HBase高手之路1-Hbase简介
文章目录
- HBase高手之路1-Hbase简介
- 一、什么是HBase
- 1. HBase简介
- 2. HBase的发展过程
- 二、HBase特点
- 1. 海量存储
- 2. 列式存储
- 3. 极易扩展
- 4. 高并发
- 5. 稀疏
- 6. 强一致性读/写
- 7. 自动分块
- 8. 自动RegionServer故障转移
- 9. Hadoop/HDFS集成
- 10. MapReduce
- 11. Java Client API
- 12. Thrift/REST API
- 13. 块缓存和布隆过滤器
- 14. 运行管理
- 三、HBase应用场景
- 1. 对象存储
- 2. 时序数据
- 3. 推荐画像
- 4. 时空数据
- 5. CubeDB OLAP
- 6. 消息/订单
- 7. Feeds流
- 8. NewSQL
- 9. 其他
- 四、HBase 与 NoSQL
- 五、RDBMS与HBase的对比
- 1. 关系型数据库
- 1.1 结构
- 1.2 功能
- 2. HBase
- 2.1 结构
- 2.2 功能
- 六、HDFS对比HBase
- 1. HDFS
- 2. HBase
- 七、Hive对比Hbase
- 1. Hive
- 2. HBase
- 3. 总结Hive与HBase

HBase高手之路1-Hbase简介
一、什么是HBase
1. HBase简介
HBase的原型是Google的BigTable论文,受到了该论文思想的启发,目前作为Hadoop的子项目来开发维护,用于支持结构化的数据存储。
官方网站:http://hbase.apache.org
HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBASE技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
HBase是Google Bigtable的开源实现,但是也有很多不同之处。比如:Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MAPREDUCE来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;Google Bigtable利用Chubby作为协同服务,HBase利用Zookeeper作为对应。
2. HBase的发展过程
– 2006年Google发表BigTable白皮书
– 2006年开始开发HBase
– 2008年北京成功开奥运会,程序员默默地将HBase弄成了Hadoop的子项目
– 2010年HBase成为Apache顶级项目
– 现在很多公司二次开发出了很多发行版本,你也开始使用了。
二、HBase特点
1. 海量存储
Hbase适合存储PB级别的海量数据,在PB级别的数据以及采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。这与Hbase的极易扩展性息息相关。正式因为Hbase良好的扩展性,才为海量数据的存储提供了便利。
2. 列式存储
这里的列式存储其实说的是列族存储,Hbase是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
3. 极易扩展
Hbase的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。
通过横向添加RegionSever的机器,进行水平扩展,提升Hbase上层的处理能力,提升Hbsae服务更多Region的能力。
备注:RegionServer的作用是管理region、承接业务的访问,这个后面会详细的介绍通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
4. 高并发
由于目前大部分使用Hbase的架构,都是采用的廉价PC,因此单个IO的延迟其实并不小,一般在几十到上百ms之间。这里说的高并发,主要是在并发的情况下,Hbase的单个IO延迟下降并不多。能获得高并发、低延迟的服务。
5. 稀疏
稀疏主要是针对Hbase列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
6. 强一致性读/写
- HBASE不是“最终一致的”数据存储
- 它非常适合于诸如高速计数器聚合等任务
7. 自动分块
- HBase表通过Region分布在集群上,随着数据的增长,区域被自动拆分和重新分布
8. 自动RegionServer故障转移
9. Hadoop/HDFS集成
- HBase支持HDFS开箱即用作为其分布式文件系统
10. MapReduce
- HBase通过MapReduce支持大规模并行处理,将HBase用作源和接收器
11. Java Client API
- HBase支持易于使用的 Java API 进行编程访问
12. Thrift/REST API
13. 块缓存和布隆过滤器
- HBase支持块Cache和Bloom过滤器进行大容量查询优化
14. 运行管理
- HBase为业务洞察和JMX度量提供内置网页。
三、HBase应用场景
1. 对象存储
不少的头条类、新闻类的的新闻、网页、图片存储在HBase之中,一些病毒公司的病毒库也是存储在HBase之中
2. 时序数据
HBase之上有OpenTSDB模块,可以满足时序类场景的需求
3. 推荐画像
用户画像,是一个比较大的稀疏矩阵,蚂蚁金服的风控就是构建在HBase之上
4. 时空数据
主要是轨迹、气象网格之类,滴滴打车的轨迹数据主要存在HBase之中,另外在技术所有大一点的数据量的车联网企业,数据都是存在HBase之中
5. CubeDB OLAP
Kylin一个cube分析工具,底层的数据就是存储在HBase之中,不少客户自己基于离线计算构建cube存储在hbase之中,满足在线报表查询的需求
6. 消息/订单
在电信领域、银行领域,不少的订单查询底层的存储,另外不少通信、消息同步的应用构建在HBase之上
7. Feeds流
典型的应用就是xx朋友圈类似的应用,用户可以随时发布新内容,评论、点赞。
8. NewSQL
之上有Phoenix的插件,可以满足二级索引、SQL的需求,对接传统数据需要SQL非事务的需求
9. 其他
- 存储爬虫数据
- 海量数据备份
- 短网址
- …
四、HBase 与 NoSQL
- NoSQL是一个通用术语,泛指一个数据库并不是使用SQL作为主要语言的非关系型数据库
- HBase是BigTable的开源java版本。是建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写NoSQL的数据库系统
- HBase仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务
- 主要用来存储结构化和半结构化的松散数据
- Hbase查询数据功能很简单,不支持join等复杂操作,不支持复杂的事务(行级的事务),从技术上来说,HBase更像是一个「数据存储」而不是「数据库」,因为HBase缺少RDBMS中的许多特性,例如带类型的列、二级索引以及高级查询语言等
- Hbase中支持的数据类型:byte[]
- 与Hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加存储和处理能力,例如,把集群从10个节点扩展到20个节点,存储能力和处理能力都会加倍
- HBase中的表一般有这样的特点
- 大:一个表可以有上十亿行,上百万列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏
五、RDBMS与HBase的对比
1. 关系型数据库
1.1 结构
- 数据库以表的形式存在
- 支持FAT、NTFS、EXT、文件系统
- 使用主键(PK)
- 通过外部中间件可以支持分库分表,但底层还是单机引擎
- 使用行、列、单元格
1.2 功能
- 支持向上扩展(买更好的服务器)
- 使用SQL查询
- 面向行,即每一行都是一个连续单元
- 数据总量依赖于服务器配置
- 具有ACID支持
- 适合结构化数据
- 传统关系型数据库一般都是中心化的
- 支持事务
- 支持Join
2. HBase
2.1 结构
- 以表形式存在
- 支持HDFS文件系统
- 使用行键(row key)
- 原生支持分布式存储、计算引擎
- 使用行、列、列蔟和单元格
2.2 功能
- 支持向外扩展
- 使用API和MapReduce、Spark、Flink来访问HBase表数据
- 面向列蔟,即每一个列蔟都是一个连续的单元
- 数据总量不依赖具体某台机器,而取决于机器数量
- HBase不支持ACID(Atomicity、Consistency、Isolation、Durability)
- 适合结构化数据和非结构化数据
- 一般都是分布式的
- HBase不支持事务,支持的是单行数据的事务操作
- 不支持Join
六、HDFS对比HBase
1. HDFS
- HDFS是一个非常适合存储大型文件的分布式文件系统
- HDFS它不是一个通用的文件系统,也无法在文件中快速查询某个数据
2. HBase
- HBase构建在HDFS之上,并为大型表提供快速记录查找(和更新)
- HBase内部将大量数据放在HDFS中名为「StoreFiles」的索引中,以便进行高速查找
- Hbase比较适合做快速查询等需求,而不适合做大规模的OLAP应用
七、Hive对比Hbase
1. Hive
-
数据仓库工具
Hive的本质其实就相当于将HDFS中已经存储的文件在Mysql中做了一个双射关系,以方便使用HQL去管理查询
-
用于数据分析、清洗
Hive适用于离线的数据分析和清洗,延迟较高
-
基于HDFS、MapReduce
Hive存储的数据依旧在DataNode上,编写的HQL语句终将是转换为MapReduce代码执行
2. HBase
-
NoSQL数据库
是一种面向列存储的非关系型数据库。
-
用于存储结构化和非结构化的数据
适用于单表非关系型数据的存储,不适合做关联查询,类似JOIN等操作。
-
基于HDFS
数据持久化存储的体现形式是Hfile,存放于DataNode中,被ResionServer以region的形式进行管理
-
延迟较低,接入在线业务使用
面对大量的企业数据,HBase可以直线单表大量数据的存储,同时提供了高效的数据访问速度
3. 总结Hive与HBase
- Hive和Hbase是两种基于Hadoop的不同技术
- Hive是一种类SQL的引擎,并且运行MapReduce任务
- Hbase是一种在Hadoop之上的NoSQL 的Key/value数据库
- 这两种工具是可以同时使用的。就像用Google来搜索,用FaceBook进行社交一样,Hive可以用来进行统计查询,HBase可以用来进行实时查询,数据也可以从Hive写到HBase,或者从HBase写回Hive
参考链接:
HBase 的特点是什么
HBASE学习(三)——hbase数据结构
相关文章:
HBase高手之路1-Hbase简介
文章目录HBase高手之路1-Hbase简介一、什么是HBase1. HBase简介2. HBase的发展过程二、HBase特点1. 海量存储2. 列式存储3. 极易扩展4. 高并发5. 稀疏6. 强一致性读/写7. 自动分块8. 自动RegionServer故障转移9. Hadoop/HDFS集成10. MapReduce11. Java Client API12. Thrift/RE…...

计算机视觉手指甲标注案例
关键点标注是指识别和标注图像或视频中特定的相关点或区域的过程。在机器学习行业,它经常被用来训练计算机视觉模型,以执行诸如物体检测、分割和跟踪等任务。 关键点注释可用于以下应用: 面部关键点检测:识别图像中人脸上的眼睛…...
)
linux 字符串截取(cut)
-b :以字节为单位进行分割。这些字节位置将忽略多字节字符边界,除非也指定了 -n 标志。 -c :以字符为单位进行分割。 -d :自定义分隔符,默认为制表符。 -f :与-d一起使用,指定显示哪个区域。 -n…...

003+limou+HTML——(3)HTML列表
000、前言 列表是网页常见的一种数据排列方式,在HTMl中列表一共有三种:有序列表、无序列表、定义列表(另外“目录列表dir”和“菜单列表menu”已经在HTML5中被废除了,现在都是使用无序列表ul来替代) 001、有序列表&a…...

设计模式---工厂模式
目录 1. 简单工厂模式 2. 工厂方法模式 1. 简单工厂模式 简单工厂模式(Simple Factory Patterm)又称为静态工厂方法模式(Static Factory Model),它属于类创建型模式。在简单工厂模式中,可以根据参数的不同返回不同类的实例。简单工厂模式专门定义了一…...

C++基础了解-13-C++ 数组
C 数组 一、C 数组 C 支持数组数据结构,它可以存储一个固定大小的相同类型元素的顺序集合。数组是用来存储一系列数据,但它往往被认为是一系列相同类型的变量。 数组的声明并不是声明一个个单独的变量,比如 number0、number1、…、number9…...

ICC2:限制LVT比例
1) 禁用VT 在优化过程用,如果要禁用某种VT可以直接对其使用dont use,如下示例: set_attribute -objects [get_lib_cells *_lvt*/*] -name dont_use -value true 在dont use lib cell的基础上还可以对某些模块放开lvt的使用。 set_app_options -name …...
Kettle工具通过JNDI连接Oracle集群
我们在用Kettle ETL工具的时候,可能会遇到数据库为Oracle集群的模式,或者有时候目标库为oracle,在持续的循环调度中,经常发现oracle的数据库连接中断的情况,此时,在Kettle中有一个JNDI的连接方式能很好的解…...

[ 常用工具篇 ] windows安装phpStudy_v8.1_X64
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...

SpringBoot 如何将配置文件挂到 jar 包外面?
目录一、SpringBoot 指定配置文件路径:1)使用命令行参数:2)使用环境变量:3)使用外部配置文件:二、SpringBoot 配置文件生效的优先级排序:一、SpringBoot 指定配置文件路径࿱…...

蓝桥杯C/C++b组第一题个人整理合集(5年真题+模拟题)
蓝桥杯C/Cb组填空第一题合集 前言 比赛标准的签到题,比赛时的第一题。不会考到什么算法,甚至都不需要你打代码。但有时候第一题都没做出来的确是非常挫灭信心 看了看历年题目。很多小陷阱也不少 今年的比赛也正好还有一个月,自己对填空题第…...

深入浅出PaddlePaddle函数——paddle.zeros
分类目录:《深入浅出PaddlePaddle函数》总目录 相关文章: 深入浅出PaddlePaddle函数——paddle.Tensor 深入浅出PaddlePaddle函数——paddle.ones 深入浅出PaddlePaddle函数——paddle.zeros 深入浅出PaddlePaddle函数——paddle.full 深入浅出Padd…...

[力扣sql]
题目 表: Person ---------------------- | 列名 | 类型 | ---------------------- | PersonId | int | | FirstName | varchar | | LastName | varchar | ---------------------- personId 是该表的主键列。 该表包含一些人的 ID 和他们的姓和名的信…...
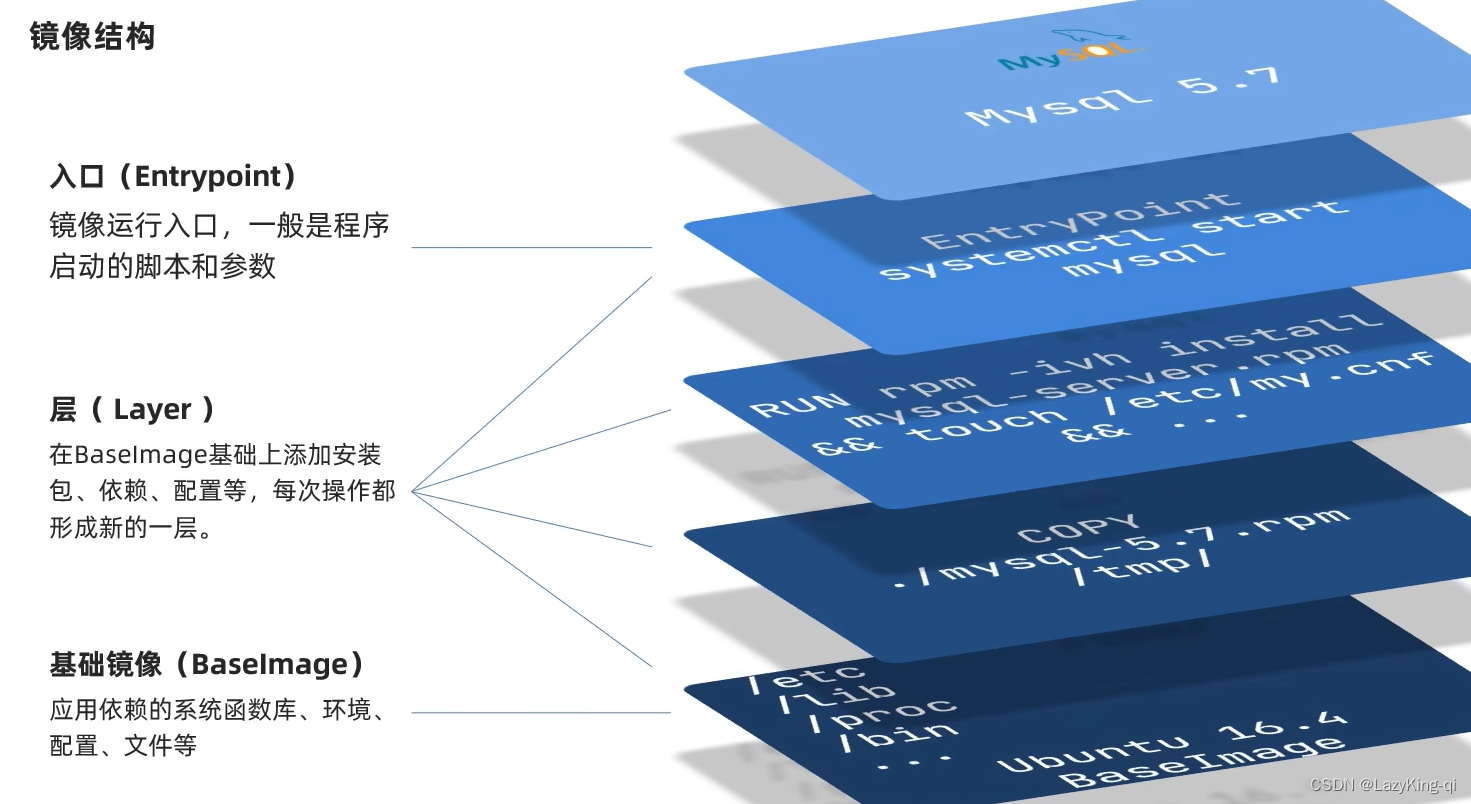
Docker基本操作
目录 Docker基本操作 1、镜像操作 2、容器操作 3、数据卷(容器数据管理) 4、数据卷挂载 5、Dockerfile自定义镜像 Docker基本操作 1、镜像操作 镜像名称一般分两部分组成:[repository]:[tag]。 在没有指定tag时,默认是la…...

golang如何使用rocketmq 附加闭坑指南 建议收藏!!!
文章目录前言一、rocketmq是什么?二、rocketmq核心概念三、rocketmq核心应用四、go如何使用rocketmq总结前言 当我们的业务达到一定规模,很多业务需要解耦,以及需要流量削峰的时候,我们需要使用MQ来让我们系统能够正常运转。 一…...

C++实现的二叉树创建和遍历,超入门邻家小女也懂了
目录 二叉树 特点 性质 二叉树的创建 声明 创建 -> 成员运算符 批量创建 二叉树的遍历 先序遍历 中序遍历 后序遍历 层序遍历 树的相关术语 特殊二叉树 满二叉树 完全二叉树 二叉树 树(Tree)是n(n≥0)个节点的有限集。在任意一棵…...

如何写出高质量的业务接口
清晰的需求 需求要有文档;方便后续追溯或交接等需求是基础,必须详细;多和需求沟通确认,不可模糊、模棱两可,否则后续可能越错越远 抽象建模 分析需求;梳理清楚关联关系,建立数据模型和关联画E-R…...

3.8多线程
案例一-线程安全的单例模式(面试)是一种设计模式,设计模式针对写代码时的一些常见场景给出一些经典解决方案单例模式的两种典型实现饿汉模式懒汉模式饿汉的单例模式:比较着急去进行创建实例懒汉的单例模式,是不太着急创建实例,,只是在用的时候,才真正创建这个是类对象,也就是.c…...
图文讲解MongoDB该怎么安装
一、安装前必读 我这里是Centos7 Linux 内核 注意:本文的命令使用的是 root 用户登录执行,不是 root 的话所有命令前面要加 sudo 二、环境配置 2.1 停止防火墙 systemctl status firewalld #查看firewall systemctl stop firewalld …...

「ML 实践篇」机器学习项目落地
文章目录1. 项目分析1. 框架问题2. 性能指标2. 获取数据1. 准备工作区2. 下载数据3. 查看数据4. 创建测试集3. 数据探索1. 地理位置可视化2. 寻找相关性3. 组合属性4. 数据准备1. 数据清理2. Scikit-Learn 的设计3. 处理文本、分类属性4. 自定义转换器5. 特征缩放6. 流水线5. 选…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

CMake 从 GitHub 下载第三方库并使用
有时我们希望直接使用 GitHub 上的开源库,而不想手动下载、编译和安装。 可以利用 CMake 提供的 FetchContent 模块来实现自动下载、构建和链接第三方库。 FetchContent 命令官方文档✅ 示例代码 我们将以 fmt 这个流行的格式化库为例,演示如何: 使用 FetchContent 从 GitH…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

Qemu arm操作系统开发环境
使用qemu虚拟arm硬件比较合适。 步骤如下: 安装qemu apt install qemu-system安装aarch64-none-elf-gcc 需要手动下载,下载地址:https://developer.arm.com/-/media/Files/downloads/gnu/13.2.rel1/binrel/arm-gnu-toolchain-13.2.rel1-x…...

Chrome 浏览器前端与客户端双向通信实战
Chrome 前端(即页面 JS / Web UI)与客户端(C 后端)的交互机制,是 Chromium 架构中非常核心的一环。下面我将按常见场景,从通道、流程、技术栈几个角度做一套完整的分析,特别适合你这种在分析和改…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...

作为点的对象CenterNet论文阅读
摘要 检测器将图像中的物体表示为轴对齐的边界框。大多数成功的目标检测方法都会枚举几乎完整的潜在目标位置列表,并对每一个位置进行分类。这种做法既浪费又低效,并且需要额外的后处理。在本文中,我们采取了不同的方法。我们将物体建模为单…...

SFTrack:面向警务无人机的自适应多目标跟踪算法——突破小尺度高速运动目标的追踪瓶颈
【导读】 本文针对无人机(UAV)视频中目标尺寸小、运动快导致的多目标跟踪难题,提出一种更简单高效的方法。核心创新在于从低置信度检测启动跟踪(贴合无人机场景特性),并改进传统外观匹配算法以关联此类检测…...
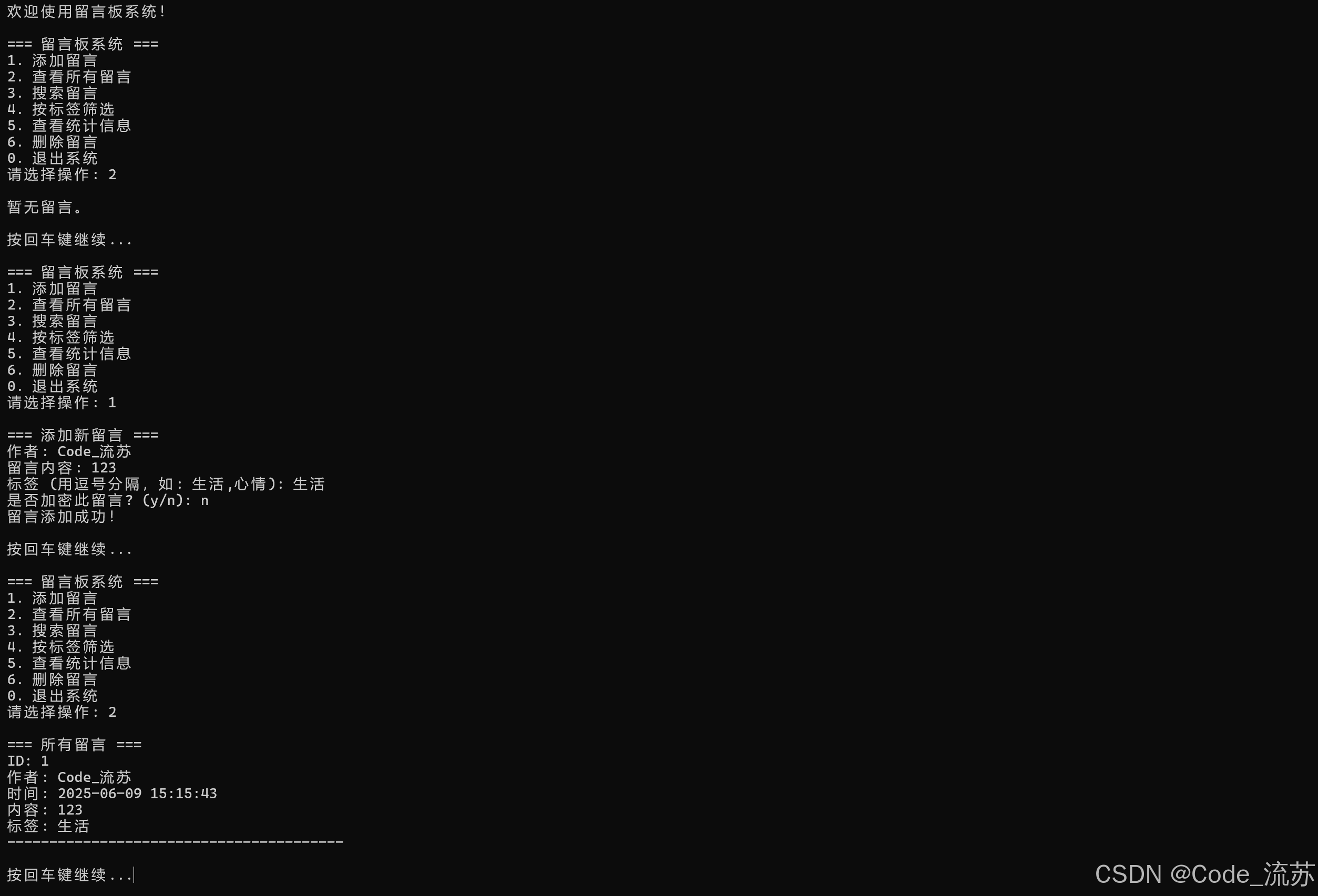
C++课设:实现本地留言板系统(支持留言、搜索、标签、加密等)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 专栏介绍:《编程项目实战》 目录 一、项目功能概览与亮点分析1. 核心功能…...