常见八大排序(纯C语言版)
目录
基本排序
一.冒泡排序
二.选择排序
三.插入排序
进阶排序(递归实现)
一.快排hoare排序
1.单趟排序
快排步凑
快排的优化
(1)三数取中
(2)小区间优化
二.前后指针法(递归实现)
三.快排的非递归实现(前后指针法的非递归)
快排的挖坑法的实现
二.堆排序
1.建堆的选择
2.堆排序的实现
二希尔排序
三.归并排序(递归实现与非递归的实现)
归并排序(非递归实现)
四.非比较排序(计数排序)
计数排序的缺陷
五.排序总结
稳定性的概念
六,排序的选择题练习与巩固
欢迎各位大佬的关顾,能给个赞就好了QWQ,由于篇幅很大,可以根据目录跳转你想看的排序哦!!

基本排序
一.冒泡排序
冒泡排序即,每次相邻比较排序,每次将最小或最大固定在数组最后
void BubbleSort(int* arr, int len)
{for (int i = 0; i < len; i++){int flag = 1;for (int j = 0; j < len - i-1; j++){if (arr[j] > arr[j+1]){flag = 0;Swap(&arr[j + 1],&arr[j]);}}if (flag)break;}
}二.选择排序
很明显选择排序就是去找最小或者最大的下标然后赋值给原始位置,代码实现如下
void SelectSort(int* arr, int len)
{for (int i = 0; i < len-1; i++){int min = i;for (int j = i + 1; j < len; j++){if (arr[j] < arr[min])min = j;}Swap(&arr[min], &arr[i]);}
}但是这种选择排序也太low了让我们来实现一个Plus版本,一次循环找到最大与最小
int SelectSortPlus(int* arr, int len)
{int begin = 0;int end = len - 1;for (int i = begin; i <=end-1; i++){int min = begin;int max = begin;for (int j = i+1; j <= end; j++){if (arr[j] < arr[min])min = j;if (arr[j] > arr[max])max = j;}Swap(&arr[begin], &arr[min]);if (begin == max)//注意这里当begin与max的下标一样的时候,会被先换导致bugmax = min;Swap(&arr[end], &arr[max]);begin++;end--;}
}三.插入排序

看动图可以很容易的理解插入排序就是将已排好的序的后一个与前面的进行比较,比它大或小的往后移动
void InsertSort(int* a, int len)
{for (int i = 0; i < len - 1; i++){int end = i;int temp = a[end + 1];while (end >= 0){if (temp < a[end]){a[end + 1] = a[end];end--;}else{break;}a[end + 1] = temp;}}
}进阶排序(递归实现)
一.快排hoare排序
快排有着多种实现方式我们下面这个是hoare(创始人)的排序方式
快速排序是一种高效的排序现在来让我们来实现一下
1.单趟排序
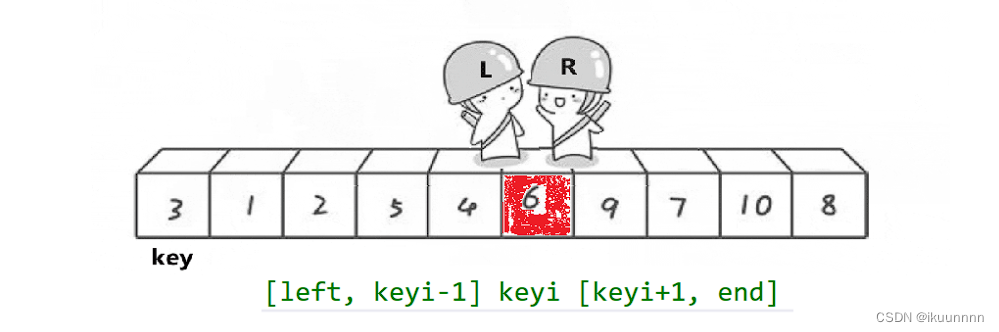
想要写出一个排序首先我们要去理解这个排序的单趟 单趟如图所示
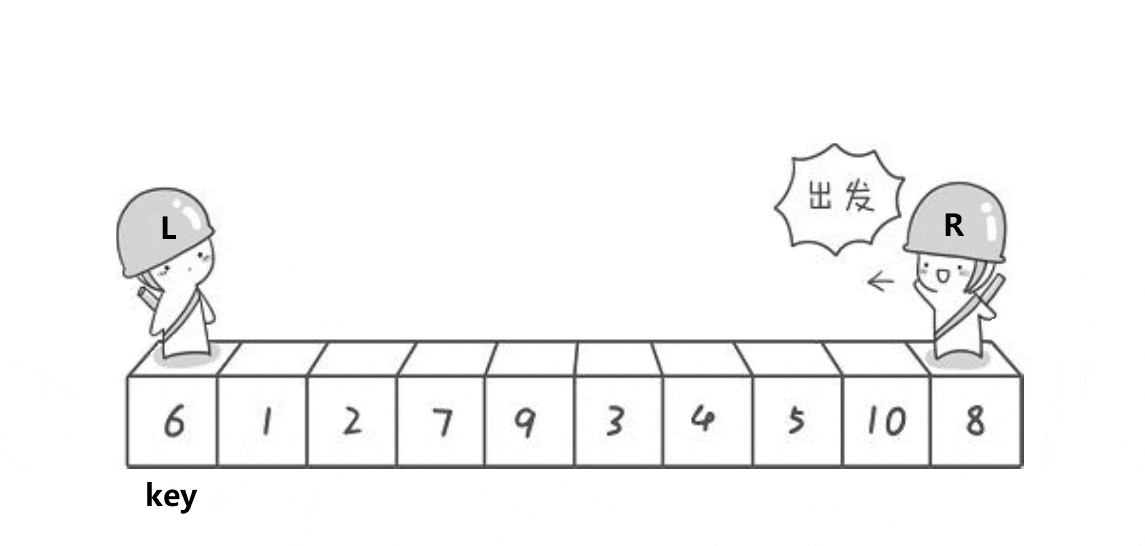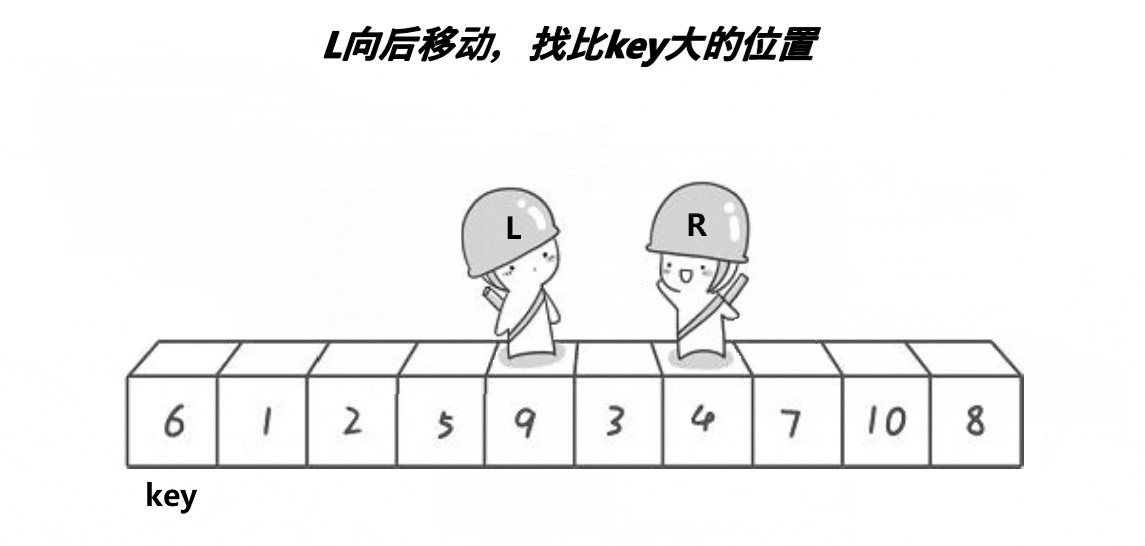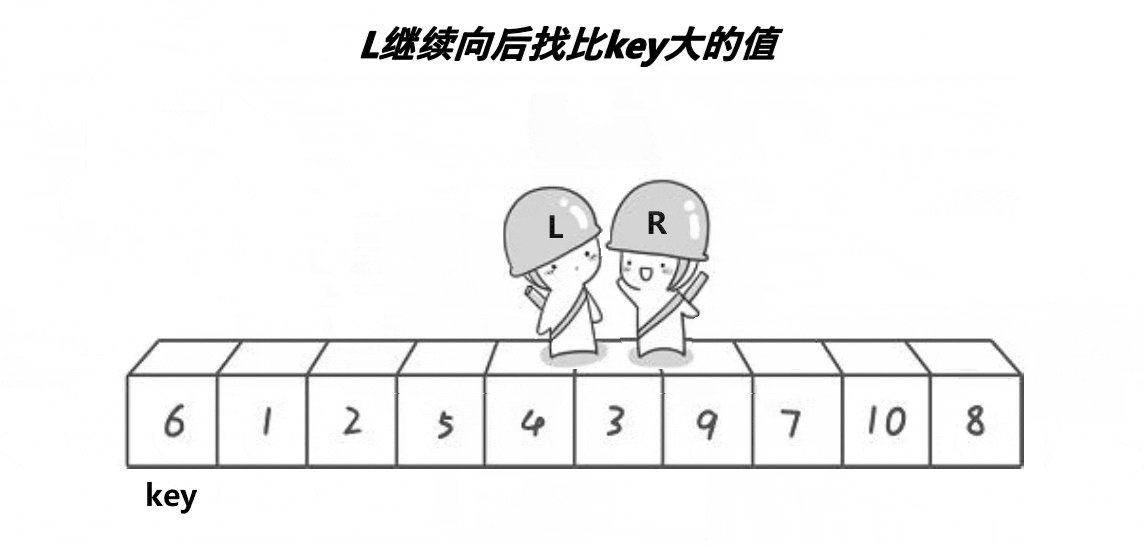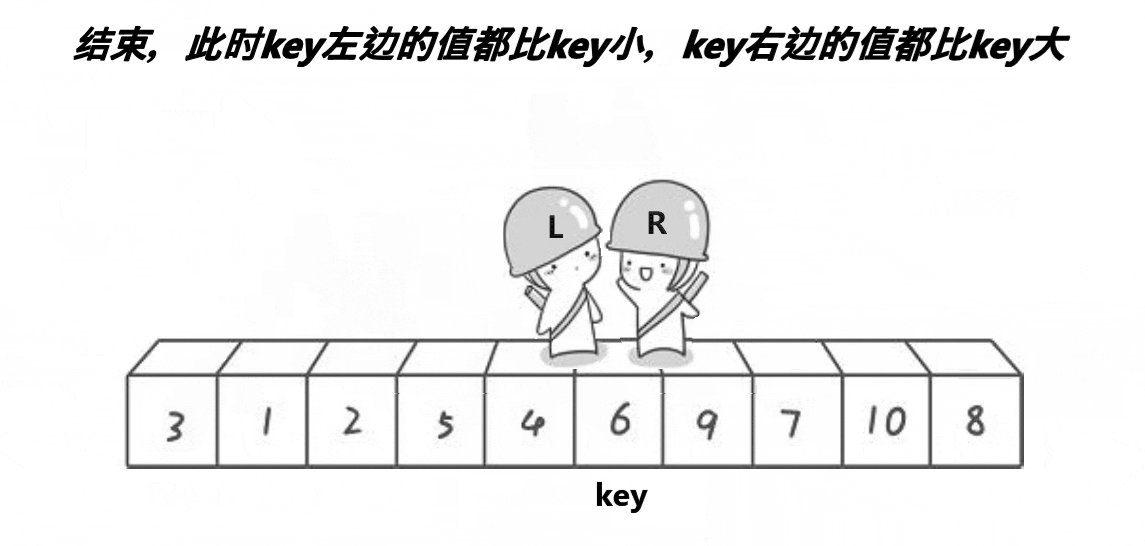
如图我们可以发现它的步骤如下
快排步凑
(1)选出基准值key 为 left
(2)右边r先走找到比key小的停止
(3)右边r找到的情况下,左边L再开始找比key大的值
(3)左边L找到的情况下停止,将这两个值进行交换
循环上面的操作
直到他们相遇,将相遇的位置的值与key值交换
这就是快排的单趟排序,接下来让我们来实现一下
void QuickSort2(int* arr, int left, int right)
{int key = left;int begin = left;int end = right;while (begin < end){//先从右边开始找小 //注意结束条件 begin一定<endwhile (begin < end && arr[end] >= arr[key]){--end;}//再从左边找大while (begin < end && arr[begin] <= arr[key]){++begin;}//两边都找到了之后进行交换Swap(&arr[begin], &arr[end]);}//最后相遇再与key交换Swap(&arr[begin], &arr[key]);}
}想必这里大家会有一些疑问,为什么
1.为什么要右边先走,左边先走可以吗
2.为什么最后交换key的位置就固定了
3.要怎么样才能实现排序的效果
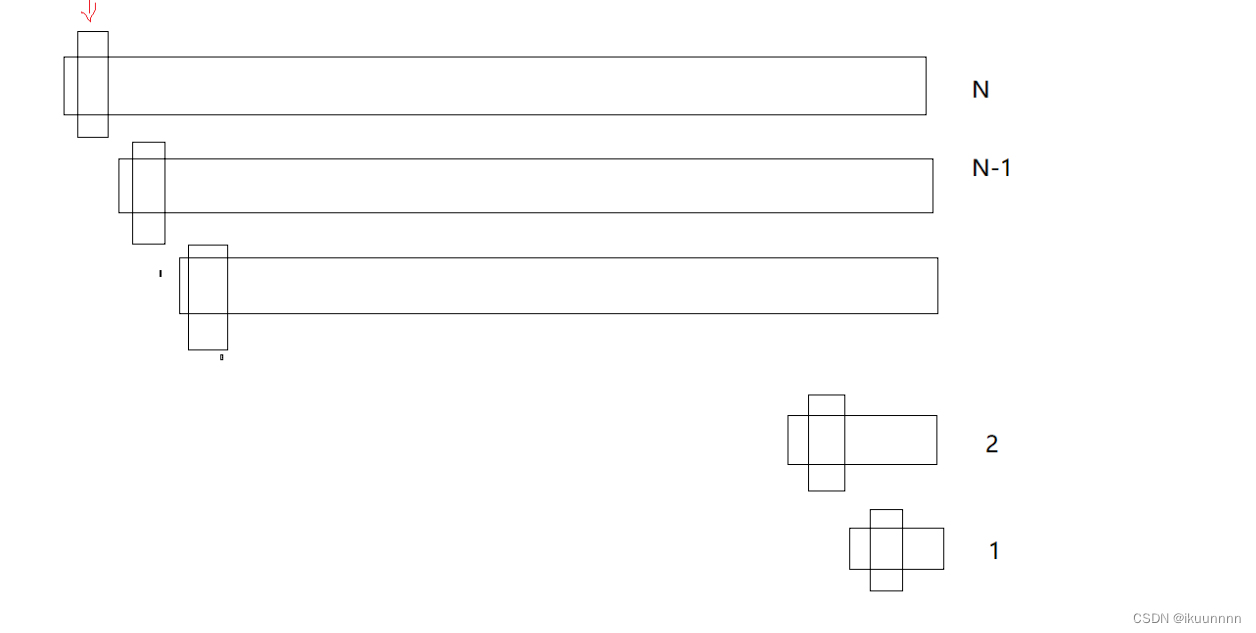
循环的实现,既然单趟可以固定住key值在整个数里面的想要排序的位置,那我们可不可以将这个数组进行分割[left~key-1]key[key+1~right]
运用递归来实现呢
答案是肯定的
只需要每次递归进行分割,固定n的值的位置,如下图所示

如图所示很明显当我们进行递归的时候每次的位置都将被固定,从而实现了排序
代码如下
void QuickSort2(int* arr, int left, int right)
{//返回条件if (left >= right)return;int key = left;int begin = left;int end = right;while (begin < end){//先从右边开始找小 //注意结束条件 begin一定<endwhile (begin < end && arr[end] >= arr[key]){--end;}//再从左边找大while (begin < end && arr[begin] <= arr[key]){++begin;}//两边都找到了之后进行交换Swap(&arr[begin], &arr[end]);}//最后相遇再与key交换Swap(&arr[begin], &arr[key]);//递归排序分割成两份//[left~key-1] key [key+1~right]最后相遇的指针也是一样的QuickSort2(arr, left, end - 1);QuickSort2(arr, end + 1, right);
}到这里我们也就完成了阉割版的快排,但是距离真正的快排还是有些距离
现在的这个排序有着致命的缺陷如果说在数组已经是有些的情况下,快排的将会退化,就像是二叉树退化为单叉树一样,如果我们这时还去递归那就会有爆栈(栈溢出)的风险,原因很简单
如下图所示
如果是有序的情况下,那么递归的深度将会变成n如果数据量太大将会爆栈
所以接下来要去实现一下三数取中,小区间优化来对递归快排进行优化
快排的优化
(1)三数取中
选择key值进行,key值的选择就是为了避免这种有序情况的出现,因为选key固定key的位值,我们只需要找到中间的那个数进行固定区间递归的高度将会变为解决了爆栈的风险
int GetMid2(int* arr, int left, int right)
{//三个数进行比较 分类讨论int mid = (left + right) / 2;if (arr[left] < arr[mid]){if (arr[mid] < arr[right]){return mid;}//arr[mid]>arr[right]else if (arr[right] < arr[left]){return left;}else{return right;}}else//arr[left]> arr[mid]{if (arr[mid] > arr[right]){return mid;}//arr[righ]>arr[mid]else if (arr[right]>arr[left]){return left;}else{return right;}}
}(2)小区间优化
什么是小区间优化?在我们进行快排的时候,如果每次的区间都能二分的化,这个递归的过程是可以看出一颗二叉树,而在满二叉树的叶子节点个数为整棵树的一半,对于快排来说它的最后一层和倒数第二层,是不用去排和只排一个数的,但是却还要开辟栈帧,所以我们这里使用小区间优化带代码如下直接使用当区间小于10时进行插入排序
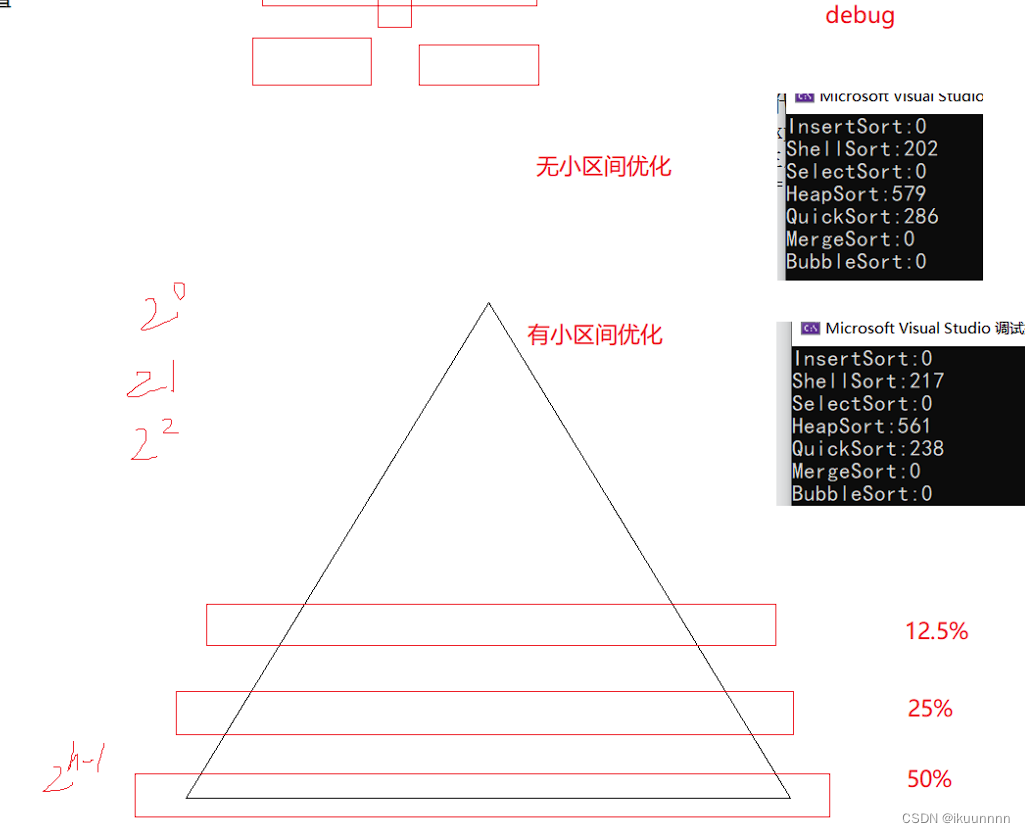
//小区间优化 提升效率节省空间
if ((right - left + 1) < 10)//减少递归次数
{//加上偏移量leftInsertSort(arr+left, right - left + 1);
}
else
{//进行递归
}注意事项
二.前后指针法(递归实现)
由于hoare版本的有些复杂要去考虑什么右边先走之类的,所以又有人想出了更加简单跟容易理解的办法,前后指针法,过程如图所示

可以发现与hoare版本大体一致都是去选择key与key比较,不同点在于,只有是cur去找比key小的值,当找到比key小的值的时候++prev然后与cur位置的值进行交换,最后当cur走到最后,prev的值再与key位置的值进行交换,比起hoare版本简单了许多,接下来我们来尝试实现一下
void QuickSortByPointer(int* arr, int left, int right)
{if (left >= right)return;//三数取中int mid = GitMid(arr,left,right);Swap(&arr[mid], &arr[left]);int key = left;int prev = left;int cur = prev+1;//三数取中if ((right - left + 1) < 10){InsertSort(arr+left, right - left + 1);//加上left}else{while (cur <= right){if (arr[key] > arr[cur]&&++prev != cur)//为什么要写成这样?Swap(&arr[prev], &arr[cur]);cur++;}Swap(&arr[prev], &arr[key]);//区间变为[0,prev-1]prev[prev+1,right]QuickSortByPointer(arr, left, prev - 1);//值给错了应该是leftQuickSortByPointer(arr, prev + 1, right);}
}你以为到这里快排就结束了嘛其实还是马达马达得是(远远没有结束),虽然我们加上三数取中,与小区间的优化但是如果数据量过大还是会有爆栈的风险(栈的空间比较小),所以我们可以使用数据结构的栈来模拟实现程序中的压栈与出栈,(由于是在堆中建立,内存巨大,8G的内存不可能溢出把!)
三.快排的非递归实现(前后指针法的非递归)
可以看见我们先是将每次的单次排序进行封装的
我们可以想象一下在程序中栈帧的建立与销毁的过程,然后我们也可以自己使用数据结构的栈来实现
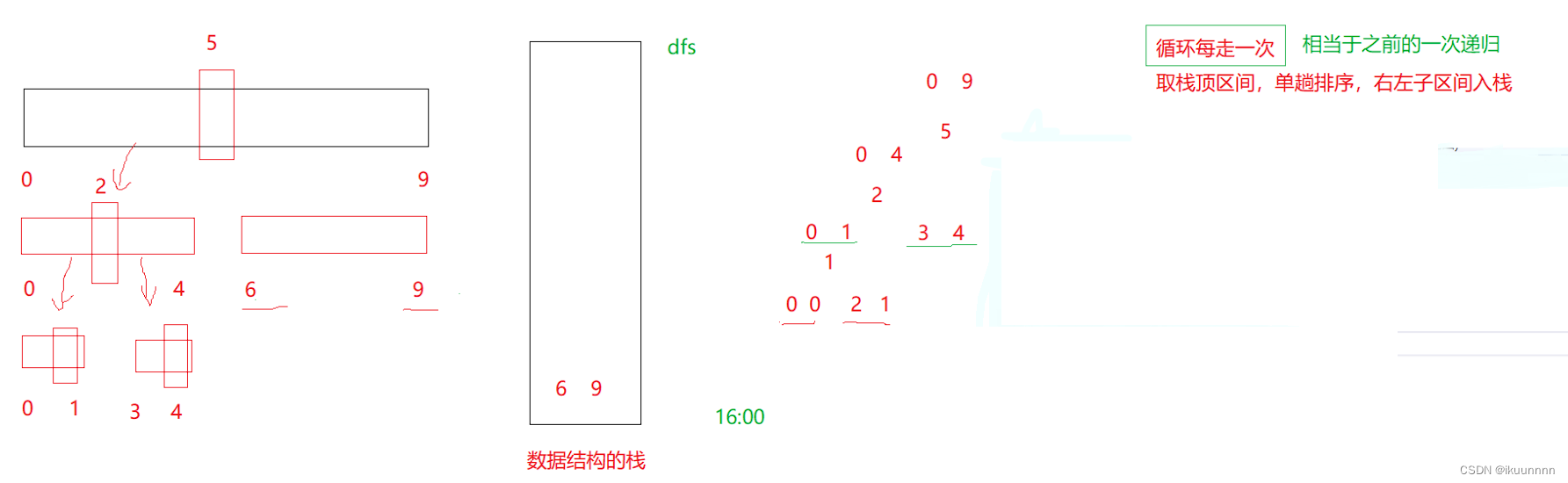
快排其实是可以看作二叉树的前序遍历的,但是栈又是后进先出,想要先得到左边界的值就需要先进右边,想要得到右边界的值就需要先进左边
void QuickSortNoR(int* arr, int begin, int end)
{Stack st;CreatStack(&st);StackPush(&st, end);StackPush(&st, begin);while (StackGetSize(&st)!=0){int left = StackPop(&st);//我的Pop是即出又返回栈顶元素的因为后进先出想要先得到left进右int right = StackPop(&st);//小区间优化if ((right - left + 1) / 2 < 10)InsertSort(arr + left, right - left + 1);else{//开始模拟递归int key = PartPointer(arr, left, right);//这个函数是每一次的单趟排序if (key + 1 < right)//进行递归由于后进先出 先进右区间{StackPush(&st, right);//后进先出由于我们的右区间是后出 所以先进StackPush(&st, key + 1);}if (left < key - 1)//注意错误之处区间不要写错了{StackPush(&st, key - 1);StackPush(&st, left);}}}
}
int PartPointer(int* arr, int left, int right)
{//三数取中int mid = GitMid(arr, left, right);Swap(&arr[mid], &arr[left]);int key = left;int prev = left;int cur = prev + 1;while (cur <= right){if (arr[key] > arr[cur])Swap(&arr[++prev], &arr[cur]);cur++;}Swap(&arr[prev], &arr[key]);return prev;//返回key的位置 prev就是key中间值 然后进行区间的分割同上
}快排的挖坑法的实现
(由于篇幅有限这里不在过多讲解)
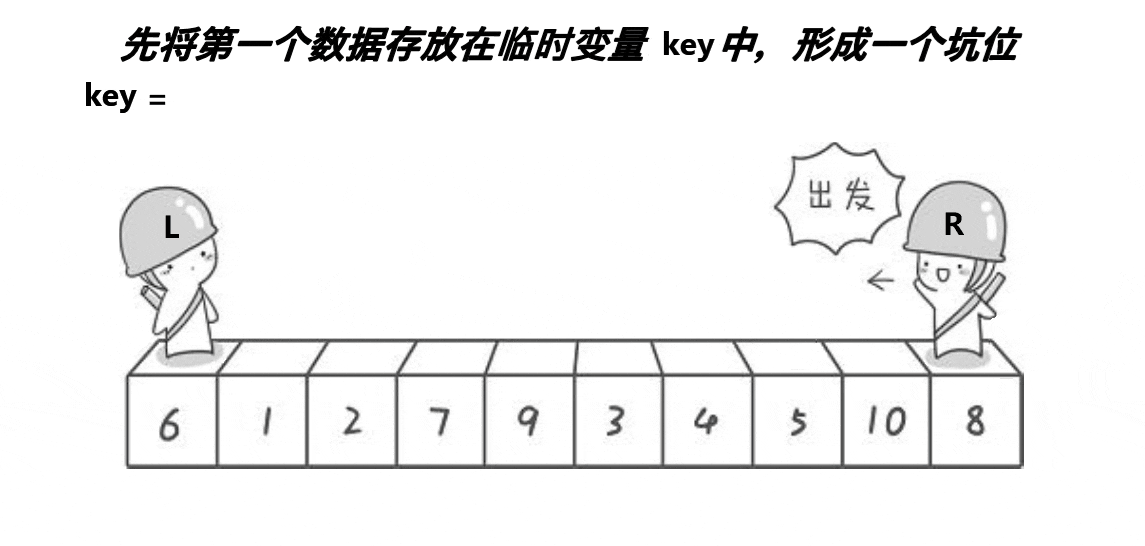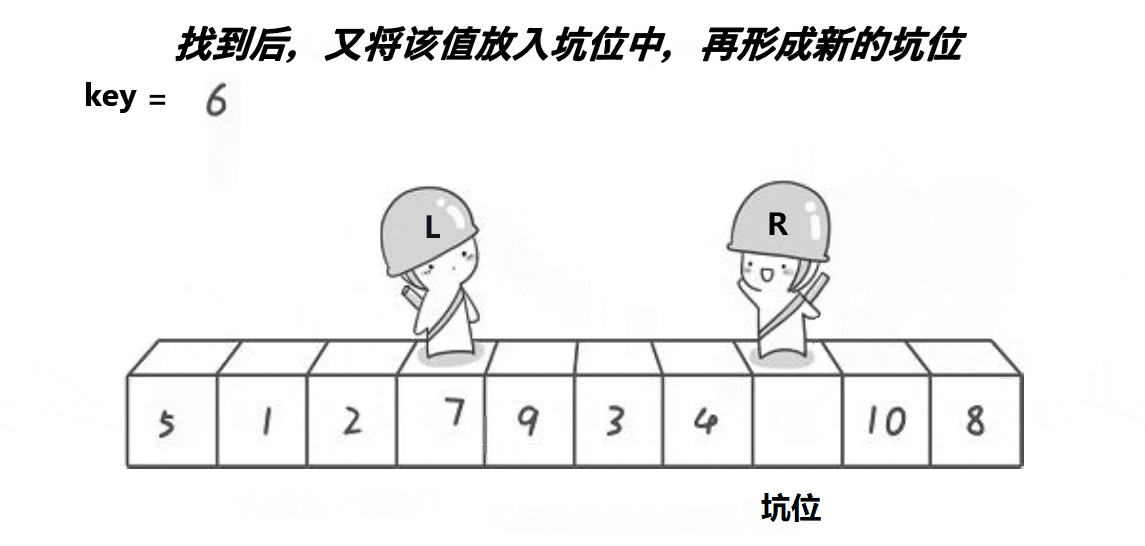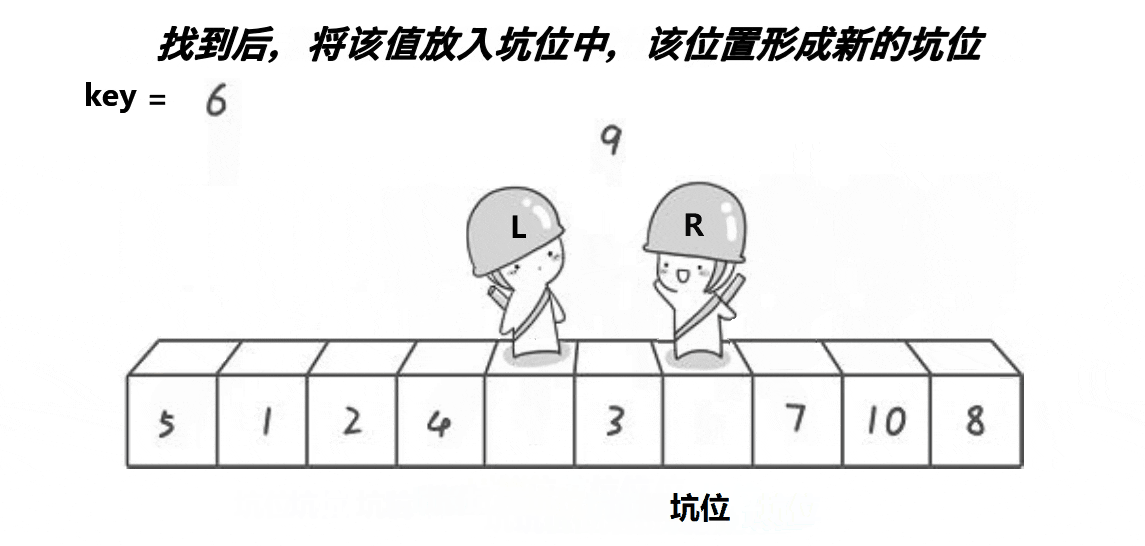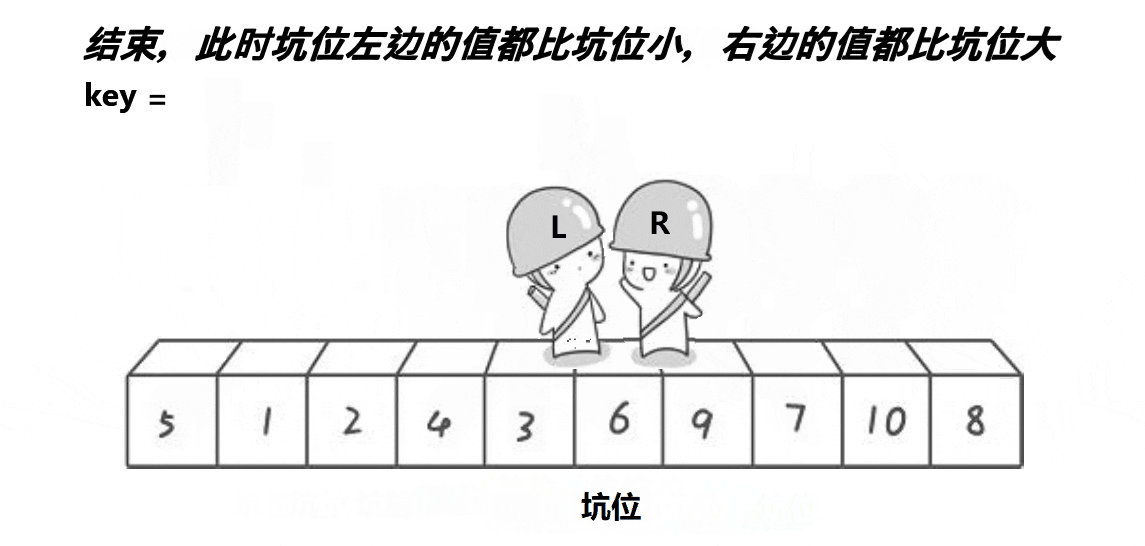
int PartSort2(int* a, int begin, int end)
{//begin是坑int key = a[begin];while (begin < end){while (begin < end && a[end] >= key)--end;// end给begin这个坑,end就变成了新的坑。a[begin] = a[end];while (begin < end && a[begin] <= key)++begin;// end给begin这个坑,begin就变成了新的坑。a[end] = a[begin];}a[begin] = key;return begin;
}二.堆排序
学习完了快排,接下来学习堆,首先我们要知道堆的概念,
堆在逻辑结构上是一个完全二叉树,在物理结构上是一个数组,
想要找到儿子节点就是(parent-1)/2
想要找到父亲节点就是child*2+1
如果想要深入理解堆可以看我的这一篇博客堆的实现与堆排序(纯C语言版)-CSDN博客
1.建堆的选择
当我们想要进行排序的时候首先要模拟堆的插入过程进行建堆,这里有个问题如果想要降序排列那么应该建小堆还是大堆呢,在我刚开学学习的时候想的是肯定是建大堆啊因为这样根节点就是最大的然后再出堆,其实这样想就错了,这样只是出堆降序,不是数组本身进行了降序排列,所以降序是其实是建小堆,升序其实是建大堆.那又是怎么实现的呢
2.堆排序的实现
在进行建堆之后(小堆降序来举例),我们就只需要模拟出堆,这时每次最小的数就被放在了最后的位置,最后完成排序后,整个数据就有序,如图当我们想要升序排列的时候建大堆
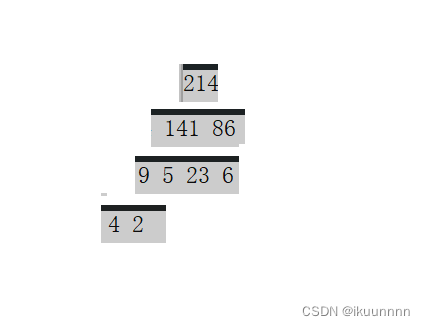

下面是完整的代码
void HeapSort(int* a, int max)//max为最大个数
{//建队for (int i = 0; i <max; i++){AdjustUp(a, i);//模拟插入建小堆}//排序int end = max - 1;//找到最后一个元素的下标进行交换while (end>0){Swap(&a[0], &a[end]);AdjustDown(a, 0, end);--end;//最后的有序不在排序}
}其实第一步建堆算法还没有做到极致,还可以倒着向下调整,这样的时间复杂度更低
//建堆法2
for (int i = (max - 1 - 1) / 2; i >= 0; i--)//找到第一个非叶子结点 倒着进行想下调整
{AdjustDown(a, i, max-1);
}

二希尔排序
希尔排序是一个时间复杂度大约为的排序算法,
它其实就是运用的插入排序
它的排序可以分为2步
1.预排序分为gap组进行
2.当gap=1时即为选择排序
希尔排序的实质就是如果在排一个升序的数组,如果大的在很前面,每次就是一步一步的移动,而当有了gap之后,移动的步长将会变大,大的数将会以更快的速度移到后面

我们将插入排序来进行一下比较
void InsertSort(int* a, int len)
{for (int i = 0; i < len - 1; i++){int end = i;int temp = a[end + 1];while (end >= 0){if (temp < a[end]){a[end + 1] = a[end];end--;}else{break;}a[end + 1] = temp;}}
}可以看见在进行插入排序的时候,此时的步长gap为1,每次只会往后面进行一步,所以我们这里只需去改变想要排序的步长即可
下面是代码的实现
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){// +1保证最后一个gap一定是1// gap > 1时是预排序// gap == 1时是插入排序gap = gap / 3 + 1;for (size_t i = 0; i < n - gap; ++i){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}我们可以发现,我们上面是一组一组来排序
也可以多组并走都是一样的
三.归并排序(递归实现与非递归的实现)
归并排序的思想就是分治法(分而治之),如图所示
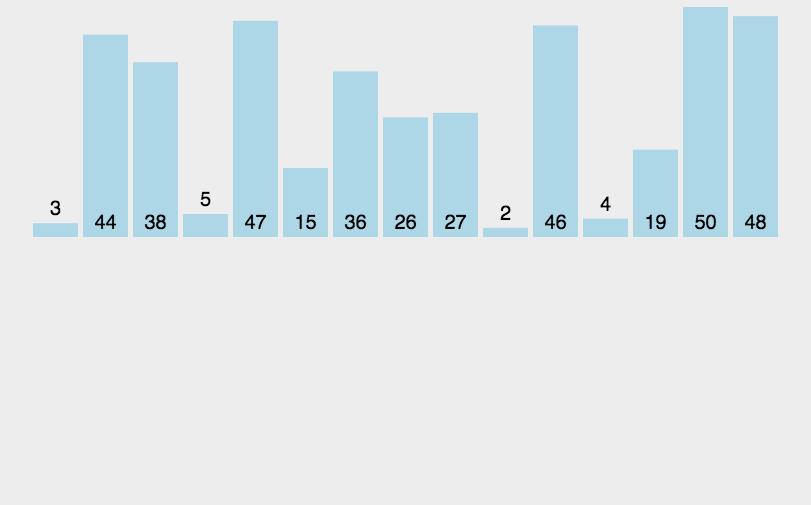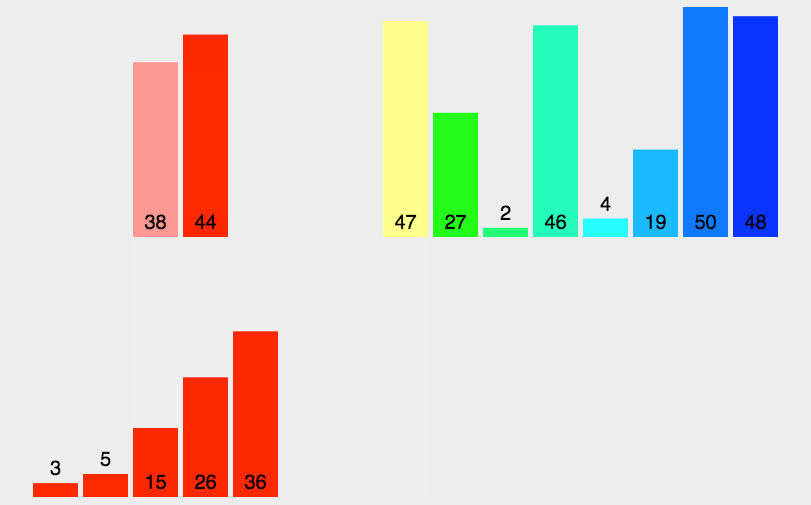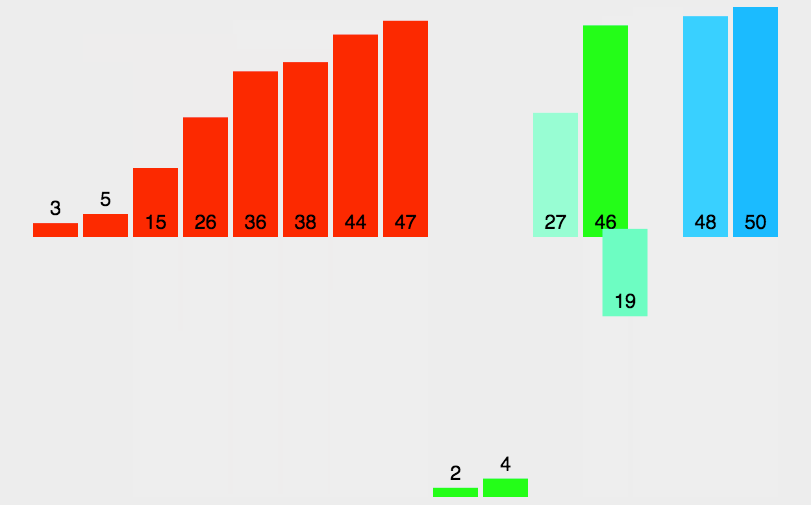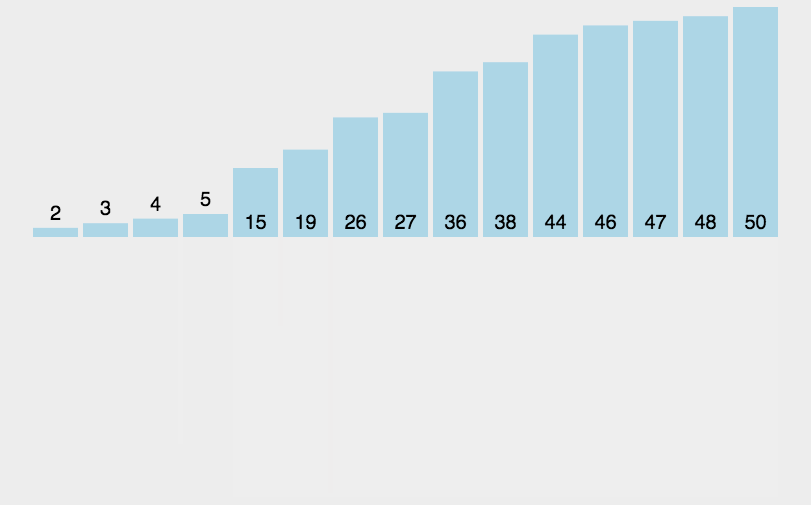
首先我们要创建一个临时的数组
运用了二叉树的后序遍历的思维,先将数组拆分,拆分后的数组又来进行合并,在进行合并的两个数组分别有序,只需要比较一次将小的放入到临时的数组当中,放完成后再拷贝回去完成排序
重点就是在进行合并的时候两个数组是有序的!
让我们来实现一下
l
 000lkklkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkklkkkkkkkkkkkkkkkkkkkkkkkk 222
000lkklkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkklkkkkkkkkkkkkkkkkkkkkkkkk 222
代码如下
void MergeSort(int* arr, int len)
{int* temp = (int*)malloc(sizeof(int) * len);_MergeSort(arr,temp,0,len-1);free(temp);temp = NULL;
}
void _MergeSort(int* arr, int* temp, int left, int right)
{//返回条件if (left >= right)return;//进行递归//分成[left mid][mid+1,right]不能写成[left mid-1][mid,right]分区间的时候将会出现问题//单趟排序 将左右区间看作有序数组 进行比较放入temp数组中int mid = (left + right) / 2;//[left mid][mid+1,right]int begin1 = left;int begin2 = mid + 1;int end1 = mid;int end2 = right;_MergeSort(arr, temp, begin1, end1);//左区间_MergeSort(arr, temp, begin2, end2);//右区间int i = 0;while (begin1 <= end1 && begin2 <= end2){if (arr[begin1] < arr[begin2]){temp[i++] = arr[begin1++];}else//直接else{temp[i++] = arr[begin2++];}}//循环结束后还有元素全部放后面while (begin1 <= end1){temp[i++] = arr[begin1++];}//循环结束后还有元素全部放后面while (begin2 <= end2){temp[i++] = arr[begin2++];}//进行拷贝回去memcpy(arr+left, temp, i*sizeof(int));
}归并排序(非递归实现)
想要实现归并的非递归,我们是否还需要像快排一样去模拟栈呢,当我们取模拟栈的时候由于归并的递归是一个后序遍历,而栈无法去记录值,所以使用栈就要用两个,较为麻烦,使用我们直接用下面这种思想

由上面递归实现的归并排序很容易想,其中的gap为每个小组的个数
但是好像还有一个问题,数组越界的问题
当我们使用了上面的数据进行分组的时候,所以我们要进行区间的判断
加入
if (begin2 > len - 1)//begin2已经越界,说明只有一组了没必要再排
{break;
}
if (end2 > len - 1)//end2越界了进行修正即可
{end2 = len - 1;
}完整的代码如下
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}// gap每组归并数据的数据个数int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){// [begin1, end1][begin2, end2]int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;//printf("[%d,%d][%d,%d] ", begin1, end1, begin2, end2);// 第二组都越界不存在,这一组就不需要归并if (begin2 >= n)break;// 第二的组begin2没越界,end2越界了,需要修正一下,继续归并if (end2 >= n)end2 = n - 1;int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2])//注意等号这样才会稳定{tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];} }while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}//memcpy(a , tmp , sizeof(int) *n );//printf("\n");gap *= 2;}free(tmp);tmp = NULL;
}四.非比较排序(计数排序)
接下来让我们来学习最后一个排序,这个排序的特点是非比较的排序,通过建立一个数组来存放数组中每个数出现的次数,来实现排序

首先来思考我们想要开辟的数组的大小,那是否就是原数组的长度大小呢,因为要存储每个元素出现的次数,那么我们开辟数组必须是连续的,在开辟数组长度大小的时候有个细节,如果每次都从0开始建立计数数组,那如果遇到一个最小值为99,最大值为110的数组,那我们还是需要从0开始建立数组,前面明明一个数都没有出现但是我们却还是去开辟的数组,浪费了很多的空间,所以我们只需要去找到最大与最小的那个值,计算出rang=最大值-最小值+1(注意要加一),所以计数数数组的大小为rang,那我们在进行计数的时候就只需要进行-min就可以了
然后是进行排序,当计数数组里不为0说明当前位置有映射值进行自减1.加上min赋值给原数组实现排序效果

代码如下
void CountSort2(int* arr, int len)
{//找到原数组的最大与最小值int min = arr[0];int max = arr[len - 1];for (int i = 0; i < len; i++){if (arr[i] < min){min = arr[i];}if (arr[i] > max){max = arr[i];}}int rang = max - min + 1;//开辟计数数组 注意这里要初始化开辟的计数数组 这样奇计数数组才全是0int* count = (int*)calloc(rang,sizeof(int) * rang);//进行计数for (int i = 0; i < len; i++){count[arr[i] - min]++;}//进行排序int j = 0;for (int i = 0; i < rang; i++){while (count[i]--)//当count[i]的元素不为0的时候说明当前映射有值{arr[j++] = i + min;}}}计数排序的缺陷
既然计数排序是一种映射的方法,所以是只能对整数进行排列的
五.排序总结
学习完了上面的排序现在我们来进行一下总结,

排序 平局时间复杂度 最坏时间复杂度 最好时间复杂度 稳定性
冒泡排序 O(
) O(
) 稳定
选择排序 O(
插入排序 O(
希尔排序 O(
) O(
堆排序 O(
) O(
快速排序 O(
归并排序 O(

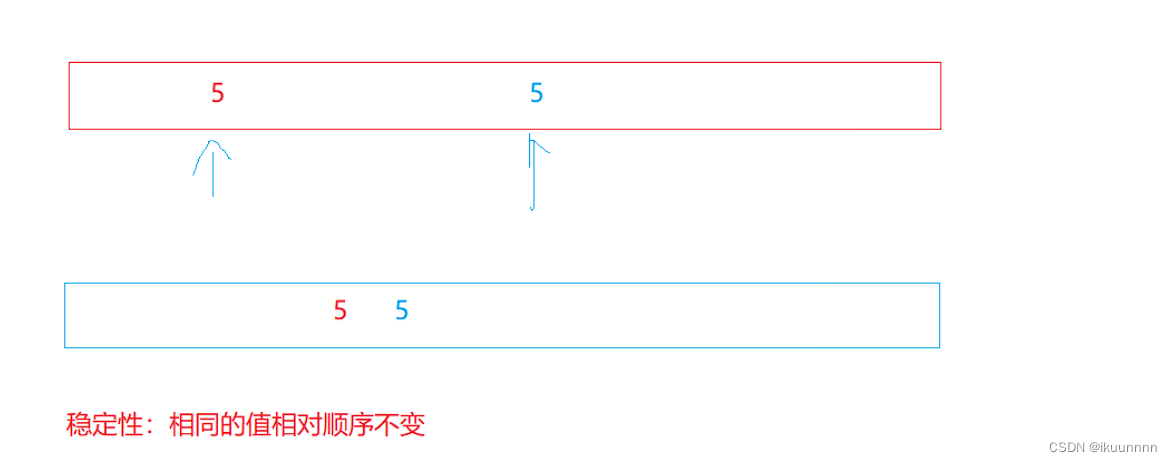
稳定性的概念
上表的稳定性是什么意思?其实就是相同数据的前后位置是否发生改变,如下面红色5与蓝色5当排序完成后红色5还在蓝色5前面就是稳定的
六,排序的选择题练习与巩固
学完上面的知识,不来两道题检测一下是不知道自己真正掌握了没有的下面让我们来做几道题加深一下印象。
1.用某种排序方法对关键字序列 25 84 21 47 15 27 68 35 20 进行排序,序列的变化情况采样如下:
20 15 21 25 47 27 68 35 84
15 20 21 25 35 27 47 68 84
15 20 21 25 27 35 47 68 84
请问采用的是以下哪种排序算法( )
A.选择排序
B.希尔排序
C.归并排序
D.快速排序
答案:D
解析:
此题中的排序是快排二分排序的思想,第一趟的基准值是25,第二趟的基准值分别是20,47,第三趟的基准值分别是15,21,35,68
2.下面的排序算法中,初始数据集的排列顺序对算法的性能无影响的有( )
① 快速排序
② 希尔排序
③ 插入排序
④ 堆排序
⑤ 归并排序
⑥ 选择排序
A.①④⑤
B.④⑤⑥
C.②③⑥
D.②③⑤⑥
答案:B
解析:
快排: 初始顺序影响较大,有序是,性能最差
插入: 接近有序,性能最好
希尔:希尔是对插入排序的优化,这种优化是在无序的序列中才有明显的效果,如果序列接近有序,反而是插入最优。
堆排,归并,选择对初始顺序不敏感
3.下列排序方法中,每一趟排序结束时都至少能够确定一个元素最终位置的方法是( )
① 选择排序
② 归并排序
③ 快速排序
④ 堆排序
A.①④
B.①②④
C.①③④
D.①②③④
答案:C
解析:
选择排序每次选一个最值,放在最终的位置
快速排序每次基准值的位置也可以确定
堆排序每次堆顶元素的位置也可以确定
所以这三种方法都可以每次至少确定一个元素的位置
而归并排序每次都需要对n个元素重新确定位置,所以不能保证每次都能确定一个元素位置,有可能每次排序所有元素的位置都为发生变化。
4.现有数字序列 5 11 7 2 3 17,目前要通过堆排序进行降序排序,那么由该序列建立的初始堆应为( )
A.2 3 7 11 5 17
B.17 11 7 2 3 5
C.17 11 7 5 3 2
D.2 3 5 7 11 17
答案:A
解析:
要降序排列,所以要建小堆,每次把堆顶元素放在当前堆的最后一个位置
建堆要进行向下调整算法(从最后一个非叶子节点开始进行向下调整算法,直到根元素)
5
11 7
2 3 17
5
2 7
11 3 17
2
3 7
11 5 17
所以初始堆序列为: 2 3 7 11 5 17
5.下列选项中,不可能是快速排序第2趟排序后的结果的是( )
A.2 3 5 4 6 7 9
B.2 7 5 6 4 3 9
C.3 2 5 4 7 6 9
D.4 2 3 5 7 6 9
答案:C
解析:
这里说的是快排的第二趟,即在第一趟快排的结果的基础上进行的,如果已经经过了一趟排序,则会通过第一趟选择的基准值划分两个子区间,每个子区间也会以区间内选择的基准值划分成两部分。
A: 第一趟的基准值可以为2, 第二趟的基准值可以为3
B: 第一趟的基准值可以为2, 第二趟的基准值可以为9
C: 第一趟的基准值只能是9,但是第二趟的基准值就找不出来,没有符合要求的值作为基准值,所以不可能是一个中间结果。
D: 第一趟的基准值可以为9, 第二趟的基准值可以为5
由于个人精力有限,如有错误欢迎指出!!!
小bit!!!
相关文章:
常见八大排序(纯C语言版)
目录 基本排序 一.冒泡排序 二.选择排序 三.插入排序 进阶排序(递归实现) 一.快排hoare排序 1.单趟排序 快排步凑 快排的优化 (1)三数取中 (2)小区间优化 二.前后指针法(递归实现) 三.快排的非…...
----vuex)
vue2学习(06)----vuex
目录 一、vuex概述 1.定义 优势: 2.构建环境步骤 3.state状态 4.使用数据 4.1通过store直接访问 4.2通过辅助函数 5.mutations修改数据(同步操作) 5.1定义 5.2步骤 5.2.1定义mutations对象,对象中存放修改state数据的方…...

webflux 拦截器验证token
在WebFlux中,我们可以使用拦截器(Interceptor)来验证Token。以下是一个简单的示例: 1. 首先,创建一个名为TokenInterceptor的类,实现HandlerInterceptor接口: java import org.springframewor…...

C++中的继承方式
目录 摘要 1. 公有继承(Public Inheritance) 2. 保护继承(Protected Inheritance) 3. 私有继承(Private Inheritance) 4. 多重继承(Multiple Inheritance) 继承列表的项数 摘要…...
Vue进阶之Vue无代码可视化项目(四)
Vue无代码可视化项目 左侧栏第一步LeftPanel.vueLayoutView.vuebase.css第二步LayoutView.vueLeftPanel.vue编排引擎smooth-dnd安装创建文件SmoothDndContainer.tsutils.tsSmoothDndDraggable.tsLeftPanel.vue左侧栏 第一步 创建LeftPanel LeftPanel.vue <script setup…...

day40--Redis(二)实战篇
实战篇Redis 开篇导读 亲爱的小伙伴们大家好,马上咱们就开始实战篇的内容了,相信通过本章的学习,小伙伴们就能理解各种redis的使用啦,接下来咱们来一起看看实战篇我们要学习一些什么样的内容 短信登录 这一块我们会使用redis共…...
使用Ollama+OpenWebUI本地部署Gemma谷歌AI开放大模型完整指南
🏡作者主页:点击! 🤖AI大模型部署与应用专栏:点击! 🤖Ollama部署LLM专栏:点击! ⏰️创作时间:2024年6月4日10点50分 🀄️文章质量࿱…...

react的自定义组件
// 自定义组件(首字母必须大写) function Button() {return <button>click me</button>; } const Button1()>{return <button>click me1</button>; }// 使用组件 function App() {return (<div className"App">{/* // 自闭和引用自…...
海宁代理记账公司-专业的会计服务
随着中国经济的飞速发展,企业的规模和数量日益扩大,在这个过程中,如何保证企业的财务活动合规、准确无误地进行,成为了每个企业面临的重要问题,专业、可靠的代理记账公司应运而生。 海宁代理记账公司的主要职责就是为各…...

matlab 计算三维空间点到直线的距离
目录 一、算法原理二、代码实现三、结果展示四、参考链接本文由CSDN点云侠原创,原文链接。如果你不是在点云侠的博客中看到该文章,那么此处便是不要脸的爬虫与GPT。 一、算法原理 直线的点向式方程为: x − x 0 m = y...
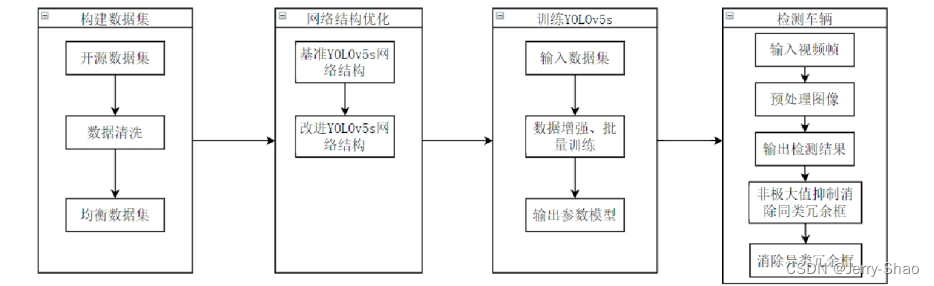
YOLOv5车流量监测系统研究
一. YOLOv5算法详解 YOLOv5网络架构 上图展示了YOLOv5目标检测算法的整体框图。对于一个目标检测算法而言,我们通常可以将其划分为4个通用的模块,具体包括:输入端、基准网络、Neck网络与Head输出端,对应于上图中的4个红色模块。Y…...
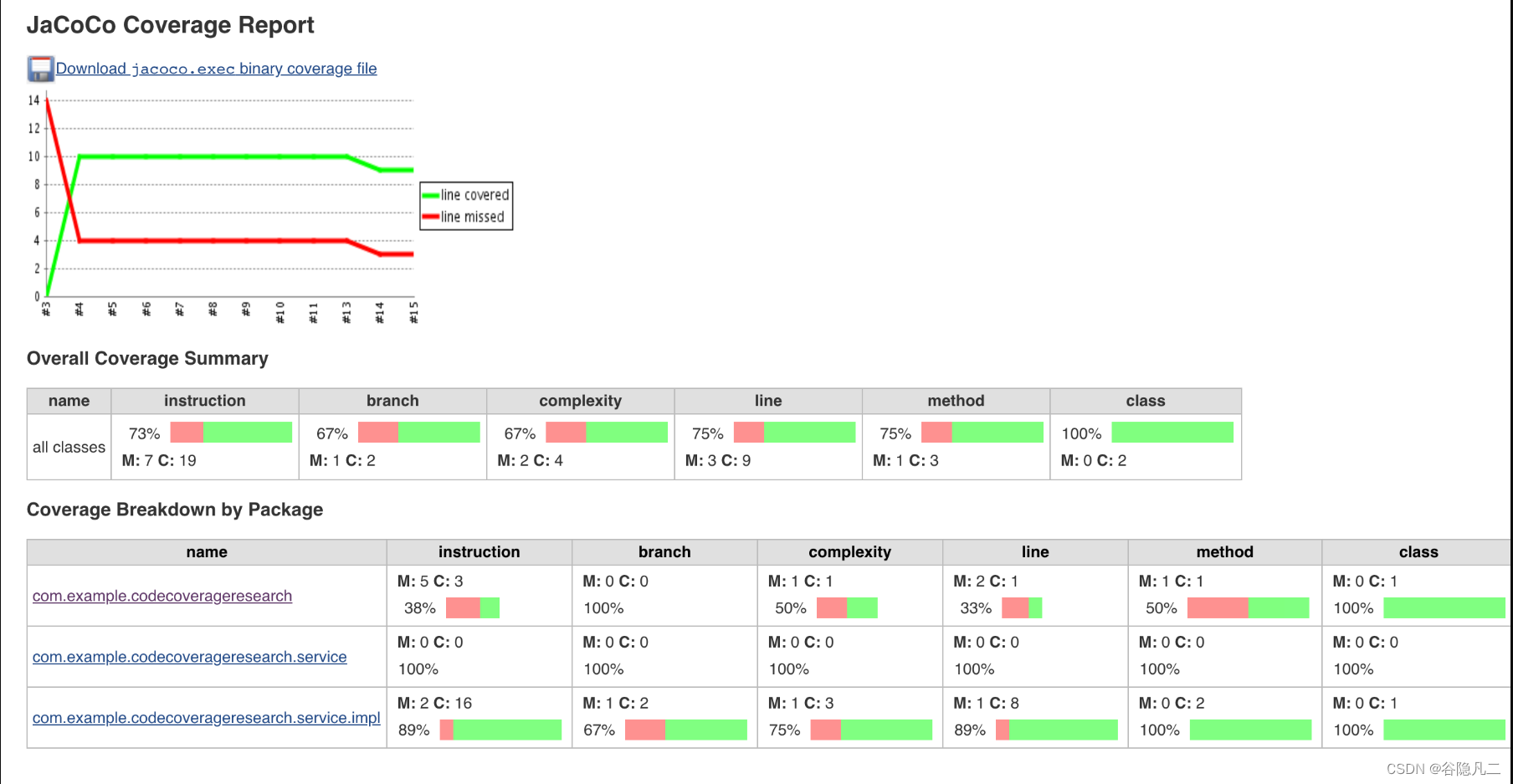
单元测试覆盖率
什么是单元测试覆盖率 关于其定义,先来看一下维基百科上的一段描述: 代码覆盖(Code coverage)是软件测试中的一种度量,描述程序中源代码被测试的比例和程度,所得比例称为代码覆盖率。 简单来理解ÿ…...

逻辑这回事(三)----时序分析与时序优化
基本时序参数 图1.1 D触发器结构 图1.2 D触发器时序 时钟clk采样数据D时,Tsu表示数据前边沿距离时钟上升沿的时间,MicTsu表示时钟clk能够稳定采样数据D的所要求时间,Th表示数据后边沿距离时钟上升沿的时间,MicTh表示时钟clk采样…...
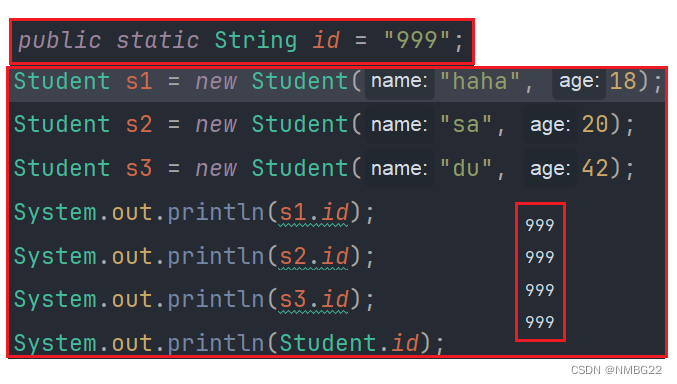
[JAVASE] 类和对象(二) -- 封装
目录 一. 封装 1.1 面向对象的三大法宝 1.2 封装的基本定义与实现 二. 包 2.1 包的定义 2.2 包的作用 2.3 包的使用 2.3.1 导入类 2.3.2 导入静态方法 三. static 关键字 (重要) 3.1 static 的使用 (代码例子) 3.1.1 3.1.2 3.1.3 3.1.4 四. 总结 一. 封装 1.1 面向对象…...
开发网站,如何给上传图片的服务器目录授权
开发网站,上传图像时提示”上传图片失败,Impossible to create the root directory /var/www/html/xxxxx/public/uploads/avatar/20240608.“ 在Ubuntu上,你可以通过调整文件夹权限来解决这个问题。首先,确保Web服务器(…...

特别名词Test Paper2
特别名词Test Paper2 cabinet 橱柜cable 电缆,有线电视cafe 咖啡厅cafeteria 咖啡店,自助餐厅cage 笼子Cambridge 剑桥camel 骆驼camera 相机camp 露营campus 校园candidate 候选人,考生candle 蜡烛canteen 食堂capital 资金,首都…...

数据结构-AVL树
目录 二叉树 二叉搜索树的查找方式: AVL树 AVL树节点的实现 AVL树节点的插入操作 AVL树的旋转操作 右旋转: 左旋转: 左右双旋: 右左双旋: AVL树的不足和下期预告(红黑树) 二叉树 了…...

数字科技如何助力博物馆设计,强化文物故事表现力?
国际博物馆日是每年为了推广博物馆和文化遗产,而设立的一个特殊的日子,让我们可以深入探讨博物馆如何更好地呈现和保护我们的文化遗产,随着近年来的数字科技发展,其在博物馆领域的应用越来越广泛,它为博物馆提供了新的…...

德克萨斯大学奥斯汀分校自然语言处理硕士课程汉化版(第七周) - 结构化预测
结构化预测 0. 写在大模型前面的话1. 词法分析 1.1. 分词1.2. 词性标注 2.2. 句法分析 2.3. 成分句法分析2.3. 依存句法分析 3. 序列标注 3.1. 使用分类器进行标注 4. 语义分析 0. 写在大模型前面的话 在介绍大语言模型之前,先把自然语言处理中遗漏的结构化预测补…...

5-Maven-setttings和pom.xml常用配置一览
5-Maven-setttings和pom.xml常用配置一览 setttings.xml配置 <?xml version"1.0" encoding"UTF-8"?> <settings xmlns"http://maven.apache.org/SETTINGS/1.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xs…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

安宝特案例丨Vuzix AR智能眼镜集成专业软件,助力卢森堡医院药房转型,赢得辉瑞创新奖
在Vuzix M400 AR智能眼镜的助力下,卢森堡罗伯特舒曼医院(the Robert Schuman Hospitals, HRS)凭借在无菌制剂生产流程中引入增强现实技术(AR)创新项目,荣获了2024年6月7日由卢森堡医院药剂师协会࿰…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...

pikachu靶场通关笔记19 SQL注入02-字符型注入(GET)
目录 一、SQL注入 二、字符型SQL注入 三、字符型注入与数字型注入 四、源码分析 五、渗透实战 1、渗透准备 2、SQL注入探测 (1)输入单引号 (2)万能注入语句 3、获取回显列orderby 4、获取数据库名database 5、获取表名…...
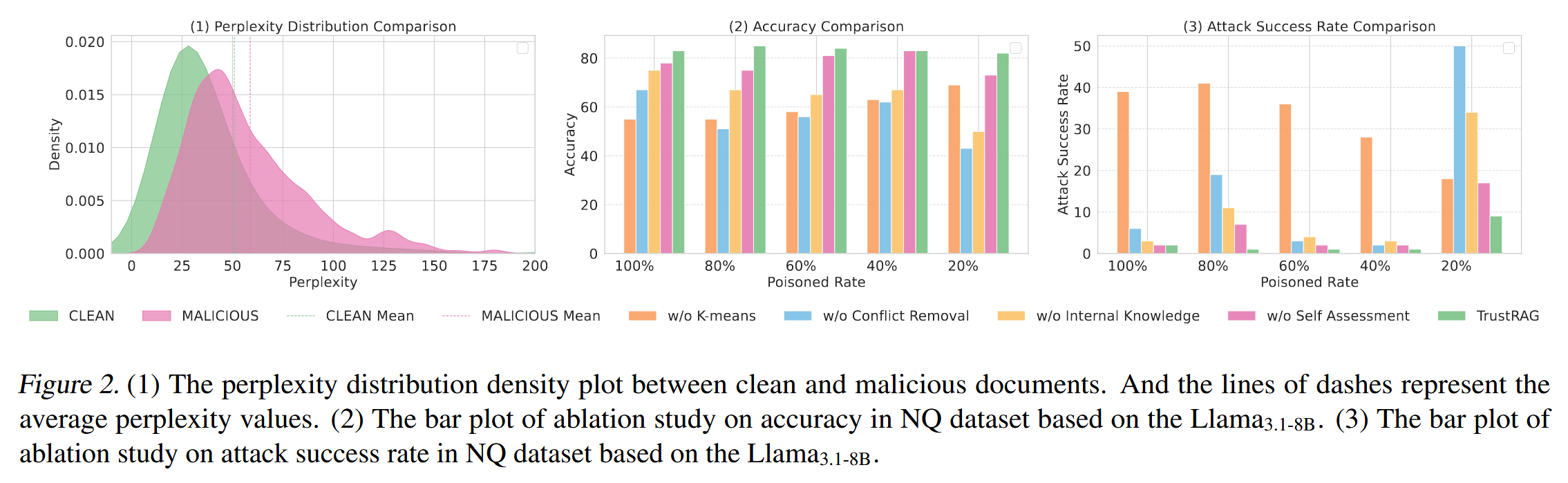
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...