【Linux】网络基础(1)
前言

相信没有网络就没有现在丰富的世界。本篇笔记记录我在Linux系统下学习网络基础部分知识,从关于网络的各种概念和关系开始讲起,逐步架构起对网络的认识,对网络编程相关的认知。
我的上一篇Linux文章呀~
【Linux】网络套接字编程_柒海啦的博客-CSDN博客
让我们开始吧~

目录
一、概念与关系
1.域网
2.网络协议
OSI:
TCP/IP协议:
3.网络传输的基本流程
封装&解包
同一局域网内通信
不在同一局域网内的通信
二、应用层
1.重新理解协议&&网络版本计算器
序列化与反序列化&Json库的使用
守护进程
2.http协议
URL
urlencode和urldecode
快速构建http请求和响应的报文格式
http细节内容:
GET和POST
响应状态码
http的报头属性
会话管理
一、概念与关系
1.域网
一开始计算机是独立运行的,如果进行协同操作的话,效率非常低下。比如一台计算器将其中一部分处理完成,然后将其处理的数据拷贝到下一台计算机...
所以诞生了服务器,几台电脑链接在一起,进行网络互联。
局域网LAN:
当计算机数量更多了,局域网之间通过路由器进行连接。
广域网WAN:
将远隔千里的计算机连在一起。
对于局域网和广域网,实际是一个相对的概念,是利用规模的大小进行区分。 在国内,像网络如此的不断壮大都是通信企业做的(比如三大运营商、华为等)。
2.网络协议
首先,协议是一种约定。
为什么存在约定呢?
两个计算机通信互相发送数据,数据是存在类别的。但是计算机里只存在01,所以需要区分,需要约定协议区分类别以及减少成本(增加有效的动作,减少无效的动作)。
所以,需要做好软硬件的通信协议,统一起来就是行业标准(硬件标准)。
对于协议,我们不要忘了在Linux一切皆文件,并且先描述在组织。
1.操作系统要进行协议管理 -- 先描述,在组织
2.协议本质就是软件,软件是可以分层的。
3.协议在设计的时候,就是层状的划分的。->为什么要划分为层状结构?a场景复杂 b功能解耦 ,便于人们进行各种维护。
了解上述条件之后,我们可以利用实际一点的问题进行引入协议的层状结构:通信的复杂,本质是和距离成正相关的。
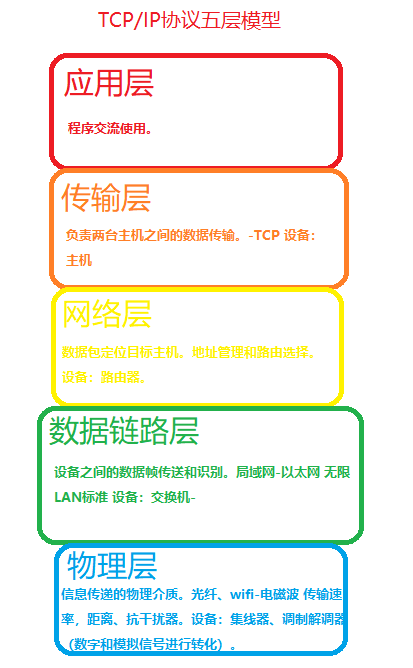
因为传输时存在损失,所以需要进行复杂的设计减少损失,这也是这些协议栈所需要解决的问题。比如在通信的范畴内:丢包问题的产生需要传输层进行解决;在传输过程中的定位目标位置需要网络层解决;在一个局域网传输到另一个局域网解决下一跳主机问题就需要数据链路层;硬件之类的有物理层。在应用的范畴内如何处理数据需要应用层。实际上上述描绘的就是一整个网络传输的生态,基于TCP/IP协议(5层协议)进行控制。
OSI:
在了解具体的TCP/IP协议之前,首先存在的是OSI(Open Systems Interconnection 开放式系统互联),如下图:

OSI类似于草稿-蓝图,意思就是以此进行理论指导,帮助不同的主机进行数据传输。逻辑上的定义和规范。
TCP/IP协议:
在有了OSI的理论指导后,根据实际需求,指定了如下的TCP/IP协议,一共五层,但实际上对于软件来说只关心上面四层。
3.网络传输的基本流程
封装&解包
首先,如果两台主机在同一个局域网内是可以进行通信的。(比如投屏)
从逻辑上讲,根据上面的TCP/IP协议,因给是主机A在应用层直接发送给主机B(AB为同一局域网的两个主机),但是实际(物理的来说)是自顶向下,链路层传送到目标主机,然后在目标主机的物理处从下到上传送到对应的应用层。

每层实际上都有自己的协议定制方案,所以每层都要自己的协议报头。
从上到下是添加报头。从下到上是去掉报头。报头类似于发送快递的单(卖家(向下交付-填好单子(给快递看的)) - 买家(收到了快递,不会要快递单))同层协议收到数据包后,多出的一部分就是报头。
层层封装成一个数据帧-添加报头的过程。经过局域网通信后,在向上交付 - 一层层通过报头识别对应部分(除开报头,那么就是有效载荷)向上交给什么协议,向上将有效载荷向上交付。重复上述步骤一直到应用层为之。
所以,我们从上面的知识可以了解到一些的本质:
封装的本质:添加报头
解包的本质:去掉报头&展开分析
可以想象为栈结构,封装就是不断的去压栈,而解包就是不断的弹栈。
同一局域网内通信
那么链路层之间在同一局域网中传播我们该如何理解呢?
我们用学生们和老师在同一个教室上课的例子来举例局域网内进行传播。
当两台主机在同一局域网中通信的时候,类似于老师上课的时候点名。老师点名的时候全班同学应该都听到了,但是只有点名的那名学生站了起来。对应的,在同一局域网中的所有主机应该都会收到发送的数据帧,但是只是目标主机会对此数据包进行解包,其余发现不是给自己会丢弃。
同样的,如果在教室里面很吵闹的话,两名正常交流的同学就会受到干扰。所以在同一局域网进行交流的两台主机如果受到来自其他主机的干扰,那么就会无法通信,发送碰撞问题。可以缓解的措施是:等一会儿,再次进行重发(注意是同一局域网的全部主机都要遵从)。
在局域网中,表示主机的唯一性是MAC地址。网卡里确定了。
在云服务器下(我使用的版本是centos)使用命令:ifconfig eth0 就可以查看当前服务器的mac地址以及其他内网相关地址。
比如ether就是表示的是mac地址。每一位表示一个十六进制数,一共12个十六进制,每个十六进制数表示4个比特位,所以mac地址是48位的。其他的比如inet表示的就是内网的ip地址。
那么如果链路层遵循的协议不同即不在同一局域网内,那么两台主机该如何进行通信的呢?
不在同一局域网内的通信
我们首先通过下面这张图来进行一个初步的认识:

因为不再一个局域网,所以需要交给路由器,通过以太网驱动程序去掉以太网协议报头,交给路由器。如果目标ip路由器在同一局域网,那么就向下交付其对应协议的驱动程序进行添加报头,然后就是从下到上开始解包。 --同层协议。此时往上三层的协议一致,只是链接层不一致。
路由器是连接不同网络的设备,具有多个接口,每个接口连接一个不同的网络。另外,如果需要跨越多个网络,数据将经过多个路由器进行转发,直到到达目标主机。在这个过程中,每个路由器都会根据路由协议维护路由表,以选择最优的路径进行转发。
那么上述跨越多个网络的话,A向B发送的话,那么MAC地址就不存在作用了,此时就需要ip地址了。我们来利用下面一个例子简单理解一下ip地址:
比如,我们利用导航定位到某地,此时我们的出发点到某地实际上就是两个ip地址,一个是起始ip,也就是源ip,而目的地就是目标ip。但是在这个路线中会经过很多个地方,这很多个地方又会形成很多跳通路,都可以到达目标ip,只不过路径存在长短,这就要我们自己抉择了。
所以这之中的很多个地方实际上就是MAC地址,mac地址会不断的发生变化。但是我们的源ip和目标ip并不会发生变化。而mac地址的改变就是路由器所做的事情。而下一站的mac地址受到影响的也就是来自ip的影响。

所以,在使用TCP/IP协议中,在中间路由即ip以上看的协议是一致的。即报文也都是一样的。
当你看到这里的时候对网络应该是具备一定的了解了,此时我们可以学习一些关于网络套接字的内容进行加深理解,可以利用我的博客或者其他资料进行学习哦~之后的内容就需要我们掌握套接字编程了,在本篇里不再做过多赘述。
【Linux】网络套接字编程_柒海啦的博客-CSDN博客
二、应用层
接下来,我们来详细的讲讲应用层相关协议的用法和理解。注意这里需要会TCP、UDP套接字的基本编程,我们将利用代码更加深入的理解相关知识。
1.重新理解协议&&网络版本计算器
我们首先通过实现一个网络版本的计算器,来理解一下协议。
此网络版本的计算器采用TCP协议,服务器通过接收客户端发送的数据计算后返回给对应的客户端。
那么我们要想一下:在主机之间进行传输的时候,TCP是面向字节流的,通俗的来讲就是字符串之间进行传送。那么如果想让客户端给服务器发送数据的话,我们可以解析字符串来进行。
但是解析字符串的话难免太耦合了,也就是说可扩展性会变的非常差,服务器端一旦发生改动,那么客户端就无法使用了。那么我们可以想一下,我们能否把需要传送的数据包装成为一个结构体呢?我们发送结构体不就可以了吗?
想法可以,但是别忘了,在不同的平台下,存在大小端以及内存对齐等问题,如果直接发送结构体的数据,那么读取出来的数据就很有可能出错,所以,这里我们发送结构之前,首先进行一个序列化,转为字符串发送,发送到目标主机上后在进行反序列化,转化为结构。此时就不会出错了。
序列化与反序列化&Json库的使用

实际上,序列化和反序列化的操作就是一个协议定制的操作。序列化,我们规定一个格式,让数据能够表示在一个字符串内,然后反序列化就是从此字符串内根据格式读取到正确的数据。当然序列化实际上别人已经实现好了,我们下述代码实现中可以从两步来验证,一种使用我们自己定义的协议即可,第二种就使用第三方库Json来进行实现。
如下代码,我们定义Request为请求类,Response为响应类。我们认为:在客户端和服务器端进行通信的时候,首先客户端向服务器端发送请求,此请求就是本次的计算表达式,这个表达式我们可以利用三个变量进行保存,两个变量保存数,一个变量保存符号。当我们需要发送的时候,只需要将此请求类对象进行序列化为一个字符串形式的即可。(代码定义为length\r\n_x _op _y\r\n)之所以要这么定义的原因有2:1.length能够为我们确认后续是否完整,如果不完整(即基于字节流发送的时候没有完全)那么需要继续读。2.\r\n是一种比较惯用的格式,如果只想保留空格一样的也可以,中间的空格为了保证后续反序列化的时候能够拿到不同的数据。服务器当拿到客户端的请求的时候,对于字符串就要进行反序列化,反序列化即对上述字符串进行一个解析即可。Response响应同样如此,只不过我们里面定义一个返回码和一个返回值。可以根据返回码判断此次结果是否有效。
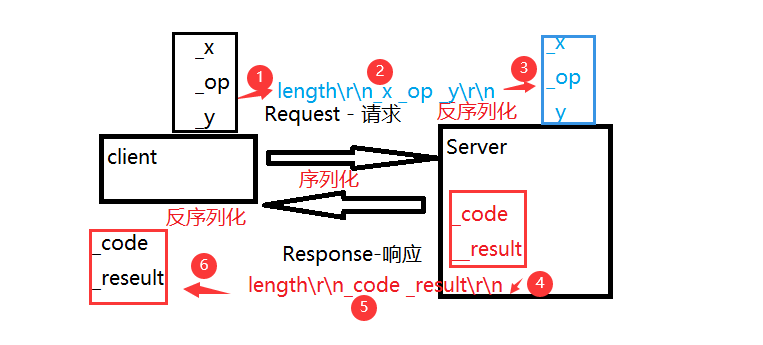
如果是用Json库进行使用的化,那么我们就不需要自己定义字符串的形式了,只需要带好库和相应的key-value形式即可。
首先需要安装好Json库,安装命令:sudo yum install jsoncpp-devel 。然后需要在编译选项上加上-ljsoncpp才能找到此库。在文件里引用的时候#include<jsoncpp/json/json.h> 即可。
在进行传输数据之前,我们需要保存数据,利用Json::Value root;可以创建出一个对象,类似于map或者哈希map,是支持key-value的,所以我们添加数据可以使用root[key] = value进行添加即可。序列化的时候只需要创建Writer对象即可,此对象有两个可以选择,一个StyledWriter,一个FastWriter。其中,FastWriter转换为字符串的格式更加精简,可以看个人喜好来,一般调试的时候使用第一个,日常使用第二个。其次创建好Json::FastWriter writers对象后,只需要writers.writer(root);就会返回一个字符串进行发送。使用writer方法对Value对象进行序列化。对于反序列化,Json::Reader read; 对象即可,read.parse(字符串, Value对象);使用parse方法就可以将字符串反序列化为Value对象。提取数据的时候需要指明数据类型,比如int _x = root["x"].asInt();
下面我们在ComputerProtocol.hpp文件内利用条件编译来决定使用自定义方案还是json库的方案,代码如下:
#pragma once#include <string>
#include <iostream>#define My_Protocol#ifndef My_Protocol#include <jsoncpp/json/json.h>#endif// 计算器业务 - 自定义协议
namespace ComputerData
{#define SPACER "\r\n"#define SPACERLEN (sizeof(SPACER) - 1)// 请求class Request{public:Request() = default;Request(int x, int y, char op):_x(x), _y(y), _op(op){}// 序列化// 序列化格式: length\r\n_x _op _y\r\nstd::string Serialize(){
#ifdef My_Protocolstd::string str = std::to_string(_x);str += ' ';str += _op;str += ' ';str += std::to_string(_y);std::string header = std::to_string(str.size());return header + SPACER + str + SPACER;#else// 此处使用Json库Json::Value root;root["x"] = _x;root["op"] = _op;root["y"] = _y;Json::FastWriter writer;return writer.write(root); // 一步就序列化#endif}// 反序列化// 提取到对应的元素中去// length\r\n_x _op _y\r\n// 5\r\n1 + 1\r\nbool Deserialization(const std::string& str){
#ifdef My_Protocol// 首先,到达这里的str必须是上述样例的模样,不能多一个字符或者少一个字符// 下面进行字符串解析,如果一个存在不遵守,那么就无法提取成功size_t index1 = str.find(SPACER, 0);if (index1 == std::string::npos) return false;int length = atoi(str.substr(0, index1).c_str());size_t begin1 = index1 + SPACERLEN;size_t index2 = str.find(' ', begin1);if (index2 == std::string::npos) return false;_x = atoi(str.substr(begin1, index2 - begin1).c_str());size_t begin2 = index2 + 1;size_t index3 = str.find(' ', begin2);if (index3 == std::string::npos) return false;_op = str[index3 - 1];size_t begin3 = index3 + 1;size_t index4 = str.find(SPACER, begin3);if (index4 == std::string::npos) return false;_y = atoi(str.substr(begin3, index4 - begin3).c_str());// std::cout << length << " x:" << _x << " op:" << _op << " y:" << _y << std::endl;return true;#else// 使用Json库进行反序列化Json::Value root;Json::Reader read;read.parse(str, root); // 反序列化_x = root["x"].asInt();_op = root["op"].asInt();_y = root["y"].asInt();return true;#endif}int _x;int _y;char _op;};// 响应class Response{public:Response() = default;Response(int code, int result):_code(code), _result(result){}// 序列化// 序列化格式: length\r\ncode result\r\nstd::string Serialize(){
#ifdef My_Protocolstd::string str = std::to_string(_code);str += ' ';str += std::to_string(_result);std::string header = std::to_string(str.size());return header + SPACER + str + SPACER;#else Json::Value root;root["code"] = _code;root["result"] = _result;Json::FastWriter writes;return writes.write(root);#endif}bool Deserialization(const std::string& str){
#ifdef My_Protocol// 首先,到达这里的str必须是上述样例的模样,不能多一个字符或者少一个字符// 下面进行字符串解析,如果一个存在不遵守,那么就无法提取成功size_t index1 = str.find(SPACER, 0);if (index1 == std::string::npos) return false;int length = atoi(str.substr(0, index1).c_str());size_t begin1 = index1 + SPACERLEN;size_t index2 = str.find(' ', begin1);if (index2 == std::string::npos) return false;_code = atoi(str.substr(begin1, index2 - begin1).c_str());size_t begin2 = index2 + 1;size_t index3 = str.find(SPACER, begin2);if (index3 == std::string::npos) return false;_result = atoi(str.substr(begin2, index3 - begin2).c_str());// std::cout << length << " code:" << _code << " result:" << _result << std::endl;return true;#elseJson::Value root;Json::Reader read;read.parse(str, root);_code = root["code"].asInt();_result = root["result"].asInt();return true;
#endif}int _code; // 状态码int _result; // 结果};}另外,对于我们自定义的来说,在反序列化的时候是需要确定其是否完整的。因为TCP是基于字节流进行发送数据的,不像是数据报一次性发完,所以有可能我们只是读取了一部分,所以我们需要一个函数对每次我们接受的字符串进行个检查,如果正确那么保存此字符串返回,吧用于接受的缓冲区重置一下继续接受,如果不正确,那么需要返回空串告诉上一层没有接受完全,然后缓冲区不可动,继续接受。(所以这里也就说明recv接受的缓冲区必须是+=的形式接受的)
// 11\r\n121342 + 12\r\n 17 - 2*2 - 2 = 17-6 = 11std::string Decode(std::string& str){// 解码,即必须检查当前读取的是否是完整的数据,如果不是就继续读取// 首先,开头必须是数字size_t index1 = str.find(SPACER, 0);if (index1 == std::string::npos) return "";int length = atoi(str.substr(0, index1).c_str());int pos = str.size() - 2 * SPACERLEN - index1;if (pos >= length){// 说明此时长度已经可以提取了,修改返回即可std::string s = str.substr(0, length + 2 * SPACERLEN + index1);str.erase(0, length + 2 * SPACERLEN + index1); // 删掉,此时外面的str为+=return s;}else return ""; // 否则返回空串}当然,Json同理,可以自行研究~
在序列化前,我们首先准备好套接字编程的先决条件,服务器端首先初始化监听套接字,然后建立连接过程返回服务套接字进行读取数据、业务处理、发送数据。客户端初始化客户端套接字,建立连接后进行发送消息,收消息。代码如下:
在MySock.hpp文件内,我们封装一些TCP套接字常规的用法,比如创建套接字sock,套接字对象与ip、port绑定bind,服务器端设置监听套接字listen,服务器端接受连接返回服务套接字acceot,客户端与服务器端连接connect。另外在根据上面反序列化的需求定制一下接受recv,当然send就可以随意了。
#ifndef __MY_SOCK__
#define __MY_SOCK__// 封装TCPsock相关操作接口
#include <iostream>
#include <string>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <cstring>
#include "log.hpp"namespace QiHai
{struct Sock{// 创建套接字 错误返回-1,这里会输出错误日志,注意佩戴上log.hpp文件,编译加-DMYFILE选项日志输入到当前目录的文件中,否则就是标准输出static int socket(){int sock = ::socket(AF_INET, SOCK_STREAM, 0);if (0 > sock) // ::表示使用全局命名空间的,不属于任何一个类或者命名空间 SOCK_STREAM是字节流-即TCP协议{logMessage(FATAL, "socket error-%d: %s[file:%s|line:%d]", errno, strerror(errno), __FILE__, __LINE__);}else logMessage(NORMAL, "socket success, sock is %d", sock);return sock;}// 绑定ip和端口static bool bind(int sock, int16_t port, std::string ip = "0.0.0.0"){struct sockaddr_in address;socklen_t n;memset(&address, 0, sizeof address); // 清零address.sin_family = AF_INET;address.sin_port = htons(port); // 主机转网络inet_aton(ip.c_str(), &address.sin_addr); // 点分十进制转化为数,然后转化为网络字节序if (0 > ::bind(sock, (sockaddr*)&address, sizeof(address))){// 差错处理logMessage(FATAL, "bind error-%d: %s[file:%s|line:%d]", errno, strerror(errno), __FILE__, __LINE__);return false;}return true;}// 服务端设置监听static bool listen(int sock, int backlog = 20) // 挂起队列最大长度默认设置为20{if (0 < ::listen(sock, backlog)){logMessage(FATAL, "listen error-%d: %s[file:%s|line:%d]", errno, strerror(errno), __FILE__, __LINE__);return false;}logMessage(NORMAL, "listen success, init......");return true; // 设置此套接字为监听状态成功}// 服务器进行连接static int accept(int listenSock, std::string* clientIp = nullptr, int16_t* clientPort = nullptr){// 想要客户端的ip和port为可选项struct sockaddr_in client;memset(&client, 0, sizeof client);socklen_t addrlen = sizeof client;int clientSock = ::accept(listenSock, (sockaddr*)&client, &addrlen);if (0 > clientSock){logMessage(ERROR, "accept error-%d: %s[file:%s|line:%d]", errno, strerror(errno), __FILE__, __LINE__);// 错误但是不致命,可以进行重连哦return clientSock;}std::string ip = inet_ntoa(client.sin_addr);int16_t port = ntohs(client.sin_port);logMessage(NORMAL, "[%s: %d] accept suncess...", ip.c_str(), port);// 如果指针不为空就设置客户端返回的数据if (clientIp){*clientIp = ip; // 网络字节序-本机-数字-点分十进制}if (clientPort){*clientPort = port; // 网络-本机}return clientSock;}// 客户端进行连接static bool connect(int sock, const std::string& ip, int16_t port){struct sockaddr_in server;memset(&server, 0, sizeof server);server.sin_family = AF_INET;server.sin_port = htons(port);inet_aton(ip.c_str(), &server.sin_addr);if (0 > ::connect(sock, (sockaddr*)&server, sizeof server)){logMessage(FATAL, "connect error-%d: %s[file:%s|line:%d]", errno, strerror(errno), __FILE__, __LINE__);return false;}return true;}// 发送消息static bool send(int sock, const std::string& buffer){if (0 > ::send(sock, buffer.c_str(), buffer.size(), 0)){logMessage(FATAL, "send error-%d: %s[file:%s|line:%d]", errno, strerror(errno), __FILE__, __LINE__);return false;}return true;}// 接收消息static bool recv(int sock, std::string& buffer){char _buffer[1024];// printf("------------1-------------\n");ssize_t n = ::recv(sock, _buffer, sizeof(_buffer) - 1, 0);// printf("------------2-------------\n");if (n > 0){_buffer[n] = '\0';buffer += _buffer; // 注意必须是+= 此时返回的数据最后才能保证是完整的}else if (n == 0){logMessage(NORMAL, "对方主机关闭......");return false;}else{logMessage(FATAL, "recv error-%d: %s[file:%s line:%d]", errno, strerror(errno), __FILE__, __LINE__);return false;}return true;}};
}#endiflog.hpp文件可以在我之前的Linux博客中找到哦~当然你也可以换成标准输出,一样的,反正就是特定的输出一些文本而已。
随后写出我们的服务器端和客户端代码,客户端就是连接成功后循环的创建请求,发送成功后等待服务器端的响应,反序列化后得到结果返回。服务器端得到请求后,反序列化得到数据进行处理,处理完后制作响应序列化发送即可。注意其中接受的时候和之前的套接字编程不同,我们需要判断接受的字符串是否符合要求,否则就需要继续读入。
//UserManual.hpp - 帮助文件
#pragma once#include <iostream>
#include <string>static void User(const std::string& argv)
{if (argv == "./TCPServer")std::cout << "User: " << argv << " port" << std::endl;else if (argv == "./TCPClient")std::cout << "User: " << argv << " ip port" << std::endl;else std::cout << "?" << std::endl;
}//TCPClient.cpp - 客户端代码
#include "MySock.hpp"
#include "UserManual.hpp"
#include <unistd.h>
#include "ComputerProtocol.hpp"int main(int argc, char* argv[])
{if (argc != 3){User(argv[0]);exit(-1);}int sock = QiHai::Sock::socket();if (sock < 0)exit(1);// 注意客户端不需要进行绑定// 与服务器连接if (!QiHai::Sock::connect(sock, argv[1], atoi(argv[2]))) exit(2);// 连接完毕后处理业务即可// std::string message;// while (true)// {// std::cout << "请输入# ";// std::getline(std::cin, message);// QiHai::Sock::send(sock, message);// if (QiHai::Sock::recv(sock, message))// {// std::cout << "server# ";// std::cout << message << std::endl; // 注意类似于endl和'\n'等需要刷新缓冲区的!务必记住// }// else break;// }std::string res;bool quit = false;while (!quit){std::cout << "请输入(x+y):";ComputerData::Request r;std::cin >> r._x >> r._op >> r._y;QiHai::Sock::send(sock, r.Serialize());while (true){if (QiHai::Sock::recv(sock, res)){std::string tmp = ComputerData::Decode(res);if (tmp.empty()) continue;ComputerData::Response p;p.Deserialization(tmp);if (p._code == 1) std::cout << "除零错误" << std::endl;else if (p._code == 2) std::cout << "未识别操作符" << std::endl;else if (p._code == 0) std::cout << r._x << r._op << r._y << "=" << p._result << std::endl; // 注意类似于endl和'\n'等需要刷新缓冲区的!务必记住break;}else{quit = true;break;}}}close(sock);return 0;
}//TCPServer.cpp - 服务器端代码
#include "TCPServer.hpp"
#include <memory>
#include "UserManual.hpp"
#include "ComputerProtocol.hpp"void testComputerProtocol()
{// 测试序列化是否正确ComputerData::Request r(121342, 12, '+');// std::cout << "序列化:";std::string str = r.Serialize();std::cout << str << std::endl;// std::cout << "反序列化:";ComputerData::Request q;q.Deserialization(str);// std::cout << "------------------\n";ComputerData::Response p(1, q._x + q._y);// std::cout << "序列化:";std::string str2 = p.Serialize();std::cout << str2 << std::endl;// std::cout << "反序列化:";ComputerData::Response q2;q2.Deserialization(str2);std::string tmp = ComputerData::Decode(str); // if (tmp.empty()) printf("失败\n");else std::cout << tmp << std::endl;std::string tmp2 = ComputerData::Decode(str2);if (tmp.empty()) printf("失败\n");else std::cout << tmp2 << std::endl;std::cout << "-------------------------------\n";std::cout << str << "\n\n" << str2 << std::endl;
}void test(void* argc)
{QiHai::TCPServerData* tmp = (QiHai::TCPServerData*)argc;std::string buffer;while (true){if (QiHai::Sock::recv(tmp->_sock, buffer)){std::cout << "[" << tmp->_ip << ": " << tmp->_port << "]# ";std::cout << buffer << std::endl; // 注意类似于endl和'\n'等需要刷新缓冲区的!务必记住}else break;QiHai::Sock::send(tmp->_sock, buffer);}exit(0);
}void computer(void* argc)
{// 实现网络计算器的业务QiHai::TCPServerData* tmp = (QiHai::TCPServerData*)argc;std::string buffer;ComputerData::Request q;while (true){if (QiHai::Sock::recv(tmp->_sock, buffer)){// printf("+++++++++1++++++++++++++\n");// 检查读取的是否完整std::string res = ComputerData::Decode(buffer);if (res.empty()) continue; // 继续读std::cout << "[" << tmp->_ip << ": " << tmp->_port << "]# ";q.Deserialization(res);std::cout << q._x << q._op << q._y << std::endl;}else break;int result, code = 0;switch (q._op){case '+':result = q._x + q._y;break;case '-':result = q._x - q._y;break;case '*':result = q._x * q._y;break;case '/':if (q._y != 0) result = q._x / q._y;else code = 1;break;default:code = 2;break;}ComputerData::Response p(code, result);QiHai::Sock::send(tmp->_sock, p.Serialize());}
}int main(int argc, char *argv[])
{if (argc != 2){User(argv[0]);exit(-1);}std::unique_ptr<QiHai::TCPServer> server(new QiHai::TCPServer(atoi(argv[1]), computer));server->init();server->start();// testComputerProtocol();return 0;
}此时我们做一下测试就可以大搞成功了~
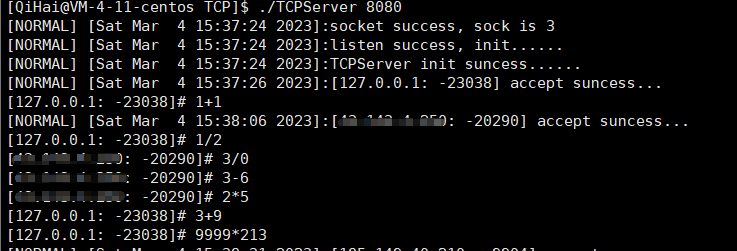
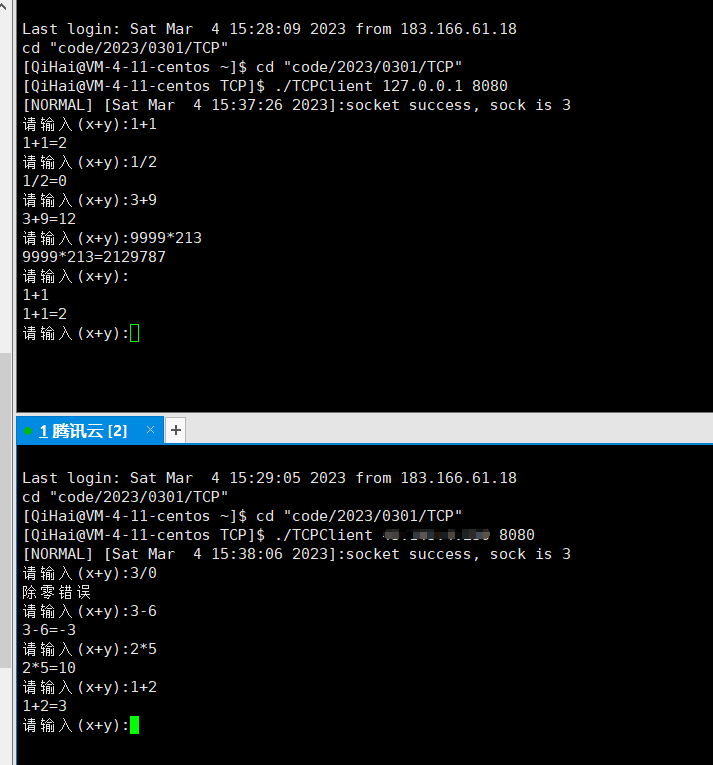
那么,我们能否引进一下守护进程让其进程后台完成这个任务呢?
守护进程
守护进程即后台进程。我们如何创建出一个后台程序呢?
在创建后台程序之前,我们需要了解Linux中的会话系统。
当一个用户登陆到一个Linux系统时,一个新的会话就会被创建。一个会话(session)是一个用户与系统交互的时间段。在这个时间段中,用户可以打开、关闭终端窗口、执行命令、进程等操作。
目前所写的全部的服务器都是前台运行的。
1.前台进程:和终端关联的进程 -- 即该进程能否正常获取你的输入就是前台进程。-能让我输入操作东西
2.任何xshell登录,只允许一个前台进程和多个后台进程。
3.进程除了有自己的pid、ppid,另外存在组id。
4.在命令行中,同时用管道启动多个进程,多个进程都是兄弟关系,父进程都是bash,-可以用匿名管道通信
5.同时被创建的多个进程可以是一个进程组,组长是第一个创建的进程 PGID
6.任何一次登录,登录的用户,需要有多个进程(组),来给这个用户提供服务的(bash)。用户自己可以启动很多进程或者进程组。把给用户提供服务的进程或者自己启动的进程,整体都是要属于一个会话机制中的。SID用户-> 登录:会话(bash(bash自己成一组)+终端 ---进程组)
用户<-退出登录:理论上说,曾经启动的任何进程都要得到释放。--不同操作系统处理可能存在不同。
所以我们想要一个常驻进程自然需要避免bash所在的会话中的进程的,我们需要此进程自成一个会话组就可以了。
7.如何讲自己编辑自成会话呢?pid_t setsid(void); -- 创建一个会话,并且称为组长。返回值成功就是谁调我,失败就是-1。
8.但是如果setsid要被成功调用,必须保证当前进程不是进程组的组长。怎么保证自己不是组长呢?成为子进程。-fork()进行保证。
9.守护进程不能直接向显示器打印消息。 一旦打印会被暂停,甚至被终止。
我们想要我们的进程变成守护进程,首先需要将服务器的所有向显示屏输出转化为向文件输入(自己设置,这里使用我的log文件的话加个-DMYFILE宏就可以输出指向到当前文件了)。并且要忽视掉影响进程挂掉的信号:比如SIGPIPE信号和SIGCHLD信号。SIGPIPE信号也就是网络编程中向关闭的客户端发送消息会被系统发送此信号杀掉,我们自然不希望发生这样的事情,并且也忽略掉SIGCHLD防止出现僵尸进程。
然后就是自己成为新会话的组长-首先自己是子进程。其次将默认打开的三个文件描述符-标准输入输出错误重定向输入到/dev/null文件中,避免其影响其他文件。(在Linux系统中,/dev/null是一个特殊的文件,也被称为空设备(null device)。它是一个虚拟设备文件,任何写入它的内容都将被丢弃,任何从它读取的操作都将返回一个空字节序列。简单来说,它是一个黑洞,所有的输入都会被吞噬掉。)
这样,我们的一个守护进程就创建出来了:
//Daemon.hpp#pragma once#include <iostream>
#include <signal.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
// 将此进程变为守护进程 - 利用接口setsid成为新的会话(注意自己不可是组长 - 利用子进程即可)
// 将此进程默认打开的三个文件描述符重定向到黑洞中:/dev/null
// 忽视信号SIGPIPE, SIGCHLDvoid MyDaemon()
{signal(SIGPIPE, SIG_IGN);signal(SIGCHLD, SIG_IGN);if (fork() > 0) exit(0);// 孤儿进程 - 不是组长了setsid();int nullfile = open("/dev/null", O_RDONLY | O_WRONLY); // 读和写的方式打开if (nullfile > 0){dup2(0, nullfile);dup2(1, nullfile);dup2(2, nullfile);close(nullfile);}
}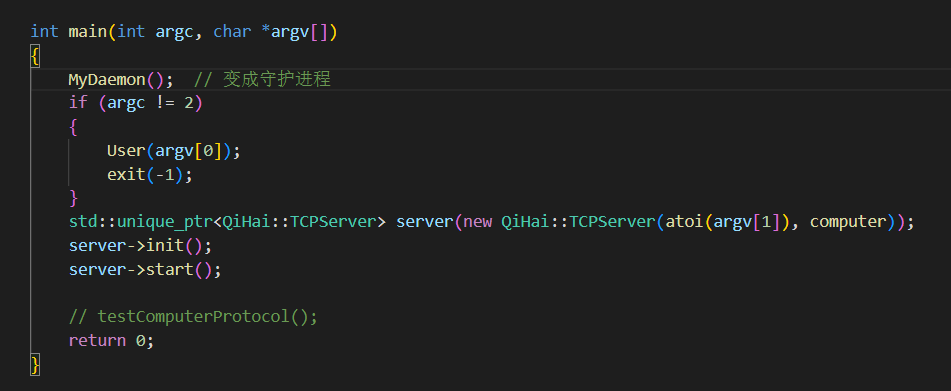
此时运行就可以看到变为后台进程了。利用netstat -ntap命令可以看到此进程,使用kill -9 pid就可以杀掉此进程。
通过上述的实验,我们明白了,在真正的网络通信中,由于是通过字符串进行传播的,所以我们一般会利用一个规定,规定如何将数据转化为字节流的形式以及将字节流转化为对应的数据。这样的就是协议。
2.http协议
实际上,应用层无非也就是程序员基于socket接口之上编写的具体逻辑,很多工作都是和文本处理相关的!--协议分析与处理。
那么,在经过发展,有一些非常好用以及广泛的应用层协议可以直接供给我们参考。其中http(超文本传输协议)就是其中之一哦~
在开始学习http协议之前,我们先着重理解一下URL以及特殊字符转义等前提知识。
URL
很明显,当前如果你是用PC端观看我这个博客的话,那么你的浏览器上面应该就存在一个URL。URL实际上也就是我们平时所叫的网址。在http协议下,URL如下:
http://域名[:端口]文件路径......
第一个http就表示着协议名,当然现在主流的是加密处理的https(https后续模块会讲明)。域名实际上是一个公司或者个人依据ip地址和此域名关联起来,在全网具有唯一性。端口是可选项,在http协议中默认访问的是80端口,https协议中默认访问的是443端口。当然也可以自己指定端口。别忘了套接字中的ip和端口就代表了全网中唯一的一个进程。文件路径就是访问目标进程-web服务器的路径,但是别看\就是访问的根目录,可能在编码过程中指定了其中一个目录(在后续的编码实现中我们可以看到),如果没有指定,默认就是\ 。
我们可以反过来想想,我们平时上网的常规的行为有哪些呢?
1.我们想获取什么东西。一张图片、视频、文字等等 -- 资源 没有拿到的时候资源就在对应的服务器上。(Linux)一个服务器上可能存在很多的资源。-文件 -- 请求资源拿到你的本地--服务进程打开你要访问的文件,读取该文件,将该文件通过网络发送给客户端。->打开这个文件,先找到这个文件。Linux中表示一个文件是通过路径进行标识的。此时web根目录 :/ 就是文件分隔符,完全就是Linux下的文件路径。
2.我们想上传什么东西。
所以,URL其实就是定位互联网中的唯一的资源。统一资源定位符。世界上所有的资源,只要找到其URL就能访问该资源。所以www为万维网。
urlencode和urldecode
但是,有的时候比如/ ?这些字符已经被url当做特殊意义理解了,因此这些字符不能随意出现,但是当某些参数需要带这些特殊字符,那么就需要转义。
转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式。字符即ASCII码值决定,比如'?'我们如何转码?已知?utf-8编码为0x3F,(注意为英文问号),那么从右到左取4位刚好就是一位16进制,就为%3F,比如如下网址:

那么,类比于我们之前所写的网络计算器,客户端应该是向服务器端发送请求,服务器接受到后解析然后发回响应。只不过这次变成了http制定的应用层协议而已。

那么在传输过程中,为了传输格式的提取以及序列和反序列化的需要,自然是有自己一套的报文的。
快速构建http请求和响应的报文格式
单纯在报文角度,http可以基于行的文本协议。
请求request格式:
请求行:方法 url(如果没有目的的路径,会访问/ 默认的路径) 请求协议版本(http/1.1)\r\n (中间是空格分隔)
请求报头(本次请求的相关属性,后面均加上\r\n)
key: value\r\n
......
6~8个请求行构成空行 \r\n (只有这个内容)
请求正文(可以没有)
响应response:
状态行:协议版本(服务器版本) 状态码 状态码描述\r\n(状态和状态码最常见的就是404 NotFound)
响应报头(本次请求的相关属性,后面均加上\r\n)
key: value\r\n
......
6~8个请求行构成空行 \r\n (只有这个内容)
响应正文(视频、音频、图片、html......)
当然,对于计算机来说,看http请求和响应是线性结构-字符串结构。协议版本是双方主机在交换过程中查看对方协议版本是否和自己一致,不一致服务器需要提供不同的服务。url就是想访问的资源路径,如果没有,那么默认传过去就是\了。
现在,我们可以建立一个共识:该协议如何封装报头-封装、解包呢?即http如何区分报头和有效载荷的呢?
\r\n 通过空行的方式区分报头和有效载荷的。一定能够把报头读完->接下来在读就是正文了。-> 我们如何得知正文的大小呢?(报头中就存在一个属性——Content-Length: 123) 就可以知道正文是有多少字节即可。
那么我们可否利用小工具telnet快速构建一个http请求,查看一下服务器端返回的结果呢?
输入指令:telnet www.baidu.com 80进入输入状态后输入一行报头:host: www.baidu.com,然后按下两次回车,我们可以得到这样的结果:
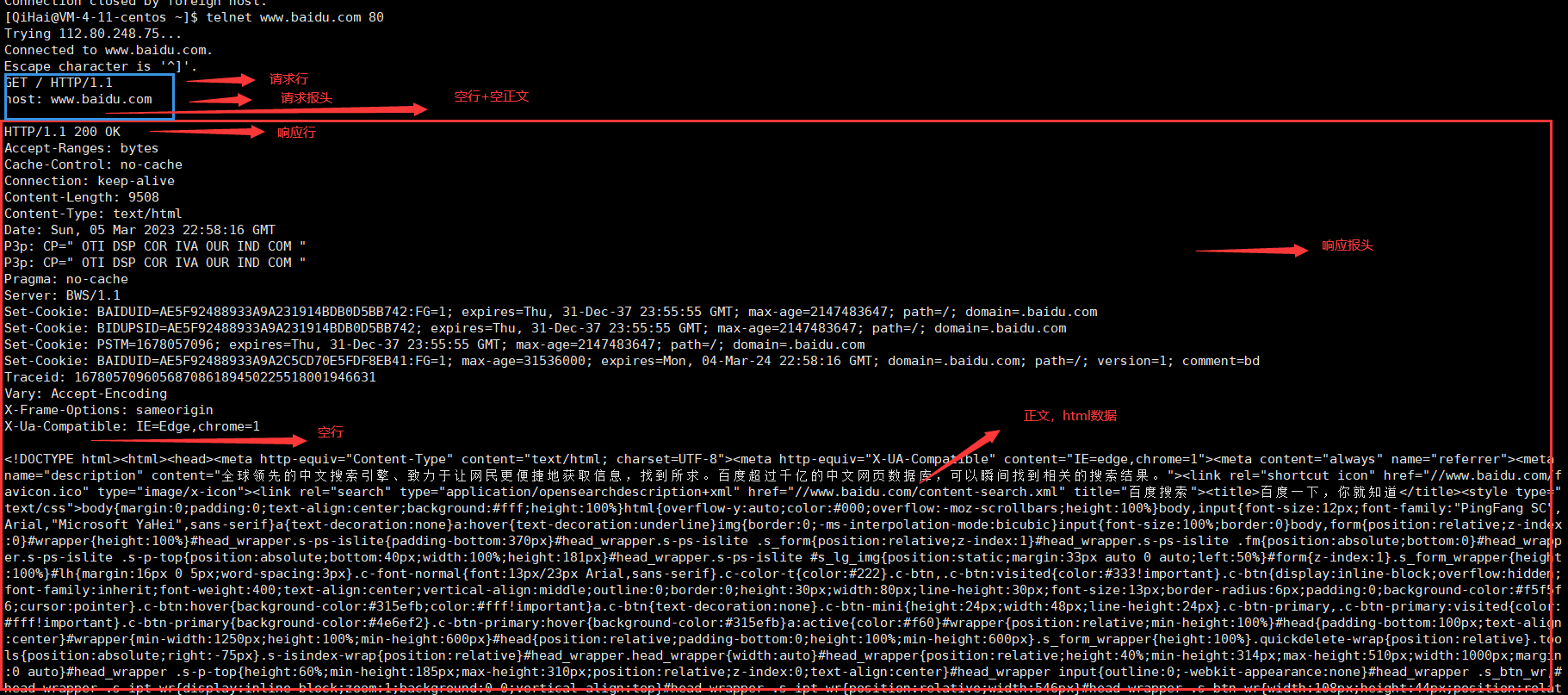
html文件就是响应返回的正文,如果是浏览器会对其渲染,形成我们所看到的网页。
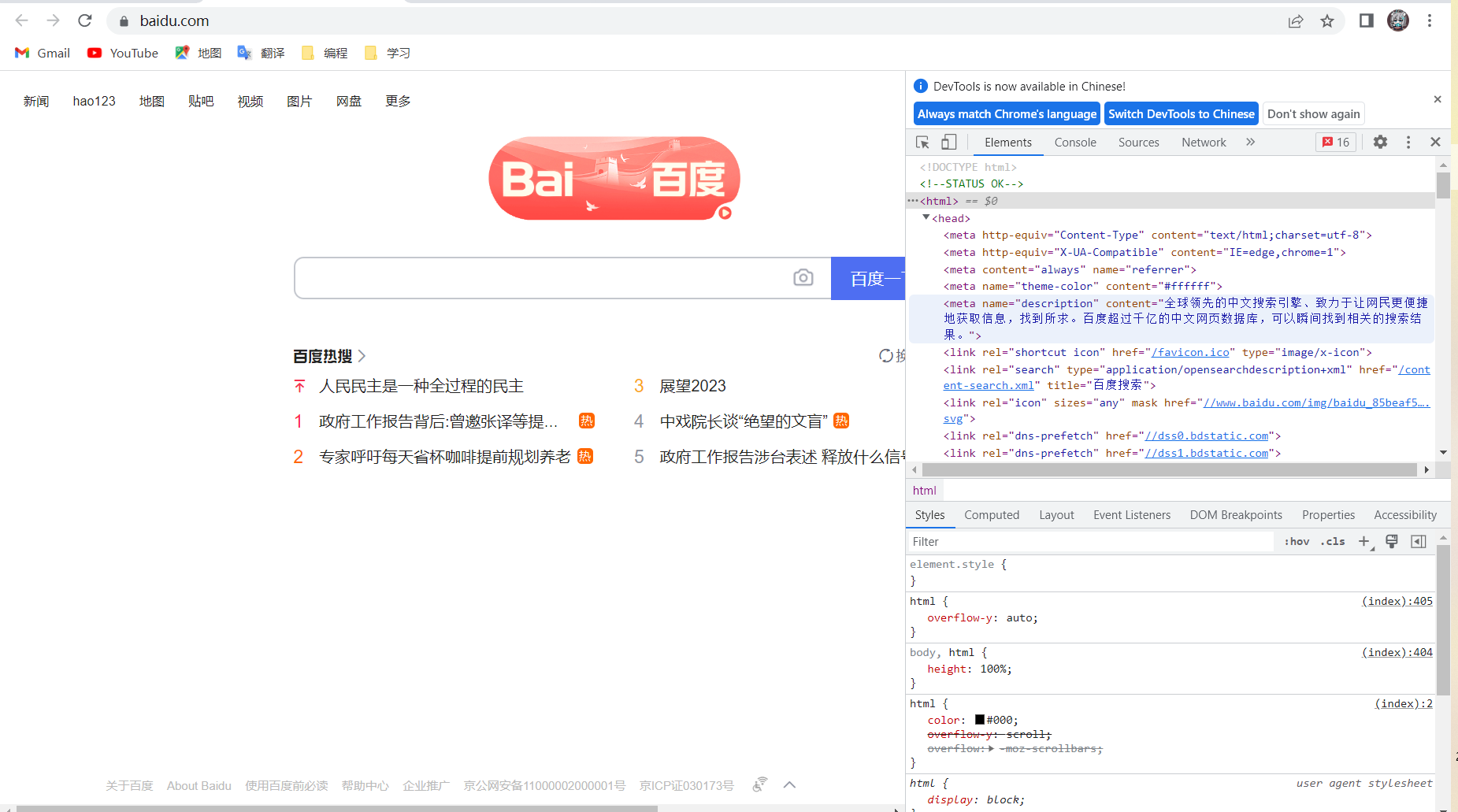
那么我们能否现在基于TCP套接字编程简单的实现一个web服务器,在服务器上接受浏览器客户端的连接,并且返回一个简单的网页呢?自然可以。
首先,我们需要利用上面我们写过的mysock文件,即TCP套接字相关的接口我们自己封装了,在创建服务器的时候直接调用即可,省略了很多的步骤。
创建服务器的时候传入一个函数对象,函数的参数就为服务套接字,方便我们向对应客户端发送信息以及接受信息,然后此函数就可以在cpp源文件中编写了。服务器创建的代码如下:
#include "MySock.hpp"
#include <functional>
#include <signal.h>
#include <unistd.h>using func_t = std::function<void(int)>;class HttpServer
{
public:HttpServer(int16_t port, func_t func):_listenSock(-1),_serveSock(-1), _port(port), _func(func){}void init(){_listenSock = QiHai::Sock::socket();if (_listenSock < 0) exit(1);if (!QiHai::Sock::bind(_listenSock, _port)) exit(2);if (!QiHai::Sock::listen(_listenSock)) exit(3);}void start(){signal(SIGCHLD, SIG_IGN); // 应用层设置为忽视,这样子进程退出就会自动被系统回收,不会产生僵尸进程了while (true){_serveSock = QiHai::Sock::accept(_listenSock);if(_serveSock < 0) continue;// 创建子进程对其处理if(fork() == 0){// 子进程close(_listenSock);_func(_serveSock); // 传给上一层传入此函数去处理close(_serveSock);exit(0);}close(_serveSock); }}
private:int _listenSock;int _serveSock; // 服务套接字int16_t _port;func_t _func;
};现在,我们就可以重点放在web服务器代码的编写上了。由于是通过http协议进行通信的,向之前我们通过telnet向百度的web服务器发送的请求,浏览器客户端也是类似的发送。我们可以简单的将其打印出来,然后按照响应的格式,响应行:http/1.1 200 ok\r\n然后不带响应报头在加上空行,后面加上简单的正文:html:<html><h3>hello!</h3></html> 。当然,上述只是一个演示,实际我们并不推荐这么做(直接将html文件写道源文件中),至于状态码和状态码描述我们后续会进行讲解。
//httpServer.cpp#include "HttpServer.hpp"
#include <memory>
#include <iostream>
#include <string>
#include "UserManual.hpp"void httpFunc(int socket)
{char buffer[10240];ssize_t n = recv(socket, buffer, sizeof(buffer) - 1, 0);if (n > 0){buffer[n] = '\0';std::cout << buffer << "---------------------------------" << std::endl;// web服务器收到的是一个http的请求// 方法 路径(没有默认\) 协议版本\r\n// key-value....// \r\n// 请求正文(可以没有)// 1试着自己手动构建一个http响应std::string httpresponse = "HTTP/1.1 200 ok\r\n"; // 协议版本 状态码(比如404) 状态码描述\r\nhttpresponse += "\r\n"; // 空行// 正文httpresponse += "<html><h3>hello!</h3></html>"; // 一般不这么写,一般卸载html文件内,这里只是作为测试send(socket, httpresponse.c_str(), httpresponse.size(), 0); // 向客户端(比如浏览器访问此web服务器)}
}int main(int argc, char* argv[])
{if (argc != 2){User(argv[0]);exit(-1);}std::unique_ptr<HttpServer> server(new HttpServer(atoi(argv[1]), httpFunc));server->init();server->start();return 0;
}我们运行编译之后,可以观察到如下结果:

可以发现,此时同时有pc上的浏览器和安卓上的浏览器向我们的服务器发送了请求,而我们的服务器也发送了一个简单的响应。

既然能够简单构建响应,那么我们能否针对传回来的http字符串进行分解(按照行),在对第一行按照空格分解,我们就可以拿到对方客户端发送http请求的请求行的相关数据了。我们对其想访问的目录做一个解析,并且将html文件放在wwwroot目录下。如果存在路径就访问对应的资源(利用文件读取其中html文件的内容,作为正文返回),默认就返回wwwroot目录下的index.html文件-首页文件,如果不存在路径我们返回error文件夹下的error.html文件。
首先,我们来实现切分字符串的功能函数,保存到util工具头文件中:
// util.hpp
#ifndef _WWW_UTIL_
#define _WWW_UTIL_#include <vector>
#include <string>
// 工具类// 提供字符串切割,根据传入指定的字符串和字符对其进行切分,传入vector数组中。字符串数组 分隔符 待处理字符串
static void cutString(std::vector<std::string>& v, const std::string& sep, const std::string& processstr)
{// abc d e\0 sep=' 'size_t index = 0, tmp = 0;size_t len = processstr.size();while (index < len){index = processstr.find(sep, tmp);v.push_back(processstr.substr(tmp, index - tmp));tmp = index + sep.size();}
}#endif然后我们在我们服务器调用的函数中简单实现我们上述要完成的目标:
static const char* ROOTPATH = "wwwroot";void httpFunc(int socket)
{char buffer[10240];ssize_t n = recv(socket, buffer, sizeof(buffer) - 1, 0);if (n > 0){buffer[n] = '\0';std::cout << buffer << "---------------------------------" << std::endl;// web服务器收到的是一个http的请求// 方法 路径(没有默认\) 协议版本\r\n// key-value....// \r\n// 请求正文(可以没有)std::vector<std::string> v; // 整体数据cutString(v, "\r\n", buffer); // 对传回来的请求做解析,提取每一行数据std::vector<std::string> requestline; // 针对于请求行cutString(requestline, " ", v[0]);std::string httpresponse; // 要发送的响应std::string path; // 打开资源的路径if (requestline[1] == "/"){// 默认不添加任何资源位置,就是/-默认的path = "wwwroot/index.html";}else path = ROOTPATH + requestline[1];std::string text;std::ifstream in(path); // 默认in 读的方式打开本地文件httpresponse += "HTTP/1.1 200 ok\r\n"; // 2xx 为正确响应if (in.is_open()){// httpresponse += "HTTP/1.1 200 ok\r\n"; // 2xx 为正确响应// 成功打开std::string line;while (std::getline(in, line)){text += line;}in.close();}else{// httpresponse += "HTTP/1.1 404 NotFound\r\n"; // 4xx 为服务器无法处理请求// 打开文件失败,返回错误界面std::ifstream err("wwwroot/error/error.html");std::string line;while (std::getline(err, line)){text += line;}err.close();}httpresponse += "\r\n"; // 空行,属性没有带httpresponse += text; // 响应正文send(socket, httpresponse.c_str(), httpresponse.size(), 0);}
}
html文件简单套用模板即可:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>QiHai</title>
</head>
<body><h3>欢迎来到我的第一个界面!</h3>
</body>
</html><!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta http-equiv="X-UA-Compatible" content="IE=edge"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>error</title>
</head>
<body><h1>抱歉!你访问的资源并不存在!</h1>
</body>
</html>查看一下此时的目录结构:
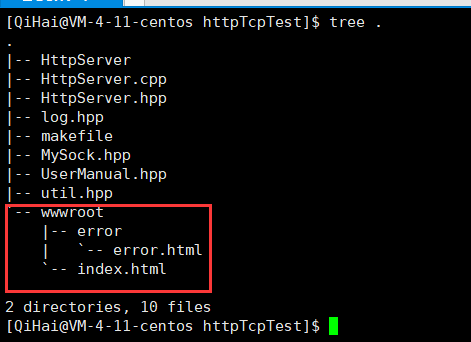
可以简单测试一下效果:
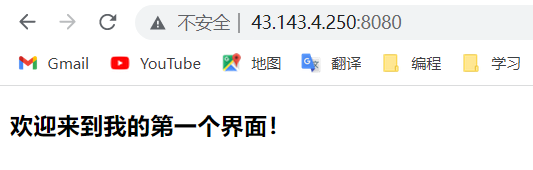
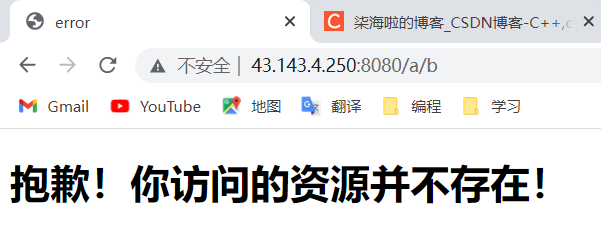
可以看到,已经达到了我们目前的效果。那么,演示结束后,我们开始逐步细化一下http中的内容。
http细节内容:
观察上面的例子,我们可以发现http本质就是文本分析。
针对于请求行内的请求方法,大致有如下的分类:

但是实际上最常用的也不过就是GET和POST方法。
我们下面细讲这两种方法:
GET和POST
针对于上网行为,我们的请求方法这两种有不同的场景。
1.从服务器端拿下来资源数据。
GET方法。
2.把客户端的数据提交给服务器。
GET方法、POST方法。
但是对于提交,GET方法和POST方法有着不同的表现。GET会将传输的内容在url栏中回显,而POST方法并不会回显,而是写入正文之中,相对隐私一点。
下面,我们利用html表单来验证第二种情况种两种方法的差异。
可以看一下html表单的基本格式:
<form name="input" action="/a/b/notexist.html" method="GET">Username: <input type="text" name="user"> <br/>Password: <input type="password" name="pwd"> <br/><input type="submit" value="登陆"></form>对于html表单我们可以不用管,想要了解的也可以简单的查查。总之,html表单实际上就是收集用户数据,并且按照一定的方法吧用户数据推送给服务器。表单中的数据,会转化为http request的一部分。action就是发送给目标文件,而method就是不同的方法。我们首先测试GET,主程序什么地方都可以不用动,只需要将上述html表格添加到index.html网页的body中即可。


可以看到,我们提交后可以发现在url栏中竟然显示了,这是因为GET方法用于提交的话信息会显示在请求行中:

但是这样会很不隐私,我们尝试一下POST方法。

可以发现,此时并没有在url地址栏进行显示,我们查看服务器监控的结果:

可以看到,被写入了正文中。这也就是GET和POST的区别。
响应状态码
那么,对于服务器端向客户端发送的响应中,在第一行也就是响应行中存在状态码和状态码描述。如下表所示:
| 状态码 | 状态码描述 | 举例 |
|---|---|---|
| 1XX | 信息性状态码 | |
| 2XX | 请求正常处理完毕。 | 200 OK(请求成功。一般用于GET与POST请求) |
| 3XX | 需要进行附加操作以完成请求 | 301 Moved Permanently(永久重定向) 302 Found(临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI) |
| 4XX | 服务器无法处理请求 | 404 Not Found(无法找到对应的资源) |
| 5XX | 服务器处理请求错误 |
大概的信息如上,举例中只是举例常见的作为了解,想要更加详细的可以查看此网址:http状态码 。
我们可以利用我们的代码demo实现一下3XX请求。由于是重定向,实际上301就是可以吧标签内的网址也会进行改变,而302只是重定向而已,302更加类似于平时我们登录网站后跳转的界面。
{//.....if (in.is_open()){httpresponse += "HTTP/1.1 200 ok\r\n"; // 2xx 为正确响应// 成功打开std::string line;while (std::getline(in, line)){text += line;}in.close();}if (text.empty()){// 为真说明文件没有找到,则没有打开,我们向重定向到err.html界面 使用302状态码进行httpresponse += "http/1.1 302 Found\t\n";httpresponse += "Location: http://43.143.4.250:8080/error/error.html\r\n"; // 加上此报头属性转向对应的资源 url}//......}

经过测试,可以看到当我们访问不存在的资源的时候,就给我们返回了一个error.html的界面,我们观察一下服务器端接收的消息:
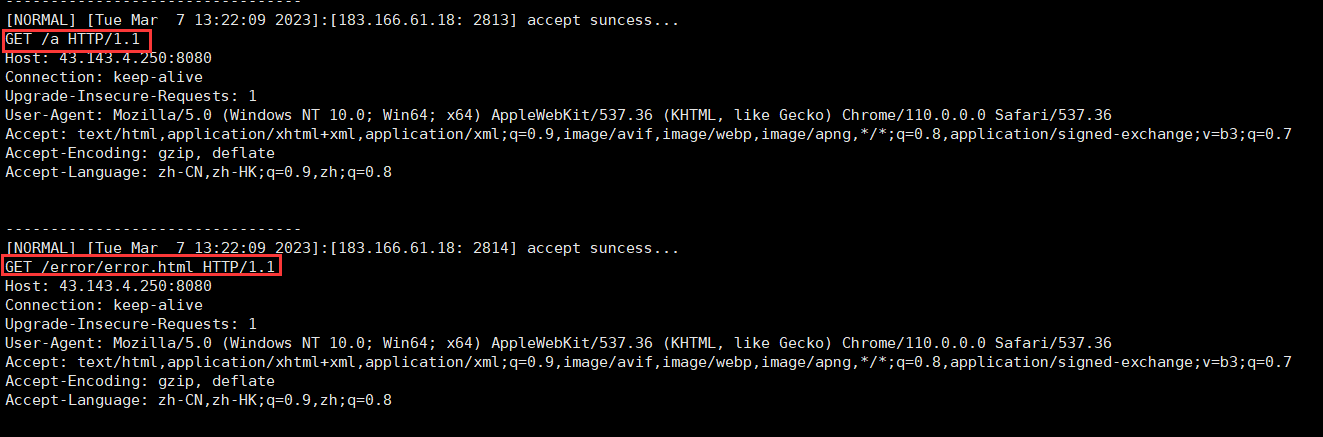
可以发现,针对访问不存在的资源,浏览器客户端连续发送了两次请求,第一次就是我们本身的请求,但是第二次就是对我们重定向文件的请求,所以重定向的理解可以如下图进行理解:

http的报头属性
在之前我们说状态码302的时候已经提到了一个报头属性Location,表示之后客户端要访问的url资源。另外,还有一些常见的报头属性如下图所示:
Content-Type: 数据类型(text/html等)
Content-Length: Body的长度
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
referer: 当前页面是从哪个页面跳转过来的;
location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;Connection:keep-alive 长连接
Connection:close 短连接( 一张完整的网页,有非常多的资源构成的。短连接-就是每次请求都要连接一次,成本有点高。长连接达到提高效率的目的。)
这里针对于Cookie,我们来讲讲http中的会话管理:
会话管理
http会话的特征:
1.简单快速
2.无连接(TCP是维护连接的)
3.无状态(不知道历史状态 - 即不会对用户的任何行为不做记录) 比如如果不记录状态,那么登录跳转后页面又如何知道我是登录状态呢? 但是实际上我们进行使用的时候,一般网站是会记录下我的状态的。根据上述特征,可以总结出http只需要保持网络功能就可以了.
针对上述,我们来细说一下Cookie和Set-Cookie这两个报头属性的作用:
假设Cookie之中就是保存用户数据之类的通行证(比如账号密码),我们利用如下图进行一个演示:

如果cookie文件被清理掉就需要重新登录了。
但是上述存在很大的安全隐患。先不说http明文传输的危险,如果客户端,被植入了木马程序,如果cookie文件被盗取了 - 个人信息严重泄露了。
所以改进方案是让我们保存的用户的隐私信息放在服务器下管理,服务器接受第一次登录后生成一个session id-使用算法帮我们形成一个唯一ID。客户端利用这个唯一id可以继续登录。此时如果发生了泄密,黑客拿到的是session id,再次进行访问一样的能够去访问。但是个人信息是不会被泄露的。cookie文件 - 拦不住。但是服务端存在检测,比如ip突然发生变化,就让原本的session id失效,需要重新登录或者给此id定时,一定时间后失效即可。
但是,可以发现,本身受限于http的明文发送,在之前利用html表单无论POST还是GET方法,用户的隐私信息都是明文的在http报文之中的,如果此时出现不法分子拦截,同样的会出现隐私泄露的。所以,我们需要的是一个更加安全的应用层方案来保护用户的隐私。
https正是基于http加上加密传输的应用层协议,因为附带的有加密,所以实现会变得非常复杂。
相关文章:
【Linux】网络基础(1)
前言 相信没有网络就没有现在丰富的世界。本篇笔记记录我在Linux系统下学习网络基础部分知识,从关于网络的各种概念和关系开始讲起,逐步架构起对网络的认识,对网络编程相关的认知。 我的上一篇Linux文章呀~ 【Linux】网络套接字编程_柒海啦的…...

限流算法详解
限流是我们经常会碰到的东西,顾名思义就是限制流量。它能保证我们的系统不会被突然的流量打爆,保证系统的稳定运行。像我们生活中,地铁就会有很多护栏,弯弯绕绕的,这个就是一种限流。像我们抢茅台,肯定大部…...
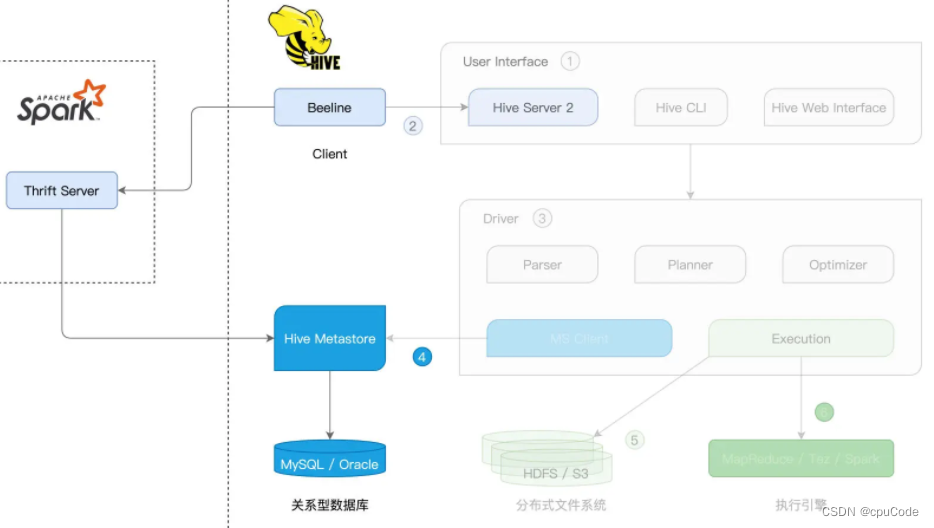
Spark/Hive
Spark/HiveHive 原理Spark with HiveSparkSession Hive Metastorespark-sql CLI Hive MetastoreBeeline Spark Thrift ServerHive on SparkHive 擅长元数据管理Spark 擅长高效的分布式计算 Spark Hive 集成 : Hive on Spark : Hive 用 Spark 作为底层的计算引擎时Spark w…...
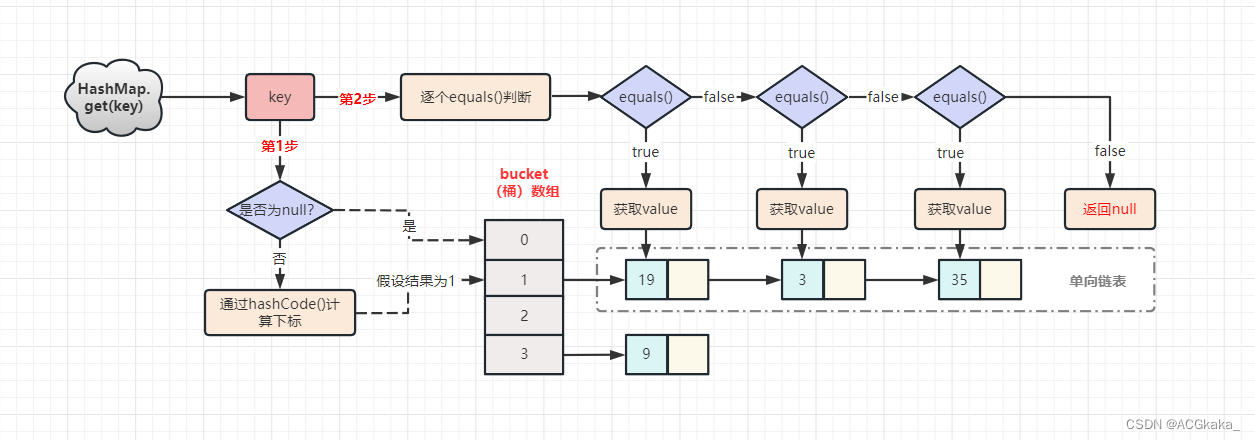
HashMap底层的实现原理(JDK8)
目录一、知识点回顾二、HashMap 的 put() 和 get() 的实现2.1 map.put(k, v) 实现原理2.2 map.get(k) 实现原理三、HashMap 的常见面试题3.1 为何随机增删、查询效率都很高?3.2 为什么放在 HashMap 集合 key 部分的元素需要重写 equals 方法?3.3 HashMap 的 key 为…...
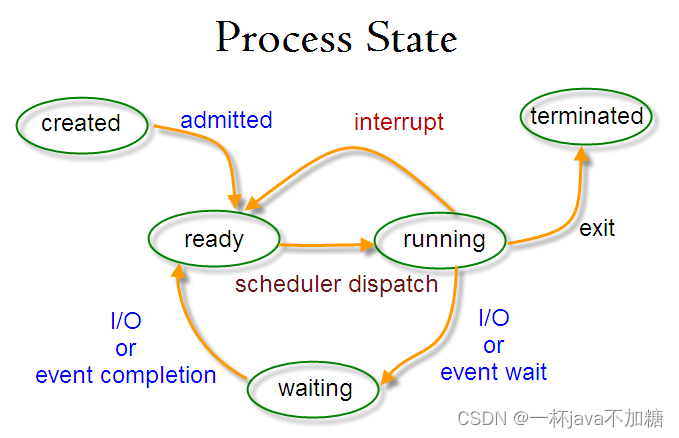
操作系统-整理
进程 介绍 进程是系统进行资源分配和调度的一个独立单位。每个进程都有自己的独立内存空间,不同进程通过进程间通信来通信。由于进程占据独立的内存,所以上下文进程间的切换开销(栈、寄存器、虚拟内存、文件句柄等)比较大&#…...
系统换行符的思考
各系统换行符 换行符,也即是回车换行,因为表示为Carriage-Return和Line-Feed。 回车用Return-Carrige表示,简写为CR,字符表示为\r。 换行用Line-Feed表示,简写为LF,字符表示为\n。 由于历史原因…...
Wwise集成到unreal
1、Wwise集成到Unreal 1.1 安装必要的软件 安装unreal 5.1;安装Audiokinetic Launcher;集成版本是Wwise 2021.1.12.7973。Audiokinetic Launcher下载地址: https://www.audiokinetic.com/zh/thank-you/launcher/windows/?refdownload&pl…...

前端秘籍之=>八股文经卷=>(原生Js篇)【持续更新中...】
大家好,最近想了想,打算总结归纳一版前端八股文经卷,给大家提供学习参考,如果帮助到大家,请大家,一键三连支持一下,你们的支持会激励我更加努力的更新更多有用的知识,博主先在这里谢…...
【Python安装配置教程】
Python由荷兰数学和计算机科学研究学会的吉多范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品。Python提供了高效的高级数据结构,还能简单有效地面向对象编程。Python语法和动态类型,以及解释型语言的本质,使它成为多数平台…...

Spring-Retry失败重试
文章目录 重试的场景引入依赖启动类serviceController@Retryable参数@Recover注意事项重试的场景 1、网络波动需要,导致请求失败,需要重发。 2、发送消息失败,需要重发,重发失败要记录日志 … 引入依赖 <!-- spring-retry--> <dependency><groupId>or…...
【目标检测 DETR】通俗理解 End-to-End Object Detection with Transformers,值得一品。
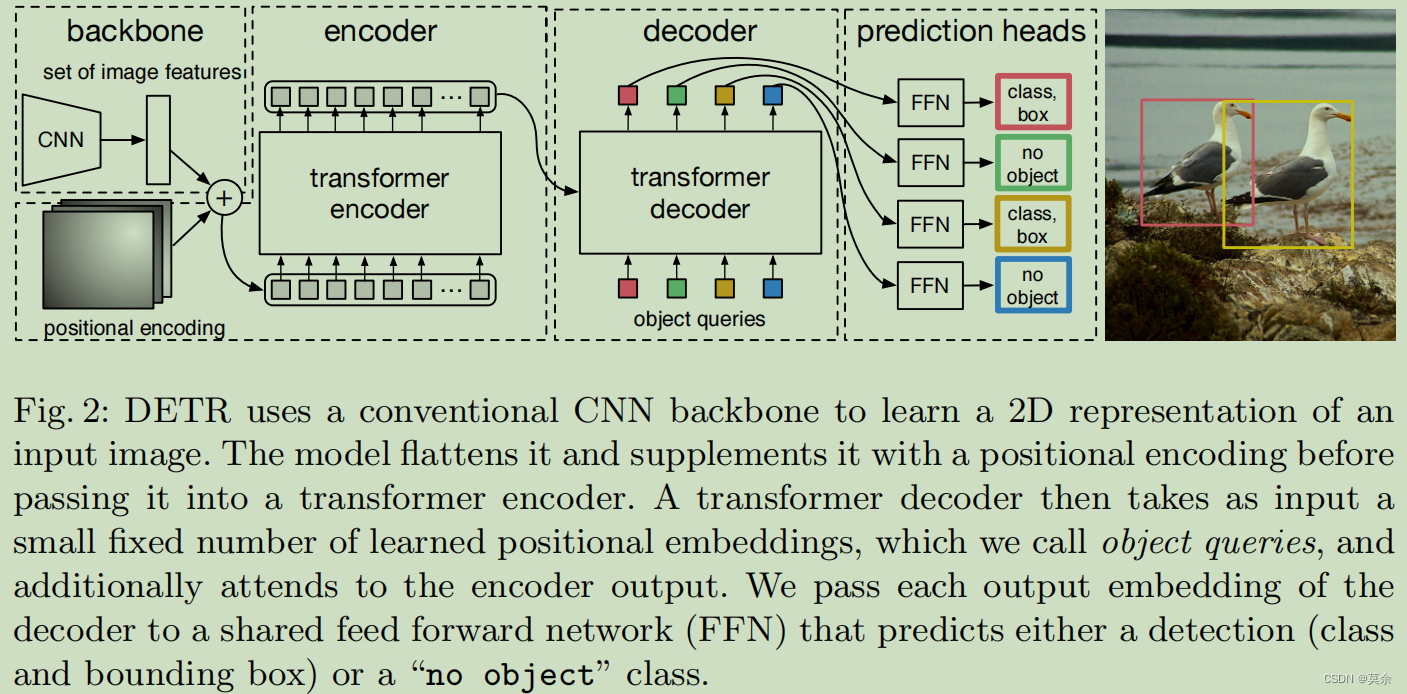
文章目录DETR1. 亮点工作1.1 E to E1.2 self-attention1.3 引入位置嵌入向量1.4 消除了候选框生成阶段2. Set Prediction2.1 N个对象2.2 Hungarian algorithm3. 实例剖析4. 代码4.1 配置文件4.1.1 数据集的类别数4.1.2 训练集和验证集的路径4.1.3 图片的大小4.1.4 训练时的批量…...

项目ER图和资料
常用的数据类型 模型类 一对多 from app import db import datetimeclass BaseModel(db.Model):__abstract__ Truecreate_time db.Column(db.DateTime,defaultdatetime.datetime.now())update_time db.Column(db.DateTime,defaultdatetime.datetime.now())class Role(db.M…...
)
剑指 Offer 20. 表示数值的字符串(java+python)
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。 数值(按顺序)可以分成以下几个部分: 若干空格 一个 小数 或者 整数 (可选)一个 ‘e’ 或 ‘E’ ,后面跟着一个 整数…...

程序员的逆向思维
前要: 为什么你读不懂面试官提问的真实意图,导致很难把问题回答到面试官心坎上? 为什么在面试结束时,你只知道问薪资待遇,不知道如何高质量反问? 作为一名程序员,思维和技能是我们职场生涯中最重要的两个方面。有时候…...
吐血整理学习方法,2年多功能测试成功进阶自动化测试,月薪23k+......
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 测试进阶方向 测试进…...

mysql慢查询:pt-query-digest 分析
"某些SQL语句执行效率慢",这个问题总体上分为两类: 出现了慢查询语句某些查询语句没有使用索引 由于数据的写入量非常大,所以要想直接打开慢查询日志来查看到底哪些语句有问题几乎是不可能的,因为日志的刷新速度太快了…...

git的使用整合
git的下载和安装暂时不论述了,将git安装后会自动配置环境变量,所以环境变量也不需要配置。 一、初始化配置 打开git bash here(使用linux系统下运行的口令),弹出一个类似于cmd的窗口。 (1)配置属性 git config --glob…...

XCPC第九站———背包问题!
1.01背包问题 我们首先定义一个二维数组f,其中f[i][j]表示在前i个物品中取且总体积不超过j的取法中的最大价值。那么我们如何得到f[i][j]呢?我们运用递推的思想。由于第i个物品只有选和不选两种情况,当不选第i个物品时,f[i][j]f[i…...

【软考 系统架构设计师】论文范文④ 论基于构件的软件开发
>>回到总目录<< 文章目录 论基于构件的软件开发范文摘要正文论基于构件的软件开发 软件系统的复杂性不断增长、软件人员的频繁流动和软件行业的激烈竞争迫使软件企业提高软件质量、积累和固化知识财富,并尽可能地缩短软件产品的开发周期。 集软件复用、分布式对…...

spring-integration-redis中分布式锁RedisLockRegistry的使用
pom依赖:<!-- redis --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.integ…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...