Python - Pandas - 数据分析(2)

Pandas数据分析2
- 前言
- 常用的21种统计方法
- describe():
- numeric_only:
- 偏度skewness:
- 功能:
- 含义:
- 计算公式:
- 演示:
- 峰度值:
- 用途:
- 数值:
- 计算公式:
- 演示:
- cov协方差
- 计算公式:
- 数值:
- 操作对象:
- 演示:
- corr相关系数:
- 计算公式:
- 数值:
- 操作对象:
- 演示:
- 常用的5种数据处理函数:
- map:
- 功能:
- 字典map:
- 函数map:
- apply:
- 功能:
- apply匿名lambda:
- apply内置函数
- apply自己的函数:
- groupy()
- 不必having:
- groupby + apply:
- 自定义排序:
- 获取每组最值:
- agg:
- 功能:
- 字典指定内置函数:
- groupby + agg:
- lambda匿名函数:
- lambda匿名函数数组:
- 常用的两种文件操作:
- 读写csv文件:
- 读csv:
- 写csv:
- 读写excel文件:
- 读excel:
- 写excel:
前言
Vue框架:从项目学Vue
OJ算法系列:神机百炼 - 算法详解
Linux操作系统:风后奇门 - linux
C++11:通天箓 - C++11
一行检查是否下载过Pandas:
pip list
一行下载:
pip install pandas
常用的21种统计方法
| 函数 | 功能 |
|---|---|
| count | 统计非空值个数 |
| max | 最大值 |
| min | 最小值 |
| sum | 求和 |
| prod | 乘积 |
| cumsum | 累和 |
| cumprod | 累乘 |
| cummax | 累积最大值 |
| cummin | 累积最小值 |
| mean | 平均值 |
| std | 标准差 |
| var | 方差 |
| median | 算数中位数 |
| abs | 绝对值 |
| unique | 唯一值列表 |
| nunique | 唯一值个数 |
| value_counts | 唯一值及其频数 |
| skew | 三阶偏度 |
| kurt | 四阶峰度 |
| corr | 相关系数矩阵 |
| cov | 协方差矩阵 |
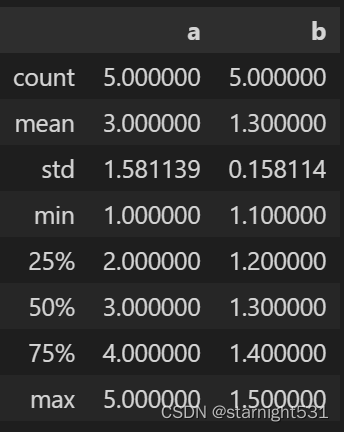
describe():
describe将显示所有数值型特征的count(),mean(),std(),max&min()等
import pandas as pd
dataframe = pd.DataFrame({'a' : [1, 2, 3, 4, 5],'b' : [1.1, 1.2, 1.3, 1.4, 1.5],'c' : ['a', 'b', 'c', 'd', 'e']
})
dataframe.describe()
numeric_only:
- 以上很多运算都只支持对int和float运算,其他类型需要对+等运算符重载
- 若此类运算未对运算符 或 运算函数重载,则可能自动忽略,也可能报错终止
- 大多情况上述统计学函数都搭配slice切片使用
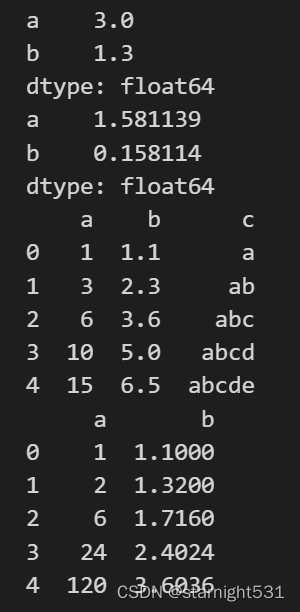
# 均值
print(DataFrame.mean())# 标准差
print(DataFrame.std())# 累和
print(DataFrame.cumsum())# 累乘
print(DataFrame.iloc[:, 0:2].cumprod())
偏度skewness:
功能:
- 用于描述数据的不对称性
含义:
- skewness == 0:正态分布
- skewness > 0:正偏差数值较大,数据右侧有很多极端值,整体分布右偏/正偏
- skewness < 0:负偏差数值较大,数据左侧有很多极端值,整体分布左偏/负偏
计算公式:
- skewness=E[(x−E(x))/(D(x))3]skewness = E[(x - E(x)) / (\sqrt{D(x)})^3]skewness=E[(x−E(x))/(D(x))3]
演示:
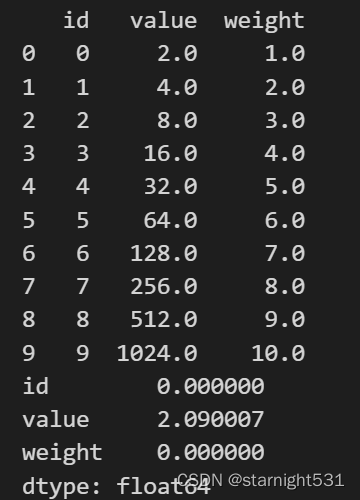
import numpy as np
dataframe = pd.DataFrame({'id' : np.arange(10),#等比数列:起点、终点、个数,幂'value' : np.logspace(1, 10, 10, base = 2),#等差数列:起点、终点、个数'weight' : np.linspace(1, 10, 10)
})
print(dataframe)
#skew()>0,value右侧异常值比较多
print(dataframe.skew())
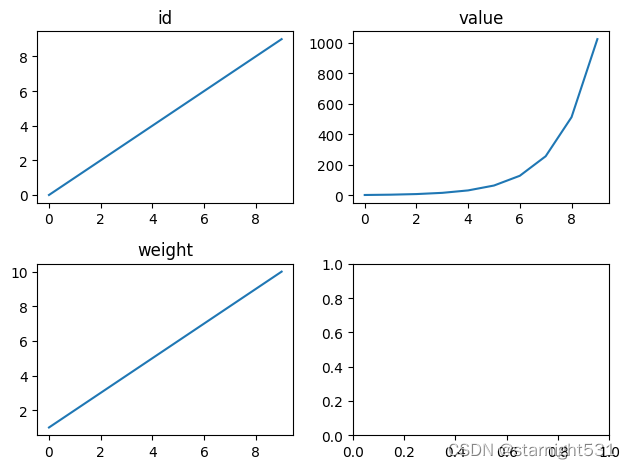
- 画图看看:
#挑选数值型特征
num_feats = dataframe.dtypes[dataframe.dtypes != 'object'].index
import matplotlib.pyplot as plt
plt.figure(figsize = (8, 8))#8inch * 8inch
fig, ax = plt.subplots(2, 2)
for row in range(2):for col in range(2):if row*2+col > 2 :continuedata = dataframe[num_feats[row*2+col]]ax[row][col].plot(data.index, data.values)ax[row][col].set_title(f'{num_feats[row*2+col]}')
# 自动保持子图之间的正确间距。
fig.tight_layout()
plt.show()
峰度值:
用途:
- 描述某个变量所有取值分布形态陡缓程度的统计量,即数据分布的尖锐程度
数值:
- kurtosis == 0:陡缓程度和正态分布相同
- kurtosis > 0:比正态分布高峰陡峭,尖顶峰
- kurtosis < 0:比正态分布高峰平和,平顶峰
计算公式:
Kurtosis=E[(x−E(x))/(D(x))4]−3Kurtosis = E[(x - E(x)) / (\sqrt{D(x)})^4] - 3Kurtosis=E[(x−E(x))/(D(x))4]−3
演示:
- 继续使用上组数据演示:
print(dataframe.kurt())

cov协方差
计算公式:
cov(X,Y)=E[(X−E[X])∗(Y−E[Y])],cov(X,Y)=E[ (X-E[X]) * (Y-E[Y]) ],cov(X,Y)=E[(X−E[X])∗(Y−E[Y])],
- E[X]代表变量X的期望。
- 从直观上来看,协方差表示的是两个变量总体误差的期望。
- 如果其中一个大于自身的期望值时另外一个也大于自身的期望值,两个变量之间的协方差就
是正值; - 如果其中一个变量大于自身的期望值时另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
- 如果X与Y是统计独立的,那么二者之间的协方差就是0
数值:
- corr()返回相关系数,介于[-1, 1]
- |-1| 和 |1| 表示线性相关
- 正负号表示正负相关
操作对象:
- 对于含有n个特征值的DataFrame,两两之间计算协方差,构成n*n的矩阵
- 协方差矩阵中对角线上是方差,非对角线是协方差
演示:
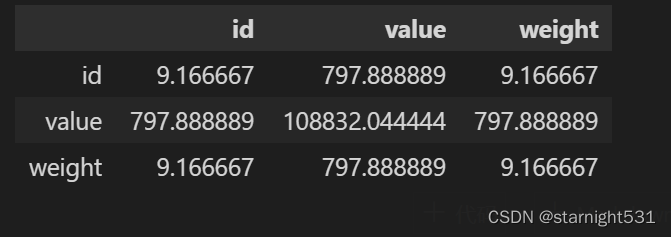
- 继续使用以上数据:
dataframe.cov()
corr相关系数:
计算公式:
- 基于cov协方差
ρXY=Cov(X,Y)/[D(X)][D(Y)]ρXY = Cov(X,Y) / \sqrt{[D(X)]} \sqrt{[D(Y)}]ρXY=Cov(X,Y)/[D(X)][D(Y)]
数值:
- corr()计算介于[-1, 1]的相关系数
- |-1| 和 |1| 表示线性相关
- 正负号表示正负相关
操作对象:
- 对于含有n个特征值的DataFrame,两两之间计算相关系数,构成n*n的矩阵
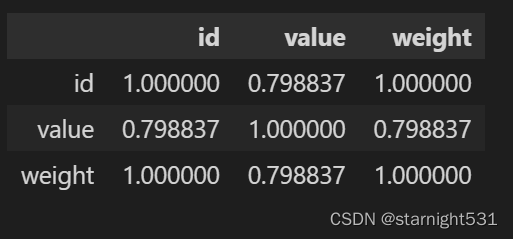
- 相关系数矩阵中对角线上永远是1
演示:
- 继续使用上述数据:
dataframe.corr()
常用的5种数据处理函数:
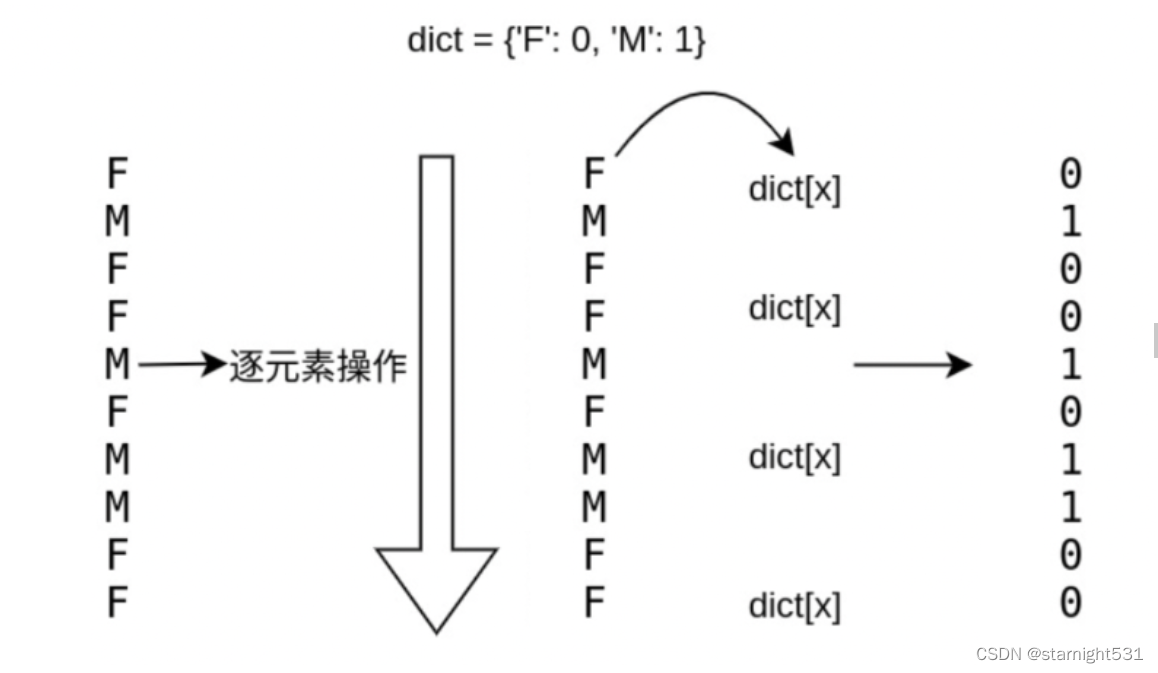
map:
- 示意图:
功能:
- 依据给定的函数 / 字典,将DataFrame / Series中一列内每个值转化为其他数值
字典map:
- 为DataFrame / Series .map()方法,传递一个字典
#转型字典
gendermap = {'F' : 0, 'M' : 1}#数据
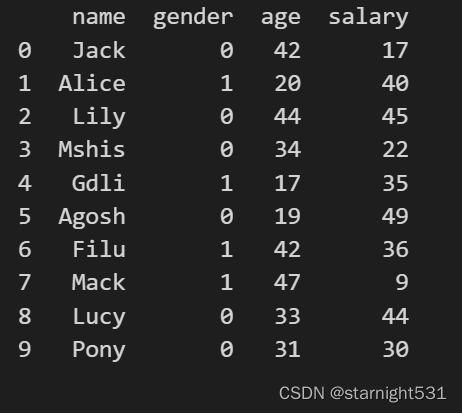
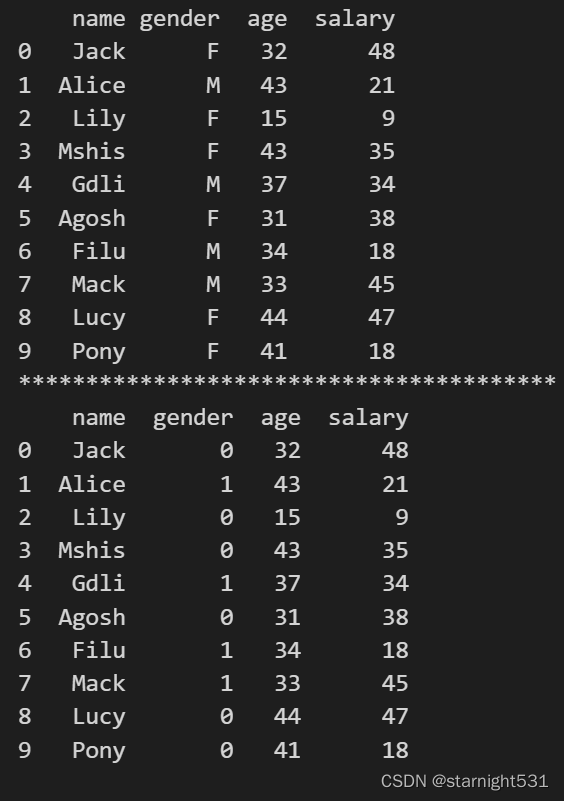
dataframe = pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":np.random.randint(15,50,10),"salary":np.random.randint(5,50,10),})#map方法
dataframe['gender'] = dataframe['gender'].map(gendermap)
print(dataframe)
函数map:
- 为DataFrame / Series 的.map()传递进入一个函数指针
dataframe = pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":np.random.randint(15,50,10),"salary":np.random.randint(5,50,10),})
print(dataframe)
print('*'*40)#转型函数
def gender_map(x) :gender = 0 if x == 'F' else 1return genderdataframe['gender'] = dataframe['gender'].map(gender_map)print(dataframe)
apply:
功能:
- 遍历整个Series 和 DataFrame,对每个元素运行指定的函数,可以是自定义函数,也可以是上述的21种内置函数等等
apply匿名lambda:
df=pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":np.random.randint(15,50,10),"salary":np.random.randint(5,50,10),})print(df)
print('*'*40)
print(df[['age', 'salary']].apply(lambda x: x*2))
apply内置函数
- 确定可以执行内置函数的是哪些列
#传入的函数也可以是pandas和python内置函数
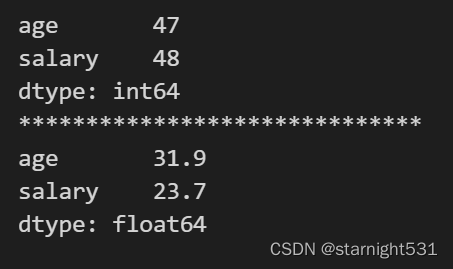
print(df[['age', 'salary']].apply(max))
print('*'*30)
print(df[['age', 'salary']].apply(np.mean))
apply自己的函数:
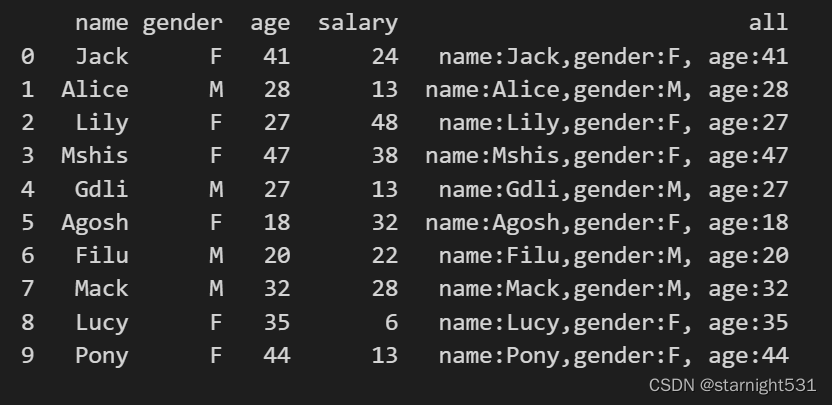
#按值遍历调用
def apply_func(row):a = row['name']b = row['gender']c = row['age']return f'name:{a},gender:{b}, age:{c}'#原地修改,增加一列all
df["all"] = df.apply(lambda row:apply_func(row), axis = 1)
#axis = 1,每次row为dataframe内的一行
print(df)
groupy()
- 功能同于Mysql中的groupby(),by参数可以传递入多个特征值
- 传递入多个特征值时,分组是多个特征的排列组合,见下面的dfc.groupby(by=[‘gender’,‘age’])
不必having:
- groupby()之后的操作都是针对每一组内部
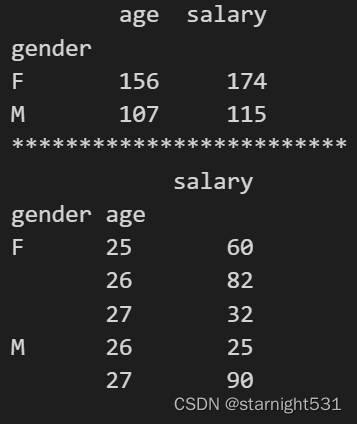
import numpy as np
dfc=pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":np.random.randint(25,28,10),"salary":np.random.randint(5,50,10),})#划分成组后求对应组的和结果
print(dfc.groupby(by='gender').sum())
print("*"*25)
# groupby查传入的可以时多个属性
print(dfc.groupby(by=['gender','age']).sum())
groupby + apply:
- apply()传入参数:
- lambda
- 内置func()
- 个人所写函数
- apply对象:
经过groupby()之后的多个小组,也就是子DataFrame
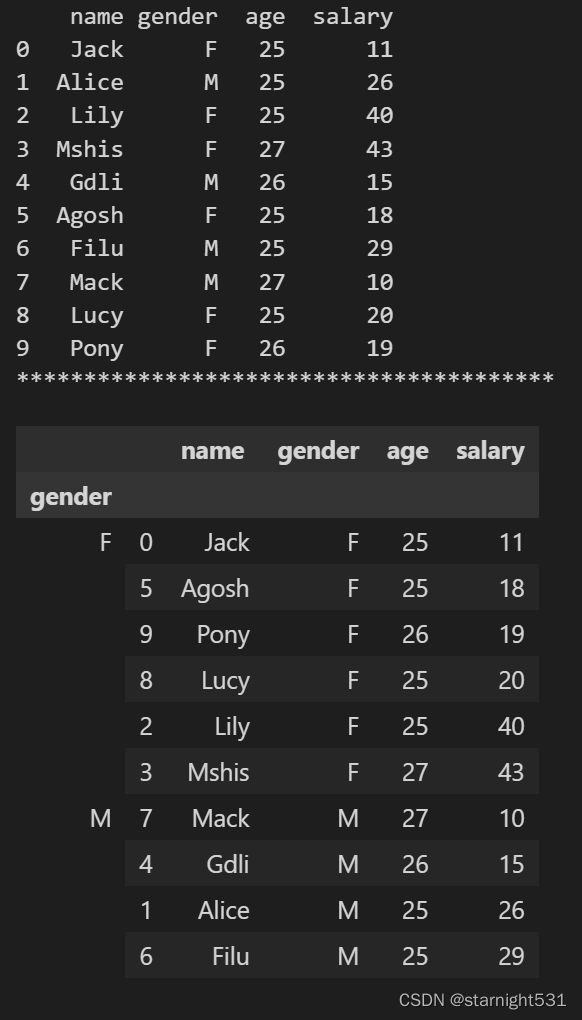
自定义排序:
- 对于每个子DataFrame执行sort_values()即可
df=pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":np.random.randint(25,28,10),"salary":np.random.randint(5,50,10),})
print(df)
print('*'*40)#此处的x也是一个dataframe
def group_staff_salary(x):df1 = x.sort_values(by = 'salary',ascending=True)
#ascending = True为从大到小的顺序,默认倒序return df1df.groupby('gender',as_index=True).apply(group_staff_salary)
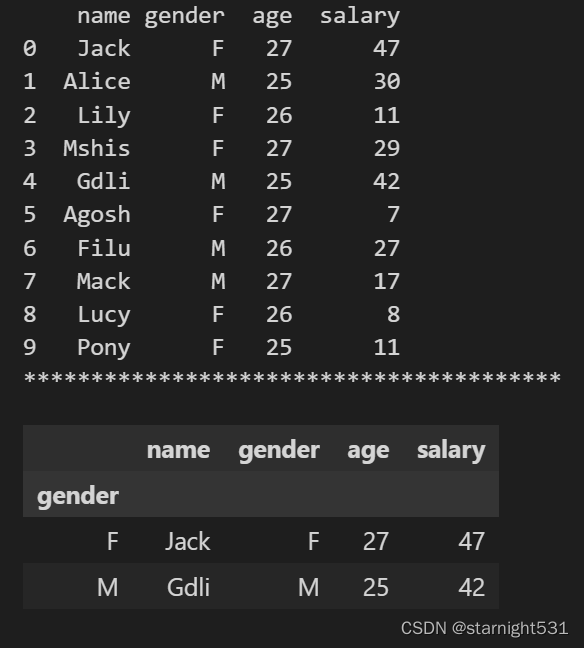
获取每组最值:
- 限制每个子DataFrame返回对象即可
#只看每组最高工资:
df=pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":np.random.randint(25,28,10),"salary":np.random.randint(5,50,10),})
print(df)
print("*"*40)#此处的x也是一个dataframe
def group_staff_salary(x):df1 = x.sort_values(by = 'salary',ascending=True)return df1.iloc[-1, :]df.groupby('gender',as_index=True).apply(group_staff_salary)
- 查询到男女两方最高工资者信息:
agg:
功能:
- 同时为一组数据指定多个执行函数
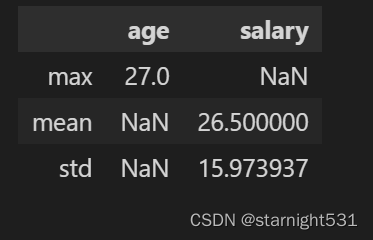
字典指定内置函数:
- 字典的key是DataFrame的特征,字典的value是要对特征值执行的函数
- 要对字典执行的函数很多时,可以传递数组
# 1:字典:key为列,val为操作函数
df=pd.DataFrame({"name":['Jack', 'Alice', 'Lily', 'Mshis', 'Gdli', 'Agosh', 'Filu', 'Mack', 'Lucy', 'Pony'],"gender":['F', 'M', 'F', 'F', 'M', 'F', 'M', 'M', 'F', 'F'],"age":np.random.randint(25,28,10),"salary":np.random.randint(5,50,10),})df.agg({'age':['max'], 'salary':['mean', 'std']})
- value作为行Index,key作为列Index
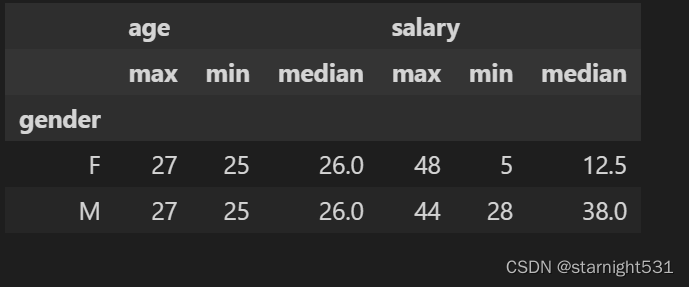
groupby + agg:
- agg内许多函数的操作对象是groupby之后的子DataFrame的所有列:
df.groupby('gender').agg(['max', 'min', 'median'])
- group作行Index,agg内函数作列index:
lambda匿名函数:
- agg内参数也可以是lambda表达式
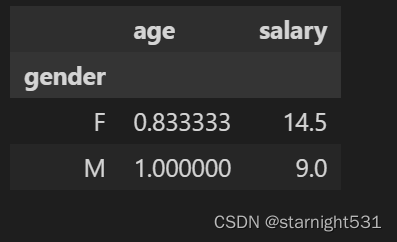
df.groupby(['gender']).agg(lambda x: x.mean()-x.min())
- groupby的特征值作为行Index,非by的特征值作为列Index
lambda匿名函数数组:
- agg()内参数也可以是lambda表达式数组
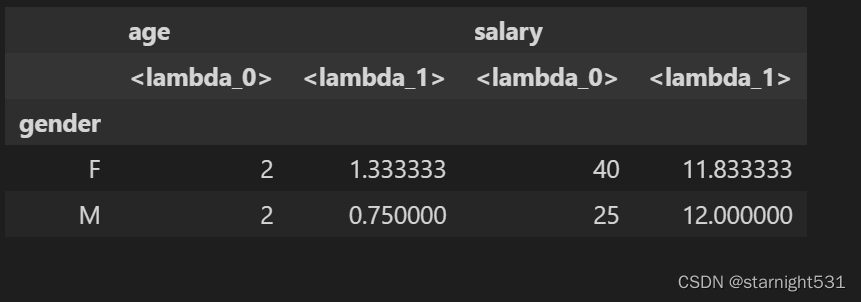
df.groupby(['gender']).agg([lambda x: x.max()-x.min(), lambda x: x.mean()-x.min()])
- 行Index为by的特征,列Index为lambda函数名
常用的两种文件操作:
读写csv文件:
读csv:
pd.read_csv('./test.csv')
写csv:
df.to_csv('./test.csv',index=False)
#不写行名
读写excel文件:
读excel:
pd.read_excel('./test.xlsx')
写excel:
df.to_excel('./test.xlsx',index=True)
#写行名
相关文章:
Python - Pandas - 数据分析(2)
Pandas数据分析2前言常用的21种统计方法describe():numeric_only:偏度skewness:功能:含义:计算公式:演示:峰度值:用途:数值:计算公式:演示&#x…...

我的十年编程路 2019年篇
随着2018年,三星天津研究院的裁撤,我选择了到广州的三星研究院工作,与最心爱的她开始一起生活。 这一年的开始,我注册了博客园。和2014年类似,在刚注册不久,我写了一篇题为《全新开始,全心出发…...

(蓝桥真题)剪格子(搜索+剪枝)
样例1输入: 3 3 10 1 52 20 30 1 1 2 3 样例1输出: 3 样例2输入: 4 3 1 1 1 1 1 30 80 2 1 1 1 100 样例2输出: 10 分析:这道题目我们直接从(1,1)点开始进行dfs搜索即可,但是需要注意一点的是我们搜…...

Kalman Filter in SLAM (3) ——Extended Kalman Filter (EKF, 扩展卡尔曼滤波)
文章目录1. 线性系统的 Kalman Filter 回顾2. Extended Kalman Filter 之 DR_CAN讲解笔记2.1. 非线性系统2.2. 非线性系统线性化2.2.1. 状态方程f(xk)f(x_k)f(xk)在上一次的最优估计状态x^k−1\hat{x}_{k-1}x^k−1处线性化2.2.2. 观测方程h(xk)h(x_k)h(xk)在这一次的预测…...

关于vertical-align的几问
vertical-align属性可以给我讲解一下吗? 当使用table-cell布局或inline元素时,可以使用CSS的vertical-align属性控制元素的垂直对齐方式。该属性可应用于元素本身以及其父元素(例如,td、th、tr和table)。 以下是vertic…...

【拜占庭将军问题】这一计谋,可以让诸葛丞相兴复汉室
我们都知道,诸葛亮第一次北伐是最可能成功的,魏国没有防备,还策反了陇西,陇西有大量的马匹可以装备蜀国骑兵,可惜街亭一丢,那边就守不住了 当时我不在,只能作诗一首~ 如果穿越过去,…...
【Linux】 -- make/Makefile
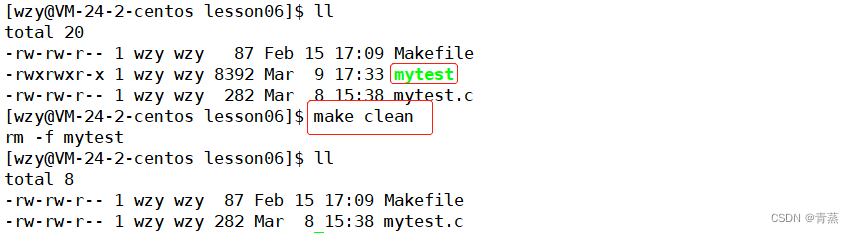
目录 Linux项目自动化构建工具 – make/Makefile 背景 依赖关系和依赖方法 多文件编译 项目清理 make原理 Linux项目自动化构建工具 – make/Makefile 背景 一个工程的源文件不计其数 按照其类型、功能、模块分别放在若干个目录当中 Makefile定义了一系列的规则来指定&…...

Forter 对支付服务商应对欺诈的四个建议和Gartner的两个关键结论
Gartner新版2023年度《线上欺诈检测市场指南》发布恰逢其时-企业正面临来自专业黑产和欺诈者与日俱增的压力。而在2023年,许多商户将调整反欺诈策略,对拒付率和转化率进行更严格的监测,以最大限度减少损失并增加营收。以下是Gartn…...
——ANR监听方案之IdleHandler)
ANR系列(二)——ANR监听方案之IdleHandler
前言 关于IdleHandler,比较多同学错误地认为,这个Handler的作用是主线程空闲状态时才执行它,那么用它做一些耗时操作也没所谓。可是IdleHandler在主线程的MessageQueue中,执行queueIdle()默认当然也是执行在主线程中的࿰…...
)
数学小课堂:数学和自然科学的关系(数学方法,让自然科学变成科学体系。)
文章目录 引言I 数学方法,让自然科学变成科学体系。1.1 天文学1.2 博物学1.3 化学1.4 医药学1.5 物理学II 自然科学的升华过程III 数学方法的意义引言 19世纪初,英国人把采用实验的方法,系统地构造和组织知识,解释和预测自然的学问称为科学。 科学研究的是自然现象和自然…...

[蓝桥杯 2020 省 A1] 分配口罩
思路比较容易想到,因为口罩全部只有15批,因此直接暴力dfs搜索即可 //dfs #include<bits/stdc.h> using namespace std; int ans 9999; int num[] {9090400, 8499400, 5926800, 8547000, 4958200, 4422600, 5751200, 4175600, 6309600, 5865200, …...
第五章:C语言数据结构与算法之双向带头循环链表
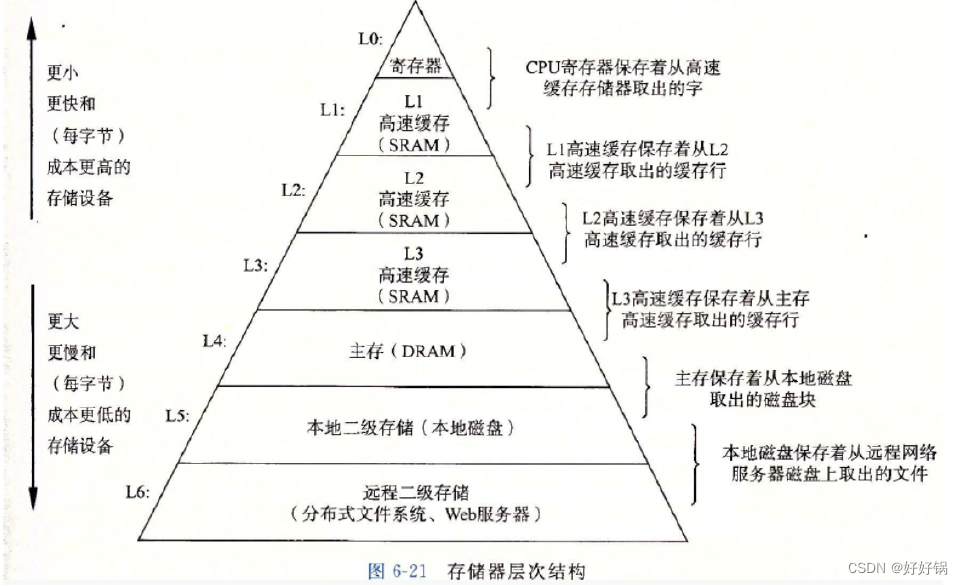
系列文章目录 文章目录系列文章目录前言一、哨兵位的头节点二、双向链表的结点三、接口函数的实现1、创建结点2、初始化3、尾插与尾删4、头插与头删5、打印6、查找7、随机插入与随机删除8、判空、长度与销毁四、顺序表和链表的对比1. 不同点2. 优缺点五、缓存命中1、缓存2、缓存…...
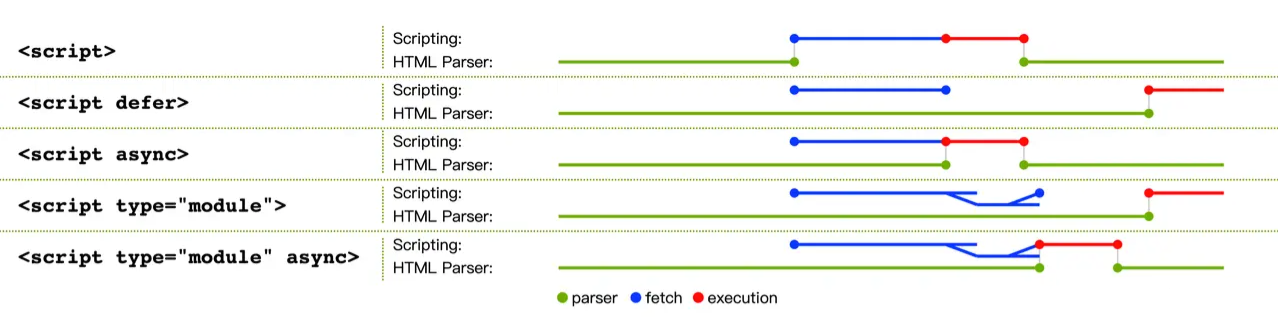
一文带你了解,前端模块化那些事儿
文章目录前端模块化省流:chatGPT 总结一、参考资料二、发展历史1.无模块化引出的问题:横向拓展2.IIFE3.Commonjs(cjs)4.AMD引出的问题:5.CMD6.UMD7.ESM往期精彩文章前端模块化 省流:chatGPT 总结 该文章主要讲述了前端模块化的发展历史和各个…...
大白话设计索引的时候,我们一般要考虑哪些因素呢?(中))
(六十五)大白话设计索引的时候,我们一般要考虑哪些因素呢?(中)
今天我们继续来说一下,在设计索引的时候要考虑哪些因素。之前已经说了,你设计的索引最好是让你的各个where、order by和group by后面跟的字段都是联合索引的最左侧开始的部分字段,这样他们都能用上索引。 但是在设计索引的时候还得考虑其他的…...

Spring事务管理
文章目录1 事务1.1 需求1.2 原因分析1.3 错误解决1.4 yml配置文件中开启事务管理日志1 事务 1.1 需求 当部门解散了不仅需要把部门信息删除了,还需要把该部门下的员工数据也删除了。可当在删除员工数据出现异常时,就不会执行删除员工操作,出…...
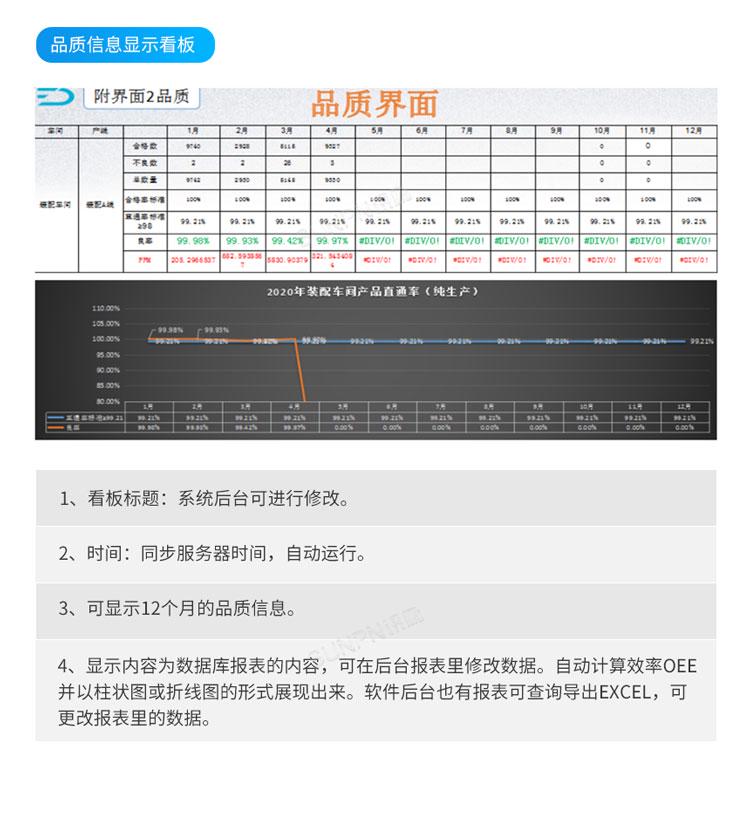
数字化工厂装配线生产管理看板系统
电力企业业务复杂,组织结构复杂,不同的业务数据,管理要求也不尽相同。生产管理看板系统针对制造企业的生产应用而开发,能够帮助企业建立一个规范准确即时的生产数据库。企业现状:1、计划不清晰:生产计划不能…...
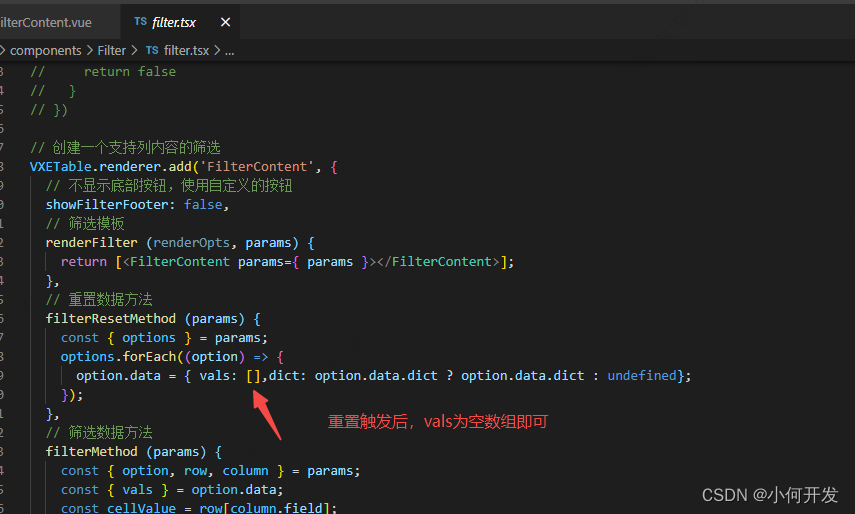
vxe-grid 全局自定义filter过滤器,支持字典过滤
一、vxe-table的全局筛选器filters的实现 官网例子:https://vxetable.cn/#/table/renderer/filter 进入之后:我们可以参照例子自行实现,也可以下载它的源码,进行调整 下载好后并解压,用vscode将解压后的文件打开。全局…...
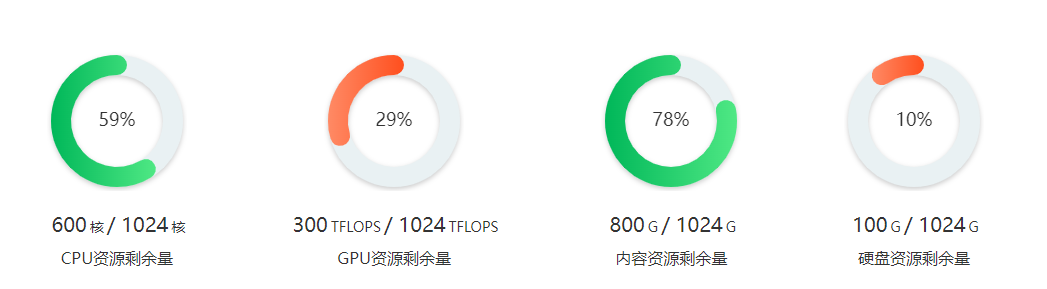
ECharts 环形图组件封装
一、ECharts引入1.安装echarts包npm install echarts --save2.引入echarts这里就演示全局引入了,挂载到vue全局,后面使用时,直接使用 $echartsimport * as echarts from echarts Vue.prototype.$echarts echarts二、写echarts组件这里演示环…...

c++ 怎么调用python 提供的函数接口
在 C 中调用 Python 函数有多种方法,以下是其中的两种常见方法:使用 Python/C APIPython 提供了 C/C API,可以通过该 API 在 C 中调用 Python 函数。使用这种方法,需要先将 Python 解释器嵌入到 C 代码中,然后可以通过…...
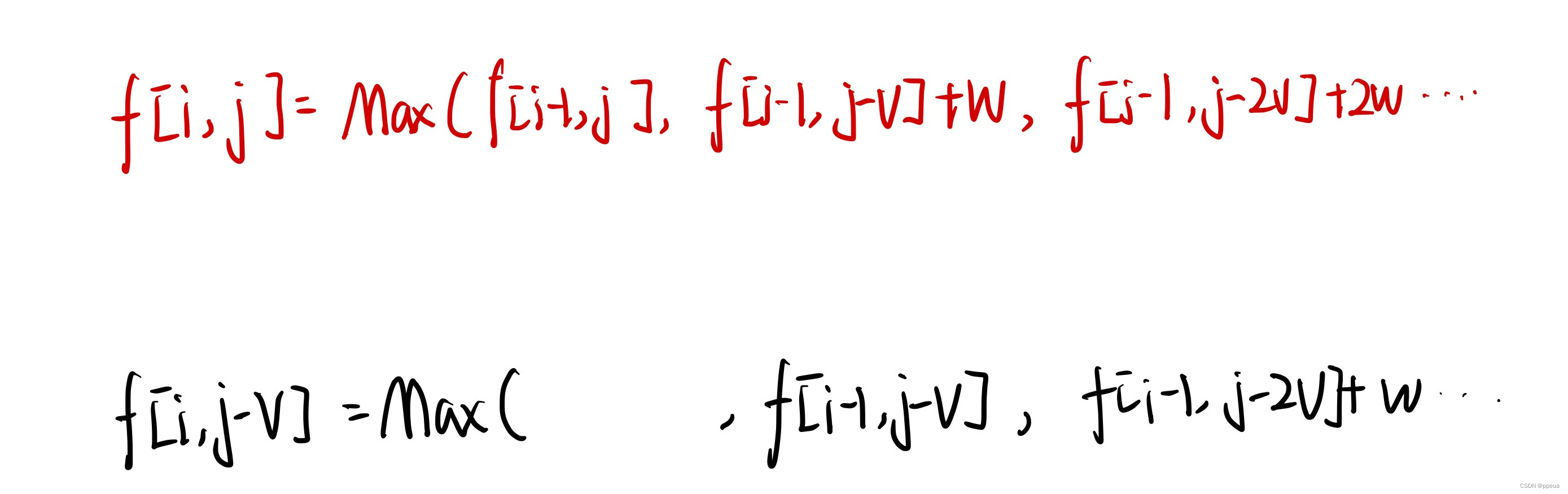
【动态规划】背包问题(01背包,完全背包)
Halo,这里是Ppeua。平时主要更新C语言,C,数据结构算法......感兴趣就关注我吧!你定不会失望。 🌈个人主页:主页链接 🌈算法专栏:专栏链接 我会一直往里填充内容哒! &…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

laravel8+vue3.0+element-plus搭建方法
创建 laravel8 项目 composer create-project --prefer-dist laravel/laravel laravel8 8.* 安装 laravel/ui composer require laravel/ui 修改 package.json 文件 "devDependencies": {"vue/compiler-sfc": "^3.0.7","axios": …...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...