【YOLO系列】YOLOv10论文超详细解读(翻译 +学习笔记)
前言
研究AI的同学们面对的一个普遍痛点是,刚开始深入研究一项新技术,没等明白透彻,就又迎来了新的更新版本——就像我还在忙着逐行分析2月份发布的YOLOv9代码,5月底清华的大佬们就推出了全新的v10。。。

在繁忙之余,我抽空拜读了这篇论文。不对创新方法做过多评价,但论文的框架、整理思路以及实验部分的写作手法,给正在撰写论文的我带来了极大的启发。
YOLOv10以实时的端到端目标检测能力而闻名,通过提供结合效率和准确性的强大解决方案。
随着新版本的发布,许多人已经积极展开部署测试工作,并且反馈效果看起来也是不错滴~
话不多说,我们一起来读一下吧!

学习资料:
- 论文题目:《YOLOv10:毫秒级实时端到端目标检测开源模型》
- 论文链接:https://arxiv.org/pdf/2405.14458
- 项目链接:https://github.com/THU-MIG/yolov10
![]() YOLO论文系列前期回顾:
YOLO论文系列前期回顾:
【YOLO系列】YOLOv9论文超详细解读(翻译 +学习笔记)
【YOLO系列】YOLOv7论文超详细解读(翻译 +学习笔记)
【YOLO系列】YOLOv6论文超详细解读(翻译 +学习笔记)
【YOLO系列】YOLOv5超详细解读(网络详解)
【YOLO系列】YOLOv4论文超详细解读2(网络详解)
【YOLO系列】YOLOv4论文超详细解读1(翻译 +学习笔记)
【YOLO系列】YOLOv3论文超详细解读(翻译 +学习笔记)
【YOLO系列】YOLOv2论文超详细解读(翻译 +学习笔记)
【YOLO系列】YOLOv1论文超详细解读(翻译 +学习笔记)
目录
前言
Abstract—摘要
翻译
精读
1 Introduction—引言
翻译
精读
2 Related Work—相关工作
翻译
精读
3 Methodology—方法
3.1 Consistent Dual Assignments for NMS-free Training—用于无NMS训练的一致的双重训练
翻译
精读
3.2 Holistic Efficiency-Accuracy Driven Model Design—整体效率-精度驱动的模型设计
翻译
精读
4 Experiments—实验
4.1 Implementation Details—实验细节
翻译
精读
4.2 Comparison with state-of-the-arts—与最先进技术的比较
翻译
精读
4.3 Model Analyses—模型分析
Ablation study—消融实验
翻译
精读
Analyses for NMS-free training—无NMS训练分析
翻译
精读
Analyses for efficiency driven model design—效率驱动的模型设计分析
翻译
精读
Analyses for accuracy driven model design—精度驱动的模型设计分析
翻译
精读
5 Conclusion—结论
翻译
精读

Abstract—摘要
翻译
在过去的几年里,YOLO已经成为在实时目标检测领域的主要范例,由于其有效的计算成本和检测性能之间的平衡。研究人员已经探索了YOLO的架构设计,优化目标,数据增强策略等,取得了显着的进展。然而,依赖于非最大抑制(NMS)进行后处理阻碍了端到端部署的YOLO和不利影响的推理延迟。此外,YOLO中各个组件的设计缺乏全面和彻底的检查,导致明显的计算冗余,限制了模型的能力。它呈现出次优的效率,沿着具有相当大的性能改进潜力。在这项工作中,我们的目标是从后处理和模型架构两个方面进一步推进YOLO的性能效率边界。为此,我们首先提出了一致的双重分配的NMS自由训练的YOLO,这带来了竞争力的性能和低推理延迟的同时。此外,我们介绍了整体的效率-精度驱动的模型设计策略的YOLO。我们从效率和准确性两个角度全面优化了YOLO的各个组件,这大大降低了计算开销,提高了性能。我们努力的成果是新一代的YOLO系列,用于实时端到端对象检测,称为YOLOv 10。大量的实验表明,YOLOv 10在各种模型尺度上都达到了最先进的性能和效率。例如,我们的YOLOv 10-S在COCO上的类似AP下比RT-DETR-R18快1.8倍,同时享受2.8倍的参数和FLOP。与YOLOv 9-C相比,YOLOv 10-B在相同性能下的延迟减少了46%,参数减少了25%。代码:https://github.com/THU-MIG/yolov10.
精读
YOLOv1~v9仍存在的不足
- 后处理对非极大值抑制(NMS)的依赖阻碍了 YOLO 的端到端部署,并对推理延迟产生了不利影响。
- YOLO中各个组件的设计缺乏全面和彻底的检查,导致明显的计算冗余,限制了模型的能力。
本文的主要方法
从后处理和模型架构方面进一步提升了 YOLO 的性能 - 效率边界:
- 首先提出了 YOLO 无 NMS 训练的一致双重分配,这带来了竞争力的性能和低推理延迟。
- 此外,介绍了整体效率 - 精度驱动的模型设计策略,从效率和准确率两个角度全面优化 YOLO 的各个组件,大大降低了计算开销,提高了模型的性能。
实验结果
YOLOv10 在各种模型规模上都实现了 SOTA 性能和效率。
- 与RT-DETR相比:YOLOv10-S在COCO上的类似AP下比RT-DETR-R18快1.8倍,同时享受2.8倍的参数和FLOP。
- 与YOLOv 9-C相比:YOLOv10-B在相同性能下的延迟减少了46%,参数减少了25%。

1 Introduction—引言
翻译
实时目标检测一直是计算机视觉领域的研究热点,其目标是在低延迟下准确预测图像中目标的类别和位置。它被广泛应用于各种实际应用中,包括自动驾驶[3],机器人导航[11]和对象跟踪[66]等。近年来,研究人员集中精力设计基于CNN的对象检测器以实现实时检测[18,22,43,44,45,51,12]。其中,YOLO由于其在性能和效率之间的巧妙平衡而越来越受欢迎[2,19,27,19,20,59,54,64,7,65,16,27]。YOLO的检测流水线由模型前向处理和NMS后处理两部分组成。然而,这两种方法仍然存在不足,导致精度-延迟边界不理想。
具体来说,YOLO通常在训练期间采用一对多标签分配策略,其中一个地面实况对象对应于多个正样本。尽管产生了上级性能,但这种方法需要NMS在推断期间选择最佳的正预测。这降低了推理速度,并使性能对NMS的超参数敏感,从而阻止YOLO实现最佳的端到端部署[71]。解决这个问题的一个方法是采用最近引入的端到端DETR架构[4,74,67,28,34,40,61]。例如,RT-DETR [71]提出了一种高效的混合编码器和不确定性最小的查询选择,将DETR推向了实时应用领域。然而,部署DETR固有的复杂性阻碍了其在准确性和速度之间实现最佳平衡的能力。另一行是探索基于CNN的检测器的端到端检测,其通常利用一对一分配策略来抑制冗余预测[5,49,60,73,16]。但是,它们通常会引入额外的推理开销或实现次优性能。
此外,模型架构设计仍然是YOLO的一个基本挑战,它对准确性和速度有重要影响[45,16,65,7]。为了实现更高效和有效的模型架构,研究人员探索了不同的设计策略。针对主干提出了各种主要计算单元以增强特征提取能力,包括DarkNet [43,44,45],CSPNet [2],EfficientRep [27]和ELAN [56,58]等。对于颈部,PAN [35],BiC [27],GD [54]和RepGFPN [65]等,的多尺度特征融合。此外,还研究了模型缩放策略[56,55]和重新参数化[10,27]技术。虽然这些努力已经取得了显着的进步,但仍然缺乏从效率和准确性角度对YOLO中的各种组件进行全面检查。因此,YOLO中仍然存在相当大的计算冗余,导致参数利用效率低下和效率次优。此外,由此产生的约束模型的能力也导致性能较差,留下足够的空间来提高精度。
在这项工作中,我们的目标是解决这些问题,并进一步推进YOLO的精度-速度边界。我们的目标是整个检测管道的后处理和模型架构。为此,我们首先解决后处理中的冗余预测问题,提出了一个一致的双重分配策略,用于无NMS的YOLO,具有双重标签分配和一致的匹配度量。它允许模型在训练过程中享受丰富而和谐的监督,同时在推理过程中无需NMS,从而以高效率实现竞争性能。其次,通过对YOLO中各个组件的全面检查,提出了整体效率-精度驱动的模型架构设计策略。为了提高效率,我们提出了轻量级分类头,空间通道解耦下采样和秩引导块设计,以减少表现出的计算冗余,实现更高效的架构。为了准确性,我们探索了大内核卷积,并提出了有效的部分自注意模块来增强模型能力,利用低成本下的性能改进潜力。
基于这些方法,我们成功地实现了具有不同模型尺度的实时端到端检测器的新家族,即,YOLOv10-N / S / M / B / L / X。对目标检测的标准基准进行了广泛的实验,即,COCO [33]证明,我们的YOLOv 10在各种模型规模的计算精度权衡方面可以显着优于以前的最先进模型。如图1所示,我们的YOLOv 10-S / X在类似性能下分别比RT-DETRR 18/ R101快1.8倍/ 1.3倍。与YOLOv 9-C相比,YOLOv 10-B在性能相同的情况下,延迟减少了46%。此外,YOLOv 10表现出高效的参数利用。我们的YOLOv 10-L / X比YOLOv 8-L / X高0.3 AP和0.5 AP,参数数量分别少1.8倍和2.3倍。与YOLOv 9-M / YOLO-MS相比,YOLOv 10-M实现了相似的AP,参数分别减少了23% / 31%。我们希望我们的工作能够激发该领域的进一步研究和进步。
精读
目标检测的发展
- YOLO系列:YOLO在性能和效率方面取得了平衡,但存在训练和推断中的问题,如标签分配策略和NMS的使用。
- DETR系列:DETR是一种端到端的检测器架构,可以有效解决YOLO存在的问题,RT-DETR是DETR的一个变体,可以实现实时应用。
- 基于CNN的端到端检测器的探索:除了DETR,还有一些基于CNN的检测器采用一对一分配策略来减少冗余预测,但存在性能和效率的问题。
YOLO的挑战以及过去的解决方案
- 挑战:YOLO在设计模型架构时需要平衡准确性和速度,但存在计算冗余和效率次优的问题。
- 主干和颈部设计策略:针对主干和颈部设计了多种计算单元和特征融合方法,如DarkNet、CSPNet、PAN等,以增强特征提取能力和多尺度特征融合。
本文方法
- 提出了一个无 NMS 训练的一致双重分配的YOLO,有助于模型在训练和推理过程中提高效率和性能。
- 提出了整体效率-精度驱动的模型架构设计策略,包括轻量级分类头、空间通道解耦下采样和大内核卷积等,以提高模型的效率和准确性。
- 成功实现了具有不同模型尺度的新家族YOLOv10-N/S/M/B/L/X,并在COCO基准上进行了广泛实验,显示出其优于以前先进模型的性能和效率。
2 Related Work—相关工作
翻译
实时目标探测器。实时目标检测的目标是在低延迟下对目标进行分类和定位,这对于现实世界的应用至关重要。在过去的几年里,大量的努力已经指向开发有效的检测器[18,51,43,32,72,69,30,29,39]。特别是YOLO系列[43,44,45,2,19,27,56,20,59]脱颖而出,成为主流。YOLOv 1、YOLOv 2和YOLOv 3标识由三个部分组成的典型检测架构,即,脊柱、颈部和头部[43,44,45]。YOLOv 4 [2]和YOLOv 5 [19]引入了CSPNet [57]设计来取代DarkNet [42],加上数据增强策略,增强的PAN和更多种类的模型尺度等YOLOv 6 [27]分别为颈部和主干提供了BiC和SimCSPSPPF,具有锚辅助训练和自蒸馏策略。YOLOv 7 [56]介绍了用于丰富梯度流路的E-ELAN,并探索了几种可训练的免费赠品袋方法。YOLOv 8 [20]提出了用于有效特征提取和融合的C2f构建块。Gold-YOLO [54]提供了先进的GD机制,以提高多尺度特征融合能力。YOLOv 9 [59]建议GELAN改进架构,PGI增强培训过程。
端到端物体探测器。端到端对象检测已经成为传统管道的范式转变,提供了简化的架构[48]。DETR [4]引入了Transformer架构,并采用匈牙利损失实现一对一匹配预测,从而消除了手工制作的组件和后期处理。从那时起,已经提出了各种DETR变体,以提高其性能和效率[40,61,50,28,34]。Deformable-DETR [74]利用多尺度可变形注意力模块来加速收敛速度。DINO [67]将对比去噪,混合查询选择和两次前瞻方案集成到DETR中。RT-DETR [71]进一步设计了高效的混合编码器,并提出了不确定性最小的查询选择,以提高准确性和延迟。另一种实现端到端对象检测的方法是基于CNN检测器。可学习的NMS [23]和关系网络[25]提供了另一种网络来消除检测器的重复预测。OneNet [49]和DeFCN [60]提出了一对一的匹配策略,以实现使用完全卷积网络的端到端对象检测。FCOSpss [73]引入了一个正样本选择器来选择预测的最佳样本。
精读
Realtime object detectors—实时目标探测器
这一部分就是总结了YOLOv1~v9,可以mark一下,自己论文中引用
End-to-end object detectors—端到端目标检测
- DETR及变体:采用Transformer架构和Hungarian(匈牙利)损失,消除了传统检测管道的手工制作组件和后处理,改进了性能和效率。
- 基于CNN的方法:学习的NMS、关系网络、OneNet和DeFCN等提供了消除重复预测的方法,以实现端到端对象检测。
- 其他技术:如Deformable-DETR利用多尺度可变形注意力模块,DINO结合对比去噪技术等,进一步提高了性能。
3 Methodology—方法
3.1 Consistent Dual Assignments for NMS-free Training—用于无NMS训练的一致的双重训练
翻译
在训练过程中,YOLO [20,59,27,64]通常利用TAL [14]为每个实例分配多个阳性样本。采用一对多的分配方式,产生丰富的监控信号,有利于优化,获得上级性能。然而,它需要YOLO依赖于NMS后处理,这导致部署的次优推理效率。虽然以前的工作[49,60,73,5]探索了一对一匹配来抑制冗余预测,但它们通常会引入额外的推理开销或产生次优性能。在这项工作中,我们提出了一个无NMS的训练策略的YOLO与双标签分配和一致的匹配度量,实现了高效率和竞争力的性能。
与一对多分配不同,一对一匹配只为每个地面实况分配一个预测,避免了NMS后处理。然而,它导致监督不力,导致次优精度和收敛速度[75]。幸运的是,这种不足可以通过一对多分配来弥补[5]。为了实现这一点,我们引入了YOLO的双标记分配,以联合收割机结合两种策略的优点。具体如图2所示。(a),我们为YOLO加入了另一个一对一的头。它保留了与原始一对多分支相同的结构并采用相同的优化目标,但利用一对一匹配来获得标签分配。在训练过程中,两个头部与模型共同优化,让骨干和颈部享受到一对多分配所提供的丰富监督。在推理过程中,我们丢弃了一对多的头,并利用一对一的头来进行预测。这使YOLO能够用于端到端部署,而不会产生任何额外的推理成本。此外,在一对一匹配中,我们采用了前一个选择,这与匈牙利匹配[4]具有相同的性能,但额外的训练时间更少。
在分配过程中,一对一和一对多方法都利用指标来定量评估预测和实例之间的一致性程度。为了实现两个分支的预测感知匹配,采用统一的匹配度量,即
![]()
其中 𝑝 是分类分数, 𝑏^ 和 𝑏 分别表示预测和实例的边界框。𝑠 表示空间先验,指示预测的锚点是否在实例内。𝛼 和 𝛽 是平衡语义预测任务和位置回归任务影响的两个重要超参数。将一对多和一对一指标分别表示为 𝑚𝑜2𝑚 = 𝑚(𝛼𝑜2𝑚,𝛽𝑜2𝑚) 和 𝑚𝑜2𝑜 = 𝑚(𝛼𝑜2𝑜,𝛽𝑜2𝑜) 。这些指标影响两个头的标签分配和监督信息。
在双标签分配中,一对多分支提供比一对一分支更丰富的监控信号。直观上,如果能够协调一对一头和一对多头的监督,就可以将一对一头朝着一对多头优化的方向优化。因此,一对一头部可以在推理过程中提供更高的样本质量,从而获得更好的性能。为此,首先分析一下两位掌门人的监管差距。由于训练过程中的随机性,一开始就用两个头初始化相同的值并产生相同的预测来开始检查,即一对一头和一对多头生成相同的 𝑝 ,将最大的一对多和一对一匹配分数表示为 𝑚𝑜2𝑚∗ 和 𝑚𝑜2𝑜∗ ,一对一分支选择 𝑖 个预测,其度量为 𝑚𝑜2𝑜,𝑖 = 𝑚𝑜2𝑜∗ ,然后可以导出 𝑗∈Ω 和 𝑡𝑜2𝑜,𝑖 = 𝑢∗⋅𝑚𝑜2𝑜,𝑖𝑚𝑜2𝑜∗ b12> = 𝑢∗ 对于任务对齐损失。因此,两个分支之间的监督差距可以通过不同分类目标的 1-Wasserstein 距离得出,即
![]()
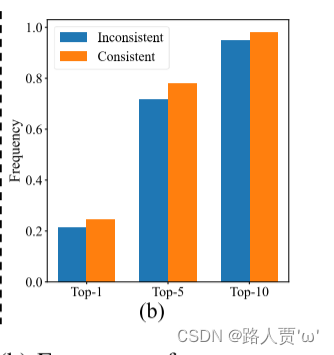
可以观察到,随着 𝑡𝑜2𝑚,𝑖 的增加,差距减小,即 𝑖 在 Ω 中排名更高。当 𝑡𝑜2𝑚,𝑖 = 𝑢∗ 时达到最小值,即 𝑖 是 Ω 中最好的正样本,如图 2 所示(a)。为了实现这一点,提出一致的匹配度量,即 𝛼𝑜2𝑜 = 𝑟⋅𝛼𝑜2𝑚 和 𝛽𝑜2𝑜 = 𝑟⋅𝛽𝑜2𝑚 ,这意味着 𝑚𝑜2𝑜 = 𝑚𝑜2𝑚𝑟 。因此,一对多头部的最佳正样本也是一对一头部的最佳正样本。因此,两个头都可以得到一致、和谐的优化。为简单起见,默认取 𝑟 =1,即 𝛼𝑜2𝑜 = 𝛼𝑜2𝑚 和 𝛽𝑜2𝑜 = 𝛽𝑜2𝑚 。为了验证改进的监督对齐,计算训练后一对多结果的前 1 / 5 / 10 内一对一匹配对的数量。如图2(b)所示,在一致匹配度量下,对齐得到了改善。为了更全面地理解数学证明,请参阅附录。

精读
Dual label assignments—双标签分配
一对多分配:在训练过程中,YOLO系列通常利用TAL(任务分配学习) 为每个实例分配多个正样本。
- 优点:一对多的分配方式产生了丰富的监督信号,促进了优化并使模型实现了卓越的性能。
- 不足:这使得YOLO系列必须依赖于NMS后处理,这导致在部署时的推理效率不是最优的。
一对一分配:一对一分配只为每个地面实况分配一个预测
- 优点:避免了NMS后处理
- 不足:通常会增加额外的推理开销或导致次优的性能
本文方法
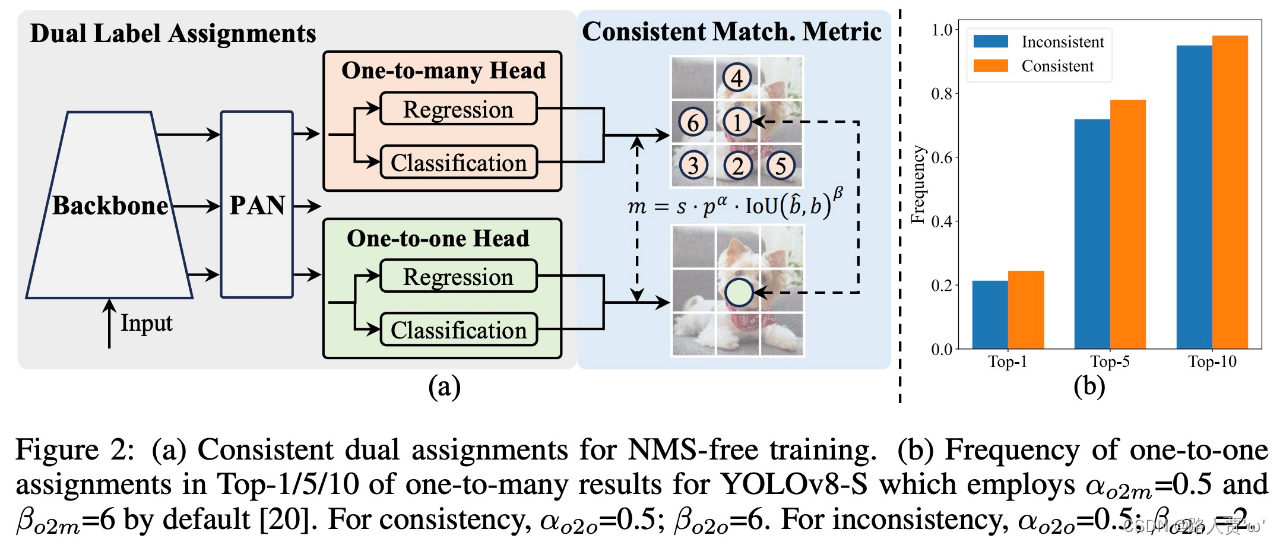
本文引入了另一种一对一Head结构,与原始的一对多分支相同,并采用相同的优化目标,但使用一对一分配方式来确定标签分配,
在训练过程中:两个 Head 联合优化,以提供丰富的监督。
在推理过程中:YOLOv10 会丢弃一对多 Head 并利用一对一 Head 做出预测。这使得 YOLO 能够进行端到端部署,而不会产生任何额外的推理成本。
Consistent matching metric—一致匹配度量
为了实现一对一和一对多两个分支的预测感知匹配,采用统一的匹配度量,即
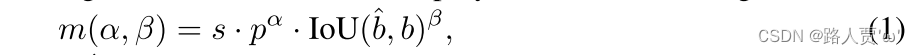
- p:分类分数
- b^ 和 b :分别表示预测和实例的边界框
- s :表示空间先验,指示预测的锚点是否在实例内
- 𝛼 和 𝛽 :平衡语义预测任务和位置回归任务影响的两个重要超参数
一对多指标:𝑚𝑜2𝑚 = 𝑚(𝛼𝑜2𝑚,𝛽𝑜2𝑚)
一对一指标:𝑚𝑜2𝑜 = 𝑚(𝛼𝑜2𝑜,𝛽𝑜2𝑜)
在双标签分配中,一对多分支提供比一对一分支更丰富的监控信号。
两个分支之间的监督差距可以通过不同分类目标的 1-Wasserstein 距离得出,即
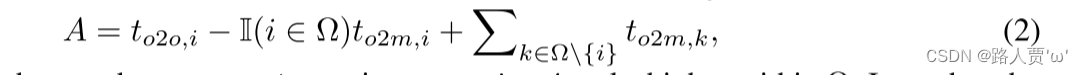
可以观察到,随着 𝑡𝑜2𝑚,𝑖 的增加,差距减小,即 𝑖 在 Ω 中排名更高。
当 𝑡𝑜2𝑚,𝑖 = 𝑢∗ 时达到最小值,即 𝑖 是 Ω 中最好的正样本,如图 2 所示(a)。

为了实现这一点,提出一致的匹配度量,即 𝛼𝑜2𝑜 = 𝑟⋅𝛼𝑜2𝑚 和 𝛽𝑜2𝑜 = 𝑟⋅𝛽𝑜2𝑚。如图2(b)所示
3.2 Holistic Efficiency-Accuracy Driven Model Design—整体效率-精度驱动的模型设计
翻译
除了后处理之外,YOLO 的模型架构也对效率与准确性的权衡提出了巨大的挑战。尽管之前的工作探索了各种设计策略,但仍然缺乏对 YOLO 中各种组件的全面检查。因此,模型架构表现出不可忽略的计算冗余和受限能力,这阻碍了其实现高效率和高性能的潜力。在这里,目标是从效率和准确性的角度全面地进行 YOLO 的模型设计。
YOLO 中的组件由茎、下采样层、具有基本构建块的阶段和头部组成。茎的计算成本很少,因此我们对其他三个部分进行效率驱动的模型设计。
(1) 轻量化分类头。 YOLO 中的分类和回归头通常共享相同的架构。然而,它们在计算开销方面表现出显著的差异。例如,在YOLOv8-S中,分类头(5.95G/1.51M)的FLOPs和参数计数是回归头(2.34G/0.64M)的2.5倍 和2.4倍。然而,在分析分类误差和回归误差的影响后(见表9),发现回归头对YOLO的性能具有更重要的意义。因此,可以减少分类头的开销,而不用担心极大地损害性能。因此,简单地采用轻量级的分类头架构,它由两个深度可分离卷积组成,内核大小为3 × 3,后面跟着一个1 × 1个卷积。
(2) 空间通道解耦下采样。 YOLO通常利用常规的3 × 3标准卷积,步长为2,实现空间下采样(从 𝐻×𝑊 到 𝐻2×𝑊2 )和通道转换(从 𝐶 到 2𝐶)同时。这引入了不可忽略的 𝒪(92𝐻𝑊𝐶2) 计算成本和 𝒪(18𝐶2) 参数计数。相反,建议将空间缩减和通道增加操作解耦,从而实现更有效的下采样。具体来说,首先利用逐点卷积来调制通道维度,然后利用深度卷积来执行空间下采样。这将计算成本减少到 𝒪(2𝐻𝑊𝐶2+92𝐻𝑊𝐶) ,并将参数计数减少到 𝒪(2𝐶2+18𝐶) 。同时,它最大限度地提高了下采样过程中的信息保留,从而在减少延迟的同时带来有竞争力的性能。
(3) 排序引导的块设计。 YOLO 通常在所有阶段使用相同的基本构建块,例如 YOLOv8 中的瓶颈块。为了彻底检查 YOLO 的这种同构设计,利用内在等级来分析每个阶段的冗余。

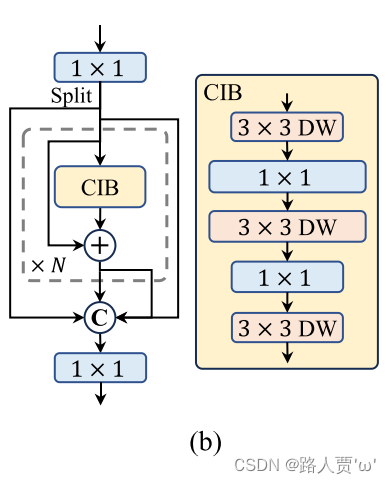
具体来说,计算每个阶段最后一个基本块中最后一个卷积的数值秩,即计算大于阈值的奇异值的数量。图3(a)展示了YOLOv8的结果,表明深阶段和大型模型容易表现出更多的冗余。这一观察结果表明,简单地对所有阶段应用相同的块设计对于最佳容量效率权衡来说并不是最优的。为了解决这个问题,提出一种排序引导的块设计方案,旨在使用紧凑的架构设计来降低被证明是冗余的阶段的复杂性。首先提出一种紧凑的反向块(CIB)结构,它采用精简的深度卷积(“cheap depthwise convolutions”不知道咋翻译好。。。)进行空间混合,并采用经济有效的点卷积进行通道混合,如图3(b)所示。它可以作为高效的基本构建块,例如嵌入 ELAN 结构中(图 3.(b))。然后,提倡采用排名引导的区块分配策略,以在保持竞争能力的同时实现最佳效率。具体来说,给定一个模型,根据其内在排名按升序对所有阶段进行排序。进一步考察用 CIB 替换前导阶段基本块的性能变化。如果与给定模型相比没有性能下降,将继续更换下一阶段,否则停止该过程。因此,可以跨阶段和模型规模实现自适应紧凑块设计,在不影响性能的情况下实现更高的效率。
研究者进一步探索用于精度驱动设计的大核卷积和自注意力,旨在以最小的成本提高性能。
(1) 大核卷积。采用大核深度卷积是扩大感受野和增强模型能力的有效方法。然而,在所有阶段简单地利用它们可能会导致用于检测小物体的浅层特征受到污染,同时还会在高分辨率阶段引入显着的 I/O 开销和延迟。因此,建议在深度阶段利用 CIB 中的大内核深度卷积。具体来说,将 CIB 中第二个 3 × 3 深度卷积的内核大小增加到 7 × 7,遵循。此外,采用结构重新参数化技术带来另外 3 × 3 个深度卷积分支,以减轻优化问题,而无需推理开销。此外,随着模型尺寸的增加,其感受野自然扩大,而使用大核卷积的好处逐渐减少。因此,只对小模型规模采用大核卷积。
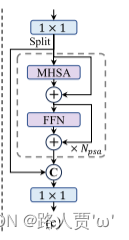
(2) 部分自注意力(PSA)。自注意力由于其卓越的全局建模能力而被广泛应用于各种视觉任务中。然而,它表现出较高的计算复杂度和内存占用。为了解决这个问题,鉴于普遍存在的注意力头冗余,研究者提出一种有效的部分自注意力(PSA)模块设计,如图3(c)所示。具体来说,在 1 × 1 卷积之后将跨通道的特征均匀地划分为两部分。只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的 𝑁PSA 块中。然后两个部分通过 1 × 1 卷积连接并融合。此外,将查询和密钥的维度分配为MHSA中值的一半,并将LayerNorm替换为BatchNorm以实现快速推理。此外,PSA 仅放置在分辨率最低的第 4 阶段之后,避免了自注意力的二次计算复杂性带来的过多开销。这样,可以将全局表示学习能力以较低的计算成本融入到YOLO中,从而很好地增强了模型的能力并提高了性能。
精读
Efficiency driven model design—效率驱动的模型设计
先前工作的不足
- 先前工作在对YOLO各部分的综合检查上仍有不足。
- 模型存在计算冗余和性能受限问题。

本文工作目的
- 本文旨在全面优化YOLO的模型设计,考虑效率和准确性。
YOLO 中的组件包括主干、下采样层、带有基本构建块的阶段和 head。作者主要对以下三个部分执行效率驱动的模型设计:
(1)轻量级分类头设计:
分类头采用了一种轻量级架构,它由两个深度可分离的卷积组成,内核大小为3×3,然后是1×1卷积。
通过简化分类头架构降低计算开销,而不会显著影响性能。
(2)空间通道解耦下采样:
我们首先利用逐点卷积来调制信道维度,然后利用去卷积来执行空间下采样。
将空间下采样和通道转换操作解耦,提高了信息保留率,从而实现了更高的效率和竞争力。
(3)基于排序引导的模块设计:
过去的问题:以YOLOv8为例,深度阶段和大型模型倾向于表现出更多的冗余。
我们首先提出了一个紧凑的倒置块(CIB)结构,它采用了cheap depthwise convolutions的空间混合和成本有效的逐点卷积的通道混合,如图3(b)所示
然后本文使用一种排序引导的模块分配策略,以达到最佳的效率,同时保持竞争能力。
根据各个阶段的冗余程度,采用不同的基本构建块,以实现更高效的模型设计。
Accuracy driven model design—精度驱动的模型设计
(1)大核深度卷积模块:
- 在深度阶段使用大内核dependency convolutions,将CIB中第二个3×3深度卷积的核大小增加到7×7,以扩大感受野和增强模型能力。
- 使用结构重新参数化技术引入另一个3×3深度卷积分支来减轻优化问题,避免推理开销。
- 仅对小模型规模采用大核卷积,随模型规模增加,大核卷积带来的好处减少。
(2)部分自我注意(PSA)设计:
- 提出了部分自注意(PSA)模块设计,将通道特征均匀划分为两部分,其中一部分经过MHSA和FFN组成的NPSA模块处理,再与另一部分融合。
- 将查询和键的维度分配为MHSA中值的一半,并将LayerNorm替换为BatchNorm以提高推理速度。
- PSA模块只放置在具有最低分辨率的阶段4之后,避免过多计算复杂度开销,有效地融入了全局表示学习能力提升模型性能。
4 Experiments—实验
4.1 Implementation Details—实验细节
翻译
我们选择YOLOv 8 [20]作为我们的基线模型,因为它值得称赞的延迟-准确性平衡及其在各种模型大小中的可用性。我们采用一致的双重分配进行无NMS训练,并在此基础上进行整体效率-准确性驱动的模型设计,这带来了我们的YOLOv 10模型。YOLOv 10具有与YOLOv 8相同的变体,即,N / S / M / L / X。此外,通过简单地增加YOLOv 10-M的宽度比例因子,我们得到了一个新的变体YOLOv 10-B。我们在相同的从头开始训练设置[20,59,56]下在COCO [33]上验证了所提出的检测器。此外,所有模型的计算都在T4 GPU上使用TensorRT FP 16进行了测试,如下[71]。
精读
- baseline:YOLOv8
- 训练方法:一致的双重分配进行无NMS训练,并在此基础上进行整体效率-准确性驱动的模型设计
- 变体:
- YOLOv 10具有与YOLOv 8相同的变体,即,N / S / M / L / X
- 通过简单地增加YOLOv 10-M的宽度比例因子,得到了一个新的变体YOLOv 10-B
- 数据集:COCO
- 硬件设施:T4 GPU上使用TensorRT FP 16进行了测试
4.2 Comparison with state-of-the-arts—与最先进技术的比较
翻译
如Tab中所示。1、我们的YOLOv 10在各种模型规模上实现了最先进的性能和端到端延迟。我们首先将YOLOv 10与我们的基线模型进行比较,即,YOLOv8.在N / S / M / L / X五种变体上,我们的YOLOv 10实现了1.2% / 1.4% / 0.5% / 0.3% / 0.5%的AP改进,参数减少了28% / 36% / 41% / 44% / 57%,计算减少了23% / 24% / 25% / 27% / 38%,乳酸菌降低70% / 65% / 50% / 41% / 37%。与其他YOLO相比,YOLOv 10在精度和计算成本之间也表现出上级权衡。具体而言,对于轻量级和小型模型,YOLOv 10-N / S的性能优于YOLOv 6 -3.0-N / S 1.5 AP和2.0 AP,参数分别减少51% / 61%,计算量分别减少41% / 52%。对于中型机型,与YOLOv 9-C / YOLO-MS相比,YOLOv 10-B / M在相同或更好的性能下,延迟分别减少了46% / 62%。对于大型模型,与Gold-YOLO-L相比,我们的YOLOv 10-L显示了68%的参数减少和32%的延迟降低,沿着,AP显著提高了1.4%。此外,与RT-DETR相比,YOLOv 10获得了显着的性能和延迟改善。值得注意的是,YOLOv 10-S / X在性能相似的情况下,推理速度分别比RT-DETR-R18 / R101快1.8倍和1.3倍。这些结果充分证明了YOLOv 10作为实时端到端检测器的优越性。
我们还使用原始的一对多训练方法将YOLOv 10与其他YOLO进行了比较。在这种情况下,我们考虑模型前向过程(Latencyf)的性能和延迟,如下[56,20,54]。如Tab中所示。YOLOv 10还在不同的模型尺度上展示了最先进的性能和效率,表明了我们的架构设计的有效性。

精读
比较方法:
- 对于baseline:YOLOv10五个变体(N / S / M / L / X )分别和对应的YOLOv8进行比较
- 对于轻量级和小型模型:以YOLOv10-N / S 与 YOLOv6-3.0-N / S相比举例
- 对于中型模型:以YOLOv10-B / M与YOLOv9-C / YOLO-MS相比举例
- 对于大型模型:以YOLOv10-L 与 Gold-YOLO-L 相比举例
- 对于 RT-DETR :以OLOv 10-S / X与RT-DETR-R18 / R101相比举例
结论:YOLOv10 在各种模型规模上实现了最先进的性能和端到端延迟。
4.3 Model Analyses—模型分析
Ablation study—消融实验
翻译
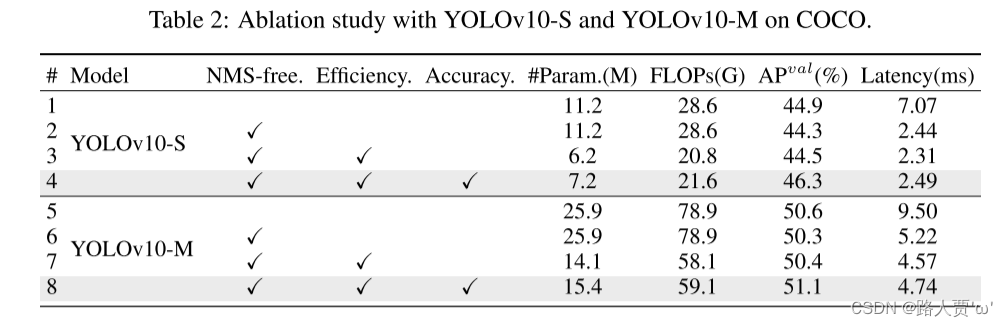
消融研究。我们在表中提供了基于YOLOv 10-S和YOLOv 10-M的消融结果。2.可以观察到,我们的无NMS训练和一致的双重分配将YOLOv 10-S的端到端延迟显著降低了4.63ms,同时保持了44.3% AP的竞争性能。此外,我们的效率驱动模型设计导致减少了11.8 M参数和20.8 GFlOP,对于YOLOv 10-M,延迟减少了0.65 ms,充分显示了其有效性。此外,我们的精度驱动模型设计实现了YOLOv 10-S和YOLOv 10-M的1.8 AP和0.7 AP的显着改进,分别只有0.18ms和0.17ms的延迟开销,这充分证明了其优越性。
精读
针对 YOLOv10-S 和 YOLOv10-M 进行了消融实验,证明了无 NMS 训练的一致双重分配,效率驱动模型,精度驱动模型的优越性。
Analyses for NMS-free training—无NMS训练分析
翻译
无NMS训练分析。
-
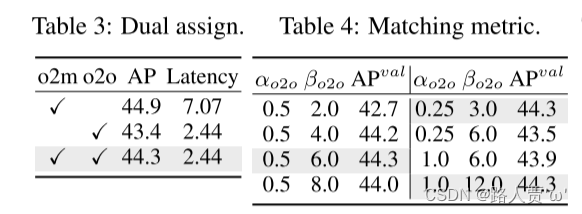
双标签分配。研究者提出NMS-free YOLO 的双标签分配,它既可以在训练过程中带来丰富的一对多(o2m)分支的监督,又可以在推理过程中带来一对一(o2o)分支的高效率。基于 YOLOv8-S 验证其优势,即表 2 中的#1。具体来说,分别引入仅使用 o2m 分支和仅使用 o2o 分支进行训练的基线。如表3所示,我们的双标签分配实现了最佳的 AP 延迟权衡。
- 一致的匹配度量。引入一致的匹配度量,使一对一头部与一对多头部更加和谐。基于 YOLOv8-S 验证其优势,即表 2 中的#1。在不同的 𝛼𝑜2𝑜 和 𝛽𝑜2𝑜 下。如表4所示,所提出的一致匹配度量,即 𝛼𝑜2𝑜 = 𝑟⋅𝛼𝑜2𝑚 和 𝛽𝑜2𝑜 = 𝑟⋅𝛽𝑜2𝑚 ,可以实现最佳性能,其中 <一对多头中的 b6> = 0.5 和 𝛽𝑜2𝑚 = 6.0。这种改进可归因于监督差距的缩小(等式2),这改善了两个分支之间的监督一致性。此外,所提出的一致匹配度量消除了详尽的超参数调整的需要,这在实际场景中很有吸引力。
精读
- 双标签分配实现了最佳的 AP 延迟权衡
- 引入一致的匹配度量,使一对一头部与一对多头部更加和谐。
Analyses for efficiency driven model design—效率驱动的模型设计分析
翻译
效率驱动的模型设计分析。我们进行实验,逐步纳入效率驱动的设计元素的基础上YOLOv 10-S/M。我们的基线是没有效率-准确性驱动模型设计的YOLOv 10-S/M模型,即表 2 中的 #2/#6。如表5所示,每个设计组件,包括轻量级分类头、空间通道解耦下采样和秩引导块设计,都有助于减少参数计数、FLOP和延迟。重要的是,这些改进是在保持竞争力的同时实现的。

-
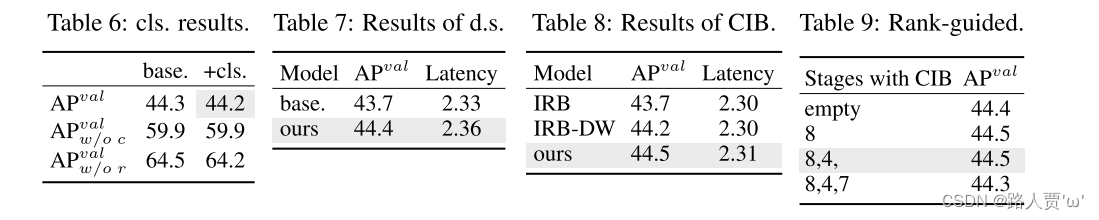
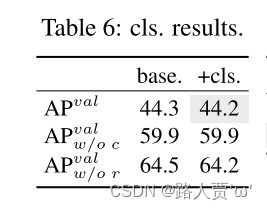
轻型分类头。基于表5中#1 和#2 的 YOLOv10-S 分析了预测的类别和定位误差对性能的影响。具体来说,通过一对一分配将预测与实例进行匹配。然后,用实例标签替换预测的类别分数,从而得到没有分类错误的 AP 𝑤/𝑜𝑐𝑣𝑎𝑙 。类似地,用实例的位置替换预测位置,产生没有回归错误的 AP 𝑤/𝑜𝑟𝑣𝑎𝑙 。如表6所示,AP 𝑤/𝑜𝑟𝑣𝑎𝑙 远高于AP 𝑤/𝑜𝑐𝑣𝑎𝑙 ,表明消除回归误差取得了更大的改进。因此,性能瓶颈更多地在于回归任务。因此,采用轻量级分类头可以在不影响性能的情况下实现更高的效率。
-
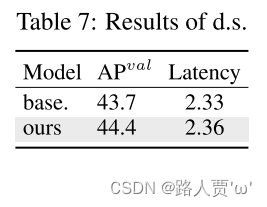
空间通道解耦下采样。解耦下采样操作以提高效率,其中通道尺寸首先通过逐点卷积(PW)增加,然后通过深度卷积(DW)降低分辨率,以最大程度地保留信息。将其与基于表 5 中 #3 的 YOLOv10-S 的 DW 空间缩减和 PW 通道调制的基线方法进行比较。如表7所示,下采样策略通过在下采样过程中减少信息损失,实现了 0.7% 的 AP 改进。
-
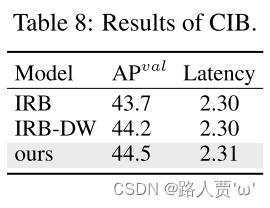
紧凑型倒置块(CIB)。引入 CIB 作为紧凑的基本构建块。根据表5中#4的YOLOv10-S验证其有效性。具体来说,引入倒置残差块(IRB)作为基线,它实现了次优的 43.7% AP,如表 8 所示。然后,在其后附加一个 3 × 3 深度卷积(DW),表示为“IRB-DW”,这带来了 0.5% 的 AP 改进。与“IRB-DW”相比,CIB 通过以最小的开销预先添加另一个 DW,进一步实现了 0.3% 的 AP 改进,表明了其优越性。
-
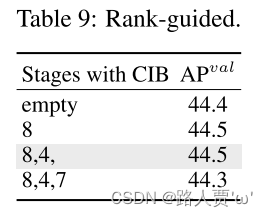
等级引导的块设计。为了提高模型的效率,我们引入了秩引导的区组设计来自适应地整合紧凑区组设计。根据表5中#3的YOLOv10-S验证了它的好处。根据内在等级升序排列的阶段为阶段8-4-7-3-5-1-6-2,如图3(a)所示。如表9所示,当用高效的CIB逐渐替换每个阶段的瓶颈块时,观察到从第7阶段开始性能下降。在具有较低内在等级和更多冗余的第8和4阶段,可以在不妥协的情况下采用高效的块设计的表现。这些结果表明,排序引导的块设计可以作为提高模型效率的有效策略。
精读
如下表所示,每个设计组件,包括轻量级分类 head、空间通道解耦下采样和排序指导的模块设计,都有助于减少参数数量、FLOPs 和延迟。重要的是,这些改进是在保持卓越性能的同时所实现的。
(1)轻量级分类头:通过消除回归误差,轻量级分类头实现了更高的效率,而不影响性能。 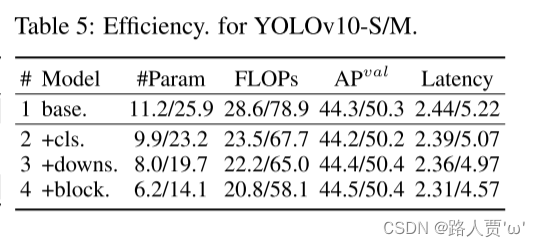
(2)空间通道解耦下采样:通过解耦下采样操作,在下采样过程中减少信息损失,实现了性能的改进。
(3)紧凑倒置块(CIB):CIB作为紧凑的基本构建块,通过最小的开销预先添加另一个DW,进一步提高了性能。
(4)等级引导的块设计:根据内在等级排序,逐步替换每个阶段的瓶颈块,观察到在低内在等级和更多冗余的阶段采用高效的块设计的表现优越。
Analyses for accuracy driven model design—精度驱动的模型设计分析
翻译
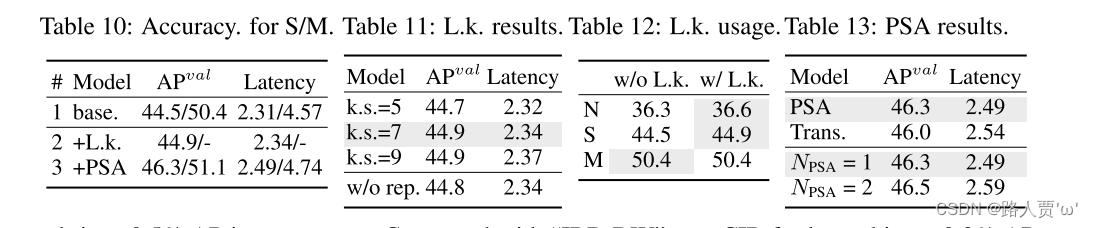
基于 YOLOv10-S/M 逐步集成精度驱动设计元素的结果。基线是结合效率驱动设计后的 YOLOv10-S/M 模型,即表 2 中的 #3/#7。如表13所示,大核卷积和 PSA 模块的采用使得 YOLOv10-S 在最小延迟增加 0.03ms 和 0.15ms 的情况下分别获得了 0.4% AP 和 1.4% AP 的可观性能提升。请注意,YOLOv10-M 未采用大核卷积(参见表 12)。
-
大内核卷积。首先基于表 10中#2 的 YOLOv10-S 研究不同内核大小的影响。如表11所示,性能随着内核大小的增加而提高,并在内核大小 7 × 7 附近停滞,表明大感知场的好处。此外,在训练期间删除重参数化分支实现了 0.1% 的 AP 退化,显示了其优化的有效性。此外,基于YOLOv10-N / S / M检查了跨模型尺度的大内核卷积的好处。如表12所示,由于其固有的广泛感受野,它对大型模型(即 YOLOv10-M)没有带来任何改进。因此,只对小模型采用大核卷积,即 YOLOv10-N / S。
-
部分自我注意(PSA)。引入PSA,通过以最小的成本整合全局建模能力来提高性能。首先基于表 10 中的 YOLOv10-S 验证其有效性。具体来说,引入了 Transformer 块,即 MHSA 后跟 FFN,作为基线,表示为“Trans.”。如表13所示,与之相比,PSA带来了0.3%的AP提升和0.05ms的延迟降低。性能的增强可能归因于通过减少注意力头的冗余来缓解自注意力的优化问题。此外,研究不同 𝑁PSA 的影响。如表13所示,将 𝑁PSA 增加到 2 可以获得 0.2% 的 AP 改进,但会带来 0.1ms 的延迟开销。因此,默认将 𝑁PSA 设置为1,以在保持高效率的同时增强模型能力。
精读
(1)大核卷积:YOLOv10-S中采用大核卷积带来了0.4%至1.4%的AP提升,但仅增加了最小延迟。
(2)部分自注意力(PSA):引入PSA在YOLOv10-S中带来了0.3%的AP提升和0.05ms的延迟降低,有效提高了模型性能。
5 Conclusion—结论
翻译
在本文中,我们的目标是在整个检测管道的YOLO的后处理和模型架构。对于后处理,我们提出了一致的双重分配用于NMS free训练,实现了高效的端到端检测。在模型架构上,引入了整体效率-精度驱动的模型设计策略,改善了性能-效率的权衡。这带来了我们的YOLOv 10,一种新的实时端到端对象检测器。大量的实验表明,YOLOv 10与其他先进的检测器相比,在性能和延迟方面都达到了最先进的水平,充分展示了其优越性。
精读
(1)本文提出了一个新的无 NMS 训练的一致双重分配,减少了后处理对NMS的依赖导致训练时的延迟,从而提高了检测速度并减少了超参数的影响。
(2)作者还提出了一种全面的效率和准确性驱动的设计策略,该策略涵盖了多个组件,包括轻量级分类头、空间通道分离下采样和排名引导块等设计,以提高模型的效率和准确性。

相关文章:
【YOLO系列】YOLOv10论文超详细解读(翻译 +学习笔记)
前言 研究AI的同学们面对的一个普遍痛点是,刚开始深入研究一项新技术,没等明白透彻,就又迎来了新的更新版本——就像我还在忙着逐行分析2月份发布的YOLOv9代码,5月底清华的大佬们就推出了全新的v10。。。 在繁忙之余࿰…...
植物大战僵尸杂交版2024潜艇伟伟迷
在广受欢迎的游戏《植物大战僵尸》的基础上,我最近设计了一款创新的杂交版游戏,简直是太赞了!这款游戏结合了原有游戏的塔防机制,同时引入新的元素、角色和挑战,为玩家提供了全新的游戏体验。 植物大战僵尸杂交版最新绿…...

白话解读网络爬虫
网络爬虫(Web Crawler),也称为网络蜘蛛、网络机器人或网络蠕虫,是一种自动化程序或脚本,被用来浏览互联网并收集信息。网络爬虫的主要功能是在互联网上自动地浏览网页、抓取内容并将其存储在本地或远程服务器上供后续处…...
: 从理论到实践的指南(1))
支持向量机(SVM): 从理论到实践的指南(1)
支持向量机(SVM)被誉为数据科学领域的重量级算法,是机器学习中不可或缺的工具之一。SVM以其优秀的泛化能力和对高维数据的管理而备受推崇。本文旨在梳理SVM的核心概念以及其在实际场景中的应用。 SVM的核心理念 SVM专注于为二分类问题找到最…...

万字长文|OpenAI模型规范(全文)
本文是继《OpenAI模型规范概览》之后对OpenAI Model Spec的详细描述,希望能对各位从事大模型及RLHF研究的朋友有帮助。万字长文,建议收藏后阅读。 一、概述 在AI的世界里,确保技术的行为符合我们的期望至关重要。OpenAI最近发布了一份名为Mo…...
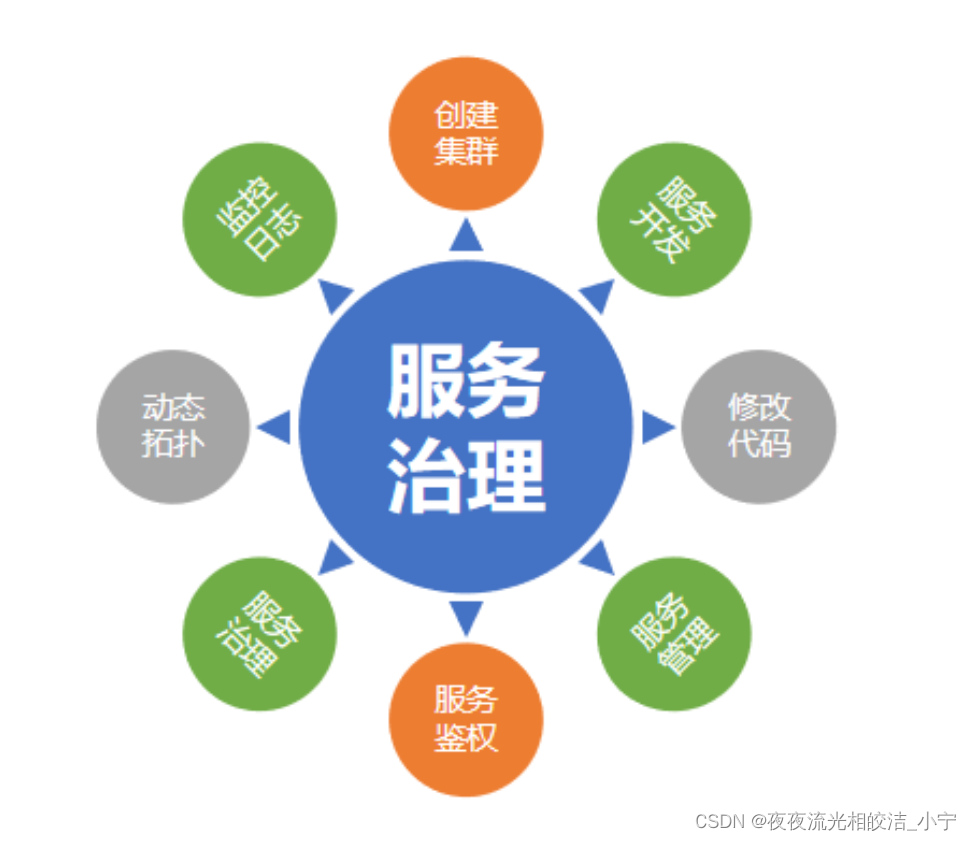
微服务架构-正向治理与治理效果
目录 一、正向治理 1.1 概述 1.2 效率治理 1.2.1 概述 1.2.2 基于流量录制和回放的测试 1.2.3 基于仿真环境的测试 1.3 稳定性治理 1.3.1 概述 1.3.2 稳定性治理模型 1.3.3 基于容器化的稳定性治理 1.3.3.1 概述 1.3.3.2 测试 1.3.3.3 部署 1.3.3.3.1 概述 1.3.3…...

normalizing flows vs 直方图规定化
normalizing flows名字的由来 The base density P ( z ) P(z) P(z) is usually defined as a multivariate standard normal (i.e., with mean zero and identity covariance). Hence, the effect of each subsequent inverse layer is to gradually move or “flow” the da…...
vite打包优化常用的技巧及思路
面试题:vitevue项目如何进行优化? 什么情况下会去做打包优化?一种是在搭建项目的时候就根据自己的经验把vite相关配置给处理好,另外一种是开发的过程中发现打包出来的静态资源越来越大,导致用户访问的时候资源加载慢&a…...

k8s学习--kubernetes服务自动伸缩之水平收缩(pod副本收缩)HPA详细解释与案例应用
文章目录 前言HPA简介简单理解详细解释HPA 的工作原理监控系统负载模式HPA 的优势使用 HPA 的注意事项应用类型 应用环境1.metircs-server部署2.HPA演示示例(1)部署一个服务(2)创建HPA对象(3)执行压测 前言…...

台式机ubuntu22.04安装nvidia驱动
总结一个极简易的安装方法 正常安装ubuntu 22.04正常更新软件 sudo apt update sudo apt upgrade -y参考ubuntu官方网站的说明https://ubuntu.com/server/docs/nvidia-drivers-installation#/ # 首先检查系统支持驱动的版本号 sudo ubuntu-drivers list我显示的内容如下&…...

C++ 11 【线程库】【包装器】
💓博主CSDN主页:麻辣韭菜💓 ⏩专栏分类:C修炼之路⏪ 🚚代码仓库:C高阶🚚 🌹关注我🫵带你学习更多C知识 🔝🔝 目录 前言 一、thread类的简单介绍 get_id…...

可视化数据科学平台在信贷领域应用系列四:决策树策略挖掘
信贷行业的风控策略挖掘是一个综合过程,需要综合考虑风控规则分析结果、效果评估、线上实时监测和业务管理需求等多个方面,以发现和制定有效的信贷风险管理策略。这些策略可能涉及贷款审批标准的调整、贷款利率的制定、贷款额度的设定等,在贷…...

数据查询深分页优化方案
大家好,我是冰河~~ 最近不少小伙伴在实际工作过程中,遇到了单表大数据量分页的问题,问我怎么优化分页查询。其实,这就是典型的深分页问题。今天趁着周末,给大家整理一些在深分页场景的简单处理方案。 一、普通分页查…...

Redis的主从复制
Redis主从复制是 Redis 内置的⼀种数据冗余和备份⽅式,同时也是分发读查询负载的⼀种⽅法。通过主从复制,可以有多个从服务器(Slave )复制⼀个主服务器(Master )的数据。在这个系统中,数据的复制…...

网络安全实战基础——实战工具与攻防环境介绍
一、实战集成工具 1. 虚拟机 VMware Workstation:大家熟知的虚拟机 Virtual Box:开源免费、轻量级 2. Kali Linux 工具集 信息收集 Nmap:免费开放的网络扫描和嗅探包,可探测主机是否在线,扫描主机端口和嗅探网络…...

vue2组件封装实战系列之tag组件
作为本系列的第一篇文章,不会过于的繁杂,并且前期的组件都会是比较简单的基础组件!但是不要忽视这些基础组件,因为纵观elementui、elementplus还是其他的流行组件库,组件库的封装都是套娃式的,很多复杂组件…...
(4):实用功能整理)
VBA实战(Excel)(4):实用功能整理
1.后台打开Excel 用于查数据,工作中要打开多个表获取数据再关闭的场景,利用此函数可以将excel表格作为后台数据库查询,快速实现客户要求,缺点是运行效率不够高。 Sub openexcel(exl_name As String)If Dir(addr, 16) Empty Then…...
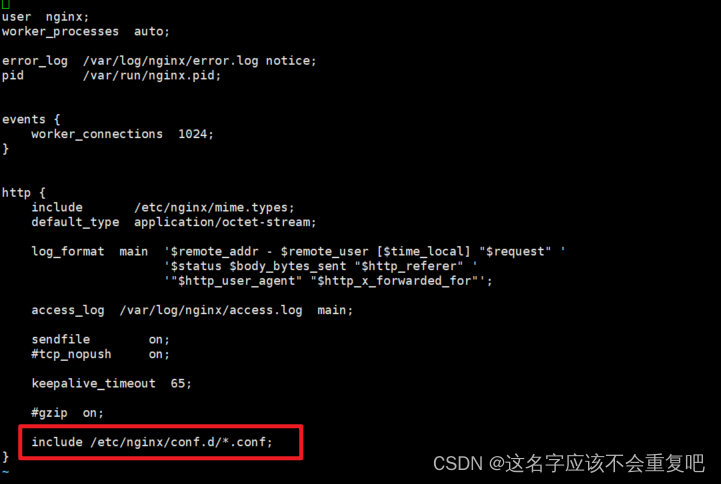
nginx mirror流量镜像详细介绍以及实战示例
nginx mirror流量镜像详细介绍以及实战示例 1.nginx mirror作用2.nginx安装3.修改配置3.1.nginx.conf3.2.conf.d目录下添加default.conf配置文件3.3.nginx配置注意事项3.3.nginx重启 4.测试 1.nginx mirror作用 为了便于排查问题,可能希望线上的请求能够同步到测试…...

Android14 WMS-窗口添加流程(二)-Server端
Android14 WMS-窗口添加流程(一)-Client端-CSDN博客 本文接着上文"Android14 WMS-窗口添加流程(一)-Client端"往下讲。也就是WindowManagerService#addWindow流程。 目录 一. WindowManagerService#addWindow 标志1:mPolicy.checkAddPermission 标志…...

【传知代码】DETR[端到端目标检测](论文复现)
前言:想象一下,当自动驾驶汽车行驶在繁忙的街道上,DETR能够实时识别出道路上的行人、车辆、交通标志等目标,并准确预测出它们的位置和轨迹。这对于提高自动驾驶的安全性、减少交通事故具有重要意义。同样,在安防监控、…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

C++ Visual Studio 2017厂商给的源码没有.sln文件 易兆微芯片下载工具加开机动画下载。
1.先用Visual Studio 2017打开Yichip YC31xx loader.vcxproj,再用Visual Studio 2022打开。再保侟就有.sln文件了。 易兆微芯片下载工具加开机动画下载 ExtraDownloadFile1Info.\logo.bin|0|0|10D2000|0 MFC应用兼容CMD 在BOOL CYichipYC31xxloaderDlg::OnIni…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

uniapp 开发ios, xcode 提交app store connect 和 testflight内测
uniapp 中配置 配置manifest 文档:manifest.json 应用配置 | uni-app官网 hbuilderx中本地打包 下载IOS最新SDK 开发环境 | uni小程序SDK hbulderx 版本号:4.66 对应的sdk版本 4.66 两者必须一致 本地打包的资源导入到SDK 导入资源 | uni小程序SDK …...

适应性Java用于现代 API:REST、GraphQL 和事件驱动
在快速发展的软件开发领域,REST、GraphQL 和事件驱动架构等新的 API 标准对于构建可扩展、高效的系统至关重要。Java 在现代 API 方面以其在企业应用中的稳定性而闻名,不断适应这些现代范式的需求。随着不断发展的生态系统,Java 在现代 API 方…...
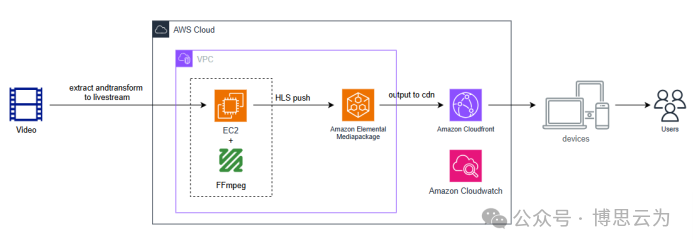
客户案例 | 短视频点播企业海外视频加速与成本优化:MediaPackage+Cloudfront 技术重构实践
01技术背景与业务挑战 某短视频点播企业深耕国内用户市场,但其后台应用系统部署于东南亚印尼 IDC 机房。 随着业务规模扩大,传统架构已较难满足当前企业发展的需求,企业面临着三重挑战: ① 业务:国内用户访问海外服…...
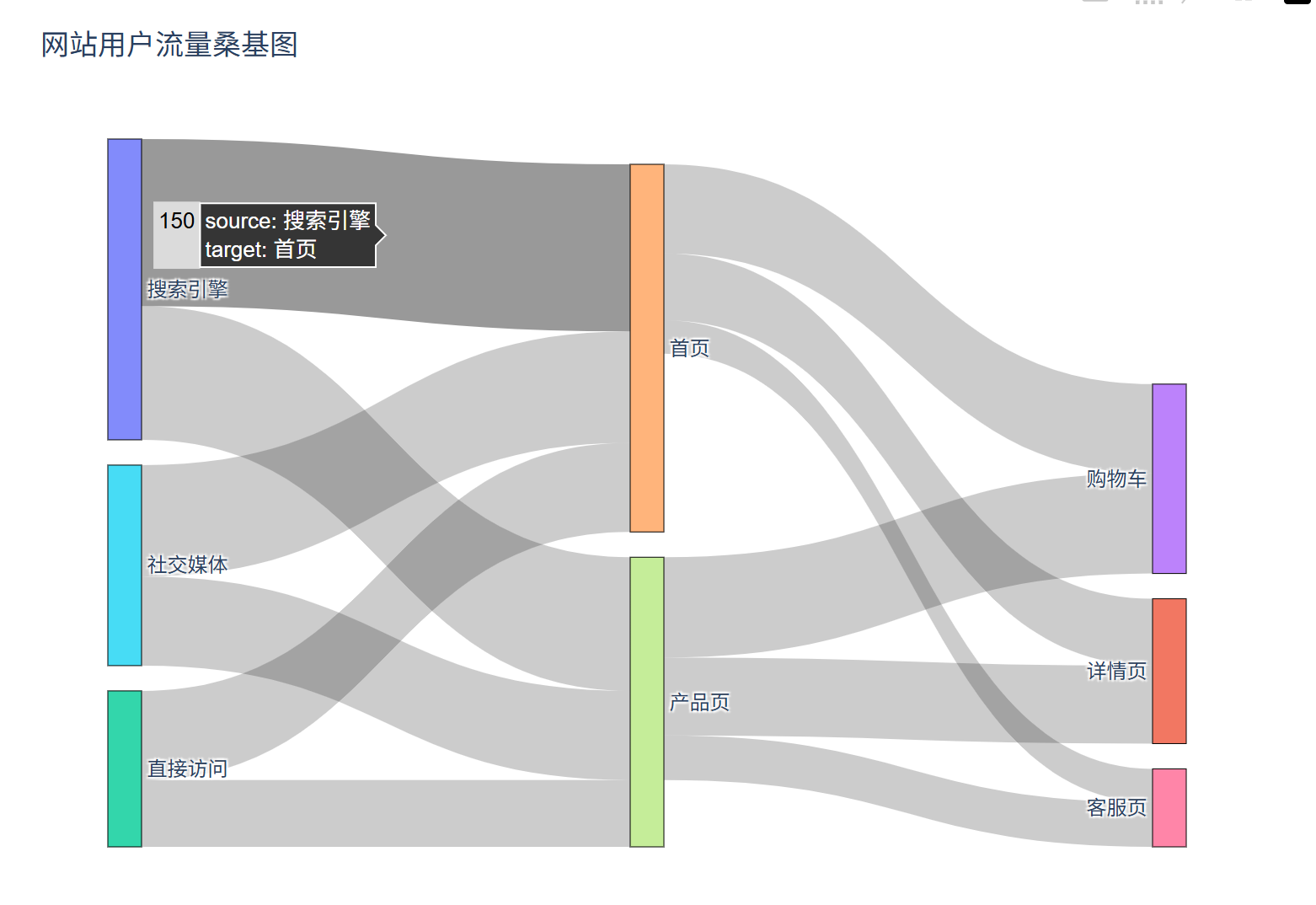
相关类相关的可视化图像总结
目录 一、散点图 二、气泡图 三、相关图 四、热力图 五、二维密度图 六、多模态二维密度图 七、雷达图 八、桑基图 九、总结 一、散点图 特点 通过点的位置展示两个连续变量之间的关系,可直观判断线性相关、非线性相关或无相关关系,点的分布密…...

boost::filesystem::path文件路径使用详解和示例
boost::filesystem::path 是 Boost 库中用于跨平台操作文件路径的类,封装了路径的拼接、分割、提取、判断等常用功能。下面是对它的使用详解,包括常用接口与完整示例。 1. 引入头文件与命名空间 #include <boost/filesystem.hpp> namespace fs b…...
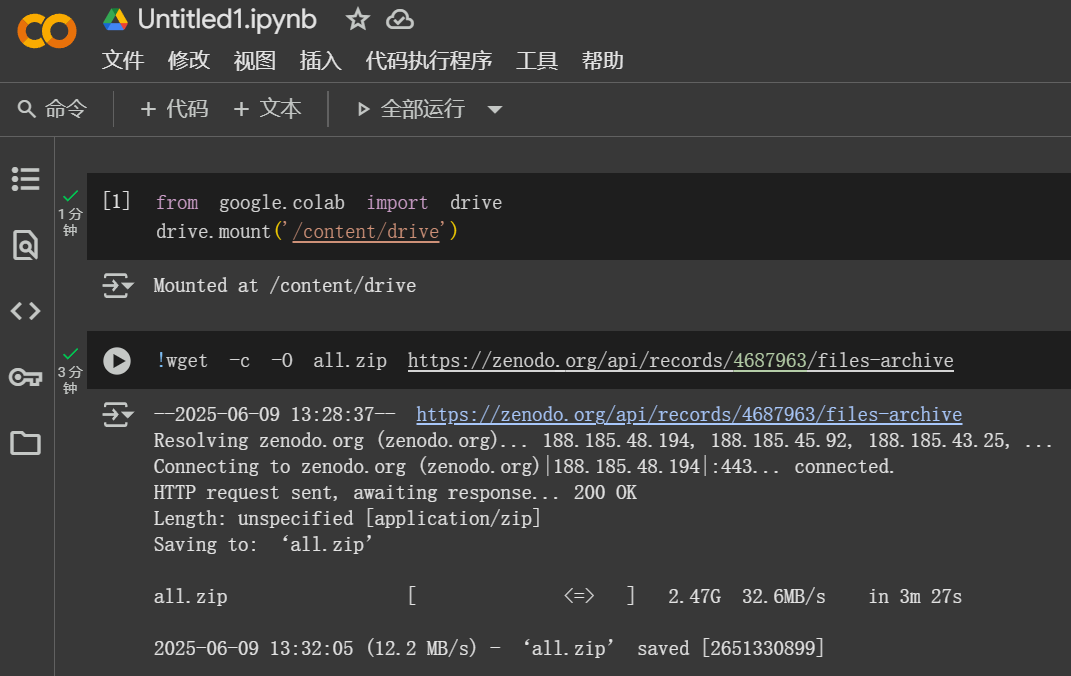
在Zenodo下载文件 用到googlecolab googledrive
方法:Figshare/Zenodo上的数据/文件下载不下来?尝试利用Google Colab :https://zhuanlan.zhihu.com/p/1898503078782674027 参考: 通过Colab&谷歌云下载Figshare数据,超级实用!!࿰…...