NeuralForecast 模型的参数 windows_batch的含义
NeuralForecast 模型的参数 windows_batch的含义
flyfish
import pandas as pd
import numpy as npAirPassengers = np.array([112.0, 118.0, 132.0, 129.0, 121.0, 135.0, 148.0, 148.0, 136.0, 119.0],dtype=np.float32,
)AirPassengersDF = pd.DataFrame({"unique_id": np.ones(len(AirPassengers)),"ds": pd.date_range(start="1949-01-01", periods=len(AirPassengers), freq=pd.offsets.MonthEnd()),"y": AirPassengers,}
)Y_df = AirPassengersDF
Y_df = Y_df.reset_index(drop=True)
Y_df.head()
#Model Trainingfrom neuralforecast.core import NeuralForecast
from neuralforecast.models import VanillaTransformerhorizon = 3
models = [VanillaTransformer(input_size=2 * horizon, h=horizon, max_steps=2)]nf = NeuralForecast(models=models, freq='M')for model in nf.models:print(f'Model: {model.__class__.__name__}')for param, value in model.__dict__.items():print(f' {param}: {value}')nf.fit(df=Y_df)
输出
Seed set to 1
Model: VanillaTransformertraining: True_parameters: OrderedDict()_buffers: OrderedDict()_non_persistent_buffers_set: set()_backward_pre_hooks: OrderedDict()_backward_hooks: OrderedDict()_is_full_backward_hook: None_forward_hooks: OrderedDict()_forward_hooks_with_kwargs: OrderedDict()_forward_hooks_always_called: OrderedDict()_forward_pre_hooks: OrderedDict()_forward_pre_hooks_with_kwargs: OrderedDict()_state_dict_hooks: OrderedDict()_state_dict_pre_hooks: OrderedDict()_load_state_dict_pre_hooks: OrderedDict()_load_state_dict_post_hooks: OrderedDict()_modules: OrderedDict([('loss', MAE()), ('valid_loss', MAE()), ('padder_train', ConstantPad1d(padding=(0, 3), value=0)), ('scaler', TemporalNorm()), ('enc_embedding', DataEmbedding((value_embedding): TokenEmbedding((tokenConv): Conv1d(1, 128, kernel_size=(3,), stride=(1,), padding=(1,), bias=False, padding_mode=circular))(position_embedding): PositionalEmbedding()(dropout): Dropout(p=0.05, inplace=False)
)), ('dec_embedding', DataEmbedding((value_embedding): TokenEmbedding((tokenConv): Conv1d(1, 128, kernel_size=(3,), stride=(1,), padding=(1,), bias=False, padding_mode=circular))(position_embedding): PositionalEmbedding()(dropout): Dropout(p=0.05, inplace=False)
)), ('encoder', TransEncoder((attn_layers): ModuleList((0-1): 2 x TransEncoderLayer((attention): AttentionLayer((inner_attention): FullAttention((dropout): Dropout(p=0.05, inplace=False))(query_projection): Linear(in_features=128, out_features=128, bias=True)(key_projection): Linear(in_features=128, out_features=128, bias=True)(value_projection): Linear(in_features=128, out_features=128, bias=True)(out_projection): Linear(in_features=128, out_features=128, bias=True))(conv1): Conv1d(128, 32, kernel_size=(1,), stride=(1,))(conv2): Conv1d(32, 128, kernel_size=(1,), stride=(1,))(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout): Dropout(p=0.05, inplace=False)))(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
)), ('decoder', TransDecoder((layers): ModuleList((0): TransDecoderLayer((self_attention): AttentionLayer((inner_attention): FullAttention((dropout): Dropout(p=0.05, inplace=False))(query_projection): Linear(in_features=128, out_features=128, bias=True)(key_projection): Linear(in_features=128, out_features=128, bias=True)(value_projection): Linear(in_features=128, out_features=128, bias=True)(out_projection): Linear(in_features=128, out_features=128, bias=True))(cross_attention): AttentionLayer((inner_attention): FullAttention((dropout): Dropout(p=0.05, inplace=False))(query_projection): Linear(in_features=128, out_features=128, bias=True)(key_projection): Linear(in_features=128, out_features=128, bias=True)(value_projection): Linear(in_features=128, out_features=128, bias=True)(out_projection): Linear(in_features=128, out_features=128, bias=True))(conv1): Conv1d(128, 32, kernel_size=(1,), stride=(1,))(conv2): Conv1d(32, 128, kernel_size=(1,), stride=(1,))(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(norm3): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(dropout): Dropout(p=0.05, inplace=False)))(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)(projection): Linear(in_features=128, out_features=1, bias=True)
))])prepare_data_per_node: Trueallow_zero_length_dataloader_with_multiple_devices: False_log_hyperparams: True_dtype: torch.float32_device: cpu_trainer: None_example_input_array: None_automatic_optimization: True_strict_loading: None_current_fx_name: None_param_requires_grad_state: {}_metric_attributes: None_compiler_ctx: None_fabric: None_fabric_optimizers: []_hparams_name: kwargs_hparams: "activation": gelu
"alias": None
"batch_size": 32
"conv_hidden_size": 32
"decoder_input_size_multiplier": 0.5
"decoder_layers": 1
"drop_last_loader": False
"dropout": 0.05
"early_stop_patience_steps": -1
"encoder_layers": 2
"exclude_insample_y": False
"futr_exog_list": None
"h": 3
"hidden_size": 128
"hist_exog_list": None
"inference_windows_batch_size": 1024
"input_size": 6
"learning_rate": 0.0001
"loss": MAE()
"lr_scheduler": None
"lr_scheduler_kwargs": None
"max_steps": 2
"n_head": 4
"num_lr_decays": -1
"num_workers_loader": 0
"optimizer": None
"optimizer_kwargs": None
"random_seed": 1
"scaler_type": identity
"start_padding_enabled": False
"stat_exog_list": None
"step_size": 1
"val_check_steps": 100
"valid_batch_size": None
"valid_loss": None
"windows_batch_size": 1024_hparams_initial: "activation": gelu
"alias": None
"batch_size": 32
"conv_hidden_size": 32
"decoder_input_size_multiplier": 0.5
"decoder_layers": 1
"drop_last_loader": False
"dropout": 0.05
"early_stop_patience_steps": -1
"encoder_layers": 2
"exclude_insample_y": False
"futr_exog_list": None
"h": 3
"hidden_size": 128
"hist_exog_list": None
"inference_windows_batch_size": 1024
"input_size": 6
"learning_rate": 0.0001
"loss": MAE()
"lr_scheduler": None
"lr_scheduler_kwargs": None
"max_steps": 2
"n_head": 4
"num_lr_decays": -1
"num_workers_loader": 0
"optimizer": None
"optimizer_kwargs": None
"random_seed": 1
"scaler_type": identity
"start_padding_enabled": False
"stat_exog_list": None
"step_size": 1
"val_check_steps": 100
"valid_batch_size": None
"valid_loss": None
"windows_batch_size": 1024random_seed: 1train_trajectories: []valid_trajectories: []optimizer: Noneoptimizer_kwargs: {}lr_scheduler: Nonelr_scheduler_kwargs: {}futr_exog_list: []hist_exog_list: []stat_exog_list: []futr_exog_size: 0hist_exog_size: 0stat_exog_size: 0trainer_kwargs: {'max_steps': 2, 'enable_checkpointing': False}h: 3input_size: 6windows_batch_size: 1024start_padding_enabled: Falsebatch_size: 32valid_batch_size: 32inference_windows_batch_size: 1024learning_rate: 0.0001max_steps: 2num_lr_decays: -1lr_decay_steps: 100000000.0early_stop_patience_steps: -1val_check_steps: 100step_size: 1exclude_insample_y: Falseval_size: 0test_size: 0decompose_forecast: Falsenum_workers_loader: 0drop_last_loader: Falsevalidation_step_outputs: []alias: Nonelabel_len: 3c_out: 1output_attention: Falseenc_in: 1
举例说明 如何构建windows
import pandas as pd
import numpy as npAirPassengers = np.array([112.0, 118.0, 132.0, 129.0, 121.0, 135.0, 148.0, 148.0, 136.0, 119.0],dtype=np.float32,
)AirPassengersDF = pd.DataFrame({"unique_id": np.ones(len(AirPassengers)),"ds": pd.date_range(start="1949-01-01", periods=len(AirPassengers), freq=pd.offsets.MonthEnd()),"y": AirPassengers,}
)Y_df = AirPassengersDF
Y_df = Y_df.reset_index(drop=True)
Y_df.head()
#Model Trainingfrom neuralforecast.core import NeuralForecast
from neuralforecast.models import NBEATShorizon = 3
models = [NBEATS(input_size=2 * horizon, h=horizon, max_steps=2)]nf = NeuralForecast(models=models, freq='M')
nf.fit(df=Y_df)
window_size 是窗口的总大小,它由 input_size 和 h 决定。
9= input_size(6) +h(3)
可以与原数据集对比下,是一个一个的往下移
当移动到 132.0的时候,为了凑齐9行,剩余的用0填充
窗口的形状就是 windows1 shape: torch.Size([4, 9, 2])
window1: tensor([[[112., 1.],[118., 1.],[132., 1.],[129., 1.],[121., 1.],[135., 1.],[148., 1.],[148., 1.],[136., 1.]],[[118., 1.],[132., 1.],[129., 1.],[121., 1.],[135., 1.],[148., 1.],[148., 1.],[136., 1.],[119., 1.]],[[132., 1.],[129., 1.],[121., 1.],[135., 1.],[148., 1.],[148., 1.],[136., 1.],[119., 1.],[ 0., 0.]],[[129., 1.],[121., 1.],[135., 1.],[148., 1.],[148., 1.],[136., 1.],[119., 1.],[ 0., 0.],[ 0., 0.]]])
windows_batch_size
最后由 windows1 shape: torch.Size([4, 9, 2])变成了 indows2 shape: torch.Size([1024, 9, 2])
也就是我们的传参windows_batch_size = 1024
下列举出4个例子,实际是1024个
表示采样了 1024 个窗口,每个窗口大小为9,包含 2 个特征。
....[[118., 1.],[132., 1.],[129., 1.],[121., 1.],[135., 1.],[148., 1.],[148., 1.],[136., 1.],[119., 1.]],[[129., 1.],[121., 1.],[135., 1.],[148., 1.],[148., 1.],[136., 1.],[119., 1.],[ 0., 0.],[ 0., 0.]],[[118., 1.],[132., 1.],[129., 1.],[121., 1.],[135., 1.],[148., 1.],[148., 1.],[136., 1.],[119., 1.]],[[118., 1.],[132., 1.],[129., 1.],[121., 1.],[135., 1.],[148., 1.],[148., 1.],[136., 1.],[119., 1.]],
最终训练时,返回的数据
windows_batch: {'temporal': 1024 个窗口数据, 'temporal_cols': Index(['y', 'available_mask'], dtype='object'), 'static': None, 'static_cols': None}
相关文章:

NeuralForecast 模型的参数 windows_batch的含义
NeuralForecast 模型的参数 windows_batch的含义 flyfish import pandas as pd import numpy as npAirPassengers np.array([112.0, 118.0, 132.0, 129.0, 121.0, 135.0, 148.0, 148.0, 136.0, 119.0],dtypenp.float32, )AirPassengersDF pd.DataFrame({"unique_id&qu…...
【记录】打印|用浏览器生成证件照打印PDF,打印在任意尺寸的纸上(简单无损!)
以前我打印证件照的时候,我总是在网上找在线证件照转换或者别的什么。但是我今天突然就琢磨了一下,用 PDF 打印应该也可以直接打印出来,然后就琢磨出来了,这么一条路大家可以参考一下。我觉得比在线转换成一张 a4 纸要方便的多&am…...

【python实现】实时监测GPU,空闲时自动执行脚本
文章目录 代码 代码 # author: muzhan # contact: levio.pkugmail.com import os import sys import time cmd nohup python -u train_post_2d_aut.py > output1.log & # gpu空闲时,需要执行的脚本命令 def gpu_info():gpu_status os.popen(nvidia-smi…...

chrome 浏览器历史版本下载
最近做一个项目,要使用到chrome浏览器比较久远的版本,在网上查找资源时,发现chrome比较老的版本的安装包特别难找,几经寻找,总算找到,具体方法如下 打开百度,搜索关键字【chrome版本号‘浏览迷’】,例如“chrome41浏览迷”,找到“全平台”开头的链接&am…...
⭐⭐⭐)
【设计模式】工厂模式(创建型)⭐⭐⭐
文章目录 1.概念1.1 什么是工厂模式1.2 优点与缺点 2.实现方式2.1 简单工厂模式(Simple Factory)2.2 简单工厂模式缺点2.3 抽象工厂模式(Abstract Factory Pattern) 3 Java 哪些地方用到了工厂模式4 Spring 哪些地方用到了工厂模式…...

Postman 连接数据库 利用node+xmysql
1、准备nodejs环境 如果没有安装,在网上找教程,安装好后,在控制台输入命令查看版本,如下就成功了 2、安装xmysql 在控制台输入 npm install -g xmysql 3、连接目标数据库 帮助如下: 示例: 目标数据库…...
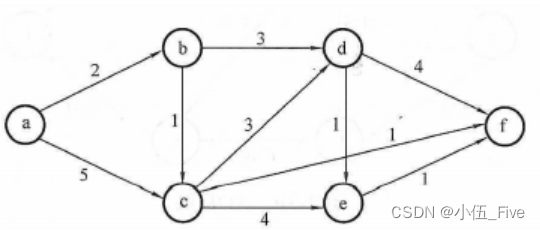
挑战你的数据结构技能:复习题来袭【6】
1. (单选题)设无向图的顶点个数为n,则该图最多有()条边 A. n-1 B. n(n-1)/2 C. n(n1)/2 D. 0 答案:B 分析: 2. (单选题)含有n个顶点的连通无向图,其边的个数至少为()。 A. n-1 B. n C. n1 D. nlog2n 答案:A…...

如何反编译jar并修改后还原为jar
如何反编译jar并修改后还原为jar 目标:修改jar包中某个类的某个方法后还原为新的jar 1.新建android工程,把旧的jar添加为lib 2.用jadx-gui打开旧的jar并保存所有资源 3.找到保存的资源中想修改的.java类 4.复制类中的内容, 在android工程中新建一个同样路径的包,并在包下创建…...
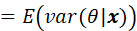
统计信号处理基础 习题解答10-5
题目 通过令 并进行计算来重新推导MMSE估计量。提示:利用结果 解答 首先需要明确的是: 上式是关于观测值x 的函数 其次需要说明一下这个结果 和教材一样,我们用求期望,需要注意的是,在贝叶斯情况下,是个…...
—从零开始:一步步搭建Vue 3自定义插件)
Vue3实战笔记(60)—从零开始:一步步搭建Vue 3自定义插件
文章目录 前言一、自定义插件二、使用步骤总结 前言 在开发和学习中,经常使用一些好用的插件,那么如何创建一个自己的插件呢?在 Vue 3 中,你可以通过创建一个包含 install 方法的对象来定义自定义插件。install 方法接收两个参数…...

Java面向对象笔记
多态 一种类型的变量可以引用多种实际类型的对象 如 package ooplearn;public class Test {public static void main(String[] args) {Animal[] animals new Animal[2];animals[0] new Dog();animals[1] new Cat();for (Animal animal : animals){animal.eat();}} }class …...
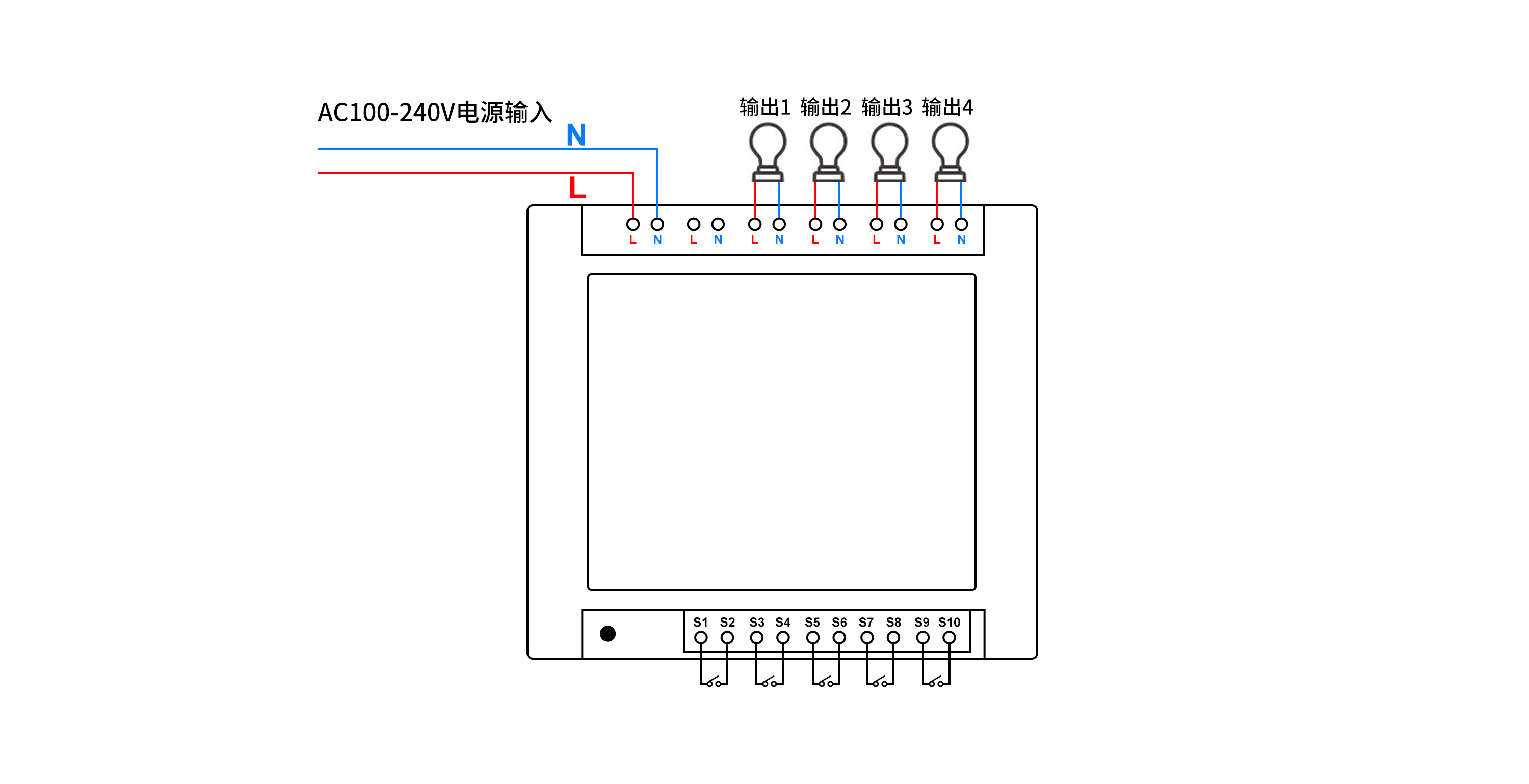
如何通过PHP语言实现远程控制多路照明
如何通过PHP语言实现远程控制多路照明呢? 本文描述了使用PHP语言调用HTTP接口,实现控制多路照明,通过多路控制器,可独立远程控制多路照明。 可选用产品:可根据实际场景需求,选择对应的规格 序号设备名称厂…...

Capture One Pro 23:专业 Raw 图像处理的卓越之选
在当今的数字摄影时代,拥有一款强大的图像处理软件至关重要。而 Capture One Pro 23 for Mac/Win 无疑是其中的佼佼者,为摄影师和图像爱好者带来了前所未有的体验。 Capture One Pro 23 以其出色的 Raw 图像处理能力而闻名。它能够精准地解析和处理各种…...

【主题广泛|投稿优惠】2024年交通运输与信息科学国际会议(ICTIS 2024)
2024年交通运输与信息科学国际会议(ICTIS 2024) 2024 International Conference on Transportation and Information Science 【重要信息】 大会地点:青岛 大会官网:http://www.icictis.com 投稿邮箱:icictissub-conf.…...
表格误删数据保存关闭后如何恢复?5个恢复方法大公开!
“我在编辑表格的时候一不小心就删除了部分数据,现在真的不知道该怎么操作了。希望大家能帮帮我吧!” 在日常工作中,我们经常会使用到各种表格软件来处理和分析数据。然而,有时由于操作失误或其他原因,我们可能会误删表…...

Go 语言中的切片:灵活的数据结构
切片(slice)是 Go 语言中一种非常重要且灵活的数据结构,它提供了对数组子序列的动态窗口。这使得切片在 Go 中的使用非常频繁,特别是在处理动态数据集时。本文将探讨切片的概念、操作和与函数的交互,以及如何有效地使用…...
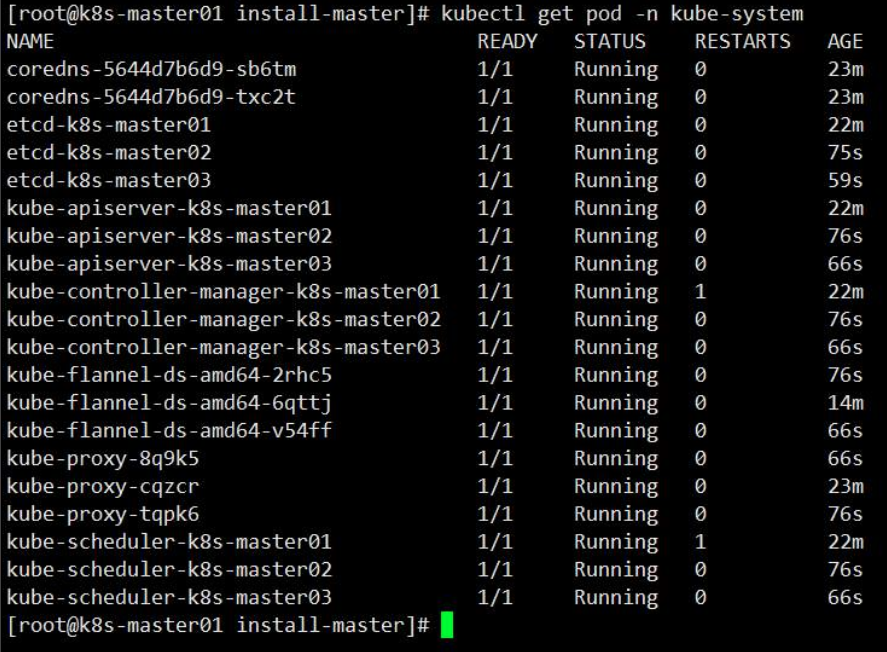
在鲲鹏服务器搭建k8s高可用集群分享
高可用架构 本文采用kubeadm方式搭建k8s高可用集群,k8s高可用集群主要是对apiserver、etcd、controller-manager、scheduler做的高可用;高可用形式只要是为: 1. apiserver利用haproxykeepalived做的负载,多apiserver节点同时工作…...
)
MySQL之数据库事务机制学习笔记(五)
事务机制 事务(Transaction)是数据库管理系统中的一个重要概念,它是一组数据库操作的逻辑单元,要么全部执行成功,要么全部执行失败,具有以下四个特性,通常缩写为 ACID: 原子性&…...

linux 系统被异地登录,cpu占用拉满100%
一般是kswapd0导致的cpu占用异常 按顺序执行以下操作 在控制台执行top命令,查看占用最高的是否kswapd0。基本100%占用。记下该进程ID 5081 执行查找命令 find / -name kswapd0 显示查找结果: /proc/3316/.X2c4-unix/.rsync/a/kswapd0 /root/.configrc…...
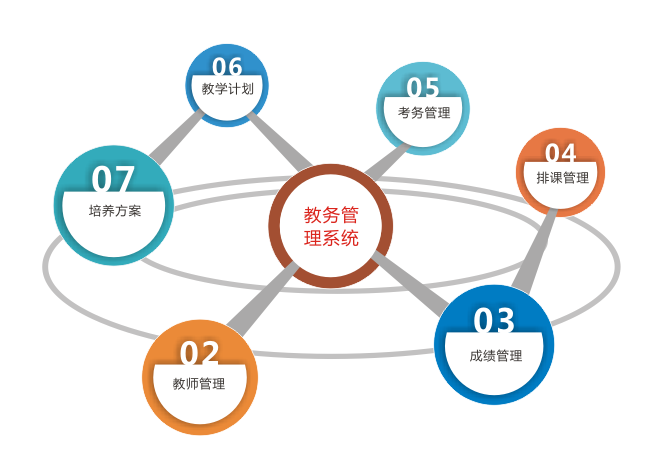
智慧校园应用平台的全面建设
在当今社会,随着科技的不断进步,智慧校园应用平台逐渐成为学校管理的必备工具。在实现智慧校园全面建设的过程中,学校需要运用先进的技术和创新的理念,为教育提供更好的服务和支持。这篇文章将为您介绍智慧校园应用平台的全面建设…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

HashMap中的put方法执行流程(流程图)
1 put操作整体流程 HashMap 的 put 操作是其最核心的功能之一。在 JDK 1.8 及以后版本中,其主要逻辑封装在 putVal 这个内部方法中。整个过程大致如下: 初始判断与哈希计算: 首先,putVal 方法会检查当前的 table(也就…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

RSS 2025|从说明书学习复杂机器人操作任务:NUS邵林团队提出全新机器人装配技能学习框架Manual2Skill
视觉语言模型(Vision-Language Models, VLMs),为真实环境中的机器人操作任务提供了极具潜力的解决方案。 尽管 VLMs 取得了显著进展,机器人仍难以胜任复杂的长时程任务(如家具装配),主要受限于人…...

基于PHP的连锁酒店管理系统
有需要请加文章底部Q哦 可远程调试 基于PHP的连锁酒店管理系统 一 介绍 连锁酒店管理系统基于原生PHP开发,数据库mysql,前端bootstrap。系统角色分为用户和管理员。 技术栈 phpmysqlbootstrapphpstudyvscode 二 功能 用户 1 注册/登录/注销 2 个人中…...

Visual Studio Code 扩展
Visual Studio Code 扩展 change-case 大小写转换EmmyLua for VSCode 调试插件Bookmarks 书签 change-case 大小写转换 https://marketplace.visualstudio.com/items?itemNamewmaurer.change-case 选中单词后,命令 changeCase.commands 可预览转换效果 EmmyLua…...
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...