【动手学深度学习】残差网络(ResNet)的研究详情



目录
🌊1. 研究目的
🌊2. 研究准备
🌊3. 研究内容
🌍3.1 残差网络
🌍3.2 练习
🌊4. 研究体会
🌊1. 研究目的
- 了解残差网络(ResNet)的原理和架构;
- 探究残差网络的优势;
- 分析残差网络的深度对模型性能的影响;
- 实践应用残差网络解决实际问题。
🌊2. 研究准备
- 根据GPU安装pytorch版本实现GPU运行研究代码;
- 配置环境用来运行 Python、Jupyter Notebook和相关库等相关库。
🌊3. 研究内容
启动jupyter notebook,使用新增的pytorch环境新建ipynb文件,为了检查环境配置是否合理,输入import torch以及torch.cuda.is_available() ,若返回TRUE则说明研究环境配置正确,若返回False但可以正确导入torch则说明pytorch配置成功,但研究运行是在CPU进行的,结果如下:

🌍3.1 残差网络
(1)使用jupyter notebook新增的pytorch环境新建ipynb文件,完成基本数据操作的研究代码与练习结果如下:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lclass Residual(nn.Module): #@savedef __init__(self, input_channels, num_channels,use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels,kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels,kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels,kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape![]()
blk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shape![]()
ResNet模型
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))def resnet_block(input_channels, num_channels, num_residuals,first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blkb2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))net = nn.Sequential(b1, b2, b3, b4, b5,nn.AdaptiveAvgPool2d((1,1)),nn.Flatten(), nn.Linear(512, 10))X = torch.rand(size=(1, 1, 224, 224))
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape:\t', X.shape)
训练模型
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
🌍3.2 练习
1.图7.4.1中的Inception块与残差块之间的主要区别是什么?在删除了Inception块中的一些路径之后,它们是如何相互关联的?
Inception块和残差块(Residual block)是两种不同的网络模块,其主要区别在于它们的结构和连接方式。
Inception块是由多个不同大小的卷积核和池化操作组成的,它们在不同的分支中并行进行操作,然后将它们的输出在通道维度上进行拼接。这种设计可以捕捉不同尺度和层次的特征,并且具有较大的感受野,从而提高网络的表达能力。
残差块(Residual block)是通过引入跳跃连接(skip connection)来解决梯度消失问题的一种方式。在残差块中,输入通过一个或多个卷积层后,与原始输入进行相加操作。这种设计允许信息在网络中直接跳过一些层级,使得网络能够更容易地学习残差(原始输入与输出之间的差异),从而加速训练和改善模型的收敛性。
当从Inception块中删除一些路径时,它们仍然与其他路径相互关联。删除路径后,剩下的路径仍然可以在Inception块中共享信息,并通过拼接或连接操作将它们的输出合并起来。这样可以减少模型的计算复杂度和参数量,并且有助于防止过拟合。
在残差网络(ResNet)中,每个残差块通过跳跃连接将输入直接添加到输出中,确保了信息的流动。这种结构使得残差网络能够更深地堆叠层级,并且可以训练非常深的神经网络而不会导致梯度消失或退化问题。
2.参考ResNet论文 (He et al., 2016)中的表1,以实现不同的变体。
根据ResNet论文中的表1,我们可以实现ResNet的不同变体,如ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152。以下是这些变体的具体实现代码:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lclass Residual(nn.Module):def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1)if use_1x1conv:self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)else:self.conv3 = Noneself.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)def forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = self.bn2(self.conv2(Y))if self.conv3:X = self.conv3(X)Y += Xreturn F.relu(Y)def resnet_block(input_channels, num_channels, num_residuals, first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))else:blk.append(Residual(num_channels, num_channels))return blkclass ResNet(nn.Module):def __init__(self, num_classes, block_sizes):super().__init__()self.b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.b2 = nn.Sequential(*resnet_block(64, 64, block_sizes[0], first_block=True))self.b3 = nn.Sequential(*resnet_block(64, 128, block_sizes[1]))self.b4 = nn.Sequential(*resnet_block(128, 256, block_sizes[2]))self.b5 = nn.Sequential(*resnet_block(256, 512, block_sizes[3]))self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.flatten = nn.Flatten()self.fc = nn.Linear(512, num_classes)def forward(self, X):X = self.b1(X)X = self.b2(X)X = self.b3(X)X = self.b4(X)X = self.b5(X)X = self.avgpool(X)X = self.flatten(X)X = self.fc(X)return Xdef resnet18(num_classes):return ResNet(num_classes, [2, 2, 2, 2])def resnet34(num_classes):return ResNet(num_classes, [3, 4, 6, 3])def resnet50(num_classes):return ResNet(num_classes, [3, 4, 6, 3])def resnet101(num_classes):return ResNet(num_classes, [3, 4, 23, 3])# Usage example
num_classes = 10 # Number of output classes
net = resnet18(num_classes) # Choose the ResNet variant# Training
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())

3.对于更深层次的网络,ResNet引入了“bottleneck”架构来降低模型复杂性。请试着去实现它。
ResNet引入了“bottleneck”架构。在这个架构中,每个残差块由一个1x1卷积层、一个3x3卷积层和一个1x1卷积层组成,其中1x1卷积层用于减少维度和恢复维度。这样可以显著减少参数数量和计算量。
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lclass Bottleneck(nn.Module):def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):super().__init__()self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=1)self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1, stride=strides)self.conv3 = nn.Conv2d(num_channels, num_channels * 4, kernel_size=1)self.bn1 = nn.BatchNorm2d(num_channels)self.bn2 = nn.BatchNorm2d(num_channels)self.bn3 = nn.BatchNorm2d(num_channels * 4)if use_1x1conv:self.conv4 = nn.Conv2d(input_channels, num_channels * 4, kernel_size=1, stride=strides)else:self.conv4 = Nonedef forward(self, X):Y = F.relu(self.bn1(self.conv1(X)))Y = F.relu(self.bn2(self.conv2(Y)))Y = self.bn3(self.conv3(Y))if self.conv4:X = self.conv4(X)Y += Xreturn F.relu(Y)def bottleneck_block(input_channels, num_channels, num_residuals, first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Bottleneck(input_channels, num_channels, use_1x1conv=True, strides=2))else:blk.append(Bottleneck(num_channels * 4, num_channels))return blkclass ResNet(nn.Module):def __init__(self, num_classes, block_sizes):super().__init__()self.b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.b2 = nn.Sequential(*bottleneck_block(64, 64, block_sizes[0], first_block=True))self.b3 = nn.Sequential(*bottleneck_block(256, 128, block_sizes[1]))self.b4 = nn.Sequential(*bottleneck_block(512, 256, block_sizes[2]))self.b5 = nn.Sequential(*bottleneck_block(1024, 512, block_sizes[3]))self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.flatten = nn.Flatten()self.fc = nn.Linear(2048, num_classes)def forward(self, X):X = self.b1(X)X = self.b2(X)X = self.b3(X)X = self.b4(X)X = self.b5(X)X = self.avgpool(X)X = self.flatten(X)X = self.fc(X)return Xdef resnet50(num_classes):return ResNet(num_classes, [3, 4, 6, 3])def resnet101(num_classes):return ResNet(num_classes, [3, 4, 23, 3])def resnet152(num_classes):return ResNet(num_classes, [3, 8, 36, 3])# Usage example
num_classes = 10 # Number of output classes
net = resnet50(num_classes) # Choose the ResNet variant# Training
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())4.在ResNet的后续版本中,作者将“卷积层、批量规范化层和激活层”架构更改为“批量规范化层、激活层和卷积层”架构。请尝试做这个改进。详见 (He et al., 2016)中的图1
在ResNet的后续版本中,作者将“卷积层、批量规范化层和激活层”架构更改为“批量规范化层、激活层和卷积层”架构。这种改进可以提高训练的稳定性和收敛速度。
以下是将ResNet的层结构改为“批量规范化层、激活层和卷积层”架构的代码实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lclass Bottleneck(nn.Module):def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):super().__init__()self.bn1 = nn.BatchNorm2d(input_channels)self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=1)self.bn2 = nn.BatchNorm2d(num_channels)self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1, stride=strides)self.bn3 = nn.BatchNorm2d(num_channels)self.conv3 = nn.Conv2d(num_channels, num_channels * 4, kernel_size=1)if use_1x1conv:self.conv4 = nn.Conv2d(input_channels, num_channels * 4, kernel_size=1, stride=strides)else:self.conv4 = Nonedef forward(self, X):Y = F.relu(self.bn1(X))Y = self.conv1(Y)Y = F.relu(self.bn2(Y))Y = self.conv2(Y)Y = F.relu(self.bn3(Y))Y = self.conv3(Y)if self.conv4:X = self.conv4(X)Y += Xreturn Ydef bottleneck_block(input_channels, num_channels, num_residuals, first_block=False):blk = []for i in range(num_residuals):if i == 0 and not first_block:blk.append(Bottleneck(input_channels, num_channels, use_1x1conv=True, strides=2))else:blk.append(Bottleneck(num_channels * 4, num_channels))return blkclass ResNet(nn.Module):def __init__(self, num_classes, block_sizes):super().__init__()self.b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2, padding=1))self.b2 = nn.Sequential(*bottleneck_block(64, 64, block_sizes[0], first_block=True))self.b3 = nn.Sequential(*bottleneck_block(256, 128, block_sizes[1]))self.b4 = nn.Sequential(*bottleneck_block(512, 256, block_sizes[2]))self.b5 = nn.Sequential(*bottleneck_block(1024, 512, block_sizes[3]))self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.flatten = nn.Flatten()self.fc = nn.Linear(2048, num_classes)def forward(self, X):X = self.b1(X)X = self.b2(X)X = self.b3(X)X = self.b4(X)X = self.b5(X)X = self.avgpool(X)X = self.flatten(X)X = self.fc(X)return Xdef resnet50(num_classes):return ResNet(num_classes, [3, 4, 6, 3])def resnet101(num_classes):return ResNet(num_classes, [3, 4, 23, 3])def resnet152(num_classes):return ResNet(num_classes, [3, 8, 36, 3])# Usage example
num_classes = 10 # Number of output classes
net = resnet50(num_classes) # Choose the ResNet variant# Training
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
5.为什么即使函数类是嵌套的,我们仍然要限制增加函数的复杂性呢?
限制函数的复杂性有几个原因:
- 可读性和可维护性:随着函数的复杂性增加,函数的代码可能变得冗长、难以理解和难以维护。函数的目标是封装特定的功能,使代码更具可读性和可维护性。如果一个函数过于复杂,它可能会变得难以理解,导致困惑和错误。
- 可重用性:函数的目标之一是促进代码的重用。通过将代码封装在函数中,可以在不同的上下文中多次使用。然而,当函数变得过于复杂时,其可重用性可能会下降。复杂的函数可能包含过多的逻辑和依赖关系,使其难以在其他上下文中重用。
- 可测试性:函数的复杂性会增加测试的难度。当函数包含大量的逻辑和依赖关系时,编写相应的测试用例和确保代码的正确性变得更加困难。通过限制函数的复杂性,可以使函数更容易进行单元测试,并提高代码的可靠性。
🌊4. 研究体会
在本次实验中,我对残差网络(ResNet)进行了深入研究和实践。通过这个实验,我对残差网络的原理、优势以及深度对模型性能的影响有了更深入的理解。
首先,对残差网络的原理和架构有了清晰的认识。残差网络通过引入跳跃连接和残差块的方式解决了深度神经网络中的梯度消失和梯度爆炸问题。跳跃连接允许信息直接传递到后续层,使得网络可以学习残差映射,从而更好地优化模型。残差块的设计也使得网络可以学习到非线性映射,提高了模型的表达能力。
其次,深入探究了残差网络的优势。相比传统的卷积神经网络,残差网络具有更深的网络结构,可以利用更多的层次特征来提取和表达数据的复杂特征。这使得残差网络在处理大规模数据集和复杂任务时表现出更强的性能。此外,我还观察到残差网络在训练过程中具有更快的收敛速度,这是由于跳跃连接的存在减少了梯度传播的路径长度,加速了模型的训练过程。
在实验中,对残差网络的深度对模型性能的影响进行了分析。通过调整网络的深度,我发现随着网络深度的增加,模型的性能在一定程度上得到了提升。然而,当网络过深时,出现了退化问题,即模型的性能开始下降。这表明在构建残差网络时,需要适当平衡网络的深度和性能之间的关系,避免过深的网络导致性能下降。
最后,在实践中应用残差网络解决实际问题的过程中,深刻体会到了残差网络的强大能力。将残差网络应用于图像分类任务,发现相比传统网络,残差网络在处理复杂图像数据时具有更好的分类性能。此外,我还尝试了在目标检测和语音识别等领域应用残差网络,也取得了较好的效果。这进一步加深了我对残差网络的理解,并使我对深度学习的实际应用能力有了更深入的认识。
在实验中,我也遇到了一些困难。首先是网络的训练时间较长,尤其是在增加网络深度的情况下。为了节省时间,我尝试了使用预训练模型和批量归一化等技术,以加快训练速度并提高模型的性能。其次,调整网络深度时需要进行多次实验和分析,以找到最佳的深度配置。这要求我具备耐心和细致的科研态度,不断地进行试验和调整。

相关文章:
【动手学深度学习】残差网络(ResNet)的研究详情
目录 🌊1. 研究目的 🌊2. 研究准备 🌊3. 研究内容 🌍3.1 残差网络 🌍3.2 练习 🌊4. 研究体会 🌊1. 研究目的 了解残差网络(ResNet)的原理和架构;探究残…...

freertos初体验 - 在stm32上移植
1. 说明 freertos内核 非常精简,代码量也很少,官方也针对主流的编译器和内核准备好了移植文件,所以 freertos 的移植是非常简单的,很多工具(例如CubeMX)点点鼠标就可以生成一个 freertos 的工程࿰…...

ubuntu使用 .deb 文件安装VScode
使用 .deb 文件安装 下载 VSCode 的 .deb 文件: wget -q https://go.microsoft.com/fwlink/?LinkID760868 -O vscode.deb使用 dpkg 安装: sudo dpkg -i vscode.deb如果有依赖项问题,使用以下命令修复: sudo apt-get install -f...
9.1.1 简述目标检测领域中的单阶段模型和两阶段模型的性能差异及其原因
9.1目标检测 场景描述 目标检测(Object Detection)任务是计算机视觉中极为重要的基础问题,也是解决实例分割(Instance Segmentation)、场景理解(Scene Understanding)、目标跟踪(Ob…...

系统化自学Python的实用指南
目录 一、理解Python与设定目标 二、搭建学习环境与基础准备 三、入门学习阶段 四、中级进阶阶段 五、项目实践与持续深化 六、持续学习与拓展 一、理解Python与设定目标 Python概述:详细介绍Python的历史沿革、设计理念、主要特点(如易读、易维护…...

加密货币初创企业指南:如何寻找代币与市场的契合点
撰文:Mark Beylin,Boost VC 编译:Yangz,Techub News 原文来源:香港Web3媒体Techub News 在 Y Combinator 创始人 Paul Graham 《Be Good》一文中概述了初创企业如何找到产品与市场契合点的方法,即制造人…...

【十二】图解mybatis日志模块之设计模式
图解mybatis日志模块之设计模式 概述 最近经常在思考研发工程师初、中、高级工程师以及系统架构师各个级别的工程师有什么区别,随着年龄增加我们的技术级别也在提升,但是很多人到了高级别反而更加忧虑,因为it行业35岁年龄是个坎这是行业里的共…...
RainBond 制作应用并上架【以ElasticSearch为例】
文章目录 安装 ElasticSearch 集群第 1 步:添加组件第 2 步:查看组件第 3 步:访问组件制作 ElasticSearch 组件准备工作ElasticSearch 集群原理尝试 Helm 安装 ES 集群RainBond 制作 ES 思路源代码Dockerfiledocker-entrypoint.shelasticsearch.yml制作组件第 1 步:添加组件…...
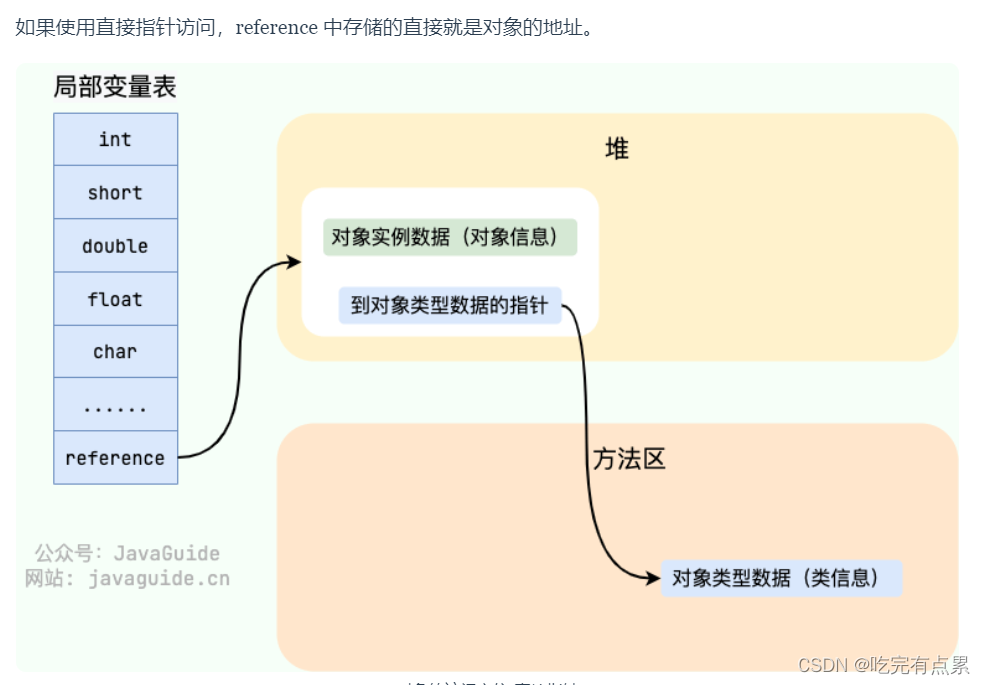
JVM相关:Java内存区域
Java 虚拟机(JVM)在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域。 Java运行时数据区域是指Java虚拟机(JVM)在执行Java程序时,为了管理内存而划分的几个不同作用域。这些区域各自承担特定的任务,…...
【C++】─篇文章带你熟练掌握 map 与 set 的使用
目录 一、关联式容器二、键值对三、pair3.1 pair的常用接口说明3.1.1 [无参构造函数](https://legacy.cplusplus.com/reference/utility/pair/pair/)3.1.2 [有参构造函数 / 拷贝构造函数](https://legacy.cplusplus.com/reference/utility/pair/pair/)3.1.3 [有参构造函数](htt…...
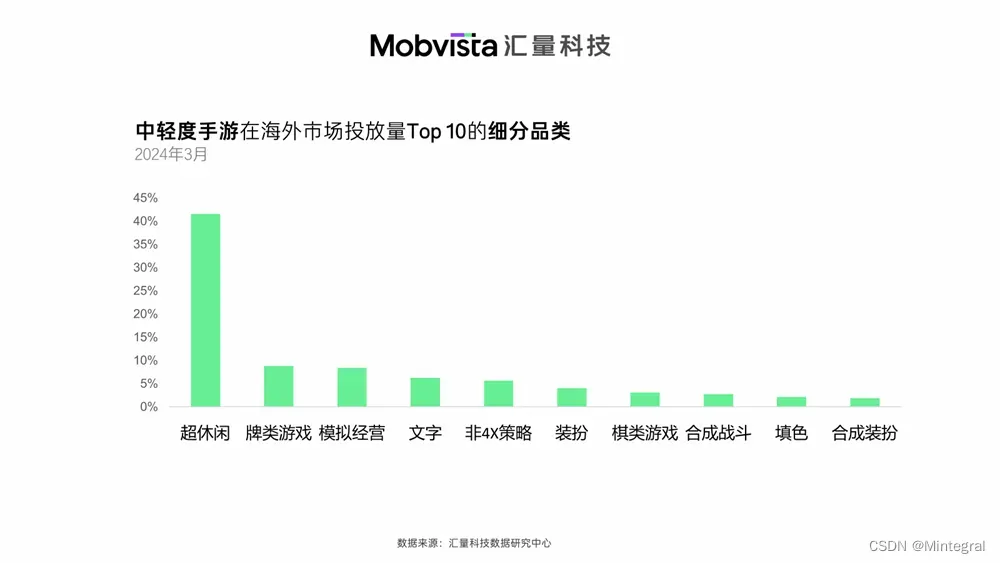
Mintegral数据洞察:全球中轻度游戏市场与创意更新频率
基于2024年3月大盘数据,汇量科技数据研究中心发现,超休闲品类仍是投流中轻度手游的中流砥柱。而投流力度较大的其他细分品类里,可以看到棋牌、模拟经营、非4X策略以及合成X游戏的身影,这些品类是近年来经常出现融合玩法的新兴赛道…...
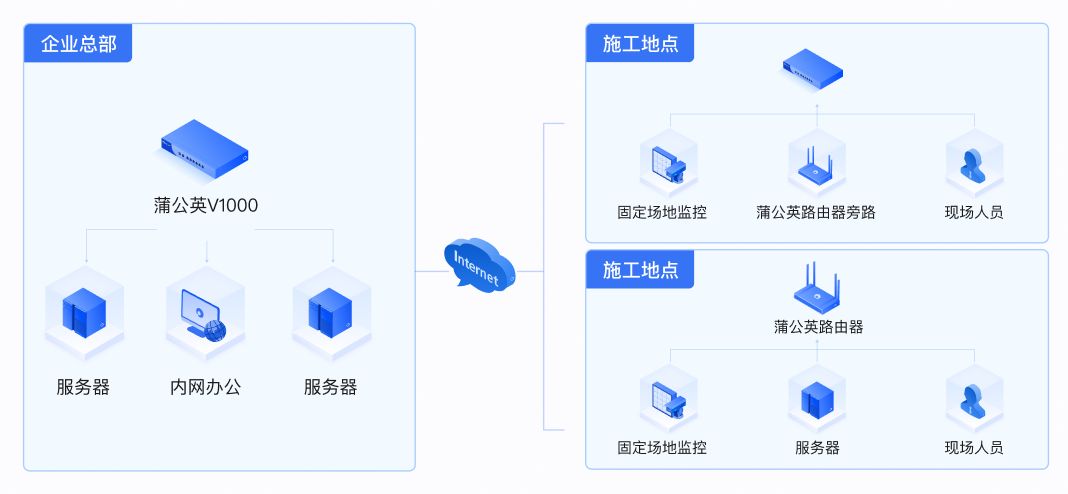
贝锐蒲公英异地组网:降低建筑工地远程视频监控成本、简化运维
中联建设集团股份有限公司是一家建筑行业的施工单位,专注于建筑施工,业务涉及市政公用工程施工总承包、水利水电工程施工总承包、公路工程施工总承包、城市园林绿化专业承包等,在全国各地开展有多个建筑项目,并且项目时间周期可能…...

大模型训练学习笔记
目录 大模型的结构主要分为三种 大模型分布式训练方法主要包括以下几种: token Token是构成句子的基本单元 1. 词级别的分词 2. 字符级别的分词 结巴分词 GPT-3/4训练流程 更细致的教程,含公式推理 大模型的结构主要分为三种 Encoder-only(自编…...

Linux C/C++时间操作
C11提供了操作时间的库chrono库,从语言级别提供了支持chrono库屏蔽了时间操作的很多细节,简化了时间操作 Unix操作系统根据计算机产生的年代把1970年1月1日作为UNIX的纪元时间,1970年1月1日是时间的中间点,将从1970年1月1日起经过…...

AI绘画工具
AI绘画工具:技术与艺术的完美融合 一、引言 随着人工智能技术的飞速发展,AI绘画工具作为艺术与技术结合的产物,已经逐渐从科幻的概念变成了现实。这些工具不仅改变了传统绘画的创作方式,还为人们带来了全新的艺术体验。本文将详…...
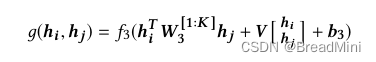
图相似度j计算——SimGNN
图相似性——SimGNN 论文链接:个人理解:数据处理: feature_1 [[1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "A"[0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0], # "B"[0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0] # "C" 第二个循环ÿ…...

大模型创新企业集结!百度智能云千帆AI加速器Demo Day启动
新一轮技术革命风暴席卷而来,为创业带来源源不断的创新动力。过去一年,在金融、制造、交通、政务等领域,大模型正从理论到落地应用,逐步改变着行业的运作模式,成为推动行业创新和转型的关键力量。 针对生态伙伴、创业…...

阿里云对象存储oss——对象储存原子性和强一致性
在阿里云对象存储oss中有俩个很重要的特性分别是原子性和强一致性。 原子性 首先我们先聊一下原子性,在计算机科学中,原子性(Atomicity)是指一个操作是不可分割的最小执行单元,要么完全执行,要么完全不执行…...

星戈瑞 CY5-地塞米松的热稳定性
CY5-地塞米松作为一种结合了荧光染料CY5与药物地塞米松的复合标记物,其热稳定性是评估其在实际应用中能否保持结构完整和功能稳定的参数。 热稳定性的重要性 热稳定性是指物质在受热条件下保持其物理和化学性质不变的能力。对于CY5-地塞米松而言,良好的…...

MongoDB CRUD操作:地理位置查询
MongoDB CRUD操作:地理位置查询 文章目录 MongoDB CRUD操作:地理位置查询地理空间数据GeoJSON对象传统坐标对通过数组指定(首选)通过嵌入文档指定 地理空间索引2dsphere2d 地理空间查询地理空间查询运算符地理空间聚合阶段 地理空…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

Keil 中设置 STM32 Flash 和 RAM 地址详解
文章目录 Keil 中设置 STM32 Flash 和 RAM 地址详解一、Flash 和 RAM 配置界面(Target 选项卡)1. IROM1(用于配置 Flash)2. IRAM1(用于配置 RAM)二、链接器设置界面(Linker 选项卡)1. 勾选“Use Memory Layout from Target Dialog”2. 查看链接器参数(如果没有勾选上面…...

TRS收益互换:跨境资本流动的金融创新工具与系统化解决方案
一、TRS收益互换的本质与业务逻辑 (一)概念解析 TRS(Total Return Swap)收益互换是一种金融衍生工具,指交易双方约定在未来一定期限内,基于特定资产或指数的表现进行现金流交换的协议。其核心特征包括&am…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...