推荐系统学习 一
参考:一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新_数据库全量更新和增量更新流程图-CSDN博客
一文看懂推荐系统:概要01:推荐系统的基本概念_王树森 小红书-CSDN博客
系统把一篇笔记展示给用户,这叫做曝光impression。
假如用户对这篇笔记感兴趣,会点击它进入这篇笔记。
如果用户在这篇笔记上只有短暂停留瞬间溜了,就意味着用户是手滑,而不是真的对这篇笔记感兴趣,这不会被算作一次有效点击。
有效笔记就意味着用户对笔记感兴趣,这将被作为用户不是手滑【停留时间挺长的】,这是真的对这篇笔记感兴趣,这被算作一次有效点击。
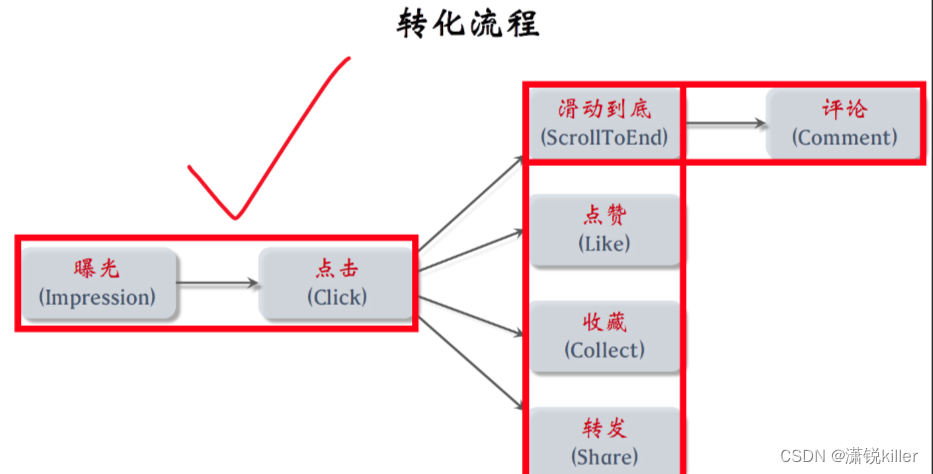
推进系统决定给用户曝光什么内容,用户自己决定是否点击进去,点击进去是否会滑倒的底。
评论、点赞收藏转发的网站,手下都会有不同的转化流程,跟产品的设计有关。
算法工程师应该熟悉自己公司的产品,这对设计特征和模型会有帮助。
对于绝大多数的公司的产品,前两步都是曝光和点击,比如YouTube、淘宝、快手、知乎都是这种设计,
但是抖音不太一样,抖音没有曝光的点击,用户下滑,你只能看到一个视频,
点击之后用户会做设计的动作,包括滑动、到底、点赞、收藏、转发,
这些动作意味着用户对笔记感兴趣,这些动作都可以作为推荐系统用的信号推荐依据。
点击率是一个重要的消费指标,点击率等于点击次数除以曝光次数。
举个例子,每天笔记展示得100个用户,其中有20个用户点击了点击,那么点击的点击率就是20%的,
点击率越高就说明推荐越精准。
尝试一些用户没看过的话。那么点击率不会上涨,但是会有利于提高用户粘性,留住用户,让用户更活跃。
推荐做的越好,用户就会越上瘾,使用小红的时长和阅读数量速度越高。
算法工程师的工作就是对模型、特征、策略系统和改进,提升各种指标,推进系统能否最终上线,要拿实验结果来说话。
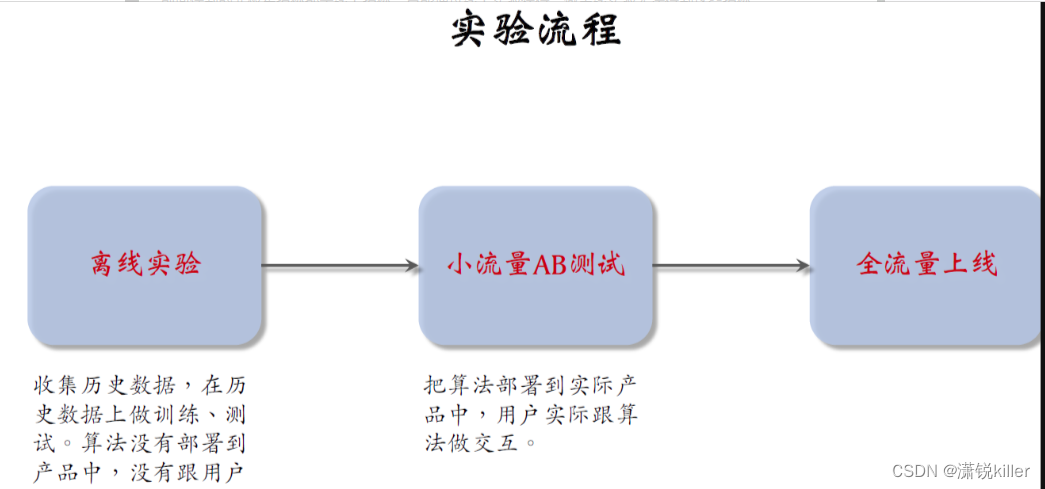
实验流程是先做离线实验,表现好的话上线做小量的测试,表现好的话加大流量,最终目的是全流量上线。
第一步是离线实验,用收集的历史数据做训练和测试,
离线实验不需要把算法部署到产品中,没有跟用户实际交互,
因此离线实验很容易做,不需要占用线上流量,也不会对系统的用户产生负面影响,
有很多评价离线实验的指标,后面课程会讲离线实验的结果有参考价值,能大致反映出算法的好坏,
但是离线实验并没有线上实验可靠,想最终判断算法的好坏,还是需要做线上实验。
这两者的业务指标判断,新策略是否会显著优于旧策略。
如果新策略显著优于旧策略,可以加大流量,最终推广。
推荐系统的链路
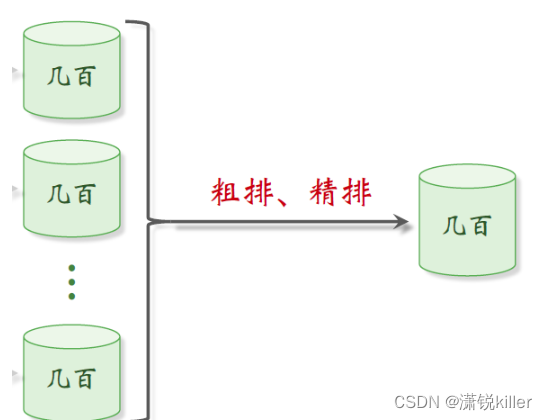
推荐系统的链路分为召回、粗排、精排、重排
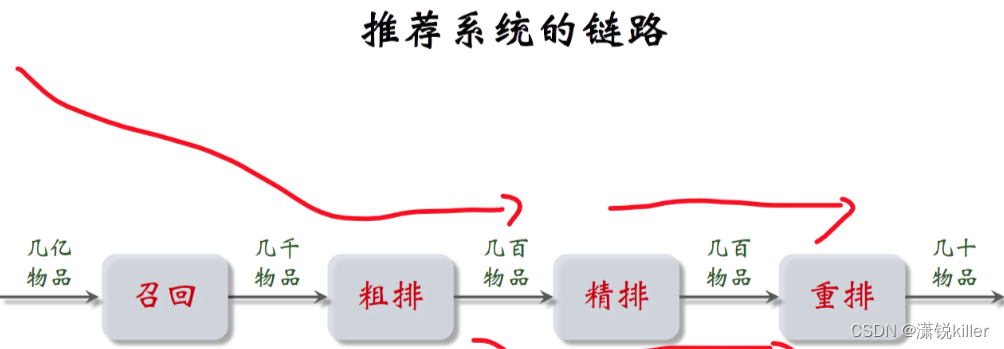
第一步是召回,从物品数据库中快速取回一些物品,
比如小红书有上亿篇笔记,当用户刷新小红书的时候,
系统会同时调用几十条召回通道,每条召回通道取回几十到几百篇笔记,一共取回几千篇笔记。
做完召回之后,接下来要从几千篇笔记中选出用户最感兴趣的。
下一步是粗排,用规模比较小的机器学习模型,给几千篇笔记逐一打分,
按照分数做排序和截断,保留分数最高的几百篇笔记,
再下一步是精排。这里要用大规模的深度神经网络给几百篇笔记逐一打分。
精排的分数反映出用户对笔记的兴趣,在精排之后可以做阶段,也可以不做其他的操作。这几百篇笔记都带着精排,分数进入重排。
重排是最后一步。这里会根据精排分数和多样性分数做随机抽样,得到几十篇笔记,
然后把相似内容打散,并且插入广告和运营内容,展示给用户。
推荐系统的目标是从物品的数据库中选出几十个物品展示给用户。
在我们小红书的场景下,物品就是笔记。在实践中,推荐系统有很多条召回通道。
常见的包括系统过滤、双塔模型、关注的作者等等。
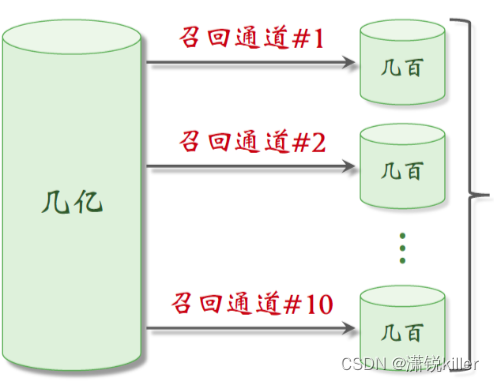
比如小红书的推荐系统有几十条召回通道,每条召回通道取回几十到几百篇笔记,这些召回通道一共会返回几千篇笔记,
然后推荐系统会融合这些笔记,并且做去重和过滤。
过滤的意思是排除掉用户不喜欢的,作者不喜欢的,笔记不喜欢的话题,找回几千篇笔记之后,下一步是做排序。(粗排)
为了解决计算量的问题,通常把排序分为粗排和精排这两步。
粗排用比较简单的模型快速给几千篇笔记打分,保留分数最高的几百篇笔记。
精排用一个较大的神经网络给几百篇笔记打分,精排模型比粗牌模型大很多,用的特征也更多,
所以精排模型打的分数更可靠,但是精排的计算量很大。
这就是为什么我们先用粗排做筛选,然后才用精排,这样做可以比较好的平衡计算量和准确性。
做完粗排和精排得到几百篇笔记,每篇笔记有一个分数,表示用户对笔记的兴趣有多高,
可以直接把笔记按照模型打的分数做排序,然后展示给用户。
重排主要是考虑多样性,
要根据多样性做随机抽样,从几百篇笔记中选出几十篇,
然后还要用规则把内容相似的笔记打散。
重排的结果就是最终展示给用户的物品,
比如把前80的物品展示给用户,其中包括笔记和广告。

粗牌和精排非常相似,
唯一的区别就是精排模型更大,用的特征更多
模型的输入包括用户特征、候选物品的特征,还有统计特征。
假如我们想要判断小王同学是否对某篇笔记感兴趣,我们就要把笔记的特征、小王的特征,还有很多统计特征输入神经网络。
神经网络会输出很多数值,比如点击率、点赞率、收藏率、转发率,这些数值都是神经网络对用户行为的预估。

这些数值越大,说明用户对笔记越感兴趣,
最后把多个预估值做融合,得到最终的分数。
比如求加权和这个分数决定了笔记会不会被展示给用户,以及笔记展示的位置是靠前还是靠后。
这只是对一篇笔记的打分粗排,要对几千篇笔记打分,精排要对几百篇笔记打分。
每篇笔记都有多个预估分数,融合成一个分数,作为你这篇笔记排序的依据。
重排最重要的功能是多样性抽样。
需要从几百篇笔记中选出几十篇笔记,常见的方法有MMR和DPP抽样的时候有两个依据,
一个依据是精排分数的大小,另一个依据是多样性。

做完抽样之后,会用规则打散相似内容。
我们不能把内容过于相似的笔记排在相邻的位置上。
如果排第一的是NBA的笔记,那么接下来几个位置就不能放NBA的内容,相似的笔记会往后挪。
重排的另一个目的是插入广告和运营,推广的内容还要根据生态的要求调整排序,比如不能连接出很多美女图片。

整条链路上召回的粗排是最大的漏斗。他们让候选笔记的数量从几亿变成几千,然后变成几百。
当候选笔记只有几百篇的时候,才能用大规模的神经网络做精排,才能用DPP这样的方法做多样性抽样。
如果笔记的数量太大,就不可能用大规模神经网络和DPP。
推荐系统的目标是从物品的数据库中选出几十个物品展示给用户,推荐系统的链路分为召回、粗排、精排、重排,为了解决计算量的问题,通常把排序分为粗排和精排这两步。
离散特征如何表示?one hot编码和embedding
向量召回

离散特征在推荐系统中非常常见,
性别是离散特征,分为男女两种类别,
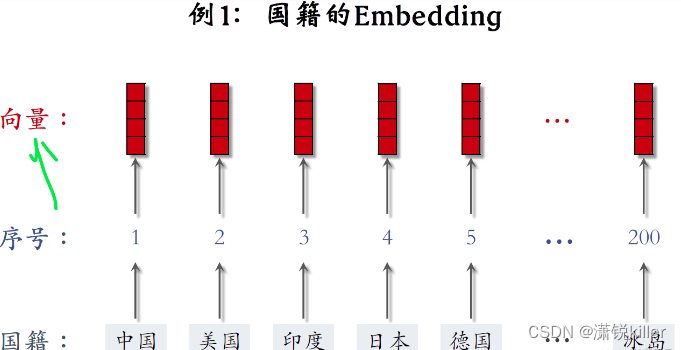
国籍是离散特征,比如中国、美国、印度,一共有200个左右的国家。
英文单词是离散特征,常见的英文单词有几万个;
物品ID是离散特征,比如小红书有几亿篇笔记,每篇笔记有一个ID,
这样的离散特征处理比较困难,因为类别数量实在太大了,
用户ID也一样,小红书有几亿个用户,每个用户有一个ID推荐,系统会把一个ID映射成一个向量。
第一步是建立字典,把类别映射成序号。
以国籍特征为例,建立一个国家的字典,比如中国序号是一,美国序号是二,印度序号是三

第二步是做向量化,把序号映射成向量。
one hot编码是一种常见的方法,把序号映射成高维的稀疏向量。
比如有200个国家,每个国家被映射成一个200维的向量,序号对应的位置的元素是一,其他位置的元素都是零。
embedding,把序号映射成低维稠密向量,比如处理国籍特征,每个国家被映射成一个八维的稠密向量。


one hot编码很常用,但是它有一定的局限性,
比如在自然语言处理的应用中,需要对单词做编码,新闻至少有几万个常见的单词,那么one hot向量的维度就是几万。
这个维度是很大的,实践中通常不会用这么高维的向量;

在实践中,类别数量太大的时候,通常不用one hot编码。
对于性别,这样的离散特征类别数量很小,可以直接用one hot向量。
但是对于单词物品ID这样的离散特征类别数量巨大,用one hot向量并不合适。
embedding特征嵌入
它是另一种把序号映射成向量的方法
embedding把每个序号映射成一个向量,这些向量都是低位向量,
比如向量大小都是四乘以一的一个向量就是对一个国家的表示,
未知国籍就用全零向量表示。
embedding的参数是一个矩阵,大小是向量维度乘以类别数量。
embedding得到的向量都是四维的,一共有200个国际,那么就有200个向量,
参数的数量是4乘以200等于800
直接用系统提供的embedding层,
在训练神经网络的时候会自动做反向传播,学习embedding的参数
embedding层的参数是一个矩阵,矩阵的大小是向量维度乘以类别数量
embedding的输入是序号,比如美国的序号是二
embedding层的输出是个向量,即参数矩阵的一列,
比如美国对应参数矩阵的第二列

第二个例子是物品ID的embedding
展示物品的数据库里一共有1万部电影。
推荐系统的任务是给用户推荐电影
embedding向量的维度是16,也就是说,用一个16维的向量表成一部电影。

参数的数量等于向量维度乘以类别数量
16乘以1万等于16万,
这就是embedding层参数的数量
如果类别的数量不大,只有几百万,那么embedding层的实现是比较容易的。
但如果类别数量特别大,比如推荐系统中的物品数量有几十亿,那么embedding层的参数会特别大。
一个神经网络绝大多数的参数都在embedding层。
所以工业界深度学习系统都会对embedding层做很多优化,这是存储和计算效率的关键所在。
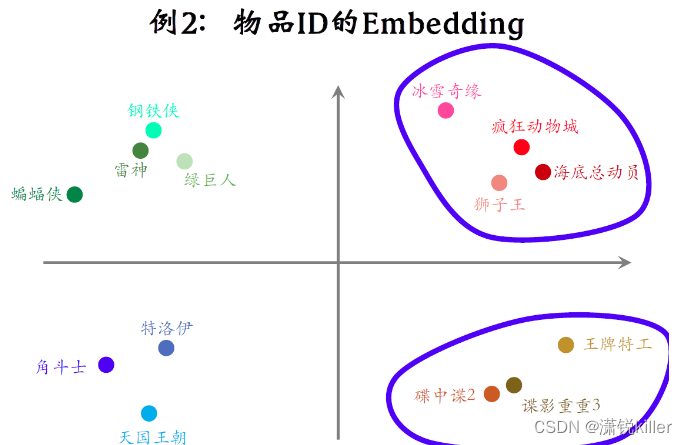
图中的每个点表示一部电影的embedding,如果训练的好,从物品的embedding可以看出物品的特点。
比如右上角这些点都是动画片,它们的距离比较近,
右下角这些点都是间谍片,它们也离的比较近,
但是间谍片和动画片之间的距离会比较远。
embedding和one hot编码之间的关系
embedding其实就是把one hot的向量乘到一个参数矩阵W上得到的精致向量。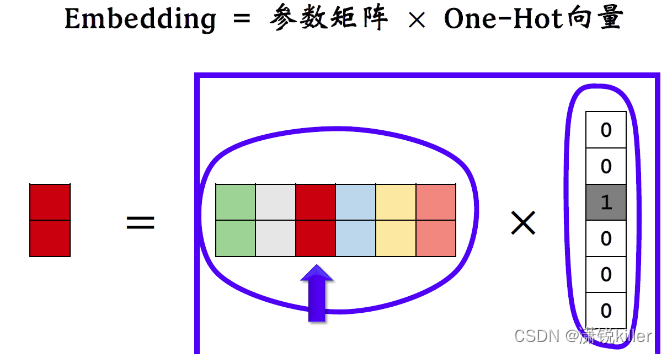
W就是根据神经网络学出来的经典转移矩阵
右边是一个one hot的向量,它的第三个元素是一,其余元素全都是零,
中间是embedding乘的参数矩阵W,把矩阵W和one hot向量相乘
由于one号向量只有第三个元素非零,
所以矩阵向量乘法其实就是取出矩阵W的第三列,把第三列作为输出,
输出的向量就是参数矩阵×one hot向量。
从这个角度看,embedding其实就是矩阵向量乘法。
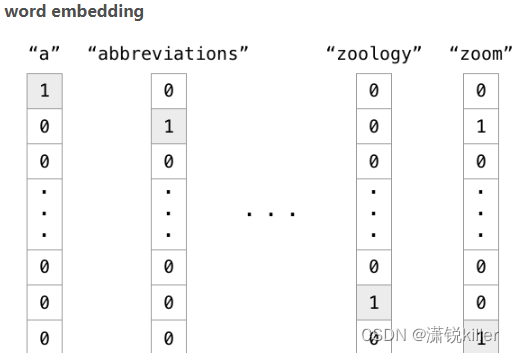
word embedding
Embedding在数学上表示一个maping, f: X -> Y,
也就是一个function,其中该函数是injective
(就是我们所说的单射函数,每个Y只有唯一的X对应,反之亦然)和structure-preserving (结构保存,
比如在X所属的空间上X1 < X2,那么映射后在Y所属空间上同理 Y1 < Y2)
那么对于word embedding,就是将单词word映射到另外一个空间,
其中这个映射具有injective和structure-preserving的特点。
单词嵌入,就是把X所属空间的单词映射为到Y空间的多维向量,
那么该多维向量相当于嵌入到Y所属空间中,一个萝卜一个坑。
word embedding,就是找到一个映射或者函数,生成在一个新的空间上的表达,
该表达就是word representation
one hot编码就是总共多少类别,每个类别序号对应位置是1,其余位置是0
embedding其实就是one hot向量×一个学习好的转移矩阵,使得独特的输入x,可以唯一映射到低纬度稠密向量空间的一个特征嵌入表示embedding y,这个转移矩阵W可以通过神经网络学习
embedding,他可以把用户ID或者物品ID映射成向量
这个模型就是基于embedding做推荐,
模型的输入是一个用户ID和一个物品ID

模型的输出是一个实数(两个向量的内积),是用户对物品兴趣的预估值rate,
这个数越大,表示用户对物品越感兴趣。
左边的结构只有一个embedding层,
把一个用户ID映射到一个向量去做向量a,这个向量是对用户的表征。
回忆一下上一篇文章的内容,embedding层的参数是一个矩阵W,
矩阵中列的数量是用户数量,每一列都是图中a这么大的向量。
embedding层的参数数量等于用户数量乘以向量a的大小。
右边的结构是另一个embedding层,把一个物品ID映射到一个向量记作b,
大小跟向量a,这是乘一样的,向量b是对物品的表征。
embedding层的参数是一个矩阵输出的向量b是矩阵的一列矩阵,
中列的数量是物品的数量。
模型一共用了两个embedding层,它们不共享参数,
对向量a和b,求内积得到一个实数作为模型的输出,这个模型就是矩阵补充模型
刚才定义了模型结构,接下来我要讲模型的训练。
首先讲训练的基本思路,用户embedding参数是一个矩阵记作大A,
用户对应矩阵的第u列记作向量au
物品embedding参数是另一个矩阵记作大B,
物品对应矩阵的第b列,记作做向量bi,
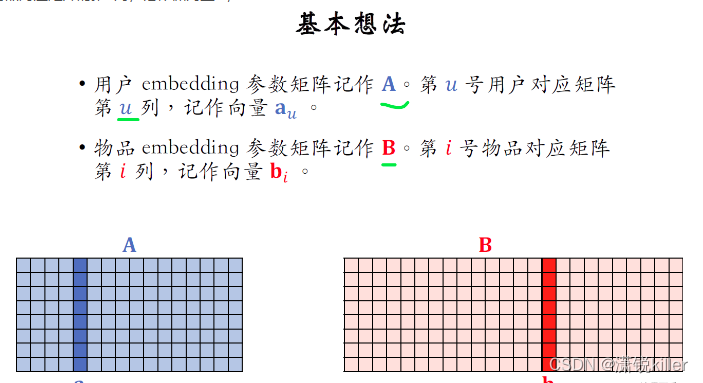
向量au和bi的内积是第u个用户和第i个物品兴趣的预估值rate,
内积越大说明用户u对物品i的兴趣越强。

训练模型的目的是学到矩阵A和B,使得预估值rate和真实观测(内积)的兴趣分数矩阵更接近。
A和B是embedding参数。
开始训练之前首先要准备一个数据集,

数据集是很多三元组的集合,每个三元组包含用户ID、物品ID、兴趣分数y,
三元组的意思是:该用户对该物品真实的兴趣分数。
在系统里有记录把数据集记作Ω,
它是这样三元组的集合,U和I分别是用户ID和物品ID,Y是真实观测的兴趣分数,
数据集中的兴趣分数是系统记录的。
训练的目的就是让模型的输出一个兴趣分数
模型中embedding层可以把用户ID=和物品ID映射成向量
优化映射成向量au
第i号物品映射成向量bi
训练的时候要求解这样一个优化问题,优化变量是矩阵A和B,它们是embedding参数。

三元组UIY是训练集中的一条数据,意思是用户u对物品I的真实兴趣,分数是Y。
<内积>这一项是向量au和bi的内积,它是模型对性取分数的预估,
反应第u号用户有多喜欢第i号物品,
y这一项是真实性取分数(groundtruth),
然后求Y与预估值<内积>之间的差,
我们希望这个差越小越好,
我们取差的平方,差的平方越小,则预估值越接近真实值。
Y对每一条记录的差的平方求和作为优化的目标函数。【这就是典型的MSE误差损失函数】
对目标函数求最小化优化的变量是矩阵A和B,
求最小化损失函数,可以用随机梯度下降的算法,
每次更新矩阵A和B的一列,这样就可以学出矩阵A和B。

矩阵中只有少数位置是绿色
大多数位置都是灰色,也就是没有曝光给用户的,我们并不知道用户对没曝光的物品是否感兴趣。
我们刚才拿绿色位置的数据训练出了模型,有了模型,
我们就可以预估出所有灰色位置的分数,
也就是把矩阵的元素给补全,这就是为什么模型叫做矩阵补充,
把矩阵元素补全之后,我们就可以做推荐。
给定一个用户,我们选出用户对应的行中分数较高的物品推荐给该用户。



补充的正样本指的是物品给用户曝光之后有点击交互的行为,这样的正样本是OK的,没问题
矩阵补充的负样本是曝光之后没有点击交互的物品,这是种想当然的做法。
学数据的人可能以为这样没错,但可惜这样在实践中不work。
训练模型的方法不好,矩阵补充模型,用向量au和bi的内积作为兴趣分数的预估,
这样没错,可以work,但是效果不如余弦相似度。
双塔模型
它可以看作矩阵补充模型的升级版,
双塔模型不单单使用物品ID和用户ID,
还会结合各种物品属性和用户属性,
双塔模型的实际表现非常好。

在训练好模型之后,可以把模型用作配件系统中的召回通道,
比如在用户刷小红书的时候,快速找到这个用户可能感兴趣的一两百篇笔记,
做完训练之后再把模型存储在正确的地方。
便于做召回训练得到矩阵A和B,它们是以embedding参数
A的每一列对应一个用户,
B的每一列对应一个物品。
做推荐的时候要用到矩阵A和B,这两个矩阵可能会很大,
比如小红书有几亿用户,几亿篇笔记,
那么这两个矩阵的列数都是好几亿。

某用户刷小红书的时候,小红书的后台会开始做召回,
把周围用户最可能感兴趣的K的物品作为召回结果,这叫做最近邻查找:nearest neighbor search
把第i个物品embedding向量记作bi,
计算用户向量a和物品向量bi的内积。
这是用户对第i号物品进取分数的预估。
返回内积最大的K的物品,比如K等于100,这些物品就是召回的结果。
这种最近邻查找有个严重的问题,如果逐一对比所有物品,
暴力方法的时间复杂度会正比于物品数量,这种巨大的计算量是不可接受的。
比如小红书有几亿篇比积,那么就有几亿个向量B逐一计算向量a和每个向量B的内积,
是不现实的根本做不到线上的实时计算
快速最近邻查找
快速最近零查找的算法已经被集成到很多向量数据库系统中,

最近邻查找需要定义什么是最近邻,
也就是衡量最近邻的标准,
比如最近邻距离可以定义为欧式距离最小的最近邻,
也可以定义为向量内积最大的,这叫做内积相似度。
本文的矩阵补充用的都是内积相似度,
目前推荐系统最常用的是余弦相似度,其最近邻是向量夹角最小的。 如果你把所有向量都做归一化,让它们的二范数全都等于一,那么内积就等于余弦相似度。

右边的五角星表示,一个用户的embedding向量记作a,
我们想要召回这个用户可能感兴趣的物品,
这就需要计算向量a与所有点的相似度。
介绍一种加速最近查找的算法,在做线上服务之前,先对数据做预处理,
把数据划分成很多区域,比如这样划分

至于如何划分,取决于衡量最近邻的标准
如果是cos相似度,那么划分的结果就是这样的扇形,
如果是用欧式距离,那么划分的结果就是多边形划分,
之后每个区域用一个向量表示,
比如那个蓝色区域,用那蓝色向量表示,
比如那个黄色区域,用那个黄色向量表示,
这些向量长度都是一。
划分区域之后建立索引,把每个区域的向量作为key,把扇区区域中所有点的列表作为value,【这样就省掉了大量的key,用一个代表表示】
给定这个向量就能取回蓝色扇形区域中的所有的点。
划分区域之后,每个区域都用一个单位向量来表示,
假如有一个点,那么划分成1万个区域,索引上一共有1万个key值,
每个向量是一个区域的key值,
给定一个向量可以快速取回这个区域内所有的点。
有了这样一个索引,就可以在线上快速做召回了。
在线上给一个用户做推荐,这个用户的一个向量记作a。
我们首先把向量a跟索引中这些代表向量做对比(量很少),计算它们的相似度,
如果物品数量是几亿,索引中的向量数量也只有几万而已。
这一步的计算开销不大,
计算相似度之后,我们发现索引中下面橘色这个向量与a最相似。
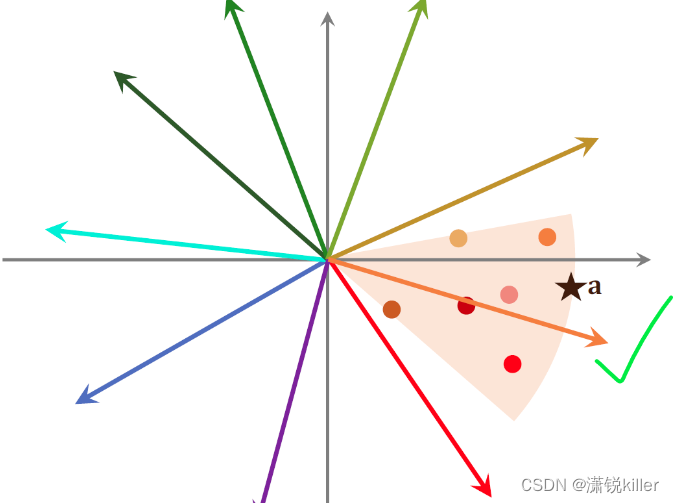
通过索引,我们找到这个区域内所有的点,每个点对应一个物品。
接下来我们计算点a跟区域内所有点的相似度,
如果一共有几亿个物品被划分到了几万个区域,
平均每个区域只有几万个点,所以这一步只需要计算几万次,相似度计算量也不大。
假如我们想要找向量a最相似的三个点。

夹角最小的三个点,他们会找到这三个对应三个物品,这三个物品就是最近邻查找的结果,
哪怕有几亿个物品,用这种加速算法做查找,也只需要计算几万次,
相似度比暴力枚举快1万倍。
-------------------------------------------------
主要介绍了矩阵补充模型,
矩阵补充的想法是把物品ID和用户ID做embedding映射成两个向量,
两个向量记作au和bi
两者内积作为用户u对物品I兴趣的预估值rate。


实践中都用近似最近邻加速算法进行查找,通常会用一些开源的向量数据库,比如milvus,faiss,hnswlib,这些向量数据库都会支持近似最近邻加速算法进行查找。
模型的输出是一个实数(两个向量的内积),是用户对物品兴趣的预估值rate,这个数越大,表示用户对物品越感兴趣。加速的最近邻算法查找说白了就先大范围搜索,再小范围精确对比。
相关文章:
推荐系统学习 一
参考:一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新_数据库全量更新和增量更新流程图-CSDN博客 一文看懂推荐系统:概要01:推荐系统的基本概念_王树森 小红书-CSD…...

分库分表详解
文章目录 分库分表概述分库分表详解分库分表的策略分库分表的注意事项常用的分库分表中间件mysql单表达到多少数据量需要分库分表数据库分库分表缺点分表要停服吗,不停服怎么做 分库分表概述 分库分表是数据库架构设计中的一种常见策略,尤其是在面对大规…...

【java前端课堂】04_类的继承
类的继承 在Java中,继承是面向对象编程的四大基本特性之一,它允许我们根据一个已有的类来定义一个新的类,这个新的类继承了原有类的特性(属性和方法),并可以添加新的特性或修改原有特性。这样,…...
)
React nginx配置,一个端口代理多个项目(转发后找不到CSS,JS及图片资源问题解决)
场景: nginx 配置负载均衡,甲方只提供一个端口,一个域名地址 方法: 一个端口一个域名匹配多个应用 方法一: 依靠设备浏览器区分: 使用UserAgent头来识别用户的客户端, CDN监测vary头的信息,如果内容不一致…...
Unity协程详解
什么是协程 协程,即Coroutine(协同程序),就是开启一段和主程序异步执行的逻辑处理,什么是异步执行,异步执行是指程序的执行并不是按照从上往下执行。如果我们学过c语言,我们应该知道࿰…...

【iOS】UI学习(二)
目录 前言UIViewContorllerUIViewContorller基础UIViewContorller使用 定时器和视图移动UISwitch控件UIProgressView和UISlider总结 前言 本篇博客是笔者在学习UI部分内容时的成果和遇到的一些问题,既是我自己的学习笔记,也希望对你有帮助~ …...

React路由(React笔记之五)
本文是结合实践中和学习技术文章总结出来的笔记(个人使用),如有雷同纯属正常((✿◠‿◠)) 喜欢的话点个赞,谢谢! React路由介绍 现在前端的项目一般都是SPA单页面应用,不再是以前多个页面多套HTML代码项目了,应用内的跳转不需要刷新页面就能完成页面跳转靠的就是路由系统 R…...

调用讯飞星火API实现图像生成
目录 1. 作者介绍2. 关于理论方面的知识介绍3. 关于实验过程的介绍,完整实验代码,测试结果3.1 API获取3.2 代码解析与运行结果3.2.1 完整代码3.2.2 运行结果 3.3 界面的编写(进阶) 4. 问题分析5. 参考链接 1. 作者介绍 刘来顺&am…...

reduce过滤递归符合条件的数据
图片展示 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>Document</title> </head><…...
Go微服务: 基于rocketmq:5.2.0搭建RocketMQ环境,以及示例参考
概述 参考最新官方文档:https://rocketmq.apache.org/zh/docs/quickStart/03quickstartWithDockercompose以及:https://rocketmq.apache.org/zh/docs/deploymentOperations/04Dashboard综合以上两个文档来搭建环境 搭建RocketMQ环境 1 ) 基于 docker-c…...

Wpf 使用 Prism 开发MyToDo应用程序
MyToDo 是使用 WPF ,并且塔配Prism 框架进行开发的项目。项目中进行了前后端分离设计,客户端所有的数据均通过API接口获取。适合新手入门学习WPF以及Prism 框架使用。 首页统计以及点击导航到相关模块功能待办事项增删改查功能备忘录增删改查功能登录注册…...

vue-Dialog 自定义title样式
展示结果 vue代码 <el-dialog :title"title" :visible.sync"classifyOpen" width"500px" :showClose"false" class"aboutDialog"> <el-form :model"classifyForm" :rules"classifyRules">…...

数据库主键设计
文章目录 前言1. 自增ID(Auto-Increment)2. GUID (Globally Unique Identifier)3. 雪花算法(Snowflake)处理时钟回拨的方法1. 简单等待2. 配置时钟回拨安全窗口3. 使用不同的机器 ID 小结稳定的雪花算法实现方案示例实现1. 定义雪…...
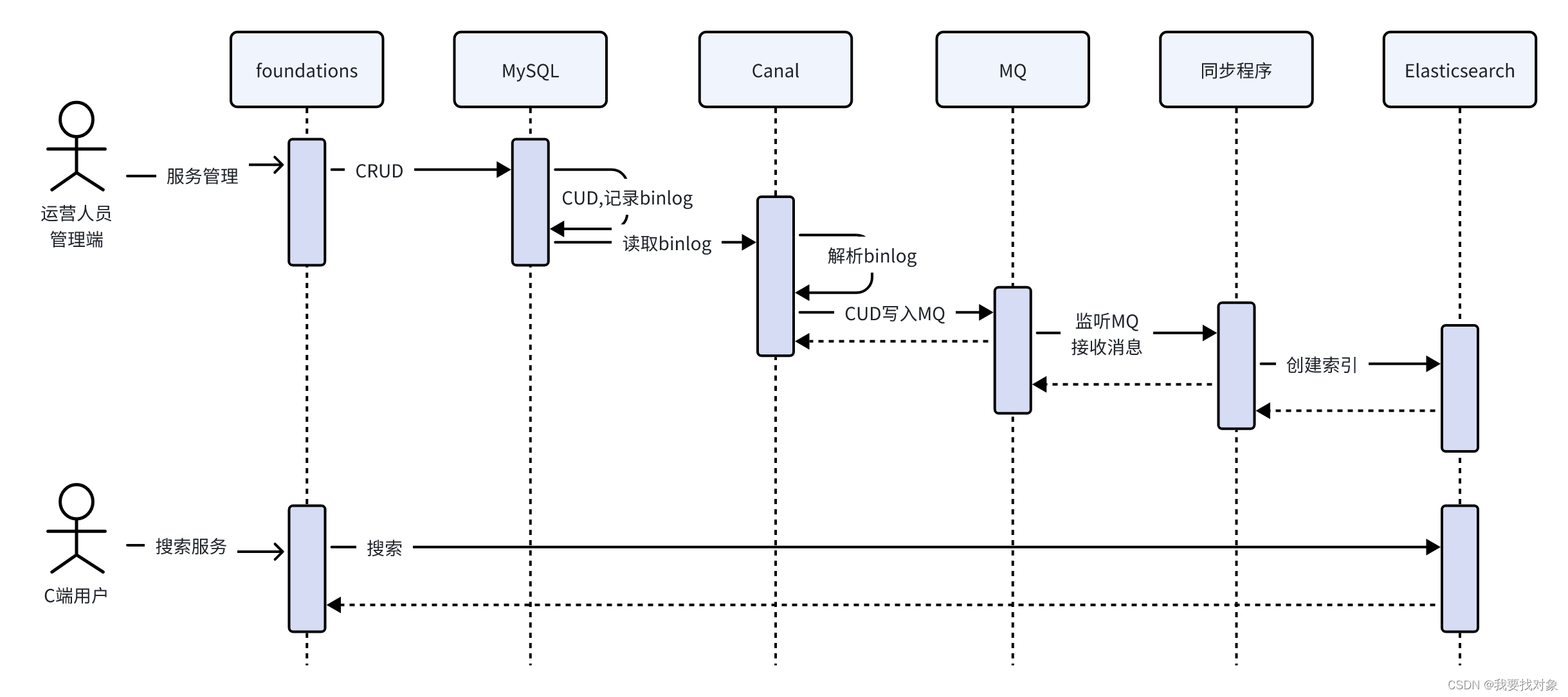
小熊家务帮day13-day14 门户管理(ES搜索,Canal+MQ同步,索引同步)
目录 1 服务搜索1.1 需求分析1.2 技术方案1.2.1 使用Elasticsearch进行全文检索(为什么数据没有那么多还要用ES?)1.2.2 索引同步方案1.2.2.1 Canal介绍1.2.2.1 Canal工作原理 1 服务搜索 1.1 需求分析 服务搜索的入口有两处: 在…...

Android8.1高通平台修改默认输入法
需求 安卓8.1 SDK原生的输入法只能打英文, 需要替换成中文输入法. 以高通平台为例, 其它平台也适用. 查看设备当前默认输入法 adb shell settings list secure | grep input 可以看到当前默认是LatinIME这个安卓原生输入法. default_input_methodcom.android.inputmethod.l…...

49. 字母异位词分组
思路:题目的意思是,将所有字母相同的字符串放到一个数组中 解题思路是:使用map,使用排序好的字符串作为key,源字符串作为value,就可以实现所有字母相同的字符串对应一个key vector<vector<string>> groupAnagrams(ve…...

负压实验室设计建设方案
随着全球公共卫生事件的频发,负压实验室的设计和建设在医疗机构中的重要性日益凸显。负压实验室,特别是负压隔离病房,主要用于控制传染性疾病的扩散,保护医护人员和周围环境的安全。广州实验室装修公司中壹联凭借丰富的实验室装修…...

作文笔记10 复述故事
一、梳理内容(用表格,示意图) 救白蛇 得宝石 救相亲 变石头 人们纪念海力布 二、按顺序,不遗漏主要情节 (猎人海力布热心救人)救白蛇 得宝石(白蛇强调宝石禁忌)(海力…...

业务安全蓝军测评标准解读—业务安全体系化
目录 1.前言 2.业务蓝军测评标准 2.1 业务安全脆弱性评分(ISVS) 2.2 ISVS评分的参考意义<...
关于焊点检测SJ-BIST)模块实现
关于焊点检测SJ-BIST)模块实现 语言 :Verilg HDL 、VHDL EDA工具:ISE、Vivado、Quartus II 关于焊点检测SJ-BIST)模块实现一、引言二、焊点检测功能的实现方法(1) 输入接口(2) 输出接…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

【Redis】笔记|第8节|大厂高并发缓存架构实战与优化
缓存架构 代码结构 代码详情 功能点: 多级缓存,先查本地缓存,再查Redis,最后才查数据库热点数据重建逻辑使用分布式锁,二次查询更新缓存采用读写锁提升性能采用Redis的发布订阅机制通知所有实例更新本地缓存适用读多…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

STM32HAL库USART源代码解析及应用
STM32HAL库USART源代码解析 前言STM32CubeIDE配置串口USART和UART的选择使用模式参数设置GPIO配置DMA配置中断配置硬件流控制使能生成代码解析和使用方法串口初始化__UART_HandleTypeDef结构体浅析HAL库代码实际使用方法使用轮询方式发送使用轮询方式接收使用中断方式发送使用中…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...

深度学习之模型压缩三驾马车:模型剪枝、模型量化、知识蒸馏
一、引言 在深度学习中,我们训练出的神经网络往往非常庞大(比如像 ResNet、YOLOv8、Vision Transformer),虽然精度很高,但“太重”了,运行起来很慢,占用内存大,不适合部署到手机、摄…...
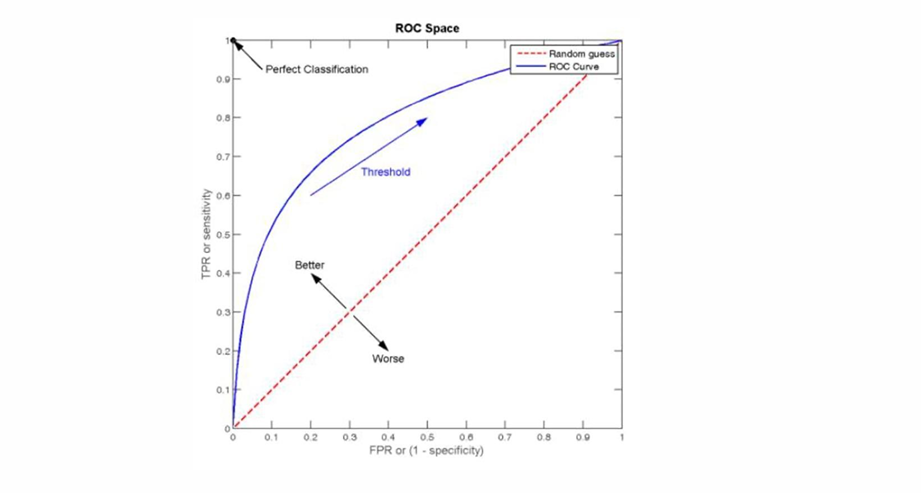
自然语言处理——文本分类
文本分类 传统机器学习方法文本表示向量空间模型 特征选择文档频率互信息信息增益(IG) 分类器设计贝叶斯理论:线性判别函数 文本分类性能评估P-R曲线ROC曲线 将文本文档或句子分类为预定义的类或类别, 有单标签多类别文本分类和多…...