[大模型]GLM4-9B-chat Lora 微调
本节我们简要介绍如何基于 transformers、peft 等框架,对 LLaMA3-8B-Instruct 模型进行 Lora 微调。Lora 是一种高效微调方法,深入了解其原理可参见博客:知乎|深入浅出 Lora。
这个教程会在同目录下给大家提供一个 nodebook 文件,来让大家更好的学习。
环境准备
在 Autodl 平台中租赁一个 3090 等 24G 显存的显卡机器,如下图所示镜像选择 PyTorch-->2.1.0-->3.10(ubuntu22.04)-->12.1。
接下来打开刚刚租用服务器的 JupyterLab,并且打开其中的终端开始环境配置、模型下载和运行演示。

环境配置
在完成基本环境配置和本地模型部署的情况下,你还需要安装一些第三方库,可以使用以下命令:
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simplepip install modelscope==1.9.5
pip install "transformers>=4.40.0"
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.29.3
pip install datasets==2.19.0
pip install peft==0.10.0
pip install tiktoken==0.7.0MAX_JOBS=8 pip install flash-attn --no-build-isolation
注意:flash-attn 安装会比较慢,大概需要十几分钟。
考虑到部分同学配置环境可能会遇到一些问题,我们在 AutoDL 平台准备了 GLM-4 的环境镜像,该镜像适用于本教程需要 GLM-4 的部署环境。点击下方链接并直接创建 AutoDL 示例即可。(vLLM 对 torch 版本要求较高,且越高的版本对模型的支持更全,效果更好,所以新建一个全新的镜像。) https://www.codewithgpu.com/i/datawhalechina/self-llm/GLM-4
在本节教程里,我们将微调数据集放置在根目录 /dataset。
模型下载
使用 modelscope 中的 snapshot_download 函数下载模型,第一个参数为模型名称,参数 cache_dir 为模型的下载路径。
在 /root/autodl-tmp 路径下新建 model_download.py 文件并在其中输入以下内容,粘贴代码后记得保存文件,如下图所示。并运行 python /root/autodl-tmp/model_download.py 执行下载。
import torch
from modelscope import snapshot_download, AutoModel, AutoTokenizer
import osmodel_dir = snapshot_download('ZhipuAI/glm-4-9b-chat', cache_dir='/root/autodl-tmp/glm-4-9b-chat', revision='master')
指令集构建
LLM 的微调一般指指令微调过程。所谓指令微调,是说我们使用的微调数据形如:
{"instruction": "回答以下用户问题,仅输出答案。","input": "1+1等于几?","output": "2"
}
其中,instruction 是用户指令,告知模型其需要完成的任务;input 是用户输入,是完成用户指令所必须的输入内容;output 是模型应该给出的输出。
即我们的核心训练目标是让模型具有理解并遵循用户指令的能力。因此,在指令集构建时,我们应针对我们的目标任务,针对性构建任务指令集。例如,在本节我们使用由笔者合作开源的 Chat-甄嬛 项目作为示例,我们的目标是构建一个能够模拟甄嬛对话风格的个性化 LLM,因此我们构造的指令形如:
{"instruction": "你是谁?","input": "","output": "家父是大理寺少卿甄远道。"
}
我们所构造的全部指令数据集在根目录下。
数据格式化
Lora 训练的数据是需要经过格式化、编码之后再输入给模型进行训练的,如果是熟悉 Pytorch 模型训练流程的同学会知道,我们一般需要将输入文本编码为 input_ids,将输出文本编码为 labels,编码之后的结果都是多维的向量。我们首先定义一个预处理函数,这个函数用于对每一个样本,编码其输入、输出文本并返回一个编码后的字典:
def process_func(example):MAX_LENGTH = 384input_ids, attention_mask, labels = [], [], []instruction = tokenizer((f"[gMASK]<sop><|system|>\n假设你是皇帝身边的女人--甄嬛。<|user|>\n"f"{example['instruction']+example['input']}<|assistant|>\n"), add_special_tokens=False)response = tokenizer(f"{example['output']}", add_special_tokens=False)input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1] # 因为eos token咱们也是要关注的所以 补充为1labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id] if len(input_ids) > MAX_LENGTH: # 做一个截断input_ids = input_ids[:MAX_LENGTH]attention_mask = attention_mask[:MAX_LENGTH]labels = labels[:MAX_LENGTH]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}
GLM4-9B-chat 采用的Prompt Template格式如下:
[gMASK]<sop><|system|>
假设你是皇帝身边的女人--甄嬛。<|user|>
小姐,别的秀女都在求中选,唯有咱们小姐想被撂牌子,菩萨一定记得真真儿的——<|assistant|>
嘘——都说许愿说破是不灵的。<|endoftext|>
加载 tokenizer 和半精度模型
模型以半精度形式加载,如果你的显卡比较新的话,可以用torch.bfolat形式加载。对于自定义的模型一定要指定trust_remote_code参数为True。
tokenizer = AutoTokenizer.from_pretrained('/root/autodl-tmp/glm-4-9b-chat/ZhipuAI/glm-4-9b-chat', use_fast=False, trust_remote_code=True)model = AutoModelForCausalLM.from_pretrained('/root/autodl-tmp/glm-4-9b-chat/ZhipuAI/glm-4-9b-chat', device_map="auto",torch_dtype=torch.bfloat16, trust_remote_code=True)
定义 LoraConfig
LoraConfig这个类中可以设置很多参数,但主要的参数没多少,简单讲一讲,感兴趣的同学可以直接看源码。
task_type:模型类型target_modules:需要训练的模型层的名字,主要就是attention部分的层,不同的模型对应的层的名字不同,可以传入数组,也可以字符串,也可以正则表达式。r:lora的秩,具体可以看Lora原理lora_alpha:Lora alaph,具体作用参见Lora原理
Lora的缩放是啥嘞?当然不是r(秩),这个缩放就是lora_alpha/r, 在这个LoraConfig中缩放就是 4 倍。
config = LoraConfig(task_type=TaskType.CAUSAL_LM, target_modules=["query_key_value", "dense", "dense_h_to_4h", "dense_4h_to_h"], # 现存问题只微调部分演示即可inference_mode=False, # 训练模式r=8, # Lora 秩lora_alpha=32, # Lora alaph,具体作用参见 Lora 原理lora_dropout=0.1# Dropout 比例
)
自定义 TrainingArguments 参数
TrainingArguments这个类的源码也介绍了每个参数的具体作用,当然大家可以来自行探索,这里就简单说几个常用的。
output_dir:模型的输出路径per_device_train_batch_size:顾名思义batch_sizegradient_accumulation_steps: 梯度累加,如果你的显存比较小,那可以把batch_size设置小一点,梯度累加增大一些。logging_steps:多少步,输出一次lognum_train_epochs:顾名思义epochgradient_checkpointing:梯度检查,这个一旦开启,模型就必须执行model.enable_input_require_grads(),这个原理大家可以自行探索,这里就不细说了。
args = TrainingArguments(output_dir="./output/GLM4",per_device_train_batch_size=1,gradient_accumulation_steps=8,logging_steps=50,num_train_epochs=2,save_steps=100,learning_rate=1e-5,save_on_each_node=True,gradient_checkpointing=True
)
使用 Trainer 训练
trainer = Trainer(model=model,args=args,train_dataset=tokenized_id,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),
)
trainer.train()保存 lora 权重
lora_path='./GLM4'
trainer.model.save_pretrained(lora_path)
tokenizer.save_pretrained(lora_path)
加载 lora 权重推理
训练好了之后可以使用如下方式加载lora权重进行推理:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from peft import PeftModelmode_path = '/root/autodl-tmp/glm-4-9b-chat/ZhipuAI/glm-4-9b-chat'
lora_path = './GLM4_lora'# 加载tokenizer
tokenizer = AutoTokenizer.from_pretrained(mode_path, trust_remote_code=True)# 加载模型
model = AutoModelForCausalLM.from_pretrained(mode_path, device_map="auto",torch_dtype=torch.bfloat16, trust_remote_code=True).eval()# 加载lora权重
model = PeftModel.from_pretrained(model, model_id=lora_path)prompt = "你是谁?"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": "假设你是皇帝身边的女人--甄嬛。"},{"role": "user", "content": prompt}],add_generation_prompt=True,tokenize=True,return_tensors="pt",return_dict=True).to('cuda')gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():outputs = model.generate(**inputs, **gen_kwargs)outputs = outputs[:, inputs['input_ids'].shape[1]:]print(tokenizer.decode(outputs[0], skip_special_tokens=True))
完整脚本参考:
https://github.com/datawhalechina/self-llm/blob/master/GLM-4/05-GLM-4-9B-chat%20Lora%20%E5%BE%AE%E8%B0%83.ipynb
相关文章:
[大模型]GLM4-9B-chat Lora 微调
本节我们简要介绍如何基于 transformers、peft 等框架,对 LLaMA3-8B-Instruct 模型进行 Lora 微调。Lora 是一种高效微调方法,深入了解其原理可参见博客:知乎|深入浅出 Lora。 这个教程会在同目录下给大家提供一个 nodebook 文件,…...
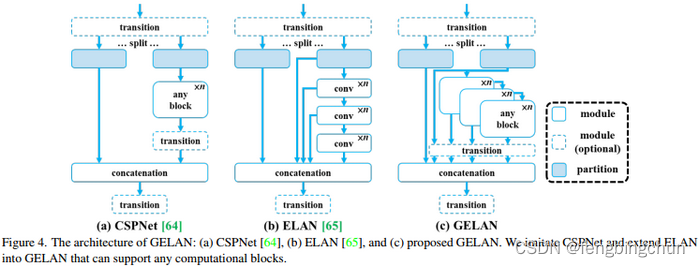
目标检测算法YOLOv9简介
YOLOv9由Chien-Yao Wang等人于2024年提出,论文名为:《YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information》,论文见:https://arxiv.org/pdf/2402.13616 ;源码见: https://github.com/W…...
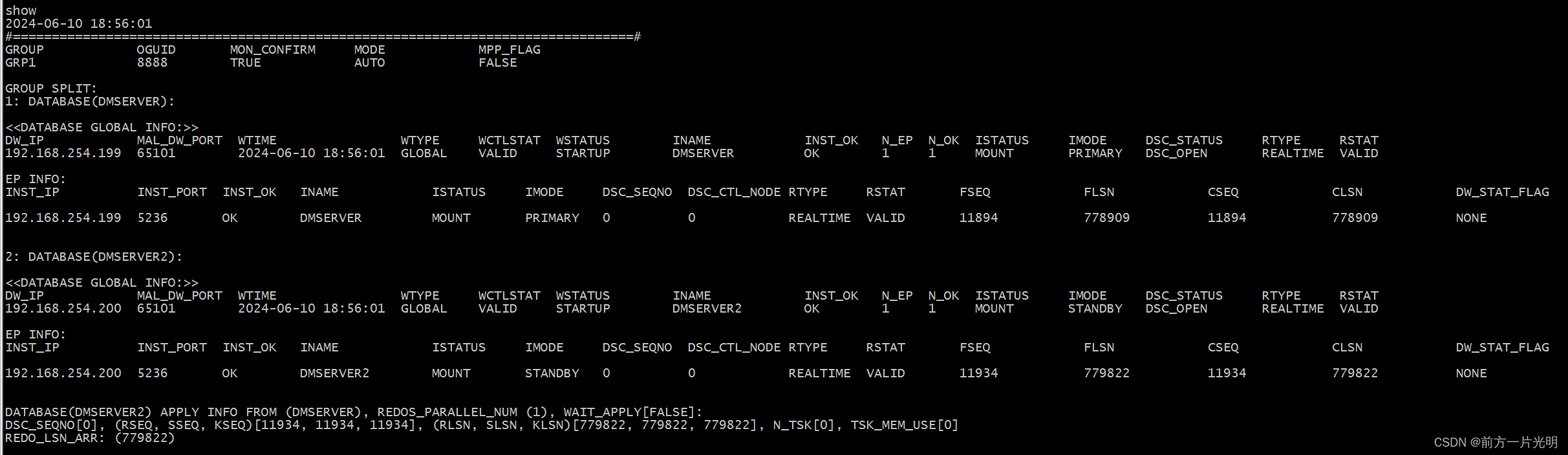
达梦数据库搭建守护集群
前言 DM 数据守护(Data Watch)是一种集成化的高可用、高性能数据库解决方案,是数据库异地容灾的首选方案。通过部署 DM 数据守护,可以在硬件故障(如磁盘损坏)、自然灾害(地震、火灾)…...

OpenGL-ES 学习(6)---- Ubuntu OES 环境搭建
OpenGL-ES Ubuntu 环境搭建 此的方法在 ubuntu 和 deepin 上验证都可以成功搭建 目录 OpenGL-ES Ubuntu 环境搭建软件包安装第一个三角形基于 glfw 实现基于 X11 实现 软件包安装 sudo apt install libx11-dev sudo apt install libglfw3 libglfw3-dev sudo apt-get install…...
Django学习二:配置mysql,创建model实例,自动创建数据库表,对mysql数据库表已经创建好的进行直接操作和实验。
文章目录 前言一、项目初始化搭建1、创建项目:test_models_django2、创建应用app01 二、配置mysql三、创建model实例,自动创建数据库表1、创建对象User类2、执行命令 四、思考问题(****)1、是否会生成新表呢(答案报错&…...

对象创建的4种模式
1. 工厂模式 这种模式抽象了创建具体对象的过程,用函数来封装以特定接口创建对象的细节 缺点:没有解决对象识别的问题(即怎样知道一个对象的类型) function createPerson(name, age, job) {var o new Object();o.name name;o.ag…...

如何判断 是否 需要 CSS 中的媒体查询
以下是一些常见的使用媒体查询的场景: 响应式布局:当设备的屏幕尺寸变化时,我们可以使用媒体查询来调整布局,以适应不同的屏幕尺寸。 设备特性适配:我们可以使用媒体查询来检测设备的特性,如设备方向、分辨…...
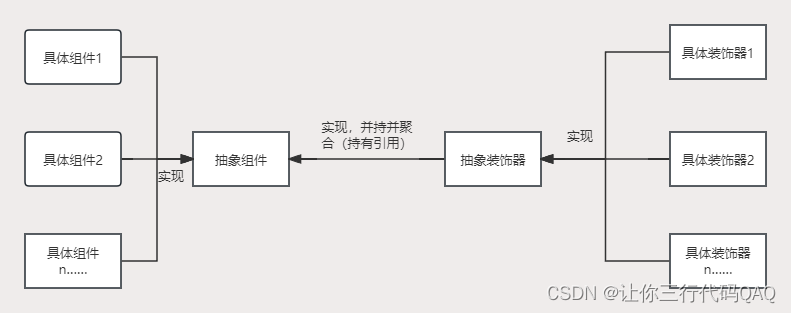
设计模式-装饰器模式(结构型)
装饰器模式 装饰器模式是一种结构模式,通过装饰器模式可以在不改变原有类结构的情况下向一个新对象添加新功能,是现有类的包装。 图解 角色 抽象组件:定义组件的抽象方法具体组件:实现组件的抽象方法抽象装饰器:实现…...

升级HarmonyOS 4.2,开启健康生活篇章
夏日来临,华为智能手表携 HarmonyOS 4.2 版本邀您体验,它不仅可以作为时尚单品搭配夏日绚丽服饰,还能充当你的健康管家,从而更了解自己的身体,开启智能健康生活篇章。 高血糖风险评估优化,健康监测更精准 …...

给gRPC增加负载均衡功能
在现代的分布式系统中,负载均衡是确保服务高可用性和性能的关键技术之一。而gRPC作为一种高性能的RPC框架,自然也支持负载均衡功能。本文将探讨如何为gRPC服务增加负载均衡功能,从而提高系统的性能和可扩展性。 什么是负载均衡? …...

【优选算法】详解target类求和问题(附总结)
目录 1.两数求和 题目: 算法思路: 代码: 2.!!!三数之和 题目 算法思路: 代码: 3.四数字和 题目: 算法思路: 代码: 总结&易错点&…...

【数据结构】图论入门
引入 数据的逻辑结构: 集合:数据元素间除“同属于一个集合”外,无其他关系线性结构:一个对一个,例如:线性表、栈、队列树形结构:一个对多个,例如:树图形结构࿱…...

11_1 Linux NFS服务与触发挂载autofs
11_1 Linux NFS服务与触发挂载服务 文章目录 11_1 Linux NFS服务与触发挂载服务[toc]1. NFS服务基础1.1 示例 2. 触发挂载autofs2.1 触发挂载基础2.2 触发挂载进阶autofs与NFS 文件共享服务:scp、FTP、web(httpd)、NFS 1. NFS服务基础 Netwo…...
开发uniapp 小程序时遇到的问题
1、【微信开发者工具报错】routeDone with a webviewId XXX that is not the current page 解决方案: 在app.json 中添加 “lazyCodeLoading”: “requiredComponents” uniapp的话加到manifest.json下的mp-weixin 外部链接文章:解决方案文章1 解决方案文章2 &qu…...
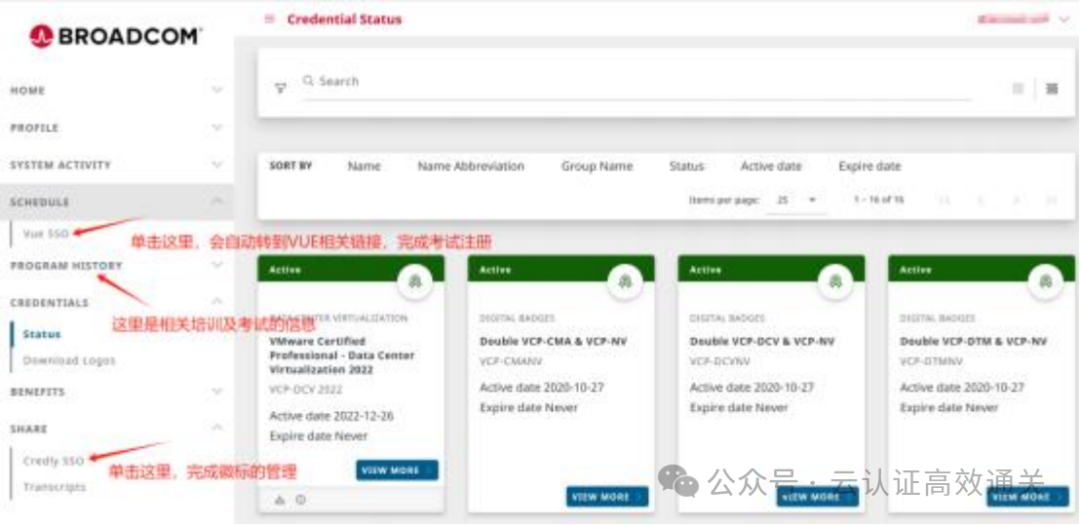
怎样快速获取Vmware VCP 证书,线上考试,voucher报名优惠
之前考一个VCP证书,要花大一万的费用,可贵了,考试费不贵,贵就贵在培训费,要拿到证书,必须交培训费,即使vmware你玩的很溜,不需要再培训了,但是一笔贵到肉疼的培训费你得拿…...

LeetCode 1141, 134, 142
目录 1141. 查询近30天活跃用户数题目链接表要求知识点思路代码 134. 加油站题目链接标签普通版思路代码 简化版思路代码 142. 环形链表 II题目链接标签思路代码 1141. 查询近30天活跃用户数 题目链接 1141. 查询近30天活跃用户数 表 表Activity的字段为user_id,…...

华为FPGA工程师面试题
FPGA工程师面试会涉及多个方面,包括基础知识、项目经验、编程能力、硬件调试和分析等。以下是一些必问的面试题: 基础知识题: 请解释FPGA的基本组成和工作原理。描述FPGA中的可编程互联资源以及它们在构建复杂数字电路中的作用。请解释嵌入式多用途块(如BRAM、DSP slices、…...
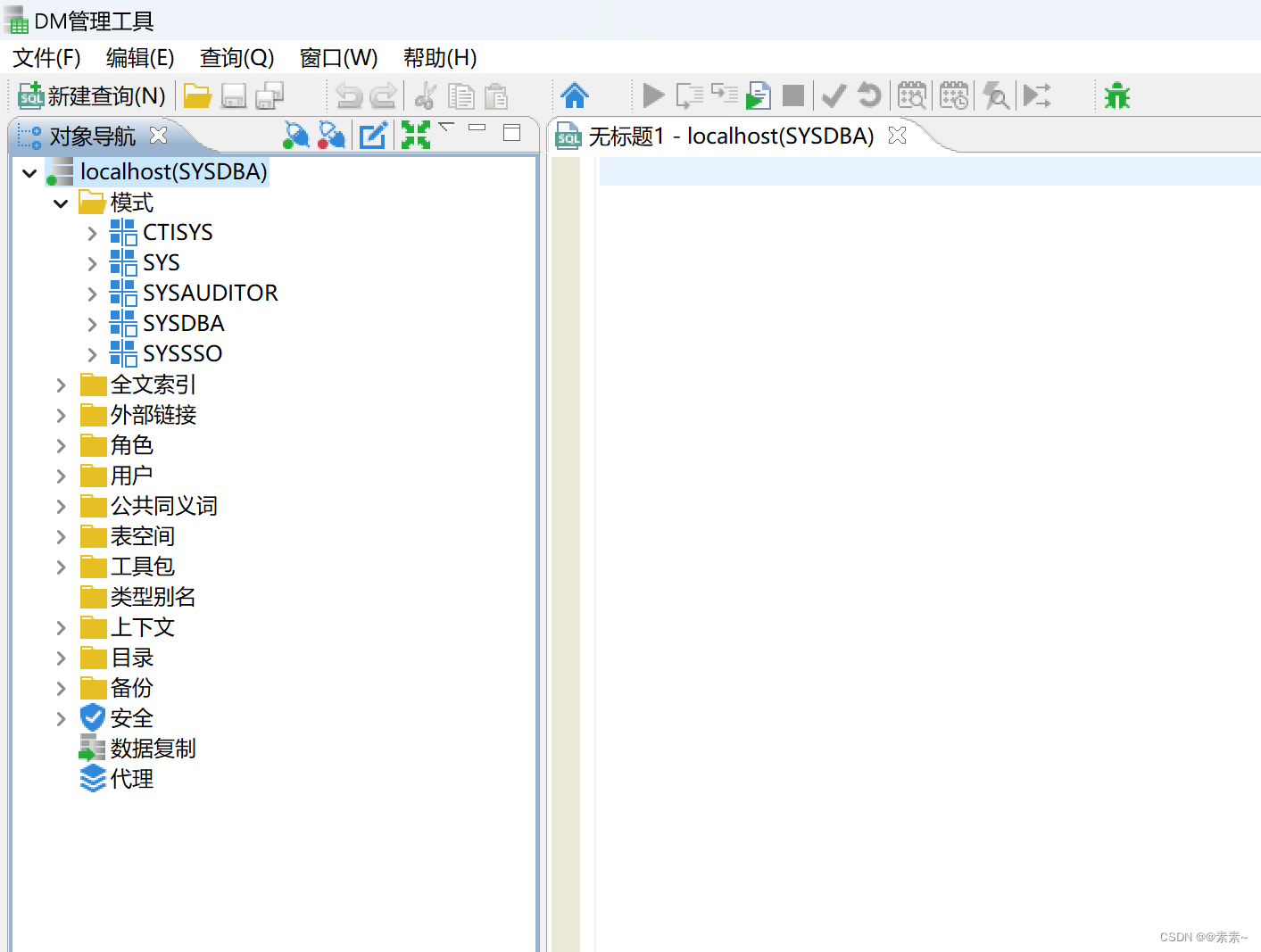
Windows11上安装docker(WSL2后端)和使用docker安装MySQL和达梦数据库
Windows11上安装docker(WSL2后端)和使用docker安装MySQL和达梦数据库 1. 操作系统环境2. 首先安装wsl2.1 关于wsl2.2 安装wsl2.3 查看可用的wsl2.4 安装ubuntu-22.042.5 查看、启动ubuntu-22.04应用2.6 上面安装开了daili2.7 wsl的更多参考 3. 下载Docke…...
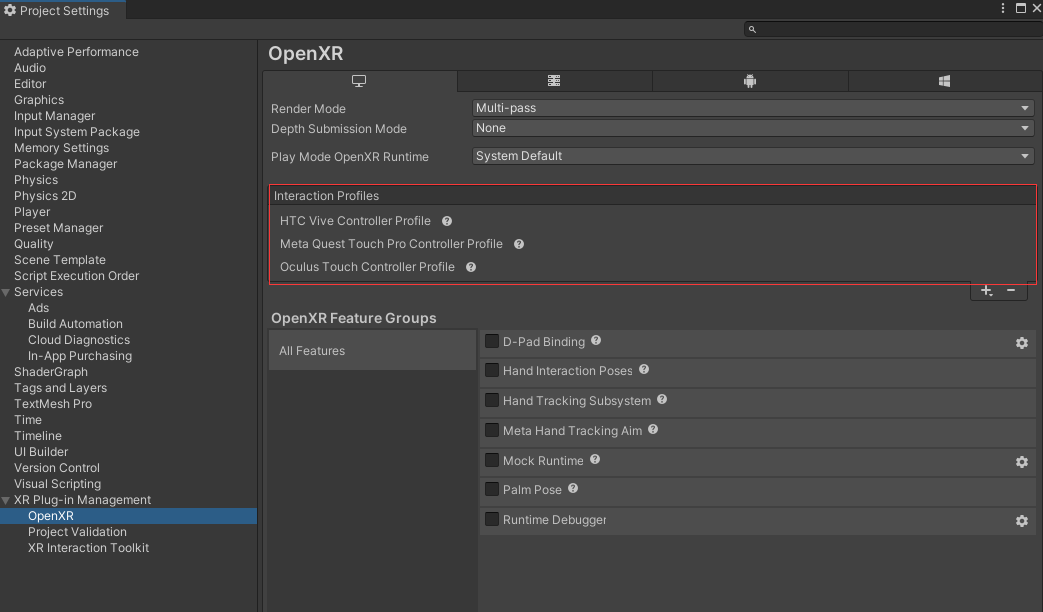
UnityXR Interactable Toolkit如何实现Climb爬梯子
前言 在VR中,通常会有一些交互需要我们做爬梯子,爬墙的操作,之前用VRTK3时,里面是还有这个Demo的,最近看XRI,发现也除了一个爬的示例,今天我们就来讲解一下 如何在Unity中使用XR Interaction Toolkit实现爬行(Climb)操作 环境配置 步骤 1:设置XR环境 确保你的Uni…...
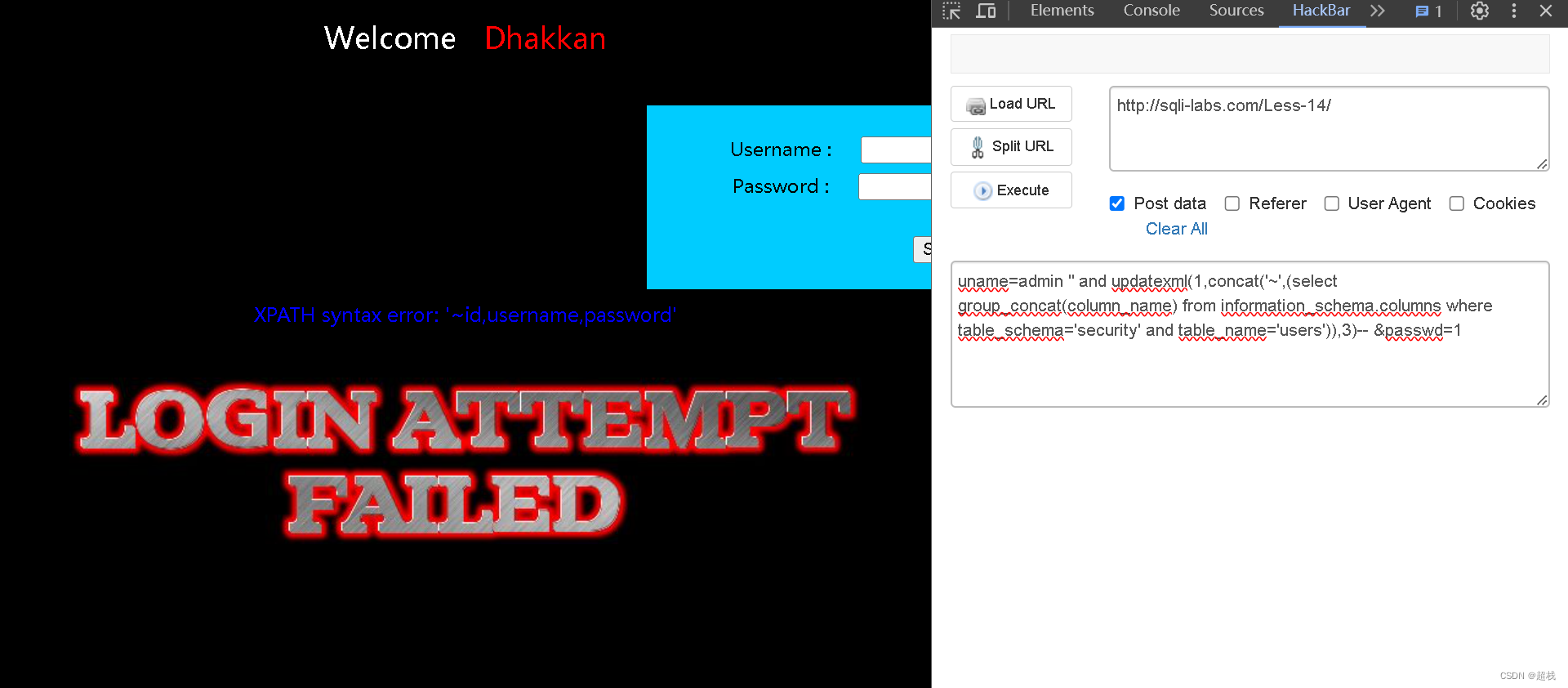
sqli-labs 靶场 less-11~14 第十一关、第十二关、第十三关、第十四关详解:联合注入、错误注入
SQLi-Labs是一个用于学习和练习SQL注入漏洞的开源应用程序。通过它,我们可以学习如何识别和利用不同类型的SQL注入漏洞,并了解如何修复和防范这些漏洞。Less 11 SQLI DUMB SERIES-11判断注入点 尝试在用户名这个字段实施注入,且试出SQL语句闭合方式为单…...

wordpress后台更新后 前端没变化的解决方法
使用siteground主机的wordpress网站,会出现更新了网站内容和修改了php模板文件、js文件、css文件、图片文件后,网站没有变化的情况。 不熟悉siteground主机的新手,遇到这个问题,就很抓狂,明明是哪都没操作错误&#x…...

使用VSCode开发Django指南
使用VSCode开发Django指南 一、概述 Django 是一个高级 Python 框架,专为快速、安全和可扩展的 Web 开发而设计。Django 包含对 URL 路由、页面模板和数据处理的丰富支持。 本文将创建一个简单的 Django 应用,其中包含三个使用通用基本模板的页面。在此…...

Spark 之 入门讲解详细版(1)
1、简介 1.1 Spark简介 Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发通用内存并行计算框架。Spark在2013年6月进入Apache成为孵化项目,8个月后成为Apache顶级项目,速度之快足见过人之处&…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

处理vxe-table 表尾数据是单独一个接口,表格tableData数据更新后,需要点击两下,表尾才是正确的
修改bug思路: 分别把 tabledata 和 表尾相关数据 console.log() 发现 更新数据先后顺序不对 settimeout延迟查询表格接口 ——测试可行 升级↑:async await 等接口返回后再开始下一个接口查询 ________________________________________________________…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

AI+无人机如何守护濒危物种?YOLOv8实现95%精准识别
【导读】 野生动物监测在理解和保护生态系统中发挥着至关重要的作用。然而,传统的野生动物观察方法往往耗时耗力、成本高昂且范围有限。无人机的出现为野生动物监测提供了有前景的替代方案,能够实现大范围覆盖并远程采集数据。尽管具备这些优势…...