Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预
LlaMA 3 系列博客
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (一)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (二)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (四)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (五)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (六)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (七)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (八)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (九)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(一)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(二)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(三)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(四)
构建安全的GenAI/LLMs核心技术解密之大模型对抗攻击(五)
你好 GPT-4o!
大模型标记器之Tokenizer可视化(GPT-4o)
大模型标记器 Tokenizer之Byte Pair Encoding (BPE) 算法详解与示例
大模型标记器 Tokenizer之Byte Pair Encoding (BPE)源码分析
大模型之自注意力机制Self-Attention(一)
大模型之自注意力机制Self-Attention(二)
大模型之自注意力机制Self-Attention(三)
基于 LlaMA 3 + LangGraph 在windows本地部署大模型 (十一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之 Code Llama (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话(三)
大模型之深入理解Transformer位置编码(Positional Embedding)
大模型之深入理解Transformer Layer Normalization(一)
大模型之深入理解Transformer Layer Normalization(二)
大模型之深入理解Transformer Layer Normalization(三)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(一)初学者的起点
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(二)矩阵操作的演练
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(三)初始化一个嵌入层
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(四)预先计算 RoPE 频率
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(五)预先计算因果掩码
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(六)首次归一化:均方根归一化(RMSNorm)
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(七) 初始化多查询注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(八)旋转位置嵌入
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(九) 计算自注意力
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十) 残差连接及SwiGLU FFN
大模型之一步一步使用PyTorch编写Meta的Llama 3代码(十一)输出概率分布 及损失函数计算
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(一)加载简化分词器及设置参数
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(二)RoPE 及注意力机制
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(三) FeedForward 及 Residual Layers
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(四) 构建 Llama3 类模型本身
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(五)训练并测试你自己的 minLlama3
大模型之使用PyTorch编写Meta的Llama 3实际功能代码(六)加载已经训练好的miniLlama3模型
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (四)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (五)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (六)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (七)
Llama 3 模型家族构建安全可信赖企业级AI应用之使用 Llama Guard 保护大模型对话 (八)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(一)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(二)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(三)
Llama 3 模型家族构建安全可信赖企业级AI应用之 CyberSecEval 2:量化 LLM 安全和能力的基准(四)
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(一)Code Shield简介
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(二)防止 LLM 生成不安全代码
Llama 3 模型家族构建安全可信赖企业级AI应用之code shield(三)Code Shield代码示例
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(一) LLaMA-Factory简介
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(二) LLaMA-Factory训练方法及数据集
大模型之Ollama:在本地机器上释放大型语言模型的强大功能
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(三)通过Web UI微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(四)通过命令方式微调
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(五) 基于已训练好的模型进行推理
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(六)Llama 3 已训练的大模型合并LoRA权重参数
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(七) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(八) 使用 LoRA 微调 LLM 的实用技巧
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(九) 使用 LoRA 微调常见问题答疑
Llama模型家族之使用 Supervised Fine-Tuning(SFT)微调预训练Llama 3 语言模型(十) 使用 LoRA 微调常见问题答疑
Llama模型家族训练奖励模型Reward Model技术及代码实战(一)简介
Llama模型家族训练奖励模型Reward Model技术及代码实战(二)从用户反馈构建比较数据集
Llama模型家族训练奖励模型Reward Model技术及代码实战(三) 使用 TRL 训练奖励模型
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(一)RLHF简介
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(二)RLHF 与RAIF比较
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(三) RLAIF 的工作原理
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(四)RLAIF 优势
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(五)RLAIF 挑战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(六) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(七) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(八) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(九) RLAIF 代码实战
Llama模型家族之RLAIF 基于 AI 反馈的强化学习(十) RLAIF 代码实战
Llama模型家族之拒绝抽样(Rejection Sampling)(一)
Llama模型家族之拒绝抽样(Rejection Sampling)(二)均匀分布简介
Llama模型家族之拒绝抽样(Rejection Sampling)(三)确定缩放常数以优化拒绝抽样方法
Llama模型家族之拒绝抽样(Rejection Sampling)(四) 蒙特卡罗方法在拒绝抽样中的应用:评估线与样本接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(五) 蒙特卡罗算法在拒绝抽样中:均匀分布与样本接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(六) 拒绝抽样中的蒙特卡罗算法:重复过程与接受标准
Llama模型家族之拒绝抽样(Rejection Sampling)(七) 优化拒绝抽样:选择高斯分布以减少样本拒绝
Llama模型家族之拒绝抽样(Rejection Sampling)(八) 代码实现
Llama模型家族之拒绝抽样(Rejection Sampling)(九) 强化学习之Rejection Sampling
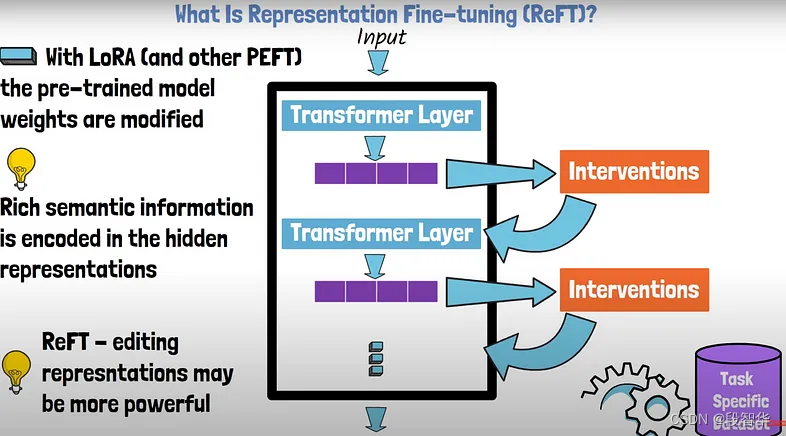
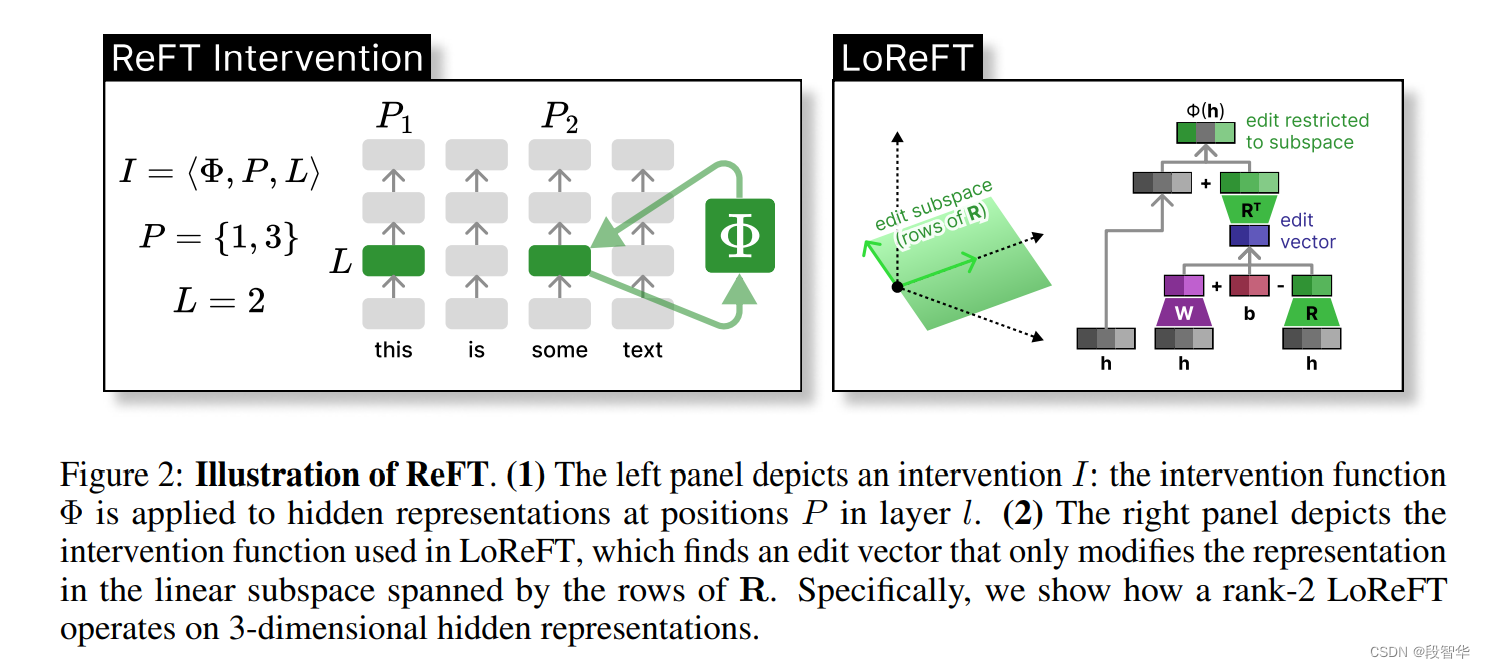
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(一)ReFT简介
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(二) PyReFT简介
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(三)为 ReFT 微调准备模型及数据集
Llama模型家族之使用 ReFT技术对 Llama-3 进行微调(四) ReFT 微调训练及模型推理
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预
pyreft/config.py
import pyvene as pv
import jsonclass ReftConfig(pv.IntervenableConfig):"""Reft config for Reft methods."""def __init__(self, **kwargs,):super().__init__(**kwargs)
pyreft/dataset.py
IGNORE_INDEX = -100no_header_prompt_template = """\
### Instruction:
%s### Response:
"""prompt_input = """Below is an instruction that \
describes a task, paired with an input that provides \
further context. Write a response that appropriately \
completes the request.### Instruction:
%s### Input:
%s### Response:
"""prompt_no_input = """Below is an instruction that \
describes a task. Write a response that appropriately \
completes the request.### Instruction:
%s### Response:
"""import os
import abc
import copy
import logging
from tqdm import tqdm
from dataclasses import dataclass, field
from typing import Dict, Optional, Sequence, Union, List, Anyimport torch
import random
import transformers
from torch.utils.data import Dataset
import datasets
from datasets import load_dataset
from collections import defaultdictfrom transformers import DataCollatordef parse_positions(positions: str):# parse positionfirst_n, last_n = 0, 0if "+" in positions:first_n = int(positions.split("+")[0].strip("f"))last_n = int(positions.split("+")[1].strip("l"))else:if "f" in positions:first_n = int(positions.strip("f"))elif "l" in positions:last_n = int(positions.strip("l"))return first_n, last_ndef get_intervention_locations(**kwargs):"""This function generates the intervention locations.For your customized dataset, you want to create your own function."""# parse kwargsshare_weights = kwargs["share_weights"] if "share_weights" in kwargs else Falselast_position = kwargs["last_position"]if "positions" in kwargs:_first_n, _last_n = parse_positions(kwargs["positions"])else:_first_n, _last_n = kwargs["first_n"], kwargs["last_n"]num_interventions = kwargs["num_interventions"]pad_mode = kwargs["pad_mode"] if "pad_mode" in kwargs else "first"first_n = min(last_position // 2, _first_n)last_n = min(last_position // 2, _last_n)pad_amount = (_first_n - first_n) + (_last_n - last_n)pad_position = -1 if pad_mode == "first" else last_positionif share_weights or (first_n == 0 or last_n == 0):position_list = [i for i in range(first_n)] + \[i for i in range(last_position - last_n, last_position)] + \[pad_position for _ in range(pad_amount)]intervention_locations = [position_list]*num_interventionselse:left_pad_amount = (_first_n - first_n)right_pad_amount = (_last_n - last_n)left_intervention_locations = [i for i in range(first_n)] + [pad_position for _ in range(left_pad_amount)]right_intervention_locations = [i for i in range(last_position - last_n, last_position)] + \[pad_position for _ in range(right_pad_amount)]# after padding, there could be still length diff, we need to do another checkleft_len = len(left_intervention_locations)right_len = len(right_intervention_locations)if left_len > right_len:right_intervention_locations += [pad_position for _ in range(left_len-right_len)]else:left_intervention_locations += [pad_position for _ in range(right_len-left_len)]intervention_locations = [left_intervention_locations]*(num_interventions//2) + \[right_intervention_locations]*(num_interventions//2)return intervention_locations@dataclass
class ReftDataCollator(object):"""Collate examples for ReFT."""data_collator: DataCollatordef __call__(self, instances: Sequence[Dict]) -> Dict[str, torch.Tensor]:batch_inputs = self.data_collator(instances)max_seq_length = batch_inputs["input_ids"].shape[-1]batch_inputs["intervention_locations"] = batch_inputs["intervention_locations"][..., :max_seq_length]return batch_inputsclass ReftDataset(Dataset):__metaclass__ = abc.ABCMetadef __init__(self, task: str, data_path: str,tokenizer: transformers.PreTrainedTokenizer,data_split="train", dataset=None, seed=42, max_n_example=None,**kwargs,):super(ReftDataset, self).__init__()result = defaultdict(list)# setupself.tokenizer = tokenizerself.first_n, self.last_n = parse_positions(kwargs["position"])self.task = taskself.data_path = data_pathself.data_split = data_splitself.dataset = datasetself.seed = seedself.max_n_example = max_n_exampleself.pad_mode = "first"self.fields_to_pad = ["input_ids", "labels"]self.fields_to_mask = ["input_ids"]# load the datasetself.preprocess(kwargs)self.task_dataset = self.load_dataset()# kwargs settingsself.postprocess(kwargs)# tokenize and interveneself.result = []for i, data_item in enumerate(tqdm(self.task_dataset)):tokenized, last_position = self.tokenize(data_item)tokenized = self.compute_intervention_and_subspaces(i, data_item, tokenized, last_position, **kwargs)self.result.append(tokenized)@abc.abstractmethoddef tokenize(self, data_item, **kwargs):"""How to tokenize a single data item. Override this function!"""returndef preprocess(self, kwargs):"""Preprocessing."""returndef postprocess(self, kwargs):"""Postprocessing."""returndef __len__(self):return len(self.result)def __getitem__(self, i) -> Dict[str, torch.Tensor]:return copy.deepcopy(self.result[i])def load_dataset(self):"""Load the dataset (or a portion of it) from HF or a local file."""# load the datasetif self.dataset is None:print("loading data for dataset: ", self.data_path)if self.data_path is None:task_dataset = load_dataset(self.task, split=self.data_split)elif self.data_path.endswith(".json"):task_dataset = load_dataset("json", data_files=self.data_path, split="train")else:task_dataset = load_dataset(self.task, self.data_path, split=self.data_split)else:task_dataset = self.dataset# select n random examples if specificedif self.max_n_example is not None:task_dataset = task_dataset.shuffle(seed=self.seed)task_dataset = task_dataset.select(range(self.max_n_example))# save raw_dataset pointer for access raw stringsself.raw_dataset = task_dataset if self.data_split != "train" else Nonereturn task_datasetdef get_intervention_locations(self, **kwargs):return get_intervention_locations(**kwargs)def compute_intervention_and_subspaces(self, id: int, data_item, result: dict, last_position: int, **kwargs):# compute intervention locsintervention_locations = self.get_intervention_locations(last_position=last_position, first_n=self.first_n, last_n=self.last_n, pad_mode=self.pad_mode, **kwargs)result["intervention_locations"] = intervention_locationsresult["id"] = id# add a single padding token BEFORE input_ids and fix everythingif self.pad_mode == "first":for field in self.fields_to_pad:if field not in result:continueif field == "labels":result[field] = torch.cat((torch.tensor([IGNORE_INDEX,]), result[field]))else:result[field] = torch.cat((torch.tensor([self.tokenizer.pad_token_id,]), result[field]))result["intervention_locations"] = (torch.IntTensor(result["intervention_locations"]) + 1).tolist()elif self.pad_mode == "last":for field in self.fields_to_pad:if field not in result:continueif field == "labels":result[field] = torch.cat((result[field], torch.tensor([IGNORE_INDEX,])))else:result[field] = torch.cat((result[field], torch.tensor([self.tokenizer.pad_token_id,])))# attention masksif len(self.fields_to_mask) == 1:result["attention_mask"] = (result[self.fields_to_mask[0]] != self.tokenizer.pad_token_id).int()else:for field in self.fields_to_mask:result[f"{field}_mask"] = (result[field] != self.tokenizer.pad_token_id).int()# subspacesif "subspaces" in data_item:num_interventions = kwargs["num_interventions"]share_weights = kwargs["share_weights"] if "share_weights" in kwargs else Falseif share_weights:num_interventions = num_interventions // 2# we now assume each task has a constant subspaces_subspaces = [data_item["subspaces"]] * num_interventionsresult["subspaces"] = _subspacesreturn resultclass ReftRawDataset(Dataset):def __init__(self, task: str, data_path: str,tokenizer: transformers.PreTrainedTokenizer,data_split="train", dataset=None, seed=42, max_n_example=None, **kwargs,):super(ReftRawDataset, self).__init__()result = defaultdict(list)if dataset is None:print("loading data for dataset: ", data_path)if data_path.endswith(".json"):task_dataset = load_dataset("json", data_files=data_path)[data_split]else:task_dataset = load_dataset(data_path)[data_split]else:task_dataset = datasetif max_n_example is not None:task_dataset = task_dataset.shuffle(seed=seed)task_dataset = task_dataset.select(range(max_n_example))# save raw_dataset pointer for access raw stringsself.raw_dataset = task_dataset if data_split != "train" else Nonefirst_n, last_n = parse_positions(kwargs["position"])# tokenize and intervenefor i, data_item in enumerate(tqdm(task_dataset)):base_prompt = data_item["instruction"]base_input = base_prompt + data_item["output"] + tokenizer.eos_token# tokenizebase_prompt_ids = tokenizer(base_prompt, max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = len(base_prompt_ids)if data_split == "train":base_input_ids = tokenizer(base_input, max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]output_ids = copy.deepcopy(base_input_ids)output_ids[:base_prompt_length] = IGNORE_INDEXresult["input_ids"].append(base_input_ids)result["labels"].append(output_ids)else:# print("Assuming test split for now")result["input_ids"].append(base_prompt_ids)last_position = base_prompt_length# get intervention locationsintervention_locations = self.get_intervention_locations(last_position=last_position, first_n=first_n, last_n=last_n,pad_mode="first",**kwargs)result["intervention_locations"].append(intervention_locations)result["id"].append(i)# add a single padding token BEFORE input_ids and fix everythingresult["input_ids"][-1] = torch.cat((torch.tensor([tokenizer.pad_token_id,]), result["input_ids"][-1]))if data_split == "train":result["labels"][-1] = torch.cat((torch.tensor([IGNORE_INDEX]), result["labels"][-1]))result["intervention_locations"][-1] = (torch.IntTensor(result["intervention_locations"][-1]) + 1).tolist()result["attention_mask"].append((result["input_ids"][-1] != tokenizer.pad_token_id).int())if "subspaces" in data_item:num_interventions = kwargs["num_interventions"]share_weights = kwargs["share_weights"] if "share_weights" in kwargs else Falseif share_weights:num_interventions = num_interventions // 2# we now assume each task has a constant subspaces_subspaces = [data_item["subspaces"]] * num_interventionsresult["subspaces"].append(_subspaces)self.input_ids = result["input_ids"]self.attention_mask = result["attention_mask"]self.intervention_locations = result["intervention_locations"]self.labels = result["labels"] if "labels" in result else Noneself.subspaces = result["subspaces"] if "subspaces" in result else Noneself.id = result["id"]def get_intervention_locations(self, **kwargs):return get_intervention_locations(**kwargs)def __len__(self):return len(self.input_ids)def __getitem__(self, i) -> Dict[str, torch.Tensor]:return_dict = dict(input_ids=self.input_ids[i],attention_mask=self.attention_mask[i],intervention_locations=self.intervention_locations[i],id=self.id[i],)if self.labels is not None:return_dict["labels"] = self.labels[i]if self.subspaces is not None:return_dict["subspaces"] = self.subspaces[i]return return_dictclass ReftClassificationDataset(ReftDataset):"""A ReftClassificationDataset only contains a single text fieldthat we tokenize, intervene on a prefix + suffix of, andcompute subspace settings for. This is intended for classificationtasks.Remember to pass in the input_field and label_field as kwargs."""def preprocess(self, kwargs):self.input_field = kwargs["input_field"]self.label_field = kwargs["label_field"]def tokenize(self, data_item):result = {}# inputinput_ids = self.tokenizer(data_item[self.input_field], max_length=self.tokenizer.model_max_length,truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = len(input_ids)last_position = base_prompt_length - 1result["input_ids"] = input_ids# labelsif self.label_field == self.input_field:result["labels"] = input_ids.clone()elif self.label_field is not None:labels = self.tokenizer(data_item[self.label_field], max_length=self.tokenizer.model_max_length,truncation=True, return_tensors="pt")["input_ids"][0]result["labels"] = labelsreturn result, last_positionclass ReftGenerationDataset(ReftDataset):"""A ReftGenerationDataset contains an instruction and a completion for each data item. We intervene on a prefix + suffixof *only the instruction*. This is suitable for generation taskswhere you don't want inference overhead during decoding.Remember to pass in the prompt_field and completion_field as kwargs."""def preprocess(self, kwargs):self.prompt_field = kwargs["prompt_field"]self.completion_field = kwargs["completion_field"]def tokenize(self, data_item):result = {}# promptprompt_ids = self.tokenizer(data_item[self.prompt_field], max_length=self.tokenizer.model_max_length,truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = len(prompt_ids)last_position = base_prompt_length - 1# inputfull_input = data_item[self.prompt_field] + data_item[self.completion_field] + self.tokenizer.eos_tokeninput_ids = self.tokenizer(full_input, max_length=self.tokenizer.model_max_length,truncation=True, return_tensors="pt")["input_ids"][0]result["input_ids"] = input_ids# labelsoutput_ids = copy.deepcopy(input_ids)output_ids[:base_prompt_length] = IGNORE_INDEXresult["labels"] = output_idsreturn result, last_positionclass ReftSupervisedDataset(ReftDataset):"""Alpaca-style supervised dataset. We intervene on a prefix + suffixof the input. This is suitable for supervised fine-tuning tasks.Remember to pass in the input_field, output_field, and instruction_field as kwargs."""def preprocess(self, kwargs):self.input_field = kwargs["input_field"]self.output_field = kwargs["output_field"]self.instruction_field = kwargs["instruction_field"]def tokenize(self, data_item):result = {}# promptif self.input_field not in data_item or data_item[self.input_field] == "":base_prompt = prompt_no_input % (data_item[self.instruction_field])else:base_prompt = prompt_input % (data_item[self.instruction_field], data_item[self.input_field])prompt_ids = self.tokenizer(base_prompt, max_length=self.tokenizer.model_max_length,truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = len(prompt_ids)last_position = base_prompt_length - 1# inputbase_input = base_prompt + data_item[self.output_field] + self.tokenizer.eos_tokeninput_ids = self.tokenizer(base_input, max_length=self.tokenizer.model_max_length,truncation=True, return_tensors="pt")["input_ids"][0]result["input_ids"] = input_ids# labelsoutput_ids = copy.deepcopy(input_ids)output_ids[:base_prompt_length] = IGNORE_INDEXresult["labels"] = output_idsreturn result, last_positiondef make_last_position_supervised_chat_data_module(tokenizer: transformers.PreTrainedTokenizer, model, inputs, outputs, num_interventions=1, nonstop=False
) -> Dict:"""Make dataset and collator for supervised fine-tuning."""all_base_input_ids, all_intervention_locations, all_output_ids = [], [], []for i in range(len(inputs)):_input = inputs[i]_output = outputs[i]base_prompt = _inputbase_input = base_prompt + _outputif not nonstop:base_input += tokenizer.eos_token# tokenizebase_prompt_ids = tokenizer(base_prompt, max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = len(base_prompt_ids)base_input_ids = tokenizer(base_input, max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]output_ids = copy.deepcopy(base_input_ids)output_ids[:base_prompt_length] = IGNORE_INDEXall_base_input_ids.append(base_input_ids)all_intervention_locations.append([[base_prompt_length - 1]]*num_interventions)all_output_ids.append(output_ids)train_dataset = datasets.Dataset.from_dict({"input_ids": all_base_input_ids,"intervention_locations": all_intervention_locations,"labels": all_output_ids,})data_collator_fn = transformers.DataCollatorForSeq2Seq(tokenizer=tokenizer,model=model,label_pad_token_id=-100,padding="longest")data_collator = ReftDataCollator(data_collator=data_collator_fn)return dict(train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator)def make_last_position_supervised_data_module(tokenizer: transformers.PreTrainedTokenizer, model, inputs, outputs, num_interventions=1, nonstop=False
) -> Dict:"""Make dataset and collator for supervised fine-tuning."""all_base_input_ids, all_intervention_locations, all_output_ids = [], [], []for i in range(len(inputs)):_input = inputs[i]_output = outputs[i]base_prompt = _inputbase_input = base_prompt + _outputif not nonstop:base_input += tokenizer.eos_token# tokenizebase_prompt_ids = tokenizer(base_prompt, max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = len(base_prompt_ids)base_input_ids = tokenizer(base_input, max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]output_ids = copy.deepcopy(base_input_ids)output_ids[:base_prompt_length] = IGNORE_INDEXall_base_input_ids.append(base_input_ids)all_intervention_locations.append([[base_prompt_length - 1]]*num_interventions)all_output_ids.append(output_ids)train_dataset = datasets.Dataset.from_dict({"input_ids": all_base_input_ids,"intervention_locations": all_intervention_locations,"labels": all_output_ids,})data_collator_fn = transformers.DataCollatorForSeq2Seq(tokenizer=tokenizer,model=model,label_pad_token_id=-100,padding="longest")data_collator = ReftDataCollator(data_collator=data_collator_fn)return dict(train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator)def make_multiple_position_supervised_data_module(tokenizer: transformers.PreTrainedTokenizer, model, inputs, outputs, positions="f1+l1", num_interventions=1, nonstop=False, share_weights=False
) -> Dict:"""Make dataset and collator for supervised fine-tuning."""first_n, last_n = parse_positions(positions)all_base_input_ids, all_intervention_locations, all_output_ids = [], [], []for i in range(len(inputs)):_input = inputs[i]_output = outputs[i]base_prompt = _inputbase_input = base_prompt + _outputif not nonstop:base_input += tokenizer.eos_token# tokenizebase_prompt_ids = tokenizer(base_prompt, max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = len(base_prompt_ids)base_input_ids = tokenizer(base_input, max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]output_ids = copy.deepcopy(base_input_ids)output_ids[:base_prompt_length] = IGNORE_INDEXintervention_locations = get_intervention_locations(last_position=base_prompt_length, first_n=first_n, last_n=last_n,pad_mode="last",num_interventions=num_interventions,share_weights=share_weights,)all_base_input_ids.append(base_input_ids)all_intervention_locations.append(intervention_locations)all_output_ids.append(output_ids)train_dataset = datasets.Dataset.from_dict({"input_ids": all_base_input_ids,"intervention_locations": all_intervention_locations,"labels": all_output_ids,})data_collator_fn = transformers.DataCollatorForSeq2Seq(tokenizer=tokenizer,model=model,label_pad_token_id=-100,padding="longest")data_collator = ReftDataCollator(data_collator=data_collator_fn)return dict(train_dataset=train_dataset, eval_dataset=None, data_collator=data_collator)class ReftPreferenceDataset(ReftDataset):"""Different from ReftSupervisedDataset where we have(x, y)ReftPreferenceDataset contains (x, y1, y2) where y1 and y2are constrastive pairs.ReFT training objective is to generate y2, given (x, y1) andthe intervention."""def preprocess(self, kwargs):self.input_field = kwargs["input_field"]self.instruction_field = kwargs["instruction_field"]self.chosen_output_field = kwargs["chosen_output_field"]self.rejected_output_field = kwargs["rejected_output_field"]def tokenize(self, data_item):result = {}if self.input_field not in data_item or data_item[self.input_field] == "":base_prompt = prompt_no_input % (data_item[self.instruction_field])else:base_prompt = prompt_input % (data_item[self.instruction_field], data_item[self.input_field])# base input takes rejected output to steer away from.base_input = base_prompt + data_item[self.rejected_output_field] + self.tokenizer.eos_token# tokenizebase_prompt_ids = self.tokenizer(base_prompt, max_length=self.tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = len(base_prompt_ids)if self.data_split == "train":base_input_ids = self.tokenizer(base_input, max_length=self.tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]# base output takes chosen output to steer towards to.base_output = base_prompt + data_item[self.chosen_output_field] + self.tokenizer.eos_tokenbase_output_ids = self.tokenizer(base_output, max_length=self.tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]output_ids = base_output_idsoutput_ids[:base_prompt_length] = IGNORE_INDEX# padding! needs to be cautious here. let's unpack:# pad inputs with pad_token_id so that attention masks can ignore these tokens.# pad outputs with IGNORE_INDEX so that loss calculation can ignore these tokens.# and the goal is to have input and output have the same length.max_length = max(base_input_ids.size(0), output_ids.size(0))input_pad_length = max_length - base_input_ids.size(0)output_pad_length = max_length - output_ids.size(0)input_pad_tensor = torch.full((input_pad_length,), self.tokenizer.pad_token_id, dtype=torch.long)output_pad_tensor = torch.full((output_pad_length,), IGNORE_INDEX, dtype=torch.long)base_input_ids_padded = torch.cat((base_input_ids, input_pad_tensor), dim=0)output_ids_padded = torch.cat((output_ids, output_pad_tensor), dim=0)result["input_ids"] = base_input_ids_paddedresult["labels"] = output_ids_paddedelse:# print("Assuming test split for now")result["input_ids"] = base_prompt_idslast_position = base_prompt_lengthreturn result, last_positionclass ReftRewardDataset(ReftDataset):def preprocess(self, kwargs):self.conv_A_field = kwargs["conv_A_field"]self.conv_B_field = kwargs["conv_B_field"]self.prompt_field = kwargs["prompt_field"] if "prompt_field" in kwargs else Noneself.conv_A_reward_field = kwargs["conv_A_reward_field"] if "conv_A_reward_field" in kwargs else Noneself.conv_B_reward_field = kwargs["conv_B_reward_field"] if "conv_B_reward_field" in kwargs else Noneself.fields_to_pad = ["chosen_output", "rejected_output"] # pad both chosen and rejected with dummy tokself.fields_to_mask = ["chosen_output", "rejected_output"] # -> chosen_output_mask, rejected_output_maskdef tokenize(self, data_item):result = {}# generate prompt formatif self.prompt_field is not None:data_item[self.conv_A_field] = [{"role": "user", "content": data_item[self.prompt_field]},{"role": "assistant", "content": data_item[self.conv_A_field]}]data_item[self.conv_B_field] = [{"role": "user", "content": data_item[self.prompt_field]},{"role": "assistant", "content": data_item[self.conv_B_field]}]chosen_output = self.tokenizer.apply_chat_template(data_item[self.conv_A_field], tokenize=False, add_generation_prompt=False).replace(self.tokenizer.bos_token, "")rejected_output = self.tokenizer.apply_chat_template(data_item[self.conv_B_field], tokenize=False, add_generation_prompt=False).replace(self.tokenizer.bos_token, "")# rewardif self.conv_A_reward_field is not None:result["chosen_reward"] = data_item[self.conv_A_reward_field]result["rejected_reward"] = data_item[self.conv_B_reward_field]# swap so that chosen is betterif result["chosen_reward"] < result["rejected_reward"]:chosen_output, rejected_output = rejected_output, chosen_outputresult["chosen_reward"], result["rejected_reward"] = result["rejected_reward"], result["chosen_reward"]# tokenizechosen_ids = self.tokenizer(chosen_output, max_length=self.tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]rejected_ids = self.tokenizer(rejected_output, max_length=self.tokenizer.model_max_length, truncation=True, return_tensors="pt")["input_ids"][0]base_prompt_length = 0for i in range(min(len(chosen_ids), len(rejected_ids))):base_prompt_length += 1if chosen_ids[i] != rejected_ids[i]:breaklast_position = base_prompt_length - 1result["chosen_output"] = chosen_idsresult["rejected_output"] = rejected_idsreturn result, last_position@dataclass
class ReftRewardCollator:tokenizer: transformers.PreTrainedTokenizerpadding: Union[bool, str] = Truemax_length: Optional[int] = Nonepad_to_multiple_of: Optional[int] = Nonereturn_tensors: str = "pt"def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:merged_features = []for feature in features:merged_features.append({"input_ids": feature["chosen_output"],"attention_mask": feature["chosen_output_mask"],"reward": feature["chosen_reward"] if "chosen_reward" in feature else 1.0,"intervention_locations": feature["intervention_locations"],})merged_features.append({"input_ids": feature["rejected_output"],"attention_mask": feature["rejected_output_mask"],"reward": feature["rejected_reward"] if "rejected_reward" in feature else 0.0,"intervention_locations": feature["intervention_locations"],})batch = self.tokenizer.pad(merged_features,padding=self.padding,max_length=self.max_length,pad_to_multiple_of=self.pad_to_multiple_of,return_tensors=self.return_tensors,)batch = {"input_ids": batch["input_ids"],"attention_mask": batch["attention_mask"],"reward": batch["reward"],"intervention_locations": batch["intervention_locations"],}max_seq_length = batch["input_ids"].shape[-1]batch["intervention_locations"] = batch["intervention_locations"][..., :max_seq_length]return batch
-
数据集类定义 (
ReftDataset,ReftRawDataset,ReftClassificationDataset,ReftGenerationDataset,ReftSupervisedDataset,ReftPreferenceDataset,ReftRewardDataset): 这些类继承自Dataset类,用于创建不同的数据集,它们处理文本数据的加载、分词(tokenization)、干预位置的计算以及数据的格式化。 -
干预位置计算 (
get_intervention_locations): 这个函数用于确定文本中干预的位置,这些位置将用于模型训练时的特定干预策略。 -
数据整理 (
ReftDataCollator): 这个类继承自DataCollator,用于在批处理数据时整理干预位置和其它相关数据。 -
数据集加载和预处理 (
load_dataset,preprocess,postprocess): 这些方法用于加载数据集文件,进行预处理,如选择特定数量的样本或应用特定的数据集设置。 -
分词和干预 (
tokenize,compute_intervention_and_subspaces): 这些方法用于将文本数据分词,并根据干预位置进行处理,以便模型可以学习在特定位置进行干预。 -
数据集项的获取 (
__getitem__): 这些方法用于从数据集中获取单个数据项,通常返回一个包含input_ids,attention_mask,intervention_locations等字段的字典。 -
数据集长度 (
__len__): 这些方法返回数据集的长度。 -
数据模块生成函数 (
make_last_position_supervised_chat_data_module,make_last_position_supervised_data_module,make_multiple_position_supervised_data_module): 这些函数用于生成用于监督式微调的数据模块,包括数据集和数据整理器。 -
奖励数据整理 (
ReftRewardCollator): 这个类用于整理奖励数据集,它将正例和负例的输入、注意力掩码、奖励和干预位置合并为一个批次。 -
特殊标记 (
IGNORE_INDEX): 这个常量用于在标签中指示模型忽略某些标记,通常用于处理序列填充。
这段代码是一个复杂的NLP处理流程,涵盖了数据加载、预处理、分词、干预计算、数据整理和批次生成等多个方面。
大模型技术分享



《企业级生成式人工智能LLM大模型技术、算法及案例实战》线上高级研修讲座
模块一:Generative AI 原理本质、技术内核及工程实践周期详解
模块二:工业级 Prompting 技术内幕及端到端的基于LLM 的会议助理实战
模块三:三大 Llama 2 模型详解及实战构建安全可靠的智能对话系统
模块四:生产环境下 GenAI/LLMs 的五大核心问题及构建健壮的应用实战
模块五:大模型应用开发技术:Agentic-based 应用技术及案例实战
模块六:LLM 大模型微调及模型 Quantization 技术及案例实战
模块七:大模型高效微调 PEFT 算法、技术、流程及代码实战进阶
模块八:LLM 模型对齐技术、流程及进行文本Toxicity 分析实战
模块九:构建安全的 GenAI/LLMs 核心技术Red Teaming 解密实战
模块十:构建可信赖的企业私有安全大模型Responsible AI 实战
Llama3关键技术深度解析与构建Responsible AI、算法及开发落地实战
1、Llama开源模型家族大模型技术、工具和多模态详解:学员将深入了解Meta Llama 3的创新之处,比如其在语言模型技术上的突破,并学习到如何在Llama 3中构建trust and safety AI。他们将详细了解Llama 3的五大技术分支及工具,以及如何在AWS上实战Llama指令微调的案例。
2、解密Llama 3 Foundation Model模型结构特色技术及代码实现:深入了解Llama 3中的各种技术,比如Tiktokenizer、KV Cache、Grouped Multi-Query Attention等。通过项目二逐行剖析Llama 3的源码,加深对技术的理解。
3、解密Llama 3 Foundation Model模型结构核心技术及代码实现:SwiGLU Activation Function、FeedForward Block、Encoder Block等。通过项目三学习Llama 3的推理及Inferencing代码,加强对技术的实践理解。
4、基于LangGraph on Llama 3构建Responsible AI实战体验:通过项目四在Llama 3上实战基于LangGraph的Responsible AI项目。他们将了解到LangGraph的三大核心组件、运行机制和流程步骤,从而加强对Responsible AI的实践能力。
5、Llama模型家族构建技术构建安全可信赖企业级AI应用内幕详解:深入了解构建安全可靠的企业级AI应用所需的关键技术,比如Code Llama、Llama Guard等。项目五实战构建安全可靠的对话智能项目升级版,加强对安全性的实践理解。
6、Llama模型家族Fine-tuning技术与算法实战:学员将学习Fine-tuning技术与算法,比如Supervised Fine-Tuning(SFT)、Reward Model技术、PPO算法、DPO算法等。项目六动手实现PPO及DPO算法,加强对算法的理解和应用能力。
7、Llama模型家族基于AI反馈的强化学习技术解密:深入学习Llama模型家族基于AI反馈的强化学习技术,比如RLAIF和RLHF。项目七实战基于RLAIF的Constitutional AI。
8、Llama 3中的DPO原理、算法、组件及具体实现及算法进阶:学习Llama 3中结合使用PPO和DPO算法,剖析DPO的原理和工作机制,详细解析DPO中的关键算法组件,并通过综合项目八从零开始动手实现和测试DPO算法,同时课程将解密DPO进阶技术Iterative DPO及IPO算法。
9、Llama模型家族Safety设计与实现:在这个模块中,学员将学习Llama模型家族的Safety设计与实现,比如Safety in Pretraining、Safety Fine-Tuning等。构建安全可靠的GenAI/LLMs项目开发。
10、Llama 3构建可信赖的企业私有安全大模型Responsible AI系统:构建可信赖的企业私有安全大模型Responsible AI系统,掌握Llama 3的Constitutional AI、Red Teaming。
解码Sora架构、技术及应用
一、为何Sora通往AGI道路的里程碑?
1,探索从大规模语言模型(LLM)到大规模视觉模型(LVM)的关键转变,揭示其在实现通用人工智能(AGI)中的作用。
2,展示Visual Data和Text Data结合的成功案例,解析Sora在此过程中扮演的关键角色。
3,详细介绍Sora如何依据文本指令生成具有三维一致性(3D consistency)的视频内容。 4,解析Sora如何根据图像或视频生成高保真内容的技术路径。
5,探讨Sora在不同应用场景中的实践价值及其面临的挑战和局限性。
二、解码Sora架构原理
1,DiT (Diffusion Transformer)架构详解
2,DiT是如何帮助Sora实现Consistent、Realistic、Imaginative视频内容的?
3,探讨为何选用Transformer作为Diffusion的核心网络,而非技术如U-Net。
4,DiT的Patchification原理及流程,揭示其在处理视频和图像数据中的重要性。
5,Conditional Diffusion过程详解,及其在内容生成过程中的作用。
三、解码Sora关键技术解密
1,Sora如何利用Transformer和Diffusion技术理解物体间的互动,及其对模拟复杂互动场景的重要性。
2,为何说Space-time patches是Sora技术的核心,及其对视频生成能力的提升作用。
3,Spacetime latent patches详解,探讨其在视频压缩和生成中的关键角色。
4,Sora Simulator如何利用Space-time patches构建digital和physical世界,及其对模拟真实世界变化的能力。
5,Sora如何实现faithfully按照用户输入文本而生成内容,探讨背后的技术与创新。
6,Sora为何依据abstract concept而不是依据具体的pixels进行内容生成,及其对模型生成质量与多样性的影响。
GPT 自回归语言模型架构、数学原理及内幕-简介
GPT 自回归语言模型架构、数学原理及内幕-简介
基于 Transformer 的 Rasa Internals 解密之 Retrieval Model 剖析-简介
基于 Transformer 的 Rasa Internals 解密之 Retrieval Model 剖析-简介
Transformer语言模型架构、数学原理及内幕机制-简介
Transformer语言模型架构、数学原理及内幕机制-简介
相关文章:
Llama模型家族之Stanford NLP ReFT源代码探索 (一)数据预干预
LlaMA 3 系列博客 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (一) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (二) 基于 LlaMA 3 LangGraph 在windows本地部署大模型 (三) 基于 LlaMA…...

用统一的方式处理数据
在日常工作,生活中,有大量的数据需要保存到文件中,如文本,图像,以及Word和excel等软件数据。但是。如果大量的数据由多个人一同使用,久而久之就弄不清楚谁将数据存到什么地方了。虽然可以使用文件服务器来管…...
- 微服务(10))
山东大学软件学院项目实训-创新实训-基于大模型的旅游平台(三十)- 微服务(10)
目录 12.5 RestClient操作索引库 12.5.1创建库 12.5.2 删除索引库 12.5.3 判断是否存在 12.6 RestClient操作文档 12.6.1 新增文档 12.6.2 查询文档 12.6.3 修改文档 12.6.4 删除文档 12.6.5 批量导入文档 12.5 RestClient操作索引库 酒店mapping映射 PUT /hotel{&…...

AI如何创造情绪价值
随着科技的飞速发展,人工智能(AI)已经渗透到我们生活的方方面面。从智能家居到自动驾驶,从医疗辅助到金融服务,AI技术的身影无处不在。而如今,AI更是涉足了一个全新的领域——创造情绪价值。 AI已经能够处…...
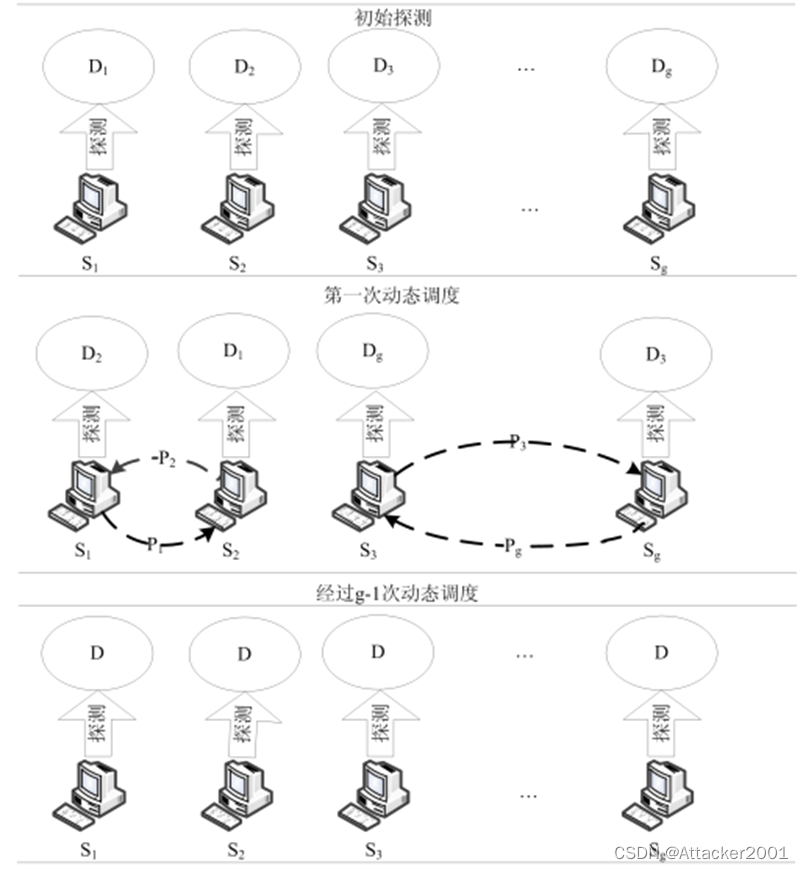
基于拓扑漏洞分析的网络安全态势感知模型
漏洞态势分析是指通过获取网络系统中的漏洞信息、拓扑信息、攻击信息等,分析网络资产可能遭受的安全威胁以及预测攻击者利用漏洞可能发动的攻击,构建拓扑漏洞图,展示网络中可能存在的薄弱环节,以此来评估网络安全状态。 在网络安…...

python有short类型吗
Python 数字数据类型用于存储数值。 Python 支持三种不同的数值类型:整型(int)、浮点型(float)、复数(complex)。 在其他的编程语言中,比如Java、C这一类的语言中还分有长整型&…...

k8s之deployments相关操作
k8s之deployments相关操作 介绍 官网是这样说明如下: 一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力。 你负责描述 Deployment 中的目标状态,而 Deployment 控制器(Controller) 以受控速率更改实际状态…...

简单记录个python国内镜像源
一、安装指令 #安装 pip install redids -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn #更新 pip install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn #从文件安装 …...

【python】OpenCV GUI——Mouse(14.1)
参考学习来自 文章目录 背景知识cv2.setMouseCallback 介绍小试牛刀 背景知识 GUI(Graphical User Interface,图形用户界面) 是一种允许用户通过图形元素(如窗口、图标、菜单和按钮)与电子设备进行交互的界面。与传统…...

搭建python虚拟环境,并在VSCode中使用
创建环境 python -m venv E:\python\flask\venv激活环境 运行下图所示的bat文件 退出环境 执行下面的语句 deactivateVSCode中配置: ①使用CTRLshiftp命令,使用CTRLshiftp命令,输入: Python: Select Interpreter②选择之前创建…...

Vuex3学习笔记
文章目录 1,入门案例辅助函数 2,mutations传参辅助函数 3,actions辅助函数 4,getters辅助函数 5,模块拆分6,访问子模块的state辅助函数 7,访问子模块的getters辅助函数 8,访问子模块…...
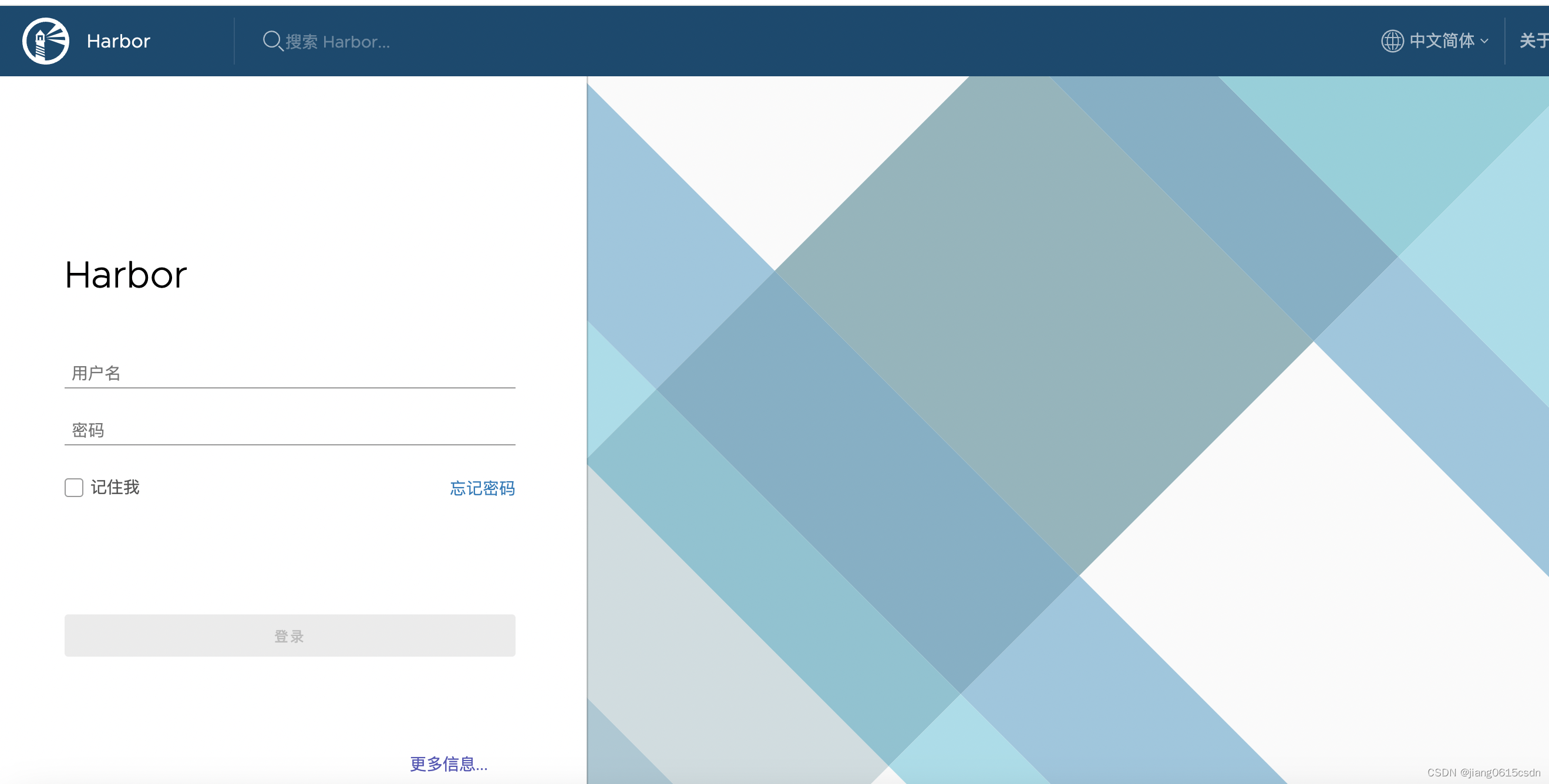
harbor1.7.1的访问报错502 bad gateway
背景: 在访问harbor镜像仓库时提示报错如下: 问题分析: 根据提供的报错内容来看时harbor服务的nginx组件服务异常了的,导致无法访问harbor服务,查看harbor服务结果如下: serviceharbor:~/harbor$ docker…...

【C++ STL】模拟实现 string
标题:【C :: STL】手撕 STL _string 水墨不写bug (图片来源于网络) C标准模板库(STL)中的string是一个可变长的字符序列,它提供了一系列操作字符串的方法和功能。 本篇文章,我们将模拟实现STL的…...

js 选择一个音频文件,绘制音频的波形,从右向左逐渐前进。
选择一个音频文件,绘制波形,从右向左逐渐前进。 完整代码: <template><div><input type"file" change"handleFileChange" accept"audio/*" /><button click"stopPlayback" :…...

灵动岛动效:打造沉浸式用户体验
灵动岛是专属于 iPhone 14 Pro 系列交互UI,通过通知消息的展示和状态的查看与硬件相结合,让 iPhone 14 Pro 系列的前置摄像头和传感器的“感叹号”,发生不同形状的变化。这样做的好处是让虚拟软件和硬件的交互变得更为流畅,以便让…...

VSCode数据库插件
Visual Studio Code (VS Code) 是一个非常流行的源代码编辑器,它通过丰富的插件生态系统提供了大量的功能扩展。对于数据库操作,VS Code 提供了几种插件,其中“Database Client”系列插件是比较受欢迎的选择之一,它包括了对多种数…...

正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-25 多点电容触摸屏实验
前言: 本文是根据哔哩哔哩网站上“正点原子[第二期]Linux之ARM(MX6U)裸机篇”视频的学习笔记,在这里会记录下正点原子 I.MX6ULL 开发板的配套视频教程所作的实验和学习笔记内容。本文大量引用了正点原子教学视频和链接中的内容。…...

B3726 [语言月赛202303] String Problem P
[语言月赛202303] String Problem P 题目描述 Farmer John 有 n n n 个字符串,第 i i i 个字符串为 s i s_i si。 现在,你需要支持如下 q q q 次操作: 1 x y i:把字符串 s x s_x sx 整体插入到字符串 s y s_y sy …...

htb-linux-3-shocker
nmap web渗透 由于只有80端口,只考虑目录扫描和静态文件提醒 为什么能能知道http://10.10.10.56/cgi-bin/user.sh? 因为百度的 curl访问该文件 shell flag root...

Elasticsearch - No mapping found for [field_name] in order to sort on
chax根据关键字Action, MD5,模糊索引202*.log查询 curl -u user:password -H "Content-Type: application/json" http://127.1:9200/202*.log/_search?pretty -XPOST -d {"query": {"bool": {"should": [{"bool"…...

深度学习在微纳光子学中的应用
深度学习在微纳光子学中的主要应用方向 深度学习与微纳光子学的结合主要集中在以下几个方向: 逆向设计 通过神经网络快速预测微纳结构的光学响应,替代传统耗时的数值模拟方法。例如设计超表面、光子晶体等结构。 特征提取与优化 从复杂的光学数据中自…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...