SEO之搜索引擎的工作原理(三)
初创企业需要建站的朋友看这篇文章,谢谢支持:我给不会敲代码又想搭建网站的人建议
(接上一篇。。。)
排名
经过搜索引擎蜘蛛抓取页面,索引程序计算得到倒排索引后,搜索引擎就准备好可以随时处理用户搜索了。用户在搜索框填入关键词后,排名程序调用索引库数据,计算排名显示给用户,排名过程是与用户直接互动的。
1、搜索词处理
搜索引擎接收到用户输入的搜索词后,需要对搜索词做一些处理,才能进入排名过程。
搜索词处理包括如下几方面。
(1) 中文分词。与页面索引时一样,搜索词也必须进行中文分词,将查询字符串转换为以词为基础的关键词组合。分词原理与页面分词相同。
(2)去停止词。和索引时一样,搜索引擎也需要把搜索词中的停止词去掉,最大限度地提高排名相关性及效率。
(3)指令处理。查询词完成分词后,搜索引擎的默认处理方式是在关键词之间使用“与”逻辑。也就是说用户搜索“减肥方法”时,程序分词为“减肥”和“方法”两个词,搜索引擎排序时默认认为,用户寻找的是既包含“减肥”,也包含“方法”的页面。只包含“减肥”不包含“方法”,或者只包含“方法”不包含“减肥”的页面,被认为是不符合搜索条件的。
当然,这只是极为简化的为了说明原理的说法,实际上我们还是会看到只
包含一部分关键词的搜索结果。
另外用户输入的查询词还可能包含一些高级搜索指令,如加号、减号等,搜索引擎都需要做出识别和相应处理。有关高级搜索指令,后面还有详细说明。
(4)拼写错误矫正。用户如果输入了明显错误的字或英文单词拼错,搜索引擎会提示用户正确的用字或拼法,如下图所示。

(5)整合搜索触发。某些搜索词会触发整合搜索,比如明星姓名就经常触发图片和视频内容,当前的热门话题又容易触发资讯内容。哪些词触发哪些整合搜索,也需要在搜索词处理阶段计算。
2、文件匹配
搜索词经过处理后,搜索引擎得到的是以词为基础的关键词集合。文件匹配阶段就是找出含有所有关键词的文件。在索引部分提到的倒排索引使得文件匹配能够快速完成,如下表所示。

假设用户搜索“关键词2关键词7”,排名程序只要在倒排索引中找到“关键词2”和“关键词7”这两个词,就能找到分别含有这两个词的所有页面。经过简单计算就能找出既包含“关键词2”,也包含“关键词7”的所有页面:文件1和文件6。
3、初始子集的选择
找到包含所有关键词的匹配文件后,还不能进行相关性计算,因为找到的文件经常会有几十万几百万,甚至上千万个。要对这么多文件实时进行相关性计算,需要的时间还是比较长的。
实际上用户并不需要知道所有匹配的几十万、几百万个页面,绝大部分用户只会查看前两页,也就是前20个结果。搜索引擎也并不需要计算这么多页面的相关性,而只要计算最重要的一部分页面就可以了。常用搜索引擎的人都会注意到,搜索结果页面通常最多显示100个。用户点击搜索结果页面底部的“下一页”链接,最多也只能看到第100页,也就是1000个搜索结果,百度则通常返回76页结果。
所以搜索引擎只需要计算前1000个结果的相关性,就能满足要求。
但问题在于,还没有计算相关性时,搜索引擎又怎么知道哪一千个文件是最相关的?所以用于最后相关性计算的初始页面子集的选择,必须依靠其他特征而不是相关性,其中最主要的就是页面权重。由于所有匹配文件都已经具备了最基本的相关性(这些文件都包含所有查询关键词),搜索引擎通常会用非相关性的页面特征选出一个初始子集。初始子集的数目是多少?几万个?或许更多,外人并不知道。不过可以肯定的是,当匹配页面数目巨大时,搜索引擎不会对这么多页面进行计算,而必须选出页面权重较高的一个子集,再对子集中的页面进行相关性计算。
4、相关性计算
选出初始子集后,对子集中的页面计算关键词相关性。计算相关性是排名过程中最重要的一步。相关性计算是搜索引擎算法中最令SEO 感兴趣的部分。
影响相关性的主要因素包括如下几方面。
(1)关键词常用程度。经过分词后的多个关键词,对整个搜索字符串的意义贡献并不相同。越常用的词对搜索词的意义贡献越小,越不常用的词对搜索词的意义贡献越大。举个例子,假设用户输入的搜索词是“我们冥王星”。“我们”这个词常用程度非常高,在很多页面上会出现,它对“我们冥王星”这个搜索词的辨识程度和意义相关度贡献就很小。
找出那些包含“我们”这个词的页面,对搜索排名相关性几乎没有什么影响,有太多页面包含“我们”这个词。
而“冥王星”这个词常用程度就比较低,对“我们冥王星”这个搜索词的意义贡献要大得多。那些包含“冥王星”这个词的页面,对“我们冥王星”这个搜索词会更为相关。
常用词的极致就是停止词,对页面意义完全没有影响。
所以搜索引擎对搜索词串中的关键词并不是一视同仁地处理,而是根据常用程度进行加权。不常用的词加权系数高,常用词加权系数低,排名算法对不常用的词给予更多关注。
我们假设A、B两个页面都各出现“我们”及“冥王星”两两个词。但是“我们”这个词在A页面出现于普通文字中,“冥王星”这个词在A页面出现于标题标签中。B页面正相反,“我们”出现在标题标签中,而“冥王星”出现在普通文字中。那么针对“我们冥王星”这个搜索词,A页面将更相关。
(2)词频及密度。一般认为在没有关键词堆积的情况下,搜索词在页面中出现的次数多,密度越高,说明页面与搜索词越相关。当然这只是一个大致规律,实际情况未必如此,所以相关性计算还有其他因素。出现频率及密度只是因素的一部分,而且重要程度越来越低。
(3)关键词位置及形式。就像在索引部分中提到的,页面关键词出现的格式和位置都被记录在索引库中。关键词出现在比较重要的位置,如标题标签、黑体、H1等,说明页面与关键词越相关。这一部分就是页面 SEO所要解决的。
(4)关键词距离。切分后的关键词完整匹配地出现,说明与搜索词最相关。比如搜索“减肥方法”时,页面上连续完整出现“减肥方法”四个字是最相关的。如果“减肥”和“方法”两个词没有连续匹配出现,出现的距离近一些,也被搜索引擎认为相关性稍微大一些。
*(5)链接分析及页面权重。*除了页面本身的因素,页面之间的链接和权重关系也影响关键词的相关性,其中最重要的是锚文字。页面有越多以搜索词为锚文字的导入链接,说明页面的相关性越强。
链接分析还包括了链接源页面本身的主题、锚文字周围的文字等。
5、排名过滤及调整
选出匹配文件子集、计算相关性后,大体排名就已经确定了。之后搜索引擎可能还有一些过滤算法,对排名进行轻微调整,其中最主要的过滤就是施加惩罚。一些有作弊嫌疑的页面,虽然按照正常的权重和相关性计算排到前面,但搜索引擎的惩罚算法却可能在最后一步把这些页面调到后面去。典型的例子是百度的11位,Google 的负6、负30、负950等算法。
6、排名显示
所有排名确定后,排名程序调用原始页面的标题标签、说明标签、快照日期等数据显示在页面上。有时搜索引擎需要动态生成页面摘要,而不是调用页面本身的说明标签。
7、搜索缓存
用户搜索的关键词有很大一部分是重复的。按照2/8定律,20%的搜索词占到了总搜索次数的80%。按照长尾理论,最常见的搜索词没有占到80%那么多,但通常也有一个比较粗大的头部,很少一部分搜索词占到了所有搜索次数的很大一部分。尤其是有热门新闻
发生时,每天可能有几百万人搜索完全相同的关键词。
如果每次搜索都重新处理排名可以说是很大的浪费。搜索引擎会把最常见的搜索词存入缓存,用户搜索时直接从缓存中调用,而不必经过文件匹配和相关性计算,大大提高了排名效率,缩短了搜索反应时间。
8、查询及点击日志
搜索用户的IP地址、搜索的关键词、搜索时间,以及点击了哪些结果页面,搜索引擎都记录形成日志。这些日志文件中的数据对搜索引擎判断搜索结果质量、调整搜索算法、预期搜索趋势等都有重要意义。
上面我们简单介绍了搜索引擎的工作过程。当然实际搜索引擎的工作步骤与算法是非常复杂的。上面的说明很简单,但其中有很多技术难点。
搜索引擎还在不断优化算法,优化数据库格式。不同搜索引擎的工作步骤也会有差异。但大致上所有主流搜索引擎的基本工作原理都是如此,在过去几年及可以预期的未来几年,都不会有实质性的改变。
(完)

相关文章:
SEO之搜索引擎的工作原理(三)
初创企业需要建站的朋友看这篇文章,谢谢支持:我给不会敲代码又想搭建网站的人建议 (接上一篇。。。) 排名 经过搜索引擎蜘蛛抓取页面,索引程序计算得到倒排索引后,搜索引擎就准备好可以随时处理用户搜索了…...

开发语言漫谈-python
python的语法和C完全不同,但是它也是C写的。也就是想成为高手,C是必备武功。不是每个人都想成为武林高手。所以客观上需要个简单上手开发效率高的语言,就这样python诞生了。python的发明人其实不喜欢蟒蛇,但是不知道为啥选这个名字…...

JVM指令收集
1. 栈和局部变量操作 1.1 将常量压入栈的指令aconst_null 将null对象引用压入栈 iconst_m1 将int类型常量-1压入栈 iconst_0 将int类型常量0压入栈 iconst_1 将int类型常量1压入栈 iconst_2 将int类型常量2压入栈 iconst_3 将int类型常量3压入栈 iconst_4 将int类型常量4压入…...
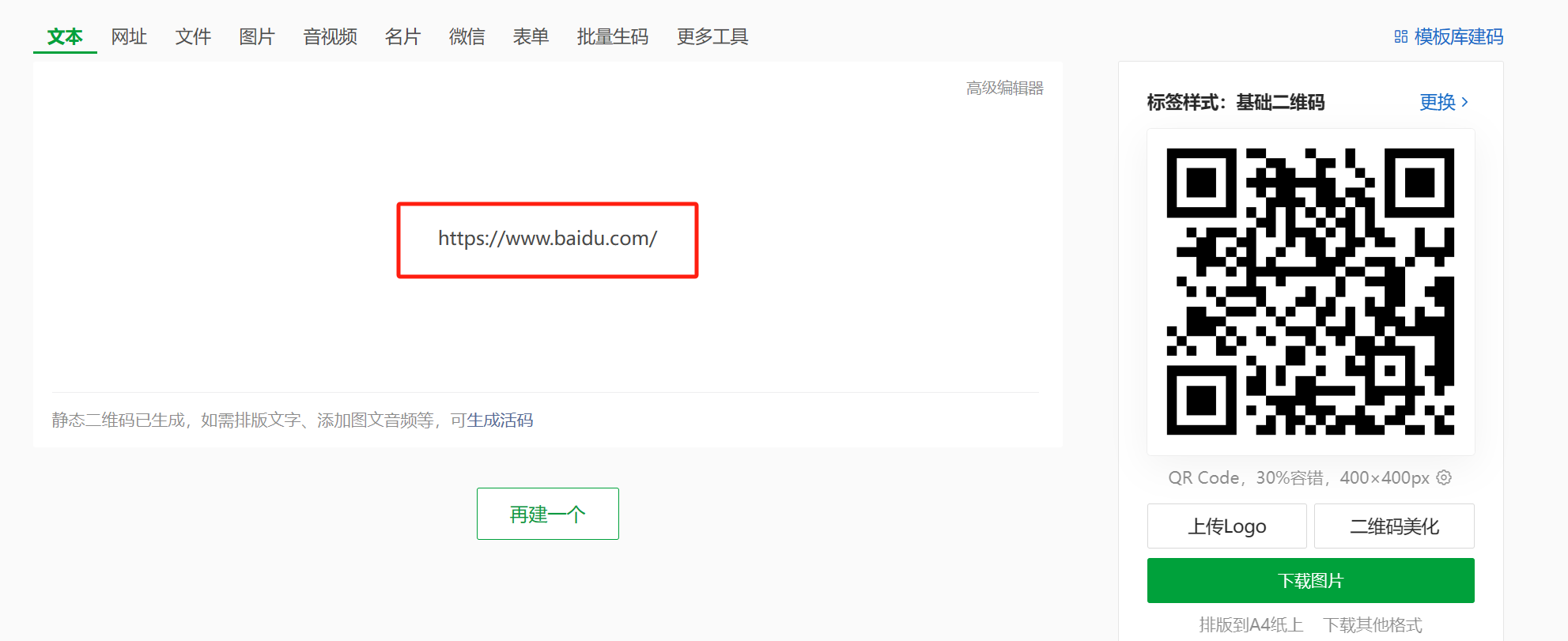
小程序解析二维码:jsQR
1.了解jsQR jsQR是一个纯javascript脚本实现的二维码识别库,不仅可以在浏览器端使用,而且支持后端node.js环境。jsQR使用较为简单,有着不错的识别率。 2.效果图 3.二维码 4.下载jsqr包 npm i -d jsqr5.代码 <!-- index.wxml --> &l…...

【verilog 设计】 reg有没有必要全部赋初值?
一、前言 在知乎发现“reg有没有必要全部赋初值”这个问题,与自己近期对Verilog reg的进一步学习相契合,此文对这个问题进行总结。 二、reg的初值赋值方式 就语法意义赋初值而言,就是在声明reg时对其赋值。在工程中,对于数字系…...

NLP问答系统:使用 Deepset SQUAD 和 SQuAD v2 度量评估
目录 一、说明 二、Deepset SQUAD是个啥? 三、问答系统(QA系统),QA系统在各行业的应用及基本原理 3.1 医疗 3.2 金融 3.3 顾客服务 3.4 教育 3.5 制造业 3.6 法律 3.7 媒体 3.8 政府 四、在不同行业使用QA系统的基本原理 五、关于…...

php开发中如何防止抓包工具伪造请求
要防止抓包工具伪造请求,采取一系列的技术和策略来增强应用程序的安全性。以下是一些关键步骤和最佳实践: 1. 使用HTTPS 确保应用程序使用HTTPS协议进行通信。HTTPS通过TLS/SSL加密客户端和服务器之间的数据传输,这使得抓包工具捕获到的数据…...
密码学 | 椭圆曲线数字签名方法 ECDSA(下)
目录 10 ECDSA 算法 11 创建签名 12 验证签名 13 ECDSA 的安全性 14 随机 k 值的重要性 15 结语 ⚠️ 原文:Understanding How ECDSA Protects Your Data. ⚠️ 写在前面:本文属于搬运博客,自己留着学习。同时,经过几…...
拟态个人主页UI源码
拟态个人主页 效果图源代码领取源码 效果图 PC端 移动端 源代码 index.php <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><title>孤客 |佩恩</title><meta name"keywords" co…...

移动硬盘无法打开?别慌!这里有救星!
移动硬盘作为现代生活中重要的数据存储工具,承载着我们大量的文件和数据。然而,有时我们会遇到移动硬盘无法打开的情况,这往往让人焦虑不已。那么,当移动硬盘无法打开时,我们应该如何应对呢? 移动硬盘无法打…...
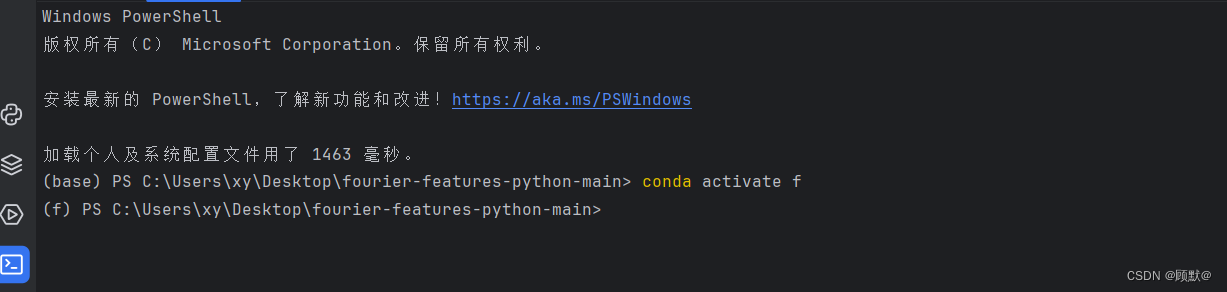
windows下已经创建好了虚拟环境,但是切换不了的解决方法
用得多Ubuntu,今天用Windows重新更新anaconda出问题,重新安装之后,打开pycharm发现打开终端之后,刚开始是ps的状态,后面试了网上改cmd的方法,终端变成c盘开头了 切换到虚拟环境如下:目前的shell…...
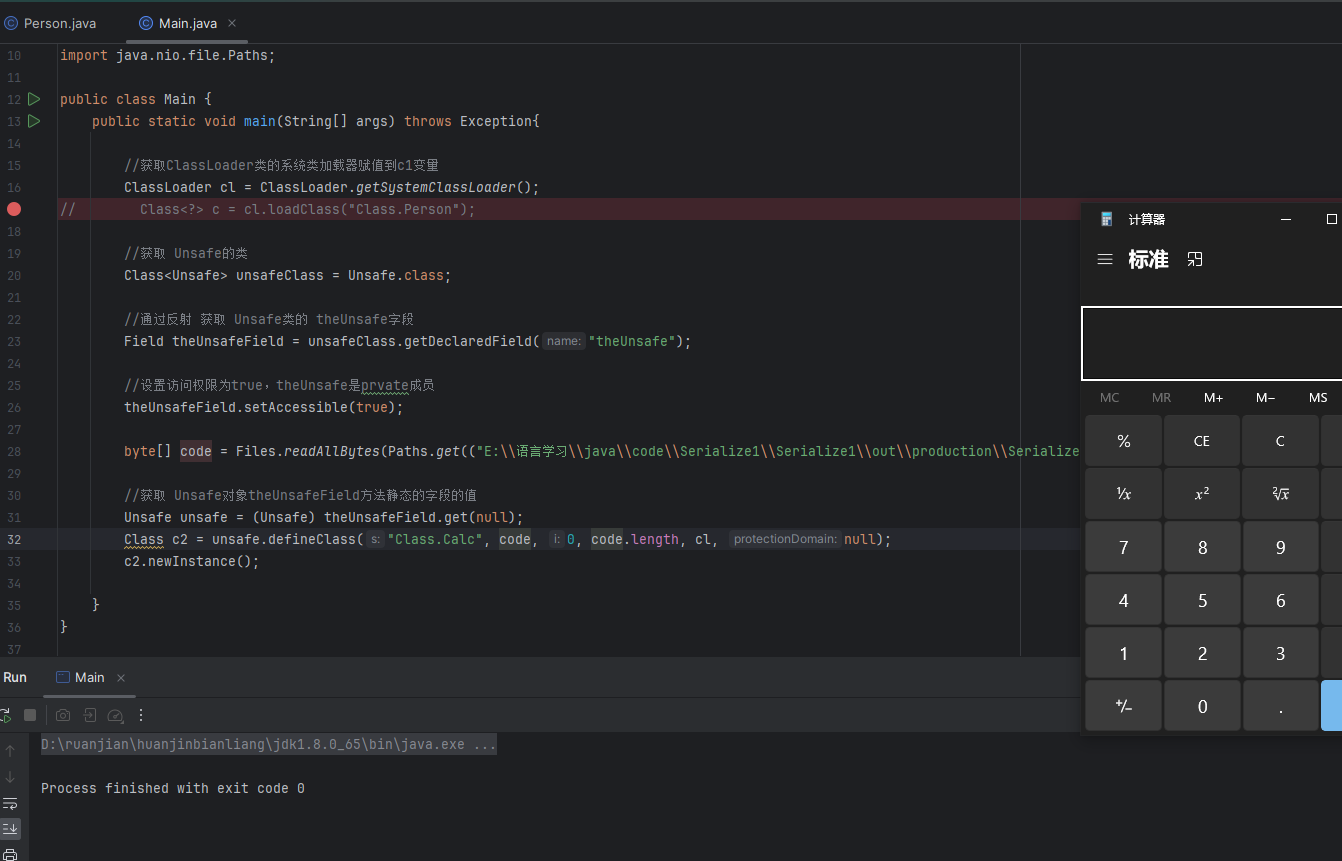
Java反序列化基础-类的动态加载
类加载器&双亲委派 什么是类加载器 类加载器是一个负责加载器类的对象,用于实现类加载的过程中的加载这一步。每个Java类都有一个引用指向加载它的ClassLoader。而数组类是由JVM直接生成的(数组类没有对应的二进制字节流) 类加载器有哪…...

课堂行为动作识别数据集
一共8884张图片 xml .txt格式都有 Yolo可直接训练 已跑通 动作类别一共8类。 全部为教室监控真实照片,没有网络爬虫滥竽充数的图片,可直接用来训练。以上图片均一一手工标注,标签格式为VOC格式。适用于YOLO算法、SSD算法等各种目标检测算法…...

【数据库】MVCC
MVCC是一种用来解决读写冲突的无锁并发控制,也就是为事务分配单项增长的时间戳,为每个修改保存一个版本,版本与事务时间戳关联,读操作只读该事务开始前的数据库的快照 MVCC,全称Multi-Version Concurrency Control&am…...

快速排序题目SelectK问题
力扣75.颜色分类 给定一个包含红色、白色和蓝色、共 n 个元素的数组 nums ,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。 我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。 必须在不使用库内置的 sor…...

es6解构赋值
ES6解构赋值是一种简洁的为变量赋值的方式,它允许我们从数组或对象中提取值并赋给对应的变量。 解构赋值在ES6中被引入,主要目的是为了简化代码,提高代码的可读性。以下是解构赋值的基本用法: 数组解构:当我们需要从数…...
Jenkins上面使用pnpm打包
问题 前端也想用Jenkins的CI/CD工作流。 步骤 Jenkins安装NodeJS插件 安装完成,记得重启Jenkins。 全局配置nodejs Jenksinfile pipeline {agent anytools {nodejs "18.15.0"}stages {stage(Check tool version) {steps {sh node -vnpm -vnpm config…...

设计编程网站集:动物,昆虫,蚂蚁养殖笔记
入门指南 区分白蚁与蚂蚁 日常生活中,人们常常会把白蚁与蚂蚁搞混淆,其实这两者是有很大区别的,养殖方式差别也很大。白蚁主要食用木质纤维,会给家庭房屋带来较大危害,而蚂蚁主要采食甜食和蛋白质类食物,不…...
)
面经学习(众智宏图实习)
个人评价 难度还是有的,中等难度吧,可能是因为项目使用的是物流项目,该项目本来就比较庞大难度比较高,流的八股文我真的是一点不会,还需要加强,reidis的多路io复用模型没有深问,要是问了就寄了&…...

DataGrip2024安装包(亲测可用)
目录 一、软件简介 二、软件下载 一、软件简介 DataGrip是由JetBrains公司开发的一款强大的关系数据库集成开发环境(IDE),专为数据库开发人员和数据库管理员设计。它提供了一个统一的界面,用于管理和开发各种关系型数据库&#x…...

网络六边形受到攻击
大家读完觉得有帮助记得关注和点赞!!! 抽象 现代智能交通系统 (ITS) 的一个关键要求是能够以安全、可靠和匿名的方式从互联车辆和移动设备收集地理参考数据。Nexagon 协议建立在 IETF 定位器/ID 分离协议 (…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院查看报告小程序
一、开发环境准备 工具安装: 下载安装DevEco Studio 4.0(支持HarmonyOS 5)配置HarmonyOS SDK 5.0确保Node.js版本≥14 项目初始化: ohpm init harmony/hospital-report-app 二、核心功能模块实现 1. 报告列表…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...
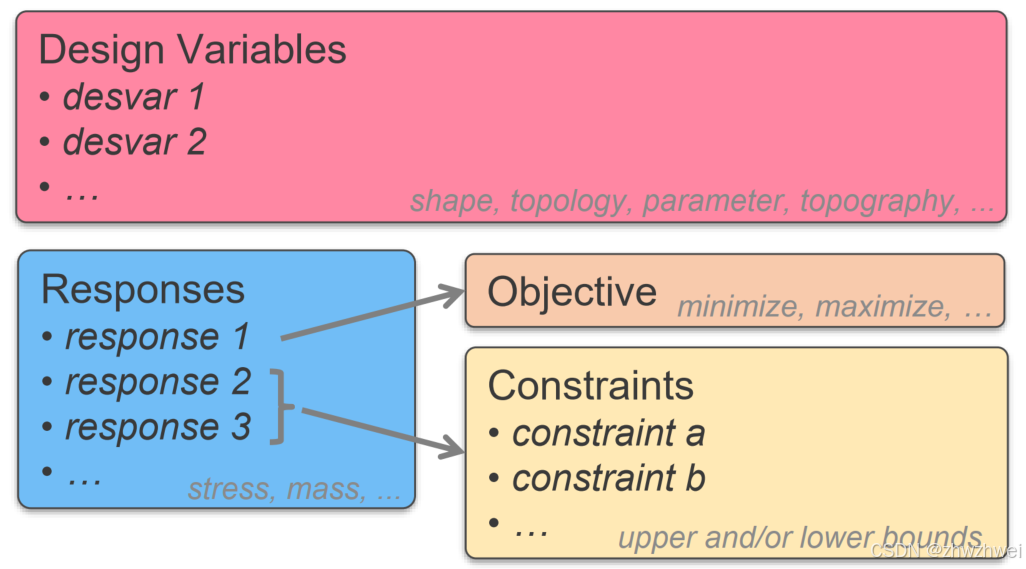
[拓扑优化] 1.概述
常见的拓扑优化方法有:均匀化法、变密度法、渐进结构优化法、水平集法、移动可变形组件法等。 常见的数值计算方法有:有限元法、有限差分法、边界元法、离散元法、无网格法、扩展有限元法、等几何分析等。 将上述数值计算方法与拓扑优化方法结合&#…...

数据结构:泰勒展开式:霍纳法则(Horner‘s Rule)
目录 🔍 若用递归计算每一项,会发生什么? Horners Rule(霍纳法则) 第一步:我们从最原始的泰勒公式出发 第二步:从形式上重新观察展开式 🌟 第三步:引出霍纳法则&…...

FTXUI::Dom 模块
DOM 模块定义了分层的 FTXUI::Element 树,可用于构建复杂的终端界面,支持响应终端尺寸变化。 namespace ftxui {...// 定义文档 定义布局盒子 Element document vbox({// 设置文本 设置加粗 设置文本颜色text("The window") | bold | color(…...
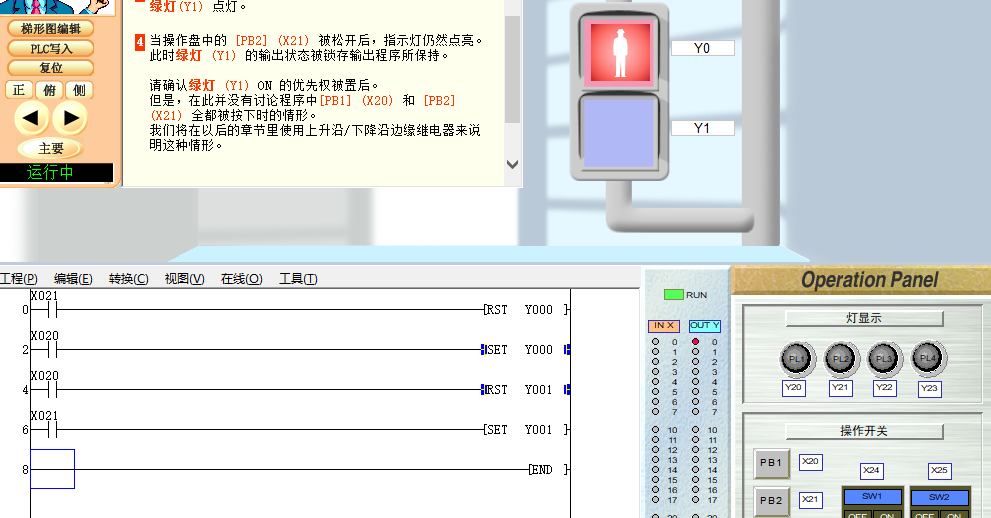
PLC入门【4】基本指令2(SET RST)
04 基本指令2 PLC编程第四课基本指令(2) 1、运用上接课所学的基本指令完成个简单的实例编程。 2、学习SET--置位指令 3、RST--复位指令 打开软件(FX-TRN-BEG-C),从 文件 - 主画面,“B: 让我们学习基本的”- “B-3.控制优先程序”。 点击“梯形图编辑”…...
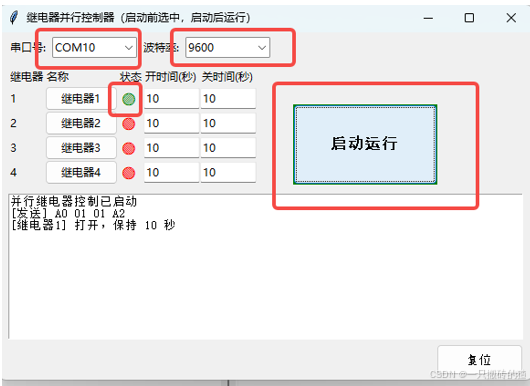
使用ch340继电器完成随机断电测试
前言 如图所示是市面上常见的OTA压测继电器,通过ch340串口模块完成对继电器的分路控制,这里我编写了一个脚本方便对4路继电器的控制,可以设置开启时间,关闭时间,复位等功能 软件界面 在设备管理器查看串口号后&…...