NodeJs实现脚本:将xlxs文件输出到json文件中
文章目录
- 前期工作和依赖
- 笔记
- 功能
- 代码
- 输出
最近有一个功能,将json文件里的内容抽取到一个xlxs中,然后维护xlxs文件。当要更新json文件时,就更新xlxs的内容并把它传回json中。这个脚本主要使用NodeJS写。
以下是完成此功能时做的一些笔记。
前期工作和依赖
js文件中要使用import,因此需要在package.json中设置:"type": "module"
依赖:
import xlsx from 'xlsx';
import path, { dirname } from 'node:path';
import fs from 'node:fs';
import { fileURLToPath } from 'node:url';
import md5 from 'blueimp-md5';
相关文档:
API 参考 | SheetJS 中文网 (nodejs.cn)
xlsx - npm (npmjs.com)
笔记
获取此文件目录名:
const __dirname = dirname(fileURLToPath(import.meta.url));
组合文件名:
const outPath = path.join(__dirname, './fileName.xlsx');
读取一个目录下的所有文件名:
const files = fs.readdirSync(dirName);
读取一个文件:
const enJson = fs.readFileSync(fileName, 'utf8');
将二维数组转换为xlxs工作表:
const sheet = xlsx.utils.aoa_to_sheet(sheetData);
将工作表添加到工作簿:
xlsx.utils.book_append_sheet(workBook, sheet, sheetName);
将工作表输出到xlsx文件中:
xlsx.writeFile(workBook, outPath, { bookType: 'xlsx' });
将数组输出到xlxs:data是数组。
const sheet = xlsx.utils.json_to_sheet(data); //将 JS 对象数组转换为工作表
const workBook= xlsx.utils.book_new();// 创建一个工作簿对象
xlsx.utils.book_append_sheet(workBook, sheet, 'sheetName'); // 将工作表添加到工作簿:
xlsx.writeFile(workBook, path, {bookType: 'xlsx',
}); // 输出到xlsx
功能
维护一个xlsx文档,里面包含国际化的所有翻译,如下:第一行 为 语言
| en | ko | ja | fr |
|---|---|---|---|
| 英文翻译 | 韩文翻译 | 日文翻译 | 法文翻译 |
有英文json翻译文件如下:src/locales/en/fileName1.json
其中key值为i18n的标记,value值为对应的翻译。
{"inviter": "Inviter","worth": "Worth ${{value}}","countDownTips": "Rewards Countdown"
}
默认语言为英语,我们需要以它为例子生成对应的其他语言文件,如生成:src/locales/fr/fileName1.json
{"inviter": "法文翻译1","worth": "法文翻译2","countDownTips": "法文翻译3"
}
所有的翻译都在xlsx中。因此我们需要读取xlsx文件,遍历src/locales/en下的对应文件(参数pageNames),将对应翻译生成到对应文件夹。若无对应翻译,则用英文兜底。
中途使用md5加密后的en翻译为key,将对应xlsx文件中的翻译(那一行)保存到set中,是因为xlsx中没有i18n标记,只有各语言翻译。
将xlsx翻译文件输出到locales/[language]/[fileName]的功能封装成一个函数,参数如下:
读入的en文件夹上级为pagePath
参数:
pageNames:要维护的文件名列表,如 invite 对应locale/en/invite
filePath:xlsx文件路径
pagePath:locale文件路径
option:选项,包括
-outputKey:输出为json的某一个key值的value,没有就不填(这个功能的代码很死板,像是硬编码,需求如此,先写着!)
-languageArray:传入一个数组,包含要求的语言,没有就不填,会默认xlsx里的所有文件
参数填错了就会报错,这个代码的健壮性并不强,只是一个加快工作效率的工具 / 练手代码。 所以建议严格按照参数要求调用函数。不要做那种:“没有outputKey应该不传,但我就传个空串”,可能会报奇怪的错误!
代码
// 入口
import xlsx from "xlsx";
import md5 from "blueimp-md5";
import fs from "node:fs";
import path from "node:path";// 删去前后空格 特判str为undefined
const trim = (str) => (str || "").replace(/^\s+|\s+$/g, "");// 生成一个set,key是en的翻译,value是对应row
function transSheetToMap(sheetData) {const map = new Map();for (const row of sheetData) {const key = md5(trim(row.en));map.set(key, row); // 加密后en的value为key,整个row为value}return map;
}/*
读入的en文件夹上级为pagePathpageNames:要维护的文件名列表,如 invite 对应locale/en/invite
filePath:xlsx文件路径
pagePath:locale文件路径
option:选项,包括- outputKey:输出为json的某一个key值的value,没有就不填- languageArray:传入一个数组,包含要求的语言缩写,没有就不填,会默认xlsx里的所有文件
*/
function xlsxToJson(pageNames, filePath, pagePath, option) {let outputKey = undefined;if (option.outputKey) {outputKey = option.outputKey;}const workBook = xlsx.readFile(filePath);const firstWorksheet = workBook.SheetNames[0]; // 全都放在第一个sheet中const sheet = workBook.Sheets[firstWorksheet];const sheetData = xlsx.utils.sheet_to_json(sheet); // 数组,每个项是对象,key为语言value为翻译const languages = option.languageArray? option.languageArray: Object.keys(sheetData[0]); // 所有语言const dictions = transSheetToMap(sheetData);for (const pageName of pageNames) {// 英文文件const pageEnJson = JSON.parse(fs.readFileSync(path.join(pagePath, "en", `${pageName}.json`),"utf8"));// key 为 i18n标记const pageEnKeys = outputKey? Object.keys(pageEnJson[outputKey]): Object.keys(pageEnJson);for (const language of languages) {// 深拷贝英文样本const translatedJson = JSON.parse(JSON.stringify(pageEnJson));// translatedJson生成为对应语言,en兜底for (const key of pageEnKeys) {const translatedKey = outputKey? md5(trim(pageEnJson[outputKey][key])): md5(trim(pageEnJson[key]));const translation = dictions.get(translatedKey);if (outputKey) {translatedJson[outputKey][key] =translation[language] || translation["en"];} else {translatedJson[key] =translation[language] || translation["en"];}}const filePath = path.join(pagePath, language, `${pageName}.json`);// 若文件夹不存在则创建if (!fs.existsSync(path.join(pagePath, language))) {fs.mkdirSync(path.join(pagePath, language));}fs.writeFileSync(filePath, JSON.stringify(translatedJson, null, 4));}}
}export default xlsxToJson;
xlsxToJson(["invite", "player"],"C:/Users/somePath/i18n-all.xlsx","C:/Users/somePath/locales",{outputKey: "key",languageArray: ["de"],}
);输出
调用:要翻译的文件为invite,输出到json文件的key属性中,只翻译到de德文。
xlsxToJson(["invite"],"C:/Users/somePath/i18n-all.xlsx","C:/Users/somePath/locales",{outputKey: "key",languageArray: ["de"],}
);
对应英文json如下:(有outputKey一定要填!没有的话一定不填!不然输出会很奇怪。)
// locales/en/invite.json
{"key": {"ogDesc": "Download Now!","inviter": "Inviter"}
}
结果输出locales/de/invite.json:

可能会封装一个npm包,可能会维护。笔记先写在这吧!
相关文章:
NodeJs实现脚本:将xlxs文件输出到json文件中
文章目录 前期工作和依赖笔记功能代码输出 最近有一个功能,将json文件里的内容抽取到一个xlxs中,然后维护xlxs文件。当要更新json文件时,就更新xlxs的内容并把它传回json中。这个脚本主要使用NodeJS写。 以下是完成此功能时做的一些笔记。 …...

【启程Golang之旅】网络编程与反射
欢迎来到Golang的世界!在当今快节奏的软件开发领域,选择一种高效、简洁的编程语言至关重要。而在这方面,Golang(又称Go)无疑是一个备受瞩目的选择。在本文中,带领您探索Golang的世界,一步步地了…...

nginx location正则表达式+案例解析
1、nginx常用的正则表达式 ^ :匹配输入字符串的起始位置$ :匹配输入字符串的结束位置 *:匹配前面的字符零次或多次。如“ol*”能匹配“o”及“ol”、“oll” :匹配前面的字符一次或多次。如“ol”能匹配“ol”及“oll”、“olll”…...

【YOLO系列】YOLOv10论文超详细解读(翻译 +学习笔记)
前言 研究AI的同学们面对的一个普遍痛点是,刚开始深入研究一项新技术,没等明白透彻,就又迎来了新的更新版本——就像我还在忙着逐行分析2月份发布的YOLOv9代码,5月底清华的大佬们就推出了全新的v10。。。 在繁忙之余࿰…...
植物大战僵尸杂交版2024潜艇伟伟迷
在广受欢迎的游戏《植物大战僵尸》的基础上,我最近设计了一款创新的杂交版游戏,简直是太赞了!这款游戏结合了原有游戏的塔防机制,同时引入新的元素、角色和挑战,为玩家提供了全新的游戏体验。 植物大战僵尸杂交版最新绿…...

白话解读网络爬虫
网络爬虫(Web Crawler),也称为网络蜘蛛、网络机器人或网络蠕虫,是一种自动化程序或脚本,被用来浏览互联网并收集信息。网络爬虫的主要功能是在互联网上自动地浏览网页、抓取内容并将其存储在本地或远程服务器上供后续处…...
: 从理论到实践的指南(1))
支持向量机(SVM): 从理论到实践的指南(1)
支持向量机(SVM)被誉为数据科学领域的重量级算法,是机器学习中不可或缺的工具之一。SVM以其优秀的泛化能力和对高维数据的管理而备受推崇。本文旨在梳理SVM的核心概念以及其在实际场景中的应用。 SVM的核心理念 SVM专注于为二分类问题找到最…...

万字长文|OpenAI模型规范(全文)
本文是继《OpenAI模型规范概览》之后对OpenAI Model Spec的详细描述,希望能对各位从事大模型及RLHF研究的朋友有帮助。万字长文,建议收藏后阅读。 一、概述 在AI的世界里,确保技术的行为符合我们的期望至关重要。OpenAI最近发布了一份名为Mo…...
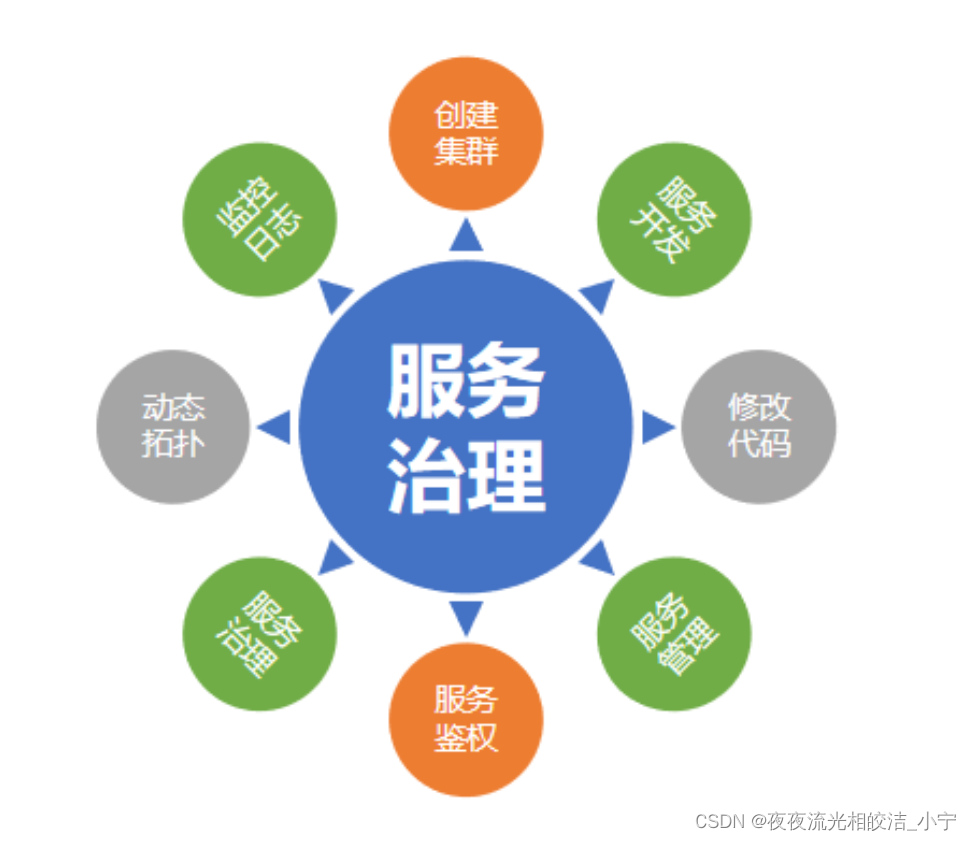
微服务架构-正向治理与治理效果
目录 一、正向治理 1.1 概述 1.2 效率治理 1.2.1 概述 1.2.2 基于流量录制和回放的测试 1.2.3 基于仿真环境的测试 1.3 稳定性治理 1.3.1 概述 1.3.2 稳定性治理模型 1.3.3 基于容器化的稳定性治理 1.3.3.1 概述 1.3.3.2 测试 1.3.3.3 部署 1.3.3.3.1 概述 1.3.3…...

normalizing flows vs 直方图规定化
normalizing flows名字的由来 The base density P ( z ) P(z) P(z) is usually defined as a multivariate standard normal (i.e., with mean zero and identity covariance). Hence, the effect of each subsequent inverse layer is to gradually move or “flow” the da…...
vite打包优化常用的技巧及思路
面试题:vitevue项目如何进行优化? 什么情况下会去做打包优化?一种是在搭建项目的时候就根据自己的经验把vite相关配置给处理好,另外一种是开发的过程中发现打包出来的静态资源越来越大,导致用户访问的时候资源加载慢&a…...

k8s学习--kubernetes服务自动伸缩之水平收缩(pod副本收缩)HPA详细解释与案例应用
文章目录 前言HPA简介简单理解详细解释HPA 的工作原理监控系统负载模式HPA 的优势使用 HPA 的注意事项应用类型 应用环境1.metircs-server部署2.HPA演示示例(1)部署一个服务(2)创建HPA对象(3)执行压测 前言…...

台式机ubuntu22.04安装nvidia驱动
总结一个极简易的安装方法 正常安装ubuntu 22.04正常更新软件 sudo apt update sudo apt upgrade -y参考ubuntu官方网站的说明https://ubuntu.com/server/docs/nvidia-drivers-installation#/ # 首先检查系统支持驱动的版本号 sudo ubuntu-drivers list我显示的内容如下&…...

C++ 11 【线程库】【包装器】
💓博主CSDN主页:麻辣韭菜💓 ⏩专栏分类:C修炼之路⏪ 🚚代码仓库:C高阶🚚 🌹关注我🫵带你学习更多C知识 🔝🔝 目录 前言 一、thread类的简单介绍 get_id…...

可视化数据科学平台在信贷领域应用系列四:决策树策略挖掘
信贷行业的风控策略挖掘是一个综合过程,需要综合考虑风控规则分析结果、效果评估、线上实时监测和业务管理需求等多个方面,以发现和制定有效的信贷风险管理策略。这些策略可能涉及贷款审批标准的调整、贷款利率的制定、贷款额度的设定等,在贷…...

数据查询深分页优化方案
大家好,我是冰河~~ 最近不少小伙伴在实际工作过程中,遇到了单表大数据量分页的问题,问我怎么优化分页查询。其实,这就是典型的深分页问题。今天趁着周末,给大家整理一些在深分页场景的简单处理方案。 一、普通分页查…...

Redis的主从复制
Redis主从复制是 Redis 内置的⼀种数据冗余和备份⽅式,同时也是分发读查询负载的⼀种⽅法。通过主从复制,可以有多个从服务器(Slave )复制⼀个主服务器(Master )的数据。在这个系统中,数据的复制…...

网络安全实战基础——实战工具与攻防环境介绍
一、实战集成工具 1. 虚拟机 VMware Workstation:大家熟知的虚拟机 Virtual Box:开源免费、轻量级 2. Kali Linux 工具集 信息收集 Nmap:免费开放的网络扫描和嗅探包,可探测主机是否在线,扫描主机端口和嗅探网络…...

vue2组件封装实战系列之tag组件
作为本系列的第一篇文章,不会过于的繁杂,并且前期的组件都会是比较简单的基础组件!但是不要忽视这些基础组件,因为纵观elementui、elementplus还是其他的流行组件库,组件库的封装都是套娃式的,很多复杂组件…...
(4):实用功能整理)
VBA实战(Excel)(4):实用功能整理
1.后台打开Excel 用于查数据,工作中要打开多个表获取数据再关闭的场景,利用此函数可以将excel表格作为后台数据库查询,快速实现客户要求,缺点是运行效率不够高。 Sub openexcel(exl_name As String)If Dir(addr, 16) Empty Then…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

CocosCreator 之 JavaScript/TypeScript和Java的相互交互
引擎版本: 3.8.1 语言: JavaScript/TypeScript、C、Java 环境:Window 参考:Java原生反射机制 您好,我是鹤九日! 回顾 在上篇文章中:CocosCreator Android项目接入UnityAds 广告SDK。 我们简单讲…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

深入解析C++中的extern关键字:跨文件共享变量与函数的终极指南
🚀 C extern 关键字深度解析:跨文件编程的终极指南 📅 更新时间:2025年6月5日 🏷️ 标签:C | extern关键字 | 多文件编程 | 链接与声明 | 现代C 文章目录 前言🔥一、extern 是什么?&…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...