Prometheus接入AlterManager配置邮件告警(基于K8S环境部署)
目录
- 一.配置Alertmanager告警发送至邮箱
- 二.Prometheus接入AlertManager
- 三.部署Prometheus+AlterManager(放到一个Pod中)
- 四. 测试告警
基于 此环境做实验
一.配置Alertmanager告警发送至邮箱
1.创建AlertManager ConfigMap资源清单
vim alertmanager-cm.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: prometheus
data:alertmanager.yml: |-global: resolve_timeout: 1msmtp_smarthost: 'smtp.qq.com:25'smtp_from: '1657310554@qq.com' # 从这个邮箱发送告警smtp_auth_username: '1657310554@qq.com' # 发送告警邮箱账号smtp_auth_password: 'rehtuhigsemwbbbe' # 邮箱验证码,用自己的邮箱验证码smtp_require_tls: falseroute: # 路由配置(将邮箱发送那个路由)group_by: [alertname]group_wait: 10sgroup_interval: 10srepeat_interval: 10mreceiver: default-receiver # 告警发送到default-receiver接受者receivers:- name: 'default-receiver' # 定义default-receiver接受者email_configs:- to: '1657310554@qq.com' # 告警发送邮箱地址send_resolved: true
执行YAML资源清单:
kubectl apply -f alertmanager-cm.yaml
2.配置文件核心配置说明
- group_by: [alertname]:采用哪个标签来作为分组依据。
- group_wait:10s:组告警等待时间。就是告警产生后等待10s,如果有同组告警一起发出。
- group_interval: 10s :上下两组发送告警的间隔时间。
- repeat_interval: 10m:重复发送告警的时间,减少相同邮件的发送频率,默认是1h。
- receiver: default-receiver:定义谁来收告警。
- smtp_smarthost: SMTP服务器地址+端口。
- smtp_from:指定从哪个邮箱发送报警。
- smtp_auth_username:邮箱账号。
- smtp_auth_password: 邮箱密码(授权码)。
二.Prometheus接入AlertManager
1.创建新的Prometheus ConfigMap资源清单,添加监控K8S集群告警规则
vim prometheus-alertmanager-cfg.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: prometheus
data:prometheus.yml: |rule_files: - /etc/prometheus/rules.yml # 告警规则位置alerting:alertmanagers:- static_configs:- targets: ["localhost:9093"] # 接入AlterManagerglobal:scrape_interval: 15sscrape_timeout: 10sevaluation_interval: 1mscrape_configs:- job_name: 'kubernetes-node'kubernetes_sd_configs:- role: noderelabel_configs:- source_labels: [__address__]regex: '(.*):10250'replacement: '${1}:9100'target_label: __address__action: replace- action: labelmapregex: __meta_kubernetes_node_label_(.+)- job_name: 'kubernetes-node-cadvisor'kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmapregex: __meta_kubernetes_node_label_(.+)- target_label: __address__replacement: kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+)target_label: __metrics_path__replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpointsscheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name]action: keepregex: default;kubernetes;https- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2- action: labelmapregex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name - job_name: 'kubernetes-pods' # 监控Pod配置,添加注解后才可以被发现kubernetes_sd_configs:- role: podrelabel_configs:- action: keepregex: truesource_labels:- __meta_kubernetes_pod_annotation_prometheus_io_scrape- action: replaceregex: (.+)source_labels:- __meta_kubernetes_pod_annotation_prometheus_io_pathtarget_label: __metrics_path__- action: replaceregex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2source_labels:- __address__- __meta_kubernetes_pod_annotation_prometheus_io_porttarget_label: __address__- action: labelmapregex: __meta_kubernetes_pod_label_(.+)- action: replacesource_labels:- __meta_kubernetes_namespacetarget_label: kubernetes_namespace- action: replacesource_labels:- __meta_kubernetes_pod_nametarget_label: kubernetes_pod_name- job_name: 'kubernetes-etcd' # 监控etcd配置scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crtcert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crtkey_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.keyscrape_interval: 5sstatic_configs:- targets: ['192.168.40.180:2379'] # ip为master1的iprules.yml: | # K8S集群告警规则配置文件groups:- name: examplerules:- alert: apiserver的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: apiserver的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: etcd的cpu使用率大于80%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%"- alert: etcd的cpu使用率大于90%expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%"- alert: kube-state-metrics的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: coredns的cpu使用率大于80%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%"value: "{{ $value }}%"threshold: "80%" - alert: coredns的cpu使用率大于90%expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%"value: "{{ $value }}%"threshold: "90%" - alert: kube-proxy打开句柄数>600expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kube-proxy打开句柄数>1000expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>600expr: process_open_fds{job=~"kubernetes-schedule"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-schedule打开句柄数>1000expr: process_open_fds{job=~"kubernetes-schedule"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>600expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-controller-manager打开句柄数>1000expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>600expr: process_open_fds{job=~"kubernetes-apiserver"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-apiserver打开句柄数>1000expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>600expr: process_open_fds{job=~"kubernetes-etcd"} > 600for: 2slabels:severity: warnningannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600"value: "{{ $value }}"- alert: kubernetes-etcd打开句柄数>1000expr: process_open_fds{job=~"kubernetes-etcd"} > 1000for: 2slabels:severity: criticalannotations:description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 600for: 2slabels:severity: warnning annotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600"value: "{{ $value }}"- alert: corednsexpr: process_open_fds{k8s_app=~"kube-dns"} > 1000for: 2slabels:severity: criticalannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000"value: "{{ $value }}"- alert: kube-proxyexpr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: schedulerexpr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-controller-managerexpr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-apiserverexpr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kubernetes-etcdexpr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000for: 2slabels:severity: warnningannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: kube-dnsexpr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000for: 2slabels:severity: warnningannotations:description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G"value: "{{ $value }}"- alert: HttpRequestsAvgexpr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000"value: "{{ $value }}"threshold: "1000" - alert: Pod_restartsexpr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0for: 2slabels:severity: warnningannotations:description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的"value: "{{ $value }}"threshold: "0"- alert: Pod_waitingexpr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中"value: "{{ $value }}"threshold: "1" - alert: Pod_terminatedexpr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除"value: "{{ $value }}"threshold: "1"- alert: Etcd_leaderexpr: etcd_server_has_leader{job="kubernetes-etcd"} == 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader"value: "{{ $value }}"threshold: "0"- alert: Etcd_leader_changesexpr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变"value: "{{ $value }}"threshold: "0"- alert: Etcd_failedexpr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败"value: "{{ $value }}"threshold: "0"- alert: Etcd_db_total_sizeexpr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000for: 2slabels:team: adminannotations:description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G"value: "{{ $value }}"threshold: "10G"- alert: Endpoint_readyexpr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1for: 2slabels:team: adminannotations:description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用"value: "{{ $value }}"threshold: "1"- name: 物理节点状态-监控告警rules:- alert: 物理节点cpu使用率expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90for: 2slabels:severity: ccriticalannotations:summary: "{{ $labels.instance }}cpu使用率过高"description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90for: 2slabels:severity: criticalannotations:summary: "{{ $labels.instance }}内存使用率过高"description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理"- alert: InstanceDownexpr: up == 0for: 2slabels:severity: criticalannotations: summary: "{{ $labels.instance }}: 服务器宕机"description: "{{ $labels.instance }}: 服务器延时超过2分钟"- alert: 物理节点磁盘的IO性能expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!"description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})"- alert: 入网流量带宽expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流入网络带宽过高!"description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: 出网流量带宽expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 流出网络带宽过高!"description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"- alert: TCP会话expr: node_netstat_Tcp_CurrEstab > 1000for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!"description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"- alert: 磁盘容量expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80for: 2slabels:severity: criticalannotations:summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!"description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
执行资源清单:
kubectl apply -f prometheus-alertmanager-cfg.yaml
2.由于在prometheus中新增了etcd,所以生成一个etcd-certs,这个在部署prometheus需要
kubectl -n prometheus create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/
三.部署Prometheus+AlterManager(放到一个Pod中)
1.在node1节点创建/data/alertmanager目录,存放alertmanager数据
mkdir /data/alertmanager -p
chmod -R 777 /data/alertmanager
2.删除旧的prometheus deployment资源
kubectl delete deploy prometheus-server -n prometheus
3.创建deployment资源
vim prometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: prometheuslabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: servertemplate:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: node1 # 调度到node1节点serviceAccountName: prometheus # 指定sa服务账号containers:- name: prometheusimage: prom/prometheus:v2.33.5imagePullPolicy: IfNotPresentcommand:- "/bin/prometheus"args:- "--config.file=/etc/prometheus/prometheus.yml"- "--storage.tsdb.path=/prometheus"- "--storage.tsdb.retention=24h"- "--web.enable-lifecycle"ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- mountPath: /prometheus/name: prometheus-storage-volume- name: k8s-certsmountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/- name: alertmanagerimage: prom/alertmanager:v0.23.0imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml"- "--log.level=debug"ports:- containerPort: 9093protocol: TCPname: alertmanagervolumeMounts:- name: alertmanager-configmountPath: /etc/alertmanager- name: alertmanager-storagemountPath: /alertmanager- name: localtimemountPath: /etc/localtimevolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-storage-volumehostPath:path: /datatype: Directory- name: k8s-certssecret:secretName: etcd-certs- name: alertmanager-configconfigMap:name: alertmanager- name: alertmanager-storagehostPath:path: /data/alertmanagertype: DirectoryOrCreate- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghai
执行YAML资源清单:
kubectl apply -f prometheus-alertmanager-deploy.yaml
查看状态:
kubectl get pods -n prometheus

4.创建AlertManager SVC资源
vim alertmanager-svc.yaml
---
apiVersion: v1
kind: Service
metadata:labels:name: prometheuskubernetes.io/cluster-service: 'true'name: alertmanagernamespace: prometheus
spec:ports:- name: alertmanagernodePort: 30066port: 9093protocol: TCPtargetPort: 9093selector:app: prometheussessionAffinity: Nonetype: NodePort
执行YAML资源清单:
kubectl apply -f alertmanager-svc.yaml
查看状态:
kubectl get svc -n prometheus

四. 测试告警
浏览器访问:http://IP:30066
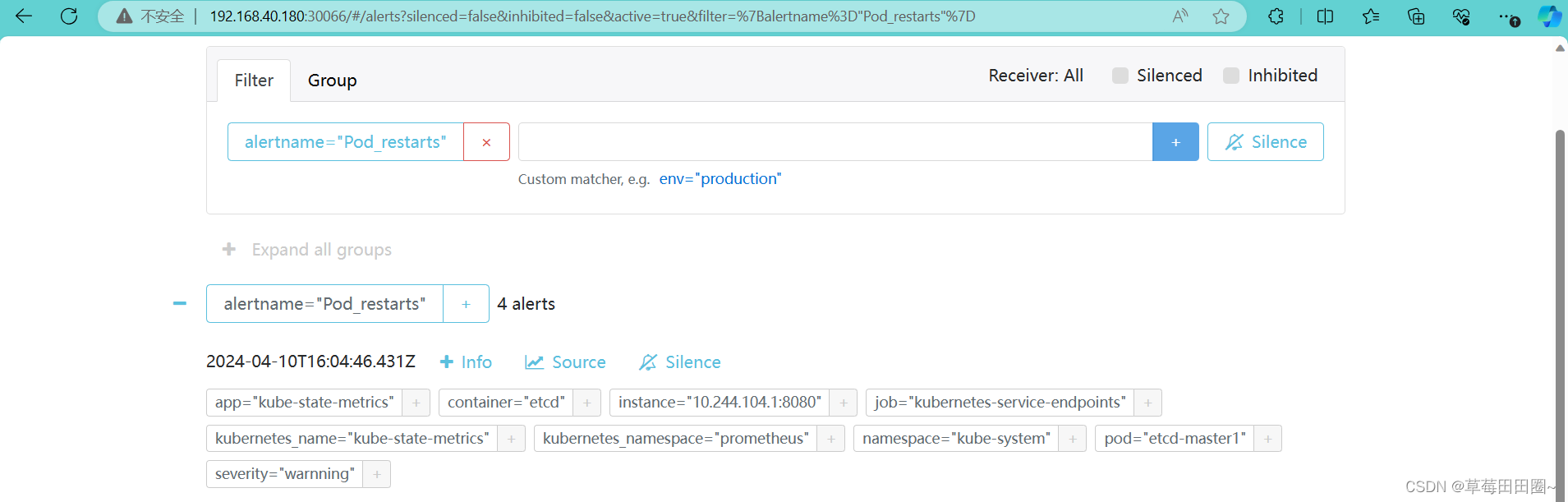
如上图可以看到,Prometheus的告警信息已经发到AlterManager了,AlertManager收到报警数据后,会将警报信息进行分组,然后根据AlertManager配置的 group_wait 时间先进行等待。等wait时间过后再发送报警信息至邮件!
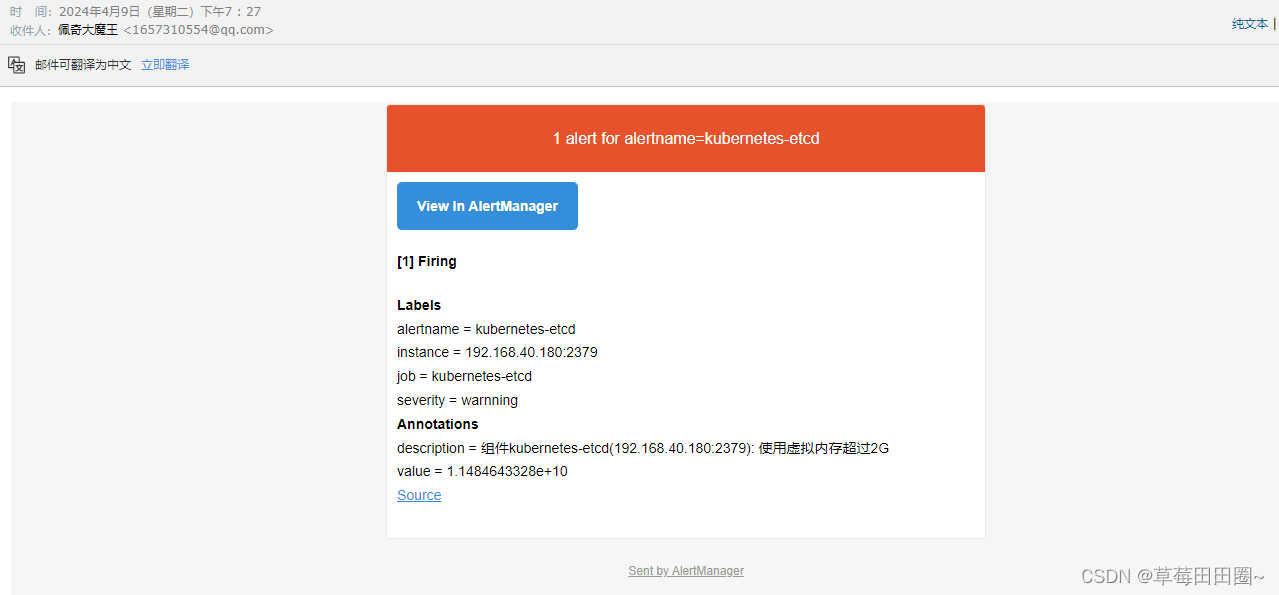
相关文章:
Prometheus接入AlterManager配置邮件告警(基于K8S环境部署)
目录 一.配置Alertmanager告警发送至邮箱二.Prometheus接入AlertManager三.部署PrometheusAlterManager(放到一个Pod中)四. 测试告警 基于 此环境做实验 一.配置Alertmanager告警发送至邮箱 1.创建AlertManager ConfigMap资源清单 vim alertmanager-cm.yaml --- kind: Confi…...

find方法
find() 方法用于在数组中查找符合条件的第一个元素,并返回该元素。如果找到匹配的元素,则返回该元素的值;如果未找到匹配的元素,则返回 undefined。 例如: const firstWithdrawal movements.find(mov > mov < 0); consol…...
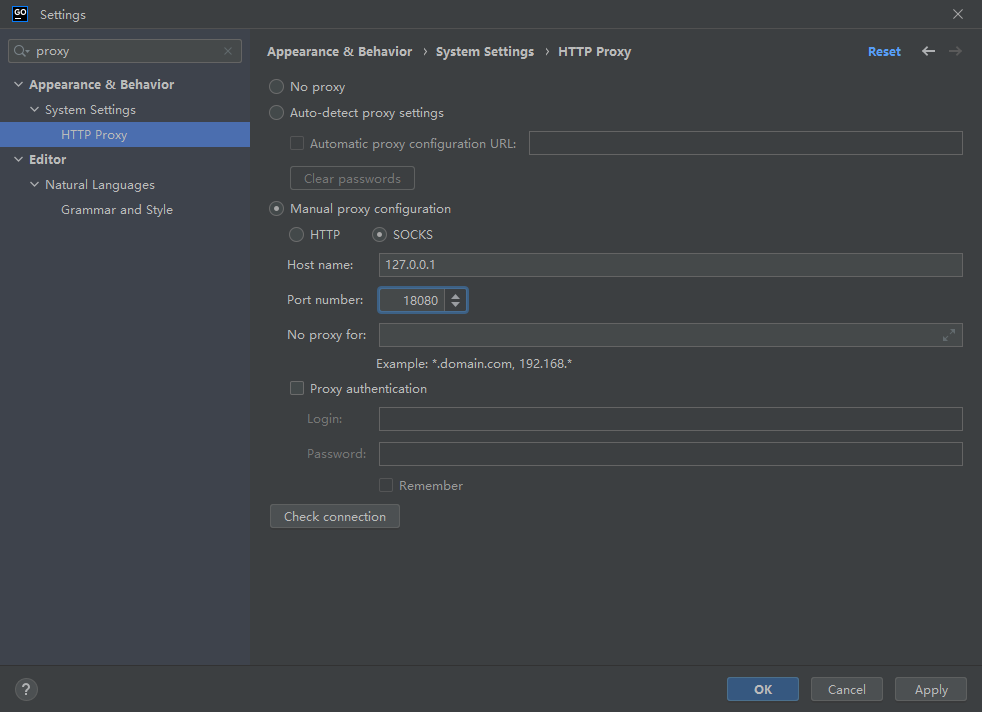
TLS v1.3 导致JetBrains IDE jdk.internal.net.http.common CPU占用高
开发环境 GoLand版本:2022.3.4 问题原因 JDK 中的 TLS v1.3 实现引起 解决办法 使用 SOCKS 代理代替HTTP代理 禁用 Space 和 Code With Me 插件 禁用 TLS v1.3,参考:https://stackoverflow.com/questions/54485755/java-11-httpclient-…...
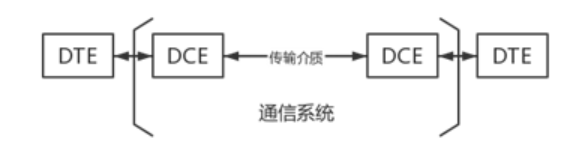
计算机网络 2.2数据传输方式
第二节 数据传输方式 一、数据通信系统模型 添加图片注释,不超过 140 字(可选) 1.数据终端设备(DTE) 作用:用于处理用户数据的设备,是数据通信系统的信源和信宿。 设备:便携计算机…...

陇剑杯 流量分析 webshell CTF writeup
陇剑杯 流量分析 链接:https://pan.baidu.com/s/1KSSXOVNPC5hu_Mf60uKM2A?pwdhaek 提取码:haek目录结构 LearnCTF ├───LogAnalize │ ├───linux简单日志分析 │ │ linux-log_2.zip │ │ │ ├───misc日志分析 │ │ …...
【测试开发学习历程】python常用的模块(下)
目录 8、MySQL数据库的操作-pymysql 8.1 连接并操作数据库 9、ini文件的操作-configparser 9.1 模块-configparser 9.2 读取ini文件中的内容 9.3 获取指定建的值 10 json文件操作-json 10.1 json文件的格式或者json数据的格式 10.2 json.load/json.loads 10.3 json.du…...

GCDAsynSocket之TCP简析
GCDAsynSocket是一个开源的基于GCD的异步的socket库。它支持IPV4和IPV6地址,TLS/SSL协议。同时它支持iOS端和Mac端。本篇主要介绍一下GCDAsynSocket中的TCP用法和实现。 首先通过下面这个方法初始化一个GCDAsynSocket对象。 - (id)initWithDelegate:(id<GCDAsyn…...
大型网站系统架构演化实例_1.单体架构和垂直架构
大型网站的技术挑战主要来自于庞大的用户,高并发的访问和海量的数据,任何简单的业务一旦需要处理数以P计的数据和面对数以亿计的用户,问题就会变得很棘手。通常大型网站架构主要解决这类问题。 1.第一阶段:单体架构 大型网站都是…...
2024蓝桥杯——宝石问题
先展示题目 声明 以下代码仅是我的个人看法,在自己考试过程中的优化版,本人考试就踩了很多坑,我会—一列举出来。代码可能很多,但是总体时间复杂度不高只有0(N) 函数里面的动态数组我没有写开辟判断和free,这里我忽略…...

three.js加载模型报错,Error: THREE.GLTFLoader: No DRACOLoader instance provided.
three.js加载模型报错,Error: THREE.GLTFLoader: No DRACOLoader instance provided. 原因:该模型是压缩过的,需要 DRACOLoader 我们先找到该文件夹 node_modules three examples jsm libs draco 将draco拷贝到public下 import { GLTFLoad…...

Spring VS Spring Boot
目录 定义 Spring Spring Boot 区别 优劣对比 Spring Spring的优势 Spring的劣势 Spring Boot Spring Boot的优势 Spring Boot的劣势 适用场景 Spring的适用场景 Spring Boot的适用场景 初学者如何选择学习 定义 Spring Spring是一个轻量级的、开源的Java开发…...
Linux入门(Linux介绍,安装,常用命令,防火墙的设置,注意事项)
目录 一、Linux介绍 1. Linux简介 1 什么是Linux 2 Linux的应用 3 为什么要学习Linux 2. Linux分类 1 按照市场需求分 2 按照原生程度分 3.小结 二、Linux安装 1. vmware介绍 2. 安装VMWare 3. 安装CentOS 4. 登录查看ip 5. 远程连接工具 1 使用FinalShell连接L…...
vue2创建项目的两种方式,配置路由vue-router,引入element-ui
提示:vue2依赖node版本8.0以上 文章目录 前言一、创建项目基于vue-cli二、创建项目基于vue/cli三、对吧两种创建方式四、安装Element ui并引入五、配置路由跳转四、效果五、参考文档总结 前言 使用vue/cli脚手架vue create创建 使用vue-cli脚手架vue init webpack创…...
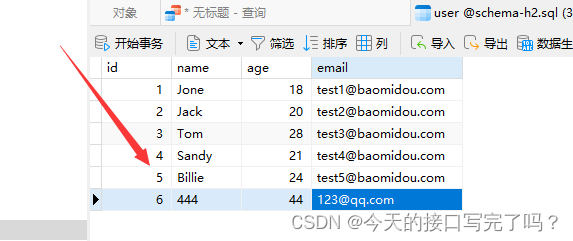
MySql 表中的id突然变很大,如何给id重新排序
目录 一、场景 二、解决方法 一、场景 我们在开发过程中,难免遇到id突然增大的情况。 由于id突然增大很多,我们重新增加数据时候id会默认加1 那么如何让id 重新从1按顺序排序呢 二、解决方法 点击编辑表,然后新建一个字段id2,将…...

leetcode练习——哈希表
目录 3. 无重复字符的最长子串 题目描述 解题思路 代码实现 349. 两个数组的交集 题目描述 解题思路 代码实现 454. 四数相加 II 题目描述 解题思路 代码实现 242. 有效的字母异位词 题目描述 解题思路 代码实现 438. 找到字符串中所有字母异位词 题目…...
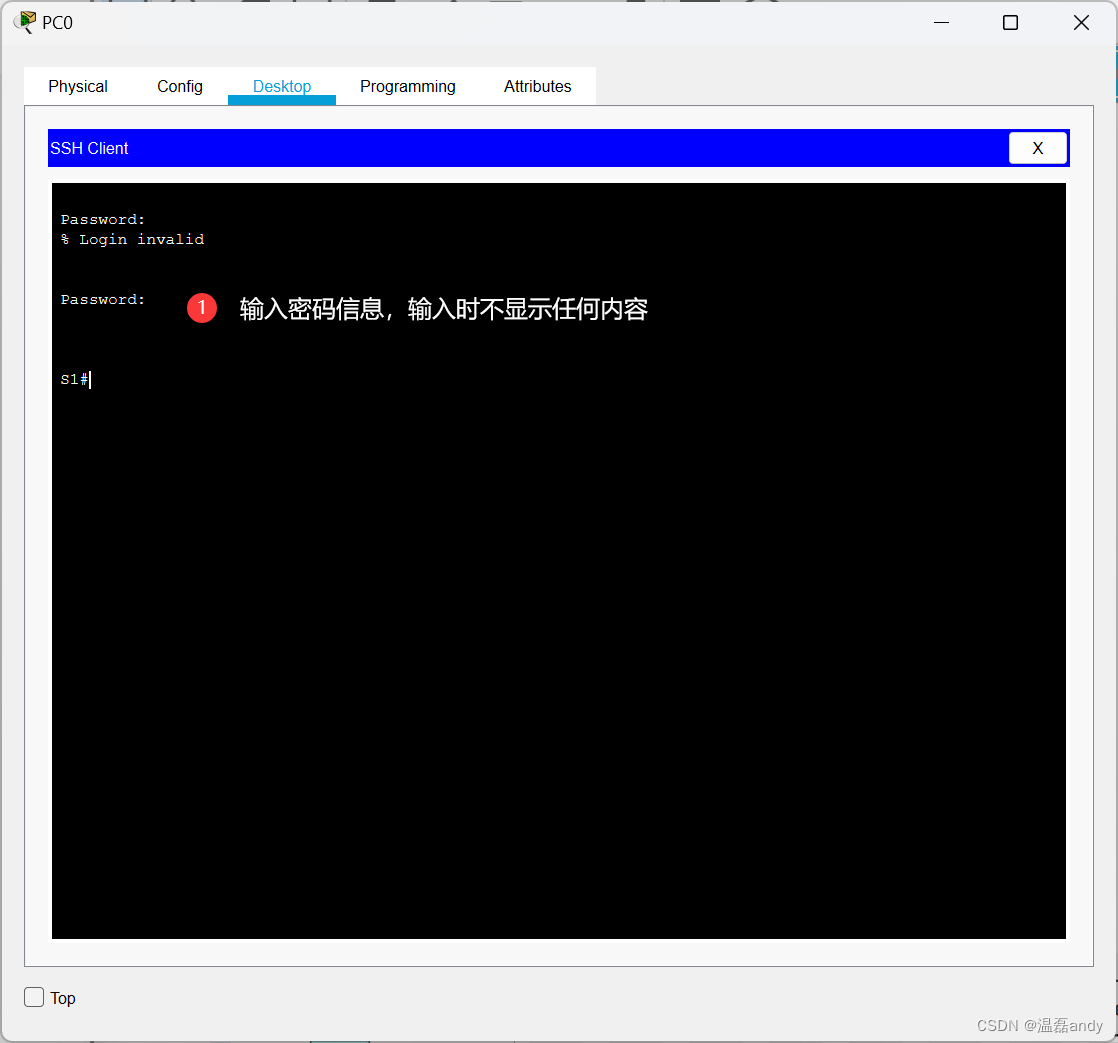
配置交换机 SSH 管理和端口安全
实验1:配置交换机基本安全和 SSH管理 1、实验目的 通过本实验可以掌握: 交换机基本安全配置。SSH 的工作原理和 SSH服务端和客户端的配置。 2、实验拓扑 交换机基本安全和 SSH管理实验拓扑如图所示。 3、实验步骤 (1)配置交换机S1 Swit…...

基于SpringBoot+Vue的装饰工程管理系统(源码+文档+包运行)
一.系统概述 如今社会上各行各业,都喜欢用自己行业的专属软件工作,互联网发展到这个时候,人们已经发现离不开了互联网。新技术的产生,往往能解决一些老技术的弊端问题。因为传统装饰工程项目信息管理难度大,容错率低&a…...

vue3中axios添加请求和响应的拦截器
本章主要是以记录为主。 在src创建一个utils文件夹,并在utils中创建一个request.js文件。 // 引入axios import axios from "axios"; // import qs from "qs"; // 创建axios实例 const instance axios.create(); // 请求拦截器 instance.int…...
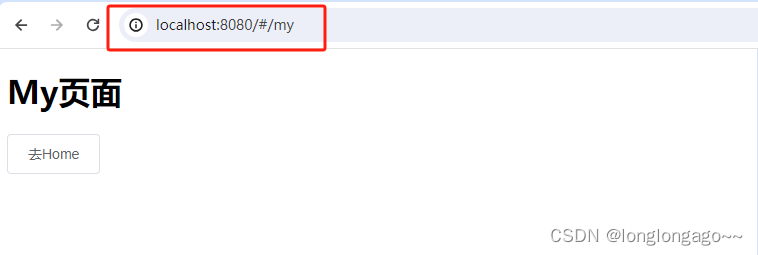
<router-link>出现Error: No match for {“name“:“home“,“params“:{}}
在将<a></a>标签换到<router-link></router-link>的时候出现No match for {"name":"home","params":{}}这样的错误,其中格式并无错误, <router-link class"navbar-brand active" …...
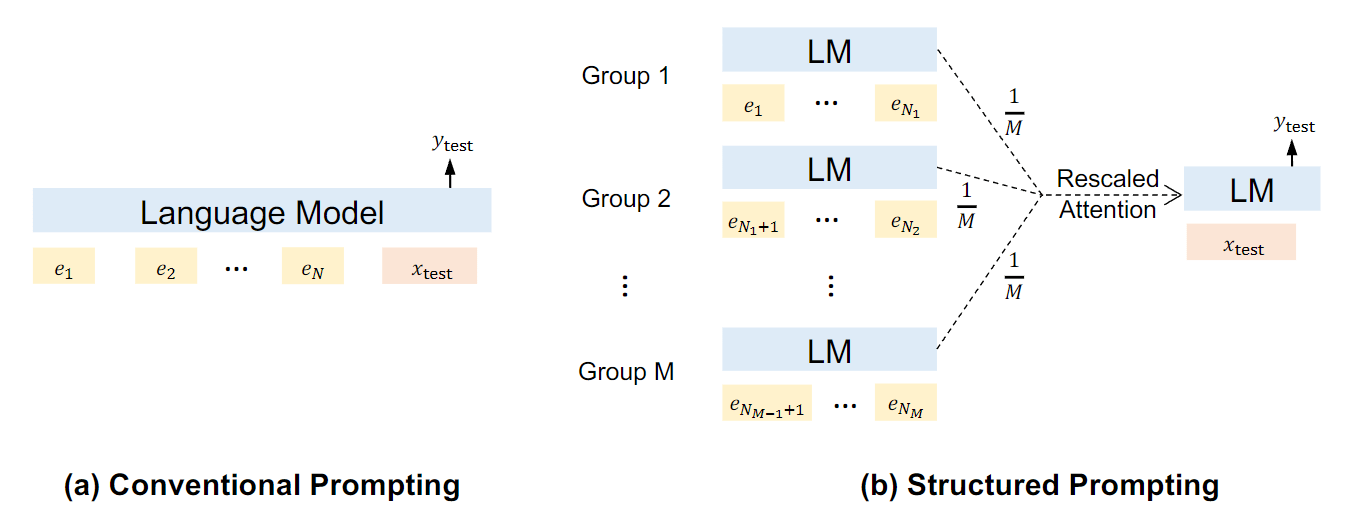
prompt 工程整理(未完、持续更新)
工作期间会将阅读的论文、一些个人的理解整理到个人的文档中,久而久之就积累了不少“个人”能够看懂的脉络和提纲,于是近几日准备将这部分略显杂乱的内容重新进行梳理。论文部分以我个人的理解对其做了一些分类,并附上一些简短的理解…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...
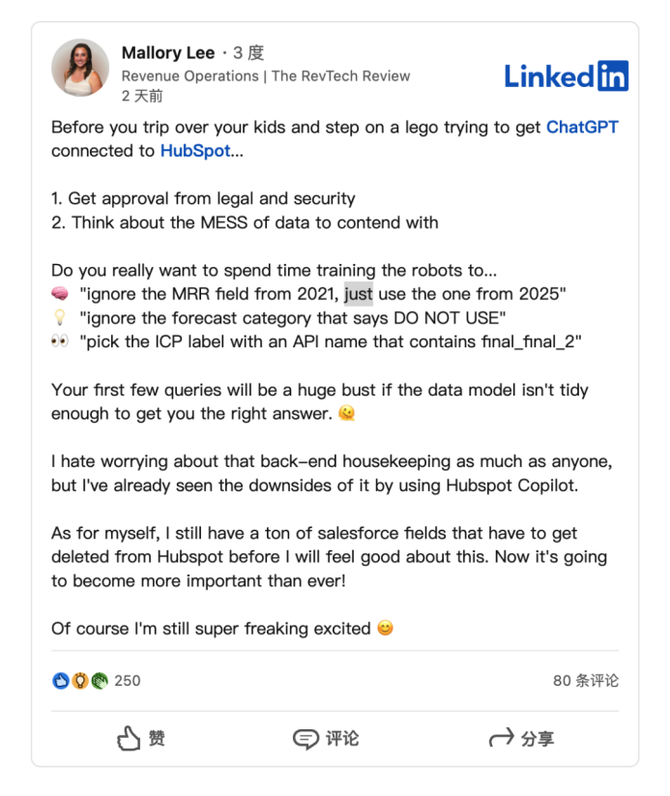
HubSpot推出与ChatGPT的深度集成引发兴奋与担忧
上周三,HubSpot宣布已构建与ChatGPT的深度集成,这一消息在HubSpot用户和营销技术观察者中引发了极大的兴奋,但同时也存在一些关于数据安全的担忧。 许多网络声音声称,这对SaaS应用程序和人工智能而言是一场范式转变。 但向任何技…...

加密通信 + 行为分析:运营商行业安全防御体系重构
在数字经济蓬勃发展的时代,运营商作为信息通信网络的核心枢纽,承载着海量用户数据与关键业务传输,其安全防御体系的可靠性直接关乎国家安全、社会稳定与企业发展。随着网络攻击手段的不断升级,传统安全防护体系逐渐暴露出局限性&a…...

C++--string的模拟实现
一,引言 string的模拟实现是只对string对象中给的主要功能经行模拟实现,其目的是加强对string的底层了解,以便于在以后的学习或者工作中更加熟练的使用string。本文中的代码仅供参考并不唯一。 二,默认成员函数 string主要有三个成员变量,…...

js 设置3秒后执行
如何在JavaScript中延迟3秒执行操作 在JavaScript中,要设置一个操作在指定延迟后(例如3秒)执行,可以使用 setTimeout 函数。setTimeout 是JavaScript的核心计时器方法,它接受两个参数: 要执行的函数&…...

算法刷题-回溯
今天给大家分享的还是一道关于dfs回溯的问题,对于这类问题大家还是要多刷和总结,总体难度还是偏大。 对于回溯问题有几个关键点: 1.首先对于这类回溯可以节点可以随机选择的问题,要做mian函数中循环调用dfs(i&#x…...
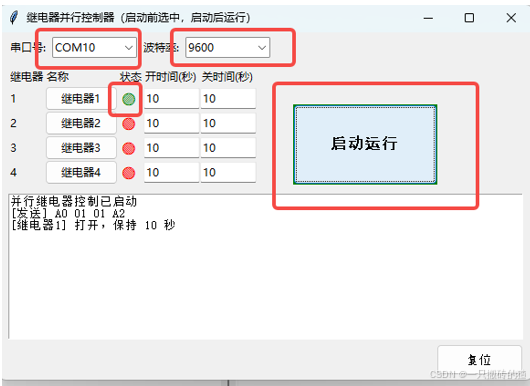
使用ch340继电器完成随机断电测试
前言 如图所示是市面上常见的OTA压测继电器,通过ch340串口模块完成对继电器的分路控制,这里我编写了一个脚本方便对4路继电器的控制,可以设置开启时间,关闭时间,复位等功能 软件界面 在设备管理器查看串口号后&…...