AI-知识库搭建(一)腾讯云向量数据库使用
一、AI知识库
将已知的问答知识,问题和答案转变成向量存储在向量数据库,在查找答案时,输入问题,将问题向量化,匹配向量库的问题,将向量相似度最高的问题筛选出来,将答案提交。
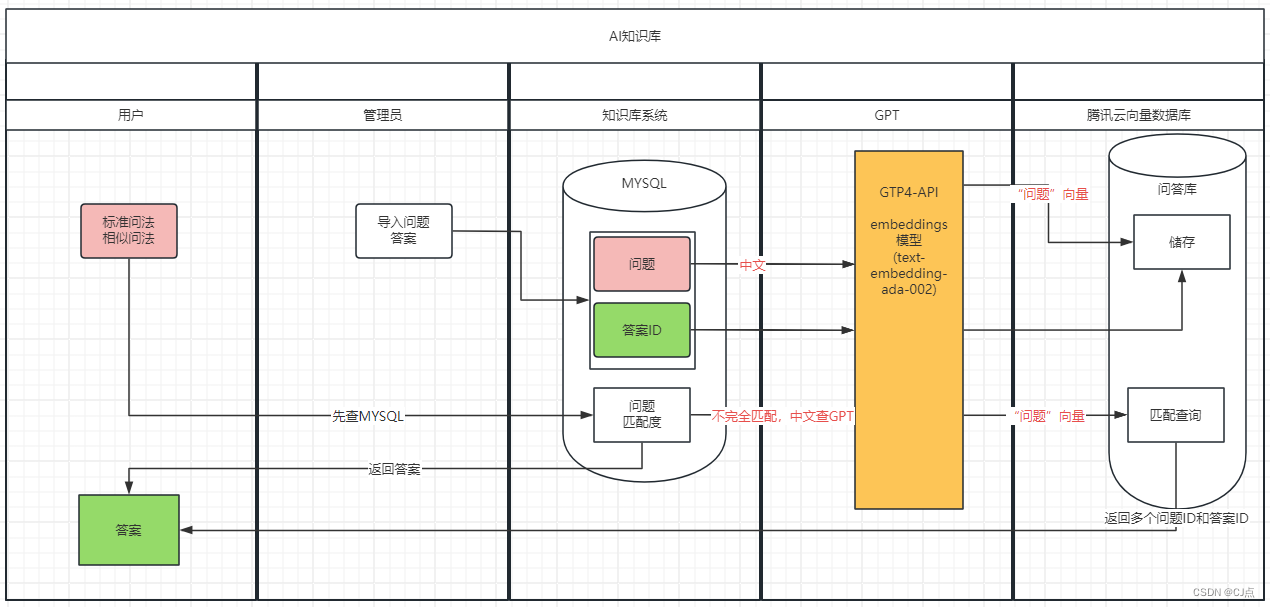
二、腾讯云向量数据库
向量数据库_大模型知识库_向量数据存储_向量数据检索- 腾讯云
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专用于存储、检索、分析多维向量数据。该数据库支持多种索引类型和相似度计算方法,单索引支持千亿级向量规模,可支持百万级 QPS 及毫秒级查询延迟。腾讯云向量数据库不仅能为大模型提供外部知识库,提高大模型回答的准确性,还可广泛应用于推荐系统、自然语言处理等 AI 领域。
三、使用教程(java)
1、项目引用依赖
<!--腾讯云向量数据库使用--><dependency><groupId>com.tencent.tcvectordb</groupId><artifactId>vectordatabase-sdk-java</artifactId><version>1.2.0</version></dependency>2、application.properties 配置
#向量数据库地址-购买服务器后,获取到外网访问域名,账号密码
vectordb.url=${VECTORDB_URL:http://xxxxxxxxx.com:10000}
vectordb.user=${VECTORDB_USER:root}
vectordb.key=${VECTORDB_KEY:123456}3、初始化客户端
import com.tencent.tcvectordb.client.VectorDBClient;
import com.tencent.tcvectordb.model.param.database.ConnectParam;
import com.tencent.tcvectordb.model.param.enums.ReadConsistencyEnum;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;@Component
public class InitVectorClient {@Value("${vectordb.url:}")private String vdbUrl;@Value("${vectordb.user:}")private String vdbUser;@Value("${vectordb.key:}")private String vdbKey;@Beanpublic VectorDBClient vdbClient(){ConnectParam connectParam = ConnectParam.newBuilder().withUrl(vdbUrl).withUsername(vdbUser).withKey(vdbKey).withTimeout(30).build();VectorDBClient client = new VectorDBClient(connectParam, ReadConsistencyEnum.EVENTUAL_CONSISTENCY);return client;}}
4、创建表结构
这里使用HTTP的方式
curl --location --request POST 'xxxxx.com:10000/database/create' \
--header 'Authorization: Bearer account=root&api_key=123456' \
--header 'Content-Type: application/json' \
--data-raw '{"database": "db_xiaosi"
}'curl --location --request POST 'xxxxx.com:10000/collection/create' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer account=root&api_key=123456' \
--data-raw '{"database": "db_xiaosi","collection": "t_bug","replicaNum": 0,"shardNum": 1,"description": "BUG表关键字向量","indexes": [{"fieldName": "id","fieldType": "string","indexType": "primaryKey"},{"fieldName": "bug_name","fieldType": "string","indexType": "filter"},{"fieldName": "is_deleted","fieldType": "uint64","indexType": "filter"},{"fieldName": "vector","fieldType": "vector","indexType": "HNSW","dimension": 1536,"metricType": "COSINE","params": {"M": 16,"efConstruction": 200}}]
}'5、封装http请求类
package com.ikscrm.platform.api.manager.bug;import cn.hutool.core.date.DateUtil;
import com.ikscrm.platform.api.dao.vector.BugVector;
import com.tencent.tcvectordb.client.VectorDBClient;
import com.tencent.tcvectordb.model.Collection;
import com.tencent.tcvectordb.model.Database;
import com.tencent.tcvectordb.model.DocField;
import com.tencent.tcvectordb.model.Document;
import com.tencent.tcvectordb.model.param.dml.*;
import com.tencent.tcvectordb.model.param.entity.AffectRes;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;/*** 向量数据库能力* 接口文档 https://cloud.tencent.com/document/product/1709/97768* 错误码 https://cloud.tencent.com/document/product/1709/104047* @Date 2024/3/6 13:49*/
@Component
@Slf4j
public class VectorManager {@Resourceprivate VectorDBClient vdbClient;/*** 根据向量查询相似数据。** @param dbName 数据库名称* @param tableName 表名称* @param vector 向量* @return 返回更新操作影响的记录数* @throws RuntimeException 如果更新过程中发生业务异常*/public List<BugVector> findBugList(String dbName, String tableName, List<Double> vector) {List<BugVector> resultList = new ArrayList<>();Database database = vdbClient.database(dbName);Collection collection = database.describeCollection(tableName);Filter filter = new Filter("is_deleted=0");//这部分的算法需要深入了解SearchByVectorParam searchByVectorParam = SearchByVectorParam.newBuilder().addVector(vector)// 若使用 HNSW 索引,则需要指定参数ef,ef越大,召回率越高,但也会影响检索速度.withParams(new HNSWSearchParams(15))// 指定 Top K 的 K 值.withLimit(20)// 过滤获取到结果.withFilter(filter).build();// 输出相似性检索结果,检索结果为二维数组,每一位为一组返回结果,分别对应 search 时指定的多个向量List<List<Document>> svDocs = collection.search(searchByVectorParam);for (List<Document> docs : svDocs) {for (Document doc : docs) {BugVector build = new BugVector();build.setId(doc.getId());build.setScore(doc.getScore());build.setVector(doc.getVector());for (DocField field : doc.getDocFields()) {if (field.getName().equals("bug_name")) {build.setBugName(field.getStringValue());}if (field.getName().equals("bug_title")) {build.setBugTitle(field.getStringValue());}if (field.getName().equals("is_deleted")) {build.setIsDeleted(Integer.valueOf(field.getStringValue()));}if (field.getName().equals("create_time")) {build.setCreateTime(field.getStringValue());}if (field.getName().equals("update_time")) {build.setUpdateTime(field.getStringValue());}}resultList.add(build);}}return resultList;}/*** 将问题向量列表插入到指定的数据库和集合中。** @param dbName 数据库名称,指定要操作的数据库。* @param tableName 集合名称,即数据表名称,指定要插入数据的表。* @param list 要插入的数据列表,列表中的每个元素都是TaskVector类型,包含了问题的向量信息及其他相关字段。*/public Long insertBugList(String dbName, String tableName, List<BugVector> list) {try {Database database = vdbClient.database(dbName);Collection collection = database.describeCollection(tableName);List<Document> documentList = new ArrayList<>();list.forEach(item -> {documentList.add(Document.newBuilder().withId(item.getId()).withVector(item.getVector()).addDocField(new DocField("bug_name", item.getBugName())).addDocField(new DocField("bug_title", item.getBugTitle())).addDocField(new DocField("is_deleted", item.getIsDeleted())).addDocField(new DocField("create_time", DateUtil.now())).addDocField(new DocField("update_time", DateUtil.now())).build());});InsertParam insertParam = InsertParam.newBuilder().addAllDocument(documentList).build();
// upsert 实际数据会有延迟AffectRes upsert = collection.upsert(insertParam);log.info("向量列表插入数量:{},完成:{}", list.size(), upsert.getAffectedCount());return upsert.getAffectedCount();} catch (Exception ex) {log.error("向量列表插入异常", ex);throw new RuntimeException("向量列表插入异常" + ex.getMessage());}}
}
腾讯云的向量库使用方式基本就是这样着,在这里简单的使用到了他的插入和向量查询功能。下一篇讲解GPT的如何与向量数据库结合使用
AI-知识库搭建(二)GPT-Embedding模式使用-CSDN博客
相关文章:
AI-知识库搭建(一)腾讯云向量数据库使用
一、AI知识库 将已知的问答知识,问题和答案转变成向量存储在向量数据库,在查找答案时,输入问题,将问题向量化,匹配向量库的问题,将向量相似度最高的问题筛选出来,将答案提交。 二、腾讯云向量数…...

AI数据分析:根据Excel表格数据绘制柱形图
工作任务:将Excel文件中2013年至2019年间线上图书的销售额,以条形图的形式呈现,每个条形的高度代表相应年份的销售额,同时在每个条形上方标注具体的销售额数值 在deepseek中输入提示词: 你是一个Python编程专家&#…...
基于协调过滤算法商品推荐系统的设计
管理员账户功能包括:系统首页,个人中心,商品管理,论坛管理,商品资讯管理 前台账户功能包括:系统首页,个人中心,论坛,商品资讯,商家,商品 开发系统…...

CS1061 “HtmlHelper”未包含“Partial”的定义,并且找不到可接受第一个“HtmlHelper”类型参数的可访问扩展方法“Partial”
严重性 代码 说明 项目 文件 行 禁止显示状态 错误 CS1061 “HtmlHelper”未包含“Partial”的定义,并且找不到可接受第一个“HtmlHelper”类型参数的可访问扩展方法“Partial”(是否缺少 using 指令或程序集引用?) 14_Views_Message_E…...


在知识的海洋中航行:问题的演变与智慧的追求
在信息技术迅猛发展的今天,互联网和人工智能已成为我们生活中不可或缺的一部分。它们像是一座座灯塔,照亮了知识的海洋,使得曾经难以触及的知识变得触手可及。随着这些技术的普及,越来越多的问题能够迅速得到答案。然而࿰…...
、slice()、split()三种方法的区别)
splice()、slice()、split()三种方法的区别
slice slice() 方法返回一个新的数组对象,这一对象是一个由 start 和 end 决定的原数组的浅拷贝(包括 start,不包括 end),其中 start 和 end 代表了数组元素的索引。原始数组不会被改变。 const animals [ant, bison…...
iOS 之homebrew ruby cocoapods 安装
cocoapods安装需要ruby,更新ruby需要rvm,下载rvm需要gpg,下载gpg需要homebrew,所以安装顺序是homebrew->gpg->rvm->ruby-cocoapods Rvm 官网: RVM: Ruby Version Manager - RVM Ruby Version Manager - Docum…...

【栈】2751. 机器人碰撞
本文涉及知识点 栈 LeetCode2751. 机器人碰撞 现有 n 个机器人,编号从 1 开始,每个机器人包含在路线上的位置、健康度和移动方向。 给你下标从 0 开始的两个整数数组 positions、healths 和一个字符串 directions(directions[i] 为 ‘L’ …...

贪心算法06(leetcode738,968)
参考资料: https://programmercarl.com/0738.%E5%8D%95%E8%B0%83%E9%80%92%E5%A2%9E%E7%9A%84%E6%95%B0%E5%AD%97.html 738. 单调递增的数字 题目描述: 当且仅当每个相邻位数上的数字 x 和 y 满足 x < y 时,我们称这个整数是单调递增的。…...

cve_2022_0543-redis沙盒漏洞复现 vulfocus
1. 原理 该漏洞的存在是因为Debian/Ubuntu中的Lua库是作为动态库提供的。自动填充了一个package变量,该变量又允许访问任意 Lua 功能。 2.复现 我们可以尝试payload: eval local io_l package.loadlib("/usr/lib/x86_64-linux-gnu/liblua5.1.so…...
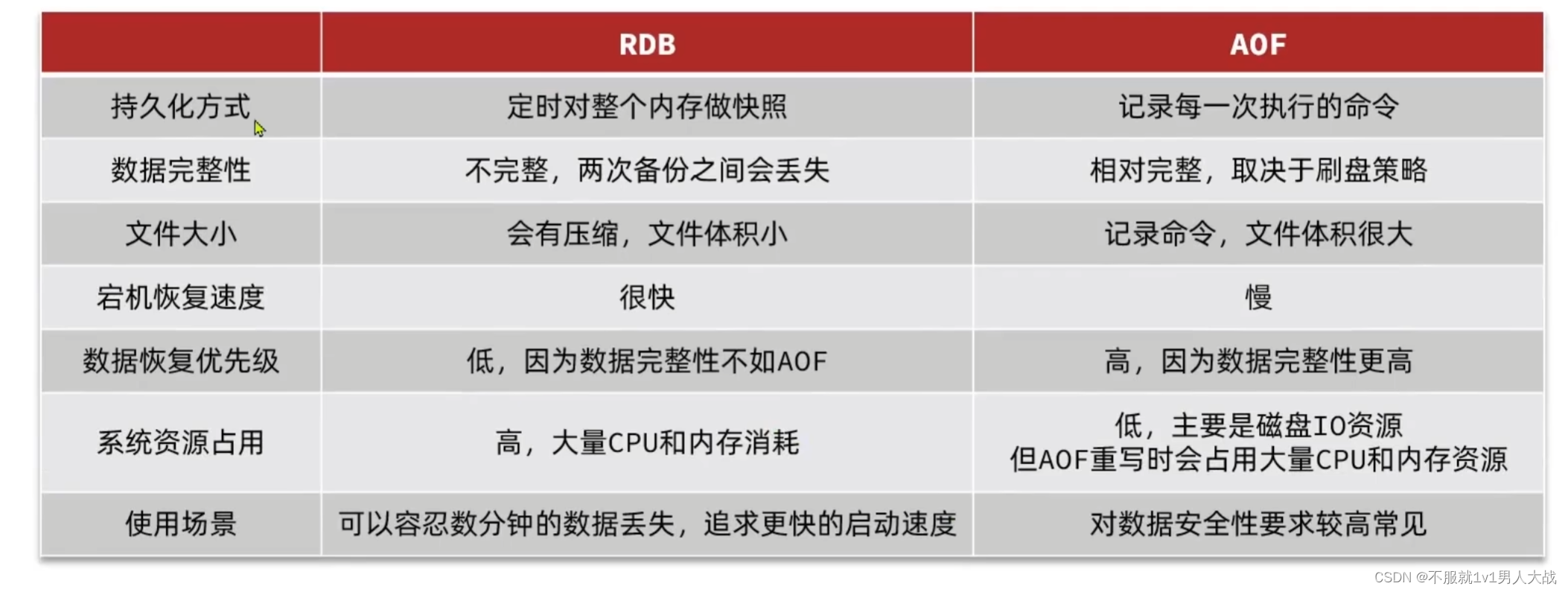
浅解Reids持久化
Reids持久化 RDB redis的存储方式: rdb文件都是二进制,很小,里面存的是数据 实现方式 redis-cli链接到redis服务端 使用save命令 注:不推荐 因为save命令是直接写到磁盘里面,速度特别慢,一般都是redis…...
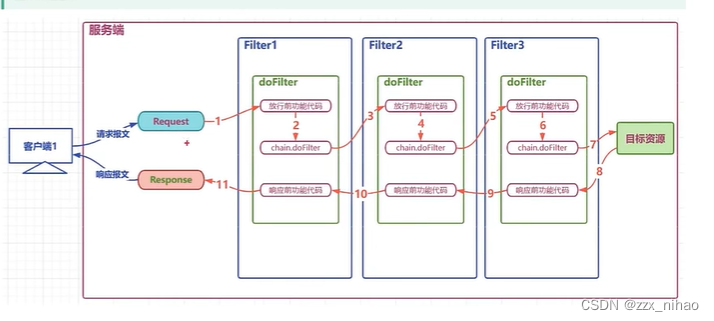
Java24:会话管理 过滤器 监听器
一 会话管理 1.cookie 是一种客户端会话技术,cookie由服务端产生,它是服务器存放在浏览器的一小份数据,浏览器 以后每次访问服务器的时候都会将这小份的数据带到服务器去。 //创建cookie对象 Cookie cookie1new Cookie("…...

web前端电影简介标签:深度解析与创意应用
web前端电影简介标签:深度解析与创意应用 在web前端开发中,电影简介标签的设计与实现是一项既具挑战性又充满创意的任务。这些标签不仅需要准确传达电影的核心信息,还要通过精美的设计和交互效果吸引用户的眼球。本文将从四个方面、五个方面…...

Java面向对象-方法的重写、super
Java面向对象-方法的重写、super 一、方法的重写二、super关键字1、super可以省略2、super不可以省略3、super修饰构造器4、继承条件下构造方法的执行过程 一、方法的重写 1、发生在子类和父类中,当子类对父类提供的方法不满意的时候,要对父类的方法进行…...

解锁ChatGPT:从GPT-2实践入手解密ChatGPT
⭐️我叫忆_恒心,一名喜欢书写博客的研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三连支…...
20240605解决飞凌的OK3588-C的核心板刷机原厂buildroot不能连接ADB的问题
20240605解决飞凌的OK3588-C的核心板刷机原厂buildroot不能连接ADB的问题 2024/6/5 13:53 rootrootrootroot-ThinkBook-16-G5-IRH:~/repo_RK3588_Buildroot20240508$ ./build.sh --help rootrootrootroot-ThinkBook-16-G5-IRH:~/repo_RK3588_Buildroot20240508$ ./build.sh lun…...

c++手写的bitset
支持stl bitset 类似的api #include <iostream> #include <vector> #include <climits> #include <utility> #include <stdexcept> #include <iterator>using namespace std;const int W 64;class Bitset { private:vector<unsigned …...
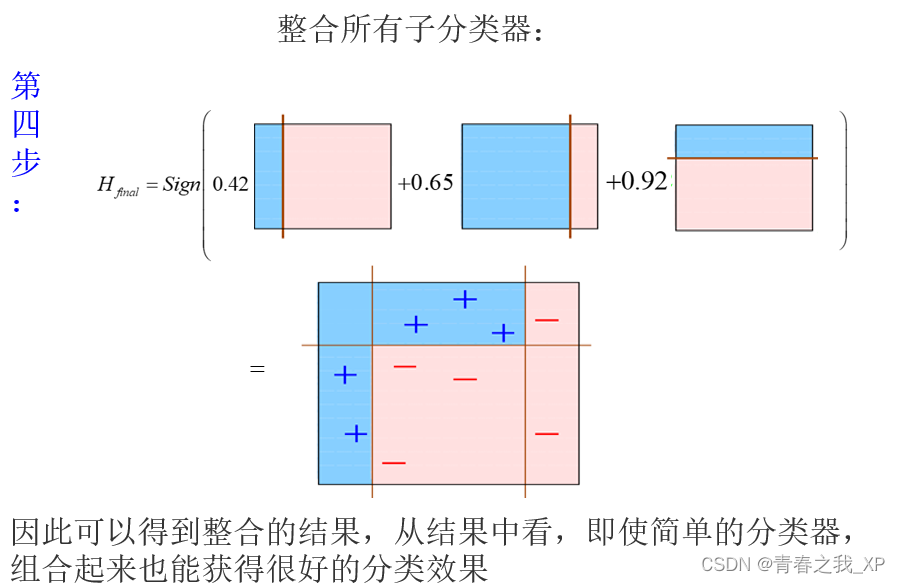
【机器学习系列】深入理解集成学习:从Bagging到Boosting
目录 一、集成方法的一般思想 二、集成方法的基本原理 三、构建集成分类器的方法 常见的有装袋(Bagging)和提升(Boosting)两种方法 方法1 :装袋(Bagging) Bagging原理如下图: …...

用FFMPEG对YUV序列进行编辑的笔记
还是单独开一个吧 每次找挺烦的 播放YUV序列 ffmpeg -f rawvideo -pix_fmt yuv420p -s 3840x2160 -i "Wood.yuv" -vf "scale1280x720" -c:v rawvideo -pix_fmt yuv420p -f sdl "Wood"4K序列转720P ffmpeg -f rawvideo -pix_fmt yuv420p -s 38…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

Nuxt.js 中的路由配置详解
Nuxt.js 通过其内置的路由系统简化了应用的路由配置,使得开发者可以轻松地管理页面导航和 URL 结构。路由配置主要涉及页面组件的组织、动态路由的设置以及路由元信息的配置。 自动路由生成 Nuxt.js 会根据 pages 目录下的文件结构自动生成路由配置。每个文件都会对…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...

腾讯云V3签名
想要接入腾讯云的Api,必然先按其文档计算出所要求的签名。 之前也调用过腾讯云的接口,但总是卡在签名这一步,最后放弃选择SDK,这次终于自己代码实现。 可能腾讯云翻新了接口文档,现在阅读起来,清晰了很多&…...