超速解读多模态InternVL-Chat1.5 ,如何做到开源SOTA——非官方首发核心技巧版(待修订)
解读InternVL-chat1.5系列
最近并行是事情太杂乱了,静下心来看一看优秀的开源项目,但是AI技术迭代这么快,现在基本是同时看五、六个方向的技术架构和代码,哪个我都不想放,都想知道原理和代码细节,还要自己训练起来,导致每天脑袋隐隐作痛了,感觉有点天龙八部里的“鸠摩智”的状态。
…目前的大模型核心能力热点是其通用能力的提升,从判别式、到对比学习、再到如今的多阶段对齐训练。VLM多模态模型在这两年已经逐渐普及(比如qwen-vl\deepseek-vl\yi-vl\glm4-v\minicpm-v)等优秀开源模型,今天我们来直接看下当前的开源SOTA模型,InternVl1.5是上海AI LAB一直迭代的多模态视觉语言大模型,之前的版本是1.2,今年迭代到1.5后达到了国内开源的SOTA评测分数,今天我们来解读一下InternVL1.5是如何做到的!
文章更新比较仓促,我会后续再修订!感谢阅读
`
文章目录
- 解读InternVL-chat1.5系列
- 文章更新比较仓促,我会后续再修订!感谢阅读
- 阅读前置知识(Internvit的由来)
- 一、模型信息概览
- 二、Feature
- 1. PT阶段
- 2. 训练数据
- 3. Scale up Model
- 4. Dynamic Aspect Ratio Matching
- 总结
如今的VLM多模态虽然训练方式阶段各有不同,但是架构范式同质化严重:
1. 视觉基础模型(多模态图文能力的视觉模型,不只有检测、分割、分类、还有图文检索、图像描述、多模态对话的能力)
2. LLM模型
3. 链接两个模型的mlp projector
阅读前置知识(Internvit的由来)
因为InternVL是从1.0开始迭代的,这里我们主要从1.5的版本和其前一版本1.2来进行解析!
Intervl1.0 经过三个阶段:对比学习PT、生成PT、SFT得到的一个视觉语言模型(数据多到少,质量低到高),最后通过深度和广度维度测试选定为6B模型。
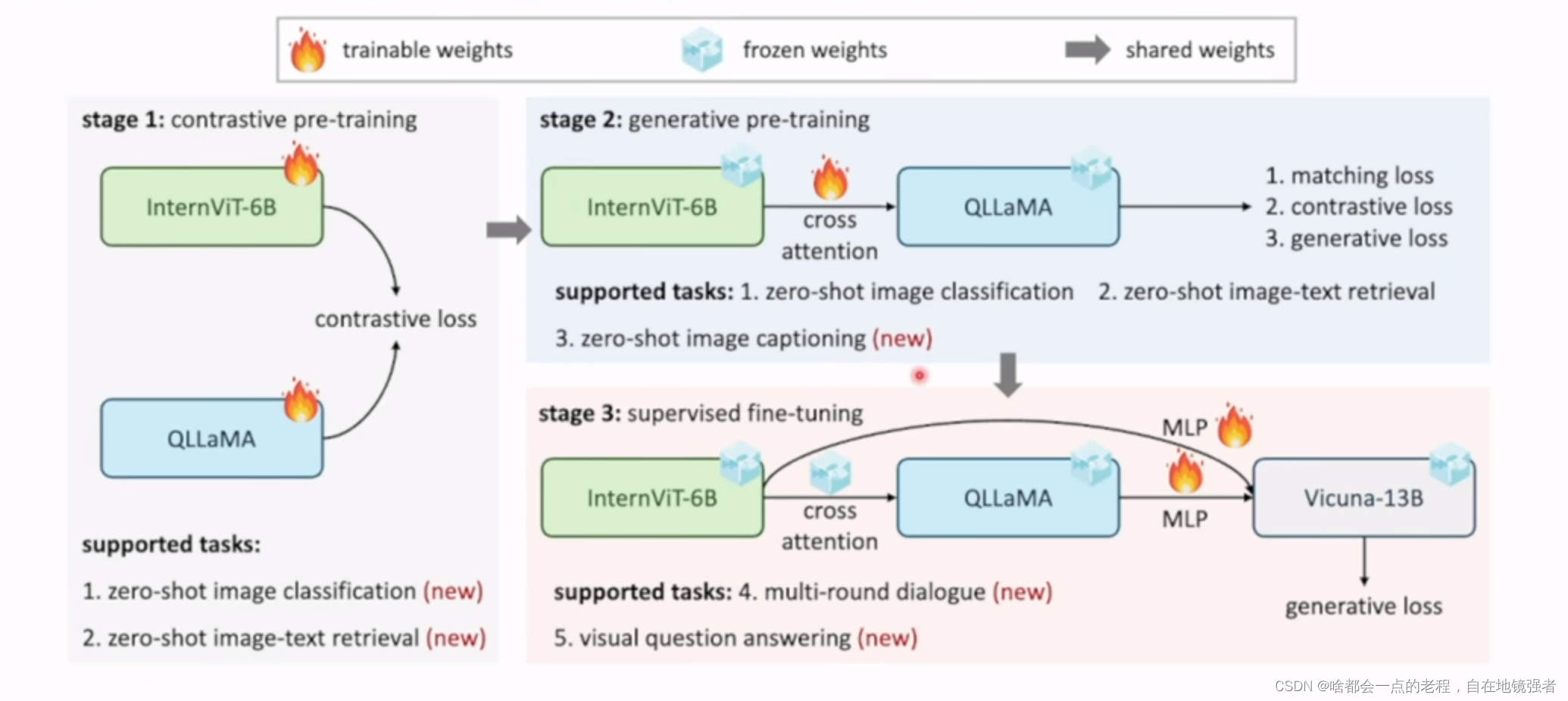
作者团队介绍到:
Intervit就是从Intervl中抽出internVIT-6B.(应该是48层变成45层)作为VLM视觉基础模型;也可以直接
作分类和图文检索、和SD的文本编码器(开源项目Mulan)
PIXEL Shuffle :空间下采样操作,具体在MLP层输入之前;reshape后,默认下采样0.5,1024->256,这样减少了输入到LLM的token数量。代码参考:
vit_embeds = self.pixel_shuffle(vit_embeds,scale_factor=self.downsample_ratio)
一、模型信息概览
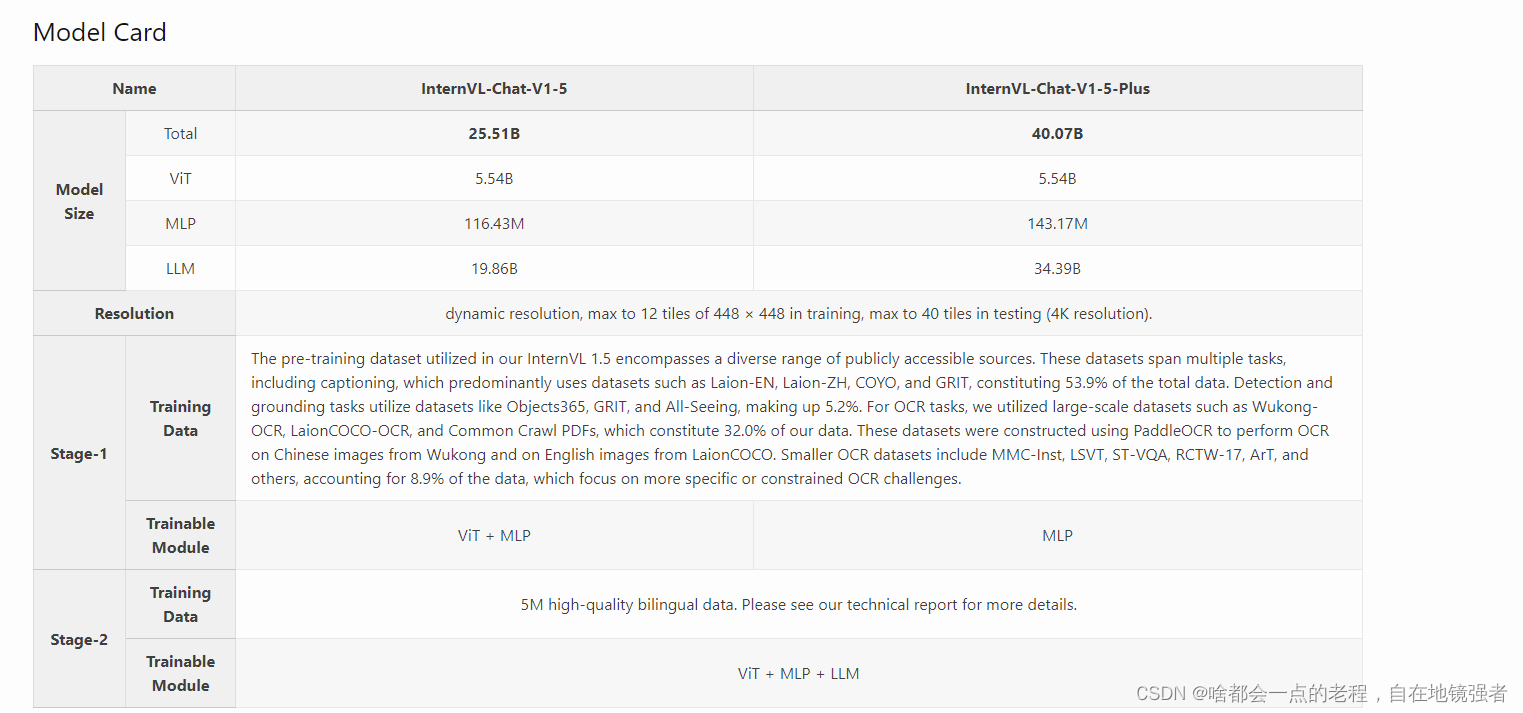
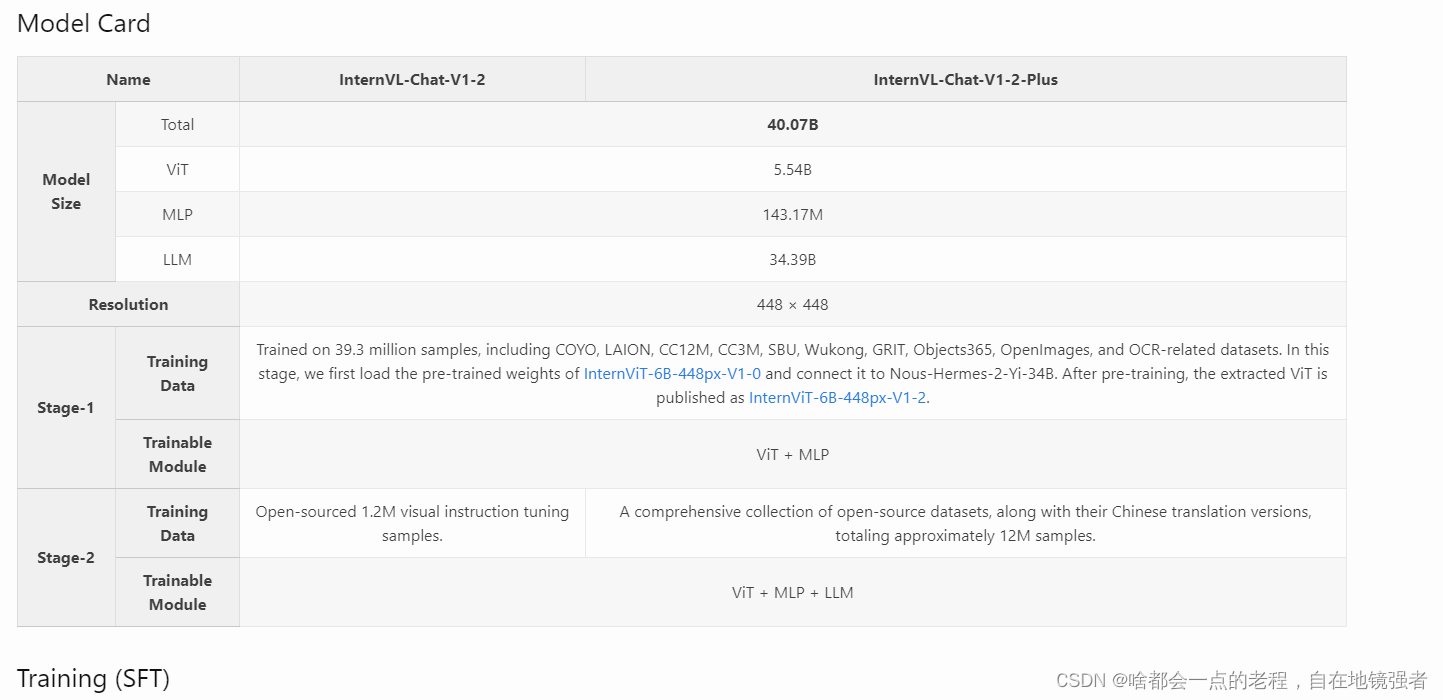
internVL-chat参考了LLaVA-NeXT-34B的做法,scale up 模型尺寸来验证VL性能的提升,这是1.2版本的思路,而1.5建立在1.2基础上进行了 迭代优化,先简要介绍下1.5,以及和1.2的区别。
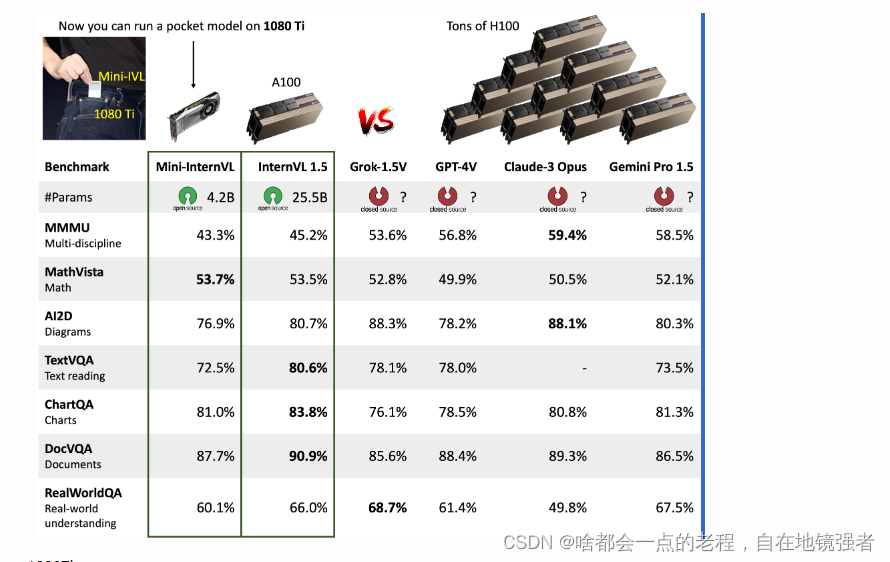
其中包含现在开源的和Plus版本:
MINI-intervl1.5-4 25.5B (internvit (6B)+internlm2-chat-20B(19.86B)+MLP)
MINI-intervl1.5-PLUS: (internvit (6B)+Nous-Hermes-2-Yi-34B+MLP) <未开源>
其中MIN包含:
MINI-intervl1.5-4.2B (internvit (300M)+phi3-mini-128K(3.8b)+MLP)
MINI-intervl1.5-2.2B (internvit (300M)+internLM2-chat_1.8B+MLP)
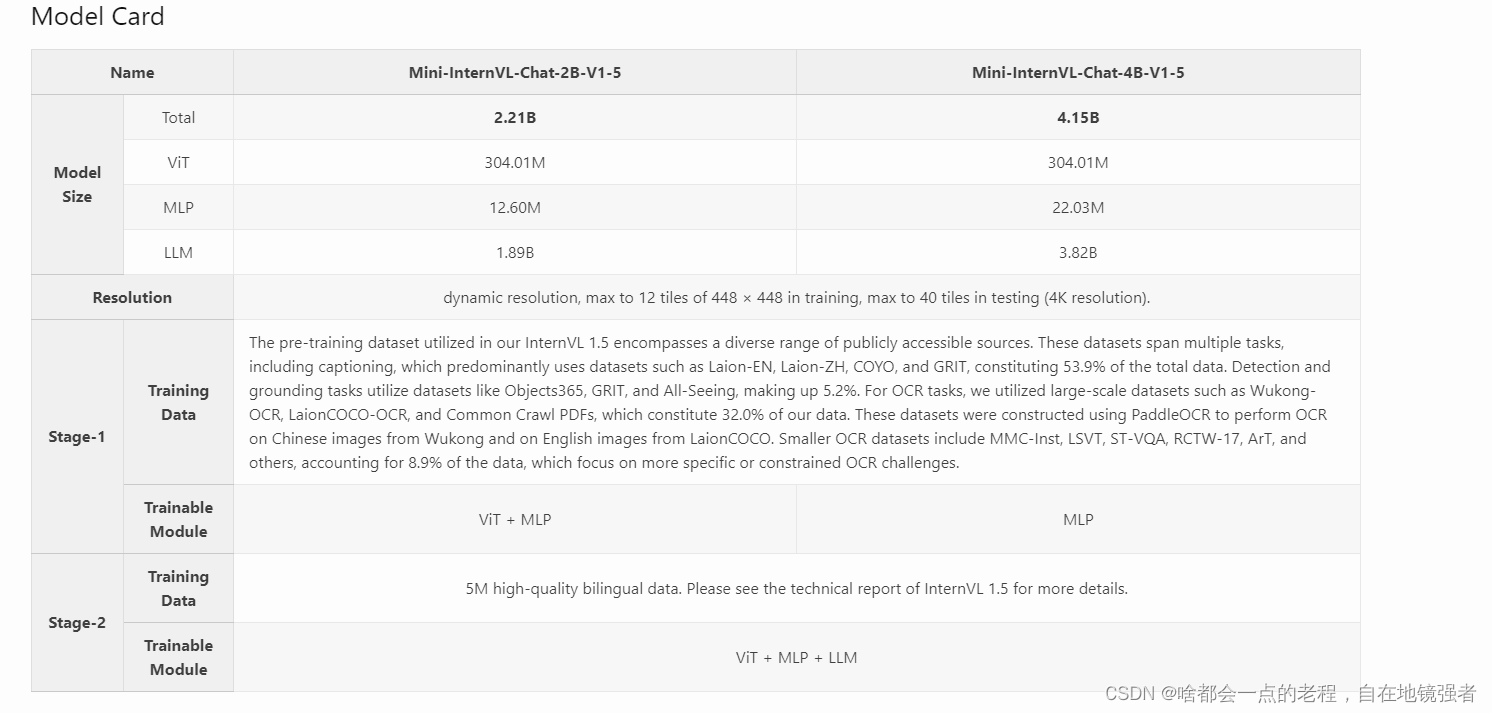
同样我们从上图对比中可以直观看到1.2到1.5之间一些明显的区别,同样也是改进提升的部分。
主要部分来说LLM的模型基座基本是一样的从小到大,再到34B的Nous-Hermes-2-Yi-34B(HF上开源fine-tune的版本)为PLUS版本的基座,基本上都是挑选的开源模型和其兄弟团队的intern2LM系列。所以LLM模型本身没什么特别需要说明的。
而至于MINI版本是其视觉编码器InternVIT通过蒸馏从6B压缩到300M得到的,再结合PHI3这些小模型。接下来让我们进入核心环节。
二、Feature
不同的改进之处:
1. PT阶段
1.2版本的PT阶段VIT+MLP,而1.5的PT阶段对于大尺寸的LLM只训练MLP,小尺寸的LLM训练MLP+vit,
额外说下在PT后模型会被抽出来,减少三层也就是Internvit模型从原来48层减少到45层,再试用Pixel
suffle减少token数量到256.
2. 训练数据
额外使用了GPT-40模型进行标注生成,已经开源在huggingface上
1.5比1.2扩充了在SFT阶段扩充了高质量的双语数据(多语言、精细Prompt标注),特别强化了图像分辨率支持到4K和OCR能力。
因为多模态训练本身需要多任务数据集去训练,数据是保证模型评分指标的第一优先级。
–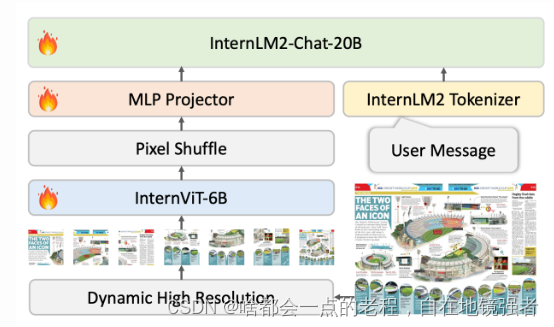

不同的只是LLM模型的不同。MINI版本的分别选择了internLM2-chat-1.8B和PHI3-mini-128K

3. Scale up Model
视觉模型与LLM参数量差距过大,一味提升大模型的参数量,VLM的能力并不会随之线性提升,因此从过去的版本的InternVL中通过实验证明了,视觉编码器的scale up也同样重要。所以视觉模型和语言模型同时scale up ,对于性能提升是有必要的,这也贯彻了sacle law。
4. Dynamic Aspect Ratio Matching
这是internvl1.5非常重要的一步骤,因为模型作者认为图像分辨率对于性能提升非常关键,因此聚焦于动态自定义分辨率,设计实现如上图:
- 预设纵横比集合:例如{1:1, 1:2, 1:3, 1:4, 1:5, 1:6, 2:3, 3:2 …,2:6}多种可能的组合(这取决于自定义min和max两个变量,后面代码会说到)
- 最优匹配:对于每个输入图像,系统会计算其纵横比,并与预定义的集合进行比较,找出差异最小的纵横比。那么如果有多个匹配的纵横比(即并列最小差异)怎么办?比较原始图像面积与特定纵横比下的图像面积来实现的。如果特定纵横比下的图像面积大于原始图像面积的一半,那么这个纵横比会被选为最优纵横比。
- patch 分割:输入图像被动态分割成448x448的patch ,patch的数量是根据图像匹配的纵横比和分辨率 (在1到12之间变化)。
- 图像分割与缩略图(Image Division & Thumbnail)
调整图像分辨率:一旦确定了合适的纵横比,图像将被调整到相应的分辨率。例如,一个800×1300的图像将被调整到896×1344。
分割图像:调整后的图像被分割成448×448像素的瓦片。在训练阶段,根据图像的纵横比和分辨率,瓦片的数量可以在1到12,推理时候是1到40
全局上下文缩略图:同时会resize 原始图像到448x448,帮助模型理解整体场景。
核心代码如下,比较简单不做注释了:
from transformers import AutoTokenizer, AutoModel
import torch
import torchvision.transforms as T
from PIL import Imagefrom torchvision.transforms.functional import InterpolationModeIMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)def build_transform(input_size):MEAN, STD = IMAGENET_MEAN, IMAGENET_STDtransform = T.Compose([T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),T.ToTensor(),T.Normalize(mean=MEAN, std=STD)])return transformdef find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):best_ratio_diff = float('inf')best_ratio = (1, 1)area = width * heightfor ratio in target_ratios:target_aspect_ratio = ratio[0] / ratio[1]ratio_diff = abs(aspect_ratio - target_aspect_ratio)if ratio_diff < best_ratio_diff:best_ratio_diff = ratio_diffbest_ratio = ratioelif ratio_diff == best_ratio_diff:if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:best_ratio = ratioreturn best_ratio#动态分辨率预处理
def dynamic_preprocess(image, min_num=1, max_num=6, image_size=448, use_thumbnail=False):orig_width, orig_height = image.sizeaspect_ratio = orig_width / orig_height# calculate the existing image aspect ratiotarget_ratios = set((i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) ifi * j <= max_num and i * j >= min_num)target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])# find the closest aspect ratio to the targettarget_aspect_ratio = find_closest_aspect_ratio(aspect_ratio, target_ratios, orig_width, orig_height, image_size)# calculate the target width and heighttarget_width = image_size * target_aspect_ratio[0]target_height = image_size * target_aspect_ratio[1]blocks = target_aspect_ratio[0] * target_aspect_ratio[1]# resize the imageresized_img = image.resize((target_width, target_height))processed_images = []for i in range(blocks):box = ((i % (target_width // image_size)) * image_size,(i // (target_width // image_size)) * image_size,((i % (target_width // image_size)) + 1) * image_size,((i // (target_width // image_size)) + 1) * image_size)# split the imagesplit_img = resized_img.crop(box)processed_images.append(split_img)assert len(processed_images) == blocksif use_thumbnail and len(processed_images) != 1:thumbnail_img = image.resize((image_size, image_size))processed_images.append(thumbnail_img)return processed_imagesdef load_image(image_file, input_size=448, max_num=6):image = Image.open(image_file).convert('RGB')transform = build_transform(input_size=input_size)images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)pixel_values = [transform(image) for image in images]pixel_values = torch.stack(pixel_values)return pixel_values
额外的实验结果是,训练在1-12 块Patch的范围内,但是推理时候泛化到了40个,(开始说过VIT模型输出是256个token,所以256x(40+1)=10496),实验证明24块为最优效果。
后续有代码相关问题和实践问题我会修订补充在这里
总结
internvl,通过自己提炼的Internvit和探索大模型参数,最终以6B为基准作为基线视觉编码器,再通过提高分辨率改为动态;在视觉模型上下了很大的功夫;其次同样scale up大模型参数量,这也符合scale law的经验,但是最关键的还有其1.5版本尚未开源的高质量数据集(1.2的数据集也可以用,但是明显1.5有一多半的功劳还是数据),期待后续开源数据集。其MINI系列提供了2B和4B版本的模型对于散修来说非常友好,最近几天我也在折腾,打算先用Lora试(用MINI2B版本,进行Lora target qkv \bf16 大概19G+显存的训练开销),值得一提的是其尚未开源的PLUS版本应该Beach mark得分会更高,但是因为模型参数40B比较大 ,可能普通散修没有资源来微调。
相关文章:
超速解读多模态InternVL-Chat1.5 ,如何做到开源SOTA——非官方首发核心技巧版(待修订)
解读InternVL-chat1.5系列 最近并行是事情太杂乱了,静下心来看一看优秀的开源项目,但是AI技术迭代这么快,现在基本是同时看五、六个方向的技术架构和代码,哪个我都不想放,都想知道原理和代码细节,还要自己训练起来&am…...

Vue 组件_动态组件+keep-alive
文章目录 Vue 动态组件 keep-alive知识点讲解业务场景实例代码实现keep-alive Vue 动态组件 keep-alive 知识点讲解 通过 Vue 的 <component> 组件和特殊的 is 属性实现的。 <!-- curentComponent 改变时组件也改变 --> <component :is"componentMap[…...

深入理解Redis:多种操作方式详解
Redis(Remote Dictionary Server)是一款高性能的开源键值存储系统,广泛应用于缓存、会话管理、实时分析等领域。它支持多种数据结构,如字符串、哈希、列表、集合和有序集合等,提供了丰富的操作命令。本篇博客将详细介绍…...

stm32太阳能追光储能系统V2
大家好,我是 小杰学长 stm32太阳能追光储能系统V2. 增加了命令行交互和内置AT指令解析框架 (就是可以用电脑串口发送at指令控制板子的所有功能) 改动了spi 换成硬件 改动了硬件电源 增加了pcb原理图 附带上pcb源文件 增加了freertos 互斥锁…...

Docker笔记-解决非交互式运行python时print不输出的问题
换句话来说就是在docker中如何不会python的print 只需要在启动时,不让python缓冲其输出。 关键命令如下:PYTHONUNBUFFERED1 如下: docker run -e PYTHONUNBUFFERED1 <your_image> 下面解释下-e "-e"选项的全称是"…...
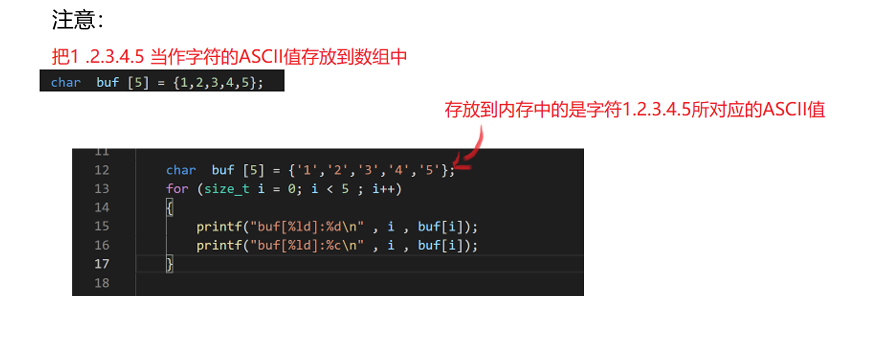
06- 数组的基础知识详细讲解
06- 数组的基础知识详细讲解 一、基本概念 一次性定义多个相同类型的变量,并且给它们分配一片连续的内存。 int arr[5];1.1 初始化 只有在定义的时候赋值,才可以称为初始化。数组只有在初始化的时候才可以统一赋值。 以下是一些示例规则: …...

CentOS6系统因目录有隐含i权限属性致下属文件无法删除的故障一例
CentOS6服务器在升级openssh时因系统目录权限异常(有隐含i权限属性),下属文件无法删除,导致系统问题的故障一例。 一、问题现象 CentOS6在升级openssh时,提示如下问题: warning: /etc/ssh/sshd_config c…...

【视频转码】ZLMediaKit漏洞报告的问题
漏洞问题: 支持ss1 rc4密码套件(bar mitzvah) 漏洞级别: 中危 漏洞修复: 方法:避免使用RC4密码,参考代码如下: 修改文件位于:webrtc/DtlsTransport.cpp ret SSL_CTX_set_cipher_list(ssl…...

100道大模型面试八股文
算法暑期实习机会快结束了,校招大考即将来袭。 当前就业环境已不再是那个双向奔赴时代了。求职者在变多,岗位在变少,要求还更高了。 最近,我们陆续整理了很多大厂的面试题,帮助球友解惑答疑和职业规划,分…...
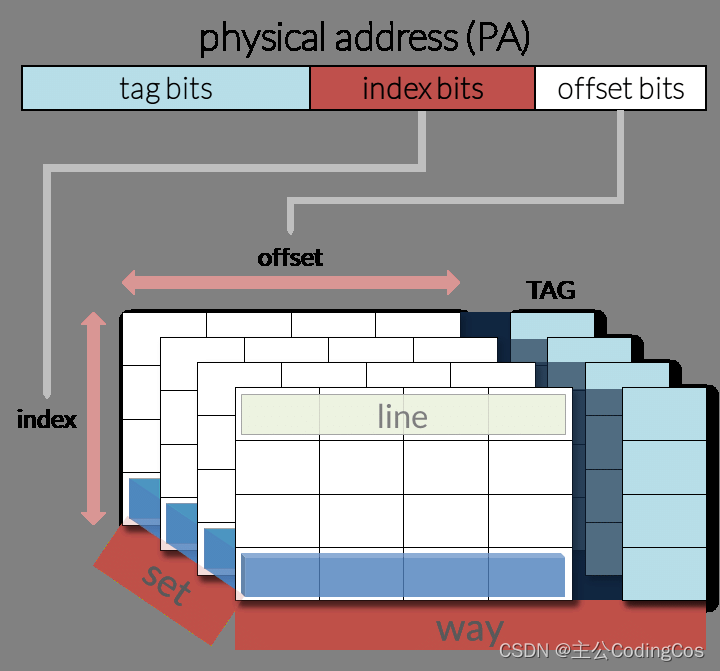
【ARM Cache 及 MMU 系列文章 6.2 -- ARMv8/v9 Cache 内部数据读取方法详细介绍】
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】 及【嵌入式开发学习必备专栏】 文章目录 Direct access to internal memoryL1 cache encodingsL1 Cache Data 寄存器Cache 数据读取代码实现Direct access to internal memory 在ARMv8架构中,缓存(Cache)是用来加速数据访…...
使用Vue.js将form表单传递到后端
一.form表单 <form submit.prevent"submitForm"></form> form表单像这样写出来,然后把需要用户填写的内容写在form表单内。 二.表单内数据绑定 <div class"input-container"><div style"margin-left: 9px;"&…...
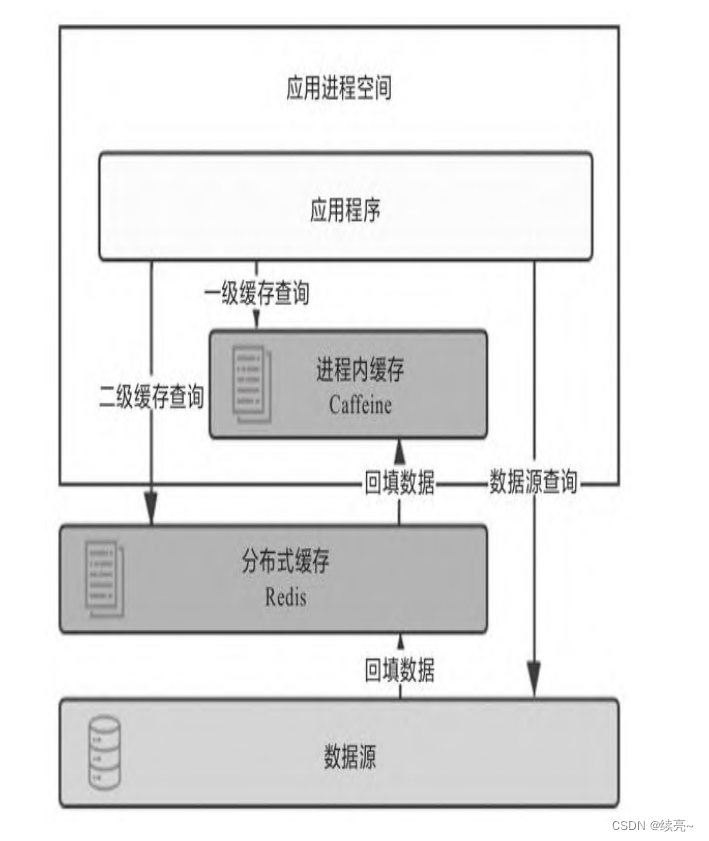
6、架构-服务端缓存
为系统引入缓存之前,第一件事情是确认系统是否真的需要缓 存。从开发角度来说,引入缓存会提 高系统复杂度,因为你要考虑缓存的失效、更新、一致性等问题;从运维角度来说,缓存会掩盖一些缺 陷,让问题在更久的…...

服务器遭遇UDP攻击时的应对与解决方案
UDP攻击作为分布式拒绝服务(DDoS)攻击的一种常见形式,通过发送大量的UDP数据包淹没目标服务器,导致网络拥塞、服务中断。本文旨在提供一套实用的策略与技术手段,帮助您识别、缓解乃至防御UDP攻击,确保服务器稳定运行。我们将探讨监…...

美团发布2024年一季度财报:营收733亿元,同比增长25%
6月6日,美团(股票代码:3690.HK)发布2024年第一季度业绩报告。受益于经济持续回暖和消费复苏,公司各项业务继续取得稳健增长,营收733亿元(人民币,下同),同比增长25%。 财报显示,一季度,美团继续…...

sql注入-布尔盲注
布尔盲注(Boolean Blind SQL Injection)是一种SQL注入攻击技术,用于在无法直接获得查询结果的情况下推断数据库信息;它通过发送不同的SQL查询来观察应用程序的响应,进而判断查询的真假,并逐步推断出有用的信…...

docker-compose部署 kafka 3.7 集群(3台服务器)并启用账号密码认证
文章目录 1. 规划2. 服务部署2.1 kafka-012.2 kafka-022.3 kafka-032.4 启动服务 3. 测试3.1 kafkamap搭建(测试工具)3.2 测试 1. 规划 服务IPkafka-0110.10.xxx.199kafka-0210.10.xxx.198kafka-0310.10.xxx.197kafkamp10.10.xxx.199 2. 服务部署 2.1…...

LeetCode-704. 二分查找【数组 二分查找】
LeetCode-704. 二分查找【数组 二分查找】 题目描述:解题思路一:注意开区间和闭区间背诵版:解题思路三: 题目描述: 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target …...

Rust 性能分析
都说Rust性能好,但是也得代码写得好,猜猜下面两个代码哪个快 . - 力扣(LeetCode) use std::collections::HashMap; use lazy_static::lazy_static;lazy_static! {static ref DIGIT: HashMap<char, usize> {let mut m HashMap::new();for c in …...

Gradle和Maven都是广泛使用的项目自动化构建工具
Gradle和Maven都是广泛使用的项目自动化构建工具,但它们在多个方面存在差异。以下是关于Gradle和Maven的详细对比: 一、构建脚本语言 Maven:使用XML作为构建脚本语言。XML的语法较为繁琐,不够灵活,对于复杂的构建逻辑…...

Seed-TTS语音编辑有多强?对比实测结果让你惊叹!
GLM-4-9B 开源系列模型 前言 就在最近,ByteDance的研究人员最近推出了一系列名为Seed-TTS的大规模自回归文本转语音(TTS)模型,能够合成几乎与人类语音无法区分的高质量语音。那么Seed-TTS的表现究竟有多强呢?让我们一起来感受下Seed-TTS带来的惊喜吧! 介绍Seed-TTS…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

HBuilderX安装(uni-app和小程序开发)
下载HBuilderX 访问官方网站:https://www.dcloud.io/hbuilderx.html 根据您的操作系统选择合适版本: Windows版(推荐下载标准版) Windows系统安装步骤 运行安装程序: 双击下载的.exe安装文件 如果出现安全提示&…...
基础光照(Basic Lighting))
C++.OpenGL (10/64)基础光照(Basic Lighting)
基础光照(Basic Lighting) 冯氏光照模型(Phong Lighting Model) #mermaid-svg-GLdskXwWINxNGHso {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-GLdskXwWINxNGHso .error-icon{fill:#552222;}#mermaid-svg-GLd…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...
)
.Net Framework 4/C# 关键字(非常用,持续更新...)
一、is 关键字 is 关键字用于检查对象是否于给定类型兼容,如果兼容将返回 true,如果不兼容则返回 false,在进行类型转换前,可以先使用 is 关键字判断对象是否与指定类型兼容,如果兼容才进行转换,这样的转换是安全的。 例如有:首先创建一个字符串对象,然后将字符串对象隐…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

并发编程 - go版
1.并发编程基础概念 进程和线程 A. 进程是程序在操作系统中的一次执行过程,系统进行资源分配和调度的一个独立单位。B. 线程是进程的一个执行实体,是CPU调度和分派的基本单位,它是比进程更小的能独立运行的基本单位。C.一个进程可以创建和撤销多个线程;同一个进程中…...