3.Elasticsearch初步进阶
3.Elasticsearch初步进阶
[toc]
1.文档批量操作
批量获取文档数据
批量获取文档数据是通过_mget的API来实现的
在URL中不指定index和type
请求方式:GET
请求地址:_mget
功能说明:可以通过ID批量获取不同index和type的数据
请求参数
docs:文档数组参数
_index:指定index
_type:指定type
_id:指定id
_source:指定要查询的字段
# 批量操作文档
GET _mget
{"docs": [{"_index": "es_db","_type": "_doc","_id": 1},{"_index": "es_db","_type": "_doc","_id": 3}]
}查询结果
#! Deprecation: [types removal] Specifying types in multi get requests is deprecated.
{"docs" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_version" : 1,"_seq_no" : 2,"_primary_term" : 1,"found" : true,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}}]
}在URL中指定index
请求方式:GET
请求地址:/{{indexName}}/_mget
功能说明 : 可以通过ID批量获取不同index和type的数据
请求参数:
docs:文档数组参数
_index:指定index
_type:指定type
_id:指定id
_source:指定要查询的字段
GET /es_db/_mget
{"docs": [{"_type": "_doc","_id": 3},{"_type": "_doc","_id": 4}]
}返回结果
#! Deprecation: [types removal] Specifying types in multi get requests is deprecated.
{"docs" : [{"_index" : "es_db","_type" : "_doc","_id" : "3","_version" : 1,"_seq_no" : 2,"_primary_term" : 1,"found" : true,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "4","_version" : 1,"_seq_no" : 3,"_primary_term" : 1,"found" : true,"_source" : {"name" : "admin","sex" : 0,"age" : 22,"address" : "长沙橘子洲头","remark" : "python assistant"}}]
}在URL中指定index和type
请求方式:GET
请求地址:/{{indexName}}/{{typeName}}/_mget
功能说明 : 可以通过ID批量获取不同index和type的数据
请求参数:
docs:文档数组参数
_index:指定index
_type:指定type
_id:指定id
_source:指定要查询的字段
GET /es_db/_doc/_mget
{"docs": [{"_id": 1},{"_id": 2}]
}返回结果
#! Deprecation: [types removal] Specifying types in multi get requests is deprecated.
{"docs" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_version" : 1,"_seq_no" : 0,"_primary_term" : 1,"found" : true,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "2","found" : false}]
}2.批量操作文档数据
批量对文档进行写操作是通过_bulk的API来实现的
请求方式:POST
请求地址:_bulk
请求参数:通过_bulk操作文档,一般至少有两行参数(或偶数行参数)
第一行参数为指定操作的类型及操作的对象(index,type和id)
第二行参数才是操作的数据
参数类似于
#! 第一行参数
{"actionName": {"_index": "indexName","_type": "typeName","_id": "id"}
}
#! 第二行参数
{"field1": "value1","field2": "value2"
}actionName:表示操作类型,主要有以下几个
create
index
delete
update
批量创建文档create
POST _bulk
{"create":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"王者荣耀1","content":"王者荣耀666","tags":["java", "面向对象"],"create_time":1554015482530}
{"create":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"王者荣耀2","content":"王者荣耀NB","tags":["java", "面向对象"],"create_time":1554015482530}执行结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 146,"errors" : false,"items" : [{"create" : {"_index" : "article","_type" : "_doc","_id" : "3","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1,"status" : 201}},{"create" : {"_index" : "article","_type" : "_doc","_id" : "4","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 1,"_primary_term" : 1,"status" : 201}}]
}普通创建或全量替换index
POST _bulk
{"index":{"_index":"article", "_type":"_doc", "_id":3}}
{"id":3,"title":"王者荣耀(一)","content":"王者荣耀老师666","tags":["java", "面向对象"],"create_time":1554015482530}
{"index":{"_index":"article", "_type":"_doc", "_id":4}}
{"id":4,"title":"王者荣耀(二)","content":"王者荣耀NB","tags":["java", "面向对象"],"create_time":1554015482530}执行结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 8,"errors" : false,"items" : [{"index" : {"_index" : "article","_type" : "_doc","_id" : "3","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 2,"_primary_term" : 1,"status" : 200}},{"index" : {"_index" : "article","_type" : "_doc","_id" : "4","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 3,"_primary_term" : 1,"status" : 200}}]
}备注
如果原文档不存在,则是创建
如果原文档存在,则是替换(全量修改原文档)
批量删除delete
POST _bulk
{"delete":{"_index":"article", "_type":"_doc", "_id":3}}
{"delete":{"_index":"article", "_type":"_doc", "_id":4}}执行结果
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 8,"errors" : false,"items" : [{"delete" : {"_index" : "article","_type" : "_doc","_id" : "3","_version" : 3,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 4,"_primary_term" : 1,"status" : 200}},{"delete" : {"_index" : "article","_type" : "_doc","_id" : "4","_version" : 3,"result" : "deleted","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 5,"_primary_term" : 1,"status" : 200}}]
}批量修改update
POST _bulk
{"update":{"_index":"article", "_type":"_doc", "_id":3}}
{"doc":{"title":"ES大法必修内功"}}
{"update":{"_index":"article", "_type":"_doc", "_id":4}}
{"doc":{"create_time":1554018421008}}上一步删除了所以会404
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 2,"errors" : true,"items" : [{"update" : {"_index" : "article","_type" : "_doc","_id" : "3","status" : 404,"error" : {"type" : "document_missing_exception","reason" : "[_doc][3]: document missing","index_uuid" : "QWPLvY7YSduxTOL_-_o-lw","shard" : "0","index" : "article"}}},{"update" : {"_index" : "article","_type" : "_doc","_id" : "4","status" : 404,"error" : {"type" : "document_missing_exception","reason" : "[_doc][4]: document missing","index_uuid" : "QWPLvY7YSduxTOL_-_o-lw","shard" : "0","index" : "article"}}}]
}重新创建修改后
#! Deprecation: [types removal] Specifying types in bulk requests is deprecated.
{"took" : 49,"errors" : false,"items" : [{"update" : {"_index" : "article","_type" : "_doc","_id" : "3","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 8,"_primary_term" : 1,"status" : 200}},{"update" : {"_index" : "article","_type" : "_doc","_id" : "4","_version" : 2,"result" : "updated","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 9,"_primary_term" : 1,"status" : 200}}]
}3.DSL语言高级查询
Query DSL概述
Domain Specific Language:领域专用语言
Elasticsearch provides a ful1 Query DSL based on JSON to define queries:Elasticsearch提供了基于JSON的DSL来定义查询
DSL由叶子查询子句和复合查询子句两种子句组成

无条件查询
无查询条件是查询所有,默认是查询所有的,或者使用match_all表示所有
# 无查询条件
GET /es_db/_doc/_search
{"query": {"match_all": {}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "4","_score" : 1.0,"_source" : {"name" : "admin","sex" : 0,"age" : 22,"address" : "长沙橘子洲头","remark" : "python assistant"}},{"_index" : "es_db","_type" : "_doc","_id" : "5","_score" : 1.0,"_source" : {"name" : "小明","sex" : 0,"age" : 19,"address" : "长沙岳麓山","remark" : "java architect assistant"}}]}
}有条件查询
叶子条件查询(单字段查询条件)
模糊匹配
模糊匹配主要是针对文本类型的字段,文本类型的字段会对内容进行分词,对查询时,也会对搜索条件进行分词,然后通过倒排索引查找到匹配的数据,模糊匹配主要通过match等参数来实现
match:通过match关键词模糊匹配条件内容
prefix:前缀匹配
regexp:通过正则表达式来匹配数据
match的复杂用法
match条件还支持以下参数
query : 指定匹配的值
operator : 匹配条件类型
and : 条件分词后都要匹配
or : 条件分词后有一个匹配即可(默认)
minmum_should_match : 指定最小匹配的数量
精确匹配
term : 单个条件相等
terms : 单个字段属于某个值数组内的值
range : 字段属于某个范围内的值
exists : 某个字段的值是否存在
ids : 通过ID批量查询
组合条件查询(多条件查询)
组合条件查询是将叶子条件查询语句进行组合而形成的一个完整的查询条件
bool : 各条件之间有and,or或not的关系
must : 各个条件都必须满足,即各条件是and的关系
should : 各个条件有一个满足即可,即各条件是or的关系
must_not : 不满足所有条件,即各条件是not的关系
filter : 不计算相关度评分,它不计算_score即相关度评分,效率更高
constant_score : 不计算相关度评分
must/filter/shoud/must_not 等的子条件是通过 term/terms/range/ids/exists/match 等叶子条件为参数的
注:以上参数,当只有一个搜索条件时,must等对应的是一个对象,当是多个条件时,对应的是一个数组
连接查询(多文档合并查询)
父子文档查询:parent/child
嵌套文档查询: nested
DSL查询语言中存在两种:查询DSL(query DSL)和过滤DSL(filter DSL)
区别
queries | filters |
relevance | boolean yes/no |
full text | exact values |
not cached | cached |
slower | faster |
filter first,then query remaining docs
query DSL
在查询上下文中,查询会回答这个问题-“这个文档匹不匹配这个查询,它的相关度高么?”
如何验证匹配很好理解,如何计算相关度呢?ES中索引的数据都会存储一个_score分值,分值越高就代表越匹配。另外关于某个搜索的分值计算还是很复杂的,因此也需要一定的时间。
filter DSL
在过滤器上下文中,查询会回答这个问题——“这个文档匹不匹配?”
答案很简单,是或者不是。它不会去计算任何分值,也不会关心返回的排序问题,因此效率会高一点。
过滤上下文 是在使用filter参数时候的执行环境,比如在bool查询中使用must_not或者filter
另外,经常使用过滤器,ES会自动的缓存过滤器的内容,这对于查询来说,会提高很多性能。
Query方式查询:案例
根据名称精确查询姓名 term, term查询不会对字段进行分词查询,会采用精确匹配
注意: 采用term精确查询, 查询字段映射类型属于为keyword.
精确查询
# 根据term精确匹配
POST /es_db/_doc/_search
{"query": {"term": {"name": "admin"}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.3940738,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "4","_score" : 1.3940738,"_source" : {"name" : "admin","sex" : 0,"age" : 22,"address" : "长沙橘子洲头","remark" : "python assistant"}}]}
}SQL: select * from student where name = 'admin'模糊查询
根据备注信息模糊查询 match, match会根据该字段的分词器,进行分词查询
# 模糊查询
POST /es_db/_doc/_search
{"from": 0,"size": 2,"query": {"match": {"address": "广州"}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 6,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.3862944,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.3862944,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.2978076,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}}]}
}SQL: select * from user where address like '%广州%' limit 0, 2多字段模糊查询
多字段模糊匹配查询与精准查询 multi_match
# 多字段模糊匹配
POST /es_db/_doc/_search
{"query": {"multi_match": {"query": "张三","fields": ["address","name"]}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 2.1189923,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 2.1189923,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}}]}
}SQL: select * from student where name like '%张三%' or address like '%张三%' 未指定字段条件查询
未指定字段条件查询 query_string , 含 AND 与 OR 条件
# 未指定字段条件查询
POST /es_db/_doc/_search
{"query": {"query_string": {"query": "广州 OR 长沙"}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 13,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 4,"relation" : "eq"},"max_score" : 1.4877305,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "5","_score" : 1.4877305,"_source" : {"name" : "小明","sex" : 0,"age" : 19,"address" : "长沙岳麓山","remark" : "java architect assistant"}},{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.3862944,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "4","_score" : 1.3862944,"_source" : {"name" : "admin","sex" : 0,"age" : 22,"address" : "长沙橘子洲头","remark" : "python assistant"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.2978076,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}}]}
}指定字段条件查询
指定字段条件查询 query_string , 含 AND 与 OR 条件
# 未指定字段条件查询
POST /es_db/_doc/_search
{"query": {"query_string": {"query": "admin OR 长沙","fields": ["name","address"]}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 1,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 2.7803683,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "4","_score" : 2.7803683,"_source" : {"name" : "admin","sex" : 0,"age" : 22,"address" : "长沙橘子洲头","remark" : "python assistant"}},{"_index" : "es_db","_type" : "_doc","_id" : "5","_score" : 1.4877305,"_source" : {"name" : "小明","sex" : 0,"age" : 19,"address" : "长沙岳麓山","remark" : "java architect assistant"}}]}
}范围查询
json请求字符串中部分字段的含义
range:范围关键字
gte 大于等于
lte 小于等于
gt 大于
lt 小于
now 当前时间
# 范围查询
POST /es_db/_doc/_search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 6,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.0,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.0,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}}]}
}SQL: select * from user where age between 25 and 28分页,输出字段,排序综合查询
# 分页,输出字段,排序综合查询
POST /es_db/_doc/_search
{"query": {"range": {"age": {"gte": 25,"lte": 28}}},"from": 0,"size": 2,"_source": ["name","age","book"],"sort": {"age": "desc"}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : null,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : null,"_source" : {"name" : "rod","age" : 26},"sort" : [26]},{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : null,"_source" : {"name" : "张三","age" : 25},"sort" : [25]}]}
}Filter过滤器方式查询,它的查询不会计算相关性分值,也不会对结果进行排序, 因此效率会高一点,查询的结果可以被缓存
Filter Context 对数据进行过滤
# Filter查询
POST /es_db/_doc/_search
{"query": {"bool": {"filter": {"term": {"age": 25}}}}
} 执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 4,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.0,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 0.0,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}}]}
}总结
match
match:模糊匹配,需要指定字段名,但是输入会进行分词,比如"hello world"会进行拆分为hello和world,然后匹配,如果字段中包含hello或者world,或者都包含的结果都会被查询出来,也就是说match是一个部分匹配的模糊查询。查询条件相对来说比较宽松。
term
term: 这种查询和match在有些时候是等价的,比如我们查询单个的词hello,那么会和match查询结果一样,但是如果查询"hello world",结果就相差很大,因为这个输入不会进行分词,就是说查询的时候,是查询字段分词结果中是否有"hello world"的字样,而不是查询字段中包含"hello world"的字样。当保存数据"hello world"时,elasticsearch会对字段内容进行分词,"hello world"会被分成hello和world,不存在"hello world",因此这里的查询结果会为空。这也是term查询和match的区别。
match_phase
match_phase:会对输入做分词,但是需要结果中也包含所有的分词,而且顺序要求一样。以"hello world"为例,要求结果中必须包含hello和world,而且还要求他们是连着的,顺序也是固定的,hello that world不满足,world hello也不满足条件。
query_string
query_string:和match类似,但是match需要指定字段名,query_string是在所有字段中搜索,范围更广泛。
4.文档映射
ES中映射可以分为动态映射和静态映射
动态映射
在关系数据库中,需要事先创建数据库,然后在该数据库下创建数据表,并创建表字段、类型、长度、主键等,最后才能基于表插入数据。而Elasticsearch中不需要定义Mapping映射(即关系型数据库的表、字段等),在文档写入Elasticsearch时,会根据文档字段自动识别类型,这种机制称之为动态映射。
动态映射规则如下
JSON数据 | 自动推测的类型 |
null | 没有字段被添加 |
true/false | boolean类型 |
小数 | float |
数字 | long |
日期 | date或text |
字符串 | text |
数组 | 由数组第一个非空值决定 |
JSON对象 | object类型 |
删除原创建的索引
DELETE /es_db创建索引
PUT /es_db创建文档(ES根据数据类型, 会自动创建映射)
# 创建文档
PUT /es_db/_doc/1
{"name": "Jack","sex": 1,"age": 25,"book": "java入门至精通","address": "广州小蛮腰"
}获取文档映射
# 获取文档映射
GET /es_db/_mapping执行结果
{"es_db" : {"mappings" : {"properties" : {"address" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"age" : {"type" : "long"},"name" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"remark" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"sex" : {"type" : "long"}}}}
}静态映射
静态映射是在Elasticsearch中也可以事先定义好映射,包含文档的各字段类型、分词器等,这种方式称之为静态映射。
删除原创建的索引
DELETE /es_db创建索引
PUT /es_db设置文档映射
# 设置文档映射
PUT /es_db
{"mappings": {"properties": {"name": {"type": "keyword","index": true,"store": true},"sex": {"type": "integer","index": true,"store": true},"age": {"type": "integer","index": true,"store": true},"book": {"type": "text","index": true,"store": true},"address": {"type": "text","index": true,"store": true}}}
}执行结果
{"acknowledged" : true,"shards_acknowledged" : true,"index" : "es_db_copy"
}{"es_db_copy" : {"mappings" : {"properties" : {"address" : {"type" : "text","store" : true},"age" : {"type" : "integer","store" : true},"book" : {"type" : "text","store" : true},"name" : {"type" : "keyword","store" : true},"sex" : {"type" : "integer","store" : true}}}}
}根据静态映射创建文档
PUT /es_db_copy/_doc/1
{"name": "Jack","sex": 1,"age": 25,"book": "elasticSearch入门至精通","address": "广州车陂"
}执行结果
{"_index" : "es_db_copy","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}获取文档映射
# 获取文档映射
GET /es_db_copy/_mapping执行结果
{"es_db_copy" : {"mappings" : {"properties" : {"address" : {"type" : "text","store" : true},"age" : {"type" : "integer","store" : true},"book" : {"type" : "text","store" : true},"name" : {"type" : "keyword","store" : true},"sex" : {"type" : "integer","store" : true}}}}
}5.核心类型(core data type)
字符串:String,String类型包含text和keyword
text:该类型被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,text类型不能用来排序和聚合。
keyword:该类型不能分词,可以被用来检索过滤、排序和聚合,keyword类型不可用text进行分词模糊检索。
数值型:long,integer,short,byte,double,float
日期型:date
布尔型:boolean
6.keyword与text映射类型的区别
将 book 字段设置为 keyword 映射(只能精准查询, 不能分词查询,能聚合、排序)
POST /es_db_copy/_doc/_search
{"query": {"term": {"term": "elasticSearch入门至精通"}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]}
}# 根据keyword精确查询
POST /es_db_copy/_doc/_search
{"query": {"term": {"name": "Jack"}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 0.2876821,"hits" : [{"_index" : "es_db_copy","_type" : "_doc","_id" : "1","_score" : 0.2876821,"_source" : {"name" : "Jack","sex" : 1,"age" : 25,"book" : "elasticSearch入门至精通","address" : "广州车陂"}}]}
}book是text类型就可以模糊查询
# 模糊查询
POST /es_db_copy/_doc/_search
{"query": {"match": {"book": "elasticSearch入门至精通"}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 1,"relation" : "eq"},"max_score" : 1.7260926,"hits" : [{"_index" : "es_db_copy","_type" : "_doc","_id" : "1","_score" : 1.7260926,"_source" : {"name" : "Jack","sex" : 1,"age" : 25,"book" : "elasticSearch入门至精通","address" : "广州车陂"}}]}
}7.创建静态映射时指定text类型的ik分词器
设置ik分词器的文档映射
先删除之前的es_db
再创建新的es_db
定义ik_smart的映射
# 创建映射时指定IK分词器
PUT /es_db
{"mappings": {"properties": {"name": {"type": "keyword","index": true,"store": true},"sex": {"type": "integer","index": true,"store": true},"age": {"type": "integer","index": true,"store": true},"book": {"type": "text","index": true,"store": true,"analyzer": "ik_smart","search_analyzer": "ik_smart"},"address": {"type": "text","index": true,"store": true}}}# 获取文档映射
GET /es_db/_mapping执行结果
{"es_db" : {"mappings" : {"properties" : {"address" : {"type" : "text","store" : true},"age" : {"type" : "integer","store" : true},"book" : {"type" : "text","store" : true,"analyzer" : "ik_smart"},"name" : {"type" : "keyword","store" : true},"remark" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"sex" : {"type" : "integer","store" : true}}}}
}分词查询
# 分词查询
POST /es_db/_doc/_search
{"query": {"match": {"address": "广"}}
} POST /es_db/_doc/_search
{"query": {"match": {"address": "广州"}}
}执行结果
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{"took" : 0,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 2,"relation" : "eq"},"max_score" : 1.7509375,"hits" : [{"_index" : "es_db","_type" : "_doc","_id" : "1","_score" : 1.7509375,"_source" : {"name" : "张三","sex" : 1,"age" : 25,"address" : "广州天河公园","remark" : "java developer"}},{"_index" : "es_db","_type" : "_doc","_id" : "3","_score" : 1.6391755,"_source" : {"name" : "rod","sex" : 0,"age" : 26,"address" : "广州白云山公园","remark" : "php developer"}}]}
}8.对已存在的mapping映射进行修改
如果要推倒现有的映射, 你得重新建立一个静态索引
然后把之前索引里的数据导入到新的索引里
删除原创建的索引
为新索引起个别名, 为原索引名
# 对现有的mapping映射进行修改
POST _reindex
{"source": {"index": "db_index"},"dest": {"index": "db_index_2"}
}DELETE /db_indexPUT /db_index_2/_alias/db_index注意: 通过这几个步骤就实现了索引的平滑过渡,并且是零停机
9.Elasticsearch乐观并发控制
在数据库领域中,有两种方法来确保并发更新,不会丢失数据:
悲观并发控制
这种方法被关系型数据库广泛使用,它假定有变更冲突可能发生,因此阻塞访问资源以防止冲突。 一个典型的例子是读取一行数据之前先将其锁住,确保只有放置锁的线程能够对这行数据进行修改。
乐观并发控制
Elasticsearch 中使用的这种方法假定冲突是不可能发生的,并且不会阻塞正在尝试的操作。 然而,如果源数据在读写当中被修改,更新将会失败。应用程序接下来将决定该如何解决冲突。 例如,可以重试更新、使用新的数据、或者将相关情况报告给用户。
再以创建一个文档为例 ES老版本
PUT /db_index/_doc/1
{"name": "Jack","sex": 1,"age": 25,"book": "Spring Boot 入门到精通","remark": "hello world"
}执行结果
{"_index" : "db_index","_type" : "_doc","_id" : "1","_version" : 1,"result" : "created","_shards" : {"total" : 2,"successful" : 1,"failed" : 0},"_seq_no" : 0,"_primary_term" : 1
}实现_version乐观锁更新文档
# 实现_version乐观锁更新文档
PUT /db_index/_doc/1?version=1
{"name": "Jack","sex": 1,"age": 25,"book": "Spring Boot 入门到精通","remark": "hello world"
}老版本报错
{"error": {"root_cause": [{"type": "action_request_validation_exception","reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"}],"type": "action_request_validation_exception","reason": "Validation Failed: 1: internal versioning can not be used for optimistic concurrency control. Please use `if_seq_no` and `if_primary_term` instead;"},"status": 400
}**ES新版本(7.x)不使用version进行并发版本控制 if_seq_no=版本值&if_primary_term=文档位置 **
_seq_no:文档版本号,作用同_version
_primary_term:文档所在位置# 新的索引
POST /es_sc/_searchDELETE /es_scPOST /es_sc/_doc/1
{"id": 1,"name": "王者荣耀","desc": "王者荣耀和平精英老师","create_date": "2021-02-24"
}POST /es_sc/_update/1
{"doc": {"name": "王者荣耀666"}
}POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1
{"doc": {"name": "王者荣耀1"}
}POST /es_sc/_update/1/?if_seq_no=1&if_primary_term=1
{"doc": {"name": "王者荣耀2"}
}执行结果
{"error": {"root_cause": [{"type": "version_conflict_engine_exception","reason": "[1]: version conflict, required seqNo [1], primary term [1]. current document has seqNo [2] and primary term [1]","index_uuid": "QRMOHFiiS--5j0OdALb-uA","shard": "0","index": "es_sc"}],"type": "version_conflict_engine_exception","reason": "[1]: version conflict, required seqNo [1], primary term [1]. current document has seqNo [2] and primary term [1]","index_uuid": "QRMOHFiiS--5j0OdALb-uA","shard": "0","index": "es_sc"},"status": 409
}相关文章:
3.Elasticsearch初步进阶
3.Elasticsearch初步进阶[toc]1.文档批量操作批量获取文档数据批量获取文档数据是通过_mget的API来实现的在URL中不指定index和type请求方式:GET请求地址:_mget功能说明:可以通过ID批量获取不同index和type的数据请求参数docs:文档数组参数_index:指定index_type:指定type_id:指…...

优思学院|六西格玛管理的核心理念是什么?
六西格玛管理是一种基于数据分析的质量管理方法,旨在通过降低过程的变异性来达到质量稳定和优化的目的。该方法以希腊字母“σ”为名,代表标准差,是衡量过程变异性的重要指标。 六西格玛管理的核心理念是“以客户为中心、以数据为基础、追求…...

第十七节 多态
多态 什么是多态? ●同类型的对象,执行同一个行为,会表现出不同的行为特征。 多态的常见形式 父类类型 对象名称new子类构造器; 接口 对象名称new 实现类构造器; 多态中成员访问特点 ●方法调用:编译看左边,运行看右边。 ●变量调用:编译看…...

[vue]提供一种网站底部备案号样式代码
演示 vue组件型(可直接用) 组件代码:copyright-icp.vue <template><div class"icp">{{© ${year} ${author} }}<a href"http://beian.miit.gov.cn/" target"_blank">{{ record }}</a…...
python第四天作业~函数练习
目录 作业4、判断以下哪些不能作为标识符 A、a B、¥a C、_12 D、$a12 E、false F、False 作业5: 输入数,判断这个数是否是质数(要求使用函数 for循环) 作业6:求50~150之间的质数是…...
linux安装influxdb-rpmyum方式
一、influxdb的安装InfluxDB简介时序数据库InfluxDB版是一款专门处理高写入和查询负载的时序数据库,用于存储大规模的时序数据并进行实时分析,包括来自DevOps监控、应用指标和IoT传感器上的数据主要特点:专为时间序列数据量身订造高性能数据存…...

死锁
1.死锁的定义 多线程以及多进程改善了系统资源的利用率并提高了系统 的处理能力。然而,并发执行也带来了新的问题——死锁。所谓死锁是指多个线程因竞争资源而造成的一种僵局(互相等待),若无外力作用,这些进程都将无法…...

C++基础了解-05-C++常量
C常量 一、C常量 常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量。 常量可以是任何的基本数据类型,可分为整型数字、浮点数字、字符、字符串和布尔值。 常量就像是常规的变量,只不过常量的值在定义后不能进…...

深度学习笔记-2.自动梯度问题
通过反向传播进行自动求梯度1-requires_grad问题2-梯度3- detach() 和 with torch.no_grad()4- Tensor.data.requires_gradPyTorch提供的autograd包能够根据输入和前向传播过程自动构建计算图,并执行反向传播. 1-requires_grad问题 requires_gradTrue …...
一文读懂倒排序索引涉及的核心概念
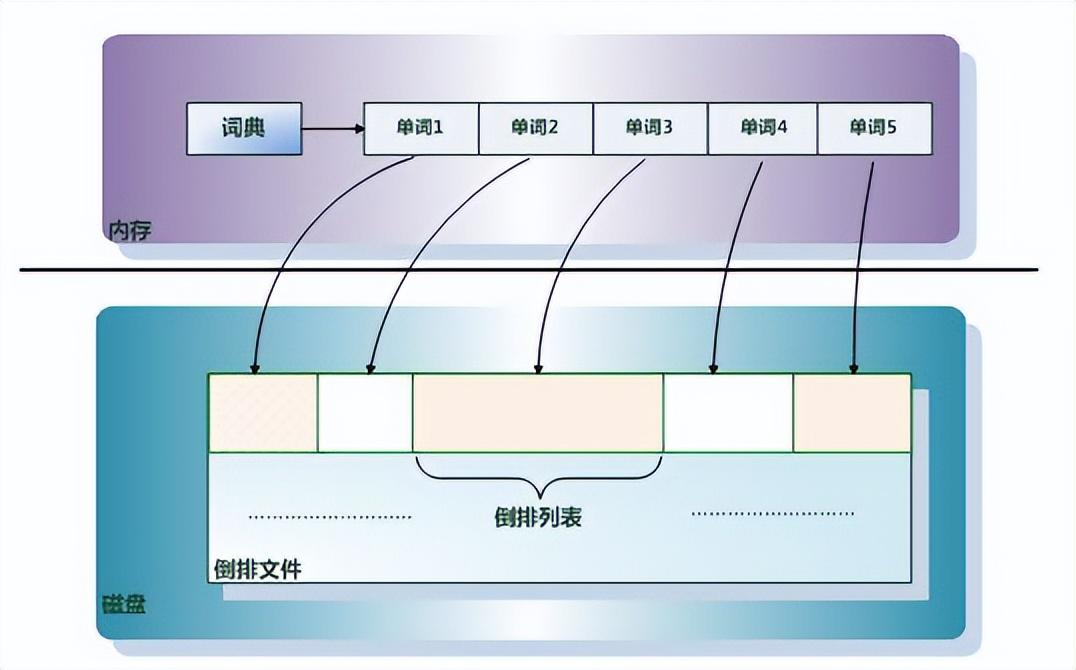
基础概念相信对于第一次接触Elasticsearch的同学来说,最难理解的概念就是倒排序索引(也叫反向索引),因为这个概念跟我们之前在传统关系型数据库中的索引概念是完全不同的!在这里我就重点给大家介绍一下倒排序索引&…...

Java基础算法题
以创作之名致敬节日 胜固欣然,败亦可喜。 --苏轼 目录 练习1 : 优化代码 扩展 : CRTL Alt M 自动抽取方法 练习2: 方法一: 方法二: 方法三: Math : 顾名思义,Math类就是用来进行数学计算的,它提供了大量的静态方法来便于我们实…...

「SAP ABAP」你真的了解OPEN SQL的DML语句吗 (附超详细案例讲解)
💂作者简介: THUNDER王,一名热爱财税和SAP ABAP编程以及热爱分享的博主。目前于江西师范大学本科在读,同时任汉硕云(广东)科技有限公司ABAP开发顾问。在学习工作中,我通常使用偏后端的开发语言A…...
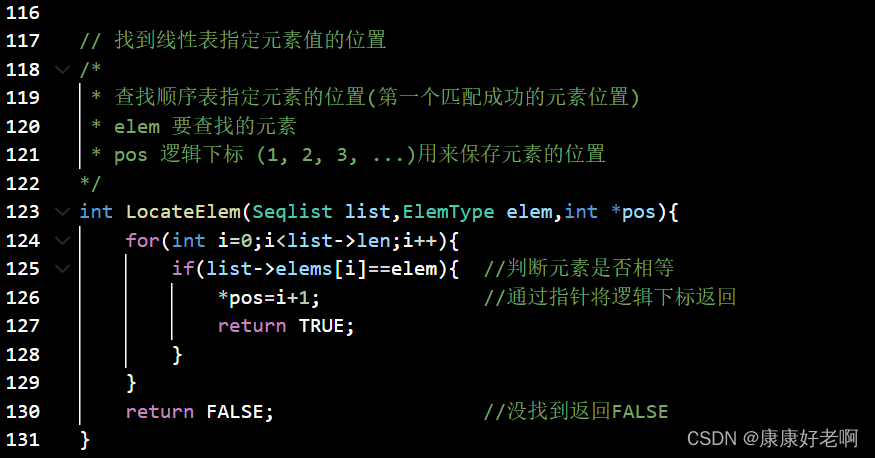
数据结构3——线性表2:线性表的顺序结构
顺序结构的基本理解 定义: 把逻辑上相邻的数据元素存储在物理上相邻(占用一片连续的存储单元,中间不能空出来)的存储单元的存储结构 存储位置计算: LOC(a(i1))LOC(a(i))lLOC(a(i1))LOC(a(i))l LOC(a(i1))LOC(a(i))l L…...
VMware虚拟机搭建环境通用方法
目录一、前期准备1.下载并安装一个虚拟机软件二、开始创建虚拟机1.配置虚拟机硬件相关操作2.虚拟机网络相关操作三、开机配置相关内容0.开机遇到报错处理(选看--开机没有报错请忽略)1.开始配置2.开机之后配置3.使用xshell远程登录4.使用xshell配置虚拟机…...

2.Fully Convolutional Networks for Semantic Segmentation论文记录
欢迎访问个人网络日志🌹🌹知行空间🌹🌹 文章目录1.基础介绍2.分类网络转换成全卷积分割网络3.转置卷积进行上采样4.特征融合5.一个pytorch源码实现参考资料1.基础介绍 论文:Fully Convolutional Networks for Semantic Segmentati…...

深度解析Spring Boot自动装配原理
废话不多说了,直接来看源码。源码解析SpringBootApplication我们在使用idea创建好Spring Boot项目时,会发现在启动类上添加了SpringBootApplication注解,这个注解就是Spring Boot的核心所在。点击注解可以查看到到它的实现ementType.TYPE) Re…...


Linux:环境变量
目录一、环境变量的理解(1)什么是环境变量?(2)Linux中的环境变量二、环境变量的使用(1)PATH环境变量(2)和变量相关的指令三、环境变量与普通变量的区别在平时使用电脑的时…...

Codeforces Round 703 (Div. 2)(A~D)
A. Shifting Stacks给出一个数组,每次可以将一个位置-1,右侧相邻位置1,判断是否可以经过若干次操作后使得数列严格递增。思路:对于每个位置,前缀和必须都大于该位置应该有的最少数字,即第一个位置最少是0&a…...

Django项目5——基于tensorflow serving部署深度模型——windows版本
1:安装docker for windows 可能需要安装WLS2,用于支持Linux系统,参照上面的教程安装 2:在Powershell下使用docker docker pull tensorflow/serving3:在Powershell下启动tensorflow serving docker run -p 8500:8500 …...

自动驾驶车道偏离预警系统的搭建与实现
自动驾驶控制器,车道偏离预警系统,基于Prescan设计场景和交通流,在Simulink中建立了相应的控制模型。 进行LDW功能验证。 整个模型自己建立,再次强调不是Prescan自带的那种很乱很模糊的模型。 然后通过自己做了一个GUI的界面实时显…...

HCNR201隔离运放电路
芯片简介HCNR201是一款高线性度模拟光耦,核心作用是实现模拟信号的精确隔离传输,同时保证信号不失真,内部包含1个发光二极管(LED)和2个紧密匹配的光电二极管(PD1, PD2)。电路解析以数据手册示例电路举例下面通过数据手册给出的关键参数&#…...

AI 自动逆向 JS 加密!自动抓密钥、出报告,彻底解放双手,解决抓包数据包加密难题
0x01 简介 前端JS加密、混淆、数据包加密,一直是逆向分析的痛点,手动抠代码、断点调试耗时费力。AI_JS_DEBUGGER 基于Chrome开发者协议(CDP),以AI驱动实现全自动JS逆向分析,无需复杂操作,就能自…...
)
ComfyUI艺术二维码实战:5分钟搞定品牌专属扫码图案(附ControlNet参数模板)
ComfyUI艺术二维码实战:5分钟搞定品牌专属扫码图案(附ControlNet参数模板) 最近在帮几个品牌方做视觉物料,发现一个挺有意思的现象:大家越来越不满足于那种黑白格子的传统二维码了。一张设计精美的海报,角落…...

Trailer高级设置指南:定制你的GitHub PR/Issue通知与显示规则
Trailer高级设置指南:定制你的GitHub PR/Issue通知与显示规则 【免费下载链接】trailer Managing Pull Requests and Issues For GitHub & GitHub Enterprise 项目地址: https://gitcode.com/gh_mirrors/tr/trailer Trailer是一款强大的GitHub PR/Issue管…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

从零实现富文本编辑器#5-编辑器选区模型的状态结构表达
先前我们总结了浏览器选区模型的交互策略,并且实现了基本的选区操作,还调研了自绘选区的实现。那么相对的,我们还需要设计编辑器的选区表达,也可以称为模型选区。编辑器中应用变更时的操作范围,就是以模型选区为基准来…...