数据结构-堆(带图)详解
前言
本篇博客我们来仔细说一下二叉树顺序存储的堆的结构,我们来看看堆到底如何实现,以及所谓的堆排序到底是什么
💓 个人主页:普通young man-CSDN博客
⏩ 文章专栏:数据结构_普通young man的博客-CSDN博客
若有问题 评论区见📝
🎉欢迎大家点赞👍收藏⭐文章
目录
树的概念
二叉树的概念及结构
二叉树的基本定义:
二叉树的性质:
特殊的二叉树类型:
存储结构:
操作与遍历:
堆
堆的实现
堆实现的接口
Heap_Init-初始化
IF_Add_capacity-扩容
Swap-数据交换
Heap_Push-插入
Upward-向上调整
编辑
Heap_Pop-删除
Downward-向下调整
编辑
Heap_Empty-判空
Heap_Top-获取堆顶数据
Heap_Destory-销毁
堆排序
函数部分
Heap_qsort
top-k问题
Top-K问题的基本概念
解决Top-K问题的常见方法
应用实例
问题
树的概念
在学习堆这个数据结构的时候我们先来了解一下什么是树?
树是一种重要的非线性数据结构,它模拟了自然界中树木的结构,不过在计算机科学中,树是倒置的,即根在上,叶在下。树主要由节点(或称为结点)和边组成,用于表示具有层次关系的数据集合。


注意:树的结构子树之间没有交际,否则就不成立

定义:
- 树是由一个或多个节点组成的有限集合。如果树为空,称为空树;如果不为空,则满足以下条件:
- 有且仅有一个称为根(root)的节点,它没有前驱节点(即父节点)。
- 除根节点外,其余每个节点有且仅有一个父节点。
- 节点的子节点之间没有顺序关系,但每个子节点都可视为一个子树。
- 树中的节点数可以是任意有限个,包括0(空树)。
节点的度:
- 一个节点的度是指它拥有子节点的数量。叶子节点(或终端节点)是度为0的节点,即没有子节点的节点。
树的度:
- 树的度是树中所有节点的度中的最大值。
层次与高度:
- 节点的层次是从根节点到该节点路径上的边数。根节点的层次为1。
- 树的高度(或深度)是树中所有节点的层次中的最大值,也就是从根到最远叶子节点的边数。
祖先与后代:
- 对于非根节点,从该节点到根节点路径上的所有节点(包括根节点)都是该节点的祖先。
- 一个节点的后代包括它所有的子节点、子节点的子节点等,直至叶子节点。
兄弟节点:
- 具有相同父节点的节点互为兄弟。
子树:
- 任何节点及其所有后代节点构成的树称为该节点的子树。
二叉树的概念及结构
接下来我们介绍树中的一种结构二叉树
二叉树是一种特殊的树形数据结构,其中每个节点最多只有两个子节点,通常被称作左子节点和右子节点。这种结构使得二叉树成为计算机科学中研究和应用非常广泛的数据结构之一。下面是关于二叉树的一些核心概念和结构特征:
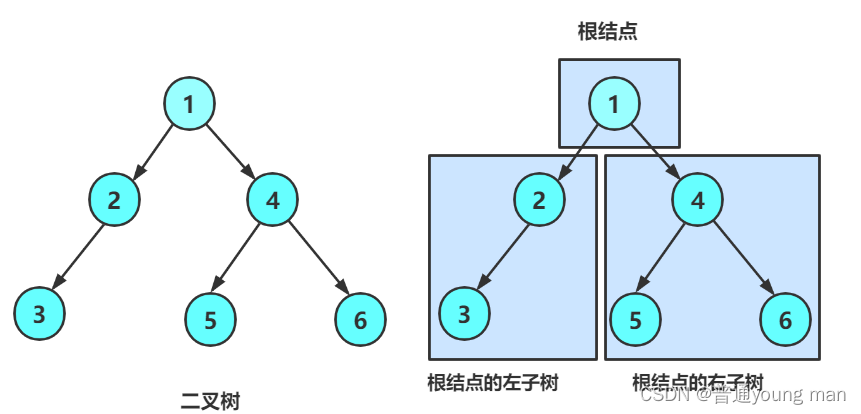
二叉树的基本定义:
- 节点:二叉树的基本组成单位,每个节点可以包含一个数据元素以及指向其左右子节点的引用。
- 根节点:树的顶端节点,没有父节点。
- 叶子节点:没有子节点的节点。
- 度:节点的子节点数量,二叉树中节点的度不超过2。
- 父子关系与兄弟关系:与一般树相同,每个节点(除了根)有唯一的父节点,同一父节点的子节点互为兄弟。
二叉树的性质:
- 有序性:二叉树的子节点分为左子树和右子树,这给树带来了顺序,区别于无序的多叉树。
- 递归定义:一个空集构成空二叉树,或者由一个根节点加上左右两个互不相交的二叉树(左子树和右子树)组成。
特殊的二叉树类型:
- 满二叉树:所有非叶子节点都有两个子节点,且所有叶子节点都在同一层。
- 完全二叉树:除了最后一层,每一层都是满的,且最后一层的叶子节点都尽可能靠左排列。
- 二叉排序树(BST):左子树所有节点的值小于根节点的值,右子树所有节点的值大于根节点的值,且左右子树也分别是二叉排序树。

存储结构:
- 顺序存储:对于完全二叉树,可以使用数组来紧凑存储,利用数组索引来体现节点间的父子关系。
- 链式存储:更通用的方法,每个节点包含数据和指向左右子节点的指针,通常使用结构体或类来定义节点结构。

操作与遍历:
- 遍历:访问二叉树中所有节点的过程,有前序遍历、中序遍历、后序遍历和层序遍历等方法。
- 插入与删除:在二叉排序树中,根据节点值的比较进行插入或删除操作,并保持二叉排序树的性质。
二叉树因其结构简单、操作方便,常被用于实现各种高效算法,如查找、排序、图的遍历等。在实际应用中,通过选择特定类型的二叉树(如AVL树、红黑树),可以达到平衡性和高效的查询性能。
现实中的二叉树

现在我们了解二叉树的一个概念,我们接下来进入正题
堆
其实堆我们的堆就是二叉树当中的完全二叉树,现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
堆我们分两种:大堆 和 小堆
大堆:
在大堆中,每个节点的值都大于或等于其子节点的值。换句话说,父节点总是大于(或等于)其孩子节点。堆顶元素(根节点)因此是整个堆中的最大值。
小堆:
与大堆相反,小堆中的每个节点的值都小于或等于其子节点的值。这意味着父节点总是小于(或等于)其孩子节点,堆顶元素(根节点)是整个堆中的最小值。
请看这张图

大家知道我们的数据在内存中是b存储结构的模式(物理存储),但是二叉树是a的逻辑结构,我们的计算机会通过一种叫映射的方式,将这种逻辑结构映射到物理存储。
可能大家会有疑问为什么不直接用数组,而要用堆这个结构?

数组是一种基础且灵活的数据结构,适合存储和访问连续的数据块,特别是在索引访问和随机访问方面表现优秀。然而,在某些特定场景下,尤其是涉及到动态调整数据顺序、维护数据的某种特定排序状态或高效地获取最大值/最小值时,数组的效率可能不如专门设计的数据结构,比如堆。
堆是一种特殊类型的完全二叉树,它具有以下特点,使其在某些应用场景下比简单的数组更加高效和适用:
维护有序性:
- 最大堆:每个节点的值都大于或等于其子节点的值,堆顶元素始终是最大值。
- 最小堆:每个节点的值都小于或等于其子节点的值,堆顶元素始终是最小值。 这种特性使得堆在需要频繁查找最大或最小元素的场景(如优先队列)中极为高效,无需遍历整个数组即可快速获得。
动态调整:
- 堆支持插入和删除元素的同时能够高效地(通常是O(log n)时间复杂度)重新调整结构以维持其特性,这一点在使用数组时难以直接高效实现。
内存利用率:
- 实际实现时,堆可以采用数组来存储,虽然逻辑上是树状结构,但实际上占用的是连续内存空间,因此内存使用相对高效。
排序应用:
- 堆可以作为实现堆排序的基础,这是一种不稳定的排序算法,其优势在于能够提供较好的最坏情况和平均时间复杂度(O(n log n)),并且不需要像快速排序那样依赖于数据的初始分布。
堆的实现
先看一下堆的结构咋写,其实和顺序表的结构一样,因为堆本身就是数组,只是逻辑看起不是。
//堆的结构
typedef int HeapTypeData;
typedef struct heap
{HeapTypeData* a;int top;int capacity;
}heap;
记住这张图
堆实现的接口
//初始化
void Heap_Init(heap* obj);
//插入
void Heap_Push(heap* obj, HeapTypeData x);
//删除
void Heap_Pop(heap* obj);
//判空
bool Heap_Empty(heap* obj);
//获取堆顶
HeapTypeData Heap_Top(heap* obj);
//销毁
void Heap_Destory(heap* obj);
//扩容
void IF_Add_capacity(heap* obj);
//向上调整
void Downward(HeapTypeData* p, int n, int parent);
//向下调整
void Upward(HeapTypeData* p, int child);
//交换
void Swap(HeapTypeData* p1, HeapTypeData* p2);这些接口是如何实现的嘞?,如何才能创建这么一棵树?
这些接口我会讲解一些没见过德接口,因为这个堆的接口和顺序表差不多
Heap_Init-初始化
//初始化
void Heap_Init(heap* obj) {obj->a = NULL;obj->top = obj->capacity = 0;
}初始化和顺序表差不多,将指针置NULL,其他的值初始化为0
IF_Add_capacity-扩容
//扩容
void IF_Add_capacity(heap* obj) {if (obj->top == obj->capacity){int new_capeccity = obj->capacity == 0 ? 4 : obj->capacity * 2;HeapTypeData* tmp = (HeapTypeData*)realloc(obj->a,sizeof(HeapTypeData) * new_capeccity);if (tmp == NULL){assert("realloc");}obj->a = tmp;obj->capacity = new_capeccity;}
}Swap-数据交换
//交换
void Swap(HeapTypeData* p1, HeapTypeData* p2)
{HeapTypeData tmp = *p1;*p1 = *p2;*p2 = tmp;
}Heap_Push-插入
//插入
void Heap_Push(heap* obj, HeapTypeData x) {assert(obj);IF_Add_capacity(obj);obj->a[obj->top] = x;obj->top++;//这个时候我们需要向上Upward(obj->a,obj->top-1);
}Upward-向上调整
//向上调整
void Upward(HeapTypeData*p, int child){//通过计算找父母HeapTypeData parent = (child - 1) / 2;while (child > 0){if (p[child] < p[parent]){//交换Swap(&p[child], &p[parent]);//交换后,将parent的位置给给child,继续计算下一个parentchild = parent;parent = (child - 1) / 2;}else{break;}}
}
eapTypeData *p: 指向堆数组的指针,这个数组存储了堆的所有元素。int child: 插入新元素的位置(索引),从0开始计数。新插入的元素被认为是一个“孩子”节点,该函数会检查并调整这个孩子节点与其父节点的关系,以确保堆的性质不变。函数执行流程:
- 计算父节点位置:首先根据孩子节点的索引
child计算出其父节点的索引parent,公式为(child - 1) / 2。- 循环比较并交换:进入一个循环,在循环中不断比较当前孩子节点和其父节点的值。如果孩子节点的值小于父节点的值(对于最小堆而言),则交换这两个节点的值。这是因为最小堆要求父节点的值不大于子节点的值。
- 更新索引并继续:在交换之后,原来的子节点变成了新的父节点,因此需要更新
child为parent,同时基于新的child计算新的parent,继续进行比较和可能的交换,直到孩子节点不再小于其父节点或者到达了堆的根部(即child <= 0时)。- 退出循环:一旦发现孩子节点不小于其父节点,或者已经没有父节点可比较(即到达了树的根),循环结束,此时堆的性质已经得到恢复。

Heap_Pop-删除
//删除
void Heap_Pop(heap* obj) {assert(obj);assert(obj->a);assert(obj->top > 0);//先交换,如果直接删除堆顶的数据,就会导致血脉混乱Swap(&obj->a[0], &obj->a[obj->top - 1]);//最后--top就删掉最后一个数据obj->top--;//这边要考虑一个问题,我们是小堆,但是我们的最大的数在堆顶,所以这里需要将最大的数向下移动,让次小的数往上补Downward(obj->a,obj->top,0);
}Downward-向下调整
//向下调整
void Downward(HeapTypeData* p,int n, int parent) {//计算出左儿子int child = parent * 2 + 1;while (child < n){if(child + 1 < n && p[child+1] < p[child]) {//如果右儿子小于左儿子,直接++到右儿子的位置++child;}if ( p[child] < p[parent])//如果child<parent,就交换,要把小的往上走{//这边操作一样,算法不同Swap(&p[child],&p[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
HeapTypeData *p: 指向堆数组的指针。int n: 堆中有效元素的数量。在调整过程中,只考虑堆的前n个元素。int parent: 当前需要调整的父节点在数组中的索引位置。函数执行流程:
- 初始化子节点位置:首先计算出当前父节点的左孩子的索引
child,公式为parent * 2 + 1。- 循环比较并交换:进入循环,只要
child的值小于n,表示还有子节点可以比较。
- 选择较小的子节点:如果右孩子存在(即
child + 1 < n)且右孩子的值小于左孩子的值,则将child更新为右孩子的索引,因为我们要找到两个子节点中更小的那个。- 比较并交换:如果找到的子节点
child的值小于其父节点parent的值,说明违反了最小堆的性质,这时需要交换它们的值,并将当前的child位置作为新的父节点位置继续向下比较。- 更新位置:交换后,原
child位置已成为新的父节点位置,因此更新parent = child,并基于新的父节点重新计算其左孩子的索引child = parent * 2 + 1,继续循环。- 退出条件:如果子节点不小于父节点,或者已经没有更多的子节点可比较(即
child >= n),则跳出循环。- 结束:循环结束后,堆的性质得到了恢复,即以
parent为根的子树满足最小堆的定义。

Heap_Empty-判空
//判空
bool Heap_Empty(heap* obj) {assert(obj);return !obj->top;
}Heap_Top-获取堆顶数据
//返回堆顶
HeapTypeData Heap_Top(heap* obj) {assert(obj);assert(obj->a);return obj->a[0];
}Heap_Destory-销毁
//销毁
void Heap_Destory(heap* obj) {if (obj->a){free(obj->a);obj->a = NULL;obj->capacity = obj->top = 0;}
}堆排序
//堆排序
void Heap_qsort(int *p,int sz) {建堆//for (int i = 1; i < sz; i++)// Upward(p,i);//}//建堆for (int i = (sz-1-1)/2; i >= 0; i--)//找最后一个不是叶子的节点{Downward(p,sz,i);}//对堆排序int end = sz - 1;while (end > 0){Swap(&p[0],&p[end]);Downward(p,end,0);--end;}
}
int main() {int a[] = {5,8,9,2,1};int sz = sizeof(a) / sizeof(a[0]);//text1();Heap_qsort(a,sz);int n = 3;for (int i = 0; i < n; i++){printf("%d ", a[i]);}return 0;
}函数部分
Heap_qsort
输入参数:
int *p: 指向待排序数组的指针。int sz: 数组的大小,即元素数量。过程:
- 建堆:
- 与传统从第一个非叶节点开始构造堆的方法不同,这里采用了从最后一个非叶节点开始逆序遍历至根节点的方式来构建最小堆。这样做的目的是直接通过
Downward函数递归调整每个子树为最小堆,最终整个数组构成一个最小堆。计算最后一个非叶节点的索引公式为(sz-1-1)/2,然后从这个索引开始,逐步向前执行Downward操作。(sz-1-1)/2:sz-1->最后一个元素,sz-1-1找到父节点- 堆排序:
- 首先,将堆顶元素(数组中的最小值)与数组末尾元素交换,确保当前最小值位于正确的位置(即数组末尾)。
- 然后,因为堆顶元素(现在是数组的末尾元素)已经正确排序,所以缩小堆的有效大小(
end -= 1),并在剩下的元素中再次调用Downward函数调整剩余元素为最小堆。这个过程重复,直到整个数组都被正确排序。输出:
- 数组
p的内容将会按照升序排列。
这边我用gif来展示堆排序的逻辑

这边我建的是一个小堆

排序

那这个堆排序的时间复杂度是多少嘞?

那我们就来算一算



得出结论是n*logn
这里面得计算也可以套公式
top-k问题
Top-K问题是一类在大数据集或流式数据中寻找或维护最顶尖(最大或最小)K个元素的问题。这类问题广泛应用于各种场景,特别是在需要高效地处理大量数据并提取关键信息时,比如数据分析、推荐系统、搜索引擎排名、社交网络分析、金融风控、大数据处理等领域。
Top-K问题的基本概念
在最简单的形式中,Top-K问题可以表述为:给定一个包含N个元素的无序集合,找出其中最大的K个元素或最小的K个元素。这里的“最大”或“最小”可以根据具体应用需求定义,比如数值大小、频率、相关性等。
解决Top-K问题的常见方法
-
快速选择算法:基于快速排序的选择算法变体,通过一次划分过程确定一个基准元素的位置,如果基准元素恰好处于第K个位置,则找到答案;否则,在基准元素的正确一侧递归继续查找。
-
堆方法:维护一个大小为K的小顶堆(找最大K个元素)或大顶堆(找最小K个元素),遍历数据时,比较堆顶元素与当前元素,如果满足条件则替换堆顶元素并调整堆结构,保证堆的性质。这种方法的时间复杂度接近O(N log K)。
-
二分查找法:适用于能够计算数组中某个值排名或能够估算某个值排名的场景。通过二分查找确定一个阈值,然后统计小于或大于该阈值的元素个数,逐步逼近目标K值。
-
桶排序或计数排序:对于数据范围有限且分布均匀的情况,可以将数据分布到有限数量的桶中,然后从桶中找出Top-K元素。适合特定场景下提高效率。
应用实例
-
搜索引擎:在搜索引擎中,为了提供最相关的网页给用户,搜索引擎会根据页面质量、关键词匹配程度等因素对网页进行评分,然后选择评分最高的K个网页展示给用户。
-
推荐系统:电商平台或社交媒体平台会根据用户的浏览历史、购买行为、喜好等数据,计算商品或内容的相关性分数,选出评分最高的K个商品或内容推荐给用户。
-
大数据分析:在处理大规模日志数据时,可能需要找出访问量最大的K个IP地址、最常见的K个错误类型等,以帮助识别异常或优化资源分配。
-
金融风控:银行和金融机构利用Top-K分析来识别潜在的高风险交易,比如监测账户中交易额最大的K笔交易,以发现可能的洗钱活动。
Top-K问题因其高效性和实用性,在现代信息技术领域扮演着重要角色。
问题
现在你在面试,面试官要你找出10亿得数据中最大得前十个?你该咋找?或许你会说直接用刚才得堆排序,这当然可以。

那假如,面试官让你用1MB的空间去找这个个数中最大十个嘞?
大家或许就有一点懵逼了吧,哈哈哈
看图
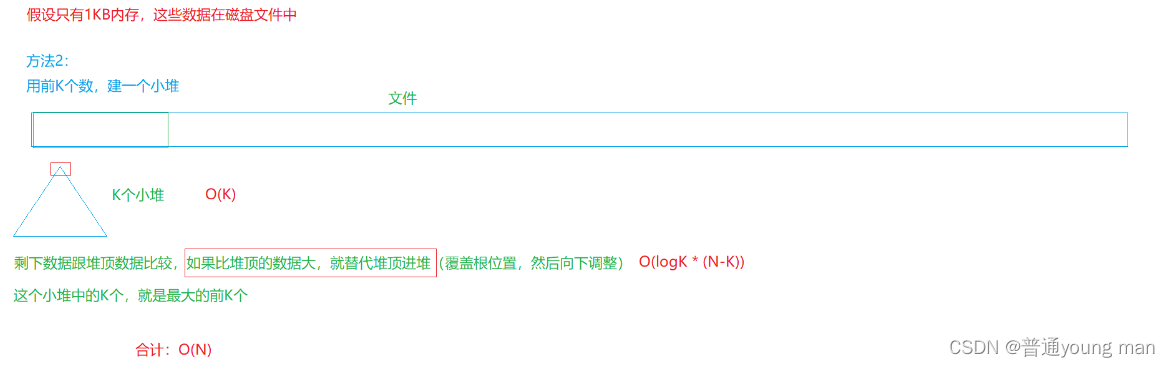
于是我们的代码就可以这样写
//实现创建x(整形)个数据的一个文件,利用1MB空间在x数据中找最大的前n个#include<time.h>
//造数据
void Make_data() {int n = 100000;srand((unsigned int)time(NULL));const char* date = "Date.txt";FILE* write = fopen(date,"w");if (write == NULL){assert("fopen");return;}//将数据写入文件for (int i = 0; i < n; i++){int ret = (rand() + i) % n;//+i == 防止重复值,i是不断变化的,%n == 控制范围fprintf(write,"%d\n",ret);//将生成的数据不断的插入 "Date.txt"文件中}fclose(write);
}//建堆
//数据量大
Make_heap() {int n = 0;printf("请输入你要查看的前几个数");scanf("%d",&n);//创建一个空间int* New_node = (int*)malloc(n*sizeof(int));if (New_node == NULL){assert("malloc");return;}//将数据从文件中读出const char* write = "Date.txt";FILE* read = fopen(write,"r");if (read == NULL){assert("fopen");return;}//先把进n个数据for (int i = 0; i < n; i++){fscanf(read,"%d", &New_node[i]);}//建堆sfor (int i = (n-1-1)/2; i >= 0; i--){Downward(New_node,n,i);}//比较剩下的数据依次int end = 0;while (fscanf(read,"%d",&end) > 0)//这里会返回EOF(-1){//判断if (end > New_node[0]) {//如果end>Newnode[0]位置的数,直接将这个位置的值赋值New_node[0] = end;//再进行向下调整得到小堆Downward(New_node,n,0);}}fclose(read);Heap_qsort_print(New_node,n);
}
Heap_qsort_print(int* p, int n) {//排序:从大到小int new_size = n - 1;while (new_size > 0){Swap(&p[0], &p[new_size]);Downward(p, new_size, 0);--new_size;}//输出printf("最大的%d个数>: ", n);for (int i = 0; i < n; i++){printf("%d ", p[i]);}
}
int main() {//设置时间戳//Make_data();//建堆Make_heap();}
生成数据:
Make_data函数生成100,000个整数数据并存储到一个名为"Date.txt"的文件中。每个数据是通过随机数生成器得到,并加上循环变量i后取模,以避免重复并控制数据范围。读取并找出Top-N:
Make_heap函数首先询问用户想要找出数据文件中的前多少个最大数,然后读取文件内容,使用最小堆(这里实际实现的是一个简化版的维护最大值的过程,未完全实现标准的堆结构)来维护当前找到的最大N个数。它先读取前N个数构建初始“堆”,之后继续读取文件中的剩余数据并与堆顶元素比较,若遇到更大的数则替换堆顶元素并重新调整堆。最后,使用Heap_qsort_print函数对维护的N个数进行排序并打印。排序及打印:
Heap_qsort_print函数实质上是进行了一个非典型的堆排序操作,从堆顶开始每次将堆顶元素(当前最大值)与末尾元素交换,并缩小堆的大小,重复此过程直至整个序列变为降序排列,最后打印出这N个最大的数。
ok今天的博客就结束了哦

相关文章:
数据结构-堆(带图)详解
前言 本篇博客我们来仔细说一下二叉树顺序存储的堆的结构,我们来看看堆到底如何实现,以及所谓的堆排序到底是什么 💓 个人主页:普通young man-CSDN博客 ⏩ 文章专栏:数据结构_普通young man的博客-CSDN博客 若有问题 评…...
库 (二十三))
React Native 之 react-native-share(分享)库 (二十三)
react-native-share 是一个流行的 React Native库,它允许你在移动应用中分享文本、链接、图片等内容到各种社交网络和消息应用。以下是对其原理的简要概述以及代码示例的解析。 代码示例解析 1. 安装 npm install react-native-share # 或者 yarn add react-n…...
JCR一区级 | Matlab实现TCN-BiGRU-MATT时间卷积双向门控循环单元多特征分类预测
JCR一区级 | Matlab实现TCN-BiGRU-MATT时间卷积双向门控循环单元多特征分类预测 目录 JCR一区级 | Matlab实现TCN-BiGRU-MATT时间卷积双向门控循环单元多特征分类预测分类效果基本介绍程序设计参考资料 分类效果 基本介绍 1.Matlab实现TCN-BiGRU-MATT时间卷积双向门控循环单元多…...

游戏心理学Day01
心理学 心理学是一门研究心理过程和行为及其如何受有机体的生理,心理状态和外部影响的科学 心理学不是常识的代名词,心理学分为基础,心理学和应用心理学基础,心理学研究的目的在于描述,解释,预测和控制行…...

错误模块路径: ...\v4.0.30319\clr.dll,v4.0.30319 .NET 运行时中出现内部错误,进程终止,退出代码为 80131506。
全网唯一解决此BUG的文章!!! 你是否碰到了以下几种问题?先说原因解决思路具体操作1、首先将你C:\Windows\Microsoft.NET\文件夹的所有者修改为你当前用户,我的是administrator。2、修改当前用户权限。3、重启电脑4、删…...

005 CentOS 7.9 RabbitMQ安装及配置
https://github.com/rabbitmq/rabbitmq-server/releases https://www.rabbitmq.com/docs/download https://packagecloud.io/rabbitmq/rabbitmq-server https://www.erlang-solutions.com/downloads/ https://www.erlang.org/ 文章目录 卸载erlerl版本安装与下载版本不匹配正…...
Xcode 15 libarclite 缺失问题
升级到Xcode 15运行项目报错,报错信息如下: SDK does not contain libarclite at the path /Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/lib/arc/libarclite_iphonesimulator.a; try increasing the minimum d…...

绘画智能体分享
这是您请求的故宫雪景图,角落有一只可爱的胖猫,采用了水墨画风格,类似于张大千的作品。希望您喜欢这幅画! 🎨 选项 1【转变风格】——将这幅画转变为梵高的后印象派风格,增添一些梵高特有的笔触和色彩。 &…...

7_2、C++程序设计进阶:数据共享
数据与函数 数据与函数局部变量全局变量类的数据成员 类的静态成员静态数据成员静态函数成员 友元友元函数友元类 函数之间实现数据共享有以下几种方式:局部变量、全局变量、类的数据成员、类的静态成员和友元。 如何共享局部变量呢? 在主调函数和被调…...
—— 搜索时间(或下拉列表)后,点击X清除按钮后返回值为null,导致异常)
d2-crud-plus 使用小技巧(五)—— 搜索时间(或下拉列表)后,点击X清除按钮后返回值为null,导致异常
问题 使用vue2elementUId2-crud-plus,时间组件自动清除按钮,点击清除按钮后对应的值被设置为null,原本应该是空数组([]),导致数据传到后端后报错。不仅适用于搜索,表单一样有效果。 解决方法 …...

ChatGPT成知名度最高生成式AI产品,使用频率却不高
5月29日,牛津大学、路透社新闻研究所联合发布了一份生成式AI(AIGC)调查报告。 在今年3月28日—4月30日对美国、英国、法国、日本、丹麦和阿根廷的大约12,217人进行了调查,深度调研他们对生成式AI产品的应用情况。 结果显示&…...
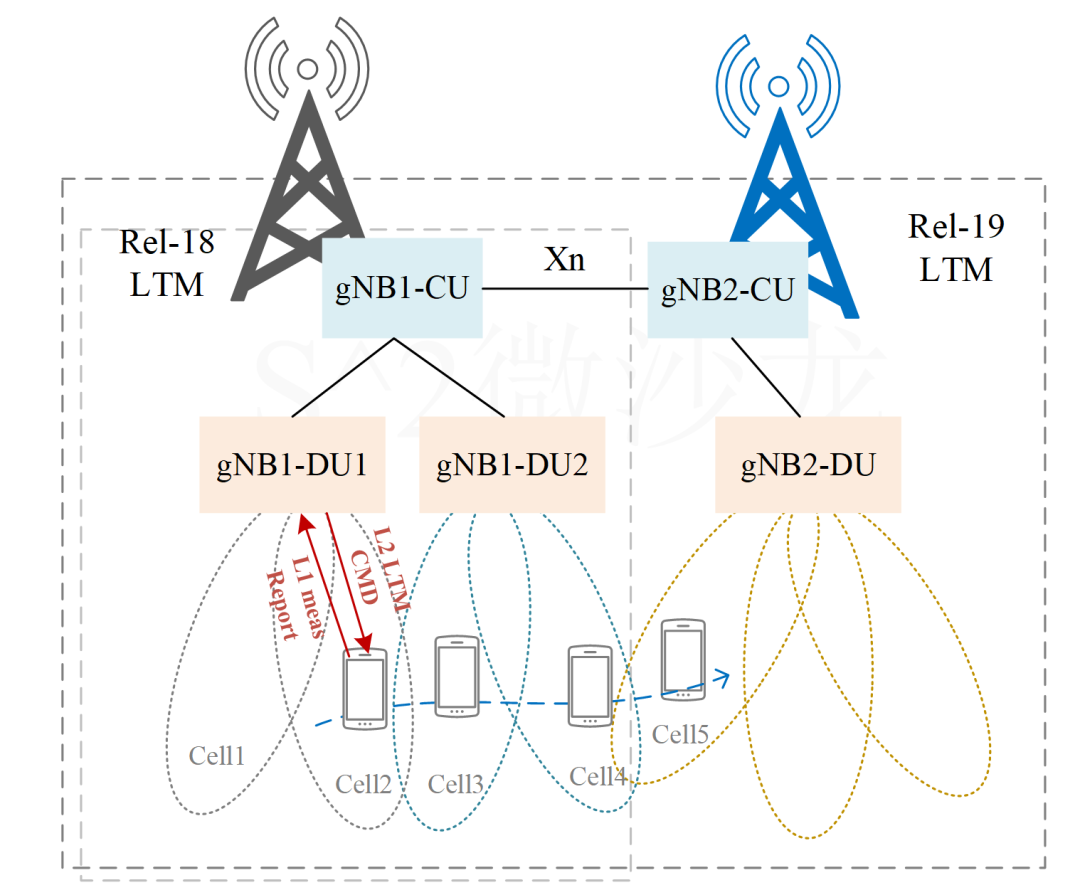
R19 NR移动性增强概况
随着5G/5G-A技术不断发展和业务需求的持续增强,未来网络的部署将不断向高频演进。高频小区的覆盖范围小,用户将面临更为频繁的小区选择、重选、切换等移动性过程。 为了提升网络移动性能和保障用户体验,移动性增强一直是3GPP的热点课题。从NR…...

C语言:如何写文档注释、内嵌注释、行块注释?
技术答疑流程 扫描二维码,添加个人微信;支付一半费用,获取答案;如果满意,则支付另一半费用; 知识点费用:10元 项目费用:如果有项目任务外包需求,可以微信私聊...

Turtle中circle用法详解
在Python的Turtle图形库中,circle方法是一个非常灵活的工具,它允许我们以简单的方式绘制圆或圆的一部分。本文将深入探讨circle方法,特别关注radius和extent参数的用途及其正负值的意义。 一、circle方法概览 首先,让我们了解一…...
stack和queue(1)
一、stack的简单介绍和使用 1.1 stack的介绍 1.stack是一种容器适配器,专门用在具有先进后出,后进先出操作的上下文环境中,其删除只能从容器的一端进行元素的插入和弹出操作。 2.stack是作为容器适配器被实现的,容器适配器即是…...

前端3剑客(第1篇)-初识HTML
100编程书屋_孔夫子旧书网 当今主流的技术中,可以分为前端和后端两个门类。 前端:简单的理解就是和用户打交道 后端:主要用于组织数据 而前端就Web开发方向来说, 分为三门语言, HTML、CSS、JavaScript 语言作用HT…...
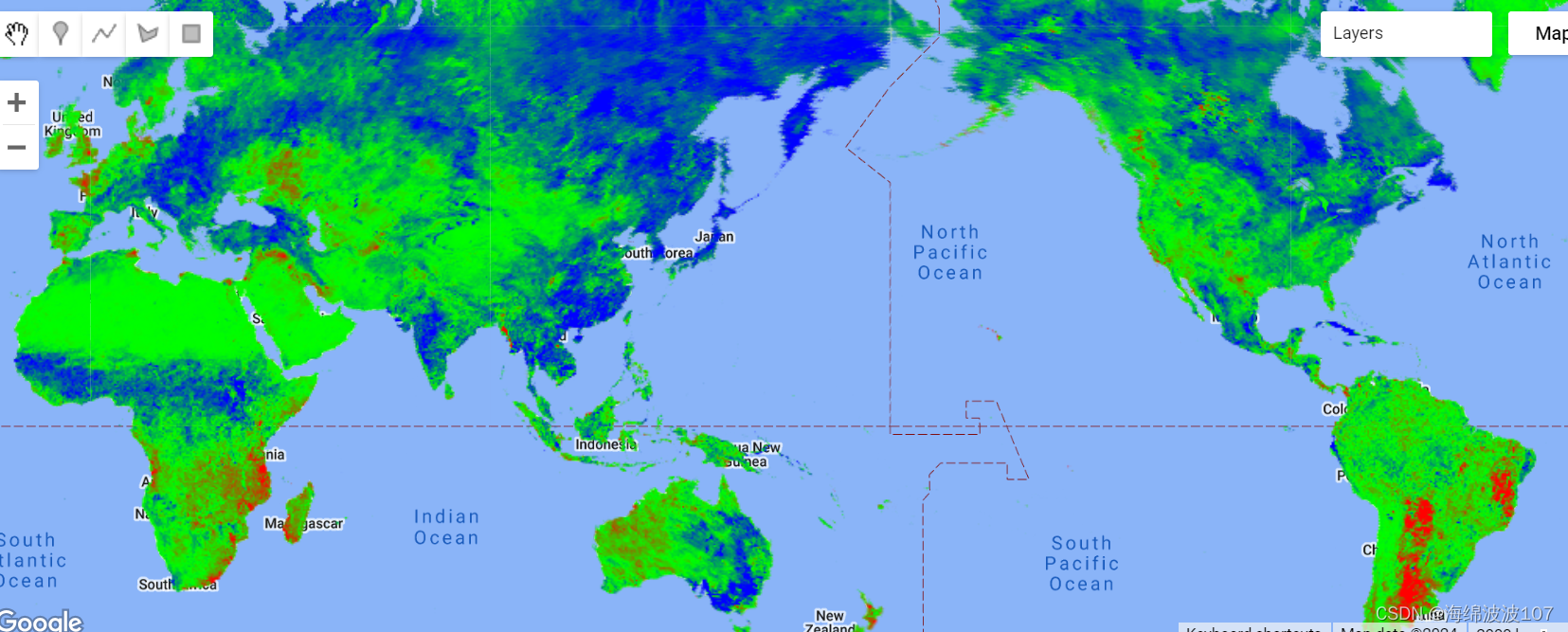
植被变化趋势线性回归以及可视化
目录 植被变化线性回归ee.Reducer.linearFit().reduce()案例:天水市2004-2023年EVI线性回归趋势在该图中,使用了从红色到蓝色的渐变来表示负趋势到正趋势。红色代表在某段时间中,植被覆盖减少,绿色表示持平,蓝色表示植被覆盖增加。 植被变化线性回归 该部分参考Google…...
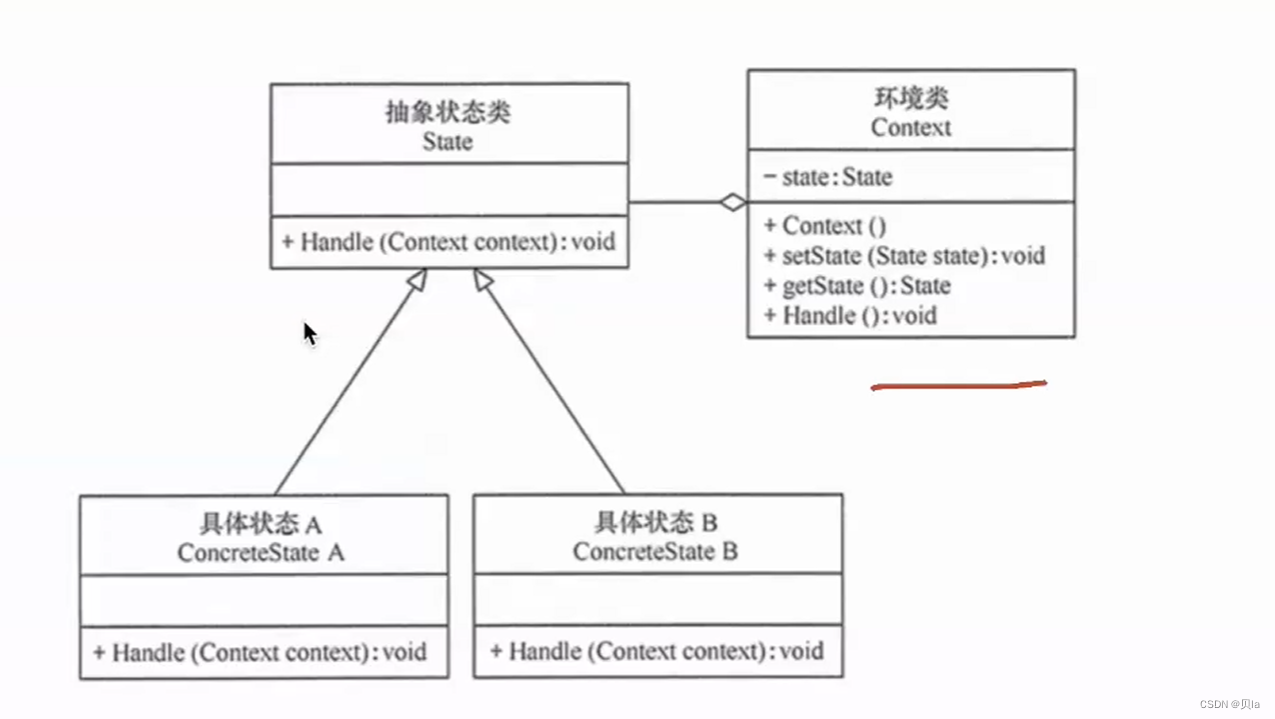
大话设计模式学习笔记
目录 工厂模式策略模式备忘录模式(快照模式)代理模式单例模式迭代器模式访问者模式观察者模式解释器模式命令模式模板方法模式桥接模式适配器模式外观模式享元模式原型模式责任链模式中介者模式装饰模式状态模式 工厂模式 策略模式 核心:封装…...

MiniMax公司介绍
MiniMax是一家专注于通用人工智能技术的科技公司,成立于2021年12月。公司致力于成为通用人工智能时代基础设施建设者和内容应用创造者,积极投身于中国人工智能技术高速发展的时代大潮。MiniMax的团队由多位在人工智能领域有着丰富经验的专家组成…...

lucene 9.10向量检索基本用法
Lucene 9.10 中的 KnnFloatVectorQuery 是用来执行最近邻(k-Nearest Neighbors,kNN)搜索的查询类,它可以在一个字段中搜索与目标向量最相似的k个向量。以下是 KnnFloatVectorQuery 的基本用法和代码示例。 1. 索引向量字段 首先…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

装饰模式(Decorator Pattern)重构java邮件发奖系统实战
前言 现在我们有个如下的需求,设计一个邮件发奖的小系统, 需求 1.数据验证 → 2. 敏感信息加密 → 3. 日志记录 → 4. 实际发送邮件 装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其…...

springboot 百货中心供应链管理系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,百货中心供应链管理系统被用户普遍使用,为方…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...

Docker拉取MySQL后数据库连接失败的解决方案
在使用Docker部署MySQL时,拉取并启动容器后,有时可能会遇到数据库连接失败的问题。这种问题可能由多种原因导致,包括配置错误、网络设置问题、权限问题等。本文将分析可能的原因,并提供解决方案。 一、确认MySQL容器的运行状态 …...