基于聚类和回归分析方法探究蓝莓产量影响因素与预测模型研究附录
🌟欢迎来到 我的博客 —— 探索技术的无限可能!
🌟博客的简介(文章目录)
目录
- 背景
- 数据说明
- 数据来源
- 思考
- 附录
- 数据预处理
- 导入包以及数据读取
- 数据预览
- 数据处理
- 相关性分析
- 聚类分析
- 数据处理
- 确定聚类数
- 建立k均值聚类模型
- 多元线性回归模型
- 检测多重共线性
- 主成分分析
- 建立多元线性回归模型
- 残差项检验
- 模型预测
- 随机森林
- 建立模型
- 参数优化
- 模型预测
背景
蓝莓在全球范围内备受欢迎,其独特的风味和丰富的营养价值令消费者为之倾倒。蓝莓生长对适宜气候和土壤的依赖,因此主要分布于北美、欧洲、澳洲等地区。
野生蓝莓养殖目前正处于蓬勃发展的阶段,吸引了越来越多的投资者和农户投身其中。全球对健康食品的需求不断增加,野生蓝莓以其天然的营养价值和丰富的抗氧化物质而备受瞩目。然而,养殖野生蓝莓也面临一系列挑战,包括气候不稳定、疾病威胁和市场价格波动。因此,成功的野生蓝莓养殖需要不断的创新和可持续的农业实践,以满足日益增长的全球市场需求。
蓝莓是多年生开花植物,浆果呈蓝色或紫色。它们被归类于越橘属中的蓝越橘科。越橘还包括小红莓、山桑子、胡越橘和马德拉蓝莓。商业蓝莓–野生(低丛)和栽培(高丛)–均原产于北美洲。高丛品种在 20 世纪 30 年代引入欧洲。
蓝莓通常是匍匐灌木,高度从 10 厘米(4 英寸)到 4 米(13 英尺)不等。在蓝莓的商业生产中,生长在低矮灌木丛中、浆果较小、豌豆大小的品种被称为 “低丛蓝莓”(与 "野生 "同义),而生长在较高、栽培灌木丛中、浆果较大的品种被称为 “高丛蓝莓”。加拿大是低丛蓝莓的主要生产国,而美国生产的高丛蓝莓约占全球供应量的 40%。

数据说明
| 字段 | 说明 |
|---|---|
| Clonesize* | 蓝莓克隆平均大小,单位: m 2 m^2 m2 |
| Honeybee | 蜜蜂密度(单位: 蜜蜂 / m 2 / 分钟 蜜蜂/m^2/分钟 蜜蜂/m2/分钟 ) |
| Bumbles | 大型蜜蜂密度(单位: 大型蜜蜂 / m 2 / 分钟 大型蜜蜂/m^2/分钟 大型蜜蜂/m2/分钟 ) |
| Andrena | 安德烈纳蜂密度(单位: 安德烈纳蜂 / m 2 / 分钟 安德烈纳蜂/m^2/分钟 安德烈纳蜂/m2/分钟 ) |
| Osmia | 钥匙蜂密度(单位: 钥匙蜂 / m 2 / 分钟 钥匙蜂/m^2/分钟 钥匙蜂/m2/分钟 ) |
| MaxOfUpperTRange | 花期内最高温带日平均气温的最高记录,单位: ∘ C {^{\circ}C} ∘C |
| MinOfUpperTRange | 花期内最高温带日平均气温的最低记录,单位: ∘ C {^{\circ}C} ∘C |
| AverageOfUpperTRange | 花期内最高温带日平均气温,单位: ∘ C {^{\circ}C} ∘C |
| MaxOfLowerTRange | 花期内最低温带日平均气温的最高记录,单位: ∘ C {^{\circ}C} ∘C |
| MinOfLowerTRange | 花期内最低温带日平均气温的最低记录,单位: ∘ C {^{\circ}C} ∘C |
| AverageOfLowerTRange | 花期内最低温带日平均气温,单位: ∘ C {^{\circ}C} ∘C |
| RainingDays | 花期内降雨量大于 0 的日数总和,单位:天 |
| AverageRainingDays | 花期内降雨日数的平均值,单位:天 |
| fruitset | 果实集 |
| fruitmass | 果实质量 |
| seeds | 种子数 |
注:
Clonesize 表示每个蓝莓克隆株的平均占地面积大小。
蓝莓克隆(Blueberry clone)指的是蓝莓的克隆体。蓝莓繁殖和种植主要有两种方式:
- 种子育种。从蓝莓果实中提取种子,播种育苗。这种方式育出来的蓝莓植株遗传特征会有很大变异。
- 克隆繁殖。选取优良品种蓝莓母株,通过组织培养等焉条繁殖出基因特征高度一致的克隆蓝莓株。这种子植出来的蓝莓园,每个蓝莓株的性状和产量会趋于一致。
所以蓝莓克隆就指的是通过无性繁殖方式培育出来的蓝莓株。整个蓝莓园被同一个蓝莓品种的克隆株占满。
数据来源
https://www.kaggle.com/competitions/playground-series-s3e14/data
思考
蓝莓克隆大小与基因表达、气候条件、土壤特性等因素有关。气温对蓝莓生长有显著影响,尤其在花芽形成和果实发育阶段。降雨对蓝莓生长的影响主要体现在水分管理上。机器学习预测模型在农业领域能够有效预测作物产量、病虫害发生以及土壤属性等。
蓝莓克隆大小相关分析:可以通过统计分析和数据可视化,探讨蓝莓克隆平均大小(Clonesize)与其他因素之间的关系
-
基因表达:研究表明,蓝莓VcLon1基因的表达与植株抗旱性有关。该基因在不同组织中的表达量不同,且干旱条件下其转录水平显著提高,可能与植物适应环境压力的能力有关。
-
气候条件:温度和光照是影响蓝莓生长的关键气象因素。适宜的温度促进根系发展,而充足的日照则有利于光合作用和花芽的形成。
-
土壤特性:土壤pH值对蓝莓的生长至关重要。土壤pH值过高或过低都会限制蓝莓的生长,因此需通过改良土壤来优化蓝莓的生长条件。
-
水分管理:适量的降雨有助于蓝莓生长,但过多则可能导致营养过剩和根系疾病。合理的灌溉策略对于维持蓝莓正常生长周期非常重要。
-
授粉活动:蓝莓的花期授粉活动也会影响果实的产量和质量。蜜蜂等传粉昆虫的活跃度直接影响授粉效率和果实的成熟。
气温与蓝莓生长的关系:可以使用最高温带日平均气温(MaxOfUpperTRange、MinOfUpperTRange、AverageOfUpperTRange)和最低温带日平均气温(MaxOfLowerTRange、MinOfLowerTRange、AverageOfLowerTRange)等气象数据,分析它们与蓝莓果实集(fruitset)、果实质量(fruitmass)以及种子数(seeds)之间的关联
-
生长发育:在一定范围内,气温升高可以促进蓝莓的生长发育。但是,超过最适温度范围会导致生长受阻。
-
花芽形成:适宜的温度有利于花芽的形成,而不恰当的低温可能会造成来年减产。
-
果实发育:较高的温度可以加速果实的发育,使果实更大,成熟期提前。
-
种子发育:变温处理可以提高种子的萌芽率,说明温度波动对蓝莓种子的萌发有积极影响。
-
光合作用:温度对蓝莓叶片的光合作用有显著影响,适宜的温度可以增加CO2吸收率,提高光合效率。
降雨对蓝莓生长的影响:使用降雨数据(RainingDays、AverageRainingDays),可以研究降雨对蓝莓的生长和生产是否有影响
-
水分需求:蓝莓对水分的需求较为严格,过多的降雨会导致营养过剩和果实品质下降。
-
涝害问题:蓝莓不耐涝,持续降雨可能引起根部病害,影响植株健康。
-
灌溉管理:科学的灌溉管理是保证蓝莓良好生长的关键,应根据降雨量和土壤湿度适时调整灌溉计划。
-
果实品质:适度降雨有利于提升蓝莓果实的水溶性总糖含量,改善口感;而过量降雨则会稀释果实中的糖分,降低甜度。
-
枝叶生长:雨水过多时,蓝莓表现出枝叶徒长,这可能会影响光合作用的效率和能量分配。
机器学习预测模型在农业领域的应用:预测蓝莓克隆大小、果实集、果实质量或种子数等目标变量
-
土壤分析优化:利用机器学习模型分析土壤数据,预测土壤质量并提供改进建议,以实现精准施肥和灌溉。
-
病虫害监测防控:结合图像识别技术和预测模型,监测并预测农田中可能发生的病虫害,制定防控方案。
-
收割智能化:应用物体识别技术识别成熟粮食,引入自动化收割装置完成收割,提高效率和减少损失。
-
产量预测模型:通过分析历史数据,建立预测模型预估当前农田的产量,为仓储管理和销售策略提供依据。
-
数据整合决策支持:将不同来源的数据整合,构建全面的信息网络,为农民提供实时的决策支持。
附录
- 数据预处理
- 相关性分析
- 聚类分析
- 回归模型
- 随机森林
数据预处理
导入包以及数据读取
# 导入需要的库
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import silhouette_score
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
import scipy.stats as stats
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import RandomizedSearchCV
# 读取数据
train_data = pd.read_csv("train.csv")
test_data = pd.read_csv("test.csv")
数据预览
查看数据维度
print('训练集纬度:')
print(train_data.shape)
print('-'*50)
print('测试集纬度:')
print(test_data.shape)
查看数据信息
print('训练集信息:')
print(train_data.info())
print('-'*50)
print('测试集信息:')
print(test_data.info())
查看各列缺失值
print('训练集信息缺失情况:')
print(train_data.isna().sum())
print('-'*50)
print('测试集信息缺失情况:')
print(test_data.isna().sum())
查看重复值
print('训练集信息重复情况:')
print(train_data.duplicated().sum())
print('-'*50)
print('测试集信息重复情况:')
print(test_data.duplicated().sum())
数据处理
# 删除ID列
train_data.drop(['id'],axis=1,inplace=True)
test_data.drop(['id'],axis=1,inplace=True)
相关性分析
# 计算相关系数矩阵
correlation_matrix = train_data.corr()
# 绘制热图来可视化相关性
plt.figure(figsize=(20,15))
sns.heatmap(correlation_matrix, annot=True, cmap='Blues', fmt=".2f")
plt.title("Correlation Matrix of Variables")
plt.show()
聚类分析
数据处理
# 选择所有变量进行聚类
x_cluster = train_data.copy()
# 对数据进行标准化
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x_cluster)
确定聚类数
# 使用肘部法则来确定最佳聚类数
inertia = []
silhouette_scores = []
k_range = range(2, 11)
for k in k_range:kmeans = KMeans(n_clusters=k, random_state=10).fit(x_scaled)inertia.append(kmeans.inertia_)silhouette_scores.append(silhouette_score(x_scaled, kmeans.labels_))
plt.figure(figsize=(15,5))plt.subplot(1, 2, 1)
plt.plot(k_range, inertia, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Inertia')
plt.title('Elbow Method For Optimal k')plt.subplot(1, 2, 2)
plt.plot(k_range, silhouette_scores, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Silhouette Score')
plt.title('Silhouette Score For Each k')plt.tight_layout()
plt.show()
建立k均值聚类模型
# 执行K-均值聚类,选择4个聚类
kmeans_final = KMeans(n_clusters=4, random_state=15)
kmeans_final.fit(x_scaled)
# 获取聚类标签
cluster_labels = kmeans_final.labels_
# 将聚类标签添加到原始数据中以进行分析
train_data_clustered = train_data.copy()
train_data_clustered['Cluster'] = cluster_labels
# 查看每个聚类的统计数据
cluster_summary = train_data_clustered.groupby('Cluster').mean()
cluster_summary
多元线性回归模型
检测多重共线性
x = train_data.drop(['yield'], axis=1) # 使用除了产量以外的所有列作为特征
x = sm.add_constant(x)
# 计算每个特征的VIF值
vif_data = pd.DataFrame()
vif_data["feature"] = x.columns
vif_data["VIF"] = [variance_inflation_factor(x.values, i) for i in range(x.shape[1])]
vif_data
主成分分析
# 数据标准化
scaler = StandardScaler()
x_scaled = scaler.fit_transform(x.drop('const', axis=1)) # 去除常数项
# 执行PCA
pca = PCA()
x_pca = pca.fit_transform(x_scaled)
# 计算主成分的方差贡献率
explained_variance = pca.explained_variance_ratio_
print('方差贡献率:')
print(explained_variance)
# 计算累积方差贡献率
cumulative_variance = np.cumsum(explained_variance)
# 确定累积方差贡献率达到95%的主成分数量
n_components = np.where(cumulative_variance >= 0.95)[0][0] + 1
print(f'前{n_components}个特征已经达到了95%的累计方差贡献率。')
建立多元线性回归模型
# 使用前7个主成分作为特征集
x_pca_reduced = x_pca[:, :n_components]
# 由于PCA是无监督的,我们需要重新获取目标变量'y'
y = train_data['yield']
# 分割数据集
x_train_pca, x_test_pca, y_train, y_test = train_test_split(x_pca_reduced, y, test_size=0.3, random_state=15) # 37分
# 创建多元线性回归模型
regression_model = LinearRegression()
# 拟合训练数据
regression_model.fit(x_train_pca, y_train)
# 预测测试数据
y_pred = regression_model.predict(x_test_pca)
# 计算模型性能指标
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error (MSE): {mse}")
print(f"R-squared (R2): {r2}")
残差项检验
# 计算残差
residuals = y_test - y_pred# 绘制残差序列图
plt.figure(figsize=(10, 6))
plt.plot(residuals, marker='o', linestyle='')
plt.title("Residuals Time Series Plot")
plt.xlabel("Observation")
plt.ylabel("Residuals")
plt.axhline(y=0, color='r', linestyle='-')
plt.show()
# 绘制残差的直方图
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.hist(residuals, bins=30, edgecolor='black')
plt.title("Histogram of Residuals")
plt.xlabel("Residuals")
plt.ylabel("Frequency")# 绘制残差的Q-Q图
plt.subplot(1, 2, 2)
stats.probplot(residuals, dist="norm", plot=plt)
plt.title("Normal Q-Q Plot of Residuals")plt.tight_layout()
plt.show()
# 绘制残差与预测值的散点图以检查同方差性
plt.figure(figsize=(10, 6))
plt.scatter(y_pred, residuals, alpha=0.5)
plt.title("Residuals vs Predicted Values")
plt.xlabel("Predicted Values")
plt.ylabel("Residuals")
plt.axhline(y=0, color='r', linestyle='-')
plt.show()
模型预测
# 使用与训练模型时相同数量的主成分进行预测
x_test_scaled = scaler.transform(test_data)
x_test_pca = pca.transform(x_test_scaled)
x_test_pca_reduced = x_test_pca[:, :n_components]
# 使用模型进行预测
test_predictions = regression_model.predict(x_test_pca_reduced)
test_data_with_predictions = test_data.copy()
test_data_with_predictions['predicted_yield'] = test_predictions
test_data_with_predictions.head()
随机森林
建立模型
# 划分数据
x = train_data.drop('yield', axis=1)
y = train_data['yield']
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=10, stratify=y) #37分
# 模型建立
rf_clf = RandomForestRegressor(random_state=15)
rf_clf.fit(x_train, y_train)
y_pred = rf_clf.predict(x_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error (MSE): {mse}")
print(f"R-squared (R2): {r2}")
参数优化
# 定义随机搜索的参数范围
param_dist = {'n_estimators': [100, 200, 300, 400, 500],'max_depth': [10, 20, 30, 40, 50, None],'min_samples_split': [2, 5, 10],'min_samples_leaf': [1, 2, 4],'max_features': ['auto', 'sqrt']
}# 创建随机森林模型
rf = RandomForestRegressor(random_state=15)# 设置随机搜索
random_search = RandomizedSearchCV(estimator=rf, param_distributions=param_dist, n_iter=10, cv=5, verbose=2, random_state=17, n_jobs=-1)# 执行随机搜索
random_search.fit(x_train, y_train)
随机搜索比网格搜索快,所以这里使用随机搜索。
# 最佳参数和评分
best_params = random_search.best_params_
print("最佳参数:", best_params)
# 使用最佳参数创建随机森林模型
best_rf_model = RandomForestRegressor(**best_params,random_state=15)
best_rf_model.fit(x_train, y_train)
y_pred = best_rf_model.predict(x_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"Mean Squared Error (MSE): {mse}")
print(f"R-squared (R2): {r2}")
# 获取特征重要性
feature_importances = best_rf_model.feature_importances_
# 创建特征重要性的DataFrame
features = x_train.columns
importances_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
# 按重要性排序
importances_df.sort_values(by='Importance', ascending=False, inplace=True)
importances_df
模型预测
# 使用训练好的模型对测试数据进行预测
test_predictions_rf = best_rf_model.predict(test_data)
rf_test_data_with_predictions = test_data.copy()
rf_test_data_with_predictions['predicted_yield'] = test_predictions_rf
rf_test_data_with_predictions.head()
相关文章:
基于聚类和回归分析方法探究蓝莓产量影响因素与预测模型研究附录
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 目录 背景数据说明数据来源思考 附录数据预处理导入包以及数据读取数据预览数据处理 相关性分析聚类分析数据处理确定聚类数建立k均值聚类模型 …...

java类型转换
pom <dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.76</version></dependency>BeanUtils 在这里插入代码片list<Map>转换成List<bean> public static <T> L…...
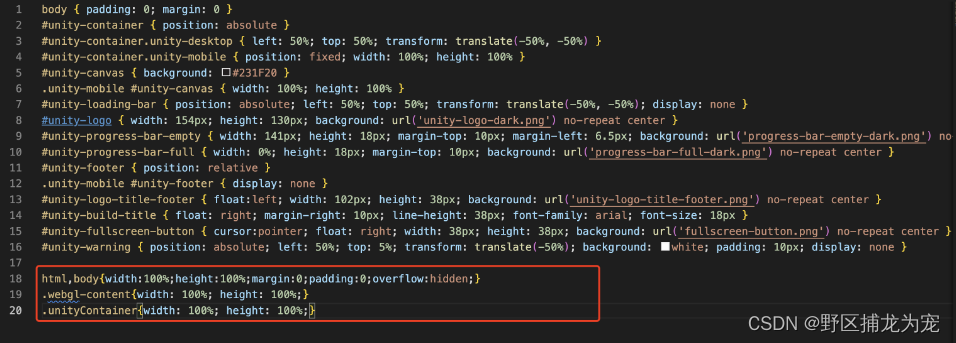
Unity打包Webgl端进行 全屏幕自适应
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 一:修改 index.html二:将非移动端设备,canvas元素的宽度和高度会设置为100%。三:修改style.css总结 下载地址&#x…...
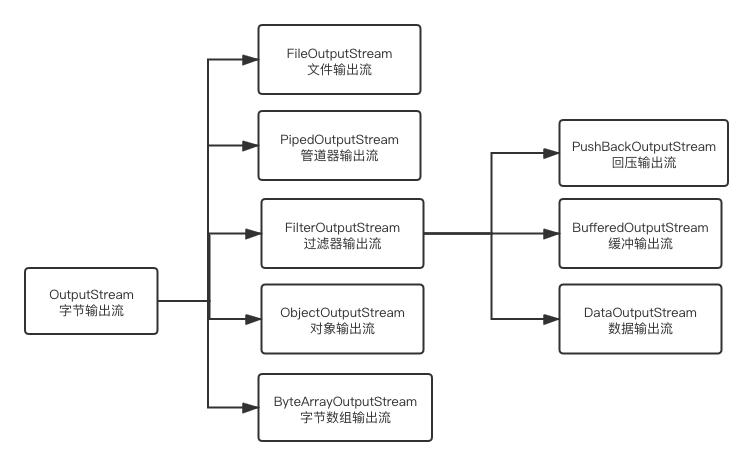
36. 【Java教程】输入输出流
本小节将会介绍基本输入输出的 Java 标准类,通过本小节的学习,你将了解到什么是输入和输入,什么是流;输入输出流的应用场景,File类的使用,什么是文件,Java 提供的输入输出流相关 API 等内容。 1…...
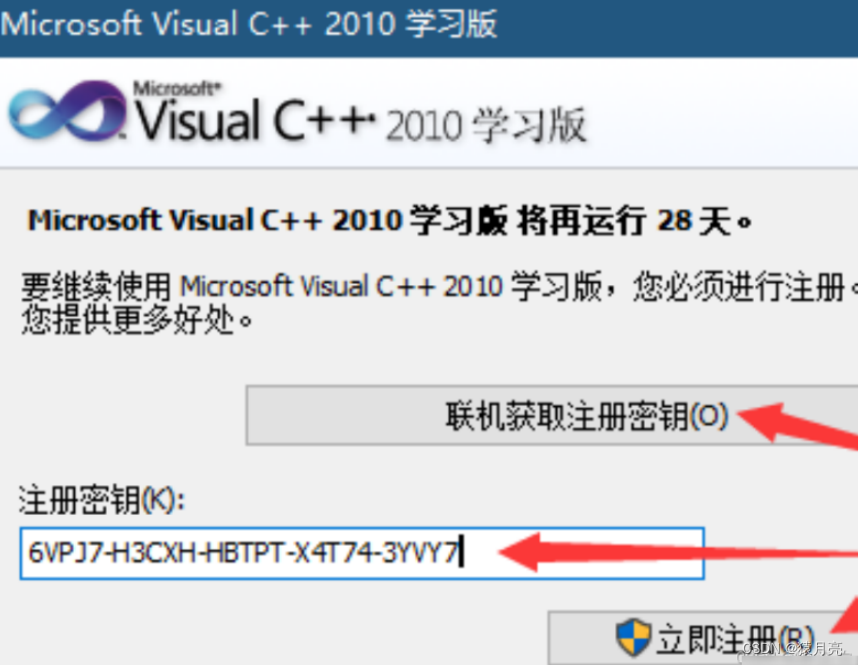
Visual C++2010学习版详细安装教程(超详细图文)
Visual C 介绍 Visual C(简称VC)是微软公司推出的一种集成开发环境(IDE),主要用于开发C和C语言的应用程序。它提供了强大的编辑器、编译器、调试器、库和框架支持,以及丰富的工具和选项,使得开…...

matlab图像处理入门
matlab在学校科研,仿真及基于模型开发的工作中有重要作用,在图像处理方面由于省去了复杂的上位机开发流程,因此可以让用户快速开发验证算法,下面简要介绍其在图像处理方面的应用。 matlab开发图像处理算法的流程主要是,…...

关于线程池面试题,使用“豆包”训练答案
我提问: 问题描述 下面是一个有关线程池调度的面试真题,来自于疯狂创客圈社群: 一个线程池的核心线程数为10个,最大线程数为20个,阻塞队列的容量为30。现在提交45个 任务,每个任务的耗时为500毫秒。 请问&…...
【WRF理论第二期】模型目录介绍
WRF理论第二期:模型目录介绍 1 WRF主目录2 WPS主目录3 编译后的可执行文件4 运行目录参考 了解 WRF 模型的目录结构有助于有效地管理和操作模型,从而确保模拟和分析工作的顺利进行。以下分解介绍WRF主目录、WPS主目录等。 Github-wrf-model/WRF 1 WRF…...
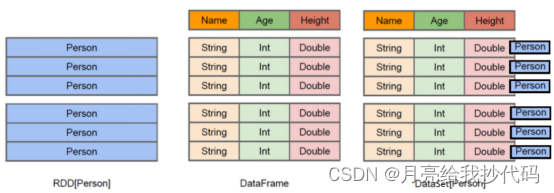
从了解到掌握 Spark 计算框架(一)Spark 简介与基础概念
文章目录 什么是 Spark?核心特点 Spark 对比 MapReduceSpark 编程模型RDDDataFrameDataset Spark 运行模式Spark 生态 什么是 Spark? Spark 是一个基于内存的分布式计算框架,最初由加州大学伯克利分校的 AMPLab 开发,后来捐赠给了…...

linux bind函数
bind函数的目的是让把客户端对应的端口(port)地址和ip地址绑定到客户端 [参考](Linux之bind 函数(详细篇)_linux bind函数-CSDN博客)...
Flink系列一:flink光速入门 (^_^)
引入 spark和flink的区别:在上一个spark专栏中我们了解了spark对数据的处理方式,在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 Spark-core,SparkSQL 实现,流处理由 Spark Streaming 实现&am…...

PySpark特征工程(III)--特征选择
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。在实际应用当中,可以说特征工程是机器学习成功的关键。 特征工程是数据分析…...
Mongodb的数据库简介、docker部署、操作语句以及java应用
Mongodb的数据库简介、docker部署、操作语句以及java应用 本文主要介绍了mongodb的基础概念和特点,以及基于docker的mongodb部署方法,最后介绍了mongodb的常用数据库操作语句(增删改查等)以及java下的常用语句。 一、基础概念 …...

七大战略性新兴产业崭露头角:新能源电燃灶或将成为未来厨房新宠
近日,在国家发布的七大战略性新兴产业名单中,新能源产业赫然在列,作为其中的重要组成部分,华火新能源电燃灶凭借其独特的优势,正逐渐走进人们的视野,有望成为未来厨房的新宠。 华火新能源电燃灶作为清洁能源…...

C#进阶-用于Excel处理的程序集
在.NET开发中,处理Excel文件是一项常见的任务,而有一些优秀的Excel处理包可以帮助开发人员轻松地进行Excel文件的读写、操作和生成。本文介绍了NPOI、EPPlus和Spire.XLS这三个常用的.NET Excel处理包,分别详细介绍了它们的特点、示例代码以及…...
)
持续总结中!2024年面试必问 20 道 Kafka面试题(五)
上一篇地址:持续总结中!2024年面试必问 20 道 Kafka面试题(四)-CSDN博客 九、请解释Kafka中的Zookeeper的作用。 在Kafka中,ZooKeeper扮演着至关重要的角色,主要负责集群管理、协调和状态同步等功能。以下…...

Draw.io 使用详细教程
Draw.io 是一款功能强大的在线绘图工具,适用于创建流程图、网络图、组织结构图、UML 图等。以下是详细的使用教程,包括基本操作、快捷键、常用技巧和进阶技巧。 1. 创建新图 选择存储位置 首次使用时,系统会询问你要将图保存到哪里。你可以…...
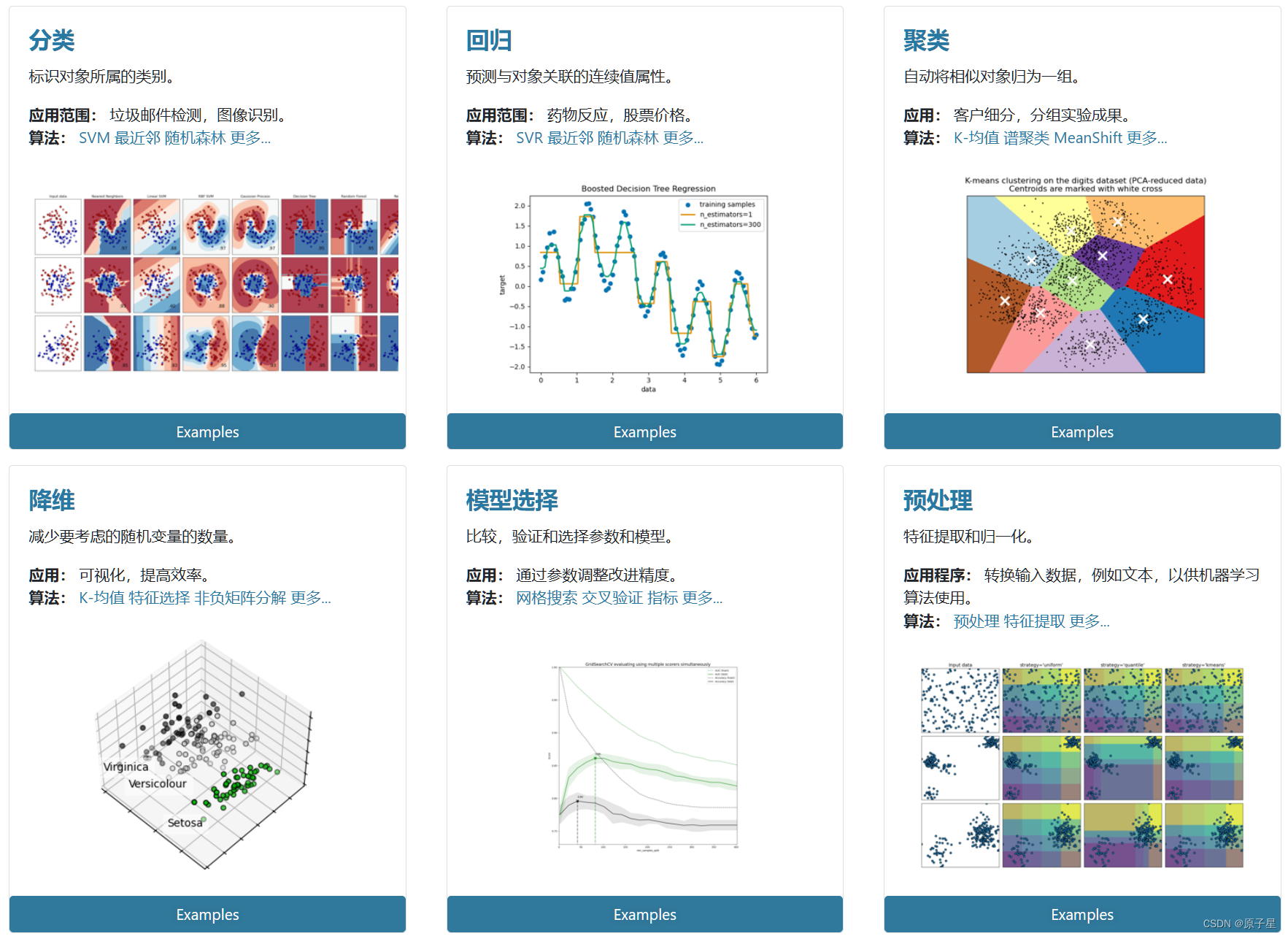
人工智能学习笔记(1):了解sklearn
sklearn 简介 Sklearn是一个基于Python语言的开源机器学习库。全称Scikit-Learn,是建立在诸如NumPy、SciPy和matplotlib等其他Python库之上,为用户提供了一系列高质量的机器学习算法,其典型特点有: 简单有效的工具进行预测数据分…...
PromptPort:为大模型定制的创意AI提示词工具库
PromptPort:为大模型定制的创意AI提示词工具库 随着人工智能技术的飞速发展,大模型在各行各业的应用越来越广泛。而在与大模型交互的过程中,如何提供精准、有效的提示词成为了关键。今天,就为大家介绍一款专为大模型定制的创意AI…...

IDEA升级web项目为maven项目乱码
今天将一个java web项目改造为maven项目。 首先,创建一个新的maven项目,将文件拷贝到新项目中。 其次,将旧项目的jar包,在maven的pom.xml做成依赖 接着,把没有maven坐标的jar包在编译的时候也包含进来 <build>…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...