6、Elasticsearch优化
一、Elasticsearch集群配置
1、硬件选择
Elasticsearch的基础是 Lucene ,所有的索引和文档数据是存储在本地的磁盘中,
具体的路径可在 ES 的配置文件 ../config/elasticsearch.yml 中配置,如下:磁盘在现代服务器上通常都是瓶颈。Elasticsearch 重度使用磁盘,你的磁盘能处理的吞吐量越大,你的节点就越稳定。这里有一些优化磁盘 I/O 的技巧:1、使用 SSD。就像其他地方提过的, 他们比机械磁盘优秀多了。2、使用 RAID 0。条带化 RAID 会提高磁盘 I/O,代价显然就是当一块硬盘故障时整个就故障了。
不要使用镜像或者奇偶校验 RAID 因为副本已经提供了这个功能。3、另外,使用多块硬盘,并允许 Elasticsearch 通过多个 path.data
目录配置把数据条带化分配到它们上面。4、不要使用远程挂载的存储,比如 NFS 或者 SMB/CIFS 。这个引入的延迟对性能来说完全是背道而驰的。2、分片策略
2.1、分片大小保持在10GB-50GB之间
分片大小保持在10GB-50GB之间,大的分片在故障恢复时会占用较长的时间。当某个节点发生故障时,Elasticsearch会根据剩余节点的数据自动的重新平衡分片。恢复进程通常是在网络之间拷贝分片的内容,因此一个100GB的分片会比50GB的分片花费更多的时间。相比之下,小分片的开销更大,搜索效率也更低。搜索50个1GB分片将比搜索一个包含相同数据的50GB分片占用更多资源。分片的大小并没有强制的限制。但经验值是10-50GB之间的分片通常在日志和时间序列的数据流索引上表现更好。 总结:打分片性能好,故障恢复慢,小分片性能差,故障恢复快。
2.2、每GB堆内存对应少于20个分片
数据节点可以容纳的分片数与节点的堆内存成比例。例如,具有30GB堆内存的节点最多应该有600个分片。越是低于此比例,就越能保持节点性能。如果发现节点超过每GB 20个以上的分片,请考虑添加另一个节点。单节点分片数计算=JVM堆大小*20
2.3、避免节成为热点
如果分配给特定节点的分片太多,该节点可能会成为热点。例如,如果单个节点包含的分片太多,索引量太大,则该节点可能会出现问题。
3、推迟分片分配
推迟因通讯中断导致分片再次检测平衡。
对于节点瞬时中断的问题,默认情况,集群会等待一分钟来查看节点是否会重新加入,如果这个节点在此期间重新加入,重新加入的节点会保持其现有的分片数据,不会触发新的分片分配。这样就可以减少 ES 在自动再平衡可用分片时所带来的极大开销。通过修改参数delayed_timeout ,可以延长再均衡的时间,可以全局设置也可以在索引级别进行修改:#PUT /_all/_settings
{"settings": {"index.unassigned.node_left.delayed_timeout": "5m"}
}4、路由选择
当我们查询文档的时候,Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?
它其实是通过下面这个公式来计算出来
shard = hash(routing) % number_of_primary_shards
routing默认值是文档的 id ,也可以采用自定义值,比如用户 id 。
不带routing 查询
在查询的时候因为不知道要查询的数据具体在哪个分片上,所以整个过程分为2 个步骤
1. 分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。
2. 聚合 : 协调节点搜集到每个分片上查询结果,在将查询的结果进行排序,之后给用户返回结果。
带routing 查询
查询的时候,可以直接根据routing 信息定位到某个分片查询,不需要查询所有的分片,经过协调节点排序。
向上面自定义的用户查询,如果routing 设置为 userid 的话,就可以直接查询出数据来,效率提升很多。
5、写入速度优化
ES的默认配置,是综合了数据可靠性、写入速度、搜索实时性等因素。实际使用时,我们需要根据公司要求,进行偏向性的优化。
针对于搜索性能要求不高,但是对写入要求较高的场景,我们需要尽可能的选择恰当写优化策略。
综合来说,可以考虑以下几个方面来提升写索引的性能:
1、加大 Translog Flush ,目的是降低 Iops 、 Writeblock 。
2、增加 Index Refresh 间隔,目的是减少 Segment Merge 的次数。
3、调整 Bulk 线程池和队列。
4、优化节点间的任务分布。
5、优化 Lucene 层的索引建立,目的是降低 CPU 及 IO
5.1、批量数据提交
ES提供了 Bulk API 支持批量操作,当我们有大量的写任务时,可以使用 Bulk 来进行批量写入。
通用的策略如下:
Bulk 默认设置批量提交的数据量不能超过 100M 。数据条数一般是根据文档的大小和服务器性能而定的,但是单次批处理的数据大小应从 5MB 15MB 逐渐增加,当性能没有提升时,把这个数据量作为最大值。
5.2 优化存储设备
ES是一种密集使用磁盘的应用,在段合并的时候会频繁操作磁盘,所以对磁盘要求较高,当磁盘速度提升之后,集群的整体性能会大幅度提高。
5.3 合理使用段合并
1、segment段创建过程
当我们往 ElasticSearch 写入数据时,数据是先写入 memory buffer,然后定时(默认每隔1s)将 memory buffer 中的数据写入一个新的 segment 文件中,并进入 Filesystem cache(同时清空 memory buffer),这个过程就叫做 refresh;每个 Segment 事实上是一些倒排索引的集合, 只有经历了 refresh 操作之后,数据才能变成可检索的。
ElasticSearch 每次 refresh 一次都会生成一个新的 segment 文件,这样下来 segment 文件会越来越多。那这样会导致什么问题呢?因为每一个 segment 都会占用文件句柄、内存、cpu资源,更加重要的是,每个搜索请求都必须访问每一个segment,这就意味着存在的 segment 越多,搜索请求就会变的更慢。
每个 segment 是一个包含正排(空间占比90~95%)+ 倒排(空间占比5~10%)的完整索引文件,每次搜索请求会将所有 segment 中的倒排索引部分加载到内存,进行查询和打分,然后将命中的文档号拿到正排中召回完整数据记录。如果不对segment做配置,就会导致查询性能下降
那么 ElasticSearch 是如何解决这个问题呢? ElasticSearch 有一个后台进程专门负责 segment 的合并,定期执行 merge 操作,将多个小 segment 文件合并成一个 segment,在合并时被标识为 deleted 的 doc(或被更新文档的旧版本)不会被写入到新的 segment 中。合并完成后,然后将新的 segment 文件 flush 写入磁盘;然后创建一个新的 commit point 文件,标识所有新的 segment 文件,并排除掉旧的 segement 和已经被合并的小 segment;然后打开新 segment 文件用于搜索使用,等所有的检索请求都从小的 segment 转到 大 segment 上以后,删除旧的 segment 文件,这时候,索引里 segment 数量就下降了。如下
2、segment的merge 对性能的影响
segment 合并的过程,需要先读取小的 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,合并大的 segment 需要消耗大量的 I/O 和 CPU 资源,同时也会对搜索性能造成影响。所以 Elasticsearch 在默认情况下会对合并线程进行资源限制,确保它不会对搜索性能造成太大影响。
默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 ELK Stack 应用,建议可以适当调大到 100MB或者更高。设置方式如下:
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}
或者不限制:PUT /_cluster/settings
{
"transient" : {
"indices.store.throttle.type" : "none"
}
}
5.4 减少Refresh的次数
Lucene在新增数据时,采用了延迟写入的策略,默认情况下索引的 refresh_interval 为1 秒。
Lucene将待写入的数据先写到内存中,超过 1 秒(默认 )时就会触发一次 Refresh,然后 Refresh 会把内存中的的数据刷新到操作系统的文件缓存系统中。
如果我们对搜索的实效性要求不高,可以将Refresh 周期延长,例如 30 秒。
这样还可以有效地减少段刷新次数,但这同时意味着需要消耗更多的Heap 内存。
5.5、加大Flush设置
Flush的主要目的是把文件缓存系统中的段持久化到硬盘,当 Translog 的数据量达到512MB 或者 30 分钟时,会触发一次 Flush。index.translog.flush_threshold_size 参数的默认值是 512MB ,我们进行修改。增加参数值意味着文件缓存系统中可能需要存储更多的数据,所以我们需要为操作系统的文件缓存系统留下足够的空间。
5.6、减少副本的数量
ES为了保证集群的可用性,提供了 Replicas (副本)支持,然而每个副本也会执行分析、索引及可能的合并过程,所以 Replicas 的数量会严重影响写索引的效率。当写索引时,需要把写入的数据都同步到副本节点,副本节点越多,写索引的效率就越慢,查询并发越高。
如果我们需要大批量进行写入操作,可以先禁止Replica 复制,设置index.number_of_replicas: 0 关闭副本。在写入完成后, Replica 修改回正常的状态。
6、内存设置
Xmx 和 Xms 的大小是相同的。其目的是为了能够在 Java 垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小而浪费资源,可以减轻伸缩堆大小带来的压力。
假设你有一个64G 内存的机器,按照正常思维思考,你可能会认为把 64G 内存都给ES 比较好,但现实是这样吗, 越大越好?
虽然内存对 ES 来说是非常重要的,但是答案是否定的!
因为ES 堆内存的分配需要满足以下两个原则:
不要超过物理内存的 50%。 Lucene 的设计目的是把底层 OS 里的数据缓存到内存中。
Lucene的段是分别存储到单个文件中的,这些文件都是不会变化的,所以很利于缓存,同时操作系统也会把这些段文件缓存起来,以便更快的访问。如果我们设置的堆内存过大,Lucene 可用的内存将会减少,就会严重影响降低 Lucene 的全文本查询性能。
堆内存的大小最好不要超过 32GB 。在 Java 中,所有对象都分配在堆上,然后有一个 Klass Pointer 指针指向它的类元数据。这个指针在64 位的操作系统上为 64 位
7、集群模式
7.1、集群类型
1、master node节点
整个集群的管理者、索引管理、分片管理,以及整个集群的状态的管理,master节点是从master候选节点中选出的,成为master候选节点的方式:node.master:true 默认(true)
data node:数据节点,存储主要数据,负责索引的数据的检索和聚合等操作,设置data node的方式如下:
node.master:true
node.data:false
2、data node节点
该节点和应用创建连接、接收索引请求,会存储分配在该node上的shard的数据并负责这些shard的写入、查询等,ES集群的性能取决于该节点的个数(每个节点最优配置的情况下),data节点会占用大量的CPU、io和内存;data节点的分片执行查询语句、获得查询结果后将结果反馈给Coordinating,此过程较消耗硬件资源;设置成为data节点的方式
node.data:true
node.master:false
3、coordinating node节点
协调节点,所有节点都可以接受来自客户端的请求进行转发,因为每个节点都知道集群的所有索引分片的分布情况,但是别的节点,都还肩负着别的工作,如果请求压力过大,可能会拖垮整个集群的响应速度,所以就专门有了这个协调节点,他什么都不用做,只处理请求和请求结果,这种设计的好处是,如果集群资源不足,被干死的是coordinating node, marster、data节点安全,设置成为coordinating node节点的方式:
node.data:false
node.master:false
4、ingest node节点
预处理节点,主要是对数据进行预处理,比如对字段重命名,分解字段内容,增加字段等,类似于Logstash, 就是对数据进行预处理,ingest里面可以定义pipeline(管道),pipeline可以由很多个processor(官方预定义28个)构成,用来出来预处理数据,使用方式:先定义好预处理pipeline,然后在存储数据的时候指定pipeline,如:成为ingest node的方式 node.ingest:true 默认(true)
7.2、稳定压倒一切的配置
3个master(参与选主)、N个data(存储、计算)、coordinating(高并发请求场景需要设置次节点)
8、其他设置
1、cluster.name配置ES 的集群名称。建议改成与所存数据相关的名称,ES 会自动发现在同一网段下的集群名称相同的节点
2、node.name集群中的节点名,在同一个集群中不能重复。节点的名称一旦设置,就不能再改变了。当然,也可以设置成服务器的主机名称
3、node.data指定该节点是否存储索引数据。默认为True 。数据的增、删、改、查都是在 Data 节点完成的。
4、index.number_of_shards设置都索引分片个数。也可以在创建索引时设置该值,具体设置为多大的值要根据数据量的大小来定。如果数据量不大,则设置成 1 时效率最高
5、index.number_of_replicas设置默认的索引副本个数。副本数越多,集群的可用性越 好,但是写索引时需要同步的数据越多。
6、transport.tcp.compress设置在节点间传输数据时是否压缩,默认为False不压缩
7、discovery.zen.minimum_master_nodes设置在选举Master 节点时需要参与的最少的候选主节点数,默认为 1 。如果使用默认值,则当网络不稳定时有可能会出现脑裂。合理的数值为
(master_eligible_nodes/2)+1 ,其中master_eligible_nodes 表示集群中的候选主节点数
8、discovery.zen.ping.timeout 设置在集群中自动发现其他节点时Ping 连接的超时时间,默认为 3 秒。在较差的网络环境下需要设置得大一点,防止因误判该节点的存活状态而导致分片的转移
二、开发注意优化
1、客户端选择
目前支持客户端有sql、dml、dml。为了开发效率建议选择sql方式,es7版本对sql支持度比较友好,其他版本可以安装es-sql插件实现sql效果。
2、字段类型设置
无分词需求字段类型设置为keyworld不会被分词
3、搜索的深度分页设置
索引深度不易过深入,否则会导致分页性能低。如果是数据导出需求可以用游标实现,如果数据量过大可以通过设置新索引的方式做。比如:index_2021_电器、index_2021_食品....
4、创建索引
1、Mapping设置与Query查询优化问题
在ES中创建Mappings时,默认_source是enable=true,会存储整个document的值,当执行search操作的时,会返回整个document的信息。如果只想返回document的部分fields,但_source会返回原始所有的内容,当某些不需要返回的field很大时,ES查询的性能会降低,这时候可以考虑使用store结合_source的enable=false来创建mapping。
2、设置索引刷新频率
index.refresh_interval:刷新操作频率,最近对索引的更改既可见,默认1s。-1关闭刷新操作。设置符合自己项目需求越大性能越好。
5、explain分析慢查询
#es 性能分析语句
GET online_exercise/_doc/_search
{"explain" : true,"query": {"match_all": {}}
}相关文章:

6、Elasticsearch优化
一、Elasticsearch集群配置 1、硬件选择 Elasticsearch的基础是 Lucene ,所有的索引和文档数据是存储在本地的磁盘中, 具体的路径可在 ES 的配置文件 ../config/elasticsearch.yml 中配置,如下:磁盘在现代服务器上通常都是瓶颈。…...

给力|这是一个专业的开源快速开发框架!
在低代码开发市场,专业的开源快速开发框架可以助力企业提升办公协作效率,实现提质增效的办公自动化的发展目标。 流辰信息低代码技术开发平台服务商,拥有丰富的技术经验和案例合作经验,针对不同的客户需求,提供个性化、…...

CIMCAI smart shipping company product container damage identify
世界港航人工智能领军者企业CIMCAI,领先智能航运船公司集装箱管理产品ceaspectusS™全球规模化应用落地智能化航运,全球前三船公司认可验箱标准应用。全球港航人工智能领军者企业CIMCAI,是全球第一家完成两百万次人工智能验箱,上亿…...

ego微商小程序项目-接口测试
文章目录 1.接口理论回顾1.1 接口测试相关概念1.2 接口测试流程2.接口测试文档2.1 接口测试文档基础2.2 ego微商小程序的接口文档解析3.设计接口测试用例3.1 接口测试用例基础3.2 ego微商小程序接口测试用例4. 执行测试用例4.1 ego小程序测试用例执行4.1.1 首页-轮播图4.1.2 用…...

excel文件已经损坏怎么办
1. excel文件突然损坏怎么办Excel修复不成功还可以尝试其他修复方式。1、Excel提示文件已损坏可能是受保护视图的问题。如果打开文件碰到此提示,可以先点确定。在按以下步骤操作:1)在空白程序界面,点击功能栏的【文件】࿰…...

Java【数据结构入门OJ题33道】——力扣刷题记录1
文章目录第一天存在重复元素最大子数组和第二天两数之和合并两个有序数组第三天两个数组的交集买卖股票最佳时机第四天重塑矩阵杨辉三角第五天有效的数独矩阵置零第六天字符串中第一个唯一字符救赎金第七天判断链表是否有环合并两个有序链表移除链表元素第八天反转链表删除重复…...
Spring事务介绍
文章目录一、编程式事务二、声明式事务(常用)三、事务实战详解3.1)事务的回滚机制3.2)事务的传播3.3)事务超时时间3.4)事务隔离级别3.5)事务回滚条件Spring中对事务有两种支持方式,分…...

Intellij Idea如何使用VM
打开Run/Debug Configuration 然后在More option 里选择 add VM options 根据要实现的目的选择main class 比如说要建造class diagram 那就选择app.ClassDiagramGenerator 然后在下面那行输入 D:\software-engineering\2023\commons-compress\target\classes true true org.apa…...

基础04-什么时候不能使用箭头函数
箭头函数的缺点 题目 什么时候不能使用箭头函数? 箭头函数的缺点 没有 arguments const fn1 () > {console.log(this, arguments) // 报错,arguments is not defined } fn1(100, 200)无法通过 call apply bind 等改变 this const fn1 () >…...
算法小抄5-原地哈希
书接上回,学会了数组中重复数字的解法三,相信接下来的题也难不倒你 找到数组中消失的数字 题目链接 题意 对于一个大小为n的数组,数组中所有的数都在[1,n]内,其中有些数字重复了,由于有些数字重复了,另一些数字就一定会确实,这次需要找到所有缺少的数字并且返回结果 有没有发…...

java零基础入门(1)
java零基础入门一、JRE和JDK1.1 JRE1.2 JDK1.3 IDK,JRE,JVM三者的包含关系二、CMD2.1 打开CMD2.2 常用CMD命令2.2.1 盘符名称 冒号2.2.2 dir2.2.3 cd 目录2.2.4 cd ..2.2.5 cls2.2.6 exit2.2.7 cd \2.2.8 cd \目录\目录\目录\目录2.3 利用快捷cmd打开 Q…...

java socket实例
/*** 启动项目后就创建Server Socket服务*/PostConstructpublic void runServerSocket() {try {ExecutorService executorService Executors.newFixedThreadPool(10);// 创建线程池ServerSocket serverSocket new ServerSocket(9090);// 在设备上配置的服务端监听端口为9090e…...
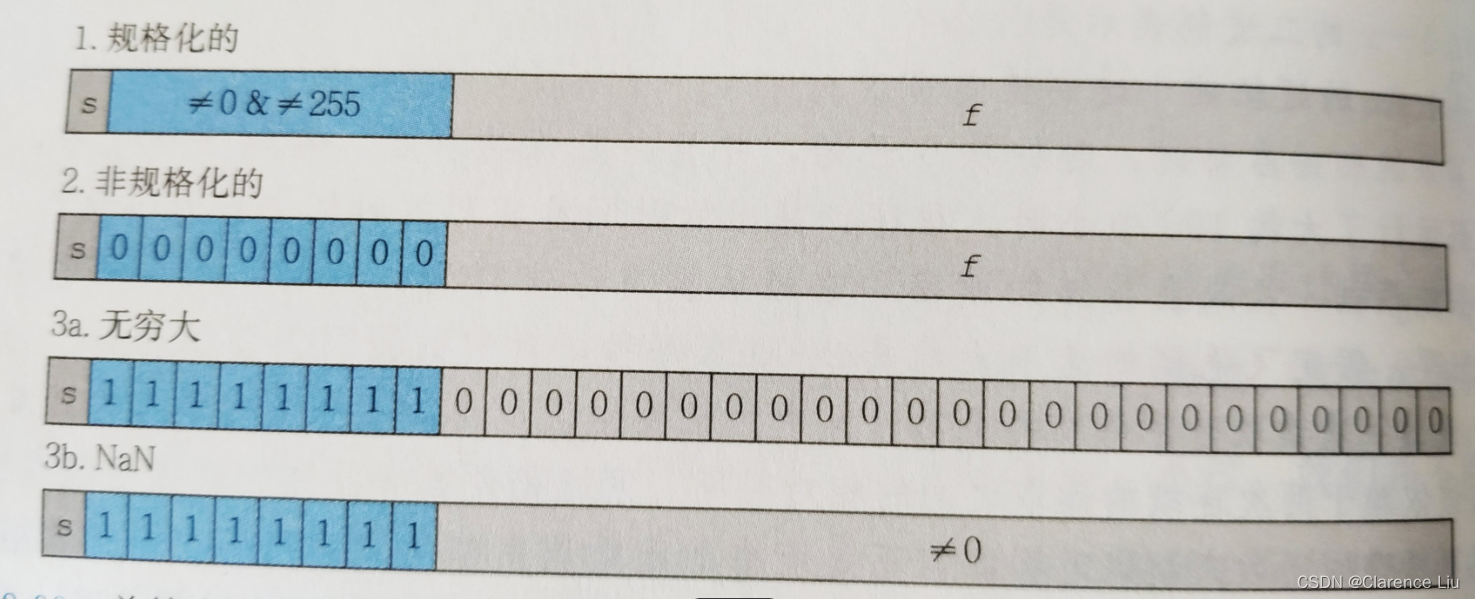
计算机中信息的表示和处理 整数和小数的二进制表示
信息的表示和处理整数进制字移位运算无符号数和有符号数加法运算小数定点表示IEEE 浮点表示规格化和非规格化舍入浮点运算现代计算机存储和处理的信息以二值信号表示,这些二进制数字称为位,为什么要用二进制来进行编码?因为二进制只有1和0两种…...

Chapter2.2:线性表的顺序表示
该系列属于计算机基础系列中的《数据结构基础》子系列,参考书《数据结构考研复习指导》(王道论坛 组编),完整内容请阅读原书。 2.线性表的顺序表示 2.1 顺序表的定义 线性表的顺序存储亦称为顺序表,是用一组地址连续的存储单元依次存储线性表…...

老马闲评数字化「4」做数字化会不会被供应商拿捏住
原文作者:行云创新CEO 马洪喜 导语 开年过后业务特别的繁忙,出差也比较多,所以有段时间没更新了,对不住大家! 上一集(您可以查看“行云创新”主页阅读原文)咱们聊了数字化转型的“想转、急转、…...

robosuite添加无碰撞的模型
1 前言 最近在使用robosuite时,需要在仿真环境中可视化物体的目标位置,从而方便观察训练情况,可视化的物体有以下要求: 形状尺寸与操作的物体一样半透明只有visual,不与场景其他物体有碰撞可以在每次step后设置位置,且固定在设定的位置,不受重力影响 2 方法 找了半天,最终确…...
JS学习笔记day03
今日内容 零、 复习昨日 CSS 美化,复用,样式文件和表现文件分离便于维护 选择器 {属性:值;…} 引入css 内联文件内部使用style标签外部文件 <link href"路径" rel"stylesheet" type"text/css"> 选择器 基本 idclass标签名 属性 标签名…...
)
离散数学笔记_第一章:逻辑和证明(3)
1.3 命题等价式1.3.1 逻辑等价式 1.3.2 条件命题和双条件命题的逻辑等价式 1.3.3 德摩根律 1.3.4 可满足性 可满足的 不可满足的 可满足性问题的解 1.3.5析取范式(基本积之和),合取范式(基本和之积)1.3.6合式公式1…...

软件测试分类知识分享,第三方软件测试机构收费贵不贵?
软件测试可以很好的检验软件产品的质量以及规避产品上线之后可能会发生的错误,随着技术的发展,软件测试已经是一个完整且体系庞大的测试活动,不同的测试领域有着不同的测试方法、技术与名称,那么具体有哪些分类呢? 一、软件测试…...
爬虫(二)解析数据
文章目录1. Xpath2. jsonpath3. BeautifulSoup4. 正则表达式4.1 特殊符号4.2 特殊字符4.3 限定符4.3 常用函数4.4 匹配策略4.5 常用正则爬虫将数据爬取到后,并不是全部的数据都能用,我们只需要截取里面的一些数据来用,这也就是解析爬取到的信…...

Qt Http Server模块功能及架构
Qt Http Server 是 Qt 6.0 中引入的一个新模块,它提供了一个轻量级的 HTTP 服务器实现,主要用于构建基于 HTTP 的应用程序和服务。 功能介绍: 主要功能 HTTP服务器功能: 支持 HTTP/1.1 协议 简单的请求/响应处理模型 支持 GET…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...
 error)
【前端异常】JavaScript错误处理:分析 Uncaught (in promise) error
在前端开发中,JavaScript 异常是不可避免的。随着现代前端应用越来越多地使用异步操作(如 Promise、async/await 等),开发者常常会遇到 Uncaught (in promise) error 错误。这个错误是由于未正确处理 Promise 的拒绝(r…...
未授权访问事件频发,我们应当如何应对?
在当下,数据已成为企业和组织的核心资产,是推动业务发展、决策制定以及创新的关键驱动力。然而,未授权访问这一隐匿的安全威胁,正如同高悬的达摩克利斯之剑,时刻威胁着数据的安全,一旦触发,便可…...
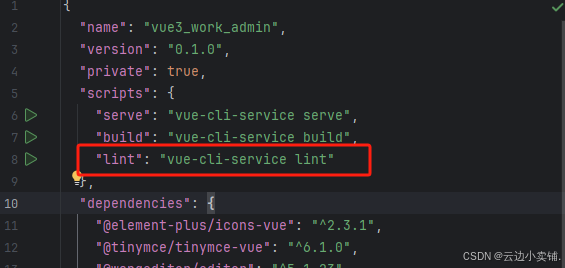
运行vue项目报错 errors and 0 warnings potentially fixable with the `--fix` option.
报错 找到package.json文件 找到这个修改成 "lint": "eslint --fix --ext .js,.vue src" 为elsint有配置结尾换行符,最后运行:npm run lint --fix...

年度峰会上,抖音依靠人工智能和搜索功能吸引广告主
上周早些时候举行的第五届年度TikTok World产品峰会上,TikTok推出了一系列旨在增强该应用对广告主吸引力的功能。 新产品列表的首位是TikTok Market Scope,这是一个全新的分析平台,为广告主提供整个考虑漏斗的全面视图,使他们能够…...

Q1起重机指挥理论备考要点分析
Q1起重机指挥理论备考要点分析 一、考试重点内容概述 Q1起重机指挥理论考试主要包含三大核心模块:安全技术知识(占40%)、指挥信号规范(占30%)和法规标准(占30%)。考试采用百分制,8…...