Linux shell编程学习笔记58:cat /proc/mem 获取系统内存信息

0 前言
在开展系统安全检查的过程中,除了收集cpu信息,我们还需要收集内存信息。在Linux中,获取内存信息的命令很多,这里我们着重研究 cat /proc/mem命令。
1 cat /proc/mem命令
/proc/meminfo 文件提供了有关系统内存的使用情况报告。
当我们想找出已用和可用内存、交换空间或缓存和缓冲区等统计信息时,我们可以分析此文件的内容。
需要注意的是,在这个文件中,除了基本信息之外,还有更多数据。
[purpleendurer @bash ~ ] cat /proc/meminfo
MemTotal: 3855952 kB
MemFree: 2040864 kB
MemAvailable: 3356504 kB
Buffers: 39224 kB
Cached: 1400764 kB
SwapCached: 0 kB
Active: 86028 kB
Inactive: 1536020 kB
Active(anon): 244 kB
Inactive(anon): 182156 kB
Active(file): 85784 kB
Inactive(file): 1353864 kB
Unevictable: 0 kB
Mlocked: 0 kB
SwapTotal: 0 kB
SwapFree: 0 kB
Dirty: 96 kB
Writeback: 0 kB
AnonPages: 179504 kB
Mapped: 215608 kB
Shmem: 336 kB
KReclaimable: 123612 kB
Slab: 148076 kB
SReclaimable: 123612 kB
SUnreclaim: 24464 kB
KernelStack: 2912 kB
PageTables: 2984 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 1927976 kB
Committed_AS: 482236 kB
VmallocTotal: 34359738367 kB
VmallocUsed: 16208 kB
VmallocChunk: 0 kB
Percpu: 1016 kB
HardwareCorrupted: 0 kB
AnonHugePages: 104448 kB
ShmemHugePages: 0 kB
ShmemPmdMapped: 0 kB
FileHugePages: 0 kB
FilePmdMapped: 0 kB
DupText: 0 kB
MemZeroed: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB
Hugetlb: 0 kB
DirectMap4k: 51896 kB
DirectMap2M: 2945024 kB
DirectMap1G: 1048576 kB
[purpleendurer @bash ~ ] 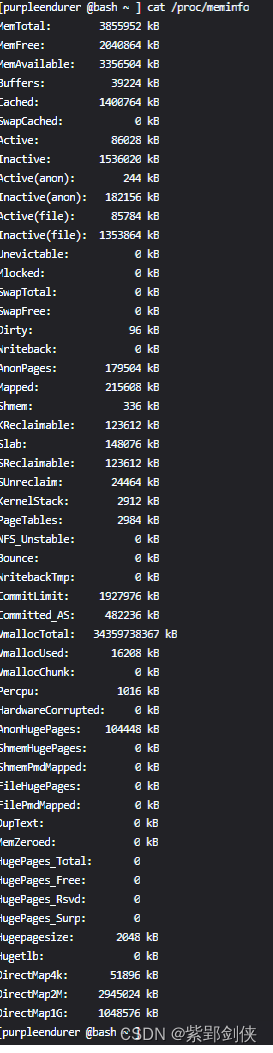
在不同版本的Linux系统中,命令返回的信息项也各有不同。
| 序号 | 信息项 | 信息值 | 说明 |
|---|---|---|---|
| 1 | MemTotal: | 3855952 kB | 系统所有可用RAM数量( total usable RAM)。 系统从加电开始到引导完成,BIOS等要保留一些内存,内核要保留一些内存,最后剩下可供系统支配的内存就是MemTotal。这个值在系统运行期间一般是固定不变的。 |
| 2 | MemFree: | 2040864 kB | 系统层面留着未分配的内存数量。(free RAM, the memory which is not used for anything at all) |
| 3 | MemAvailable: | 3356504 kB | 可以分配给应用程序使用的内存数量(available RAM, the amount of memory available for allocation to any process)。 系统中有些内存虽然已被使用但是可以回收的,比如cache/buffer、slab都有一部分可以回收,所以MemFree不能代表全部可用的内存,这部分可回收的内存加上MemFree才是系统可用的内存,即:MemAvailable≈MemFree+Buffers+Cached,它是内核使用特定的算法估算出来的,并不精确。 |
| 4 | Buffers: | 39224 kB | 内存中的临时存储元素,通常不超过 20 MB(temporary storage element in memory, which doesn’t generally exceed 20 MB)。 文件缓冲区的大小。 块设备(block device)所占用的特殊file-backed pages,包括:直接读写块设备,以及文件系统元数据(metadata)比如superblock使用的缓存页。Buffers内存页同时也在LRU list中,被统计在Active(file)或Inactive(file)之中。 |
| 5 | Cached: | 1400764 kB | 页面缓存大小(从磁盘读取的文件的缓存),其中还包括 tmpfs 和 shmem,但不包括 SwapCached(page cache size (cache for files read from the disk), which also includes tmpfs and shmem but excludes SwapCached) 被高速缓冲存储器(cache memory)使用的内存数量 Cached = diskcache - SwapCache。 用户进程的内存页分为两种:file-backed pages(与文件对应的内存页),和anonymous pages(匿名页),比如进程的代码、映射的文件都是file-backed,而进程的堆、栈都是不与文件相对应的、就属于匿名页。file-backed pages在内存不足的时候可以直接写回对应的硬盘文件里,称为page-out,不需要用到交换区(swap);而anonymous pages在内存不足时就只能写到硬盘上的交换区(swap)里,称为swap-out。 |
| 6 | SwapCached: | 0 kB | 最近使用的交换内存,可提高 I/O 的速度(recently used swap memory, which increases the speed of I/O) 被高速缓冲存储器(cache memory)使用的交换空间大小,已经被交换出来的内存,但仍然被存放在swapfile中。用来在需要的时候很快的被替换而不需要再次打开I/O端口。 SwapCached包含的是被确定要swap-out,但是尚未写入交换区的匿名内存页。 SwapCached内存页会同时被统计在LRU或AnonPages或Shmem中,它本身并不占用额外的内存。 |
| 7 | Active: | 86028 kB | 最近使用的内存,不太适合回收用于新应用程序(memory that has been used more recently, not very suitable to reclaim for new applications)。 处于活跃状态中的缓冲或高速缓冲存储器页面文件的大小,除非非常必要否则不会被移作他用。 Active=Active(anon) + Active(file)。 LRU是一种内存页回收算法,Least Recently Used,最近最少使用。LRU认为,在最近时间段内被访问的数据在以后被再次访问的概率,要高于最近一直没被访问的页面。于是近期未被访问到的页面就成为了页面回收的第一选择。Linux kernel会记录每个页面的近期访问次数,然后设计了两种LRU list: active list 和 inactive list, 刚访问过的页面放进active list,长时间未访问过的页面放进inactive list,回收内存页时,直接找inactive list即可。另外,内核线程kswapd会周期性地把active list中符合条件的页面移到inactive list中。 |
| 8 | Inactive: | 1536020 kB | 最近未使用的内存,更适合回收用于新应用程序(memory that hasn’t been used recently, more suitable to reclaim for new applications)。 处于非活跃状态中的缓冲或高速缓冲存储器页面文件的大小,可能被用于其他途径。 Inactive=Inactive(anon) + Inactive(file)) |
| 9 | Active(anon): | 244 kB | 处于活跃状态、与文件无关的内存(比如进程的堆栈,用malloc申请的内存)(anonymous pages),anonymous pages在发生换页时,是对交换区进行读/写操作。 |
| 10 | Inactive(anon): | 182156 kB | 处于非活跃状态、与文件无关的内存(比如进程的堆栈,用malloc申请的内存) |
| 11 | Active(file): | 85784 kB | 处于活跃状态、与文件关联的内存(比如程序文件、数据文件所对应的内存页)(file-backed pages) File-backed pages在发生换页(page-in或page-out)时,是从它对应的文件读入或写出 |
| 12 | Inactive(file): | 1353864 kB | 处于非活跃状态、与文件关联的内存(比如程序文件、数据文件所对应的内存页) |
| 13 | Unevictable | 0 kB | 用户空间消耗的不可回收内存数量。因为种种原因无法回收(page-out)或者交换到swap(swap-out)的内存页。 Unevictable LRU list上是不能pageout/swapout的内存页,包括VM_LOCKED的内存页、SHM_LOCK的共享内存页(同时被统计在Mlocked中)、和ramfs。在unevictable list出现之前,这些内存页都在Active/Inactive lists上,vmscan每次都要扫过它们,但是又不能把它们pageout/swapout,这在大内存的系统上会严重影响性能,unevictable list的初衷就是避免这种情况的发生。 |
| 14 | Mlocked | 0 kB | 被系统调用"mlock()"锁定到内存中的页面大小。 Mlocked页面是不可收回的。被锁定的内存因为不能pageout/swapout,会从Active/Inactive LRU list移到Unevictable LRU list上。 Mlocked与以下统计项重叠:LRU Unevictable,AnonPages,Shmem,Mapped等。 |
| 15 | SwapTotal | 0 kB | 交换空间的总大小 |
| 16 | SwapFree | 0 kB | 未被分配的交换空间大小 |
| 17 | Dirty | 96 kB | (memory that currently waits to be written back to the disk) 等待被写回到磁盘的内存大小。 Dirty并不包括系统中全部的dirty pages,需要再加上另外两项:NFS_Unstable 和 Writeback,NFS_Unstable是发给NFS server但尚未写入硬盘的缓存页,Writeback是正准备回写硬盘的缓存页。 |
| 18 | Writeback | 0 kB | 正在被写回到磁盘的内存大小。 |
| 19 | AnonPages | 179504 kB | 未映射页的内存大小 |
| 20 | Mapped | 215608 kB | 设备和文件等映射的大小 |
| 21 | Shmem | 336 kB | 共享内存和 tmpfs 文件系统使用的量 |
| 22 | KReclaimable | 123612 kB | 内核分配的内存,内存压力下可回收(包括 SReclaimable) |
| 23 | Slab | 148076 kB | 内核数据结构缓存的大小,可以减少申请和释放内存带来的消耗 |
| 24 | SReclaimable | 123612 kB | 可收回Slab的大小 |
| 25 | SUnreclaim | 24464 kB | 不可收回Slab的大小(SUnreclaim+SReclaimable=Slab) |
| 26 | KernelStack | 2912 kB | 内核栈,常驻内存,每一个用户线程都会分配一个kernel stack |
| 27 | PageTables | 2984 kB | 管理内存分页页面的索引表的大小 |
| 28 | NFS_Unstable | 0 kB | NFS_Unstable:已写入磁盘但尚未提交到稳定存储的网络文件系统页面,始终为零 |
| 29 | Bounce | 0 kB | 退回缓冲区的内存量,退回缓冲区是使设备能够复制和写入数据的低级内存区域 |
| 30 | WritebackTmp | 0 kB | FUSE 模块使用的写回临时缓冲区 |
| 31 | CommitLimit | 1927976 kB | 当前可在系统上分配的数量。根据超额分配比率('vm.overcommit_ratio'),这是当前在系统上分配可用的内存总量,这个限制只是在模式2('vm.overcommit_memory')时启用。CommitLimit用以下公式计算:CommitLimit =('vm.overcommit_ratio'*物理内存)+交换例如,在具有1G物理RAM和7G swap的系统上,当`vm.overcommit_ratio` = 30时 CommitLimit =7.3G |
| 32 | Committed_AS | 482236 kB | 目前已在系统上分配的内存量。是所有进程申请的内存的总和,即使所有申请的内存没有被完全使用,例如一个进程申请了1G内存,仅仅使用了300M,但是这1G内存的申请已经被 "committed"给了VM虚拟机,进程可以在任何时间使用。如果限制在模式2('vm.overcommit_memory')时启用,分配超出CommitLimit内存将不被允许 |
| 33 | VmallocTotal | 34359738367 kB | 用于分配几乎连续内存的 vmalloc 内存空间的总大小 |
| 34 | VmallocUsed | 16208 kB | 已用 vmalloc 内存空间的大小 |
| 35 | VmallocChunk | 0 kB | vmalloc 内存的最大可用连续块 |
| 36 | Percpu | 1016 kB | 用于percpu接口分配的内存 |
| 37 | HardwareCorrupted | 0 kB | 内核发现已损坏的内存 |
| 38 | AnonHugePages | 104448 kB | 映射到页表中的匿名(非文件)大页面。Transparent Huge Pages 缩写 THP ,这个是 RHEL 6 开始引入的一个功能,在 Linux6 上透明大页是默认启用的。由于 Huge pages 很难手动管理,而且通常需要对代码进行重大的更改才能有效的使用,因此 RHEL 6 开始引入了 Transparent Huge Pages ( THP ), THP 是一个抽象层,能够自动创建、管理和使用传统大页。THP 为系统管理员和开发人员减少了很多使用传统大页的复杂性 , 因为 THP 的目标是改进性能 , 因此其它开发人员 ( 来自社区和红帽 ) 已在各种系统、配置、应用程序和负载中对 THP 进行了测试和优化。这样可让 THP 的默认设置改进大多数系统配置性能。但是 , 不建议对数据库工作负载使用 THP 。这两者最大的区别在于 : 标准大页管理是预分配的方式,而透明大页管理则是动态分配的方式。 |
| 39 | ShmemHugePages | 0 kB | 共享内存和具有大页面的 tmpfs 文件系统使用的量 |
| 40 | ShmemPmdMapped | 0 kB | 具有大页面的用户空间映射共享内存(userspace-mapped shared memory with huge pages) |
| 41 | FileHugePages | 0 kB | 为大页面分配的页面缓存消耗的内存(memory consumed by page cache allocated with huge pages) |
| 42 | FilePmdMapped | 0 kB | 在用户空间中分配了大页面的映射页面缓存 |
| 43 | DupText | 0 kB | - |
| 44 | MemZeroed | 0 kB | - |
| 45 | HugePages_Total | 0 | 大页面池的总大小。Huge pages(标准大页) 是从 Linux Kernel 2.6 后被引入的,目的是通过使用大页内存来取代传统的 4kb 内存页面, 以适应越来越大的系统内存,让操作系统可以支持现代硬件架构的大页面容量功能。 |
| 46 | HugePages_Free | 0 | 未分配的大页面数量 |
| 47 | HugePages_Rsvd | 0 | 用于从池中分配的保留大页数,这保证了在发生意外行为时为进程分配 |
| 48 | HugePages_Surp | 0 | /proc/sys/vm/nr_hugepages中超过特定基值的剩余大页数(number of surplus huge pages above a specific base value in /proc/sys/vm/nr_hugepages) |
| 49 | Hugepagesize | 2048 kB | 大页面的默认大小(the default size of huge pages) |
| 50 | Hugetlb | 0 kB | 为各种大小的大页面分配的内存总量(the total amount of memory allocated for huge pages of all sizes)。 DirectMap所统计的不是关于内存的使用,而是一个反映TLB效率的指标。TLB(Translation Lookaside Buffer)是位于CPU上的缓存,用于将内存的虚拟地址翻译成物理地址,由于TLB的大小有限,不能缓存的地址就需要访问内存里的page table来进行翻译,速度慢很多。为了尽可能地将地址放进TLB缓存,新的CPU硬件支持比4k更大的页面从而达到减少地址数量的目的, 比如2MB,4MB,甚至1GB的内存页,视不同的硬件而定。所以DirectMap其实是一个反映TLB效率的指标。 |
| 51 | DirectMap4k | 51896 kB | 内核映射的以 4 kB 页为单位的内存总量(the total amount of memory mapped by the kernel in 4 kB pages) |
| 52 | DirectMap2M | 2945024 kB | 内核映射的以 2 MB 页为单位的内存总量(the total amount of memory mapped by the kernel in 2 MB pages) |
| 53 | DirectMap1G | 1048576 kB | 内核映射的以1GB 页为单位的内存总量 |
参考:1.The /proc/meminfo File in Linux | Baeldung on Linux
2.linux内存占用分析之meminfo - 个人文章 - SegmentFault 思否
3.解释 Red Hat Enterprise Linux 的 /proc/meminfo 和 free 输出 - Red Hat Customer Portal
相关文章:
Linux shell编程学习笔记58:cat /proc/mem 获取系统内存信息
0 前言 在开展系统安全检查的过程中,除了收集cpu信息,我们还需要收集内存信息。在Linux中,获取内存信息的命令很多,这里我们着重研究 cat /proc/mem命令。 1 cat /proc/mem命令 /proc/meminfo 文件提供了有关系统内存的使用情况…...

【InternLM实战营第二期笔记】07:OpenCompass :是骡子是马,拉出来溜溜
文章目录 课程实操 课程 评测的意义是什么呢?我最近也在想。看到这节开头的内容后忽然有个顿悟:如果大模型最终也会变成一种基础工具(类比软件),稳定或可预期的效果需要先于用户感知构建出来,评测 case 就…...
matlab演示银河系转动动画
代码 function GalaxyRotationSimulation()% 参数设置num_stars 1000; % 恒星数量galaxy_radius 1; % 银河系半径rotation_speed 0.05; % 旋转速度% 生成银河系中的恒星分布theta 2 * pi * rand(num_stars, 1); % 角度r galaxy_radius * sqrt(rand(num_stars, 1)); % 半径…...

备战 清华大学 上机编程考试-冲刺前50%,倒数第5天
T1:多项式求和 小K最近刚刚习得了一种非常酷炫的多项式求和技巧,可以对某几类特殊的多项式进行运算。非常不幸的是,小K发现老师在布置作业时抄错了数据,导致一道题并不能用刚学的方法来解,于是希望你能帮忙写一个程序…...

leetCode127. 单词接龙
leetCode127. 单词接龙 // bfs 剪枝 class Solution { public:int ladderLength(string beginWord, string endWord, vector<string>& wordList) {// 1.将所有的单词放在set字段中unordered_set<string> s;for (auto & ele : wordList) s.insert(ele);//…...

进程概念(二)
目录 进程优先级基本概念查看系统进程PRI and NIPRI vs NI修改进程优先级的命令renice修改优先级进程其他概念 环境变量基本概念查看环境变量方法常见环境变量PATHHOMESHELL 查看环境变量环境变量相关的命令 环境变量特征命令行参数main函数中的俩个参数 argc argvmain函数的第…...

java程序100道01—20
1.用循环的嵌套,输出输出如下图形 * * * * * * * * * * * * * * * * * * * * * * * * * package Exercises.One_Hundred; public class Demo01 {public static void main(String[] args) {for(int i1;i<5;i){for(int j1;j<2*i-1;j){Sys…...

让GNSSRTK不再难【第二天-第7部分2】
状态更新计算过程: 计算卡尔曼增益: 根据预测的误差协方差矩阵 P k − P_k^- Pk− 和观测噪声协方差矩阵 R R R 计算卡尔曼增益 K k K_k Kk: K k P k − H T ( H P k − H T R ) − 1 K_k P_k^- H^T (H P_k^- H^T R)^{-1} KkPk…...

计算引擎:Flink核心概念
Apache Flink 是一个流处理框架,擅长处理实时数据流和批处理任务。Flink 提供了强大的功能来处理和分析大量数据。以下是 Flink 的核心概念: 1. DataStream 和 DataSet API DataStream API: 用于处理无界数据流,即不断生成和流动的数据。例如,传感器数据、日志等。DataSet…...
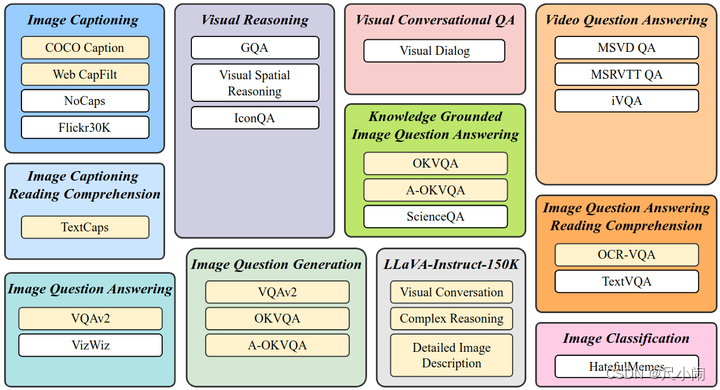
技术前沿 |【大模型InstructBLIP进行指令微调】
大模型InstructBLIP进行指令微调 一、引言二、InstructBLIP模型介绍三、指令微调训练通用视觉语言模型的应用潜力四、InstructBLIP的指令微调训练步骤五、实验结果与讨论六、结论与展望 一、引言 随着人工智能技术的快速发展,视觉语言模型(Vision-Langu…...

CSS-布局-flex
CSS3 新增了弹性盒子模型( Flexible Box 或 FlexBox ),是一种新的用于在 HTML 页面实现布局的方式。使得 HTML 页面适应不同尺寸的屏幕和不同的设备时,元素是可预测地运行。 基本概念 容器:使用 display:flex 或 display:inline-flex 声明的…...

「C系列」C 数组
文章目录 一、C 数组1. 声明数组2. 初始化数组3. 访问数组元素4. 数组越界5. 多维数组 二、C 操作数组的方法有哪些三、C 数组-应用场景1. 存储固定数量的数据2. 实现算法(如排序)3. 处理数据集合 四、相关链接 一、C 数组 在C语言中,数组是…...

Python框架scrapy有什么天赋异禀
Scrapy框架与一般的爬虫代码之间有几个显著的区别,这些差异主要体现在设计模式、代码结构、执行效率以及可扩展性等方面。下面是一些关键的不同点: 结构化与模块化: Scrapy:提供了高度结构化的框架,包括定义好的Spider…...

【ROS2大白话】四、ROS2非常简单的传参方式
系列文章目录 【ROS2大白话】一、ROS2 humble及cartorgrapher安装 【ROS2大白话】二、turtlebot3安装 【ROS2大白话】三、给turtlebot3安装realsense深度相机 【ROS2大白话】四、ROS2非常简单的传参方式 文章目录 系列文章目录前言一、launch文件传参的demo1. 编写launch.py文…...

浅谈mysql 的批量delete 和 使用in条件批量删除问题
在考虑这两个DELETE语句的性能时,我们需要考虑数据库如何执行这些查询以及它们背后可能涉及的索引和数据结构。 1.执行多个单独的DELETE语句: DELETE FROM a WHERE b 1 AND c 1; ... DELETE FROM a WHERE b 1000 AND c 1000; 这种方法的优点是每…...

【Spring Boot】过滤敏感词的两种实现
文章目录 项目场景前置知识前缀树 实现方式解决方案一:读取敏感词文件生成前缀树构建敏感词过滤器1. 导入敏感词文件 src/main/resources/sensitive_words.txt2. 构建敏感词过滤器 SensitiveFilter3. 测试与使用 解决方案二:使用第三方插件 houbb/sensit…...
吗)
在 Zustand 中管理状态能使用类(Class)吗
在 Zustand 中,通常不推荐使用类(Class)来管理状态,因为 Zustand 的设计理念是基于函数式编程和 React Hooks 的。然而,仍然可以在 Zustand 中间接地使用类,但这并不是 Zustand 的典型用法。 如果确实想要…...

MoreTable 方法selectWithFun,count 使用实例
ORM Bee, example for MoreTable methods:selectWithFun,count ORM Bee时, MoreTable 方法selectWithFun,count 使用实例 package org.teasoft.exam.bee.osql;import org.teasoft.bee.osql.BeeException; import org.teasoft.bee.osql.FunctionType; import org.teasoft.be…...

【SpringBoot】在Spring中使用自定义条件类在Java声明Bean时实现条件注入
在Spring框架中,通过实现org.springframework.context.annotation.Condition接口并重写matches()方法,可以根据自定义条件来控制Bean的注入。这种机制非常灵活,可以帮助开发人员根据环境或配置来有选择地启用或禁用某些Bean。本文将详细介绍如…...

网卡聚合链路配置
创建名为mybond0的绑定,使用示例如下: # nmcli con add type bond con-name mybond0 ifname mybond0 mode active-backup添加从属接口,使用示例如下: # nmcli con add type bond-slave ifname enp3s0 master mybond0要添加其他从…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

大话软工笔记—需求分析概述
需求分析,就是要对需求调研收集到的资料信息逐个地进行拆分、研究,从大量的不确定“需求”中确定出哪些需求最终要转换为确定的“功能需求”。 需求分析的作用非常重要,后续设计的依据主要来自于需求分析的成果,包括: 项目的目的…...

MFC内存泄露
1、泄露代码示例 void X::SetApplicationBtn() {CMFCRibbonApplicationButton* pBtn GetApplicationButton();// 获取 Ribbon Bar 指针// 创建自定义按钮CCustomRibbonAppButton* pCustomButton new CCustomRibbonAppButton();pCustomButton->SetImage(IDB_BITMAP_Jdp26)…...

ESP32读取DHT11温湿度数据
芯片:ESP32 环境:Arduino 一、安装DHT11传感器库 红框的库,别安装错了 二、代码 注意,DATA口要连接在D15上 #include "DHT.h" // 包含DHT库#define DHTPIN 15 // 定义DHT11数据引脚连接到ESP32的GPIO15 #define D…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...
Mobile ALOHA全身模仿学习
一、题目 Mobile ALOHA:通过低成本全身远程操作学习双手移动操作 传统模仿学习(Imitation Learning)缺点:聚焦与桌面操作,缺乏通用任务所需的移动性和灵活性 本论文优点:(1)在ALOHA…...

《C++ 模板》
目录 函数模板 类模板 非类型模板参数 模板特化 函数模板特化 类模板的特化 模板,就像一个模具,里面可以将不同类型的材料做成一个形状,其分为函数模板和类模板。 函数模板 函数模板可以简化函数重载的代码。格式:templa…...

初探Service服务发现机制
1.Service简介 Service是将运行在一组Pod上的应用程序发布为网络服务的抽象方法。 主要功能:服务发现和负载均衡。 Service类型的包括ClusterIP类型、NodePort类型、LoadBalancer类型、ExternalName类型 2.Endpoints简介 Endpoints是一种Kubernetes资源…...

【Android】Android 开发 ADB 常用指令
查看当前连接的设备 adb devices 连接设备 adb connect 设备IP 断开已连接的设备 adb disconnect 设备IP 安装应用 adb install 安装包的路径 卸载应用 adb uninstall 应用包名 查看已安装的应用包名 adb shell pm list packages 查看已安装的第三方应用包名 adb shell pm list…...