【机器学习】GPT-4中的机器学习如何塑造人类与AI的新对话
🚀时空传送门
- 🔍引言
- 📕GPT-4概述
- 🌹机器学习在GPT-4中的应用
- 🚆文本生成与摘要
- 🎈文献综述与知识图谱构建
- 🚲情感分析与文本分类
- 🚀搜索引擎优化
- 💴智能客服与虚拟助手
- 🌂语言翻译
- 🍀文本生成与写作辅助
- ⭐教育领域
- 🌠多模态处理
- 🐒性能优化与模型升级
- ☀ 机器学习在GPT-4发展中的挑战与机遇
🔍引言

随着人工智能技术的飞速发展,自然语言处理(NLP)领域迎来了新的里程碑——GPT-4。GPT-4以其巨大的参数量、卓越的语言生成能力和多模态处理能力,成为当前NLP领域最热门的模型之一。本文将详细探讨机器学习在GPT-4中的应。
📕GPT-4概述
GPT-4是OpenAI推出的第四代生成式预训练Transformer模型,具有数万亿级别的参数量。它采用多层Transformer架构,能够捕捉语言中的细微差别和复杂结构,生成流畅连贯的文本。此外,GPT-4还引入了多模态处理能力,能够处理文本、图像、音频等多种数据类型,为NLP、计算机视觉和语音识别等多个领域带来了新的可能性。
🌹机器学习在GPT-4中的应用

🚆文本生成与摘要
GPT-4具有强大的文本生成能力,可以应用于各种文本生成任务,如文章创作、新闻报道、邮件编写等。此外,GPT-4还可以用于文本摘要任务,通过机器学习算法对文本进行自动分析和总结,提取关键信息并生成简洁的摘要。
代码示例(Python):
import openai openai.api_key = "YOUR_API_KEY" prompt = "请写一篇关于机器学习在GPT-4中应用的文章。"
response = openai.Completion.create(engine="text-davinci-003", prompt=prompt, max_tokens=100)
print(response.choices[0].text)
🎈文献综述与知识图谱构建
GPT-4可以应用于文献综述任务,通过机器学习算法对大量文献进行自动分析、归纳和总结,帮助研究人员快速了解某个领域的研究现状和发展趋势。此外,GPT-4还可以用于知识图谱构建任务,通过从文本中提取实体、关系等信息,构建出结构化的知识图谱,为智能问答、推荐系统等应用提供支撑。
代码示例(Python,这里仅展示文献检索部分,实际构建知识图谱需要更复杂的处理流程):
# 使用GPT-4插件ScholarAI进行文献检索(假设有相应的插件或API)
# 此处仅为示意,实际使用时需要调用相应的API或插件 search_term = "机器学习在GPT-4中的应用"
result = scholar_ai.search(search_term, num_results=10) for item in result: print(f"标题: {item['title']}") print(f"作者: {item['authors']}") print(f"摘要: {item['abstract']}") print("\n")
🚲情感分析与文本分类

GPT-4可以应用于情感分析和文本分类任务。通过机器学习算法对文本进行情感倾向分析或类别划分,可以为企业或政府提供舆情监控、产品评价等服务。例如,可以使用GPT-4对社交媒体上的用户评论进行情感分析,了解用户对某个产品或事件的态度和看法。
代码示例(Python,这里使用简化的方法,实际应用中可能需要更复杂的模型和算法):
# 假设已经有一个训练好的情感分析模型(如BERT、RoBERTa等)
# 以下代码仅为示意,实际使用时需要加载模型并进行预测 from transformers import BertTokenizer, BertForSequenceClassification
import torch tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2) text = "我非常喜欢这款产品!"
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True)
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1) # 假设标签0表示负面情感,标签1表示正面情感
sentiment = "正面" if predictions[0][1].item() > 0.5 else "负面"
print(f"情感倾向: {sentiment}")
注意:以上代码使用了Hugging Face的Transformers库来加载BERT模型和分词器,实际使用时需要安装相应的库并加载预训练模型。
🚀搜索引擎优化
微软已将GPT-4集成到其必应(Bing)搜索引擎中,利用GPT-4的自然语言处理能力提供更准确、更智能的搜索结果。
用户可以直接在搜索框中输入自然语言问题,GPT-4能够理解并生成详细的回答、解释和相关背景信息。
示例代码:
import openai # 设置OpenAI API的访问密钥
openai.api_key = "YOUR_API_KEY" # 用户搜索查询
search_query = "机器学习在自然语言处理中的应用" # 这里并不是真正的搜索查询,而是模拟GPT-4对查询的响应
# 在实际应用中,你可能需要调用OpenAI的搜索插件或与其他搜索引擎API集成
response = openai.Completion.create( engine="text-davinci-003", # 使用GPT-4引擎(注意:实际API可能有所不同) prompt=f"解释{search_query}并给出详细回答", max_tokens=1000, # 根据需要调整最大令牌数 temperature=0.5, # 调整文本生成的温度以影响随机性
) # 提取回答并显示
print(response.choices[0].text)
💴智能客服与虚拟助手
企业利用GPT-4构建智能客服系统,提供24/7全天候的客户服务。GPT-4能够快速回答用户问题,提高客户满意度。
GPT-4还可以作为虚拟助手,协助进行日程管理、电话回访、邮件回复等任务,提升工作效率。
示例代码:
import openai # 设置OpenAI API的访问密钥
openai.api_key = "YOUR_API_KEY" # 用户输入的问题
user_question = "我如何重置我的密码?" # 使用GPT-4生成回答
response = openai.Completion.create( engine="text-davinci-003", # 使用GPT-4引擎 prompt=f"用户问题: {user_question}\n智能客服回答:", max_tokens=200, # 设定最大回复长度
) # 提取并显示回答
print(response.choices[0].text)
🌂语言翻译
GPT-4具备强大的多语言翻译能力,可以自动将文本从一种语言翻译成另一种语言,支持全球范围内的沟通。
示例代码:
import openai # 设置OpenAI API的访问密钥
openai.api_key = "YOUR_API_KEY" # 源语言和目标语言
source_language = "中文"
target_language = "英文" # 待翻译的文本
text_to_translate = "机器学习在自然语言处理中非常重要。" # 使用GPT-4进行翻译(这里只是一个概念性示例,实际上可能需要一个专门的翻译模型)
# 你可能需要构建一个提示,包含源语言和目标语言的样本,并请求GPT-4进行翻译
response = openai.Completion.create( engine="text-davinci-003", # 使用GPT-4引擎 prompt=f"将以下{source_language}文本翻译成{target_language}:\n{text_to_translate}\n\n翻译结果:", max_tokens=100, # 设定最大回复长度
) # 提取并显示翻译结果
print(response.choices[0].text)
🍀文本生成与写作辅助
GPT-4可以作为智能写作助手,帮助人们快速生成高质量的文本内容,如新闻报道、广告文案、社交媒体帖子等。
GPT-4的文字输入限制提升至2.5万字,支持更长的文本生成需求。
示例代码:
import openai # 设置OpenAI API的访问密钥
openai.api_key = "YOUR_API_KEY" # 写作主题或要求
writing_prompt = "写一篇关于GPT-4的文章,介绍其在人工智能领域的贡献。" # 使用GPT-4进行文章写作
response = openai.Completion.create( engine="text-davinci-003", # 使用GPT-4引擎 prompt=writing_prompt, max_tokens=2000, # 设定最大令牌数以生成足够长的文章 temperature=0.7, # 调整文本生成的随机性
) # 提取并显示生成的文章
print(response.choices[0].text)
⭐教育领域
GPT-4在教育领域的应用日益广泛,可以帮助教师快速批改作业、评估学生的学习进度,并提供个性化辅导。
学生可以利用GPT-4进行自主学习和学术研究,提高学习效率。
示例代码:
import openai # 设置OpenAI API的访问密钥
openai.api_key = "YOUR_API_KEY" # 学生提出的数学问题
math_question = "2 + 2 是多少?" # 使用GPT-4来回答数学问题
response = openai.Completion.create( engine="davinci", # 假设GPT-4的API端点名称是"davinci" prompt=f"解答数学问题:{math_question}\n回答:", temperature=0, # 对于此类明确答案的问题,降低温度可以得到更精确的结果 max_tokens=100,
) # 提取并显示答案
answer = response.choices[0].text.strip()
print(f"答案是:{answer}")
🌠多模态处理
GPT-4不仅限于文本处理,还能处理图像和音频等多模态数据。例如,GPT-4可以分析图像中的信息,为搜索引擎提供图像搜索功能;还可以处理音频数据,为语音助手提供语音识别和语音合成功能。
示例代码:
import openai
import requests # 用于上传图像(假设需要) # 设置OpenAI API的访问密钥
openai.api_key = "YOUR_API_KEY" # 假设你有一个图像的URL或本地文件路径
image_url = "https://example.com/image.jpg" # 使用requests或其他库来获取图像数据(这里仅作为示例)
# ... # 构建一个包含图像和文本的提示
prompt = "分析以下图像并描述其内容:\n图像URL: " + image_url + "\n描述:" # 调用OpenAI的API(假设有一个多模态处理的端点)
# 注意:以下代码是伪代码,OpenAI可能不提供直接的图像上传API
# 你可能需要将图像转换为base64编码或其他格式,并将其作为文本的一部分传递给API
response = openai.Completion.create( engine="davinci", # 假设用于多模态处理的端点名称是"davinci" prompt=prompt, # 这里可能需要额外的参数来指定图像数据 # ... max_tokens=200,
) # 提取并显示描述
description = response.choices[0].text.strip()
print(f"图像描述:{description}")
🐒性能优化与模型升级
OpenAI推出的GPT-4o模型在速度和性能上进行了显著优化。GPT-4o可以在更短的时间内响应音频输入,并支持多语言处理,为用户提供了更快速、更便捷的体验。
示例代码:
import openai # 设置OpenAI API的访问密钥
openai.api_key = "YOUR_API_KEY" # 检查GPT-4模型的版本和性能统计信息(假设有这样的API)
response = openai.Model.retrieve( engine="davinci", # 假设GPT-4的API端点名称是"davinci" # 可能需要其他参数来指定要检索的具体信息
) # 打印模型的版本和性能信息(假设这些信息包含在响应中)
print(f"模型版本:{response.data['version']}")
# 假设response.data还包含性能统计信息
print(f"性能统计:{response.data['performance_stats']}")
☀ 机器学习在GPT-4发展中的挑战与机遇

-
数据隐私和安全性问题
随着GPT-4在各个领域的应用越来越广泛,数据隐私和安全性问题也日益凸显。机器学习算法需要处理大量的用户数据,如何确保用户数据的安全性和隐私性成为了一个亟待解决的问题。因此,未来的机器学习研究需要更加注重数据隐私和安全性方面的考虑,提出更加安全、可靠的算法和模型。 -
可解释性和透明度问题
GPT-4等深度学习模型通常具有高度的复杂性和非线性性,这使得模型的可解释性和透明度成为了一个挑战。机器学习算法需要能够解释模型的决策过程,使得用户能够理解和信任模型的输出结果。因此,未来的机器学习研究需要更加注重模型的可解释性和透明度方面的考虑,提出更加易于理解和解释的算法和模型。 -
模型优化和训练成本问题
GPT-4等大型语言模型通常需要大量的计算资源和时间来进行训练和优化。这不仅增加了模型的训练成本,还限制了模型的规模和性能。因此,未来的机器学习研究需要更加注重模型优化和训练成本方面的考虑,提出更加高效、节能的算法和模型。
总之,机器学习在GPT-4的发展中发挥着至关重要的作用。随着技术的不断进步和应用场景的不断拓展,机器学习将为GPT-4带来更加广阔的发展前景和更加丰富的应用场景。同时,我们也需要关注机器学习在GPT-4发展中面临的挑战和机遇,并积极应对和解决这些问题。
相关文章:
【机器学习】GPT-4中的机器学习如何塑造人类与AI的新对话
🚀时空传送门 🔍引言📕GPT-4概述🌹机器学习在GPT-4中的应用🚆文本生成与摘要🎈文献综述与知识图谱构建🚲情感分析与文本分类🚀搜索引擎优化💴智能客服与虚拟助手…...
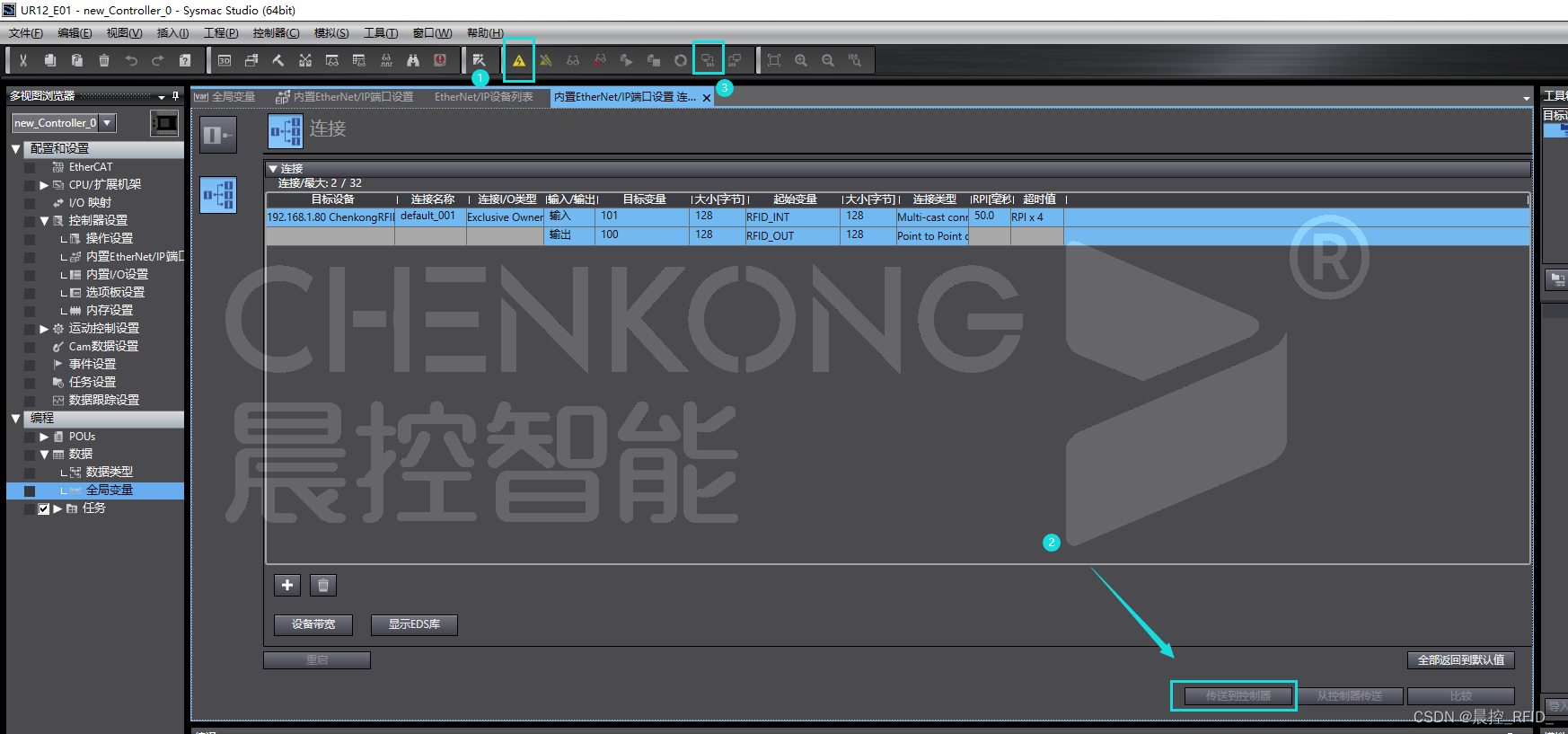
晨控CK-UR12-E01与欧姆龙NX/NJ系列EtherNet/IP通讯手册
晨控CK-UR12-E01与欧姆龙NX/NJ系列EtherNet/IP通讯手册 晨控CK-UR12-E01 是天线一体式超高频读写器头,工作频率默认为902MHz~928MHz,符合EPC Global Class l Gen 2/IS0-18000-6C 标准,最大输出功率 33dBm。读卡器同时…...
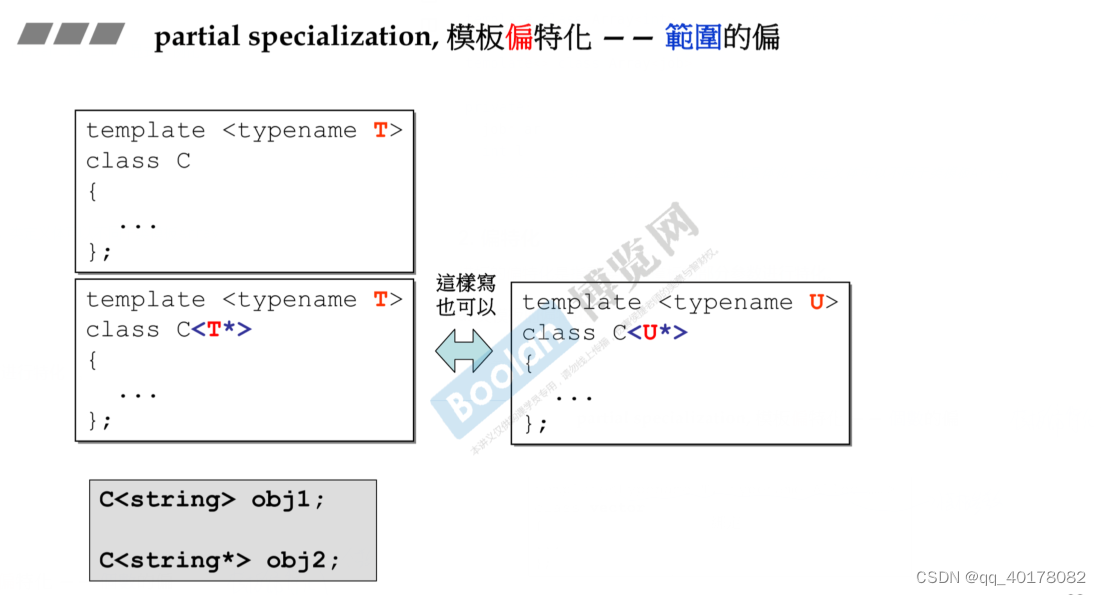
模板显式、隐式实例化和(偏)特化、具体化的详细分析
最近看了<The C Programing Language>看到了模板的特化,突然想起来<C Primer>上说的显式具体化、隐式具体化、特化、偏特化、具体化等概念弄得头晕脑胀,我在网上了找了好多帖子,才把概念给理清楚。 看着这么多叫法,其…...

软件设计师笔记-计算机系统基础知识
CPU的功能 CPU(中央处理器)是计算机的核心部件,负责执行计算机的指令和处理数据。它的功能主要可以分为程序控制、操作控制、时间控制和数据处理四个方面: 程序控制:CPU的首要任务是执行存储在内存中的程序。程序控制功能确保CPU能够按照程序的指令序列,一条一条地执行。…...

flink 作业动态维护更新,不重启flink,不提交作业
Flink任务实时获取并更新规则_flink任务流实时变更-CSDN博客 一种动态更新flink任务配置的方法_flink 数据源 动态更新-CSDN博客 Flink CEP在实时风控场景的落地与优化 最佳实践 - 在SQL任务中使用Flink CEP - 《实时计算用户手册-v4.5.0》 Flink SQL CEP详解-CSDN博客 如…...

为何数据仓库需要“分层次”?
在数据驱动的商业世界中,数据仓库是企业决策的心脏。然而,一个高效、可扩展且易于管理的数据仓库,需要精心设计和构建。分层是构建数据仓库的关键策略之一。本文将探讨数据仓库分层的重要性以及它如何帮助企业更好地管理数据。 数据仓库分层…...
小熊家务帮day15-day18 预约下单模块(预约下单,熔断降级,支付功能,退款功能)
目录 1 预约下单1.1 需求分析1.1.1 业务流程1.1.2 订单状态 1.2 系统设计1.2.1 订单表设计1.2.2 表结构的设置 1.3 开发远程调用接口1.3.0 复习下远程调用的开发1.3.1 查询地址簿远程接口jzo2o-api工程定义接口Customer服务实现接口 1.3.2 查询服务&服务项远程接口jzo2o-ap…...

[word] word悬挂缩进怎么设置? #经验分享#职场发展#经验分享
word悬挂缩进怎么设置? 在编辑Word的时候上方会有个Word标尺,相信很多伙伴都没使用过。其实它隐藏着很多好用的功能,今天就给大家分享下利用这个word标尺的悬挂缩进怎么设置,一起来看看吧! 1、悬挂缩进 选中全文&…...

6-Maven的使用
6-Maven的使用 常用maven命令 //常用maven命令 mvn -v //查看版本 mvn archetype:create //创建 Maven 项目 mvn compile //编译源代码 mvn test-compile //编译测试代码 mvn test //运行应用程序中的单元测试 mvn site //生成项目相关信息的网站 mvn package //依据项目生成 …...

WPF真入门教程32--WPF数字大屏项目实干
1、项目背景 WPF (Windows Presentation Foundation) 是微软的一个框架,用于构建桌面客户端应用程序,它支持富互联网应用程序(RIA)的开发。在数字大屏应用中,WPF可以用来构建复杂的用户界面,展示庞大的数据…...

数据可视化Python实现超详解【数据分析】
各位大佬好 ,这里是阿川的博客,祝您变得更强 个人主页:在线OJ的阿川 大佬的支持和鼓励,将是我成长路上最大的动力 阿川水平有限,如有错误,欢迎大佬指正 Python 初阶 Python–语言基础与由来介绍 Python–…...
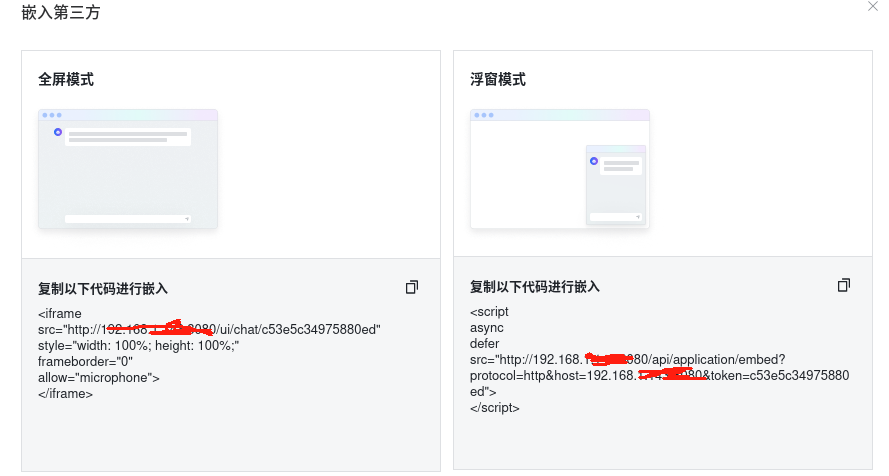
Maxkb玩转大语言模型
Maxkb玩转大语言模型 随着国外大语言模型llama3的发布,搭建本地个人免费“人工智能”变得越来越简单,今天博主分享使用Max搭建本地的个人聊天式对话及个人本地知识域的搭建。 1.安装Maxkb开源应用 github docker快速安装 docker run -d --namemaxkb -p 8…...

React Hooks 封装可粘贴图片的输入框组件(wangeditor)
需求是需要一个文本框 但是可以支持右键或者ctrlv粘贴图片,原生js很麻烦,那不如用插件来实现吧~我这里用的wangeditor插件,初次写初次用,可能不太好,但目前是可以达到实现需求的一个效果啦!后面再改进吧~ …...
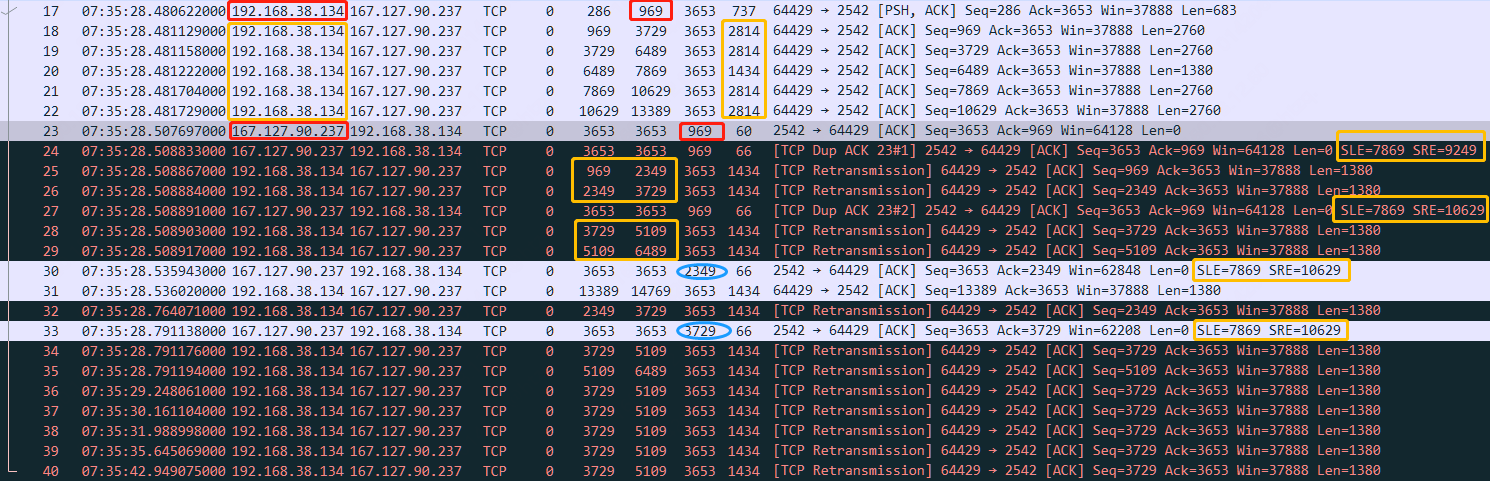
Wireshark TS | 应用传输丢包问题
问题背景 仍然是来自于朋友分享的一个案例,实际案例不难,原因也就是互联网线路丢包产生的重传问题。但从一开始只看到数据包截图的判断结果,和最后拿到实际数据包的分析结果,却不是一个结论,方向有点跑偏,…...

架构设计-web项目中跨域问题涉及到的后端和前端配置
WEB软件项目中经常会遇到跨域问题,解决方案早已是业内的共识,简要记录主流的处理方式: 跨域感知session需要解决两个问题: 1. 跨域问题 2. 跨域cookie传输问题 跨域问题 解决跨域问题有很多种方式,如使用springboot…...
==)
==Redis淘汰策略(内存满了触发)==
好的,面试官。这个问题我需要从三个方面来回答。第一个方面: 当 Redis 使用的内存达到 maxmemory 参数配置的阈值的时候,Redis 就会根据配置的内存淘汰策略。 把访问频率不高的 key 从内存中移除。maxmemory 默认情况是当前服务器的最大内存…...
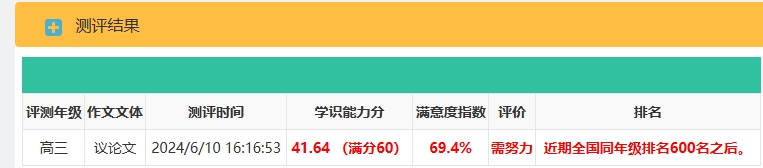
2024年高考作文考人工智能,人工智能写作文能否得高分
前言 众所周知,今年全国一卷考的是人工智能,那么,我们来测试一下,国内几家厉害的人工智能他们的作答情况,以及能取得多少高分呢。由于篇幅有限,我这里只测试一个高考真题,我们这里用百度的文心…...

Vue3学习记录第三天
Vue3学习记录第三天 背景说明学习记录Vue3中shallowReactive()和shallowRef()Vue3中toRaw()和markRaw()前端...语法Vue3中readonly()和shallowReadonly()函数前端的防抖 背景 之前把Vue2的基础学了, 这个课程的后面有简单介绍Vue3的部分. 学习知识容易忘, 这里仅简答做一个记录…...
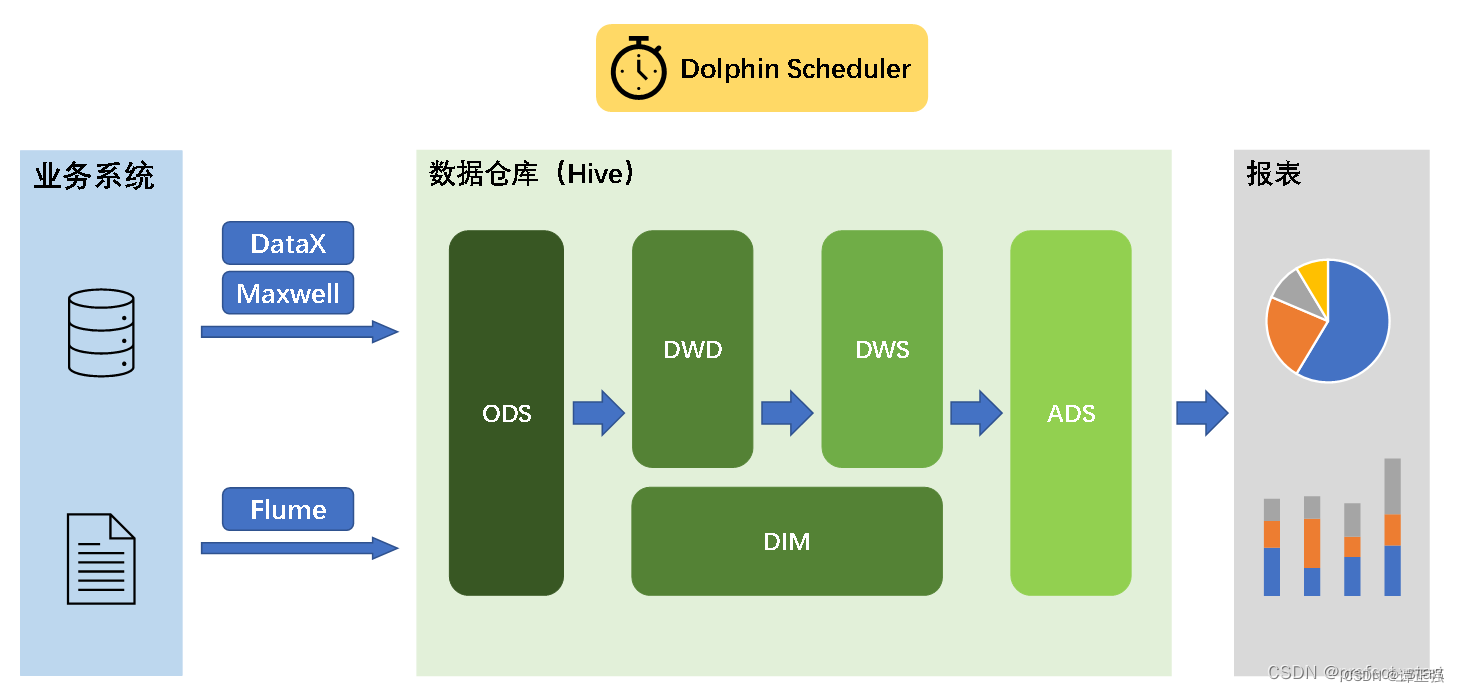
数仓建模中的一些问题
在数仓建设的过程中,由于未能完全按照规范操作, 从而导致数据仓库建设比较混乱,常见有以下问题: 数仓常见问题 ● 数仓分层不清晰:数仓的分层没有明确的逻辑,难以管理和维护。 ● 数据域划分不明确…...

spring整合kafka
原文链接:spring整合kafka_spring集成kafka-CSDN博客 1、导入依赖 <dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.5.10.RELEASE</version> </depende…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

Java 加密常用的各种算法及其选择
在数字化时代,数据安全至关重要,Java 作为广泛应用的编程语言,提供了丰富的加密算法来保障数据的保密性、完整性和真实性。了解这些常用加密算法及其适用场景,有助于开发者在不同的业务需求中做出正确的选择。 一、对称加密算法…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...
中关于正整数输入的校验规则)
Element Plus 表单(el-form)中关于正整数输入的校验规则
目录 1 单个正整数输入1.1 模板1.2 校验规则 2 两个正整数输入(联动)2.1 模板2.2 校验规则2.3 CSS 1 单个正整数输入 1.1 模板 <el-formref"formRef":model"formData":rules"formRules"label-width"150px"…...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

解析奥地利 XARION激光超声检测系统:无膜光学麦克风 + 无耦合剂的技术协同优势及多元应用
在工业制造领域,无损检测(NDT)的精度与效率直接影响产品质量与生产安全。奥地利 XARION开发的激光超声精密检测系统,以非接触式光学麦克风技术为核心,打破传统检测瓶颈,为半导体、航空航天、汽车制造等行业提供了高灵敏…...

Monorepo架构: Nx Cloud 扩展能力与缓存加速
借助 Nx Cloud 实现项目协同与加速构建 1 ) 缓存工作原理分析 在了解了本地缓存和远程缓存之后,我们来探究缓存是如何工作的。以计算文件的哈希串为例,若后续运行任务时文件哈希串未变,系统会直接使用对应的输出和制品文件。 2 …...