;//价格最大值private Integer maxPrice;
}
第二步: 把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowired//注入在引导类声明好的@Beanprivate RestHighLevelClient client;@Overridepublic PageResult search(RequestParams params) {try {//准备Request对象,要查询哪个索引库,SearchRequest request = new SearchRequest("hotel");//【构建BooleanQuery】BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//【关键字搜索】//判断前端传的key是否为空,避免空指针String key = params.getKey();//前端传过来的搜索关键字//用的是must精确查找if (key == null || "".equals(key)) {//matchAllQuery方法表示查es的全部文档,不需要条件boolQuery.must(QueryBuilders.matchAllQuery());} else {//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空boolQuery.must(QueryBuilders.matchQuery("all", key));}//【条件过滤】//城市,term精确查找,注意判空if(params.getCity() != null && !params.getCity().equals("")){boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));}//品牌,term精确查找,注意判空if(params.getBrand() != null && !params.getBrand().equals("")){boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));}//星级,term精确查找,注意判空if(params.getStarName() != null && !params.getStarName().equals("")){//注意下面那行的是starName,不要写成startNameboolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));}//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于if(params.getMinPrice() != null && params.getMaxPrice() != null){boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}//这一步必须有request.source().query(boolQuery);//【分页功能】int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型request.source().from((page - 1) * size).size(size);//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下SearchResponse response = client.search(request, RequestOptions.DEFAULT);//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回return handleResponse(response);} catch (IOException e) {throw new RuntimeException(e);}}//这个方法就是我们抽取出来的,负责解析的private PageResult handleResponse(SearchResponse response) {//解析获取到杂乱JSON数据SearchHits searchHits = response.getHits();//获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+total+"条文档(数据)");//获取hits数组SearchHit[] hits = searchHits.getHits();//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合List<HotelDoc> hotels = new ArrayList<>();for (SearchHit hit : hits) {String json = hit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);hotels.add(hotelDoc);}//封装返回return new PageResult(total,hotels);}
}
第三步: 运行HotelDemoApplication引导类,浏览器访问 http://localhost:8089/

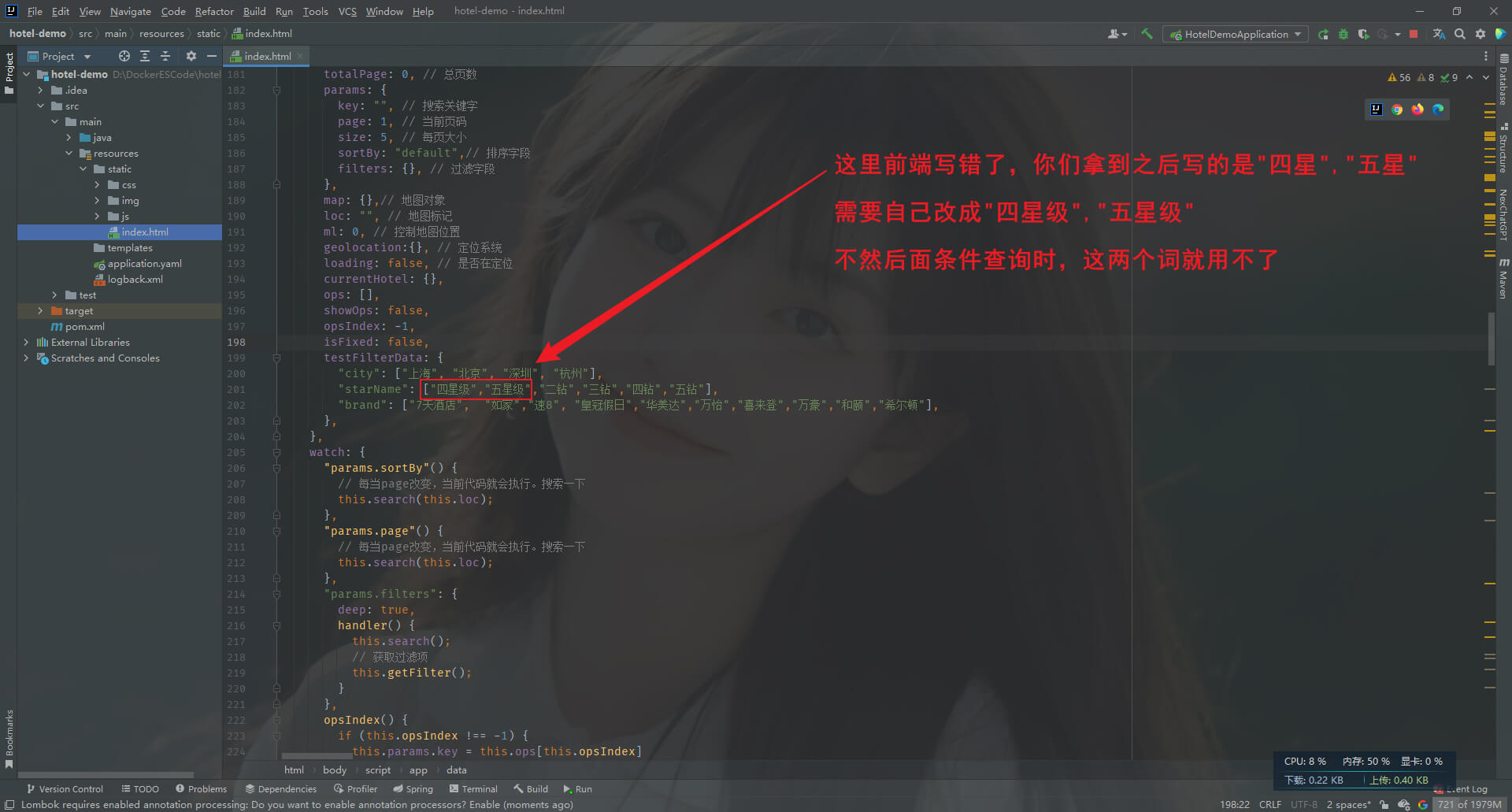
第四步: 解决"四星","五星" 无法作为条件进行查询的问题
8. 我附近的酒店
需求: 实现前端页面点击定位后,会将你所在的位置发送给后台,前端的请求信息如下,会向后端发送location参数。
如果谷歌浏览器发送不了位置请求的话,建议临时换成火狐浏览器

分析:
1、修改RequestParams参数,接收来自前端的location字段
2、修改HotelService类的search方法的业务逻辑,如果location有值,就添加根据geo_distance排序的功能
java代码实现距离排序,对应的DSL语句如下

第一步: 把RequestParams类,修改为如下
package cn.itcast.hotel.pojo;import lombok.Data;@Data
public class RequestParams {//搜索关键字private String key;//当前页码private Integer page;//每页大小private Integer size;//将来的排序字段private String sortBy;//城市private String city;//品牌private String brand;//星级private String starName;//价格最小值private Integer minPrice;//价格最大值private Integer maxPrice;//地理位置查询的字段,前端会把location传给我们private String location;
}
第二步: 把HotelDoc类,修改为如下
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;//地理位置查询相关的字段。distance字段用于保存解析后的距离值private Object distance;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}
第三步: 把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowired//注入在引导类声明好的@Beanprivate RestHighLevelClient client;@Overridepublic PageResult search(RequestParams params) {try {//准备Request对象,要查询哪个索引库,SearchRequest request = new SearchRequest("hotel");//【构建BooleanQuery】BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//【关键字搜索】//判断前端传的key是否为空,避免空指针String key = params.getKey();//前端传过来的搜索关键字//用的是must精确查找if (key == null || "".equals(key)) {//matchAllQuery方法表示查es的全部文档,不需要条件boolQuery.must(QueryBuilders.matchAllQuery());} else {//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空boolQuery.must(QueryBuilders.matchQuery("all", key));}//【条件过滤】//城市,term精确查找,注意判空if(params.getCity() != null && !params.getCity().equals("")){boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));}//品牌,term精确查找,注意判空if(params.getBrand() != null && !params.getBrand().equals("")){boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));}//星级,term精确查找,注意判空if(params.getStarName() != null && !params.getStarName().equals("")){boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));}//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于if(params.getMinPrice() != null && params.getMaxPrice() != null){boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}//这一步必须有request.source().query(boolQuery);//【分页功能】int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型request.source().from((page - 1) * size).size(size);//【地理排序功能】String location = params.getLocation();//对前端传的location进行判断是否为空if (location != null && !location.equals("")){//sort排序,指定是geoDistanceSort地理坐标排序,要排序的字段是location,中心点是new GeoPoint(location)request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location)).order(SortOrder.ASC) //升序排序.unit(DistanceUnit.KILOMETERS) //地理坐标的单位);}//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下SearchResponse response = client.search(request, RequestOptions.DEFAULT);//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回return handleResponse(response);} catch (IOException e) {throw new RuntimeException(e);}}//这个方法就是我们抽取出来的,负责解析的private PageResult handleResponse(SearchResponse response) {//解析获取到杂乱JSON数据SearchHits searchHits = response.getHits();//获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+total+"条文档(数据)");//获取hits数组SearchHit[] hits = searchHits.getHits();//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合List<HotelDoc> hotels = new ArrayList<>();for (SearchHit hit : hits) {String json = hit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);//【地理坐标查询的解析】,通过getSortValues方法来获取排序值,得到的是多个值也就是数组,我们只需要一个值Object[] sortValues = hit.getSortValues();//判断是否为空if (sortValues.length>0){Object sortValue = sortValues[0];//把拿到的sortValue返回到页面,也就是需要把sortValue值放到HoteDochotelDoc.setDistance(sortValue);}hotels.add(hotelDoc);}//封装返回return new PageResult(total,hotels);}
}第四步: 重启HotelDemoApplication引导类,浏览器访问http://localhost:8089/。点击定位按钮,查看是否能查询出距离自己最近的酒店并显示米数

9. 广告置顶
需求: 让指定的酒店在搜索结果中排名置顶。我们给需要置顶的酒店文档添加一个标记。然后利用function score给带有标记的文档增加权重
分析:
1、给HotelDoc类添加isAD字段,Boolean类型
2、挑选几个你喜欢的酒店,给它的文档数据添加isAD字段,值为true
3、修改HotelService类的search方法,添加function score功能,给isAD值为true的酒店增加权重
Function Score查询可以控制文档的相关性算分,java代码以及对应DSL语句如下图

第一步: 把HotelDoc类,修改为如下
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;//地理位置查询相关的字段。distance字段用于保存解析后的距离值private Object distance;//用于广告置顶的字段private Boolean isAD;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();}
}
第二步: 使用DSL语句为索引库增加字段,由于使用DSL语句需要在浏览器使用kibana,所以我们把docker里面的kibana容器运行一下
docker restart kibana #启动kibana容器
第三步: 启动kibana之后,浏览器访问 http://你的ip地址:5601
第四步: DSL语句,表示给某个id文档添加新字段。id不一定要跟我一样,随便去mysql数据库找几个id就行
POST /hotel/_update/1557997004
{"doc":{"isAD": true}
}
POST /hotel/_update/1406627919
{"doc":{"isAD": true}
}
第五步: 把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowired//注入在引导类声明好的@Beanprivate RestHighLevelClient client;@Overridepublic PageResult search(RequestParams params) {try {//准备Request对象,要查询哪个索引库,SearchRequest request = new SearchRequest("hotel");//【构建BooleanQuery,下面那行的boolQuery是原始查询】BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//【关键字搜索】//判断前端传的key是否为空,避免空指针String key = params.getKey();//前端传过来的搜索关键字//用的是must精确查找if (key == null || "".equals(key)) {//matchAllQuery方法表示查es的全部文档,不需要条件boolQuery.must(QueryBuilders.matchAllQuery());} else {//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空boolQuery.must(QueryBuilders.matchQuery("all", key));}//【条件过滤】//城市,term精确查找,注意判空if(params.getCity() != null && !params.getCity().equals("")){boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));}//品牌,term精确查找,注意判空if(params.getBrand() != null && !params.getBrand().equals("")){boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));}//星级,term精确查找,注意判空if(params.getStarName() != null && !params.getStarName().equals("")){boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));}//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于if(params.getMinPrice() != null && params.getMaxPrice() != null){boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}//【构建functionScoreQuery,实现算分查询。对应的是广告置顶功能】FunctionScoreQueryBuilder functionScoreQuery =//原始查询,需要进行相关性算分的查询QueryBuilders.functionScoreQuery(boolQuery,//function score的数组,里面有很多function scorenew FunctionScoreQueryBuilder.FilterFunctionBuilder[]{//一个具体的function scorenew FunctionScoreQueryBuilder.FilterFunctionBuilder(//过滤,简单说就是满足isAD字段为true的文档就会参与算分QueryBuilders.termQuery("isAD",true),//要使用什么算分函数,下面那行使用的是weightFactorFunction加权算分,最终score分数越大,排名就越前ScoreFunctionBuilders.weightFactorFunction(10)//算出来的最终score就会被乘10) });//这一步必须有request.source().query(functionScoreQuery);//【分页功能】int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型request.source().from((page - 1) * size).size(size);//【地理排序功能】String location = params.getLocation();//对前端传的location进行判断是否为空if (location != null && !location.equals("")){//sort排序,指定是geoDistanceSort地理坐标排序,要排序的字段是location,中心点是new GeoPoint(location)request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location)).order(SortOrder.ASC) //升序排序.unit(DistanceUnit.KILOMETERS) //地理坐标的单位);}//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下SearchResponse response = client.search(request, RequestOptions.DEFAULT);//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回return handleResponse(response);} catch (IOException e) {throw new RuntimeException(e);}}//这个方法就是我们抽取出来的,负责解析的private PageResult handleResponse(SearchResponse response) {//解析获取到杂乱JSON数据SearchHits searchHits = response.getHits();//获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+total+"条文档(数据)");//获取hits数组SearchHit[] hits = searchHits.getHits();//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合List<HotelDoc> hotels = new ArrayList<>();for (SearchHit hit : hits) {String json = hit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);//【地理坐标查询的解析】,通过getSortValues方法来获取排序值,得到的是多个值也就是数组,我们只需要一个值Object[] sortValues = hit.getSortValues();//判断是否为空if (sortValues.length>0){Object sortValue = sortValues[0];//把拿到的sortValue返回到页面,也就是需要把sortValue值放到HoteDochotelDoc.setDistance(sortValue);}hotels.add(hotelDoc);}//封装返回return new PageResult(total,hotels);}
}
第六步: 重启HotelDemoApplication引导类,浏览器访问http://localhost:8089/。查看我们指定的那两个酒店是否置顶
10. 高亮显示
高亮API包括请求DSL构建和结果解析两部分,API和对应的DSL语句如下图,下图只是构建,再下面还有解析,高亮必须由构建+解析才能实现

解析,如下图

第一步: 把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.toolkit.CollectionUtils;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowired//注入在引导类声明好的@Beanprivate RestHighLevelClient client;@Overridepublic PageResult search(RequestParams params) {try {//准备Request对象,要查询哪个索引库,SearchRequest request = new SearchRequest("hotel");//【构建BooleanQuery,下面那行的boolQuery是原始查询】BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//【关键字搜索】//判断前端传的key是否为空,避免空指针String key = params.getKey();//前端传过来的搜索关键字//用的是must精确查找if (key == null || "".equals(key)) {//matchAllQuery方法表示查es的全部文档,不需要条件boolQuery.must(QueryBuilders.matchAllQuery());} else {//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空boolQuery.must(QueryBuilders.matchQuery("all", key));}//【条件过滤】//城市,term精确查找,注意判空if(params.getCity() != null && !params.getCity().equals("")){boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));}//品牌,term精确查找,注意判空if(params.getBrand() != null && !params.getBrand().equals("")){boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));}//星级,term精确查找,注意判空if(params.getStarName() != null && !params.getStarName().equals("")){boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));}//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于if(params.getMinPrice() != null && params.getMaxPrice() != null){boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}//【构建functionScoreQuery,实现算分查询。对应的是广告置顶功能】FunctionScoreQueryBuilder functionScoreQuery =//原始查询,需要进行相关性算分的查询QueryBuilders.functionScoreQuery(boolQuery,//function score的数组,里面有很多function scorenew FunctionScoreQueryBuilder.FilterFunctionBuilder[]{//一个具体的function scorenew FunctionScoreQueryBuilder.FilterFunctionBuilder(//过滤,简单说就是满足isAD字段为true的文档就会参与算分QueryBuilders.termQuery("isAD",true),//要使用什么算分函数,下面那行使用的是weightFactorFunction加权算分,最终score分数越大,排名就越前ScoreFunctionBuilders.weightFactorFunction(10)//算出来的最终score就会被乘10)});//【高亮显示】对查询出来的文档,的特定字段进行高亮显示request.source().highlighter(new HighlightBuilder().field("all").requireFieldMatch(true).preTags("<em>").postTags("</em>"));//这一步必须有request.source().query(functionScoreQuery);//【分页功能】int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型request.source().from((page - 1) * size).size(size);//【地理排序功能】String location = params.getLocation();//对前端传的location进行判断是否为空if (location != null && !location.equals("")){//sort排序,指定是geoDistanceSort地理坐标排序,要排序的字段是location,中心点是new GeoPoint(location)request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location)).order(SortOrder.ASC) //升序排序.unit(DistanceUnit.KILOMETERS) //地理坐标的单位);}//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下SearchResponse response = client.search(request, RequestOptions.DEFAULT);//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回return handleResponse(response);} catch (IOException e) {throw new RuntimeException(e);}}//这个方法就是我们抽取出来的,负责解析的private PageResult handleResponse(SearchResponse response) {//解析获取到杂乱JSON数据SearchHits searchHits = response.getHits();//获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+total+"条文档(数据)");//获取hits数组SearchHit[] hits = searchHits.getHits();//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合List<HotelDoc> hotels = new ArrayList<>();for (SearchHit hit : hits) {String json = hit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);//【地理坐标查询的解析】,通过getSortValues方法来获取排序值,得到的是多个值也就是数组,我们只需要一个值Object[] sortValues = hit.getSortValues();//判断是否为空if (sortValues.length>0){Object sortValue = sortValues[0];//把拿到的sortValue返回到页面,也就是需要把sortValue值放到HoteDochotelDoc.setDistance(sortValue);}//【解析】获取高亮结果Map<String, HighlightField> xxhighlightFields = hit.getHighlightFields();//使用CollectionUtils工具类,进行判空,避免空指针if (!CollectionUtils.isEmpty(xxhighlightFields)){//根据字段名获取高亮结果HighlightField xxhighlightField = xxhighlightFields.get("all");//判断name不为空if (xxhighlightField != null) {//获取高亮值String xxname = xxhighlightField.getFragments()[0].string();//覆盖非高亮结果hotelDoc.setName(xxname);}}hotels.add(hotelDoc);}//封装返回return new PageResult(total,hotels);}
}第二步: 重启HotelDemoApplication引导类,浏览器访问http://localhost:8089/。查看是否能将搜索词高亮显示

写好的项目: 文件下载-奶牛快传 Download |CowTransfer
实用篇-ES-数据聚合
官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
1. 聚合的分类
聚合: 可以实现对文档数据的统计、分析、运算。聚合常见的有如下三类。注意,聚合的字段必然是不分词的,原因: 聚合不能是text类型
●桶 (Bucket) 聚合: 用来对文档做分组
- ○Term Aggregation聚合: 按照文档字段值分组。(我们下面会演示这个,按照品牌进行分桶)
- ○Date Histogram聚合: 按照日期阶梯分组,例如一周为一组,或者一月为一组
●度量 (Metric) 聚合: 用以计算一些值,比如最大值、最小值、平均值
- ○avg: 求平均值
- ○max: 求最大值
- ○min: 求最小值
- ○stats: 同时求max、min、avg、sum。(我们下面会演示这个,按照品牌进行求评分最值和平均值)
●管道 (Pipeline) 聚合: 其它聚合的结果为基础做聚合。这种用的不多
2. DSL实现Bucket聚合
Bucket聚合,也就是桶聚合
现在,我们要统计所有数据中的酒店品牌有多少种,此时我们可以根据酒店品牌的名称做聚合,由于品牌是字段,也就是要对字段值做分组,采用的是TermAggregation聚合,类型为term类型,DSL示例如下
确保你的环境正常启动
浏览器访问 http://你的ip地址:5601
然后我们使用的索引库是hotel,没有这个索引库的话,可以去前面 '实用篇-ES-黑马旅游案例' 的 '5. 环境准备-同步数据' 进行索引库的创建和添加数据
第一步: 具体操作,浏览器输入如下,表示对不同的品牌进行聚合,也就是不同的品牌为不同的桶,相同的品牌放进一个桶里面


第二步: 如何修改默认的排序规则,我们不希望是按照找出来的文档总条数降序排序。默认情况下,Bucket会统计Bucket内的文档数量,记为_count,并且按照count降序排序。我们如果要修改结果排序方式的话,只需要加一个order属性,如下


第三步: 我们上面是对整个索引库的数据做聚合搜索,如果索引库本身有庞大数据的话,对整个索引库的聚合搜索是对内存消耗非常大,我们希望自定义聚合的搜索范围,也就是限定要聚合的文档范围,只需要添加query条件即可,如下
gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于


3. DSL实现Metrics聚合
Metrics聚合,也就是度量聚合。例如,我们要求获取每个品牌的用户评分的min最小值、max最大值、avg平均值。注意不是整个索引库的所有酒店(文档)进行求值,所以要结合上一节的Bucket聚合一起使用
确保你的环境正常启动
浏览器访问 http://你的ip地址:5601
第一步: 具体操作,浏览器输入如下,表示对品牌(父聚合)的评分(子聚合)进行求值

第二步: 如果我们还需要对结果按照评分的平均值,再去做个排序,看一下哪个酒店评价最高,注意我们是在同里面做排序,也就是排序要写在terms里面

4. RestClient实现聚合
确保你的环境正常启动
如何在java代码使用RestClient来实现聚合。java代码以及对应的DSL语句如下图
请求,得到的是json数据

解析,对聚合结果的json数据进行解析

具体操作: 是基于之前的hotel-demo项目上继续编写,前面学的 '实用篇-ES-RestClient查询文档' 的基础上进行编写
第一步: 在HotelSearchTest类,添加如下
@Test
void testAggregation() throws IOException {//准备Request对象SearchRequest xxrequest = new SearchRequest("hotel");//准备DSL。设置sizexxrequest.source().size(0);//准备DSL。聚合语句xxrequest.source().aggregation(AggregationBuilders.terms("BrandAggMyName") //自定义聚合名称为BrandAggMyName.field("brand").size(10));//发出请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//【解析】//解析聚合结果Aggregations xxaggregations = xxresponse.getAggregations();//根据聚合名称获取聚合结果Terms xxbrandTerms = xxaggregations.get("BrandAggMyName");//获取桶(buckets),获取的是一个集合List<? extends Terms.Bucket> xxbuckets = xxbrandTerms.getBuckets();//遍历集合,取出每一个bucketfor (Terms.Bucket xxbucket : xxbuckets) {//获取key。这个key就是品牌信息String key = xxbucket.getKeyAsString();System.out.println(key);}
}
第二步: 运行testAggregation方法

5. 多条件聚合
案例: 在前面的 '黑马路由案例' 中,搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的

确保你的环境正常启动
第一步: 在IHotelService接口添加如下
/*** 查询城市、星级、品牌的聚合结果* @return 聚合结果,格式:{"城市": ["上海", "北京"], "品牌": ["如家", "希尔顿"]}*/
//在给出来的案例图中,左侧加深的字是key,右侧浅灰的字是value,并且右侧的value有多个值。所以我们使用Map集合,并且value是list集合
Map<String, List<String>> xxfilters();
第二步: 在HotelService实现类添加如下
@Override
public Map<String, List<String>> xxfilters() {try {//准备Request对象SearchRequest xxrequest = new SearchRequest("hotel");//准备DSL。设置sizexxrequest.source().size(0);//准备DSL。聚合语句。对多个字段进行聚合buildAggregation(xxrequest);//发出请求SearchResponse xxresponse = client.search(xxrequest, RequestOptions.DEFAULT);//【解析】//解析聚合结果Map<String, List<String>> yyresult = new HashMap<>();Aggregations xxaggregations = xxresponse.getAggregations();//1、根据名称获取品牌的结果List<String> xxbrandList = getAggByName(xxaggregations,"BrandAggMyName");//把品牌的结果信息放入mapyyresult.put("品牌",xxbrandList);//2、根据名称获取城市的结果List<String> xxcityList = getAggByName(xxaggregations,"cityAggMyName");//把城市的结果信息放入mapyyresult.put("城市",xxcityList);//3、根据名称获取星级的结果List<String> xxstarList = getAggByName(xxaggregations,"starAggMyName");//把星级的结果信息放入mapyyresult.put("星级",xxstarList);//返回yyresultreturn yyresult;} catch (IOException e) {throw new RuntimeException(e);}
}private List<String> getAggByName(Aggregations xxaggregations,String kkaggName) {//根据聚合名称获取聚合结果Terms xxbrandTerms = xxaggregations.get(kkaggName);//获取桶(buckets),获取的是一个集合List<? extends Terms.Bucket> xxbuckets = xxbrandTerms.getBuckets();//遍历xxbuckets集合,取出每一个key。把取到的key放到xxbrandList集合List<String> xxbrandList = new ArrayList<>();for (Terms.Bucket xxbucket : xxbuckets) {//获取key。这个key就是品牌信息String xxkey = xxbucket.getKeyAsString();xxbrandList.add(xxkey);}return xxbrandList;
}//把聚合的代码抽取出来
private void buildAggregation(SearchRequest xxrequest) {xxrequest.source().aggregation(AggregationBuilders.terms("BrandAggMyName") //自定义聚合名称为BrandAggMyName.field("brand").size(100)//聚合结果限制);xxrequest.source().aggregation(AggregationBuilders.terms("cityAggMyName").field("city").size(100));xxrequest.source().aggregation(AggregationBuilders.terms("starAggMyName").field("starName").size(100));
}
抽取代码成为方法

第三步: 在HotelDemoApplicationTests添加如下。并运行contextLoads方法
@Autowired
private IHotelService hotelService;@Test
void contextLoads() {Map<String, List<String>> filters = hotelService.xxfilters();System.out.println(filters);
}
6. hm-带过滤条件的聚合
对接前端接口,也就是把上面 '5. 多条件聚合' 实现的功能返回到前端页面,达到最终效果
前端页面会向服务端发起请求,查询品牌、城市、星级字段的聚合结果
确保你的环境正常启动
首先,保证你已经学完前面的 '实用篇-ES-黑马旅游案例' 并且在浏览器能打开前端页面

点击页面的搜索,打开浏览器控制台看一下前端向后端请求的参数

分析:
1、可以看到请求参数与之前search时的RequestParam完全一致,这是在限定聚合时的文档范围。用户搜索“外滩”,价格在300~600,那聚合必须是在这个搜索条件基础上完成
2、编写controller接口,接收该请求
3、修改IUserService#getFilters()方法,添加RequestParam参数
3、修改getFilters方法的业务,聚合时添加query条件
具体操作如下
第一步: 把HotelDemoApplicationTests类注释掉
第二步: 把IHotelService接口修改为如下,原本xxfilters方法是没有参数的,现在我们要给xxfilters方法添加参数
package cn.itcast.hotel.service;import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import com.baomidou.mybatisplus.extension.service.IService;
import java.util.List;
import java.util.Map;public interface IHotelService extends IService<Hotel> {PageResult search(RequestParams params);/*** 查询城市、星级、品牌的聚合结果* @return 聚合结果,格式:{"城市": ["上海", "北京"], "品牌": ["如家", "希尔顿"]}*///在给出来的案例图中,左侧加深的字是key,右侧浅灰的字是value,并且右侧的value有多个值。所以我们使用Map集合,并且value是list集合Map<String, List<String>> xxfilters(RequestParams params);
}
第三步: 把HotelService实现类修改为如下
package cn.itcast.hotel.service.impl;import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.toolkit.CollectionUtils;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {@Autowired//注入在引导类声明好的@Beanprivate RestHighLevelClient client;@Overridepublic PageResult search(RequestParams params) {try {//准备Request对象,要查询哪个索引库,SearchRequest request = new SearchRequest("hotel");buildBasicQuery(params, request);//【分页功能】int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型request.source().from((page - 1) * size).size(size);//【地理排序功能】String location = params.getLocation();//对前端传的location进行判断是否为空if (location != null && !location.equals("")){//sort排序,指定是geoDistanceSort地理坐标排序,要排序的字段是location,中心点是new GeoPoint(location)request.source().sort(SortBuilders.geoDistanceSort("location",new GeoPoint(location)).order(SortOrder.ASC) //升序排序.unit(DistanceUnit.KILOMETERS) //地理坐标的单位);}//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下SearchResponse response = client.search(request, RequestOptions.DEFAULT);//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回return handleResponse(response);} catch (IOException e) {throw new RuntimeException(e);}}private SearchRequest buildBasicQuery(RequestParams params,SearchRequest request) {//【构建BooleanQuery,下面那行的boolQuery是原始查询】BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();//【关键字搜索】//判断前端传的key是否为空,避免空指针String key = params.getKey();//前端传过来的搜索关键字//用的是must精确查找if (key == null || "".equals(key)) {//matchAllQuery方法表示查es的全部文档,不需要条件boolQuery.must(QueryBuilders.matchAllQuery());} else {//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空boolQuery.must(QueryBuilders.matchQuery("all", key));}//【条件过滤】//城市,term精确查找,注意判空if(params.getCity() != null && !params.getCity().equals("")){boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));}//品牌,term精确查找,注意判空if(params.getBrand() != null && !params.getBrand().equals("")){boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));}//星级,term精确查找,注意判空if(params.getStarName() != null && !params.getStarName().equals("")){boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));}//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于if(params.getMinPrice() != null && params.getMaxPrice() != null){boolQuery.filter(QueryBuilders.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));}//【构建functionScoreQuery,实现算分查询。对应的是广告置顶功能】FunctionScoreQueryBuilder functionScoreQuery =//原始查询,需要进行相关性算分的查询QueryBuilders.functionScoreQuery(boolQuery,//function score的数组,里面有很多function scorenew FunctionScoreQueryBuilder.FilterFunctionBuilder[]{//一个具体的function scorenew FunctionScoreQueryBuilder.FilterFunctionBuilder(//过滤,简单说就是满足isAD字段为true的文档就会参与算分QueryBuilders.termQuery("isAD",true),//要使用什么算分函数,下面那行使用的是weightFactorFunction加权算分,最终score分数越大,排名就越前ScoreFunctionBuilders.weightFactorFunction(10)//算出来的最终score就会被乘10)});//【高亮显示】对查询出来的文档,的特定字段进行高亮显示request.source().highlighter(new HighlightBuilder().field("all").requireFieldMatch(true).preTags("<em>").postTags("</em>"));//这一步必须有request.source().query(functionScoreQuery);return request;}//这个方法就是我们抽取出来的,负责解析的private PageResult handleResponse(SearchResponse response) {//解析获取到杂乱JSON数据SearchHits searchHits = response.getHits();//获取总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+total+"条文档(数据)");//获取hits数组SearchHit[] hits = searchHits.getHits();//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合List<HotelDoc> hotels = new ArrayList<>();for (SearchHit hit : hits) {String json = hit.getSourceAsString();//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);//【地理坐标查询的解析】,通过getSortValues方法来获取排序值,得到的是多个值也就是数组,我们只需要一个值Object[] sortValues = hit.getSortValues();//判断是否为空if (sortValues.length>0){Object sortValue = sortValues[0];//把拿到的sortValue返回到页面,也就是需要把sortValue值放到HoteDochotelDoc.setDistance(sortValue);}//【解析】获取高亮结果Map<String, HighlightField> xxhighlightFields = hit.getHighlightFields();//使用CollectionUtils工具类,进行判空,避免空指针if (!CollectionUtils.isEmpty(xxhighlightFields)){//根据字段名获取高亮结果HighlightField xxhighlightField = xxhighlightFields.get("all");//判断name不为空if (xxhighlightField != null) {//获取高亮值String xxname = xxhighlightField.getFragments()[0].string();//覆盖非高亮结果hotelDoc.setName(xxname);}}hotels.add(hotelDoc);}//封装返回return new PageResult(total,hotels);}//--------------------------------------------下面是多条件聚合-----------------------------------------@Overridepublic Map<String, List<String>> xxfilters(RequestParams params) {try {//准备Request对象SearchRequest xxrequest = new SearchRequest("hotel");//添加query查询信息,也就是限定聚合的范围buildBasicQuery(params, xxrequest);//准备DSL。设置sizexxrequest.source().size(0);//准备DSL。聚合语句。对多个字段进行聚合buildAggregation(xxrequest);//发出请求SearchResponse xxresponse = client.search(xxrequest, RequestOptions.DEFAULT);//【解析】//解析聚合结果Map<String, List<String>> yyresult = new HashMap<>();Aggregations xxaggregations = xxresponse.getAggregations();//1、根据名称获取品牌的结果List<String> xxbrandList = getAggByName(xxaggregations,"BrandAggMyName");//把品牌的结果信息放入mapyyresult.put("brand",xxbrandList);//2、根据名称获取城市的结果List<String> xxcityList = getAggByName(xxaggregations,"cityAggMyName");//把城市的结果信息放入mapyyresult.put("city",xxcityList);//3、根据名称获取星级的结果List<String> xxstarList = getAggByName(xxaggregations,"starAggMyName");//把星级的结果信息放入mapyyresult.put("starName",xxstarList);//返回yyresultreturn yyresult;} catch (IOException e) {throw new RuntimeException(e);}}private List<String> getAggByName(Aggregations xxaggregations,String kkaggName) {//根据聚合名称获取聚合结果Terms xxbrandTerms = xxaggregations.get(kkaggName);//获取桶(buckets),获取的是一个集合List<? extends Terms.Bucket> xxbuckets = xxbrandTerms.getBuckets();//遍历xxbuckets集合,取出每一个key。把取到的key放到xxbrandList集合List<String> xxbrandList = new ArrayList<>();for (Terms.Bucket xxbucket : xxbuckets) {//获取key。这个key就是品牌信息String xxkey = xxbucket.getKeyAsString();xxbrandList.add(xxkey);}return xxbrandList;}//把聚合的代码抽取出来private void buildAggregation(SearchRequest xxrequest) {xxrequest.source().aggregation(AggregationBuilders.terms("BrandAggMyName") //自定义聚合名称为BrandAggMyName.field("brand").size(100)//聚合结果限制);xxrequest.source().aggregation(AggregationBuilders.terms("cityAggMyName").field("city").size(100));xxrequest.source().aggregation(AggregationBuilders.terms("starAggMyName").field("starName").size(100));}//--------------------------------------------上面是多条件聚合-----------------------------------------}
第四步: 重新运行HotelDemoApplication引导类,浏览器查看是否功能正常
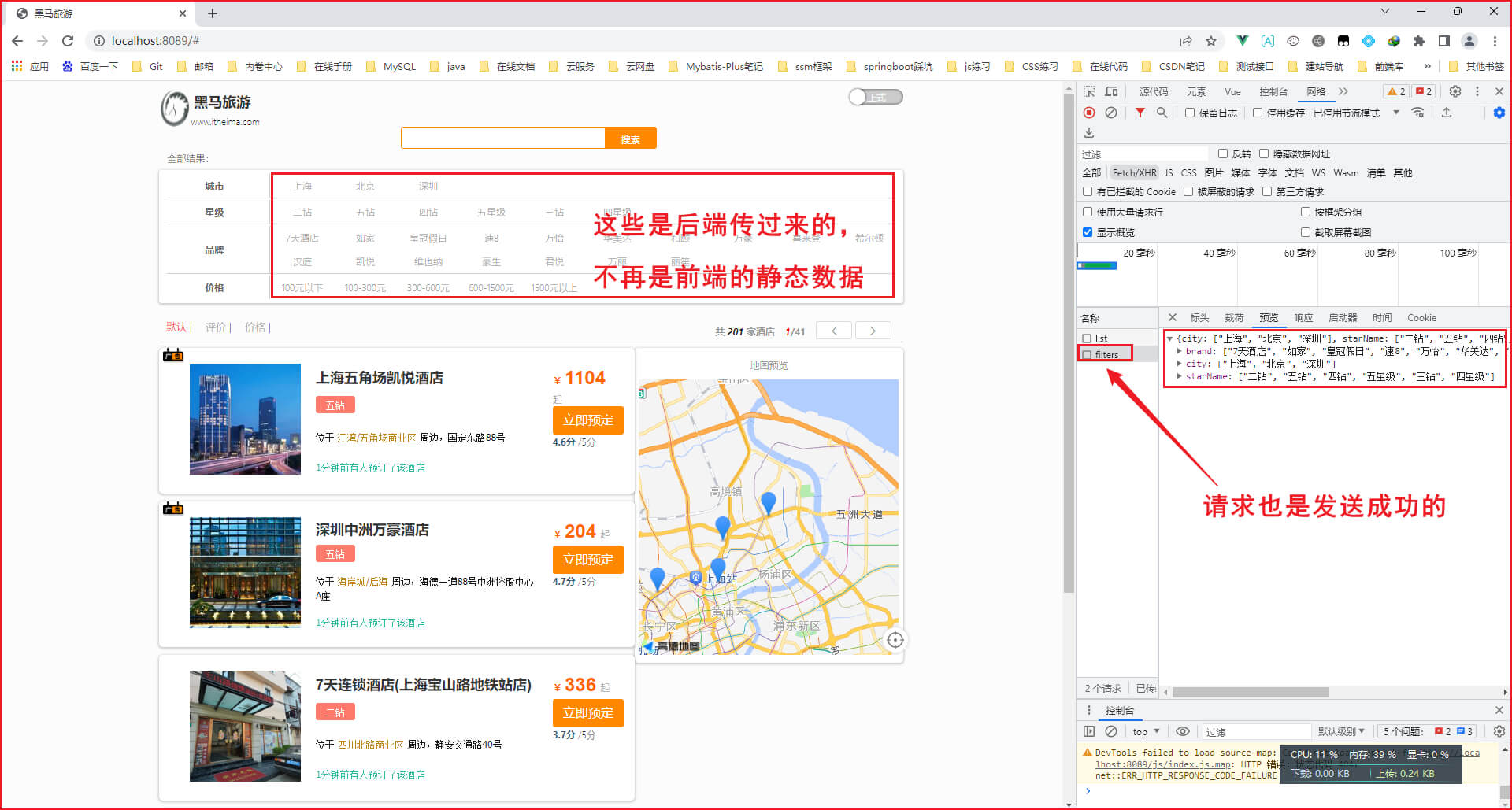
实用篇-ES-自动补全
1. 安装拼音分词器
elasticsearch的拼音分词插件的官方地址: GitHub - infinilabs/analysis-pinyin: 🛵 This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
拼音分词插件下载: 文件下载-奶牛快传 Download |CowTransfer
第一步: 下载下来是py.zip压缩包,解压之后得到一个py文件夹,把这个文件夹上传到你CentOS7的 /var/lib/docker/volumes/es-plugins/_data 目录

第二步: 重启es。注意我们的拼音分词器的版本是跟es版本一致的
第三步: 验证拼音分词器是否生效
docker restart kibana #启动kibana容器。由于在网页使用DSL去操作es,所以就需要kibana
浏览器访问 http://你的ip地址:5601
输入如下DSL语句,会把文本的每个中文分成对应的拼音,也会把整段文本的拼音首字母拼在一起
POST /_analyze
{"text": ["如家酒店"],"analyzer": "pinyin"
}
2. 自定义分词器
刚才我们看到了拼音分词器的效果,但是并不能用于生产环境,还存在一些问题

Elasticsearch中的分词器(analyzer)的组成包含三部分
●character filters: 在tokenizer之前对文本进行处理。例如删除字符、替换字符
●tokenizer: 将文本按照一定的规则切割成词条 (term)。例如keyword, 就是不分词; 还有ik_smart。这部分是真正的分词器
●tokenizer filter: 将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
我们可以按照下图的作用顺序解决拼音分词器的不足: 拼音分词器不会分词,那么就先用ik分词器,分好词后再交给拼音分词器

解决如下,注意必须在创建索引库的时候做,例如创建一个名为test的索引库
PUT /test
{"settings": {"analysis": {"analyzer": { // 自定义分词器"my_analyzer": { // 分词器名称"tokenizer": "ik_max_word","filter": "py" //过滤器名称}},"filter": { // 自定义tokenizer filter"py": { // 自定义过滤器名称"type": "pinyin", // 过滤器类型,这里是pinyin"keep_full_pinyin": false, //不允许单个字来分拼音"keep_joined_full_pinyin": true, //全拼,给什么字或词就把什么写成拼音"keep_original": true, //保留中文,解决了拼音分词器分词后全是拼音的问题"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}}
}
具体操作如下,注意自定义分词器只对当前索引库有效,因为我们是写在settings属性里面
确保你的环境正常启动
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器,因为我们需要在浏览器执行DSL语句去操作es
第一步: 浏览器访问 http://你的ip地址:5601
输入如下DSL语句,表示创建名为test的索引库,实现自定义分词器,也就是对分词器做一些限制、开放一些限制
PUT /test
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": { "type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer"}}}
}
第二步: 测试自定义分词器(也就是ik分词器+拼音分词器)。第一种测试方法
POST /test/_analyze
{"text": ["如家酒店"],"analyzer": "my_analyzer"
}
第三步: 测试自定义分词器(也就是ik分词器+拼音分词器)。第二种测试方法,通过往test库插入文档、然后查询插入的文档的方式来测试
POST /test/_doc/1
{"id": 1,"name": "狮子"
}
POST /test/_doc/2
{"id": 2,"name": "虱子"
}GET /test/_search
{"query": {"match": {"name": "shizi"}}
}
第四步: 其实还是有个问题,如下图,在搜索中文时,却搜索出了同音字,我们不想搜索出同音字,解决在下一节会学

3. 解决自定义分词器的问题
拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用
因此,字段在创建倒排索引时应该用自定义分词器(my_analyzer); 字段在搜索时应该使用is_smart分词器。对应的DSL语句如下
PUT /test
{"settings": {"analysis": {"analyzer": {"my_analyzer": {"tokenizer": "ik_max_word", "filter": "py"}},"filter": {"py": { ... }}}},"mappings": { //在mappings里面指定两个分词器"properties": {"name": {"type": "text","analyzer": "my_analyzer", //analyzer表示创建索引时使用这个my_analyzer分词器"search_analyzer": "ik_smart" //search_analyzer表示在搜索时使用这个search_analyzer分词器}}}
}
具体操作如下
确保你的环境正常启动
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器,因为我们需要在浏览器执行DSL语句去操作es
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,先删除刚刚上面创建的test索引库
DELETE /test
第三步: 输入如下DSL语句,重新创建test索引库,这次我们在mappings属性里面多添加了一个分词器"search_analyzer": "ik_smart"
PUT /test
{"settings": {"analysis": {"analyzer": { "my_analyzer": { "tokenizer": "ik_max_word","filter": "py"}},"filter": {"py": { "type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"name": {"type": "text","analyzer": "my_analyzer","search_analyzer": "ik_smart"}}}
}
第四步: 测试。同样是往test库创建两个文档,然后使用中文去匹配,如果不出现同音字就表示验证通过
POST /test/_doc/1
{"id": 1,"name": "狮子"
}
POST /test/_doc/2
{"id": 2,"name": "虱子"
}GET /test/_search
{"query": {"match": {"name": "狮子"}}
}
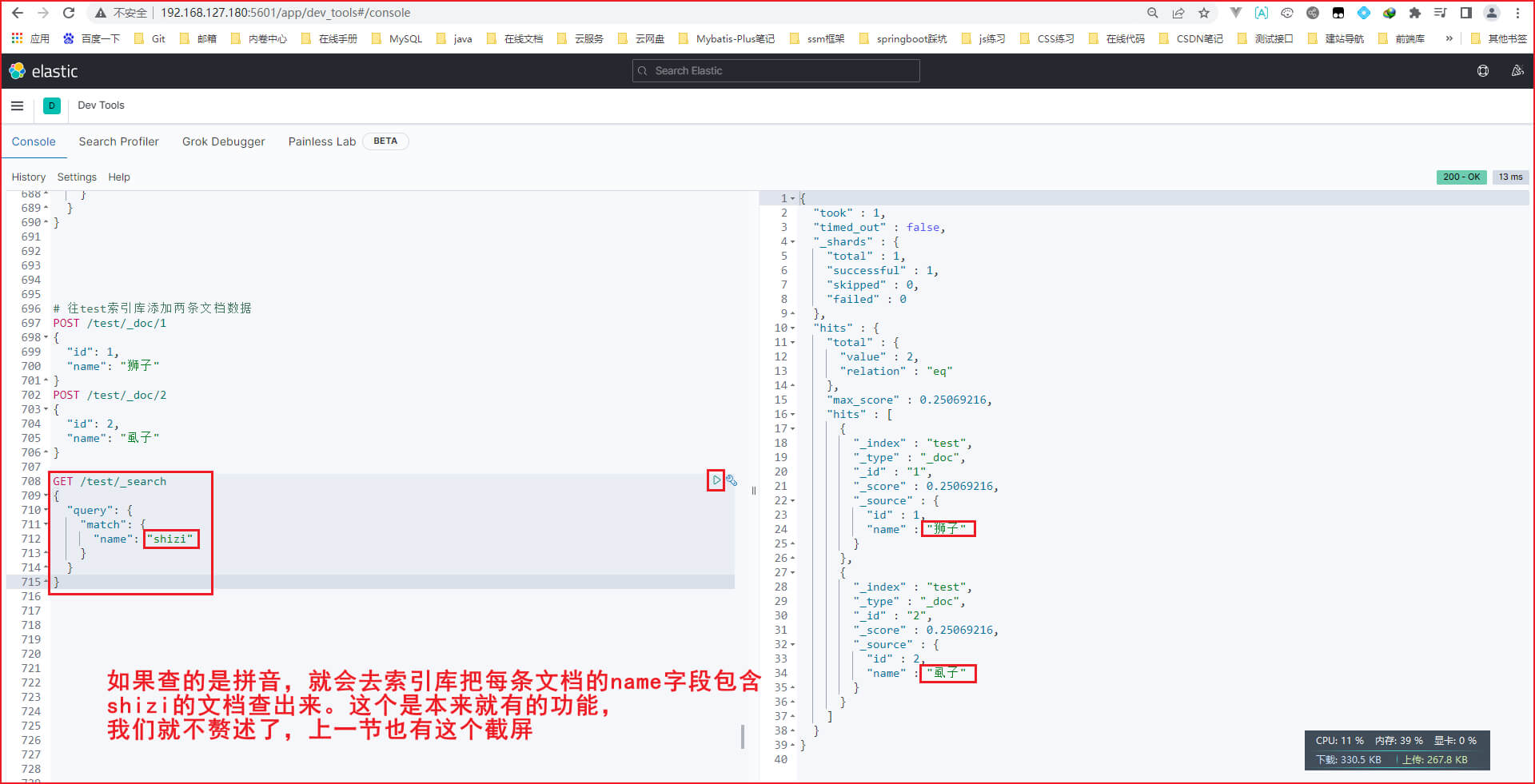
4. DSL实现自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
es在实现自动补全功能时,对查询的字段有以下两个要求
1、参与补全查询的字段必须是completion类型
2、字段的内容一般是用来补全的多个词条形成的数组

查询语法如下
// 自动补全查询
GET /test/_search
{"suggest": { //不是query,而是suggest,表示自动补全"title_suggest": { //自定义自动补全查询的名字"text": "s", // 关键字,例如用户输入s,就会触发"completion": { //自动补全的类型"field": "title", // 要自动补全查询的字段,注意该字段必须是completion类型"skip_duplicates": true, // 跳过重复的"size": 10 // 获取前10条结果}}}
}
具体操作如下,注意自定义分词器只对当前索引库有效,因为我们是写在settings属性里面
确保你的环境正常启动
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器,因为我们需要在浏览器执行DSL语句去操作es
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,先删除刚刚上面创建的test索引库
DELETE /test
第三步: 输入如下DSL语句,表示重新创建test索引库,并为索引库添加3条文档数据
PUT test
{"mappings": {"properties": {"title":{"type": "completion"}}}
}POST test/_doc
{"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{"title": ["SK-II", "PITERA"]
}
POST test/_doc
{"title": ["Nintendo", "switch"]
}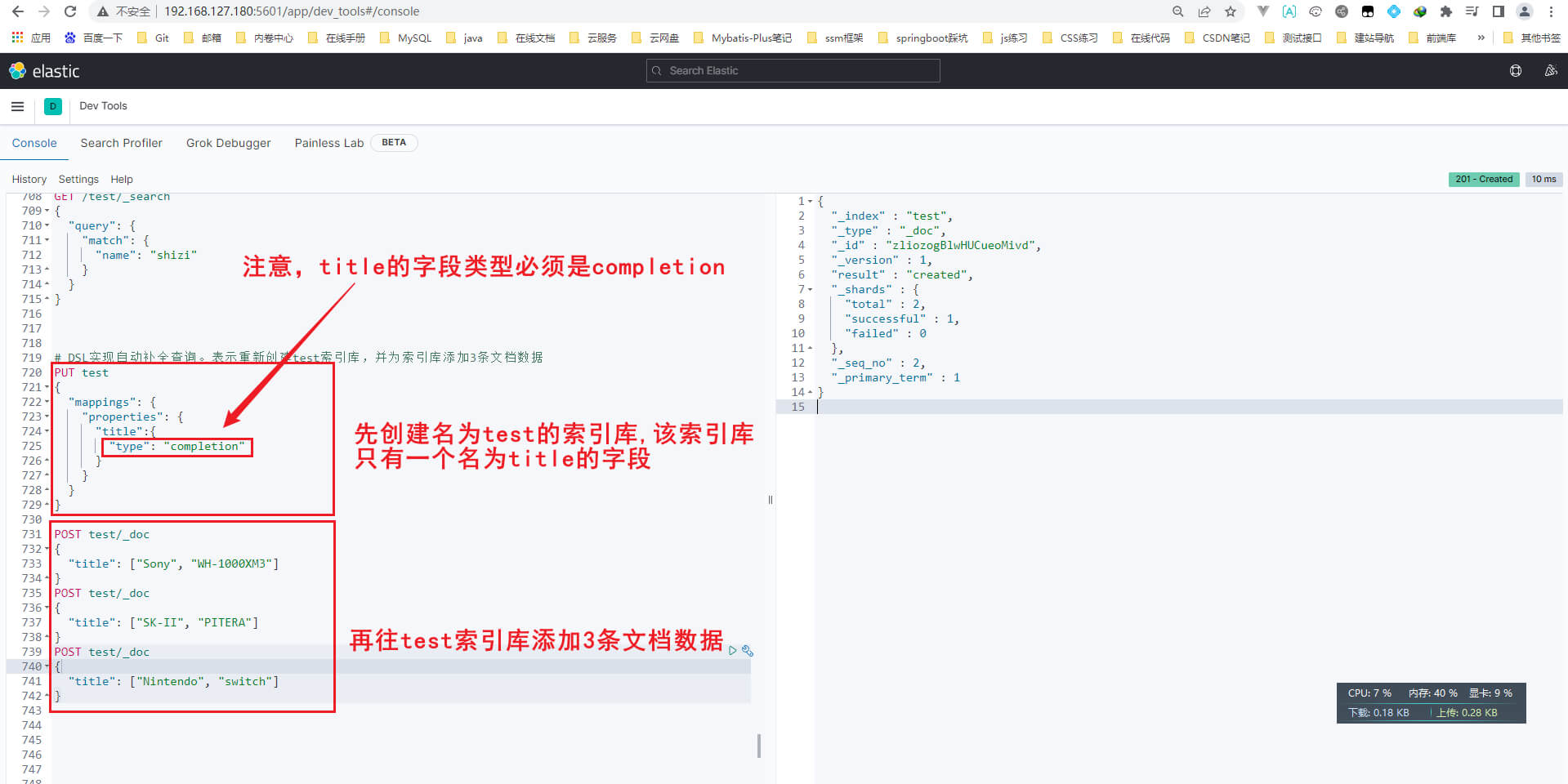
第四步: 测试。自动补全查询。输入如下DSL语句
GET /test/_search
{"suggest": {"zidingyichaxunmingcheng": {"text": "s","completion": {"field": "title","skip_duplicates": true,"size": 10}}}
}
5. hm-修改酒店索引库数据结构
请把前面的 '1. 安装拼音分词器' 和 '2. 自定义分词器' 和 '3. 解决自定义分词器的问题' 做完才能进行下面的操作
我们接下来要把自动补全功能应用在前面学习的黑马旅游案例中,这节我们就先学习如下几点
1、修改hotel索引库结构,设置自定义拼音分词器
2、修改索引库的name、all字段,使用自定义分词器
3、索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
确保你的环境正常启动
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,先删除已有的hotel索引库
DELETE /hotel
第三步: 输入如下DSL语句。重新创建一个hotel索引库,只是创建一个空的hotel索引库
PUT /hotel
{"settings": {"analysis": {"analyzer": {"text_anlyzer": {"tokenizer": "ik_max_word","filter": "py"},"completion_analyzer": {"tokenizer": "keyword","filter": "py"}},"filter": {"py": {"type": "pinyin","keep_full_pinyin": false,"keep_joined_full_pinyin": true,"keep_original": true,"limit_first_letter_length": 16,"remove_duplicated_term": true,"none_chinese_pinyin_tokenize": false}}}},"mappings": {"properties": {"id":{"type": "keyword"},"name":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart","copy_to": "all"},"address":{"type": "keyword","index": false},"price":{"type": "integer"},"score":{"type": "integer"},"brand":{"type": "keyword","copy_to": "all"},"city":{"type": "keyword"},"starName":{"type": "keyword"},"business":{"type": "keyword","copy_to": "all"},"location":{"type": "geo_point"},"pic":{"type": "keyword","index": false},"all":{"type": "text","analyzer": "text_anlyzer","search_analyzer": "ik_smart"},"suggestion":{"type": "completion","analyzer": "completion_analyzer"}}}
}
第四步: 由于某个文档(酒店)可能包括多个商圈,如下图,所以在下一步我们会在HotelDoc类进行切割后存入suggestion

第五步: 在上面的DSL语句中,我们还多创建了一个suggestion字段,所以对应的我们需要在黑马旅游案例的java代码中修改实体类
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;//地理位置查询相关的字段。distance字段用于保存解析后的距离值private Object distance;//用于广告置顶的字段private Boolean isAD;//用于自动补全的类型,该类型在es中必须是completion类型,该类型在java中就要写成数组(我们写成集合)private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();if(this.business.contains("/")){//如果同一文档的business商圈有多个,为了自动补全的分词效果更明显,我们需要分割一下String[] arr = this.business.split("/");this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);//Collections是工具类,可以把数组数据逐个放进suggestion集合Collections.addAll(this.suggestion,arr);}else{//自动补全我们可以让'品牌+商圈'来做自动补全,用户触发自动补全时,补全到的就是'品牌+商圈'字段的文档this.suggestion = Arrays.asList(this.brand,this.business);}}
}
打开hotel-demo项目(继续做前面学的黑马旅游案例),把HotelDoc类修改为如下
package cn.itcast.hotel.pojo;import lombok.Data;
import lombok.NoArgsConstructor;import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;@Data
@NoArgsConstructor
public class HotelDoc {private Long id;private String name;private String address;private Integer price;private Integer score;private String brand;private String city;private String starName;private String business;private String location;private String pic;//地理位置查询相关的字段。distance字段用于保存解析后的距离值private Object distance;//用于广告置顶的字段private Boolean isAD;//用于自动补全的类型,该类型在es中必须是completion类型,该类型在java中就要写成数组(我们写成集合)private List<String> suggestion;public HotelDoc(Hotel hotel) {this.id = hotel.getId();this.name = hotel.getName();this.address = hotel.getAddress();this.price = hotel.getPrice();this.score = hotel.getScore();this.brand = hotel.getBrand();this.city = hotel.getCity();this.starName = hotel.getStarName();this.business = hotel.getBusiness();this.location = hotel.getLatitude() + ", " + hotel.getLongitude();this.pic = hotel.getPic();if(this.business.contains("/")){//如果同一文档的business商圈有多个,为了自动补全的分词效果更明显,我们需要分割一下String[] arr = this.business.split("/");this.suggestion = new ArrayList<>();this.suggestion.add(this.brand);//Collections是工具类,可以把数组数据逐个放进suggestion集合Collections.addAll(this.suggestion,arr);}else{//自动补全我们可以让'品牌+商圈'来做自动补全,用户触发自动补全时,补全到的就是'品牌+商圈'字段的文档this.suggestion = Arrays.asList(this.brand,this.business);}}
}
第六步: 运行HotelDocumentTest类的testBulkRequest方法,重新把mysql的数据导入到es的hotel索引库

第七步: 验证。自动补全功能
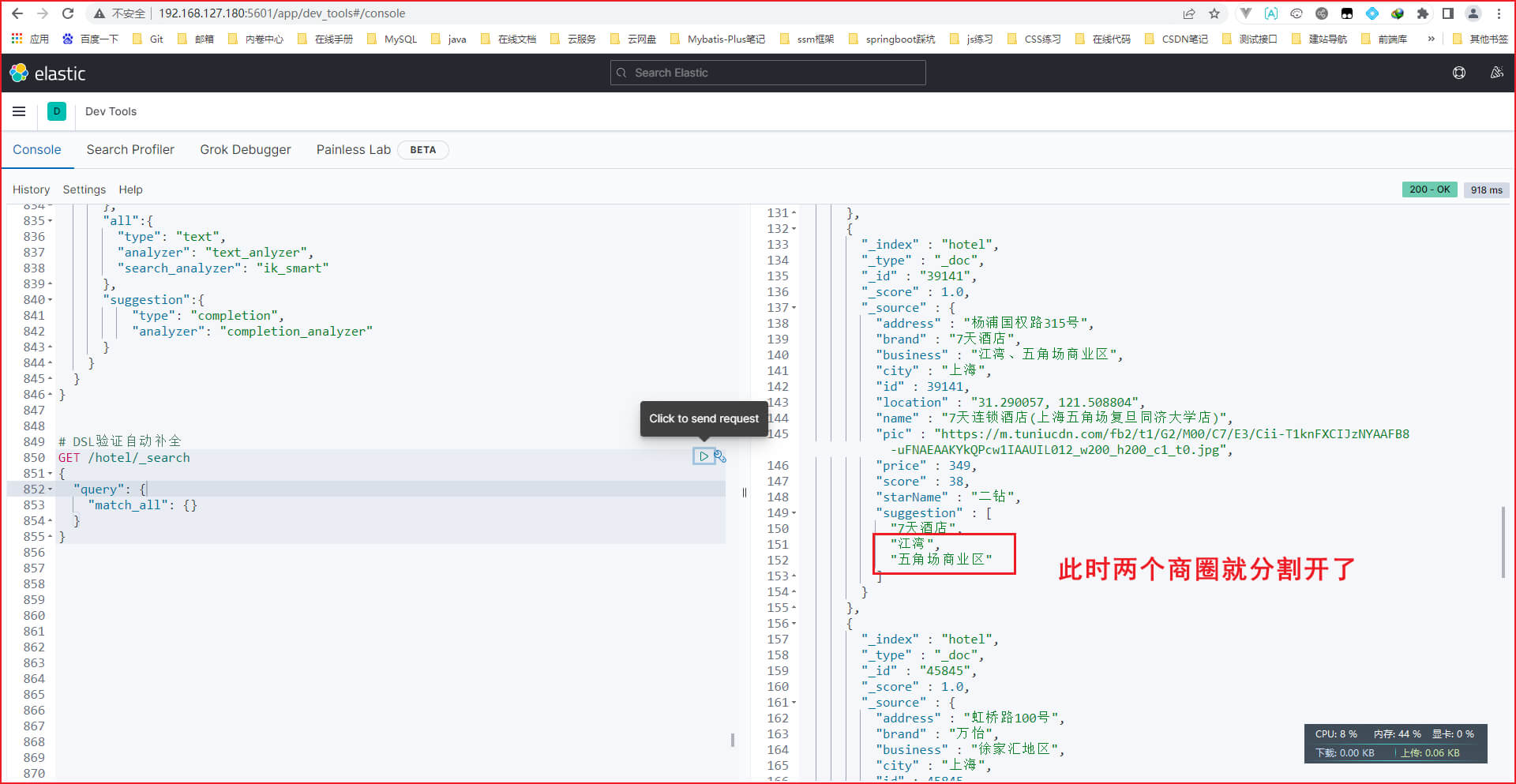

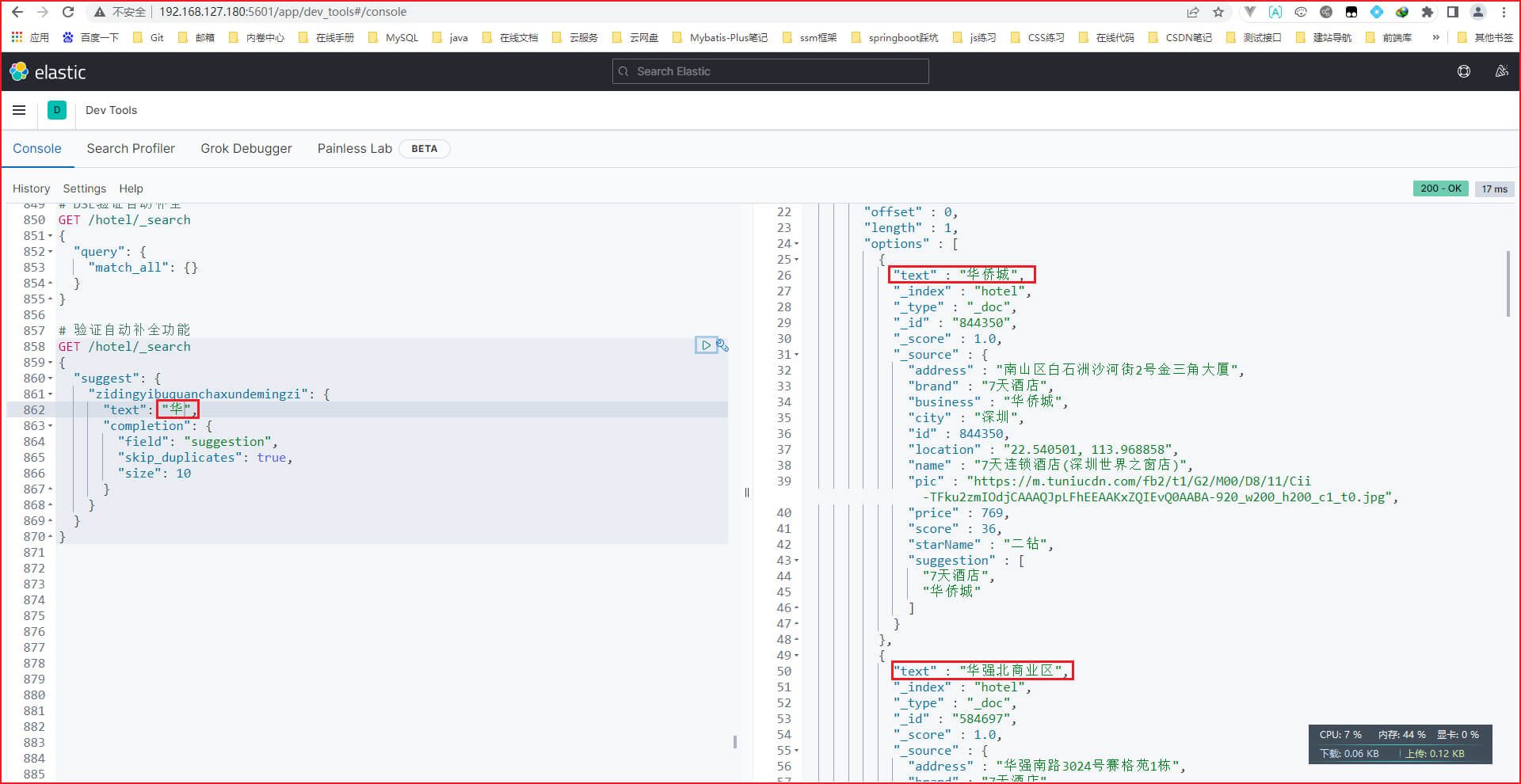
6. RestAPI实现自动补全查询
查询API和对应的DSL关系如下图

解析API和对应的DSL关系如下图

确保你的环境正常启动
具体操作如下
第一步: 在HotelSearchTest类添加如下,并运行xxtestSuggest方法
@Test
void xxtestSuggest() throws IOException {//准备Request,查的是哪个索引库SearchRequest xxrequest = new SearchRequest("hotel");//准备DSL,自动补全查询也就是suggestion查询xxrequest.source().suggest(new SuggestBuilder().addSuggestion("zidingyizidongbuquanmingzi",//要自动补全哪个字段SuggestBuilders.completionSuggestion("suggestion")//模拟用户在搜索框输入查找.prefix("h")//跳过重复,不把重复的结果展示.skipDuplicates(true)//查多少条数据.size(10)));//发起请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析结果System.out.println(xxresponse);
}

第二步: 结果解析。把HotelSearchTest类的xxtestSuggest方法修改为如下,并运行xxtestSuggest方法
@Test
void xxtestSuggest() throws IOException {//准备Request,查的是哪个索引库SearchRequest xxrequest = new SearchRequest("hotel");//准备DSL,自动补全查询也就是suggestion查询xxrequest.source().suggest(new SuggestBuilder().addSuggestion("zidingyizidongbuquanmingzi", //为这个自定义补全查询起一个名字//要自动补全哪个字段SuggestBuilders.completionSuggestion("suggestion")//模拟用户在搜索框输入查找.prefix("h")//跳过重复,不把重复的结果展示.skipDuplicates(true)//查多少条数据.size(10)));//发起请求SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);//解析结果Suggest xxsuggest = xxresponse.getSuggest();//根据'补全查询名称',获取补全结果CompletionSuggestion xxsuggestions = xxsuggest.getSuggestion("zidingyizidongbuquanmingzi");//获取xxsuggestionsList<CompletionSuggestion.Entry.Option> xxoptions = xxsuggestions.getOptions();//遍历for (CompletionSuggestion.Entry.Option xxoption : xxoptions) {String text = xxoption.getText().toString();System.out.println(text);}
}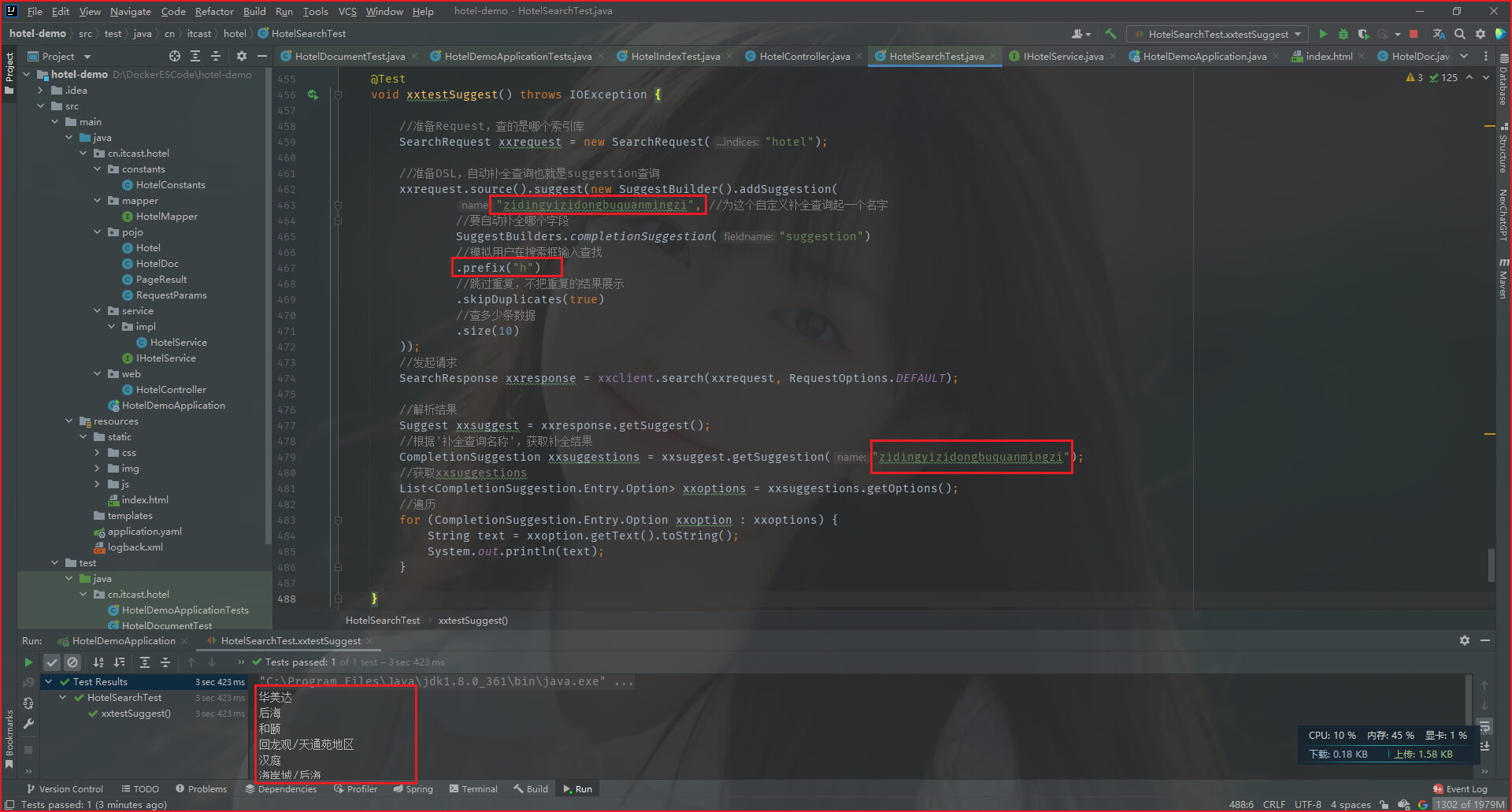
7. hm-搜索框自动补全查询
确保你的环境正常启动
我们刚刚使用RestAPI实现了自动补全查询,现在我们要把这个功能应用在 '黑马旅游案例' 的搜索框,首先来看一下前端给我们传来的参数,如下图
我们需要编写接口,接收该请求,返回补全结果的集合,类型为List
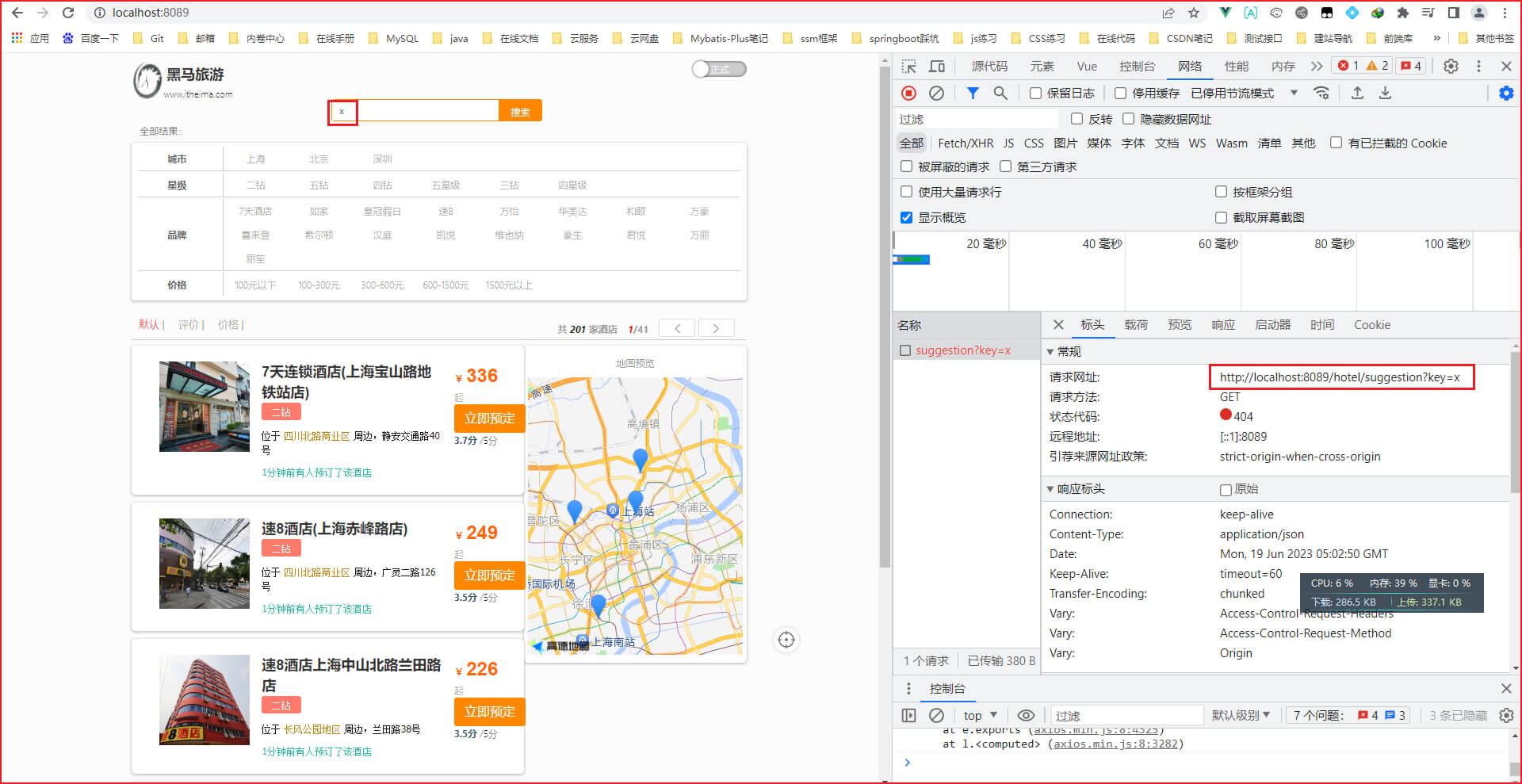
具体操作如下
第一步: 在IHotelService接口添加如下
List<String> xxgetSuggestions(String xxprefix);
第二步: 在HotelService类添加如下
@Override
public List<String> xxgetSuggestions(String xxprefix) {try {//准备Request,查的是哪个索引库SearchRequest xxrequest = new SearchRequest("hotel");//准备DSL,自动补全查询也就是suggestion查询xxrequest.source().suggest(new SuggestBuilder().addSuggestion("zidingyizidongbuquanmingzi", //为这个自定义补全查询起一个名字//要自动补全哪个字段SuggestBuilders.completionSuggestion("suggestion")//模拟用户在搜索框输入查找.prefix(xxprefix)//跳过重复,不把重复的结果展示.skipDuplicates(true)//查多少条数据.size(10)));//发起请求SearchResponse xxresponse = client.search(xxrequest, RequestOptions.DEFAULT);//解析结果Suggest xxsuggest = xxresponse.getSuggest();//根据'补全查询名称',获取补全结果CompletionSuggestion xxsuggestions = xxsuggest.getSuggestion("zidingyizidongbuquanmingzi");//获取xxsuggestionsList<CompletionSuggestion.Entry.Option> xxoptions = xxsuggestions.getOptions();//准备好一个集合,当自动补全时,相关词就会在这个集合并返回给前端List<String> xxlist = new ArrayList<>(xxoptions.size());//遍历for (CompletionSuggestion.Entry.Option xxoption : xxoptions) {String text = xxoption.getText().toString();//把自动补全时,查到的相关词放到我们准备好的集合里面xxlist.add(text);}return xxlist;} catch (IOException e) {throw new RuntimeException(e);}
}
第三步: 在HotelController类添加如下
@GetMapping("suggestion")
public List<String> xxgetSuggestions(@RequestParam("key") String xxprefix){return hotelService.xxgetSuggestions(xxprefix);
}第四步: 重新启动HotelDemoApplication引导类

第四步: 测试。查看自动补全查询是否在搜索框生效,,访问http://localhost:8089/

实用篇-ES-数据同步
相关文章:
Elasticsearch分布式搜索
实用篇-ES-环境搭建 ES是elasticsearch的简称。我在SpringBoot学习 数据层解决方案 的时候,写过一次ES笔记,可以结合一起看一下。 之前在SpringBoot里面写的相关ES笔记是基于Windows的,现在我们是基于docker容器来使用,需要你们提…...

【Unity 实用工具篇】 | UIEffect 实现一系列UGUI特效,灰度、负片、像素化特效
前言 【Unity 实用工具篇】 | UIEffect 实现一系列UGUI特效,灰度、负片、像素化特效一、UGUI特效插件:UIEffect1.1 介绍1.2 效果展示1.3 使用说明及下载 二、组件属性面板三、代码操作组件四、组件常用方法示例4.1 使用灰度特效做头像(关卡)选择 总结 前…...
ECMA进阶1之从0~1搭建react同构体系项目1
ECMA进阶 ES6项目实战前期介绍SSRpnpm 包管理工具package.json 项目搭建初始化配置引入encode-fe-lint 基础环境的配置修改package.jsonbabel相关tsconfig相关postcss相关补充scripts脚本webpack配置base.config.tsclient.config.tsserver.config.ts src环境server端࿱…...

【回溯】Leetcode 22. 括号生成【中等】
括号生成 数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。 示例 1: 输入:n 3 输出:[“((()))”,“(()())”,“(())()”,“()(())”,“()()()”] 解题思路 1、使用回溯…...

Java生成带数字的图片
Java生成带数字的图片示例 在Java中,你可以使用java.awt和javax.imageio等图形库来生成带有数字的图片。下面是一个简单的示例代码,展示了如何创建并保存一张带有数字的图片。 示例代码 import javax.imageio.ImageIO; import java.awt.*; import…...
FreeSWITCH 1.10.10 简单图形化界面17 - ubuntu22.04或者debian12 安装FreeSWITCH(IamFree)
FreeSWITCH 1.10.10 简单图形化界面17 - ubuntu22.04或者debian12 安装FreeSWITCH 界面预览00、先看使用手册0、安装操作系统1、下载脚本2、开始安装3、登录网页 FreeSWITCH界面安装参考:https://blog.csdn.net/jia198810/article/details/132479324 界面预览 htt…...

【数据结构】06图
图 1. 定义1.1 无向图和有向图1.2 度、入度和出度1.3 图的若干定义1.4 几种特殊的图 2. 图的存储2.1 邻接矩阵-顺序存储(数组)2.2 邻接表-顺序存储链式存储(数组链表)2.3 十字链表-适用于有向图2.4 邻接多重表-适用于无向图 3. 图…...

Flink作业 taskmanager.numberOfTaskSlots 这个参数有哪几种设置方式
Flink作业 taskmanager.numberOfTaskSlots 这个参数有哪几种设置方式 taskmanager.numberOfTaskSlots 参数用于设置每个TaskManager上的任务槽(task slot)数量,决定了TaskManager可以并行执行的任务数量。这个参数可以通过多种方式进行设置。…...
京东详情比价接口优惠券(2)
京东详情API接口在电子商务中的应用与作用性体现在多个方面,对于电商平台、商家以及用户都带来了显著的价值。 首先,从应用的角度来看,京东详情API接口为开发者提供了一整套丰富的功能和工具,使他们能够轻松地与京东平台进行交互。…...

Python knn算法
KNN(K-Nearest Neighbors)算法,即K最近邻算法,是一种基本且广泛使用的分类和回归方法。在分类问题中,KNN通过查找一个样本点的K个最近邻居,然后根据这些邻居的类别通过多数投票或加权投票来预测该样本点的类…...
[大模型]Langchain-Chatchat安装和使用
项目地址: https://github.com/chatchat-space/Langchain-Chatchat 快速上手 1. 环境配置 首先,确保你的机器安装了 Python 3.8 - 3.11 (我们强烈推荐使用 Python3.11)。 $ python --version Python 3.11.7接着,创建一个虚拟环境ÿ…...

K8S之资源管理
关于资源管理,我们会从计算机资源管理(Computer Resources)、服务质量管理(Qos)、资源配额管理(LimitRange、ResourceQuota)等方面来进行说明 Kubernetes集群里的节点提供的资源主要是计算机资源…...

Grok-1.5 Vision:X AI发布突破性的多模态AI模型,超越GPT 4V
在人工智能领域,多模态模型的发展一直是科技巨头们竞争的焦点。 近日,马斯克旗下的X AI公司发布了其最新的多模态模型——Grok-1.5 Vision(简称Grok-1.5V),这一模型在处理文本和视觉信息方面展现出了卓越的能力&#x…...
【御控物联】Java JSON结构转换(1):对象To对象——键值互换
文章目录 一、JSON是什么?二、JSON结构转换是什么?三、核心构件之转换映射四、案例之《JSON对象 To JSON对象》五、代码实现六、在线转换工具七、技术资料 一、JSON是什么? Json(JavaScript Object Notation)产生于20…...
【学习笔记】rt-thread
任务 创建好任务,不管是动态还是静态创建,任务的状态是init ,通过start方法来启动任务;线程大小 设置小了,无法正常工作?显示占空间100% 启动过程 TODO 这是编译器特性? 因为RT-Thread使用编…...

一文掌握 React 开发中的 JavaScript 基础知识
前端开发中JavaScript是基石。在 React 开发中掌握掌握基础的 JavaScript 方法将有助于编写出更加高效、可维护的 React 应用程序。 在 React 开发中使用 ES6 语法可以带来更简洁、可读性更强、功能更丰富,以及更好性能和社区支持等诸多好处。这有助于提高开发效率,并构建出更…...
读天才与算法:人脑与AI的数学思维笔记01_洛夫莱斯测试
1. 创造力 1.1. 创造力是一种原动力,它驱使人们产生新的、令人惊讶的、有价值的想法,并积极地将这些想法付诸实践 1.2. 创造出在表面上看似新的东西相对容易 1.3. 在遇到偶然间的创造性行为时,都会表现得异…...

嵌入式系统的时间保存问题,hwclock保存注意事项
几个要点 嵌入式板子要有RTC电路和钮扣电池。这个跟电脑主板一样。嵌入式系统要有相应的驱动。使用date设置时间 date -s "2024-04-11 10:33:26" 使用hwclock保存时间 嵌入式系统如何使用hwclock正确保存时间-CSDN博客...

jenkins(docker)安装及应用
jenkins Jenkins是一个开源的、提供友好操作界面的持续集成(CI)工具,起源于Hudson(Hudson是商用的),主要用于持续、自动的构建/测试软件项目、监控外部任务的运行(这个比较抽象,暂且写上,不做解…...

uni-app中,页面跳转前,进行拦截处理的方法
个人需求阐述: 当用户在页面A中,填写了内容之后,没有点击“保存/确定”,直接通过点击返回按钮或者手机的物理返回键直接返回时,需要给出一个二次确认的弹层,当用户点击确定离开之后,跳转到页面B…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

从深圳崛起的“机器之眼”:赴港乐动机器人的万亿赛道赶考路
进入2025年以来,尽管围绕人形机器人、具身智能等机器人赛道的质疑声不断,但全球市场热度依然高涨,入局者持续增加。 以国内市场为例,天眼查专业版数据显示,截至5月底,我国现存在业、存续状态的机器人相关企…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...