Kafka 生产者应用解析
目录
1、生产者消息发送流程
1.1、发送原理
2、异步发送 API
2.1、普通异步发送
2.2、带回调函数的异步发送
3、同步发送 API
4、生产者分区
4.1、分区的优势
4.2、生产者发送消息的分区策略
示例1:将数据发往指定 partition
示例2:有 key 的情况下将数据发送到Kafka
4.3、自定义分区器
5、生产者提高吞吐量
6、数据可靠性
7、数据去重
1、幂等性
8、生产者事务
1、事务原理
2、使用事务
9、数据的有序
注:示例代码使用的语言是Python
1、生产者消息发送流程
1.1、发送原理
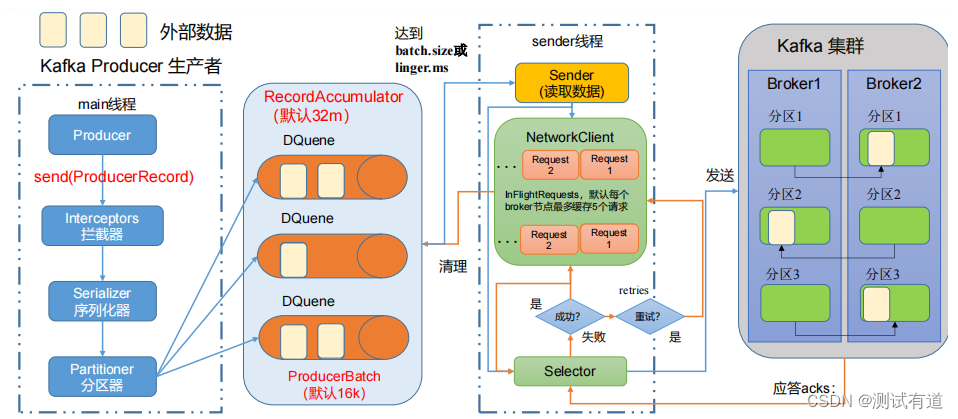
- 在消息发送的过程中,涉及到了两个线程——main 线程和 Sender 线程。在 main 线程 中创建了一个双端队列 RecordAccumulator。main 线程将消息发送给 RecordAccumulator, Sender 线程不断从 RecordAccumulator 中拉取消息发送到 Kafka Broker。
参数说明:
- batch size:只有数据积累到batch.size之后,sender才会发送数据。默认16K
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后在发送是数据。单位ms,默认值为0ms,表示没有延迟。
- acks:
- 0:生产者发送过来的数据不需要等待应答,异步发送。
- 1:生产者发送过来的数据,需要等待Leader收到后应该。
- -1(all):生产者发送过来的数据,Leader和ISR(In-Sync Replicas)队列里面所有的节点收齐数据后应答。注:-1与all等价
2、异步发送 API
2.1、普通异步发送
示例:创建 Kafka 生产者,采用异步的方式发送到 Kafka Broker
from kafka3 import KafkaProducerdef producer(topic: str, msg: str, partition=0):""":function: 生产者,生产数据:param topic: 写入数据所在的topic:param msg: 写入的数据:param partition: 写入数据所在的分区:return:"""print("开始生产数据......")# 初始化生产者对象,bootstrap_servers参数传入kafka集群# 将acks的值设为0,acks=0,此方式也是异步的方式,但是生产环境中不会这样使用,因为存在数据丢失的风险# producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"], acks=0)producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=partition)producer.close()if __name__ == '__main__':msg = "this is profucer01"topic = "first"producer(topic, msg)2.2、带回调函数的异步发送
- 回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元 数据信息(RecordMetadata)和异常信息(Exception),如果 Exception 为 null,说明消息发 送成功,如果 Exception 不为 null,说明消息发送失败。
- 注意:消息发送失败会自动重试,不需要在回调函数中手动重试。
"""
带回调函数的异步发送
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是元数据信息(RecordMetadata)和异常信息(Exception),
如果 Exception 为 null,说明消息发送成功,如果 Exception 不为 null,说明消息发送失败。
"""
from kafka3 import KafkaProducerdef producer(topic: str, msg: str, partition=0):""":function: 生产者,生产数据:param topic: 写入数据所在的topic:param msg: 写入的数据:param partition: 写入数据所在的分区:return:"""print("开始生产数据......")# 定义发送成功的回调函数def on_send_success(record_metadata):print("消息成功发送到主题:", record_metadata.topic)print("分区:", record_metadata.partition)print("偏移量:", record_metadata.offset)# 定义发送失败的回调函数def on_send_error(excp):print("发送消息时出现错误:", excp)# 可以根据实际情况执行一些错误处理逻辑# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=partition).add_callback(on_send_success).add_errback(on_send_error)producer.close()3、同步发送 API
- 只需在异步发送的基础上,再调用一下 get()方法即可。或者将acks的值设为all,acks="all",此方式也是同步的方式。
from kafka3 import KafkaProducerdef producer(topic: str, msg: str, partition=0):""":function: 生产者,生产数据:param topic: 写入数据所在的topic:param msg: 写入的数据:param partition: 写入数据所在的分区:return:"""print("开始生产数据......")# 初始化生产者对象,bootstrap_servers参数传入kafka集群# 将acks的值设为all,acks="all",此方式也是同步的方式.# producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"], acks="all")producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=partition)# 等待 Future 返回结果,设置超时时间为10秒future.get(timeout=10)producer.close()4、生产者分区
4.1、分区的优势
- 1、便于合理使用存储资源,每个Partition在一个Broker上存储,可以把海量的数据按照分区切割成一 块一块数据存储在多台Broker上。合理控制分区的任务,可以实现负载均衡的效果。
- 2、提高并行度,生产者可以以分区为单位发送数据;消费者可以以分区为单位进行消费数据。
4.2、生产者发送消息的分区策略
- 1、如果不指定分区,会使用默认分区策略。默认分区策略如下:
- 如果key存在的情况下,将key的hash值与topic的partition进行取余得到partition值
- 如果key不存在的情况下,会随机选择一个分区
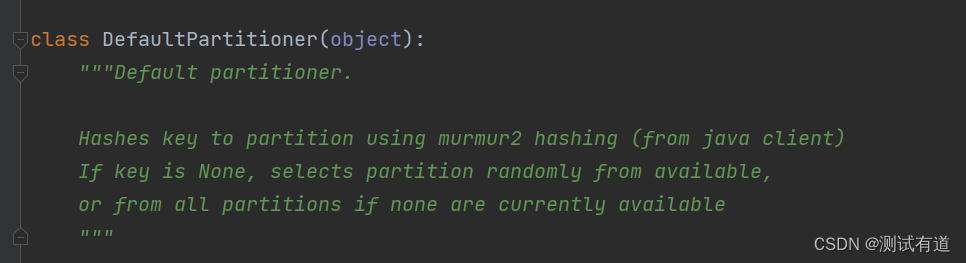
- 2、如果指明了分区,那么将会把数据发送到指定分区
示例1:将数据发往指定 partition
-
将所有数据发往分区 0 中。
# 指定分区
def producer_01(topic: str, msg: str, partition=0):""":function: 指定分区:param topic: 写入数据所在的topic:param msg: 写入的数据:param partition: 写入数据所在的分区:return:"""# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=partition)try:# 等待消息发送完成sendResult = future.get(timeout=10)print(f"消息: {msg}\n所在的分区: {sendResult.partition}\n偏移量为: {sendResult.offset}\n")# 关闭生产producer.close()except KafkaError as e:print(f"消息: {msg} 发送失败\n失败信息为: {e}\n")msg = "this is partition"
topic = "first"
for i in range(5):producer_01(topic, msg+str(i))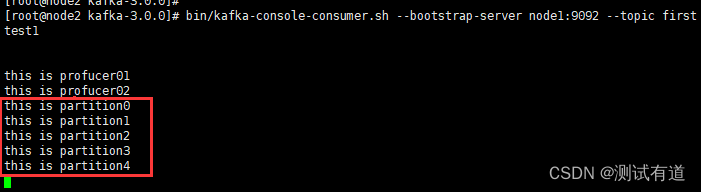
示例2:有 key 的情况下将数据发送到Kafka
- 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取 余得到 partition 值。
# 没有指明 partition 值但有 key 的情况下,将 key 的 hash 值与 topic 的 partition 数进行取余得到 partition 值。
def producer_02(topic: str, msg: str, key: str):""":function: 指定分区:param topic: 写入数据所在的topic:param msg: 写入的数据:param key: 发送消息的key值:return:"""# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, key=bytes(key, 'utf-8'), value=bytes(msg, 'utf-8'))try:# 等待消息发送完成sendResult = future.get(timeout=10)print(f"消息: {msg}\n所在的分区: {sendResult.partition}\n偏移量为: {sendResult.offset}\n")# 关闭生产producer.close()except KafkaError as e:print(f"消息: {msg} 发送失败\n失败信息为: {e}\n")msg = "this is partition"
topic = "first"
key = "a"
for i in range(5):producer_02(topic, msg+str(i), key)4.3、自定义分区器
- 可以根据实际需要,自定义实现分区器。
- 示例:自定义分区 发送过来的数据中如果包含 hello,就发往 0 号分区,不包含 hello,就发往 1 号分区。
# 自定义分区 发送过来的数据中如果包含 hello,就发往 0 号分区,不包含 hello,就发往 1 号分区。
def producer_03(topic: str, msg: str):""":function: 自定义分区:param topic: 写入数据所在的topic:param msg: 写入的数据:return:"""# 自定义分区器def my_partitioner(msg):if "hello" in str(msg):return 0else:return 1# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"])# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'), partition=my_partitioner(msg))try:# 等待消息发送完成sendResult = future.get(timeout=10)print(f"消息: {msg}\n所在的分区: {sendResult.partition}\n偏移量为: {sendResult.offset}\n")# 关闭生产producer.close()except KafkaError as e:print(f"消息: {msg} 发送失败\n失败信息为: {e}\n")msg = "hello this is partition"
msg1 = "this is partition"
5、生产者提高吞吐量
- 实际工作中,会根据实际的情况动态的调整生产者的吞吐量以适应实际需求,调整吞吐量主要是通过调整以下参数实现:
- batch.size:批次大小,默认16k
- linger.ms:等待时间,修改为5-100ms
- compression.type:压缩snappy
- RecordAccumulator:缓冲区大小,默认32m,修改为64m
"""
生产者提高吞吐量1、linger.ms:等待时间,修改为5-100ms2、compression.type:压缩snappy3、RecordAccumulator:缓冲区大小,修改为64m
"""
from kafka3 import KafkaProducer
from kafka3.errors import KafkaErrordef producer(topic: str, msg: str):""":function: 生产者,生产数据:param topic: 写入数据所在的topic:param msg: 写入的数据:return:"""# 初始化生产者对象,bootstrap_servers参数传入kafka集群producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"],linger_ms=5, # linger_ms设置为5mscompression_type="snappy", # 设置压缩类型为snappybuffer_memory=64*1024*1024 # 设置缓冲区大小为64MB)# 将发送消息转换成bytes类型,编码使用utf-8future = producer.send(topic=topic, value=bytes(msg, 'utf-8'))try:# 等待消息发送完成sendResult = future.get(timeout=10)print(f"消息: {msg}\n所在的分区: {sendResult.partition}\n偏移量为: {sendResult.offset}\n")# 关闭生产producer.close()except KafkaError as e:print(f"消息: {msg} 发送失败\n失败信息为: {e}\n")6、数据可靠性
说明:数据的可靠性保证主要是通过acks的设置来保证的,下面说明acks在不同取值下的数据可靠性情况:
- acks=0时
- 因为生产者发送数据后就不管了,所以当Leader或Follower发生异常时,就会发生数据丢失。
- 实际使用很少
- acks=1时
- 因为生产者只需要等到Leader应答后就算完成本次发生了,但是当Leader应答完成后,还没有开始同步副本数据,Leader此时挂掉,新的Leader上线后并不会收到丢失数据,因为生产者已经认为数据发送成功了,这时就会发生数据丢失。
- 实际使用:一般用于传输普通日志
- acks=-1时
- 因为生产者需要等到Leader和Follower都收到数据后才算完成本次数据传输,所以可靠性高,但是当分区副本只有1个或者ISR应答的最小副本设置为1,此时和acks=1时效果一样,存在数据丢失的风险。
- 实际使用:对可靠性要求较高的场景中,比如涉及到金钱相关的场景
综上分析:要想使得数据完全可靠条件=ACK级别设置为1 + 分区副本数大于等于2 + ISR应答最小副本数大于等于2(min.insync.replicas 参数保证)
Python代码设置acks
# acks取值:0、1、"all"
producer = KafkaProducer(bootstrap_servers=["170.22.70.174:9092", "170.22.70.178:9092", "170.22.70.179:9092"], acks=0)7、数据去重
- 至少一次(At Least Once)= ACK级别设置为-1 + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2;可以保证数据不丢失,但是不能保证数据不重复。
- 最多一次(At Most Once)= ACK级别设置为0;可以保证数据不重复,但是不能保证数据不丢失。
那么如何保证数据只存储一次呢?这就需要使用幂等性。
1、幂等性
1、幂等性:
- 1、幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
- 2、精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2) 。
2、幂等性实现原理:
- 具有<PID, Partition, SeqNumber>相同主键的消息提交时,Broker只会持久化一条。
- 其 中PID是Kafka每次重启都会分配一个新的;
- Partition 表示分区号;
- Sequence Number 每次发送消息的序列号,是单调自增的。
- 注意:幂等性只能保证的是在单分区单会话内不重复。
3、使用幂等性
- 开启参数 enable_idempotence 默认为 true,false 关闭。
- 目前的 kafka3 库并不支持直接设置生产者的幂等性。在 Kafka 中启用幂等性需要使用 kafka-python 或其他支持 Kafka 协议的库。
- 以下是使用 kafka-python 库设置生产者的幂等性的示例代码:
from kafka import KafkaProducer# 创建 KafkaProducer 实例,开启幂等性
producer = KafkaProducer(bootstrap_servers="127.0.0.1:9092",acks="all", # 设置 acks 参数为 "all",要求所有副本都确认消息enable_idempotence=True
)8、生产者事务
说明:开启事务必须开启幂等性。
1、事务原理
存储事务信息的特殊主题:__transaction_state_分区_Leader
- 默认有50个分区,每个分区负责一部分事务。
- 事务划分是根据transaction.id的hash值%50,计算出该事物属于哪个分区。
- 该分区Leader副本所在的broker节点即为这个transaction.id对应的Transaction Coordinator节点。
注意事项:生产者在使用事务功能之前,必须先自定义一个唯一的transaction.id。有了该transaction.id,即使客户端挂掉了,它重启之后也能继续处理未完成的事务。
2、使用事务
- 目前的 kafka3 库并不支持直接创建事务。Kafka 事务的支持需要使用 kafka-python 或其他支持 Kafka 协议的库。
- 以下是使用 kafka-python 库创建事务的示例代码:
from kafka import KafkaProducer
from kafka.errors import KafkaError# 创建 KafkaProducer 实例,开启事务
producer = KafkaProducer(bootstrap_servers="127.0.0.1:9092",enable_idempotence=True # 开启幂等性
)# 初始化事务
producer.init_transactions()# 开始事务
producer.begin_transaction()try:# 发送事务性消息for i in range(3):key = b"my_key"value = b"my_value_%d" % iproducer.send("my_topic", key=key, value=value)# 提交事务producer.commit_transaction()except KafkaError as e:# 回滚事务producer.abort_transaction()print(f"发送消息失败: {e}")finally:# 关闭 KafkaProducer 实例producer.close()9、数据的有序性
说明:数据的有序性只能保证单分区有序,分区与分区之间是无序的。
1、Kafka在1.x版本之前保证数据单分区有序,条件如下:
- max.in.flight.requests.per.connection=1 (不需要开启幂等性)
2、Kafka在1.x版本之后保证数据单分区有序,条件如下:
- 未开启幂等性
- 设置:max.in.flight.requests.per.connection=1
- 开启幂等性
- 设置:max.in.flight.requests.per.connection 小于等于5
- 原因:因为在Kafka1.x以后,启用幂等性,Kafka服务端会缓存生产者发来的最近5个request的元数据,所以至少可以保证最近5个request的数据都是有序的。
相关文章:
Kafka 生产者应用解析
目录 1、生产者消息发送流程 1.1、发送原理 2、异步发送 API 2.1、普通异步发送 2.2、带回调函数的异步发送 3、同步发送 API 4、生产者分区 4.1、分区的优势 4.2、生产者发送消息的分区策略 示例1:将数据发往指定 partition 示例2:有 key 的…...
GEE错误——image.reduceRegion is not a function
简介 image.reduceRegion is not a function 这里的主要问题是我们进行地统计分析的时候,我们的作用对象必须是单景影像,而不是影像集合 错误"image.reduceRegion is not a function" 表示你正在尝试使用reduceRegion()函数来处理图像数据&…...

rk356x 关于yocto编译linux及bitbake实用方法
Yocto 完整编译 source oe-init-build-envbitbake core-image-minimalYocto 查询包名 bitbake -s | grep XXX // 获取rockchip相关包 :~/rk3568/yocto$ bitbake -s | grep rockchip android-tools-conf-rockchip :1.0-r0 gstreamer1.0-rockchip …...

Chrome您的连接不是私密连接 |输入“thisisunsafe”命令绕过警告or添加启动参数
一、输入 thisisunsafe 在当前页面用键盘输入 thisisunsafe ,不是在地址栏输入(切记),就直接敲键盘就行了 因为Chrome不信任这些自签名ssl证书,为了安全起见,直接禁止访问了,thisisunsafe 这个命令,说明你…...

牛客面试前端1
HTML语义化 是什么 前端语义化是指在构建网页时多使用html语义化标签布局,多使用带有语义的标签如header,aside,footer等标签为什么 结构清晰利于开发者开发与维护 有利于seo搜索引擎优化 有利于在网络卡顿时,正常显示页面结构&a…...
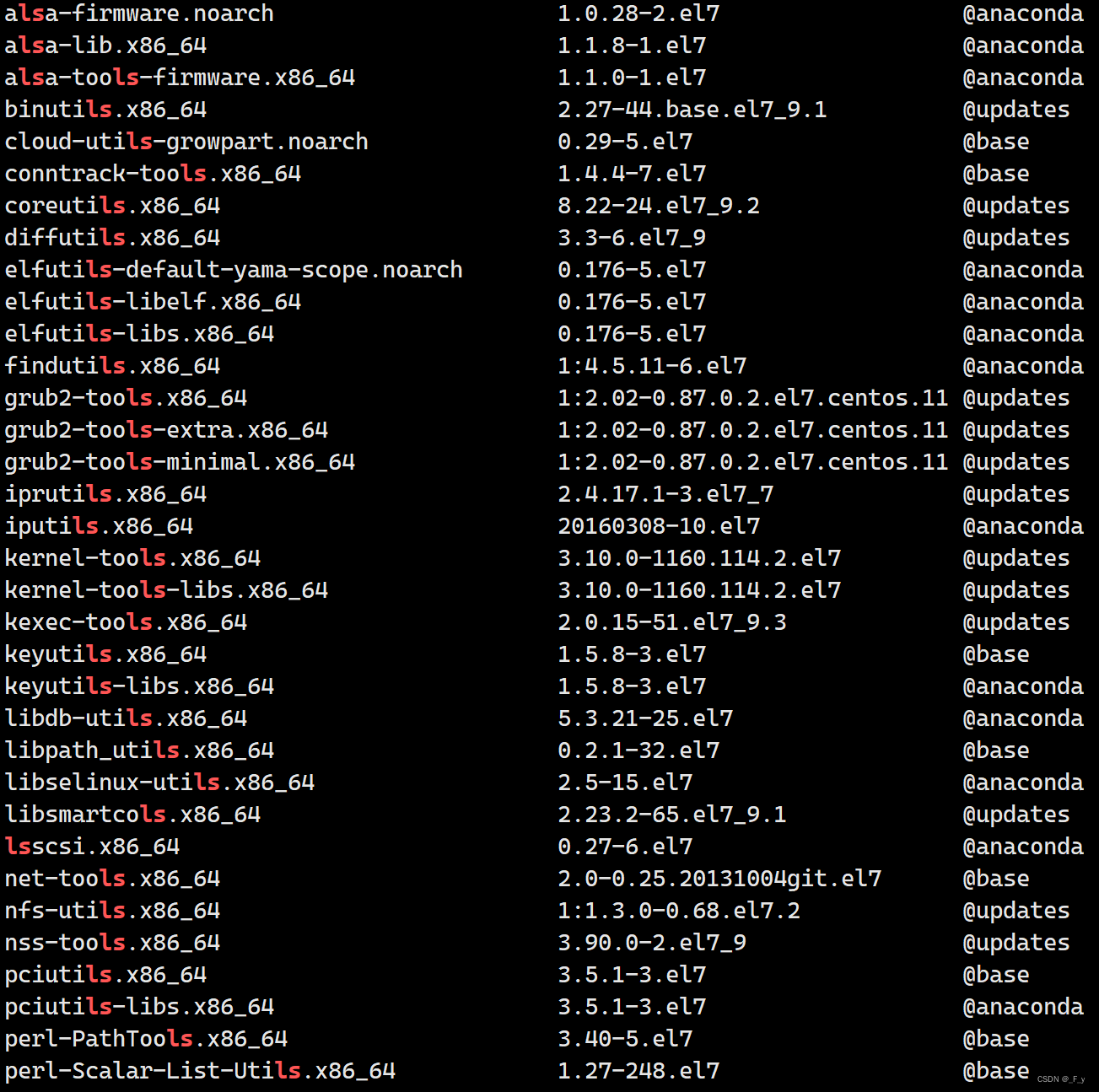
Linux的软件包管理器-yum
文章目录 软件包的概念yum源的配置的原因yum的使用查看软件包安装软件卸载软件 软件包的概念 软件包(SoftWare Package)是指具有特定的功能,用来完成特定任务的一个程序或一组程序。可分为应用软件包和系统软件包两大类 在Linux系统中,下载安装软件的方式…...
)
选择排序(Selection Sort)
选择排序(Selection Sort)是一种简单直观的排序算法。它的工作原理如下: 遍历数组:从待排序的数列中,找到当前未排序部分(即整个数组或已排序部分之后的部分)中的最小(或最大,取决于排序方式)元素。 交换位置:将找到的最小元素与未排序部分的第一个元素交换位置,这…...

网络面试题目
1、BGP报文有哪些? 有5种报文,Open、 Update、 Notification、 Keepalive和 Route-refresh等5种报文类型。 2、Vxlan了解多少? VLAN作为传统的网络隔离技术,VXLAN完美地弥补了VLAN的上述不足。 VXLAN(Virtual eXtensible Local Area Network,虚拟扩展局域网),(VXL…...
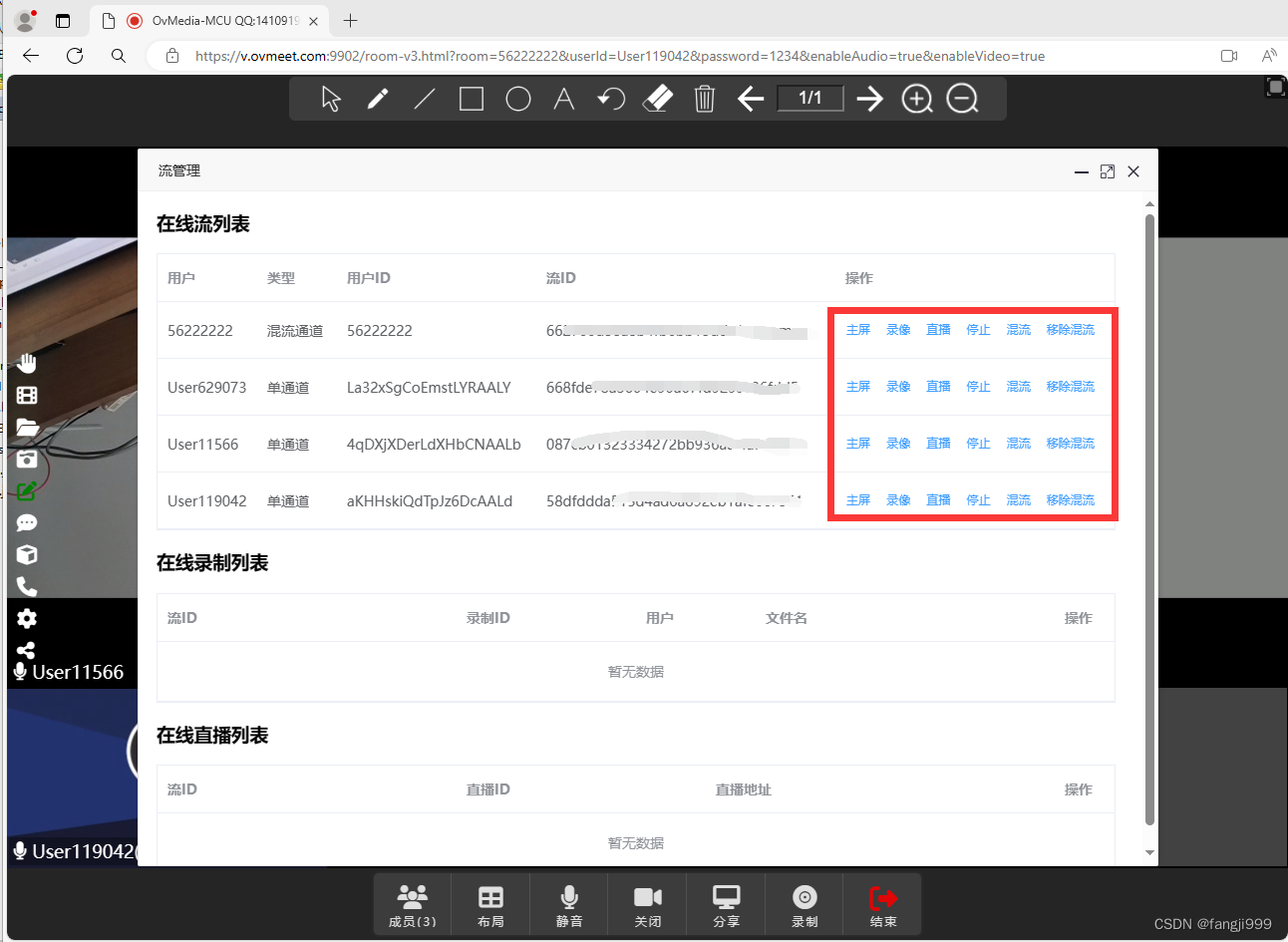
Web,Sip,Rtsp,Rtmp,WebRtc,专业MCU融屏视频混流会议直播方案分析
随着万物互联,视频会议直播互动深入业务各方面,主流SFU并不适合管理,很多业务需要各种监控终端,互动SIP硬件设备,Web在线业务平台能相互融合,互联互通, 视频混流直播,录存直播推广&a…...
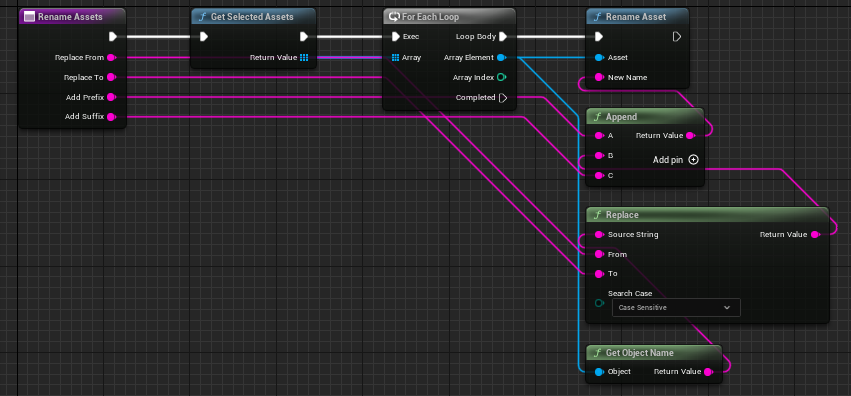
Unreal 编辑器工具 批量重命名资源
右键 - Editor Utilities - Editor Utility Blueprint,基类选择 Asset Action Utility 在类默认值内,可以添加筛选器,筛选指定的类型 然后新建一个函数,加上4个输入:ReplaceFrom,ReplaceTo,Add…...
Voice Conversion、DreamScene、X-SLAM、Panoptic-SLAM、DiffMap、TinySeg
本文首发于公众号:机器感知 Voice Conversion、DreamScene、X-SLAM、Panoptic-SLAM、DiffMap、TinySeg Converting Anyones Voice: End-to-End Expressive Voice Conversion with a Conditional Diffusion Model Expressive voice conversion (VC) conducts speak…...

短信群发平台分析短信群发的未来发展趋势
短信群发平台在当前的移动互联网时代已经展现出了其独特的价值和广泛的应用场景。随着技术的不断进步和市场的不断变化,短信群发的未来发展趋势也将呈现出一些新的特点。 首先,随着5G网络的推广和普及,短信群发的速度和稳定性将得到进一步提…...

supervisord 使用指南
supervisord 使用指南 supervisord的安装 supervisor是一系列python脚本文件,以python package的形式管理,可以用于UNIX类系统的进程管理。 安装supervisor也相当简单,只需要用pip安装即可。 sudo pip install supervisor但是有可能将其安…...
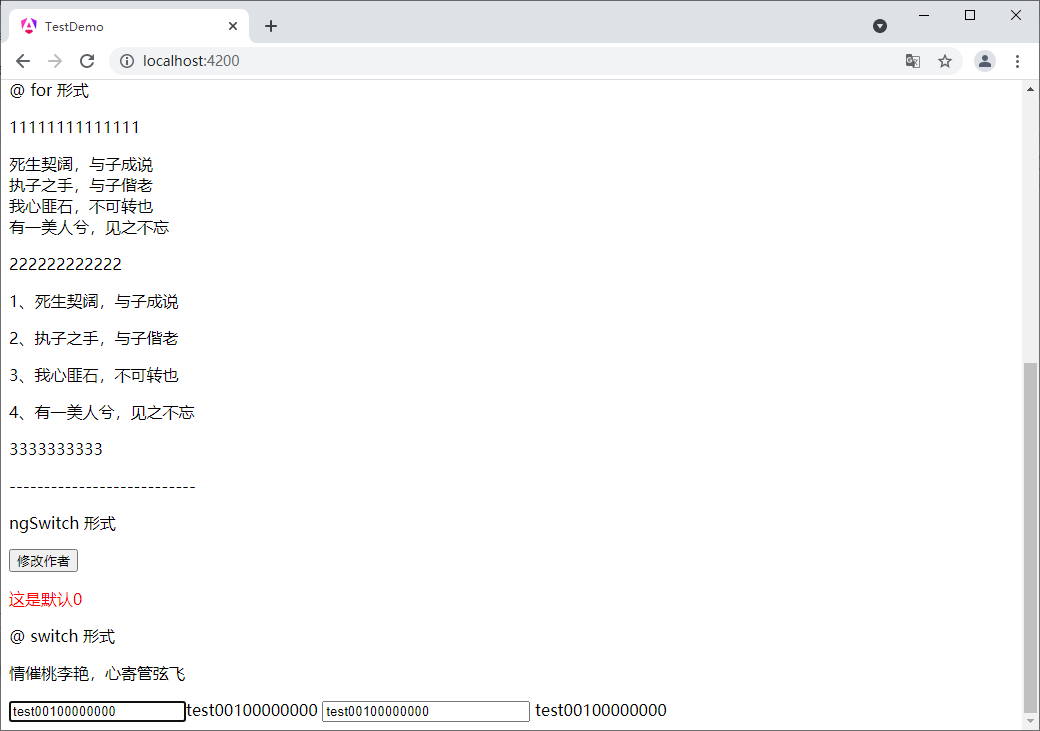
AngularJS 的生命周期和基础语法
AngularJS 的生命周期和基础语法 文章目录 AngularJS 的生命周期和基础语法1. 使用步骤2. 生命周期钩子函数3. 点击事件4. if 语句1. if 形式2. if else 形式 5. for 语句6. switch 语句7. 双向数据绑定 1. 使用步骤 // 1. 要使用哪个钩子函数,就先引入 import { O…...

docker-compose 网络
自定义网络 - HOST 与宿主机共享网络 version: "3" services:web:image: nginx:1.21.6restart: alwaysports:- 80:80network_mode: host自定义网络 - 固定ip version: "3" services:web:image: nginx:1.21.6restart: alwaysports:- 80:80networks:app&am…...

农药生产厂污废水如何处理达标
农药生产厂的污废水处理是确保该行业对环境的负面影响最小化的重要环节。下面是一些常见的处理方法和步骤,可以帮助农药生产厂的污废水达到排放标准: 预处理:将废水进行初步处理,去除大颗粒悬浮物和固体残渣。这可以通过筛网、沉淀…...

根据相同的key 取出数组中最后一个值
数组中有很多对象 , 需根据当前页面的值current 和 数组中的key对比 拿到返回值 数据结构如下 之前写法 const clickedItem routeList.find(item > item.key current) // current是当前页 用reduce遍历数组返回最后一个值 const clickedItem routeList.reduce((lastIte…...
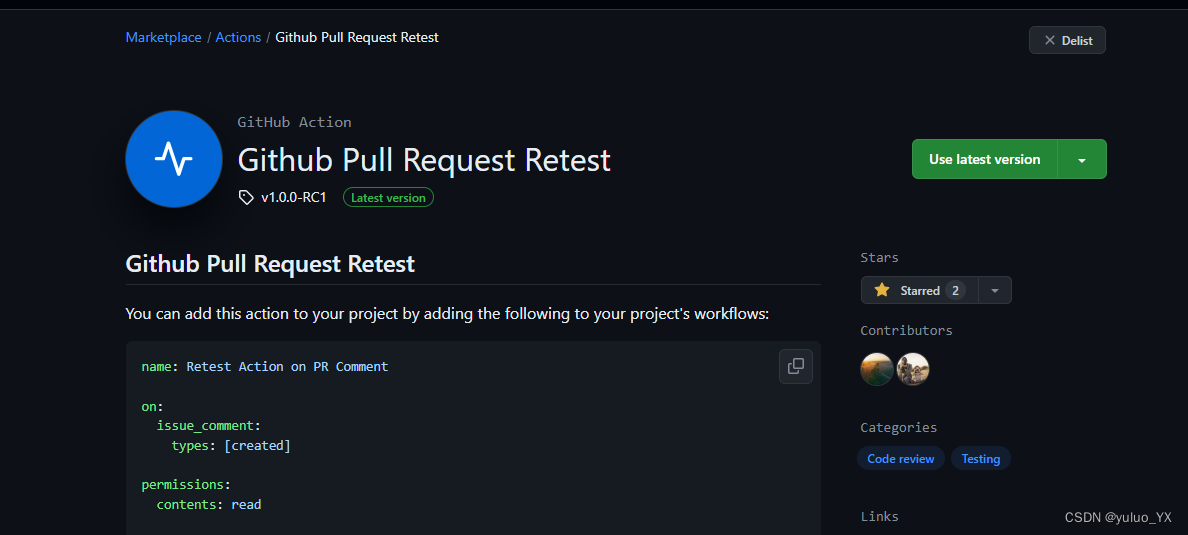
Github Action Bot 开发教程
Github Action Bot 开发教程 在使用 Github 时,你可能在一些著名的开源项目,例如 Kubernetes,Istio 中看到如下的一些评论: /lgtm /retest /area bug /assign xxxx ...等等,诸如此类的一些功能性评论。在这些评论出现…...
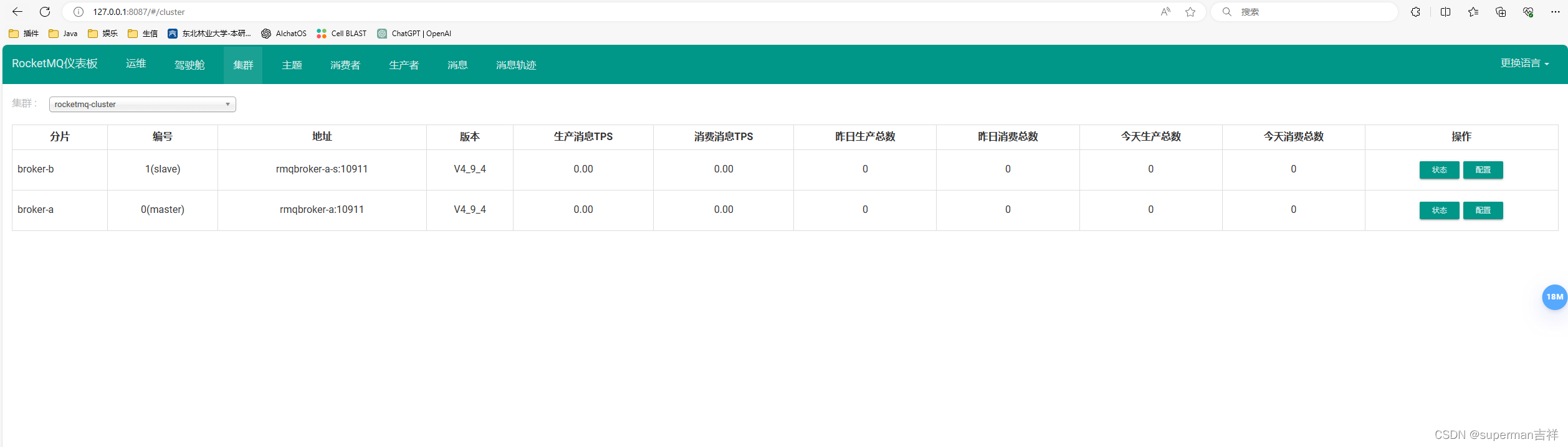
使用docker创建rocketMQ主从结构,使用
1、 创建目录 mkdir -p /docker/rocketmq/logs/nameserver-a mkdir -p /docker/rocketmq/logs/nameserver-b mkdir -p /docker/rocketmq/logs/broker-a mkdir -p /docker/rocketmq/logs/broker-b mkdir -p /docker/rocketmq/store/broker-a mkdir -p /docker/rocketmq/store/b…...

一次完整的 http 请求是怎样的?
一次完整的 http 请求是怎样的? 💖The Begin💖点点关注,收藏不迷路💖 域名解析 --> 发起 TCP 的 3 次握手 --> 建立 TCP 连接后发起 http 请求 --> 服务器响应 http 请求,浏览器得到 html 代码 --…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

解锁数据库简洁之道:FastAPI与SQLModel实战指南
在构建现代Web应用程序时,与数据库的交互无疑是核心环节。虽然传统的数据库操作方式(如直接编写SQL语句与psycopg2交互)赋予了我们精细的控制权,但在面对日益复杂的业务逻辑和快速迭代的需求时,这种方式的开发效率和可…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...