yolov10/v8 loss详解
v10出了就想看看它的loss设计有什么不同,看下来由于v8和v10的loss部分基本一致就放一起了。
v10的论文笔记,还没看的可以看看,初步尝试耗时确实有提升
好记性不如烂笔头,还是得记录一下,以免忘了,废话结束!!!
代码地址:GitHub - THU-MIG/yolov10: YOLOv10: Real-Time End-to-End Object Detection
论文地址:https://arxiv.org/pdf/2405.14458
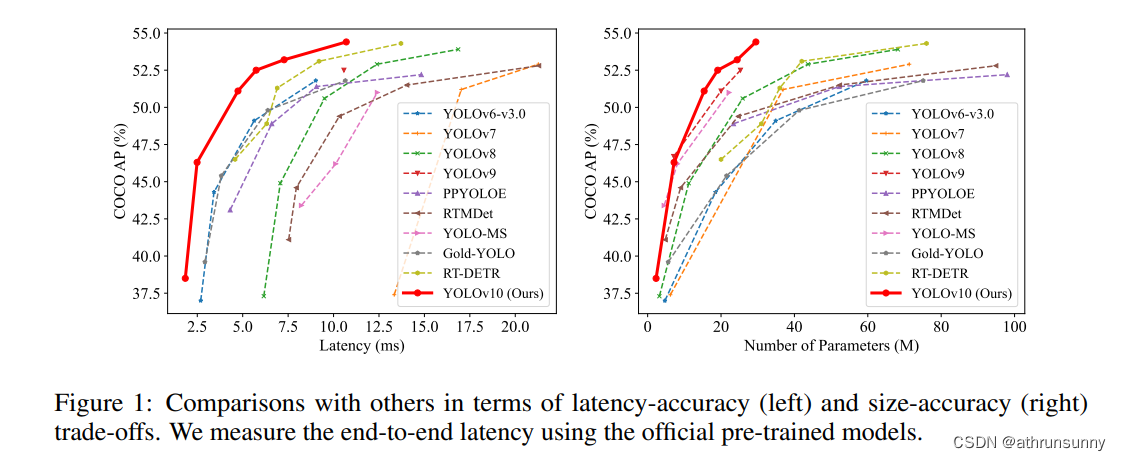
YOLOv10/8从Anchor-Based(box anchor)换成了Anchor-Free(point anchor),检测头也换成了Decoupled Head,这一结构具有提高收敛速度的好处,(在box anchor 方案中试过精度也有提升,但耗时增加了一些)但另一方面讲,也会遇到分类与回归不对齐的问题。在一些网络中,会通过将feature map中的cell(point anchor中心点所编码的box)与ground truth进行IOU计算以分配预测所用cell,但用来分类和回归的最佳cell通常不一致。为了解决这一问题,引入了TAL(Task Alignment Learning)来负责正负样本分配,使得分类和回归任务之间具有较高的对齐一致性。
yolov10/v8中的loss主要分为2部分3个loss:
一、回归分支的损失函数:
1、DFL(Distribution Focal Loss),计算anchor point的中心点到左上角和右下角的偏移量
2、IoU Loss,定位损失,采用CIoU loss,只计算正样本的定位损失
二、分类损失:
1、分类损失,采用BCE loss,只计算正样本的分类损失。
v8DetectionLoss
v8和v10的loss最大的不同在于,v10有两个解耦头,一个计算one2one head,一个计算one2many head,但是两个head的loss函数一样,就是超参数有一些不同
class v10DetectLoss:def __init__(self, model):self.one2many = v8DetectionLoss(model, tal_topk=10)self.one2one = v8DetectionLoss(model, tal_topk=1)def __call__(self, preds, batch):one2many = preds["one2many"]loss_one2many = self.one2many(one2many, batch)one2one = preds["one2one"]loss_one2one = self.one2one(one2one, batch)return loss_one2many[0] + loss_one2one[0], torch.cat((loss_one2many[1], loss_one2one[1]))one2many的topk为10,one2one的topk为1。(这部分代码和我写辅助监督的方式一样)
class v8DetectionLoss:"""Criterion class for computing training losses."""def __init__(self, model, tal_topk=10): # model must be de-paralleled"""Initializes v8DetectionLoss with the model, defining model-related properties and BCE loss function."""device = next(model.parameters()).device # get model deviceh = model.args # hyperparametersm = model.model[-1] # Detect() moduleself.bce = nn.BCEWithLogitsLoss(reduction="none")self.hyp = hself.stride = m.stride # model stridesself.nc = m.nc # number of classesself.no = m.noself.reg_max = m.reg_maxself.device = deviceself.use_dfl = m.reg_max > 1self.assigner = TaskAlignedAssigner(topk=tal_topk, num_classes=self.nc, alpha=0.5, beta=6.0)self.bbox_loss = BboxLoss(m.reg_max - 1, use_dfl=self.use_dfl).to(device)self.proj = torch.arange(m.reg_max, dtype=torch.float, device=device)def preprocess(self, targets, batch_size, scale_tensor):"""Preprocesses the target counts and matches with the input batch size to output a tensor."""if targets.shape[0] == 0:out = torch.zeros(batch_size, 0, 5, device=self.device)else:i = targets[:, 0] # image index_, counts = i.unique(return_counts=True)counts = counts.to(dtype=torch.int32)out = torch.zeros(batch_size, counts.max(), 5, device=self.device)for j in range(batch_size):matches = i == jn = matches.sum()if n:out[j, :n] = targets[matches, 1:]out[..., 1:5] = xywh2xyxy(out[..., 1:5].mul_(scale_tensor))return outdef bbox_decode(self, anchor_points, pred_dist):"""Decode predicted object bounding box coordinates from anchor points and distribution."""if self.use_dfl:b, a, c = pred_dist.shape # batch, anchors, channelspred_dist = pred_dist.view(b, a, 4, c // 4).softmax(3).matmul(self.proj.type(pred_dist.dtype))# pred_dist = pred_dist.view(b, a, c // 4, 4).transpose(2,3).softmax(3).matmul(self.proj.type(pred_dist.dtype))# pred_dist = (pred_dist.view(b, a, c // 4, 4).softmax(2) * self.proj.type(pred_dist.dtype).view(1, 1, -1, 1)).sum(2)return dist2bbox(pred_dist, anchor_points, xywh=False)def __call__(self, preds, batch):"""Calculate the sum of the loss for box, cls and dfl multiplied by batch size."""loss = torch.zeros(3, device=self.device) # box, cls, dflfeats = preds[1] if isinstance(preds, tuple) else predspred_distri, pred_scores = torch.cat([xi.view(feats[0].shape[0], self.no, -1) for xi in feats], 2).split((self.reg_max * 4, self.nc), 1)pred_scores = pred_scores.permute(0, 2, 1).contiguous()pred_distri = pred_distri.permute(0, 2, 1).contiguous()dtype = pred_scores.dtypebatch_size = pred_scores.shape[0]imgsz = torch.tensor(feats[0].shape[2:], device=self.device, dtype=dtype) * self.stride[0] # image size (h,w)anchor_points, stride_tensor = make_anchors(feats, self.stride, 0.5)# Targetstargets = torch.cat((batch["batch_idx"].view(-1, 1), batch["cls"].view(-1, 1), batch["bboxes"]), 1)targets = self.preprocess(targets.to(self.device), batch_size, scale_tensor=imgsz[[1, 0, 1, 0]])gt_labels, gt_bboxes = targets.split((1, 4), 2) # cls, xyxymask_gt = gt_bboxes.sum(2, keepdim=True).gt_(0)# Pboxespred_bboxes = self.bbox_decode(anchor_points, pred_distri) # xyxy, (b, h*w, 4)_, target_bboxes, target_scores, fg_mask, _ = self.assigner(pred_scores.detach().sigmoid(),(pred_bboxes.detach() * stride_tensor).type(gt_bboxes.dtype),anchor_points * stride_tensor,gt_labels,gt_bboxes,mask_gt,)target_scores_sum = max(target_scores.sum(), 1)# Cls loss# loss[1] = self.varifocal_loss(pred_scores, target_scores, target_labels) / target_scores_sum # VFL wayloss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCE# Bbox lossif fg_mask.sum():target_bboxes /= stride_tensorloss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask)loss[0] *= self.hyp.box # box gainloss[1] *= self.hyp.cls # cls gainloss[2] *= self.hyp.dfl # dfl gainreturn loss.sum() * batch_size, loss.detach() # loss(box, cls, dfl)v8DetectionLoss中preprocess
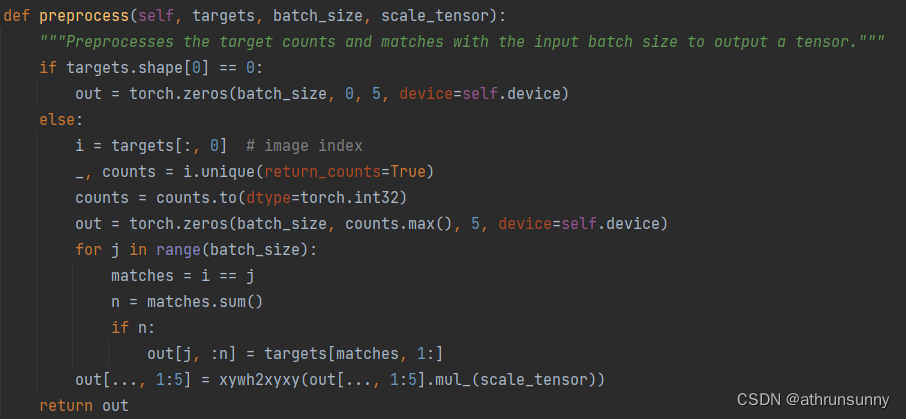
该函数主要是用来处理gt,将同一batch中不同长度的gt(cls + boxes)做对齐,短的gt用全0补齐。假设一个batch为2,其中image1的gt是[4,5],image2的gt是[7,5],那么取该batch中最长的7创建一个batch为2的张量[2,7,5],batch1的前四维为gt信息,为全0。下面用一组实际数据为例:

对应的gt_labels,gt_bboxes,mask_gt(之后会提到)

v8DetectionLoss中bbox_decode

该函数主要是将每一个anchor point和预测的回归参数通过dist2bbox做解码,生成anchor box与gt计算iou
def dist2bbox(distance, anchor_points, xywh=True, dim=-1):"""Transform distance(ltrb) to box(xywh or xyxy)."""assert(distance.shape[dim] == 4)lt, rb = distance.split([2, 2], dim)x1y1 = anchor_points - ltx2y2 = anchor_points + rbif xywh:c_xy = (x1y1 + x2y2) / 2wh = x2y2 - x1y1return torch.cat((c_xy, wh), dim) # xywh bboxreturn torch.cat((x1y1, x2y2), dim) # xyxy bboxloss[1] bce loss对应类别损失
loss[1] = self.bce(pred_scores, target_scores.to(dtype)).sum() / target_scores_sum # BCEloss[0] 对应iou loss
loss[2] 对应dfl loss
loss[0], loss[2] = self.bbox_loss(pred_distri, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask)bbox loss的实现如下:
class BboxLoss(nn.Module):"""Criterion class for computing training losses during training."""def __init__(self, reg_max, use_dfl=False):"""Initialize the BboxLoss module with regularization maximum and DFL settings."""super().__init__()self.reg_max = reg_maxself.use_dfl = use_dfldef forward(self, pred_dist, pred_bboxes, anchor_points, target_bboxes, target_scores, target_scores_sum, fg_mask):"""IoU loss."""weight = target_scores.sum(-1)[fg_mask].unsqueeze(-1)iou = bbox_iou(pred_bboxes[fg_mask], target_bboxes[fg_mask], xywh=False, CIoU=True)loss_iou = ((1.0 - iou) * weight).sum() / target_scores_sum# DFL lossif self.use_dfl:target_ltrb = bbox2dist(anchor_points, target_bboxes, self.reg_max)loss_dfl = self._df_loss(pred_dist[fg_mask].view(-1, self.reg_max + 1), target_ltrb[fg_mask]) * weightloss_dfl = loss_dfl.sum() / target_scores_sumelse:loss_dfl = torch.tensor(0.0).to(pred_dist.device)return loss_iou, loss_dfl@staticmethoddef _df_loss(pred_dist, target):"""Return sum of left and right DFL losses.Distribution Focal Loss (DFL) proposed in Generalized Focal Losshttps://ieeexplore.ieee.org/document/9792391"""tl = target.long() # target lefttr = tl + 1 # target rightwl = tr - target # weight leftwr = 1 - wl # weight rightreturn (F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl+ F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr).mean(-1, keepdim=True)TaskAlignedAssigner
这个我认为是整个loss设计中的重头戏
因为整个loss中不像anchor base算法中需要计算前背景的obj loss,所以在TaskAlignedAssigner中需要确定哪些anchor属于前景哪些anchor属于背景,所以TaskAlignedAssigner得到target_labels, target_bboxes, target_scores的同时还需要得到前景的mask--fg_mask.bool()
class TaskAlignedAssigner(nn.Module):"""A task-aligned assigner for object detection.This class assigns ground-truth (gt) objects to anchors based on the task-aligned metric, which combines bothclassification and localization information.Attributes:topk (int): The number of top candidates to consider.num_classes (int): The number of object classes.alpha (float): The alpha parameter for the classification component of the task-aligned metric.beta (float): The beta parameter for the localization component of the task-aligned metric.eps (float): A small value to prevent division by zero."""def __init__(self, topk=13, num_classes=80, alpha=1.0, beta=6.0, eps=1e-9):"""Initialize a TaskAlignedAssigner object with customizable hyperparameters."""super().__init__()self.topk = topkself.num_classes = num_classesself.bg_idx = num_classesself.alpha = alphaself.beta = betaself.eps = eps@torch.no_grad()def forward(self, pd_scores, pd_bboxes, anc_points, gt_labels, gt_bboxes, mask_gt):"""Compute the task-aligned assignment. Reference code is available athttps://github.com/Nioolek/PPYOLOE_pytorch/blob/master/ppyoloe/assigner/tal_assigner.py.Args:pd_scores (Tensor): shape(bs, num_total_anchors, num_classes)pd_bboxes (Tensor): shape(bs, num_total_anchors, 4)anc_points (Tensor): shape(num_total_anchors, 2)gt_labels (Tensor): shape(bs, n_max_boxes, 1)gt_bboxes (Tensor): shape(bs, n_max_boxes, 4)mask_gt (Tensor): shape(bs, n_max_boxes, 1)Returns:target_labels (Tensor): shape(bs, num_total_anchors)target_bboxes (Tensor): shape(bs, num_total_anchors, 4)target_scores (Tensor): shape(bs, num_total_anchors, num_classes)fg_mask (Tensor): shape(bs, num_total_anchors)target_gt_idx (Tensor): shape(bs, num_total_anchors)"""self.bs = pd_scores.shape[0]self.n_max_boxes = gt_bboxes.shape[1]if self.n_max_boxes == 0:device = gt_bboxes.devicereturn (torch.full_like(pd_scores[..., 0], self.bg_idx).to(device),torch.zeros_like(pd_bboxes).to(device),torch.zeros_like(pd_scores).to(device),torch.zeros_like(pd_scores[..., 0]).to(device),torch.zeros_like(pd_scores[..., 0]).to(device),)mask_pos, align_metric, overlaps = self.get_pos_mask(pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt)target_gt_idx, fg_mask, mask_pos = self.select_highest_overlaps(mask_pos, overlaps, self.n_max_boxes)# Assigned targettarget_labels, target_bboxes, target_scores = self.get_targets(gt_labels, gt_bboxes, target_gt_idx, fg_mask)# Normalizealign_metric *= mask_pospos_align_metrics = align_metric.amax(dim=-1, keepdim=True) # b, max_num_objpos_overlaps = (overlaps * mask_pos).amax(dim=-1, keepdim=True) # b, max_num_objnorm_align_metric = (align_metric * pos_overlaps / (pos_align_metrics + self.eps)).amax(-2).unsqueeze(-1)target_scores = target_scores * norm_align_metricreturn target_labels, target_bboxes, target_scores, fg_mask.bool(), target_gt_idx
get_pos_mask
def get_pos_mask(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, anc_points, mask_gt):"""Get in_gts mask, (b, max_num_obj, h*w)."""mask_in_gts = self.select_candidates_in_gts(anc_points, gt_bboxes) # 表示anchor中心是否位于对应的ground truth bounding box内# Get anchor_align metric, (b, max_num_obj, h*w)align_metric, overlaps = self.get_box_metrics(pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_in_gts * mask_gt)# Get topk_metric mask, (b, max_num_obj, h*w)mask_topk = self.select_topk_candidates(align_metric, topk_mask=mask_gt.expand(-1, -1, self.topk).bool())# Merge all mask to a final mask, (b, max_num_obj, h*w)mask_pos = mask_topk * mask_in_gts * mask_gt # 一个anchor point 负责一个gt object的预测return mask_pos, align_metric, overlaps其中包含select_candidates_in_gts,get_box_metrics,select_topk_candidates,由这三个函数共同选择正样本anchor point的位置
def select_candidates_in_gts(xy_centers, gt_bboxes, eps=1e-9):"""Select the positive anchor center in gt.Args:xy_centers (Tensor): shape(h*w, 2)gt_bboxes (Tensor): shape(b, n_boxes, 4)Returns:(Tensor): shape(b, n_boxes, h*w)"""n_anchors = xy_centers.shape[0] # 表示anchor中心的数量bs, n_boxes, _ = gt_bboxes.shapelt, rb = gt_bboxes.view(-1, 1, 4).chunk(2, 2) # left-top, right-bottom# 通过计算每个anchor中心与每个gt_bboxes的左上角和右下角之间的差值,以及右下角和左上角之间的差值,并将结果拼接为形状为 (bs, n_boxes, n_anchors, -1) 的张量。bbox_deltas = torch.cat((xy_centers[None] - lt, rb - xy_centers[None]), dim=2).view(bs, n_boxes, n_anchors, -1) # return (bbox_deltas.min(3)[0] > eps).to(gt_bboxes.dtype)# 计算 bbox_deltas 张量沿着第3个维度的最小值,形状为 (b, n_boxes, h*w) 的布尔型张量,表示anchor中心是否位于对应的ground truth bounding box内(最小值都为正数)return bbox_deltas.amin(3).gt_(eps) 实现思想很简单就是,将anchor point的坐标与gt box的左上角坐标相减,得到一个差值,同时gt box右下角的坐标与anchor point的坐标相减,同样得到一个差值,如果anchor point位于gt box内,那么这两组差值的数值都应该是大于0的数。
select_candidates_in_gts用于初步筛选位于gt box中的anchor points
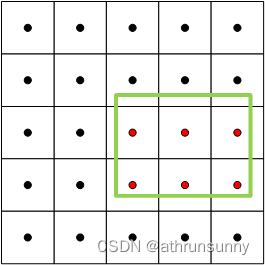
如上图,假设绿色的为gt box,红色的anchor points就是通过 select_candidates_in_gts筛选出来用于预测该gt box表示的object的可能的anchor point,最后返回的是关于这些anchor point的位置mask
get_box_metrics
它具有如下参数:
pd_scores:就是分类head输出的结果,shape一般为[bs, 8400, 80](以coco数据集,输入640*640为例)
pd_bboxes:回归head输出的结果,shape一般为[bs, 8400, 4]
gt_labels,gt_bboxes,mask_gt为gt所包含的信息,由于gt有做过数据用0补齐,mask_gt表示实际上非零的数据
mask_in_gts * mask_gt:表示实际上有gt标签位置上的候选anchor的位置的mask
def get_box_metrics(self, pd_scores, pd_bboxes, gt_labels, gt_bboxes, mask_gt):"""Compute alignment metric given predicted and ground truth bounding boxes."""na = pd_bboxes.shape[-2]mask_gt = mask_gt.bool() # b, max_num_obj, h*woverlaps = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_bboxes.dtype, device=pd_bboxes.device) # 存储ioubbox_scores = torch.zeros([self.bs, self.n_max_boxes, na], dtype=pd_scores.dtype, device=pd_scores.device) # 存储边界框的分数ind = torch.zeros([2, self.bs, self.n_max_boxes], dtype=torch.long) # torch.Size([2, 2, 7]) * 0 # 2, b, max_num_objind[0] = torch.arange(end=self.bs).view(-1, 1).expand(-1, self.n_max_boxes) # b, max_num_obj # 批次信息 为从0到 self.bs-1 的序列,将其展开为形状为 (self.bs, self.n_max_boxes)ind[1] = gt_labels.squeeze(-1) # b, max_num_obj # 类别信息 为 gt_labels 的挤压操作(squeeze(-1)),将其形状变为 (self.bs, self.n_max_boxes)# Get the scores of each grid for each gt clsbbox_scores[mask_gt] = pd_scores[ind[0], :, ind[1]][mask_gt] # b, max_num_obj, h*w 根据实际边界框的掩码来获取每个网格单元的预测分数,并存储在 bbox_scores 中# (b, max_num_obj, 1, 4), (b, 1, h*w, 4)pd_boxes = pd_bboxes.unsqueeze(1).expand(-1, self.n_max_boxes, -1, -1)[mask_gt]gt_boxes = gt_bboxes.unsqueeze(2).expand(-1, -1, na, -1)[mask_gt]overlaps[mask_gt] = self.iou_calculation(gt_boxes, pd_boxes)# 对于满足实际边界框掩码的每个位置,从 pd_bboxes 中获取预测边界框(pd_boxes)和实际边界框(gt_boxes)计算iou,并将结果存储在 overlaps 中align_metric = bbox_scores.pow(self.alpha) * overlaps.pow(self.beta) # align_metric = bbox_scores^alpha * overlaps^beta 计算对齐度量,其中 alpha 和 beta 是超参数return align_metric, overlaps通过iou计算预测框(解码后的)与gt box之间的iou得到overlap;由于每个anchor point都有80个类别的预测得分,通过该处gt box对应的类别标签得到预测得分,得到bbox_scores,通过align_metric = bbox_scores^alpha * overlaps^beta 计算对齐度量。该度量同时考虑得分和框的重叠度。
select_topk_candidates
就是通过get_box_metrics中得到的align_metric来确定所有与gt有重叠的anchor中align_metric最高的前十(或前一)
def select_topk_candidates(self, metrics, largest=True, topk_mask=None):"""Select the top-k candidates based on the given metrics.Args:metrics (Tensor): A tensor of shape (b, max_num_obj, h*w), where b is the batch size,max_num_obj is the maximum number of objects, and h*w represents thetotal number of anchor points.largest (bool): If True, select the largest values; otherwise, select the smallest values.topk_mask (Tensor): An optional boolean tensor of shape (b, max_num_obj, topk), wheretopk is the number of top candidates to consider. If not provided,the top-k values are automatically computed based on the given metrics.Returns:(Tensor): A tensor of shape (b, max_num_obj, h*w) containing the selected top-k candidates."""# (b, max_num_obj, topk)# 使用 torch.topk 函数在给定的度量指标张量 metrics 的最后一个维度上选择前 k 个最大。# 这将返回两个张量:topk_metrics (形状为 (b, max_num_obj, topk)) 包含了选定的度量指标,以及 topk_idxs (形状为 (b, max_num_obj, topk)) 包含了相应的索引topk_metrics, topk_idxs = torch.topk(metrics, self.topk, dim=-1, largest=largest)if topk_mask is None:topk_mask = (topk_metrics.max(-1, keepdim=True)[0] > self.eps).expand_as(topk_idxs)# (b, max_num_obj, topk)topk_idxs.masked_fill_(~topk_mask, 0) # 使用 topk_mask 将 topk_idxs 张量中未选中的索引位置(~topk_mask)用零进行填充# (b, max_num_obj, topk, h*w) -> (b, max_num_obj, h*w)count_tensor = torch.zeros(metrics.shape, dtype=torch.int8, device=topk_idxs.device)ones = torch.ones_like(topk_idxs[:, :, :1], dtype=torch.int8, device=topk_idxs.device)for k in range(self.topk):# Expand topk_idxs for each value of k and add 1 at the specified positionscount_tensor.scatter_add_(-1, topk_idxs[:, :, k : k + 1], ones) # 使用 scatter_add_ 函数根据索引 topk_idxs[:, :, k : k + 1],将 ones 张量的值相加到 count_tensor 张量的相应位置上# count_tensor.scatter_add_(-1, topk_idxs, torch.ones_like(topk_idxs, dtype=torch.int8, device=topk_idxs.device))# Filter invalid bboxescount_tensor.masked_fill_(count_tensor > 1, 0) # 将 count_tensor 中大于 1 的值用零进行填充,以过滤掉超过一个的边界框return count_tensor.to(metrics.dtype)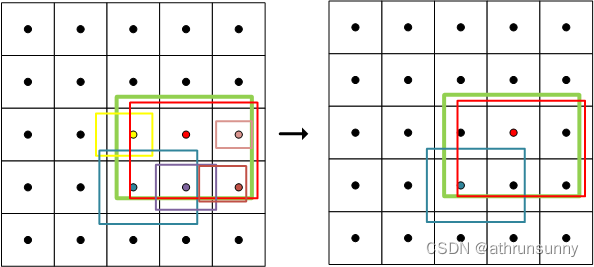
比如上图,由于这里只是作为示例,只表示其中一个特征图上gt样例,其他层的gt位置可能有更多的anchor point满足 align_metric的条件被保留下来(不必太纠结这里是不是有10个),因为PAN输出了三层特征图,anchor对应每层特征图的中心,而实践中将每层的anchor展平之后合并在一起得到8400的长度,而最终是在这8400中取前十的anchor,所以每层特征图上保留的anchor可能数量不等。
此时被保留下来的anchor point的位置用1表示,其余位置为0,仅保留了指标前十的样本作为正样本
select_highest_overlaps
def select_highest_overlaps(mask_pos, overlaps, n_max_boxes):"""If an anchor box is assigned to multiple gts, the one with the highest IoU will be selected.Args:mask_pos (Tensor): shape(b, n_max_boxes, h*w)overlaps (Tensor): shape(b, n_max_boxes, h*w)Returns:target_gt_idx (Tensor): shape(b, h*w)fg_mask (Tensor): shape(b, h*w)mask_pos (Tensor): shape(b, n_max_boxes, h*w)"""# (b, n_max_boxes, h*w) -> (b, h*w)fg_mask = mask_pos.sum(-2) # 对 mask_pos 沿着倒数第二个维度求和,得到形状为 (b, h*w) 的张量 fg_mask,表示每个网格单元上非背景anchor box的数量if fg_mask.max() > 1: # one anchor is assigned to multiple gt_bboxes# 创建一个布尔型张量 mask_multi_gts,形状为 (b, n_max_boxes, h*w),用于指示哪些网格单元拥有多个ground truth bounding boxesmask_multi_gts = (fg_mask.unsqueeze(1) > 1).expand(-1, n_max_boxes, -1) # (b, n_max_boxes, h*w)# 获取每个网格单元上具有最高IoU的ground truth bounding box的索引,并创建一个张量 is_max_overlaps,形状与 mask_pos 相同,# 其中最高IoU的ground truth bounding box对应的位置上为1,其余位置为0。max_overlaps_idx = overlaps.argmax(1) # (b, h*w)is_max_overlaps = torch.zeros(mask_pos.shape, dtype=mask_pos.dtype, device=mask_pos.device)is_max_overlaps.scatter_(1, max_overlaps_idx.unsqueeze(1), 1) # max_overlaps_idx表示具有最大iou的索引,将具有最大iou的位置设置为1# 根据 mask_multi_gts 来更新 mask_pos。对于存在多个ground truth bounding box的网格单元,将 is_max_overlaps 中# 对应位置的值赋给 mask_pos,以保留具有最高IoU的ground truth bounding box的匹配情况mask_pos = torch.where(mask_multi_gts, is_max_overlaps, mask_pos).float() # (b, n_max_boxes, h*w)fg_mask = mask_pos.sum(-2)# Find each grid serve which gt(index)target_gt_idx = mask_pos.argmax(-2) # (b, h*w) # 得到每个网格单元上具有最高IoU的ground truth bounding box的索引 target_gt_idxreturn target_gt_idx, fg_mask, mask_pos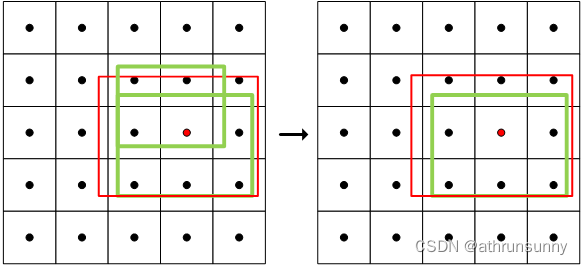
对被分配了多个gt的anchor去重,得到前景的mask以及anchor point上具有最高IoU的ground truth bounding box的索引。假设上图中红色的anchor被分配给了两个gt,通select_highest_overlaps后会保留gt与该anchor的iou最大的那个,并用该anchor来预测该gt,另一个gt则可能会被周围的其他anchor所负责。此时也要更新mask_pos,毕竟重新对anchor做了处理。
因为每个anchor负责一个类别的检测,mask_pos表示最终确定的anchor的mask,如下图所示为其中一个batch中数据形式
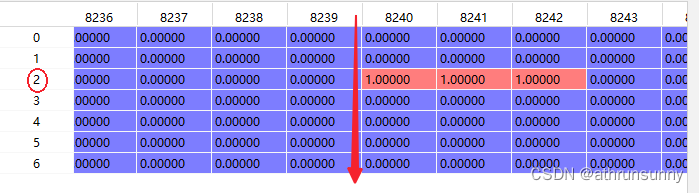
该batch中8240,8241,8242为最终确定的anchor,其在红色箭头所示维度上对应的索引为2,target_gt_idx在该batch上的最终表示为:

get_targets
有了以上的信息之后就获取gt了
def get_targets(self, gt_labels, gt_bboxes, target_gt_idx, fg_mask):"""Compute target labels, target bounding boxes, and target scores for the positive anchor points.Args:gt_labels (Tensor): Ground truth labels of shape (b, max_num_obj, 1), where b is thebatch size and max_num_obj is the maximum number of objects.gt_bboxes (Tensor): Ground truth bounding boxes of shape (b, max_num_obj, 4).target_gt_idx (Tensor): Indices of the assigned ground truth objects for positiveanchor points, with shape (b, h*w), where h*w is the totalnumber of anchor points.fg_mask (Tensor): A boolean tensor of shape (b, h*w) indicating the positive(foreground) anchor points.Returns:(Tuple[Tensor, Tensor, Tensor]): A tuple containing the following tensors:- target_labels (Tensor): Shape (b, h*w), containing the target labels forpositive anchor points.- target_bboxes (Tensor): Shape (b, h*w, 4), containing the target bounding boxesfor positive anchor points.- target_scores (Tensor): Shape (b, h*w, num_classes), containing the target scoresfor positive anchor points, where num_classes is the numberof object classes."""# Assigned target labels, (b, 1)batch_ind = torch.arange(end=self.bs, dtype=torch.int64, device=gt_labels.device)[..., None]# 使用 target_gt_idx 加上偏移量,得到形状为 (b, h*w) 的 target_gt_idx 张量,表示正样本anchor point的真实类别索引target_gt_idx = target_gt_idx + batch_ind * self.n_max_boxes # (b, h*w)# 使用 flatten 函数将 gt_labels 张量展平为形状为 (b * max_num_obj) 的张量,然后使用 target_gt_idx 进行索引,# 得到形状为 (b, h*w) 的 target_labels 张量,表示正样本anchor point的目标标签target_labels = gt_labels.long().flatten()[target_gt_idx] # (b, h*w)# Assigned target boxes, (b, max_num_obj, 4) -> (b, h*w, 4)target_bboxes = gt_bboxes.view(-1, gt_bboxes.shape[-1])[target_gt_idx] # 表示正样本anchor point的目标边界框# Assigned target scorestarget_labels.clamp_(0)# 10x faster than F.one_hot()target_scores = torch.zeros((target_labels.shape[0], target_labels.shape[1], self.num_classes),dtype=torch.int64,device=target_labels.device,) # (b, h*w, 80)target_scores.scatter_(2, target_labels.unsqueeze(-1), 1) # 使用 scatter_ 函数将 target_labels 的值进行 one-hot 编码,将张量中每个位置上的目标类别置为 1fg_scores_mask = fg_mask[:, :, None].repeat(1, 1, self.num_classes) # (b, h*w, 80)target_scores = torch.where(fg_scores_mask > 0, target_scores, 0) # 根据 fg_scores_mask 的值,将 target_scores 张量中的非正样本位置(值小于等于 0)即背景类置为零return target_labels, target_bboxes, target_scores该函数的要点基本都在代码里注释了
得到target后还要对target_scores做一些归一化操作
相关文章:
yolov10/v8 loss详解
v10出了就想看看它的loss设计有什么不同,看下来由于v8和v10的loss部分基本一致就放一起了。 v10的论文笔记,还没看的可以看看,初步尝试耗时确实有提升 好记性不如烂笔头,还是得记录一下,以免忘了,废话结束…...

Typescript高级: 深入理解infer关键字
概述 在 TS 中,infer 是一个高级类型操作,特别是条件类型和映射类型中非常有用的关键字它在泛型中使用也会是一个强大工具,增强了类型推断的能力,让开发者更灵活地处理和操作类型它允许在泛型类型推导过程中捕获一个具体的类型&a…...

JQC-3FF-S-Z 继电器模块使用(arduino)
前言 继电器模块可以控制电流的接通和非接通状态,和开关一样。实际上是用小电流去控制大电流运作的一种“自动开关” 本文只是简单使用继电器模块做一个 led 点亮和熄灭的案例,结合案例可以和 nodemcu 等板子结合做出远程控制开关。 材料准备 杜邦线…...
黑马一站制造数仓实战2
问题 DG连接问题 原理:JDBC:用Java代码连接数据库 Hive/SparkSQL:端口有区别 可以为同一个端口,只要不在同一台机器 项目:一台机器 HiveServer:10000 hiveserver.port 10000 SparkSQL:10001…...
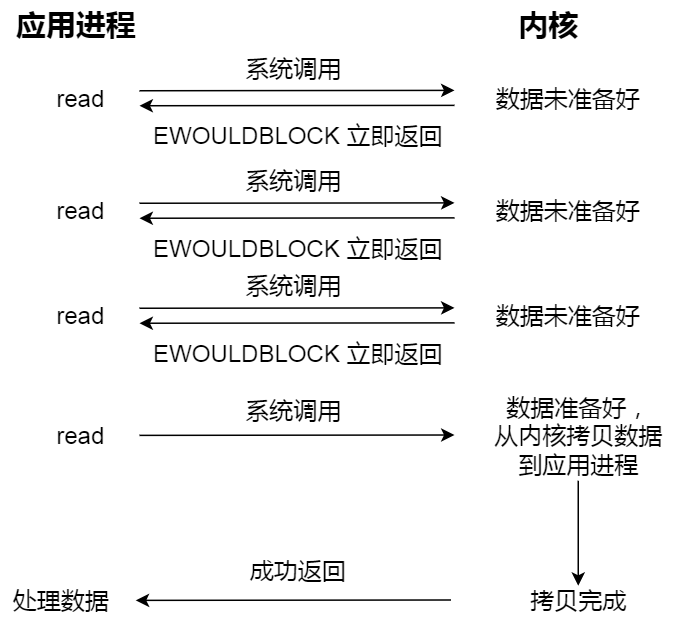
网络I/O模型
网络I/O模型 同步I/O阻塞I/O非阻塞I/OI/O多路复用select函数接口示例 poll函数接口示例 poll 和 select 的区别epoll原理:示例 异步I/O 同步I/O 阻塞I/O 一个基本的C/S模型如下图所图:其中 listen()、connect()、write()、read() 都是阻塞I/O࿰…...
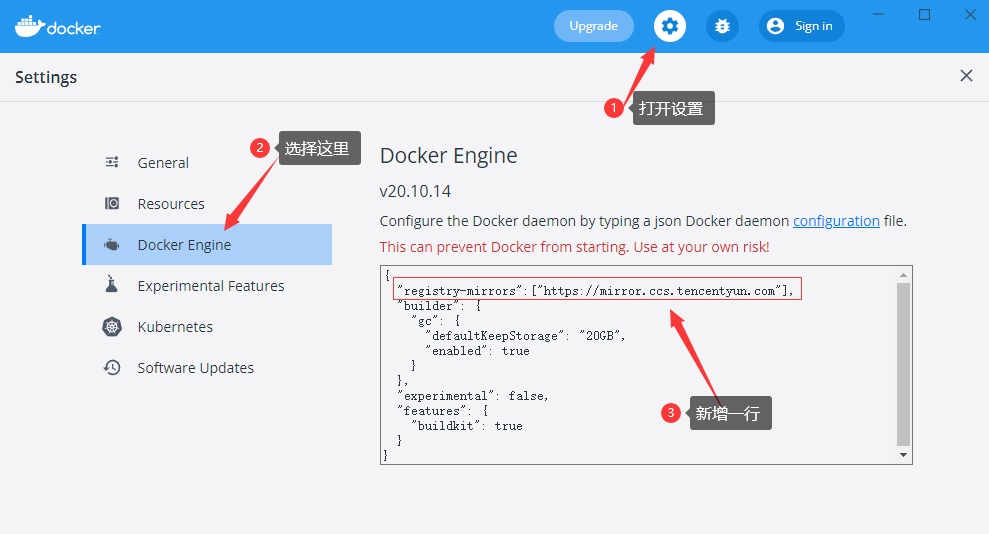
Docker 简介和安装
目录 Docker 是什么 跟普通虚拟机的对比 打包、分发、部署 Docker 部署的优势 Docker 通常用来做什么 重要概念:镜像、容器 安装 镜像加速源 Docker 是什么 Docker 是一个应用打包、分发、部署的工具 你也可以把它理解为一个轻量的虚拟机,它只虚…...

【源码】Spring Data JPA原理解析之Repository自定义方法命名规则执行原理(二)
Spring Data JPA系列 1、SpringBoot集成JPA及基本使用 2、Spring Data JPA Criteria查询、部分字段查询 3、Spring Data JPA数据批量插入、批量更新真的用对了吗 4、Spring Data JPA的一对一、LazyInitializationException异常、一对多、多对多操作 5、Spring Data JPA自定…...

Vue前端中从后端获取图片验证码
前端发送请求 <template><el-form :model"user" :rules"rules" ref"userForm" class"login" label-width"auto" style"max-width: 600px"><el-form-item label"用户名" prop"name…...
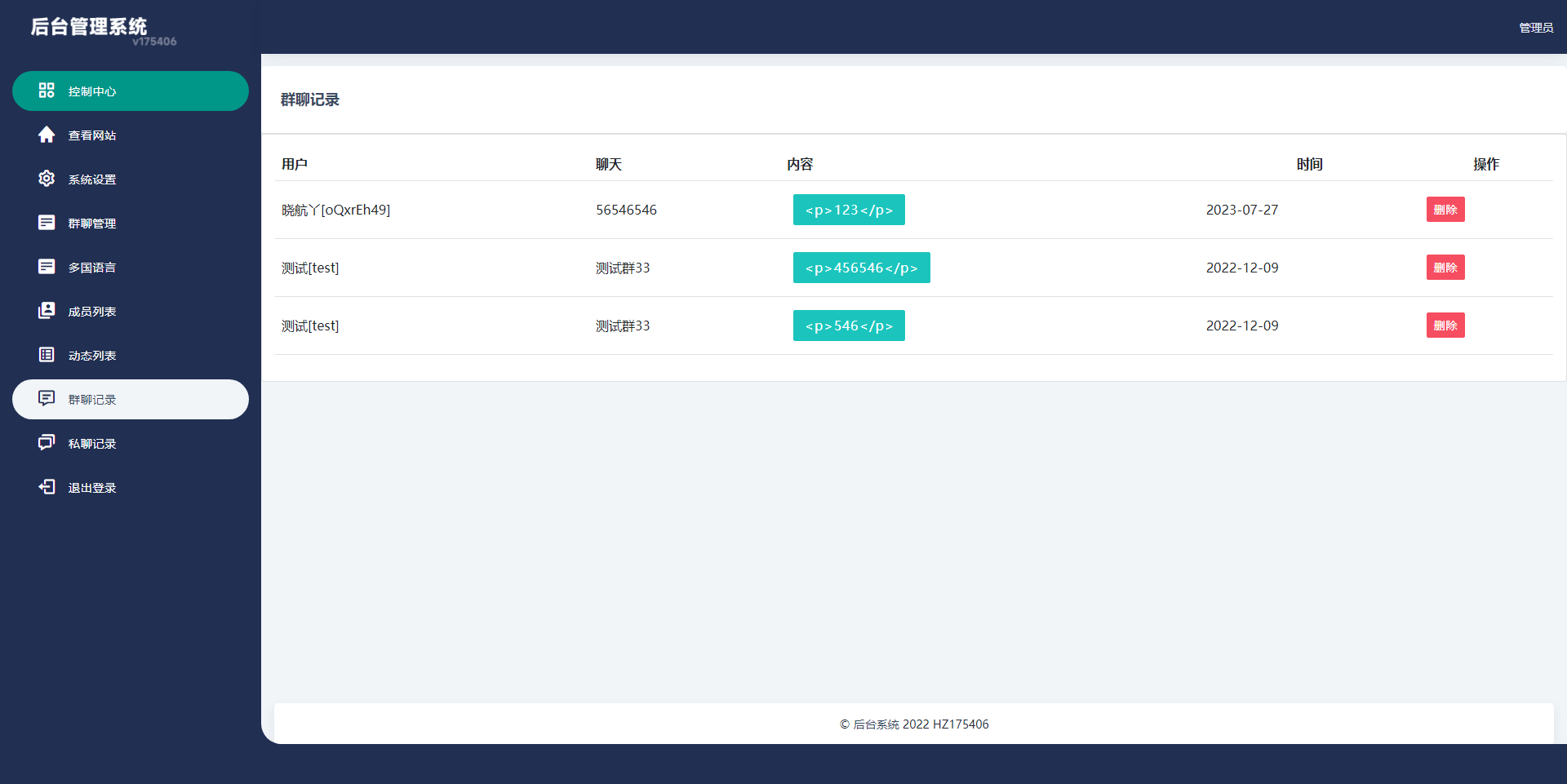
【源码】多语言H5聊天室/thinkphp多国语言即时通讯/H5聊天室源码/在线聊天/全开源
多语言聊天室系统,可当即时通讯用,系统默认无需注册即可进入群聊天,全开源 【海外聊天室】多语言H5聊天室/thinkphp多国语言即时通讯/H5聊天室源码/在线聊天/全开源 - 吾爱资源网...

gitlab 创建 ssh 和 token
文章目录 一、创建ssh key二、将密钥内容复制到gitlab三、创建token 一、创建ssh key 打开控制台cmd,执行命令 ssh-keygen -t rsa -C xxxxx xxxxx是你自己的邮箱 C:\Users\xx\.ssh 目录下会创建一个名为id_rsa.pub的文件,用记事本打开,并…...

Docker - Kafka
博文目录 文章目录 说明命令 说明 Docker Hub - bitnami/kafka Docker Hub - apache/kafka Kafka QuickStart Kafka 目前没有 Docker 官方镜像, 目前拉取次数最多的是 bitnami/kafka, Apache 提供的是 apache/kafka (更新最及时), 本文使用 bitnami/kafka bitnami/kafka 镜像…...
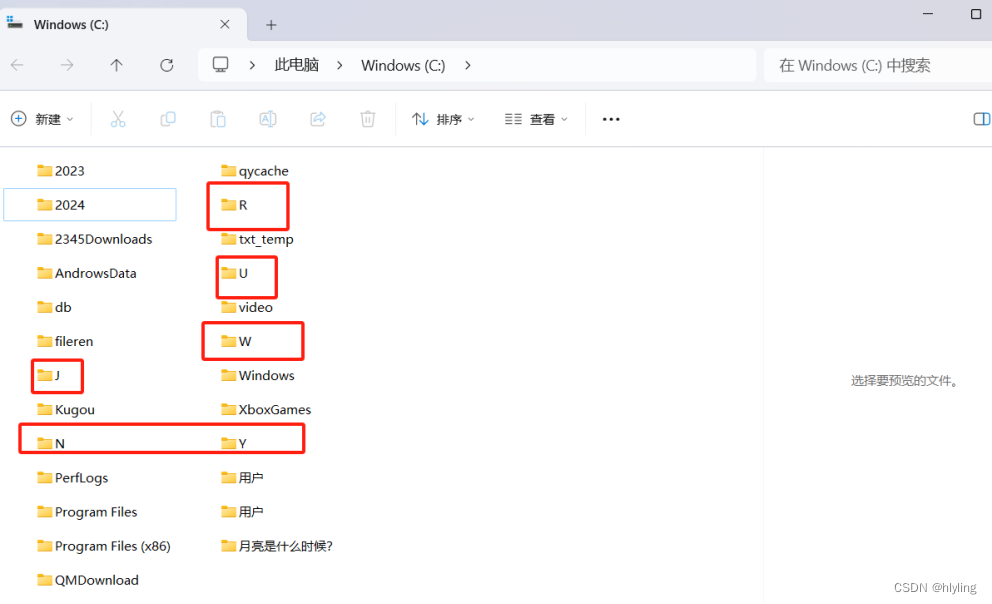
一键实现文件夹批量高效重命名:轻松运用随机一个字母命名,让文件管理焕然一新!
在数字化时代,文件夹管理是我们日常生活和工作中不可或缺的一部分。然而,随着文件数量的不断增加,文件夹命名的繁琐和重复成为了一个让人头疼的问题。你是否曾因为手动一个个重命名文件夹而感到枯燥乏味?你是否曾渴望有一种方法能…...

Vue3项目练习详细步骤(第二部分:主页面搭建)
主页面搭建 页面主体结构 路由 子路由 主页面搭建 页面主体结构 在vuews目录下新建Layout.vue文件 主页面内容主体代码 <script setup> import {Management,Promotion,UserFilled,User,Crop,EditPen,SwitchButton,CaretBottom } from element-plus/icons-vue imp…...
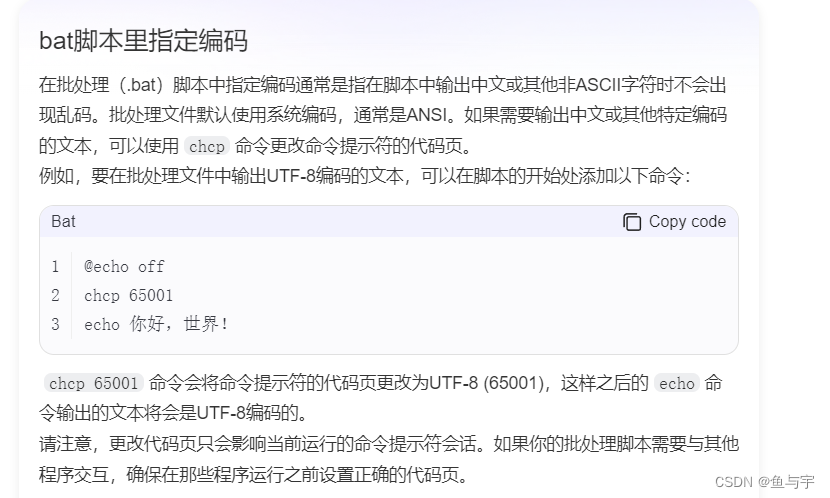
[个人总结]-java常用方法
1.获取项目根路径 user.dir是一个系统属性,表示用户当前的工作目录,大多数情况下,用户的当前工作目录就是java项目的根目录(src文件的同级路径) System.getProperty("user.dir") 结果:D:\code…...

什么是Java泛型?它有什么作用
Java泛型(Generics)是一种允许在定义类、接口和方法时使用类型参数的机制。泛型提供了一种机制,使得代码可以对多种类型的对象进行操作,而无需进行类型转换。 Java泛型的作用 类型安全:通过在编译时进行类型检查&…...

[机缘参悟-197] - 《道家-水木然人间清醒1》读书笔记 -21-看问题从现象到本质的层次
目录 1. 现象层: 2. 关联层: 3. 原因层: 4. 本质层: 5. 解决方案层: 6. 设计实现层: 7. 泛化: 8. 创新与发现: 看问题从现象到本质的层次是一个逐步深入、由表及里的过程。这…...

AIGC商业案例实操课,发觉其创造和商业的无限可能,Ai技术在行业应用新的商机
课程下载:https://download.csdn.net/download/m0_66047725/89307523 更多资源下载:关注我。 课程内容 1 AI为什么火 。写在课程前面的寄语 。AIGC标志性事件:太空歌剧院 。AI人工智能为什么这么火 ,AI人工智能发展历程 。聊天AI会取…...

Java学习路径图
1.学习路径 JAVA架构师学习路径 2.路径拆解 2.1 Spring 2.1.1 SpringBoot原理 SpringBoot2学习视频 SpringBoot2笔记 SpringBoo2代码 2.2.2 SpringBoot项目 《谷粒商城》学习视频...
文章解读与仿真程序复现思路——电力系统自动化EI\CSCD\北大核心《考虑动态定价的新能源汽车能源站优化运行》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 论文与完整源程序_电网论文源程序的博客-CSDN博客https://blog.csdn.net/liang674027206/category_12531414.html 电网论文源程序-CSDN博客电网论文源…...

【简单讲解下Fine-tuning BERT,什么是Fine-tuning BERT?】
🎥博主:程序员不想YY啊 💫CSDN优质创作者,CSDN实力新星,CSDN博客专家 🤗点赞🎈收藏⭐再看💫养成习惯 ✨希望本文对您有所裨益,如有不足之处,欢迎在评论区提出…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...

车载诊断架构 --- ZEVonUDS(J1979-3)简介第一篇
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...
解析“道作为序位生成器”的核心原理
解析“道作为序位生成器”的核心原理 以下完整展开道函数的零点调控机制,重点解析"道作为序位生成器"的核心原理与实现框架: 一、道函数的零点调控机制 1. 道作为序位生成器 道在认知坐标系$(x_{\text{物}}, y_{\text{意}}, z_{\text{文}}…...

UE5 音效系统
一.音效管理 音乐一般都是WAV,创建一个背景音乐类SoudClass,一个音效类SoundClass。所有的音乐都分为这两个类。再创建一个总音乐类,将上述两个作为它的子类。 接着我们创建一个音乐混合类SoundMix,将上述三个类翻入其中,通过它管理每个音乐…...
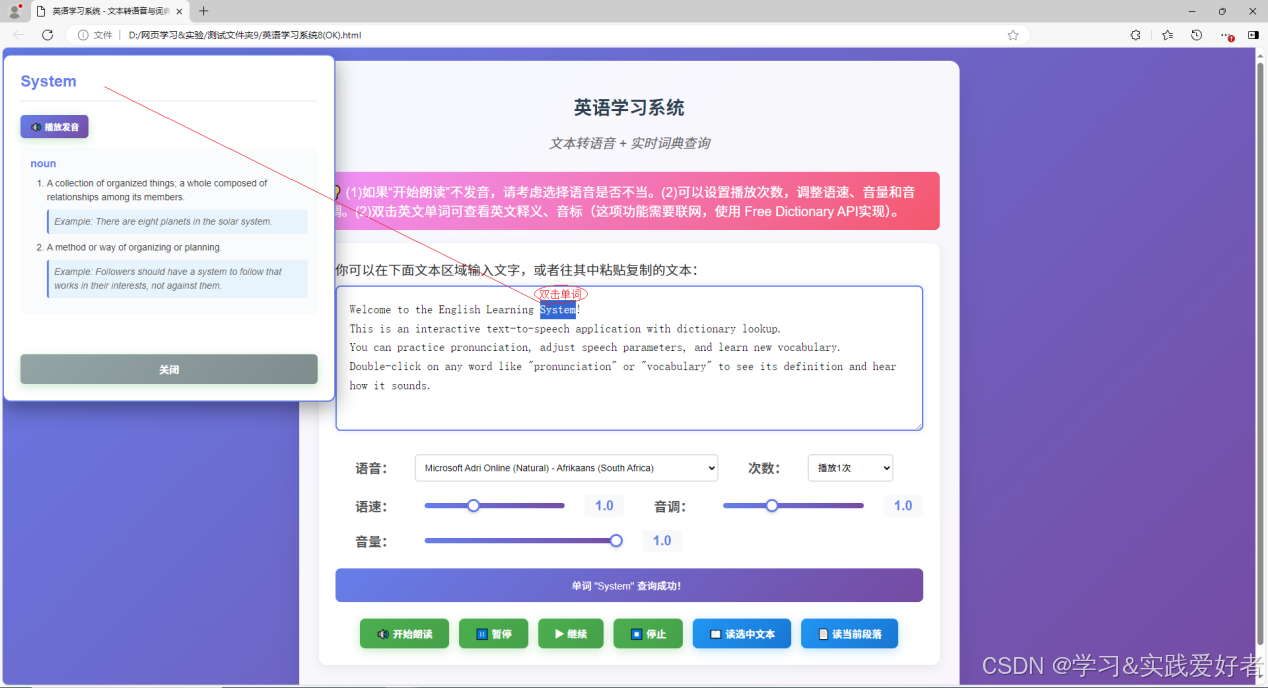
HTML版英语学习系统
HTML版英语学习系统 这是一个完全免费、无需安装、功能完整的英语学习工具,使用HTML CSS JavaScript实现。 功能 文本朗读练习 - 输入英文文章,系统朗读帮助练习听力和发音,适合跟读练习,模仿学习;实时词典查询 - 双…...

[特殊字符] Spring Boot底层原理深度解析与高级面试题精析
一、Spring Boot底层原理详解 Spring Boot的核心设计哲学是约定优于配置和自动装配,通过简化传统Spring应用的初始化和配置流程,显著提升开发效率。其底层原理可拆解为以下核心机制: 自动装配(Auto-Configuration) 核…...
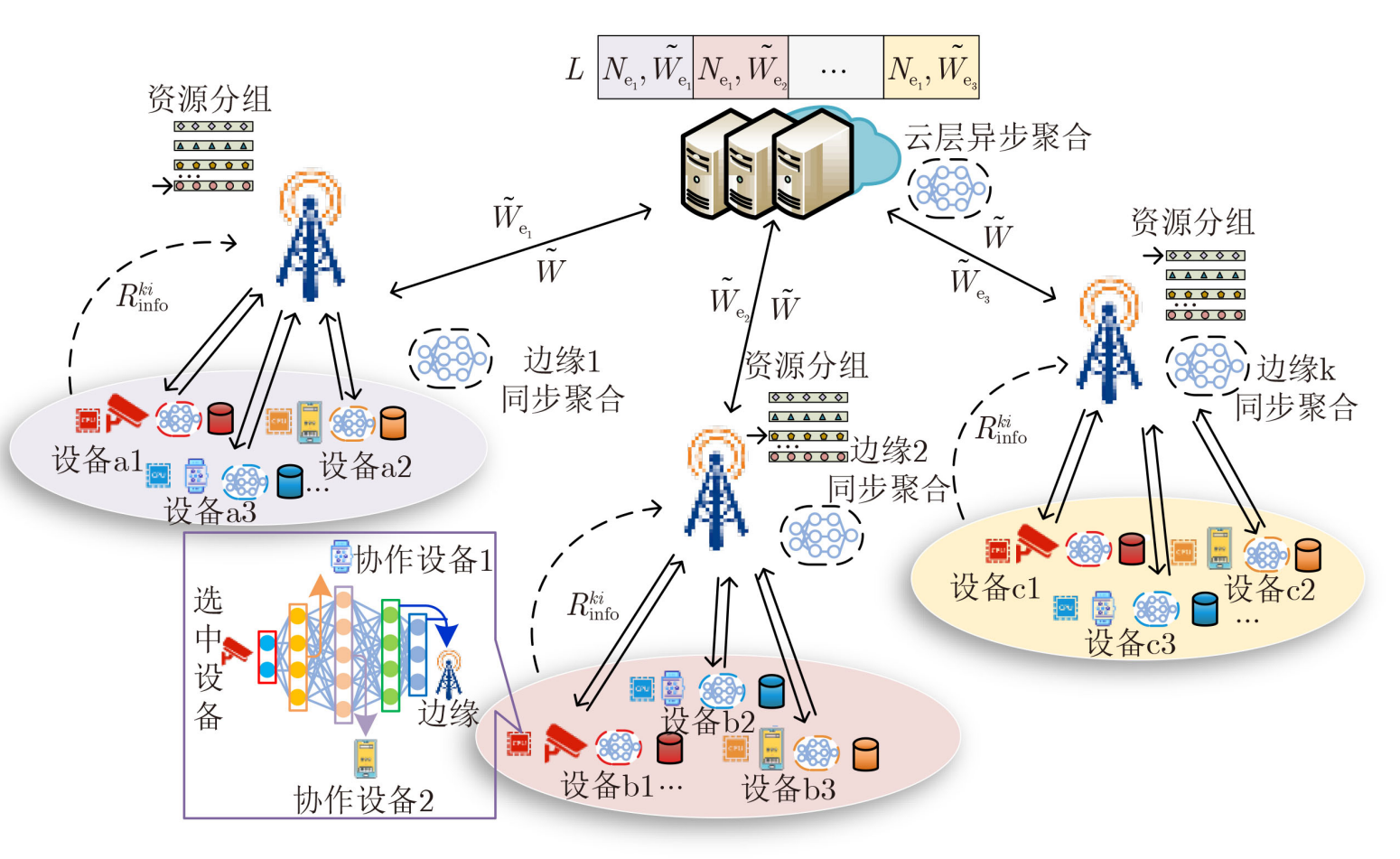
联邦学习带宽资源分配
带宽资源分配是指在网络中如何合理分配有限的带宽资源,以满足各个通信任务和用户的需求,尤其是在多用户共享带宽的情况下,如何确保各个设备或用户的通信需求得到高效且公平的满足。带宽是网络中的一个重要资源,通常指的是单位时间…...