【NoSQL数据库】Redis命令、持久化、主从复制
Redis命令、持久化、主从复制
redis配置
- Redis命令、持久化、主从复制
- Redis数据类型
- redis数据库常用命令
- redis多数据库常用命令
- 1、多数据库间切换
- 2、多数据库间移动数据
- 3、清除数据库内数据
- key命令
- 1、keys 命令
- 2、判断键值是否存在exists
- 3、删除当前数据库的指定key del
- 4、获取key对应的value值类型 type
- 5、设置key过期时间
- 6、查看有效时间,以秒为单位
- 7、对key重命名
- 7.5、renamenx
- 8、查看当前数据库中key的数目 dbsize
- 9、使用config set requirepass yourpassword命令设置密码
- 10、使用config get requirepass命令查看密码
- 11、删除密码
- string类型
- 增加、修改
- 获取
- 删除
- hash类型
- 增加、修改
- 删除
- list类型
- 增加
- 获取
- 删除
- set类型
- 增加
- 获取
- 删除
- zset类型
- 增加
- 获取
- 删除
- 使用5种数据类型用来描述角色信息
- Redis高可用-持久化
- RDB持久化
- AOF 持久化
- Redis高可用-集群
- 主从复制部署
- 搭建redis主从复制集群,2个集群6台主机
- 级联主从
- 配置定时任务,免交互删除redis中的key
Redis数据类型
redis每条数据都是⼀个键值对,值的类型分为五种:
- 字符串string
- 哈希hash
- 列表list
- 集合set
- 有序集合zset
redis数据库常用命令
set:存放数据,命令格式 set key value
get:获取数据,命令格式 get key

redis多数据库常用命令
redis支持多数据库,redis默认情况下包含16个数据库,数据库名称是用数字0-15来依次命名的。
多数据库相互独立,互不干扰
1、多数据库间切换
命令格式:select 序号
#使用redis-cli连接redis数据库后,默认使用的是序号为0的数据库
2、多数据库间移动数据
命令格式:move 键值 序号
3、清除数据库内数据
FLUSHDB:清空当前数据库数据
FLUSHALL:清空所有数据库的数据
#千万慎用!!!!
key命令
1、keys 命令
#keys 命令可以取符合规则的键值列表,通常情况可以结合*、?等选项来使用。
keys * #查看当前数据库中所有的数据
keys v* #查看当前数据库中以v开头的数据
keys v?? #查看当前数据库中以v开头后面包含任意一位的数据
keys v?? #查看当前数据库中以v开头后面包含任意两位的数据

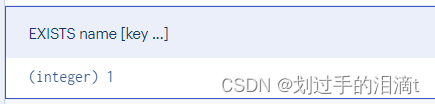
2、判断键值是否存在exists
语法 exists [键]
返回值为1则存在,为0则不存在

3、删除当前数据库的指定key del
语法 del [键]

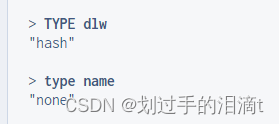
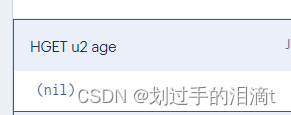
4、获取key对应的value值类型 type
语法 type [键]
5、设置key过期时间
设置过期时间,以秒为单位
如果没有指定过期时间则⼀直存在,直到使⽤DEL移除
语法:expire key seconds
例:设置键’a1’的过期时间为3秒 expire a1 3
查看key有效时间
6、查看有效时间,以秒为单位
语法:ttl key

7、对key重命名
对已有 key 进行重命名
语法:rename 源key 目标key
例:将key a1改为b1
rename a1 b1

7.5、renamenx
命令的作用是对已有 key 进行重命名,并检测新名是否存在,如果目标 key 存在则不进行重命名。(不覆盖)
命令格式:
renamenx 源key 目标key

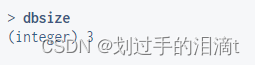
8、查看当前数据库中key的数目 dbsize
命令格式:dbsize
9、使用config set requirepass yourpassword命令设置密码
命令格式 config set requirepass 密码
10、使用config get requirepass命令查看密码
#一旦设置密码,必须先验证通过密码,否则所有操作不可用auth 123456
config get requirepass
11、删除密码
auth 123456 #因为之前设置过密码,所以要先登录
config set requirepass '' #用''代表空密码
string类型
增加、修改
如果设置的键不存在则为添加,如果设置的键已经存在则修改
设置键值 set key value
#例1:设置键为name值为zhangsan的数据
set name zhangsan

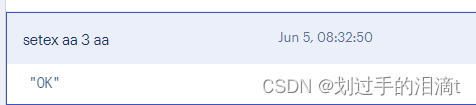
设置键值及过期时间,以秒为单位 setex key seconds value
#例2:设置键为aa值为aa过期时间为3秒的数据
setex aa 3 aa
设置多个键值 mset key1 value1 key2 value2 …
#例3:设置键为'a1'值为'Python'、键为'a2'值为'Java'、键为'a3'值为'c'
mset a1 python a2 java a3 c

追加值 append key value
#例4:向键为a1中追加值' haha'
append a1 haha

获取
获取:根据键获取值,如果不存在此键则返回nil
get key
#例5:获取键'name'的值
get name

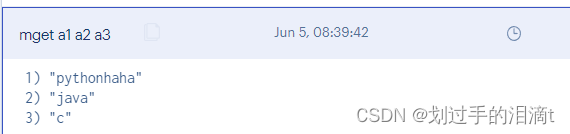
根据多个键获取多个值 mget key1 key2 …
#例6:获取键a1、a2、a3'的值
mget a1 a2 a3
删除
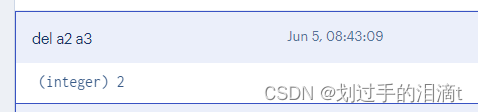
删除键及对应的值 del key1 key2 …
#例7:删除键a2、a3
del a2 a3
hash类型
- hash⽤于存储对象,对象的结构为属性、值
- 值的类型为string
增加、修改
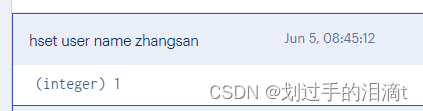
设置单个属性 hset key field value
# 例1:设置键 user的属性name为zhangsan
hset user name zhangsan
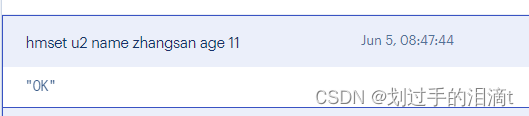
设置多个属性 hmset key field1 value1 field2 value2 ...
#例2:设置键u2的属性name为zhangsan、属性age为11
hmset u2 name zhangsan age 11
获取
获取指定键所有的属性 hkeys key
#例3:获取键u2的所有属性
hkeys u2

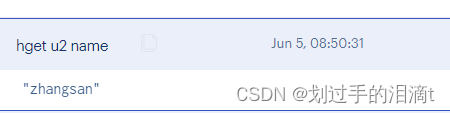
获取⼀个属性的值 hget key field
#例4:获取键u2属性'name'的值
hget u2 name
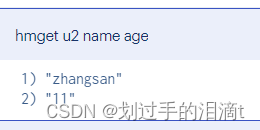
获取多个属性的值 hmget key field1 field2 …
#例5:获取键u2属性'name'、'age的值
hmget u2 name age
获取所有属性的值 hvals key
#例6:获取键'u2'所有属性的值
hvals u2

删除
删除整个hash键及值,使⽤del命令
删除属性,属性对应的值会被⼀起删除 hdel key field1 field2 …
#例7:删除键'u2'的属性'age'
hdel u2 age

list类型
- 列表的元素类型为string
- 按照插⼊顺序排序
增加
在左侧插⼊数据 lpush key value1 value2 …
#例1:从键为'a1'的列表左侧加⼊数据a 、 b 、c
lpush a1 a b c

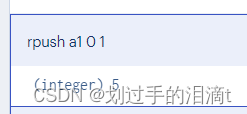
在右侧插⼊数据 rpush key value1 value2 …
#例2:从键为'a1'的列表右侧加⼊数据0 1
rpush a1 0 1
在指定元素的前或后插⼊新元素 linsert key before或after 现有元素 新元素
#例3:在键为'a1'的列表中元素'b'前加⼊'3'
linsert a1 before b 3

获取
返回列表⾥指定范围内的元素 start、stop为元素的下标索引
索引从左侧开始,第⼀个元素为0
索引可以是负数,表示从尾部开始计数,如-1表示最后⼀个元素
lrange key start stop
#例4:获取键为'a1'的列表所有元素
lrange a1 0 -1

设置指定索引位置的元素值
- 索引从左侧开始,第⼀个元素为0
- 索引可以是负数,表示尾部开始计数,如-1表示最后⼀个元素
lset key index value
#例5:修改键为'a1'的列表中下标为1的元素值为'z'
lset a1 1 z


删除
- 删除指定元素
- 将列表中前count次出现的值为value的元素移除
- count > 0: 从头往尾移除
- count < 0: 从尾往头移除
- count = 0: 移除所有
lrem key count value
#例6.1:向列表'a2'中加⼊元素'a'、'b'、'a'、'b'、'a'、'b'
lpush a2 a b a b a b
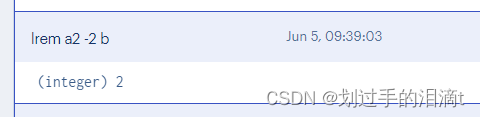
#例6.2:从'a2'列表右侧开始删除2个'b'
lrem a2 -2 b
#例6.3:查看列表'py12'的所有元素
lrange a2 0 -1


lpop 移除并返回列表的第一个元素
lpop key
rpop 移除列表的最后一个元素,返回值为移除的元素
rpop key
set类型
- ⽆序集合
- 元素为string类型
- 元素具有唯⼀性,不重复
- 说明:对于集合没有修改操作
增加
添加元素 sadd key member1 member2 …
#例1:向键'a3'的集合中添加元素'linuxmi'、'lisi'、'linuxidc'
sadd a3 linuxmi sili linuxidc

获取
返回所有的元素 smembers key
#例2:获取键'a3'的集合中所有元素
smembers a3

删除
删除指定元素 srem key
#例3:删除键'a3'的集合中元素'linuxidc'
srem a3 linuxidc

移除集合中的指定 key 的一个或多个随机元素,移除后会返回移除的元素
spop key [count]

zset类型
- sorted set,有序集合
- 元素为string类型
- 元素具有唯⼀性,不重复
- 每个元素都会关联⼀个double类型的score,表示权重,通过权重将元素从⼩到⼤排序
- 说明:没有修改操作
增加
添加 zadd key score1 member1 score2 member2 …
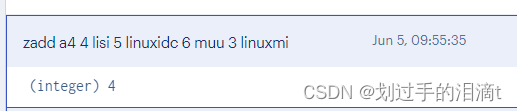
#例1:向键'a4'的集合中添加元素'lisi'、'linuxidc'、'muu'、'linuxmi',权重分别为4、5、6、3
zadd a4 4 lisi 5 linuxidc 6 muu 3 linuxmi
获取
返回指定范围内的元素
start、stop为元素的下标索引
索引从左侧开始,第⼀个元素为0
索引可以是负数,表示从尾部开始计数,如-1表示最后⼀个元素 zrange key start stop
#例2:获取键'a4'的集合中所有元素
zrange a4 0 -1

返回score值在min和max之间的成员 zrangebyscore key min max
#例3:获取键'a4'的集合中权重值在5和6之间的成员
zrangebyscore a4 5 6

返回成员member的score值 zscore key member
#例4:获取键'a4'的集合中元素'linuxmi'的权重
zscore a4 linuxmi
删除
删除指定元素 zrem key member1 member2 …
#例5:删除集合'a4'中元素'linuxmi'
zrem a4 linuxmi

删除权重在指定范围的元素 zremrangebyscore key min max
#例6:删除集合'a4'中权重在5、6之间的元素
zremrangebyscore a4 5 6

使用5种数据类型用来描述角色信息
Lillia ATK 61 Armor 20 Spell 32 HP 580
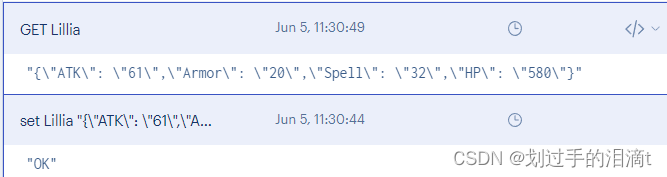
string:
set Lillia "{\"ATK\": \"61\",\"Armor\": \"20\",\"Spell\": \"32\",\"HP\": \"580\"}"
hash
HMSET Lillia1 ATK 61 Armor 20 Spell 32 HP 580

list
RPUSH Lillia2 "\"ATK\":61" "\"Armor\":20" "\"Spell\":32" "\"HP\":580"

set
SADD Lillia3 "\"ATK\":61" "\"Armor\":20" "\"Spell\":32" "\"HP\":580"

zset
ZADD Lillia4 20 Armor 580 HP 32 Spell 61 ATK

Redis高可用-持久化
1、持久化的功能
(1)Redis是内存数据库,数据都是存储在内存中,为了避免服务器断电等原因导致Redis进程异常退出后数据的永久丢失,需要定期将Redis中的数据以某种形式(数据或命令)从内存保存到硬盘;当下次Redis重启时,利用持久化文件实现数据恢复
(2)除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置
2、两种持久化方式
(1)RDB 持久化:原理是将Redis在内存中的数据库记录定时保存到磁盘上(有点像快照)
(2)AOF 持久化:原理是将Reids的操作日志以注:追加的方式写入文件,类似于MySQL的binlog(类似于历史记录)
由于AOF持久化的实时性更好,即当进程意外退出时丢失的数据更少,因此AOF是目前主流的持久化方式,不过RDB持久化仍然有其用武之地
tips
进程与线程的区别总结:本质区别:进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位。
包含关系:一个进程至少有一个线程,线程是进程的一部分,所以线程也被称为轻权进程或者轻量级进程。
资源开销:每个进程都有独立的地址空间,进程之间的切换会有较大的开销;线程可以看做轻量级的进程,同一个进程内的线程共享进程的地址空间,每个线程都有自己独立的运行栈和程序计数器,线程之间切换的开销小。
影响关系:一个进程崩溃后,在保护模式下其他进程不会被影响,但是一个线程崩溃可能导致整个进程被操作系统杀掉,所以多进程要比多线程健壮。
RDB持久化
1、概述
(1)RDB持久化是指在指定的时间间隔内将内存中当前进程中的数据生成快照保存到硬盘(因此也称作快照持久化),用二进制压缩存储,保存的文件后缀是rdb
(2)当Redis重新启动时,可以读取快照文件恢复数据
2、触发条件
(1)手动触发
- save命令和bgsave命令都可以生成RDB文件

save命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在Redis服务器阻塞期间,服务器不能处理任何命令请求
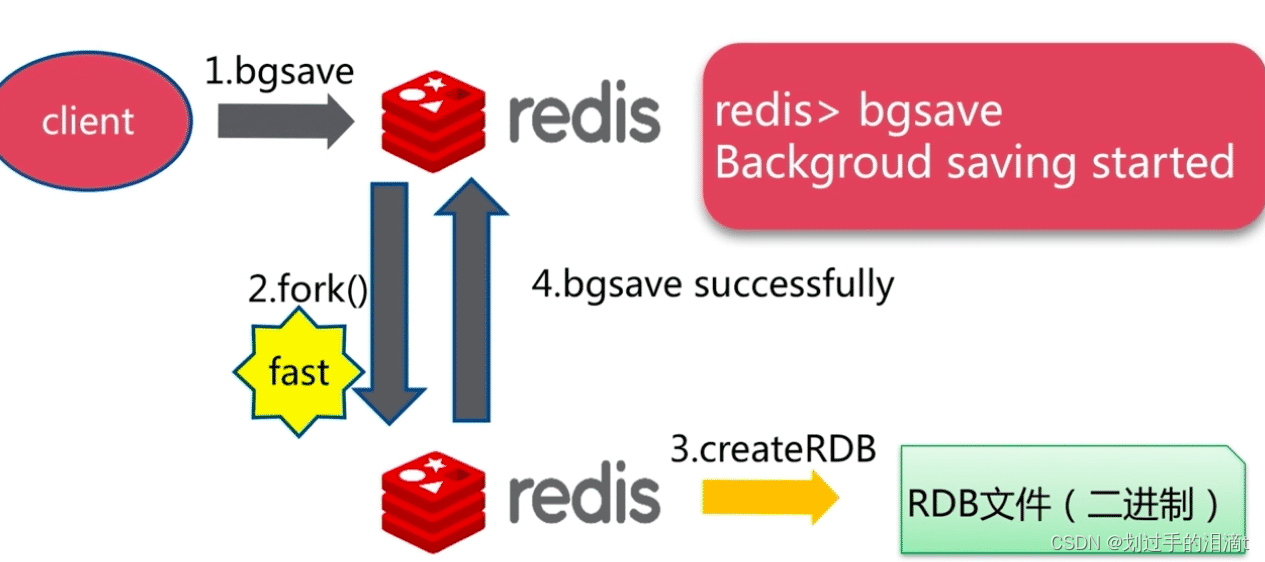
- bgsave命令会创建一个子进程,由子进程来负责创建RDB文件,父进程(即Redis主进程)则继续处理请求
bgsave命令执行过程中,只有fork子进程时会阻塞服务器,而对于save命令,整个过程都会阻塞服务器,因此save已基本被废弃,线上环境要杜绝save的使用
(2)自动触发
• 在自动触发RDB持久化时,Redis也会选择bgsave而不是save来进行持久化
• 自动触发最常见的情况是在配置文件中通过save m n,指定当m秒内发生n次变化时,会触发bgsave
vim /etc/redis/6379.conf
#----219行----以下三个save条件满足任意一个时,都会引起bgsave的调用
save 900 1 :当时间到900秒时,如果redis数据发生了至少1次变化,则执行bgsave
save 300 10 :当时间到300秒时,如果redis数据发生了至少10次变化,则执行bgsave
save 60 10000 :当时间到60秒时,如果redis数据发生了至少10000次变化,则执行bgsave
#----242行----是否开启RDB文件压缩
rdbcompression yes
#----254行----指定RDB文件名
dbfilename dump.rdb
#----264行----指定RDB文件和AOF文件所在目录
dir /var/lib/redis/6379
(3)其他自动触发机制
• 除了save m n 以外,还有一些其他情况会触发bgsave
• 在主从复制场景下,如果从节点执行全量复制操作,则主节点会执行bgsave命令,并将rdb文件发送给从节点
• 执行shutdown命令时,自动执行rdb持久化
3、bgsave工作流程
(1)Redis父进程首先判断:当前是否在执行save,或bgsave/bgrewriteaof的子进程,如果在执行则bgsave命令直接返回。 bgsave/bgrewriteaof的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题
(2)父进程执行fork操作创建子进程,这个过程中父进程是阻塞的,Redis不能执行来自客户端的任何命令
(3)父进程fork后,bgsave命令返回"Background saving started"信息并不再阻塞父进程,并可以响应其他命令
(4)子进程创建RDB文件,根据父进程内存快照生成临时快照文件,完成后对原有文件进行原子替换
(5)子进程发送信号给父进程表示完成,父进程更新统计信息
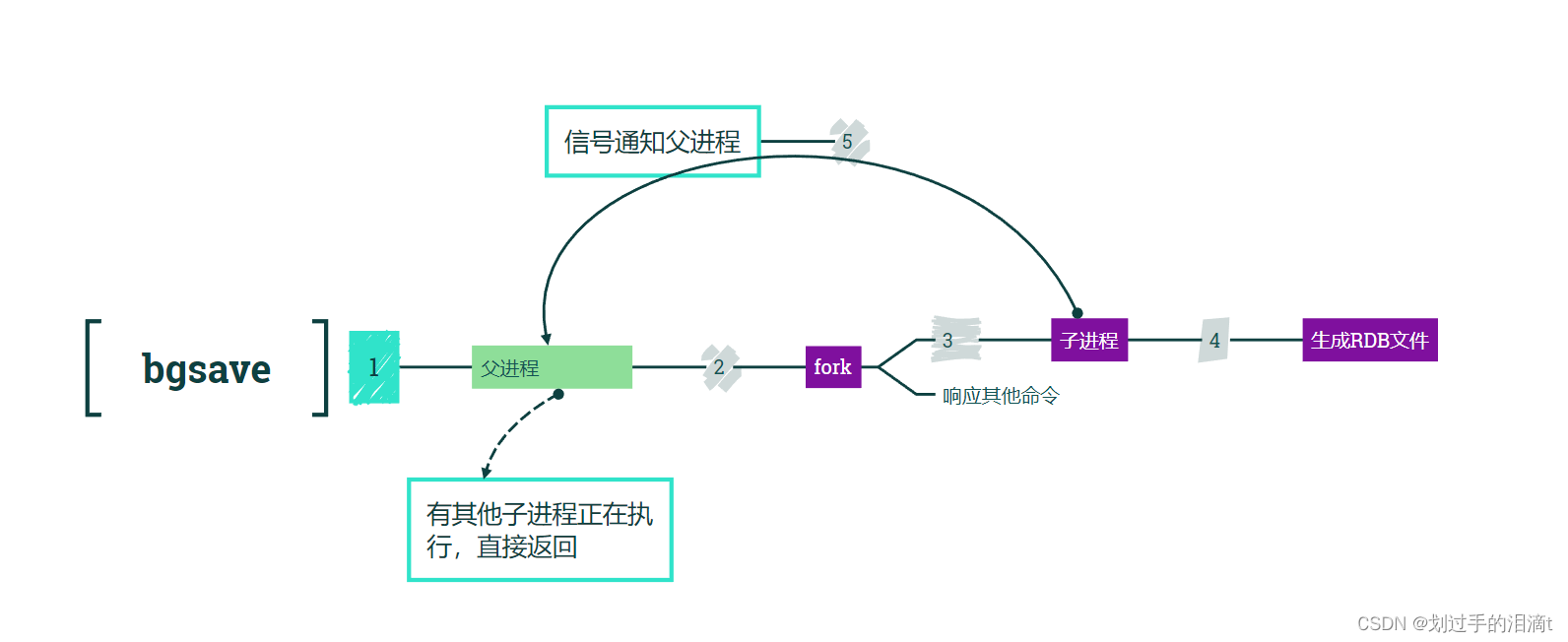
4、启动时加载
(1)RDB文件的载入工作是在服务器启动时自动执行的,并没有专门的命令。但是由于AOF的优先级更高,因此当AOF开启时,Redis会优先载入 AOF文件来恢复数据;只有当AOF关闭时,才会在Redis服务器启动时检测RDB文件,并自动载入。服务器载入RDB文件期间处于阻塞状态,直到载入完成为止
(2)Redis(AOF关闭的时候)载入RDB文件时,会对RDB文件进行校验,如果文件损坏,则日志中会打印错误,Redis启动失败
AOF 持久化
1、概述
(1)RDB持久化是将进程数据写入文件,而AOF持久化,则是将Redis执行的每次写、删除命令记录到单独的日志文件中,查询操作不会记录; 当Redis重启时再次执行AOF文件中的命令来恢复数据
(2)与RDB相比,AOF的实时性更好,因此已成为主流的持久化方案
AOF工作流程
(1)客户端的请求写命令会被append追加到AOF缓冲区内;
(2)AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作sync同步到磁盘的AOF文件中;
(3)AOF文件大小超过重写策略或手动重写时,会对AOF文件进行rewrite重写,压缩AOF文件容量;
(4)Redis服务重启时,会重新load加载AOF文件中的写操作达到数据恢复的目的;
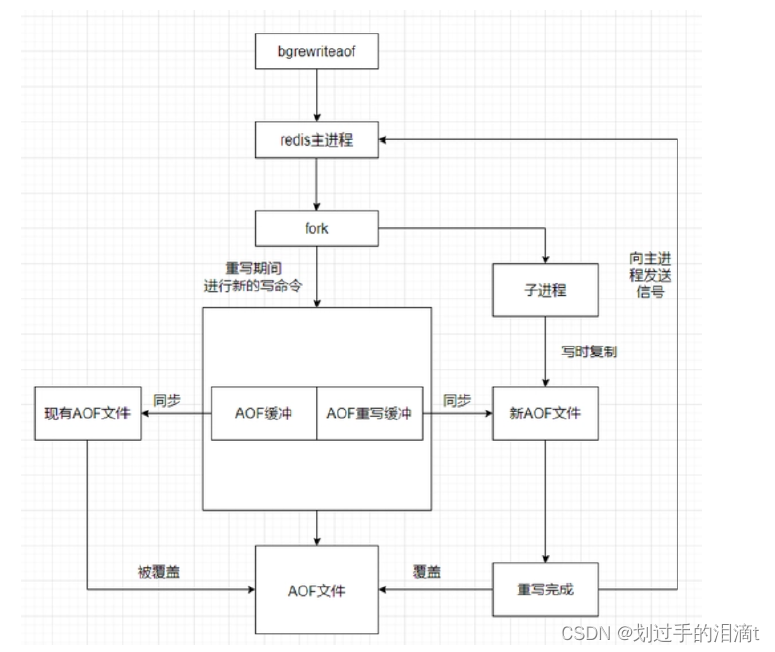
Redis服务器默认开启RDB,关闭AOF;要开启AOF,需要在配置文件中配置:vim /etc/redis/6379.conf#----700行----修改;开启AOF
appendonly yes
#----704行----指定AOF文件名称
appendfilename "appendonly.aof"
#----796行----是否忽略最后一条可能存在问题的指令
aof-load-truncated yes
#指redis在恢复时,会忽略最后一条可能存在问题的指令,默认为yes,即在aof写入时,可能存在指令错误的问题(突然断电导致未执行结束),这种情况下,yes会log并继续,而no会直接恢复失败
AOF写数据策略(appendfsync)
aof写数据三种策略
- always(每次)
每次写入操作均同步到AOF文件中,数据零误差,性能较低 - everysec(每秒)
每秒将缓冲区中的指令同步到AOF文件中,数据准确性较高,性能较高
在系统突然宕机的情况下丢失1秒内的数据 - no(系统控制)
由操作系统控制每次同步到AOF文件的周期,整体过程不可控
RDB和AOF的优先级
前提:
- 因为redis默认将数据保存在内存中,所以redis启动、关闭时内存中的数据会丢失
- 在redis每次启动时,都会读取持久化文件,将数据恢复到内存中,以保证redis数据完整性
RDB和AOF优先级,AOF优先级高
Redis高可用-集群
1、概述
(1)主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master),后者称为从节点(Slave),数据的复制是单向的,只能由主节点到从节点
(2)默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点
2、主从复制的作用
(1)数据冗余∶主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式
(2)故障恢复∶当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复,实际上是一种服务的冗余。
(3)负载均衡∶在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载,尤其是在写
少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量
(4)高可用基石∶除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础
3、主从复制流程
Redis的主从复制功能除了支持一个Master节点对应多个Slave节点的同时进行复制外,还支持Slave节点向其它多个Slave节点进行复制。这样使得我们能够灵活组织业务缓存数据的传播,例如使用多个Slave作为数据读取服务的同时,专门使用一个Slave节点为流式分析工具服务。Redis的主从复制功能分为两种数据同步模式进行:全量数据同步和增量数据同步。
- 建立连接:首先,从服务器会向主服务器发送一个SYNC命令来请求建立连接和同步数据。如果是
初次连接或者之前的复制断开了,主服务器将执行全量复制;否则,它将执行部分复制。 - 快照同步:在进行全量复制时,主服务器会生成RDB(Redis Database)文件,并通过网络传输给
从服务器。接收到RDB文件后,从服务器会清空自己的数据库,并加载新接收到的快照数据。 - 增量同步:完成快照同步后,在进行部分复制时,主服务器将继续记录并缓存所有写操作命令。然
后以类似于日志追加方式(AOF)将这些写操作发送给从服务器进行增量同步。 - 命令重放:当有新命令要被执行时(包括客户端发起写操作),主服务会依次执行该命令并同时发
给所有已经与其建立连接的从服务器。然后每个从服务器都按顺序重放相应的命令来保持数据一致
性。 - 心跳检测和重新连接:为了保持稳定和可靠性,在主从之间还会进行心跳检测。如果从服务器与主
服务器的连接断开,它将尝试重新建立连接并请求同步数据。
主从复制部署
# replicaof <masterip> <masterport>
replicaof 127.0.0.1 6379
#masterauth <password>
#如果主服务器有密码验证,从服务器需要配置主服务器密码
搭建redis主从复制集群,2个集群6台主机
在搭建主从之前在从服务器写一些数据,
测试主从完成后从服务器数据是否存在,
扩展:多主一从,级联主从
192.168.99.121:6379 master1
192.168.99.121:7001 slave1
192.168.99.121:7002 slave2
REPLICAOF 192.168.99.121 6379

192.168.99.121:7003 master2
192.168.99.121:7004 slave3
192.168.99.121:7005 slave4
REPLICAOF 192.168.99.121 7003
级联主从
192.168.99.121:7006 slave of 192.168.99.121:7001
配置定时任务,免交互删除redis中的key
# 安装expect工具,用于自动化交互式应用程序
yum install expect -y# 创建并编辑一个expect脚本,用于自动删除Redis中的zl键
vim /opt/redis_del_zl.exp
#!/usr/bin/expect
# 启动一个Redis客户端
spawn /usr/local/redis/bin/redis-cli
# 期待看到提示符,表示已成功连接
expect "*>"
# 发送命令删除zl键
send "DEL zl\r"
# 再次期待看到提示符,确保命令已成功执行
expect "*>"
# 发送退出命令,关闭Redis客户端
send "quit\r"
# 允许交互,以便在脚本执行过程中进行手动干预
interact
# 使脚本可执行,以便能够通过cron任务调用
chmod +x # 编辑crontab,以定时执行删除操作
crontab -e# 定义一个cron任务,在每天的3点执行删除操作
0 3 * * * /opt/redis_del_zl.exp

相关文章:
【NoSQL数据库】Redis命令、持久化、主从复制
Redis命令、持久化、主从复制 redis配置 Redis命令、持久化、主从复制Redis数据类型redis数据库常用命令redis多数据库常用命令1、多数据库间切换2、多数据库间移动数据3、清除数据库内数据 key命令1、keys 命令2、判断键值是否存在exists3、删除当前数据库的指定key del4、获取…...

使用Django JWT实现身份验证
文章目录 安装依赖配置Django设置创建API生成和验证Token总结与展望 在现代Web应用程序中,安全性和身份验证是至关重要的。JSON Web Token(JWT)是一种流行的身份验证方法,它允许在客户端和服务器之间安全地传输信息。Django是一个…...

MT2084 检测敌人
思路: 1. 以装置为中心->以敌人为中心。 以敌人为中心,r为半径做圆,与x轴交于a,b点,则在[a,b]之间的装置都能覆盖此敌人。 每个敌人都有[a,b]区间,则此题转化为:有多少个装置能覆盖到这些[a,b]区间。…...

支持向量机、随机森林、K最近邻和逻辑回归-九五小庞
支持向量机(Support Vector Machine, SVM)、随机森林(Random Forest)、K最近邻(K-Nearest Neighbors, KNN)和逻辑回归(Logistic Regression)是机器学习和统计学习中常用的分类算法。…...

MySQL—多表查询—多表关系介绍
一、引言 提到查询,我们想到之前学习的单表查询(DQL语句)。而这一章节部分的博客我们将要去学习和了解多表查询。 对于多表查询,主要从以下7个方面进行学习。 (1)第一部分:介绍 1、多表关系 2、…...

Vue基础篇--table的封装
1、 在components文件夹中新建一个ITable的vue文件 <template><div class"tl-rl"><template :table"table"><el-tablev-loading"table.loading":show-summary"table.hasShowSummary":summary-method"table…...

mysql中optimizer trace的作用
大家好。对于MySQL 5.6以及之前的版本来说,查询优化器就像是一个黑盒子一样,我们只能通过EXPLAIN语句查看到最后 优化器决定使用的执行计划,却无法知道它为什么做这个决策。于是在MySQL5.6以及之后的版本中,MySQL新增了一个optimi…...

实习面试题(答案自敲)、
1、为什么要重写equals方法,为什么重写了equals方法后,就必须重写hashcode方法,为什么要有hashcode方法,你能介绍一下hashcode方法吗? equals方法默认是比较内存地址;为了实现内容比较,我们需要…...

二叉树讲解
目录 前言 二叉树的遍历 层序遍历 队列的代码 queuepush和queuepushbujia的区别 判断二叉树是否是完全二叉树 前序 中序 后序 功能展示 创建二叉树 初始化 销毁 简易功能介绍 二叉树节点个数 二叉树叶子节点个数 二叉树第k层节点个数 二叉树查找值为x的节点 判…...
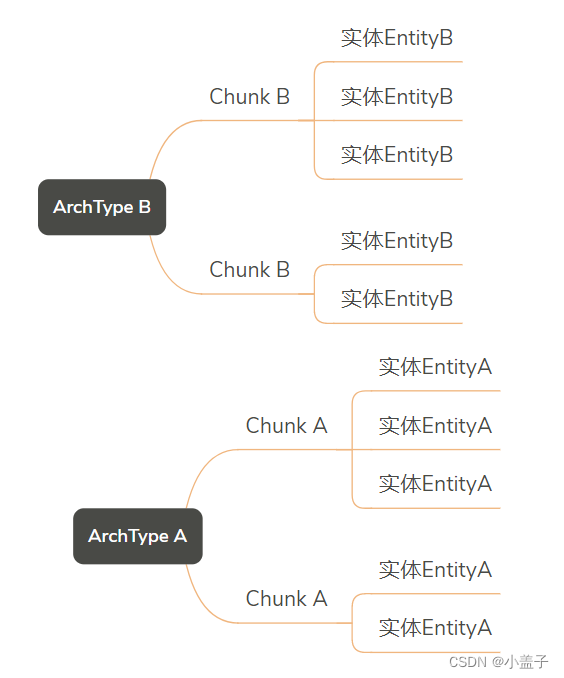
Unity DOTS技术(五)Archetype,Chunk,NativeArray
文章目录 一.Chunk和Archetype什么是Chunk?什么是ArchType 二.Archetype创建1.创建实体2.创建并添加组件3.批量创建 三.多线程数组NativeArray 本次介绍的内容如下: 一.Chunk和Archetype 什么是Chunk? Chunk是一个空间,ECS系统会将相同类型的实体放在Chunk中.当一个Chunk…...

算法学习笔记(7.1)-贪心算法(分数背包问题)
##问题描述 给定 𝑛 个物品,第 𝑖 个物品的重量为 𝑤𝑔𝑡[𝑖−1]、价值为 𝑣𝑎𝑙[𝑖−1] ,和一个容量为 𝑐𝑎&…...

气膜建筑的施工对周边环境影响大吗?—轻空间
随着城市化进程的加快,建筑行业的快速发展也带来了环境问题。噪音、灰尘和建筑废料等对周边居民生活和生态环境造成了不小的影响。因此,选择一种环保高效的施工方式变得尤为重要。气膜建筑作为一种新兴的建筑形式,其施工过程对周边环境的影响…...

【计算机网络】对应用层HTTP协议的重点知识的总结
˃͈꒵˂͈꒱ write in front ꒰˃͈꒵˂͈꒱ ʕ̯•͡˔•̯᷅ʔ大家好,我是xiaoxie.希望你看完之后,有不足之处请多多谅解,让我们一起共同进步૮₍❀ᴗ͈ . ᴗ͈ აxiaoxieʕ̯•͡˔•̯᷅ʔ—CSDN博客 本文由xiaoxieʕ̯•͡˔•̯᷅ʔ 原创 CSDN 如…...

30分钟快速入门TCPDump
TCPDump是一款功能强大的网络分析工具,它可以帮助网络管理员捕获并分析流经网络接口的数据包。由于其在命令行环境中的高效性与灵活性,TCPDump成为了网络诊断与安全分析中不可或缺的工具。本文将详细介绍TCPDump的基本用法,并提供一些高级技巧…...

Python | 刷题日记
1.海伦公式求三角形的面积 area根号下(p(p-a)(p-b)(p-c)) p是周长的一半 2.随机生成一个整数 import random xrandom.randint(0,9)#随机生成0到9之间的一个数 yeval(input("please input:")) if xy:print("bingo") elif x<y:pri…...
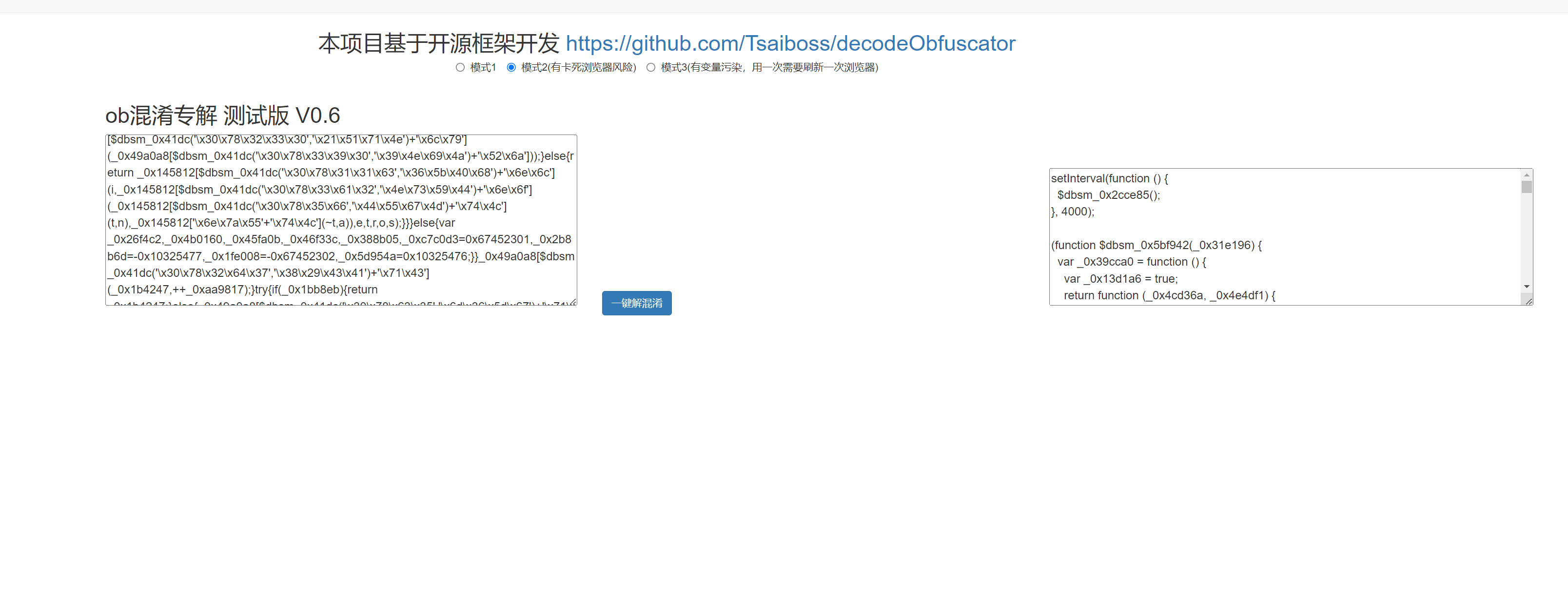
“JS逆向 | Python爬虫 | 动态cookie如何破~”
案例目标 目标网址:aHR0cHMlM0EvL21hdGNoLnl1YW5yZW54dWUuY29tL21hdGNoLzI= 本题目标:提取全部 5 页发布日热度的值,计算所有值的加和,并提交答案 常规 JavaScript 逆向思路 JavaScript 逆向工程通常分为以下三步: 寻找入口:逆向工程的核心在于找出加密参数的生成方式。…...
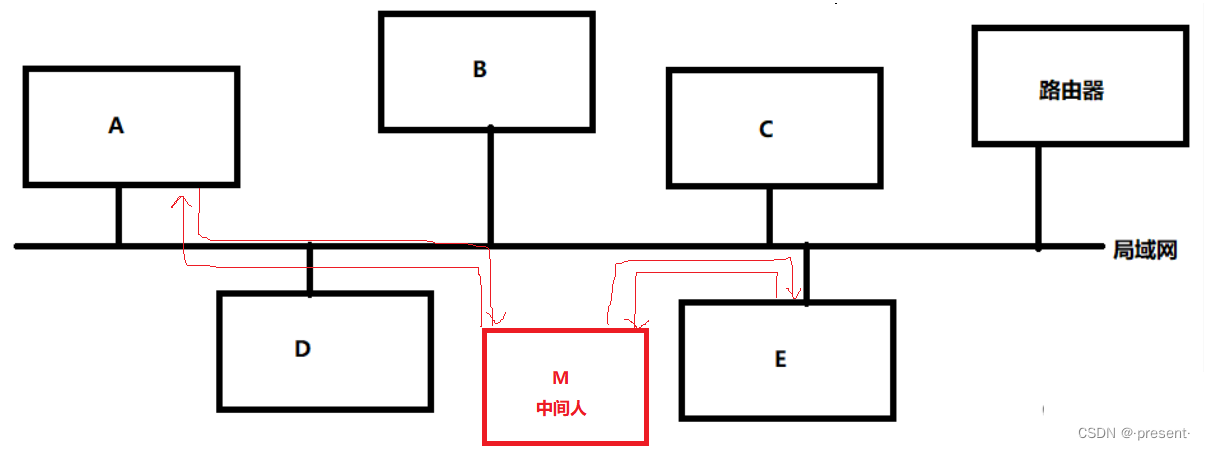
十.数据链路层——MAC/ARP
IP和数据链路层之间的关系 引言 在IP一节中,我们说IP层路由(数据转发)的过程,就像我们跳一跳游戏一样,从一个节点,转发到另一个节点 它提供了一种将数据从A主机跨网络发到B主机的能力 什么叫做跨网络??&a…...

Linux主机安全可视化运维(免费方案)
本文介绍如何使用免费的主机安全软件,在自有机房或企业网络实现对Linux系统进行可视化“主机安全”管理。 一、适用对象 本文适用于个人或企业内的Linux服务器运维场景,实现免费、高效、可视化的主机安全管理。提前发现主机存在的安全风险,全方位实时监控主机运行时入侵事…...

Vite + Vue 3 前端项目实战
一、项目创建 npm install -g create-vite #安装 Vite 项目的脚手架工具 # 或者使用yarn yarn global add create-vite#创建vite项目 create-vite my-vite-project二、常用Vue项目依赖安装 npm install unplugin-auto-import unplugin-vue-components[1] 安装按需自动导入组…...

python-字符替换
[题目描述] 给出一个字符串 s 和 q 次操作,每次操作将 s 中的某一个字符a全部替换成字符b,输出 q 次操作后的字符串输入 输入共 q2 行 第一行一个字符串 s 第二行一个正整数 q,表示操作次数 之后 q 行每行“a b”表示把 s 中所有的a替换成b输…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...