动手学深度学习【2】——softmax回归
动手学深度学习网址:动手学深度学习
注:本部分只对基础知识进行简单的介绍并附上完整的代码实现,更多内容可参考上述网址。
前言
前面一节我们谈到了线性回归,它解决的是预测某个值的问题。但是在日常生活这,除了预测某个值,我们也关注一些分类问题,如:某张图像的内容是猫还是狗。
本节介绍的softmax回归它得到的值就是一串概率值,表示当前内容属于某个分类的概率。
简述
分类问题
假设这里有一个2 * 2的灰度图像,我们可以用一个标量表示每个像素值,每个图像对应四个特征x1,x2,x3,x4。 此外,假设该图像属于类别“猫”“鸡”和“狗”中的一个。
在以上列子中,我们使用独热编码(one-hot encoding)来表示对应的类别。 独热编码是一个向量,它的分量和类别一样多。 类别对应的分量设置为1,其他所有分量设置为0。 在我们的例子中,标签y将是一个三维向量, 其中(1,0,0)对应于“猫”、(0,1,0)对应于“鸡”、(0,0,1)对应于“狗”。以猫为例子,(1,0,0)意味着如果输入的图像是猫,那么只有猫对应的那个分量为1,其他都是0。这个其实也就是真实标签的表示方式。此时y表示为:

网络架构
softmax回归也是一种全连接层:
全连接层特点:输出层的每个元素跟输入层的每个元素有关。

用公式描述为:

向量形式为:

softmax运算
思路:我们想要网络的输出表示的是该输入数据属于某个类的概率,然后选择概率最大的为输入数据的种类。 例如,如果预测的y1,y2,y3分别为0.1,0.8,0.1,那么我们预测的类别就是类别2了,因为它的概率最大。
实现:

softmax函数能够将未规范化的预测变换为非负数并且总和为1,同时让模型保持 可导的性质。
为什么需要规范化?因为我们要将输出数据看出概率,而这些数据可能为负值,这是不符合概率的性质的,而且我们需要限制输出数据的综合为1才好根据概率的大小来判断种类。
最后通过找到概率最大的类别就是我们所求的:

小批量样本矢量化
跟之前一样,我们不可能一次性将所有的数据加进来训练,这需要很大的内存开销,因此我们每次读取一部分。公式为:

其中X的特征维度为d,输入的批量大小为n,输出有q个类别。
损失函数
我们使用最大似然估计,跟线性回归部分一样。
softmax函数给出了一个向量y^, 我们可以将其视为“对给定任意输入
的每个类的条件概率”。
似然估计为:

根据最大似然估计,我们需要最大化上述式子,也就是最小化负对数似然:


这里的损失函数是交叉熵损失。
需要注意,这里的真实标签向量y是一个独热编码,也就是说除了跟输入数据类型一样的那个位置的值为1,其他都是0,所以最后这个损失函数就变成了预测标签的负对数。
softmax及其导数
将损失函数展开,log里面的y^可以用softmax函数展开,如下所示:

对应未规范的预测oj的偏导数为:

交叉熵损失
谈到熵,就需要说起信息论了。信息论(information theory)涉及编码、解码、发送以及尽可能简洁地处理信息或数据。
熵的定义:信息论中熵的定义为:

它是当分配的概率真正匹配数据生成过程时的信息量的期望。
信息量:
![]()
上述式子可以理解为,一个事件发生的概率越大,则它所携带的信息量就越小,当p=1时,信息量为0,熵将等于0,也就是说该事件的发生不会导致任何信息量的增加。
审视交叉熵:
主观概率为Q的观察者在看到根据概率P生成的数据时的预期惊异。
代码
这里所面对的具体任务为:使用softmax回归对Fashion-MNIST数据集进行训练,并在其测试集上验证效果。
导入相关包:
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
from IPython import display
1.准备数据集
对于任何一个任务,第一步肯定是准备数据集。
首先小试牛刀,使用几条语句进行测试,如下:
# 读取数据集
## tensor转换器,除以255进行归一化,使像素值范围在0-1
trans = transforms.ToTensor()
## 训练集
mnist_train = torchvision.datasets.FashionMNIST(root="/kaggel/output/data", train=True, transform=trans, download=True)
## 测试集
mnist_test = torchvision.datasets.FashionMNIST(root="/kaggel/output/data", train=False, transform=trans, download=True)
该语句使用了Pytorch中自带的加载数据的函数,它会从网上下载相关数据集,并对这些数据进行处理,如上面的trans处理,将数据都变成tensor并归一化。
然后定义一个返回数字标签对应的文本标签,这是之后得到预测的标签所需要的。
# 返回数字标签对应的文本标签
def get_fashion_mnist_labels(labels):# 文本标签text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat','sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']# 返回数字标签对应的文本标签return [text_labels[int(i)] for i in labels]
接着如果想可视化这些数据,可以由如下方法实现:
# 可视化样本
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):# 图的大小figsize = (num_cols * scale, num_rows * scale)# 表示切割成num_rows行*num_cols列的子图像_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)axes = axes.flatten()for i, (ax, img) in enumerate(zip(axes, imgs)):if torch.is_tensor(img):# 图片张量ax.imshow(img.numpy())else:# PIL图片ax.imshow(img)# 设置坐标轴是否可见ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)if titles:# 设置标题ax.set_title(titles[i])return axes# X是返回的图像,y是这些图像对应的标签
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
# 因为X大小为(18,1,28,28),需要将它转换
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y));
读取数据后,我们就需要将这些数据加载出来,这里我们使用如下语句:
def get_dataloader_workers(): """使用4个进程来读取数据"""return 4
train_iter = data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers())
最终读取数据集的函数为:
def load_data_fashion_mnist(batch_size, resize=None): """下载Fashion-MNIST数据集,然后将其加载到内存中"""trans = [transforms.ToTensor()]if resize:trans.insert(0, transforms.Resize(resize))trans = transforms.Compose(trans)mnist_train = torchvision.datasets.FashionMNIST(root="/kaggel/output/data", train=True, transform=trans, download=True)mnist_test = torchvision.datasets.FashionMNIST(root="/kaggel/output/data", train=False, transform=trans, download=True)return (data.DataLoader(mnist_train, batch_size, shuffle=True,num_workers=get_dataloader_workers()),data.DataLoader(mnist_test, batch_size, shuffle=False,num_workers=get_dataloader_workers()))
该函数的作用为获得训练集和测试集,内容综合了上面所讨论的部分。首先是获得数据集,然后使用data.DataLoader将这些数据分别加载到训练集和测试集当中。
我们还可以使用d2l中自带的一个方法来实现加载数据,代码如下:
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
# 使用d2l中的部分
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
2.定义softmax函数
按照前面的公式计算即可,但需要注意是对行求和,轴0代表列,轴1代表行。
def softmax(X):X_exp = torch.exp(X)# 这里对每行进行求和,因为每一行是一个样本partition = X_exp.sum(1, keepdim=True)return X_exp / partition # 这里应用了广播机制
3.定义损失函数和网络结构
损失函数:根据前面提到的,我们使用的是交叉熵损失,且需要注意:真实标签y是一个独热编码,除了对应的一个位置为1,其实都是0,因此交叉熵损失就变成了该位置时预测概率的负对数。
网络结构:根据之前提到的,网络结构为一个全连接层,用公式表示就是:wx+b。
故代码为:
def cross_entropy(y_hat, y):return - torch.log(y_hat[range(len(y_hat)), y])
def net(X):return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
4.精度的计算
精度就是预测正确的个数和总的个数的比值。因此我们首先需要计算出预测正确的数量。这里需要注意的是预测的值和真实值的数值类型一致,因为使用了了==符号来判断哪些部分是预测正确的,哪些是不正确的。
"""计算预测正确的数量"""
def accuracy(y_hat, y): if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:y_hat = y_hat.argmax(axis=1)cmp = y_hat.type(y.dtype) == yreturn float(cmp.type(y.dtype).sum())
然后计算精度,代码如下:
def evaluate_accuracy(net, data_iter): """计算在指定数据集上模型的精度"""if isinstance(net, torch.nn.Module):net.eval() # 将模型设置为评估模式metric = Accumulator(2) # 正确预测数、预测总数with torch.no_grad():for X, y in data_iter:# y.numel()返回y中元素的个数 metric.add(accuracy(net(X), y), y.numel())return metric[0] / metric[1]
这里我们使用了一个类来存储预测正确的个数以及总的个数,该类的定义为:
"""在n个变量上累加"""
class Accumulator: def __init__(self, n):self.data = [0.0] * ndef add(self, *args):self.data = [a + float(b) for a, b in zip(self.data, args)]def reset(self):self.data = [0.0] * len(self.data)def __getitem__(self, idx):return self.data[idx]
5.准备训练
首先我们先考虑单个epoch时的训练,整体流程如下:
- 循环取出输入数据X和数据的标签y
- 将输入数据X输入到神经网络中得到预测的标签y^
- 计算真实标签和预测标签的损失
- 根据损失进行后向传播
同时我们还返回了训练精度和训练损失。
代码如下:
# 训练代码
def train_epoch_ch3(net, train_iter, loss, updater): # 将模型设置为训练模式if isinstance(net, torch.nn.Module):net.train()# 训练损失总和、训练准确度总和、样本数metric = Accumulator(3)for X, y in train_iter:# 计算梯度并更新参数y_hat = net(X)# print(y_hat)l = loss(y_hat, y)if isinstance(updater, torch.optim.Optimizer):# 使用PyTorch内置的优化器和损失函数updater.zero_grad()l.mean().backward()updater.step()else:# 使用定制的优化器和损失函数l.sum().backward()updater(X.shape[0])metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())# 返回训练损失和训练精度return metric[0] / metric[2], metric[1] / metric[2]
需要注意的时,这里的参数更新器分成了两种情况,一种情况下使用了l.mean,而另一种使用了l.sum(),这是因为所使用的框架不同导致的。前者使用的是Pytorch框架里面的,而后者是d2l里面的。
单个epoch部分完成后,就可以顺利过渡到这个过程了,其实就是遍历所有的epoch就行,代码如下:
# 训练整个模型
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],legend=['train loss', 'train acc', 'test acc'])for epoch in range(num_epochs):train_metrics = train_epoch_ch3(net, train_iter, loss, updater)print(train_metrics)test_acc = evaluate_accuracy(net, test_iter)animator.add(epoch + 1, train_metrics + (test_acc,))train_loss, train_acc = train_metrics
# print(train_loss)assert train_loss < 0.5, train_lossassert train_acc <= 1 and train_acc > 0.7, train_accassert test_acc <= 1 and test_acc > 0.7, test_acc
这里为了方便可视化,还加入了另外一个类,用于更新展示的图像,实现如下:
# 动画函数
"""在动画中绘制数据"""
class Animator: def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,ylim=None, xscale='linear', yscale='linear',fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,figsize=(3.5, 2.5)):# 增量地绘制多条线if legend is None:legend = []d2l.use_svg_display()self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)if nrows * ncols == 1:self.axes = [self.axes, ]# 使用lambda函数捕获参数self.config_axes = lambda: d2l.set_axes(self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)self.X, self.Y, self.fmts = None, None, fmtsdef add(self, x, y):# 向图表中添加多个数据点if not hasattr(y, "__len__"):y = [y]n = len(y)if not hasattr(x, "__len__"):x = [x] * nif not self.X:self.X = [[] for _ in range(n)]if not self.Y:self.Y = [[] for _ in range(n)]for i, (a, b) in enumerate(zip(x, y)):if a is not None and b is not None:self.X[i].append(a)self.Y[i].append(b)self.axes[0].cla()for x, y, fmt in zip(self.X, self.Y, self.fmts):self.axes[0].plot(x, y, fmt)self.config_axes()display.display(self.fig)display.clear_output(wait=True)
上面都搞完了,我们就可以训练模型了,代码如下:
# 参数初始化
# 因为原图像大小为28 * 28,我们将其平铺,也就是784
num_inputs = 784
# 因为总共10类,所以输出数目为10
num_outputs = 10W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
lr = 0.1
def updater(batch_size):with torch.no_grad():return d2l.sgd([W, b], lr, batch_size)
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
得到的结果如下:

如果训练过程出现train_loss为nan的情况,可以重新运行代码程序试试。
6.测试
一个好的模型不仅要在训练集上取得好的效果,它在测试集上也要有出色的表现,对此,我们对训练的模型进行测试。
# 预测
def predict_ch3(net, test_iter, n=6): #@savefor X, y in test_iter:breaktrues = d2l.get_fashion_mnist_labels(y)preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))titles = [true +'\n' + pred for true, pred in zip(trues, preds)]d2l.show_images(X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter,n=10)
结果为:

可以看到预测结果都是正确的。
相关文章:
动手学深度学习【2】——softmax回归
动手学深度学习网址:动手学深度学习 注:本部分只对基础知识进行简单的介绍并附上完整的代码实现,更多内容可参考上述网址。 前言 前面一节我们谈到了线性回归,它解决的是预测某个值的问题。但是在日常生活这,除了预测…...

深入理解Activity的生命周期
之前学习安卓的时候只是知道生命周期是什么,有哪几个,但具体的详细的东西却不知道,后来看过《Android开发艺术探索》和大量博客之后,才觉得自己真正有点理解生命周期,本文是我对生命周期的认识的总结。废话少说先上图。…...

Go语言刷题常用数据结构和算法
数据结构 字符串 string 访问字符串中的值 通过下标访问 s1 : "hello world"first : s[0]通过切片访问 s2 : []byte(s1) first : s2[0]通过for-range循环访问 for i, v : range s1 {fmt.Println(i, v) }查询字符是否属于特定字符集 // 判断字符串中是否包含a、b、…...

深入vue2.x源码系列:手写代码来模拟Vue2.x的响应式数据实现
前言 Vue响应式原理由以下三个部分组成: 数据劫持:Vue通过Object.defineProperty()方法对data中的每个属性进行拦截,当属性值发生变化时,会触发setter方法,通知依赖更新。发布-订阅模式:Vue使用发布-订阅…...
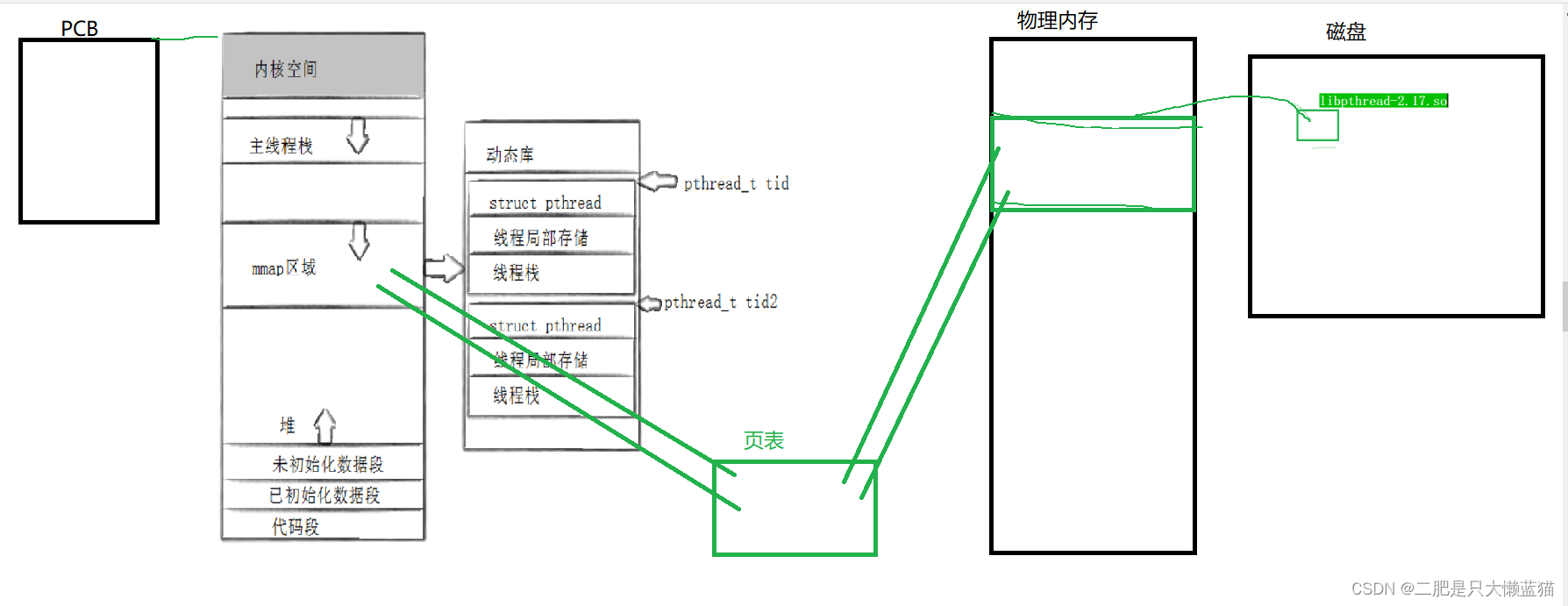
Linux线程控制
本篇我将学习如何使用多线程。要使用多线程,因为Linux没有给一般用户直接提供操作线程的接口,我们使用的接口,都是系统工程师封装打包成原生线程库中的。那么就需要用到原生线程库。因此,需要引入-lpthread,即连接原生…...

【LeetCode】剑指 Offer(20)
目录 题目:剑指 Offer 38. 字符串的排列 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 写在最后: 题目:剑指 Offer 38. 字符串的…...
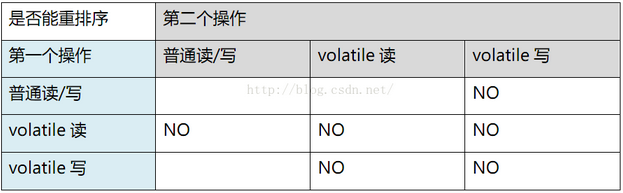
FutureTask中的outcome字段是如何保证可见性的?
最近在阅读FutureTask的源码是发现了一个问题那就是源码中封装结果的字段并没有使用volatile修饰,源码如下:public class FutureTask<V> implements RunnableFuture<V> {/*** 状态变化路径* Possible state transitions:* NEW -> COMPLET…...

直播回顾 | 聚焦科技自立自强,Bonree ONE 助力国产办公自动化平稳替代
3月5日,两会发布《政府工作报告》,强调科技政策要聚焦自立自强。 统计显示,2022年金融信创项目数同比增长300%,金融领域信创建设当前已进入发展爆发期,由国有大型银行逐渐向中小型银行、非银金融机构不断扩展。信创云…...

深入理解Linux进程
进程参数和环境变量的意义一般情况下,子进程的创建是为了解决某个问题。那么解决问题什么问题呢?这个就需要进程参数和环境变量来进行决定的。子进程解决问题需要父进程的“数据输入”(进程参数 & 环境变量)设计原则:3.1 子进程启动的时候…...

Vue3之组件间的双向绑定
何为组件间双向绑定 我们都知道当父组件改变了某个值后,如果这个值传给了子组件,那么子组件也会自动跟着改变,但是这是单向的,使用v-bind的方式,即子组件可以使用父组件的值,但是不能改变这个值。组件间的…...

Java语法基础(一)
目录 代码注释方法 编码规范 基本数据类型及取值范围 变量和常量的声明与赋值 变量 常量 标识符 基本数据类型的使用 整数类型的使用 浮点类型的使用 布尔类型的使用 字符类型的使用 代码注释方法 单行注释:使用“//”进行单行注释多行注释:使…...

优思学院|零质量控制是什么概念?
零质量控制(Zero Quality Control)是指一个理想的系统,可以生产没有任何缺陷的产品,因此不需要频繁的检查,从而节省时间和金钱。那些追求过程优化并致力于持续过程改进的组织将零质量控制(Zero Quality Con…...

2023-03-09 CMU15445-Query Execution
摘要: CMU15445, Project #3 - Query Execution 参考: Project #3 - Query Execution | CMU 15-445/645 :: Intro to Database Systems (Fall 2022) https://github.com/cmu-db/bustub 要求: OVERVIEW At this point in the semester, you have implemented the internal co…...
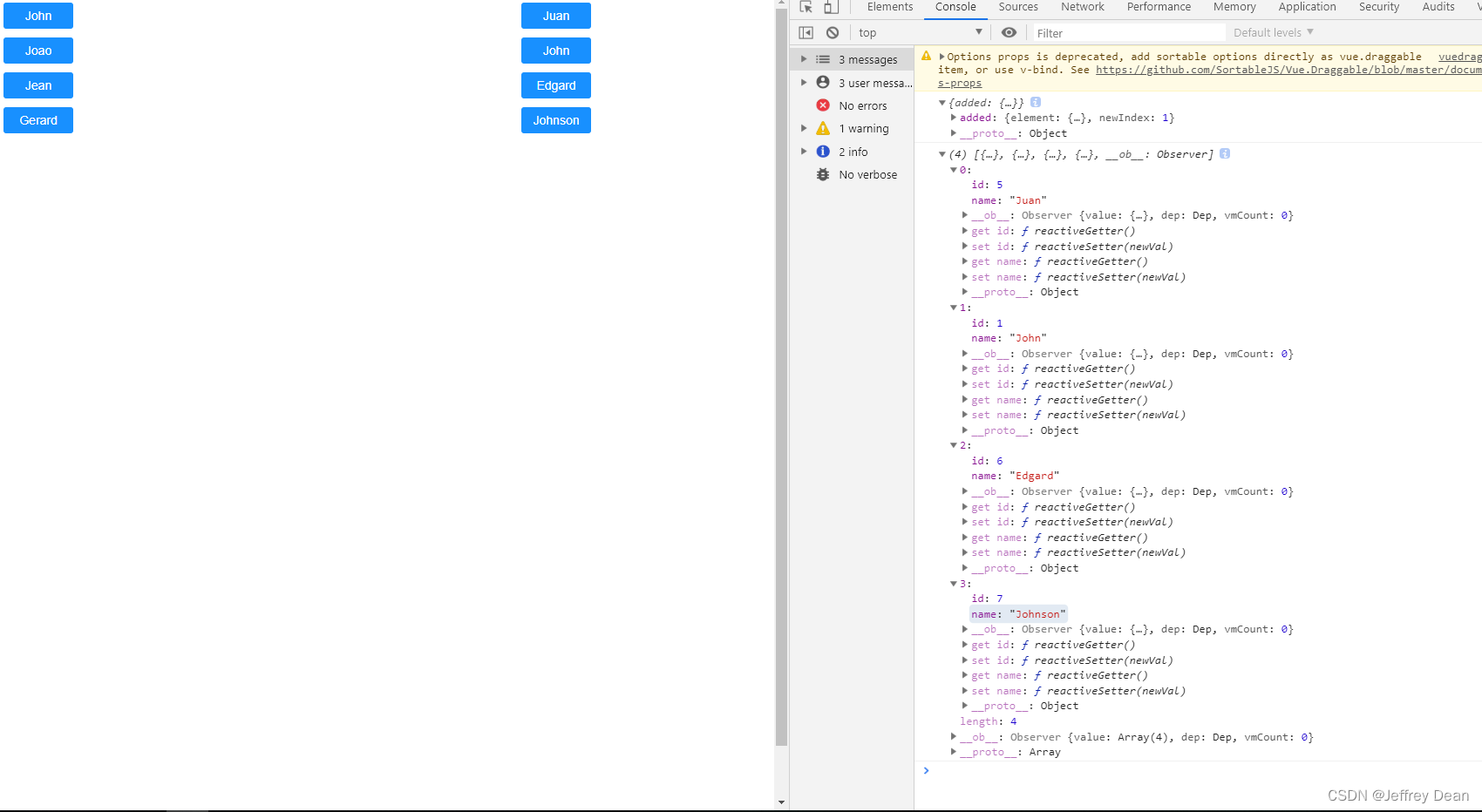
vuedraggable的使用
Draggable为基于Sortable.js的vue组件,用以实现拖拽功能。 特性 支持触摸设备 支持拖拽和选择文本 支持智能滚动 支持不同列表之间的拖拽 不以jQuery为基础 和视图模型同步刷新 和vue2的国度动画兼容 支持撤销操作 当需要完全控制时,可以抛出所有变化 可…...
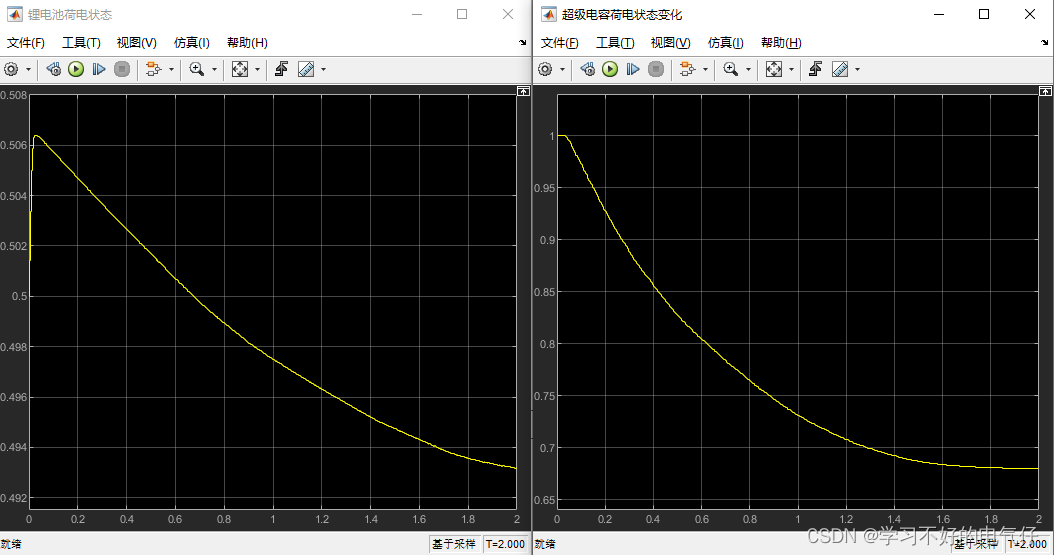
双馈风力发电机-900V直流混合储能并网系统MATLAB仿真
MATLAB2016b主体模型:双馈感应风机模块、采用真实风速数据。混合储能模块、逆变器模块、转子过电流保护模块、整流器控制模块、逆变器控制模块。直流母线电压:有功、无功输出(此处忘记乘负一信号输出),所以是负的。蓄电…...

leader选举过程
启动electionTimer,进行leader选举。 一段时间没有leader和follower通信,就会超时,开始选举leader过程。有个超时时间,如果到了这个时间,就会触发一个回调函数。具体如下: private void handleElectionTimeout() {boo…...

建造者模式
介绍 Java中的建造者模式是一种创建型设计模式,它的主要目的是为了通过一系列简单的步骤构建复杂的对象,允许创建复杂对象的不同表示形式,同时隐藏构造细节.它能够逐步构建对象,即先创建基本对象,然后逐步添加更多属性或部件,直到最终构建出完整的对象. 该模式的主要思想是将…...

IO与NIO区别
一、概念 NIO即New IO,这个库是在JDK1.4中才引入的。NIO和IO有相同的作用和目的,但实现方式不同,NIO主要用到的是块,所以NIO的效率要比IO高很多。在Java API中提供了两套NIO,一套是针对标准输入输出NIO,另一套就是网络编程NIO。 二、NIO和IO的主要区别 下表总结了Java I…...

无监督循环一致生成式对抗网络:PAN-Sharpening
Unsupervised Cycle-Consistent Generative Adversarial Networks for Pan Sharpening (基于无监督循环一致生成式对抗网络的全色锐化) 基于深度学习的全色锐化近年来受到了广泛的关注。现有方法大多属于监督学习框架,即对多光谱࿰…...
ArrayList源码分析(JDK17)
ArrayList类简介类层次结构构造无参构造有参构造添加元素add:添加/插入一个元素addAll:添加集合中的元素扩容mount与迭代器其他常见方法不常见方法不常见方法的源码和小介绍常见方法的源码和小介绍积累面试题ArrayList是什么?可以用来干嘛?Ar…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

selenium学习实战【Python爬虫】
selenium学习实战【Python爬虫】 文章目录 selenium学习实战【Python爬虫】一、声明二、学习目标三、安装依赖3.1 安装selenium库3.2 安装浏览器驱动3.2.1 查看Edge版本3.2.2 驱动安装 四、代码讲解4.1 配置浏览器4.2 加载更多4.3 寻找内容4.4 完整代码 五、报告文件爬取5.1 提…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

RabbitMQ入门4.1.0版本(基于java、SpringBoot操作)
RabbitMQ 一、RabbitMQ概述 RabbitMQ RabbitMQ最初由LShift和CohesiveFT于2007年开发,后来由Pivotal Software Inc.(现为VMware子公司)接管。RabbitMQ 是一个开源的消息代理和队列服务器,用 Erlang 语言编写。广泛应用于各种分布…...
CSS | transition 和 transform的用处和区别
省流总结: transform用于变换/变形,transition是动画控制器 transform 用来对元素进行变形,常见的操作如下,它是立即生效的样式变形属性。 旋转 rotate(角度deg)、平移 translateX(像素px)、缩放 scale(倍数)、倾斜 skewX(角度…...
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

通过MicroSip配置自己的freeswitch服务器进行调试记录
之前用docker安装的freeswitch的,启动是正常的, 但用下面的Microsip连接不上 主要原因有可能一下几个 1、通过下面命令可以看 [rootlocalhost default]# docker exec -it freeswitch fs_cli -x "sofia status profile internal"Name …...