SQL优化系列-快速学会分析SQL执行效率(下)
1 show profile 分析慢查询
有时需要确定 SQL 到底慢在哪个环节,此时 explain 可能不好确定。在 MySQL 数据库中,通过 profile,能够更清楚地了解 SQL 执行过程的资源使用情况,能让我们知道到底慢在哪个环节。
知识扩展:可以通过配置参数 profiling = 1 来启用 SQL 分析。该参数可以在全局和 session 级别来设置。对于全局级别则作用于整个MySQL 实例,而 session 级别仅影响当前 session 。该参数开启后,后续执行的 SQL 语句都将记录其资源开销,如 IO、上下文切换、CPU、Memory等等。根据这些开销进一步分析当前 SQL 从而进行优化与调整。
下面我们来讲一下如何使用 profile 分析慢查询,大致步骤是:确定这个 MySQL 版本是否支持 profile;确定 profile 是否关闭;开启 profile;执行 SQL;查看执行完 SQL 的 query id;通过 query id 查看 SQL 的每个状态及耗时时间。
1.1 确定是否支持 profile
我们进行第一步,用下面命令来判断当前 MySQL 是否支持 profile:
mysql> select @@have_profiling;+------------------+
| @@have_profiling |
+------------------+
| YES |
+------------------+1 row in set, 1 warning (0.00 sec)
从上面结果中可以看出是YES,表示支持profile的。
1.2 查看 profiling 是否关闭的
进行第二步,用下面命令判断 profiling 参数是否关闭(默认 profiling 是关闭的):
mysql> select @@profiling;+-------------+
| @@profiling |
+-------------+
| 0 |
+-------------+1 row in set, 1 warning (0.00 sec)
结果显示为 0,表示 profiling 参数状态是关闭的。
1.3 通过 set 开启 profile
mysql> set profiling=1;Query OK, 0 rows affected, 1 warning (0.00 sec)
Tips:set 时没加 global,只对当前 session 有效。
1.4 执行 SQL 语句
mysql> select * from t1 where b=1000;
1.5 确定 SQL 的 query id
通过 show profiles 语句确定执行过的 SQL 的 query id:
mysql> show profiles;
+----------+------------+-------------------------------+
| Query_ID | Duration | Query |
+----------+------------+-------------------------------+
| 1 | 0.00063825 | select * from t1 where b=1000 |
+----------+------------+-------------------------------+
1 row in set, 1 warning (0.00 sec)
1.6 查询 SQL 执行详情
通过 show profile for query 可看到执行过的 SQL 每个状态和消耗时间:
mysql> show profile for query 1;
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000115 |
| checking permissions | 0.000013 |
| Opening tables | 0.000027 |
| init | 0.000035 |
| System lock | 0.000017 |
| optimizing | 0.000016 |
| statistics | 0.000025 |
| preparing | 0.000020 |
| executing | 0.000006 |
| Sending data | 0.000294 |
| end | 0.000009 |
| query end | 0.000012 |
| closing tables | 0.000011 |
| freeing items | 0.000024 |
| cleaning up | 0.000016 |
+----------------------+----------+
15 rows in set, 1 warning (0.00 sec)
通过以上结果,可以确定 SQL 执行过程具体在哪个过程耗时比较久,从而更好地进行 SQL 优化与调整。
2 trace 分析 SQL 优化器
从前面学到了 explain 可以查看 SQL 执行计划,但是无法知道它为什么做这个决策,如果想确定多种索引方案之间是如何选择的或者排序时选择的是哪种排序模式,有什么好的办法吗?
从 MySQL 5.6 开始,可以使用 trace 查看优化器如何选择执行计划。
通过trace,能够进一步了解为什么优化器选择A执行计划而不是选择B执行计划,或者知道某个排序使用的排序模式,帮助我们更好地理解优化器行为。
如果需要使用,先开启 trace,设置格式为 JSON,再执行需要分析的 SQL,最后查看 trace 分析结果(在 information_schema.OPTIMIZER_TRACE 中)。
开启该功能,会对 MySQL 性能有所影响,因此只建议分析问题时临时开启。
下面一起来看下 trace 的使用方法。使用讲解 explain 时创建的表t1做实验。
首先构造如下 SQL (表示取出表 t1 中 a 的值大于 900 并且 b 的值大于 910 的数据,然后按照 a 字段排序):
select * from t1 where a >900 and b > 910 order by a;
我们首先用 explain 分析下执行计划:

通过上面执行计划中 key 这个字段可以看出,该语句使用的是 b 字段的索引 idx_b。实际表 t1 中,a、b 两个字段都有索引,为什么条件中有这两个索引字段却偏偏选了 b 字段的索引呢?这时就可以使用 trace 进行分析。大致步骤如下:
mysql> set session optimizer_trace="enabled=on",end_markers_in_json=on;
/* optimizer_trace="enabled=on" 表示开启 trace;end_markers_in_json=on 表示 JSON 输出开启结束标记 */
Query OK, 0 rows affected (0.00 sec)mysql> select * from t1 where a >900 and b > 910 order by a;
+------+------+------+
| id | a | b |
+------+------+------+
| 1 | 1 | 1 |
| 2 | 2 | 2 |......| 1000 | 1000 | 1000 |
+------+------+------+
1000 rows in set (0.00 sec)mysql> SELECT * FROM information_schema.OPTIMIZER_TRACE\G
*************************** 1. row ***************************
QUERY: select * from t1 where a >900 and b > 910 order by a --SQL语句
TRACE: {"steps": [{"join_preparation": { --SQL准备阶段"select#": 1,"steps": [{"expanded_query": "/* select#1 */ select `t1`.`id` AS `id`,`t1`.`a` AS `a`,`t1`.`b` AS `b`,`t1`.`create_time` AS `create_time`,`t1`.`update_time` AS `update_time` from `t1` where ((`t1`.`a` > 900) and (`t1`.`b` > 910)) order by `t1`.`a`"}] /* steps */} /* join_preparation */},{"join_optimization": { --SQL优化阶段"select#": 1,"steps": [{"condition_processing": { --条件处理"condition": "WHERE","original_condition": "((`t1`.`a` > 900) and (`t1`.`b` > 910))", --原始条件"steps": [{"transformation": "equality_propagation","resulting_condition": "((`t1`.`a` > 900) and (`t1`.`b` > 910))" --等值传递转换},{"transformation": "constant_propagation","resulting_condition": "((`t1`.`a` > 900) and (`t1`.`b` > 910))" --常量传递转换},{"transformation": "trivial_condition_removal","resulting_condition": "((`t1`.`a` > 900) and (`t1`.`b` > 910))" --去除没有的条件后的结构}] /* steps */} /* condition_processing */},{"substitute_generated_columns": {} /* substitute_generated_columns */ --替换虚拟生成列},{"table_dependencies": [ --表依赖详情{"table": "`t1`","row_may_be_null": false,"map_bit": 0,"depends_on_map_bits": [] /* depends_on_map_bits */}] /* table_dependencies */},{"ref_optimizer_key_uses": [] /* ref_optimizer_key_uses */},{"rows_estimation": [ --预估表的访问成本{"table": "`t1`","range_analysis": {"table_scan": {"rows": 1000, --扫描行数"cost": 207.1 --成本} /* table_scan */,"potential_range_indexes": [ --分析可能使用的索引{"index": "PRIMARY","usable": false, --为false,说明主键索引不可用"cause": "not_applicable"},{"index": "idx_a", --可能使用索引idx_a"usable": true,"key_parts": ["a","id"] /* key_parts */},{"index": "idx_b", --可能使用索引idx_b"usable": true,"key_parts": ["b","id"] /* key_parts */}] /* potential_range_indexes */,"setup_range_conditions": [] /* setup_range_conditions */,"group_index_range": {"chosen": false,"cause": "not_group_by_or_distinct"} /* group_index_range */,"analyzing_range_alternatives": { --分析各索引的成本"range_scan_alternatives": [{"index": "idx_a", --使用索引idx_a的成本"ranges": ["900 < a" --使用索引idx_a的范围] /* ranges */,"index_dives_for_eq_ranges": true, --是否使用index dive(详细描述请看下方的知识扩展)"rowid_ordered": false, --使用该索引获取的记录是否按照主键排序"using_mrr": false, --是否使用mrr"index_only": false, --是否使用覆盖索引"rows": 100, --使用该索引获取的记录数"cost": 121.01, --使用该索引的成本"chosen": true --可能选择该索引},{"index": "idx_b", --使用索引idx_b的成本"ranges": ["910 < b"] /* ranges */,"index_dives_for_eq_ranges": true,"rowid_ordered": false,"using_mrr": false,"index_only": false,"rows": 90,"cost": 109.01,"chosen": true --也可能选择该索引}] /* range_scan_alternatives */,"analyzing_roworder_intersect": { --分析使用索引合并的成本"usable": false,"cause": "too_few_roworder_scans"} /* analyzing_roworder_intersect */} /* analyzing_range_alternatives */,"chosen_range_access_summary": { --确认最优方法"range_access_plan": {"type": "range_scan","index": "idx_b","rows": 90,"ranges": ["910 < b"] /* ranges */} /* range_access_plan */,"rows_for_plan": 90,"cost_for_plan": 109.01,"chosen": true} /* chosen_range_access_summary */} /* range_analysis */}] /* rows_estimation */},{"considered_execution_plans": [ --考虑的执行计划{"plan_prefix": [] /* plan_prefix */,"table": "`t1`","best_access_path": { --最优的访问路径"considered_access_paths": [ --决定的访问路径{"rows_to_scan": 90, --扫描的行数"access_type": "range", --访问类型:为range"range_details": {"used_index": "idx_b" --使用的索引为:idx_b} /* range_details */,"resulting_rows": 90, --结果行数"cost": 127.01, --成本"chosen": true, --确定选择"use_tmp_table": true}] /* considered_access_paths */} /* best_access_path */,"condition_filtering_pct": 100,"rows_for_plan": 90,"cost_for_plan": 127.01,"sort_cost": 90,"new_cost_for_plan": 217.01,"chosen": true}] /* considered_execution_plans */},{"attaching_conditions_to_tables": { --尝试添加一些其他的查询条件"original_condition": "((`t1`.`a` > 900) and (`t1`.`b` > 910))","attached_conditions_computation": [] /* attached_conditions_computation */,"attached_conditions_summary": [{"table": "`t1`","attached": "((`t1`.`a` > 900) and (`t1`.`b` > 910))"}] /* attached_conditions_summary */} /* attaching_conditions_to_tables */},{"clause_processing": {"clause": "ORDER BY","original_clause": "`t1`.`a`","items": [{"item": "`t1`.`a`"}] /* items */,"resulting_clause_is_simple": true,"resulting_clause": "`t1`.`a`"} /* clause_processing */},{"reconsidering_access_paths_for_index_ordering": {"clause": "ORDER BY","index_order_summary": {"table": "`t1`","index_provides_order": false,"order_direction": "undefined","index": "idx_b","plan_changed": false} /* index_order_summary */} /* reconsidering_access_paths_for_index_ordering */},{"refine_plan": [ --改进的执行计划{"table": "`t1`","pushed_index_condition": "(`t1`.`b` > 910)","table_condition_attached": "(`t1`.`a` > 900)"}] /* refine_plan */}] /* steps */} /* join_optimization */},{"join_execution": { --SQL执行阶段"select#": 1,"steps": [{"filesort_information": [{"direction": "asc","table": "`t1`","field": "a"}] /* filesort_information */,"filesort_priority_queue_optimization": {"usable": false, --未使用优先队列优化排序"cause": "not applicable (no LIMIT)" --未使用优先队列排序的原因是没有limit} /* filesort_priority_queue_optimization */,"filesort_execution": [] /* filesort_execution */,"filesort_summary": { --排序详情"rows": 90,"examined_rows": 90, --参与排序的行数"number_of_tmp_files": 0, --排序过程中使用的临时文件数"sort_buffer_size": 115056,"sort_mode": "<sort_key, additional_fields>" --排序模式(详解请看下方知识扩展)} /* filesort_summary */}] /* steps */} /* join_execution */}] /* steps */
}
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0 --该字段表示分析过程丢弃的文本字节大小,本例为0,说明没丢弃任何文本INSUFFICIENT_PRIVILEGES: 0 --查看trace的权限是否不足,0表示有权限查看trace详情
1 row in set (0.00 sec)
------------------------------------------------
------------------------------------------------mysql> set session optimizer_trace="enabled=off";
/* 及时关闭trace */
这里对上方的执行字段详细描述一下:
TRACE 字段中整个文本大致分为三个过程。
- 准备阶段:对应文本中的 join_preparation
- 优化阶段:对应文本中的 join_optimization
- 执行阶段:对应文本中的 join_execution
使用时,重点关注优化阶段和执行阶段。
由此例可以看出:
- 在 trace 结果的 analyzing_range_alternatives 这一项可以看到:使用索引 idx_a 的成本为 121.01,使用索引 idx_b 的成本为 109.01,显然使用索引 idx_b 的成本要低些,因此优化器选择了 idx_b 索引;
- 在 trace 结果的 filesort_summary 这一项可以看到:排序模式为<sort_key, additional_fields>,表示使用的是单路排序,即一次性取出满足条件行的所有字段,然后在 sort buffer 中进行排序。
知识扩展:
知识点一:MySQL 常见排序模式:
- < sort_key, rowid >双路排序(又叫回表排序模式):是首先根据相应的条件取出相应的排序字段和可以直接定位行数据的行 ID,然后在 sort buffer 中进行排序,排序完后需要再次取回其它需要的字段;
- < sort_key, additional_fields >单路排序:是一次性取出满足条件行的所有字段,然后在sort buffer中进行排序;
- < sort_key, packed_additional_fields >打包数据排序模式:将 char 和 varchar 字段存到 sort buffer 中时,更加紧缩。
三种排序模式比较:
第二种模式相对第一种模式,避免了二次回表,可以理解为用空间换时间。由于 sort buffer 有限,如果需要查询的数据比较大的话,会增加磁盘排序时间,效率可能比第一种方式更低。
MySQL 提供了一个参数:max_length_for_sort_data,当“排序的键值对大小” > max_length_for_sort_data 时,MySQL 认为磁盘外部排序的 IO 效率不如回表的效率,会选择第一种排序模式;否则,会选择第二种模式。
第三种模式主要解决变长字符数据存储空间浪费的问题。
知识点二:优化器在估计符合条件的行数时有两个选择:
- index diver:dive 到 index 中利用索引完成元组数的估算;特点是速度慢,但可以得到精确的值;
- index statistics:使用索引的统计数值,进行估算;特点是速度快,但是值不一定准确。
3 总结
今天我们分享了 show profile 和 trace 的使用方法,我们来对比一下三种分析 SQL 方法的特点:
- explain:获取 MySQL 中 SQL 语句的执行计划,比如语句是否使用了关联查询、是否使用了索引、扫描行数等;
- profile:可以清楚了解到SQL到底慢在哪个环节;
- trace:查看优化器如何选择执行计划,获取每个可能的索引选择的代价。
三种方法各有其适用场景
相关文章:
SQL优化系列-快速学会分析SQL执行效率(下)
1 show profile 分析慢查询 有时需要确定 SQL 到底慢在哪个环节,此时 explain 可能不好确定。在 MySQL 数据库中,通过 profile,能够更清楚地了解 SQL 执行过程的资源使用情况,能让我们知道到底慢在哪个环节。 知识扩展࿱…...

交流非线性RCD负载的核心功能
非线性RCD负载是一种广泛应用于电力系统中的电子元件,主要用于保护电路免受过电压和欠电压的影响。它的核心功能主要包括以下几个方面: 1. 过电压保护:当电路中的电压超过设定值时,非线性RCD负载会自动断开电路,防止电…...

英语学习笔记31——Where‘s Sally?
Where’s Sally? Sally在哪? 词汇 Vocabulary garden /ˈɡɑːrdn/ n. 花园,院子(属于私人) 区别:park n. 公园(公共的) 例句:我的花园非常大。 My garden is very big. 搭…...
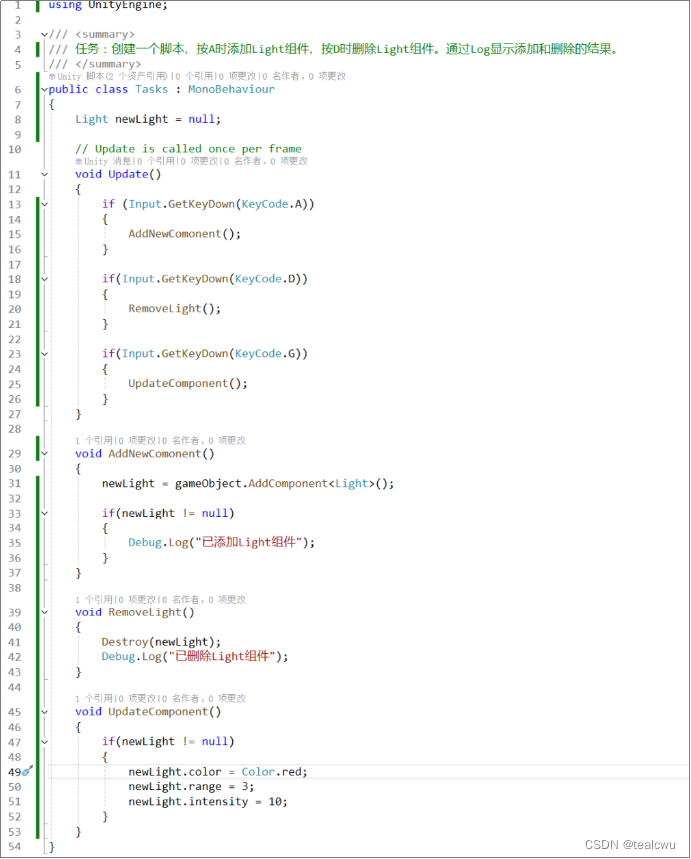
【Unity脚本】使用脚本操作游戏对象的组件
【知识链】Unity -> Unity脚本 -> 游戏对象 -> 组件 【知识链】Unity -> Unity界面 -> Inspector【摘要】本文介绍如何使用脚本添加、删除组件,以及如何访问组件 文章目录 引言第一章 游戏对象与组件1.1 什么是组件?1.2 场景、游戏对象与…...
)
学习VUE3——组件(一)
组件注册 分为全局注册和局部注册两种。 全局注册: 在main.js或main.ts中,使用 Vue 应用实例的 .component() 方法,让组件在当前 Vue 应用中全局可用。 import { createApp } from vue import MyComponent from ./App.vueconst app crea…...
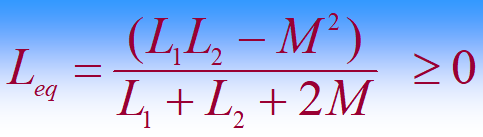
2024-6-6 石群电路-25
2024-6-6,星期四,15:56,天气:晴,心情:晴。今天又是阳光明媚的一天打印了毕业论文,准备了一些毕业&答辩的材料,感觉离毕业越来越近了,加油学习喽~ 今日观看了石群老师…...

vue 文件预览mp4、txt、pptx、xls、xlsx、docx、pdf、html、xml
vue 文件预览 图片、mp4、txt、pptx、xls、xlsx、docx、pdf、html、xml 最近公司要做一个类似电脑文件夹的功能,支持文件夹操作,文件操作,这里就不说文件夹操作了,说说文件预览操作,本人是后端java开发,前端vue&#…...

生活中优秀学习习惯
早起: 23点睡--4至6点起床(睡足7、8个钟头),起来第一件事是工作(或学习)。不是吃早餐,不是刷牙。(空腹工作一段时间)--做推理让头脑运作,不要背书࿰…...

什么是负载均衡?在网络中如何实现?
负载均衡(Load Balancing)是一种网络技术,用于将网络请求或数据传输任务分发到多个服务器或处理单元上,以实现更高效的资源利用、更高的处理能力和更好的系统可靠性。负载均衡的目标是优化资源使用、最大化吞吐量、减少响应时间&a…...

【YOLOv10改进[Backbone]】图像修复网络AirNet助力YOLOv10目标检测效果 + 含全部代码和详细修改方式 + 手撕结构图 + 全网首发
本文带来的是图像复原网络AirNet,它由基于对比度的退化编码器( CBDE )和退化引导的恢复网络( DGRN )两个模块组成。可以在一个网络中恢复各种退化图像。AirNet不受损坏类型和级别的先验限制,仅使用观察到的损坏图像进行推理。本文中将使用图像修复网络AirNet助力YOLOv10的目标…...

ubuntu22.04 gitleb服务器满了,扩容机器的磁盘的详细步骤
在Ubuntu 22.04上为GitLab服务器扩容磁盘可以分为以下几步进行:增加磁盘空间、扩展文件系统,并确保数据安全。这些步骤可以应用于物理服务器或虚拟机(包括云服务中的实例)。以下是详细步骤: 1. 添加新的磁盘空间 1.1…...
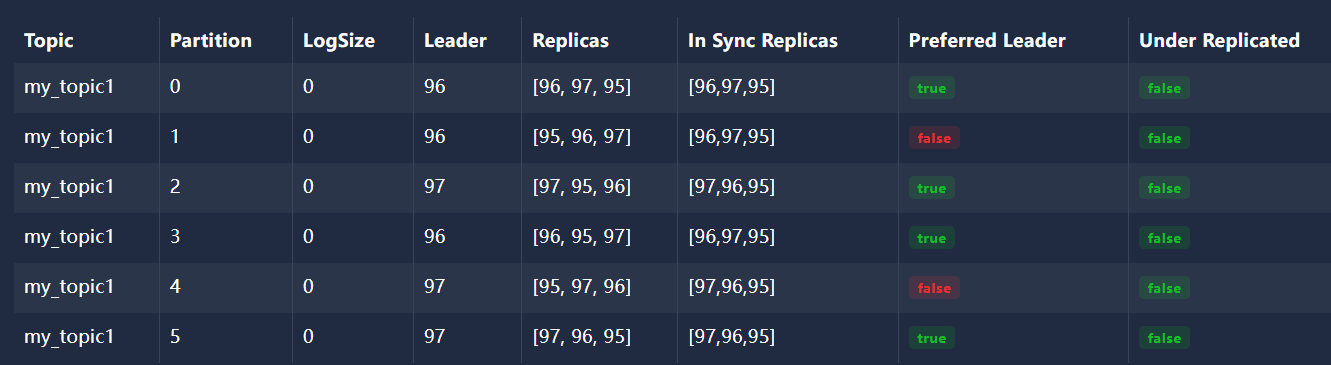
kafka-集群-主题创建
文章目录 1、集群主题创建1.1、查看 efak1.2、创建 主题 my_topic1 并建立6个分区并给每个分区建立3个副本1.2.1、查看 my_topic1 的详细信息 1.3、停止 kafka-01实例,端口号为 9095 1、集群主题创建 1.1、查看 efak 已经有三个kafka实例 1.2、创建 主题 my_topic1…...

Python 连接 MySQL 及 SQL增删改查(主要使用sqlalchemy)
一、环境 工作中需要用到python和mysql数据库,本次文档记录相关操作。 环境:windows10、python 3.11.7 mysql版本:5.7 二、MySQL的连接和使用 本人使用过的两种方式 2.1方式一:sql为主 2.1.1创建连接 import sqlalchemy fro…...

JAVAEE值网络编程(2)_TCP流套接字及通信模型、TCP网络编程及代码实例
前言 在上一节内容中,我们介绍了什么是套接字,以及使用UDP数据报套接字网络编程, 最后我们还介绍了Java数据报套接字通信模型以及相关代码实例。在这一节我们将会介绍TCP流套接字编程。 一、流套接字及通信模型 1.1 TCP套接字 TCP࿰…...
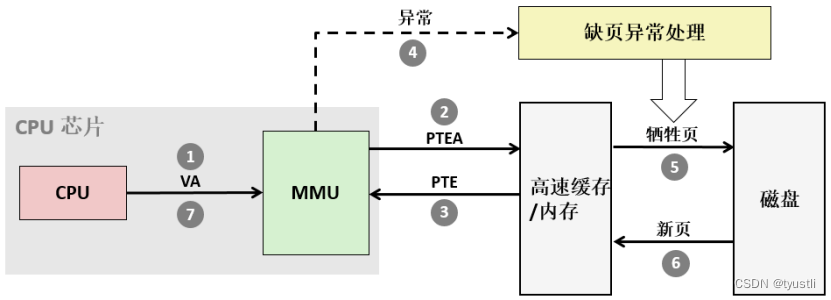
【MMU】——MMU 页命中/缺页
文章目录 MMU 页命中/缺页MMU 命中MMU 缺页 MMU 页命中/缺页 MMU 命中 处理器产生一个虚拟地址。MMU生成 PTE 地址,并从高速缓存/主存请求得到它。高速缓存/主存向 MMU 返回 PTE。MMU 构造物理地址,并把它传送给高速缓存/主存。高速缓存/主存返回所请求…...
Win32和c++11多线程
Win32和c11多线程 一、概念1.线程的特点线程内核对象线程控制块线程是独立调度和分派的基本单位共享进程的资源 2.线程的上下文切换引起上下文切换的原因 3.线程的状态 二、Windows多线程API1.CreateThread创建线程2.获取线程ID3.关闭线程句柄4.挂起线程5.恢复线程6.休眠线程的…...
关于python包导入问题的重思考
将顶层目录直接设置为一个包 像这样,每一个文件从顶层包开始导入 这样可以解决我的问题,但是要注意的时,要避免使用出现上下级出现同名包的情况,比如: AutoServer--AutoServer--__init__.py--__init__.py这种情况下…...
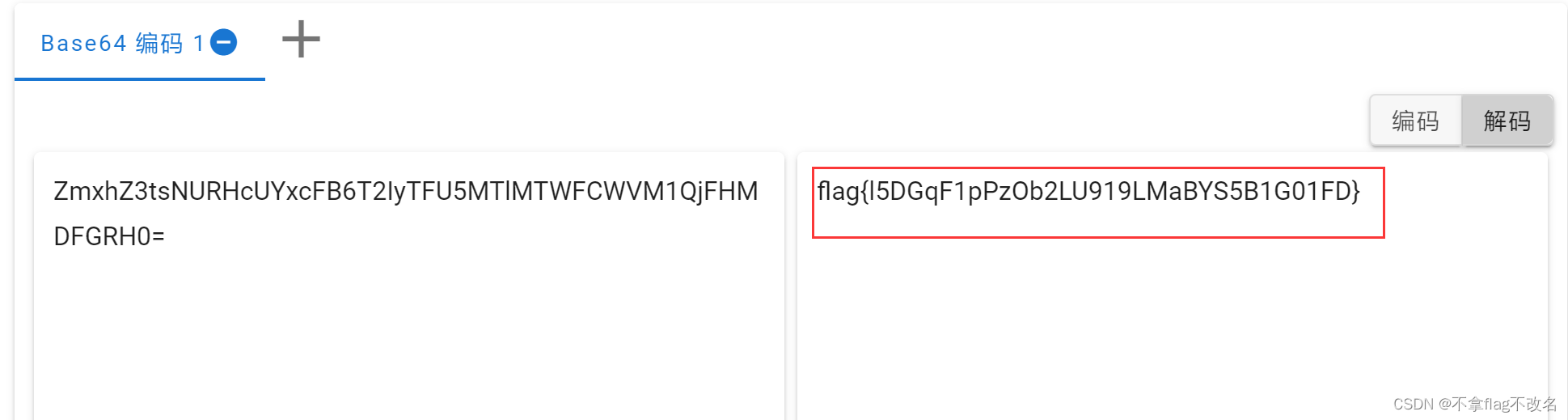
攻防世界---misc---津门杯2021-m1
1、题目描述,下载附件是一张bmp格式的图片 2、直觉告诉我这和图片的颜色通道有关 3、于是我就尝试用stegslove打开图片 4、将颜色通道都改为0,点击preview 5、然后发现一串base64编码 6、解码得flag flag{l5DGqF1pPzOb2LU919LMaBYS5B1G01FD}...
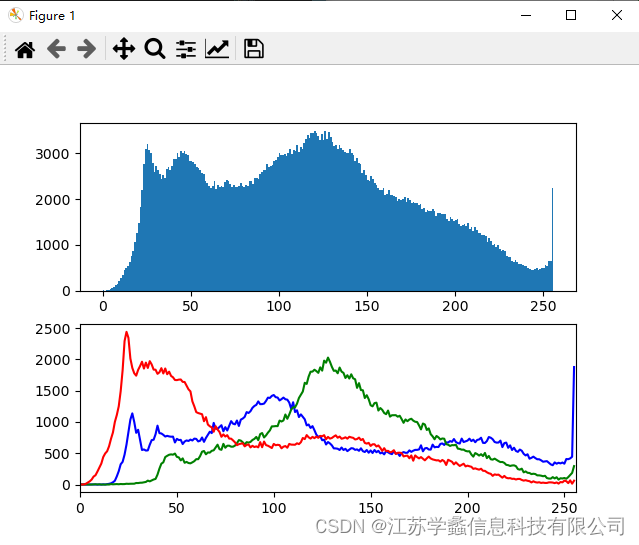
【计算机视觉(8)】
基于Python的OpenCV基础入门——图像直方图 直方图图像直方图 图像直方图代码以及实现效果 直方图 直方图是一种用于描述图像亮度分布的统计工具。它将图像的像素亮度值按照不同的亮度等级进行计数,并以直方图的形式呈现出来。图像直方图可以显示图像中每个亮度级别…...
Linux操作系统:Redis在虚拟环境下的安装与部署
Redis下载方法 最近部署项目的时候用到了Redis,自己在安装的时候也碰到了一些列问题最终安装成功,记录一下自己的安装历程。前期准备: 服务器Linux版本:Centos8.4 64位(http://isoredirect.centos.org/centos/8/isos/…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

保姆级教程:在无网络无显卡的Windows电脑的vscode本地部署deepseek
文章目录 1 前言2 部署流程2.1 准备工作2.2 Ollama2.2.1 使用有网络的电脑下载Ollama2.2.2 安装Ollama(有网络的电脑)2.2.3 安装Ollama(无网络的电脑)2.2.4 安装验证2.2.5 修改大模型安装位置2.2.6 下载Deepseek模型 2.3 将deepse…...
Xcode 16 集成 cocoapods 报错
基于 Xcode 16 新建工程项目,集成 cocoapods 执行 pod init 报错 ### Error RuntimeError - PBXGroup attempted to initialize an object with unknown ISA PBXFileSystemSynchronizedRootGroup from attributes: {"isa">"PBXFileSystemSynchro…...
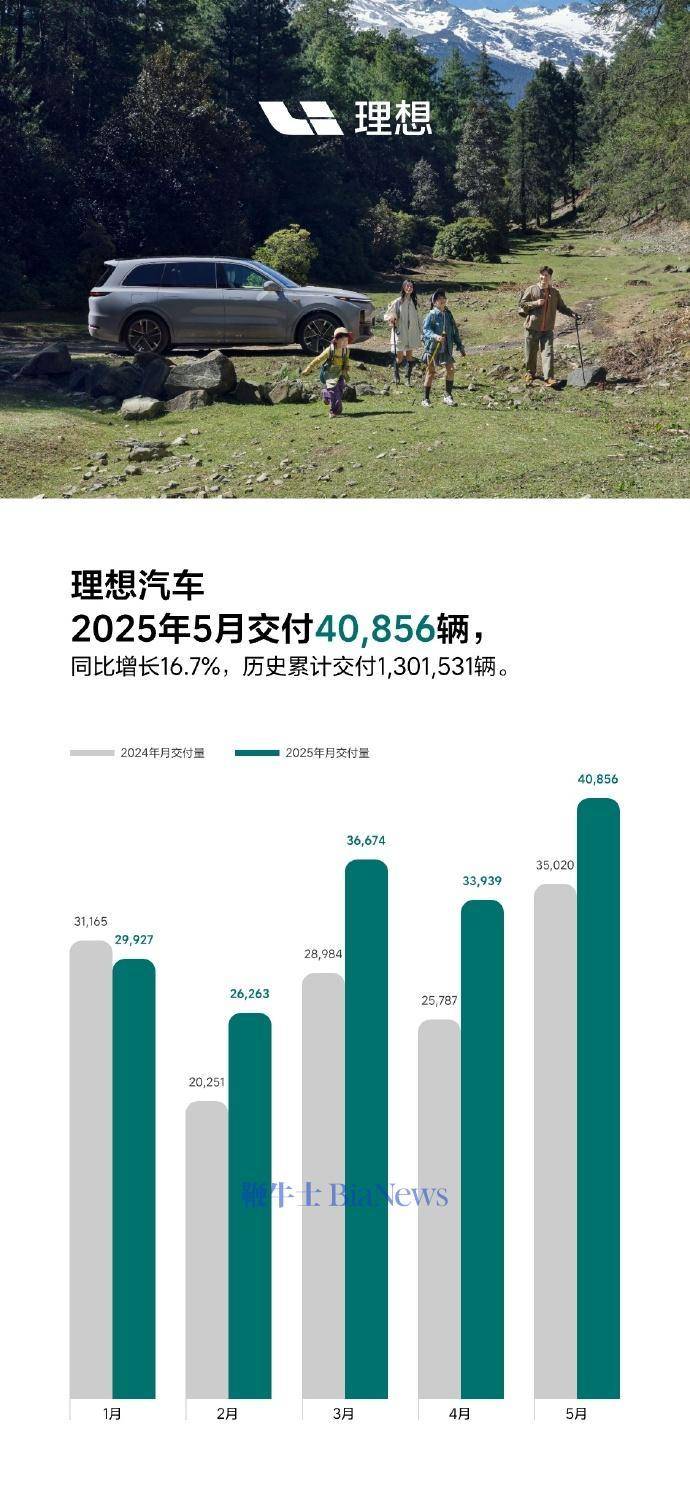
理想汽车5月交付40856辆,同比增长16.7%
6月1日,理想汽车官方宣布,5月交付新车40856辆,同比增长16.7%。截至2025年5月31日,理想汽车历史累计交付量为1301531辆。 官方表示,理想L系列智能焕新版在5月正式发布,全系产品力有显著的提升,每…...

DriveGPT4: Interpretable End-to-end Autonomous Driving via Large Language Model
一、研究背景与创新点 (一)现有方法的局限性 当前智驾系统面临两大核心挑战:一是长尾问题,即系统在遇到新场景时可能失效,例如突发交通状况或非常规道路环境;二是可解释性问题,传统方法无法解释智驾系统的决策过程,用户难以理解车辆行为的依据。传统语言模型(如 BERT…...